Data Processing with Missing Information Haixuan Yang Haixuan Yang Supervisors: Supervisors: Prof. Irwin King & Prof. Michael R. Lyu

Data Processing with Missing Information Haixuan Yang Supervisors: Haixuan Yang Supervisors: Prof. Irwin King & Prof. Michael R. Lyu.
Dec 22, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Data Processing with Missing Information
Haixuan YangHaixuan YangSupervisors: Supervisors: Prof. Irwin King & Prof. Michael R. Lyu

2
OutlineOutline IntroductionIntroduction Link AnalysisLink Analysis
– PreliminariesPreliminaries– Related WorkRelated Work– Predictive Ranking ModelPredictive Ranking Model– Block Predictive Ranking ModelBlock Predictive Ranking Model– Experiment SetupExperiment Setup– ConclusionsConclusions
Information SystemsInformation Systems– PreliminariesPreliminaries– Related WorkRelated Work– Generalized Dependency Degree Generalized Dependency Degree ’’ – Extend Extend ’’ to Incomplete Information Systems to Incomplete Information Systems– ExperimentsExperiments– ConclusionsConclusions
Future WorkFuture Work

3
IntroductionIntroduction
We handle missing information in two areasWe handle missing information in two areas– Link analysis on the web.Link analysis on the web.– Information systems with missing values.Information systems with missing values.
In both areas, there is a common simple In both areas, there is a common simple technique: using the sample to estimate the technique: using the sample to estimate the density. If the total number of the sample is density. If the total number of the sample is nn, , and the number for a phenomena in the sample is and the number for a phenomena in the sample is mm, then the probabilty for this phenomena is , then the probabilty for this phenomena is estimated as estimated as m/nm/n..
In both areas, the difficulty is how to use the In both areas, the difficulty is how to use the above simple technique in its right places.above simple technique in its right places.

4
Link AnalysisLink Analysis

5
PreliminariesPreliminaries PageRank (1998)PageRank (1998)
– It uses the link information to rank web page;It uses the link information to rank web page;
– The importance of a page depends on the number of pages The importance of a page depends on the number of pages that point to it;that point to it;
– The importance of a page also depends on the importance of The importance of a page also depends on the importance of pages that point to it.pages that point to it.
– If If xx is the rank vector, then the rank is the rank vector, then the rank xxii can be expressed as can be expressed as
xAfex T ])1[(
n
jji
n
jjiji xfxax
11
)1(
Where
.otherwise,0
i,tofromlinkaisthereif,/1 jda j
ij dj is the outdegree of the node j
fi: probability that the user will randomly jump to the node i
: probability that the user follows the actual link structure.

6
PreliminariesPreliminaries ProblemsProblems
– ManipulationManipulation– The “richer-get-richer” phenomenonThe “richer-get-richer” phenomenon– Computation EfficiencyComputation Efficiency– Dangling nodes problemDangling nodes problem

7
PreliminariesPreliminaries Nodes that either have no out-link or for which no Nodes that either have no out-link or for which no
out-link is known are called dangling nodes.out-link is known are called dangling nodes. Dangling nodes problemDangling nodes problem
– It is hard to sample the entire web.It is hard to sample the entire web.• Page et al (1998) reported that they have Page et al (1998) reported that they have 5151 million URL million URL
not downloaded yet when they have not downloaded yet when they have 2424 million pages million pages downloaded.downloaded.
• Eiron et al (2004) reported that the number of uncrawled Eiron et al (2004) reported that the number of uncrawled pages (pages (3.753.75 billion billion) still far exceeds the number of crawled ) still far exceeds the number of crawled pages (pages (1.11.1 billion billion).).
– Including dangling nodes in the overall ranking may not Including dangling nodes in the overall ranking may not only change the rank value of non-dangling nodes but only change the rank value of non-dangling nodes but also change the order of them.also change the order of them.

8
An exampleAn example
If we ignore the dangling node 3, then the ranks for nodes 1 and 2 are .)5.0,5.0(),( 21 xx
If we consider the dangling node 3, then the ranks are by the revised pagerank algorithm (Kamvar 2003).
)3032.0,3936.0,3032.0(),,( 321 xxx

9
Related workRelated work
Page (1998): Simply removing them. After doing Page (1998): Simply removing them. After doing so, they can be added back in. The details are so, they can be added back in. The details are missing. missing.
Amati (2003): Handle dangling nodes robustly Amati (2003): Handle dangling nodes robustly based on a modified graph. based on a modified graph.
Kamvar (2003): Add uniform random jump from Kamvar (2003): Add uniform random jump from dangling nodes to all nodes.dangling nodes to all nodes.
Eiron (2004): Speed up the model in Kamvar Eiron (2004): Speed up the model in Kamvar (2003), but sacrificing accuracy. Furthermore, (2003), but sacrificing accuracy. Furthermore, suggest algorithm that penalize the nodes that suggest algorithm that penalize the nodes that link to dangling nodes of class 2 that we will link to dangling nodes of class 2 that we will define later.define later.

10
Related work - Amati (2003)Related work - Amati (2003)

11
Related work - Kamvar (2003)Related work - Kamvar (2003)

12
Related work - Eiron (2004)Related work - Eiron (2004)

13
Predictive Ranking ModelPredictive Ranking Model
Classes of Dangling nodesClasses of Dangling nodes– Nodes that are found but not visited at current time are Nodes that are found but not visited at current time are
called dangling nodes of class 1.called dangling nodes of class 1.– Nodes that have been tried but not visited successfully Nodes that have been tried but not visited successfully
are called dangling nodes of class 2.are called dangling nodes of class 2.– Nodes, which have been visited successfully but from Nodes, which have been visited successfully but from
which no outlink is found, are called dangling nodes of which no outlink is found, are called dangling nodes of class 3.class 3.
Handle different kind of dangling nodes in Handle different kind of dangling nodes in different way. Our work focuses on dangling different way. Our work focuses on dangling nodes of class 1, which cause missing nodes of class 1, which cause missing information. information.

14
1 2 3 4
5 6
7
Illustration of dangling nodesIllustration of dangling nodes
At time 1
visited node:1.
Dangling nodes of class 1: 2, 4, 5,7.
At time 2,
1 2 4
5
2 3
6
Dangling nodes of class 3 : 7
Visited nodes : 1,7,2;
Dangling nodes of class 1: 3,4,5,6
77
Known information at time 2: red links
Missing information at time 2:
White links

15
Predictive Ranking ModelPredictive Ranking Model
For dangling nodes of class 3, we use the same For dangling nodes of class 3, we use the same technique as Kamvar (2003).technique as Kamvar (2003).
For dangling nodes of class 2, we ignore them at For dangling nodes of class 2, we ignore them at current model although it is possible to combine current model although it is possible to combine the push-back algorithm (Eiron 2004) with our the push-back algorithm (Eiron 2004) with our model. (Penalizing nodes is a subjective matter.) model. (Penalizing nodes is a subjective matter.)
For dangling nodes of class 1, we try to predict For dangling nodes of class 1, we try to predict the missing information about the link structrue.the missing information about the link structrue.

16
Predictive Ranking Model (Cont.)Predictive Ranking Model (Cont.)
Suppose that all the nodes V can be partitioned into three Suppose that all the nodes V can be partitioned into three subsets: . subsets: . – denotes the set of all denotes the set of all non-dangling nodesnon-dangling nodes (that have been (that have been
crawled successfully and have at least one out-link); crawled successfully and have at least one out-link);
– denotes the set of all denotes the set of all dangling nodes of class 3dangling nodes of class 3; ;
– denotes the set of all denotes the set of all dangling nodes of class 1dangling nodes of class 1; ; For each node v in V, the real in-degree of v is For each node v in V, the real in-degree of v is not knownnot known. . For each node v in , the real out-degree of v is For each node v in , the real out-degree of v is knownknown.. For each node v in , the real out-degree of v is For each node v in , the real out-degree of v is knownknown to to
be zero. be zero. For each node v in , the real out-degree of v is For each node v in , the real out-degree of v is unknownunknown..
21 ,, DDC
1D
2D
C
C
1D
2D

17
Predictive Ranking Model (Cont.)Predictive Ranking Model (Cont.)
We predict the real in-degree of v by the number We predict the real in-degree of v by the number of found links from C to v.of found links from C to v.– Assumption: the number of found links from C to v is Assumption: the number of found links from C to v is
proportional to the real number of links from V to v.proportional to the real number of links from V to v.• For example, For example,
if C and have if C and have 100100 nodes, nodes,
V has V has 10001000 nodes, nodes,
and if the number of links from C to v is and if the number of links from C to v is 55,,
then we estimate that the number of links from V to v is then we estimate that the number of links from V to v is 5050. .
The difference between these two numbers is The difference between these two numbers is distributed uniformly to the nodes in .distributed uniformly to the nodes in .
1D
2D

18
NQD
MPCA
Predictive Ranking ModelPredictive Ranking Model
Models the missing information from unvisited nodes to nodes in V: from D2 to V.
)(
1
1
22
1
11
1
)(
)()(00
00)(
)()(0
000)(
)()(
mmnn
nn
mmn
vfdvd
mmn
vfdvdmmn
vfdvd
N
M
1
Model the known link information as Page (1998): from C to V.
Model the user’s behavior as Kamvar (2003) when facing dangling nodes of class 3: from D1 to V.
n : the number of nodes in V;
m: the number of nodes in C;
m1: the number of nodes in D1.

19
Predictive Ranking ModelPredictive Ranking Model
nnnnn ffff
ffff
ffff
f
f
f
2222
1111
2
1
111
Model users’ behavior (called as “teleportation”) as Page (1998) and Kamvar (2003) when the users get bored in following actual links and they may
jump to some nodes randomly.
xAfex T ])1[( f Te
85.0
Tnxxxx ),,,( 21 is the rank vector.

20
Block Predictive Ranking ModelBlock Predictive Ranking Model
Predict the in-degree of v more accurately.Predict the in-degree of v more accurately. Divide all nodes into p blocks (v[1], v[2], …, v[p]) Divide all nodes into p blocks (v[1], v[2], …, v[p])
according to their top level domains (for example, according to their top level domains (for example, edu), or domains (for example, stanford.edu), or edu), or domains (for example, stanford.edu), or the countries (for example, cn).the countries (for example, cn).
Assumption: the number of found links from C[i] Assumption: the number of found links from C[i] (C[i] is the meet of C and V[i]) to v is proportional (C[i] is the meet of C and V[i]) to v is proportional to the real number of links from V[i] to v. to the real number of links from V[i] to v. Consequently, the matrix A is changed. Consequently, the matrix A is changed.
Other parts are same as the Predictive Ranking Other parts are same as the Predictive Ranking Model. Model.

21
Block Predictive Ranking ModelBlock Predictive Ranking Model
p
p
NNNQD
MMMPCA
21
21
Models the missing information from unvisited nodes in 1st block to nodes in V.

22
Experiment SetupExperiment Setup
Get two datasets (by Patrick Lau): one is within the domain Get two datasets (by Patrick Lau): one is within the domain cuhk.edu.hk, the other is outside this domain. In the first cuhk.edu.hk, the other is outside this domain. In the first dataset, we snapshot 11 matrices during the process of dataset, we snapshot 11 matrices during the process of crawling; in the second dataset, we snapshot 9 matrices.crawling; in the second dataset, we snapshot 9 matrices.
Apply both Predictive Ranking Model and the revised Apply both Predictive Ranking Model and the revised RageRank Model (RageRank Model (Kamvar 2003) to these snapshots.Kamvar 2003) to these snapshots.
Compare the results of both models at time t with the future Compare the results of both models at time t with the future results of both models. results of both models. – The future results rank more nodes than the current results. The future results rank more nodes than the current results.
So it is difficult to make a direct comparison.So it is difficult to make a direct comparison.

23
Illustration for comparisonIllustration for comparison
future result
current result
Cut
Normalize
Difference computed by 1-norm

24
Within domain cuhk.edu.hkWithin domain cuhk.edu.hk
Data Description
Time t 1 2 3 4 5 6 7 8 9 10 11
Vnum[t] 7712 78662 109383 160019 252522 301707 373579 411724 444974 471684 502610
Tnum[t] 18542 120970 157196 234701 355720 404728 476961 515534 549162 576139 607170
Time t 1 2 3 4 5 6 7 8 9 10 11
PreRank 5 3 2 2 2 2 2 2 2 2 2
PageRank 12 4 3 2 2 2 2 2 2 2 2
Number of iterations

25
Within domain cuhk.edu.hkWithin domain cuhk.edu.hk
Comparison Based on future PageRank result at time 11.
PageRank result at time t
PageRank result at time 11
PreRank result at time t
Difference
Difference

26
Within domain cuhk.edu.hkWithin domain cuhk.edu.hk
Comparison Based on future PageRank result at time 11.
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1 2 3 4 5 6 7 8 9 10 11
Time
Difference
PreRank
PageRank
Visited nodes at time 11: 502610Found nodes at time 11: 607170

27
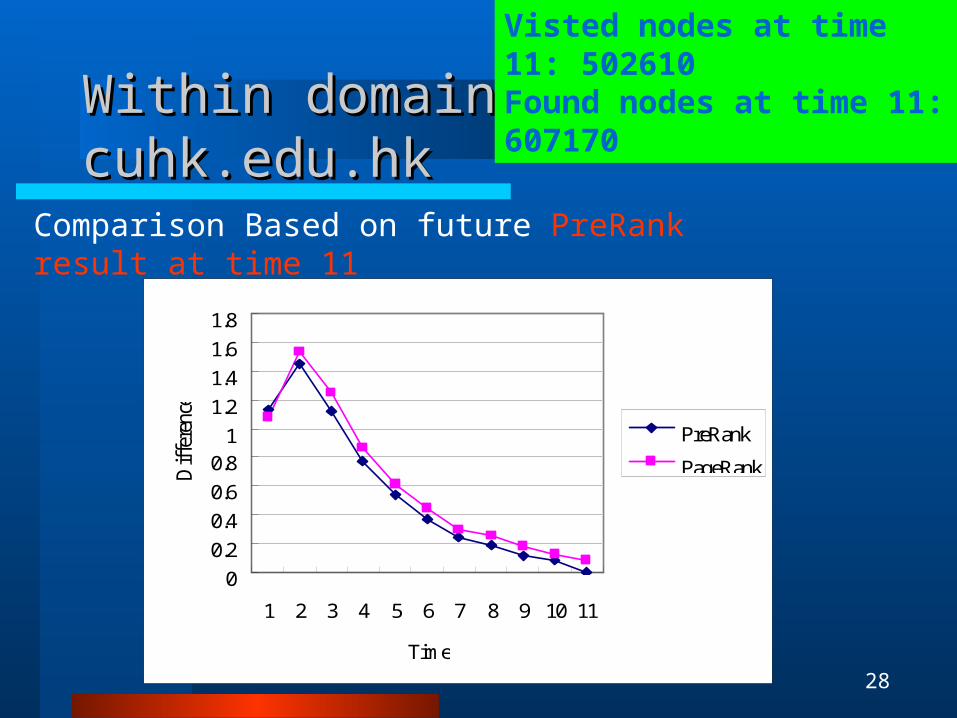
Within domain cuhk.edu.hkWithin domain cuhk.edu.hk
Comparison Based on future PreRank result at time 11.
PageRank result at time t
PreRank result at time 11
PreRank result at time t
Difference
Difference
28
Within domain cuhk.edu.hkWithin domain cuhk.edu.hk
Comparison Based on future PreRank result at time 11
0
0.2
0.4
0.6
0.81
1.2
1.4
1.6
1.8
1 2 3 4 5 6 7 8 9 10 11
Time
Difference
PreRank
PageRank
Visted nodes at time 11: 502610Found nodes at time 11: 607170

29
Outside cuhk.edu.hkOutside cuhk.edu.hk
Data Description
Time t 1 2 3 4 5 6 7 8 9
Vnum[t] 4611 6785 10310 16690 20318 23453 25417 28847 39824
Tnum[t] 87930 121961 164701 227682 290731 322774 362440 413053 882254
Time t 1 2 3 4 5 6 7 8 9
PreRank 2 2 2 1 1 1 1 1 1
PageRank 3 3 3 2 2 2 2 2 1
Number of iterations

30
Outside cuhk.edu.hkOutside cuhk.edu.hk
Comparison Based on future PageRank result at time 9
0
0.2
0.4
0.6
0.8
1
1.2
1 2 3 4 5 6 7 8 9
Time
Differen
ce PreRank
PageRank
Visted nodes at time 9: 39824Found nodes at time 9: 882254Actual nodes: more than 4 billions

31
Outside cuhk.edu.hkOutside cuhk.edu.hk
Comparison Based on future PreRank result at time 9
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1 2 3 4 5 6 7 8 9
Time
Difference PreRank
PageRank
Visted nodes at time 9: 39824Found nodes at time 9: 882254Actual nodes: more than 4 billions

32
Conclusions Conclusions on PreRankon PreRank
PreRank performs better than PageRank in PreRank performs better than PageRank in accuracy in a close web.accuracy in a close web.
PreRank needs less iterations than PageRank PreRank needs less iterations than PageRank (outside our expectation !)(outside our expectation !)..

33
Information Systems (IS)Information Systems (IS)

34
PreliminariesPreliminaries In Rough Set Theory, the dependency degree In Rough Set Theory, the dependency degree
is a traditional measure, which expresses the is a traditional measure, which expresses the percentage of objects that can be correctly percentage of objects that can be correctly classified into D-class by employing attribute C. classified into D-class by employing attribute C. However, However, does not accurately express the does not accurately express the dependency between C and D. dependency between C and D. ==00 when there is no deterministic rule. when there is no deterministic rule.
The table in next slide is an Information system. The table in next slide is an Information system.

35
=0 when C={a}, D={d}. But in fact D depends on C to some degree.
An exampleAn example
AttributeAttribute
ObjectObjectHeadache (a)Headache (a) Muscle Pain (b)Muscle Pain (b) Body Body
Temperature (c)Temperature (c) Influenza (d)Influenza (d)
e1e1 YY YY Normal(0)Normal(0) NN
e2e2 YY YY High(1)High(1) YY
e3e3 YY YY Very high(2)Very high(2) YY
e4e4 NN YY Normal(0)Normal(0) NN
e5e5 NN NN High(1)High(1) NN
e6e6 NN YY Very high(2)Very high(2) YY
e7e7 YY NN High(1)High(1) YY

36
Original Definition of Original Definition of
||
|),(|),(
U
DCPOSDC )(),(
/XCDCPOS
DUX where
U is set of all objects
X is one D-class
is the lower approximation
of X
)(XC
Each block is a C-class

37
PreliminariesPreliminaries Incomplete IS: has missing values.Incomplete IS: has missing values.
AttributeAttribute
ObjectObjectHeadache (a)Headache (a) Muscle Pain (b)Muscle Pain (b) Body Body
Temperature (c)Temperature (c) Influenza (d)Influenza (d)
e1e1 YY YY Normal(0)Normal(0) NN
e2e2 YY ** High(1)High(1) YY
e3e3 YY YY ** YY
e4e4 NN ** Normal(0)Normal(0) NN
e5e5 NN NN High(1)High(1) NN
e6e6 NN YY Very high(2)Very high(2) YY
e7e7 YY NN High(1)High(1) YY

38
Related work Related work
Lingras (1998): represents missing values by the Lingras (1998): represents missing values by the set of all possible values, by which a rule set of all possible values, by which a rule extraction method is proposed.extraction method is proposed.
Kryszkiewicz (1999): establishes a similarity Kryszkiewicz (1999): establishes a similarity relation based on the missing values, upon which relation based on the missing values, upon which a method for computing optimal certain rules is a method for computing optimal certain rules is proposed.proposed.
Leung (2003): introduces maximal consistent Leung (2003): introduces maximal consistent block technique for rule acquisition in incomplete block technique for rule acquisition in incomplete information systems.information systems.

39
Related workRelated work
The conditional entropy, The conditional entropy,
is used in C4.5 (Quinlan, 1993).is used in C4.5 (Quinlan, 1993).
c d
c d
cdcdc
cdcdcCDH
])|(Pr[log]|Pr[]Pr[
])|(Pr[log]|Pr[]Pr[)|(
2
2

40
Definition of Definition of
)()( |)(|
|)()(|
||
1),(
xDxCUx xC
xCxD
UDC
We find the following variation of .
U: universe of objects;
C, D: sets of attributes;
C(x): C-class containing x;
D(x): D-class containing x.

41
U: universe of objects;
C, D: sets of attributes;
C(x): C-class containing x;
D(x): D-class containing x.
Generalized Dependency Degree Generalized Dependency Degree ’’
Ux xC
xCxD
UDC
|)(|
|)()(|
||
1),('
The first form of ’ is defined as ’ is defined as

42
Variations of Variations of ’’ and and
1)(),(
)()(),(rConDCMinRr
rConrStrDC
),(
)()(),('DCMinRr
rConrStrDC
Where MinR(C,D) denotes the set of all minimal rules. Minimal rule takes the following form:
mmnn vbvbvbuauaua ...... 22112211
},...,,,{ 321 naaaaC },...,,,{ 321 mbbbbD
The second form of ’’

43
Properties of Properties of ’’
1),('0 21 RR
).,('),(' 2211
RUURRMinR
’ ’ can be extended to equivalence relations Rcan be extended to equivalence relations R1 1 and Rand R22. .
Ux xR
xRxR
URR
|)(|
|)()(|
||
1),('
1
1221
),('),(' 2121 RRRRRR
),('),(' 2121 RRRRRR
Property 1.
Property 2.
Property 3.
Property 4.

44
Extend Extend ’’ to incomplete IS to incomplete IS Replace the missing value by the probabilistic Replace the missing value by the probabilistic
distribution.distribution.
AttributeAttribute
ObjectObjectHeadache (a)Headache (a) Muscle Pain (b)Muscle Pain (b) Body Body
Temperature (c)Temperature (c) Influenza (d)Influenza (d)
e1e1 YY YY Normal(0)Normal(0) NN
e2e2 YY High(1)High(1) YY
e3e3 YY YY ** YY
e4e4 NN ** Normal(0)Normal(0) NN
e5e5 NN NN High(1)High(1) NN
e6e6 NN YY Very high(2)Very high(2) YY
e7e7 YY NN High(1)High(1) YY
}/,/{ 21 NPYP
}/,/{ 21 NQYQ
}2/,1/,0/{ 321 SSS
where 5/311 QP 5/222 QP 6/1,6/3,6/2 321 SSS

45
Extend to incomplete IS (Cont.)Extend to incomplete IS (Cont.)
Then use the second form of the generalized Then use the second form of the generalized dependency degree dependency degree
),(
)()(),('DCMinRr
rConrStrDC
as our definition of as our definition of ’’ in an incomplete IS. in an incomplete IS.
We need to define the strength and confidence of We need to define the strength and confidence of a rule.a rule.

46
Extend to incomplete IS (Cont.)Extend to incomplete IS (Cont.)
The confidence of a rule is defined as The confidence of a rule is defined as
||)(||/||)(||)( cardcardCon
The strength of a rule is defined as The strength of a rule is defined as
||)(||/||)(||)( cardcardStr
The set , is defined inductively as The set , is defined inductively as |||| ||||

47
Extend to incomplete IS (Cont.)Extend to incomplete IS (Cont.)
)}(])([,|/)({|||| xpvxaPUxxxpva S
,|||||||||||| SSS
,|||||||||||| SSS
SS ||~||||||~
where SS |||||||| is the algebraic sum of the fuzzy sets SS and ||||||||
SS |||||||| is the algebraic product of the fuzzy sets SS and ||||||||
S||~|| is the complement of the fuzzy sets S||||

48
c d
c d
cdcdc
cdcdcCDH
])|(Pr[log]|Pr[]Pr[
])|(Pr[log]|Pr[]Pr[)|(
2
2
The conditional entropy is as follows:
’(C,D) can be proved to be
c d
c d
cdc
cdcDC
]|[Pr]Pr[
])|[Pr]Pr[),('
2
2
Comparison with conditional entropyComparison with conditional entropy
The third form of ’’

49
• The conditional entropy H(D|C) is used in C4.5
• We replace H(D|C) with ’(C,D) in C4.5 algorithm such that a new C4.5 algorithm is formed.
Comparison by experimentsComparison by experiments

50
We use all the same eleven datasets with missing We use all the same eleven datasets with missing values from the UCI Repository as Quinlan uses values from the UCI Repository as Quinlan uses in his paper. in his paper.
Improved use of continuous attributes in C4.5. Journal of Artificial Improved use of continuous attributes in C4.5. Journal of Artificial Intelligence Research, 4, 77-90, 1996.Intelligence Research, 4, 77-90, 1996.
Both old C4.5 and new C4.5 use ten-fold cross-Both old C4.5 and new C4.5 use ten-fold cross-validations with each task.validations with each task.
Datasets we useDatasets we use

51
datasetdataset CasesCases ClassesClasses ContCont DiscrDiscr
AnnealAnneal 898898 66 66 3232
AutoAuto 205205 66 1515 1010
Breast-wBreast-w 699699 22 99 00
ColicColic 368368 22 77 1515
Credit-aCredit-a 690690 22 66 99
Heart-cHeart-c 303303 22 66 77
Heart-hHeart-h 294294 22 88 55
HepatitisHepatitis 155155 22 66 1313
AllhyperAllhyper 37723772 55 77 2222
LaborLabor 5757 22 88 88
SickSick 37723772 22 77 2222
Description of the Datasets

52
datasetdataset OOld C4.5ld C4.5unpruned unpruned
(%)(%)
OOld C4.5ld C4.5pruned (%)pruned (%)
NNew C4.5ew C4.5unpruned(%)unpruned(%)
NNew C4.5ew C4.5pruned(%)pruned(%)
AnnealAnneal 3.93.9 4.64.6 6.16.1 7.97.9
AutoAuto 20.520.5 2222 2222 22.522.5
Breast-wBreast-w 5.75.7 4.34.3 4.24.2 4.54.5
ColicColic 19.819.8 1616 16.316.3 15.415.4
Credit-aCredit-a 19.719.7 17.117.1 15.215.2 15.615.6
Heart-cHeart-c 22.422.4 21.421.4 23.423.4 23.123.1
Heart-hHeart-h 24.224.2 22.822.8 20.720.7 21.121.1
HepatitisHepatitis 2020 19.919.9 19.319.3 19.319.3
AllhyperAllhyper 1.41.4 1.41.4 1.11.1 1.21.2
LaborLabor 24.724.7 26.326.3 15.715.7 19.319.3
SickSick 1.21.2 1.11.1 11 11
Mean error rates of both algorithms

53
datasetdataset OOld C4.5ld C4.5 NNew C4.5ew C4.5UnprunedUnpruned
Reduced Reduced rate(%)rate(%)
NNew C4.5ew C4.5prunedpruned
Reduced Reduced rate(%)rate(%)
AnnealAnneal 6.8006.800 4.6004.600 3232..4 4 5.1005.100 2525.0.0
AutoAuto 9.7009.700 2.6002.600 7373..2 2 2.6002.600 7373..22
Breast-wBreast-w 1.6001.600 1.0001.000 3737..5 5 1.0001.000 3737..55
ColicColic 4.1004.100 1.5001.500 6363..4 4 1.5001.500 6363..44
Credit-aCredit-a 8.3008.300 2.4002.400 7171..1 1 2.5002.500 6969..99
Heart-cHeart-c 2.0002.000 0.7000.700 6565..0 0 0.9000.900 5555.0.0
HepatitisHepatitis 0.9000.900 0.6000.600 3333..3 3 0.7000.700 2222..22
AllhyperAllhyper 45.00045.000 18.50018.500 5858..9 9 18.50018.500 5858..99
LaborLabor 0.4000.400 0.1000.100 7575..0 0 0.4000.400 00.0.0
SickSick 38.10038.100 17.10017.100 5555..1 1 20.80020.800 4545..44
Average run time of both algorithms
Tim
e Unit:
0.01s

54
Conclusions on experimentsConclusions on experiments
1.1. TTheoretical complexity:heoretical complexity: The new C4.5 does not need the The new C4.5 does not need the MDL (Minimum Description Length) principal to correct the MDL (Minimum Description Length) principal to correct the bias towards the continuous attribute, and it does not bias towards the continuous attribute, and it does not need the pruning procedure. need the pruning procedure.
2.2. Speed:Speed: The new C4.5 outperforms the original C4.5 The new C4.5 outperforms the original C4.5 greatly in run time, becausegreatly in run time, becausea)a) To compute To compute ’,’, we only need to compute the square of we only need to compute the square of
the frequency, while the computation of the often used the frequency, while the computation of the often used conditional entropy needs to compute the time conditional entropy needs to compute the time consuming logarithm of the frequency.consuming logarithm of the frequency.
b)b) The building tree procedure in the new C4.5 algorithm The building tree procedure in the new C4.5 algorithm stops earlier. stops earlier.
c)c) Omitting the pruning procedure can also save us an Omitting the pruning procedure can also save us an amount of time. amount of time.
3.3. Prediction accuracy:Prediction accuracy: The new C4.5 is a little better than the The new C4.5 is a little better than the original C4.5 in prediction accuracy in these 11 datasets.original C4.5 in prediction accuracy in these 11 datasets.

55
Conclusions on Conclusions on ’’
The first form in terms of equivalent relation is The first form in terms of equivalent relation is most important.most important.– It is simple.It is simple.– It is flexible and so can be extended to arbitrary relation.It is flexible and so can be extended to arbitrary relation.– It bridges the gap between It bridges the gap between used in RST and the used in RST and the
conditional entropy use in Machine Learning.conditional entropy use in Machine Learning. The second form in terms of minimal rule and the The second form in terms of minimal rule and the
first form share the advantage of being easily first form share the advantage of being easily understood.understood.
The third form in terms of probability is The third form in terms of probability is computing-efficient.computing-efficient.

56
Conclusions on Conclusions on ’ ’ (Cont.)(Cont.)
The generalized dependency degree has good The generalized dependency degree has good properties, such as Partial Order Preserving properties, such as Partial Order Preserving Property and Anti- Partial Order Preserving Property and Anti- Partial Order Preserving Property .Property .
Its value is betweenIts value is between 0 0 and and 11..

57
Future WorkFuture Work
DeepenDeepen– In the area of link analysisIn the area of link analysis
• Estimate the web structure more accurately.Estimate the web structure more accurately.
• Conduct experiment on large real dataset to support the Conduct experiment on large real dataset to support the Block Predictive Ranking Model.Block Predictive Ranking Model.
• Speed up the predictive ranking algorithmSpeed up the predictive ranking algorithm
– In the area of decision treeIn the area of decision tree• Instead of branching on one attribute, we can branch on Instead of branching on one attribute, we can branch on
more than one attributes.more than one attributes.
• Handle missing value more accurately.Handle missing value more accurately.

58
Future Work (Cont.)Future Work (Cont.)
WidenWiden– In the area of link analysisIn the area of link analysis
• Push-back algorithm can be combined with our PreRank Push-back algorithm can be combined with our PreRank algorithmalgorithm.
– In the area of decision treeIn the area of decision tree• Create decision forest using the new C4.5 algorithm.Create decision forest using the new C4.5 algorithm.
– In other areas such as SVM (Support Vector Machine).In other areas such as SVM (Support Vector Machine).

59
Q & AQ & A
Related Documents











