CS 717: Programming for Fault- tolerance Keshav Pingali Cornell University

CS 717: Programming for Fault-tolerance Keshav Pingali Cornell University.
Dec 22, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

CS 717: Programming for Fault-tolerance
Keshav Pingali
Cornell University

Background for this talk
• Performance still important• But ability of software to adapt to faults is
becoming crucial• Most existing work by OS/distributed
systems people• Program analysis/compiling perspective:
– new ways of looking at problems – new questions

Computing Model
• Message-passing (MPI)• Fixed number of processes• Abstraction: process actions
– compute – send(m,r) //send message m to process r– receive(s) //receive message from process s– receive_any() //receive message from any
process
• FIFO channels between processes

Fault Model
• Fail-stop processes (cf. Byzantine failure)
• Multiple failures possible
• Number of processes before crash
= Number of processes after crash recovery
(cf. N M)

Goals of fault recovery protocol
• Resilience to failure of any number of processes• Efficient recovery from failure of small number of
processes• Avoid rolling back processes that have not failed• Do not modify application code if possible• Use application-level information to reduce
overheads• Reduce disk accesses

Mechanisms
• Stable storage:– disk– survives process crashes– accessible to surviving processes
• Volatile log: – RAM associated with process– evaporates when process fails
• Piggybacking: – protocol information hitched onto application messages

Key idea: causality (Lamport)
• Execution events: compute, send, receive• Happened-before relation on execution events: e1 < e2
– e1,e2 done by same process, and e1 was done before e2– e1 is send and e2 is matching receive– transitivity: there exists ek such that e1 < ek and ek < e2
• Intuition: like coarse-grain dependence information
a
b
c
d e
fP
Q
Ra
bc
d
e
f
z
z

Key idea: consistent cut
• Set containing one state for each process (“timeline”)• Event e behind timeline => events that “happened-before” e are also behind timeline• Intuitively, every message that has been received by a process has already been
sent by some other process (as in I,II,IV)• There may be messages “in-flight” (as in II)
P
Q
(I) (II) (III) (IV)

Classification of recovery protocols
Recovery Protocols
Check-pointing Message-logging
Uncoordinated Coordinated
Blocking Non-blocking
each process saves its stateindependently of others
hardware/softwarebarrier
distributed snap-shot
log messages and replay
processes co-operativelysave distributed state
save state on stable storage

Classification of recovery protocols
Recovery Protocols
Check-pointing Message-logging
Uncoordinated Coordinated
Blocking Non-blocking
each process saves its stateindependently of others
hardware/softwarebarrier
distributed snap-shot
log messages and replay
processes co-operativelysave distributed state
save state on stable storage
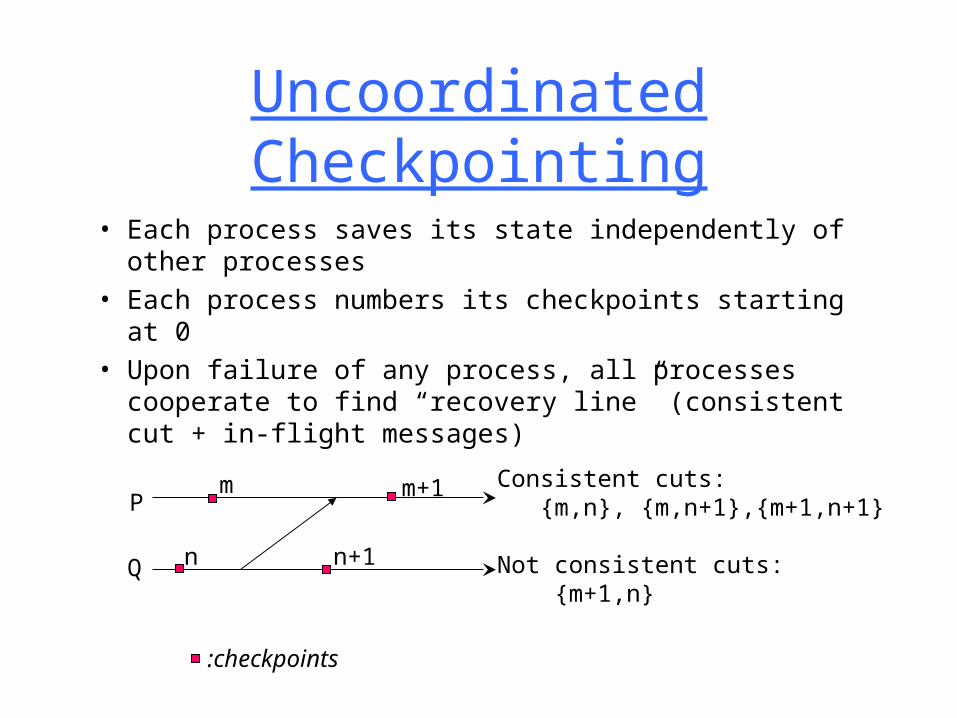
Uncoordinated Checkpointing
• Each process saves its state independently of other processes
• Each process numbers its checkpoints starting at 0
• Upon failure of any process, all processes cooperate to find “recovery line” (consistent cut + in-flight messages)
m m+1
n n+1
Consistent cuts: {m,n}, {m,n+1},{m+1,n+1}
Not consistent cuts: {m+1,n}
P
Q
:checkpoints

Rollback dependency graph
• Nodes: for each process– one node per checkpoint– one node for current state
• Edges: (Sn Rm) if
• Algorithm: propagate badness starting from current state nodes of failed processes
m
n
R
S
Intuition: if Sn cannot be on recovery line, neither can Rm

Example00 01 02 03
10 11 12 13
20 21 22 23
30 31 32 33
00 01 02 03
10 11 12 13
20 21 22 23
30 31 32 33
X
X
00 01 03
10 11 12 13
20 21 22 23
30 31 32 33
(a) Time-line (b) Roll-back dependence graph
© Propagation of badness
: state on recovery line
02
XX
XX
P0
P1
P2
P3

Protocol
• Each process maintains “next-checkpoint-#”– Incremented when checkpoint is taken
• Send: piggyback “next-checkpoint-#” on message• Receive/receive_any: save (Q,data,n) in log• At checkpoint:
– save local state and log on stable storage– empty log
• SOS from a process: – Send current log to recovery manager– Wait to be informed about where to rollback to– Rollback
• In-flight messages: omitted from talk
n
P
Q (data,n)

Discussion• Easy to modify our algorithm to find recovery line with no
in-flight messages• No messages or coordination required to take local
checkpoints• Protocol can boot-strap on any algorithm for saving
uniprocessor state• Cascading rollback possible• Discarding local checkpoints: requires finding current
recovery line (global coordination…)• One process fails => all processes may be rolled back

Classification of recovery protocols
Recovery Protocols
Check-pointing Message-logging
Uncoordinated Coordinated
Blocking Non-blocking
each process saves its stateindependently of others
hardware/softwarebarrier
distributed snap-shot
log messages and replay
processes co-operativelysave distributed state
save state on stable storage

Non-blocking Coordinated Checkpointing
• Distributed snapshot algorithms– Chandy and Lamport, Dijkstra, etc.
• Key features: (cf. uncoordinated chkpting)– Processes do not necessarily save local state at
same time or same point in program– Coordination ensures saved states form
consistent cut

Chandy/Lamport algorithm• Process graph
– Static
– Forms strongly connected component
• Some process is “checkpoint coordinator”– Initiates taking of snapshot
– Detects when all processes have completed local checkpoints
– Advances global snapshot number
• Coordination is done using marker tokens sent along process graph channels

Protocol (simplified)• Coordinator
– Saves its local state– Sends marker tokens on all outgoing edges
• Other processes– When first marker is received, save local state and send marker
tokens on all outgoing channels.
• All processes– Subsequent markers are simply eaten up.– Once markers have been received on all input channels, inform
coordinator that local checkpoint is done.
• Coordinator– once all processes are done, advances snapshot number
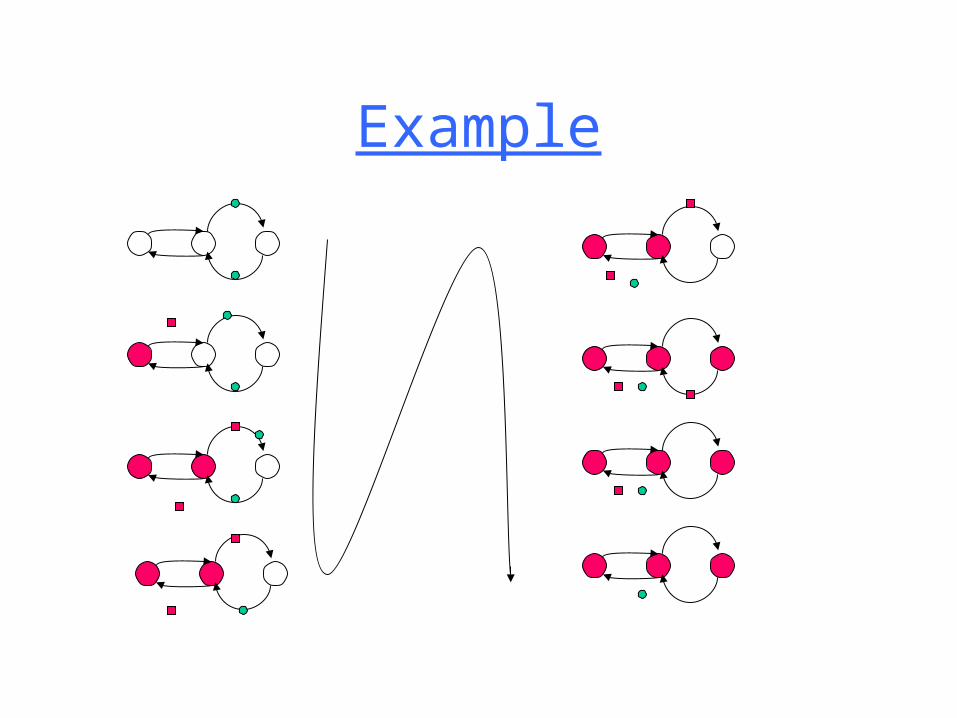
Example

Sketch of correctness proof
• P must have sent marker on channel PQ before it sent application message d
• Q must have received marker before it received d• So Q must have taken checkpoint before receiving d anti-causal message like d cannot exist
d
P
Q
Can anti-causal message d exist?

Discussion
• Easy to modify protocol to save in-flight messages with local check-point
• No cascading roll-back
• Number of coordination messages
= |E| + |N|
• Discarding snapshots is easy
• One process fails all processes roll back

Classification of recovery protocols
Recovery Protocols
Check-pointing Message-logging
Uncoordinated Coordinated
Blocking Non-blocking
each process saves its stateindependently of others
hardware/softwarebarrier
distributed snap-shot
log messages and replay
processes co-operativelysave distributed state
save state on stable storage

Message Logging
• When process P fails, it is restarted from the beginning.
• To redo computations, P needs messages sent to it by other processes before it failed.
• Other processes help process P by replaying messages they had sent it, but are not themselves rolled back.
• In principle, no stable storage required.

Example
• Data structures: each process p maintains– SENDLOG[q]: messages sent to q by p– REPLAYLOG[q]: messages from q that are being
replayed
rcv(P)
rcv(R)rcv(P) rcv(P)
rcv(R)
rcv(P)
SOS
SOS
d1 d3
d2
<d1,d3>
<d2>
XQ
R
P

How about messages sent by failed process?
• Each process p maintains– RC[q]: number of messages received from q
– SS[q]: number of messages to q that must be suppressed during recovery
SOS
SOS
<d1,d3>,1
<d2>,0
X
R
P
snd(P)
snd(P)d4d1 d3
d2
Q

Protocol
• Each process p maintains– SENDLOG[q]: messages sent to q – RC[q]: # of messages received from q – REPLAYLOG[q]: messages from q that are
being replayed during recovery of p– SS[q]:# of messages to q that must be
suppressed during recovery of p

Protocol (contd)
• Send(q,d):– Append d to SENDLOG[q]– If (SS[q] > 0) then SS[q]--; else MPI_SEND(…);
• Receive(q):– If (REPLAYLOG[q] is empty) then {MPI_RECEIVE(…); RC[q]++;} else getNext(REPLAYLOG[q]);

Protocol (contd)
• SOS(q):– MPI_SEND(…,q,<SENDLOG[q],RC[q]>)– SS[q] = 0;

Protocol(contd)• Fail:
– for each other process q do {REPLAYLOG[q] = SENDLOG[q] = empty; SS[q] = RC[q] = 0; MPI_SEND(..,q,SOS); } for each other process q do {discard application messages till you get SOS response; update REPLAYLOG[q],SS[q],RC[q] from response; } start execution from initial state;

Problem with receive_any
• Process Q uses receive_any’s to receive d1 from P first and d2 from R next
• Then it sends message to T containing data that might depend on receipt order of these messages
• During recovery, Q does not know what choices it made before failure
d1
d2rcv?()
rcv?()SOS
SOSSOS
<d1>,0
<d2>,0
<>,1
rcv?()
P
Q
R
T
X

Discussion• Resilient to any number of failures• Only failed processes are rolled back• SENDLOG keeps growing as messages are
exchanged– Do coordinated check-pointing once in a while to
discard logs
• “Deterministic” protocol: does not work if program has receive_any’s
• Orphan process: state of T depends on lost choices

Solutions
• Pessimistic protocol: no orphans– process saves non-deterministic choices on stable
storage before sending any message
• Optimistic protocol: (Bacon/Strom/Yemeni)– during recovery, find orphans and kill them off
• Causal logging: no orphans– piggyback choices on outgoing messages
– ensures receiving process knows all choices it is causally dependent on

Example
• Message carries all choices it is causally dependent on
• Optimization: avoid resending same information
ABP
Q
R
?
?
<P:A,B>
<P:A,B, Q:P>
?

Discussion
• Piggybacked choices on incoming messages are stored in log
• Log also stores choices made by process• Optimized protocol sends incremental choice log
on outgoing messages• Resilient to any number of failures
– any process affected by my choices knows my choices and sends them to me if I fail
– if no process knows what choices I made, I am free to choose differently when I recover

Trade-off between resilience and overhead
• Suppose resilience needs only for f (< N) failures– stop propagating choice once choice has been
logged in f+1 processes• Hard problem
– how do we know in a distributed system that some piece of information has been sent to at least f+1 processes…..
• FBL protocols (Alvisi/Marzullo)
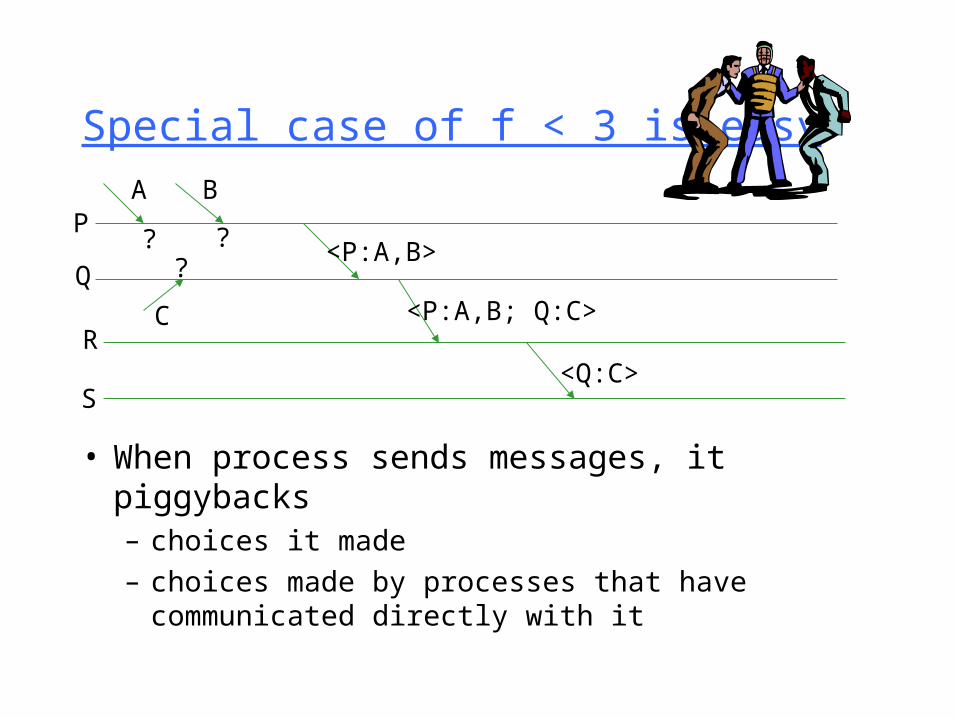
Special case of f < 3 is easy
• When process sends messages, it piggybacks– choices it made
– choices made by processes that have communicated directly with it
? ??
A BP
Q
R
S
<P:A,B>
<P:A,B; Q:C>C
<Q:C>

Discussion
• Check-pointing + logging:– check-pointing gives resilience to any number
of failures but rolls back all processes– logging gives optimized resilience to small
number of failures– check-pointing reduces size of logs
• Overhead in tracking non-deterministic choices in receive_any’s may be substantial

Research Questions

(1) How much non-determinism needs to be tracked in scientific programs?
• Many uses of receive_any are actually deterministic in a “global” sense.
(see next slide)
• These choices need not be tracked.

Deterministic uses of receive_any
• Implementation of reduction operations– No need to track choices
• Stateless servers– compute server– read-only data look-up
• Other patterns?
??d1
d2 d1+d2
??

(2) Happened-before is an approximation of “causality” (dependence).How to exploit
this?
• Post hoc ergo procter hoc
• In general, an event is dependent only on a subset of events that happened-before it.
– (eg) think dependence analysis of sequential programs
• Can we reduce piggybacking overheads by using program analysis to compute dependence more precisely?
??Stateless server
d1 f(d1)
d2 f(d2)

(3) Recovery program need not be same as source program.
• Can we compile an optimized “recovery script” for the case of single process failure?
• During recovery, suppress not only messages that were already sent by failed process but also the associated computations if possible
??Stateless server
d1 f(d1)
d2 f(d2)

(4) Recovery with different number of processes
• Requires application intervention
• Some connection with load-balancing (“load-imbalancing”)
• Virtualization of names

(5) How do we extend this to active-message and shared-memory models?
• Active-messages: one-sided communication (as in Blue Gene)
• Shared-memory: – connection with memory consistency models– acquire/release etc. have no direct analog in
message-passing recovery model

(6) How do we handle Byzantine failures?
– Fail-stop behavior is idealization• In reality, processes may corrupt state, send bad data
etc.
– How do we detect and correct such problems?– Redundancy is key, but TMR is too blunt an
instrument.– Generalize approaches like check-sums,
Hamming codes, etc.• Fault-tolerant BLAS: Dongarra et al, Van de Geijn

d
E(d)E(d)
Encode
f
f
Decode
f(E(d))
f(d)
Simple integrity test tells you if f(E(d) is OK
Related Documents











