CS 267 Spring 2008 Horst Simon UC Berkeley May 15, 2008 Code Generation Framework for Process Network Models onto Parallel Platforms Man-Kit Leung, Isaac Liu, Jia Zou Final Project Presentation

CS 267 Spring 2008 Horst Simon UC Berkeley May 15, 2008 Code Generation Framework for Process Network Models onto Parallel Platforms Man-Kit Leung, Isaac.
Dec 20, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

CS 267 Spring 2008Horst SimonUC BerkeleyMay 15, 2008
Code Generation Framework for Process Network Models onto Parallel Platforms
Man-Kit Leung, Isaac Liu, Jia Zou
Final Project Presentation

Leung, Liu ,Zou 2 / 18 CS267 Sp 08 Final Presentation UC Berkeley
Outline
• Motivation• Demo• Code Generation Framework• Application and Results• Conclusion

Leung, Liu ,Zou 3 / 18 CS267 Sp 08 Final Presentation UC Berkeley
Motivation
• Parallel programming is difficult…- Functional correctness
- Performance debugging + tuning (Basically, trial & error)
• Code generation as a tool– Systematically explore implementation space
– Rapid development / prototyping– Optimize performance– Maximize (programming) reusability
– Correct-by-construction [E. Dijkstra ’70]– Minimize human errors (bugs)– Eliminates the need for low-level testing
– Because, otherwise, manual coding is too costly• Especially true for multiprocessors/distributed platforms
Leung, Liu ,Zou 4 / 18 CS267 Sp 08 Final Presentation UC Berkeley
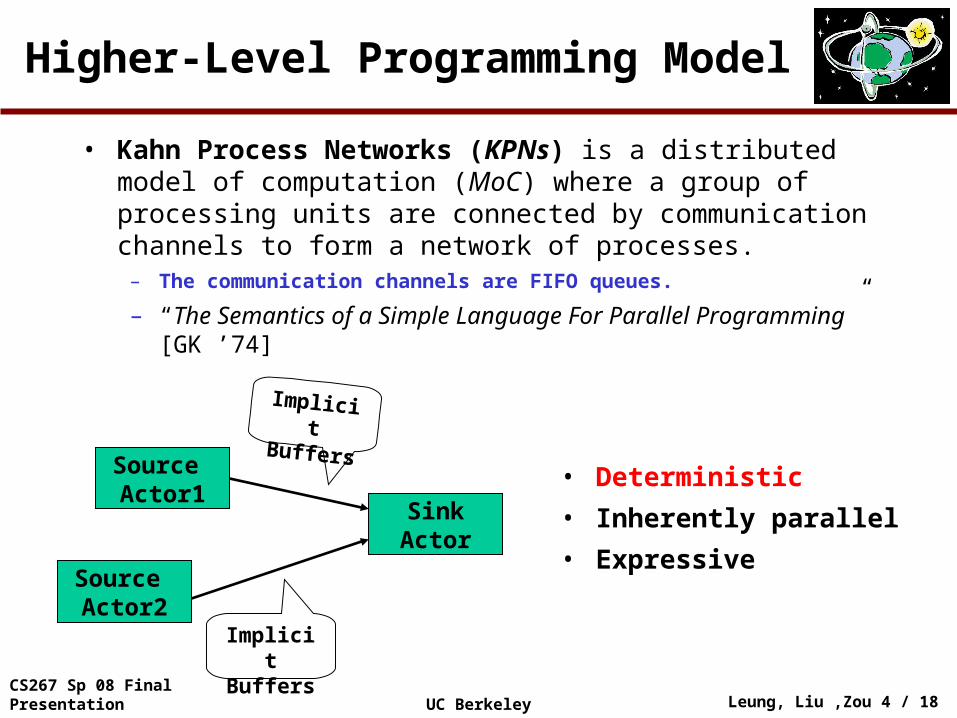
Higher-Level Programming Model
Source Actor1
SinkActor
Source Actor2
Implicit Buffers
Implicit Buffers
• Kahn Process Networks (KPNs) is a distributed model of computation (MoC) where a group of processing units are connected by communication channels to form a network of processes.
– The communication channels are FIFO queues.
– “The Semantics of a Simple Language For Parallel Programming” [GK ’74]
• Deterministic
• Inherently parallel
• Expressive

Leung, Liu ,Zou 5 / 18 CS267 Sp 08 Final Presentation UC Berkeley
MPI Code Generation Workflow
Analyze & annotate model • Assume weights on edges & nodes• Generate cluster info (buffer & grouping)
Analyze & annotate model • Assume weights on edges & nodes• Generate cluster info (buffer & grouping)
Generate MPI code• SIMD (Single Instruction Multiple Data)
Generate MPI code• SIMD (Single Instruction Multiple Data)
Execute code • Obtain execution statistics for tuning
Execute code • Obtain execution statistics for tuning
Partitioning(Mapping)
Model
Given a (KPN) ModelGiven a (KPN) Model
Executable
Code Generation

Leung, Liu ,Zou 6 / 18 CS267 Sp 08 Final Presentation UC Berkeley
Demo
The codegen facility is in the Ptolemy II nightly release
- http://chess.eecs.berkeley.edu/ptexternal/nightly/

Leung, Liu ,Zou 7 / 18 CS267 Sp 08 Final Presentation UC Berkeley
Partitioning(Mapping)
Models
Code Generation
Executable
Role of Code Generation
Ptolemy IIPtolemy II
Platform-based Design [AS ‘02]

Leung, Liu ,Zou 8 / 18 CS267 Sp 08 Final Presentation UC Berkeley
Implementation Spacefor Distributed Environment
• Mapping• # of logical processing units• # of cores / processors• Network costs
• Latency• Throughput
• Memory Constraint• Communication buffer size
• Minimization metrics• Costs• Power consumption• …

Leung, Liu ,Zou 9 / 18 CS267 Sp 08 Final Presentation UC Berkeley
Partition
• Using node and edge weights abstractions• Annotation on the model
• From the model, the input file to Chaco is generated.
• After Chaco produces the output file, the partitions are automatically annotated onto the model.

Leung, Liu ,Zou 10 / 18 CS267 Sp 08 Final Presentation UC Berkeley
Multiprocessor Architectures
• Shared Memory vs. Message Passing– We want to generate code that will run on both
kinds of architectures– Message passing:
• Message Passing Interface(MPI) as the implementation
– Shared memory:• Pthread implementation available for comparison• UPC and OpenMP as future work

Leung, Liu ,Zou 11 / 18 CS267 Sp 08 Final Presentation UC Berkeley
Pthread Implementation
void Actor1 (void) { ...}void Actor2 (void) { ...}
void Model (void) {
pthread_create(&Actor1…);
pthread_create(&Actor2…);
pthread_join(&Actor1…);
pthread_join(&Actor2…);
}
Model
Leung, Liu ,Zou 12 / 18 CS267 Sp 08 Final Presentation UC Berkeley
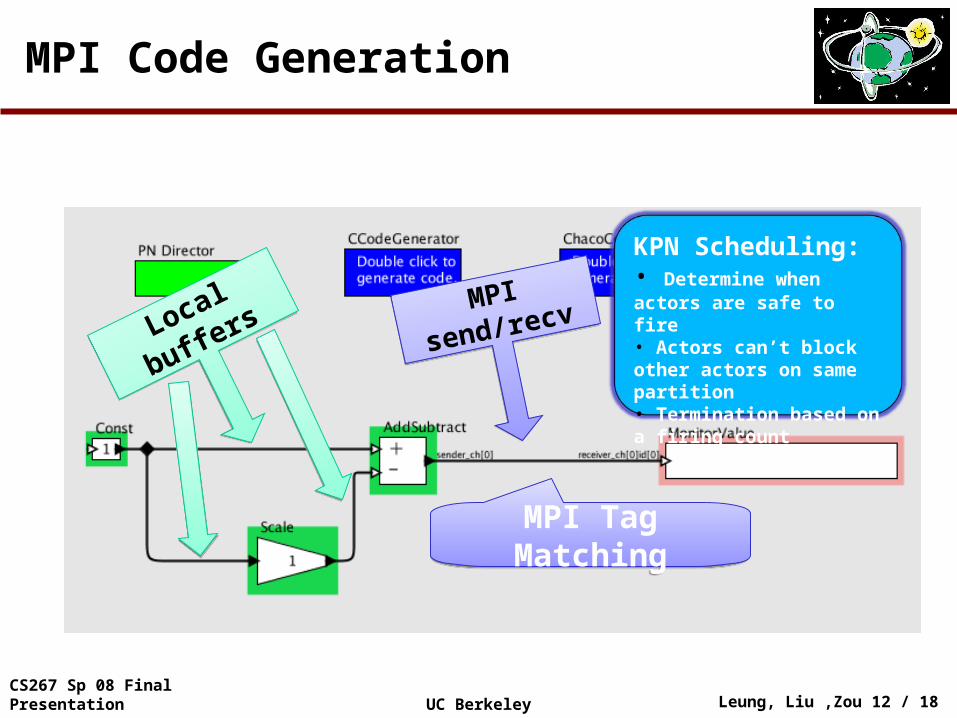
MPI Code Generation
Local buffers
Local buffersMPI send/recvMPI send/recv
MPI Tag MatchingMPI Tag Matching
KPN Scheduling: • Determine when actors are safe to fire• Actors can’t block other actors on same partition• Termination based on a firing count

Leung, Liu ,Zou 13 / 18 CS267 Sp 08 Final Presentation UC Berkeley
Sample MPI Program
main() {
if (rank == 0) {
Actor0();
Actor1();
}
if (rank == 1) {
Actor2();
}
...
}
Actor#() {
[1] MPI_Irecv(input);
[2] if (hasInput && !sendBufferFull){
[3] output = localCalc();
[4] MPI_Isend(1, output);
}
}
Leung, Liu ,Zou 14 / 18 CS267 Sp 08 Final Presentation UC Berkeley
Application

Leung, Liu ,Zou 15 / 18 CS267 Sp 08 Final Presentation UC Berkeley
Execution Platform
NERSC Jacquard CharacteristicsProcessor type Opteron 2.2 GHz
Processor theoretical peak 4.4 GFlops/sec
Number of application processors 712
3.13 TFlops/sec
356
Processors per node 2
Physical memory per node 6 GBytes
Usable memory per node 3-5 GBytes
8
Number of login nodes 4
Switch Interconnect InfiniBand
4.5 usec
620 MB/s
Global shared disk GPFS
Usable disk space 30 TBytes
Batch system PBS Pro
System theoretical peak
(computational nodes)
Number of shared-memory
application nodes
Number of shared-memory spare
application nodes
(In service when possible.)
Switch MPI Unidirectional
Latency
Switch MPI Unidirectional
Bandwidth (peak)
Leung, Liu ,Zou 16 / 18 CS267 Sp 08 Final Presentation UC Berkeley
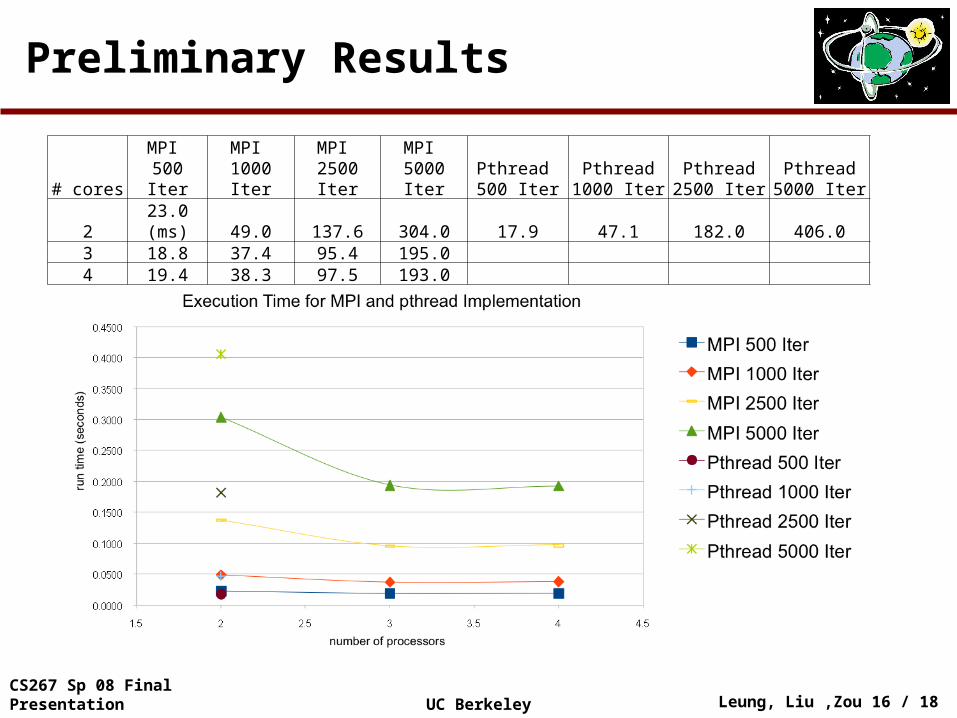
Preliminary Results
# coresMPI
500 IterMPI
1000 IterMPI
2500 IterMPI
5000 IterPthread 500 Iter
Pthread 1000 Iter
Pthread 2500 Iter
Pthread 5000 Iter
2 23.0 (ms) 49.0 137.6 304.0 17.9 47.1 182.0 406.03 18.8 37.4 95.4 195.04 19.4 38.3 97.5 193.0
Leung, Liu ,Zou 17 / 18 CS267 Sp 08 Final Presentation UC Berkeley
Conclusion & Future Work
• Conclusion- Framework for code generation to parallel
platforms
- Generate scalable MPI code from Kahn Process Network models
• Future Work- Target more platforms ( UPC, OpenMP etc)
- Additional profiling techniques
- Support more partitioning tools
- Improve performance on generated code

Leung, Liu ,Zou 18 / 18 CS267 Sp 08 Final Presentation UC Berkeley
Acknowledgments
• Edward Lee• Horst Simon • Shoaib Kamil• Ptolemy II developers• NERSC• John Kubiatowicz

Leung, Liu ,Zou 19 / 18 CS267 Sp 08 Final Presentation UC Berkeley
Extra slides

Leung, Liu ,Zou 20 / 18 CS267 Sp 08 Final Presentation UC Berkeley
Why MPI
• Message passing– Good for distributed (shared-nothing) systems
• Very generic– Easy to set up– Required setup (i.e. mpicc and etc.) for one
“master”– Worker nodes only need to have SSH
• Flexible (explicit)– Nonblocking + blocking send/recv
• Cons: required explicit syntax modification (as opposed to OpenMP, Erlang, and etc.)– Solution: automatic code generation
Leung, Liu ,Zou 21 / 18 CS267 Sp 08 Final Presentation UC Berkeley
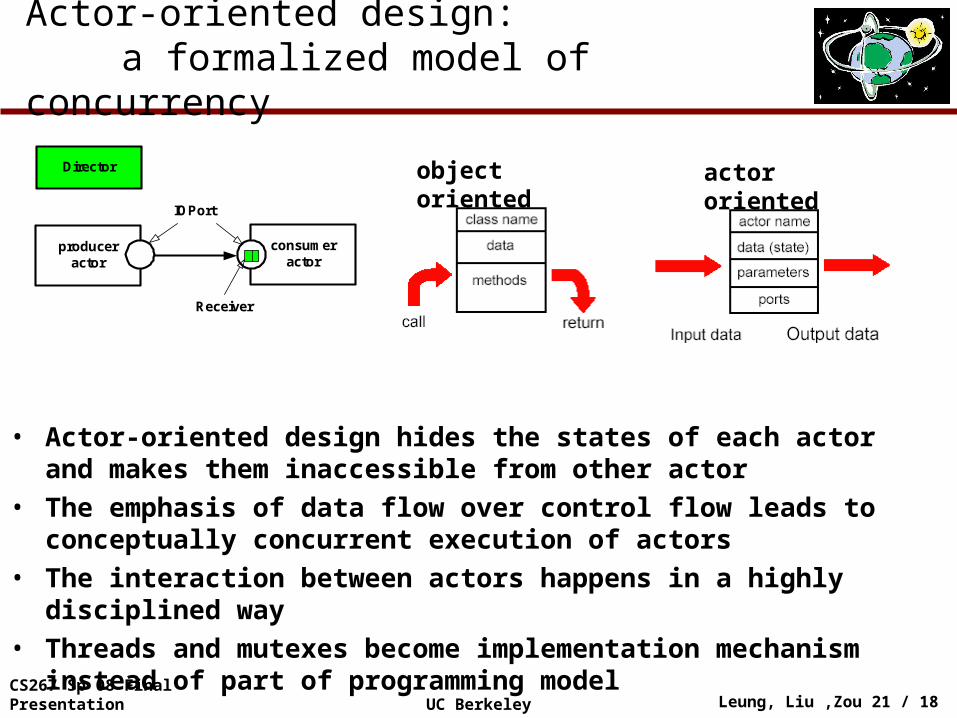
Actor-oriented design: a formalized model of concurrency
produceractor
consumeractor
IOPort
Receiver
Director object oriented actor oriented
• Actor-oriented design hides the states of each actor and makes them inaccessible from other actor
• The emphasis of data flow over control flow leads to conceptually concurrent execution of actors
• The interaction between actors happens in a highly disciplined way • Threads and mutexes become implementation mechanism instead of
part of programming model

Leung, Liu ,Zou 22 / 18 CS267 Sp 08 Final Presentation UC Berkeley
Pthread implementation
• Each actor as a separate thread• Implicit buffers
– Each buffer has a read and write count– Condition variable: sleeps and wakes up
threads– Capacity of the buffer
• A global notion of scheduling exists– OS level– All actors are at blocking-read mode implies
the model should terminate

Leung, Liu ,Zou 23 / 18 CS267 Sp 08 Final Presentation UC Berkeley
MPI Implementation
• Mapping of actors to cores is needed.– Classic graph partitioning problem– Nodes: actors– Edges: messages– Node weights: computations on each actor– Edge weights: amount of messages
communicated– Partitions: processors
• Chaco chosen as the graph partitioner.

Leung, Liu ,Zou 24 / 18 CS267 Sp 08 Final Presentation UC Berkeley
Partition Profiling
• Challenge: providing the user with enough information so node weights and edge weights can be annotated and modified to achieve load balancing.– Solution 1: Static analysis– Solution 2: Simulation– Solution 3: Dynamic load balancing– Solution 4: Profiling the current run and feed
the information back to the user
Related Documents











