Datasets with Bioschemas Alejandra Gonzalez-Beltran(*), Philippe Rocca-Serra(*), Susanna Sansone(*) and the bioCADDIE Team and Commmunity (*) Oxford e-Research Centre, University of Oxford Bioschemas community meeting, Harpenden,Hertfordshire, UK 8th-9th November 2016

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Datasets with Bioschemas
Alejandra Gonzalez-Beltran(*), Philippe Rocca-Serra(*), Susanna Sansone(*) and the bioCADDIE Team and Commmunity
(*) Oxford e-Research Centre, University of Oxford
Bioschemas community meeting, Harpenden,Hertfordshire, UK
8th-9th November 2016

The problem
how to describe scientific(*) datasets to enable data discovery
(*) considering in particular
biological and biomedical datasets

Design principles
The model for data description to be designed around the Dataset entity, i.e. a unit of information stored by a data repository:
● Archived experimental datasets which do not change after deposition to the repository; e.g. dbGAP, GEO, ClinicalTrials.org
● Datasets in reference knowledge bases, describing dynamic concepts, such as “genes” whose definition morphs over time; e.g. UniProt
Additionally:
● A dataset and related datasets may available in multiple repositories
● A dataset may be available in multiple forms
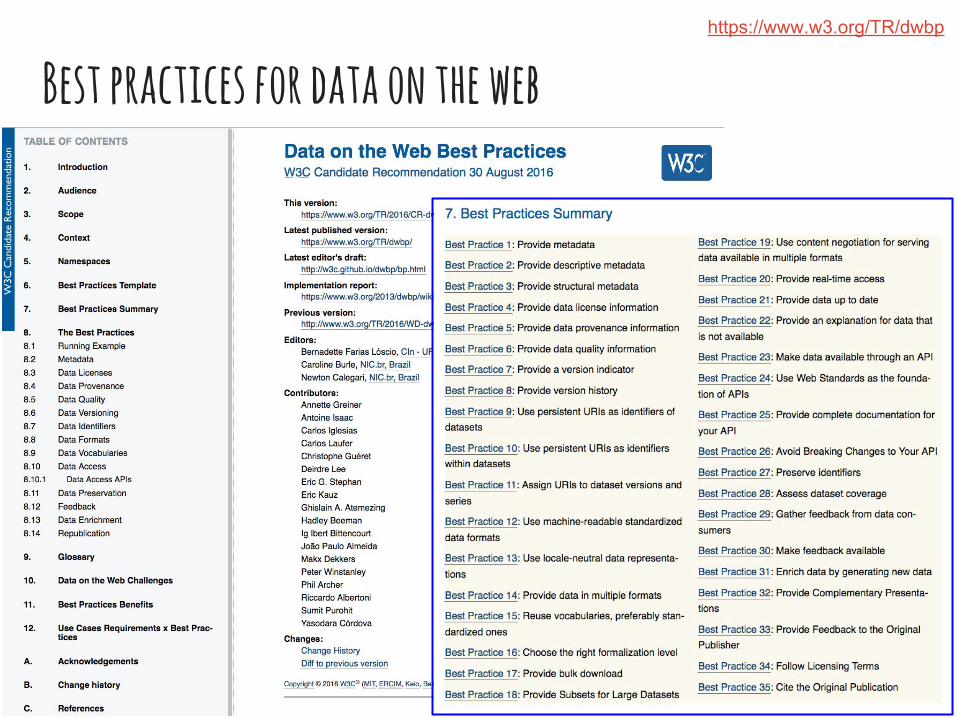
Best practices for data on the webhttps://www.w3.org/TR/dwbp

The approach: convergence of metadata elements derived from use cases (top-down) and models/schemas (bottom-up)top-down approach bottom-up approach
(v1.0, v1.1, v2.0, v2.1)
Model serialised as JSON-schemas / JSON-LD with schema.org annotations
Evaluation through Mapping 50+ repositories
Available through DataCite API, mapped to Data citation metadata

Extracting requirements from use cases❖ Selected competency questions
✧ representative set collected from: use cases workshop, white paper, submitted by the community and from NIH and Phil Bourne’s ADDS office
✧ key metadata elements processed: abstracted, color-coded and terms binned binned as Material, Process, Information, Properties; relation identified

Mapping existing metadata schemas/models
❖ schema.org❖ DataCite❖ RIF-CS❖ W3C HCLS dataset descriptions (mapping of many models including DCAT, PROV,
VOID, Dublin Core)❖ Project Open Metadata (used by HealthData.gov is being added in this new
iteration)
❖ ISA❖ BioProject❖ BioSample
❖ MiNIML❖ PRIDE-ml❖ MAGE-tab❖ GA4GH metadata schema❖ SRA xml❖ CDISC SDM / element of BRIDGE model
bottom-up approach
https://biosharing.org/collection/bioCADDIEhttps://github.com/biocaddie/WG3-MetadataSpecifications/

DATS: DAta Tag Suite
Core entities Biomedical extension
Like the JATS (Journal Article Tag Suite) is used by
PubMed to index literature,
a DATS (DatA Tag Suite) is needed for a scalable way to index data sources in the DataMed prototype
https://github.com/biocaddie/WG3-MetadataSpecifications/

Dats - community-driven modelhttps://biocaddie.org/group/working-groups

Dats - community-driven model

DATS core

DATS core and biomedical extension

https://github.com/biocaddie/WG3-MetadataSpecifications/

Mapping dats to schema.org ✧ Missing elements (needed by DATS) submitted to
the tracker; Roughly 80 % of DATS entities and properties can be mapped but alignment is not perfect/less precise), the remaining 20% constitute major gaps
✧
✧ Tracking schema.org and its related Health and Life Science extension evolution (the latter focuses on clinical studies)


https://developers.google.com/search/docs/data-types/datasets
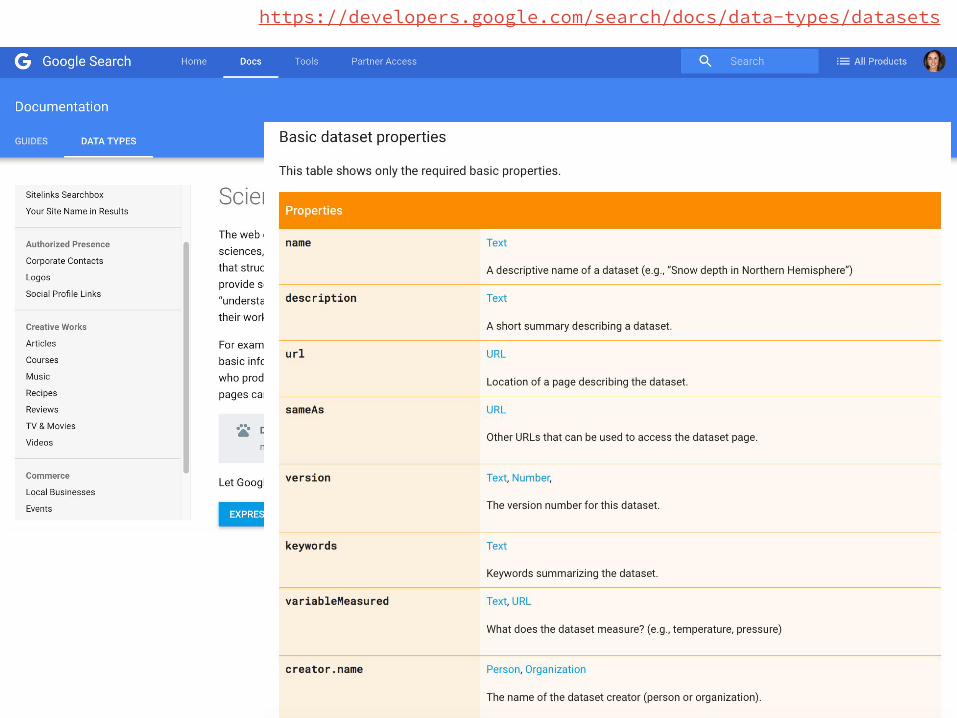
https://developers.google.com/search/docs/data-types/datasets

Adoption and integration


Dats exported by https://github.com/datacite/spinone/issues/3
● An API endpoint that returns
DataCite metadata in DATS
format is work in progress:
http://api.datacite.org/dats
● DataCite Metadata Schema allows
for a RelatedIdentifier with the HasMetadata relation type this allows linking to the DATS
metadata from a DataCite
metadata record
Martin FennerDataCite

Dats and DCIP supplement mapping
Citation metadata for repositories’ landing page

Mapping between omics-di and DATS
❖ Overlap with DATS
core elements
✧ In red some
DATS extended
elements

Development of a bioschemas specification for datasets

Using the DATS experience for the bioschemas dataset specificationNext step...
Related Documents











