Dark Knowledge Alex Tellez & Michal Malohlava www.h2o.ai

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript


DARK KNOWLEDGE?Geoff ’s been busy at Google. Recently, he published a paper talking
about ‘Dark Knowledge’. Sounds creepy….
What problem is this referring to?Model complexity with respect to deployment.
Ensembles (RF / GBM) + DNN are slow to train + predictand require lots of memory (READ: $$$)
What’s the solution?Train a simpler model that extracts the ‘dark knowledge’ from the DNN
(or ensemble) we want to mimic. The simpler model can then be deployed at a cheaper ‘cost’.

WHY NOW?CLEARLY, this is a good idea BUT why hasn’t there been more
investigation to an otherwise very promising approach?
Our Perception
We equate the knowledge in a trained model learned parameters(i.e. weights)
How can you change the ‘form’ of the model but keep the same knowledge?
…which is why we have trouble with this question:
Answer: By using soft targets to train a simpler model to extract the ‘dark knowledge’ from the more complex model.

GAME-PLAN1. Import Higgs-Boson Dataset (~11 million rows, 5 GBs)
2. Create FOUR splits of our dataset
3. Train a ‘cumbersome’ deep neural network
4. Predict targets for transfer dataset append as ‘soft targets’ for distilled model.
5. Train ‘distilled’ model on soft targets to learn ‘Dark Knowledge’
6. Compare ‘distilled’ model vs. ‘cumbersome’ model on validation data

FOUR DATASETS?
The original Higgs-Boson Dataset: 11 million rowsSplit this into….
data.train - 8.8 million rowsdata.test - 550k rows
‘Cumbersome Model’
data.transfer - 1.1 million rows ‘Distilled Model’(labels = prediction from
‘Cumbersome’ Model
Model Comparisondata.valid - 550k rows
1.2.
3.
4.

THE ‘CUMBERSOME’ NET
Inputs: 29 machine + human generated features# of Layers: 3
# of Hidden Neurons: 1,024 / layer (3,072 total)Activation Function: Rectifier w/ Dropout (default = 50%)
Input Dropout: 10%, L1-regularization: 0.0001
Total Training Time: 24 mins. 20 seconds

‘CUMBERSOME’ NET CONT’D.
27% Model Error
~ 0.82 AUC
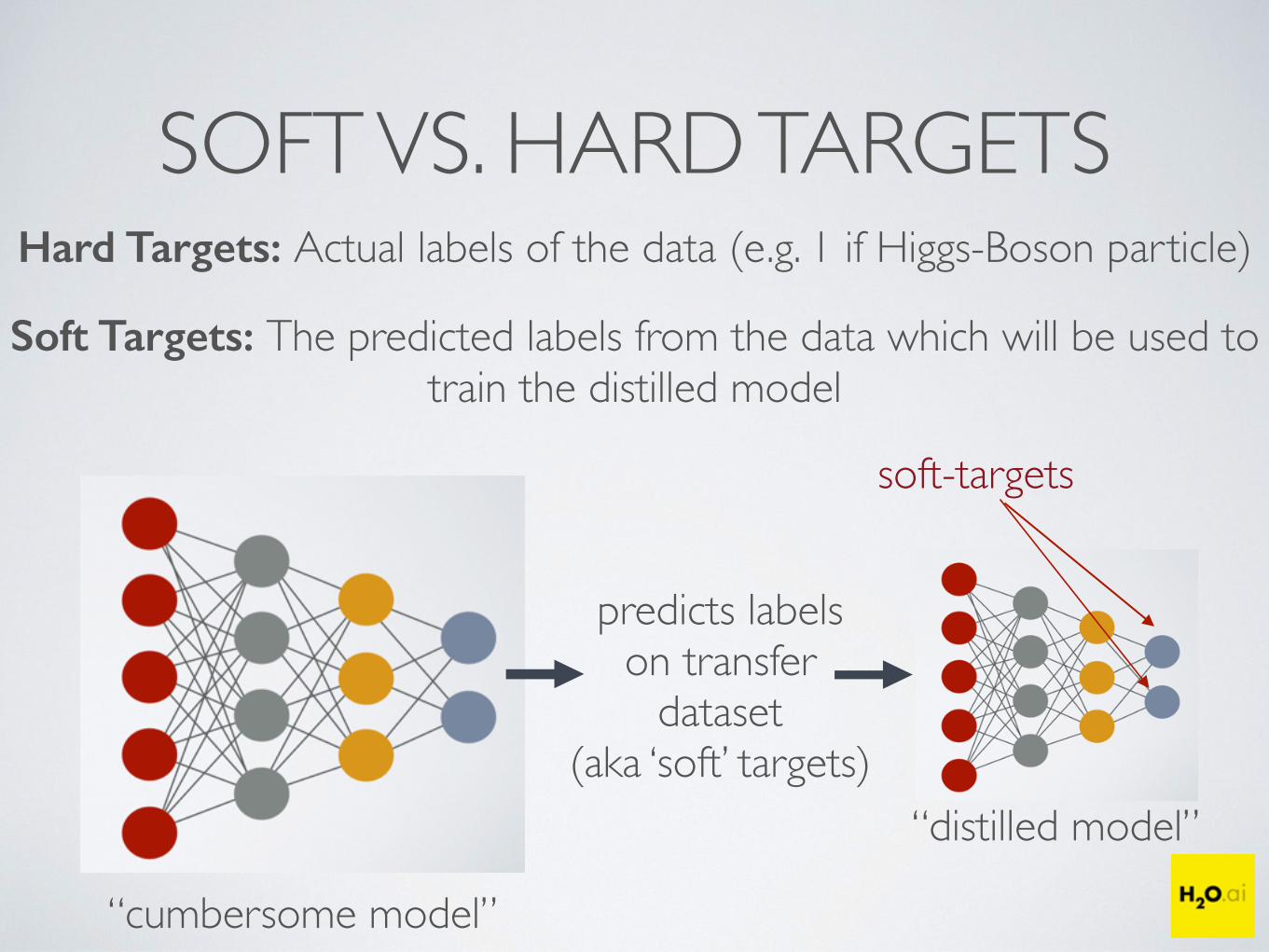
SOFT VS. HARD TARGETSHard Targets: Actual labels of the data (e.g. 1 if Higgs-Boson particle)
Soft Targets: The predicted labels from the data which will be used totrain the distilled model
soft-targets
“distilled model”
“cumbersome model”
predicts labelson transfer
dataset(aka ‘soft’ targets)

TRAIN ‘DISTILLED’ NETAFTER cumbersome model predicts labels on transfer data,
use these labels as ‘soft targets’ to train distilled network
‘Cumbersome’ Net ‘Distilled’ Net
3 layers x 1,024 neurons / layer 2 layers x 800 neurons / layerRectifier w/ Dropout Rectifier
Input Dropout + L1-regular. No Input Dropout OR L1-regular.

‘DISTILLED’ NET CONT’D.~ 3 minutes to train
High AUC on ‘soft’ targets

THE REAL ACID TESTSo we have 2 models:
Cumbersome Model: Trained w/ DReD NetDistilled Model: Trained w/ Soft Targets on Transfer Dataset
NOW, it’s time to score each model against the validation dataset (which has hard targets)

NOT SHABBY…Cumbersome Model Confusion Matrix:
Distilled Model Confusion Matrix:
A difference of 737 errors (!!)

WHAT NOW?
If you want to know more read:“Distilling the Knowledge in a Neural Network” - G.E. Hinton
Alex: [email protected] Michal: [email protected]
Coming Soon: “The Hinton Trick” will be added to H2O’s algo roadmap!
Next Test: Try some ensemble approaches (e.g. Random Forest, Gradient Boosting Machine)
Result: Our ‘simple’ net does a very decent job compared to the complex net having learned ‘dark knowledge’