Hierarchical Words detection especially new words in Chinese language Chengyuan Zhuang Mingming Du Haili Wang

Data Mining Project
Aug 19, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Hierarchical Words detection especially new words in Chinese
language
Chengyuan ZhuangMingming Du
Haili Wang

Tired of downloading .arff files and running them in Weka?
OK, let's do something more
challenging and fun!
Who is he?
Kobe In Chinese?
科比
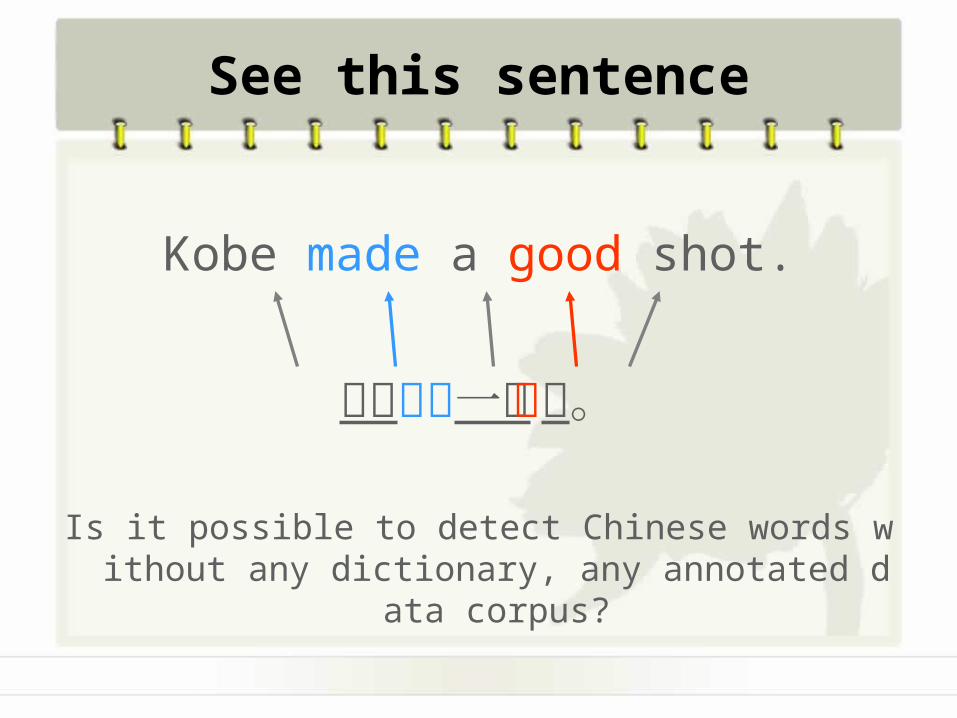
See this sentence
Kobe made a good shot.
科比投了一个好球。
Is it possible to detect Chinese words without any dictionary, any annotated data corpus?
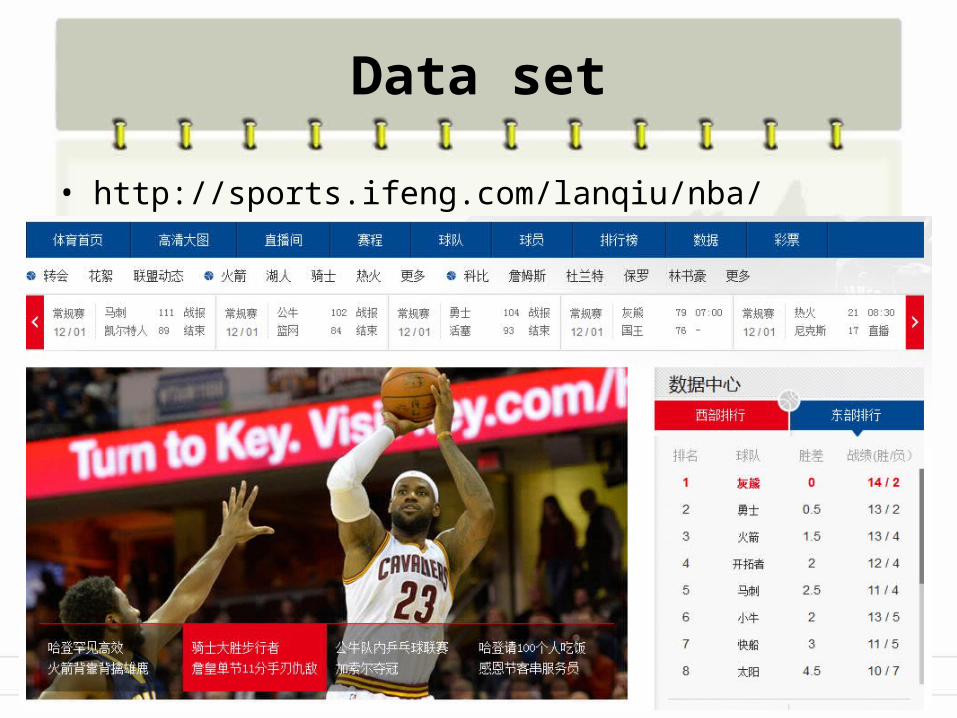
Data set
• http://sports.ifeng.com/lanqiu/nba/

Over 600 Chinese web pages
Can we succeed?

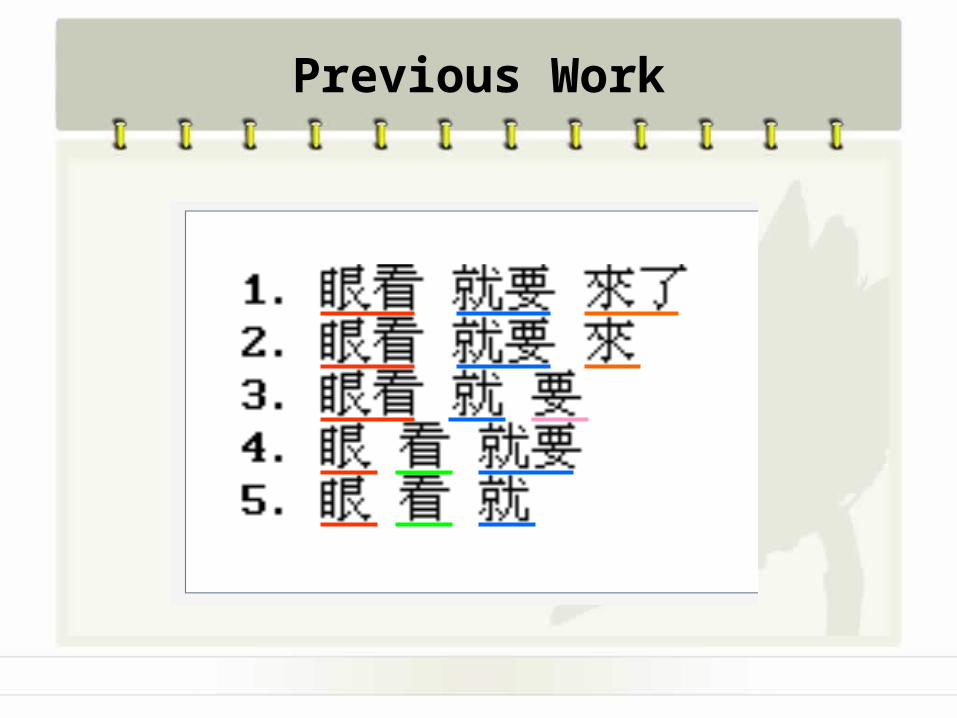
Previous Work
• Dictionary-based approaches
Scan forward and backward from a sentence to detect words in dictionary.
One most popular method is: Maximum Matching (MM), usually augmented with heuristics to deal with ambiguities.
Matching forward and backward from a sentence.
Previous Work

Previous Work
• Limitation: only words that are stored in the dictionary can be identified.
How about Out of vocabulary (OOV) word? (e.g. domain-specific terms, person names and
newly produced words increasing everyday)

Previous Work
• Supervised machine-learning approaches
Be formulated as a binary classification task
Each character in the text string is predicted to be: 1. the beginning of a word (labeled as class "B") 2. intra-word characters (labeled as class "I")or: 1. the beginning of a word (labeled as class "B") 2. the middle of a word (labeled as class "M") 3. the end of a word (labeled as class "E")

Previous Work
• Lots of algorithms can make this binary or ternary boundary decision:
Naive Bayes (NB)
Decision Tree (DT)
Support Vector Machine (SVM)
Conditional Random Field (CRF).
Previous Work
• Kawtrakul et al. (1997) proposed a language modeling technique based on a tri-gram Markov Model to select the optimal segmentation path.
• Meknavin et al. (1997) constructed a machine learning model by using the Part-Of-Speech (POS) features.

Previous Work
• Limitation: totally rely on annotated data corpus, hard to deal with unseen words
• Contradictory: Part-Of-Speech (POS), Markov Model, Words' boundary all from previous word, how to use that dealing with new words?
Want to understand text to do that?
That's an even harder problem!

Previous Work
• Unsupervised machine-learning approaches
Sproat and Shih(1993) proposed a method using neither lexicon nor segmented corpus.
For input texts, simply grouping character pairs with high value of mutual information into words.
Fully automatic, although many limitations(e.g., over generate unreasonable words, can only treat bi-character words)

Our method
• The formal definition is: Two events A and B are independent if and only if
their joint probability equals the product of their probabilities: P(A ^ B) = P(A) * P(B).
Two nearby characters A, B can be seen as two events
totally independent (e.g. not form a word) => P(AB) = P(A) * P(B)
close relationship (e.g. A, B from a word) => P(AB) >> P(A) * P(B)

Our method
• We define P(likelihood) = P(AB) / [ P(A) * P(B) ]
• If character A and character B are totally independent, then P(likelihood) should be 1
• The higher P(likelihood) is above 1, the less likely they are independent, which means they are not happen together by chance, they have close relationship.

Our method
• There are 2000 ~ 4000 core Chinese characters
• Over 9000 characters total
• Typically, character probability is 1 / 1000 ~ 1 / 9000
• Frequent words could be 1 / 100 ~ 1 / 500

Our method
• The formulas are:
P(A | B) = P(AB) / P(B)
P(B | A) = P(AB) / P(A)
• Define P(given) = max [ P(A | B), P(B | A) ]

Our method
• For tri-character words:• View tri-character word ABC as two parts: AB, C or A, BC
P1(likelihood) = P(ABC) / [ P(AB) * P(C) ]
P2(likelihood) = P(ABC) / [ P(A) * P(BC) ]
Define P(likelihood) = min[ P1(likelihood), P2(likelihood) ]

Our method
• Set threshold:
P(likelihood) = 100
P(given) = 0.5 (for not so confident case)

Measure freeness

Our result
• Top 20 bi-character words

Our result
• Top 20 tri-character words

Most frequent words
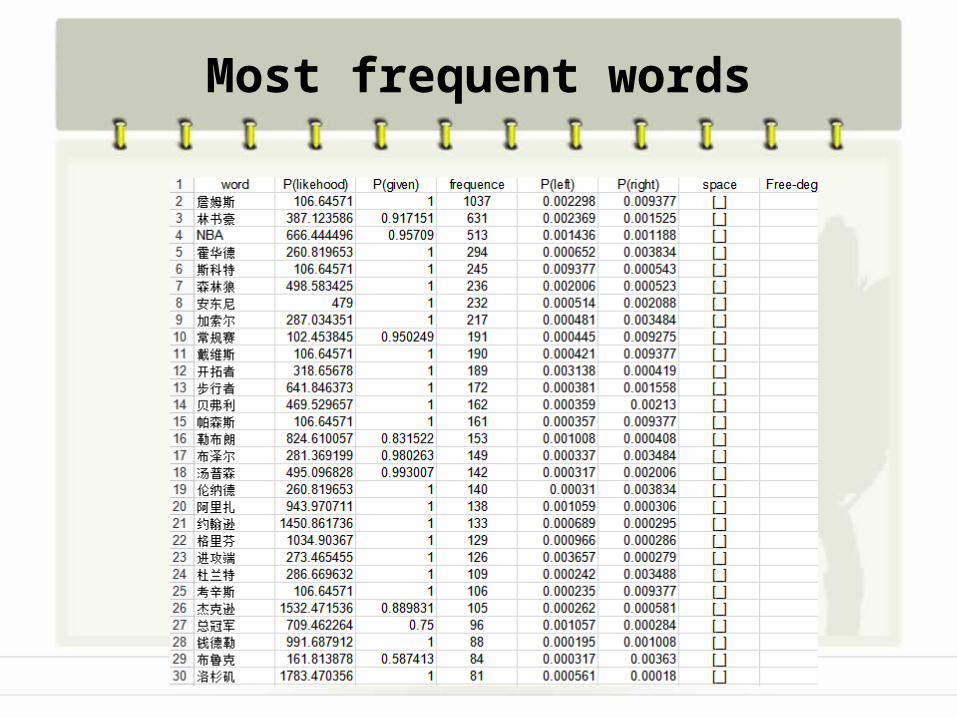
Most frequent words

Compare to other approach
Future Work
• Incorporate syntactic knowledge and high quality dictionary
• Annotated data corpus could also be considered
• Extend our approach to quadri-character words or even more-character words

Any questions, suggestions?
Thank you!
Related Documents











