Feature Extraction: Modern Questions and Challenges Dmitry Storcheus Google Research co-authors: Mehryar Mohri (NYU Courant), Afshin Rostamizadeh (Google)

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Feature Extraction: Modern Questions and Challenges
Dmitry Storcheus Google Research
co-authors: Mehryar Mohri (NYU Courant), Afshin Rostamizadeh (Google)

Feature Extraction (FE)Def: Feature Extraction (FE) is any algorithm that transformation raw data into features that can be used as an input for a learning algorithm.
Examples
Construct bag-of-words vector from an email
Remove stopwords in a sentence
Apply PCA projection to high-dimensional data

Why Feature Extraction?Excessive amount of raw features available (image classification, spam detection)
Learning algorithms are already well-studied
No ML algorithm can perform stable without feature engineering, but if features are extracted well, even linear methods show great results
Companies invest in feature extraction pipelines

Goals of this talk
Structured survey of Feature Extraction methods
Open research problems + some solutions from Google
Empirical advice

Benefits of FEIncrease learning accuracy by taking out the most significant information from raw data (Guyon, 2003).
Denoising
Reduce overfitting to train set
Memory optimization
Train and inference time optimization

Classification of FE methodsVariable subset selection [Blum, 1997; Kohavi, 1997]: Choose best k variables out of existing ones
Feature Construction: make new variables
Normalization (Lp unit ball or custom metric)
Nonlinear transformation to existing variables
Feature Crossing
Clustering [Duda, 2001]

Classification of FE methodsDimensionality Reduction: project data into low-dimensional subspace
Principal Component Analysis [Pearson, 1901]
Linear Discriminant Analysis [Fisher, 1938]
Random Projection [Hegde, 2008]
Manifold Learning: project data onto a nonlinear low-dimensional manifold
Isometric Feature Mapping [Tenenbaum, 2000]
Locally Linear Embedding [Roweis, 2000]
Laplacian Eigenmap [Belkin, 2003]

Classification of FE methodsDistance metric learning: learn a custom distance function on data
Local LDA [Hastie, 1996]
Relevance Component Analysis [Bar-Hillel, 2003]
Multiple Kernel Learning [Cortes, 2009]
Representation Learning [Bengio, 2013]: extracting features at each level of neural network
Autoencoders [Bengio, 2007]
Restricted Bolzmann Machines [Hinton, 2003]

Questions and challenges
Should Feature Extraction be supervised?
Should Feature Extraction be coupled with a classifier?
How to make Feature Extraction methods scalable?
What is the connection between convex and non-convex methods?

Questions and challenges
Should Feature Extraction be supervised?
Should Feature Extraction be coupled with a classifier?
We address these 2 questions on the example of nonlinear dimensionality reduction

Dimensionality reduction
Determine a lower dimensional space preserving various geometric properties of the input.
X PX
P
PCA: captures variance
Isomap: preserves distances along manifold
MVU: preserves angles
()
Kernel PCA with specific
kernel function[Ham et al.,2004]

Principal Component AnalysisSetting
real-valued training sample of size m
mean centered data matrix
sample covariance matrix
matrix of top d eigenvectors of is
PCA of is
X 2 Rn⇥m
C =1
mXX>
U 2 Rm⇥dC
X U>X

Principal Component AnalysisPseudocode
input
centered data matrix
number of principal components
1. compute
2. = TopEigenVectors // LAPACK:dsyevx(), runtime
return
X
d
C =1
mXX>
�C, d
�U O(dm2)
U>X

Principal Component AnalysisEmpirical results of PCA
up to +10% accuracy improvement for face recognition [Yang, 2004]
+3% improvement in accuracy on drug discovery data [Janecek, 2008]
+7% accuracy on email classification with 128 principal components out of 57021 total [Gomez, 2008]
Eige
nvalue
0
0.25
0.5
0.75
1
1 2 3 4 5 6 7 8 9 10
Eige
nvalue
0
0.25
0.5
0.75
1
1 2 3 4 5 6 7 8 9 10

Dimensionality reduction
Determine a lower dimensional space preserving various geometric properties of the input.
X PX
P
PCA: captures variance
Isomap: preserves distances along manifold
MVU: preserves angles
()
Kernel PCA with specific
kernel function[Ham et al.,2004]

Kernel PCAProblem set up: doing PCA in Reproducing Kernel Hilbert Space
training sample
Kernel function
example
Reproducing Kernel Hilbert Space and a map
K(xi, xj) : Rn ⇥ Rn 7! R
S = x1, ..., xm 2 Rn
K(xi, xj) = exp
✓� kxi � xjk2
2�
2
◆
HK �K : Rn 7! HK
K(xi, xj) = h�K(xi),�K(xj)iHK

Kernel PCA
Problem set up
is a sample covariance operator of kernel
eigenspace of corresponding to top eigenvalues
is principal component projection
Kernel PCA of point is
C : HK 7! HK K
U 2 HK C d
⇧U : H 7! U 2 H
x ⇧U�K(x)

Kernel PCA - pseudocodeinput
sample
number of principal components
1. compute normalized kernel matrix , s.t.
2. = TopEigenVectors
3. =TopEigenValues
4. for i=1 to m
for k=1 to d
return matrix of coordinates
d
U
K [K]i,j =1
m
K(xi, xj)�K, d
�
S = x1, ..., xm 2 Rn
�
[⇧]k,i =1p�k
mX
t=1
K(xi, xt)Ut,k
⇧
�K, d
�

Kernel PCA
Empirical results
[Sholkopf, 1998] on USPS dataset (handwritten digits) linear SVM shows 91% accuracy, while Kernel PCA+ SVM gives 96% accuracy with only 20% of total principal components

Generalized Nonlinear Dimensionality Reduction
Space: let be the reproducing Hilbert space of some kernel and let be the feature map of kernel
Projection: let be some orthogonal projection in
Dim reduction applied to point is x 2 X
K� : x 7! K(x, ·)
P�(x)
K
P
HK
HK

Open problemsHow to choose kernel function K and projection P?
Different kernel means different nonlinear dim reduction method
Can we automatically adjust kernel functor for different problems?
Can this be done in supervised manner?

How to choose P and K?
Traditionally the choice is based on optimizing geometric properties (e.g. PCA, Isomap, MVU).
However is it a good choice if we use dimensionality reduction for feature generation? E.g. we want to use reduced data as an input for a learning problem?
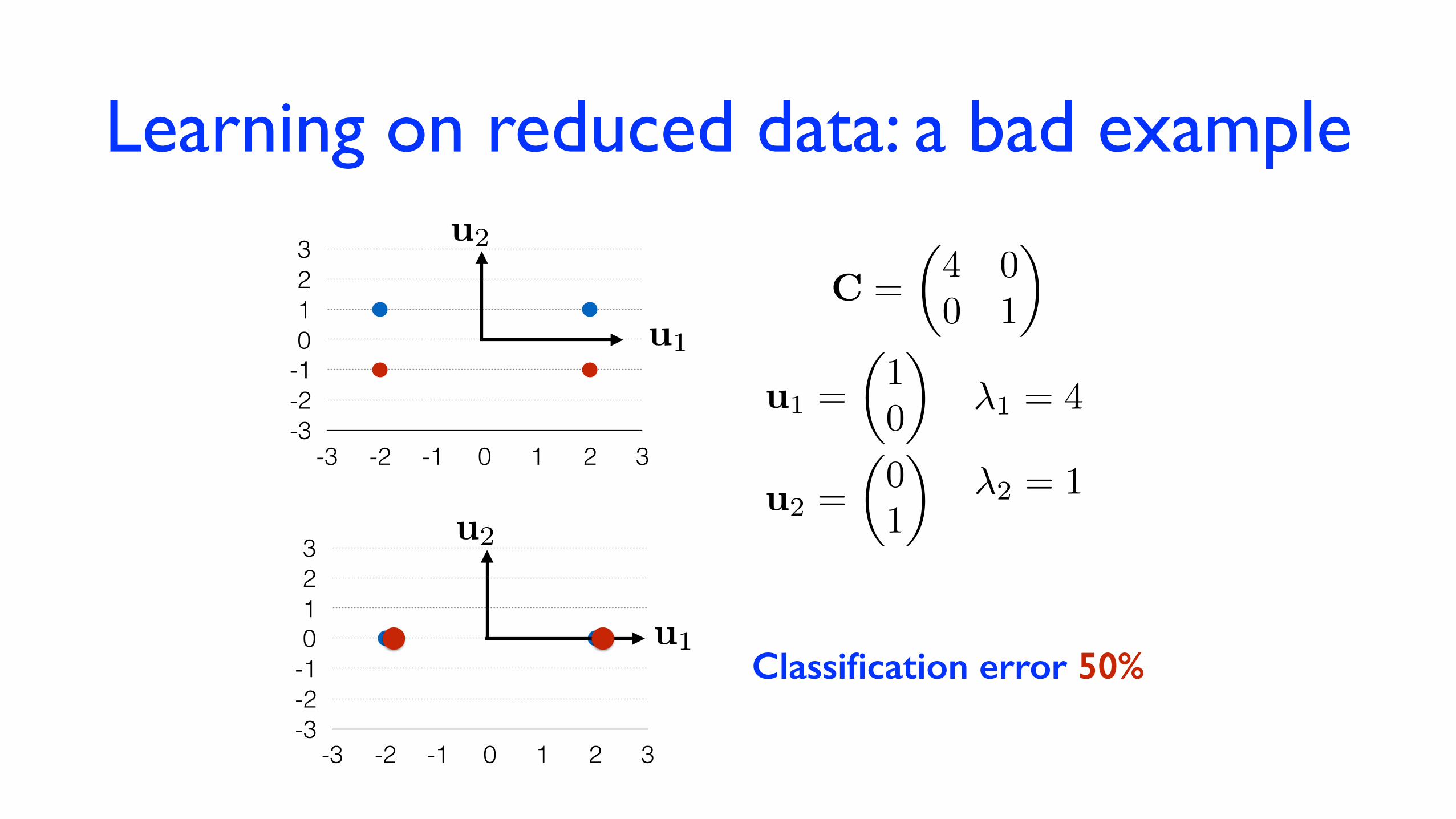
Learning on reduced data: a bad example
-3-2-10123
-3 -2 -1 0 1 2 3
u2
u1
C =
✓4 00 1
◆
u1 =
✓10
◆
u2 =
✓01
◆�1 = 4
�2 = 1
-3-2-10123
-3 -2 -1 0 1 2 3
u2
u1Classification error 50%

Coupled Nonlinear Dimensionality Reduction Learner receives:
p PSD kernels
Learner constructs a space , which is the reproducing space of a mixed kernel
Learner constructs a projection which is the Kernel PCA projection with kernel
K1, . . . ,Kp
H
Kµ =pX
k=1
µkKk
Kµ
⇧U

Hypothesis setHypothesis set
Consists of linear maps in the projected subspace of
Parametrized by and
Feature map is the feature mapping of kernel
Projection is based on the unlabeled set
Regularization is a convex set from which is selected.
⇧U : H 7! U 2 H
H
H =
⇢x 7! hw,⇧U�(x)iH : kwkH 1,µ 2 M
�.
� : X 7! H Kµ
U
M µ
w µ

Objective function
For any convex loss function
the coupled training of dimensionality reduction + classifier is
h = argminkwk1;µ2M�L(w, µ)
�
L(w, µ)

Supervised Nonlinear Dimensionality Reduction - conclusion [Storcheus, 2015]
Learning error depends on log(p), take many base kernels
Joint learning of kernel and separation hyperplane is suggested
Automatic learning of dim reduction method by learning a kernel function
Coupled algorithm:
Structural risk minimization
Fit and by minimizing training loss. w µ

Thank you for your attention

References-11. Guyon, Isabelle, and André Elisseeff. "An introduction to variable and feature selection." The Journal of Machine Learning
Research 3 (2003): 1157-1182.
2. Blum, Avrim L., and Pat Langley. "Selection of relevant features and examples in machine learning." Artificial intelligence 97, no. 1 (1997): 245-271.
3. Duda, Richard O., Peter E. Hart, and David G. Stork. "Unsupervised learning and clustering." Pattern classification (2001): 519-598.
4. Hegde, Chinmay, Michael Wakin, and Richard Baraniuk. "Random projections for manifold learning." In Advances in neural information processing systems, pp. 641-648. 2008.
5. Tenenbaum, Joshua B., Vin De Silva, and John C. Langford. "A global geometric framework for nonlinear dimensionality reduction." Science 290, no. 5500 (2000): 2319-2323.
6. Roweis, Sam T., and Lawrence K. Saul. "Nonlinear dimensionality reduction by locally linear embedding." Science 290, no. 5500 (2000): 2323-2326.
7. Belkin, Mikhail, and Partha Niyogi. "Laplacian eigenmaps for dimensionality reduction and data representation." Neural computation 15, no. 6 (2003): 1373-1396.
8. Cortes, Corinna, Mehryar Mohri, and Afshin Rostamizadeh. "Learning non-linear combinations of kernels." In Advances in

References-II1. Yang, Jian, David Zhang, Alejandro F. Frangi, and Jing-yu Yang. "Two-dimensional PCA: a new approach to appearance-based
face representation and recognition." Pattern Analysis and Machine Intelligence, IEEE Transactions on 26, no. 1 (2004): 131-137.
2. Janecek, Andreas GK, and Wilfried N. Gansterer. "A comparison of classiffication accuracy achieved with wrappers, filters and PCA'." In Workshop on New Challenges for Feature Selection in Data Mining and Knowledge Discovery. 2008.
3. Gomez, Juan Carlos, and Marie-Francine Moens. "PCA document reconstruction for email classification." Computational Statistics & Data Analysis 56, no. 3 (2012): 741-751.
4. Schölkopf, Bernhard, Alexander Smola, and Klaus-Robert Müller. "Kernel principal component analysis." In Artificial Neural Networks—ICANN'97, pp. 583-588. Springer Berlin Heidelberg, 1997.
5. Storcheus, Dmitry, Mehryar Mohri, and Afshin Rostamizadeh. "Foundations of Coupled Nonlinear Dimensionality Reduction." arXiv preprint arXiv:1509.08880 (2015).
6. Bengio, Yoshua, Aaron Courville, and Pierre Vincent. "Representation learning: A review and new perspectives." Pattern Analysis and Machine Intelligence, IEEE Transactions on 35, no. 8 (2013): 1798-1828.
7. Ham, Jihun, Daniel D. Lee, Sebastian Mika, and Bernhard Schölkopf. "A kernel view of the dimensionality reduction of manifolds." In Proceedings of the twenty-first international conference on Machine learning, p. 47. ACM, 2004.

Back-up slides

General Framework
Define a learning scenario that describes every FE method
Implement this scenario by Kernel PCA algorithm that generalizes most feature extraction methods
Linear dimensionality reduction, manifold learning, shallow neural nets

FE learning scenarioLearner receives:
(partially) labeled training sample of size
Drawn over input space
Feature space
Feature Extraction:
Family of functions
Classification:
Family of functions
mS̃ = ((x̃1, y1), . . . , (x̃m, ym))
X̃
X
F : X̃ 7! X
H : X 7! {�1, 1}

FE Learning scenarioFE stage
for any feature extraction function let the features extracted from input data point be
apply to training set to get
Classification stage
Apply to sample with extracted features
Testing stage:
the classification of a test point is a composition
xi = f(x̃i)f 2 F
S̃ S = ((x1, y1), ..., (xm, ym))
h 2 H S
x
h(f(x))

FE Learning problem
The learning problem is to find best and
How?
By minimizing loss function on training set
f? 2 F h? 2 H

FE Learning problem
Types of loss functions w.r.t. feature extraction
unsupervised
supervised decoupled
supervised coupled

Different loss functions - different methods
for example, if F are orthogonal projections and X star R^d
L is reconstruction error, then f^star is PCA Projection
L is scattered distances, the f^star is multidimensional scaling
Variance within classes - LDA

Ongoing work: algorithm

Computation of hypothesisLabeled training sample .
Compute for .
Indexing: index over the base kernels and index over eigenvalues.
Eigenvalues of have the form .
Binary selection variables if eigenspace of is included in projection.
Coordinates of in the range of are .
Other constants relative to the training set are .
k 2 [1, p] j 2 [1, u]
CU µk�j(CU,k)
⇠k,j = 1
⇧Uw 2 H zk,j
h(xn)S = ((x1, y1), . . . , (xm, ym))
h(xn) xn 2 S
µk�j(CU,k)
ck,j(xn)

Computation of hypothesisNumerical expression
optimize for and
Constraints
h(xn)
h(xn) =X
k,j
⇠k,jck,j(xn)zk,jpµk
µ z
kzk2 1
µ 2 M

Optimization problem
Minimize a training loss
Over a convex set
kzk2 1
µ 2 M
minµ,z
1
m
X
n
L
X
k,j
⇠k,jck,j(xn)zk,jpµk, yn
!
Related Documents











