CSE 326: Data Structures Part 8 Graphs Henry Kautz Autumn Quarter 2002

CSE 326: Data Structures Part 8 Graphs Henry Kautz Autumn Quarter 2002.
Dec 24, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

CSE 326: Data StructuresPart 8
Graphs
Henry Kautz
Autumn Quarter 2002

Outline
• Graphs (TO DO: READ WEISS CH 9)• Graph Data Structures• Graph Properties• Topological Sort• Graph Traversals
– Depth First Search
– Breadth First Search
– Iterative Deepening Depth First
• Shortest Path Problem– Dijkstra’s Algorithm

Graph ADTGraphs are a formalism for representing
relationships between objects– a graph G is represented as G = (V, E)• V is a set of vertices• E is a set of edges
– operations include:• iterating over vertices
• iterating over edges
• iterating over vertices adjacent to a specific vertex
• asking whether an edge exists connected two vertices
Han
Leia
Luke
V = {Han, Leia, Luke}E = {(Luke, Leia), (Han, Leia), (Leia, Han)}
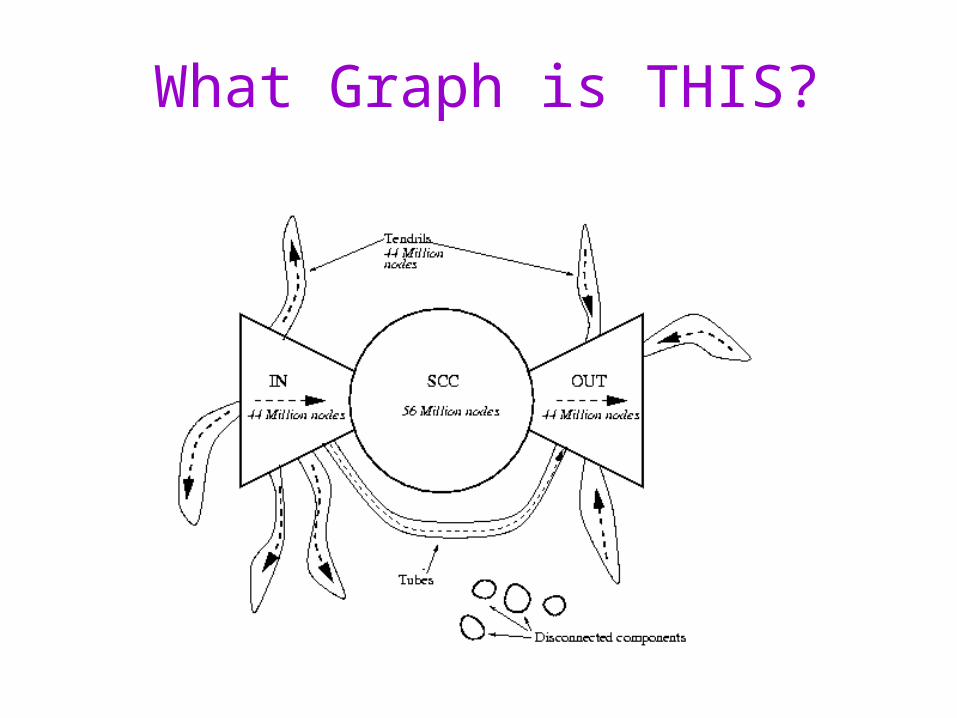
What Graph is THIS?
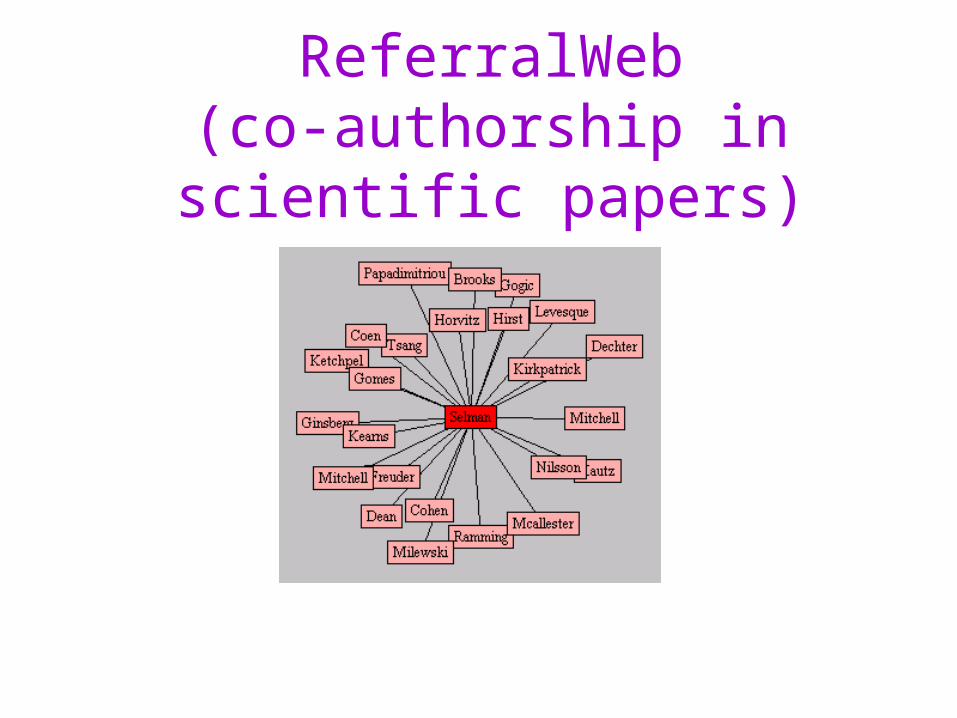
ReferralWeb(co-authorship in scientific papers)
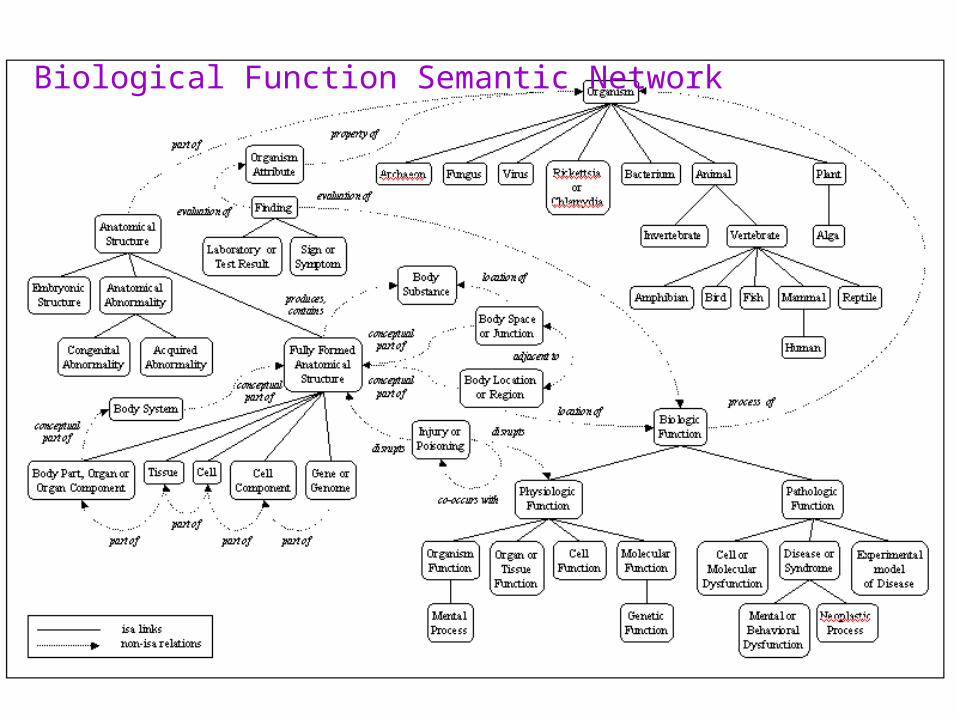
Biological Function Semantic Network
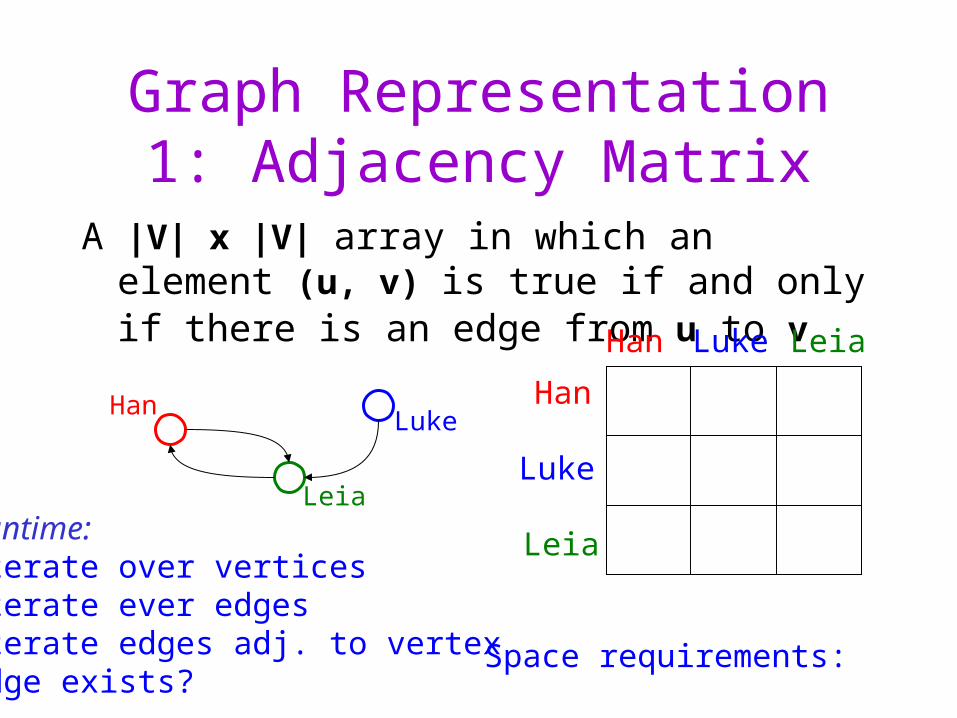
Graph Representation 1: Adjacency Matrix
A |V| x |V| array in which an element (u, v) is true if and only if there is an edge from u to v
Han
Leia
Luke
Han Luke Leia
Han
Luke
LeiaRuntime:iterate over verticesiterate ever edgesiterate edges adj. to vertexedge exists?
Space requirements:

Graph Representation 2: Adjacency List
A |V|-ary list (array) in which each entry stores a list (linked list) of all adjacent vertices
Han
Leia
LukeHan
Luke
Leia
space requirements:
Runtime:iterate over verticesiterate ever edgesiterate edges adj. to vertexedge exists?

Directed vs. Undirected Graphs
Han
Leia
Luke
Han
Leia
Luke
• In directed graphs, edges have a specific direction:
• In undirected graphs, they don’t (edges are two-way):
• Vertices u and v are adjacent if (u, v) E

Graph Density
A sparse graph has O(|V|) edges
A dense graph has (|V|2) edges
Anything in between is either sparsish or densy depending on the context.

Weighted Graphs
20
30
35
60
Mukilteo
Edmonds
Seattle
Bremerton
Bainbridge
Kingston
Clinton
There may be more information in the graph as well.
Each edge has an associated weight or cost.
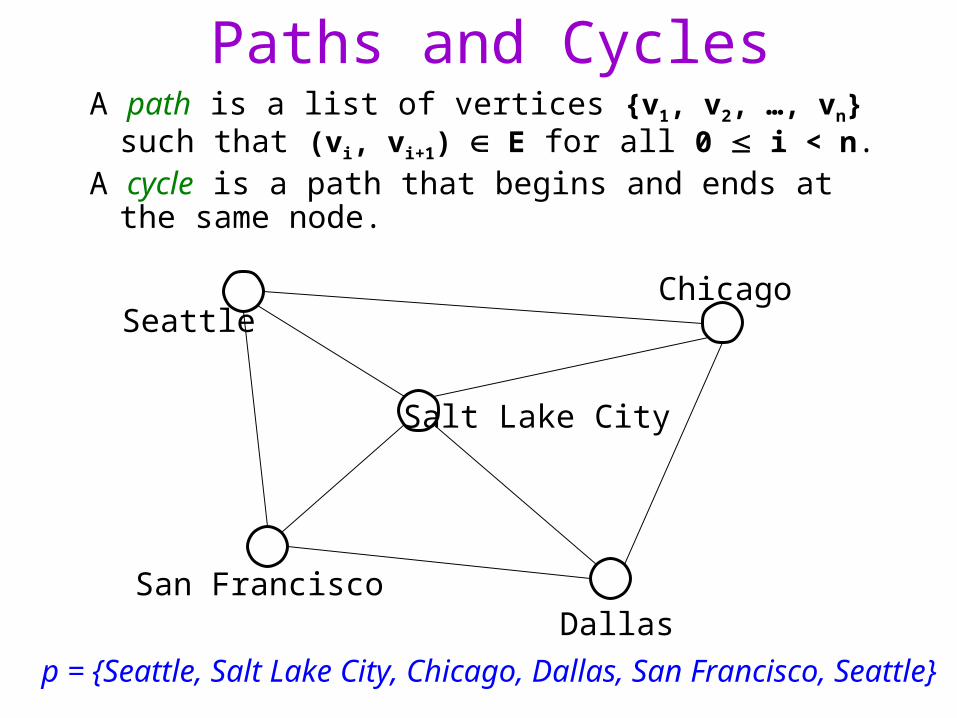
Paths and CyclesA path is a list of vertices {v1, v2, …, vn} such
that (vi, vi+1) E for all 0 i < n.A cycle is a path that begins and ends at the same
node.
Seattle
San FranciscoDallas
Chicago
Salt Lake City
p = {Seattle, Salt Lake City, Chicago, Dallas, San Francisco, Seattle}
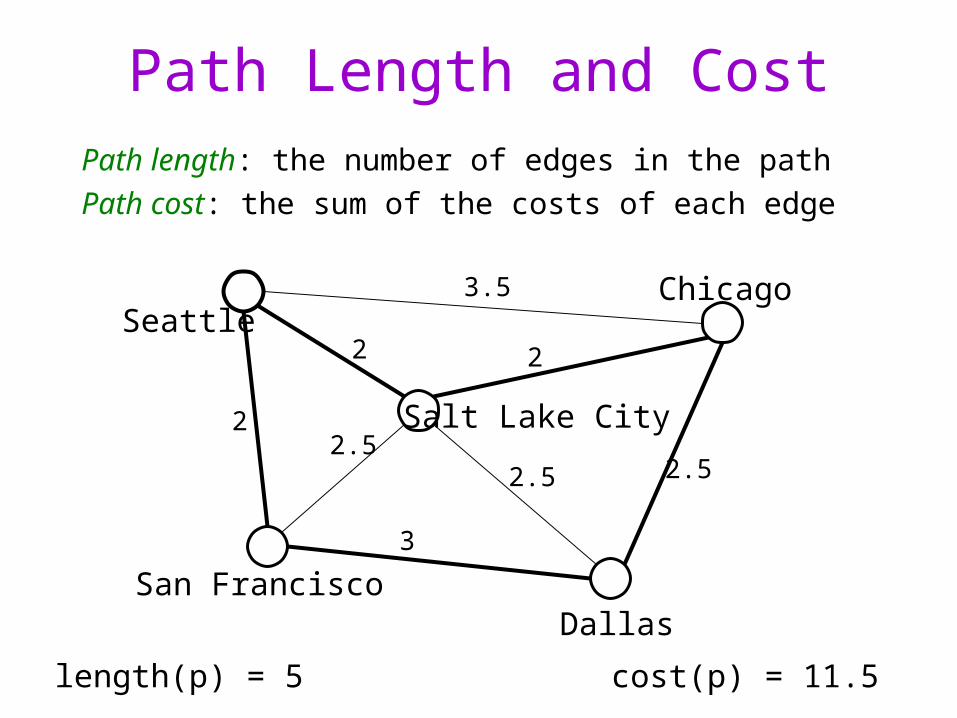
Path Length and Cost
Path length: the number of edges in the path
Path cost: the sum of the costs of each edge
Seattle
San FranciscoDallas
Chicago
Salt Lake City
3.5
2 2
2.5
3
22.5
2.5
length(p) = 5 cost(p) = 11.5
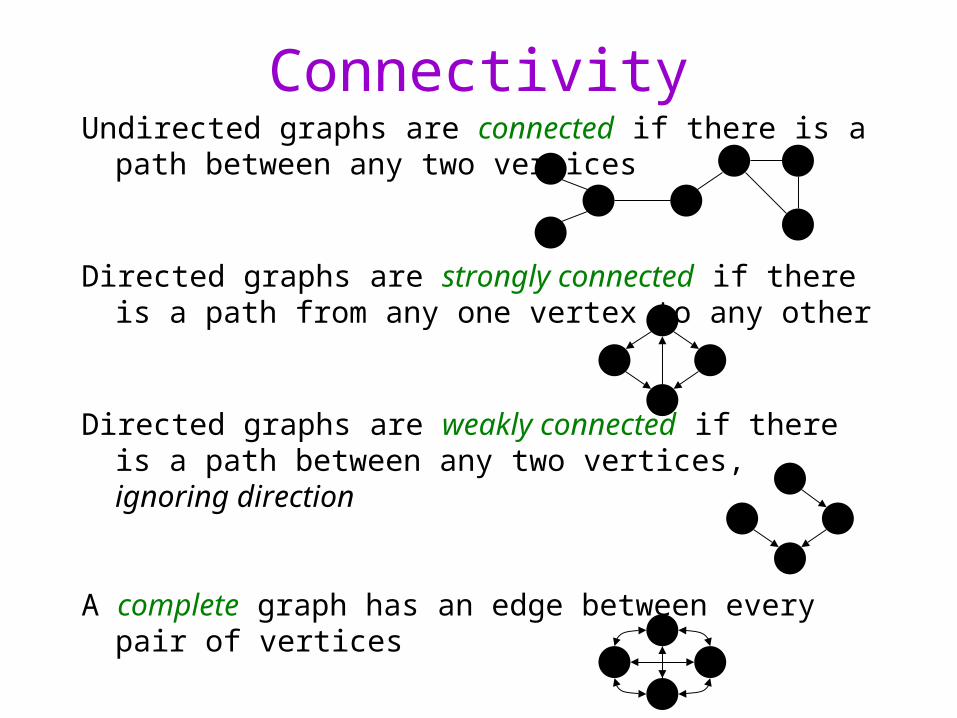
ConnectivityUndirected graphs are connected if there is a path between
any two vertices
Directed graphs are strongly connected if there is a path from any one vertex to any other
Directed graphs are weakly connected if there is a path between any two vertices, ignoring direction
A complete graph has an edge between every pair of vertices
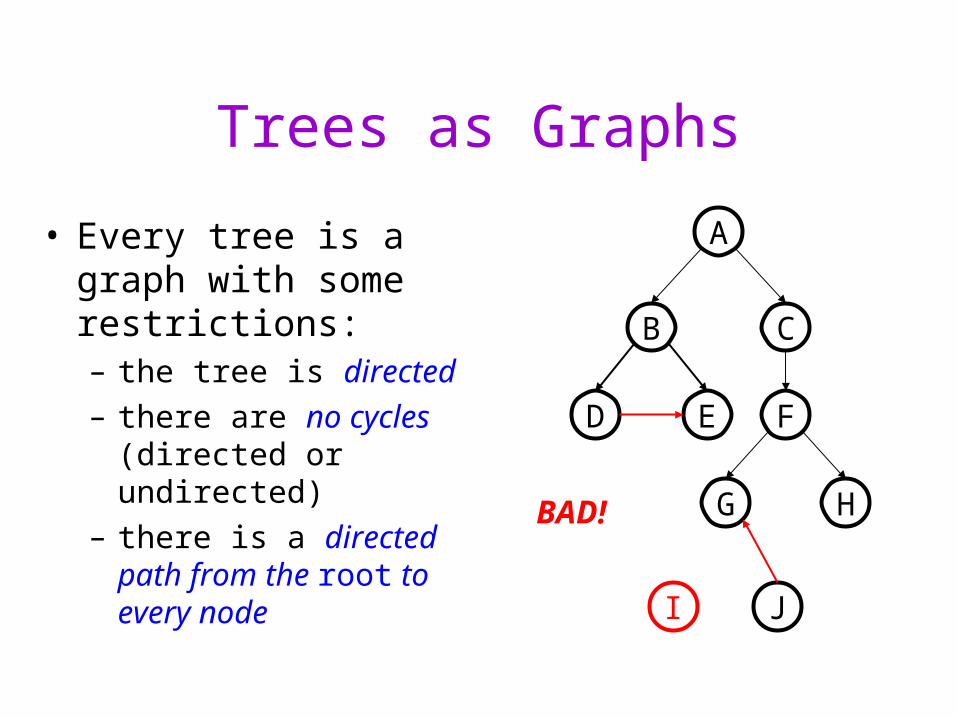
Trees as Graphs
• Every tree is a graph with some restrictions:– the tree is directed
– there are no cycles (directed or undirected)
– there is a directed path from the root to every node
A
B
D E
C
F
HG
JI
BAD!
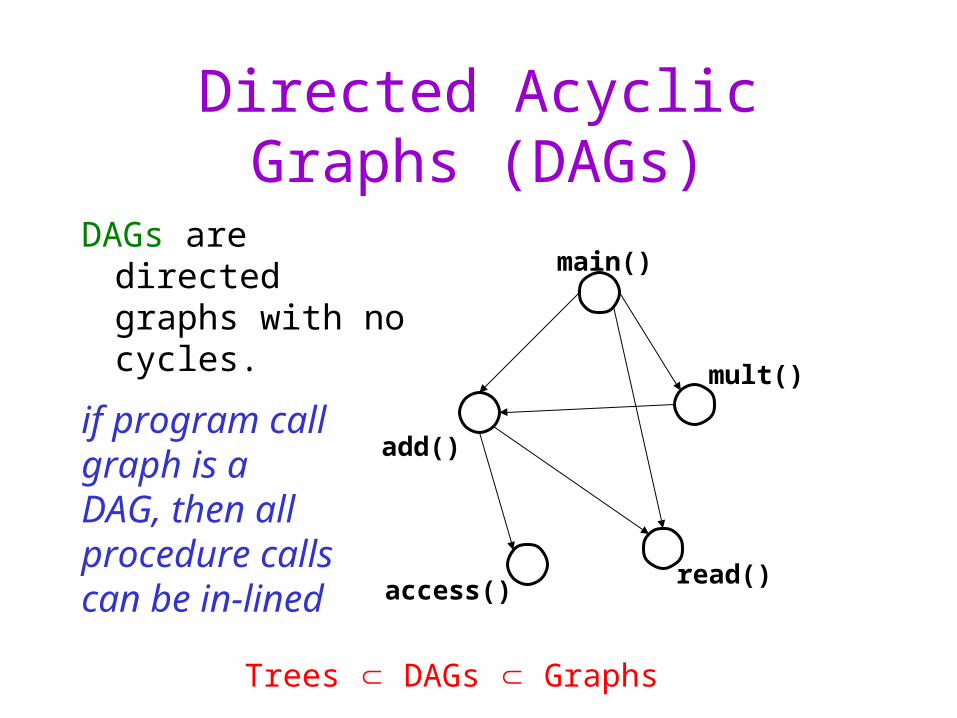
Directed Acyclic Graphs (DAGs)
DAGs are directed graphs with no cycles.
main()
add()
access()
mult()
read()
Trees DAGs Graphs
if program call graph is a DAG, then all procedure calls can be in-lined
Application of DAGs: Representing Partial Orders
check inairport
calltaxi
taxi toairport
reserveflight
packbagstake
flight
locategate
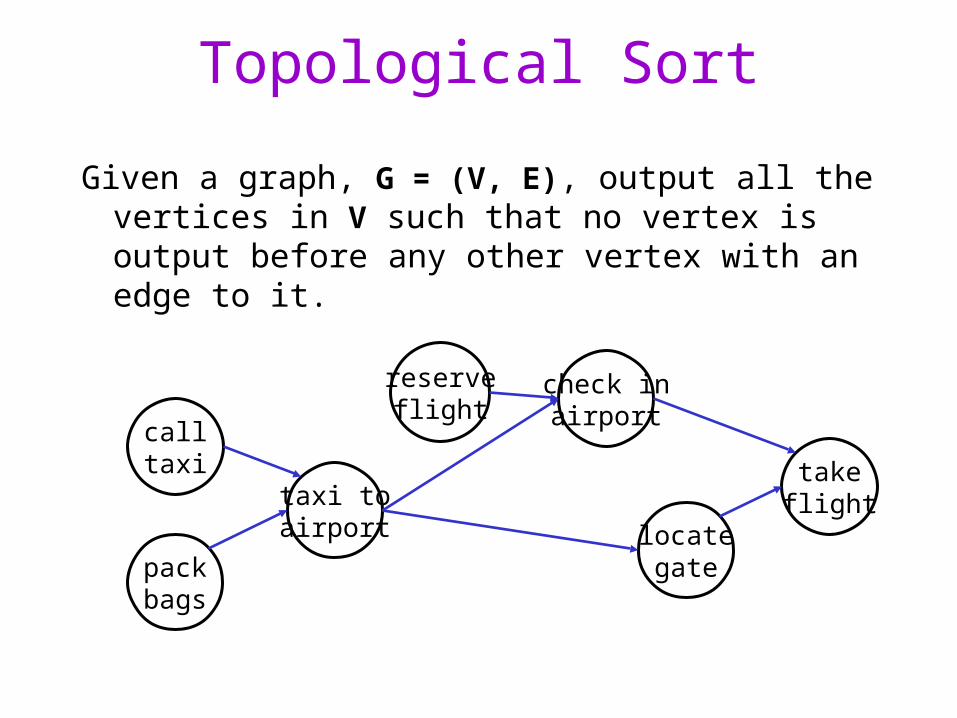
Topological Sort
Given a graph, G = (V, E), output all the vertices in V such that no vertex is output before any other vertex with an edge to it.
check inairport
calltaxi
taxi toairport
reserveflight
packbags
takeflight
locategate

Topo-Sort Take One
Label each vertex’s in-degree (# of inbound edges)
While there are vertices remaining
Pick a vertex with in-degree of zero and output it
Reduce the in-degree of all vertices adjacent to it
Remove it from the list of vertices
runtime:

Topo-Sort Take Two
Label each vertex’s in-degree
Initialize a queue (or stack) to contain all in-degree zero vertices
While there are vertices remaining in the queue
Remove a vertex v with in-degree of zero and output it
Reduce the in-degree of all vertices adjacent to v
Put any of these with new in-degree zero on the queue
runtime:
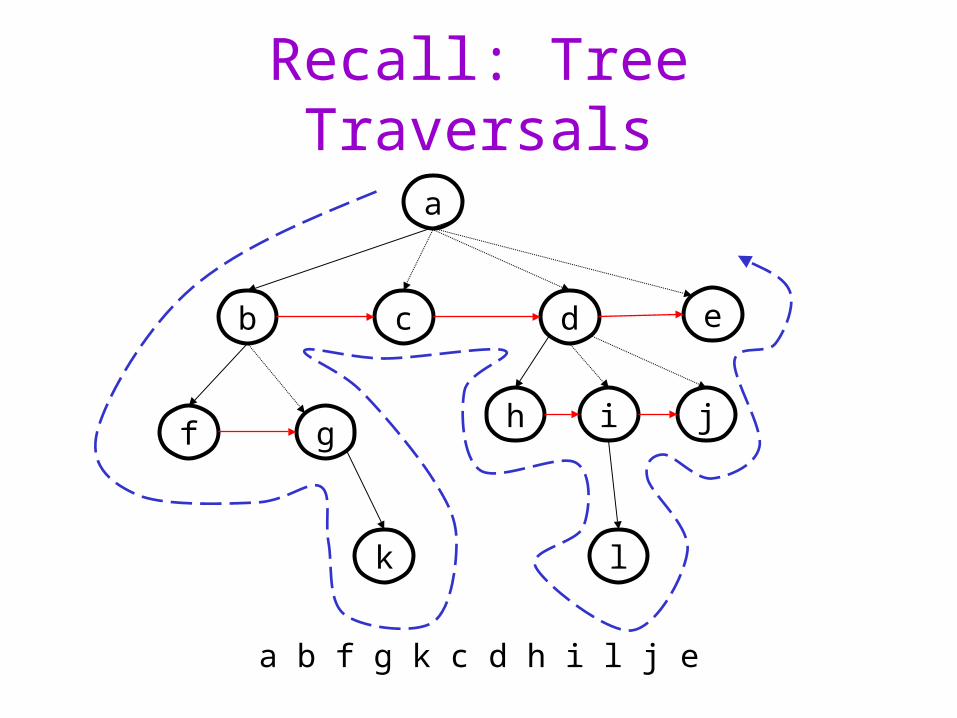
Recall: Tree Traversals
a
i
d
h j
b
f
k l
ec
g
a b f g k c d h i l j e

Depth-First Search• Pre/Post/In – order traversals are examples of
depth-first search– Nodes are visited deeply on the left-most branches
before any nodes are visited on the right-most branches• Visiting the right branches deeply before the left would still be
depth-first! Crucial idea is “go deep first!”
• Difference in pre/post/in-order is how some computation (e.g. printing) is done at current node relative to the recursive calls
• In DFS the nodes “being worked on” are kept on a stack

Iterative Version DFSPre-order Traversal
Push root on a Stack
Repeat until Stack is empty:
Pop a node
Process it
Push it’s children on the Stack
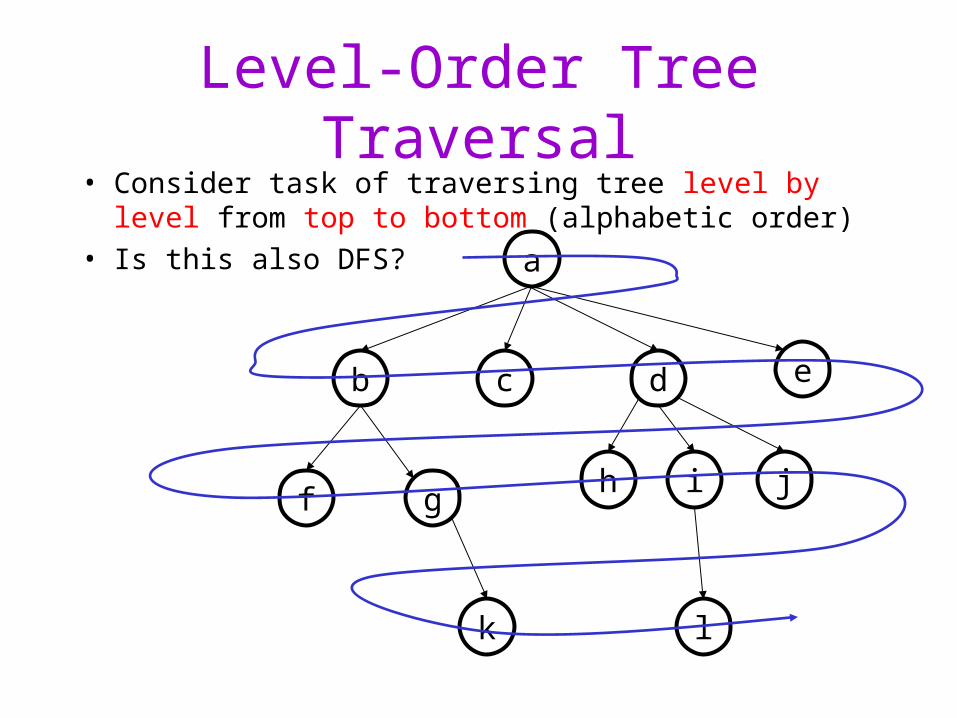
Level-Order Tree Traversal• Consider task of traversing tree level by level from top to
bottom (alphabetic order)
• Is this also DFS? a
i
d
h j
b
f
k l
ec
g

Breadth-First Search
• No! Level-order traversal is an example of Breadth-First Search
• BFS characteristics– Nodes being worked on maintained in a FIFO Queue, not a stack– Iterative style procedures often easier to design than recursive
procedures
Put root in a QueueRepeat until Queue is empty:
Dequeue a nodeProcess itAdd it’s children to queue
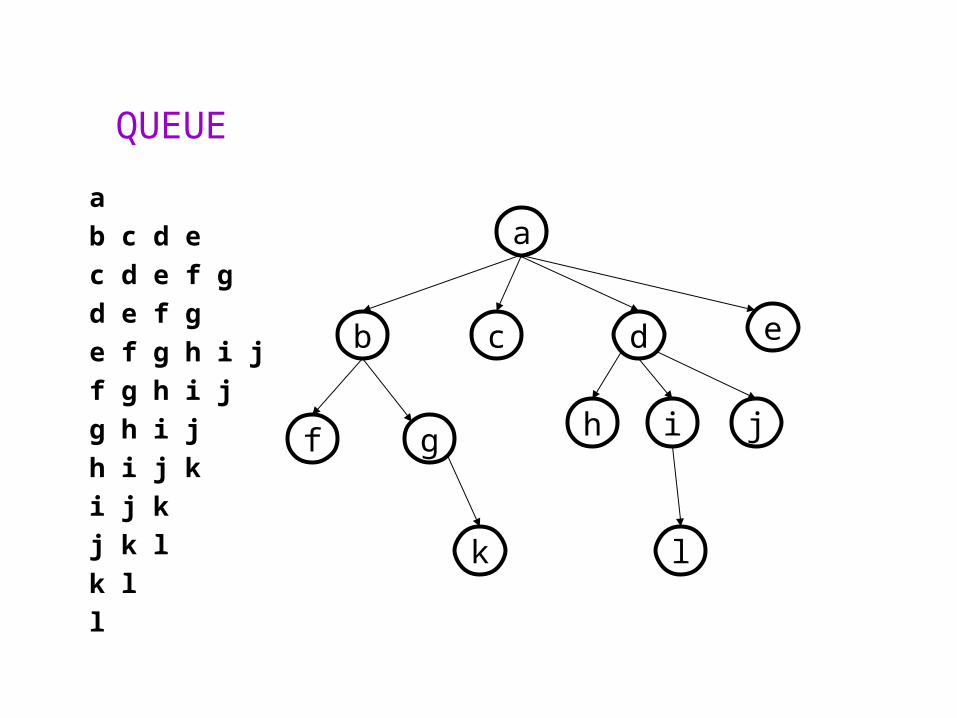
QUEUE
a
b c d e
c d e f g
d e f g
e f g h i j
f g h i j
g h i j
h i j k
i j k
j k l
k l
l
a
i
d
h j
b
f
k l
ec
g

Graph Traversals• Depth first search and breadth first search also work for
arbitrary (directed or undirected) graphs– Must mark visited vertices so you do not go into an infinite
loop!
• Either can be used to determine connectivity:– Is there a path between two given vertices?
– Is the graph (weakly) connected?
• Important difference: Breadth-first search always finds a shortest path from the start vertex to any other (for unweighted graphs)– Depth first search may not!

Demos on Web Page
DFSBFS

Is BFS the Hands Down Winner?• Depth-first search
– Simple to implement (implicit or explict stack)
– Does not always find shortest paths
– Must be careful to “mark” visited vertices, or you could go into an infinite loop if there is a cycle
• Breadth-first search– Simple to implement (queue)
– Always finds shortest paths
– Marking visited nodes can improve efficiency, but even without doing so search is guaranteed to terminate

Space Requirements
Consider space required by the stack or queue…• Suppose
– G is known to be at distance d from S
– Each vertex n has k out-edges
– There are no (undirected or directed) cycles
• BFS queue will grow to size kd
– Will simultaneously contain all nodes that are at distance d (once last vertex at distance d-1 is expanded)
– For k=10, d=15, size is 1,000,000,000,000,000

DFS Space Requirements• Consider DFS, where we limit the depth of the search
to d– Force a backtrack at d+1
– When visiting a node n at depth d, stack will contain• (at most) k-1 siblings of n
• parent of n
• siblings of parent of n
• grandparent of n
• siblings of grandparent of n …
• DFS queue grows at most to size dk– For k=10, d=15, size is 150
– Compare with BFS 1,000,000,000,000,000

Conclusion
• For very large graphs – DFS is hugely more memory efficient, if we know the distance to the goal vertex!
• But suppose we don’t know d. What is the (obvious) strategy?

Iterative Deepening DFSIterativeDeepeningDFS(vertex s, g){for (i=1;true;i++)
if DFS(i, s, g) return;}// Also need to keep track of path foundbool DFS(int limit, vertex s, g){if (s==g) return true;if (limit-- <= 0) return false;for (n in children(s))
if (DFS(limit, n, g)) return true;return false;
}

Analysis of Iterative Deepening
• Even without “marking” nodes as visited, iterative-deepening DFS never goes into an infinite loop– For very large graphs, memory cost of keeping track of
visited vertices may make marking prohibitive
• Work performed with limit < actual distance to G is wasted – but the wasted work is usually small compared to amount of work done during the last iteration

Asymptotic Analysis
• There are “pathological” graphs for which iterative deepening is bad:
S G
n=d
2
Iterative Deepening DFS =
1 2 3 ... ( )
BFS = ( )
n O n
O n

A Better CaseSuppose each vertex n has k out-edges, no cycles
• Bounded DFS to level i reaches ki vertices
• Iterative Deepening DFS(d) =
1
( )
BFS = ( )
di d
i
d
k O k
O k
ignore low order terms!

(More) Conclusions
• To find a shortest path between two nodes in a unweighted graph, use either BFS or Iterated DFS
• If the graph is large, Iterated DFS typically uses much less memory
– Later we’ll learn about heuristic search algorithms, which use additional knowledge about the problem domain to reduce the number of vertices visited

Single Source, Shortest Path for Weighted Graphs
Given a graph G = (V, E) with edge costs c(e), and a vertex s V, find the shortest (lowest cost) path from s to every vertex in V
• Graph may be directed or undirected• Graph may or may not contain cycles• Weights may be all positive or not• What is the problem if graph contains cycles
whose total cost is negative?
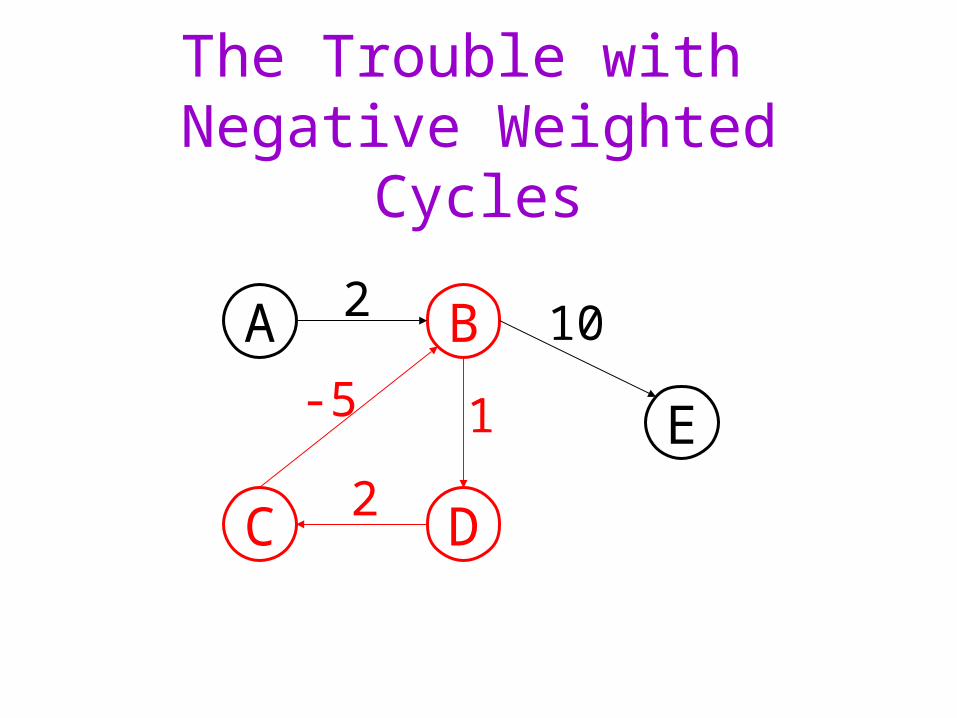
The Trouble with Negative Weighted Cycles
A B
C D
E
2 10
1-5
2

Edsger Wybe Dijkstra (1930-2002)
• Invented concepts of structured programming, synchronization, weakest precondition, and "semaphores" for controlling computer processes. The Oxford English Dictionary cites his use of the words "vector" and "stack" in a computing context.
• Believed programming should be taught without computers• 1972 Turing Award• “In their capacity as a tool, computers will be but a ripple
on the surface of our culture. In their capacity as intellectual challenge, they are without precedent in the cultural history of mankind.”

Dijkstra’s Algorithm for Single Source Shortest Path
• Classic algorithm for solving shortest path in weighted graphs (with only positive edge weights)
• Similar to breadth-first search, but uses a priority queue instead of a FIFO queue:– Always select (expand) the vertex that has a lowest-
cost path to the start vertex – a kind of “greedy” algorithm
• Correctly handles the case where the lowest-cost (shortest) path to a vertex is not the one with fewest edges

Pseudocode for Dijkstra
Initialize the cost of each vertex to cost[s] = 0;heap.insert(s);While (! heap.empty())
n = heap.deleteMin()For (each vertex a which is adjacent to n along edge e)
if (cost[n] + edge_cost[e] < cost[a]) thencost [a] = cost[n] + edge_cost[e]previous_on_path_to[a] = n;if (a is in the heap) then heap.decreaseKey(a)
else heap.insert(a)

Important Features
• Once a vertex is removed from the head, the cost of the shortest path to that node is known
• While a vertex is still in the heap, another shorter path to it might still be found
• The shortest path itself from s to any node a can be found by following the pointers stored in previous_on_path_to[a]
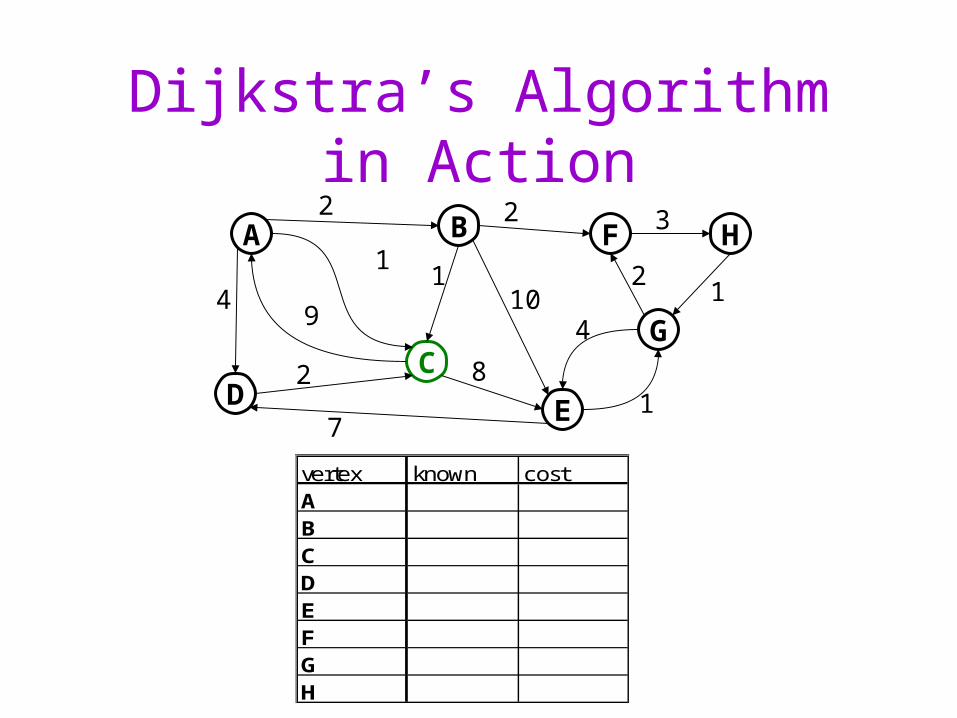
Dijkstra’s Algorithm in Action
A
C
B
D
F H
G
E
2 2 3
21
1
410
8
11
94
2
7
vertex known costABCDEFGH

Demo
Dijkstra’s

Data Structures for Dijkstra’s Algorithm
Select the unknown node with the lowest cost
findMin/deleteMin
a’s cost = min(a’s old cost, …)
decreaseKey
|V| times:
|E| times:
runtime: O(|E| log |V|)
O(log |V|)
O(log |V|)

CSE 326: Data StructuresLecture 8.B
Heuristic Graph Search
Henry Kautz
Winter Quarter 2002

Homework Hint - Problem 4
You can turn in a final version of your answer to problem 4 without penalty on Wednesday.
11 2 1 1
1
2
1 2
final mod in case sum is
Let ( ... ) be the interpretation of a bit string
as a bin
( ) mod ( mod
ary numbe
mod ) mod
( ( mod )) mod ( )
r. Then:
mod
( ... ) 2 ( .kk k k k k k
k k k
a b p a p b p p
c a p
p
b b b b
p ca p
b b b b b b b
1.. )b

Outline
• Best First Search• A* Search• Example: Plan Synthesis
• This material is NOT in Weiss, but is important for both the programming project and the final exam!

Huge Graphs• Consider some really huge graphs…
– All cities and towns in the World Atlas
– All stars in the Galaxy
– All ways 10 blocks can be stacked
Huh???
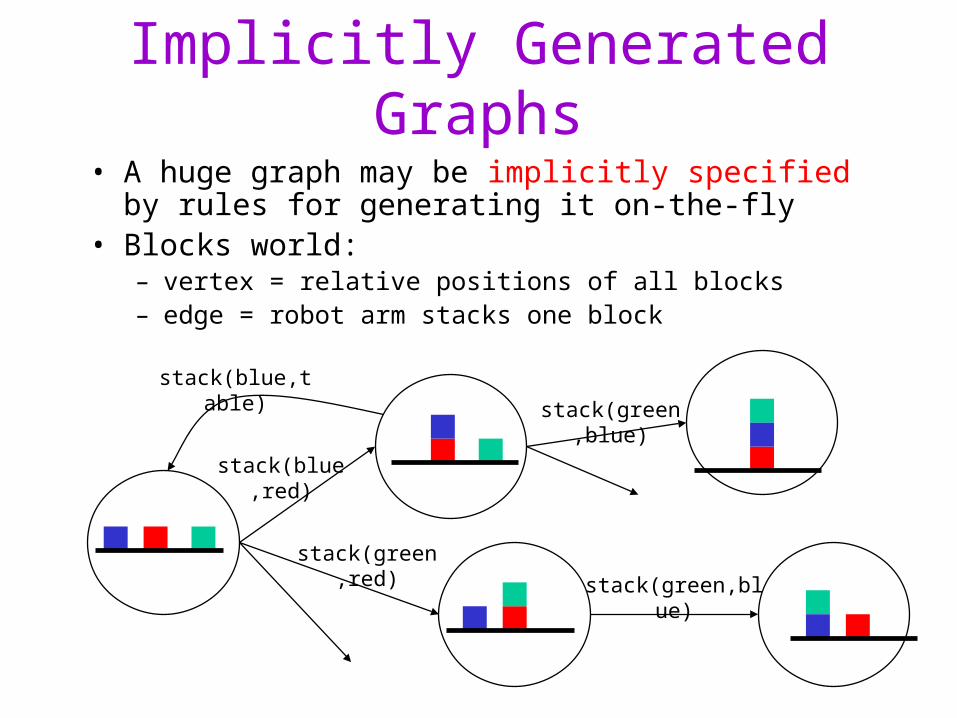
Implicitly Generated Graphs
• A huge graph may be implicitly specified by rules for generating it on-the-fly
• Blocks world: – vertex = relative positions of all blocks– edge = robot arm stacks one block
stack(blue,red)
stack(green,red)
stack(green,blue)
stack(blue,table)
stack(green,blue)

Blocks World
• Source = initial state of the blocks• Goal = desired state of the blocks• Path source to goal = sequence of actions
(program) for robot arm!• n blocks nn vertices• 10 blocks 10 billion vertices!

Problem: Branching Factor
• Cannot search such huge graphs exhaustively. Suppose we know that goal is only d steps away.
• Dijkstra’s algorithm is basically breadth-first search (modified to handle arc weights)
• Breadth-first search (or for weighted graphs, Dijkstra’s algorithm) – If out-degree of each node is 10, potentially visits 10d vertices– 10 step plan = 10 billion vertices visited!
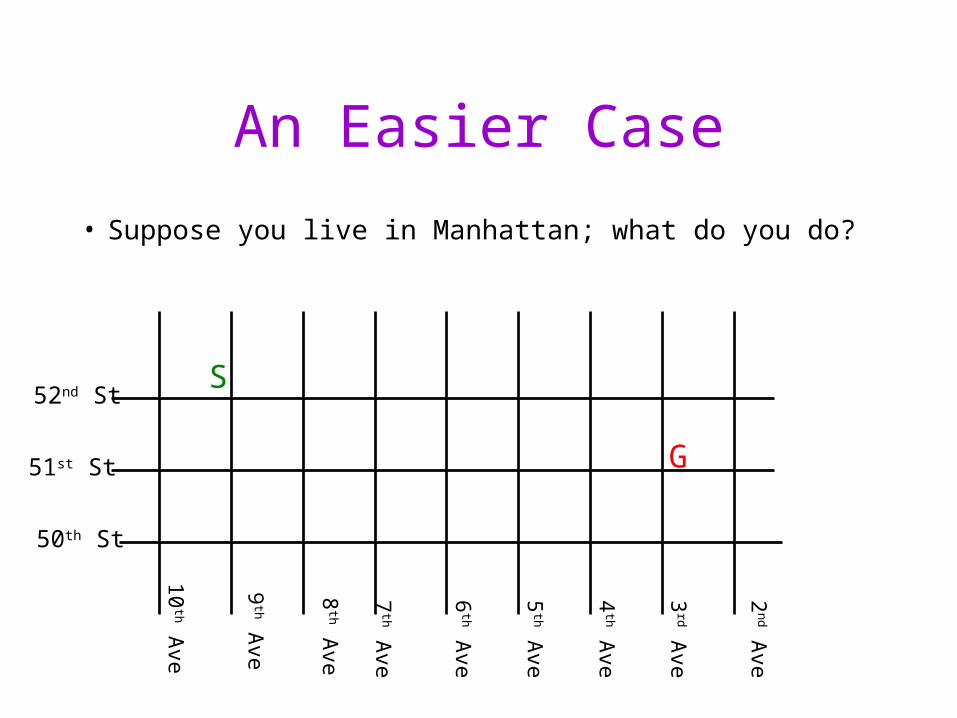
An Easier Case
• Suppose you live in Manhattan; what do you do?
52nd St
51st St
50th St
10th A
ve
9th A
ve
8th A
ve
7th A
ve
6th A
ve
5th A
ve
4th A
ve
3rd A
ve
2nd A
ve
S
G

Best-First Search
• The Manhattan distance ( x+ y) is an estimate of the distance to the goal– a heuristic value
• Best-First Search– Order nodes in priority to minimize estimated distance
to the goal h(n)
• Compare: BFS / Dijkstra– Order nodes in priority to minimize distance from the
start
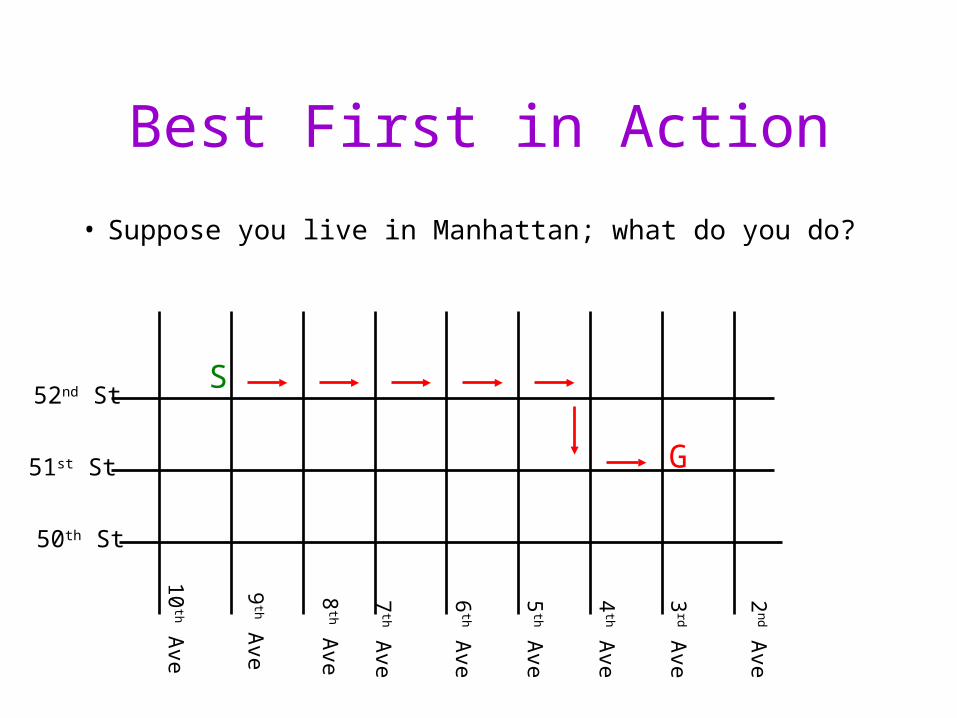
Best First in Action
• Suppose you live in Manhattan; what do you do?
52nd St
51st St
50th St
10th A
ve
9th A
ve
8th A
ve
7th A
ve
6th A
ve
5th A
ve
4th A
ve
3rd A
ve
2nd A
ve
S
G
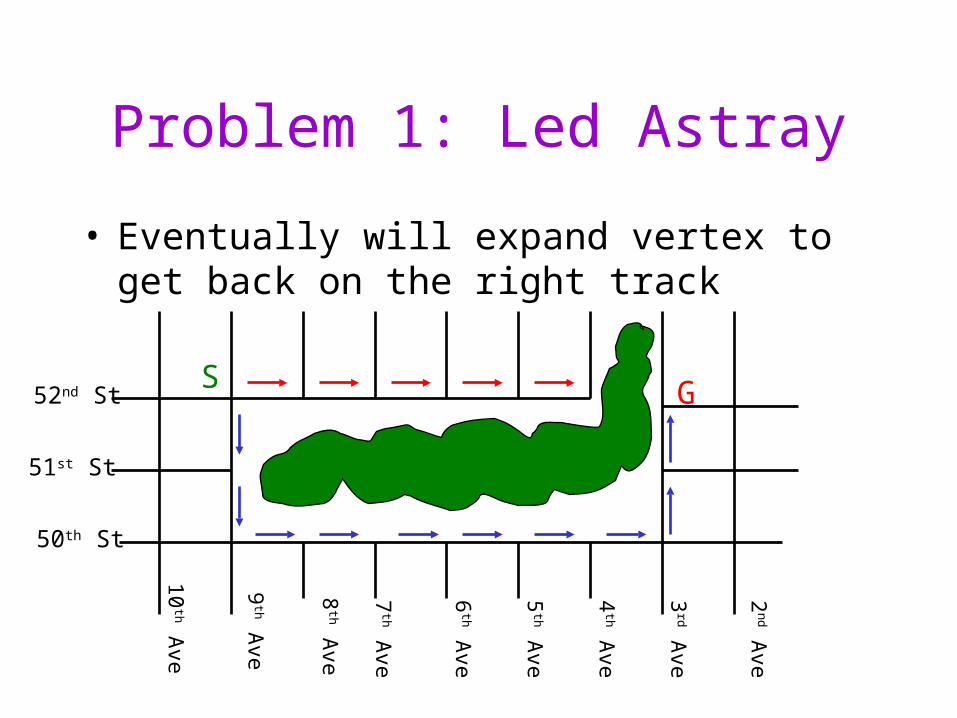
Problem 1: Led Astray
• Eventually will expand vertex to get back on the right track
52nd St
51st St
50th St
10th A
ve
9th A
ve
8th A
ve
7th A
ve
6th A
ve
5th A
ve
4th A
ve
3rd A
ve
2nd A
ve
S G

Problem 2: Optimality
• With Best-First Search, are you guaranteed a shortest path is found when– goal is first seen?
– when goal is removed from priority queue (as with Dijkstra?)

Sub-Optimal Solution• No! Goal is by definition at distance 0: will be
removed from priority queue immediately, even if a shorter path exists!
52nd St
51st St
9th A
ve
8th A
ve
7th A
ve
6th A
ve
5th A
ve
4th A
veS
G
(5 blocks)
h=2
h=1h=4
h=5

Synergy?
• Dijkstra / Breadth First guaranteed to find optimal solution
• Best First often visits far fewer vertices, but may not provide optimal solution
– Can we get the best of both?

A* (“A star”)
• Order vertices in priority queue to minimize
(distance from start) + (estimated distance to goal)
f(n) = g(n) + h(n)
f(n) = priority of a node
g(n) = true distance from start
h(n) = heuristic distance to goal

Optimality• Suppose the estimated distance (h) is
always less than or equal to the true distance to the goal– heuristic is a lower bound on true distance
• Then: when the goal is removed from the priority queue, we are guaranteed to have found a shortest path!
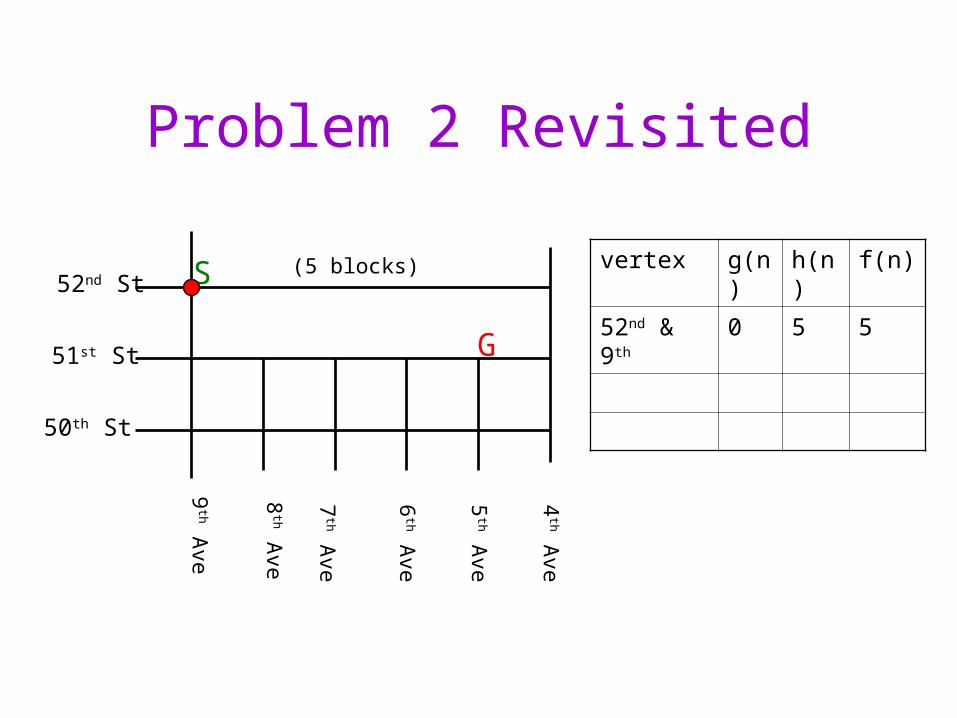
Problem 2 Revisited
52nd St
51st St
9th A
ve
8th A
ve
7th A
ve
6th A
ve
5th A
ve
4th A
ve
S
G
(5 blocks)
50th St
vertex g(n) h(n) f(n)
52nd & 9th 0 5 5
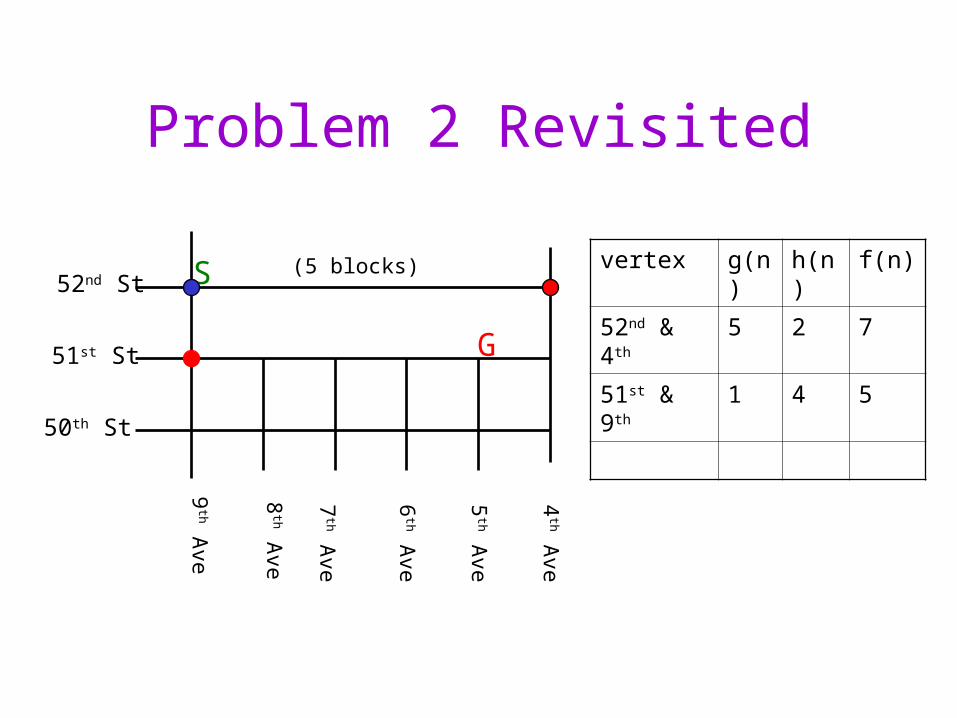
Problem 2 Revisited
52nd St
51st St
9th A
ve
8th A
ve
7th A
ve
6th A
ve
5th A
ve
4th A
ve
S
G
(5 blocks)
50th St
vertex g(n) h(n) f(n)
52nd & 4th 5 2 7
51st & 9th 1 4 5
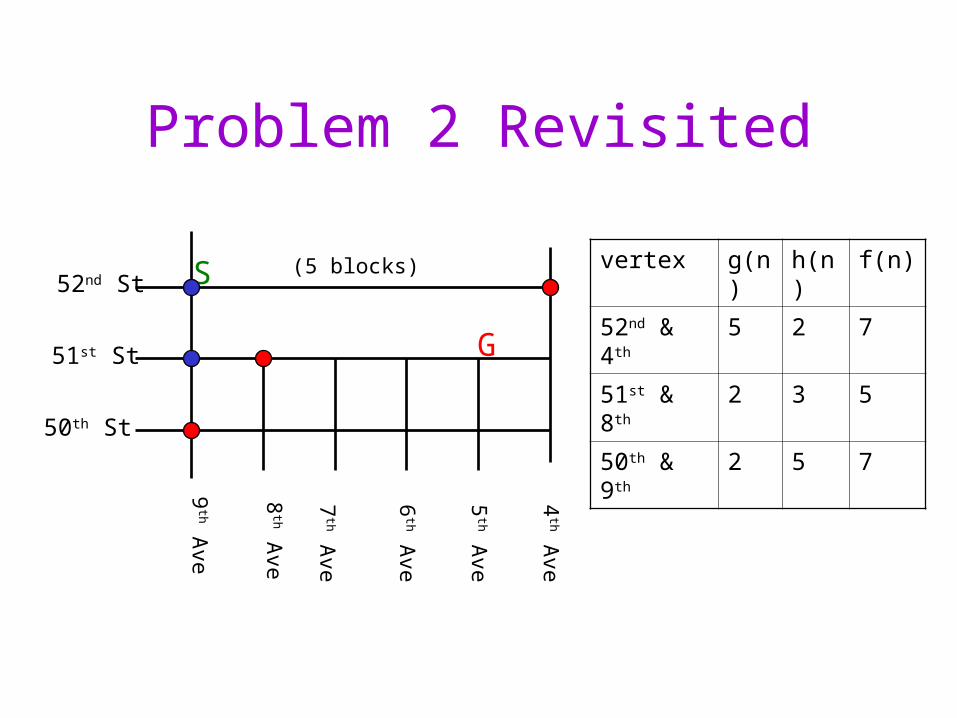
Problem 2 Revisited
52nd St
51st St
9th A
ve
8th A
ve
7th A
ve
6th A
ve
5th A
ve
4th A
ve
S
G
(5 blocks)
50th St
vertex g(n) h(n) f(n)
52nd & 4th 5 2 7
51st & 8th 2 3 5
50th & 9th 2 5 7
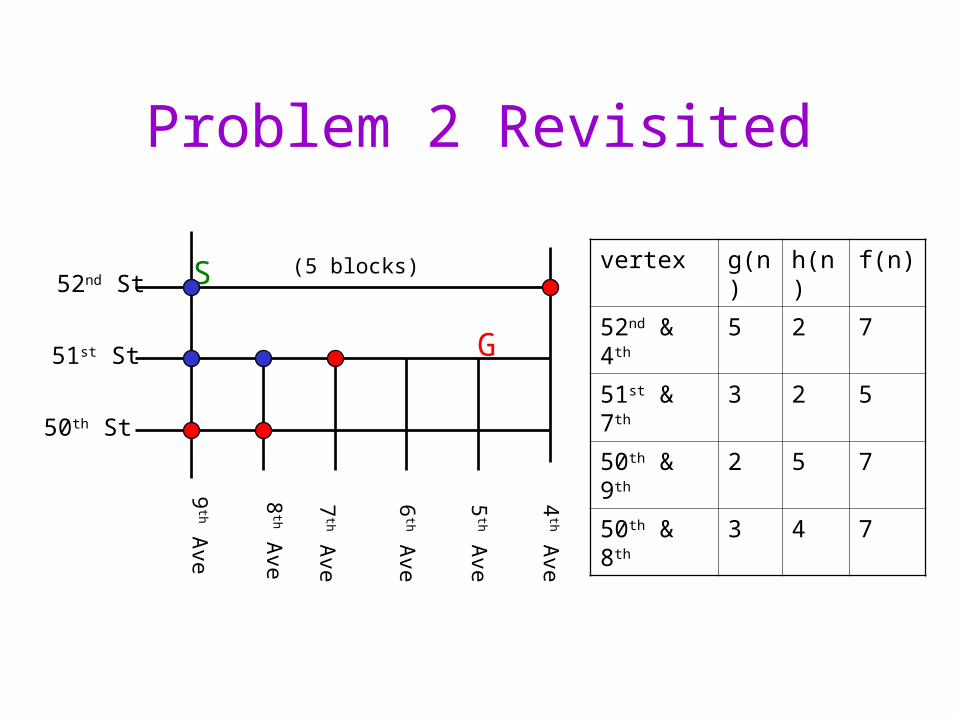
Problem 2 Revisited
52nd St
51st St
9th A
ve
8th A
ve
7th A
ve
6th A
ve
5th A
ve
4th A
ve
S
G
(5 blocks)
50th St
vertex g(n) h(n) f(n)
52nd & 4th 5 2 7
51st & 7th 3 2 5
50th & 9th 2 5 7
50th & 8th 3 4 7

Problem 2 Revisited
52nd St
51st St
9th A
ve
8th A
ve
7th A
ve
6th A
ve
5th A
ve
4th A
ve
S
G
(5 blocks)
50th St
vertex g(n) h(n) f(n)
52nd & 4th 5 2 7
51st & 6th 4 1 5
50th & 9th 2 5 7
50th & 8th 3 4 7
50th & 7th 4 3 7
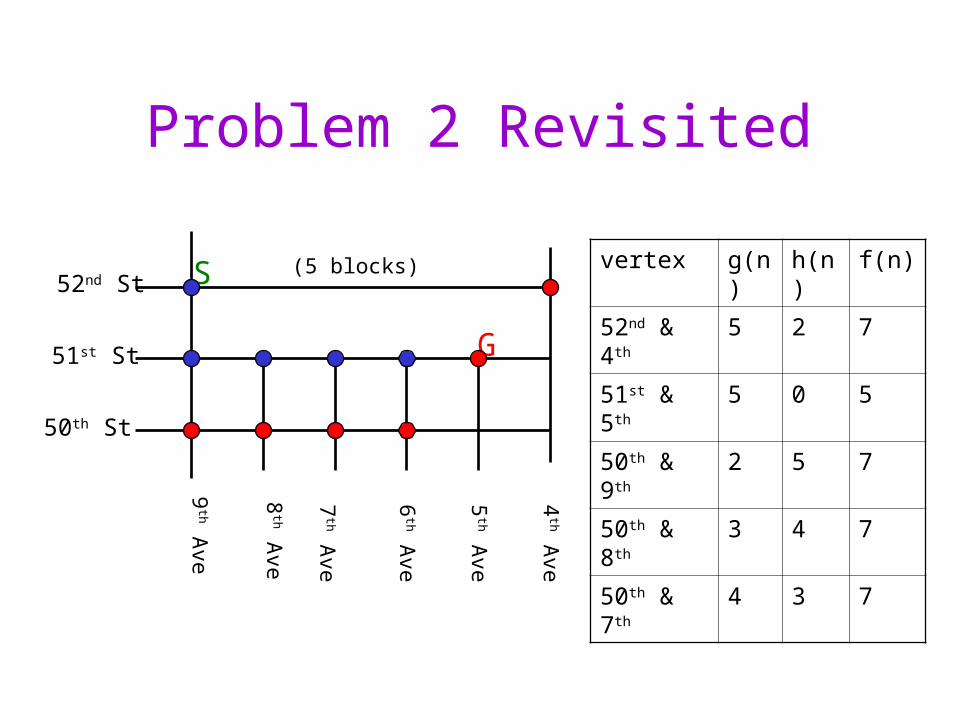
Problem 2 Revisited
52nd St
51st St
9th A
ve
8th A
ve
7th A
ve
6th A
ve
5th A
ve
4th A
ve
S
G
(5 blocks)
50th St
vertex g(n) h(n) f(n)
52nd & 4th 5 2 7
51st & 5th 5 0 5
50th & 9th 2 5 7
50th & 8th 3 4 7
50th & 7th 4 3 7
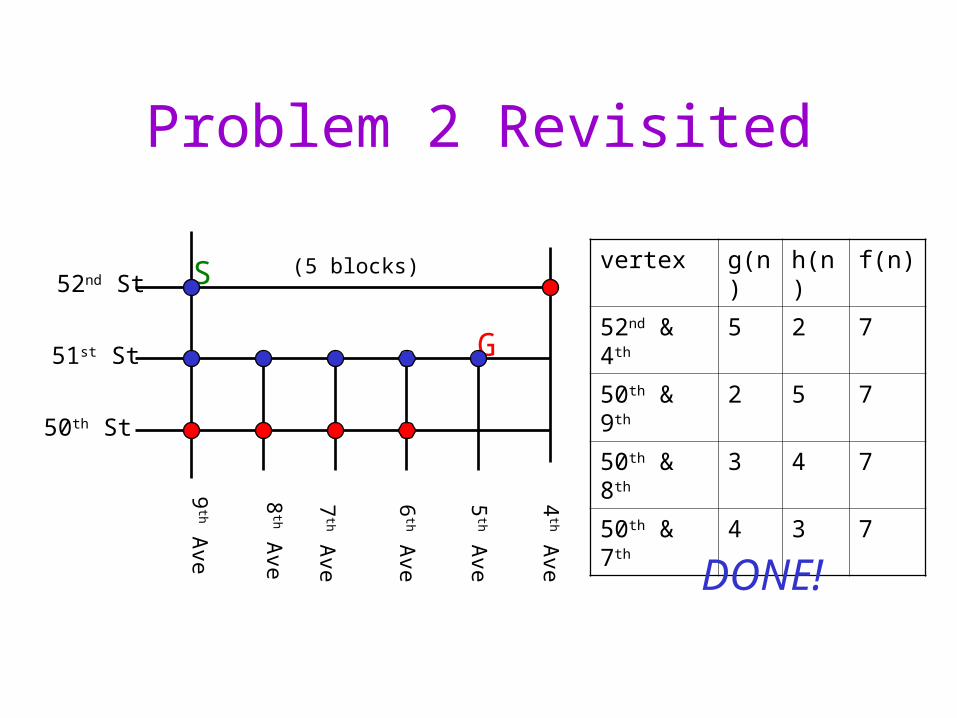
Problem 2 Revisited
52nd St
51st St
9th A
ve
8th A
ve
7th A
ve
6th A
ve
5th A
ve
4th A
ve
S
G
(5 blocks)
50th St
vertex g(n) h(n) f(n)
52nd & 4th 5 2 7
50th & 9th 2 5 7
50th & 8th 3 4 7
50th & 7th 4 3 7
DONE!
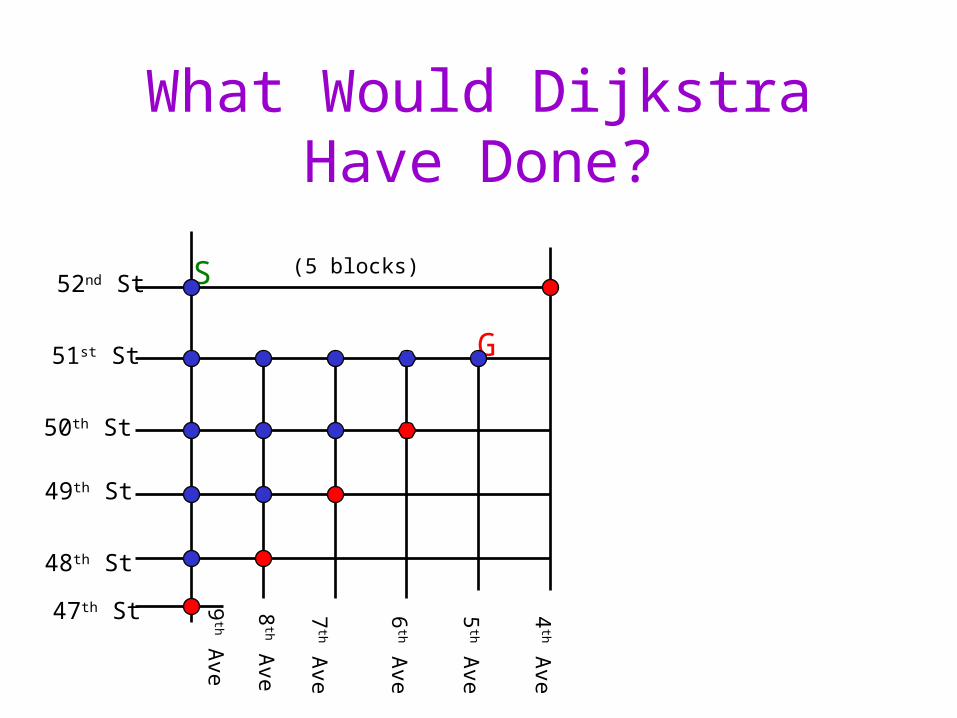
What Would Dijkstra Have Done?
52nd St
51st St
9th A
ve
8th A
ve
7th A
ve
6th A
ve
5th A
ve
4th A
ve
S
G
(5 blocks)
50th St
49th St
48th St
47th St

Proof of A* Optimality
• A* terminates when G is popped from the heap.• Suppose G is popped but the path found isn’t optimal:
priority(G) > optimal path length c
• Let P be an optimal path from S to G, and let N be the last vertex on that path that has been visited but not yet popped.There must be such an N, otherwise the optimal path would have been
found.priority(N) = g(N) + h(N) c
• So N should have popped before G can pop. Contradiction.
S
N
Gnon-optimal path to G
portion of optimal path found so far
undiscovered portion of shortest path
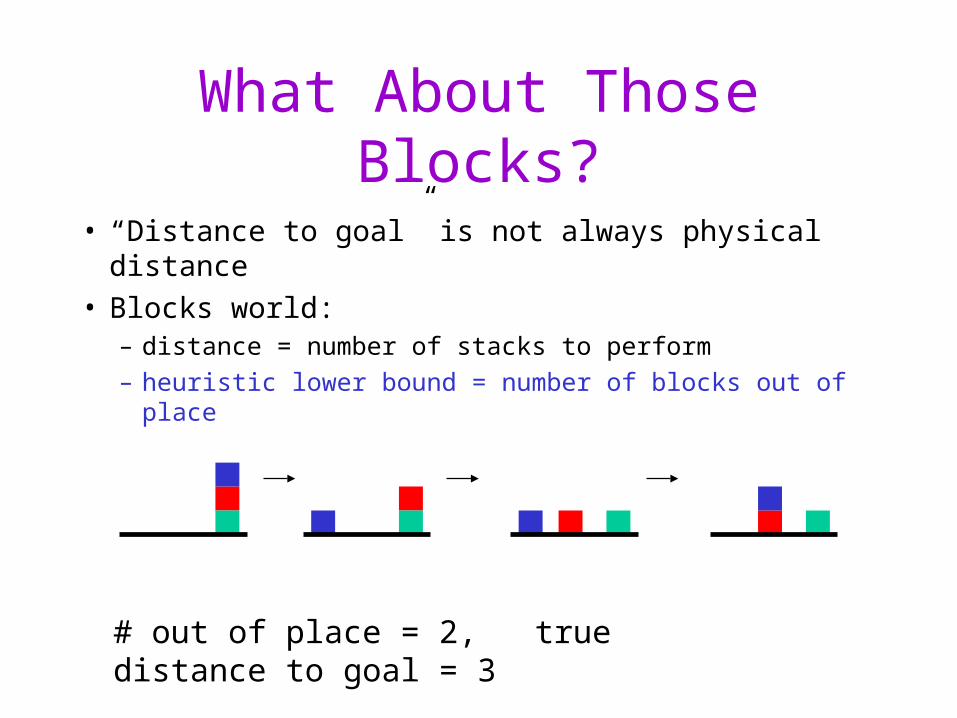
What About Those Blocks?
• “Distance to goal” is not always physical distance• Blocks world:
– distance = number of stacks to perform
– heuristic lower bound = number of blocks out of place
# out of place = 2, true distance to goal = 3
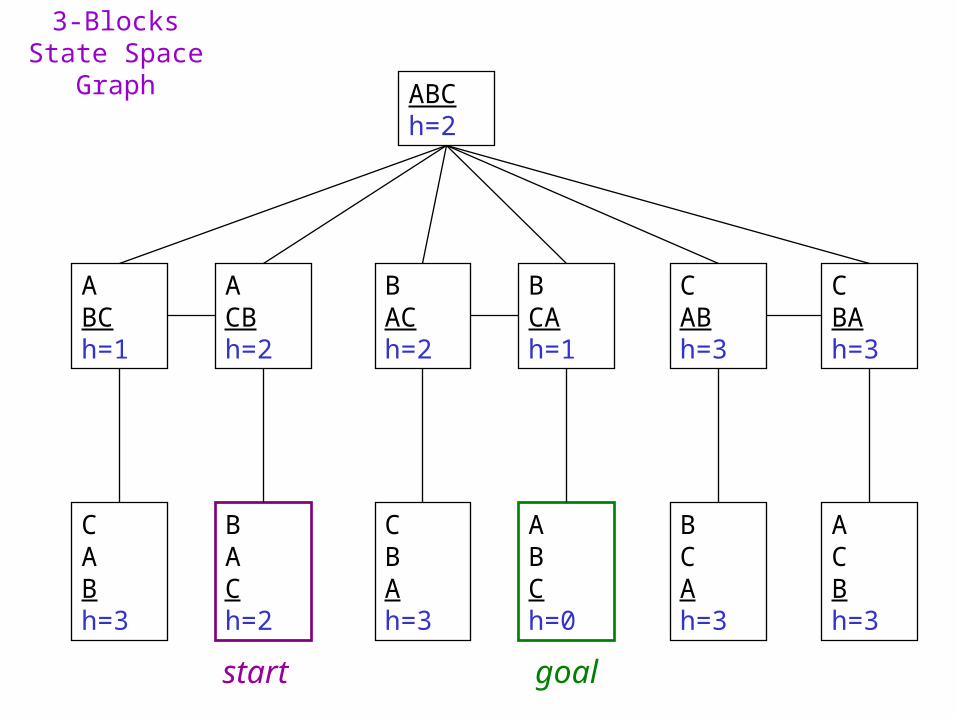
3-Blocks State Space Graph
ABCh=2
CABh=3
BACh=2
ABCh=1
CBAh=3
ACBh=2
BCAh=1
BCAh=3
CBAh=3
CABh=3
ACBh=3
BACh=2
ABCh=0
start goal
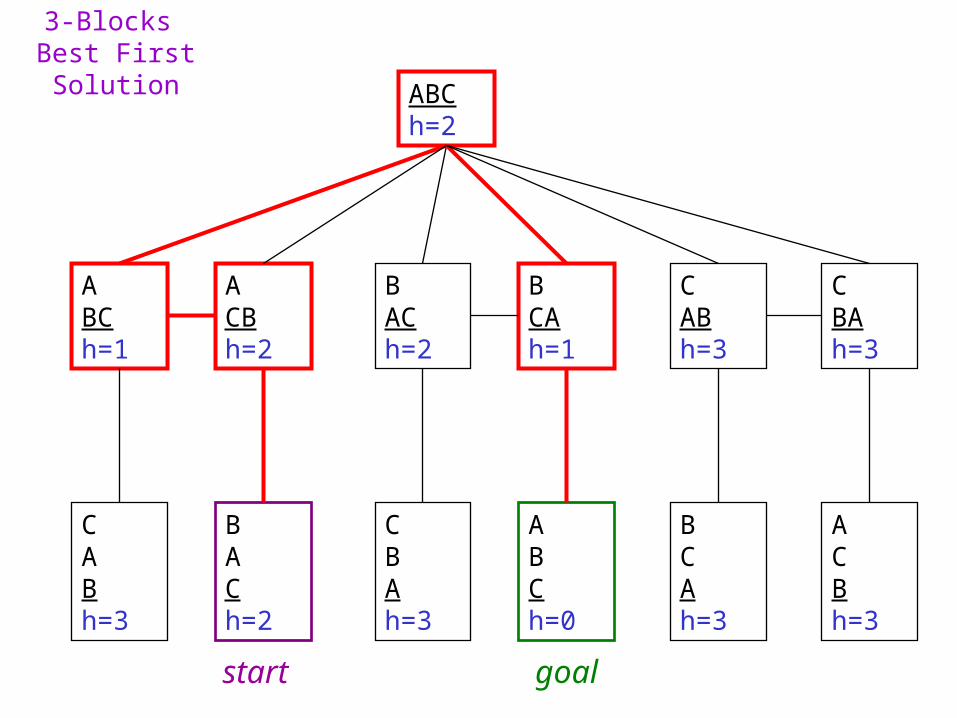
3-Blocks Best First Solution ABC
h=2
CABh=3
BACh=2
ABCh=1
CBAh=3
ACBh=2
BCAh=1
BCAh=3
CBAh=3
CABh=3
ACBh=3
BACh=2
ABCh=0
start goal
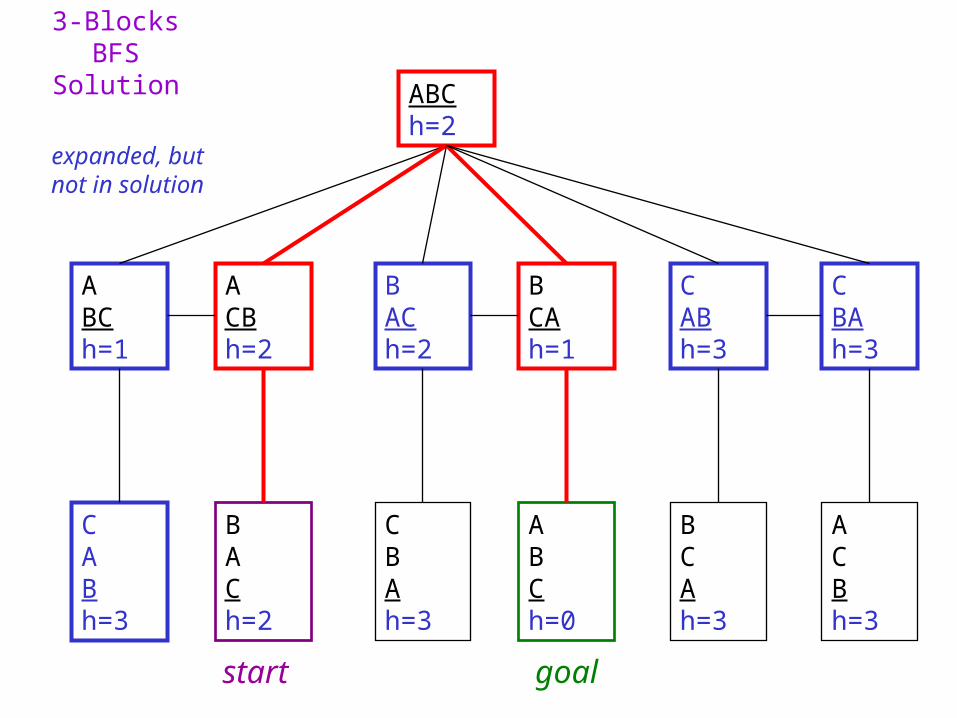
3-Blocks BFS Solution
ABCh=2
CABh=3
BACh=2
ABCh=1
CBAh=3
ACBh=2
BCAh=1
BCAh=3
CBAh=3
CABh=3
ACBh=3
BACh=2
ABCh=0
expanded, but not in solution
start goal
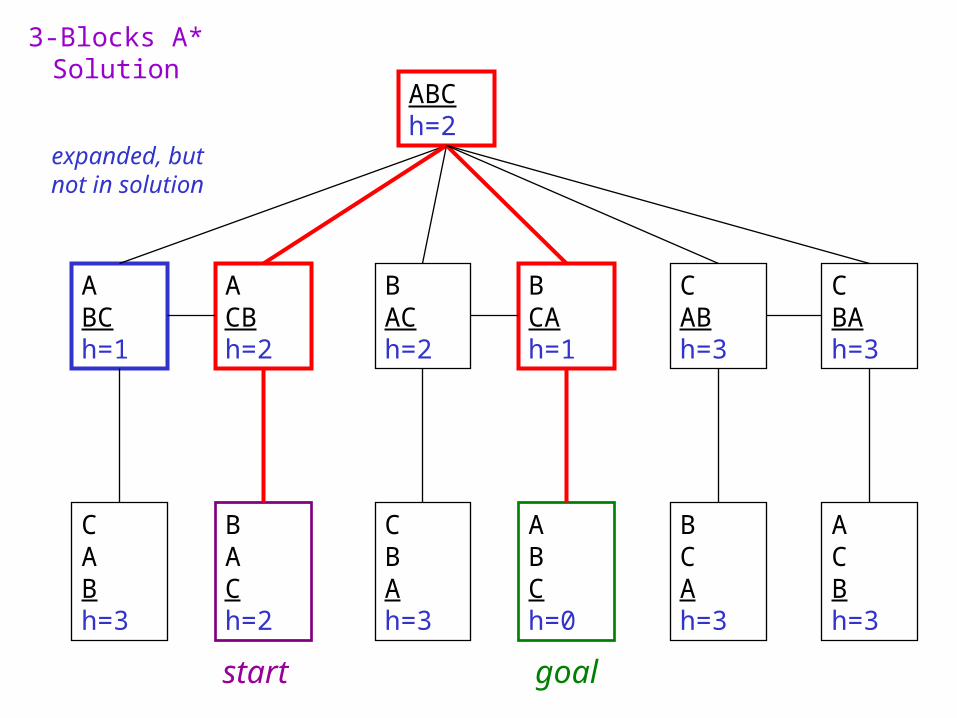
3-Blocks A* Solution
ABCh=2
CABh=3
BACh=2
ABCh=1
CBAh=3
ACBh=2
BCAh=1
BCAh=3
CBAh=3
CABh=3
ACBh=3
BACh=2
ABCh=0
expanded, but not in solution
start goal

Other Real-World Applications
• Routing finding – computer networks, airline route planning
• VLSI layout – cell layout and channel routing• Production planning – “just in time” optimization• Protein sequence alignment• Many other “NP-Hard” problems
– A class of problems for which no exact polynomial time algorithms exist – so heuristic search is the best we can hope for

Coming Up
• Other graph problems– Connected components
– Spanning tree

CSE 326: Data StructuresPart 8.C
Spanning Trees and More
Henry Kautz
Autumn Quarter 2002

Today
• Incremental hashing• MazeRunner project• Longest Path?• Finding Connected Components
– Application to machine vision
• Finding Minimum Spanning Trees– Yet another use for union/find

Incremental Hashing
11 1
2 1 12 2
11 1
11 1
11
1 11
11 1
1
2
1
( ... ) % %
( ..
%
%
% %
. ) %
n nn i n i
n i n ii i
nn
n
nn i
nn i
n ii
nn n i
ii
nn i
n
n
i
i
in
i
h a a c a p a c a p
a c a p
a c
h a a c a p
c a c a
ca p
a p c
a
c cp a
c
a
11 11
%
( ... )
%
%nnn
p
a c a c a p
p
h a

Maze Runner
20 15
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|* |
+ + + + + + + + + + + + + + + + + + + + +
| | | | | | | | | | | | | | | | | | | | |
+-+-+-+-+ +-+ +-+ +-+ +-+-+ +-+-+-+-+-+-+
| | | | | | | | | | | |
+-+-+-+-+-+-+-+-+-+-+-+ + + + + + + +-+ +
|X | | | | | |
+-+ + +-+-+ +-+-+-+ +-+ +-+ +-+-+-+-+-+-+
| | | | | | | | | | | | | | | | | |
+ + + + + + + + + +-+ + + +-+ + + +-+ +-+
| | | | | | | | | | | | | | |
+-+-+ + + + + + + + + + + + + +-+ + + + +
| | | | | | | | | |
+ + + +-+ + + + + + + + + + + + + + + + +
| | | | | | | | | | | | | | |
+ + + + + + + + + + + + + + +-+-+-+-+ +-+
| | | | | | | | | | | | | | | |
+ + + + + + + + + + +-+ +-+-+ + + +-+-+ +
| | | | | | | | | | | | | | | |
+-+-+-+-+-+-+-+-+-+-+-+-+ +-+-+-+-+-+-+-+
| | | | | | | | | | | | |
+ + + + + + + + + + +-+ +-+-+-+-+ +-+-+-+
| | | | | | | | | | | | | |
+ + + + +-+ +-+ + + + + +-+ + +-+ + + + +
| | | | | | | | | | | |
+ + +-+-+-+-+ +-+ +-+-+-+ +-+-+ +-+ +-+ +
| | | | | | | | | | | | | | | | | |
+ + + + + + + + + + + + + + + + + + +-+ +
| | | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
•DFS, iterated DFS, BFS, best-first, A*
•Crufty old C++ code from fresh clean Java code
•Win fame and glory by writing a nice real-time maze visualizer

Java Note
Java lacks enumerated constants…
enum {DOG, CAT, MOUSE} animal;
animal a = DOG;
Static constants not type-safe…
static final int DOG = 1;
static final int CAT = 2;
static final int BLUE = 1;
int favoriteColor = DOG;

Amazing Java Trickpublic final class Animal {
private Animal() {}
public static final Animal DOG = new Animal();
public static final Animal CAT = new Animal();
}
public final class Color {
private Color() {}
public static final Animal BLUE = new Color();
}
Animal x = DOG;
Animal x = BLUE; // Gives compile-time error!

Longest Path Problem
• Given a graph G=(V,E) and vertices s, t• Find a longest simple path (no repeating vertices)
from s to t.• Does “reverse Dijkstra” work?

Dijkstra
Initialize the cost of each vertex to cost[s] = 0;heap.insert(s);While (! heap.empty())
n = heap.deleteMin()For (each vertex a which is adjacent to n along edge e)
if (cost[n] + edge_cost[e] < cost[a]) thencost [a] = cost[n] + edge_cost[e]previous_on_path_to[a] = n;if (a is in the heap) then heap.decreaseKey(a)
else heap.insert(a)

Reverse Dijkstra
Initialize the cost of each vertex to cost[s] = 0;heap.insert(s);While (! heap.empty())
n = heap.deleteMax()For (each vertex a which is adjacent to n along edge e)
if (cost[n] + edge_cost[e] > cost[a]) thencost [a] = cost[n] + edge_cost[e]previous_on_path_to[a] = n;if (a is in the heap) then heap.increaseKey(a)
else heap.insert(a)
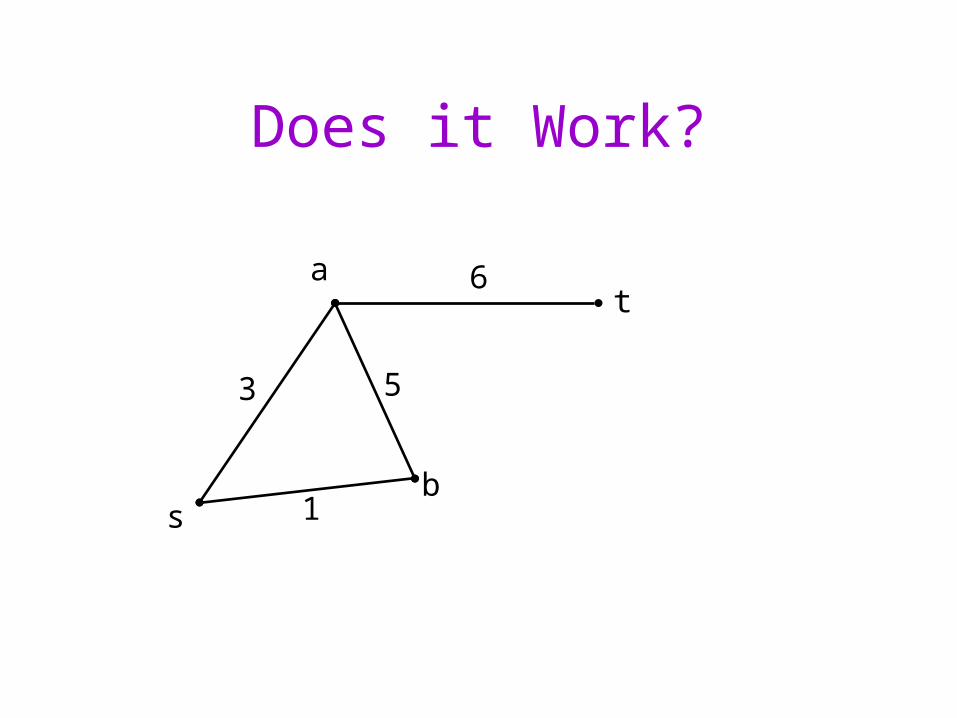
Does it Work?
s
ta
b
3
1
5
6

Problem
• No clear stopping condition!• How many times could a vertex be inserted in the
priority queue?– Exponential!
– Not a “good” algorithm!
• Is the better one?
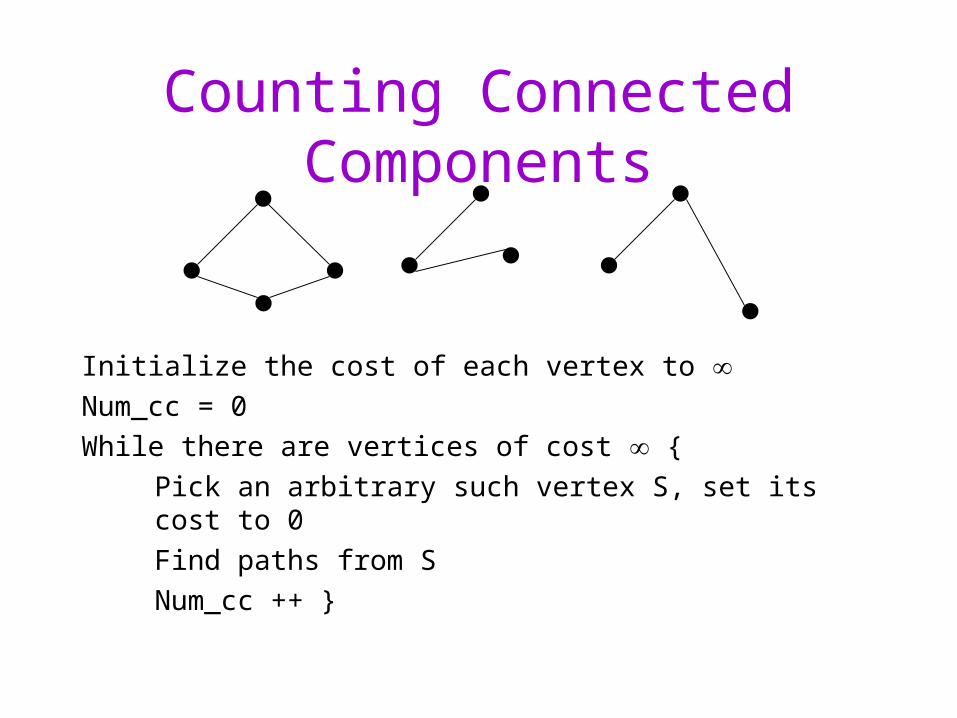
Counting Connected Components
Initialize the cost of each vertex to Num_cc = 0
While there are vertices of cost {
Pick an arbitrary such vertex S, set its cost to 0
Find paths from S
Num_cc ++ }
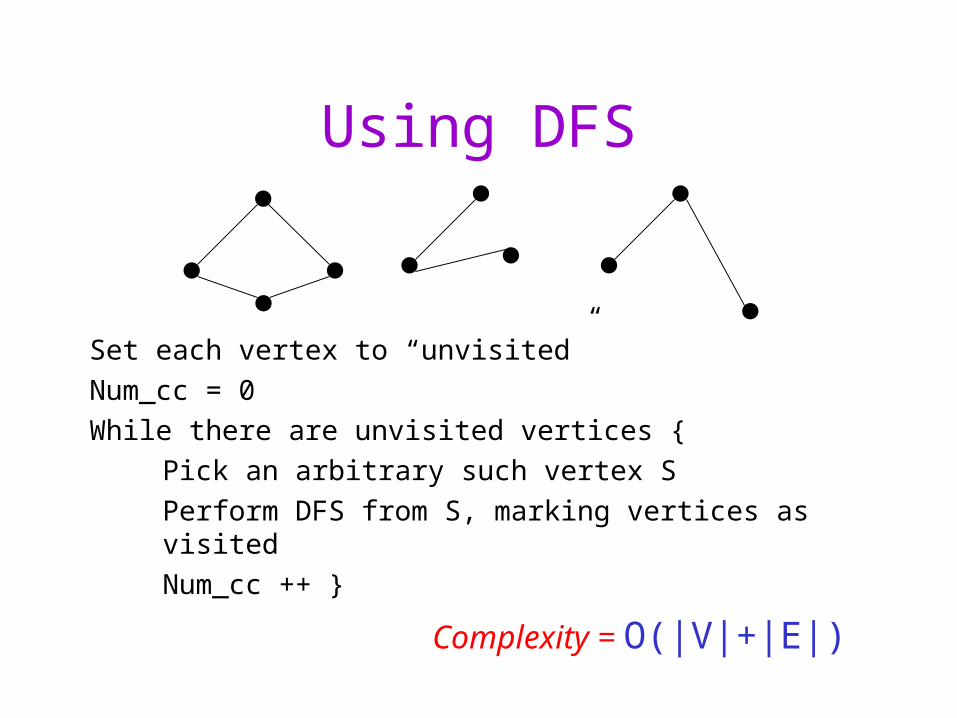
Using DFS
Set each vertex to “unvisited”
Num_cc = 0
While there are unvisited vertices {
Pick an arbitrary such vertex S
Perform DFS from S, marking vertices as visited
Num_cc ++ }
Complexity = O(|V|+|E|)

Using Union / Find
Put each node in its own equivalence class
Num_cc = 0
For each edge E = <x,y>
Union(x,y)
Return number of equivalence classes
Complexity =

Using Union / Find
Put each node in its own equivalence class
Num_cc = 0
For each edge E = <x,y>
Union(x,y)
Return number of equivalence classes
Complexity = O(|V|+|E| ack(|E|,|V|))

Machine Vision: Blob Finding
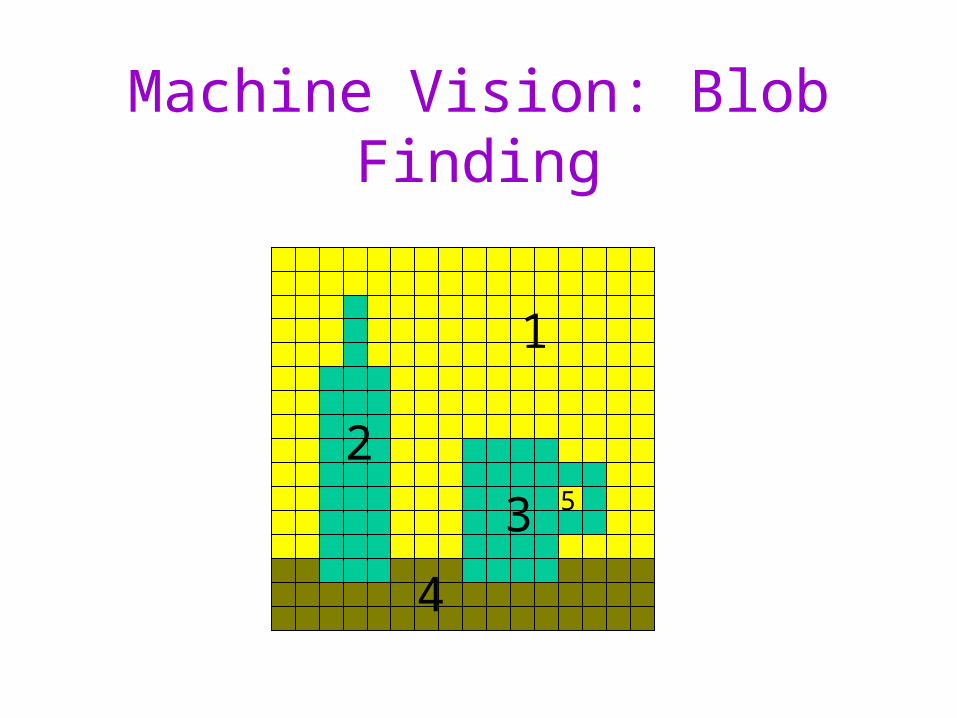
Machine Vision: Blob Finding
1
2
3
4
5

Blob Finding
• Matrix can be considered an efficient representation of a graph with a very regular structure
• Cell = vertex• Adjacent cells of same color = edge between
vertices• Blob finding = finding connected components

Tradeoffs
• Both DFS and Union/Find approaches are (essentially) O(|E|+|V|) = O(|E|) for binary images
• For each component, DFS (“recursive labeling”) can move all over the image – entire image must be in main memory
• Better in practice: row-by-row processing– localizes accesses to memory
– typically 1-2 orders of magnitude faster!

High-Level Blob-Labeling
• Scan through image left/right and top/bottom
• If a cell is same color as (connected to) cell to right or below, then union them
• Give the same blob number to cells in each equivalence class

Blob-Labeling AlgorithmPut each cell <x,y> in it’s own equivalence classFor each cell <x,y>
if color[x,y] == color[x+1,y] thenUnion( <x,y>, <x+1,y> )
if color[x,y] == color[x,y+1] thenUnion( <x,y>, <x,y+1> )
label = 0For each root <x,y>
blobnum[x,y] = ++ label;For each cell <x,y>
blobnum[x,y] = blobnum( Find(<x,y>) )
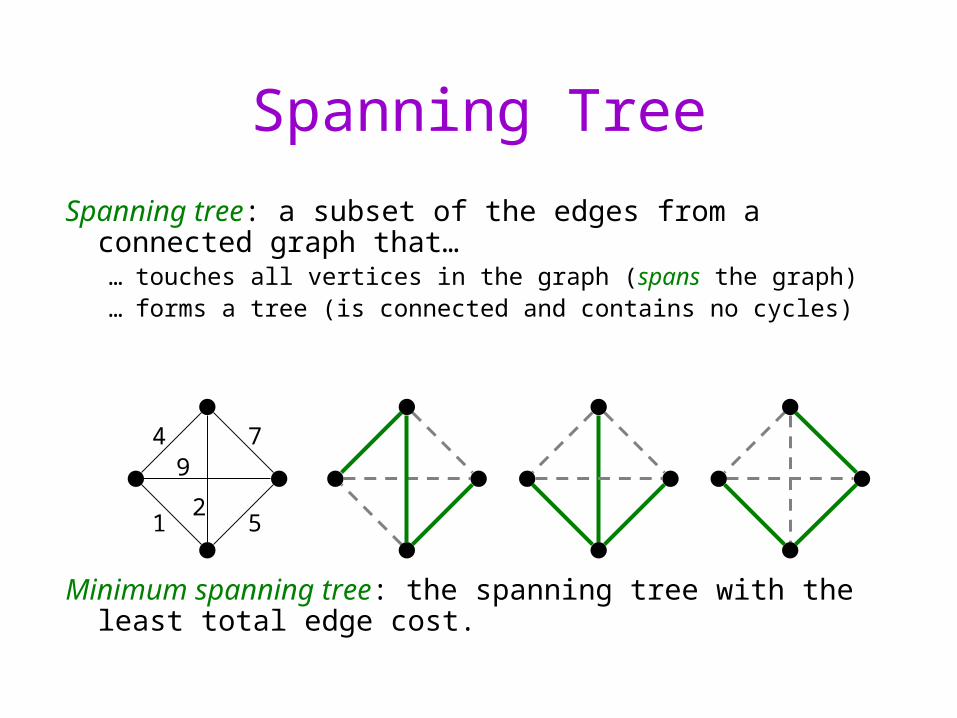
Spanning tree: a subset of the edges from a connected graph that……touches all vertices in the graph (spans the graph)…forms a tree (is connected and contains no cycles)
Minimum spanning tree: the spanning tree with the least total edge cost.
Spanning Tree
4 7
1 5
9
2
Applications of Minimal Spanning Trees
• Communication networks
• VLSI design
• Transportation systems

Kruskal’s Algorithm for Minimum Spanning Trees
A greedy algorithm:
Initialize all vertices to unconnected
While there are still unmarked edgesPick a lowest cost edge e = (u, v) and mark it
If u and v are not already connected, add e to the minimum spanning tree and connect u and v
Sound familiar? (Think maze generation.)
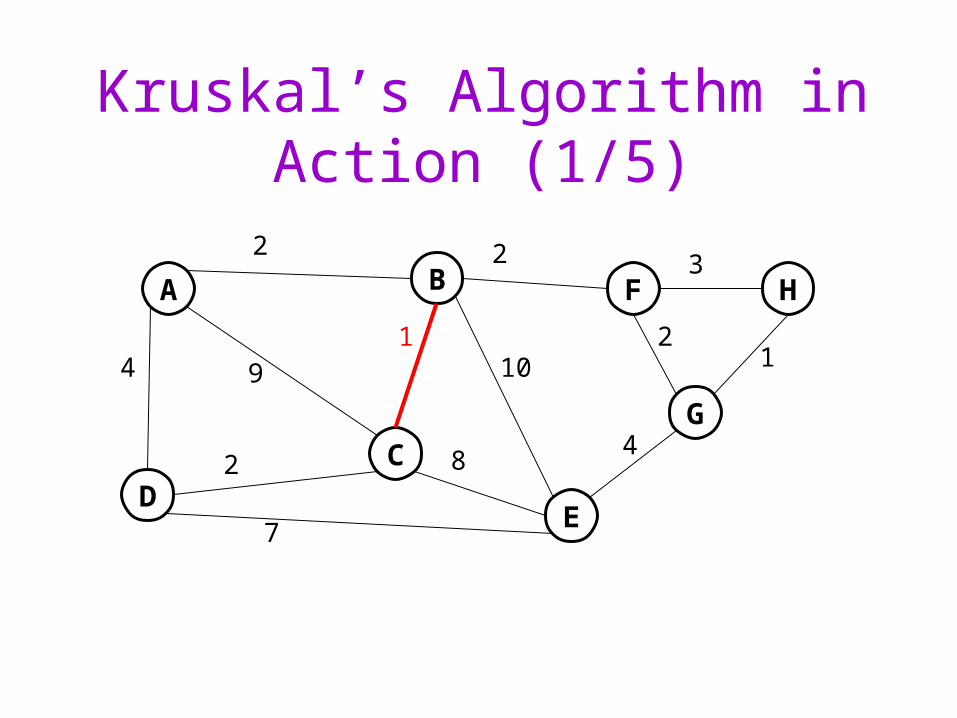
Kruskal’s Algorithm in Action (1/5)
A
C
B
D
F H
G
E
2 2 3
21
4
10
8
194
2
7
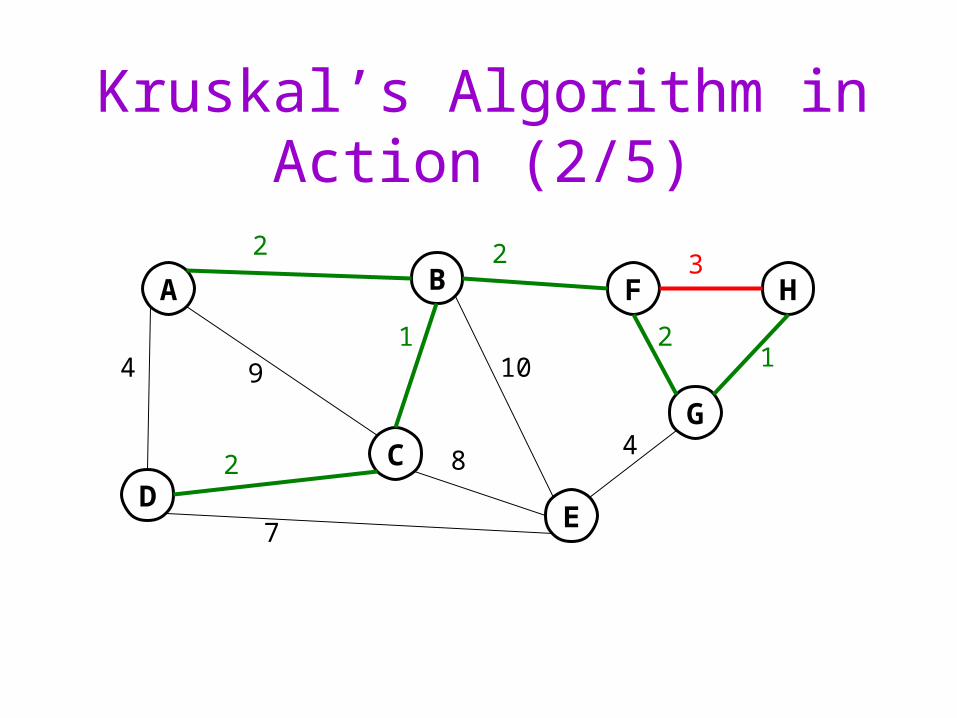
Kruskal’s Algorithm in Action (2/5)
A
C
B
D
F H
G
E
2 2 3
21
4
10
8
194
2
7
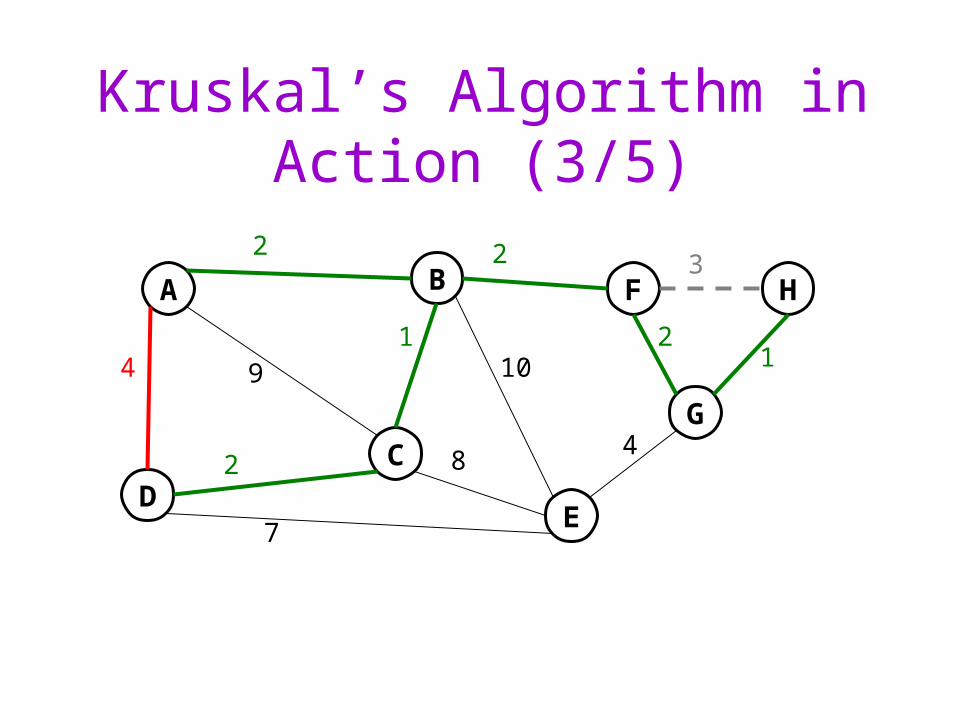
Kruskal’s Algorithm in Action (3/5)
A
C
B
D
F H
G
E
2 2 3
21
4
10
8
194
2
7
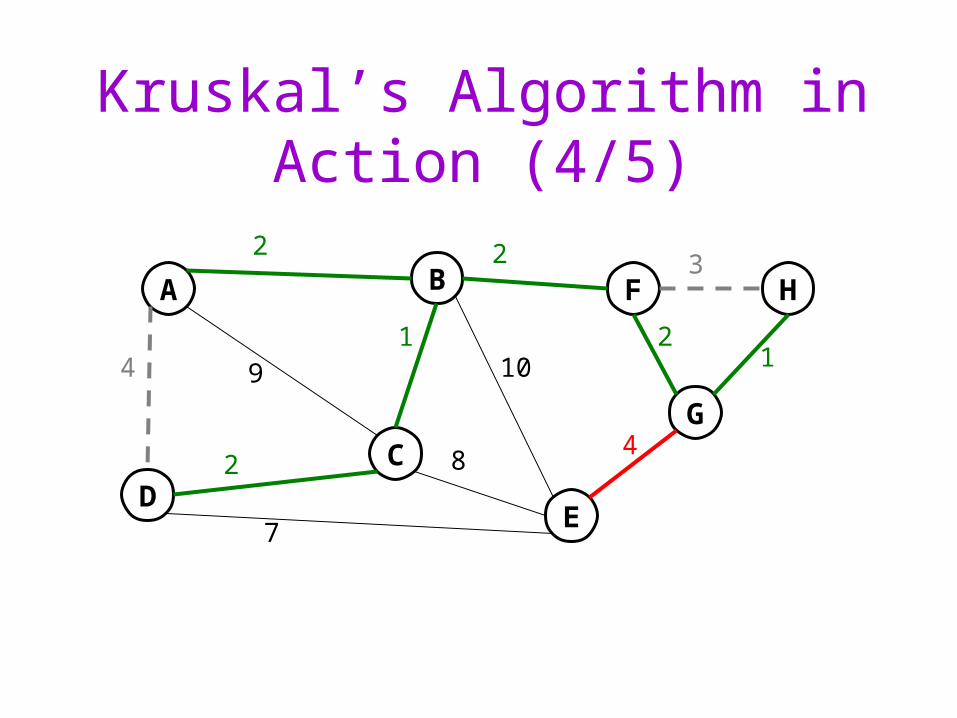
Kruskal’s Algorithm in Action (4/5)
A
C
B
D
F H
G
E
2 2 3
21
4
10
8
194
2
7
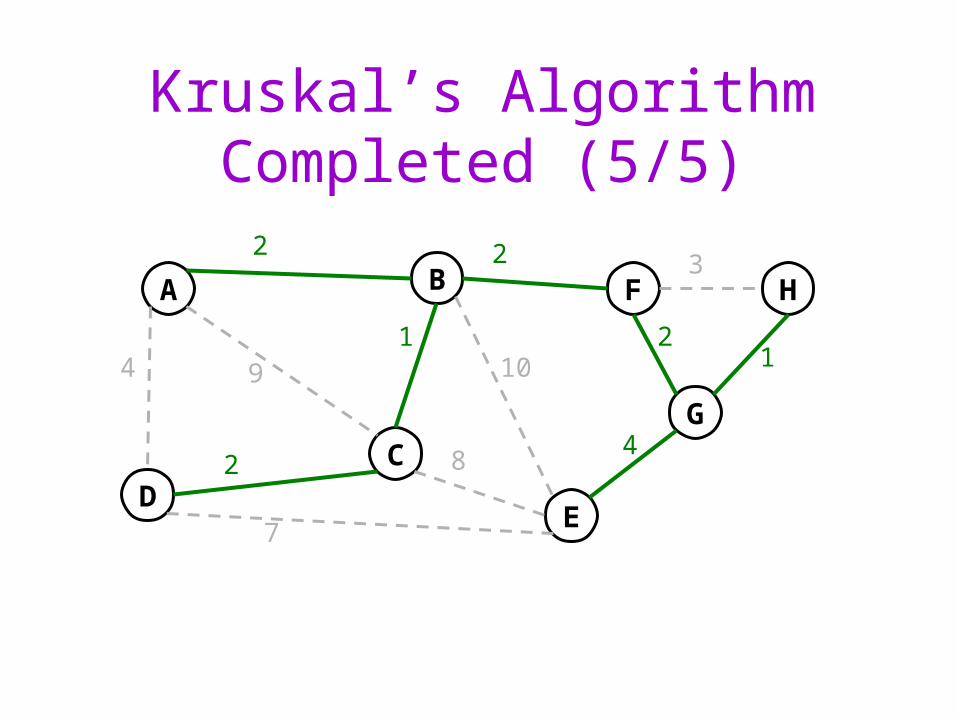
Kruskal’s Algorithm Completed (5/5)
A
C
B
D
F H
G
E
2 2 3
21
4
10
8
194
2
7

Why Greediness WorksProof by contradiction that Kruskal’s finds a minimum
spanning tree:• Assume another spanning tree has lower cost than
Kruskal’s.• Pick an edge e1 = (u, v) in that tree that’s not in
Kruskal’s.• Consider the point in Kruskal’s algorithm where u’s set
and v’s set were about to be connected. Kruskal selected some edge to connect them: call it e2 .
• But, e2 must have at most the same cost as e1 (otherwise Kruskal would have selected it instead).
• So, swap e2 for e1 (at worst keeping the cost the same)• Repeat until the tree is identical to Kruskal’s, where the
cost is the same or lower than the original cost: contradiction!

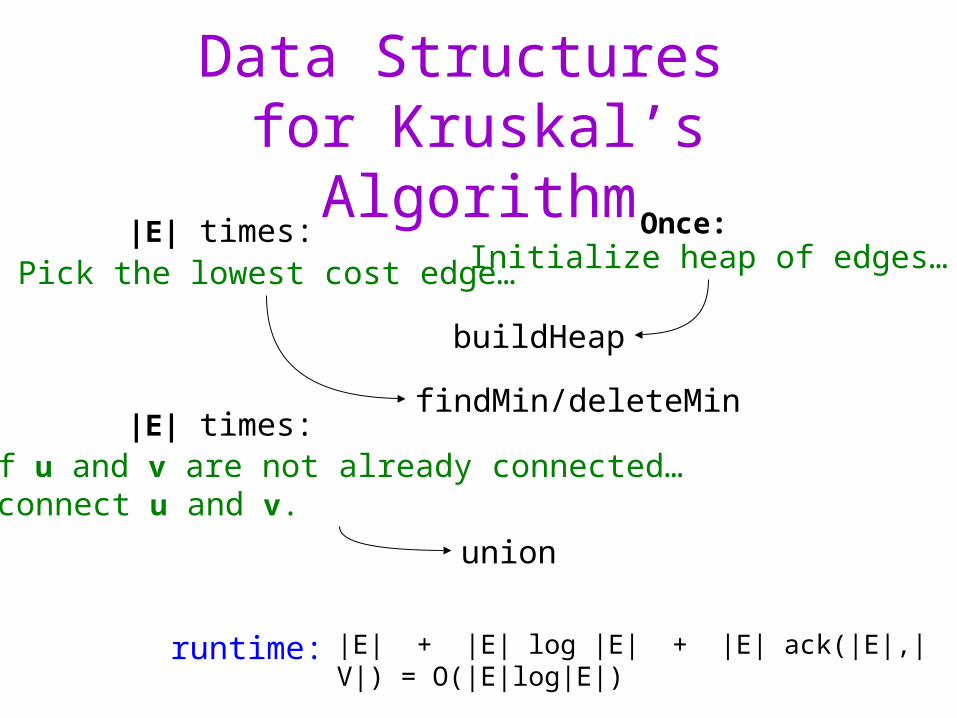
Data Structures for Kruskal’s Algorithm
Pick the lowest cost edge…
findMin/deleteMin
If u and v are not already connected… …connect u and v.
union
|E| times:
|E| times:
runtime:
Once:Initialize heap of edges…
buildHeap
|E| + |E| log |E| + |E| ack(|E|,|V|)
Data Structures for Kruskal’s Algorithm
Pick the lowest cost edge…
findMin/deleteMin
If u and v are not already connected… …connect u and v.
union
|E| times:
|E| times:
runtime:
Once:Initialize heap of edges…
buildHeap
|E| + |E| log |E| + |E| ack(|E|,|V|) = O(|E|log|E|)

Prim’s Algorithm
• Can also find Minimum Spanning Trees using a variation of Dijkstra’s algorithm:
Pick a initial nodeUntil graph is connected:
Choose edge (u,v) which is of minimum cost among edges where u is in tree but v is notAdd (u,v) to the tree
• Same “greedy” proof, same asymptotic complexity

Coming Up
• Application: Sentence Disambiguation• All-pairs Shortest Paths• NP-Complete Problems• Advanced topics
– Quad trees
– Randomized algorithms

Sentence Disambiguation
• A person types a message on their cell phone keypad. Each button can stand for three different letter (e.g. “1” is a, b, or c), but the person does not explicitly indicate which letter is meant. (Words are separated by blanks – the “0” key.)
• Problem: How can the system determine what sentence was typed? – My Nokia cell phone does this!
• How can this problem be cast as a shortest-path problem?
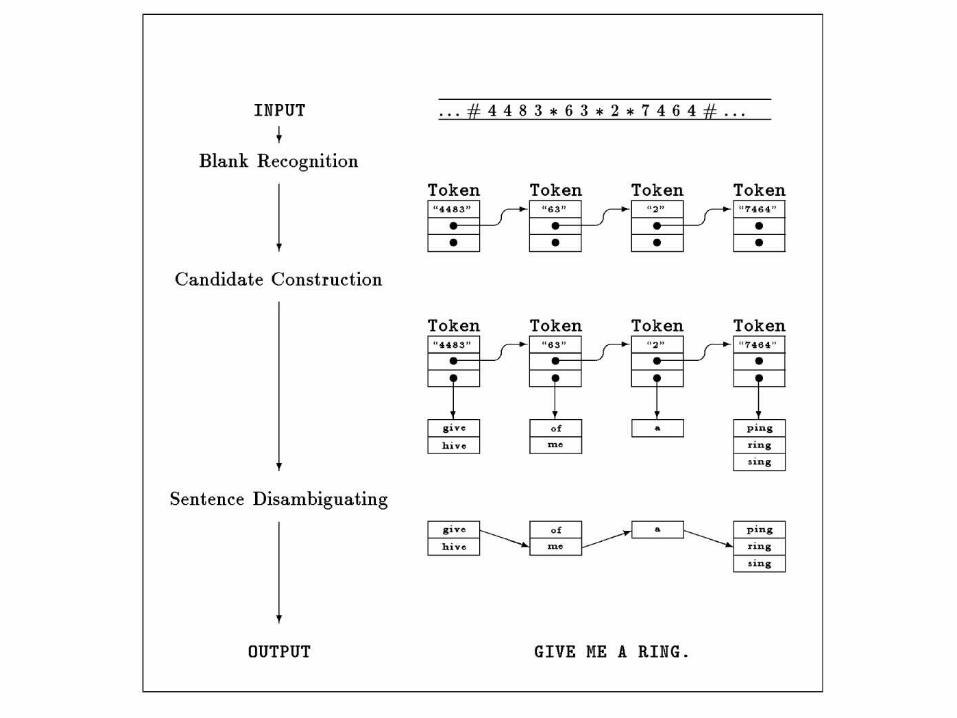

Sentence Disambiguation as Shortest Path
Idea:• Possible words are vertices• Directed edge between adjacent possible words• Weight on edge from W1 to W2 is probability that
W2 appears adjacent to W1
– Probabilities over what?! Some large archive (corpus) of text
– “Word bi-gram” model
• Find the most probable path through the graph
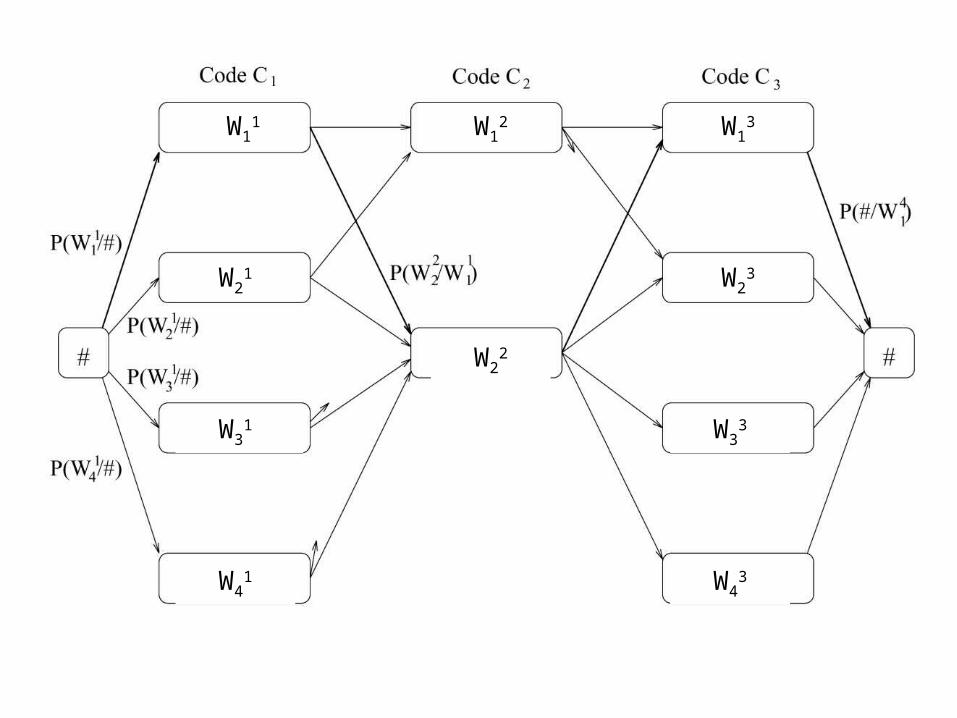
W11
W11W3
1
W41
W21
W12
W22
W13
W23
W33
W43

Technical Concerns
• Isn’t “most probable” actually longest (most heavily weighted) path?!
• Shouldn’t we be multiplying probabilities, not adding them?!
1 2 3 1 2 1 3 2 3(# #) ( | #) ( | ) ( | ) (# | )P w w w P w P w w P w w P w

Logs to the Rescue
• Make weight on edge fromW1 to W2 be
- log P(W2 | W1)
• Logs of probabilities are always negative numbers, so take negative logs
• The lower the probability, the larger the negative log! So this is shortest path
• Adding logs is the same as multiplying the underlying quantities

To Think About
• This really works in practice – 99% accuracy!
• Cell phone memory is limited – how can we use as little storage as possible?
• How can the system customize itself to a user?

Question
Which graph algorithm is asymptotically better:
(|V||E|log|V|)
(|V|3)

All Pairs Shortest Path
• Suppose you want to compute the length of the shortest paths between all pairs of vertices in a graph…– Run Dijkstra’s algorithm (with priority queue)
repeatedly, starting with each node in the graph:
– Complexity in terms of V when graph is dense:

Dynamic Programming Approach
,
, ,
1, 2
, , 1, , 1, ,
,
1, ,
Note that path for
distance from to that u
either does not use ,
or merges the paths
ses
only ,..., as intermediates
min{ , }
and
k i j
k i j i j
k
k i j
k
i
k i j k i k k k j
k k j
D v v
v v v
D D D D
D v
v v v v

Floyd-Warshall Algorithm// C – adjacency matrix representation of graph// C[i][j] = weighted edge i->j or if none// D – computed distancesFW(int n, int C [][], int D [][]){ for (i = 0; i < N; i++){ for (j = 0; j < N; j++) D[i][j] = C[i][j]; D[i][i] = 0.0; } for (k = 0; k < N; k++) for (i = 0; i < N; i++) for (j = 0; j < N; j++) if (D[i][k] + D[k][j] < D[i][j]) D[i][j] = D[i][k] + D[k][j];}
Run time =
How could we compute the paths?
Related Documents











