Data modeling Dimensions

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Data modelingDimensions

Structure of dimension tables I
•Must have a primary key•Use surrogate keys that are meaningless integers or identifiers•Best performance when the joins between facts and dimensions are on single integer fields•Natural key versus surrogate key - natural key is a more meaningful col•When dimensions are static, there is a 1-1 mapping between natural key and surrogate key•Descriptive components of the dimension table are a major contributions to dim tables - may be

Structure of dimension tables II
•efficient generation and maintenance of the surrogate keys is important for success•Surrogate keys should not be smart/intelligent/meaningful because
–definition required them to be meaningless so that they don’t have to change over time–performance can be better instead of using concatenated natural keys–data type mismatch is ensured. no alpha numeric values should be allowed. data type should always be integer/number–removes the dependency on the source system

Creating dimension tables I
•may be done internally by the ETL system like lookup tables•can be extracted from data sources•data cleaning is important for big complex dimensions•conforming consists of aligning the content from different parts of the data warehouse•data delivery module for looking after SCDs

Flat and snowflake dimensions I
•Dimensions are flat denormalized tables•should have small cardinality•limited values•if staging data has data in 3NF, these attended 2NF dimensions are easily produced with a simple query on the 3NF source•only requirement is that every attribute is single valued (atomic) in the primary key•disadvantage of snowflake schema -- Many to 1 relations are hard to look at, complex schemas are difficult to end users
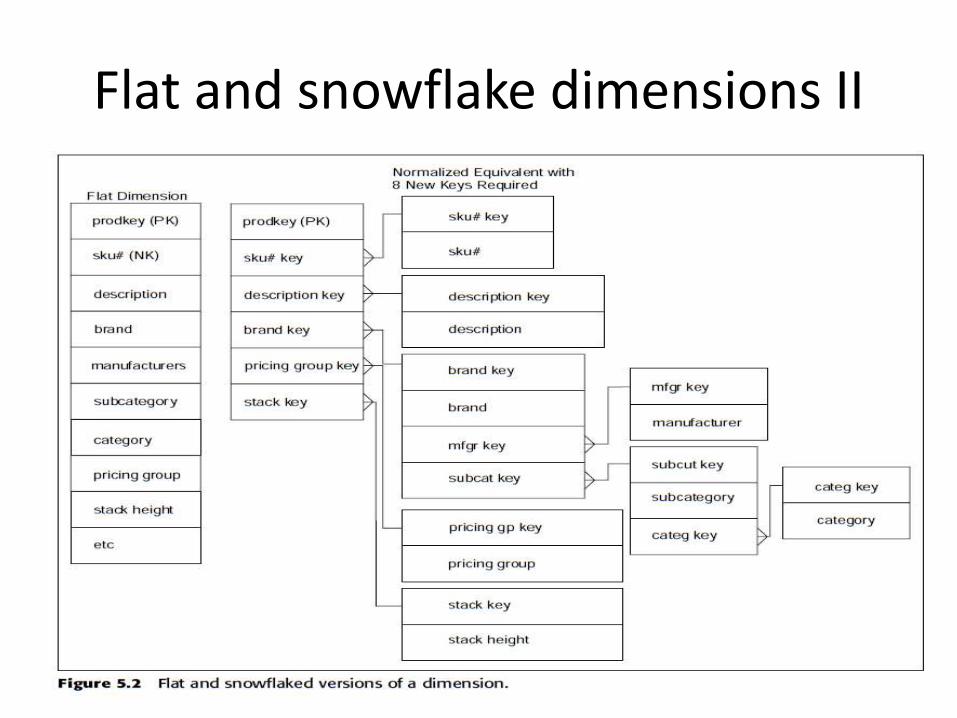
Flat and snowflake dimensions II

Flat and snowflake dimensions III
•If an attribute takes multiple values in the presence of a primary key, then it cannot be included in the dimension. •Eq. Cash Register id of retail store: grain is individual store•For every new dimension record a fresh surrogate key should be assigned

Some typical dimensions I
•Date and time dimensions:a huge table with a primary key and all
possible fields of date, day, month, year, timestamp, fiscal year, quarter etc.•Small dimensions:
Mainly used for lookups
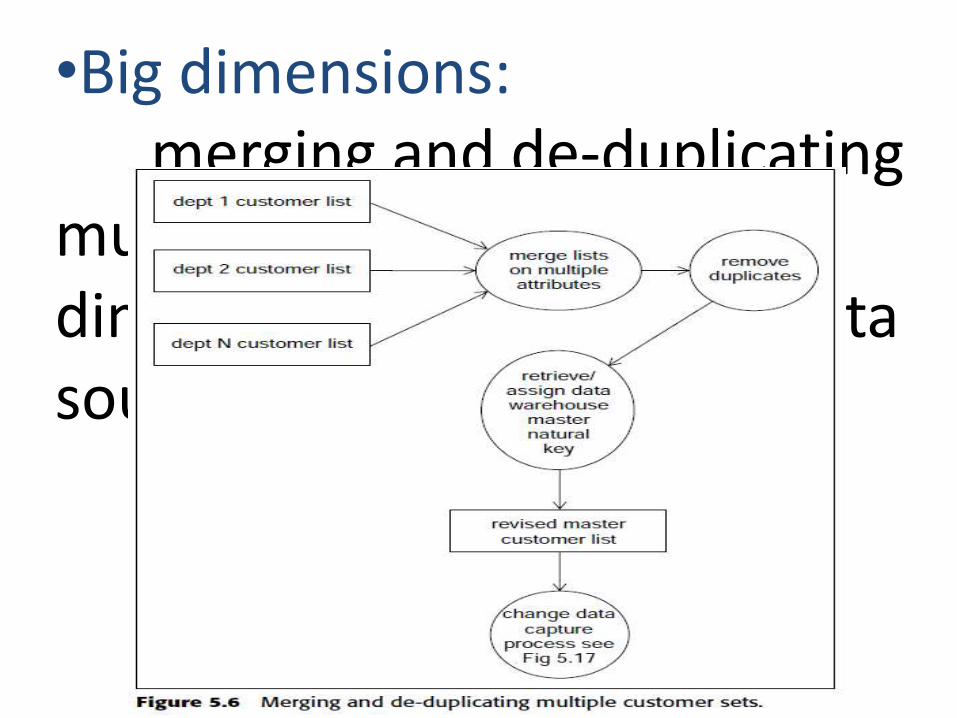
•Big dimensions:merging and de-duplicating
multiple attributes for same dimension, from different data sources.

Dimension tables structures I
•Dimensions can be modeled as flat and snowflakes•Flat dimensions are denormalized tables•The Dimension tables should be modeled in such a way that they have small cardinality•Every dimension table should have limited values•Populating the data from staging to data warehouse:
–If staging data has data in 3NF, the attended 2NF dimensions are easily produced with a simple query on the 3NF source

Dimension tables structures II
•Snow flaking is defined as creating sub-dimensions or•dimensions of other dimensions. This makes the schema much more cleaner•If an attribute takes multiple values in the presence of a primary key, then it cannot be included in the dimension for every new dimension records a fresh surrogate key should be assigned•A good design practice: identify the correlation between dimensions to determine the

Roles, sub-dimensions and empty dimensions I
•Roles:–Concept of using the same table attached to a fact multiple times– E.g. 2 roles of employee dimension - manager and employee

Roles, sub-dimensions and empty dimensions II
•Sub dimensions:–Sub dimensions are defined using foreign keys in the parent dimension table–they are called as outriggers

Roles, sub-dimensions and empty dimensions III
•Degenerate dimensions:–Problem: Parent-child data relationship into dimensional framework, the natural key of the parent is usually left as orphan–Solution: to avoid this, the natural key of parent is given a special status called empty or degenerate dimension arises in every parent-child relations–e.g. : order number, shipment number, billing number etc.–They often play an integral role in the fact table’s primary key.

Roles, sub-dimensions and empty dimensions II
•ETL dimensional delivery module must convert selected fields in the input data for the dimension to foreign key references•About multi valued dimensions and bridge tables
–May be linked to a fact table via bridge tables–Helps to avoid many-many joins by “creating a group entity"–Time-varying bridge tables are seen in case of Type2 SCDs–Performance overheads for updates and queries may be higher

Roles, sub-dimensions and empty dimensions III

Roles, sub-dimensions and empty dimensions IV
•Ragged hierarchies–Arise due to the hierarchies seen in the organization–May be related to people, roles, products, billing information etc.–Pre-dominant characteristic: The parent member of at least one member of a dimension is not in the level immediately above the member
•It can be implemented as recursive pointer (pointer to a dimension within the same table to another field) or as a hierarchy bridge table


SCDs - recap I
•type 0–Passive–Data never changes
•type 1–Overwrite data–Using update or insert functionality–May cause performance problems–May need support of rollback

SCDs - recap II
• type 2–Also called partitioning history–Every time a change happens a new surrogate primary key is assigned and all fact tables now onwards use this new foreign key–A cube-form representation with time as one of the dimension

SCDs - recap III•type 3
–Called as alternative realities–Old value of the attribute remains valid as a second choice–Creates a new column for a change
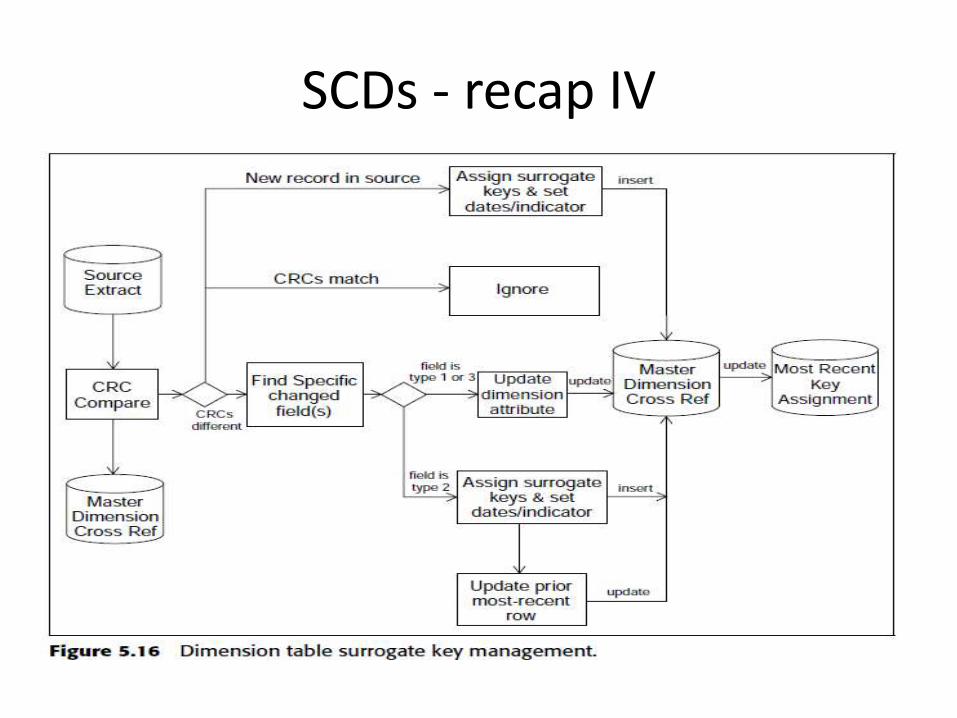
SCDs - recap IV

SCDs - recap V
•Hybrid slowly changing dimension

Handling late arriving data
•Required fixes–insert a new records capturing the change–scan the dimension after the required date of modification and destructively overwrite the changed attribute–update the fact tables that reference the modified dimension
•In real time systems, the dimension data usually arrives after the fact data.•In such cases it is important to point the fact table records to a special placeholder and then update the same once the dimensions are

Process of loading dimensions I
•Some dimensions are created automatically without involving the ETL process•Operational code translated into words and have no external•sources•Remaining ones are extracted from outside sources. They need special processing as below:
–Data cleaning: identifying and correcting or removing inaccurate, incorrect , incomplete data–Data conforming: aligning the content of some fields in the dimension with similar fields–Data delivering: managing SCDs, creating the

Process of loading dimensions III
•All dimensions are attended out - denormalized•Create a snowflake dimension if it is not possible to logically attend out the dimensions•Identify the fields in every dimension table as primary / surrogate key (joins with the foreign key in the fact table),natural key (descriptor of the data), descriptive attributes (textual details)
Related Documents











![Data Modeling [Comparison of data modeling techniques ] By Renjini Sindhuri.](https://static.cupdf.com/doc/110x72/5517cb1555034616658b4aae/data-modeling-comparison-of-data-modeling-techniques-by-renjini-sindhuri.jpg)