Lecture 8: Convolutional Neural Networks on Videos Bohyung Han Computer Vision Lab. [email protected] CSED703R: Deep Learning for Visual Recognition (2016S) CNNs on Videos • Challenges in video processing using CNNs A large number of frames: high computational complexity Variable lengths Temporal dependency of data • Relevant problems Action detection and recognition Video event detection Object detection and recognition in videos Scene recognition in videos Visual tracking … 2 Action Recognition • Classifying actions From images or videos Deep learning vs. shallow learning Slightly different from detection and localization • Deep learning for action recognition Not yet mature Approaches based on • Convolutional neural networks • Recurrent neural networks Algorithms based on deep learning started to outperform the methods based on handcrafted features. 3 Datasets • UCF‐101 101 classes: approximately 13,320 realistic videos, collected from YouTube 5 types: human‐object interaction, body motion only, human‐human inter action, playing musical instruments, sports Three training/testing splits 4 http://crcv.ucf.edu/data/UCF101.php

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Lecture 8: Convolutional Neural Networks on Videos
Bohyung HanComputer Vision [email protected]
CSED703R: Deep Learning for Visual Recognition (2016S)
CNNs on Videos
• Challenges in video processing using CNNs A large number of frames: high computational complexity Variable lengths Temporal dependency of data
• Relevant problems Action detection and recognition Video event detection Object detection and recognition in videos Scene recognition in videos Visual tracking …
2
Action Recognition
• Classifying actions From images or videos Deep learning vs. shallow learning Slightly different from detection and localization
• Deep learning for action recognition Not yet mature Approaches based on
• Convolutional neural networks• Recurrent neural networks
Algorithms based on deep learning started to outperform the methods based on handcrafted features.
3
Datasets
• UCF‐101 101 classes: approximately 13,320 realistic videos, collected from YouTube 5 types: human‐object interaction, body motion only, human‐human inter
action, playing musical instruments, sports Three training/testing splits
4http://crcv.ucf.edu/data/UCF101.php

Datasets
• Sports‐1M 487 classes, 1000‐3000 videos per class 1M YouTube videos The classes are arranged in a manually‐curated taxonomy. Noisy labels due to automated annotation process
5http://cs.stanford.edu/people/karpathy/deepvideo/
Datasets
• HMDB‐51 A large human motion database 7000 clips for 51 classes Original and stabilized versions are available. STIP (Space Time Interest Point) features are available.
6http://serre‐lab.clps.brown.edu/resource/hmdb‐a‐large‐human‐motion‐database/
Action Recognition Research
7
Title Venue AlgorithmAccuracy
Sports‐1M
UCF101
Action Recognition with Improved Trajectories
ICCV 13 Improved densetrajectory (iDT)
85.9
Bag of Visual Words and Fusion Methods for Action Recognition: Comprehensive Study and Good Practice
arXiv 14 iDT with higher dimensional encoding
87.9
Large‐scale Video Classification with CNNs CVPR 14 Spatial‐temporal CNN 60.9 65.4
Two‐Stream CNNs for Action Recognition in Videos
NIPS 14 Two‐stream CNN fused by SVM
88.0
Long‐Term Recurrent Convolutional Networks for Visual Recognition and Description
CVPR 15 CNN + LSTM 82.9
Beyond Short Snippets: Deep Networks for Video Classification
CVPR 15 Two‐stream + temporalfeature pooling
72.4 88.6
Learning Spatiotemporal Features with 3D Convolutional Networks
ICCV 15 Spatiotemporal 3D‐CNN + iDT
61.1 90.4
Action Recognition with Trajectory‐Pooled Deep‐Convolutional Descriptors
CVPR 15 Two‐stream model + iDT
91.5
Actions ∼ Transformations CVPR 16 92.4
Improved Dense Trajectory (iDT)
• Main idea Global motion compensation:
removing trajectories from camera motion
Outlier rejection: removing matches from human regions
• Feature encoding Extraction of Trajectory, HOG,
HOF, and MBH Bag of trajectory features Fisher vector + PCA
8H. Wang, C. Schmid: Action Recognition with Improved Trajectories. ICCV 2013
It demonstrates very good accuracy even compared with deep learning approaches.
Large‐Scale Video Classification
• Contributions Construction a large‐scale dataset, Sports‐1M Providing quantitative accuracies of several baseline algorithms
• Cons Still worse than iDT algorithm with large margin Still no sophisticated idea of video level prediction
9A. Kapathy et al.: Large‐scale Video Classification with Convolutional Neural Networks. CVPR 2014
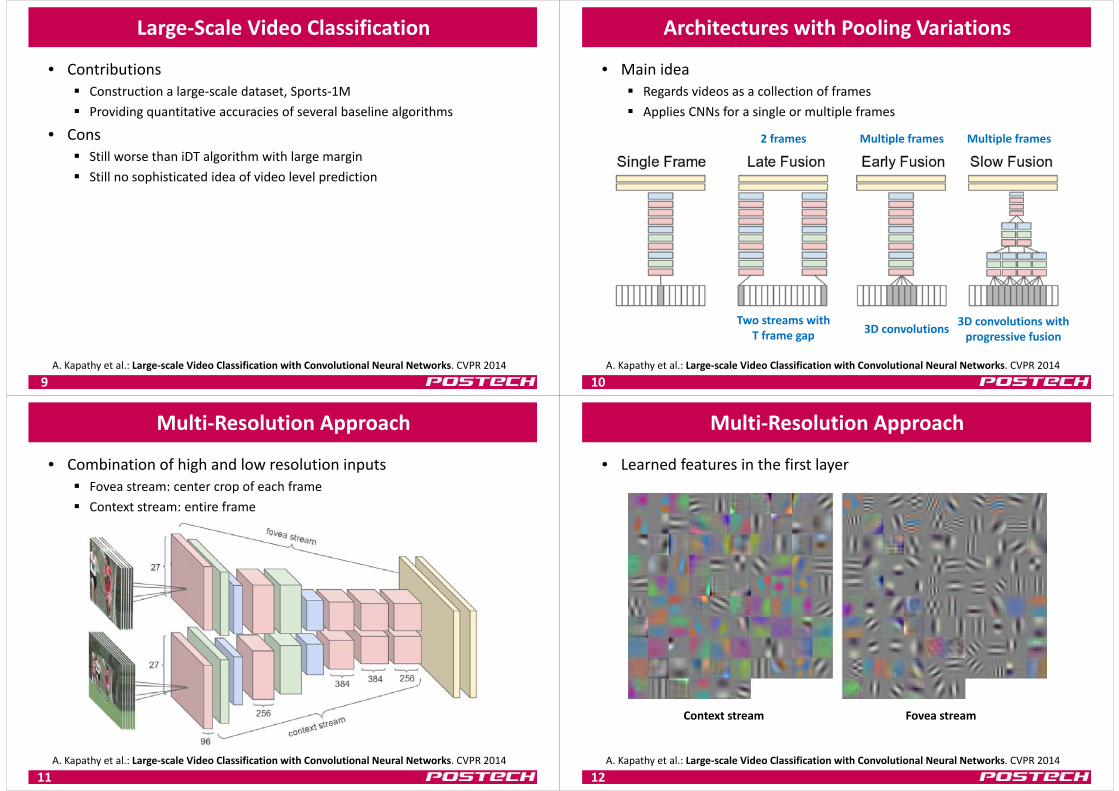
Architectures with Pooling Variations
• Main idea Regards videos as a collection of frames Applies CNNs for a single or multiple frames
10A. Kapathy et al.: Large‐scale Video Classification with Convolutional Neural Networks. CVPR 2014
Two streams with T frame gap 3D convolutions 3D convolutions with
progressive fusion
2 frames Multiple frames Multiple frames
Multi‐Resolution Approach
• Combination of high and low resolution inputs Fovea stream: center crop of each frame Context stream: entire frame
11A. Kapathy et al.: Large‐scale Video Classification with Convolutional Neural Networks. CVPR 2014
Multi‐Resolution Approach
• Learned features in the first layer
12
Context stream Fovea stream
A. Kapathy et al.: Large‐scale Video Classification with Convolutional Neural Networks. CVPR 2014
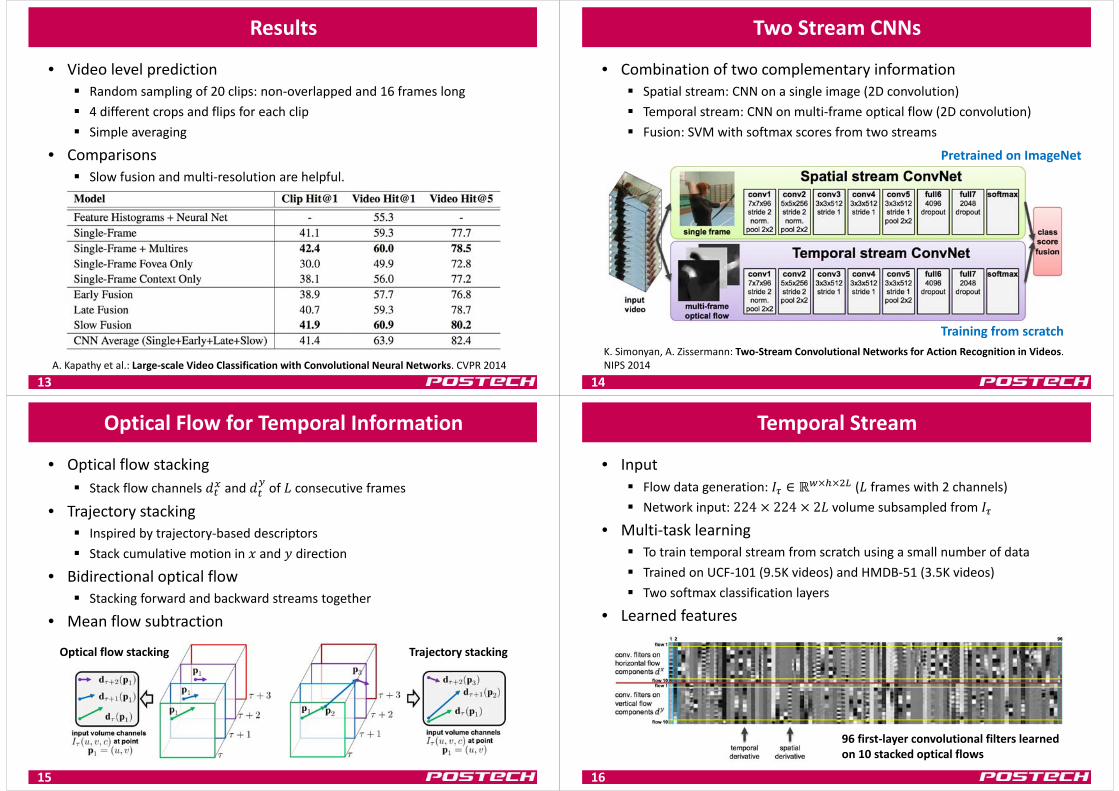
Results
• Video level prediction Random sampling of 20 clips: non‐overlapped and 16 frames long 4 different crops and flips for each clip Simple averaging
• Comparisons Slow fusion and multi‐resolution are helpful.
13A. Kapathy et al.: Large‐scale Video Classification with Convolutional Neural Networks. CVPR 2014
Two Stream CNNs
• Combination of two complementary information Spatial stream: CNN on a single image (2D convolution) Temporal stream: CNN on multi‐frame optical flow (2D convolution) Fusion: SVM with softmax scores from two streams
14
K. Simonyan, A. Zissermann: Two‐Stream Convolutional Networks for Action Recognition in Videos. NIPS 2014
Pretrained on ImageNet
Training from scratch
Optical Flow for Temporal Information
• Optical flow stacking Stack flow channels and of consecutive frames
• Trajectory stacking Inspired by trajectory‐based descriptors Stack cumulative motion in and direction
• Bidirectional optical flow Stacking forward and backward streams together
• Mean flow subtraction
15
Optical flow stacking Trajectory stacking
Temporal Stream
• Input Flow data generation: ∈ ( frames with 2 channels) Network input: 224 224 2 volume subsampled from
• Multi‐task learning To train temporal stream from scratch using a small number of data Trained on UCF‐101 (9.5K videos) and HMDB‐51 (3.5K videos) Two softmax classification layers
• Learned features
16
96 first‐layer convolutional filters learned on 10 stacked optical flows
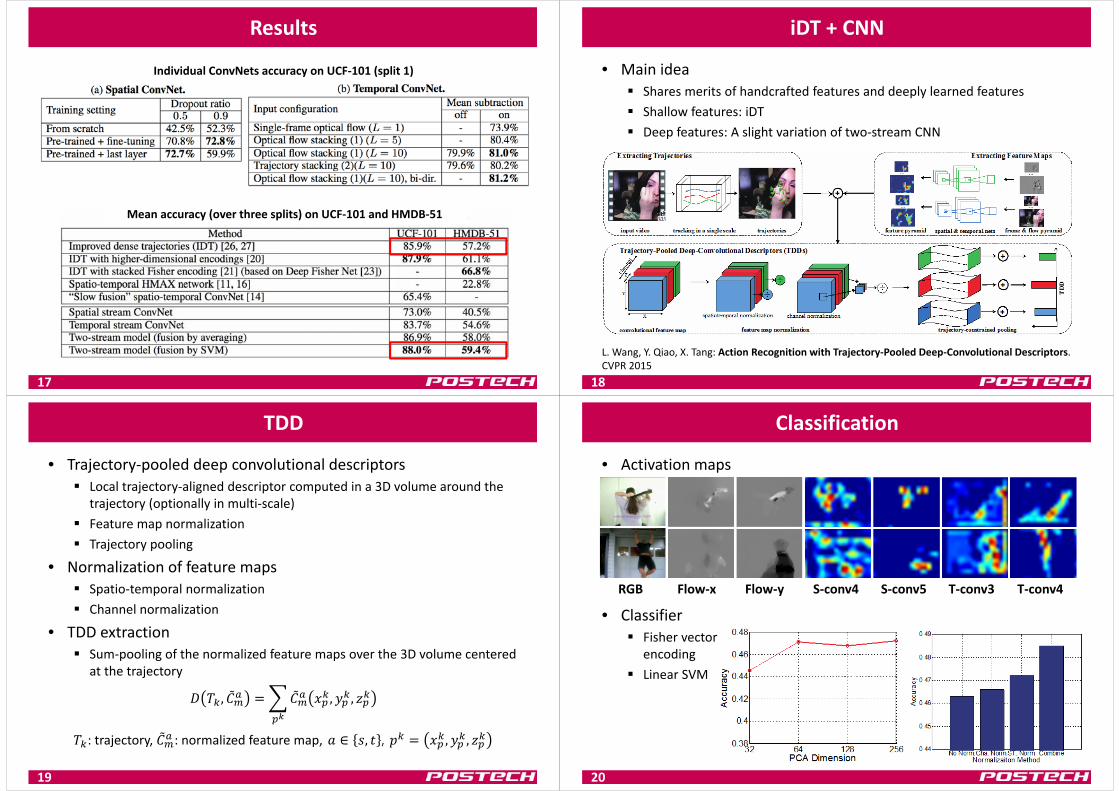
Results
17
Individual ConvNets accuracy on UCF‐101 (split 1)
Mean accuracy (over three splits) on UCF‐101 and HMDB‐51
iDT + CNN
• Main idea Shares merits of handcrafted features and deeply learned features Shallow features: iDT Deep features: A slight variation of two‐stream CNN
18
L. Wang, Y. Qiao, X. Tang: Action Recognition with Trajectory‐Pooled Deep‐Convolutional Descriptors. CVPR 2015
TDD
• Trajectory‐pooled deep convolutional descriptors Local trajectory‐aligned descriptor computed in a 3D volume around the
trajectory (optionally in multi‐scale) Feature map normalization Trajectory pooling
• Normalization of feature maps Spatio‐temporal normalization Channel normalization
• TDD extraction Sum‐pooling of the normalized feature maps over the 3D volume centered
at the trajectory
19
, , ,: trajectory, : normalized feature map, ∈ , , , ,
Classification
• Activation maps
• Classifier Fisher vector
encoding Linear SVM
20
RGB Flow‐x Flow‐y S‐conv4 S‐conv5 T‐conv3 T‐conv4

Results
21
L. Wang, Y. Qiao, X. Tang: Action Recognition with Trajectory‐Pooled Deep‐Convolutional Descriptors. CVPR 2015
Action Recognition by 3D CNNs
• Generalized version of 2Dconvolution Convolution in spatio‐temporal
domain More parameters for
convolutions
22
S. Ji, W. Xu, M. Yang, K. Yu: 3D Convolutional Neural Networks for Human Action Recognition. ICML 2010
2D convolution 3D convolution
D. Tran, L. Bourdev, R. Fergus, L. Torresani, M. Paluri: Learning Spatiotemporal Features with 3D Convolutional Networks. ICCV 2015
Architecture[JiICML10]
• Standard CNN architecture 1 hardwired convolutional layer 3 additional convolutional layers 2 pooling layers 1 fully connected layer
23
H1: 33@60x40 C2:
23*2@54x34
7x7x3 3D convolution
2x2 subsampling
S3: 23*2@27x17
7x6x3 3D convolution
C4: 13*6@21x12
3x3 subsampling
S5: 13*6@7x4
7x4 convolution
C6: 128@1x1
full connnection
hardwired
input: 7@60x40
S. Ji, W. Xu, M. Yang, K. Yu: 3D Convolutional Neural Networks for Human Action Recognition. ICML 2010
Architecture[TranICCV15]
• Components 8 convolutions layers: 3x3x3 with stride 1x1x1 5 max‐pooling layers: 2x2x2 with stride 2x2x2 (1x2x2 with stride 1x2x2 for
pool1) 2 fully connected layers Softmax layer
24
Conv1a
64
Conv2a
128
Pool1
Conv3a
256
Pool2
Conv3b
256
Pool3
Conv4a
512
Conv4b
512
Pool4
Conv5a
512
Conv5b
512
Pool5
FC 409
6
FC 409
6
Softmax
D. Tran, L. Bourdev, R. Fergus, L. Torresani, M. Paluri: Learning Spatiotemporal Features with 3D Convolutional Networks. ICCV 2015

Feature Embedding
• Comparison C3D looks better. But, the comparison is not fair.
25
DeCAF
C3D
DeCAFDeCAF
Accuracy with linear SVM
D. Tran, L. Bourdev, R. Fergus, L. Torresani, M. Paluri: Learning Spatiotemporal Features with 3D Convolutional Networks. ICCV 2015
Deconvolutions for Analysis (conv2a)
26
The learned filters detect moving edges and blobs.
The learned filters detect changes in shots, edge orientations, and colors.
Deconvolutions for Analysis (conv3b)
27
The feature maps detect moving corners and textures.
The feature maps detect moving body parts.
The feature maps detect object trajectories and circular objects.
Results
28
D. Tran, L. Bourdev, R. Fergus, L. Torresani, M. Paluri: Learning Spatiotemporal Features with 3D Convolutional Networks. ICCV 2015
Action recognition results on UCF101
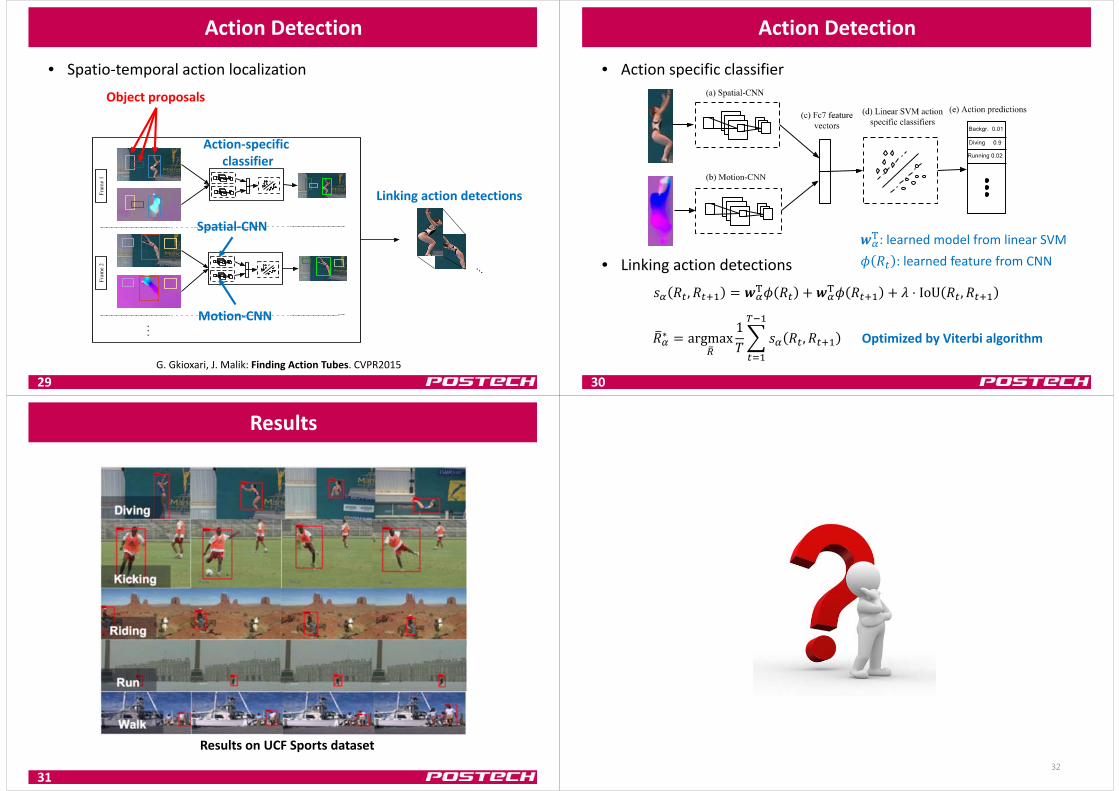
Action Detection
• Spatio‐temporal action localization
29G. Gkioxari, J. Malik: Finding Action Tubes. CVPR2015
Action‐specific classifier
Spatial‐CNN
Motion‐CNN
Object proposals
Linking action detections
Action Detection
• Action specific classifier
• Linking action detections
30
, ⋅ IoU ,∗ argmax 1 , Optimized by Viterbi algorithm
: learned model from linear SVM: learned feature from CNN
Results
31
Results on UCF Sports dataset32
Related Documents




![Object class Lecture 12: Image Generation CNN Viewpoint ...cvlab.postech.ac.kr/~bhhan/class/cse703r_2016s/csed703r_lecture12.pdf · [Aubry14] M. Aubry, D. Maturana, A. Efros, J. Sivic:Seeing](https://static.cupdf.com/doc/110x72/5be8144a09d3f26f698db4a9/object-class-lecture-12-image-generation-cnn-viewpoint-cvlab-bhhanclasscse703r2016scsed703rlecture12pdf.jpg)





