CUDA C

CUDA_C
Dec 08, 2015
Cuda C introduction
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

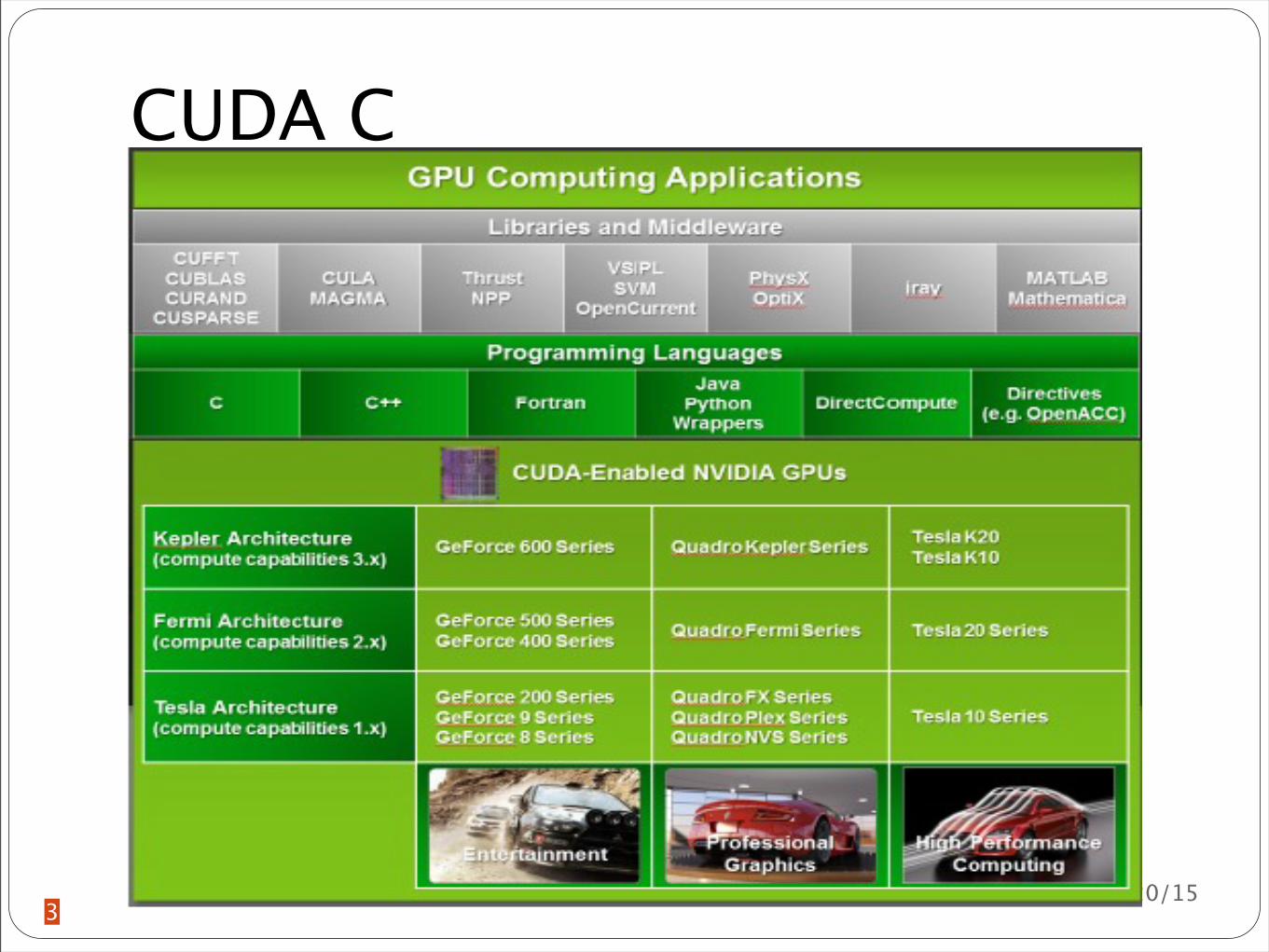
CUDA C
082015
CUDA
2
A general purpose parallel computing platform and programming model
Introduced in 2006 by NVIDIAEnhances the compute engine in GPUs to solve complex computation problems in an efficient way
Comes with a software environment that allows developers to use C as a high level programming language other languages application programming interfaces or directives-based approaches are supported such as FORTRAN DirectCompute OpenACC
082015
CUDA C
3
082015
CUDA C - A scalable programming Model
4
Mainstream processors are parallelAdvent of many-core and multi-core chips
3D graphics applications transparently scale their parallelism on GPUs with varying number of coresChallenge To develop application software that scales transparently with the number of cores
Let programmers focus on parallel algorithmsNot on the mechanics of a parallel programming language
0820155
Facing the challenge using minimal set of language extensionsHierarchy of threads Shared MemoryBarrier synchronization
Partition the problem into coarse sub problemsSolved independently in parallel by blocks of threads
Partition sub-problems into finer piecesSolved cooperatively in parallel by all threads within the block
CUDA C - A scalable programming Model
082015
CUDA C - A scalable programming Model
6
Each block of threads can be scheduled on any of the available multiprocessorsWithin a GPU in any order concurrently or sequentially
A compiled CUDA program can execute on any number of multiprocessors
Only the runtime system needs to know the physical multiprocessor count
082015
Automatic Scalability
7
A multi threaded program is partitioned into blocks of threads that execute independently from each other so that a GPU with more cores will automatically execute the program in less time than GPU with fewer cores
082015
Heterogeneous Computing
8
Host CPU and its memory (host memory)Device GPU and its memory (device memory)
082015
Heterogeneous Computing
9
082015
GPU programming model
10
Serial code executes in a HOST(CPU) thread
Parallel code executes in many concurrent DEVICE(GPU) threads across multiple parallel processing elements
082015
Compiling CUDA C Programs
11
Refer httpdocsnvidiacomcudacuda-compiler-driver-nvccaxzz3Qz0M7rGW
082015
Compiling CUDA C Programs
12
Source files for CUDA applications Mixture of conventional C++ host code plus GPU device (ie GPU-)
functions CUDA compilation trajectory
Separates the device functions from the host code Compiles the device functions using proprietary NVIDIA compilers
assemblers Compiles the host code using a general purpose CC++ compiler that is
available on the host platform and Embeds the compiled GPU functions in the host object file
In the linking stage specific CUDA runtime libraries are added for supporting remote SIMD procedure calling and for providing explicit GPU manipulation such as allocation of GPU memory buffers and host-GPU data transfer
082015
Purpose of NVCC
13
Compilation trajectory involves Splitting compilation preprocessing and merging steps for each CUDA source file
CUDA compiler driver nvcc hides the intricate details of CUDA compilation from developers
nvcc mimics the behavior of the GNU compiler gcc it accepts a range of conventional compiler options such as for defining macros and includelibrary paths and for steering the compilation process
All non-CUDA compilation steps are forwarded to a general purpose C compiler that is supported by nvcc
08201514
Source Kirk and Hwu
NVCC Compiler
Host C preprocessor compilerlinker
Device just-in time compiler
Heterogeneous Computing Platform with CPUs GPUs
Host Code
Device Code (PTX)
Integrated C programs with CUDA extensions
08201515
Nvccrsquos basic workflow separates device code and host code and thenCompiles the device code into an assembly form (PTX code) or binary form (cubin object)
Modifies the host code by replacing syntax in kernels by necessary CUDA C runtime function calls to load and launch each compiled kernel from the PTX code cubin object
Modified host code is output as object code by letting nvcc invoke the host compiler during last compilation stage
082015
Anatomy of a CUDA C Program
16
Step 1 Copy input data from host memory to device memory
082015
Anatomy of a CUDA C Program
17
Step 2 Launch a kernel on the device
082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
CUDA
2
A general purpose parallel computing platform and programming model
Introduced in 2006 by NVIDIAEnhances the compute engine in GPUs to solve complex computation problems in an efficient way
Comes with a software environment that allows developers to use C as a high level programming language other languages application programming interfaces or directives-based approaches are supported such as FORTRAN DirectCompute OpenACC
082015
CUDA C
3
082015
CUDA C - A scalable programming Model
4
Mainstream processors are parallelAdvent of many-core and multi-core chips
3D graphics applications transparently scale their parallelism on GPUs with varying number of coresChallenge To develop application software that scales transparently with the number of cores
Let programmers focus on parallel algorithmsNot on the mechanics of a parallel programming language
0820155
Facing the challenge using minimal set of language extensionsHierarchy of threads Shared MemoryBarrier synchronization
Partition the problem into coarse sub problemsSolved independently in parallel by blocks of threads
Partition sub-problems into finer piecesSolved cooperatively in parallel by all threads within the block
CUDA C - A scalable programming Model
082015
CUDA C - A scalable programming Model
6
Each block of threads can be scheduled on any of the available multiprocessorsWithin a GPU in any order concurrently or sequentially
A compiled CUDA program can execute on any number of multiprocessors
Only the runtime system needs to know the physical multiprocessor count
082015
Automatic Scalability
7
A multi threaded program is partitioned into blocks of threads that execute independently from each other so that a GPU with more cores will automatically execute the program in less time than GPU with fewer cores
082015
Heterogeneous Computing
8
Host CPU and its memory (host memory)Device GPU and its memory (device memory)
082015
Heterogeneous Computing
9
082015
GPU programming model
10
Serial code executes in a HOST(CPU) thread
Parallel code executes in many concurrent DEVICE(GPU) threads across multiple parallel processing elements
082015
Compiling CUDA C Programs
11
Refer httpdocsnvidiacomcudacuda-compiler-driver-nvccaxzz3Qz0M7rGW
082015
Compiling CUDA C Programs
12
Source files for CUDA applications Mixture of conventional C++ host code plus GPU device (ie GPU-)
functions CUDA compilation trajectory
Separates the device functions from the host code Compiles the device functions using proprietary NVIDIA compilers
assemblers Compiles the host code using a general purpose CC++ compiler that is
available on the host platform and Embeds the compiled GPU functions in the host object file
In the linking stage specific CUDA runtime libraries are added for supporting remote SIMD procedure calling and for providing explicit GPU manipulation such as allocation of GPU memory buffers and host-GPU data transfer
082015
Purpose of NVCC
13
Compilation trajectory involves Splitting compilation preprocessing and merging steps for each CUDA source file
CUDA compiler driver nvcc hides the intricate details of CUDA compilation from developers
nvcc mimics the behavior of the GNU compiler gcc it accepts a range of conventional compiler options such as for defining macros and includelibrary paths and for steering the compilation process
All non-CUDA compilation steps are forwarded to a general purpose C compiler that is supported by nvcc
08201514
Source Kirk and Hwu
NVCC Compiler
Host C preprocessor compilerlinker
Device just-in time compiler
Heterogeneous Computing Platform with CPUs GPUs
Host Code
Device Code (PTX)
Integrated C programs with CUDA extensions
08201515
Nvccrsquos basic workflow separates device code and host code and thenCompiles the device code into an assembly form (PTX code) or binary form (cubin object)
Modifies the host code by replacing syntax in kernels by necessary CUDA C runtime function calls to load and launch each compiled kernel from the PTX code cubin object
Modified host code is output as object code by letting nvcc invoke the host compiler during last compilation stage
082015
Anatomy of a CUDA C Program
16
Step 1 Copy input data from host memory to device memory
082015
Anatomy of a CUDA C Program
17
Step 2 Launch a kernel on the device
082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA C
3
082015
CUDA C - A scalable programming Model
4
Mainstream processors are parallelAdvent of many-core and multi-core chips
3D graphics applications transparently scale their parallelism on GPUs with varying number of coresChallenge To develop application software that scales transparently with the number of cores
Let programmers focus on parallel algorithmsNot on the mechanics of a parallel programming language
0820155
Facing the challenge using minimal set of language extensionsHierarchy of threads Shared MemoryBarrier synchronization
Partition the problem into coarse sub problemsSolved independently in parallel by blocks of threads
Partition sub-problems into finer piecesSolved cooperatively in parallel by all threads within the block
CUDA C - A scalable programming Model
082015
CUDA C - A scalable programming Model
6
Each block of threads can be scheduled on any of the available multiprocessorsWithin a GPU in any order concurrently or sequentially
A compiled CUDA program can execute on any number of multiprocessors
Only the runtime system needs to know the physical multiprocessor count
082015
Automatic Scalability
7
A multi threaded program is partitioned into blocks of threads that execute independently from each other so that a GPU with more cores will automatically execute the program in less time than GPU with fewer cores
082015
Heterogeneous Computing
8
Host CPU and its memory (host memory)Device GPU and its memory (device memory)
082015
Heterogeneous Computing
9
082015
GPU programming model
10
Serial code executes in a HOST(CPU) thread
Parallel code executes in many concurrent DEVICE(GPU) threads across multiple parallel processing elements
082015
Compiling CUDA C Programs
11
Refer httpdocsnvidiacomcudacuda-compiler-driver-nvccaxzz3Qz0M7rGW
082015
Compiling CUDA C Programs
12
Source files for CUDA applications Mixture of conventional C++ host code plus GPU device (ie GPU-)
functions CUDA compilation trajectory
Separates the device functions from the host code Compiles the device functions using proprietary NVIDIA compilers
assemblers Compiles the host code using a general purpose CC++ compiler that is
available on the host platform and Embeds the compiled GPU functions in the host object file
In the linking stage specific CUDA runtime libraries are added for supporting remote SIMD procedure calling and for providing explicit GPU manipulation such as allocation of GPU memory buffers and host-GPU data transfer
082015
Purpose of NVCC
13
Compilation trajectory involves Splitting compilation preprocessing and merging steps for each CUDA source file
CUDA compiler driver nvcc hides the intricate details of CUDA compilation from developers
nvcc mimics the behavior of the GNU compiler gcc it accepts a range of conventional compiler options such as for defining macros and includelibrary paths and for steering the compilation process
All non-CUDA compilation steps are forwarded to a general purpose C compiler that is supported by nvcc
08201514
Source Kirk and Hwu
NVCC Compiler
Host C preprocessor compilerlinker
Device just-in time compiler
Heterogeneous Computing Platform with CPUs GPUs
Host Code
Device Code (PTX)
Integrated C programs with CUDA extensions
08201515
Nvccrsquos basic workflow separates device code and host code and thenCompiles the device code into an assembly form (PTX code) or binary form (cubin object)
Modifies the host code by replacing syntax in kernels by necessary CUDA C runtime function calls to load and launch each compiled kernel from the PTX code cubin object
Modified host code is output as object code by letting nvcc invoke the host compiler during last compilation stage
082015
Anatomy of a CUDA C Program
16
Step 1 Copy input data from host memory to device memory
082015
Anatomy of a CUDA C Program
17
Step 2 Launch a kernel on the device
082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
CUDA C - A scalable programming Model
4
Mainstream processors are parallelAdvent of many-core and multi-core chips
3D graphics applications transparently scale their parallelism on GPUs with varying number of coresChallenge To develop application software that scales transparently with the number of cores
Let programmers focus on parallel algorithmsNot on the mechanics of a parallel programming language
0820155
Facing the challenge using minimal set of language extensionsHierarchy of threads Shared MemoryBarrier synchronization
Partition the problem into coarse sub problemsSolved independently in parallel by blocks of threads
Partition sub-problems into finer piecesSolved cooperatively in parallel by all threads within the block
CUDA C - A scalable programming Model
082015
CUDA C - A scalable programming Model
6
Each block of threads can be scheduled on any of the available multiprocessorsWithin a GPU in any order concurrently or sequentially
A compiled CUDA program can execute on any number of multiprocessors
Only the runtime system needs to know the physical multiprocessor count
082015
Automatic Scalability
7
A multi threaded program is partitioned into blocks of threads that execute independently from each other so that a GPU with more cores will automatically execute the program in less time than GPU with fewer cores
082015
Heterogeneous Computing
8
Host CPU and its memory (host memory)Device GPU and its memory (device memory)
082015
Heterogeneous Computing
9
082015
GPU programming model
10
Serial code executes in a HOST(CPU) thread
Parallel code executes in many concurrent DEVICE(GPU) threads across multiple parallel processing elements
082015
Compiling CUDA C Programs
11
Refer httpdocsnvidiacomcudacuda-compiler-driver-nvccaxzz3Qz0M7rGW
082015
Compiling CUDA C Programs
12
Source files for CUDA applications Mixture of conventional C++ host code plus GPU device (ie GPU-)
functions CUDA compilation trajectory
Separates the device functions from the host code Compiles the device functions using proprietary NVIDIA compilers
assemblers Compiles the host code using a general purpose CC++ compiler that is
available on the host platform and Embeds the compiled GPU functions in the host object file
In the linking stage specific CUDA runtime libraries are added for supporting remote SIMD procedure calling and for providing explicit GPU manipulation such as allocation of GPU memory buffers and host-GPU data transfer
082015
Purpose of NVCC
13
Compilation trajectory involves Splitting compilation preprocessing and merging steps for each CUDA source file
CUDA compiler driver nvcc hides the intricate details of CUDA compilation from developers
nvcc mimics the behavior of the GNU compiler gcc it accepts a range of conventional compiler options such as for defining macros and includelibrary paths and for steering the compilation process
All non-CUDA compilation steps are forwarded to a general purpose C compiler that is supported by nvcc
08201514
Source Kirk and Hwu
NVCC Compiler
Host C preprocessor compilerlinker
Device just-in time compiler
Heterogeneous Computing Platform with CPUs GPUs
Host Code
Device Code (PTX)
Integrated C programs with CUDA extensions
08201515
Nvccrsquos basic workflow separates device code and host code and thenCompiles the device code into an assembly form (PTX code) or binary form (cubin object)
Modifies the host code by replacing syntax in kernels by necessary CUDA C runtime function calls to load and launch each compiled kernel from the PTX code cubin object
Modified host code is output as object code by letting nvcc invoke the host compiler during last compilation stage
082015
Anatomy of a CUDA C Program
16
Step 1 Copy input data from host memory to device memory
082015
Anatomy of a CUDA C Program
17
Step 2 Launch a kernel on the device
082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

0820155
Facing the challenge using minimal set of language extensionsHierarchy of threads Shared MemoryBarrier synchronization
Partition the problem into coarse sub problemsSolved independently in parallel by blocks of threads
Partition sub-problems into finer piecesSolved cooperatively in parallel by all threads within the block
CUDA C - A scalable programming Model
082015
CUDA C - A scalable programming Model
6
Each block of threads can be scheduled on any of the available multiprocessorsWithin a GPU in any order concurrently or sequentially
A compiled CUDA program can execute on any number of multiprocessors
Only the runtime system needs to know the physical multiprocessor count
082015
Automatic Scalability
7
A multi threaded program is partitioned into blocks of threads that execute independently from each other so that a GPU with more cores will automatically execute the program in less time than GPU with fewer cores
082015
Heterogeneous Computing
8
Host CPU and its memory (host memory)Device GPU and its memory (device memory)
082015
Heterogeneous Computing
9
082015
GPU programming model
10
Serial code executes in a HOST(CPU) thread
Parallel code executes in many concurrent DEVICE(GPU) threads across multiple parallel processing elements
082015
Compiling CUDA C Programs
11
Refer httpdocsnvidiacomcudacuda-compiler-driver-nvccaxzz3Qz0M7rGW
082015
Compiling CUDA C Programs
12
Source files for CUDA applications Mixture of conventional C++ host code plus GPU device (ie GPU-)
functions CUDA compilation trajectory
Separates the device functions from the host code Compiles the device functions using proprietary NVIDIA compilers
assemblers Compiles the host code using a general purpose CC++ compiler that is
available on the host platform and Embeds the compiled GPU functions in the host object file
In the linking stage specific CUDA runtime libraries are added for supporting remote SIMD procedure calling and for providing explicit GPU manipulation such as allocation of GPU memory buffers and host-GPU data transfer
082015
Purpose of NVCC
13
Compilation trajectory involves Splitting compilation preprocessing and merging steps for each CUDA source file
CUDA compiler driver nvcc hides the intricate details of CUDA compilation from developers
nvcc mimics the behavior of the GNU compiler gcc it accepts a range of conventional compiler options such as for defining macros and includelibrary paths and for steering the compilation process
All non-CUDA compilation steps are forwarded to a general purpose C compiler that is supported by nvcc
08201514
Source Kirk and Hwu
NVCC Compiler
Host C preprocessor compilerlinker
Device just-in time compiler
Heterogeneous Computing Platform with CPUs GPUs
Host Code
Device Code (PTX)
Integrated C programs with CUDA extensions
08201515
Nvccrsquos basic workflow separates device code and host code and thenCompiles the device code into an assembly form (PTX code) or binary form (cubin object)
Modifies the host code by replacing syntax in kernels by necessary CUDA C runtime function calls to load and launch each compiled kernel from the PTX code cubin object
Modified host code is output as object code by letting nvcc invoke the host compiler during last compilation stage
082015
Anatomy of a CUDA C Program
16
Step 1 Copy input data from host memory to device memory
082015
Anatomy of a CUDA C Program
17
Step 2 Launch a kernel on the device
082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
CUDA C - A scalable programming Model
6
Each block of threads can be scheduled on any of the available multiprocessorsWithin a GPU in any order concurrently or sequentially
A compiled CUDA program can execute on any number of multiprocessors
Only the runtime system needs to know the physical multiprocessor count
082015
Automatic Scalability
7
A multi threaded program is partitioned into blocks of threads that execute independently from each other so that a GPU with more cores will automatically execute the program in less time than GPU with fewer cores
082015
Heterogeneous Computing
8
Host CPU and its memory (host memory)Device GPU and its memory (device memory)
082015
Heterogeneous Computing
9
082015
GPU programming model
10
Serial code executes in a HOST(CPU) thread
Parallel code executes in many concurrent DEVICE(GPU) threads across multiple parallel processing elements
082015
Compiling CUDA C Programs
11
Refer httpdocsnvidiacomcudacuda-compiler-driver-nvccaxzz3Qz0M7rGW
082015
Compiling CUDA C Programs
12
Source files for CUDA applications Mixture of conventional C++ host code plus GPU device (ie GPU-)
functions CUDA compilation trajectory
Separates the device functions from the host code Compiles the device functions using proprietary NVIDIA compilers
assemblers Compiles the host code using a general purpose CC++ compiler that is
available on the host platform and Embeds the compiled GPU functions in the host object file
In the linking stage specific CUDA runtime libraries are added for supporting remote SIMD procedure calling and for providing explicit GPU manipulation such as allocation of GPU memory buffers and host-GPU data transfer
082015
Purpose of NVCC
13
Compilation trajectory involves Splitting compilation preprocessing and merging steps for each CUDA source file
CUDA compiler driver nvcc hides the intricate details of CUDA compilation from developers
nvcc mimics the behavior of the GNU compiler gcc it accepts a range of conventional compiler options such as for defining macros and includelibrary paths and for steering the compilation process
All non-CUDA compilation steps are forwarded to a general purpose C compiler that is supported by nvcc
08201514
Source Kirk and Hwu
NVCC Compiler
Host C preprocessor compilerlinker
Device just-in time compiler
Heterogeneous Computing Platform with CPUs GPUs
Host Code
Device Code (PTX)
Integrated C programs with CUDA extensions
08201515
Nvccrsquos basic workflow separates device code and host code and thenCompiles the device code into an assembly form (PTX code) or binary form (cubin object)
Modifies the host code by replacing syntax in kernels by necessary CUDA C runtime function calls to load and launch each compiled kernel from the PTX code cubin object
Modified host code is output as object code by letting nvcc invoke the host compiler during last compilation stage
082015
Anatomy of a CUDA C Program
16
Step 1 Copy input data from host memory to device memory
082015
Anatomy of a CUDA C Program
17
Step 2 Launch a kernel on the device
082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Automatic Scalability
7
A multi threaded program is partitioned into blocks of threads that execute independently from each other so that a GPU with more cores will automatically execute the program in less time than GPU with fewer cores
082015
Heterogeneous Computing
8
Host CPU and its memory (host memory)Device GPU and its memory (device memory)
082015
Heterogeneous Computing
9
082015
GPU programming model
10
Serial code executes in a HOST(CPU) thread
Parallel code executes in many concurrent DEVICE(GPU) threads across multiple parallel processing elements
082015
Compiling CUDA C Programs
11
Refer httpdocsnvidiacomcudacuda-compiler-driver-nvccaxzz3Qz0M7rGW
082015
Compiling CUDA C Programs
12
Source files for CUDA applications Mixture of conventional C++ host code plus GPU device (ie GPU-)
functions CUDA compilation trajectory
Separates the device functions from the host code Compiles the device functions using proprietary NVIDIA compilers
assemblers Compiles the host code using a general purpose CC++ compiler that is
available on the host platform and Embeds the compiled GPU functions in the host object file
In the linking stage specific CUDA runtime libraries are added for supporting remote SIMD procedure calling and for providing explicit GPU manipulation such as allocation of GPU memory buffers and host-GPU data transfer
082015
Purpose of NVCC
13
Compilation trajectory involves Splitting compilation preprocessing and merging steps for each CUDA source file
CUDA compiler driver nvcc hides the intricate details of CUDA compilation from developers
nvcc mimics the behavior of the GNU compiler gcc it accepts a range of conventional compiler options such as for defining macros and includelibrary paths and for steering the compilation process
All non-CUDA compilation steps are forwarded to a general purpose C compiler that is supported by nvcc
08201514
Source Kirk and Hwu
NVCC Compiler
Host C preprocessor compilerlinker
Device just-in time compiler
Heterogeneous Computing Platform with CPUs GPUs
Host Code
Device Code (PTX)
Integrated C programs with CUDA extensions
08201515
Nvccrsquos basic workflow separates device code and host code and thenCompiles the device code into an assembly form (PTX code) or binary form (cubin object)
Modifies the host code by replacing syntax in kernels by necessary CUDA C runtime function calls to load and launch each compiled kernel from the PTX code cubin object
Modified host code is output as object code by letting nvcc invoke the host compiler during last compilation stage
082015
Anatomy of a CUDA C Program
16
Step 1 Copy input data from host memory to device memory
082015
Anatomy of a CUDA C Program
17
Step 2 Launch a kernel on the device
082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Heterogeneous Computing
8
Host CPU and its memory (host memory)Device GPU and its memory (device memory)
082015
Heterogeneous Computing
9
082015
GPU programming model
10
Serial code executes in a HOST(CPU) thread
Parallel code executes in many concurrent DEVICE(GPU) threads across multiple parallel processing elements
082015
Compiling CUDA C Programs
11
Refer httpdocsnvidiacomcudacuda-compiler-driver-nvccaxzz3Qz0M7rGW
082015
Compiling CUDA C Programs
12
Source files for CUDA applications Mixture of conventional C++ host code plus GPU device (ie GPU-)
functions CUDA compilation trajectory
Separates the device functions from the host code Compiles the device functions using proprietary NVIDIA compilers
assemblers Compiles the host code using a general purpose CC++ compiler that is
available on the host platform and Embeds the compiled GPU functions in the host object file
In the linking stage specific CUDA runtime libraries are added for supporting remote SIMD procedure calling and for providing explicit GPU manipulation such as allocation of GPU memory buffers and host-GPU data transfer
082015
Purpose of NVCC
13
Compilation trajectory involves Splitting compilation preprocessing and merging steps for each CUDA source file
CUDA compiler driver nvcc hides the intricate details of CUDA compilation from developers
nvcc mimics the behavior of the GNU compiler gcc it accepts a range of conventional compiler options such as for defining macros and includelibrary paths and for steering the compilation process
All non-CUDA compilation steps are forwarded to a general purpose C compiler that is supported by nvcc
08201514
Source Kirk and Hwu
NVCC Compiler
Host C preprocessor compilerlinker
Device just-in time compiler
Heterogeneous Computing Platform with CPUs GPUs
Host Code
Device Code (PTX)
Integrated C programs with CUDA extensions
08201515
Nvccrsquos basic workflow separates device code and host code and thenCompiles the device code into an assembly form (PTX code) or binary form (cubin object)
Modifies the host code by replacing syntax in kernels by necessary CUDA C runtime function calls to load and launch each compiled kernel from the PTX code cubin object
Modified host code is output as object code by letting nvcc invoke the host compiler during last compilation stage
082015
Anatomy of a CUDA C Program
16
Step 1 Copy input data from host memory to device memory
082015
Anatomy of a CUDA C Program
17
Step 2 Launch a kernel on the device
082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
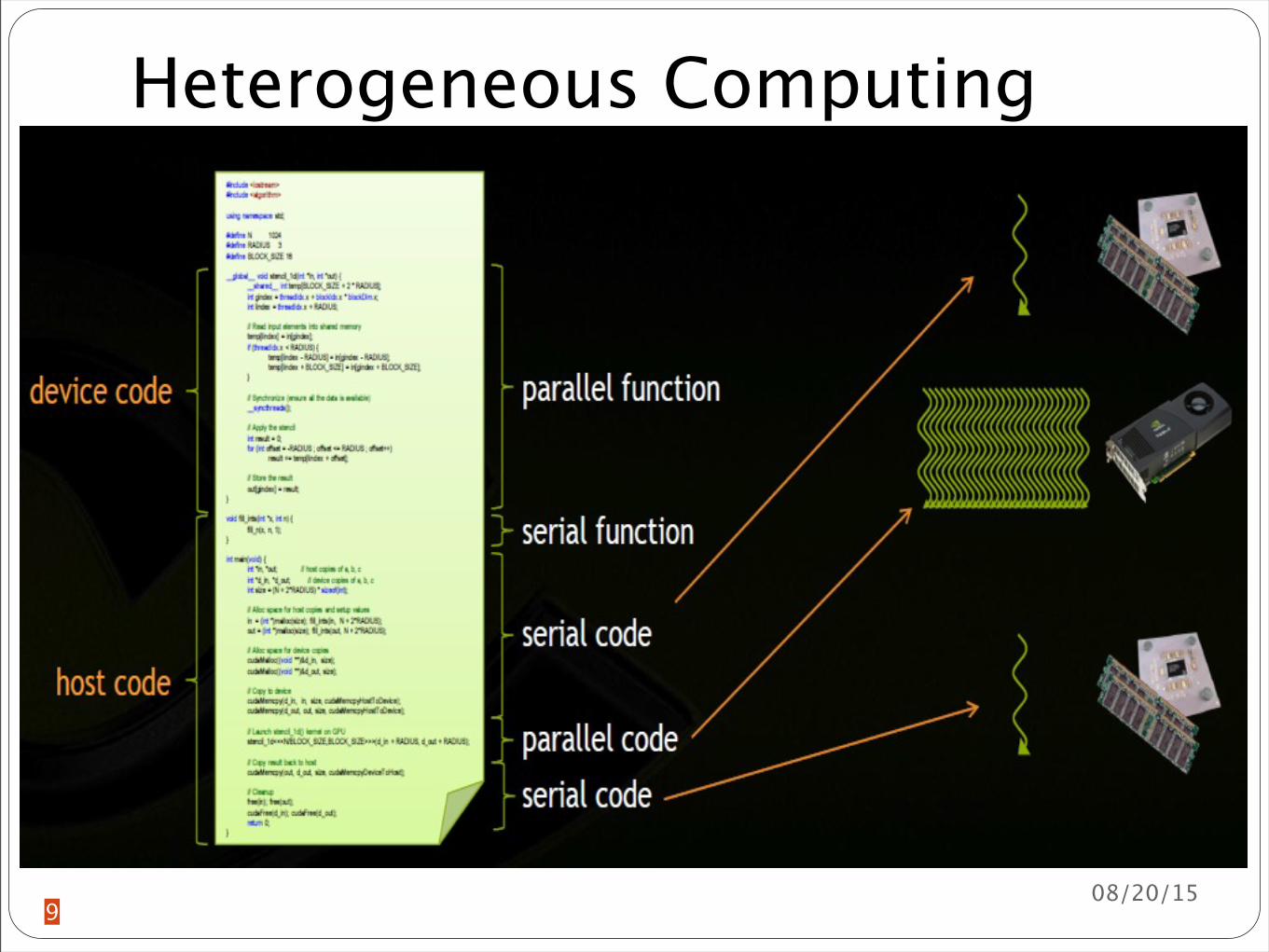
082015
Heterogeneous Computing
9
082015
GPU programming model
10
Serial code executes in a HOST(CPU) thread
Parallel code executes in many concurrent DEVICE(GPU) threads across multiple parallel processing elements
082015
Compiling CUDA C Programs
11
Refer httpdocsnvidiacomcudacuda-compiler-driver-nvccaxzz3Qz0M7rGW
082015
Compiling CUDA C Programs
12
Source files for CUDA applications Mixture of conventional C++ host code plus GPU device (ie GPU-)
functions CUDA compilation trajectory
Separates the device functions from the host code Compiles the device functions using proprietary NVIDIA compilers
assemblers Compiles the host code using a general purpose CC++ compiler that is
available on the host platform and Embeds the compiled GPU functions in the host object file
In the linking stage specific CUDA runtime libraries are added for supporting remote SIMD procedure calling and for providing explicit GPU manipulation such as allocation of GPU memory buffers and host-GPU data transfer
082015
Purpose of NVCC
13
Compilation trajectory involves Splitting compilation preprocessing and merging steps for each CUDA source file
CUDA compiler driver nvcc hides the intricate details of CUDA compilation from developers
nvcc mimics the behavior of the GNU compiler gcc it accepts a range of conventional compiler options such as for defining macros and includelibrary paths and for steering the compilation process
All non-CUDA compilation steps are forwarded to a general purpose C compiler that is supported by nvcc
08201514
Source Kirk and Hwu
NVCC Compiler
Host C preprocessor compilerlinker
Device just-in time compiler
Heterogeneous Computing Platform with CPUs GPUs
Host Code
Device Code (PTX)
Integrated C programs with CUDA extensions
08201515
Nvccrsquos basic workflow separates device code and host code and thenCompiles the device code into an assembly form (PTX code) or binary form (cubin object)
Modifies the host code by replacing syntax in kernels by necessary CUDA C runtime function calls to load and launch each compiled kernel from the PTX code cubin object
Modified host code is output as object code by letting nvcc invoke the host compiler during last compilation stage
082015
Anatomy of a CUDA C Program
16
Step 1 Copy input data from host memory to device memory
082015
Anatomy of a CUDA C Program
17
Step 2 Launch a kernel on the device
082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
GPU programming model
10
Serial code executes in a HOST(CPU) thread
Parallel code executes in many concurrent DEVICE(GPU) threads across multiple parallel processing elements
082015
Compiling CUDA C Programs
11
Refer httpdocsnvidiacomcudacuda-compiler-driver-nvccaxzz3Qz0M7rGW
082015
Compiling CUDA C Programs
12
Source files for CUDA applications Mixture of conventional C++ host code plus GPU device (ie GPU-)
functions CUDA compilation trajectory
Separates the device functions from the host code Compiles the device functions using proprietary NVIDIA compilers
assemblers Compiles the host code using a general purpose CC++ compiler that is
available on the host platform and Embeds the compiled GPU functions in the host object file
In the linking stage specific CUDA runtime libraries are added for supporting remote SIMD procedure calling and for providing explicit GPU manipulation such as allocation of GPU memory buffers and host-GPU data transfer
082015
Purpose of NVCC
13
Compilation trajectory involves Splitting compilation preprocessing and merging steps for each CUDA source file
CUDA compiler driver nvcc hides the intricate details of CUDA compilation from developers
nvcc mimics the behavior of the GNU compiler gcc it accepts a range of conventional compiler options such as for defining macros and includelibrary paths and for steering the compilation process
All non-CUDA compilation steps are forwarded to a general purpose C compiler that is supported by nvcc
08201514
Source Kirk and Hwu
NVCC Compiler
Host C preprocessor compilerlinker
Device just-in time compiler
Heterogeneous Computing Platform with CPUs GPUs
Host Code
Device Code (PTX)
Integrated C programs with CUDA extensions
08201515
Nvccrsquos basic workflow separates device code and host code and thenCompiles the device code into an assembly form (PTX code) or binary form (cubin object)
Modifies the host code by replacing syntax in kernels by necessary CUDA C runtime function calls to load and launch each compiled kernel from the PTX code cubin object
Modified host code is output as object code by letting nvcc invoke the host compiler during last compilation stage
082015
Anatomy of a CUDA C Program
16
Step 1 Copy input data from host memory to device memory
082015
Anatomy of a CUDA C Program
17
Step 2 Launch a kernel on the device
082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Compiling CUDA C Programs
11
Refer httpdocsnvidiacomcudacuda-compiler-driver-nvccaxzz3Qz0M7rGW
082015
Compiling CUDA C Programs
12
Source files for CUDA applications Mixture of conventional C++ host code plus GPU device (ie GPU-)
functions CUDA compilation trajectory
Separates the device functions from the host code Compiles the device functions using proprietary NVIDIA compilers
assemblers Compiles the host code using a general purpose CC++ compiler that is
available on the host platform and Embeds the compiled GPU functions in the host object file
In the linking stage specific CUDA runtime libraries are added for supporting remote SIMD procedure calling and for providing explicit GPU manipulation such as allocation of GPU memory buffers and host-GPU data transfer
082015
Purpose of NVCC
13
Compilation trajectory involves Splitting compilation preprocessing and merging steps for each CUDA source file
CUDA compiler driver nvcc hides the intricate details of CUDA compilation from developers
nvcc mimics the behavior of the GNU compiler gcc it accepts a range of conventional compiler options such as for defining macros and includelibrary paths and for steering the compilation process
All non-CUDA compilation steps are forwarded to a general purpose C compiler that is supported by nvcc
08201514
Source Kirk and Hwu
NVCC Compiler
Host C preprocessor compilerlinker
Device just-in time compiler
Heterogeneous Computing Platform with CPUs GPUs
Host Code
Device Code (PTX)
Integrated C programs with CUDA extensions
08201515
Nvccrsquos basic workflow separates device code and host code and thenCompiles the device code into an assembly form (PTX code) or binary form (cubin object)
Modifies the host code by replacing syntax in kernels by necessary CUDA C runtime function calls to load and launch each compiled kernel from the PTX code cubin object
Modified host code is output as object code by letting nvcc invoke the host compiler during last compilation stage
082015
Anatomy of a CUDA C Program
16
Step 1 Copy input data from host memory to device memory
082015
Anatomy of a CUDA C Program
17
Step 2 Launch a kernel on the device
082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Compiling CUDA C Programs
12
Source files for CUDA applications Mixture of conventional C++ host code plus GPU device (ie GPU-)
functions CUDA compilation trajectory
Separates the device functions from the host code Compiles the device functions using proprietary NVIDIA compilers
assemblers Compiles the host code using a general purpose CC++ compiler that is
available on the host platform and Embeds the compiled GPU functions in the host object file
In the linking stage specific CUDA runtime libraries are added for supporting remote SIMD procedure calling and for providing explicit GPU manipulation such as allocation of GPU memory buffers and host-GPU data transfer
082015
Purpose of NVCC
13
Compilation trajectory involves Splitting compilation preprocessing and merging steps for each CUDA source file
CUDA compiler driver nvcc hides the intricate details of CUDA compilation from developers
nvcc mimics the behavior of the GNU compiler gcc it accepts a range of conventional compiler options such as for defining macros and includelibrary paths and for steering the compilation process
All non-CUDA compilation steps are forwarded to a general purpose C compiler that is supported by nvcc
08201514
Source Kirk and Hwu
NVCC Compiler
Host C preprocessor compilerlinker
Device just-in time compiler
Heterogeneous Computing Platform with CPUs GPUs
Host Code
Device Code (PTX)
Integrated C programs with CUDA extensions
08201515
Nvccrsquos basic workflow separates device code and host code and thenCompiles the device code into an assembly form (PTX code) or binary form (cubin object)
Modifies the host code by replacing syntax in kernels by necessary CUDA C runtime function calls to load and launch each compiled kernel from the PTX code cubin object
Modified host code is output as object code by letting nvcc invoke the host compiler during last compilation stage
082015
Anatomy of a CUDA C Program
16
Step 1 Copy input data from host memory to device memory
082015
Anatomy of a CUDA C Program
17
Step 2 Launch a kernel on the device
082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Purpose of NVCC
13
Compilation trajectory involves Splitting compilation preprocessing and merging steps for each CUDA source file
CUDA compiler driver nvcc hides the intricate details of CUDA compilation from developers
nvcc mimics the behavior of the GNU compiler gcc it accepts a range of conventional compiler options such as for defining macros and includelibrary paths and for steering the compilation process
All non-CUDA compilation steps are forwarded to a general purpose C compiler that is supported by nvcc
08201514
Source Kirk and Hwu
NVCC Compiler
Host C preprocessor compilerlinker
Device just-in time compiler
Heterogeneous Computing Platform with CPUs GPUs
Host Code
Device Code (PTX)
Integrated C programs with CUDA extensions
08201515
Nvccrsquos basic workflow separates device code and host code and thenCompiles the device code into an assembly form (PTX code) or binary form (cubin object)
Modifies the host code by replacing syntax in kernels by necessary CUDA C runtime function calls to load and launch each compiled kernel from the PTX code cubin object
Modified host code is output as object code by letting nvcc invoke the host compiler during last compilation stage
082015
Anatomy of a CUDA C Program
16
Step 1 Copy input data from host memory to device memory
082015
Anatomy of a CUDA C Program
17
Step 2 Launch a kernel on the device
082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

08201514
Source Kirk and Hwu
NVCC Compiler
Host C preprocessor compilerlinker
Device just-in time compiler
Heterogeneous Computing Platform with CPUs GPUs
Host Code
Device Code (PTX)
Integrated C programs with CUDA extensions
08201515
Nvccrsquos basic workflow separates device code and host code and thenCompiles the device code into an assembly form (PTX code) or binary form (cubin object)
Modifies the host code by replacing syntax in kernels by necessary CUDA C runtime function calls to load and launch each compiled kernel from the PTX code cubin object
Modified host code is output as object code by letting nvcc invoke the host compiler during last compilation stage
082015
Anatomy of a CUDA C Program
16
Step 1 Copy input data from host memory to device memory
082015
Anatomy of a CUDA C Program
17
Step 2 Launch a kernel on the device
082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

08201515
Nvccrsquos basic workflow separates device code and host code and thenCompiles the device code into an assembly form (PTX code) or binary form (cubin object)
Modifies the host code by replacing syntax in kernels by necessary CUDA C runtime function calls to load and launch each compiled kernel from the PTX code cubin object
Modified host code is output as object code by letting nvcc invoke the host compiler during last compilation stage
082015
Anatomy of a CUDA C Program
16
Step 1 Copy input data from host memory to device memory
082015
Anatomy of a CUDA C Program
17
Step 2 Launch a kernel on the device
082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
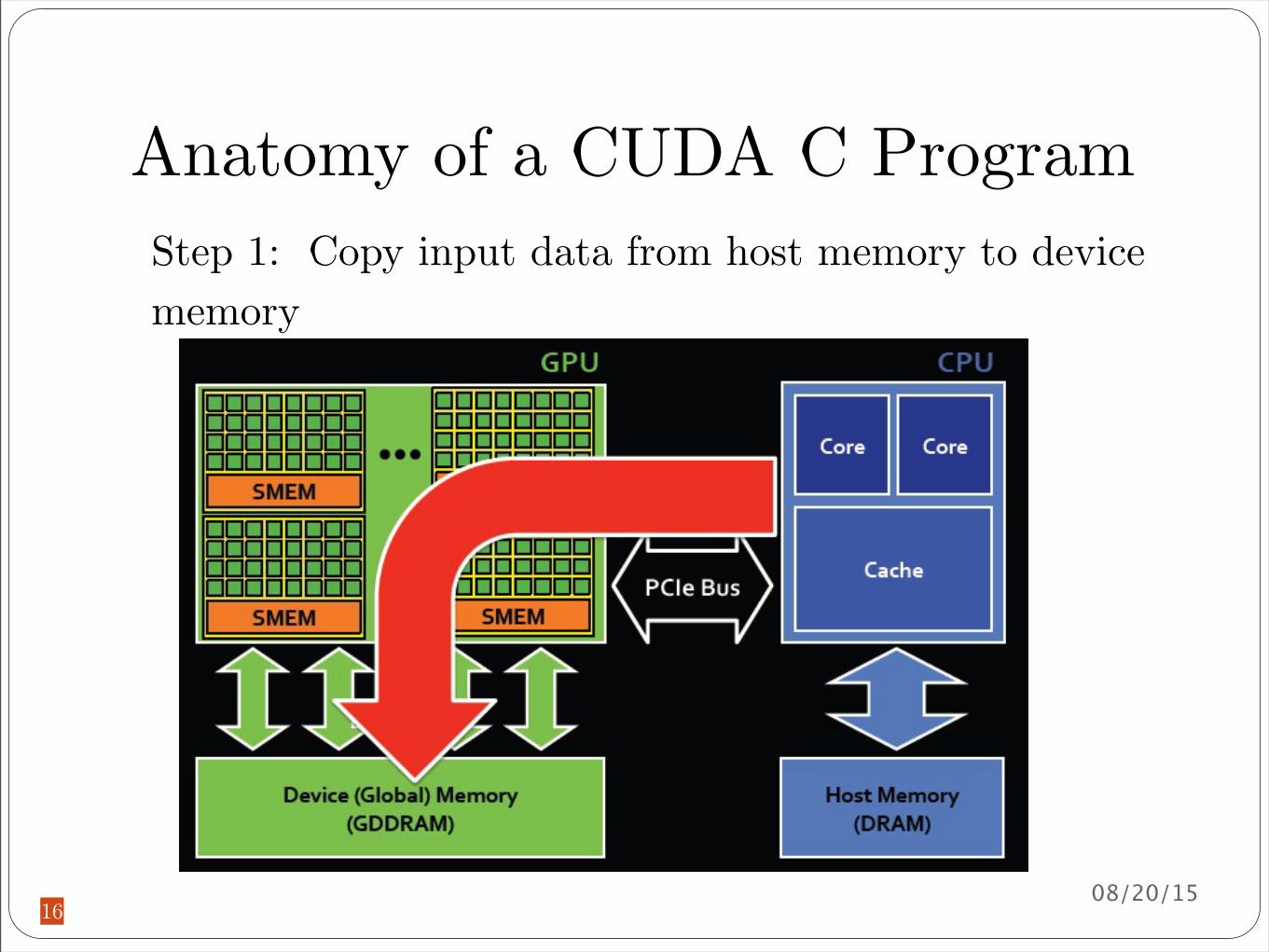
082015
Anatomy of a CUDA C Program
16
Step 1 Copy input data from host memory to device memory
082015
Anatomy of a CUDA C Program
17
Step 2 Launch a kernel on the device
082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
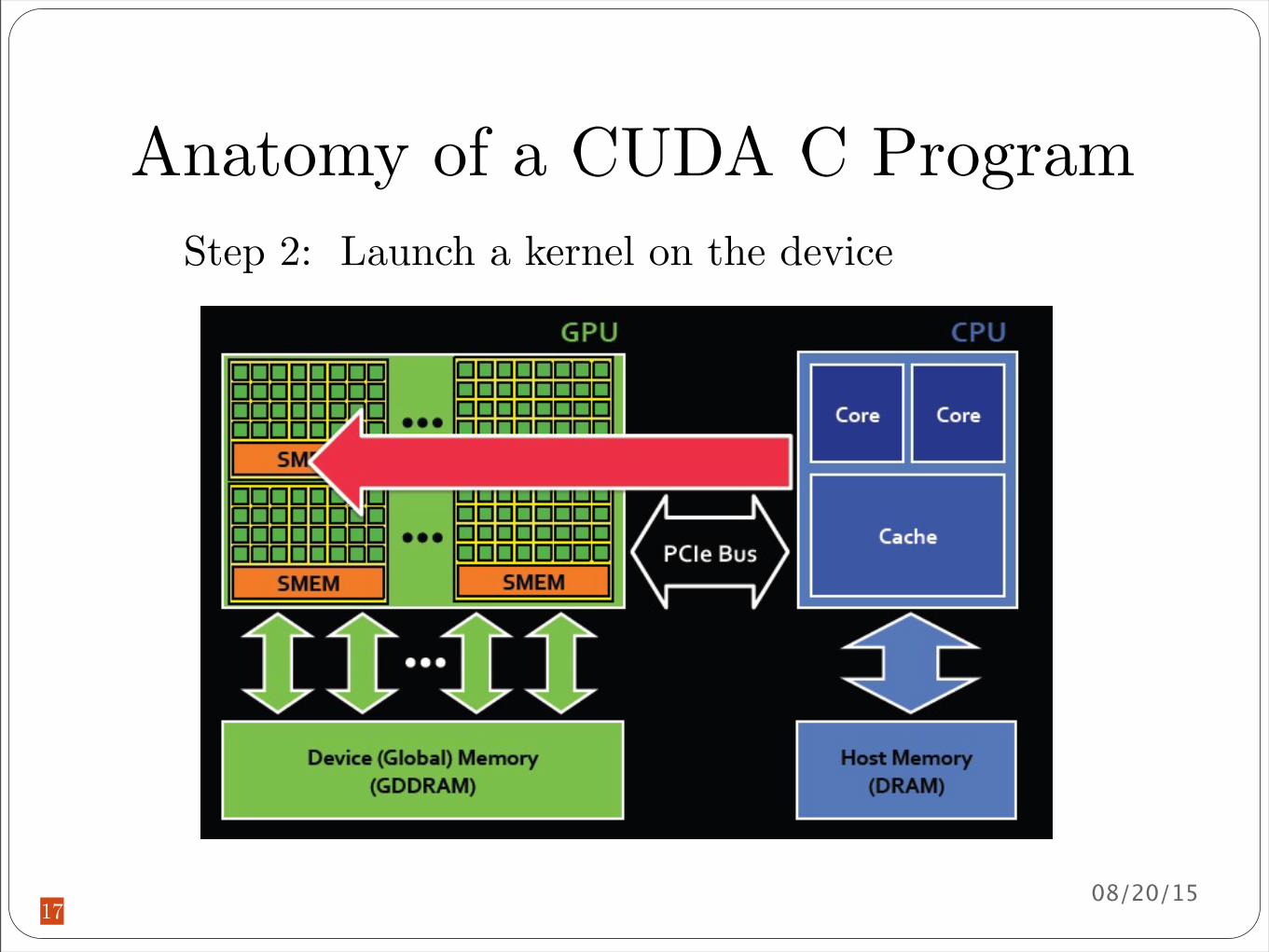
082015
Anatomy of a CUDA C Program
17
Step 2 Launch a kernel on the device
082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Anatomy of a CUDA C Program
18
Step 3 Execute the kernel on the device caching data on chip for performance
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
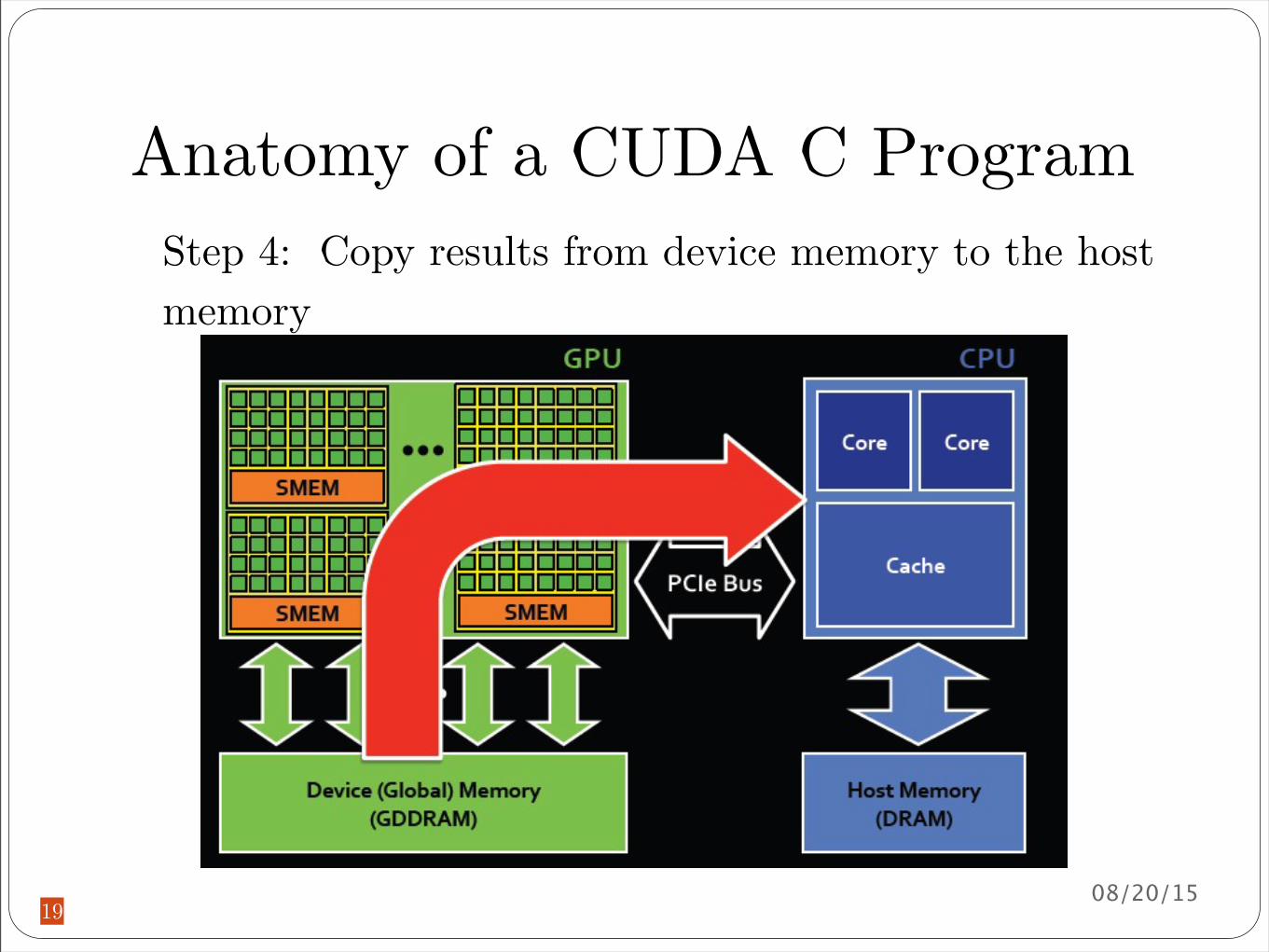
082015
Anatomy of a CUDA C Program
19
Step 4 Copy results from device memory to the host memory
082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Thread
20
Simplified view of how a processor executes a programConsists of Code of the programParticular point in the code that is being executedValues of its variables and data structures
In CUDA execution of each thread is sequential But CUDA program initiates parallel execution by launching kernel functionsCauses the underlying mechanisms to create many threads that process different parts of the data in parallel
082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
CUDA Kernels
21
Kernel is function that executes parallel portions of an application on the device and can be called from the hostOne kernel is executed at a time by many threads
Execute as an array of threads in parallelAll threads run same codeEach thread has an ID that is used to compute memory addresses and make control decisions
Can only access device memory
082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Thread Hierarchies
22
GridOne or more thread blocksOrganized as a 3D array of blocks
Block3D array of threadsEach block in a grid has the same number of threads (dimension)
Each thread in a block can SynchronizeAccess shared memory
082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Thread Hierarchies
23
A kernel is executed as a grid of thread blocksAll threads share data memory space
A thread block is a batch of threads that can cooperate with each other bySynchronizing their executionFor hazard-free shared memory accesses
Efficiently sharing data through a low latency shared memory
Two threads from two different blocks cannot cooperate
082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Thread Hierarchies
24
08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

08201525
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
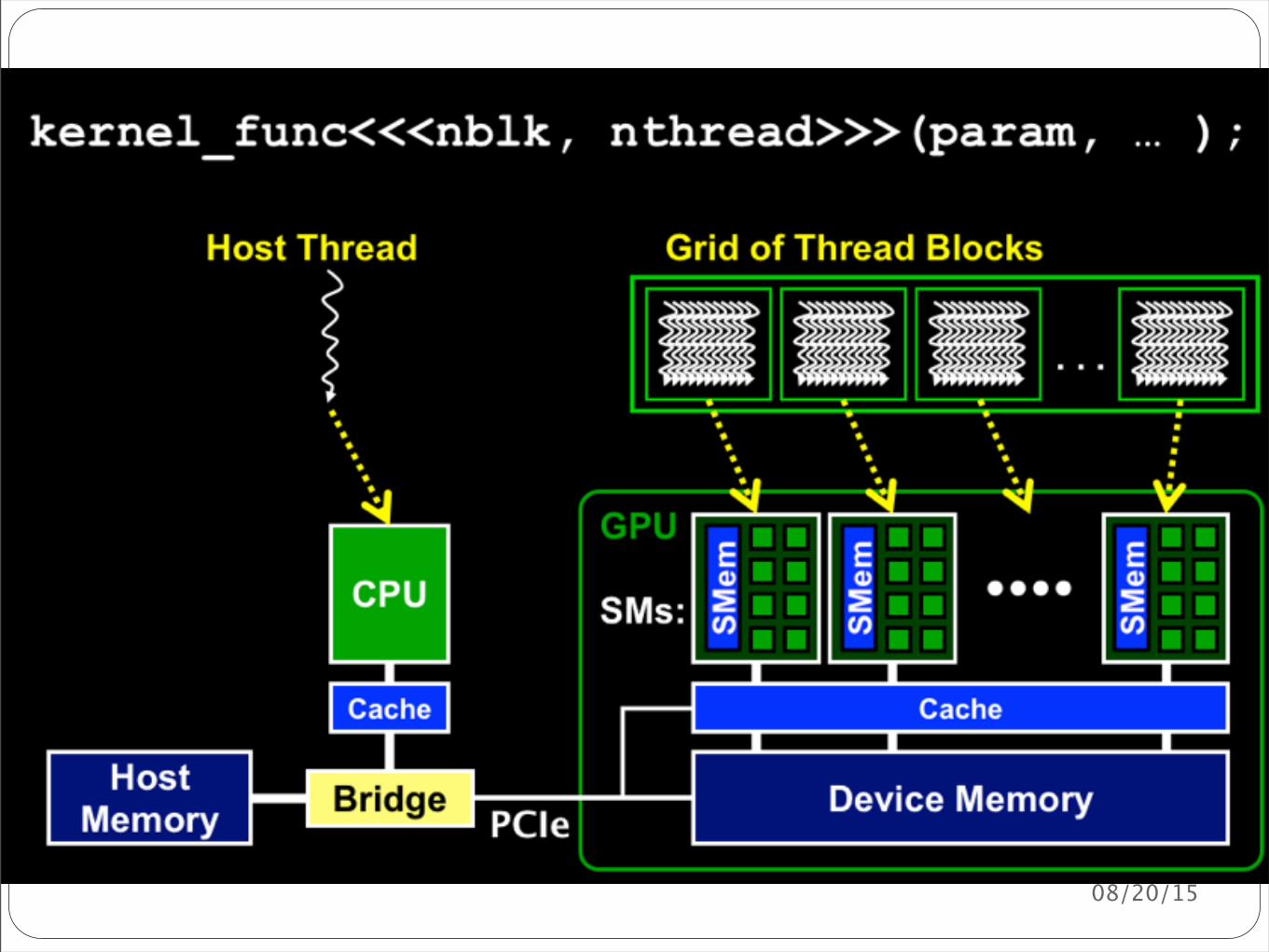
082015
082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Thread Hierarchies
27
Thread BlockGroup of threadsG80 and GT200 Up to 512 threadsFermi Up to 1024 threads
Reside on same processor coreShare memory of that core
082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Threads Representation
28
Initialize many threads Hundreds or Thousands to wake up a GPU from its Bed
082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
CUDA Thread Organization
29
Threads are grouped into blocks Blocks are grouped into Grids
Kernels are executed as a Grid of Block of Threads
082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
CUDA Thread Organization
30
Only one kernel can execute on a device at one time
08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

08201531
082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
CUDA Thread Organization
32
All threads in a grid execute the same kernel functionRely on unique coordinates to distinguish themselves
Two-level hierarchy using unique coordinatesblockIdx (for block index) ndash shared by all threads in a block threadIdx (for thread index) ndash unique within a blockUsed together to make a unique ID for each thread per kernel
Built-in pre-initialized variables accessed within kernelsReferences to them return coordinates of the thread when executed
Kernel launch specifies the dimensions of the grid and each blockgridDim and blockDim
08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

08201533
Your First CUDA Program
082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Program 1 Hello World
34
Standard C that runs on the hostNVIDIA compiler (nvcc) can be used to compile programs with no device code
int main(void) printf(Hello Worldn) return 0
Output $ nvcc hello_worldcu $ aout Hello World $
082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Program 1 Hello World with Device Code
35
Source J sanders etal Cuda by example
__global__ void mykernel(void) int main(void) mykernelltltlt11gtgtgt() printf(Hello Worldn) return 0
bull Two new syntactic elements
082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Program 1 Hello World with Device Code
36
CUDA CC++ keyword __global__ indicates a function that Runs on the device Is called from host code
nvcc separates source code into host and device components Device functions (eg mykernel()) processed by NVIDIA compiler
Host functions (eg main()) processed by standard host compiler gcc clexe
__global__ void mykernel(void)
082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Program 1 Hello World with Device Code
37
Triple angle brackets mark a call from host code to device code Also called a ldquokernel launchrdquo Wersquoll return to the parameters (11) in a moment
Thatrsquos all that is required to execute a function on the GPU
mykernelltltlt11gtgtgt()
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
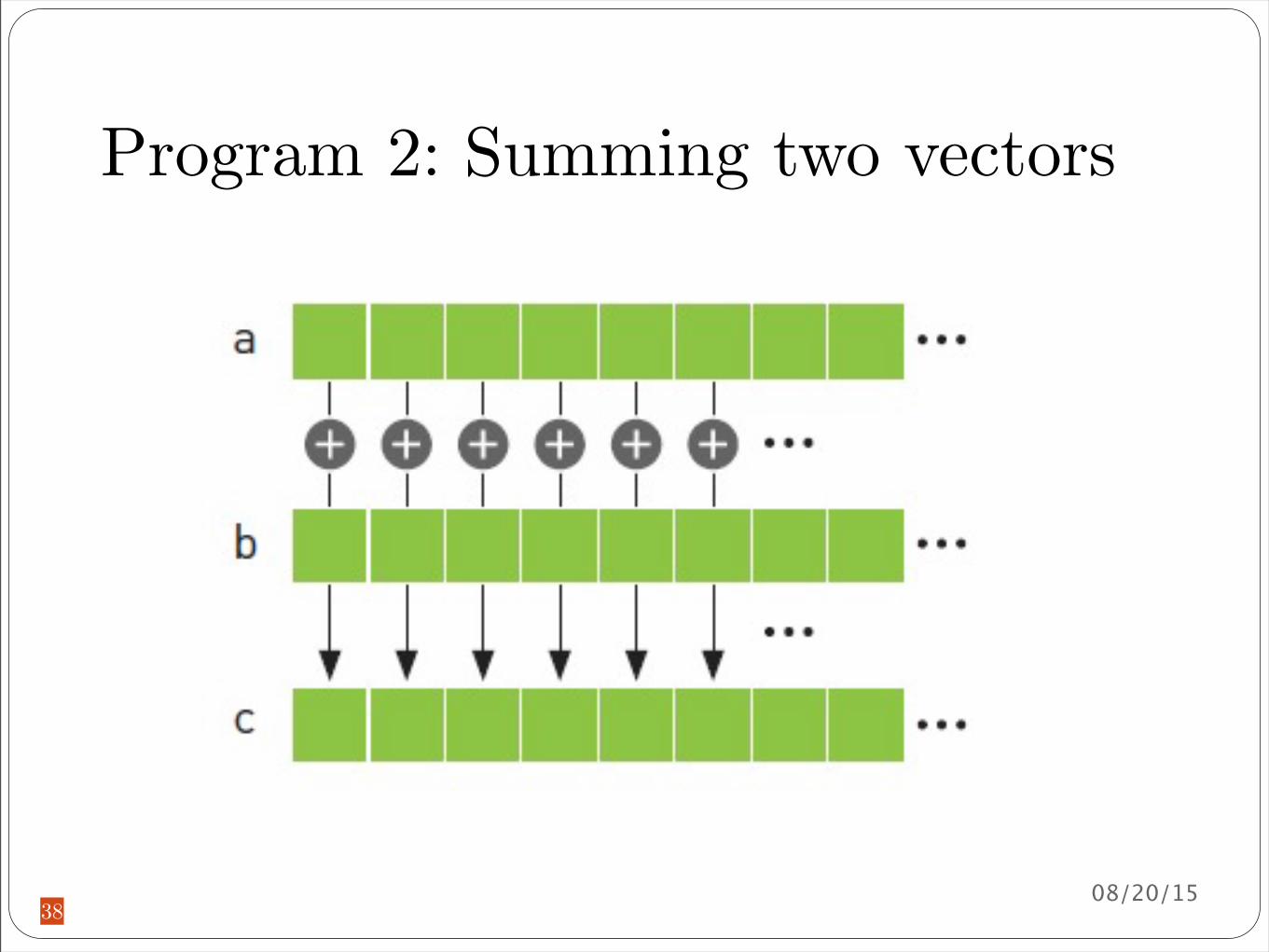
082015
Program 2 Summing two vectors
38
08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

08201539
Source J sanders etal Cuda by example
08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

08201540
Can also be written in this way
bull Suggest a potential way to parallelize the code on a system with multiple CPUs or CPU cores
bull For example with a dual-core processor bull Can change the increment to 2bull Have one core initialize the loop with tid = 0 and another with tid = 1 bull The first core would add the even-indexed elements and the second core would add the odd-indexed elements
082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Multi-core CPU vector sum
41
082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
GPU vector sum
42
includeltcudahgthellipvoid vecAdd(float A float B float C int n)
1 Allocate device memory for A B and C Copy A and B to device memory
2 Kernel launch code ndash to have the device perform the actual vector addition
3 Copy C from the device memory to the host memory Free memory allocated on the device
08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

08201543
bull N is the number of parallel blocks specified while launching the kernel
bull Below we can see four blocks all running through the same copy of the device code but having different values for the block id
082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
CUDA Device Memory Model
44
082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
CUDA Device Memory Model
45
Global and Constant MemoryWritten and read by host by calling API functionsConstant Memory short-latency high-bandwidth read-only access by the device$
Register and shared memory (on-chip memories)Accessed at high speed in a parallel mannerRegistersAllocated to individual threadsEach thread can only access its own registers
082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
CUDA Device Memory Model
46
Kernel function uses registers to hold frequently accessed variables private to each thread
Shared memory is allocated to thread blocksAll threads in a block can access the variables Efficient means for threads to cooperate by sharing input data and intermediate results
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
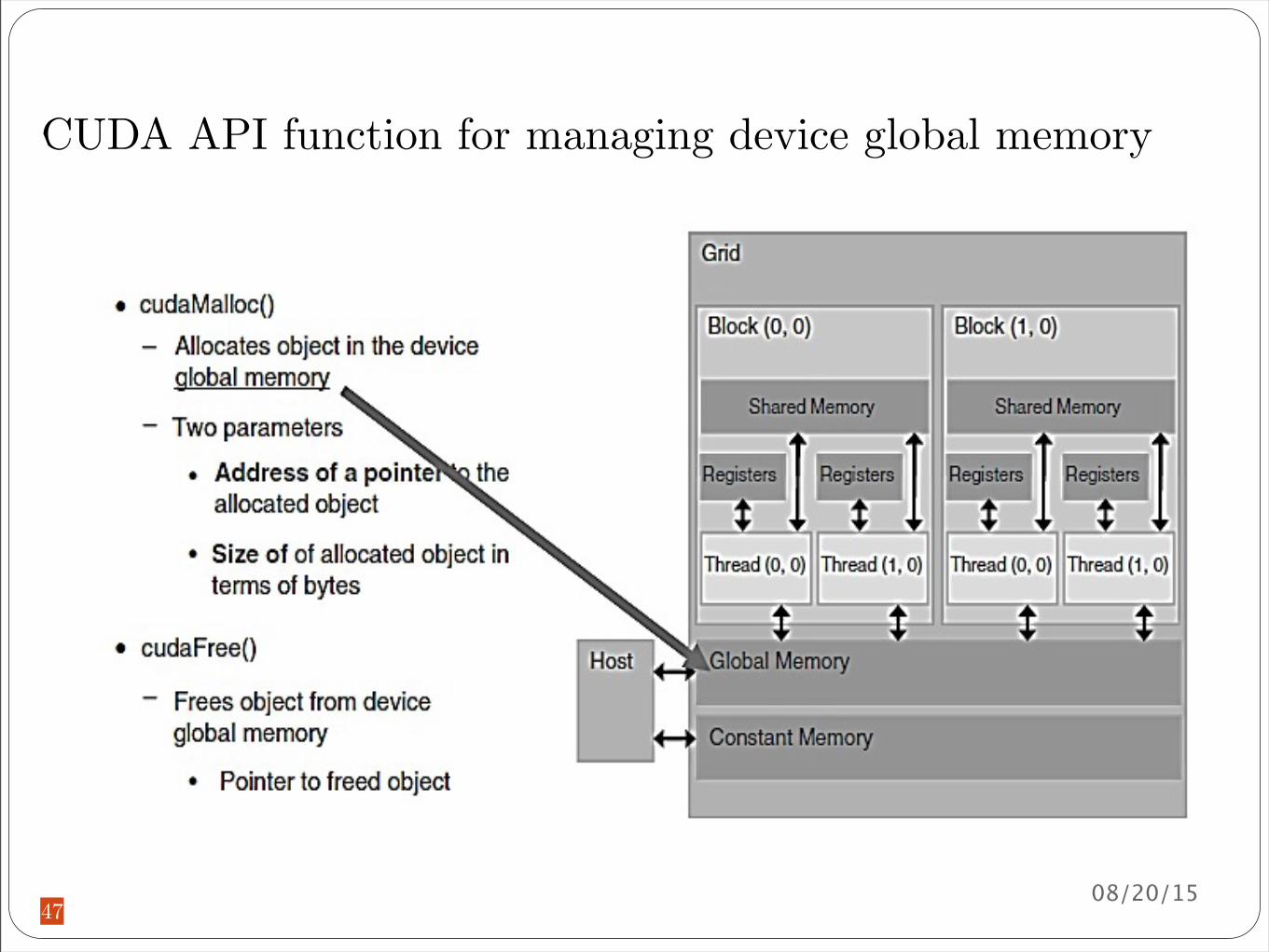
082015
CUDA API function for managing device global memory
47
082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
cudaMalloc()
48
First parameter address of a pointer variable that must point to the allocated object after allocationThe address of the pointer variable should be cast to (void ) Function expects a generic pointer value Allows the cudaMalloc() function to write the address of the allocated object into the pointer variable
The second parameter size of the object to be allocated in terms of bytes
float d_Aint size = n sizeof(float)cudaMalloc((void)ampd_A size)hellipcudaFree(d_A)
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
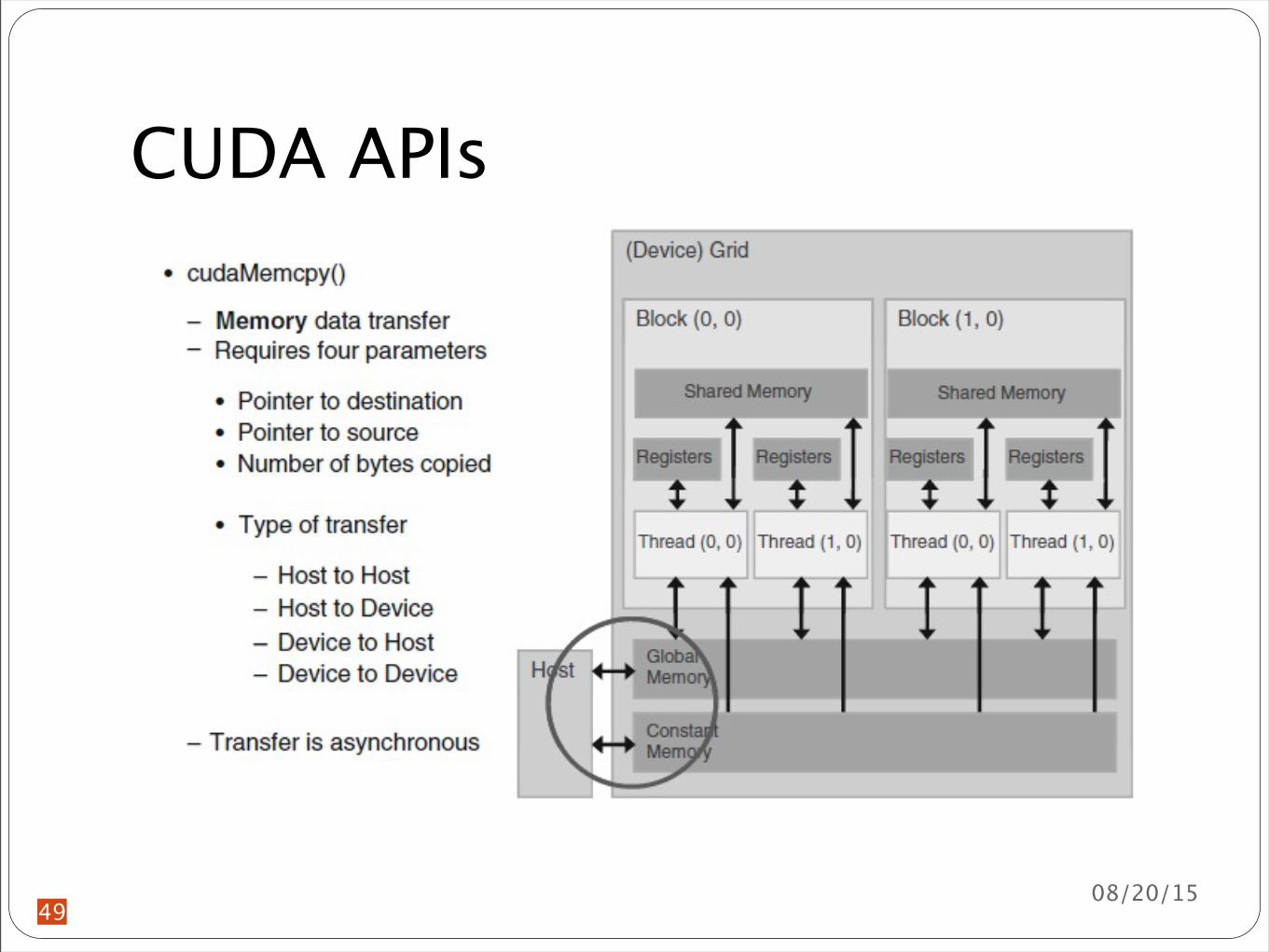
082015
CUDA APIs
49
082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
cudaMemcpy()
50
Cannot be used to copy between different GPUsCan be used to transfer data in both directions by Proper ordering of source and destination pointers and Using the appropriate constant for transfer type
Four symbolic predefined constants cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice
cudaMemcpy(d_A A size cudaMemcpyHostToDevice)cudaMemcpy(d_C C size cudaMemcpyDeviceToHost)
082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
GPU vector sum
51
includeltcudahgthellipvoid vecAdd(float A float B float C int n) int size = n sizeof(float) float d_A d_B d_C$ cudaMalloc((void) ampd_A size) cudaMemcpy(d_A A size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_B size) cudaMemcpy(d_B B size cudaMemcpyHostToDevice) cudaMalloc((void) ampd_C size)
Kernel invocation code cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
Free device memory cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
CUDA Extensions to function declaration
52
Executed on the
Only callable from the
__device__ float DeviceFunc() Device Device
__global__ void KernelFunc() Device Host
__host__ float HostFunc() Host Host
082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
CUDA Memory Hierarchy
53
Thread Registers and Local Memory Blocks Shared Memory
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
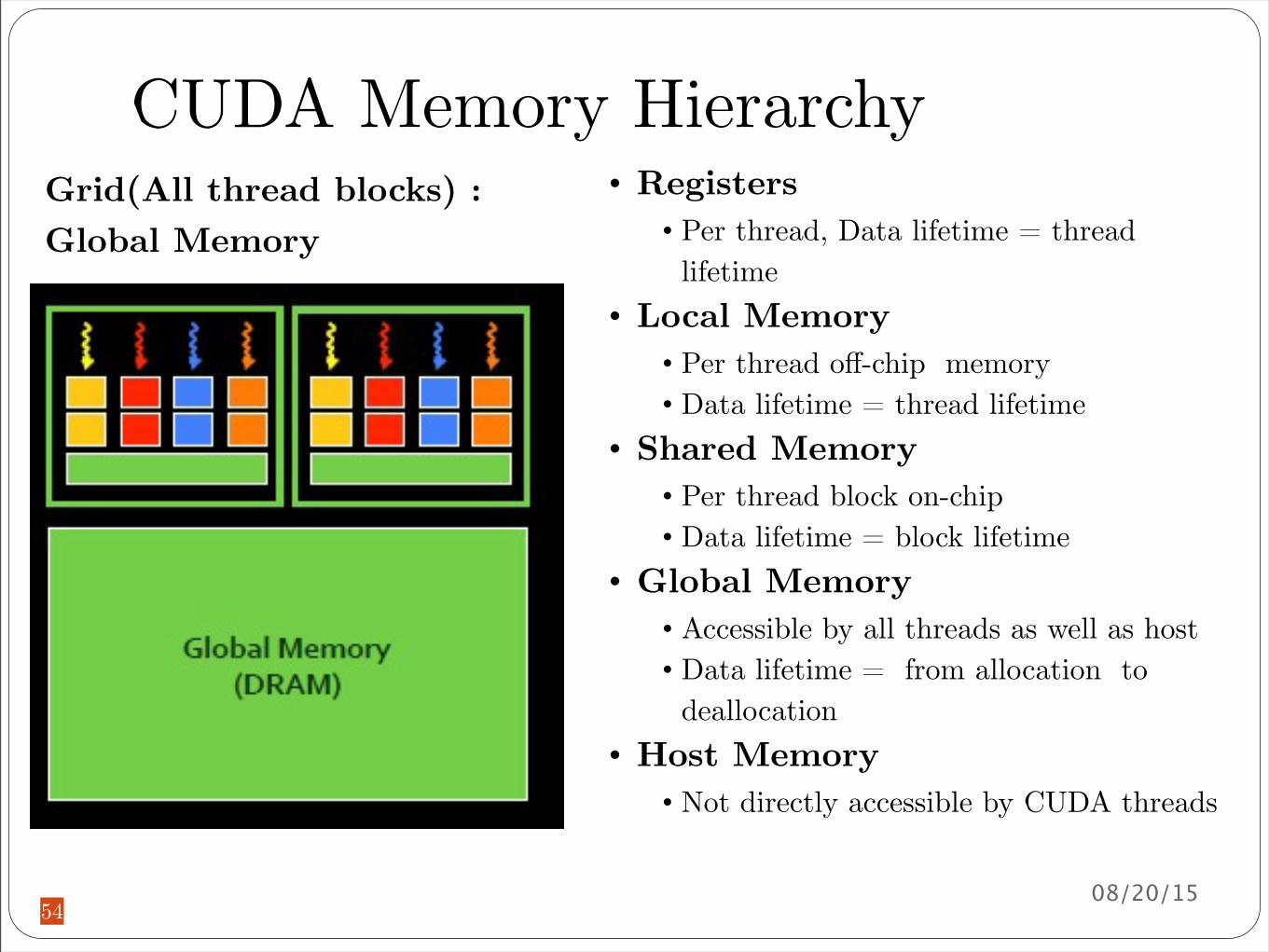
082015
CUDA Memory Hierarchy
54
Grid(All thread blocks) Global Memory
bull Registersbull Per thread Data lifetime = thread lifetime
bull Local Memorybull Per thread off-chip memorybull Data lifetime = thread lifetime
bull Shared Memorybull Per thread block on-chipbull Data lifetime = block lifetime
bull Global Memorybull Accessible by all threads as well as hostbull Data lifetime = from allocation to deallocation
bull Host Memorybull Not directly accessible by CUDA threads
08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

08201555
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
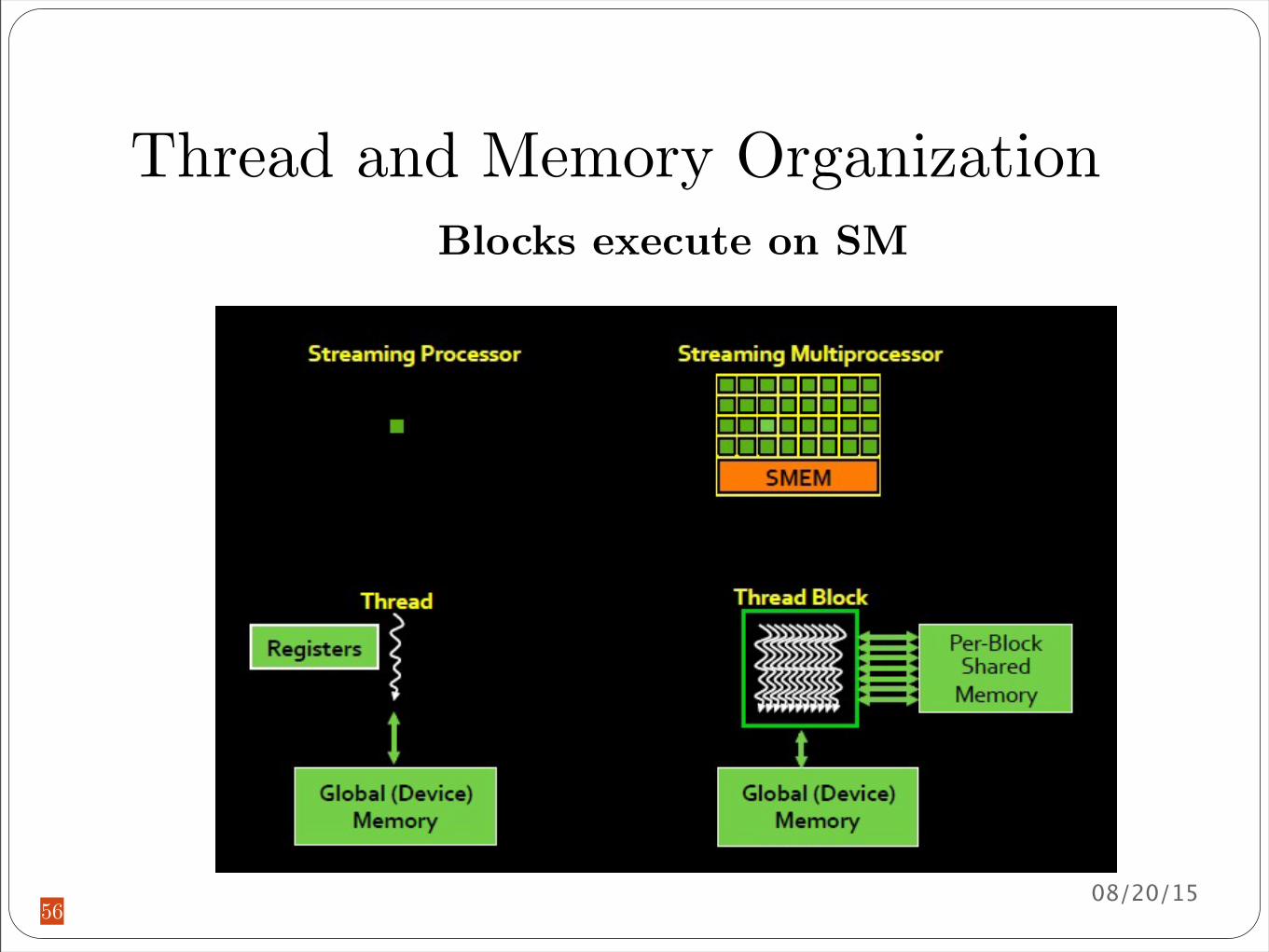
082015
Thread and Memory Organization
56
Blocks execute on SM
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)
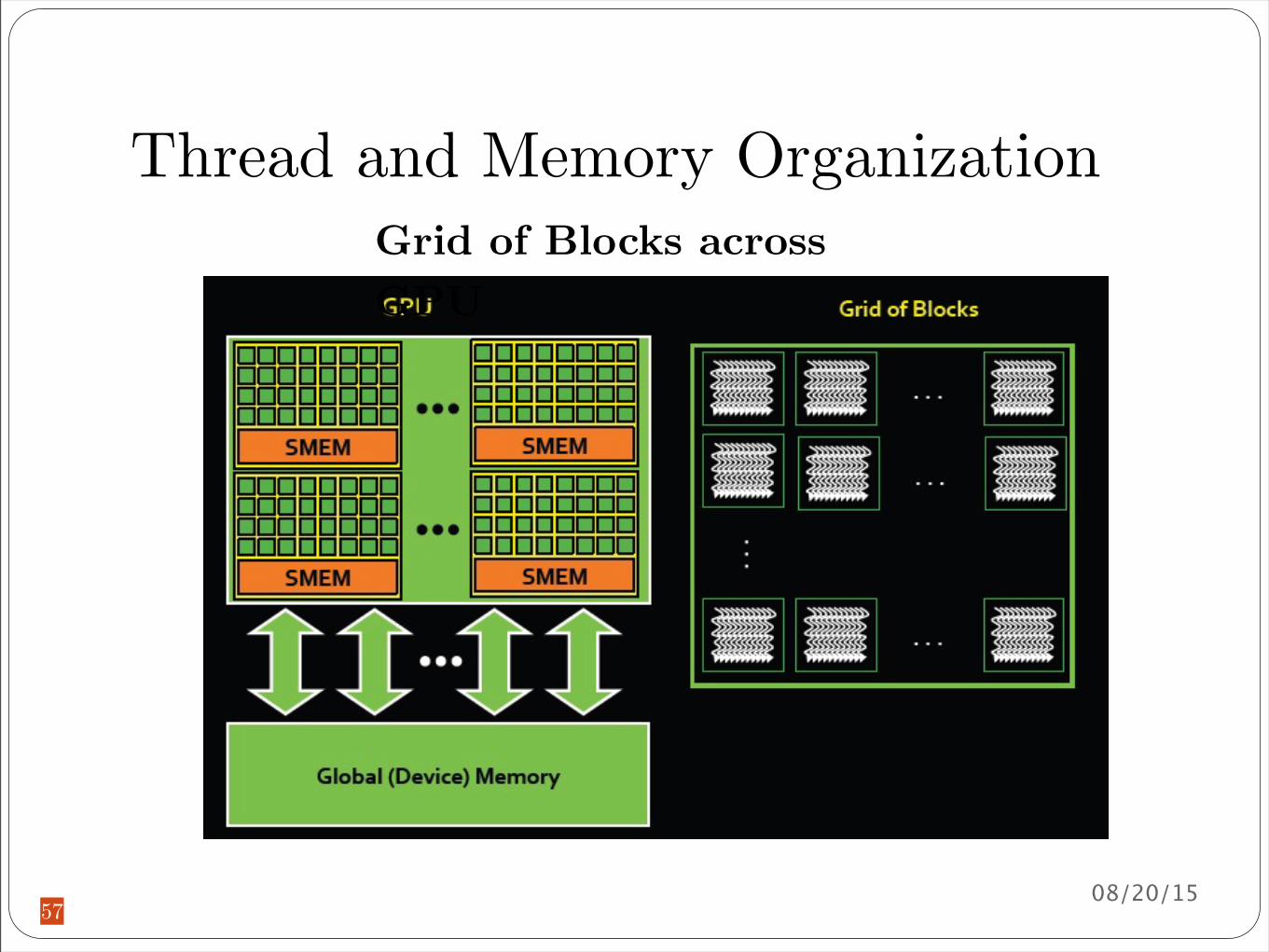
082015
Thread and Memory Organization
57
Grid of Blocks across GPU
082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Thread and Block Indexing
58
Each Thread has an IDPredefined variables that allow a thread to access the hardware registers at runtime that provide the identifying coordinates to the thread
Threads 3D IDs and unique within a BlockBuilt-in variables threadIdx blockIdx blockDim gridDim
082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Thread Indexing
59
bull Grid consists of N thread blocksbullEach with a blockIdxx value that ranges from 0 to N ndash 1
bull Each block consists of M threadsbullEach with a threadIdxx value that ranges from 0 to M ndash 1
bull All blocks at the grid level are organized as a one-dimensional (1D) arraybull All threads within each block are also organized as a 1D array bull Each grid has a total of NM threads
082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Thread Indexing
60
Thread id= blockIdxx blockDimx + threadIdxxThread 3 of Block 0 has a threadID value of 0M +3Thread 3 of Block 5 has a threadID value of 5M+3
Eg A grid with 128(N) blocks and 32(M) threads in each blockTotal of 12832=4096 threads in a grid
Each thread should have a unique ID Thread 3 of Block 0 has a threadID value of 032 +3Thread 3 of Block 5 has a threadID value of 532+3=163Thread 15 of block 102 threadID =
082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Thread and Block Indexing
61
Grid Dimension lt3 2gtgridDimx=3gridDimy=2
blockIdxx=1blockIdxy=1
Block Dimension lt5 3gtblockDimx=5blockDimy=3
threadIdxx=4threadIdxy=2
082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Vector Addition Kernel Function
62
__global__ void vecAddKernel(float A float B float C int n) int i = threadIdxx + blockDimx blockIdxx if(i lt n) C[i] = A[i] + b[i]
bull The if(iltn) statement allows the kernel to process vectors of arbitrary lengths
bull Example If vector length is 100 and thread block dimension is 32 then four thread blocks need to be launched (128 threads) Last 28 threads in block 3 need to be disabled
082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Thread Indexing and Organization
63
In generalGrid is organized as a 3D array of blocksBlock is organized as 3D array of threads
Exact organization of a grid is determined by the execution configuration provided at kernel launch
When the host code invokes a kernel it sets the grid and thread block dimensions via execution configuration parameters
2 parameters One describes the configuration of the grid Number of blocksSecond one describes the configuration of blocks groups of threads
Each parameter is dim3 type ndash C struct type with 3 unsigned integer fields x y and z (three dimensions)
082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Thread Indexing and Organization
64
For 1D and 2D gridsblocks the unused fields should be set to 1
1D grid with 128 blocks each of which consists of 32 threadsTotal number of threads = 128 32 = 4096$ dim3 dimGrid(128 1 1)$ dim3 dimBlock(32 1 1)$ vecAddKernelltltltdimGrid dimBlockgtgtgt(hellip)dimBlock and dimGrid are programmer defined variablesThese variables can have any names as long as they are of type dim3 and kernel launch uses appropriate names
082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Thread Indexing and Organization
65
If a Grid Block has only 1 Dimension instead of dim3 use arithmetic expressions to specify the configuration
Compiler takes the expression as x dimensions and assumes y and z are 1$ vecAddKernelltltltceil(n2560) 256gtgtgt(hellip) gridDim and blockDim are part of CUDA C specification and
cannot be changed The x field of the predefined variables gridDim and blockDim get
preinitialized based on the execution configuration parameters If n is 4000 then gridDimx = 16 and blockDimx = 256
082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Thread Indexing and Organization
66
Allowed values of gridDimx gridDimy and gridDimz range from 1 to 65536
All threads in a block share same blockIdxx blockIdxy and blockIdxz
In a gridThe blockIdxx ranges between 0 and gridDimx ndash 1The blockIdxy ranges between 0 and gridDimy ndash 1 The blockIdxz ranges between 0 and gridDimz ndash 1
Total size of a block is limited to 1024 threadsFlexibility to divide into 3 dimensionsExample blockDim values
(512 1 1) (8 16 4) and (32 16 2) (32 32 32)
08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

08201567
2D grid (2 2 1) consisting of 3D blocks (4 2 2)
Host codedim3 dimGrid(2 2 1)dim3 dimBlock(4 2 2)KernelltltltdimGriddimBlockgtgtgt()
082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
CUDA execution configuration parameters
68
$ Eg dim3 dimBlock(53) dim3 dimGrid(32)Kernel call Eg gaussltltltdimGriddimBlockgtgtgt( )
082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Kernel Launch Statement
69
vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)
Number of thread blocks
Number of threads in each block
bull If there are 1000 threads we launch ceil(10002560) = 4 thread blocks
bull It will launch 4 256 = 1024 threadsbull Number of thread blocks depends on the length of the
vectors (n)bull If n = 750bull 3 thread blocks
bull If n = 4000 bull 16 thread blocks
082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)

082015
Vector Addition Kernel Launch
70
includeltcudahgtvoid vecAdd(float A float B float C int n) int size = n sizeof(float)$ float d_A d_B d_C$ cudaMalloc((void) ampd_A size)$ cudaMemcpy(d_A A size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_B size)$ cudaMemcpy(d_B B size cudaMemcpyHostToDevice)$ cudaMalloc((void) ampd_C size)
$ vecAddKernelltltltceil(n2560) 256gtgtgt(d_A d_B d_C n)$ cudaMemcpy(C d_C size cudaMemcpyDeviceToHost)
$ Free device memory$ cudaFree(d_A) cudaFree(d_B) cudaFree(d_C)