Milind Kukanur, June 2016 CUDA 8 OVERVIEW

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Milind Kukanur, June 2016
CUDA 8 OVERVIEW

2
CUDA TOOLKIT 8 Everything you need to accelerate applications
19x
HPGMG with AMR
Larger Simulations &
More Accurate Results
P100/CUDA 8 speedup over K80/CUDA 7.5
3.5 x 1.5 x VASP MILC
developer.nvidia.com/cuda-toolkit
Comprehensive C/C++ development environment
Out of box performance on Pascal
Unified Memory on Pascal enables simple programming with large datasets
New critical path analysis quickly identifies system-level bottlenecks

3
CUDA 8 — WHAT’S NEW
PASCAL SUPPORT UNIFIED MEMORY
DEVELOPER TOOLS LIBRARIES
New Architecture
NVLINK
HBM2 Stacked Memory
Page Migration Engine
Larger Datasets
Demand Paging
New Tuning APIs
Data Coherence & Atomics
New nvGRAPH library
cuBLAS improvements for Deep Learning
Critical Path Analysis
2x Faster Compile Time
OpenACC Profiling
Debug CUDA Apps on Display GPU

4
MASSIVE LEAP IN PERFORMANCE
0x
5x
10x
15x
20x
25x
30x
NAMD VASP MILC HOOMD Blue AMBER Caffe/Alexnet
2x K80 2x P100 (PCIe) 4x P100 (PCIe)
Speed-u
p v
s D
ual Socket
Bro
adw
ell
CPU: Xeon E5-2697v4, 2.3 GHz, 3.6 GHz Turbo Caffe Alexnet: batch size of 256 Images; VASP, NAMD, HOOMD-Blue, and AMBER average speedup across a basket of tests
With CUDA 8 on Pascal

5
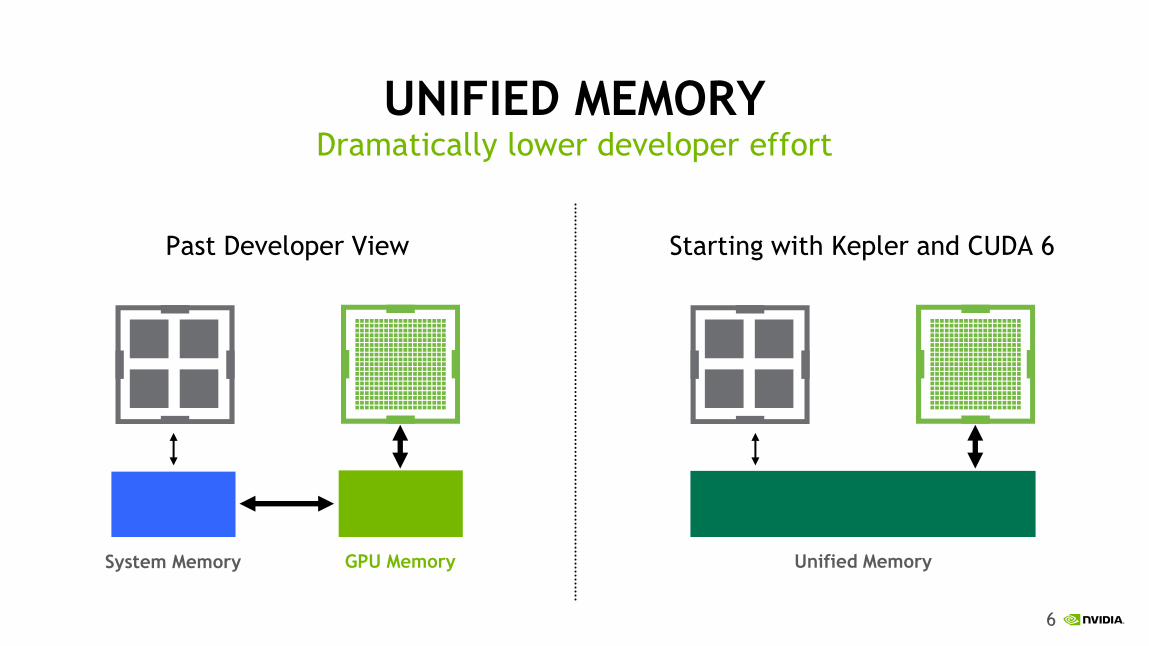
UNIFIED MEMORY
6
UNIFIED MEMORY
Past Developer View
Dramatically lower developer effort
Starting with Kepler and CUDA 6
System Memory GPU Memory Unified Memory
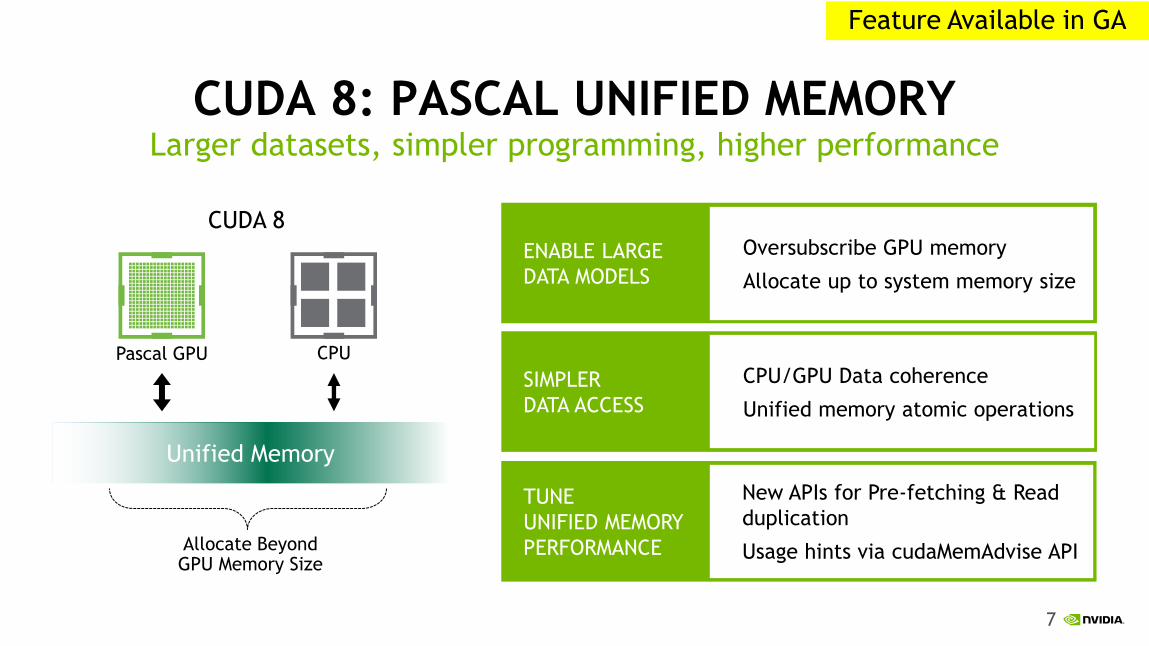
7
CUDA 8: PASCAL UNIFIED MEMORY Larger datasets, simpler programming, higher performance
ENABLE LARGE
DATA MODELS
Oversubscribe GPU memory
Allocate up to system memory size
TUNE
UNIFIED MEMORY
PERFORMANCE
New APIs for Pre-fetching & Read
duplication
Usage hints via cudaMemAdvise API
SIMPLER
DATA ACCESS
CPU/GPU Data coherence
Unified memory atomic operations
Allocate Beyond GPU Memory Size
Unified Memory
Pascal GPU CPU
CUDA 8
Feature Available in GA
Unified Memory
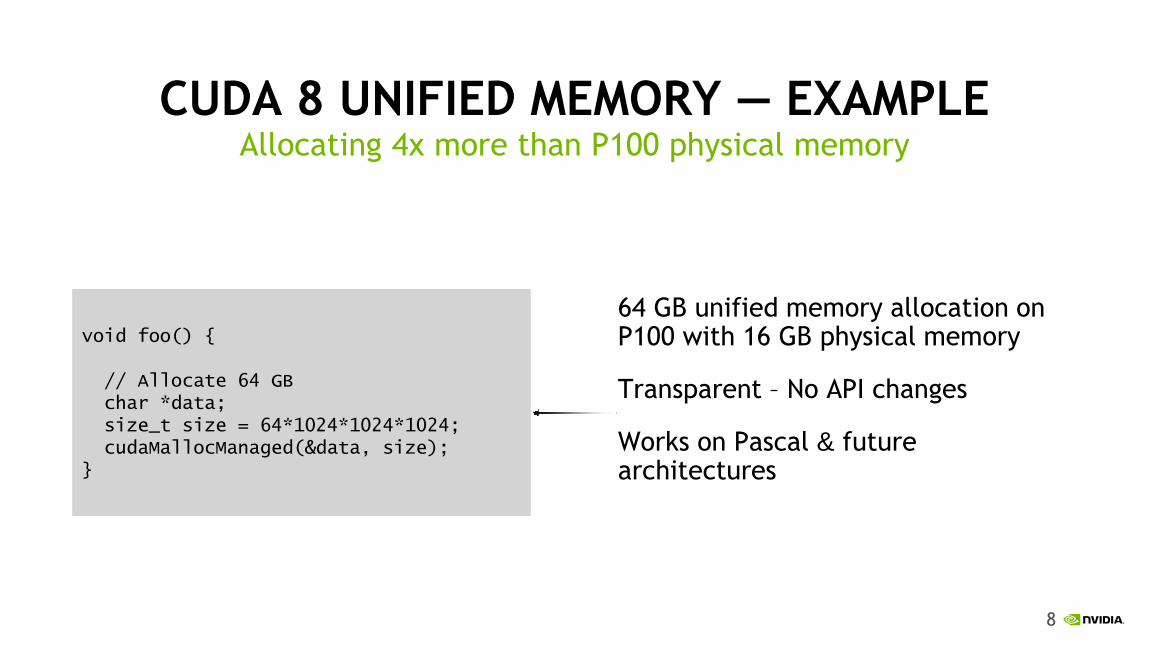
8
CUDA 8 UNIFIED MEMORY — EXAMPLE
64 GB unified memory allocation on P100 with 16 GB physical memory
Transparent – No API changes
Works on Pascal & future architectures
Allocating 4x more than P100 physical memory
void foo() { // Allocate 64 GB char *data; size_t size = 64*1024*1024*1024; cudaMallocManaged(&data, size); }

9
CUDA 8 UNIFIED MEMORY — EXAMPLE
Both CPU code and CUDA kernel accessing ‘data’ simultaneously
Possible with CUDA 8 unified memory on Pascal
Accessing data simultaneously by CPU and GPU codes
__global__ void mykernel(char *data) { data[1] = ‘g’; } void foo() { char *data; cudaMallocManaged(&data, 2); mykernel<<<...>>>(data); // no synchronize here data[0] = ‘c’; cudaFree(data); }
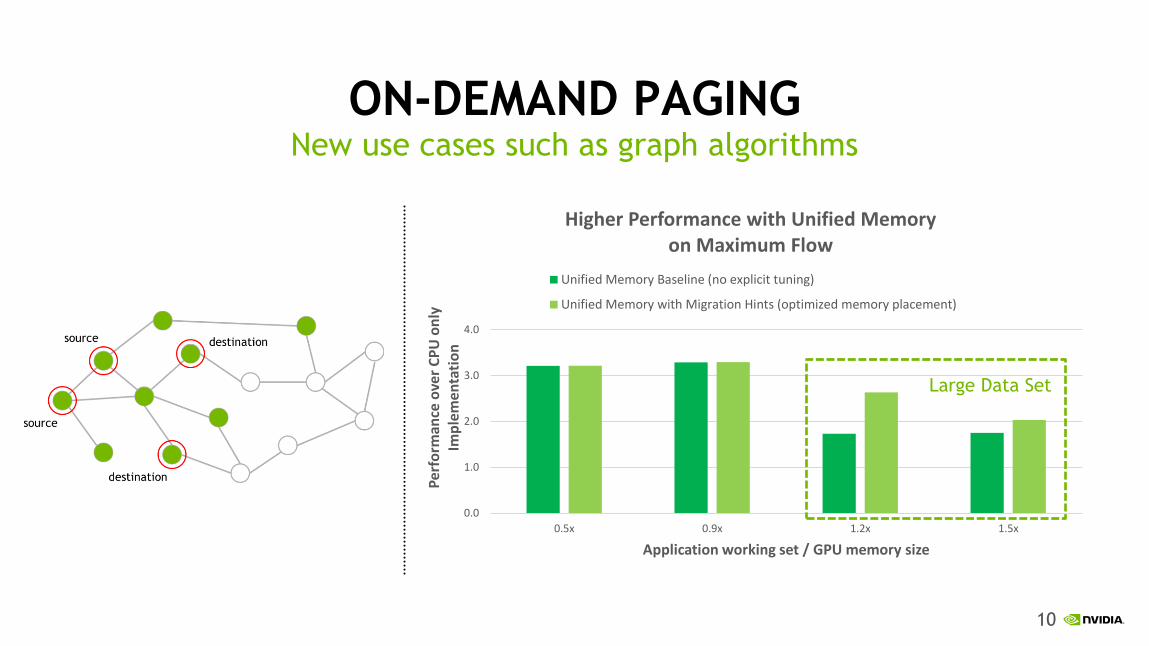
10
ON-DEMAND PAGING New use cases such as graph algorithms
0.0
1.0
2.0
3.0
4.0
0.5x 0.9x 1.2x 1.5x
Per
form
ance
ove
r C
PU
on
ly
Imp
lem
enta
tio
n
Application working set / GPU memory size
Higher Performance with Unified Memory on Maximum Flow
Unified Memory Baseline (no explicit tuning)
Unified Memory with Migration Hints (optimized memory placement)
Large Data Set
11
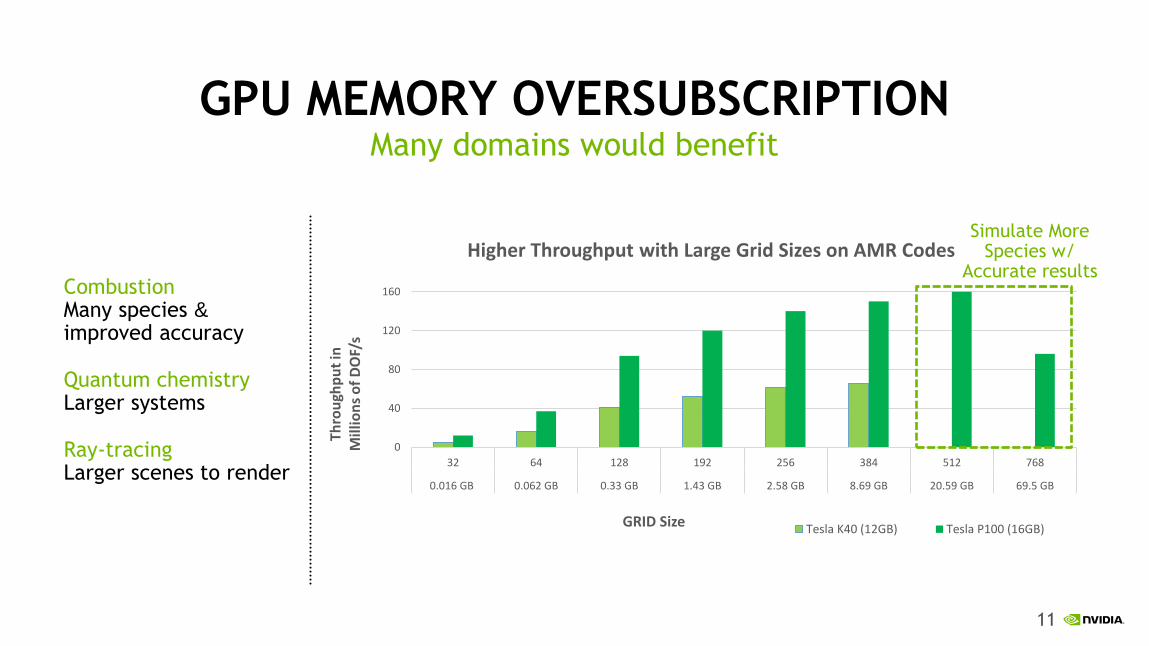
GPU MEMORY OVERSUBSCRIPTION
Combustion Many species & improved accuracy
Quantum chemistry Larger systems
Ray-tracing Larger scenes to render
Many domains would benefit
0
40
80
120
160
32 64 128 192 256 384 512 768
0.016 GB 0.062 GB 0.33 GB 1.43 GB 2.58 GB 8.69 GB 20.59 GB 69.5 GB
Thro
ugh
pu
t in
M
illio
ns
of
DO
F/s
GRID Size
Higher Throughput with Large Grid Sizes on AMR Codes
Tesla K40 (12GB) Tesla P100 (16GB)
Simulate More Species w/
Accurate results

12
LIBRARIES
13
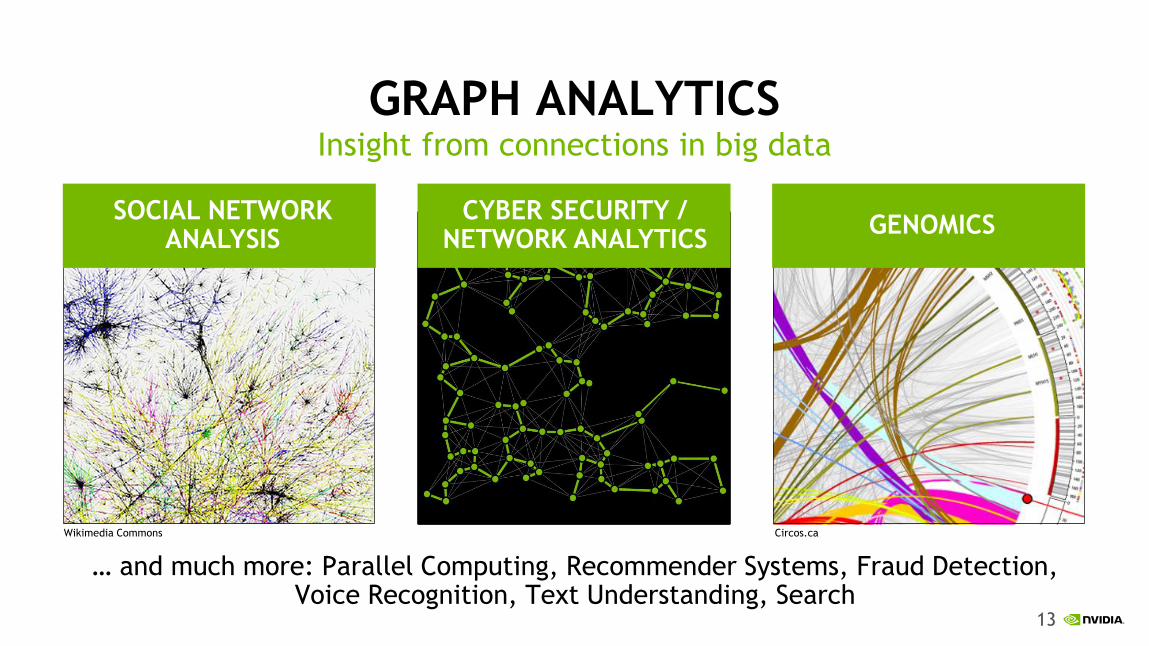
GRAPH ANALYTICS
… and much more: Parallel Computing, Recommender Systems, Fraud Detection, Voice Recognition, Text Understanding, Search
Insight from connections in big data
GENOMICS
CYBER SECURITY / NETWORK ANALYTICS
SOCIAL NETWORK ANALYSIS
Wikimedia Commons Circos.ca
14 CPU System: 4U server w/ 4x12-core Xeon E5-2697 CPU, 30M Cache, 2.70 GHz, 512 GB RAM
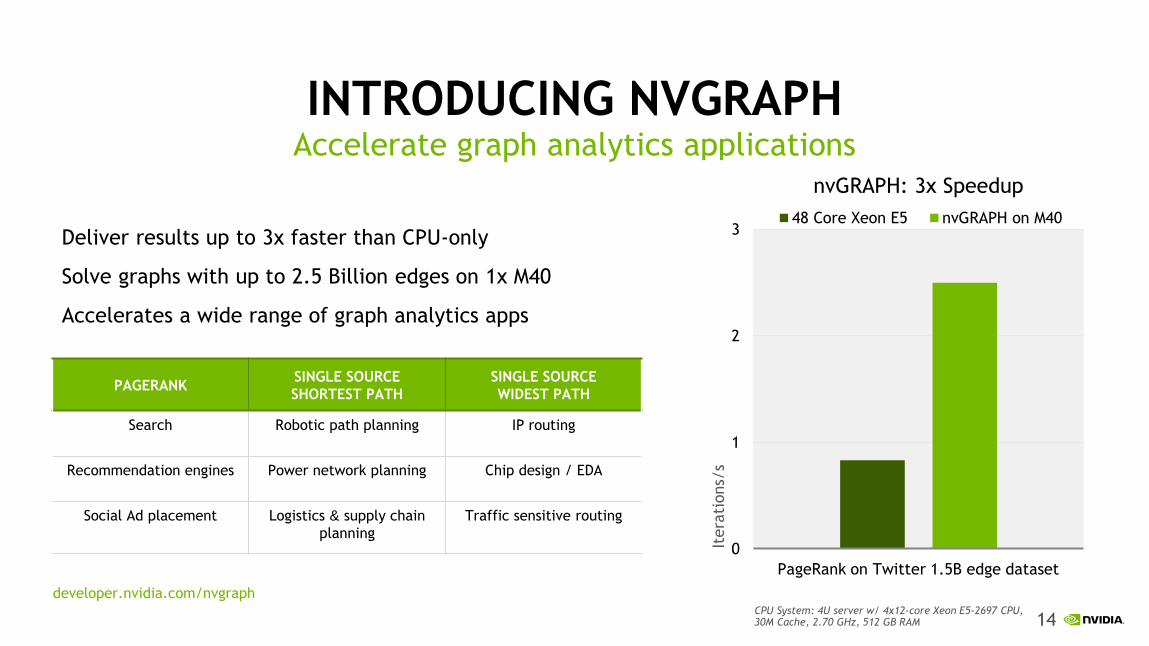
INTRODUCING NVGRAPH
Deliver results up to 3x faster than CPU-only
Solve graphs with up to 2.5 Billion edges on 1x M40
Accelerates a wide range of graph analytics apps
Accelerate graph analytics applications
developer.nvidia.com/nvgraph
0
1
2
3
Itera
tions/
s
nvGRAPH: 3x Speedup
48 Core Xeon E5 nvGRAPH on M40
PageRank on Twitter 1.5B edge dataset
PAGERANK SINGLE SOURCE
SHORTEST PATH
SINGLE SOURCE
WIDEST PATH
Search Robotic path planning IP routing
Recommendation engines Power network planning Chip design / EDA
Social Ad placement Logistics & supply chain
planning
Traffic sensitive routing

15 NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE.
ADDITIONAL LIBRARY IMPROVEMENTS
cuBLAS-XT and nvBLAS will now accept argument from device memory, so users can keep data in device memory and chain together accelerated operations
Improved new Strided Batched GEMM are easier to use and yield higher performance on newer GPUs
Improved SGEMM performance for small arrays where m and n are not a multiple of the tile size
8-bit integer input and output for certain cuBLAS routines
cuBLAS, nvBLAS, cuBLAS-XT, and cuSPARSE

16
DEVELOPER TOOLS
17
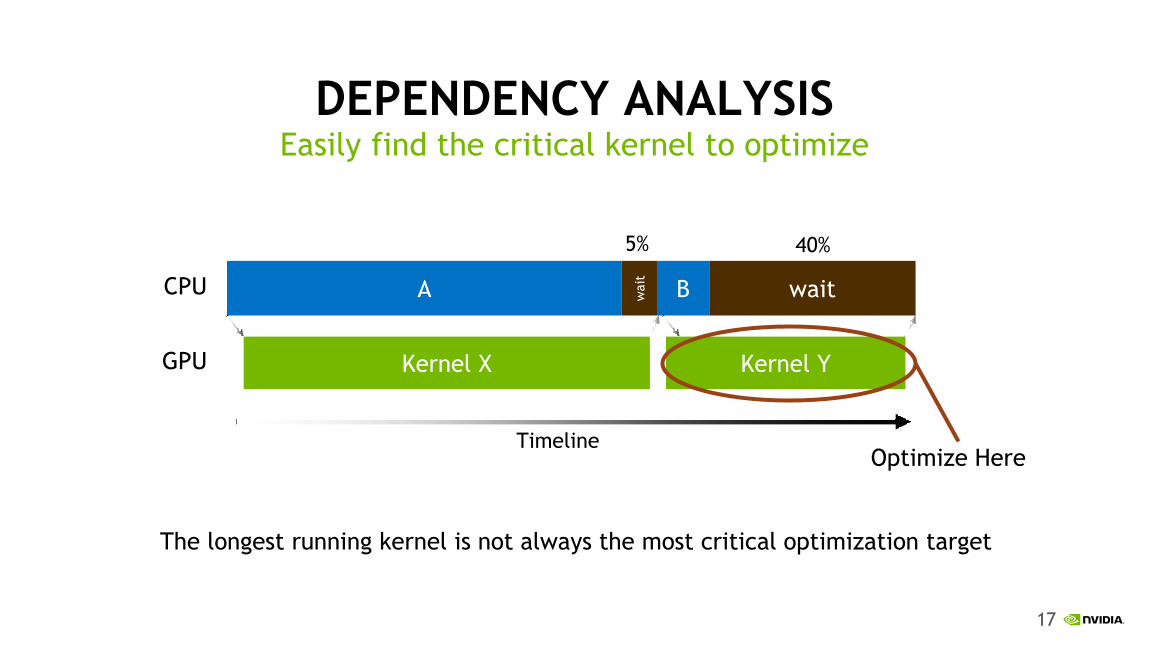
DEPENDENCY ANALYSIS
The longest running kernel is not always the most critical optimization target
Easily find the critical kernel to optimize
A wait
B wait
Kernel X Kernel Y
5% 40%
Timeline Optimize Here
CPU
GPU
18 NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE.
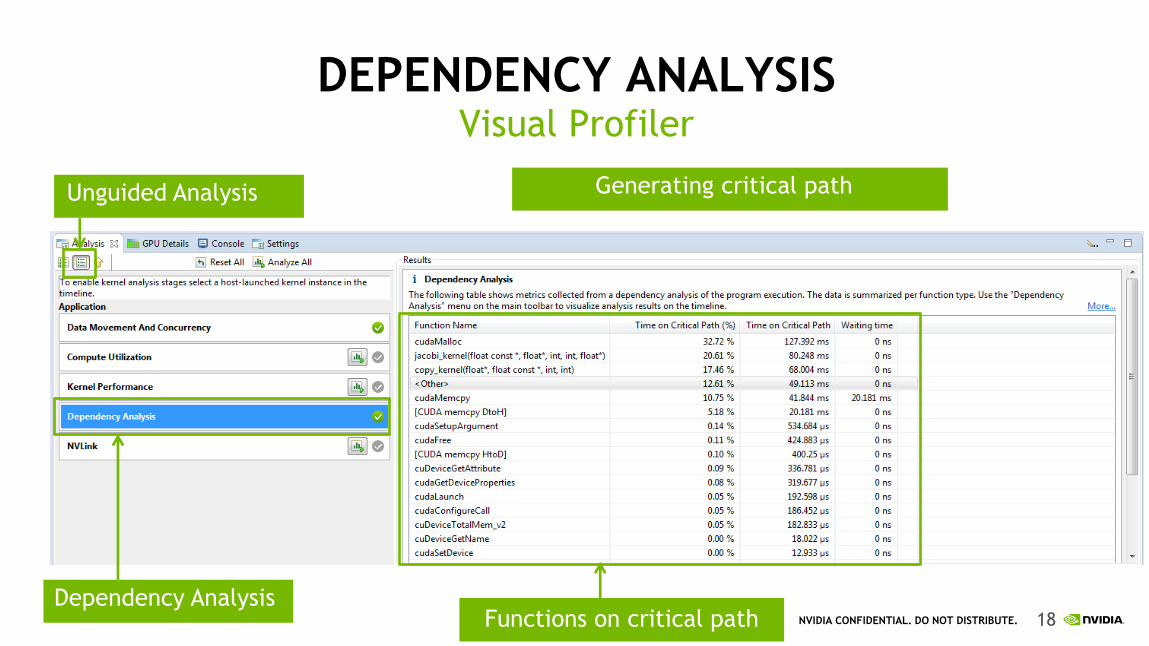
DEPENDENCY ANALYSIS Visual Profiler
Unguided Analysis Generating critical path
Dependency Analysis Functions on critical path
19
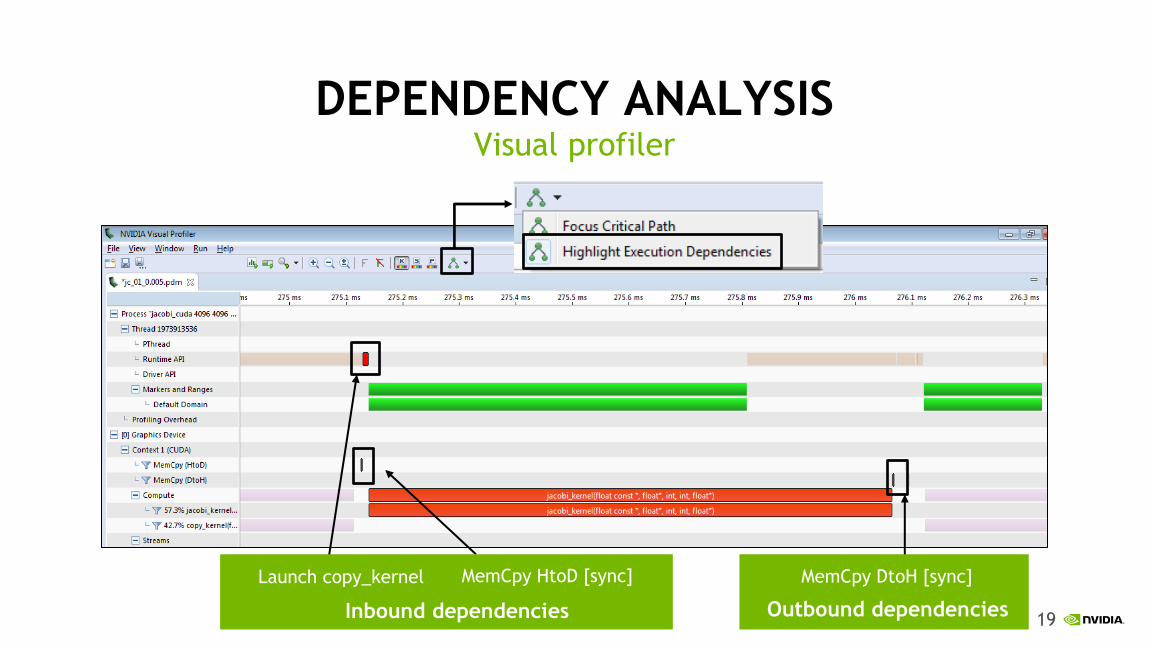
DEPENDENCY ANALYSIS Visual profiler
Inbound dependencies
Launch copy_kernel MemCpy HtoD [sync]
Outbound dependencies
MemCpy DtoH [sync]
20
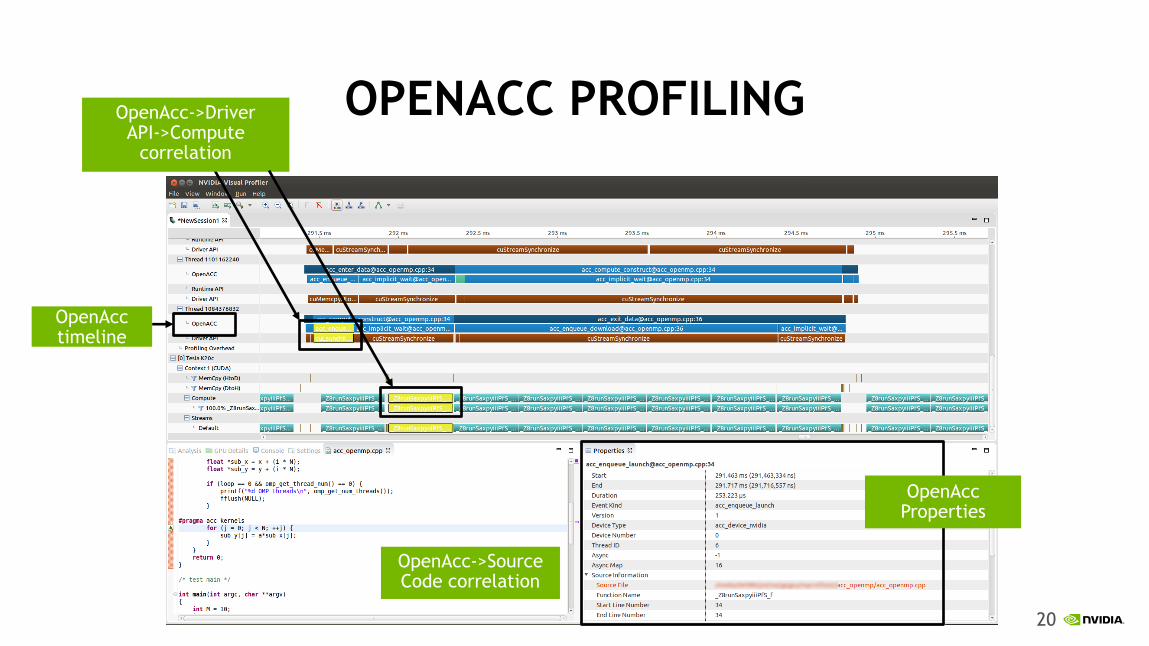
OPENACC PROFILING OpenAcc->Driver API->Compute
correlation
OpenAcc->Source Code correlation
OpenAcc timeline
OpenAcc Properties
21
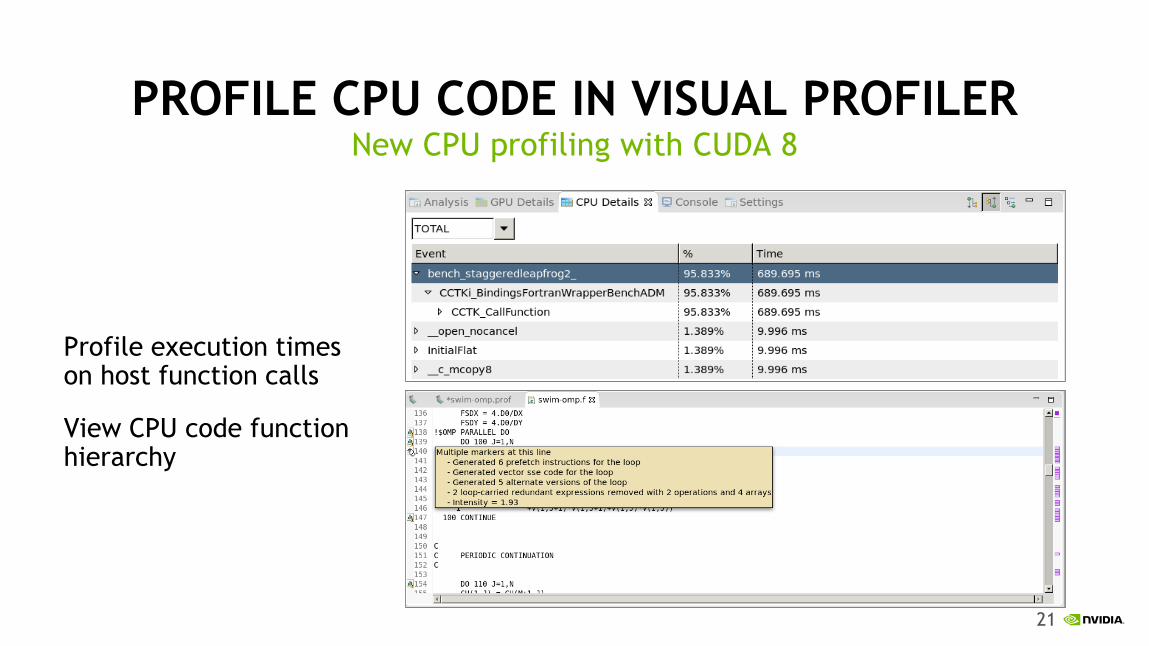
PROFILE CPU CODE IN VISUAL PROFILER
Profile execution times on host function calls
View CPU code function hierarchy
New CPU profiling with CUDA 8

22
MORE CUDA 8 PROFILER FEATURES
Unified memory profiling
NVLink topology and bandwidth profiling

23
COMPILER
24
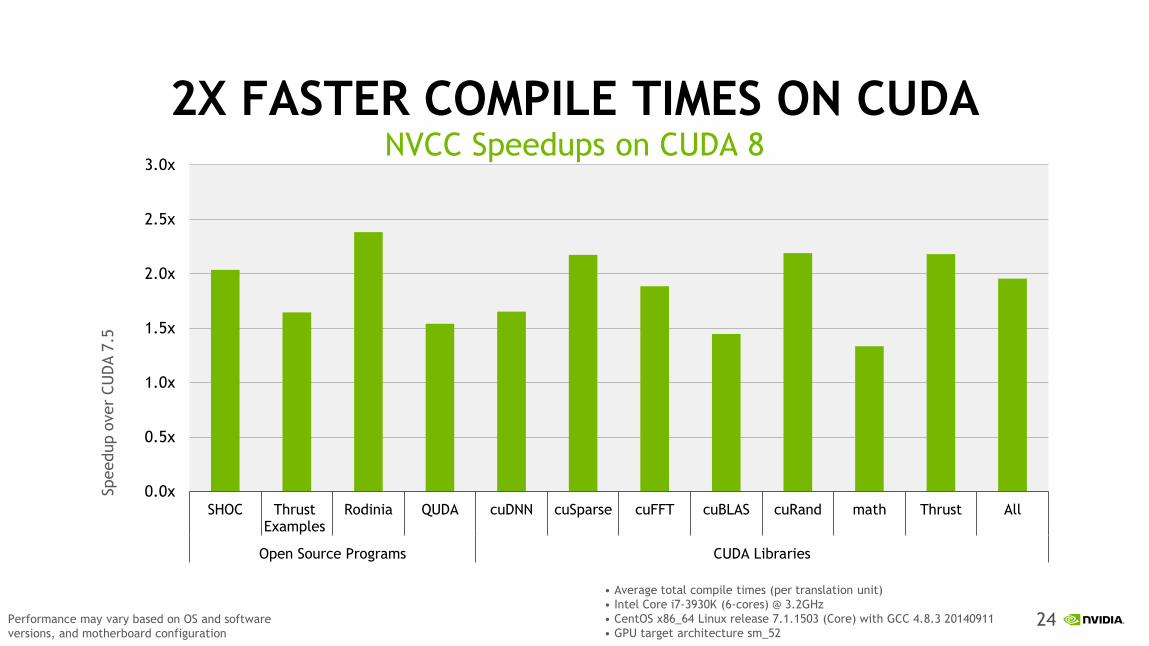
2X FASTER COMPILE TIMES ON CUDA NVCC Speedups on CUDA 8
Performance may vary based on OS and software
versions, and motherboard configuration
• Average total compile times (per translation unit)
• Intel Core i7-3930K (6-cores) @ 3.2GHz
• CentOS x86_64 Linux release 7.1.1503 (Core) with GCC 4.8.3 20140911
• GPU target architecture sm_52
Speedup o
ver
CU
DA 7
.5
0.0x
0.5x
1.0x
1.5x
2.0x
2.5x
3.0x
SHOC ThrustExamples
Rodinia QUDA cuDNN cuSparse cuFFT cuBLAS cuRand math Thrust All
Open Source Programs CUDA Libraries

25
__global__ template <typename F, typename T> void apply(F function, T *ptr) { *ptr = function(ptr); } int main(void) { float *x; cudaMallocManaged(&x, 2); auto square = [=] __host__ __device__ (float x) { return x*x; }; apply<<<1, 1>>>(square, &x[0]); ptr[1] = square(&x[1]); cudaFree(x); }
HETEROGENEOUS C++ LAMBDA
__host__ __device__ lambda
Combined CPU/GPU lambda functions
Call lambda from device code
Pass lambda to CUDA kernel
… or call it from host code
Experimental feature in CUDA 8. `nvcc --expt-extended-lambda`

26
HETEROGENEOUS C++ LAMBDA Usage with thrust
__host__ __device__ lambda
Experimental feature in CUDA 8. `nvcc --expt-extended-lambda`
void saxpy(float *x, float *y, float a, int N) { using namespace thrust; auto r = counting_iterator(0); auto lambda = [=] __host__ __device__ (int i) { y[i] = a * x[i] + y[i]; }; if(N > gpuThreshold) for_each(device, r, r+N, lambda); else for_each(host, r, r+N, lambda); }
Use lambda in thrust::for_each on host or device

27
OTHER FEATURES

28
GPUDIRECT ASYNC*
Eliminate CPU as the critical path in the GPU initiated data transfers
GPU directly triggers data transfers without CPU coordination
CPU is unblocked to perform other tasks
Achieve higher MPI application performance across large clusters
HCA GPU
CPU
IO Hub
*Supported on Tesla and Quadro GPUs with Mellanox InfiniBand
HCA
IB HCA
29
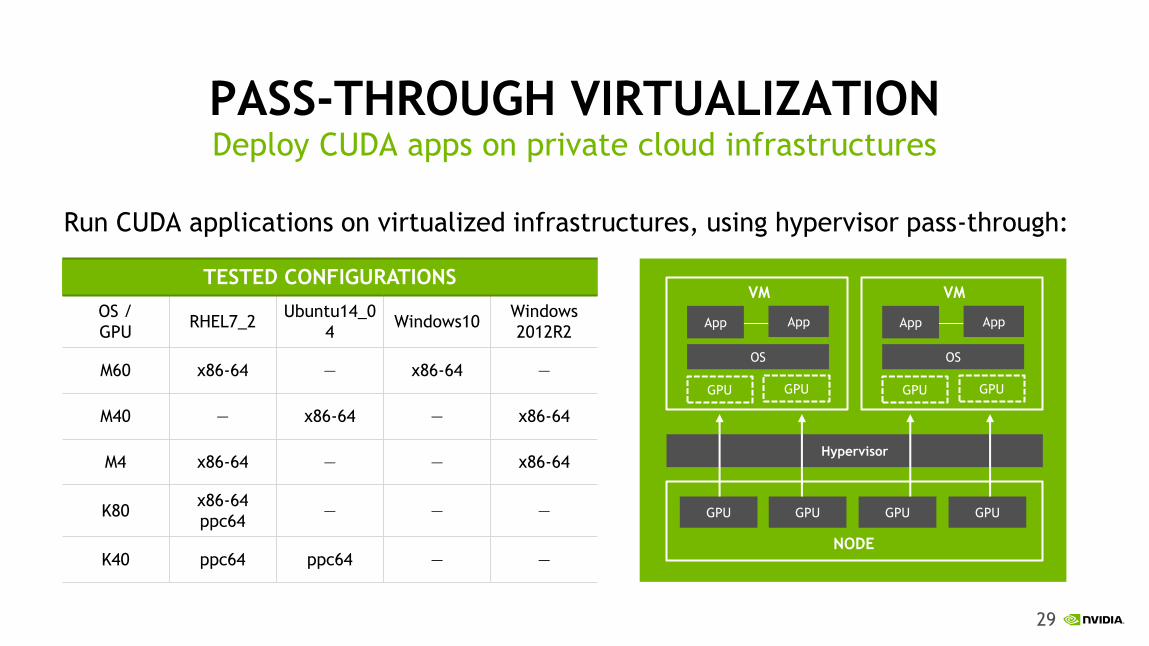
PASS-THROUGH VIRTUALIZATION
Run CUDA applications on virtualized infrastructures, using hypervisor pass-through:
Deploy CUDA apps on private cloud infrastructures
TESTED CONFIGURATIONS
OS /
GPU RHEL7_2
Ubuntu14_0
4 Windows10
Windows
2012R2
M60 x86-64 — x86-64 —
M40 — x86-64 — x86-64
M4 x86-64 — — x86-64
K80 x86-64
ppc64 — — —
K40 ppc64 ppc64 — — NODE
Hypervisor
VM
OS
GPU GPU
App App
VM
OS
GPU GPU
App App
GPU GPU GPU GPU

30
CUDA 8 PLATFORM SUPPORT
OS
Windows: Windows Server 2016
Linux: Fedora 23, Ubuntu 16.04, SLES 11 SP4
Mac: OS X 10.12
Compiler
Windows: VS 2015 and VS 2015 Community
Linux: PGI C++ 16.1/16.4, Clang 3.7, ICC 16.0
New OS and compilers added

31 NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE.
CUDA 8 – GET STARTED TODAY
Release Candidate Available Now
Join developer program to download CUDA & provide feedback
General Availability in August
Everything You Need to Accelerate Applications
developer.nvidia.com/cuda-toolkit

THANK YOU
Related Documents











