Data-Warehouse-Technologien Prof. Dr.-Ing. Kai-Uwe Sattler 1 Prof. Dr. Gunter Saake 2 Dr. Veit Köppen 2 1 TU Ilmenau FG Datenbanken & Informationssysteme 2 Universität Magdeburg Institut für Technische und Betriebliche Informationssysteme Letzte Änderung: 15.10.2018 c Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 0–1

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Data-Warehouse-Technologien
Prof. Dr.-Ing. Kai-Uwe Sattler1 Prof. Dr. Gunter Saake2
Dr. Veit Köppen2
1TU IlmenauFG Datenbanken & Informationssysteme
2Universität MagdeburgInstitut für Technische und Betriebliche Informationssysteme
Letzte Änderung: 15.10.2018
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 0–1

Teil VI
Speicherstrukturen für Data Warehouse

Speicherstrukturen für Data Warehouse
Speicherstrukturen für Data Warehouse
1 Relationale Speicherung
2 Multidimensionale Speicherung
3 Speicherungsvarianten
4 Spaltenorientierte Speicherung
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–1

Speicherstrukturen für Data Warehouse Relationale Speicherung
Relationale Speicherung – ROLAP
Umsetzung von Star- bzw. Snowflake-Schema auf RelationenVerbreitetste Form der Speicherung von DW-Tabellen(Details: siehe VL „Datenbank-Implementierungstechniken“)Besonderheiten
I Sehr große Faktentabellen→ Beschleunigung der Zugriffe durchPartitionierung
I Multidimensionale Zugriffe→ spezielle Cluster- und IndexstrukturenI Update-Charakteristik (Anhängen von Daten)
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–2

Speicherstrukturen für Data Warehouse Relationale Speicherung
Partitionierung
Unabhängig von und ergänzend zu Indexverfahren:Aufteilung umfangreicher Relationen in kleinere Teilrelationen(sogenannte Partitionen oder Fragmente)Größe und Inhalt der Partitionen richtet sich nach Anfrage- undAktualisierungscharakteristikUrsprünglich für verteilte Datenbanken um Lastverteilung aufmehreren Knoten zu unterstützenPartitionierung umfasst die logische Aufteilung von Relationen,die physische Verteilung ist Aufgabe der Allokation
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–3

Speicherstrukturen für Data Warehouse Relationale Speicherung
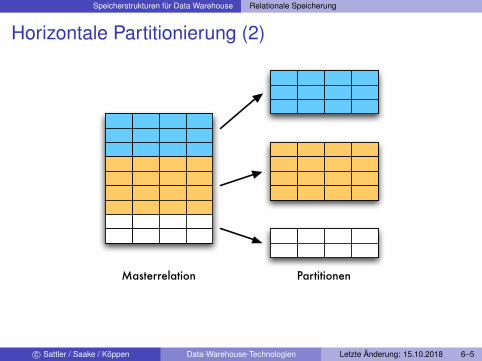
Horizontale Partitionierung
Masterrelation R wird vollständig in mehrere paarweise disjunkteTeilrelationen R1, ...,Rn aufgeteilt:
R = R1 ∪ ... ∪ Rn; Ri ∩ Rj = ∅ für i 6= j
Verschiedene Formen der Aufteilung:I Range-Partitionierung:
F Jede Partition wird durch ein Selektionskriterium definiertRi := σϕ(R) mit ϕ Selektionsbedingung (range restriction)
I Hash-Partitionierung:F Hashfunktion (angewendet auf das ganze Tupel oder einzelne
Attribute) bestimmt, zu welcher Partition ein Tupel gehörtF Tupel mit gleichem Hashwert (oder Hashwerten in einem
vorgegebenem Bereich) befinden sich in einer Partition
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–4
Speicherstrukturen für Data Warehouse Relationale Speicherung
Horizontale Partitionierung (2)
Masterrelation Partitionen
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–5

Speicherstrukturen für Data Warehouse Relationale Speicherung
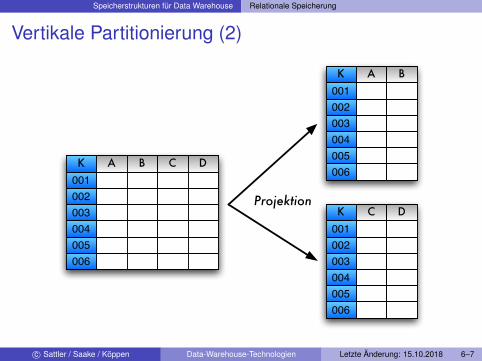
Vertikale Partitionierung
Verteilung einzelner Attribute (Spalten) auf PartitionenPartition entspricht einer Projektion auf die Masterrelation:
Ri := πattrlist(R)
Für Rekonstruierbarkeit der Masterrelation muss gemeinsamesAttribut in jeweils zwei Partitionen existieren
I I.d.R. ist Primärschlüssel in allen Partitionen enthalten
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–6
Speicherstrukturen für Data Warehouse Relationale Speicherung
Vertikale Partitionierung (2)
A B CK001002003004005006
Projektion
D
A BK001002003004005006
C DK001002003004005006
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–7
Speicherstrukturen für Data Warehouse Relationale Speicherung
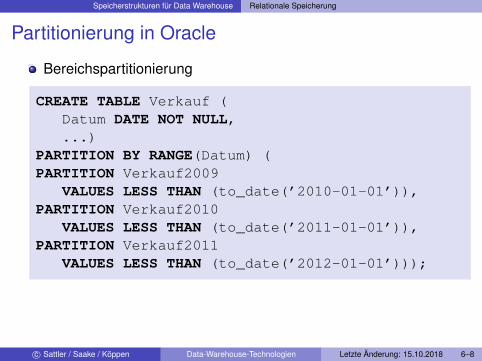
Partitionierung in Oracle
Bereichspartitionierung
CREATE TABLE Verkauf (Datum DATE NOT NULL,...)
PARTITION BY RANGE(Datum) (PARTITION Verkauf2009
VALUES LESS THAN (to_date(’2010-01-01’)),PARTITION Verkauf2010
VALUES LESS THAN (to_date(’2011-01-01’)),PARTITION Verkauf2011
VALUES LESS THAN (to_date(’2012-01-01’)));
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–8
Speicherstrukturen für Data Warehouse Relationale Speicherung
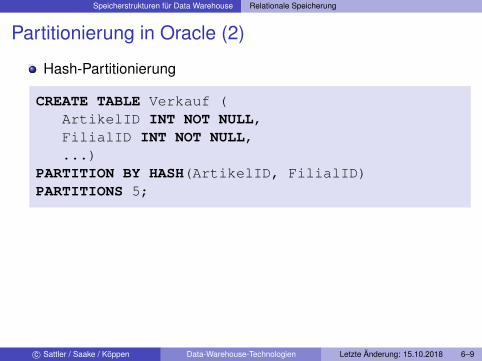
Partitionierung in Oracle (2)
Hash-Partitionierung
CREATE TABLE Verkauf (ArtikelID INT NOT NULL,FilialID INT NOT NULL,...)
PARTITION BY HASH(ArtikelID, FilialID)PARTITIONS 5;
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–9

Speicherstrukturen für Data Warehouse Relationale Speicherung
Partitionierung in Data Warehouses
Horizontale Partitionierung (insb. Range-Partitionierung) erlaubtz.B. große Faktentabellen in handlichere Teile zu zerlegen
I Selektionsbedingungen für einzelne Partitionen sollten die inAnfragen häufig vorkommenden Bereichseinschränkungenberücksichtigen
Vertikale Partitionierung erfordert i.d.R. teure Join-Operation zumWiederzusammensetzen der Tupel;
I Kann zum Abspalten selten angefragter Attribute eingesetzt werdenI Verkleinerung von Fakten- oder Dimensionstabellen, auf die häufig
zugegriffen wird
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–10

Speicherstrukturen für Data Warehouse Relationale Speicherung
Partitionierung in Data Warehouses (2)
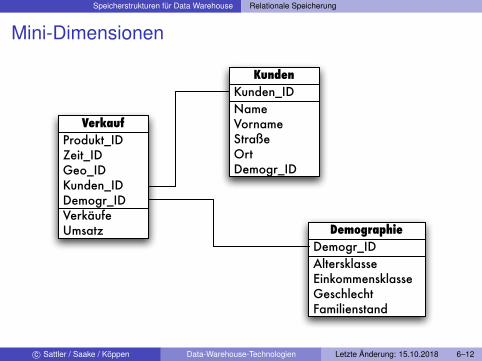
Spezialfall vertikaler Partitionierung: Mini-DimensionenGelegentlich werden Dimensionstabellen riesig groß:z.B. Kundentabelle mit mehreren Millionen Datensätzen
I Viele Attribute werden nie oder nur selten angefragt, da sie fürAuswertungen uninteressant sind
oderI es gibt disjunkte Attributgruppen, die immer nur für verschiedene
Anwendungen bzw. verschiedene Arten von Auswertungen benötigtwerden
Abtrennung von Attributen durch vertikale Partitionierung erlaubtdann eine deutliche Verkleinerung der einzelnenDimensionstabellen
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–11
Speicherstrukturen für Data Warehouse Relationale Speicherung
Mini-Dimensionen
VerkaufProdukt_IDZeit_IDGeo_IDKunden_IDDemogr_IDVerkäufeUmsatz
KundenKunden_IDNameVornameStraßeOrtDemogr_ID
DemographieDemogr_IDAltersklasseEinkommensklasseGeschlechtFamilienstand
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–12

Speicherstrukturen für Data Warehouse Relationale Speicherung
Spezielle Tabellentypen in DB2
Append-Mode-TabellenI optimiert für insert-OperationenI Tupel werden am Ende angefügt, ohne Freispeicher auf Seiten zu
berücksichtigenBereichsgeclusterte Tabellen (range-clustered tables – RCT)
I Für SequenzdatenMultidimensional-geclusterte Tabellen (multidimensionalclustering tables – MDC)
I Speicherung in mehreren Dimensionen clusterweise
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–13
Speicherstrukturen für Data Warehouse Relationale Speicherung
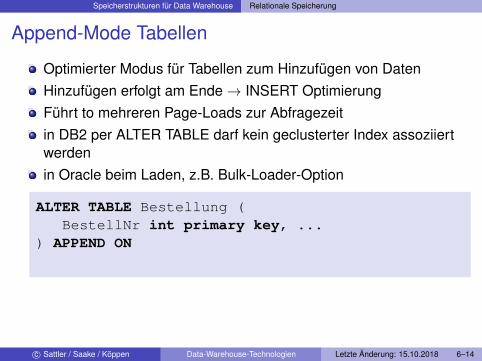
Append-Mode Tabellen
Optimierter Modus für Tabellen zum Hinzufügen von DatenHinzufügen erfolgt am Ende→ INSERT OptimierungFührt to mehreren Page-Loads zur Abfragezeitin DB2 per ALTER TABLE darf kein geclusterter Index assoziiertwerdenin Oracle beim Laden, z.B. Bulk-Loader-Option
ALTER TABLE Bestellung (BestellNr int primary key, ...
) APPEND ON
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–14

Speicherstrukturen für Data Warehouse Relationale Speicherung
Bereichsgeclusterte Tabellen
Nutzung ein Sequenznummer (frei wählbares Attribut) als logischRowid zur Ermittlung der physischen SpeicheradresseVorab-Allokation des gesamten Speicherplatzes der TabelleEinsortierung des Tupels über SequenznummerZugriff über Sequenznummer→ kein zusätzlicher Indexnotwendig
CREATE TABLE Bestellung (BestellNr int primary key, ...
) ORGANIZE BY KEY SEQUENCE(BestellNr starting from 1 ending at 10000)
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–15

Speicherstrukturen für Data Warehouse Relationale Speicherung
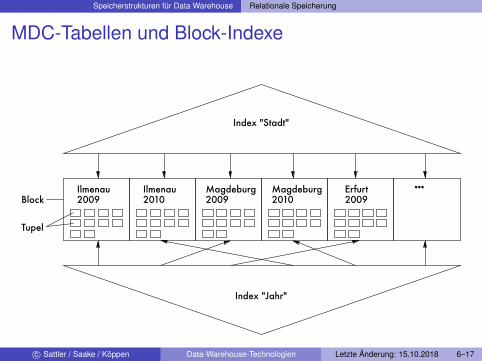
MDC-Tabellen
Tabellen üblicherweise max. nach einem Index geclusteredScan über anderen Index im Worst Case: 1 Seitenzugriff pro TupelMDC:
I Tupel mit gleichen Werten bzgl. mehrerer Attribute (Dimensionen)auf gleicher Seite bzw. im gleichen Extent speichern
I Indexierung über Block-Indexe (dünn besetzte Indexe)
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–16
Speicherstrukturen für Data Warehouse Relationale Speicherung
MDC-Tabellen und Block-Indexe
Index "Jahr"
2009Ilmenau2010
Magdeburg2009
Magdeburg2010
Erfurt2009
...Block
Tupel
Index "Stadt"
Ilmenau
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–17
Speicherstrukturen für Data Warehouse Relationale Speicherung
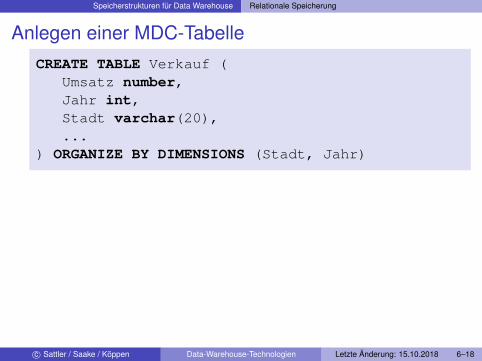
Anlegen einer MDC-TabelleCREATE TABLE Verkauf (
Umsatz number,Jahr int,Stadt varchar(20),...
) ORGANIZE BY DIMENSIONS (Stadt, Jahr)
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–18

Speicherstrukturen für Data Warehouse Multidimensionale Speicherung
Multidimensionale Speicherung – MOLAP
Verwendung unterschiedlicher Datenstrukturen für Datenwürfelund DimensionSpeicherung des Würfels als ArrayOrdnung der Dimension für Adressierung der WürfelzellennotwendigHäufig proprietäre Strukturen (und Systeme)
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–19

Speicherstrukturen für Data Warehouse Multidimensionale Speicherung
Datenstrukturen für Dimensionen
Endliche, geordnete Liste von DimensionswertenDimensionswerte: einfache unstrukturierte Datentypen (String,Integer, Date)Ordnung der Dimensionswerte (interne ganze Ordnungszahl 2oder 4 Byte)→ Endlichkeit der Werteliste
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–20

Speicherstrukturen für Data Warehouse Multidimensionale Speicherung
Datenstruktur für Würfel
Für n Dimensionen: n-dimensionaler Raummi Dimensionswerte der Dimension i: Aufteilung des Würfels in mparallele EbenenDurch Endlichkeit der Dimensionswerteliste: endliche, gleichgroßeListe von Ebenen je DimensionZelle eines n-dimensionalen Würfels wird eindeutig über n-Tupelvon Dimensionswerten identifiziertZelle kann ein oder mehrere Kennzahlen eines zuvor definiertenDatentyps aufnehmenBei mehreren Kennzahlen: Alternative→ mehrere Datenwürfel
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–21
Speicherstrukturen für Data Warehouse Multidimensionale Speicherung
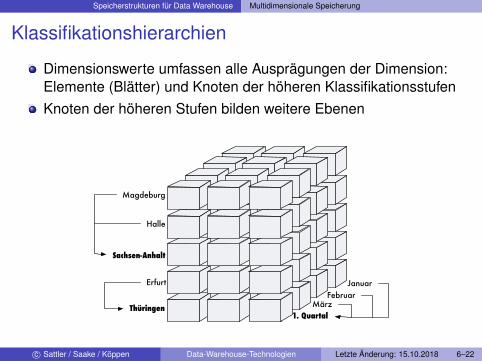
Klassifikationshierarchien
Dimensionswerte umfassen alle Ausprägungen der Dimension:Elemente (Blätter) und Knoten der höheren KlassifikationsstufenKnoten der höheren Stufen bilden weitere Ebenen
Magdeburg
Halle
Sachsen-Anhalt
Erfurt
Thüringen
JanuarFebruar
März1. Quartal
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–22

Speicherstrukturen für Data Warehouse Multidimensionale Speicherung
Berechnung von Aggregationen
Echtzeit:I Bei Anfrage von Zellen, die Werte einer höheren, aggregierten
Klassifikationsstufe repräsentieren→ Berechnung aus DetaildatenI Hohe Aktualität, jedoch hoher AufwandI Eventuell Caching
Vorberechnung:I Nach Übernahme der Detaildaten→ Berechnung und Eintragen
der Aggregationswerte in entsprechende ZellenI Neuberechnung nach jeder Datenübernahme notwendigI Hohe Anfragegeschwindigkeit, jedoch Zunahme der Würfelgröße
und Laufzeitaufwand
Ausweg: inkrementelle Vorberechnung
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–23

Speicherstrukturen für Data Warehouse Multidimensionale Speicherung
Weitere Datenstrukturen
AttributeI Klassifizierende Merkmale einer DimensionI Identifizierung von Untermengen von Dimensionswerten (z.B.
“Produktfarbe“)I Nicht zur Vorberechnung vorgesehen
Virtueller WürfelI Umfasst abgeleitete Daten („Gewinn“, „prozentualer Umsatz“)I Ableitung aus anderen Würfel durch Anwendung von
Berechnungsfunktionen ≈ Sichten im relationalen ModellTeilwürfel
I Kombination mehrerer Ebenen eines Würfels→ virtuell
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–24

Speicherstrukturen für Data Warehouse Multidimensionale Speicherung
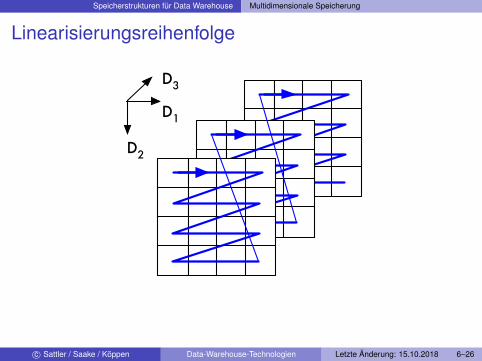
Array-Speicherung
Speicherung des Würfels: n-dimensionales Array→ Linearisierung in eine eindimensionale ListeIndizes des Arrays→ Koordinaten der Würfelzellen (Dimensionen Di)Indexberechnung für Zelle z mit Koordinaten x1...xn
Index(z) = x1 +(x2−1)|D1|+(x3−1)|D1||D2|+ · · ·+(xn−1)|D1| · · · |Dn−1|
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–25
Speicherstrukturen für Data Warehouse Multidimensionale Speicherung
Linearisierungsreihenfolge
D2
D1
D3
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–26

Speicherstrukturen für Data Warehouse Multidimensionale Speicherung
Array-Speicherung: Probleme
Zahl der Plattenzugriffe bei ungünstigenLinearisierungsreihenfolgen
I Reihenfolge der Dimensionen ist bei Definition des Würfels zubeachten
Caching zur Reduzierung notwendigSpeicherung dünn besetzter Würfel
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–27
Speicherstrukturen für Data Warehouse Multidimensionale Speicherung
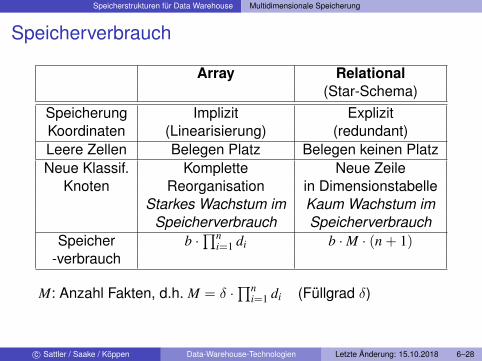
Speicherverbrauch
Array Relational(Star-Schema)
Speicherung Implizit ExplizitKoordinaten (Linearisierung) (redundant)Leere Zellen Belegen Platz Belegen keinen PlatzNeue Klassif. Komplette Neue Zeile
Knoten Reorganisation in DimensionstabelleStarkes Wachstum im Kaum Wachstum im
Speicherverbrauch SpeicherverbrauchSpeicher b ·
∏ni=1 di b ·M · (n + 1)
-verbrauch
M: Anzahl Fakten, d.h. M = δ ·∏n
i=1 di (Füllgrad δ)
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–28
Speicherstrukturen für Data Warehouse Multidimensionale Speicherung
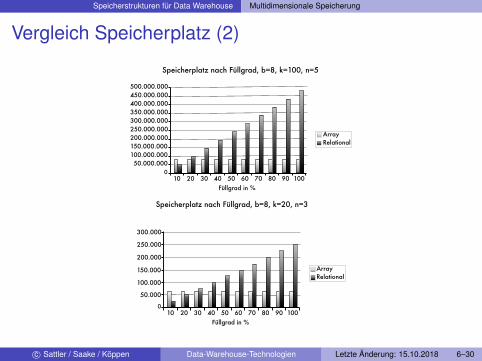
Vergleich Speicherplatz
FaktorenI FüllgradI k: Anzahl KnotenI n: Anzahl Dimensionen
Schon bei geringen Füllgraden ist Array Speicherplatz-effizienterPerformance hängt von vielen Faktoren ab
I IndexierungI Sequential readsI ...
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–29
Speicherstrukturen für Data Warehouse Multidimensionale Speicherung
Vergleich Speicherplatz (2)
050.000.000
100.000.000150.000.000200.000.000250.000.000300.000.000350.000.000400.000.000450.000.000500.000.000
10 20 30 40 50 60 70 80 90 100Füllgrad in %
Speicherplatz nach Füllgrad, b=8, k=100, n=5
ArrayRelational
0
50.000
100.000
150.000
200.000
250.000
300.000
10 20 30 40 50 60 70 80 90 100Füllgrad in %
Speicherplatz nach Füllgrad, b=8, k=20, n=3
ArrayRelational
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–30

Speicherstrukturen für Data Warehouse Multidimensionale Speicherung
Grenzen der multidimensionalen Speicherung
Skalierbarkeitsprobleme aufgrund dünn besetzter DatenräumeTeilweise einseitige Optimierung bezüglich LeseoperationenOrdnung der Dimensionswerte notwendig (durchArray-Speicherung)
I Erschwert Änderungen an den Dimensionen
Kein Standard für multidimensionale DBMSSpezialwissen notwendig
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–31

Speicherstrukturen für Data Warehouse Multidimensionale Speicherung
Hybride Speicherung – HOLAP
Verbindung der Vorteile beider WeltenI Relational (Skalierbarkeit, Standard)I Multidimensional (analytische Mächtigkeit, direkte
OLAP-Unterstützung)Speicherung:
I Relationale Datenbank: DetaildatenI Multidimensionale Datenbank: aggregierte DatenI Multidimensionale Speicherstrukturen als „intelligenter“ Cache für
häufig angeforderte Datenwürfel
Transparenter Zugriff über multidimensionales Anfragesystem
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–32

Speicherstrukturen für Data Warehouse Speicherungsvarianten
Speicherungsvarianten
Ziel:I Optimierung für Leseoperationen, spez. OLAP-Anfragen
(Aggregationen)I Schnelles Laden der tatsächlich benötigten Daten in Hauptspeicher
für BerechnungAspekte:
I Partitionierung: leere Bereiche entfernenI Komprimierung: Speicherung von Nullwerten und redundanten
Daten vermeidenI Indexierung (nächstes Kapitel):
F Von Datenblöcken (Grid-Files, R+-Bäume, Zwei-Ebenen)F In einem Datenblock (Array-/relationale Speicherung der Zellen, RLE,
Bitmap)
Insgesamt: Erhaltung der räumlichen Nachbarschaftsbeziehungder Zellen im Sekundärspeicher (multidimensionales Clustering)
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–33

Speicherstrukturen für Data Warehouse Speicherungsvarianten
Partitionierung von Datenwürfeln
Ziel:I Entfernen leerer Bereiche aus WürfelI Optimierte Speicherung für Zugriffsmuster: häufig zugegriffene
Bereiche in einigen wenigen BlöckenKriterien:
I Art der PartitionierungI Steuerung: Optimierung der Partitionierung für AnwendungI Werkzeugunterstützung: für Steuerung der Partitionierung
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–34

Speicherstrukturen für Data Warehouse Speicherungsvarianten
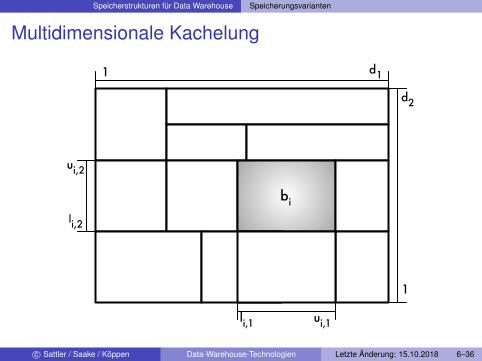
Art der Partitionierung
Aufteilung eines Würfels in nicht überlappende Bereiche(multidimensionale Intervalle)Allgemeine Form: multidimensionale Kachelung
I Geg.: n-dimensionales Array mit Dimensionswerten
D = [1 : d1, ..., 1 : dn]
I Kachelung: Menge von Sub-Arrays, die Bereichen b1, ..., bm derDimensionswerte entsprechen
b1 = [l1,1 : u1,1, ..., l1,n : u1,n], ..., bm = [lm,1 : um,1, ..., lm,n : um,n],
so dass bi ∩ bj = ∅ für i 6= j und bi ⊆ D, i, j = 1, ...,m und jedebesetzte Zelle einem Sub-Array angehört
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–35
Speicherstrukturen für Data Warehouse Speicherungsvarianten
Multidimensionale Kachelung
bi
1 d1
1
d2
ui,2
li,2
li,1 ui,1
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–36
Speicherstrukturen für Data Warehouse Speicherungsvarianten
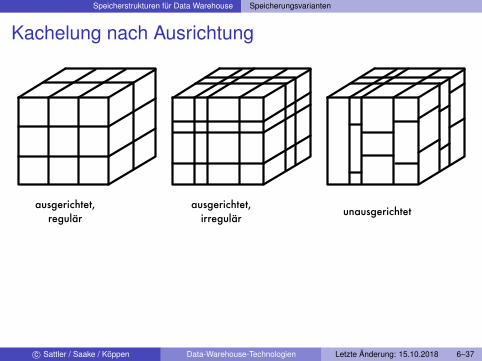
Kachelung nach Ausrichtung
ausgerichtet, regulär
ausgerichtet, irregulär
unausgerichtet
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–37
Speicherstrukturen für Data Warehouse Speicherungsvarianten
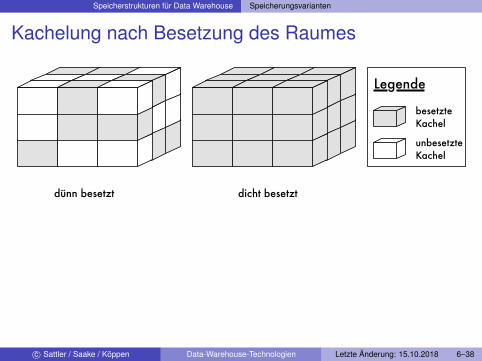
Kachelung nach Besetzung des Raumes
dünn besetzt dicht besetzt
Legende
besetzteKachel
unbesetzte Kachel
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–38

Speicherstrukturen für Data Warehouse Speicherungsvarianten
Steuerung der Partitionierung
Automatische Partitionierung:I Automatisches Finden der Partitionierung für optimale Ausführung
der OperationenI Nutzung des Füllgrades der BereicheI Nutzung von Zugriffsstatistiken
Bedeutung bestimmter Dimensionen/ DimensionskombinationenI Besondere Behandlung der ZeitdimensionI Partitionierung nach Zeitreihen (spezielle Formate für Reihen von
Werten, z.B. täglich, wöchentlich, etc.)Zwei-Ebenen-Speicherung
I Nur Speicherung von verwendeten Kombinationen dünn besetzterDimensionen
Partitionenspezifikation des AnwendersI Direkte Spezifikation jedes BereichesI Dimensionspartitionen
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–39

Speicherstrukturen für Data Warehouse Speicherungsvarianten
Speicherung der Zellen
Verwendung eines bestimmten Speicherformats für jedenDatenblockUnterstützung verschiedener Speicherformate (in Abhängigkeitvom Füllgrad)Ab bestimmten Füllgrad: Array-Speicherung effizienter alsrelationale Speicherung
I Grund: Speicherung der Koordinaten als Schlüssel bei relationalerSpeicherung notwendig
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–40

Speicherstrukturen für Data Warehouse Speicherungsvarianten
Minimaler Füllgrad für optimale Speicherung
Ab einem berechenbaren minimalen Füllgrad istArray-Speicherung besser als relationale SpeicherungMinimaler Füllgrad δ ist maximales δ so dass gilt:
Ixrel + δ
n∏i=1
Li ·
sc +
n∑j=1
sj
< Ixarr +
n∏i=1
Li · sc
Li: Länge des Sub-Array in Dimension i
sc: Speichergröße der Zellen (Platzverbrauch aller Kenngrößeneiner Zelle)sj: Speichergröße der Dimensionsattribute j
Ixrel: Speichergröße der Indizierung (relationale Speicherung)Ixarr: Speichergröße der Indizierung (Array-Speicherung)
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–41

Speicherstrukturen für Data Warehouse Speicherungsvarianten
Minimaler Füllgrad: Beispiel
Annahme: Ixrel und Ixarr gleich, sj = sc = 8
2 Dimensionen:
δ
2∏j=1
Li · 24 <2∏
j=1
Li · 8
Array-Speicherung effizienter ab Füllgrad 0.33
Für drei Dimensionen: 0.25
⇒ Füllgrad sinkt mit steigender Anzahl von Dimensionen
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–42

Speicherstrukturen für Data Warehouse Speicherungsvarianten
Zwei-Ebenen-Datenstruktur
Obere Ebene indiziert Datenblöcke, die auf unterer Ebenegespeichert werdenUntere Ebene: Array mit allen möglichen Kombinationen vonDimensionswertenZellen des Array:
I Zeiger auf Datenblock, der Datenwerte für entsprechendenDimensionswert der dicht besetzten Dimensionen enthält
I NULL für leeren Bereich
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–43
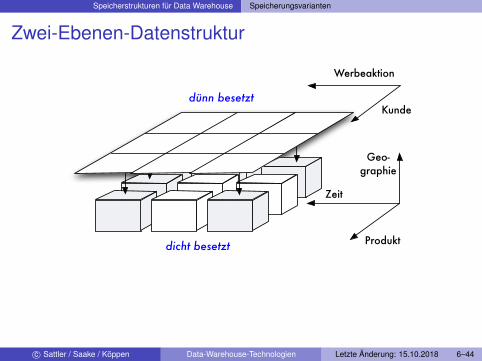
Speicherstrukturen für Data Warehouse Speicherungsvarianten
Zwei-Ebenen-Datenstruktur
Werbeaktion
Kunde
Zeit
Geo-graphie
Produkt
dünn besetzt
dicht besetzt
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–44
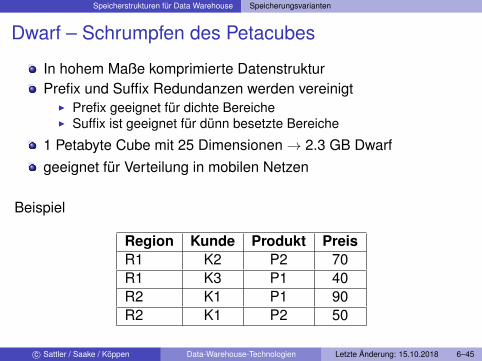
Speicherstrukturen für Data Warehouse Speicherungsvarianten
Dwarf – Schrumpfen des Petacubes
In hohem Maße komprimierte DatenstrukturPrefix und Suffix Redundanzen werden vereinigt
I Prefix geeignet für dichte BereicheI Suffix ist geeignet für dünn besetzte Bereiche
1 Petabyte Cube mit 25 Dimensionen→ 2.3 GB Dwarfgeeignet für Verteilung in mobilen Netzen
Beispiel
Region Kunde Produkt PreisR1 K2 P2 70R1 K3 P1 40R2 K1 P1 90R2 K1 P2 50
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–45
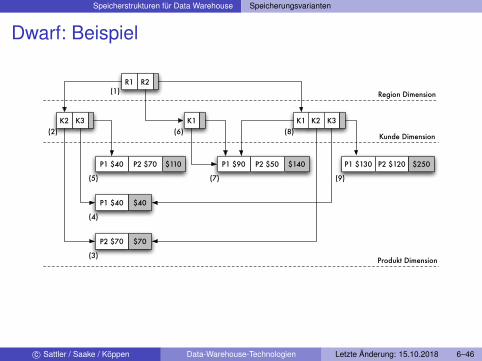
Speicherstrukturen für Data Warehouse Speicherungsvarianten
Dwarf: Beispiel
P1 $40 P2 $70 $110 P1 $90 P2 $50 $140 P1 $130 P2 $120 $250
P1 $40 $40
P2 $70 $70
K2 K3
R1 R2
K1 K1 K2 K3
Region Dimension
Kunde Dimension
Produkt Dimension(3)
(9)
(1)
(2)
(4)
(8)
(7)
(6)
(5)
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–46

Speicherstrukturen für Data Warehouse Speicherungsvarianten
Weitere multidimensionale Speicherstrukturen
Cube Forests und Hierarchically Cube Forests [Johnson &Shasha 1996, 1997]CubeTree [Roussopoulos & Kotidis & Roussopoulos 1997]CubiST [Fu & Hammer 2000]Condensed Cube [Wang & Lu & Feng & Yu 2002]Quotient Cube [Lakshmanan & Pei & Han 2002]m-Dwarf [Michalarias & Omelchenko & Lenz 2009]
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–47

Speicherstrukturen für Data Warehouse Speicherungsvarianten
Weitere multidimensionale Speicherstrukturen (2)Basierend auf Iceberg Cubes
Bottom-Up Cube [Beyer & Ramakrishnan 1999]H-Cubing [Han & Pei & Dong & Wang 2001]Star Cubing [Xin & Han & Li & Wah 2003]
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–48

Speicherstrukturen für Data Warehouse Speicherungsvarianten
Zusammenfassung
Relationale vs. multidimensionale Speicherungrelationale Erweiterungen
I PartitionierungI spezielle Tabellentypen
Spezialitäten der multidimensionalen SpeicherungI Array-SpeicherungI KachelungI Umgang mit dünn besetzten Würfeln
Hybride Formen
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–49

Speicherstrukturen für Data Warehouse Spaltenorientierte Speicherung
Motivation für Spaltenorientierte Datenhaltung
Anfragen dienen Analyse von Daten (lange Transaktionen)Datenbestand stabil, d.h. wenige/keine UpdatesImport von Daten (oft) über ETL-ProzessEinzelwerte oft uninteressant (vgl. Anwendungsfelder DWH)Häufig erstellen und verarbeiten aggregierter Werte
I AVG(), SUM(), COUNT()I GROUP BY (CUBE)I CUBE-Operationen
Für Aggregatfunktionen (z.B. AVG()) einzelne Spalten interessantAuch Gruppierungen (und CUBE) intuitive spaltenweiseBearbeitung
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–50

Speicherstrukturen für Data Warehouse Spaltenorientierte Speicherung
Datenexplosion
Datenbestände im OLAP-Bereich wachsen ständig ↪→ Daten inzentralisierten Systemen kaum noch verwaltbarHistorisierung der Daten erhöht Datenvolumen zusätzlichOLAP-Anfragen sehr speicher- und rechenintensiv ↪→ Verteilungder Last notwendigFür Aggregationen (OLAP) ist eine vertikale Partitionierung/Fragmentierung sinnvoll ↪→ bereits bestehende Partitionierungvon Column Stores ausnutzenAktuelle Systeme setzen Kompressionstechniken zurDatenvolumenreduktion ein
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–51

Speicherstrukturen für Data Warehouse Spaltenorientierte Speicherung
OLAP: Row Store
Historisch: Anwendung in On-lineTransactional Processing (OLTP) mitkurzen Transaktionen, z.B.BuchungstransaktionenAbbildung von Tupeln in DBMS, d.h.Tupel sequentiell gespeichertVerarbeitung ganzer Tupel fürAggregatsfunktionen ↪→ I/O OverheadInsgesamt: Tupel-orientiertephysische Speicherung ungünstig fürOLAP
Magdeburg 20102341Guinness
Ilmenau 20104944Pinot Noir
Ilmenau 20105543Merlot
Magdeburg 20104325Merlot
Ort JahrUmsatzProdukt
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–52

Speicherstrukturen für Data Warehouse Spaltenorientierte Speicherung
OLAP: Column Store
Neue Architektur für OLAP notwendig↪→ Column StoresTupel spaltenweise partitioniert, d.h.Werte einer Column sequentiellgespeichert (und sortiert)Aggregatsfunktionen arbeiten direktauf Spalten ↪→ nur benötige DateneingelesenInsgesamt: Column Stores könnenAggregationen viel effektiverbearbeiten
Magdeburg
IlmenauIlmenau
MagdeburgOrt
2010
20102010
2010Jahr
2341
49445543
4325Umsatz
Guinness
Pinot NoirMerlot
MerlotProdukt
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–53

Speicherstrukturen für Data Warehouse Spaltenorientierte Speicherung
Kompression
Row StoresI Kompression relations- oder partitionsweiseI Verschiedene Datentypen ↪→ Trade off bei
Kompressionstechnikauswahl notwendigI Übliche Kompressionsraten 2:1 bis 5:1
Column StoresI Kompression je Column möglichI Nutzung verschiedenster Techniken, z.B. Run Length Encoding
(RLE), Wörterbuchkodierung (Lempel-Ziv)I Auswahl bester Kompressionstechnik je Spalte, d.h. für jeden
DatentypI Übliche Kompressionsraten 10:1 bis 40:1
Column Stores reduzieren I/O Overhead und verringernDatenvolumen z.T. erheblich ↪→ bessere Ausnutzung desHauptspeichers
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–54

Speicherstrukturen für Data Warehouse Spaltenorientierte Speicherung
Anfragebearbeitung
Column Stores basieren auch auf relationalem Datenmodell ↪→Verwendung der relationalen Algebra und derer OperationenLogischer Anfrageplan wie bei Row StoresArchitekturspezifische Ausführung transparentBitoperationen von Natur aus unterstützt (vgl. Bitmap-Join-Index)Spaltenweise Kompression erlaubt Bearbeitung ohneDekompression
I Verlustfreie Kompressionstechniken (Bekannteste: Lempel-Ziv undDerivate) ↪→ gleiche (unkomprimierte) Werte haben gleichekomprimierte Darstellung
I D.h. Vergleichswert wird falls nötig vor Anfrageausführung inkomprimierte Darstellung überführt ↪→ gut geeignet für nichtvektorbasierte Joins
I Ordnungserhaltende Techniken wie RLE ↪→Werte ggf. direktvergleichbar oder wie bei verlustfreier Kompression
I D.h. Aggregatfunktionen wie MIN/MAX oder SUM können Datenkomprimiert verarbeiten
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–55
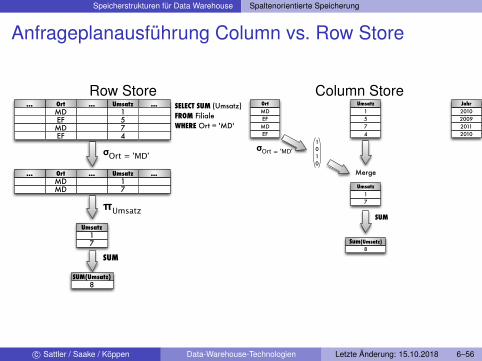
Speicherstrukturen für Data Warehouse Spaltenorientierte Speicherung
Anfrageplanausführung Column vs. Row Store
Row Store...
EF
EFMD
MDOrt ...
5
47
1Umsatz... SELECT SUM (Umsatz)
FROM FilialeWHERE Ort = 'MD'
σOrt = 'MD'
...
MDMDOrt ...
71
Umsatz...
πUmsatz
71
Umsatz
SUM
8SUM(Umsatz)
Column Store
EF
EFMD
MDOrt
2009
20102011
2010Jahr
5
47
1Umsatz
σOrt = 'MD'1010
Merge
71
Umsatz
SUM
8Sum(Umsatz)
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–56
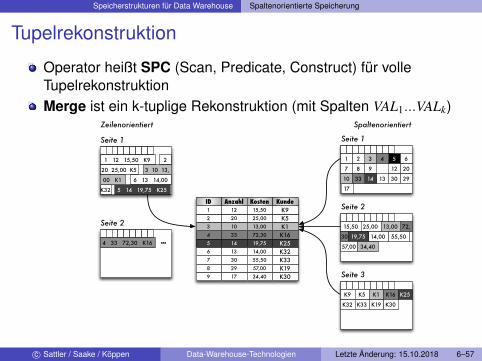
Speicherstrukturen für Data Warehouse Spaltenorientierte Speicherung
Tupelrekonstruktion
Operator heißt SPC (Scan, Predicate, Construct) für volleTupelrekonstruktionMerge ist ein k-tuplige Rekonstruktion (mit Spalten VAL1...VALk)
20 K525,002
33 K1672,30410 K113,003
12 K915,501Anzahl KundeKostenID
14 K2519,755
30 K3355,50713 K3214,006
17 K3034,40929 K1957,008
Zeilenorientiert Spaltenorientiert
6 13 14,00
5 14 19,75 K25
3 10 13,
1 12 15,50 K9 2
K32
20 25,00 K5
00 K1
Seite 1
4 33 72,30 K16
Seite 2
53 41 2 6
12 20987
10 30 29131433
17
Seite 1
13,0025,0015,50 72,
30 14,0019,75 55,50
57,00 34,40
Seite 2
K32 K33 K19
K1 K25K16K9 K5
Seite 3
K30
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–57

Speicherstrukturen für Data Warehouse Spaltenorientierte Speicherung
Materialisierungszeitpunkt
Frühe Materialisierung (EM)I Anfragebearbeitung sehr nah an Row StoresI Aggregatfunktionen auf einzelnen ColumnsI Tupelrekonstruktion sobald Tupel verwendetI Zumeist Verwendung bei tupel-orientierter Anfragebearbeitung
Späte Materialisierung (LM)I So lang wie möglich auf Columns arbeitenI Mehrfacher Zugriff auf Basistabellen und/oder ZwischenergebnisseI Folge: Anfrageplan kein Baum mehrI Aber: Gleichzeitige Bearbeitung auf komprimierten und
unkomprimierten Daten möglichI Notwendig für (effektive) spalten-orientierte Anfragebearbeitung
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–58
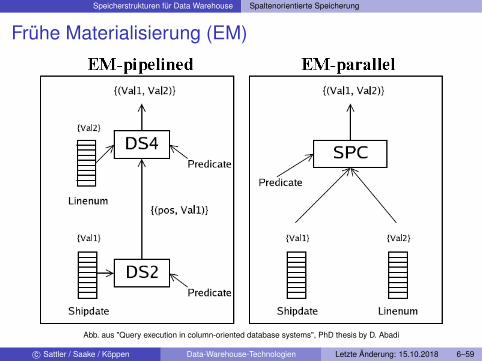
Speicherstrukturen für Data Warehouse Spaltenorientierte Speicherung
Frühe Materialisierung (EM)
Abb. aus "Query execution in column-oriented database systems", PhD thesis by D. Abadi
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–59
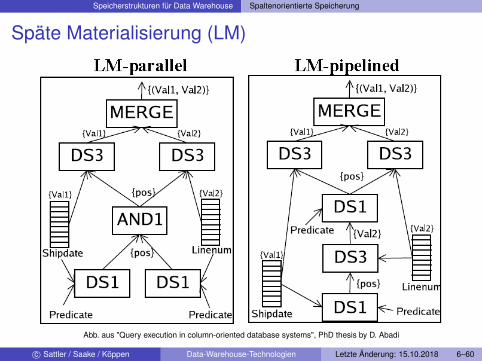
Speicherstrukturen für Data Warehouse Spaltenorientierte Speicherung
Späte Materialisierung (LM)
Abb. aus "Query execution in column-oriented database systems", PhD thesis by D. Abadi
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–60

Speicherstrukturen für Data Warehouse Spaltenorientierte Speicherung
Nachteile
Tupelrekonstruktion verursacht KostenKosten für Einfügeoperation durch Partitionierung der TupelUpdates benötigen TupelrekonstruktionFolge: Insert- und Update-in-place nicht möglichAber: Updates und Inserts in OLAP/DWH Anwendung selten odernur durch ETL
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–61

Speicherstrukturen für Data Warehouse Spaltenorientierte Speicherung
Lösungsansätze
Tupel-orientierte Anfragebearbeitung und frühe MaterialisierungC-Store/Vertica
I Read-optimized (RS) and write-optimized Storage (WS)I Verschiedene sich überlappende Projektionen im RSI Inserts und Updates nur im WSI Tuple mover übermittelt Daten vom WS in RS zu geringer Last
(offline)SybaseIQ (erster kommerzieller Column Store)
I Ähnlich zum C-Store-AnsatzI System unterteilt in Read- und Write- bzw. Read/Write-KnotenI Abgleich im Hintergrund zu Zeiten geringer Last
RedundanzI Daten column- und row-orientiert im HauptspeicherI Datenbank redundant als Column und Row StoreI Virtualisierung des Datenwürfels
...c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–62

Speicherstrukturen für Data Warehouse Spaltenorientierte Speicherung
Systeme
KommerziellI SybaseIQI VerticaI Infobright ICEI Tenbase (webbasiert)I BigTable (Google, nicht relational)I ...
FreiI Infobright ICE Community EditionI LucidDBI MonetDBX100 (Ingres/Vectorwise)I C-Store (benötigt alten gcc)I Hbase (Apache), Hypertable, Cassandra (Facebook) alles
BigTable-DerivateI ...
Im Gegensatz zu Row Stores weichen Column StoreImplementierungen untereinander sehr stark ab
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–63

Speicherstrukturen für Data Warehouse Spaltenorientierte Speicherung
Zusammenfassung
Row Stores nicht optimal für OLAP- und DWH-AnwendungenColumn Stores besser geeignet für AggregatsfunktionenColumn Stores verringern Datenvolumen z.T. drastisch ↪→geringerer I/O, bessere Ausnutzung des HauptspeichersDarstellung von Tupeln erzeugt Kosten in Column Stores(Tupelrekonstruktion)Column Stores zeigen Schwächen bei Inserts und UpdatesSehr viele und stark unterschiedliche Implementierungen fürColumn Stores
c© Sattler / Saake / Köppen Data-Warehouse-Technologien Letzte Änderung: 15.10.2018 6–64
Related Documents











