Data Transformation for Privacy-Preserving Data Mining Stanley R. M. Oliveira Database Systems Laboratory Computing Science Department University of Alberta, Canada Graduate Seminar November 26 th , 2004 Database Laboratory

Data Transformation for Privacy-Preserving Data Mining Stanley R. M. Oliveira Database Systems Laboratory Computing Science Department University of Alberta,
Dec 21, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Data Transformation for Privacy-Preserving Data Mining
Stanley R. M. Oliveira
Database Systems Laboratory
Computing Science Department
University of Alberta, Canada
Graduate Seminar
November 26th, 2004
Database Laboratory

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
2
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Motivation• Changes in technology are making privacy harder.
• The new challenge of Statistical Offices.
• Data Mining plays an outstanding role in business collaboration.
• The traditional solution “all or nothing” has been too rigid.
• The need for techniques to enforce privacy concerns when data are shared for mining.
Introduction

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
3
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
PPDM: Increasing Number of Papers
14
1 1
7
3 4
1417
30
0
5
10
15
20
25
30
35
1991 1995 1996 1998 1999 2000 2001 2002 2003 2004
Num
ber
of p
aper
s
Conceptive Landmark Deployment Landmark
Introduction
Prospective Landmark

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
4
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
PPDM: Privacy Violation
• Privacy violation in data mining: misuse of data.
• Defining privacy preservation in data mining:
Individual privacy preservation: protection of personally identifiable information.
Collective privacy preservation: protection of users’ collective activity.
Introduction

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
5
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
• Scenario 1: A hospital shares some data for research purposes.
• Scenario 2: Outsourcing the data mining process.
• Scenario 3: A collaboration between an Internet marketing company and an on-line retail company.
A few Examples of Scenarios in PPDMIntroduction

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
6
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
A Taxonomy of the Existing Solutions
Data Partitioning
Data Modification
Data Restriction
Data Ownership
Fig.1: A Taxonomy of PPDM Techniques
Contributions
Introduction

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
7
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Problem Definition
• To transform a database into a new one that conceals sensitive information while preserving general patterns and trends from the original database.
Non-sensitive patterns and trends
Data miningThe transformation
processOriginal Database
Transformed Database
Framework

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
8
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Problem Definition (cont.)
• Problem 1: Privacy-Preserving Association Rule Mining
I do not address privacy of individuals but the problem of protecting sensitive knowledge.
• Assumptions:
The data owners have to know in advance some knowledge (rules) that they want to protect.
The individual data values (e.g., a specific item) are not restricted but the relationships between items.
Framework

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
9
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Problem Definition (cont.)
• Problem 2: Privacy-Preserving Clustering
I protect the underlying attribute values of objects subjected to clustering analysis.
• Assumptions:
Given a data matrix Dmn, the goal is to transform D into D' so that the following restrictions hold:
A transformation T:D D’ must preserve the privacy of individual records.
The similarity between objects in D and D' must be the same or slightly altered by the transformation process.
Framework

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
10
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
A Framework for Privacy PPDM
A schematic view of the framework for privacy preservation
Library ofAlgorithms
PPDTMethods
Metrics
RetrievalFacilities
Sanitization
Privacy Preserving Framework
TransformedDatabase
Original data Collective Transformation
Individual Transformation
ServerClient
Framework

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
11
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Privacy-Preserving Association Rule Mining
D D’
TransactionalDatabase
SanitizedDatabase
The sanitization process
IdentifyDiscovered
Patterns
ClassifyDiscovered
Patterns
Select theSensitive
Transactions
Modify someSensitive
Transactions
Step 1 Step 2 Step 4Step 3
TID List of Items
T1 A B C D
T2 A B C
T3 A B D
T4 A C D
T5 A B C
T6 B D
A sample transactional database
T1, T3A,B D
Inverted File
Sensitive Sensitive Rules Transaction IDs
T1, T4A,C D
The corresponding inverted file
PP-Assoc. Rules
Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
12
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
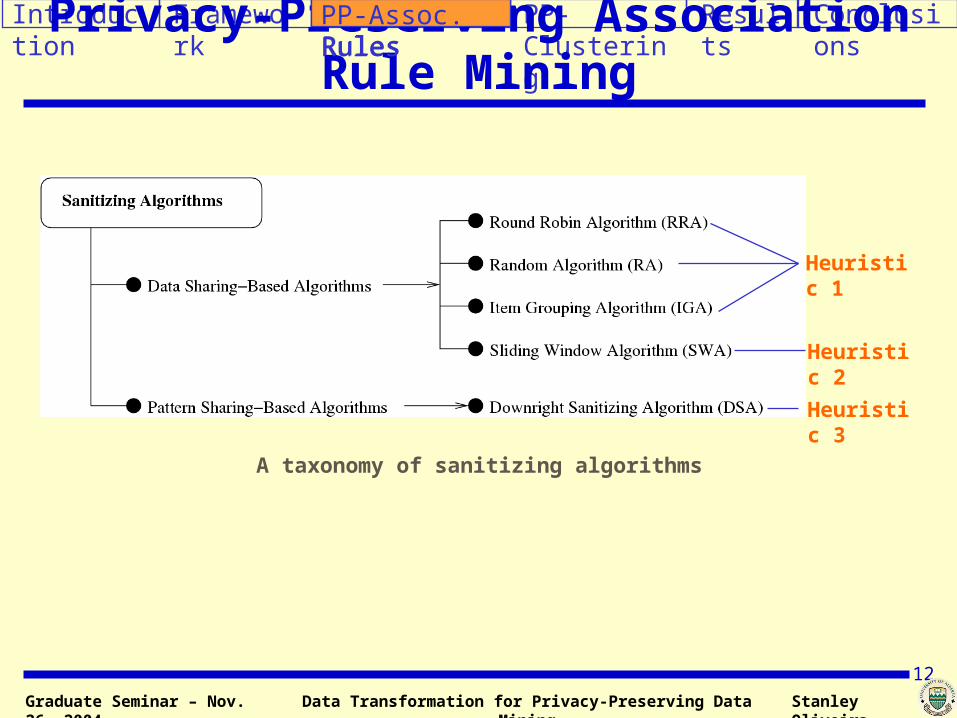
Privacy-Preserving Association Rule Mining
A taxonomy of sanitizing algorithms
Heuristic 1
Heuristic 2
Heuristic 3
PP-Assoc. Rules

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
13
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
• Definition: Let D be a transactional database and ST a set of all sensitive transactions in D. The degree of a sensitive transactions t, such that t ST, is defined as the number of sensitive association rules that can be found in t.
Heuristic 1: Degree of Sensitive Transactions
TID List of Items
T1 A B C D
T2 A B C
T3 A B D
T4 A C D
T5 A B C
T6 B D
A sample transactional database
T1, T3A,B D
Inverted File
Sensitive Sensitive Rules Transaction IDs
T1, T4A,C D
The corresponding inverted file
Degree(T1) = 2
Degree(T3) = 1
Degree(T4) = 1
PP-Assoc. Rules

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
14
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
1. Scan a database and identify the sensitive transactions for each restrictive patterns;
2. Based on the disclosure threshold , compute the number of sensitive transactions to be sanitized;
3. For each restrictive pattern, identify a candidate item that should be eliminated (victim item);
4. Based on the number found in step 3, remove the victim items from the sensitive transactions.
PP-Assoc. Rules
Data Sharing-Based Algorithms

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
15
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Data Sharing-Based Algorithms
The Round Robin Algorithm (RRA)
• Step 1: Sensitive transactions: A,BD = {T1, T3}; A,CD = {T1, T4}
• Step 2: Select the number of sensitive transactions: (a) = 50%; (b) = 0%
• Step 3: Identify the victim items (taking turns): = 50% Victim(T1) = A; Victim(T1) = A (Partial Sanitization) = 0% Victim(T3) = B; Victim(T4) = C (Full Sanitization)
• Step 4: Sanitize the marked sensitive transactions.
TID List of Items
T1 B C D
T2 A B C
T3 A B D
T4 A C D
T5 A B C
T6 B D
Partial Sanitization
Sensitive Rules (SR):
Rule 1: A,BD
Rule 2: A,CD
TID List of Items
T1 A B C D
T2 A B C
T3 A B D
T4 A C D
T5 A B C
T6 B D
Transactional Database
TID List of Items
T1 B C D
T2 A B C
T3 A D
T4 A D
T5 A B C
T6 B D
Full Sanitization
PP-Assoc. Rules

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
17
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Data Sharing-Based Algorithms (cont.)
The Item Grouping Algorithm (IGA)
• Step 1: Sensitive transactions: A,BD = {T1, T3}; A,CD = {T1, T4}
• Step 2: Select the number of sensitive transactions: = 0%
• Step 3: Identify the victim items (grouping sensitive rules): Victim(T1) = D; Victim(T3) = D; Victim(T4) = D (Full Sanitization)
• Step 4: Sanitize the marked sensitive transactions.
Sensitive Rules (SR):
Rule 1: A,BD
Rule 2: A,CD
TID List of Items
T1 A B C D
T2 A B C
T3 A B D
T4 A C D
T5 A B C
T6 B D
Transactional Database
TID List of Items
T1 B C D
T2 A B C
T3 A B
T4 A C
T5 A B C
T6 B D
Sanitized Database
PP-Assoc. Rules
Victim Item
Sup(D) Sup(A)
DB CA
Group Sensitive Rules

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
18
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
• For every group of K transactions:
Step1: Distinguishing the sensitive transactions from the non-sensitive ones;
Step 2: Selecting the victim item for each sensitive rule;
Step 3: Computing the number of sensitive transactions to be sanitized;
Step 4: Sorting the sensitive transactions by size;
Step 5: Sanitizing the sensitive transactions.
Heuristic 2: Size of Sensitive Transactions
PP-Assoc. Rules

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
19
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Novelties of this Approach• The notion of disclosure threshold for every single
pattern Mining Permissions (MP).
• Each mining permission mp = <sri, i>, where i sri set of sensitive rules SR; and i [0 … 1].
• Mining Permissions allow an DBA to put different weights for different rules to hide.
• All the thresholds i can also be set to the same value, if needed.
PP-Assoc. Rules

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
20
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
The Sliding Window Algorithm (SWA)
• Step 1: Sensitive transactions: A,BD = {T1, T3}; A,CD = {T1, T4}
• Step 2: Identify the victim items (based on frequencies of the items in SR): Victim(T3) = B; Victim(T4) = A; Victim(T1) = D;
• Step 3: Select the number of sensitive transactions: = 0%
• Step 4: Sort sensitive transactions by size: A,BD = {T3, T1}; A,CD = {T4, T1}
• Step 5: Sanitize the marked sensitive transactions.
Sensitive Rules (SR):
Rule 1: A,BD
Rule 2: A,CD
TID List of Items
T1 A B C D
T2 A B C
T3 A B D
T4 A C D
T5 A B C
T6 B D
Transactional Database
TID List of Items
T1 A B C
T2 A B C
T3 A D
T4 C D
T5 A B C
T6 B D
Sanitized Database
Data Sharing-Based Algorithms (cont.)PP-Assoc. Rules

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
21
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
1. Hiding Failure:
3. Artifactual Patterns:
4. Difference between D and D’:
Database D
Database D’
Data Sharing-Based Metrics
)(#
)'(#
DS
DSHF
R
R)(#
)'(#)(#
DS
DSDSMC
R
RR
2. Misses Cost:
|'|
|'||'|
R
RRRAP
n
iDDn
iD
ififif
DDDif1
'
1
)]()([)(
1)',(
PP-Assoc. Rules

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
22
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Pattern Sharing-Based Algorithm
Sanitization ShareAR generation
D’ D’D
Data Sharing-Based Approach
Association
Rules(D’)
ShareSanitizationD
AR generation Association
Rules(D)
Pattern Sharing-Based Approach
Association
Rules(D’)
Discovered
Patterns (D’)
PP-Assoc. Rules
Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
24
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
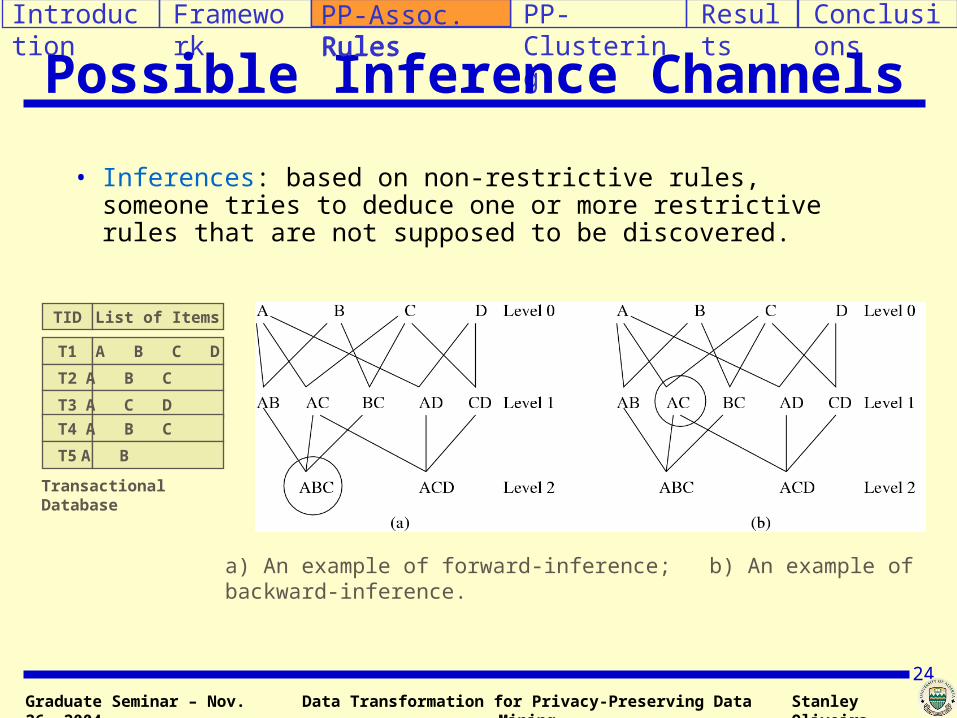
Possible Inference Channels
• Inferences: based on non-restrictive rules, someone tries to deduce one or more restrictive rules that are not supposed to be discovered.
a) An example of forward-inference; b) An example of backward-inference.
PP-Assoc. Rules
TID List of Items
T1 A B C D
T2 A B C
T3 A C D
T4 A B C
T5 A B
Transactional Database

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
25
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
• 1. Side Effect Factor (SEF) SEF =
• 2. Recovery Factor (RF) RF = [0, 1]
Rules to hide
Sensitive rulesSR
Non-Sensitive rules~SR
Rules hidden
R’: rules to share
R: all rules
Problem 1: RSE (Side effect)
Problem 2: Inference(recovery factor)
Pattern Sharing-Based Metrics
|)||(|
|))||'(||(|
R
R
SR
SRR
PP-Assoc. Rules

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
26
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Heuristic 3: Rule Sanitization• Step1: Identifying the sensitive itemsets.
• Step 2: Selecting the subsets to sanitize.
• Step 3: Sanitizing the set of supersets of marked pairs in level1.
Step2Step3
Step1
*
*
ABCAC
Sensitive Rules:Frequent pattern lattice
A B C D
AB AC BC AD CD
ABC ACD
Level 0
Level 1
Level 2
The Downright Sanitizing Algorithm (DSA)
PP-Assoc. Rules

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
27
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Privacy-Preserving Clustering (PPC)
• PPC over Centralized Data:
The attribute values subjected to clustering are available in a central repository.
• PPC over Vertically Partitioned Data:
There are k parties sharing data for clustering, where k 2;
The attribute values of the objects are split across the k parties.
Objects IDs are revealed for join purposes only. The values of the associated attributes are private.
PP-Clustering

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
28
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Object Similarity-Based Representation (OSBR)
Example 1: Sharing data for research purposes (OSBR).
12810944689044286
2518340765828446
1297724705240254
1748124536456342
1939132638075123
PR_intQRSInt_defheart
rate
weightageID
A sample of the cardiac arrhythmia database(UCI Machine Learning Repository)
Original Data Transformed Data
0995.3130.4082.4020.3
0176.3884.3690.3
0477.2348.3
0243.2
0
DM
The corresponding dissimilarity matrix
PP-Clustering

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
29
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Object Similarity-Based Representation (OSBR)
• The Security of the OSBR:Lemma 1: Let DMmm be a dissimilarity matrix,
where m is the number of objects. It is impossible to determine the coordinates of the two objects by knowing only the distance between them.
• The Complexity of the OSBR:Communication cost is of the order O(m2), where m
is the number of objects under analysis.
PP-Clustering
Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
30
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
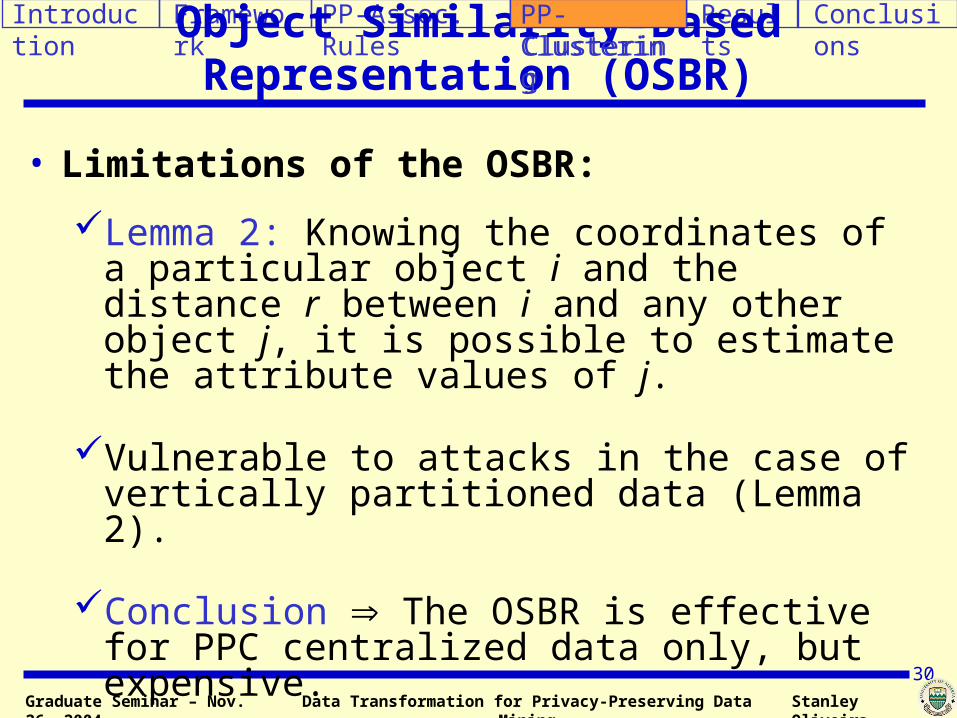
• Limitations of the OSBR:
Lemma 2: Knowing the coordinates of a particular object i and the distance r between i and any other object j, it is possible to estimate the attribute values of j.
Vulnerable to attacks in the case of vertically partitioned data (Lemma 2).
Conclusion The OSBR is effective for PPC centralized data only, but expensive.
Object Similarity-Based Representation (OSBR)
PP-Clustering

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
31
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Dimensionality Reduction Transformation (DRBT)
• General Assumptions:
The attribute values subjected to clustering are numerical only.
In PPC over centralized data, object IDs should be replaced by fictitious identifiers;
In PPC over vertically partitioned data, object IDs are used for the join purposes between the parties involved in the solution.
The transformation (random projection) applied to the data might slightly modify the distances between data points.
PP-Clustering

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
32
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Dimensionality Reduction Transformation (DRBT)
• Random projection from d to k dimensions:
D’ n k = Dn d • Rd k (linear transformation), where
D is the original data, D’ is the reduced data, and R is a random matrix.
• R is generated by first setting each entry, as follows:
(R1): rij is drawn from an i.i.d. N(0,1) and then normalizing the columns to unit length;
(R2): rij =6/1
3/2
6/1
1
0
1
3
yprobabilitwith
yprobabilitwith
yprobabilitwith
PP-Clustering

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
33
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Dimensionality Reduction Transformation (DRBT)
• PPC over Centralized Data (General Approach):Step 1 - Suppressing identifiers.
Step 2 - Normalizing attribute values subjected to clustering.
Step 3 - Reducing the dimension of the original dataset by using random projection.
Step 4 – Computing the error that the distances in k-d space suffer from:
• PPC over Vertically Partitioned Data: It is a generalization of the solution for PPC over centralized
data.
)/())ˆ((,
2
,
22 ji
ijji
ijij dddError
PP-Clustering

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
34
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Dimensionality Reduction Transformation (DRBT)
12810944689044286
2518340765828446
1297724705240254
1748124536456342
1939132638075123
PR_intQRSInt_defheart
rate
weightageID
A sample of the cardiac arrhythmia database(UCI Machine Learning Repository)
Original Data
ID Att1 Att2 Att3 Att1 Att2 Att3
123 -50.40 17.33 12.31 -55.50 -95.26 -107.93
342 -37.08 6.27 12.22 -51.00 -84.29 -83.13
254 -55.86 20.69 -0.66 -65.50 -70.43 -66.97
446 -37.61 -31.66 -17.58 -85.50 -140.87 -72.74
286 -62.72 37.64 18.16 -88.50 -50.22 -102.76
Transformed Data
RP1: The random matrix is based on the Normal distribution.
RP2: The random matrix is based on a much simpler distribution.
RP1 RP2
PP-Clustering

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
35
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Dimensionality Reduction Transformation (DRBT)
• The Security of the DRBT:
Lemma 3: A random projection from d to k dimensions, where k d, is a non-invertible linear transformation.
• The Complexity of the DRBT:
The complexity of space requirements is of order O(m), where m is the number of objects.
The communication cost is of order O(mlk), where l represents the size (in bits) required to transmit a dataset from one party to a central or third party.
PP-Clustering

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
36
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Dimensionality Reduction Transformation (DRBT)
C1’ C2’ … Ck’
C1 freq1,1 freq1,2 … freq1,k
C2 freq2,1 freq2,2 … freq2,k
… … … … …
Ck freqk,1 freqk,2 … freqk,k
• The Accuracy of the DRBT:
Precision (P) =
Recall (R) =
|| '
,
i
ji
c
freq
||,
i
ji
c
freq
F-measure (F) = RP
RP
2
Overall F-measure (F) =
k
ii
k
iii
c
cFc
1
1
||
)(||
PP-Clustering

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
37
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Results and Evaluation
Dataset # records # items Avg.Length Shortest
Record
Longest
Record
BMS 59,602 497 2.51 1 145
Retail 88,162 16,470 10.30 1 76
Kosarak 990,573 41,270 8.10 1 1065
Reuters 7,774 26,639 46.81 1 427
Accidents 340,183 468 33.81 18 51
Mushroom 8,124 119 23.00 23 23
Chess 3,196 75 37.00 37 37
Connect 67,557 129 43.00 43 43
Pumbs 49,046 2,113 74.00 74 74
Results
Datasets used in our performance evaluation
Association
Rules
Clustering

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
38
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Data Sharing-Based Algorithms
• Item Group Algorithm (IGA) [Oliveira & Zaiane, PSDM 2002].
• Sliding Window Algorithm (SWA) [Oliveira & Zaïane, ICDM 2003].
• Round Robin Algorithm (RRA) [Oliveira & Zaïane, IDEAS 2003].
• Random Algorithm (RA) [Oliveira & Zaïane, IDEAS 2003].
• Algo2a [E. Dasseni et al., IHW 2001].
Results

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
39
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Methodology• The Sensitive rules selected based on four scenarios: S1: Rules with items mutually exclusive. S2: Rules selected randomly. S3: Rules with very high support. S4: Rules with low support.
• The effectiveness of the algorithms was measured based on: C1: = 0%, fixed the minimum support () and minimum
confidence (). C2: the same as C1 but varied the number of sensitive rules. C3: = 0%, fixed the minimum confidence () and the number of
sensitive rules, and varied the minimum support ().
Results

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
41
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Measuring Effectiveness
S4
Algorithm = 0% 6 sensitive rules
S1 S2 S3
Kosarak IGA IGA IGA IGA
Retail IGA SWA RA RA
Reuters IGA IGA IGA IGA
BMS-1 IGA IGA IGA IGA
S4
Algorithm = 0% varying values of
S1 S2 S3
Kosarak IGA IGA IGA IGA
Retail IGA SWA RA RRA
Reuters IGA IGA IGA IGA
BMS-1 IGA IGA IGA IGA
Misses Cost under condition C1
Misses Cost under condition C3
SWA
S4
Algorithm = 0% 6 sensitive rules
S1 S2 S3
Kosarak SWA SWA SWA SWA
Retail SWA
Reuters SWA SWA
BMS-1 SWA SWA
Dif (D, D’ ) under conditions C1 and C3
SWA SWA
SWA
SWA
SWA
SWA
IGA / SWA
S4
Algorithm = 0% varying the # of rules
S1 S2 S3
Kosarak IGA IGA IGA
Retail IGA
Reuters IGA
BMS-1 IGA
IGA
RA RA
IGA
IGAAlgo2a/IGA
Misses Cost under condition C2
IGA IGA
IGA
Results
Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
42
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
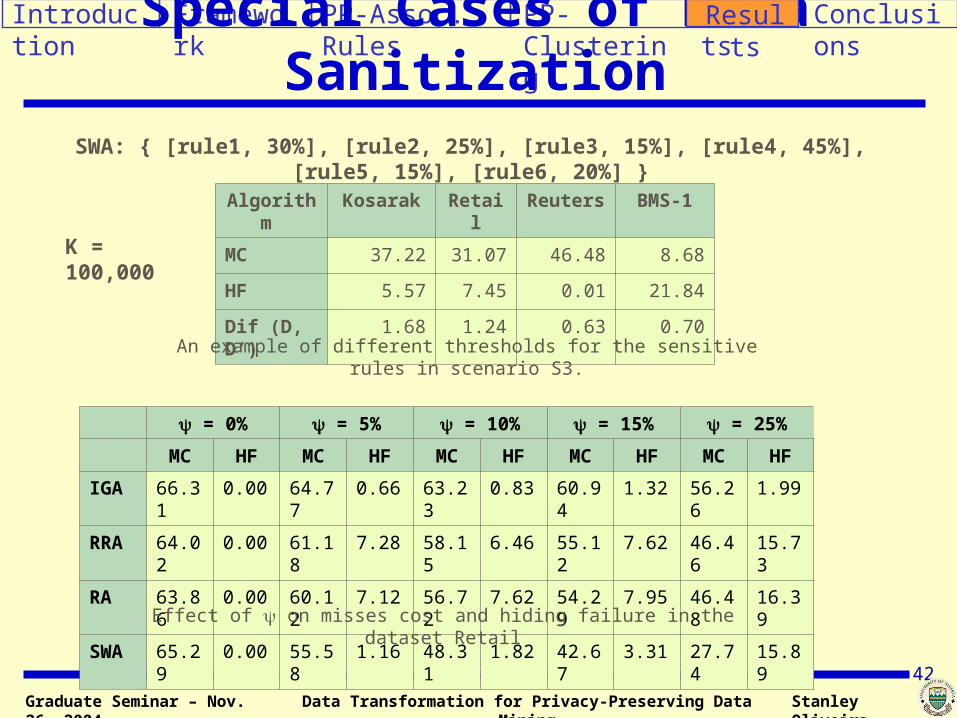
Special Cases of Data Sanitization
Algorithm Kosarak Retail Reuters BMS-1
MC 37.22 31.07 46.48 8.68
HF 5.57 7.45 0.01 21.84
Dif (D, D’) 1.68 1.24 0.63 0.70
An example of different thresholds for the sensitive rules in scenario S3.
SWA: { [rule1, 30%], [rule2, 25%], [rule3, 15%], [rule4, 45%], [rule5, 15%], [rule6, 20%] }
= 0% = 5% = 10% = 15% = 25%
MC HF MC HF MC HF MC HF MC HF
IGA 66.31 0.00 64.77 0.66 63.23 0.83 60.94 1.32 56.26 1.99
RRA 64.02 0.00 61.18 7.28 58.15 6.46 55.12 7.62 46.46 15.73
RA 63.86 0.00 60.12 7.12 56.72 7.62 54.29 7.95 46.48 16.39
SWA 65.29 0.00 55.58 1.16 48.31 1.82 42.67 3.31 27.74 15.89
K = 100,000
Effect of on misses cost and hiding failure in the dataset Retail
Results

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
43
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
CPU Time
Results of CPU time for the sanitization process
Results

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
44
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
• Downright Sanitizing Algorithm (DSA) [Oliveira & Zaiane, PAKDD 2004].
• We used the data-sharing algorithm IGA for our comparison study.
• Methodology:
1) We used IGA to sanitize the datasets.
2) We used Apriori to extract the rules to share (all the datasets).
1) We used Apriori to extract the rules from the datasets.
2) We used DSA to sanitize the rules mined in the previous step.
Pattern Sharing-based Algorithm
IGA
DSA
Results

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
45
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Measuring EffectivenessDataset = 0% 6 sensitive rules
S1 S2 S3 S4
Kosarak IGA DSA DSA DSA
Retail DSA DSA DSA IGA
Reuters DSA DSA DSA IGA
BMS-1 DSA DSA DSA DSA
The best algorithm in terms of misses cost
Dataset = 0% varying # of rules
S1 S2 S3 S4
Kosarak IGA DSA DSA IGA /
DSA
Retail DSA DSA IGA / DSA
IGA
Reuters IGA /
DSA
DSA DSA IGA
BMS-1 DSA DSA DSA DSA
Dataset = 0% 6 sensitive rules
S1 S2 S3 S4
Kosarak IGA DSA DSA DSA
Retail DSA DSA DSA IGA
Reuters DSA DSA DSA IGA
BMS-1 DSA DSA DSA DSA
The best algorithm in terms of misses cost varying the number of rules to sanitize
The best algorithm in terms of side effect factor
Results

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
47
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Lessons Learned• Large dataset are our friends.
• The benefit of index: at most two scans to sanitize a dataset.
• The data sanitization paradox.
• The outstanding performance of IGA and DSA.
• Rule sanitization reduces inference channels, and does not change the support and confidence of the shared rules.
• DSA reduces the flexibility of information sharing.
Results

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
48
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Evaluation: DRBT
• Methodology: Step 1: Attribute normalization. Step 2: Dimensionality reduction (two approaches). Step 3: Computation of the error produced on reduced
datasets. Step 4: Run K-means to find the clusters in the original and
reduced datasets. Step 5: Computation of F-measure (experiments repeated 10
times). Step 6: Comparison of the clusters generated from the
original and the reduced datasets.
Results

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
49
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
DRBT: PPC over centralized DataTransformation dr = 37 dr = 34 dr = 31 dr = 28 dr = 25 dr = 22 dr = 16
RP1 0.00 0.015 0.024 0.033 0.045 0.072 0.141
RP2 0.00 0.014 0.019 0.032 0.041 0.067 0.131
The error produced on the dataset Chess (do = 37)
Data K = 2 K = 3 K = 4 K = 5
Transformation Avg Std Avg Std Avg Std Avg Std
RP2 0.941 0.014 0.912 0.009 0.881 0.010 0.885 0.006
Average of F-measure (10 trials) for the dataset Accidents (do = 18, dr = 12)
Data K = 2 K = 3 K = 4 K = 5
Transformation Avg Std Avg Std Avg Std Avg Std
RP2 1.000 0.000 0.948 0.010 0.858 0.089 0.833 0.072
Average of F-measure (10 trials) for the dataset Iris (do = 5, dr = 3)
Results

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
50
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
DRBT: PPC over Vertically Centralized Data
No. Parties RP1 RP2
1 0.0762 0.0558
2 0.0798 0.0591
3 0.0870 0.0720
4 0.0923 0.0733
The error produced on the dataset Pumsb (do = 74)
Data K = 2 K = 3 K = 4 K = 5
Transformation Avg Std Avg Std Avg Std Avg Std
1 0.909 0.140 0.965 0.081 0.891 0.028 0.838 0.041
2 0.904 0.117 0.931 0.101 0.894 0.059 0.840 0.047
3 0.874 0.168 0.887 0.095 0.873 0.081 0.801 0.073
4 0.802 0.155 0.812 0.117 0.866 0.088 0.831 0.078
Average of F-measure (10 trials) for the dataset Pumsb (do = 74, dr = 38)
Results

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
51
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Contributions of this Research
• Foundations for further research in PPDM.
• A taxonomy of PPDM techniques.
• A family of privacy-preserving methods.
• A library of sanitizing algorithms.
• Retrieval facilities.
• A set of metrics.
Conclusions

Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
52
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Future Research
• Privacy definition in data mining.
• Combining sanitization and randomization.
• New method for PPC (k-anonymity + isometries + data distortion)
• Sanitization of documents repositories.
Conclusions
Data Transformation for Privacy-Preserving Data MiningGraduate Seminar – Nov. 26, 2004 Stanley Oliveira
53
Introduction Framework ResultsPP-ClusteringPP-Assoc. Rules Conclusions
Thank You!
Conclusions
Related Documents











