Data Integration and Data Integration and Information Retrieval: Information Retrieval: Moving from the Ivory Tower into the Moving from the Ivory Tower into the Corporate Office Corporate Office Tae W. Ryu Department of Computer Science California State University, Fullerton

Data Integration and Information Retrieval: Moving from the Ivory Tower into the Corporate Office Tae W. Ryu Department of Computer Science California.
Dec 22, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Data Integration and Information Data Integration and Information Retrieval: Retrieval:
Moving from the Ivory Tower into the Corporate OfficeMoving from the Ivory Tower into the Corporate Office
Tae W. Ryu
Department of Computer ScienceCalifornia State University, Fullerton

Summary of Today’s TalkSummary of Today’s Talk
Past and current research activitiesData integration and information retrievalCommercial application to Real Estate
business by Mr. ShinQuestions & answers

A Bioinformatics Project at CSUFA Bioinformatics Project at CSUF
A bioinformatics research group (BIG) involving several faculty members and students from Computer Science, Biology, Biochemistry, Mathematics at CSUF and Pomona College in Claremont started in 2001
Bioinformatics is the study of the biological systems using computers.
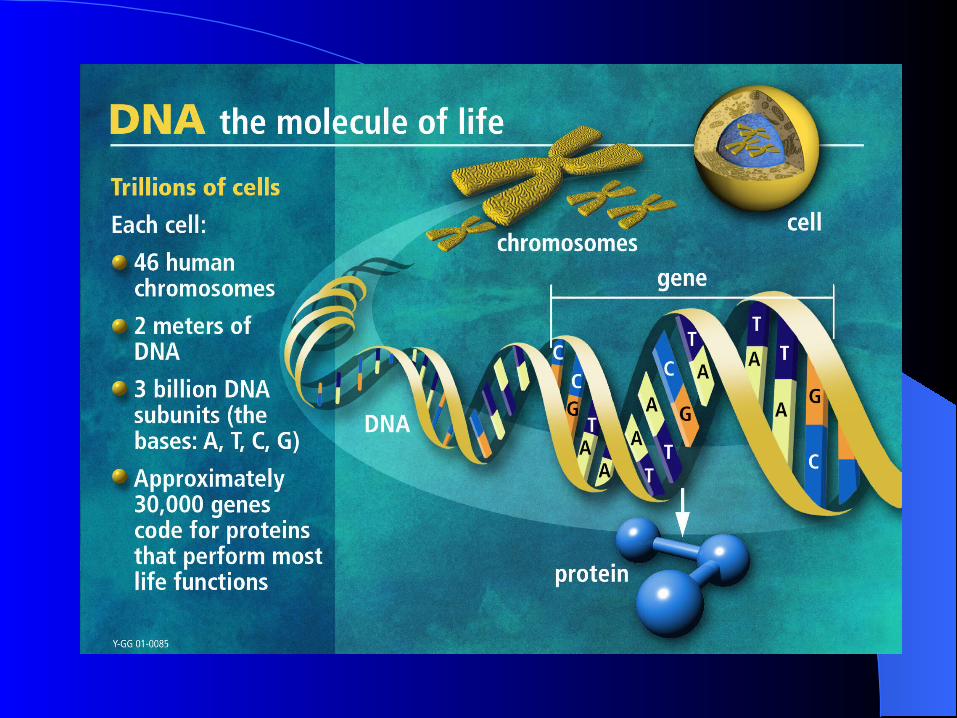
DNA DNA the molecule of lifethe molecule of life

DNADNA(Deoxyribonucleic Acid)(Deoxyribonucleic Acid)
DNA is double-stranded– Base pairs (A-T, G-C) are complementary, known as
Watson-Crick bps
A double-stranded DNA sequence can be represented by strings of letters (1D) in either direction– 5' ... TACTGAA ... 3' – 3' ... ATGACTT ... 5'
Length of DNA in bps (e.g. 100kbp)

Genes and Genetic CodeGenes and Genetic Code
What are genes?– Specific sequence of nucleotides (A,T,G,C) along a
chromosome carrying information for constructing a protein
Who defined the concept of a gene?– Mendel – 1860’s (DNA was elucidated 75 years later)
What is the genetic code? – 3 base pairs in a gene = a codon (representing one
amino acid) Genome is a complete set of chromosomes.

Non-coding Regions in DNANon-coding Regions in DNA
• Over 90% of the Human genome is non-coding sequences (intergenic region or junk DNA).
• The role of this region is yet unknown but is speculated to be very important.
Gene Gene Gene
Intergenic regions (non-coding) and Introns

Our Project GoalOur Project Goal
Understand the importance and roles of those non-coding regions (intergenic regions) in DNA– Build a high-quality of integrated data source
for the non-coding sequences (intergenic regions) in Eukaryotic genomes
– Seek pilot projects for bioinformatics research and education at CSUF

Bioinformatics andBioinformatics andIntegrated Biological DataIntegrated Biological Data
Major task for bioinformatists is to make sense out the biological data – Typical tasks
Modeling, sequence to structure or functional class, structure to function or mechanism
– How? Biology-oriented approach:
– Experiment and DNA manipulation in a Wet-Lab Computer-oriented approach:
– Data mining, pattern recognition and discovery, prediction model, simulation, etc.
Success in most bioinformatics research requires– An integrated view of all the relevant data
High quality of genomic sequence data and other relevant data The results of analyses, such as, patterns produced by other research
– User friendly and powerful information retrieval tool– Data analysis and interpretation
Data analysis by data mining and statistical approaches Interpretation by biologists (with strong domain knowledge)

Obstacles to Data IntegrationObstacles to Data Integration Data spread over multiple, heterogeneous data sources
– Databases (MySql, Oracle, SQL Server, etc.)– Semi-structured sequence files (text or XML)– HTML format in Web sites– Output of analytic programs (BLAST, PFAM, etc.)
Not all sources represent biology optimally– Semantics of sources can differ widely
Genbank is sequence-centric, not gene-centric SwissProt is sequence-centric, not domain-centric
– Use different terms and definitions Biological ontologies are being built now
Lack of standards in data representation– XML is emerging as a standard for data transfer

More ObstaclesMore Obstacles Poor data quality (errors) and incomplete data
– due to errors in Labs– due to the large amount of data that is computer-
generated using heuristic algorithms Data in the original data sources is changing
This is a really challenging problem that requires in-depth knowledge of both Computer Science and Molecular Biology– Several approaches are possible (cross-validation, re-
experiment) but still limited

Possible ApproachesPossible Approaches Database approach (conventional)
– Relational or object-oriented database Data warehouse (or Data mart)
– Data warehouse maintains an integrated high-quality, current (or historical), and consistent data.
Data mart is a small scale of data warehouse
– Often important prerequisite for sophisticated data mining
Ideal approach (a future system)– A comprehensive information management system with
all the above components plus powerful search engine and intelligent information retrieval based on text mining
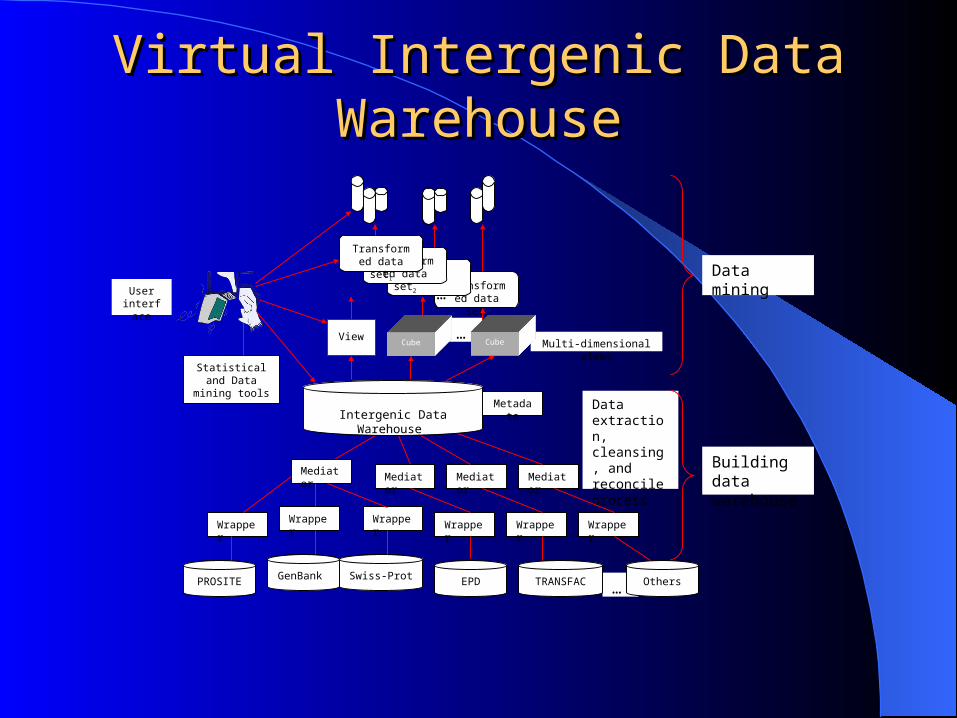
Data extraction, cleansing, and reconcile process
Transformed data setn
…Transformed
data set2
…
User interface
Building data warehouse
Data mining
…
…
GenBank
Multi-dimensional views
EPDSwiss-Prot
Cube
Wrapper WrapperWrapper
Mediator Mediator
Metadata
Transformed data set1
View
PROSITE
Wrapper
TRANSFAC
Wrapper
Mediator
Others
Wrapper
Mediator
Intergenic Data Warehouse
Statistical and Data mining
tools
Cube
Virtual Intergenic Data WarehouseVirtual Intergenic Data Warehouse

Current ProgressCurrent Progress Intergenic Database (IGDB version 1.1)
– Integrated from genbank for Caenorhabditis elegans (nematode) and Saccharomyces cerevisiae (baker’s yeast), and Arabidopsis thaliana (mouse-ear cress) genomes
– Mouse, Mosquito, Human are under way
Pattern Summary System (PATSS) – Summarize the sequence patterns generated by BLAST– Pattern visualization with alignment tools– Distributed BLAST using Web service and clustered computers
Ontology-based data integration– Intelligent wrapper and mediator– Structure description language for data extraction
Powerful information retrieval system based on customized search engine with the support of text mining
– Web crawlers and customized search engine, document indexing– Text mining, natural language processing
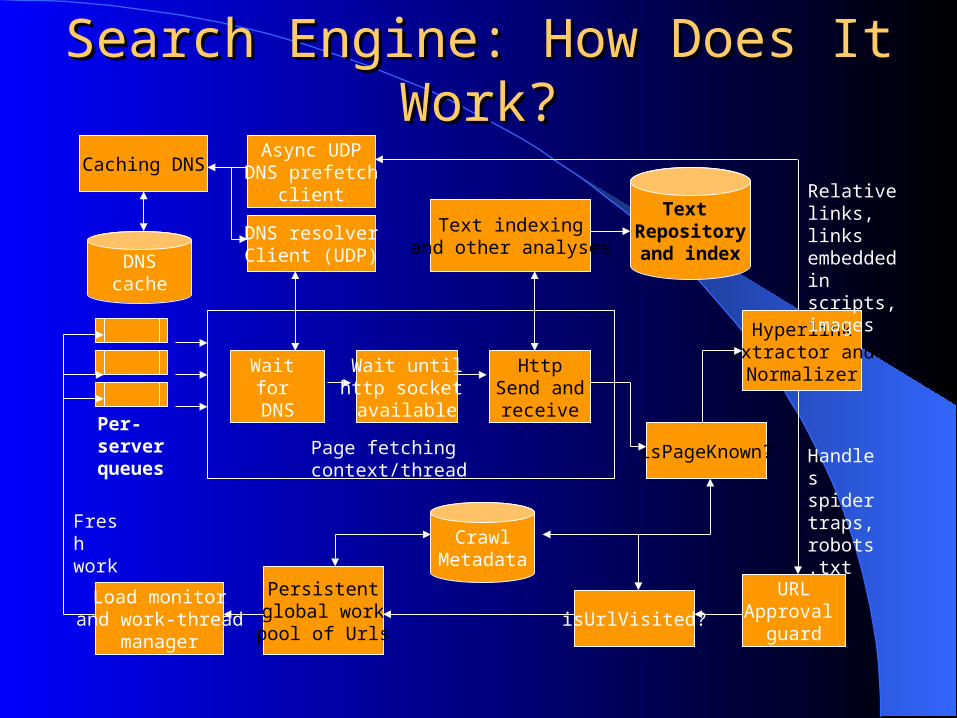
Search Engine: How Does It Work?Search Engine: How Does It Work?
Per-server queues
Persistentglobal workpool of Urls
URLApproval
guard
isPageKnown?
HyperlinkExtractor andNormalizer
isUrlVisited?
Wait for
DNS
Wait untilhttp socket
available
HttpSend andreceive
Page fetching context/thread
Load monitorand work-thread
manager
Caching DNSAsync UDP
DNS prefetchclient
DNS resolverClient (UDP)
Text indexingand other analyses
CrawlMetadata
Text Repositoryand indexDNS
cache
Fresh work
Relative links, links embedded in scripts, images
Handles spider traps, robots.txt

Search Engine for Web Data Integration and RetrievalSearch Engine for Web Data Integration and Retrieval
t: token id d: document id s: a bit to specify if the document has been deleted or inserted
(d,t)
Batch sort
Fast indexing(may not
be compact)(d,t,s)
Batch sort
(t,d,s) Merge-purge Build compactindex (may
hold partly in RAM)
(t,d)
Queryprocessor
Querylogs
Stop-pressindex
Mainindex
New or deleted documents
Fresh batch of documents
May preserve this sorted sequence
UserText mining

What is Text Mining?What is Text Mining? Text mining is the process of extracting interesting/useful
patterns from text documents (1997 by data mining group). Text is the most natural form of storing and exchanging
information– Very high commercial potential– Study indicates that 80% of company’s information was contained in text
documents such as emails, memos, reports, etc.
Applications– Customer profile analysis
mining incoming emails for customer’s complaint and feedback
– Information dissemination organizing and summarizing trade news and reports for personalized information service
– Security email or message scan, spam blocker
– Patent analysis analyzing patent databases for major technology players and trends
– Extracting specific information from the Web (Web mining) More powerful and intelligent search engine

Text Mining FrameworkText Mining Framework
Information extraction: machine readable dictionaries and lexical knowledge bases are essential.
– Fact extraction: pattern matching, lexical analysis, syntactic and semantic structure
– Fact integration and knowledge representation Information mining: mostly based on data mining and machine learning techniques
– Episodes and episode rules– Conceptual clustering and concept hierarchies– Text categorization
clustering, classification (machine learning approach)
– Text summarization– Visualization – Natural language processing (very computationally expensive)
Commercial products (mostly for categorization, summarization, visualization)
– iMiner (IBM), TextWise (Syracuse), cMap (Canis), etc.
Document retrievalText documents Information mining InterpretationInformation extraction
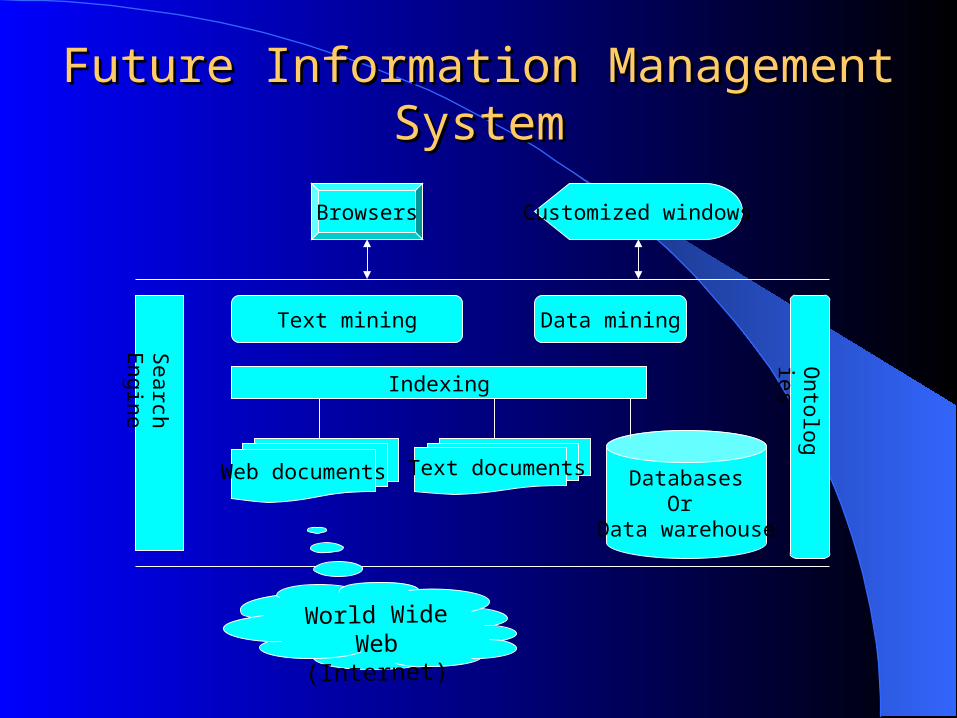
Future Information Management SystemFuture Information Management System
DatabasesOr
Data warehouse
Web documents Text documents
Indexing
Browsers Customized windows
Search E
ngine
Ontologies
Text mining
World Wide Web(Internet)
Data mining

Techniques Used for Real Estate Techniques Used for Real Estate Business by Mr. ShinBusiness by Mr. Shin
Data integration from multiple data sources– Database integration– Information extraction from Web using Web
crawler
Customized search engine with the support of text mining
User friendly information retrieval tool

Thank You. Thank You.
Related Documents











