Data Integration in the Life Sciences Kenneth Griffiths and Richard Resnick

Data Integration in the Life Sciences Kenneth Griffiths and Richard Resnick.
Dec 24, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Data Integration in the Life Sciences
Kenneth Griffiths and Richard Resnick

Tutorial Agenda
1:30 – 1:45 Introduction1:45 – 2:00 Tutorial Survey2:00 – 3:00 Approaches to Integration3:00 – 3:05 Bio Break3:05 – 4:00 Approaches to Integration (cont.)4:00 – 4:15 Question and Answer4:15 – 4:30 Break4:30 – 5:00 Metadata Session5:00 – 5:30 Domain-specific example (GxP)5:30 Wrap-up

Life Science Data
Recent focus on genetic data“genomics: the study of genes and their function. Recent advances in genomics are bringing about a revolution in our understanding of the molecular mechanisms of disease, including the complex interplay of genetic and environmental factors. Genomics is also stimulating the discovery of breakthrough healthcare products by revealing thousands of new biological targets for the development of drugs, and by giving scientists innovative ways to design new drugs, vaccines and DNA diagnostics. Genomics-based therapeutics include "traditional" small chemical drugs, protein drugs, and potentially gene therapy.”
The Pharmaceutical Research and Manufacturers of America - http://www.phrma.org/genomics/lexicon/g.html
Study of genes and their function
Understanding molecular mechanisms of disease
Development of drugs, vaccines, and diagnostics

The Study of Genes...
• Chromosomal location
• Sequence
• Sequence Variation
• Splicing
• Protein Sequence• Protein Structure

… and Their Function
• Homology
• Motifs
• Publications
• Expression
• HTS
• In Vivo/Vitro Functional Characterization
Understanding Mechanisms of Disease
Metabolic and
regulatory pathway induction

Development of Drugs, Vaccines, Diagnostics
Differing types of Drugs, Vaccines, and Diagnostics• Small molecules• Protein therapeutics• Gene therapy• In vitro, In vivo diagnostics
Development requires• Preclinical research• Clinical trials• Long-term clinical research
All of which often feeds back into ongoing Genomics research and discovery.

The Industry’s Problem
Too much unintegrated data:– from a variety of incompatible sources
– no standard naming convention
– each with a custom browsing and querying mechanism (no common interface)
– and poor interaction with other data sources

What are the Data Sources?
• Flat Files• URLs• Proprietary Databases• Public Databases• Data Marts• Spreadsheets• Emails• …

Sample Problem: Hyperprolactinemia
Over production of prolactin– prolactin stimulates mammary gland
development and milk production
Hyperprolactinemia is characterized by:– inappropriate milk production– disruption of menstrual cycle– can lead to conception difficulty

Understanding transcription factors for prolactin production
“Show me all genes in the public literature that are putatively related to hyperprolactinemia, have more than 3-fold expression differential between hyperprolactinemic and normal pituitary cells, and are homologous to known transcription factors.”
“Show me all genes that are homologous to known transcription factors”
SEQUENCE
1Q“Show me all genes that have more than 3-fold expression differential between hyperprolactinemic and normal pituitary cells”EXPRESSION
2Q
“Show me all genes in the public literature that are putatively related to hyperprolactinemia”
LITERATURE
3Q
(Q1Q2Q3)


Approaches to IntegrationIn order to ask this type of question across multiple domains, data integration at some level is necessary. When discussing the different approaches to data integration, a number of key issues need to be addressed:
• Accessing the original data sources• Handling redundant as well as missing data• Normalizing analytical data from different data
sources• Conforming terminology to industry standards• Accessing the integrated data as a single logical
repository• Metadata (used to traverse domains)

Approaches to Integration (cont.)
So if one agrees that the preceding issues are important, where are they addressed? In the client application, the middleware, or the database? Where they are addressed can make a huge difference in usability and performance. Currently there are a number of approaches for data integration:
• Federated Databases• Data Warehousing• Indexed Data Sources• Memory-mapped Data Structures

Federated Database Approach
genbank proprietary
SeqWeb
SEQUENCE
Medline
PubMed Proprietary App
LITERATURE
Integrated Application
Middleware (CORBA, DCOM, etc)
“Show me all genes that are homologous to known transcription factors”
“Show me all genes that have more than 3-fold expression differential between hyperprolactinemic and normal cells
“Show me all genes in the public literature that are putatively related to hyperprolactinemia”
(Q1Q2Q3)
EXPRESSION
cDNAµArraydb
TxP App
Oligo TxP DB

Advantages to Federated Database Approach
• quick to configure
• architecture is easy to understand - no knowledge of the domain is necessary
• achieves a basic level of integration with minimal effort
• can wrapper and plug in new data sources as they come into existence

Problems with Federated Database Approach
• Integration of queries and query results occurs at the integrated application level, requiring complex low-level logic to be embedded at the highest level
• Naming conventions across systems must be adhered to or query results will be inaccurate - imposes constraints on original data sources
• Data sources are not necessarily clean; integrating dirty data makes integrated dirty data.
• No query optimization across multiple systems can be performed
• If one source system goes down, the entire integrated application may fail
• Not readily suitable for data mining, generic visualization tools
• Relies on CORBA or other middleware technology, shown to have performance (and reliability?) problems
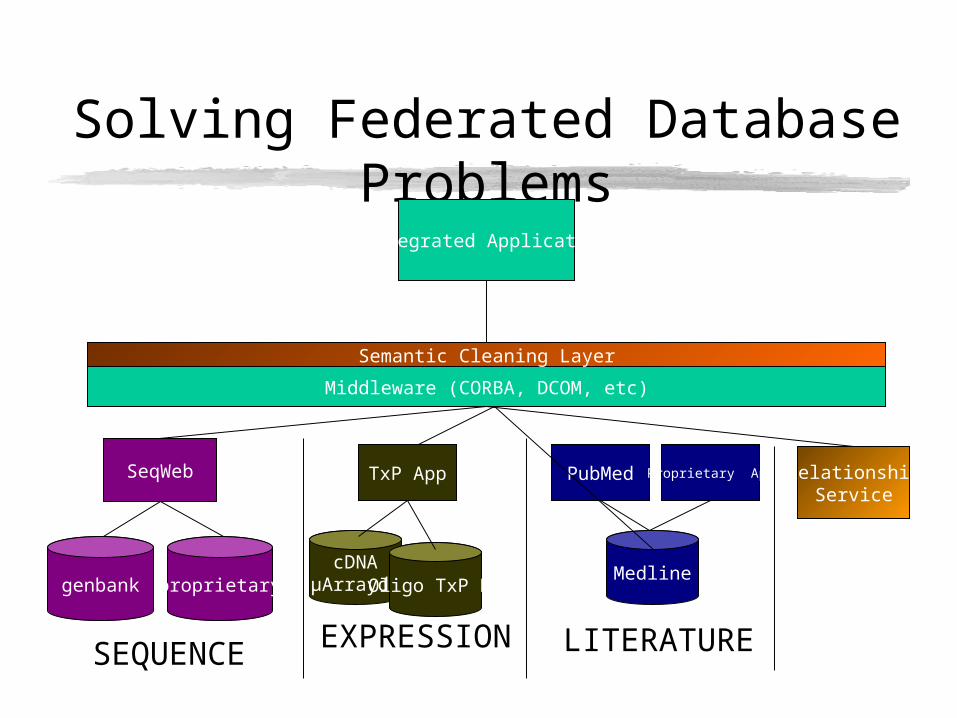
Solving Federated Database Problems
genbank proprietary
SeqWeb
SEQUENCE
Medline
PubMed Proprietary App
LITERATURE
Integrated Application
Middleware (CORBA, DCOM, etc)
EXPRESSION
cDNAµArraydb
TxP App
Oligo TxP DB
RelationshipService
Semantic Cleaning Layer
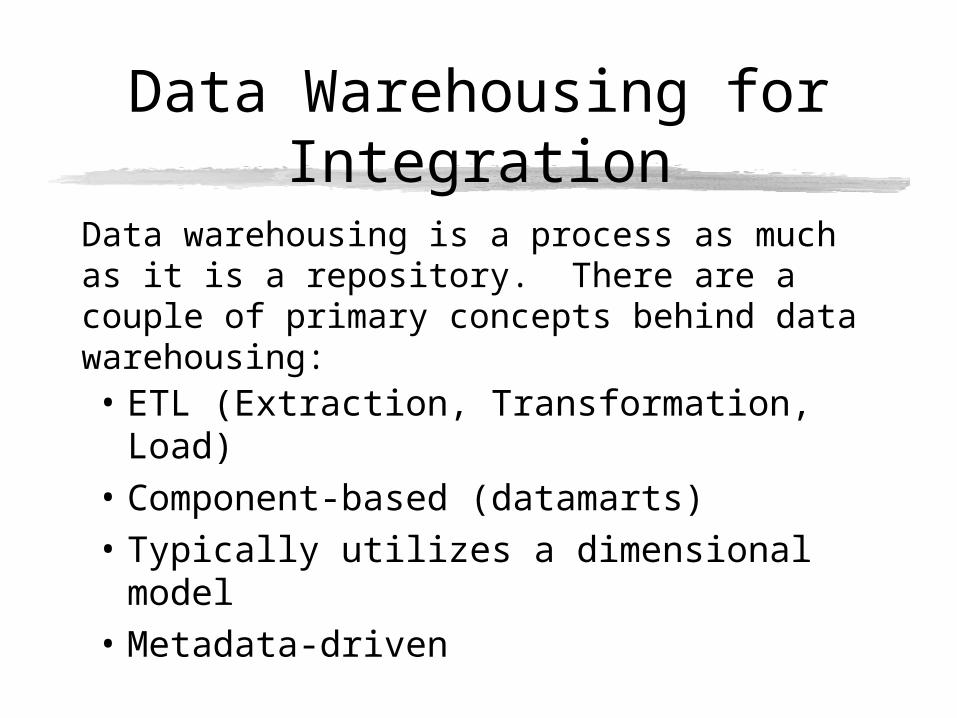
Data Warehousing for Integration
Data warehousing is a process as much as it is a repository. There are a couple of primary concepts behind data warehousing:
• ETL (Extraction, Transformation, Load)
• Component-based (datamarts)
• Typically utilizes a dimensional model
• Metadata-driven
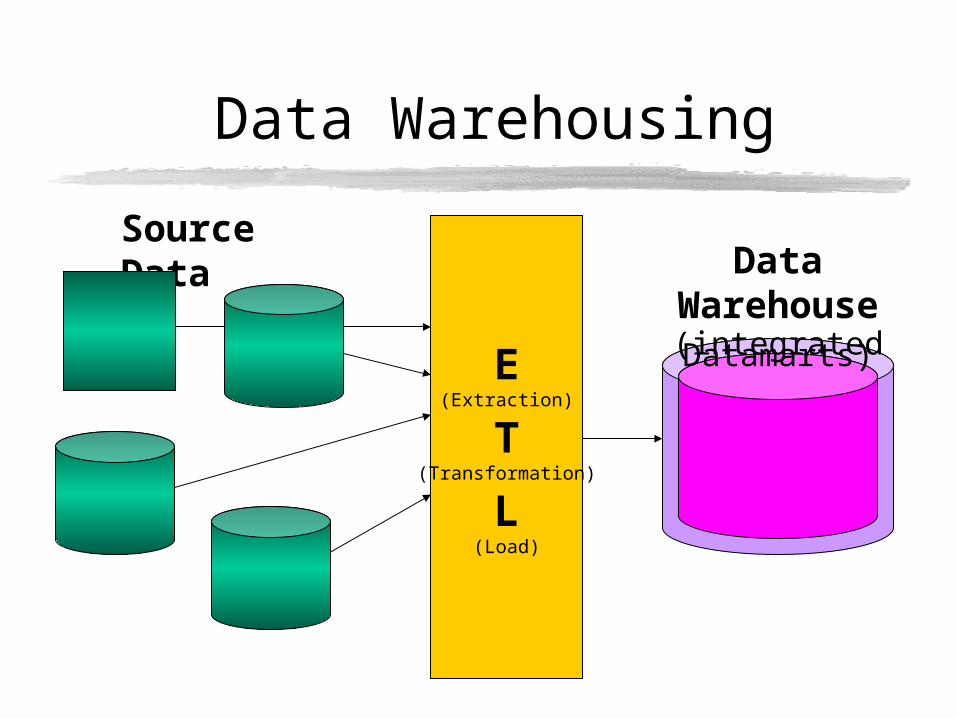
Data Warehousing
E(Extraction)
T(Transformation)
L(Load)
Source DataData Warehouse
(integrated Datamarts)
Metadata layer
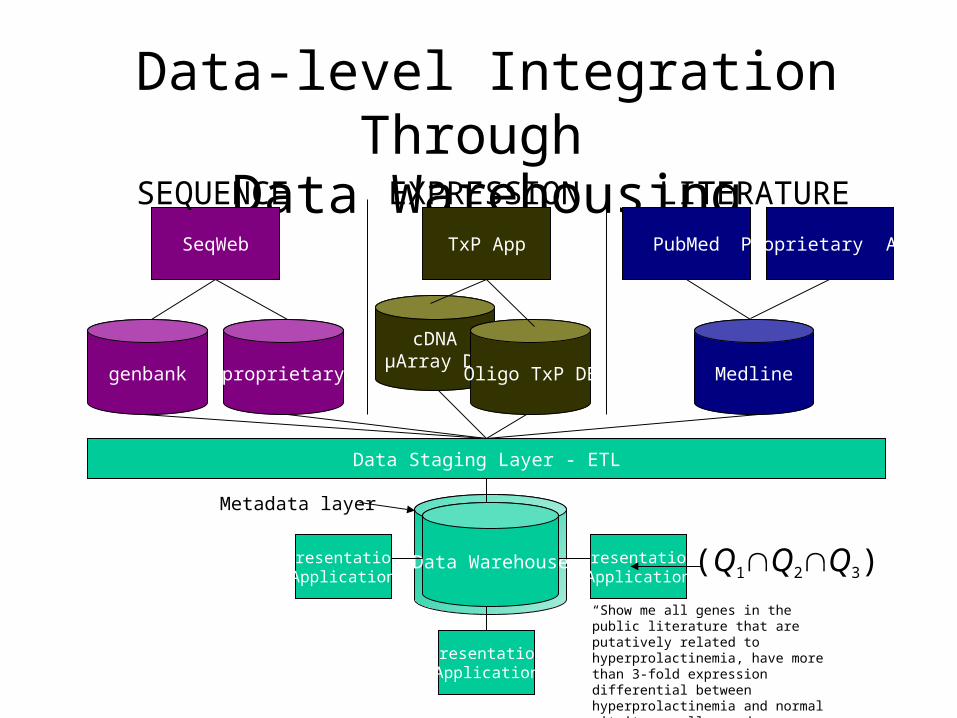
Data-level Integration Through Data Warehousing
Data WarehousePresentationApplication
PresentationApplication
PresentationApplication
“Show me all genes in the public literature that are putatively related to hyperprolactinemia, have more than 3-fold expression differential between hyperprolactinemia and normal pituitary cells, and are homologous to known transcription factors.”
(Q1Q2Q3)
genbank proprietary
SeqWeb
SEQUENCE EXPRESSION
cDNAµArray DB
TxP App
Medline
PubMed Proprietary App
LITERATURE
Oligo TxP DB
Data Staging Layer - ETL

Storage area and set of processes that• extracts source data• transforms data
• cleans incorrect data, resolves missing elements, standards conformance
• purges fields not needed• combines data sources• creates surrogate keys for data to avoid dependence on legacy keys• builds aggregates where needed• archives/logs
• loads and indexes data
Does not provide query or presentation services
Data Staging

• Sixty to seventy percent of development is here
• Engineering is generally done using database automation and scripting technology
• Staging environment is often an RDBMS
• Generally done in a centralized fashion and as often as desired, having no effect on source systems
• Solves the integration problem once and for all, for most queries
Data Staging (cont.)

Warehouse Development and Deployment
Two development paradigms:
Top-down warehouse design: conceptualize the entire warehouse, then build, tends to take 2 years or more, and requirements change too quickly
Bottom-up design and deployment: pivoted around completely functional subsections of the Warehouse architecture, takes 2 months, enables modular development.

Warehouse Development and Deployment (cont.)
The Data Mart:
“A logical subset of the complete data warehouse”
• represents a completable project
• by itself is a fully functional data warehouse
• A Data Warehouse is the union of all constituent data marts.
• Enables bottom-up development

Warehouse Development and Deployment (cont.)
Examples of data marts in Life Science:– Sequence/Annotation - brings together sequence and annotation from
public and proprietary dbs
– Expression Profiling datamart - integrates multiple TxP approaches (cDNA, oligo)
– High-throughput screening datamart - stores HTS information on proprietary high-throughput compound screens
– Clinical trial datamart - integrates clinical trial information from multiple trials
All of these data marts are pieced together along conformed entities as they are developed, bottom up

Advantages of Data-level Integration Through Data Warehousing
• Integration of data occurs at the lowest level, eliminating the need for integration of queries and query results
• Run-time semantic cleaning services are no longer required - this work is performed in the data staging environment
• FAST!
• Original source systems are left completely untouched, and if they go down, the Data Warehouse still functions
• Query optimization across multiple systems’ data can be performed
• Readily suitable for data mining by generic visualization tools

Issues with Data-level Integration Through Data Warehousing
• ETL process can take considerable time and effort• Requires an understanding of the domain to
represent relationships among objects correctly• More scalable when accompanied by a Metadata
repository which provides a layer of abstraction over the warehouse to be used by the application. Building this repository requires additional effort.

Indexing Data Sources
• Indexes and links a large number of data sources (e.g., files, URLs)
• Data integration takes place by using the results of one query to link and jump to a keyed record in another location
• Users have the ability to develop custom applications by using a vendor-specific language

Indexed Data Source Architecture
Index Traversal Support Mechanism
I
Sequence indexed data sources
I
GxP indexed data sources
I
SNP information

Indexed Data Sources: Pros and Cons
Advantages• quick to set up• easy to understand• achieves a basic level
of integration with minimal effort
Disadvantages• does not clean and
normalize the data• does not have a way to
directly integrate data from relational DBMSs
• difficult to browse and mine
• sometimes requires knowledge of a vendor-specific language

Memory-mapped Integration
• The idea behind this approach is to integrate the actual analytical data in memory and not in a relational database system
• Performance is fast since the application retrieves the data from memory rather than disk
• True data integration is achieved for the analytical data but the descriptive or complementary data resides in separate databases

Memory-mapped Integrated Data
Memory Map Architecture
Sample/SourceInformation
SequenceDB #2
DescriptiveInformation
SequenceDB #1
Data Integration Layer
CORBA

Memory Maps: Pros and Cons
Advantages• true “analytical” data
integration• quick access• cleans analytical data• simple matrix
representation
Disadvantages• typically does not put non-
analytical data (gene names, tissue types, etc.) through the ETL process
• not easily extensible when adding new databases with descriptive information
• performance hit when accessing anything outside of memory (tough to optimize)
• scalability restricted by memory limitations of machine
• difficult to mine due to complicated architecture

The Need for Metadata
For all of the previous approaches, one underlying concept plays a critical role to their success: Metadata.
Metadata is a concept that many people still do not fully understand. Some common questions include:
• What is it?• Where does it come from?• Where do you keep it?• How is it used?

Metadata
“The data about the data…”
• Describes data types, relationships, joins, histories, etc.
• A layer of abstraction, much like a middle layer,
except...
• Stored in the same repository as the data, accessed in a
consistent “database-like” way

Metadata (cont.)
Back-end metadata - supports the developers
Source system metadata: versions, formats, access stats, verbose information
Business metadata: schedules, logs, procedures, definitions, maps, security
Database metadata - data models, indexes, physical & logical design, security
Front-end metadata - supports the scientist and application
Nomenclature metadata - valid terms, mapping of DB field names to understandable names
Query metadata - query templates, join specifications, views, can include back-end metadata
Reporting/visualization metadata - template definitions, association maps, transformations
Application security metadata - security profiles at the application level

Metadata Benefits
• Enables the application designer to develop generic applications that grow as the data grows
• Provides a repository for the scientist to become better informed on the nature of the information in the database
• Is a high-performance alternative to developing an object-relational layer between the database and the application
• Extends gracefully as the database extends


Integration Technologies
• Technologies that support integration efforts
• Data Interchange
• Object Brokering
• Modeling techniques

Data Interchange
• Standards for inter-process and inter-domain communication
• Two types of data
• Data – the actual information that is being interchanged
• Metadata – the information on the structural and semantic aspects of
the Data
• Examples:
• EMBL format
• ASN.1
• XML

XML Emerges
• Allows uniform description of data and metadata
– Metadata described through DTDs
– Data conforms to metadata description
• Provides open source solution for data integration between components
• Lots of support in CompSci community (proportional to cardinality of
Perl modules developed)– XML::CGI - a module to convert CGI parameters to and from XML
– XML::DOM - a Perl extension to XML::Parser. It adds a new 'Style' to XML::Parser,called 'Dom', that allows XML::Parser to build an Object Oriented data structure with a DOM Level 1
compliant interface.
– XML::Dumper - a simple package to experiment with converting Perl data structures to XML and converting XML to perl data structures.
– XML::Encoding - a subclass of XML::Parser, parses encoding map XML files.
– XML::Generator is an extremely simple module to help in the generation of XML.
– XML::Grove - provides simple objects for parsed XML documents. The objects may be modified but no checking is performed.
– XML::Parser - a Perl extension interface to James Clark's XML parser, expat
– XML::QL - an early implementation of a note published by the W3C called "XML-QL: A Query Language for XML".
– XML::XQL - a Perl extension that allows you to perform XQL queries on XML object trees.

XML in Life Sciences
• Lots of momentum in Bio community
• GFF (Gene Finding Features)
• GAME (Genomic Annotation Markup Elements)
• BIOML (BioPolymer markup language)
• EBI’s XML format for gene expression data
• …
• Will be used to specify ontological descriptions of
Biology data

XML – DTDs
• Interchange format defined through a DTD – Document Type
Definition <!ELEMENT bioxml-game:seq_relationship (bioxml-game:span, bioxml-
game:alignment?)>
<!ATTLIST bioxml-game:seq_relationship
seq IDREF #IMPLIED
type (query | subject | peer | subseq) #IMPLIED
>
• And data conforms to DTD<seq_relationship seq="seq1 "type="query">
<span>
<begin>10</begin>
<end>15</end>
</span>
</seq_relationship>
<seq_relationship seq="seq2" type="subject"> <span> <begin>20</begin> <end>25</end> </span> <alignment> query: atgccg ||| || subject: atgacg </alignment></seq_relationship>

XML Summary
• Metadata and data have same format
• HTML-like
• Broad support in CompSci and Biology
• Sufficiently flexible to represent any data model
• XSL style sheets map from one DTD to another
• Doesn’t allow for abstraction or partial inheritance
• Interchange can be slow in certain data migration tasks
Benefits Drawbacks

Object Brokering
• The details of data can often be encapsulated in objects– Only the interfaces need definition– Forget DTDs and data description
• Mechanisms for moving objects around based solely on their interfaces would allow for seamless integration
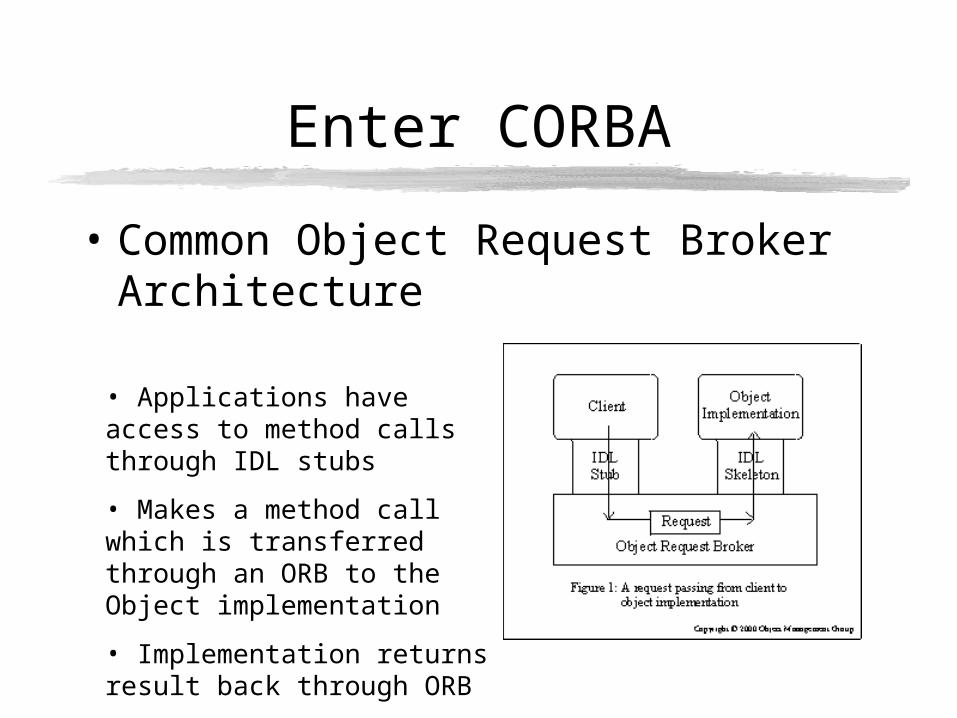
Enter CORBA
• Common Object Request Broker Architecture
• Applications have access to method calls through IDL stubs
• Makes a method call which is transferred through an ORB to the Object implementation
• Implementation returns result back through ORB

CORBA IDL
• IDL – Interface Definition Language– Like C++/Java headers, but with slightly more
type flexibility interface BioSequence { readonly attribute string name; readonly attribute Identifier id; readonly attribute string description; readonly attribute string seq; readonly attribute unsigned long length; readonly attribute Basis the_basis; string seq_interval(in Interval the_interval) raises(IntervalOutOfBounds); AnnotationList get_annotations( in unsigned long how_many, in SeqRegion seq_region, out AnnotationIterator the_rest) raises(SeqRegionOutOfBounds, SeqRegionInvalid); unsigned long num_annotations(in SeqRegion seq_region) raises(SeqRegionOutOfBounds, SeqRegionInvalid); void add_annotation( in Annotation the_annotation) raises(NotUpdateable, SeqRegionOutOfBounds); };

CORBA Summary
• Distributed
• Component-based architecture
• Promotes reuse
• Doesn’t require knowledge of implementation
• Platform independent
• Distributed
• Level of abstraction is sometimes not useful
• Can be slow to broker objects
• Different ORBS do different things
• Unreliable?
• OMG website is brutal
Benefits Drawbacks

Modeling Techniques
E-R Modeling• Optimized for transactional data
• Eliminates redundant data
• Preserves dependencies in UPDATEs
• Doesn’t allow for inconsistent data
• Useful for transactional systems
Dimensional Modeling• Optimized for queryability and performance
• Does not eliminate redundant data, where appropriate
• Constraints unenforced
• Models data as a hypercube
• Useful for analytical systems

Illustrating Dimensional Data Space
Sample problem: monitoring a temperature-sensitive room for fluctuations
x
y
z
x, y, z, and time uniquely determine a temperature value:(x,y,z,t) temp
Nomenclature:“x, y, z, and t are dimensions”“temperature is a fact”“the data space is a hypercube of size 4”
Independent variables Dependent variables

Dimensional Modeling Primer
• Represents the data domain as a collection of hypercubes that share dimensions– Allows for highly understandable data spaces
– Direct optimizations for such configurations are provided through most DBMS frameworks
– Supports data mining and statistical methods such as multi-dimensional scaling, clustering, self-organizing maps
– Ties in directly with most generalized visualization tools
– Only two types of entities - dimensions and facts
Y Dimension
Time Dimension
Z Dimension
X Dimension
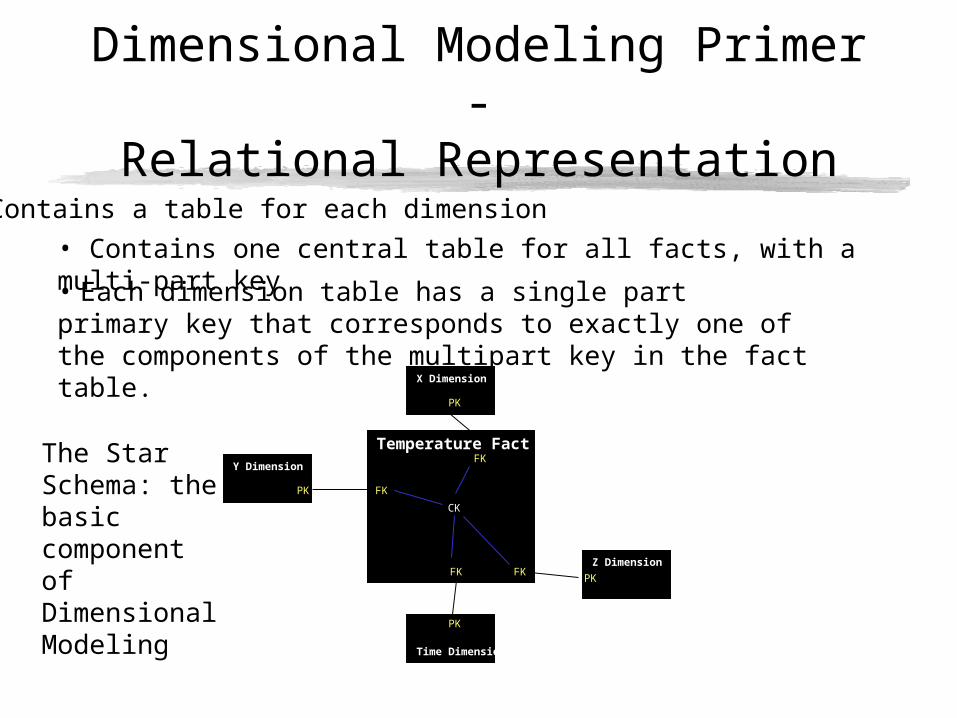
Dimensional Modeling Primer -Relational Representation
• Contains one central table for all facts, with a multi-part key
Temperature Fact
FK
FK FK
FK
CK
PK
PK
PK
PK
• Contains a table for each dimension
• Each dimension table has a single part primary key that corresponds to exactly one of the components of the multipart key in the fact table.
The Star Schema: the basic component of Dimensional Modeling

Dimensional Modeling Primer -Relational Representation
• Each dimension table most often contains descriptive textual information about a particular scientific object. Dimension tables are typically the entry points into a datamart. Examples: “Gene”, “Sample”, “Experiment”
• The fact table relates the dimensions that surround it, expressing a many-to-many relationship. The more useful fact tables also contain “facts” about the relationship -- additional information not stored in any of the dimension tables.
The Star Schema: the basic component of Dimensional Modeling
Y Dimension
Time Dimension
Z Dimension
X Dimension
Temperature Fact
FK
FK FK
FK
CK
PK
PK
PK
PK

Dimensional Modeling Primer -Relational Representation
• Dimension tables are typically small, on the order of 100 to 100,000 records. Each record measures a physical or conceptual entity.
• The fact table is typically very large, on the order of 1,000,000 or more records. Each record measures a fact around a grouping of physical or conceptual entities.
The Star Schema: the basic component of Dimensional Modeling
Y Dimension
Time Dimension
Z Dimension
X Dimension
Temperature Fact
FK
FK FK
FK
CK
PK
PK
PK
PK

Dimensional Modeling Primer -Relational Representation
Neither dimension tables nor fact tables are necessarily normalized!
• Normalization increases complexity of design, worsens performance with joins
• Non-normalized tables can easily be understood with SELECT and GROUP BY
• Database tablespace is therefore required to be larger to store the same data - the gain in overall performance and understandability outweighs the cost of extra disks!
The Star Schema: the basic component of Dimensional Modeling
Y Dimension
Time Dimension
Z Dimension
X Dimension
Temperature Fact
FK
FK FK
FK
CK
PK
PK
PK
PK

Sequenceseq_idbaseslength
Runrun_idwhowhenpurpose
Clustercluster_id
Subclustersubcluster_id
Membershipstartlengthorientation
ParamSetparamset_id
Parametersparam_nameparam_value
Resultresultrunkey(fk)seqkey(fk)
“Show me all sequences in the same cluster as sequence XA501 from my last run.”
PROBLEMS• not browsable (confusing)• poor query performance• little or no data mining support
SELECT SEQ_IDFROM SEQUENCE, MEMBERSHIP, SUBCLUSTERWHERE SEQUENCE.SEQKEY = MEMBERSHIP.SEQKEYAND MEMBERSHIP.SUBCLUSTERKEY = SUBCLUSTER.SUBCLUSTERKEYAND SUBCLUSTER.CLUSTERKEY = ( SELECT CLUSTER.CLUSTERKEY FROM SEQUENCE, MEMBERSHIP, SUBCLUSTER, CLUSTER, RESULT, RUN WHERE SEQUENCE.RESULTKEY = RESULT.RESULTKEY AND RESULT.RUNKEY = RUN.RUNKEY AND SEQUENCE.SEQKEY = MEMBERSHIP.SEQKEY AND MEMBERSHIP.SUBCLUSTERKEY = SUBCLUSTER.SUBCLUSTERKEY AND SUBCLUSTER.CLUSTERKEY = CLUSTER.CLUSTERKEY AND SEQUENCE.SEQID = ‘XA501’ AND RESULT.RUNID = ‘my last run’)
Case in Point:Sequence Clustering

Membership Factsseq_idcluster_idsubcluster_idrun_idparamset_id
run_daterun_initiatorseq_startseq_endseq_orientationcluster_sizesubcluster_size
CONCEPTUAL IDEA - The Star Schema:
A historical, denormalized, subject-oriented view of scientific facts -- the data mart.
A centralized fact table stores the single scientific fact of sequence membership in cluster and a subcluster.
Smaller dimensional tables around the fact table represent key scientific objects (e.g., sequence).
Benefits• Highly browsable, understandable model for scientists• Vastly improved query performance• Immediate data mining support• Extensible “database componentry” model
Parametersparamset_idparam_nameparam_value
Sequenceseq_idbaseslengthtype
“Show me all sequences in the same cluster as sequence XA501 from my last run.”
SELECT SEQ_IDFROM MEMBERSHIP_FACTSWHERE CLUSTER_ID IN ( SELECT CLUSTER_ID FROM MEMBERSHIP_FACTS WHERE SEQ_ID = ‘XA501’ AND RUN_ID = ‘my last run’)Run
run_idrun_daterun_initiatorrun_purposerun_remarks
Dimensionally Speaking…Sequence Clustering

Dimensional Modeling - Strengths
• Predictable, standard framework allows database systems and
end user query tools to make strong assumptions about the data
• Star schemas withstand unexpected changes in user behavior --
every dimension is equivalent: symmetrically equal entry points
into the fact table.
• Gracefully extensible to accommodate unexpected new data
elements and design decisions
• High performance, optimized for analytical queries

The Need for Standards
In order for any integration effort to be successful, there needs to be agreement on certain topics:
• Ontologies: concepts, objects, and their relationships
• Object models: how are the ontologies represented as objects
• Data models: how the objects and data are stored persistently

Standard Bio-Ontologies
Currently, there are efforts being undertaken to help identify a practical set of technologies that will aid in the knowledge management and exchange of concepts and representations in the life sciences.
GO Consortium: http://genome-www.stanford.edu/GO/
The third annual Bio-Ontologies meeting is being held after ISMB 2000 on August 24th.

Standard Object Models
Currently, there is an effort being undertaken to develop object models for the different domains in the Life Sciences. This is primarily being done by the Life Science Research (LSR) working group within the OMG (Object Management Group). Please see their homepage for further details:
http://www.omg.org/homepages/lsr/index.html

In Conclusion• Data integration is the problem to solve to support human and
computer discovery in the Life Sciences.
• There are a number of approaches one can take to achieve data integration.
• Each approach has advantages and disadvantages associated with it. Particular problem spaces require particular solutions.
• Regardless of the approach, Metadata is a critical component for any integrated repository.
• Many technologies exist to support integration.
• Technologies do nothing without syntactic and semantic standards.


Accessing Integrated Data
Once you have an integrated repository of information, access tools enable future experimental design and discovery. They can be categorized into four types:
– browsing tools– query tools– visualization tools– mining tools

Browsing
One of the most critical requirements that is overlooked is the ability to “browse” the integrated repository since users typically do not know what is in it and are not familiar with other investigator’s projects. Requirements include:
• ability to view summary data• ability to view high level descriptive information on
a variety of objects (projects, genes, tissues, etc.)• ability to dynamically build queries while browsing
(using a wizard or drag and drop mechanism)

Querying
Along with browsing, retrieving the data from the repository is one of the most underdeveloped areas in bioinformatics. All of the visualization tools that are currently available are great at visualizing data. But if users cannot get their data into these tools, how useful are they? Requirements include:
• ability to intelligently help the user build ad-hoc queries (wizard paradigm, dynamic filtering of values)
• provide a “power user” interface for analysts (query templates with the ability to edit the actual SQL)
• should allow users to iterate over the queries so they do not have to build them from scratch each time
• should be tightly integrated with the browser to allow for easier query construction

Visualizing
There are a number of visualization tools currently available to help investigators analyze their data. Some are easier to use than others and some are better suited for either smaller or larger data sets. Regardless, they should all provide the ability to:• be easy to use• save templates which can be used in future visualizations• view different slices of the data simultaneously• apply complex statistical rules and algorithms to the data
to help elucidate associations and relationships

Data Mining
Life science has large volumes of data that, in its rawest form, is not easy to use to help drive new experimentation. Ideally, one would like to automate data mining tools to extract “information” by allowing them to take advantage of a predicable database architecture. This is more easily attainable using dimensional modeling (star schemas), however, since E-R schemas are very different from database to database and do not conform to any standard architecture.

ANALYSIS
Analysis_Key
Analysis_Decision
ALGORITHM
Algorithm_key
Algorithm_Name
SNP_FREQUENCY
Frequency_Key
Linkage_KeyPopulation_KeyAllele_KeyAllele_Frequency
SNP_POPULATION
Population_Key
Sample_Size
ALLELE
Allele_Key
Map_KeyAllele_NameBase_Change
PCR_PROTOCOL
Protocol_Key
Method_KeySource_KeyBuffer_Key
STS_SOURCE
Source_Key
QUALIFIER
Qualifier_Key
Map_KeyChip_KeyGene_Name
RNA_SOURCE
RNA_Source_Key
Treatment_KeyGenotype_KeyCell_Line_KeyTissue_KeyDisease_KeySpecies
CHIP
Chip_Key
Chip_NameSpecies
PARAMETER_SET
Parameter_Set_Key
GE_RESULTS
Results_Key
Analysis_KeyParameter_Set_KeyQualifier_KeyRNA_Source_KeyExpression_LevelAbsent_PresentFold_ChangeType
SCORE
Score_Key
Alignment_KeyP_ValueScorePercent_Homology
ALIGNMENT
Alignment_Key
Algorithm_keySequence_Key
PARAMETER_SET
Parametet_Set_Key
Algorithm_key
SEQUENCE_DATABASE
Seq_DB_Key
Seq_DB_Name
SEQUENCE
Sequence_Key
Map_KeyQualifier_KeySeq_DB_KeyTypeName
MAP_POSITION
Map_Key
DISEASE
Disease_Key
Name
TISSUE
Tissue_Key
Name
PCR_BUFFER
Buffer_Key
SNP_METHOD
Method_Key
ORGANISM
Organism_Key
Seq_DB_KeySpecies
CELL_LINE
Cell_Line_Key
Name
GENOTYPE
Genotype_Key
Name
TREATMENT
Treatmemt_Key
Name
Linkage
Linkage_Key
Disease_LinkLinkage_Distance
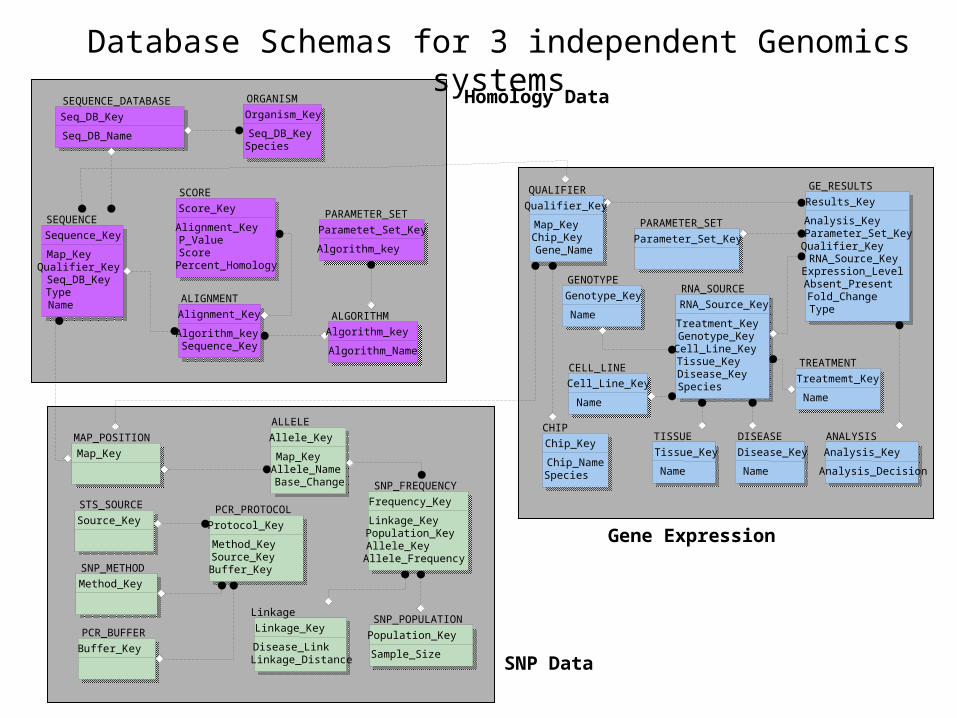
Gene Expression
SNP Data
Homology Data
Database Schemas for 3 independent Genomics systems
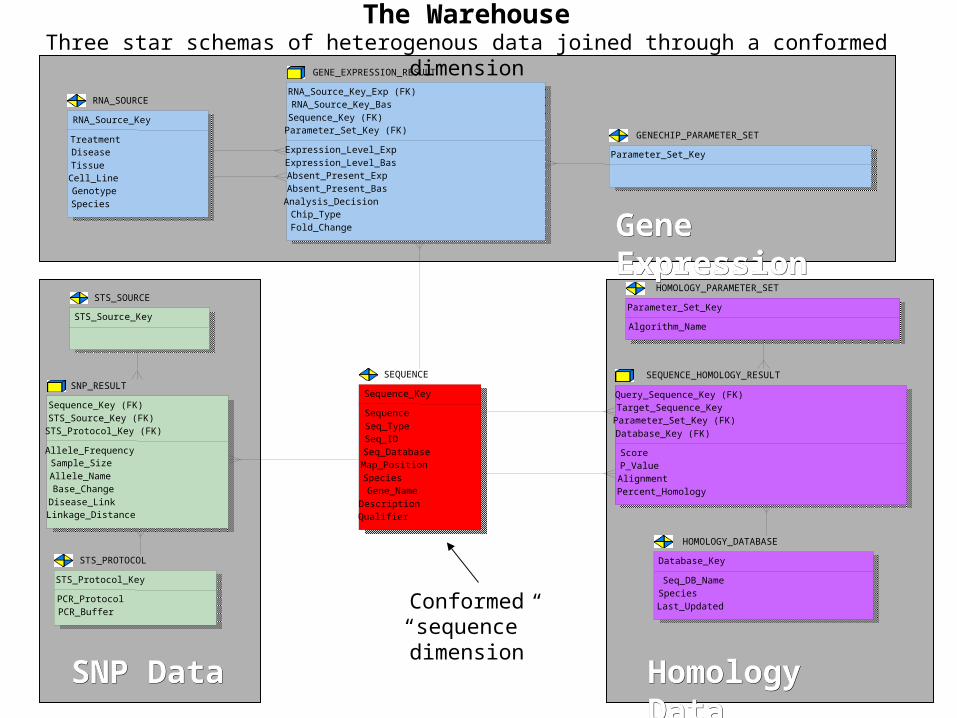
HOMOLOGY_DATABASE
Database_Key
Seq_DB_NameSpeciesLast_Updated
GENE_EXPRESSION_RESULT
RNA_Source_Key_Exp (FK)RNA_Source_Key_BasSequence_Key (FK)Parameter_Set_Key (FK)
Expression_Level_ExpExpression_Level_BasAbsent_Present_ExpAbsent_Present_Bas
Analysis_DecisionChip_TypeFold_Change
GENECHIP_PARAMETER_SET
Parameter_Set_Key
SEQUENCE_HOMOLOGY_RESULT
Query_Sequence_Key (FK)Target_Sequence_KeyParameter_Set_Key (FK)
Database_Key (FK)
ScoreP_ValueAlignment
Percent_Homology
RNA_SOURCE
RNA_Source_Key
TreatmentDisease
TissueCell_LineGenotypeSpecies
SEQUENCE
Sequence_Key
Sequence
Seq_TypeSeq_IDSeq_DatabaseMap_PositionSpeciesGene_Name
DescriptionQualifier
SNP_RESULT
Sequence_Key (FK)STS_Source_Key (FK)STS_Protocol_Key (FK)
Allele_FrequencySample_SizeAllele_NameBase_ChangeDisease_LinkLinkage_Distance
STS_SOURCE
STS_Source_Key
STS_PROTOCOL
STS_Protocol_Key
PCR_ProtocolPCR_Buffer
HOMOLOGY_PARAMETER_SET
Parameter_Set_Key
Algorithm_Name
Gene ExpressionGene Expression
SNP DataSNP Data Homology DataHomology Data
Three star schemas of heterogenous data joined through a conformed dimensionThe Warehouse
Conformed “sequence” dimension
Related Documents











