Daniel J. Abadi · Adam Marcus · Samuel R. Madden ·Kate Hollenbach Presenter: Vishnu Prathish Date: Oct 1 st 2013 CS 848 – Information Integration on the WEB with RDF, OQL and SPARQL SW-Store: a vertically partitioned DBMS for Semantic Web data management

Daniel J. Abadi · Adam Marcus · Samuel R. Madden ·Kate Hollenbach Presenter: Vishnu Prathish Date: Oct 1 st 2013 CS 848 – Information Integration on the.
Jan 02, 2016
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Daniel J. Abadi · Adam Marcus · Samuel R. Madden ·Kate Hollenbach
Presenter: Vishnu Prathish
Date: Oct 1st 2013
CS 848 – Information Integration on the WEB with RDF, OQL and SPARQL
SW-Store: a vertically partitioned DBMS for Semantic Web data management

Overview
1. The Problem and the Solution• Motivation• Current State of Art - RDF in RDBMS and Property tables• Vertically Partitioned Approach• Column Oriented DBMS for Vertical Partitioning
2. Benchmarks, Comparisons and Results
3. SW-Store – Design • System Architecture • Storage System• Query Engine and Query Translation • The rest of it• Conclusion

Motivation• Efficient storage mechanism for RDF triples
Query : Find the authors of books whose title contains the word “Transaction”
The easy way : Have a three column schema with subject , property and object as labels

Motivation• Efficient storage mechanism for RDF triples
Query : Find the authors of books whose title contains the word “Transaction”
“5 way self join”
The easy way : Have a three column schema with subject , property and object as labels
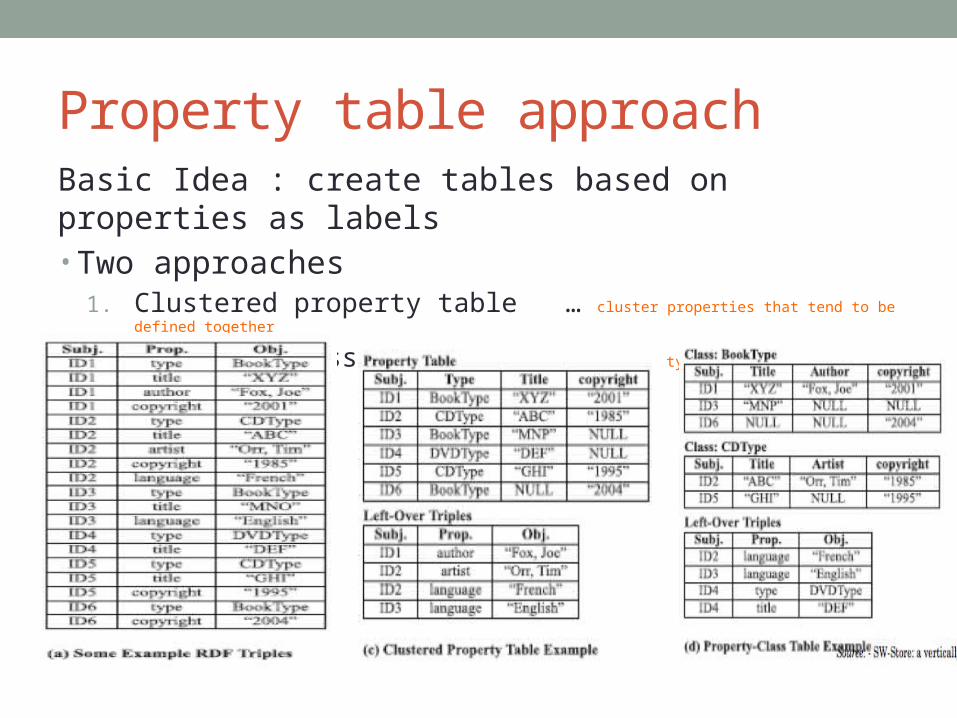
Property table approachBasic Idea : create tables based on properties as labels• Two approaches
1. Clustered property table … cluster properties that tend to be defined together
2. Property class table … cluster based on type property of subjects

Two sides of coin• Advantages:
• Significantly reduces subject-subject self joins on triples table• Opens up possibility of attribute typing.
• Disadvantages:• Many queries will still need joins as they will access data from
multiple tables• Unstructured data – Subjects won’t have all properties defined. • Multivalued attributes.

A simpler alternative : Vertical partitioning
Basic Idea: Subject-Object columns for each property.
Advantages:• Effective handling of multivalued attributes• Elimination of null values – heterogeneous records • Only property tables required by a query needs to be read• No clustering algorithms• Fewer unions
But of course,
• Number of joins required just exploded!!• Slower inserts

Extending a column oriented DBMS• Basic Idea: store as collections of columns rather than collection of rows
• No wastage of bandwidth as projections on data happen before it is pulled into main memory.
• Record header is stored in separate columns thus reducing the tuple width and letting us choose different compression techniques for each column.
Source: smithal – spatial databases CSCI 8715

Benchmark and EvaluationBarton Libraries dataset provided by Simile Project at MITA benchmark set of 7 queries of varying type
• Triple Data store• Property tables• Vertically partitioned
– row oriented• Vertically partitioned
– Column oriented

Results• Property table and vertical partitioning outperforms triple
store by a factor of 2-3.• C-Store adds another factor of 10 performance
improvement• For Property table, careful selection of column names are
required.• Vertical partitioning represents the best case and worst
case scenario• Linear scaling for all tested queries

• Hybrid storage representation
• Single columned • Column oriented sparse
compression schemes
SW-Store – A standalone vertically partitioned database/storage layer
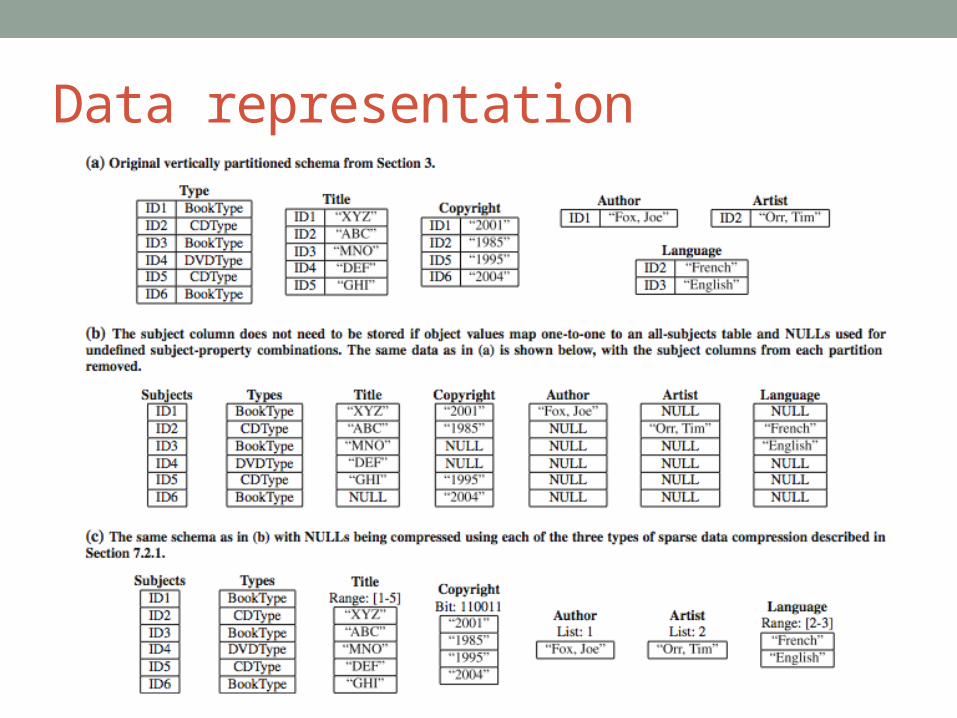
Data representation

Query engine and Query Translation
• Each column scanned to produce tuples that satisfies all three predicates
• Tupleize operator becomes merge join over two column vertical partitions
• Query translator converts

Overflow table to perform updates• A mechanism to support inserts in a batch.• Additional table in the standard triples schema • Not indexed or read optimized• Properties that appear very small number of times in
overflow table are not merged due to cost of merging. • Horizontal “chunks” to improve the efficiency of merging
• Disadvantage: • Queries must go to both overflow table and vertical partitions• Merge must be performed – Still expensive

Discussions:• Multivalued attributes can not be implemented. • Overflow table – Significant overhead???• “Overflow tables might turn out to be useful while adding
very rare predicates” – How?• Queries that do not restrict on property values are very
rare for RDF applications. -- ?• Potential scalability issues when the number of properties
are high?• Queries including unrestricted property problem are
removed from the validation dataset. – what would be the impact?What if queries are not restricted to a limited number of properties? Are real world queries like this?

Thank you!
Related Documents











