Data Mining in DNA: Data Mining in DNA: Using the SUBDUE Using the SUBDUE Knowledge Discovery Knowledge Discovery System to Find System to Find Potential Gene Potential Gene Regulatory Sequences Regulatory Sequences by by Ronald K. Maglothin Ronald K. Maglothin

Data Mining in DNA: Using the SUBDUE Knowledge Discovery System to Find Potential Gene Regulatory Sequences by Ronald K. Maglothin.
Dec 19, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Data Mining in DNA: Using Data Mining in DNA: Using the SUBDUE Knowledge the SUBDUE Knowledge
Discovery System to Find Discovery System to Find Potential Gene Regulatory Potential Gene Regulatory
SequencesSequences
byby
Ronald K. MaglothinRonald K. Maglothin

Committee MembersCommittee Members
• Dr. Lawrence B. Holder, Dr. Lawrence B. Holder, SupervisorSupervisor
• Dr. Diane J. CookDr. Diane J. Cook
• Dr. Lynn L. PetersonDr. Lynn L. Peterson

OutlineOutline
• DNA Sequence DomainDNA Sequence Domain
• SUBDUE Knowledge Discovery SystemSUBDUE Knowledge Discovery System
• Experiments with Unsupervised Experiments with Unsupervised SUBDUESUBDUE
• Experiments with Supervised SUBDUEExperiments with Supervised SUBDUE
• Conclusion and Future WorkConclusion and Future Work

DNA StructureDNA Structure
• All cells use DNA to store their All cells use DNA to store their genetic information.genetic information.
• A DNA molecule is composed of A DNA molecule is composed of two linear strands coiled in a two linear strands coiled in a double helix.double helix.
• Each strand is made of the Each strand is made of the bases adenine (A), thymine (T), bases adenine (A), thymine (T), cytosine (C), and guanine (G), cytosine (C), and guanine (G), joined in a linear sequence.joined in a linear sequence.
DNA SequenceDNA Sequence
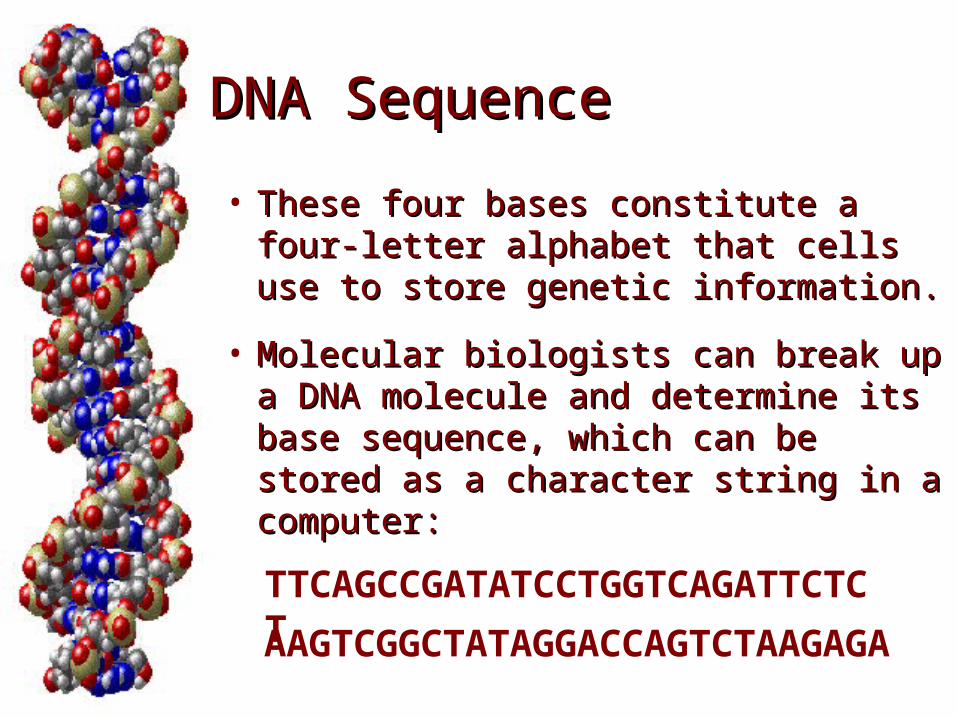
• These four bases constitute a four-These four bases constitute a four-letter alphabet that cells use to letter alphabet that cells use to store genetic information.store genetic information.
• Molecular biologists can break up a Molecular biologists can break up a DNA molecule and determine its DNA molecule and determine its base sequence, which can be stored base sequence, which can be stored as a character string in a computer:as a character string in a computer:
TTCAGCCGATATCCTGGTCAGATTCTCTAAGTCGGCTATAGGACCAGTCTAAGAGA

GenesGenes
• A A genegene is a DNA sequence that is a DNA sequence that encodes instructions for building a encodes instructions for building a protein.protein.
• Gene expressionGene expression is the process of is the process of using a gene to make a protein:using a gene to make a protein:
DNADNA RNRNAA
ProteinProteintranscriptiontranscription translationtranslation
genegene transcripttranscript productproduct

Gene RegulationGene Regulation
• Primary mechanism is to control Primary mechanism is to control the rate of DNA transcription:the rate of DNA transcription:– Faster transcription more proteinFaster transcription more protein
– Slower transcription less proteinSlower transcription less protein
• Transcription rate is controlled Transcription rate is controlled by by transcription factors,transcription factors, which which are proteins which bind to are proteins which bind to specific DNA sequences.specific DNA sequences.

Human Genome ProjectHuman Genome Project• A U.S.-led, worldwide effort to A U.S.-led, worldwide effort to
determine the complete DNA determine the complete DNA sequence for humans, as well as sequence for humans, as well as several other organisms.several other organisms.
• These sequences will be used to These sequences will be used to study:study:– mechanisms of diseasemechanisms of disease
– growth and developmentgrowth and development
– evolutionary relationshipsevolutionary relationships

A Genome is a LOT of A Genome is a LOT of DataData• Raw sequence (text)Raw sequence (text)
– Human (2005): 3 x 10Human (2005): 3 x 10 9 9 base pairs base pairs
– Yeast (finished): 1.2 x 10Yeast (finished): 1.2 x 1077 base pairs base pairs
• Annotated sequence (Relational Annotated sequence (Relational DB)DB)– Links to 3D structures of protein Links to 3D structures of protein
products, other genes in family, products, other genes in family, known transcription factors, journal known transcription factors, journal references, and other databases.references, and other databases.

A Rich Domain for A Rich Domain for Knowledge DiscoveryKnowledge Discovery
• Most of the sequences (and Most of the sequences (and genes) have unknown function.genes) have unknown function.
• Efficient algorithms are needed to:Efficient algorithms are needed to:– identify important patternsidentify important patterns
– identify and classify possible genesidentify and classify possible genes
– infer relationships between genesinfer relationships between genes
– predict protein structurepredict protein structure

The SUBDUE Knowledge The SUBDUE Knowledge Discovery SystemDiscovery System
• Input: A graph Input: A graph GG
• Output: A list of substructures Output: A list of substructures that compress that compress G G wellwell
• Uses a computationally-Uses a computationally-constrained beam search and constrained beam search and inexact graph matchinexact graph match
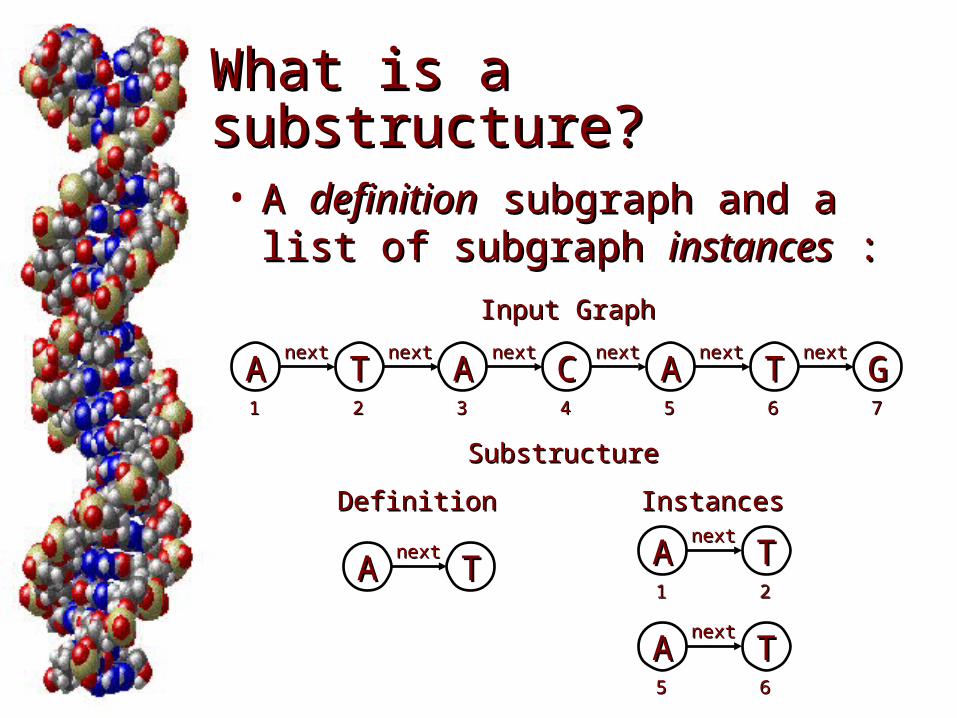
What is a substructure?What is a substructure?
• A A definitiondefinition subgraph and a list subgraph and a list of subgraph of subgraph instancesinstances : :
AA AA AATT TTCC GGnextnext nextnextnextnextnextnextnextnextnextnext
Input GraphInput Graph
SubstructureSubstructure
DefinitionDefinition InstancesInstances
11 776655443322
AA TT11 22
AA TTnextnext
nextnext
AA TTnextnext
6655

MDL HeuristicMDL Heuristic
• SUBDUE uses the Minimum SUBDUE uses the Minimum Description Length Principle to Description Length Principle to evaluate substructures.evaluate substructures.
• Description Length of a graph is Description Length of a graph is the number of bits needed to the number of bits needed to send the graph’s adjacency send the graph’s adjacency matrix to a remote computer.matrix to a remote computer.
• Goal is to minimize DL(S) + DL(G|Goal is to minimize DL(S) + DL(G|S).S).

SUBDUE ParametersSUBDUE Parameters
• Iterations: Graph is compressed Iterations: Graph is compressed using the best substructure, using the best substructure, discovery is restarteddiscovery is restarted
• Threshold: Controls how much two Threshold: Controls how much two subgraphs can differ to be subgraphs can differ to be considered similarconsidered similar
• Beam Width: The number of Beam Width: The number of substructures in the expansion listsubstructures in the expansion list
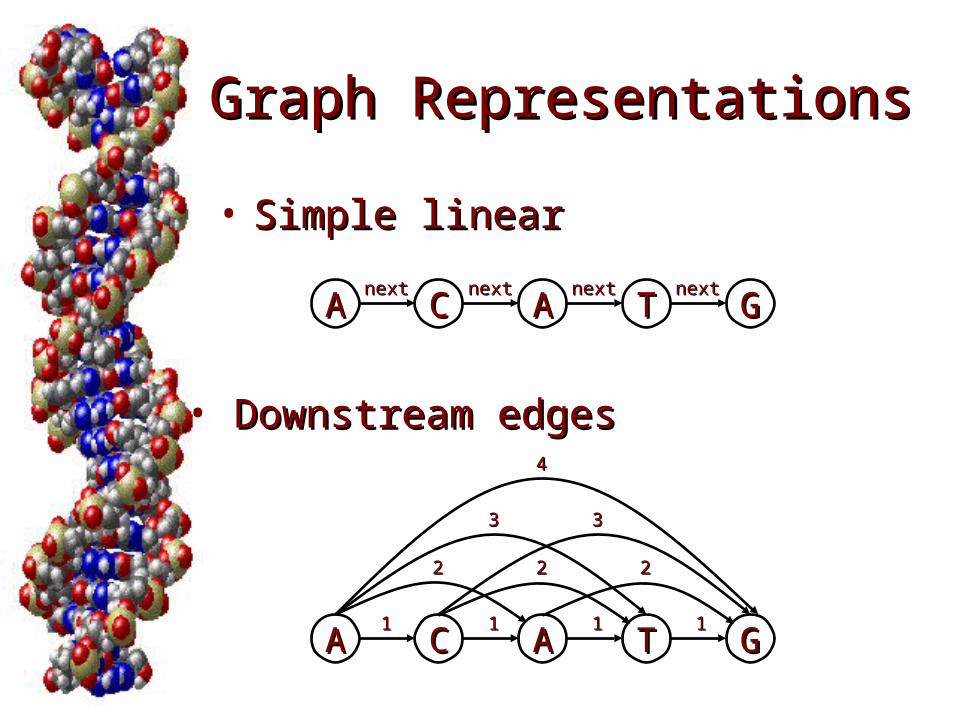
Graph RepresentationsGraph Representations
• Simple linearSimple linear
AA AA TTCC GGnextnextnextnextnextnextnextnext
• Downstream edgesDownstream edges
AA AA TTCC GG11 111111
222222
33 33
44
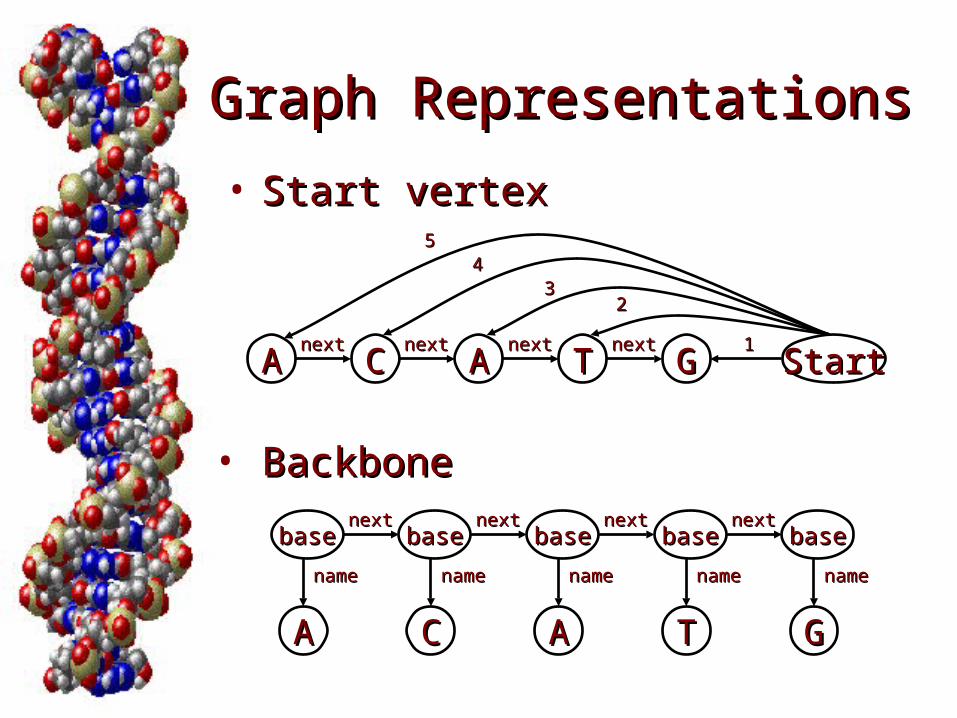
Graph RepresentationsGraph Representations
• Start vertexStart vertex
AA AA TTCC GGnextnextnextnextnextnextnextnext
StartStart11
2233
4455
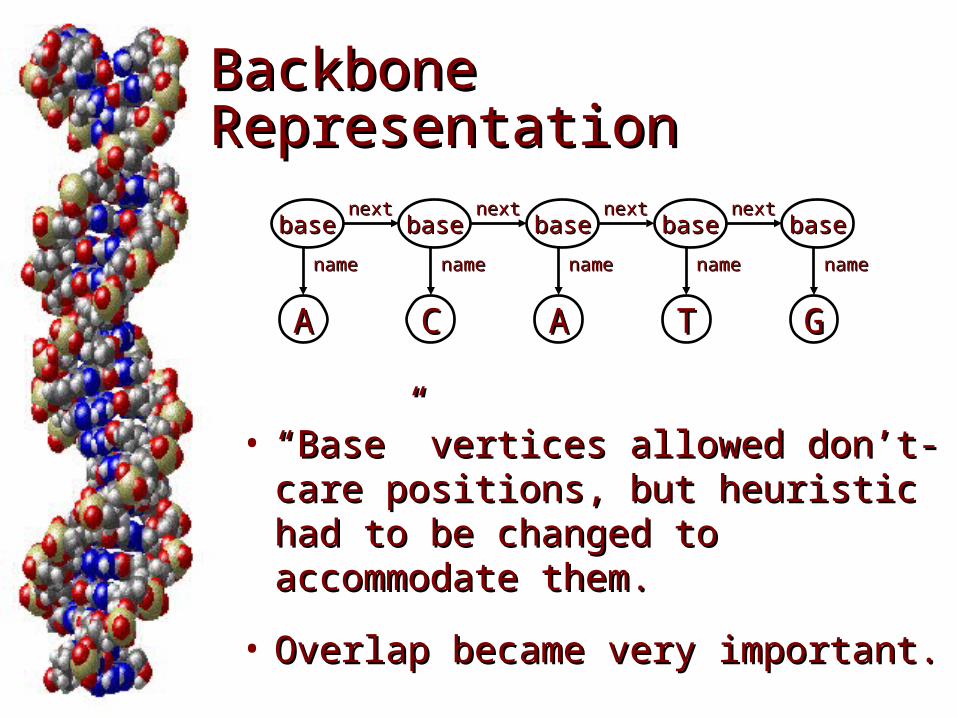
• BackboneBackbone
basebase basebase basebase basebase basebasenextnextnextnextnextnextnextnext
AAAA CC TT GG
namename namenamenamenamenamenamenamename
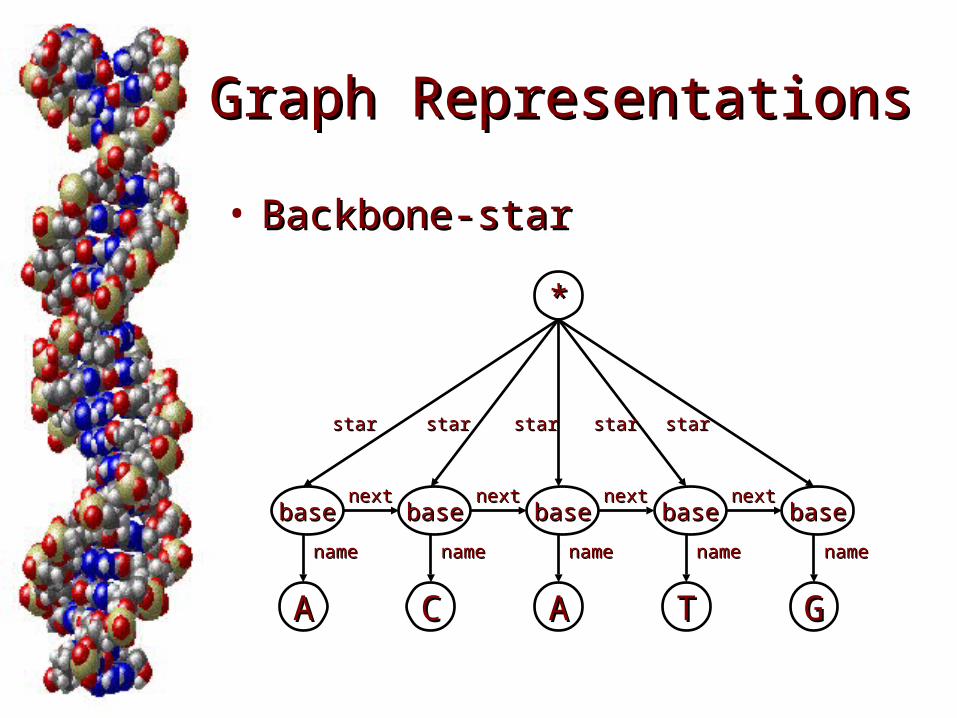
Graph RepresentationsGraph Representations
• Backbone-starBackbone-star
basebase basebase basebase basebase basebasenextnextnextnextnextnextnextnext
AAAA CC TT GG
namename namenamenamenamenamenamenamename
**
starstar starstar starstar starstar starstar

Unsupervised SUBDUEUnsupervised SUBDUE• Input: An entire yeast chromosomeInput: An entire yeast chromosome
• Heuristic:Heuristic:
S)|DL(GDL(S)1
Value
• Results: Not good; patterns with two Results: Not good; patterns with two
to three basesto three bases
AA AA TTCC GGnextnextnextnextnextnextnextnext

Polynomial HeuristicPolynomial Heuristic
stancesNumberOfIn
inition)SizeOf(DefValue 2
Pattern Instances
TTTTTTTTTTTG 196
AAATTTTTTATT 158
TTTTTTTTTTGC 158
TTTTAATTTTTT 155
GAAATTTTTTAA 144
0.2 Threshold

Unsupervised SUBDUE -Unsupervised SUBDUE -DiscussionDiscussion• Random noise is not a meaningful Random noise is not a meaningful
kind of pattern variation in DNA.kind of pattern variation in DNA.
• Unsupervised SUBDUE finds DNA Unsupervised SUBDUE finds DNA patterns that are hard to evaluate patterns that are hard to evaluate and that are not focused on any and that are not focused on any target concept.target concept.
• We need to give SUBDUE more We need to give SUBDUE more targeted input data and to modify targeted input data and to modify the system to use it effectively.the system to use it effectively.

Supervised SUBDUESupervised SUBDUE
• Give SUBDUE two graphs: a graph Give SUBDUE two graphs: a graph of positive instances of a target of positive instances of a target concept, and a graph of negative concept, and a graph of negative instances.instances.
• SUBDUE discovers substructures in SUBDUE discovers substructures in the positive graph, finds instances the positive graph, finds instances in the negative graph, and bases in the negative graph, and bases the overall heuristic value on the the overall heuristic value on the values in both graphs.values in both graphs.

New Data SetsNew Data Sets
• Clusters of coexpressed yeast Clusters of coexpressed yeast genes compiled by Brazma et al., genes compiled by Brazma et al., from expression data generated from expression data generated by DeRisi et al.by DeRisi et al.
• The expression level of each gene The expression level of each gene in a cluster changed at the same in a cluster changed at the same time and by a similar degree time and by a similar degree during the experiment; perhaps during the experiment; perhaps some genes in a cluster are some genes in a cluster are regulated by similar mechanisms?regulated by similar mechanisms?

New Data SetsNew Data Sets
• Positive examples:Positive examples:– 300-bp upstream windows (both 300-bp upstream windows (both
strands) for all genes in a given strands) for all genes in a given clustercluster
• Negative examples:Negative examples:– 300-bp upstream windows for genes 300-bp upstream windows for genes
not in the cluster, ORnot in the cluster, OR
– 300-bp windows randomly selected 300-bp windows randomly selected from the complete genome (probably from the complete genome (probably not involved in gene regulation)not involved in gene regulation)

Supervised HeuristicSupervised Heuristic
• Based on the substructure’s values in Based on the substructure’s values in the positive and negative graphsthe positive and negative graphs
S)|DL(GDL(S)S)|DL(GDL(S)
S)|DL(GDL(S)1
/S)|DL(GDL(S)
1
Value/ Value Value
-
-
-
• Numerator set to 1 when no Numerator set to 1 when no negative instancesnegative instances

Compression RatioCompression Ratio
• Normalize the graph values by using Normalize the graph values by using the inverse of the graph compressionthe inverse of the graph compression
S)|DL(GDL(S))DL(G
S)|DL(GDL(S))DL(G
Value

Negative Graph ValueNegative Graph Value
• When there are no negative When there are no negative instances, setting numerator to 1 instances, setting numerator to 1 actually penalizes such substructures.actually penalizes such substructures.
• Using 2 x DL(GUsing 2 x DL(G--) in this situation gave ) in this situation gave better results.better results.
S)|DL(GDL(S)S)|DL(GDL(S)
Value -

Ratio Heuristic ResultsRatio Heuristic Results
Cluster Best Pattern Instances
c2_4.2222200.39 CCCCTTA 7
c2_4.2222201.41 ATATAATA 10
c2_4.2222210.37 GATATATA 6
cr2_4.222202.55 ATATATATATATAT 6
cr4.111101.77 CCCCTTA 10

Concept DL HeuristicConcept DL Heuristic
• Based on the size of a message Based on the size of a message containing the compressed containing the compressed positive graph, plus the errors positive graph, plus the errors (negative instances).(negative instances).
S))|DL(G-S)|DL(G(DL(S)- Value -
S)|DL(G-)DL(GS)|DL(GDL(S)

Concept DL Heuristic Concept DL Heuristic ResultsResults
Cluster Best Pattern Instances
c2_4.2222200.39 AAAAAA 53
c2_4.2222201.41 AAAAAA 41
c2_4.2222210.37 AAAAAA 38
cr2_4.222202.55 AAAAAA 66
cr4.111101.77 ATATAA 57
• Relative graph size affected resultsRelative graph size affected results
Backbone RepresentationBackbone Representation
• ““Base” vertices allowed don’t-Base” vertices allowed don’t-care positions, but heuristic had care positions, but heuristic had to be changed to accommodate to be changed to accommodate them.them.
• Overlap became very important.Overlap became very important.
basebase basebase basebase basebase basebasenextnextnextnextnextnextnextnext
AAAA CC TT GG
namename namenamenamenamenamenamenamename
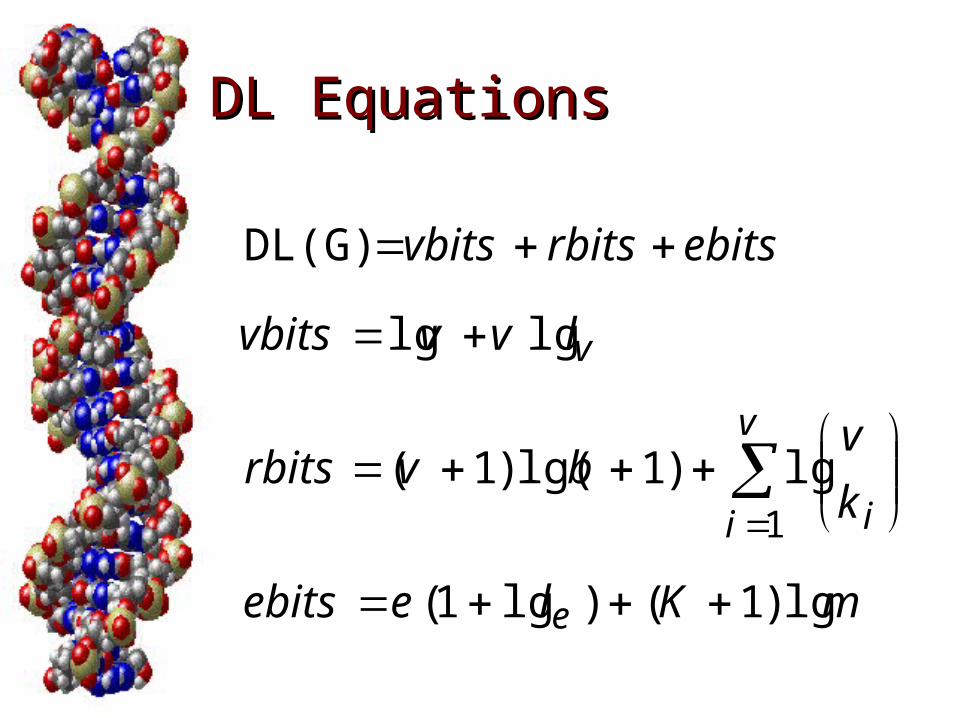
DL EquationsDL Equations
mKleebits
k
vbvrbits
lvvvbits
ebitsrbitsvbits
e
v
i i
v
lg)1()lg1(
lg)1lg()1(
lglg
DL(G)
1

Negative Graph ValueNegative Graph Value
• Using 2 x DL(GUsing 2 x DL(G--) for no negative ) for no negative instances favored such instances favored such substructures too strongly.substructures too strongly.
)DL(GDL(S))DL(G
S)|DL(GDL(S))DL(G
Value
-
-
-
--
1 where vv ll

Compression Difference Compression Difference HeuristicHeuristic
• Use subtraction with the compression Use subtraction with the compression values instead of division.values instead of division.
S)|DL(GDL(S))DL(G
S)|DL(GDL(S))DL(G
Value Value Value -

ResultsResults
Pattern N+ N- TRANSFAC matches
ATCCAT 16 12 MOUSE(3), HS(4), RAT(2),HCMV(1), RICE(1)
GGGA.G.A 19 16 MOUSE(2), HS(3), RABBIT(1)
TCCCT 65 35 Y$G3PDH_01
AAGGG 95 37 CAMV(2), RAT(9), AD(3),DROME(8), MOUSE(14),HS(30), DROOR(1), PCF(1),HPV(1), CHICK(2),RABBIT(1), EBV(1)
CCCT 128 76 Y$BCY_01, Y$GAL1_04,Y$X40_01, Y$CYC1_12,Y$GAL1_14, Y$G3PDH_01,Y$POX1_01, Y$DDR2_01,Y$DDR2_02, Y$TPI_02
Cluster cr4.111101.77Cluster cr4.111101.77
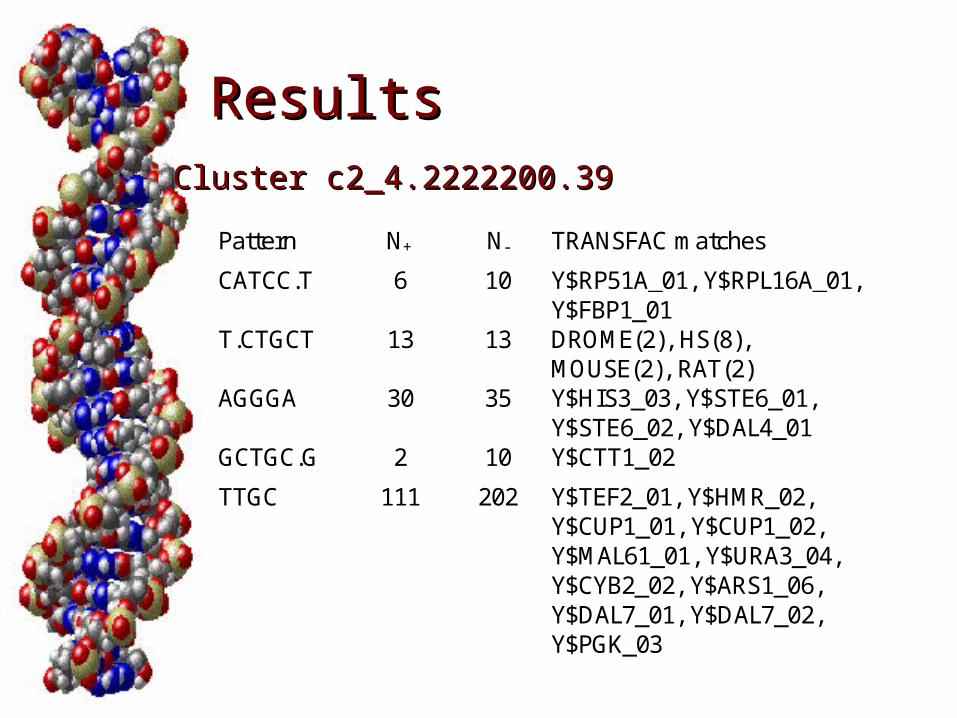
ResultsResults
Pattern N+ N- TRANSFAC matches
CATCC.T 6 10 Y$RP51A_01, Y$RPL16A_01,Y$FBP1_01
T.CTGCT 13 13 DROME(2), HS(8),MOUSE(2), RAT(2)
AGGGA 30 35 Y$HIS3_03, Y$STE6_01,Y$STE6_02, Y$DAL4_01
GCTGC.G 2 10 Y$CTT1_02
TTGC 111 202 Y$TEF2_01, Y$HMR_02,Y$CUP1_01, Y$CUP1_02,Y$MAL61_01, Y$URA3_04,Y$CYB2_02, Y$ARS1_06,Y$DAL7_01, Y$DAL7_02,Y$PGK_03
Cluster c2_4.2222200.39Cluster c2_4.2222200.39

Results of Brazma et al.Results of Brazma et al.
Pattern N+ TRANSFAC matches
CCCCT..T 27 Y$DDR2_01, Y$DDR2_02,Y$TPI_02
A..AGGGG 27 none
GGGGC 27 Y$GAL2_02, Y$SUC2_02,Y$RRNA_01, Y$ERG11_01
GCCCC 27 Y$CYB2_02
G..GGGG 28 Y$CYC1_04, Y$CYC1_05,Y$CYC1_06
Cluster c2_4.2222200.39Cluster c2_4.2222200.39

Brazma HeuristicBrazma Heuristic
• Based on number of positive and Based on number of positive and negative instancesnegative instances
667.4NN
Value

SUBDUE Using Brazma SUBDUE Using Brazma HeuristicHeuristic
Pattern N+ N- TRANSFAC matches
CCCCT.AT 10 0 Y$DDR2_02
AT.AGGGG 10 0 CHICK$VIT2_18
A…GGGGG 10 2 Y$SUC2_02
CCCC..CT 14 4 Y$GAL3_01, Y$MAL2R_01
CCGGG.T 5 0 Y$CYC1_04, Y$CYC1_05,Y$CYC1_06, Y$MAL63_01
Cluster c2_4.2222200.39Cluster c2_4.2222200.39

ConclusionConclusion
• SUBDUE can be used to discover SUBDUE can be used to discover likely transcription factor binding likely transcription factor binding sites.sites.
• Patterns found by SUBDUE are Patterns found by SUBDUE are different from those found by different from those found by string-based algorithms, due to string-based algorithms, due to the graph representation, beam the graph representation, beam search, and different search search, and different search heuristic.heuristic.

ConclusionConclusion• Patterns found by unsupervised Patterns found by unsupervised
SUBDUE in DNA are difficult to SUBDUE in DNA are difficult to evaluate.evaluate.
• Using supervised SUBDUE can greatly Using supervised SUBDUE can greatly focus the search on the target concept.focus the search on the target concept.
• Choosing the right graph Choosing the right graph representation and heuristic are critical representation and heuristic are critical to success.to success.

Future WorkFuture Work
• Further refinement of the Further refinement of the supervised MDL heuristic.supervised MDL heuristic.
• Application of graph grammar Application of graph grammar theory to SUBDUE’s search.theory to SUBDUE’s search.
• Close collaboration with molecular Close collaboration with molecular biologists to select data sets and biologists to select data sets and evaluate results.evaluate results.
Related Documents











