KATHOLIEKE UNIVERSITEIT LEUVEN FACULTEIT INGENIEURSWETENSCHAPPEN DEPARTEMENT ELEKTROTECHNIEK Kasteelpark Arenberg 10, B-3001 Leuven-Heverlee Cryptographic Algorithms and Protocols for Security and Privacy in Wireless Ad Hoc Networks Promotor: Prof. dr. ir. B. Preneel Proefschrift voorgedragen tot het behalen van het doctoraat in de ingenieurswetenschappen door Stefaan SEYS mei 2006

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

A KATHOLIEKE UNIVERSITEIT LEUVEN
FACULTEIT INGENIEURSWETENSCHAPPEN
DEPARTEMENT ELEKTROTECHNIEK
Kasteelpark Arenberg 10, B-3001 Leuven-Heverlee
Cryptographic Algorithms and Protocols for
Security and Privacy in Wireless Ad Hoc Networks
Promotor:
Prof. dr. ir. B. Preneel
Proefschrift voorgedragen tot
het behalen van het doctoraat
in de ingenieurswetenschappen
door
Stefaan SEYS
mei 2006


A KATHOLIEKE UNIVERSITEIT LEUVEN
FACULTEIT INGENIEURSWETENSCHAPPEN
DEPARTEMENT ELEKTROTECHNIEK
Kasteelpark Arenberg 10, B-3001 Leuven-Heverlee
Cryptographic Algorithms and Protocols for
Security and Privacy in Wireless Ad Hoc Networks
Jury:
Prof. H. Neuckermans, voorzitter
Prof. B. Preneel, promotor
Prof. C. Mitchell (RHUL)
Prof. F. Piessens
Prof. J. Vandewalle
Prof. I. Verbauwhede
Proefschrift voorgedragen tot
het behalen van het doctoraat
in de ingenieurswetenschappen
door
Stefaan SEYS
U.D.C. 681.3*D46 mei 2006

c© Katholieke Universiteit Leuven – Faculteit IngenieurswetenschappenArenbergkasteel, B-3001 Heverlee (Belgium)
Alle rechten voorbehouden. Niets uit deze uitgave mag vermenigvuldigd en/ofopenbaar gemaakt worden door middel van druk, fotocopie, microfilm, elektron-isch of op welke andere wijze ook zonder voorafgaande schriftelijke toestemmingvan de uitgever.
All rights reserved. No part of the publication may be reproduced in any formby print, photoprint, microfilm or any other means without written permissionfrom the publisher.
D/2006/7515/53
ISBN 90-5682-719-7

Acknowledgements
There are lots of people I would like to thank for a variety of reasons.
First, I want to thank my promotor Prof. Bart Preneel for giving me the oppor-tunity to pursue a Ph.D. at COSIC. Bart is especially thanked for his guidanceand advice (quite literally 24/7) during the past years, and for carefully readingand correcting earlier drafts of this thesis.
I am also very grateful to Prof. Frank Piessens and Prof. Chris Mitchell formanaging to read the whole manuscript so thoroughly in record time and pro-viding helpful suggestions and comments to improve this thesis. I want to thankProf. Joos Vandewalle and Prof. Ingrid Verbauwhede for kindly accepting to bemembers of the jury, and Prof. Neuckermans for chairing it.
A big thanks goes to all my past and current COSIC fellows for their friendlinessand help. In particular, I would like to thank Claudia Dıaz for the enjoyabletime we spent researching all things anonymous, and Dave Singelee for our joinedwork on ad hoc network security. Special thanks go to my former colleagues JorisClaessens for setting a great example, and Wim Moreau for making me feel athome in COSIC from day one. I thank my long-time officemates and friendsRobert Maier, Thomas Herlea and Dave Singelee for always living up to thehundreds of small and bigger requests I must have made during the past years. Iwould also like to thank Karel Wouters and Dave for taking care of some of myresponsibilities during the busy time of writing this thesis.
Pela Noe deserves a big thank you for keeping me from drowning in my oh-so dreaded paperwork and other practical matters. I also thank Pela for herfriendship and showing interest in life outside COSIC. I would like to thankElvira Wouters for her patience and valuable help with all sorts of administrativematters.
A word of thanks also goes to my long-time friends for showing (or at leastfeigning) interest in my work and providing an easy escape from my Ph.D life.
i

ii
I would like to thank my family for their continuous encouragements, especiallymy parents for their unconditional support, and finally my partner Michele forher love and enthusiasm.
I want to acknowledge the K.U.Leuven and the Institute for the Promotion ofInnovation by Science and Technology in Flanders (IWT), for funding my researchwork.
Stefaan SeysMay 2006

Abstract
Wireless ad hoc networks are the next evolutionary step in digital communica-tion systems. Supporting security and privacy are essential before these networkscan become an everyday reality. Without the necessary measures, wireless com-munications are easy to intercept and the activities of the users can be traced.Moreover, the specific properties of wireless ad hoc networks, in particular thelack of fixed servers and the limited resources of the network devices, presentinteresting challenges when designing security and privacy solutions in this en-vironment. This thesis presents solutions for a number of important securityproblems in wireless ad hoc networks.
The thesis starts with an overview of the efficiency of the most important crypto-graphic primitives, including block ciphers, stream ciphers, hash functions, publickey cryptosystems, and digital signature schemes. Efficiency means cycles (or en-ergy) per Byte or operation. The information that is collected here was used inthe design of the cryptographic protocols presented in the thesis.
One-time signature schemes based on a one-way function are an attractive so-lution for low-power devices, as they can be efficiently implemented using blockciphers or hash functions. The drawback is that they require large keys that canonly be used once. This thesis evaluates the overall performance of several one-time signature schemes and public key authentication mechanisms, and comparesthem with conventional signature schemes.
Cooperation can be useful to share the load of a demanding task in resourceconstrained environments. This thesis presents a construction to transform a one-time signature scheme into a cooperative threshold one-time signature scheme,which allows multiple users to jointly sign a message. This scheme is used tobuild a complete authentication mechanism for sensor networks.
Key establishment is a difficult task in ad hoc networks due to the absence offixed servers. The thesis presents a key establishment scheme for dynamic ad hoc
iii

iv
networks that does not rely on fixed servers or public key cryptography. Thiskey establishment scheme is integrated with an existing routing scheme for adhoc networks. The security and efficiency of the resulting scheme are analyzed.
Finally, the thesis deals with privacy in ad hoc networks. The state of the artof anonymous routing schemes for ad hoc networks is presented and analyzed.Following this analysis, the thesis presents a novel anonymous routing schemefor wireless ad hoc networks that protects the anonymity of the users against astronger adversary, while being more efficient than previous works. The securityand efficiency of this scheme are analyzed.

Samenvatting
Draadloze ad-hoc netwerken zijn de volgende evolutionaire stap in digitale com-municatiesystemen. Vooraleer deze netwerken op grote schaal ingezet kunnenworden, zal men de nodige maatregelen moeten ondernemen om de beveiligingen privacy van de gebruikers en hun gegevens te kunnen garanderen. Zonder ex-tra maatregelen is het eenvoudig om draadloze communicatie te onderscheppenen de activiteiten van de gebruikers te volgen. Het ontwerp van deze maatregelenwordt bemoeilijkt door de specifieke eigenschappen van ad-hoc netwerken, in hetbijzonder de afwezigheid van vaste servers en de beperkte rekenkracht, geheugen,bandbreedte en energievoorraad van de mobiele toestellen. Dit resulteert danook in een boeiend en uitdagend onderzoeksdomein. Deze thesis is gericht op hetoplossen van een aantal belangrijke beveiligingsproblemen.
De thesis begint met een overzicht van de efficientie van de belangrijkste crypto-grafische primitieven: blok- en stroomcijfers, hashfuncties, publieke-sleutelvercij-feringsalgoritmen en digitale handtekeningen. Efficientie betekent hier het aantalprocessorcycli (of energieverbruik) per Byte of per operatie. De informatie diehier verzameld is, werd gebruikt in het ontwerp van de protocollen die in dezethesis gepresenteerd worden.
Eenmalige-handtekeningschema’s, die gebaseerd zijn op een eenwegsfunctie, zijninteressant voor toestellen met beperkte capaciteiten, aangezien zij efficient ge-implementeerd kunnen worden op basis van blokcijfers of hashfuncties. Het na-deel van deze schema’s is echter dat ze erg grote sleutels nodig hebben die slechtseenmaal gebruikt kunnen worden. Deze thesis evalueert de globale performantievan verschillende eenmalige-handtekeningschema’s en authentiseringsmechanis-men voor publieke sleutels; en vergelijkt deze met conventionele schema’s.
Deze thesis stelt een constructie voor om eenmalige-handtekeningschema’s omte zetten naar een drempelschema. In dit schema kunnen een aantal knopensamenwerken om een handtekening te plaatsen. Deze vorm van samenwerkingkan bruikbaar zijn daar zij toelaat een zware taak te verdelen over verschillende
v

vi Abstract in Dutch
toestellen. Dit schema wordt vervolgens gebruikt om een volledig authentise-ringsmechanisme voor sensornetwerken te ontwerpen.
Het afspreken van geheime sleutels is niet eenvoudig in ad-hoc netwerken door deafwezigheid van vaste servers. Deze thesis stelt een mechanisme voor om geheimesleutels af te spreken in een dynamisch ad-hoc netwerk. Om het systeem zo effi-cient mogelijk te houden, maken we geen gebruik van publieke-sleutelcryptografie.Het schema werkt autonoom, zonder hulp van vaste knopen die dienst doen alssleutelverdelingscentra. Dit schema wordt vervolgens geıntegreerd met een rou-teringsprotocol voor ad-hoc netwerken. De veiligheid en de efficientie van hetprotocol worden geanalyseerd.
Ten slotte handelt deze thesis ook over privacy in ad-hoc netwerken. De thesisgeeft een volledig overzicht en analyse van de state-of-the-art van anonieme rou-teringsprotocollen voor ad-hoc netwerken. Na deze analyse volgt de beschrijvingvan een nieuw anoniem routeringsprotocol dat bestaande protocollen tracht teverbeteren op twee gebieden: efficientie en anonimiteit. De veiligheid en effi-cientie van het schema worden geanalyseerd.

List of Tables
2.1 Performance of ASIC implementations of 128-bit AES and MUGI. 172.2 Power consumptions of SHA-1, AES, RSA, DSA and ECDSA on
a 32-bit Intel StrongARM SA1100 @ 206MHz. . . . . . . . . . . . 172.3 Performance of 128-bit AES on several platforms. . . . . . . . . . . 172.4 Software performance of cryptographic primitives. . . . . . . . . . 322.5 Elliptic curve, symmetric primitives, RSA and discrete log in F∗q
key length comparison. . . . . . . . . . . . . . . . . . . . . . . . . . 322.6 Software performance of public key primitives. . . . . . . . . . . . 33
3.1 Cost of the LDW for different group sizes g. . . . . . . . . . . . . . 463.2 Authentication paths for a Merkle tree with 8 leaves. . . . . . . . . 493.3 Efficiency of one-time signature schemes. . . . . . . . . . . . . . . . 663.4 Summary of digital signature costs for message hash size s = 160. . 68
5.1 Expected number of turns before a node is no longer isolated. . . . 995.2 Efficiency of the EHBT scheme. . . . . . . . . . . . . . . . . . . . . 1025.3 Maximum supported compromised link keys for several configura-
tions. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
6.1 Comparison of different anonymous routing schemes. . . . . . . . . 1316.2 Average privacy and privacy/cost ratio of two probability distri-
butions for TTL value selection. . . . . . . . . . . . . . . . . . . . . 1436.3 Average privacy and privacy/cost ratio of two probability distri-
butions for padding length selection. . . . . . . . . . . . . . . . . . 146
vii


List of Figures
2.1 Schematic model of an encryption scheme. . . . . . . . . . . . . . . 152.2 Schematic model of a digital signature scheme. . . . . . . . . . . . 21
3.1 Security level offered by the HORS scheme. . . . . . . . . . . . . . 433.2 Evolution of the number of public keys when using the HORS
signature scheme. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 443.3 Example Merkle hash tree with 8 leaves. . . . . . . . . . . . . . . . 483.4 Public key chains . . . . . . . . . . . . . . . . . . . . . . . . . . . . 523.5 Signing efficiency of one-time signature schemes. . . . . . . . . . . 633.6 Verification efficiency of one-time signature schemes. . . . . . . . . 643.7 Communication efficiency of one-time signature schemes. . . . . . . 643.8 Energy consumption of signer (communications and computations). 653.9 Energy consumption of verifier (communications and computations). 653.10 Overall energy consumption of one-time signature schemes. . . . . 66
4.1 Preparation phase of the cooperative threshold one-time signaturescheme. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
4.2 Example sensor network with three cells. . . . . . . . . . . . . . . . 83
5.1 Evolution of node W ’s neighborhood as it travels through the net-work. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
5.2 Multiple routes that can be used to establish link keys. . . . . . . . 945.3 Network model. Nodes move on the grid of the torus. . . . . . . . 995.4 Probability of having at least one node in the overlap between two
consecutive neighborhoods. . . . . . . . . . . . . . . . . . . . . . . 1005.5 Probability that a node does not share a key with any of the nodes
in its neighborhood. . . . . . . . . . . . . . . . . . . . . . . . . . . 100
ix

x List of Figures
6.1 Intercepting and blocking of messages. . . . . . . . . . . . . . . . . 1146.2 DSR route discovery process. . . . . . . . . . . . . . . . . . . . . . 1206.3 Trapdoor Boomerang Onion used in ANODR. . . . . . . . . . . . . 1236.4 ANODR Route Request and Reply messages transmitted by node
Ni, and elements stored in its routing table. . . . . . . . . . . . . . 1246.5 ASR Route Request and Reply messages, and elements stored in
the routing table by node Ni. . . . . . . . . . . . . . . . . . . . . . 1256.6 MASK Route Request and Reply messages, and elements stored
in the routing table by node Ni. . . . . . . . . . . . . . . . . . . . 1276.7 SDAR Route Request and Reply messages, and elements stored in
the routing table by node Ni. . . . . . . . . . . . . . . . . . . . . . 1296.8 Hidden route from source S to destination D. . . . . . . . . . . . . 1346.9 Evolution of padding and TTL values of a message. . . . . . . . . . 1406.10 Privacy and cost of an exponential probability distribution for
TTL value selection. . . . . . . . . . . . . . . . . . . . . . . . . . . 1446.11 Privacy and cost of an exponential probability distribution for
padding length selection. . . . . . . . . . . . . . . . . . . . . . . . . 146

List of Acronyms
ADSL Asymmetric Digital Subscriber LineAES Advanced Encryption StandardAODV Ad hoc On-demand Distance Vector (Routing)APES Anonymity and Privacy in Electronic Services (IWT/STWW
Project)AP Access PointBS Base StationCA Certification AuthorityCBC Cipher Block ChainingCCM Counter with CBC-MACCFB Cipher FeedbackDES Data Encryption StandardDHIES Diffie-Hellman Integrated Encryption SchemeDSN Distributed Sensor NetworkDSR Dynamic Source RoutingDoS Denial of ServiceDSA Digital Signature AlgorithmDSS Digital Signature StandardECB Electronic CodebookECC Error-Correcting CodeECDSA Elliptic Curve Digital Signature AlgorithmECIES Elliptic Curve Integrated Encryption SchemeECPM Elliptic Curve Point MultiplicationEHBT Efficient Hierarchical Binary Tree (protocol)FIPS Federal Information Processing Standards
xi

xii List of Acronyms
FPGA Field-Programmable Gate ArrayGPS Global Positioning SystemsGSM Global System for Mobile CommunicationsIOI Item of InterestIP Internet ProtocolISP Internet Service ProviderKDC Key Distribution CenterLAN Local Area NetworkLDM Lamport-Diffie one-time signature scheme with Merkle
improvementLDW Lamport-Diffie one-time signature scheme with Winternitz
improvementLFSR Linear Feedback Shift RegisterMAC Message Authentication CodeMANET Mobile Ad hoc NetworkMCSP Mobile Communication Service ProviderNAT Network Address TranslationNIST National Institute for Standards and TechnologyNSA National Security AgencyOEAP Optimal Asymmetric Encryption PaddingOFB Output FeedbackOCB Offset Codebook ModeOSI Open Systems InterconnectionOTS One-Time Signature (scheme)OWF One-Way FunctionPET Privacy Enhancing TechniquePGP Pretty Good PrivacyPKI Public Key InfrastructurePSS Probabilistic Signature SchemePSEC Provably Secure Elliptic Curve (cryptosystem)RFID Radio Frequency IdentificationRREQ Route RequestRREP Route ReplySIM Subscriber Identity Module

xiii
SSH Secure ShellSSL Secure Socket LayerSTS Station-to-Station (protocol)TBO Trapdoor Boomerang OnionTCP Transmission Control ProtocolTTL Time-to-LiveTORA Temporally Ordered Routing AlgorithmURL Universal Resource LocatorWEP Wired Equivalent PrivacyWLAN Wireless Local Area Network


List of Notations
x ∈R S Element x is selected uniformly random from the set S.
QRn The set of quadratic residues modulo integer n.
{0, 1}n Bit-string of length n, i.e., any piece of digital data ({0, 1}∗indicates arbitrary length).
{0, 1}nR A uniform random selected bit-string of length n ({0, 1}∗R in-dicates arbitrary length, i.e., a source of random bits).
Int(x) The value of the bit-string x interpreted as an integer (withlittle or big endian).
bxc The largest integer less than or equal to x.
dxe The smallest integer larger than or equal to x.
a | b, a 6 | b Integer a divides b, integer a does not divide b.
|x| Bit-length of x.
i = a→ b For all integers i ranging from a to b, starting from a.
Proc(x) Indicates a procedure or algorithm using input x.
Proc(x) Indicates the output of the algorithm Proc(x).
xv

xvi List of Notations
〈a, b〉 The concatenation of bit-strings a and b. This notation is onlyused if using a, b is confusing.
Ek[m] The encryption with a symmetric cipher of message m usingsecret key k.
MACk[m] The Message Authentication Code of message m using secretkey k.
PubD(m) The encryption with an asymmetric cipher of message m usingthe public key of user D (if we need to specify a specific publickey, we will use Pubpk (m)).
SignD(m) A digital signature on message m using the private key of userD (if we need to specify a specific private key, we will useSignsk (m)).
Ek[a], MACk[·] Shorthand for 〈Ek [a], MACk [a]〉. This notation can also beused with other operators, e.g., 〈Ek [a],SignD(·)〉.
Ek[a,MACk[·]] Shorthand for 〈Ek [a, MACk [a]]〉. This notation can also beused with other operators, e.g., 〈Ek [a,SignD(·)]〉.
SignRSAD(m) RSA signature on message m using the private key of user D.
SignOTD(m) One-time signature on message m using D’s private key. Here,we assume that the one-time signature scheme does not includepadding and hashing of the message.
S −→ D : m Sender S transmits message m to destination D.
S −→ ∗ : m Sender S broadcasts message m.

Contents
Acknowledgements i
Abstract iii
Abstract in Dutch v
List of Tables vii
List of Figures ix
List of Acronyms xi
List of Notations xv
Contents xvii
Summary in Dutch xxi
1 Introduction 11.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 This thesis and related work . . . . . . . . . . . . . . . . . . . . . . 31.3 Outline and main contributions . . . . . . . . . . . . . . . . . . . . 7
2 Efficiency of Cryptographic Primitives 112.1 Symmetric primitives . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.1.1 Symmetric encryption . . . . . . . . . . . . . . . . . . . . . 122.1.2 Efficiency of symmetric techniques . . . . . . . . . . . . . . 15
2.2 Public key cryptography . . . . . . . . . . . . . . . . . . . . . . . . 19
xvii

xviii Contents
2.2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . 192.2.2 Public key certificates . . . . . . . . . . . . . . . . . . . . . 202.2.3 The RSA, Rabin and DSA public-key encryption and sig-
nature schemes . . . . . . . . . . . . . . . . . . . . . . . . . 222.2.4 Elliptic curve cryptography . . . . . . . . . . . . . . . . . . 272.2.5 Efficiency of public key cryptography . . . . . . . . . . . . . 29
2.3 Conclusions and future work . . . . . . . . . . . . . . . . . . . . . 31
3 Efficiency of One-Time Signature Schemes 353.1 Lamport-Diffie one-time signatures . . . . . . . . . . . . . . . . . . 36
3.1.1 Lamport-Diffie scheme with Merkle improvement . . . . . . 373.1.2 Lamport-Diffie scheme with Winternitz improvement . . . . 37
3.2 The HORS one-time signature scheme . . . . . . . . . . . . . . . . 393.2.1 On the security of HORS . . . . . . . . . . . . . . . . . . . 41
3.3 Efficiency of one-time signature schemes . . . . . . . . . . . . . . . 433.3.1 Efficiency of the LDM . . . . . . . . . . . . . . . . . . . . . 453.3.2 Efficiency of the LDW . . . . . . . . . . . . . . . . . . . . . 453.3.3 Efficiency of the HORS scheme . . . . . . . . . . . . . . . . 46
3.4 One-time public key authentication . . . . . . . . . . . . . . . . . . 473.4.1 Merkle trees . . . . . . . . . . . . . . . . . . . . . . . . . . . 473.4.2 One-way chains . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.5 Efficiency of one-time signature schemes with public key authen-tication . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 523.5.1 Efficiency of Merkle tree authentication . . . . . . . . . . . 523.5.2 Efficiency of one-way chain authentication . . . . . . . . . . 57
3.6 Comparison . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 613.7 Conclusions and future work . . . . . . . . . . . . . . . . . . . . . 67
4 Efficient Cooperative Signatures 714.1 Threshold signatures . . . . . . . . . . . . . . . . . . . . . . . . . . 724.2 Threshold Lamport-Diffie signatures . . . . . . . . . . . . . . . . . 734.3 Multi-signer LDW signatures . . . . . . . . . . . . . . . . . . . . . 744.4 Cooperative threshold one-time signatures . . . . . . . . . . . . . . 75
4.4.1 Signature generation . . . . . . . . . . . . . . . . . . . . . . 764.4.2 Signature verification . . . . . . . . . . . . . . . . . . . . . 784.4.3 Informal Security proof of our scheme . . . . . . . . . . . . 80

Contents xix
4.5 Application of our scheme in sensor networks . . . . . . . . . . . . 814.5.1 Network operation . . . . . . . . . . . . . . . . . . . . . . . 814.5.2 Strong authentication between query nodes and cells . . . . 834.5.3 One-time secret key updates . . . . . . . . . . . . . . . . . 85
4.6 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
5 Dynamic Key Establishment 895.1 Secure Neighborhood Discovery protocol . . . . . . . . . . . . . . . 90
5.1.1 Neighborhood . . . . . . . . . . . . . . . . . . . . . . . . . . 905.1.2 Bootstrapping the system: key pre-distribution . . . . . . . 915.1.3 Dynamic Neighborhood Discovery . . . . . . . . . . . . . . 91
5.2 Establishing link keys . . . . . . . . . . . . . . . . . . . . . . . . . 935.2.1 Normal operation . . . . . . . . . . . . . . . . . . . . . . . . 935.2.2 Exceptional operation . . . . . . . . . . . . . . . . . . . . . 94
5.3 Implementation based on DSR . . . . . . . . . . . . . . . . . . . . 955.4 Performance evaluation . . . . . . . . . . . . . . . . . . . . . . . . 96
5.4.1 Analytic model and simulations . . . . . . . . . . . . . . . . 965.4.2 Efficiency of the scheme . . . . . . . . . . . . . . . . . . . . 101
5.5 Security analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1025.5.1 Informal analysis of the Secure Neighborhood Discovery . . 1025.5.2 Informal analysis of AuthDSR . . . . . . . . . . . . . . . . 1035.5.3 Evolution of compromised link keys . . . . . . . . . . . . . 104
5.6 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
6 Privacy in Ad Hoc Networks 1076.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
6.1.1 Privacy in a digitized world . . . . . . . . . . . . . . . . . . 1086.1.2 Anonymity at different layers . . . . . . . . . . . . . . . . . 110
6.2 Anonymity: definitions and requirements . . . . . . . . . . . . . . 1116.2.1 Definitions . . . . . . . . . . . . . . . . . . . . . . . . . . . 1116.2.2 Adversary model . . . . . . . . . . . . . . . . . . . . . . . . 1126.2.3 Goals . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
6.3 Anonymous connections in wired networks . . . . . . . . . . . . . . 1166.3.1 Overview of existing technologies . . . . . . . . . . . . . . . 117
6.4 Anonymous connections in mobile ad hoc networks . . . . . . . . . 1196.4.1 On demand routing protocols . . . . . . . . . . . . . . . . . 119

xx Contents
6.4.2 A generic anonymous on demand routing protocol . . . . . 1216.4.3 Evaluation of state of the art . . . . . . . . . . . . . . . . . 1216.4.4 Comparison and evaluation . . . . . . . . . . . . . . . . . . 129
6.5 ARM: efficient anonymous routing for mobile ad hoc networks . . 1306.5.1 Trapdoor identifier . . . . . . . . . . . . . . . . . . . . . . . 1306.5.2 Route discovery . . . . . . . . . . . . . . . . . . . . . . . . . 1326.5.3 Route reply . . . . . . . . . . . . . . . . . . . . . . . . . . . 1346.5.4 Data forwarding . . . . . . . . . . . . . . . . . . . . . . . . 1366.5.5 Padding and time-to-live schemes . . . . . . . . . . . . . . . 1376.5.6 Variations . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
6.6 Analysis of the padding and time-to-live schemes . . . . . . . . . . 1396.6.1 Privacy offered by random TTL selection . . . . . . . . . . 1396.6.2 Privacy offered by random padding selection . . . . . . . . 1436.6.3 Analysis of our protocol . . . . . . . . . . . . . . . . . . . . 147
6.7 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
7 Conclusions and Future Research 1497.1 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1497.2 Future work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
References 153
Index 169
List of Publications 171

Algoritmen en protocollenvoor beveiliging en privacy indraadloze ad-hoc netwerken
Nederlandse samenvatting
Hoofdstuk 1: Inleiding
Door de steeds verdergaande miniaturisatie van computersystemen is het tegen-woordig mogelijk om toestellen te ontwikkelen die een relatief krachtige proces-sor, opslagcapaciteit en communicatiemogelijkheden bundelen in een draagbareverpakking. Typische voorbeelden zijn PDA’s en mobiele telefoons. Momen-teel worden meestal rechtstreekse punt-tot-punt-verbindingen gebruikt, zoals bij-voorbeeld een mobiele telefoon naar een basisstation of een PDA naar een WiFitoegangspunt. Een andere mogelijkheid, die momenteel sterk in ontwikkeling is,zijn draadloze ad-hoc netwerken of Mobile Ad hoc Networks (MANET’s). Ineen ad-hoc netwerk vormen knopen automatisch en autonoom een netwerk vanzodra ze in elkaars bereik komen. Wanneer een knoop wil communiceren meteen andere knoop die buiten zijn bereik is, dan wordt het bericht doorgestuurdvan knoop naar knoop tot de eindbestemming bereikt wordt. MANET’s kun-nen bijvoorbeeld ingezet worden om snel en goedkoop een communicatienetwerkop te zetten in gebieden waar er geen bestaande infrastructuur is, of waar dezevernietigd werd, zoals in ramp- en oorlogsgebieden. Een ander voorbeeld vanad-hoc netwerken zijn sensornetwerken. Sensornetwerken bestaan uit duizenden
xxi

xxii Summary in Dutch
miniatuursensors die draadloos met elkaar communiceren over een ad-hoc net-werk. Mogelijke toepassingen van sensornetwerken zijn het opmeten van bodem-en weercondities op akkers, detecteren van barsten in grote bouwwerken zoalsbruggen, enz.
Omdat het relatief eenvoudig is om draadloze communicatie ongedetecteerd teonderscheppen, speelt de beveiliging van deze netwerken een cruciale rol in deontwikkeling ervan. De beveiliging van ad-hoc netwerken is niet vanzelfsprekenddoor verschillende redenen. Ten eerste zijn de knopen beperkt in rekencapaciteit,geheugen, bandbreedte en energievoorraad. Dit betekent dat de beveiligingsme-chanismen zo efficient mogelijk moeten zijn. Ten tweede zijn er niet altijd vas-te knopen (“servers”) in het netwerk die kunnen aangesproken worden om eenbepaalde dienst te leveren. Hierdoor zijn de meeste traditionele beveiligingsme-chanismen (bijvoorbeeld voor het afspreken van sleutels) niet van toepassing inad-hoc netwerken. Ten slotte wordt de beveiliging bemoeilijkt door de multi-hoproutering en het feit dat de knopen zich vrij kunnen bewegen door het netwerk.Naast beveiliging is ook de privacy van de gebruiker van belang. Door gebruikte maken van draadloze communicatie laat de gebruiker immers automatischsporen na van zijn activiteiten. Privacy zal zeker een belangrijke rol spelen inad-hoc netwerken, daar iedere gebruiker mogelijk berichten zal doorsturen vanandere gebruikers. Ad-hoc netwerken zorgen dus voor nieuwe uitdagingen inzakebeveiliging en privacy.
Deze thesis levert een bijdrage tot mogelijke oplossingen voor een deel van dezeuitdagingen. Deze thesis bestudeert niet een bepaald onderdeel tot in de klein-ste details, maar behandelt meerdere uiteenlopende aspecten. Hoofdstuk 2 geefteen overzicht van de state-of-the-art van cryptografische primitieven en geeft eenanalyse van de efficientie van deze algoritmen. De ontwerpen in de volgendehoofdstukken zijn gebaseerd op de resultaten die in dit hoofdstuk verzameld wer-den. Hoofdstuk 3 geeft een gedetailleerde analyse van de efficientie van eenmaligedigitale handtekeningen die gebaseerd zijn op een eenwegsfunctie. Deze analysehoudt rekening met alle aspecten van het gebruik van digitale handtekeningenin een draadloze omgeving: genereren van sleutels, berekenen van een handte-kening, verifieren van een handtekening, doorsturen van een handtekening enverificatie van een eenmalige publieke sleutels. In hoofdstuk 4 stellen we een con-structie voor om eenmalige-handtekeningschema’s om te vormen tot cooperatieveeenmalige-handtekeningschema’s. Met dit schema kunnen verschillende gebrui-kers samen een handtekening zetten op een bepaald bericht. In een tweede deelvan dit hoofdstuk tonen we hoe dit schema kan ingezet worden in een completeoplossing voor de authentisering van berichten in sensornetwerken. Hoofdstuk5 handelt over een sleutelverdelingssysteem voor dynamische ad-hoc netwerken.Via dit systeem kunnen knopen sleutels afspreken met andere knopen in hun

xxiii
steeds veranderende buurt. We tonen ook aan dat hetzelfde systeem kan ge-bruikt worden om een sleutel af te spreken met knopen die verder (meer dan eenhop) verwijderd zijn. Ten slotte bespreken we hoe het systeem kan geıntegreerdworden in een bestaand routeringsprotocol voor ad-hoc netwerken. Hoofdstuk6 handelt over de privacy in ad-hoc netwerken. Het hoofdstuk begint met eeninleiding tot het onderzoeksdomein en stelt de state-of-the-art voor van anoniemerouteringsprotocollen voor ad-hoc netwerken. Daarna stellen we een nieuw ano-niem routeringsprotocol voor dat ontworpen werd om efficienter te zijn en meeranonimiteit te bieden dan bestaande voorstellen. Hoofdstuk 7 sluit de thesis afen formuleert nieuwe uitdagingen voor de toekomst.
Hoofdstuk 2: Efficientie van cryptografische primitie-ven
Bijna alle protocollen voor de beveiliging van netwerken en computersystemenmaken in meer of mindere mate gebruik van cryptografische primitieven. Zoalsin de inleiding vermeld werd, hebben we bij het ontwerp van de protocollendie we voorstellen in hoofdstukken 3 tot en met 6, getracht om een zo efficientmogelijke oplossing te bieden. Dit hoofdstuk is dan ook gericht op de efficientievan de belangrijkste klassen van cryptografische primitieven: symmetrische blok-en stroomcijfers, hashfuncties, asymmetrische vercijferingsschema’s en digitalehandtekeningschema’s.
Efficientie van symmetrische primitieven
Symmetrische vercijferingssystemen maken gebruik van een geheime sleutel diegekend is door twee partijen: de partij die een boodschap vercijfert en de partijdie de boodschap zal ontcijferen.
Blokcijfers transformeren een klaartekstblok van vaste lengte naar een cijfertekst-blok van vaste lengte. Er zijn verschillende manieren (“modes of operation”)om klaarteksten die langer zijn dan de bloklengte te vercijferen. In 2000 werdRijndael verkozen als de nieuwe Advanced Encryption Standard (AES) voor deVerenigde Staten. Rijndael won de wedstrijd die uitgeschreven werd door de Na-tional Institute for Standards and Technology (NIST) in 1997 om de bestaandeData Encryption Standard (DES) te vervangen. Als opvolger van de DES, zalde AES de de facto cryptografische standaard worden voor de vercijfering in hetbankwezen, administraties en de industrie. Een belangrijk criterium bij het ont-werp van de AES was veelzijdigheid. Dit betekent dat het algoritme efficient moet

xxiv Summary in Dutch
geımplementeerd kunnen worden op uiteenlopende platformen, zowel in softwareals in hardware. Deze veelzijdigheid zorgt ervoor dat de AES een zeer performantblokcijfer is, en een ideaal referentiepunt is om andere algoritmen aan te toetsen.
In tegenstelling tot blokcijfers, produceren stroomcijfers een oneindig lange pseu-do-willekeurige bitstroom S(k) die enkel afhangt van de sleutel. Een boodschapm kan dan vercijferd worden door deze samen te tellen (XOR) met de pseudo-willekeurige bitstroom S(k): c = m ⊕ S(k). Om de cijfertekst c te ontcijferenmoet deze operatie gewoon herhaald worden: m = c ⊕ S(k). Stroomcijfers heb-ben het voordeel dat er niet moet gewacht worden tot een klaartekstblok gevuldis en dat er geen foutpropagatie is (zolang de stromen gesynchroniseerd blijven).Draadloze communicatiesystemen maken meestal gebruik van stroomcijfers omde communicatie te vercijferen. Zo maken Bluetooth en GSM gebruik van res-pectievelijk het E0 en A5/1 stroomcijfer. Deze algoritmen werden ontworpen omzo efficient mogelijk te zijn, zowel in energieverbruik als in het aantal poortenin de hardware-implementatie. Het WEP-algoritme dat gebruikt wordt in deIEEE 802.11 standaard voor draadloze netwerken maakt gebruik van het RC4stroomcijfer. RC4 is zeer snel in software en heeft zeer weinig werkgeheugennodig (< 1 kByte).
Cryptografische hashfuncties spelen een belangrijke rol in integriteitsbeschermingvan berichten en in digitale handtekeningschema’s. Een hashfunctie beeldt bitrij-en van willekeurige lengte af op bitrijen van een vaste lengte. Een hashfunctie Hmoet minstens voldoen aan de volgende drie eigenschappen: (1) eenwegsfunctie:het is onmogelijk om uit een hashwaarde h een bericht m te berekenen zodatH(m) = h, (2) zwak botsingsvrij: het is onmogelijk om, gegeven een boodschapm, een tweede boodschap m′ te vinden met H(m) = H(m′) en (3) sterk bot-singsvrij: het is onmogelijk om twee verschillende boodschappen te vinden metdezelfde hashwaarde.
In het kader van het NESSIE project werden de snelheid en de veiligheid vanverschillende cryptografische primitieven geevalueerd. Een deel van de resultatenzijn samengevat in Tabel 1.
Efficientie van publieke-sleutelcryptografie
In tegenstelling tot symmetrische cryptografische systemen maakt publieke-sleu-telcryptografie gebruik van twee verschillende sleutels: een private (geheime) eneen publieke sleutel. De publieke sleutel wordt afgeleid uit de private sleutel, om-gekeerd is dit niet mogelijk. De private sleutel wordt nooit vrijgegeven, terwijlde publieke sleutel door iedereen gekend mag zijn.

xxv
Bij publieke-sleutelvercijfering worden de private en publieke sleutel gegenereerddoor de ontvanger Bob (de persoon die boodschappen zal ontcijferen). Een bood-schap vercijferen voor Bob verloopt zo: Alice verkrijgt de publieke sleutel vanBob, gebruikt deze om haar bericht te vercijferen en stuurt het resultaat naarBob. Bob gebruikt dan zijn private sleutel om het ontvangen bericht te ontcij-feren. Merk op dat iedereen Bob’s publieke sleutel mag gebruiken om berichtennaar hem te sturen. Bij symmetrische cryptografie zou Bob met iedere zendereen andere geheime sleutel moeten afspreken.
Bij digitale handtekeningschema’s is het gebruik van de publieke en private sleutelomgekeerd: de zender gebruikt zijn private sleutel om een boodschap te handte-kenen. De ontvanger gebruikt de publieke sleutel van de zender om zijn handte-kening te controleren. Aangezien de publieke sleutel voor iedereen beschikbaaris, kan dus iedereen handtekeningen van alle gebruikers controleren.
De veiligheid van de meeste publieke-sleutelsystemen is gebaseerd op een “moei-lijk” wiskundig probleem. Zo is de veiligheid van het veel gebruikte RSA encryp-tie- en handtekeningschema gerelateerd aan de moeilijkheid om grote getallen tefactoriseren. Het nadeel van publieke-sleutelsystemen is dat ze veel minder effi-cient zijn dan symmetrische primitieven (zie Tabel 1). Publieke-sleutelsystemendie gebruik maken van elliptische krommen (zoals ECDSA) hebben het voordeeldat ze efficienter zijn dan hun tegenhangers (zoals DSA) die werken in het veldF∗q en dat ze dezelfde veiligheid kunnen bieden met kleine sleutellengtes. Zo isECDSA met een 160-bit sleutel even veilig als DSA met een 1024-bit sleutel.
Conclusies
Uit Tabel 1 blijkt duidelijk dat symmetrische primitieven veel efficienter zijn danpublieke-sleutelsystemen. Publieke-sleutelsystemen die gebruik maken van ellip-tische krommen zijn efficienter dan hun tegenhangers die werken in het veld F∗q enbieden bovendien dezelfde veiligheid met kortere sleutels. Ten slotte merken weop dat de publieke operaties (vercijferen en handtekeningen verifieren) van RSAen Rabin ongeveer twee maal zo snel zijn dan de ECDSA-operaties. De geheimeoperaties zijn dan weer veel minder efficient. In de volgende hoofdstukken heb-ben we steeds getracht om deze efficientieverschillen optimaal te benutten, d.w.z.dat de minst krachtige knopen in het netwerk steeds enkel de efficiente operatiesmoeten uitvoeren.

xxvi Summary in Dutch
Tabel 1. Performantie van cryptografische primitieven in software [134].
Algoritme |sleutel| Platform|hash| PIII/Linux Athlon
AES 128 25/26/523 30/31/500RC4 128 7.3/2659 11/2600RIPEMD-160 160 18/16/1339 21/12/1493SHA-1 160 15/16/1024 12/12/825SHA-2 256 40/44/2747 34/39/2369SHA-2 512 83/157/11K 71/106/9752RSA-OAEP 1024 2026K/42M/1654M 2289K/48M/2027MECDSA-GF(2p) 160 4775K/6085K/4669K 4464K/572K/4354KECDSA-GF(2163) 163 5061K/6809K/4852K 4602K/6159K/4426KRSA-PSS 1024 42M/2029K/1334M 48M/2288K/1419M
Voor de AES en RSA-OAEP zijn dit vercijfer-/ontcijfer-/sleutel-initialisatietijden. VoorRC4 is dit genereren van de sleutelstroom/sleutel-initialisatie. Voor de hashfuncties isdit hash/initialisatie/initialisatie+finalisatie. Voor de ECDSA en RSA-PSS zijn dithandteken-/verificatie-/sleutelgeneratietijden. De symmetrische primitieven zijn geme-ten in cycli/Byte of cycli/initialisatie, de asymmetrische in cycli/aanroep.
Hoofdstuk 3: Efficientie van eenmalige digitale hand-tekeningen
Uit het vorige hoofdstuk blijkt dat symmetrische primitieven veel efficienter zijndan publieke-sleutelsystemen. Zelf met de snelste publieke-sleuteloperaties, RSAvercijfering of verificatie, neemt een publieke-sleuteloperatie evenveel tijd in danhet vercijferen van 80 kBytes met AES. Dit heeft ons gemotiveerd om een gede-tailleerde studie te maken van de efficientie van eenmalige-handtekeningschema’sdie enkel gebruik maken van eenwegsfuncties. Daar eenwegsfuncties efficientgeımplementeerd kunnen worden via blokcijfers of hashfuncties, lijken deze sche-ma’s op het eerste zicht efficienter te zijn dan conventionele handtekeningsche-ma’s zoals RSA, DSA en ECDSA. Het nadeel van deze systemen is echter dateen publieke sleutel slechts eenmaal gebruik kan worden. Hierdoor is een ef-ficient mechanisme voor het authentiseren van meerdere publieke sleutels eenbelangrijk aspect bij het gebruik van eenmalige-handtekeningschema’s. In dithoofdstuk evalueren we dan ook alle aspecten van het gebruik van eenmalige-handtekeningschema’s: (1) genereren van de private en publieke sleutels, (2)authentiseren van de publieke sleutels, (3) handtekeningen zetten en verifierenen (4) de communicatiekost.

xxvii
De belangrijkste bijdragen in dit hoofdstuk zijn:
– Een gedetailleerde evaluatie van de efficientie van drie besproken eenmalige-handtekeningschema’s: LDM, LDW en HORS.
– Een gedetailleerde evaluatie van de efficientie van twee authentiseringsme-chanismen: Merkle-bomen en eenwegskettingen.
– Een analyse van de veiligheid van het HORS-schema.
Eenmalige-handtekeningschema’s
We hebben drie verschillende eenmalige-handtekeningschema’s geevalueerd: hetLamport-Diffie-schema met verbeteringen door Merkle (LDM), het Lamport-Diffie-schema met verbeteringen door Winternitz (LDW) en het HORS-schema.Deze schema’s maken enkel gebruik van een eenwegsfunctie f . In zijn eenvou-digste vorm kan het Lamport-Diffie-schema gebruikt worden om een bit te hand-tekenen. De private sleutel bestaat uit twee willekeurige getallen x0 en x1. Depublieke sleutel wordt berekend door de functie f toe te passen op de privatesleutel. Dit resulteert in het koppel {f(x0), f(y0)}. De handtekening voor bit bis xb. Het is duidelijk dat eenzelfde sleutelpaar maar eenmaal gebruikt kan wor-den. Om meerdere bits te tekenen wordt dit schema meerdere keren herhaald.In dit geval bestaat de private sleutel dus uit meerdere willekeurige getallen:sk = {x1, x2, . . . , xt}.
Authentisering van de eenmalige publieke sleutels
Iedere ontvanger heeft een geauthentiseerde kopie nodig van de publieke sleutelom een handtekening te kunnen verifieren. Aangezien een publieke sleutel slechtseenmaal kan gebruikt worden in deze schema’s, is er nood aan een efficientemanier om meerdere publieke sleutels te authentiseren. In deze thesis hebben wijtwee mechanismen bestudeerd: Merkle-bomen en eenwegskettingen.
Merkle-bomen
Een Merkle-boom is een binaire boom met op iedere knoop een getal van l bits. Dewaarde van iedere interne knoop is gelijk aan het resultaat van een eenwegsfunctietoegepast op de twee kinderen (zie Fig. 1):
{leaf i = P [i, i] = leafcalc(i) ,
P [i, j] = f(〈P [i , (i + j − 1 )/2 ],P [(i + j + 1 )/2 , j ]〉) .

xxviii Summary in Dutch
Hierin is leafcalc het algoritme dat gebruikt wordt om de onderste bladen van deboom te berekenen. In dit geval bestaat leafcalc uit twee deeltaken: het genererenvan een publieke sleutel en het berekenen van de hashwaarde van deze publiekesleutel. Iedere hashwaarde die zo bekomen wordt, is een blad van de boom.
De volledige boom wordt berekend door de gebruiker S, die handtekeningen wilplaatsen. We veronderstellen dat iedere gebruiker V , die handtekeningen wilverifieren, een geauthentiseerde kopie heeft gekregen van de top van de boom(P [1, 8] in Fig. 1). Een bepaald blad van de boom, neem leaf 3 in Fig. 1, kan opde volgende manier geauthentiseerd worden: gebruiker S berekent het blad leaf 4
en de interne knopen P [5, 8] en P [1, 2]. Deze waarden, het authentiseringspadgenoemd, stuurt hij samen met de derde publieke sleutel (die bij leaf 3 hoort)door naar gebruiker V . Gebruiker V berekent nu leaf 3 (leaf 3 is de hashwaardevan de ontvangen publieke sleutel) en berekent uit leaf 3 en de ontvangen leaf 4
de waarde P [3, 4]. Deze waarde combineert hij met de ontvangen waarde P [1, 2]om P [1, 4] te berekenen. Uit P [1, 4] en P [5, 8] kan hij uiteindelijk de top vande boom berekenen. Indien deze dezelfde is als de geauthentiseerde kopie diegebruiker V al in zijn bezit had, dan wordt de publieke sleutel aanvaard.
Wanneer Merkle-bomen gebruikt worden in combinatie met een eenmalig-hand-tekeningschema, dan bestaat het plaatsen van een handtekening uit de volgendehandelingen:
1. Berekenen van de top van de boom. Hiervoor moeten alle publieke sleutels,die in de toekomst gebruikt zullen worden, berekend worden. Dit moet slechtseen keer gebeuren per boom. De top van de boom wordt verspreid naar allegebruikers die handtekeningen zullen verifieren.
2. Genereren van de publieke en private sleutel die voor deze handtekeninggebruikt zullen worden.
3. Berekenen van het authentiseringspad. Jakobsson et al. [80] hebben hiervooreen algoritme ontwikkeld dat slechts O(log2(N)/ log2(log2(N))) invocatiesvan f nodig heeft per pad dat berekend moet worden.
4. Berekenen van de handtekening.
5. Doorsturen van de handtekening, de publieke sleutel en het authentiserings-pad.
Om een handtekening te verifieren, controleert men eerst de authenticiteit van deontvangen publieke sleutel (via het authentiseringspad en de top van de gebruikteMerkle-boom) en daarna de handtekening zelf.

xxix
P [1, 8]
P [1, 4]
P [1, 2]
leaf1
· · ·
leaf2
· · ·
P [3, 4]
leaf3
· · ·
leaf4
· · ·
P [5, 8]
P [5, 6]
leaf5
· · ·
leaf6
· · ·
P [7, 8]
leaf7
· · ·
leaf8
· · ·
1
Figuur 1. Merkle tree met 8 bladen. De top P [1, 8] kan gebruikt worden omheel de boom te authentiseren.
Eenwegskettingen
Een tweede efficiente methode om publieke sleutels te authentiseren is het ge-bruik van eenwegskettingen. De persoon die handtekeningen wil plaatsen, begintmet het genereren van een private sleutel: skN = {x1, x2, . . . , xt}. In plaatsvan de functie f eenmaal toe te passen om de publieke sleutel te bekomen,past de gebruiker de functie N -maal toe. Hier is N het aantal publieke sleu-tels die geauthentiseerd kunnen worden met de eenwegskettigen. De laatste setvan waarden die zo bekomen wordt, pk1 = {fN (x1), fN (x2), . . . , fN (xt)}, isde eerste publieke sleutel die gebruikt zal worden. Deze wordt op een geau-thentiseerde manier doorgegeven aan alle personen die handtekeningen willenverifieren (zoals de top van de Merkle-boom). De voorlaatste set van waarden,sk1 = {fN−1(x1), fN−1(x2), . . . , fN−1(xt)}, is de eerste private sleutel die zalgebruikt worden om een handtekening te plaatsen. Aangezien een handtekeningbestaat uit een deel van de private sleutel, kan deze geverifieerd worden door defunctie f toe te passen en na te kijken of dat men de overeenkomstige waardenuit de publieke sleutel pk1 bekomt. Eenmaal het sleutelpaar (pk1, sk1) gebruiktis, worden de vorige set van waarden op de kettingen de nieuwe private sleu-tel: sk2 = {fN−2(x1), fN−2(x2), . . . , fN−2(xt)}. De nieuwe publieke sleutel isgelijk aan de oude private sleutel: pk2 = sk1. Dit proces wordt verder gezettot de oorspronkelijke private sleutel skN bereikt is. Op deze manier kunnen Nhandtekeningen geplaatst worden.
Wanneer eenwegskettingen gebruikt worden in combinatie met een eenmalig-handtekeningschema, dan bestaat het plaatsen van een handtekening uit de vol-gende handelingen:

xxx Summary in Dutch
1. Berekenen van de eenwegskettingen. Hiervoor moeten alle publieke sleutels,die in de toekomst gebruikt zullen worden, berekend worden. Dit moet slechtseen keer gebeuren. De laatste bekomen waarden worden verspreid naar allegebruikers die handtekeningen willen verifieren.
2. Genereren van de private sleutel die voor deze handtekening gebruikt zalworden. Voor de eerste handtekening is dit het meeste werk, omdat dantot het einde van de kettingen moet gerekend worden. Voor iedere volgendehandtekening wordt dit steeds minder intensief, omdat steeds een kleiner deelvan de kettingen berekend moet worden.
3. Berekenen van de handtekening.
4. Doorsturen van de handtekening. Bemerk dat hier geen publieke sleutel moetdoorgestuurd worden.
Efficientie van de verschillende schema’s
We hebben de performantie geevalueerd van de drie eenmalige-handtekening-schema’s in combinatie met de twee mechanismen om publieke sleutels te au-thentiseren. Deze evaluatie resulteerde in algebraısche uitdrukkingen voor alleverschillende aspecten en numerieke evaluaties. Figuur 2 geeft de totale kost perhandtekening in mJ van de verschillende schema’s. In dit scenario werd veron-dersteld dat er een handtekening gestuurd wordt naar 10 personen ter verificatie.Verder werd er verondersteld dat de top van de Merkle-boom of de eerste pu-blieke sleutel (in het geval van eenwegskettingen) geauthentiseerd werd met eenECDSA-handtekening. Deze initialisatiekost zorgt ervoor dat de kost per handte-kening in eerste instantie kleiner wordt als het aantal handtekeningen per boomof set van eenwegskettingen groter wordt.
Hoofdstuk 4: Efficiente cooperatieve digitale handte-keningen
In dit hoofdstuk stellen we een constructie voor die het mogelijk maakt om ie-der eenmalig-handtekeningschema om te zetten naar een drempelschema. In ditschema kunnen een aantal knopen samenwerken om een handtekening te plaat-sen. In een (t, n)-drempelschema moeten minstens t knopen samenwerken omeen correcte handtekening te verkrijgen.
De belangrijkste bijdragen in dit hoofdstuk zijn:

xxxi
0 200 400 600 800 1000 1200 1400 1600 1800 20000
1000
2000
3000
4000
5000
6000
# signatures
mJ/
sign
atur
e
HORS−18 with Merkle
LDW with OWC
ECDSA
LDM with Merkle
HORS−18 with OWC
LDM with OWC
HORS−20 with Merkle
HORS−20 with OWC
LDW with Merkle
Figuur 2. Vergelijking van het energieverbruik van de verschillende handteke-ningschema’s. We veronderstellen hier 1 persoon die een handtekening plaats diedoor 10 personen geverifieerd wordt.
– We stellen een constructie voor om een eenmalig-handtekeningschema om tezetten naar een drempelschema.
– We tonen aan hoe dit kan ingezet worden in een authentiseringsmechanismevoor sensornetwerken.
Cooperatief eenmalig-handtekeningschema
Traditionele handtekeningschema’s zijn gebaseerd op “eenvoudige” wiskundigeuitdrukkingen. Zo bestaat een RSA-handtekening in essentie uit het berekenenvan een modulaire macht: s = md (mod pq). Hierin is s de handtekening,m de boodschap en {d, p, q} de geheime sleutel. Dit maakt het mogelijk omeen drempelschema te bouwen via mathematische constructies. Een eenvoudigdrempelschema voor RSA kan eruit bestaan de geheime sleutel d te verdelen intwee delen d1 en d2, zodat d1 + d2 = d. Deze sleutels worden verdeeld tussentwee gebruikers. Deze gebruikers rekenen dan ieder een “halve” handtekeninguit: s1 = md
1 (mod pq) en s2 = md2 (mod pq). Het product van deze twee
halve handtekeningen is een geldige RSA-handtekening die geplaatst werd metde sleutel d: s1s2 = s. Daar eenmalige-handtekeningschema’s die gebaseerd

xxxii Summary in Dutch
ECC (H ) = α code words
ω symbols
k users H′
5
H
Figuur 3. Voorbereidingsfase van het cooperatief eenmalig-handtekeningsche-ma.
zijn op eenwegsfuncties niet kunnen beschreven worden met elegante wiskundeuitdrukkingen, is het niet mogelijk een gelijkaardige constructie te gebruiken.
Om toch een drempelschema te kunnen construeren, geven we iedere gebrui-ker een eigen volledige private en publieke sleutel. De redundantie wordt danniet toegevoegd aan de handtekeningen zelf (zoals in het voorbeeld van de RSA-constructie), maar aan het bericht dat getekend zal worden. Figuur 3 toontdit proces. Eerst wordt de hashwaarde H van het bericht berekend. Op dezehashwaarde wordt een foutcorrigerende code toegepast die de nodige redundan-tie toevoegt, dit resulteert in ECC (H). Iedere gebruiker zal een deel van dezeECC (H) handtekenen. De persoon die de handtekening wil controleren, verza-melt en verifieert eerst alle individuele partiele handtekeningen. Daarna gebruikthij de foutcorrigerende code om H ′ te bereken uit de gereconstrueerde ECC ′(H).Indien de berekende H ′ gelijk is aan de hashwaarde van de gehandtekende bood-schap, dan wordt de volledige handtekening geaccepteerd.
Na een gedetailleerde beschrijving, geven we een veiligheidsanalyse van de con-structie.
Authentisering in sensornetwerken
Na de beschrijving van het cooperatief eenmalig-handtekeningschema, geven weaan hoe het kan ingezet worden om efficiente data-authentisering te bieden insensornetwerken. In vele sensornetwerken worden sensorknopen gegroepeerd inclusters. Wanneer bijvoorbeeld de temperatuur van een kamer opgevraagd wordt,dan worden de verschillende opmetingen van een volledige cluster eerst lokaalverwerkt tot een globaal resultaat. Dit resultaat wordt dan als antwoord terug-gestuurd.

xxxiii
Wij stellen een authentiseringsmethode voor die toelaat dat al de knopen in een-zelfde cluster samenwerken om een bericht te authentiseren. Daarnaast stellenwe ook een efficiente methode voor om de publieke en private sleutels te hernieu-wen. Het volledige systeem is zo ontworpen dat de zwakke sensorknopen nooitrekenintensieve taken moeten uitvoeren, maar dat deze taken steeds door desterke “‘query”-knoop (de knoop die de gegevens van het sensornetwerk uitleest)uitgevoerd worden.
Hoofdstuk 5: Dynamisch sleutelbeheer
Wanneer symmetrische cijfers worden gebruikt om gegevens te vercijferen, dan ishet essentieel dat de twee communicerende partijen kunnen beschikken over eengedeelde geheime sleutel. In dit hoofdstuk stellen we een mechanisme voor om de-ze sleutel af te spreken in een dynamisch ad-hoc netwerk. Om het systeem zo effi-cient mogelijk te houden, maken we geen gebruik van publieke-sleutelcryptografie.
De belangrijkste bijdragen in dit hoofdstuk zijn:
– We stellen een efficient sleutelbeheersysteem voor ad-hoc netwerken voor. Ditschema werkt autonoom, zonder hulp van vaste knopen die dienst doen alssleutelverdelingscentra.
– We tonen aan hoe dit schema kan geıntegreerd worden met een routerings-schema voor ad-hoc netwerken.
– We hebben de veiligheid en de efficientie van het voorgestelde systeem gea-nalyseerd.
Initialisatie
Ons systeem is een uitbreiding van “key pre-distribution”-schema’s (KPD) naareen omgeving waar knopen zich vrij kunnen bewegen. In een KPD-schema wor-den geheime sleutels in de knopen geınstalleerd voor ze uitgezet worden. Eeneenvoudig KPD-schema kan er bijvoorbeeld in bestaan dat iedere knoop 60 wil-lekeurig gekozen sleutels krijgt uit een set van 5000 sleutels. De kans dat tweeknopen dan een sleutel delen is ongeveer 50%. Er bestaan vele variaties diebijvoorbeeld rekening houden met de plaats waar een knoop waarschijnlijk zalterechtkomen, enz.

xxxiv Summary in Dutch
Sleutels opzetten met de buurt
Eenmaal de knopen uitgezet zijn, proberen zij sleutels af te spreken met alleknopen in hun buurt. Een buurt met straal l wordt gedefinieerd als alle knopendie bereikbaar zijn in maximaal l hops. Indien een knoop geen sleutel deelt viahet KPD-schema met een of meerdere van zijn buren, dan zal hij via andereknopen waarmee hij wel een sleutel deelt, een sleutel opzetten met deze buren.
Na deze initiele fase deelt elke knoop een geheime sleutel met alle andere knopenin zijn buurt. Veronderstel nu dat (door de mobiliteit van de knopen) een nieuweknoop B in de buurt van knoop A komt. Knoop A zal nu een sleutel met denieuwe knoop afspreken. Met zeer grote waarschijnlijkheid zullen er meerderepaden zijn tussen knopen A en B, waarbij iedere hop op dit pad beschermd is dooreen sleutel die gedeeld is door de twee eindpunten van deze hop (aangezien iedereknoop sleutels deelt met zijn gehele buurt). Knoop A stuurt via een van dezepaden een bericht naar knoop B met de vraag een sleutel af te spreken. Knoop Bgenereert dan een willekeurige sleutel en verdeelt deze in stukken via een (m,n)“secret sharing”-mechanisme. Met dit mechanisme heeft men minstens m van den delen van de sleutel nodig om deze te reconstrueren. Knoop B stuurt nu iederdeel over een verschillend pad naar knoop A. Hierbij worden de delen hop-per-hop vercijferd via de bestaande sleutels. Knoop A reconstrueert de sleutel uitminstens m delen. Het “secret sharing”-mechanisme heeft twee voordelen. Teneerste mogen een aantal delen van de geheime sleutel verloren gaan en ten tweedemoet een aanvaller minstens m delen bemachtigen om het geheim te achterhalen.
Integratie met een routeringsprotocol
In dit deel tonen we aan hoe ons sleutelbeheersysteem geıntegreerd kan wordenin bestaande routeringsprotocollen, in het bijzonder het Dynamic Source Rou-ting (DSR) protocol. De integratie van de twee systemen, routering enerzijds ensleutelbeheer anderzijds, heeft twee voordelen. Ten eerste kan het routeringspro-tocol beveiligd worden met de sleutels die opgezet worden via het sleutelbeheersysteem en ten tweede wordt de extra overhead vermeden die gecreeerd wordt,wanneer de twee systemen onafhankelijk van elkaar geımplementeerd worden.
Performantie- en veiligheidsanalyse
Ten slotte geven we een performantie- en veiligheidsanalyse van het voorgestel-de sleutelbeheersysteem. De performantieanalyse is gebaseerd op een analytischmodel en op simulaties om aan te tonen dat het analytisch model accuraat is.

xxxv
In de veiligheidsanalyse wordt de veiligheid van het sleutelbeheersysteem en hetgeıntegreerd routeringsprotocol besproken. Ten slotte hebben we, via een eenvou-dig analytisch model, achterhaald hoe snel het aantal gecompromitteerde knopengroeit wanneer een aanvaller een fractie c van de geheime sleutels achterhaaldheeft. Deze analyse geeft aan dat het schema veiliger wordt wanneer men destraal l van de buurt kleiner maakt, en wanneer men het (m,n) “secret sharing”-mechanisme minder robuust maakt (een kleinere m kiest).
Hoofdstuk 6: Privacy in ad-hoc netwerken
Dit laatste hoofdstuk handelt over privacy in ad-hoc netwerken. In de huidigesamenleving, waar de digitalisering zich blijft uitbreiden, wordt onze privacysteeds meer bedreigd. Met de huidige technologie is het mogelijk om op zeer kortetijd zeer grote hoeveelheden gegevens te verwerken (bedenk bijvoorbeeld hoe snelde Google zoekmachine resultaten kan produceren). Door de digitalisering vandiensten laten we ook steeds meer sporen na van onze handelingen. Al onzebanktransacties en informatie over telefoongesprekken worden opgeslagen, onskoopgedrag wordt verzameld via klantenkaarten, enz. Door het gebruik vanmobiele telefonie, zoals GSM, wordt niet alleen informatie over de gesprekkenopgeslagen, maar ook de locatie van waar we belden. Met de introductie vanad-hoc netwerken, waarin iedere gebruiker mogelijk berichten zal doorsturen vanandere gebruikers, zal dit probleem nog groter worden. In dit geval kunnen weniet langer vertrouwen op de mobiele operator om onze gegevens te beschermen.
We vatten dit hoofdstuk aan met een inleiding tot het privacy-domein. Daarnageven we een volledig overzicht en analyse van de state-of-the-art van anoniemerouteringsprotocollen voor ad-hoc netwerken. In de analyse duiden we de zwakkeen sterke punten aan van de voorgestelde protocollen.
Na deze inleiding stellen we een eigen protocol voor anonieme routering in ad-hocnetwerken voor. In ons voorstel trachten we de bestaande protocollen te verbe-teren op twee gebieden: op het gebied van efficientie en de geboden anonimiteit.
De belangrijkste bijdragen in dit hoofdstuk zijn:
– We geven een overzicht van de state-of-the-art in anonieme routeringsproto-collen voor ad-hoc netwerken.
– We presenteren een nieuw schema dat meer privacy biedt en efficienter is dande bestaande voorstellen.
– We geven een gedetailleerde analyse van de anonimiteit die geboden wordt.

xxxvi Summary in Dutch
DN1
N2
S
Figuur 4. Route tussen zender S en bestemming D. De volle lijn duidt eenechte route tussen S en D aan, terwijl de stippelijnen nepberichten aanduidenom de locatie van de echte route te beschermen.
ARM: anonieme routering voor mobiele ad-hoc netwerken
Een eerste onderdeel van het anoniem routeringsprotocol is de constructie vaneenmalige pseudoniemen die knopen kunnen gebruiken om elkaar te contacteren.De voorgestelde constructie is gebaseerd op een geheime sleutel die gedeeld wordttussen de twee communicerende partijen. De pseudoniemen die op deze manierbekomen worden, hebben het voordeel dat ze op een efficiente manier herkendkunnen worden door de andere partij, zonder dat enige andere partij een ideeheeft aan wie het bericht gericht is.
Eenmaal een nieuw pseudoniem geconstrueerd is, kan het gebruikt worden omeen of meerdere paden op te zetten naar de andere partij. Het opzetten vandeze paden gebeurt zodanig dat de deelnemende knopen (die berichten zullendoorsturen naar elkaar tot de eindbestemming bereikt is) geen idee hebben wiede communicerende partijen zijn of waar deze gelocaliseerd zijn. Onze oplossingbiedt dus bescherming tegen de knopen die deel uitmaken van het netwerk. Daar-naast biedt onze oplossing ook bescherming tegen een aanvaller die alle berichtenin het netwerk kan afluisteren. Het is duidelijk dat, wanneer deze aanvaller her-haaldelijk een bericht ziet passeren over eenzelfde route, hij kan aannemen datde eindpunten van deze route met elkaar communiceren. Daarom stellen we eensysteem voor om de locatie van een echte route te beschermen via nepberichten(zie Fig. 4).
Om deze bescherming te bieden maken we zowel gebruik van een “padding”-schema (hierdoor krijgen berichten een willekeurige lengte) en een “time-to-live”-schema (de nepberichten sterven uit nadat ze een aantal hops afgelegd hebben).Na de voorstelling van ons anoniem routeringsprotocol geven we een gedetailleer-

xxxvii
de analyse van de anonimiteit en efficientie die geboden wordt door padding entime-to-live schema’s.


Chapter 1
Introduction
1.1 Motivation
The short but rapidly evolving history of digital communication systems hasrecently taken another turn. Since their introduction in the 1940s, digital com-puters have evolved from room-filling machines, available only to a few largeorganizations, to affordable, light and portable devices. In parallel, starting inthe late 1950s, computer networks evolved from small isolated networks centeredaround a mainframe, to the now omnipresent Internet, connecting computersaround the globe. Until recently, computers were typically connected to a wallsocket using a wire, limiting the mobility of the users. With the introductionof the 802.11 Wireless Local Area Network (WLAN) standard in the 1990s, itis now possible to make a wireless connection to an Access Point (AP), whichreplaces the traditional Ethernet socket. These recent advances in wireless tech-nologies and further miniaturization of computer systems, enable the next majorevolutionary step: Mobile Ad hoc Networks (MANETs).
The most important characteristics of MANETs are [121]:
– Self-organized and Decentralized: An ad hoc network establishes itself themoment two or more devices enter each others’ communication range. Thishappens without the use of any fixed infrastructure, but relies solely on thedevices that make up the ad hoc network.
– Dynamic network topology: In many situations, the devices will be mobile.Next to this, due to power considerations, devices can turn themselves off atany time. Both actions imply a changing network topology.
1

2 Chapter 1. Introduction
– Multi-hop, wireless connections: Obviously, nodes can only be mobile if theyare linked through wireless connections. Possible technologies include radioand infrared. In order to be able to communicate with devices that are out ofrange, intermediate devices will forward data packets in a hop-by-hop fashion.
– Heterogeneity: The devices that make up an ad hoc network can have verydifferent capabilities (ranging from radio enabled light switches, al the wayup to laptops).
MANETs make it possible to rapidly deploy networks in areas that have noexisting communications infrastructure, making them extremely well suited toestablishing communications in disaster areas or war zones. Other applicationsinclude urban mesh networks and car to car networks. Urban mesh networks havethe potential to allow users to bypass broadband providers. A single house couldconnect to the Internet and then extend access to the entire neighborhood viawireless, multi-hop ad hoc networking. Cars could benefit in many ways from acommunication link. Next to the obvious benefits to business and entertainmentapplications, safety on the road would also improve: traffic congestion avoidance,collision avoidance, braking coordination, remote diagnostics, etc.
One specific example of MANETs are Distributed Sensor Networks (DSNs). Sen-sor networks consist of thousands of miniature sensors (referred to as motes)that are deployed in some area of interest [14, 90, 135, 171, 174]. These sensors,equipped with the necessary computing power and communication capabilities,form a wireless ad hoc network to collect and forward the necessary sensing data.Typical characteristics of sensor networks (in addition to those of a MANET)are:
– Unattended: Once the sensors have been deployed, they may be physicallyimpossible to reach.
– Limited power supply: In many situations, the sensor node’s energy is sup-plied by a battery. If the sensor’s cannot be reached, then the battery cannotbe replaced.
– Limited processing power: Cheap miniature sensors with ultra-low powerbudgets will not be equipped with fast, multimedia-enabled processors.
– Limited bandwidth: Fast transmission speeds are not required and requiremore power.
Possible applications of sensor networks include: (1) A farmer or ecologist couldequip motes with sensors that detect temperature, humidity, etc., making eachmote a mini weather station. Scattered throughout a field, orchard or forest,these motes would allow the tracking of micro-climates, detect diseases, etc. (2)

1.2 This thesis and related work 3
A biologist could equip an endangered animal with a collar containing a motethat senses position, temperature, etc. As the animal moves around, the motegathers data from the sensors. This data is collected by an ad hoc network ofdata retrieving motes scattered throughout the animals natural habitat. (3) Sky-scrapers, bridges and other large structures could be fitted with motes that areequipped with a positioning system. Minute changes in related position of motescan be used to detect cracks and creases in these structures.
Providing security is an important issue that needs to be solved before MANETscan become an everyday reality. Wireless communications are easy to interceptwithout detection. Moreover, radio waves travel through walls and windows, andcan be intercepted outside the physical perimeter of homes and corporations. Themedia attention given to the failing Wired Equivalent Privacy (WEP)1 protocol[24, 63, 170], and in a lesser degree, to the Bluetooth security shortcomings[82], proves that security is deemed important by the general public. Due tothe specific properties of wireless ac hoc networks, it is not straightforward toprovide security services. First of all, there are no online central servers that canbe used to facilitate security services such as signing public key certificates orestablishing session keys. Secondly, multi-hop routing implies that every node inthe system is a potential router for any other node. Mechanisms need to be inplace to establish the level of trust we have in these other nodes, to protect ourdata from them, etc. Thirdly, because of the dynamic network topology, routeswill continuously change. New nodes will enter a node’s neighborhood, while oldnodes leave the neighborhood. This means that nodes will continuously have toestablish new trust relationships. Finally, the security mechanisms will have tooperate on nodes with limited resources. Traditional security mechanisms werenot designed with the specific properties of ad hoc networks in mind. Therefore,the majority of these mechanisms are not directly applicable to MANETs. Sincethe late 1990s, a substantial research effort has been directed at designing securitymechanisms for wireless ad hoc networks.
1.2 This thesis and related work
Providing security for ad hoc networks encompasses the complete informationsecurity research domain, ranging from developing efficient cryptographic primi-tives to preparing security policies. We can distinguish several subtopics (manyof them a complete research field themselves):
1WEP was the first mechanism proposed to secure IEEE 802.11 wireless Local Area Networks(LANs).

4 Chapter 1. Introduction
Efficient cryptographic primitives
Many security mechanisms rely on cryptography. Because of the limited resourcesof the nodes in an ad hoc network, it is important that these cryptographicprimitives are as efficient as possible. Efficiency has always been an importantcharacteristic of cryptographic primitives, but when designing protocols for adhoc networks, their efficiency should be considered as important as the securitythey offer. We provide a detailed analysis of the efficiency of the most commoncryptographic primitives in Chapter 2. In Chapter 3, we present a detailedanalysis of the efficiency of one-time signature schemes based on a universal one-way function. Finally, in Chapter 4 we show how it is possible to constructcooperative threshold one-time signature schemes, in which multiple users cancooperate to sign a message.
Authentication and Key establishment
Cryptography reduces the confidentiality and integrity of a message to the con-fidentiality and integrity of a key. When using symmetric cryptography, theparties involved have to negotiate a secret key. A good key establishment schemeprovides entity authentication (all parties know the identity of the other par-ties with whom they are establishing a key), key authentication (all parties areassured that no unauthorized parties could have obtained the secret key), andkey confirmation (all parties are assured that all other parties have knowledgeof the secret key). Key establishment schemes can be divided into three majorcategories: (1) key pre-distribution schemes, (2) schemes using a trusted thirdparty, and (3) schemes based on public key cryptography.
Key pre-distribution schemes have received a lot of attention in the setting of adhoc networks. They are very suited for ad hoc networks as they do not requirea trusted third party to be available at all times, and are very efficient (theydo not require computations and very little communications). Eschenauer andGligor [58] were the first to propose random key pre-distribution to establish keysin ad hoc networks. They propose installing a random subset of a larger batchof keys in every node. After deployment, the nodes check whether they sharea key with one or more of their neighbors. For example, two nodes will shareat least one key with a probability of 50% if each of them receives 60 differentkeys out of a batch of 5000 keys. Many variations and adaptations have beenproposed subsequently (e.g., based on location information, using structured keydistribution instead of random distribution, etc.). We refer to [37] for an overview.Du et al. have combined Blom’s key pre-distribution scheme [22] with random keypre-distribution, resulting in a scheme with a nice threshold property. As long as

1.2 This thesis and related work 5
less than or equal to λ nodes have been compromised, uncompromised nodes aresecure; when more than λ nodes are compromised, all pairwise keys in the entirenetwork are compromised [56]. These proposals are all targeted at static (ornear-static) networks. In Chapter 5 we propose a key establishment scheme thatextends key pre-distribution schemes to the setting of dynamic networks. Thisscheme uses key pre-distribution as a bootstrap mechanism and allows nodes tocontinuously establish pairwise keys with their neighbors or any other node inthe network. We achieve this by allowing every node in the network to becomea trusted third party for any other node.
Schemes using trusted third parties are not really suited for ad hoc networks asthey assume that the trusted third party is available to anybody. However, theycan be applied in a distributed fashion as in the scheme we propose in Chapter 5.
The disadvantage of public key based schemes is that they require certificatesand that public key algorithms are inefficient (Chapter 2). Zhou and Haas [185]propose to distribute the task of the Certification Authority (CA) to multiplenodes using a threshold scheme. This has two advantages: (1) if one or moreof the CAs becomes unreachable, a node can still obtain a certificate, and (2)an adversary will have to compromise multiple CAs before he can falsify cer-tificates. We have extended this idea in [156]. The self-organized Public KeyInfrastructure (PKI) for ad hoc networks was introduced by Hubaux et al. [75].Their scheme is similar to Pretty Good Privacy (PGP) [187] in the sense thatpublic key certificates are issued by the users. However, as opposed to PGP,certificates are stored and distributed by the users (and not by certificate direc-tories). Each user maintains a local repository that contains a limited number ofcertificates. When user u wants to obtain the public key of user v, they mergetheir local repositories, and u tries to find an appropriate certificate chain from uto v in the merged repositories. A third mechanism to authenticate public keysis using identity-based public key systems [23]. In identity-based schemes, thepublic key is mathematically derived from the identity of the user, i.e., knowingthe identity of a user automatically provides you with an authenticated copy ofthat user’s public key. This has been adapted to ad hoc networks in, a.o., [42, 93].Finally, we mention the work by Jakobsson and Pointcheval [81]. They propose avariation on the well known Station-to-Station (STS) protocol [107, Sect. 12.6],that is specifically designed for efficiency.
Carman et al. [35, 36] have analyzed several approaches for key managementin sensor networks. They present detailed performance evaluation of severalschemes, including key pre-distribution, protocols using a trusted server, au-tonomous key agreement protocols and the use of identity-based public key cryp-tography.

6 Chapter 1. Introduction
Broadcast authentication
Unless directed antennas are used, radio transmissions are automatically broad-cast transmissions. In multi-hop routing this is important as it allows to use allnodes within range as potential routers for our messages. In order to preventan adversary from flooding the entire network with messages, authentication ofbroadcast messages is an important aspect of ad hoc network security. Oneobvious solution would be to attach a digital signature to every broadcast mes-sage, as the same signature can be verified by every recipient. The inefficiencyof digital signature schemes combined with the fact that broadcast is the mainmethod of establishing routes in ad hoc networks, means that this is not an idealsolution. Perrig et al. propose different protocols that uses efficient Message Au-thentication Codes (MACs) [124, 126] or one-time signature [125] to authenticatebroadcast messages. As MACs are symmetric primitives, the key to create andverify a MAC value is the same. This means that every node v that can verify abroadcast message originating at node u, can also impersonate node u. Perrig etal. solve this by introducing time as an asymmetric property in the system. Thesender u computes a MAC of his broadcast message using a key k that is notknown to the other nodes at the moment of broadcast. After a short time delay,the key k is released to the other nodes. The other nodes can authenticate thiskey k using one-way chains (see Sect. 3.4.2 on p. 49). The moment the key isreleased, it cannot be used any more to create MACs, only to verify them. Thedisadvantage of this mechanism is that it requires a synchronized clock.
Secure Routing
Almost all ad hoc routing schemes [121, 127] use broadcast at some point. There-fore, most proposals for secure broadcast also include a section on how to use thesecure broadcast mechanism to create secure routing schemes [125, 126]. Hu etal. [73] present a secure broadcast mechanism that can use serveral authentica-tion methods, they also discuss a number of attacks on ad hoc routing schemes.Papadimitratos and Haas propose a scheme based on MACs that only requiresthat the two communicating nodes share a secret key [118]. In [117] they presenta protocol that is based on digital signatures. Other schemes based on digitalsignatures include [71, 167]. In Chapter 5 we show how our key establishmentprotocol can be built on top of the Dynamic Source Routing (DSR) routingprotocol, and how we can use the established keys to build a secure version ofDSR.

1.3 Outline and main contributions 7
Privacy
Privacy is an important issue for mobile wireless networks. Soon after the publi-cation of the Bluetooth standard, it was shown that it is straightforward to tracka device’s whereabouts [82]. As many wireless devices are also personal devices(e.g., PDA, cell phone, etc.), this implies that it is possible to track people asthey move about. The moment ubiquitous computing becomes a reality, the pri-vacy risks become even higher. People will be able to use their personal deviceto connect to a wide range of services anytime, anywhere. In high density areas,such as city centers, shopping malls and airports, multi-hop ad hoc networks canbe used to offer connectivity to these services. Not only the service providers,but all users, will have to be trusted not to reveal private information aboutother users. It is clear that, as we progress more and more towards ubiquitouscomputing, privacy enabling techniques become more and more important. Weprovide a detailed overview of the state in the art of privacy preserving ad hocrouting schemes in Chapter 6. We propose a new efficient anonymous routingscheme that protects against a more powerful adversary.
Incentives and reputation schemes
Ad hoc networks rely on other devices (usually owned by different users) to for-ward messages for each other. An important issue here is that the average useris selfish and is likely to abuse the system by not forwarding messages of others.This has triggered research towards techniques to provide users with an incentiveto forward messages. The field can be split into two different approaches: award-ing well behaving users and punishing misbehaving users. The awarding schemes[33, 34, 79, 184] usually involve paying users to forward messages, in many casesusing a micro-payment scheme [102, 112, 146]. The downside of these proto-cols are their overhead and the fact that they require some fixed infrastructure.Reputation systems work by detecting and punishing the misbehaving nodes,so that cooperation is more attractive than cheating [30, 31, 32, 74, 105, 113].The disadvantage of reputation schemes is that it is difficult to distinguish be-tween malicious behavior and broken links, device failures, etc. They also havedifficulties to prevent users from framing other users.
1.3 Outline and main contributions
The outline of this doctoral thesis is the following:

8 Chapter 1. Introduction
– Chapter 1 presents the motivation and context of the work described in thisthesis.
– Chapter 2 shows the state of the art of cryptographic primitives and pro-vides a detailed analysis of their efficiency. The design decisions made in thesubsequent chapters were based on the information provided in this chapter.
– Chapter 3 provides a detailed analysis of the efficiency of one-time signatureschemes based on a universal one-way function and compares them withtraditional signature schemes such as the Elliptic Curve Digital SignatureAlgorithm (ECDSA). This analysis takes into account all aspects of usingthese schemes in a wireless environment, including authentication of the one-time public keys. This chapter is an extended version of the research resultsthat we have published in [159].
– Chapter 4 shows how it is possible to construct cooperative threshold one-time signature schemes, in which multiple users can cooperate to sign a mes-sage. In the second part of this chapter, we show how to build a completedata authentication mechanism, that allows multiple sensor nodes to jointlyauthenticate data packets. In this scheme, the sensor nodes are only requiredto perform the efficient public operations (i.e., encryption and signature ver-ification) of the RSA or Rabin public key systems, while the computationaldemanding tasks are off-loaded to the powerful query nodes. This chapterextends the research results that we have published in [158].
– Chapter 5 presents a key establishment and secure routing protocol fordynamic ad hoc networks. The key establishment scheme, which is based onsecret sharing, allows nodes to securely maintain pairwise keys and broadcastkeys with their 1-hop neighborhood. The same mechanism also allows anytwo arbitrary nodes to securely establish a pairwise key. We show how tointegrate the key establishment protocol with the DSR protocol. This workwas partially presented in [160].
– Chapter 6 describes a novel anonymous routing scheme for ad hoc networks.The chapter starts with an introduction to the field of anonymity and thepresentation of the state of the art in anonymous routing schemes for adhoc networks. We show the strengths and weaknesses of these schemes, withrespect to both the anonymity they offer and their efficiency. Next, we presenta novel anonymous routing scheme that outperforms existing proposals bothconcerning efficiency and the provided anonymity. We show and analyze howit is possible to hide routes by allowing limited broadcast, and how to selecttime-to-live values in order to achieve optimal performance with respect toanonymity. This chapter extends the research results that we have published

1.3 Outline and main contributions 9
in [157].
– Chapter 7 summarizes the conclusions and provides possible directions forfuture research.
We have worked on other research publications that have not been included inthis thesis. In [48, 50], we introduce an information theoretic model that can beused to measure the degree of anonymity provided by schemes for anonymousconnections. In [156], we present a key management scheme for ad hoc networksbased on hierarchical and distributed PKI. An extension of the “Resurrectingduckling” protocol by Stajano and Anderson [168, 169] was presented in [154].Finally, in [155] we show how to mitigate denial-of-service attacks on ad hocnetworks by authenticating every single message in the network.


Chapter 2
Efficiency of CryptographicPrimitives
As mentioned in the introductory chapter of this thesis, a large part of our re-search was motivated by the restrictions of the mobile devices for which ourprotocols are designed. In this chapter we describe and evaluate the efficiencyof the most common cryptographic primitives, both symmetric techniques andpublic-key techniques. This chapter is not intended as a rigorous and detailedexplanation of the cryptographic primitives we describe, but rather to help under-stand the performance differences between these primitives. As such, we will notdefine every notion that is required to completely analyze many security aspects.For example, we will use the terms “easy”, “hard”, “infeasible”, etc. withoutmathematical definitions to describe the exact meaning of these terms. We referto [104, 107, 130] for exact definitions, detailed descriptions and rigorous securityanalyses of the primitives we briefly discuss here.
Contributions in this chapter
– This chapter gives an overview of the state of the art of current cryptographicprimitives and provides a detailed analysis of their efficiency.
– We also explain why certain schemes are more efficient than others.
– The information provided in this chapter is necessary to explain the designdecisions we made in the following chapters.
11

12 Chapter 2. Efficiency of Cryptographic Primitives
2.1 Symmetric primitives
There are three fundamental classes of symmetric primitives: stream ciphers,block ciphers, and cryptographic hash functions. Stream ciphers and block ci-phers are usually used to provide confidentiality, i.e., hiding messages from unau-thorized parties using encryption. The other main application of block ciphersis the construction of MACs. MACs are used to provide message integrity andauthentication. Message integrity allows detection of unauthorized modifica-tions of messages, while entity authentication provides the recipient with proofof the identity of the source of the message (see [107] for exact definitions).Finally, cryptographic hash functions have multiple applications, e.g., integrityprotection, preparing messages for digital signatures, building one-time signatureschemes, etc.
2.1.1 Symmetric encryption
Shannon was one of the pioneers in the field of cryptography [162]. Shannondescribed a good encryption algorithm as a mixing-transformation which dis-tributes the meaningful messages from the sparse region of meaningful messagesfairly uniformly over the entire message space. Note that for Shannon the plain-text space is a sparse region inside the larger message space (the ciphertext space).Although nowadays, it is no longer true for all encryption algorithms that theplaintext space is the same as (or a subspace of) the ciphertext space, this notionof mixing-transformation still remains meaningful. Nowadays, an essential prop-erty of a good encryption algorithm is that the ciphertexts have a distribution inthe ciphertext space which is indistinguishable from the uniform distribution inthe same space.
The basic model of an encryption scheme is depicted in Fig. 2.1. Alice wants totransmit a secret message to Bob over an insecure channel in such a way that anadversary Eve is not able to learn the message although she can eavesdrop on thechannel. For this purpose Alice and Bob use an encryption scheme. Syntactically,an encryption scheme can be defined as follows:
Definition 2.1 (Encryption scheme). Let the set of plaintext messages, theset of ciphertext messages (cryptograms), the encryption and decryption key spacebe M, C,PK and SK respectively. An encryption scheme consists of three algo-rithms Gen, E and D:
– The encryption-decryption key pair (pk , sk) is generated by the efficient keygeneration algorithm Gen : {0, 1}∗R → PK× SK.

2.1 Symmetric primitives 13
– Messages are encrypted with the efficient encryption algorithm E : PK×M→C. We denote this by
c = Epk (m) .
– Cryptograms are decrypted with the efficient decryption algorithm D : SK ×C →M. We denote this by
m = Dsk (c) .
Here, “efficient” means that the required time is polynomial in the bit-length ofthe input.
In the case of symmetric encryption schemes, the encryption and decryption keyis the same and needs to be exchanged between Alice and Bob beforehand. Inasymmetric or public key cryptosystems there are two different keys, one forencryption and one for decryption. The encryption key pk is made public, whilethe decryption key sk is kept secret by its owner (see Sect. 2.2).
Block ciphers
If block ciphers are used for encryption, messages are divided into data blocksof a fixed length and each block is treated as one message in either M or C.For many older block ciphers the block size is 64 bits (e.g., DES), while theblock size for new designs is usually 128 bits (e.g., AES). Usually, a block cipherconsists of a round function that is iterated for several rounds. In each round, anappropriate transformation is applied using a subkey derived from the originalsecret key. These subkeys are generated by the key scheduling algorithm ofthe cipher. Every round makes cryptanalysis of the cipher more difficult, thusimproving security. Inevitably, every round added to the cipher also makes thecipher slower as more computations are required.
For plaintext messages that are much longer than the particular block size (asis usually the case), different modes of operation can be used. Examples of suchmodes are Electronic Codebook (ECB), Cipher Block Chaining (CBC), CipherFeedback (CFB), Output Feedback (OFB), and Counter Mode [107]. In ECBevery plaintext block is encrypted one after another using the same key, while inCBC the previous ciphertext block is added (using XOR) to the plaintext blockbefore it is encrypted. The last three modes effectively turn the block cipherin a stream cipher (each mode having different properties with respect to errorpropagation). Note that ECB should not be used as it immediately reveals infor-mation on the plaintext (identical plaintext blocks result in identical ciphertextblocks). Furthermore, these modes do not offer message authentication. Message

14 Chapter 2. Efficiency of Cryptographic Primitives
authentication can be achieved by appending a MAC of the message, or by usingencryption modes that combine confidentiality and authentication. One exampleof such a mode is Offset Codebook Mode (OCB) [148].
Stream ciphers
Stream ciphers are, in essence, keyed deterministic random bit generators. Theytransform a given key k into an infinitely long (ultimately periodic) pseudo-random bit stream S(k). The bit stream S(k) can be used to encrypt a messagestream m by adding (XOR) the two streams together c = m ⊕ S(k). Thisencrypted stream can be decrypted using the same random bit stream S(k):m = c ⊕ S(k). The Vernam cipher can be seen as a particular stream cipherwhere S(k) = k, i.e., the key k itself is used as random key stream to encrypt amessage m. Obviously this requires a key k with length |k| = |m|. It is importantto note that a key stream s = S(k) should only be used once for encryption.Suppose two messages are encrypted with the same key stream: c1 = m1⊕ s andc2 = m2 ⊕ s. Adding the two ciphertexts yields c1 ⊕ c2 = m1 ⊕m2, i.e., the sumof two ciphertexts is equal to the sum of two plaintexts. Assuming that the twoplaintexts are not completely random (but are, for example, English texts), thenstatistical techniques make it possible to reveal information on the two messagesfrom their sum. Therefore, the Vernam cipher is also called the one-time pad.
Cryptographic hash functions
A hash function is a deterministic function which maps a bit string of arbitrarylength to a fixed length hash value. A cryptographic hash function H should atleast have the following security properties (besides being efficient):
Definition 2.2 (Collision resistance). It should be computationally infeasibleto find two distinct inputs with the same hash value. Because of the birthday para-dox [107], it is necessary that the output space of the hash function is sufficientlylarge.1
Definition 2.3 (Pre-image resistance). Given a hash value h, it should becomputationally infeasible to find an input string x such that H(x) = h.
Definition 2.4 (Second pre-image resistance). Given an input string x, itshould be computationally infeasible to find a second input string y 6= x such thatH(y) = H(x).
1The hash size has to grow as computers become faster, nowadays the hash size should beat least 160 bits.

2.1 Symmetric primitives 15
pk
sk
Alice Bob
E D
Gen
m c m
Eve
Figure 2.1. Schematic model of an encryption scheme.
2.1.2 Efficiency of symmetric techniques
AES and Rijndael
Rijndael was elected as the winner of the contest for the new Advanced Encryp-tion Standard (AES) for the United States in October 2000. This contest was or-ganized in 1997 by the National Institute for Standards and Technology (NIST) tofind a replacement for the Data Encryption Standard (DES), which was adoptedas the national standard in 1976. The AES was adopted by NIST as US FederalInformation Processing Standards (FIPS) PUB 197 in November 2001. As thesuccessor of the DES, the AES will become the worldwide de facto cryptographicstandard for banking, administrations and industry. In June 2003, the NationalSecurity Agency (NSA) has approved the AES with a 128-bit key for use up to“SECRET” level and the 192-bit AES for use up to “TOP SECRET” level.
The AES supports a subset of the key and block sizes of the Rijndael cipher.Only the 128-bit block size is supported by the AES, while Rijndael also offers160, 192, 224, and 256 bits. Rijndael supports key sizes of 160 and 224 bits inaddition to the three key sizes of the AES: 128, 192, and 256 bits.
One important evaluation criterion of the AES selection procedure was versatilityof the algorithm, meaning the ability to be implemented efficiently on differentplatforms. The AES has to run on an 8-bit micro-controller and smart card,

16 Chapter 2. Efficiency of Cryptographic Primitives
it should be possible to create an AES implementation on dedicated hardwarethat supports on the fly encryption at Gigabit per second rates, and it should beimplementable efficiently in software on a wide range of platforms and operatingsystems. As a result, the AES is a versatile algorithm and is ideal as a referencepoint to benchmark the efficiency of other ciphers.
Table 2.1 lists the performance of several 128-bit key AES implementations inhardware (encryption only). The last column (Indicator) gives an overall indi-cation of the efficiency of the implementation, as it shows how many bits theimplementation can output per processor cycle and per gate used.
The software performance of the AES depends on the platform on which thealgorithm is executed. In [134] the performance of all the NESSIE candidatesis evaluated. They report the following performance for 128-bit AES: 17–56 cy-cles/Byte for encryption and decryption, and 493–1461 cycles for the key sched-ule. The best performance was found on a DEC Alpha processor, while the IntelPentium I/MMX provided the worst performance. The NESSIE report [134] alsoshows that the AES is one of the best performing block ciphers overall, indicatingthat it might be difficult to substantially improve this design in the future.
Table 2.2 shows power consumption measurements on a 32-bit Intel StrongARMmicroprocessors by Potlapally et al. [133]. Next to the performance of the AES,the performance of SHA-1, the Digital Signature Algorithm (DSA), and the pub-lic key algorithms RSA, DSA and ECDSA is presented. These measurementsclearly show the performance gap between symmetric and asymmetric techniques.
Table 2.3 shows the energy efficiency of the AES implementations on severalplatforms [176]. The last column show the number of bits that can be encryptedwith one Joule. In hardware, a dedicated AES co-processor is 10 times moreenergy efficient than a Field-Programmable Gate Array (FPGA) implementa-tion. In software, hand optimized assembly code is about 10 times more efficientthan compiled C code, which in turn is about 1000 times more efficient thanJava code running in a Java Virtual Machine. This shows that offering cryp-tographic capabilities to low power devices requires dedicated algorithm-specificco-processors.
Stream ciphers: RC4, E0, A5/1 and MUGI
As the AES is one of the best block cipher designs with respect to performanceand security, we will not evaluate any other block cipher. We will now show howand where stream cipher designs could offer better performance compared to theAES.

2.1 Symmetric primitives 17
Table 2.1. Performance of ASIC implementations of 128-bit AES and MUGI.
Ref. Gate Count Clock Freq. Throughput Norm. TP Indicator[103] [MHz] [Gbit/s] [bit/cycle] [ 10−3bit
cycle×gate ]AES
[77] 612.834 15.243 1.950 127.93 0.209[97] 173 100 1.82 18.20 0.105[150] 24.7 192 0.794 4.14 0.167[150] 14.9 114 0.469 4.11 0.276
MUGI
[115] 26.1 45.7 2.922 63.94 2.45[115] 42.3 42.3 0.676 15.98 0.888
Table 2.2. Power consumptions of SHA-1, AES, RSA, DSA and ECDSA on a32-bit Intel StrongARM SA1100 @ 206MHz [133].
Operation |key| Power consumption|hash|
SHA-1 160 0.76 µJ/ByteAES key scheduling 128 7.83 µJAES encryption 128 1.21 µJ/Byte
Verification Signing
RSA 1024 15.97 mJ 546.5 mJDSA 1024 338.02 mJ 313.6 mJECDSA-GF(2163) 163 196.2 mJ 134.2 mJ
Table 2.3. Performance of 128-bit AES on several platforms [176].
Technologie Throughput Power Merit [bit/J]0.18µm CMOS 2 Gbps 56 mW 35.7 Gbit/JFPGA 1.32 Gbps 480 mW 2.7 Gbit/J (1/10)Asm on Pentium III 648 Mbps 41.4 W 15 Mbit/J (1/1.9 103)C on Emb Sparc 133 Kbps 120 mW 1.1 Mbit/J (1/3.3 104)Java on Emb Sparc 450 bps 120 mW 3.7 Kbit/J (1/107)

18 Chapter 2. Efficiency of Cryptographic Primitives
– RC4 was developed by Rivest in 1992 [145]. It is the cryptographic algo-rithm on which the IEEE 802.11’s WEP standard for wireless LANs is based.Although WEP itself is flawed [63], this is due to incorrect use of RC4 andnot an inherent flaw of RC4 itself. With a throughput of 8 cycles/Byte [134],RC4 is very efficient in software. Another advantage of RC4 is that it has avery small memory footprint (essentially a single lookup table of 256 Bytesand some simple logic to permute this table). It does not perform very wellin hardware (13 Kgates with a throughput of 3 cycles/Byte [94]).
– E0 and A5/1 are widely used stream ciphers based on Linear FeedbackShift Registers (LFSRs). The former is used in the Bluetooth standard, whilethe latter is used in the Global System for Mobile Communications (GSM)systems (outside Europe, the A5/2 cipher is used). These algorithms weredesigned to achieve a high energy efficiency with a small hardware footprint.They were not designed to be fast, as GSM or Bluetooth throughput is notvery high. In theory, E0 can be implemented in hardware using 1637 gates,while A5/1 can be implemented in 752 gates [8]. As they are LFSR designs,they can output 1 bit per cycle, thus they require 8 cycles per Byte.
– MUGI is a stream cipher designed by Hitachi, Ltd and K.U.Leuven [116,178]. The design goal was to perform as well as the AES in software, whileoutperforming it in hardware. In 2005, MUGI was selected for the firststream cipher standard ISO/IEC 18033-4. The MUGI self-evaluation report[115] shows a software performance of 21.8 cycles/Byte. The hardware per-formance is shown in Table 2.1.
Hash functions: RIPEMD-160, SHA-1, SHA-224/256/384/512
SHA-1 is the successor of SHA-0 as the FIPS Secure Hash Standard. Both algo-rithms were designed by the NSA. In 1993, the United States standards agencyNIST published the first Secure Hash Standard (FIPS PUB 180), now known asSHA-0. Shortly after publication, the NSA withdrew SHA-0 and it was replacedby the revised version SHA-1 (FIPS PUB 180-1) in 1995. More recently, NISTpublished four more hash functions in the SHA family, sometimes collectivelyreferred to as SHA-2. The first three of these variants, with hash lengths of 256,384 and 512 bits, were published in 2001. In 2002, NIST finalized them in theFIPS PUB 180-2 standard, which also includes SHA-1. Finally, in 2004, SHA-224 (with a 224-bit hash length) was added to this standard (this matches the224-bit key length of two-key triple DES [107]). SHA-256 and SHA-512 are novelhash designs using 32- and 64-bit words respectively. Their structures are almostidentical, using different parameters and number of rounds. SHA-224 and SHA-384 are simply truncated versions of the first two (using different initial values).

2.2 Public key cryptography 19
SHA-1 is also a mandatory part of the Digital Signature Standard (DSS) whichwas published in 1994 by NIST (FIPS PUB 186).
RIPEMD-160 [55] was published in 1996 as a secure replacement for the 128-bithash functions MD4, MD5, and RIPEMD. MD4 and MD5 were developed by RSAData Security, while RIPEMD was developed in the framework of the Europeanproject RIPE (RACE Integrity Primitives Evaluation). RIPEMD-160 is part ofthe ISO/IEC international standard ISO/IEC 10118-3:2003 on dedicated hashfunctions. RIPEMD-160 was designed in the open academic community (as wasthe AES), in contrast to the NSA-designed SHA family.
Table 2.4 compares these hash functions to the other cryptographic primitiveswhen implemented in software.
2.2 Public key cryptography
2.2.1 Introduction
In 1976 Diffie and Hellman first described the framework for public-key cryp-tography [52, 53]. They envisioned that it is possible to design a cryptosystembased on trapdoor one-way functions.
Definition 2.5 (Trapdoor one-way function–informal definition). A one-way function is a function f mapping X to Y such that
– it is easy to compute f(x) for all x ∈ X ;– given a value y it is infeasible to compute x such that f(x) = y for almost all
y ∈ Y.
A trapdoor one-way function has the following additional property:
– given a value y ∈ Y and some additional trapdoor information it is easy tocompute x = f−1(y).
Diffie and Hellman also introduced the notion of digital signatures. A digitalsignature allows to uniquely bind a message to its sender. This connection canonly be created by the sender, but it can be verified by everybody.
In contrast to symmetric cryptography, two different keys are used in public-keycryptography, a private key (known only by the owner of this key) and a public

20 Chapter 2. Efficiency of Cryptographic Primitives
key (known by everybody). Clearly, it is necessary that computing the secret keyfrom the public key is intractable.
Figure 2.1 shows a schematic overview of a public key encryption schemedefined in Def. 2.1. Alice wishes to send a private message to Bob. First, Bobgenerates his public and private key, and transfers his public key to Alice over anauthenticated channel. It is crucial that Alice has confirmation that the publickey she receives is actually the public key of Bob and not somebody else’s (seeSect. 2.2.2). Alice now encrypts her message using Bob’s public key and transfersher cryptogram to Bob. Finally, Bob decrypts the cryptogram to retrieve Alice’smessage.
Figure 2.2 shows a schematic overview of a digital signature scheme definedin Def. 2.6. Alice wishes to send a message to Bob in such a way that Bob canverify the integrity of the message he receives, i.e., Bob can detect that Eve haschanged the message m into m′. First, Alice generates her public and privatekey, and transfers her public key to Bob over an authenticated channel. Alice nowsigns her message using her private key and transfers the message and signatureto Bob. Finally, Bob can verify the signature using Alice’s public key.
Definition 2.6 (Digital signature scheme). Let the set of plaintext messages,the signature space, the signing and verification key space be M,S,SK and PKrespectively. A digital signature scheme consists of three algorithms Gen, Signand Verify:
– The verification-signing key pair (pk , sk) is generated by the efficient keygeneration algorithm Gen : {0, 1}∗R → PK× SK.
– Signatures are generated with the efficient signing algorithm Sign : SK×M→S. We denote this by
s = Signsk (m) .
– Signatures are verified with the efficient verification algorithm Verify : PK ×S → {true, false}. We denote this by
Verifypk (m, s) ?= true .
Here, “efficient” means that the required time is polynomial in the bit-length ofthe input.
2.2.2 Public key certificates
If one uses public key cryptography it is essential to know to whom a publickey belongs. For example, in Fig. 2.1, Alice has to be sure that the public key

2.2 Public key cryptography 21
Gen
sk
pk
Alice Bob
Sign Verifym m;s
Eve
m m!0
true orfalse
Figure 2.2. Schematic model of a digital signature scheme.
she has obtained belongs to Bob and not to Eve. Without additional measures,Eve could provide Alice with her public key, claiming that it is Bob’s public key.Unknowingly, Alice would use this public key to encrypt messages intended forBob, while they would only be intelligible to Eve (who owns the correspondingprivate key).
One solution is for Alice and Bob to meet in private and exchange public keys.This way they are sure that they have obtained authentic copies of each other’spublic keys. Note that if they can arrange to meet in private, then they could aswell agree on a symmetric secret key. Obviously, this mechanism cannot be usedwhen, for example, setting up a Secure Socket Layer (SSL) connection to an onlineshop. Therefore, SSL and many other systems employ public key certificates [95]to establish a secure link between a public key and the identity of the owner ofthis public key. In its basic form, a certificate consists of a public key, the identityof the owner and a digital signature that binds the two together. In a PublicKey Infrastructure (PKI) , this signature is generated by a third party, called theCertification Authority (CA). Now, Alice needs an authentic copy of the pubickey of Bob’s CA to be able to verify the signature in the certificate. Once thiscertificate has been verified, Alice has proof that the public key contained in thecertificate is indeed Bob’s, and she can safely use it to encrypt messages to Bob.Obviously, a single CA can create multiple certificates. All these certificates canthen be verified using the CA’s public key. In large-scale deployments, not one

22 Chapter 2. Efficiency of Cryptographic Primitives
but multiple CAs are used to obtain a hierarchical PKI. In such a hierarchy, thepublic keys of the CA’s themselves are certified by higher order CAs, etc. Thetop level CA of the hierarchy is referred to as the root CA. In SSL, the publickeys of these root CAs are built in the user’s browser. Note that a PKI does nothave to be hierarchic, but can have any structure that suits the specific scenariofor which it is used.
2.2.3 The RSA, Rabin and DSA public-key encryption and sig-nature schemes
RSA
The best known public-key encryption scheme is RSA. It was invented by Rivest,Shamir and Adleman in 1978 [147]. RSA is the first practical realization of public-key cryptography based on the notion of trapdoor one-way functions envisionedby Diffie and Hellman [52, 53]. In 1998, RSA was included in the DSS (FIPSPUB 186-1).
The textbook version of the RSA encryption scheme is depicted in Alg. 2.1, whilethe signature scheme is depicted in Alg. 2.2.
The security of RSA against a chosen-plaintext attack relies on the difficulty ofcomputing the e-th root of a ciphertext c modulo a composite integer n. Thisis known as the RSA problem. The difficulty of the RSA problem depends onthe difficulty of the integer factorization problem, i.e., given an odd compositeinteger with at least two distinct prime factors it is hard to provide one of theseprime factors. Clearly, an algorithm that solves the integer factorization problemwill solve the RSA problem since this is exactly what happens in the RSA keysetup process. However, the converse is still an open problem: can the integerfactorization problem be hard if the RSA problem is not hard? For a rigoroussecurity analysis of the RSA scheme and further references we refer to [104].
The naive description of the RSA encryption scheme in Alg. 2.1 is obviouslyflawed if the number of plaintext messages is small. Given the encryption ofonly a few possible plaintexts, the adversary can encrypt every possible plaintextusing the public key and verify whether the result is equal to the ciphertext. Thisclearly indicates that the simplified RSA algorithm in Alg. 2.1 should not be usedin practice. Bellare and Rogaway [10] have proposed a provably secure way ofencrypting messages using RSA or Rabin (see below), known as the OptimalAsymmetric Encryption Padding (OEAP) scheme. The proof of security forOEAP relies on the random oracle model, in which hash functions are modeled asbeing truly random functions. Although this model is not realistically attainable,

2.2 Public key cryptography 23
there is evidence that practical instantiations of provably secure schemes are stillbetter than schemes without provable security [9].
Looking at simplified descriptions of RSA in Alg. 2.1 and Alg. 2.2, it is easyto see that for the textbook version of the RSA signing procedure is the sameas the RSA decryption procedure, and signature verification is the same as en-cryption. Without additional measures, it is straightforward to forge a signature(i.e., generate a valid signature without knowledge of the private key (n, d) ona message that has not been signed by the owner of the private key). Anybodywith knowledge of the public key (e, n) can pick a random number s ∈ Z∗n andcompute
m = se (mod n) . (2.1)
Obviously, this construction yields a valid message-signature pair (m, s). An-other way of forging a message is due to the multiplicative property of the RSAfunction. Suppose Eve has obtained two valid message-signature pairs (m1, s1)and (m2, s2). By multiplying the signatures she gets a valid signature on theproduct of the two messages:
s1 × s2 (mod n) = md1 ×md
2 (mod n) = (m1 ×m2)d (mod n) .
These methods of forgery are known as existential forgeries.
Definition 2.7 (Existential forgery). An adversary is able to forge a signaturefor at least one message. The adversary has little or no control over the messagewhose signature is obtained, and the legitimate signer may be involved in thedeception [107, Chapter 11].
A usual method of detecting existential forgeries is to add recognizable redun-dancy to the message to be signed, which permits a verifier the correct “format”of the signed message. The most common method for adding recognizable in-formation to a message is to apply a cryptographic hash function. Let H besuch a hash function mapping {0, 1}∗ toM. A “message” m ∈M is only recog-nized as meaningful if the signer can show a bit-string M such that m = H(M).Now, computing a message m from a signature s as in Eq. (2.1) no longer pro-vides a useful forgery if the adversary cannot also come up with a pre-image M .Computing a pre-image from a hash value is prevented by the pre-image resis-tance property of the hash function H. In order to prevent an adversary, whohas obtained a message-signature pair (m, s), from generating a second messagem′ 6= m that results in the same signature s, the hash function also has to besecond pre-image resistant (which implies pre-image resistance). Usually, thishash computation (and other measures such as padding) are an integral part ofa digital signature scheme. Bellare and Rogaway [11] have presented a provably

24 Chapter 2. Efficiency of Cryptographic Primitives
Algorithm 2.1 The RSA public-key encryption system
Key setup
1. Generate two large distinct random primes p and q such that |p| ≈ |q|;2. compute n = pq and φ(n) = (p− 1)(q − 1);3. generate a random integer e such that 1 < e < φ(n) and gcd(e, φ(n)) = 1;4. use the extended Euclidean algorithm to compute the unique integer d such
that 1 < d < φ and ed = 1 (mod φ(n));5. publish (n, e) as the public key, keep (p, q, d) or (n, d) as the private key.
Encryption
Given a public key (n, e), the ciphertext c of message m ∈ Z∗n is
c = E(n,e)(m) = me (mod n) .
Decryption
To decrypt the ciphertext c using the secret key (n, d) one computes
m = D(n,d)(c) = cd (mod n) .
secure way of creating signatures with RSA and Rabin (see below), known asthe Probabilistic Signature Scheme (PSS). The proof of security for PSS relieson the random oracle model, in which hash functions are modeled as being trulyrandom functions. In contrast, the method for creating digital signatures withRSA that is described in PKCS #1 [132] has not been proven secure, even if theunderlying RSA primitive is secure. PSS-R is a message recovery variant of PSSwith the same provable security.
The Rabin public-key encryption and signature scheme
The Rabin public-key encryption scheme is very similar to RSA, but it uses theeven2 public exponent e = 2 [137]. This is not a special case of RSA as thesecurity is based on factoring; furthermore, the Rabin encryption function is notone-to-one: every ciphertext c = m2 mod n results in four possible plaintexts.Redundancy in the plaintext is required to ensure that only one square root is alegitimate message after decryption.
2All possible RSA public exponents e are odd.

2.2 Public key cryptography 25
Algorithm 2.2 The RSA signature scheme
Key setup
The key setup is the same as the key setup of the RSA encryption scheme(Alg. 2.1).
Signature generation
The signature of message m ∈ Z∗n is
s = Sign(n,d)(m) = md (mod n) .
Signature verification
Given a public key (n, e) and a message-signature pair (m, s), the verifier canverify the signature with the following procedure:
Verify(n,e)(m, s) = true if m = se (mod n) .
(To prevent existential forgery, the message m should be “recognizable”.)
Alg. 2.3 and Alg. 2.4 show the Rabin encryption scheme and Rabin signaturescheme respectively. Note that for the signature scheme it is necessary thatm ∈ QRn. If n is an RSA modulus, a quarter of the elements of Z∗n are in QRn.This means that the message space is reduced with two bits compared to theRSA scheme, but with suitable formatting one can make sure that m ∈ QRn.
The security of the Rabin scheme is based on the difficulty of computing a squareroot modulo a composite integer, and was the first provable secure public-keycryptosystem: the security of the Rabin cryptosystem is exactly the intractabil-ity of the integer factorization problem (see [104, 137] for a complete securityanalysis).
The Rabin public operations are extremely efficient as they only require a singlemodular squaring. By comparison, RSA with e = 216 + 1 requires 16 modularsquarings and 1 multiplication. The Rabin private operations are comparable inefficiency to the RSA private operations.
The DSA
The DSA is part of the DSS which was first announced in 1991 by NIST andpublished in 1994 (FIPS PUB 186). The security of the DSA is based on the

26 Chapter 2. Efficiency of Cryptographic Primitives
Algorithm 2.3 The Rabin public-key encryption system
Key setup
1. Generate two large distinct random primes p and q such that |p| ≈ |q|;2. compute n = pq;3. generate a random integer b ∈R Z∗n;4. publish (n, b) as the public key, keep (p, q) as the private key.
Encryption
Given a public key (n, b), the ciphertext c of message m ∈ Z∗n is
c = E(n,b)(m) = m(m + b) (mod n) .
Decryption
To decrypt the ciphertext c using the secret key (p, q) one solves the quadraticequation
m2 + bm− c = 0 (mod n) for m < n .
Algorithm 2.4 The Rabin signature scheme
Key setup
1. Generate an RSA modulus n = pq.2. publish (n) as the public key, keep (p, q) as the private key.
Signature generation
The signature of message m ∈ QRn is
s = Sign(n,d)(m) = m1/2 (mod n) .
Signature verification
Given a public key n and a message-signature pair (m, s), the verifier can verifythe signature with the following procedure:
Verifyn(m, s) = true if m = s2 (mod n) .
(To prevent existential forgery, the message m should be “recognizable”.)

2.2 Public key cryptography 27
difficulty of computing a discrete logarithm in the finite cyclic group F∗q with qprime. This is called the discrete logarithm problem: Given the integers x andy = xα ∈ F∗q (with x a generating element of the group, and α < q − 1), findthe discrete logarithm α of y. As the best algorithms known for the integerfactorization and discrete log problems have the same expected running times[107], the required key sizes for RSA and the DSA are the same. The DSAalgorithm is shown in Alg. 2.5.
2.2.4 Elliptic curve cryptography
The security of many asymmetric cryptographic primitives (e.g., the DSA) relieson the difficulty of computing a discrete logarithm in a finite cyclic group. Inelliptic curve cryptography, this group is provided by an elliptic curve E definedover Fq with q = pm and p a prime number, and a definition of a method toadd two points on the curve. The elliptic curve discrete logarithm problem canbe defined as follows: given the points P ∈ E and Q = αP (with α an integersmaller than the order P ), find the discrete logarithm α of Q.
A well known elliptic curve based digital signature scheme is the ECDSA [86].The ECDSA is the elliptic curve analogue of the DSA. It was added to theDSS in 2000 (FIPS PUB 186-2). The algorithm is shown in Alg. 2.6. Two wellknown elliptic curve based encryption schemes are the Elliptic Curve IntegratedEncryption Scheme (ECIES) [166] (also known as the Elliptic Curve AugmentedEncryption Scheme or simply the Elliptic Curve Encryption Scheme) and Prov-ably Secure Elliptic Curve (PSEC) [166]. The security of ECIES is based on thedifficulty of the Computational Diffie-Hellman problem for elliptic curves: Giventhe points P ∈ E , Q = αP and R = βP (with α, β integers smaller than theorder P ), compute αβP . The ECIES is closely related to the Diffie-HellmanIntegrated Encryption Scheme (DHIES) construction in [1]. PSEC is a familyof Diffie-Hellman based encryption schemes that are all provably secure in therandom oracle model. The security of each member of the family is based ona different variant of the Diffie-Hellman problem. Note that these encryptionschemes have been standardized by different standardization bodies, and unfor-tunately the versions are not always compatible.
The advantage of elliptic curves is that they can provide the same level of securityas RSA or the DSA with substantially smaller key sizes. Note that the signaturesizes for the DSA and the ECDSA are exactly the same (2 times the field size).Table 2.5 lists elliptic curve key lengths and rough estimates of key sizes ofsymmetric primitives, RSA and discrete log based cryptosystems (both over F∗qand elliptic curves) that provide the same level of security. These estimates wereobtained from [151], and they are roughly the same as those proposed in a very

28 Chapter 2. Efficiency of Cryptographic Primitives
Algorithm 2.5 The DSA signature scheme
Setup of system parameters
1. Generate two primes p and q such that q|p− 1;(typical parameter sizes are: |p| = 1024 and |q| = 160)
2. select an element g ∈ Z∗p of order q.
Key setup
1. Select a random integer x ∈R Zq;2. compute y = g−x;3. publish y as the public key, and keep x as the private key.
Signature generation
1. Select a random integer k ∈R Zq;2. compute l = gk (mod p);3. compute r = H(m, l), where H is a hash algorithm that maps {0, 1}∗ toZq;
4. compute s = k + xr (mod q), if s = 0 the go back to step 1;5. the signature of message m is (r, s).
Signature verification
Given a public key y, the system parameters and a message-signature pair(m, (r, s)), the verifier can verify the signature with the following procedure:
1. Compute w = gsyr (mod p);2. compute v = H(m, w);3. Verifyy(m, (r, s)) = true if v = r.

2.2 Public key cryptography 29
detailed paper by Lenstra and Verheul [99]. Table 2.5 also shows how fast the keysizes grow (compared to the security of an 80-bit symmetric key). This meansthat in the future, the key size advantage of elliptic curve based cryptosystemswill only improve.
2.2.5 Efficiency of public key cryptography
Tables 2.2, 2.4 and 2.6 show performance measurements of several public keyprimitives on different platforms (please refer to the sources for exact details onthe algorithms and elliptic curves). For RSA and Rabin we note that the publicoperations, encryption and signature verification, are far more efficient than theprivate operations, since they use a short public exponent. Popular choices aree = 3 or e = 216+1; this is much smaller than the private exponent d (|d| ≈ |n| ≥1024). Looking at Alg. 2.1 and Alg. 2.2, we see that the modular exponentiationsxe (mod n) and xd (mod n) are required for the public and private operationsrespectively. Modular exponentiation is faster for smaller exponents (e.g., usingthe square/multiply algorithm, 1/2 multiplication and 1 squaring is required forevery bit in the exponent). For e = 3 the public operations are 20 to 70 timesmore efficient than the private operations, for e = 216 + 1 this is 15 to 25 times.Note that this ratio depends on the modulus size (the larger the modulus, thelarger the difference). The efficiency of Rabin is similar to the efficiency of RSAwith e = 3 (the public operations requiring only a single squaring).
For the discrete log based primitives (including the elliptic curve based ones), wesee that the private operations are more efficient than the public operations (ex-cept for the PSEC family). This is because the private operations in the DSA, theECDSA and the ECIES only require a single modular exponentiation or Ellip-tic Curve Point Multiplication (ECPM), while the public operations require twomodular exponentiations or ECPMs (see Alg. 2.6). As these are the most expen-sive operations in the algorithms (the point-multiplication kP requires around10 integer-multiplications for every bit in k [18, chapter V ]), they determine theefficiency of the algorithm. We see that in practice the private operations areabout 2 to 3 times more efficient than the public operations. PSEC requires twoECPMs for both operations.
Commercial button cell battery energy densities range from 1000–2500 J/cm3.Using the numbers in Table 2.2 we see that it is possible to encrypt 826–2066MByte using AES per cm3 of battery volume and about 5100–12,700 ECDSAsignature verifications in a 163-bit field.

30 Chapter 2. Efficiency of Cryptographic Primitives
Algorithm 2.6 The ECDSA signature scheme
Setup of system parameters
Select an elliptic curve E defined over Fq (with q = pm, where p is a primenumber), and a publicly known point G ∈ E of large prime order n.
Key setup
1. Select a random integer d ∈R [1, n[,2. compute Q = dG,3. publish Q as the public key, and keep d as the private key.
Signature generation
1. Select a random integer k ∈R [1, n[;2. compute kG = (x1, y1);3. compute r = x1 (mod n), if r = 0 the go back to step 1;4. compute s = k−1(H(m) + dr) (mod n), where H is a hash algorithm that
maps {0, 1}∗ to [1, n[; if s = 0 the go back to step 1;5. the signature of message m is (r, s).
Signature verification
Given a public key Q, the system parameters and a message-signature pair(m, (r, s)), the verifier can verify the signature with the following procedure:
1. Verify that r and s are integers in the interval [1, n[;2. compute w = s−1 (mod n);3. compute u1 = H(m)w (mod n) and u2 = rw (mod n);4. compute u1G + u2Q = (x0, y0) and v = x0 (mod n);5. VerifyQ(m, (r, s)) = true if v = r.

2.3 Conclusions and future work 31
RSA (Rabin) vs. DSA
The dominating computation in the RSA and the DSA private operations is asingle modular exponentiation αβ (mod n). The size of the modulus |n| is thesame for both algorithms. However, the size of the exponent β is much smallerfor the DSA (e.g., for 1024-bit security, the size of the secret RSA exponent|β| = |d| ≈ 1024, while for the DSA |β| = |q| ≈ 160). This means that for theprivate operations the DSA is more efficient than RSA. For the public operationRSA is much more efficient than the DSA, because of the small exponent e. Thisis also visible in the measurements in Table 2.6.
RSA vs. elliptic curve based primitives
Based on the numbers in Tables 2.2, 2.4 and 2.6, we conclude that for publicoperations, RSA is about 2 to 12 times more efficient than elliptic curve basedprimitives (we have excluded the results on the 200 MHz Pentium Pro in Table 2.6as these seems to be a rather slow implementation of the ECDSA). RSA is about4 to 15 times slower than elliptic curve based primitives for the private operations.
2.3 Conclusions and future work
In this chapter we have evaluated the efficiency of both symmetric and publickey cryptographic primitives. We have used the AES as a reference point andshown how and where stream ciphers can offer better performance. We have alsopresented a collection of measurements that allow us to compare the performanceof symmetric primitives to public key primitives. The main contribution of thischapter is that it provides a clear overview of the state of the art in cryptographicprimitives and their efficiency.
The list of evaluated cryptographic primitives is far from complete. We feel thatlimiting ourselves to AES for block ciphers is justified by the fact that AESoutperforms almost all other block ciphers and is (or will become) the de factoencryption standard of the future. For public key systems, we have coveredthe most common schemes, but we did not touch upon some schemes that areradically different from the ones we evaluated. In particular one-time digitalsignatures based on one-way functions and Multivariate Quadratic schemes [182].The former we will evaluate in detail in the next chapter, while the latter are leftfor future work.

32 Chapter 2. Efficiency of Cryptographic Primitives
Table 2.4. Software performance of cryptographic primitives [134].
Primitive name |key| Platform|hash| PIII/Linux Athlon
AES 128 25/26/523 30/31/500RC4 128 7.3/2659 11/2600RIPEMD-160 160 18/16/1339 21/12/1493SHA-1 160 15/16/1024 12/12/825SHA-2 256 40/44/2747 34/39/2369SHA-2 512 83/157/11K 71/106/9752RSA-OAEP 1024 2026K/42M/1654M 2289K/48M/2027MECDSA-GF(2p) 160 4775K/6085K/4669K 4464K/572K/4354KECDSA-GF(2163) 163 5061K/6809K/4852K 4602K/6159K/4426KRSA-PSS 1024 42M/2029K/1334M 48M/2288K/1419M
For the AES and RSA-OAEP the entries are encrypt/decrypt/key setup times.For RC4 this is key stream generation/key setup. For the hash functions this ishash/initialize/initialize+finalize. For the ECDSA and RSA-PSS the entries aresign/verify/key generation times. The symmetric primitives are measured in cy-cles/Byte or cycles/setup, the asymmetric in cycles/invocation.
Table 2.5. Elliptic curve, symmetric primitives, RSA and discrete log in F∗q keylength comparison.
Symmetric primitive Elliptic curve discrete log (F∗q) and RSAkey lengths key lengths key lengths
80 160 1024112 224 (×1.4) 2048 (×2)128 256 (×1.6) 3072 (×3)192 384 (×2.4) 7680 (×7.5)256 512 (×3.2) 15360 (×15)

2.3 Conclusions and future work 33
Table 2.6. Software performance of public key primitives.
Scheme ∗Encryption ∗Decryption Key generationVerification Signing
Estimated performance on Pentium III ([134])
RSA-OAEP∗ (e = 3) 1 11 –Rabin-SAEP∗ 0.5 11 –ECIES∗ 5 2.5 –PSEC family∗ 5 5 –
Measured performance on Pentium Pro @ 200MHz ([180])
RSA (e = 3) 0.6 43 1100DSA 27 7 7ECDSA 19 5 7
Measured perf. on Intel 386 @ 10MHz (RIM pager) ([28])
RSA (e = 3) 301 15,889 580,405RSA (e = 216 + 1) 1,008 15,889 580,405DSA 18,566 9,529 –ECIES 1,759 1,065 751ECDSA 1,826 1,011 751
Measured perf. on 8-bit ATmega128 @ 8MHz ([68])
RSA (e = 216 + 1) 430 10,990 –Elliptic Curve Point Multiplication: 810ECDSA > 2× 810 > 810 –ECIES∗ > 2× 810 > 810 –PSEC family∗ > 2× 810 > 2× 810 –
All parameters are selected to provide a security of 280, i.e., 1024 bits for factorizationor discrete log based schemes and 160 bits for elliptic curves. All entries are measuredin milliseconds.


Chapter 3
Efficiency of One-TimeSignature Schemes
In the previous chapter we have shown that symmetric primitives are far moreefficient than public key systems. Even for the most efficient public key operation,RSA encryption or signature verification, it is possible to encrypt about 13 kBytesusing AES for the cost of a single public key operation using a 1024-bit key. Forthe least efficient public key operation, RSA decryption or signature generation,this becomes about 450 kBytes.
This motivated us to make a detailed investigation of the efficiency of one-timesignature schemes solely based on symmetric techniques. These digital signatureare presented by their authors as efficient and fast, and are assumed to be lesspower consuming than schemes based on expensive operations such as modularexponentiation. To the best of our knowledge, these claims are not supportedby any efficiency evaluation that includes all aspects of using these schemes inwireless environments: energy consumption of key generation, signing and veri-fication, and the communication cost of the signatures and the required authen-tication data. We present a detailed analysis of two one-time signature schemes(the Lamport-Diffie scheme [98] and the HORS scheme [144]) together with twopublic key authentication mechanisms that make it possible to turn these one-time schemes into “real” digital signature algorithms. We compare the powerconsumption of these schemes with the power consumption of the ECDSA.
35

36 Chapter 3. Efficiency of One-Time Signature Schemes
Contributions in this chapter
This chapter extends the research results that were published in [159]. Thecontributions presented here are:
– A detailed efficiency evaluation of the Lamport-Diffie one-time signaturescheme with Merkle improvement (LDM), Lamport-Diffie one-time signaturescheme with Winternitz improvement (LDW) and HORS one-time signatureschemes.
– A detailed efficiency evaluation of Merkle hash trees and one-time chainswhen they are used to authenticate public keys of one-time signature schemes.
– A security analysis of the HORS one time signature scheme.
3.1 Lamport-Diffie one-time signatures
One-time signatures have been known since the late 1970s. They were introducedby Diffie and Hellman [53], Lamport [98] and Rabin [136]; but they are usuallyknown in the form presented by Merkle [109, 110]. These schemes are based onone-way function, rather than on trapdoor functions that are used in traditionalschemes such as RSA and the DSA.
In its basic form, the Lamport-Diffie scheme can be used to sign a single bit ofdata. The secret key consists of two random values x0 and x1, while the publickey is obtained by applying the One-Way Function (OWF) f to the secret values,resulting in the pair {f(x0), f(x1)}. The signature for bit b is xb. The security ofthis scheme relies on the one-wayness of the function f , i.e., given the public key,it is impossible to compute the private key (and thus forge a signature) withoutbreaking the one-way property of f . It is also clear that a public/private key paircan only be used once since the signature is equal to part of the private key. Tosign longer messages, several instances of this scheme are used. In order to signan s-bit message one requires 2s public key values and 2s private key values. Asignature consists of s values.
After the introduction of one-time signatures, a number of variants and improve-ments were proposed: Bos and Chaum [25], and Bleichenbacher and Maurer[19, 20, 21] formalized a generalization and suggested signatures based on acyclicgraphs. Even et al. [60] combine one-time signatures and traditional signaturesto form a hybrid scheme. They propose an on-line/off-line scheme in which themessage-dependent signature generation is fast, but the preparation for the nextsignature, as well as signature verification, are slow. Vaudenay [175] extends the

3.1 Lamport-Diffie one-time signatures 37
results of Merkle [109, 110] and proposes a one-time signature scheme based oninteractive proofs of knowledge. Perrig [125] presents a one-time signature schemeaimed at very fast signature verification at the cost of signing time and key size.Reyzin and Reyzin [144] propose a variant of the scheme proposed by Bos andChaum [25] that allows to sign r ≥ 1 messages with a single public/private keypair (see Sect. 3.2). This scheme is further improved by Pieprzyk et al. [131].
3.1.1 Lamport-Diffie scheme with Merkle improvement
Merkle [108] proposed an improvement that allows to reduce the key sizes bya factor of two and the signature size by almost a factor of two. Instead ofgenerating two private key values for every bit in the message, Merkle suggeststo only generate one value. The public key values are still obtained by applyingthe function f to the private key values. Now, for every bit in the message thatis ‘1’, include the corresponding private key value in the signature; for every bitthat is ‘0’, omit the corresponding private key value. On average, this resultsin a signature that contains s/2 private key values. Obviously, the verifier canalways claim not to have received a particular private key value, and thereforepretend that some of the ‘1’ bits in the message that was signed were actually‘0’ bits. This can be remedied by adding a count of the ‘1’ bits to the messagebefore signing it. This count requires log2(s) bits. We will refer to this schemeas the LDM (Alg. 3.1).
The security of the scheme can be reduced to the one-wayness of the function f .In order to prevent attackers from building a large table of evaluations of f , f canbe made different for each signature by defining f(x) to be g(Salt ||x), where g is aone-way function and Salt is generated at random by the signer and transmittedto the verifier as part of the public key. Suitable g’s can be constructed fromefficient block ciphers such as the AES or from fast hash functions such as SHA-1.As with other digital signature schemes, we assume that the message m is hashedwith a cryptographic hash function such as SHA-1 before it is fed to the signingalgorithm.
3.1.2 Lamport-Diffie scheme with Winternitz improvement
In [110] Merkle proposes a different variant of the Lamport-Diffie scheme, at-tributed by Merkle to Winternitz. This scheme reduces the size of the signatureat the cost of additional computations. Instead of applying the OWF f onceto the private key to obtain the public key, the function f is applied iterativelya fixed number of times. With every resulting public/private key value pair it

38 Chapter 3. Efficiency of One-Time Signature Schemes
Algorithm 3.1 Lamport-Diffie one-time signature scheme with Merkle improve-ment (LDM)
Setup of system parameters
Select a OWF f mapping {0, 1}l to {0, 1}l. Let s be the fixed length of themessages to be signed (s = |m|).Key setup
1. Generate t = s + dlog2(s)e random values x1, x2, . . . , xt with |xi| = l,2. let sk = {x1, x2, . . . , xt},3. compute pk = {f(x1), f(x2), . . . f(xt)},4. publish pk as the one-time public key, keep sk as the one-time private key.
Signature generation
Let bi be the i-th bit of 〈m,w〉 with w the Hamming weight of the message m.The signature of message m is
σ = Signsk (m) = {all xi for which bi = 1} .
Signature verification
Given a public key pk = {v1, v2, . . . , vt} and a message-signature pair (m,σ), theverifier can verify the signature with the following procedure (bi is the i-th bit of〈m,w〉):
Verifypk (m,σ) = true if f(σα) = vi for all i where bi = 1 .
(σα indicates the corresponding value in the signature, e.g., α = 3 for the 3rd ‘1’bit in 〈m,w〉.)

3.2 The HORS one-time signature scheme 39
is possible to sign multiple bits. Briefly the scheme works as follows: To sign4 bits with a single public/private key value pair, we apply the function f 15times (= 24 − 1), thus the public key becomes v = f15(x). To sign the message1001 (9 in decimal), the signer makes σ = f15−9(x) public. Anyone can checkthat f9(σ) = f9(f15−9(x)) = v, thus confirming that f15−9(x) was made public.No one besides the signer could have generated this value. Again extra redun-dancy has to be added to the signature in order to prevent people from changingthe signature on 1001 into a signature on, for example 1000 (8 in decimal), bycomputing f(f15−9(x)) = f15−8(x).
The complete scheme is described in Alg. 3.2. Note that a different mechanismis used to add the necessary redundancy to the signature. This solution reducesthe signature size even further at the cost of additional computations. The re-dundancy in this scheme is encoded in the signature value σ0 and requires oneadditional public/private key value pair {x0, v0}. Again we assume that themessage m is hashed before it is fed to the signing algorithm.
3.2 The HORS one-time signature scheme
Reyzin and Reyzin propose a very efficient one-time signature scheme based onsubset selection [144]. Their scheme builds on a construction proposed by Bosand Chaum in [25] that allows to sign r ≥ 1 messages with a single public/privatekey pair.
In short, the signature scheme proposed by Bos and Chaum works as follows: thepublic/private key pair is generated as in the basic Lamport-Diffie scheme, i.e.,the public key is obtained by applying a OWF f to each of the t values of theprivate key. The signing algorithm uses a bijective function S that, on input m(0 ≤ m <
(tk
)), outputs the m-th k-element subset of the set T = {1, 2, . . . , t}. Let
this subset be {i1, i2, . . . , ik}. The signature for message m is {xi1 , xi2 , . . . , xik}.
Because each message results in a different k-element subset (due to the bijectiveproperty of S), in order to forge a signature after obtaining a single message-signature pair, the forger will have to invert the OWF f at least once (i.e., forall elements in the forged signature that are not part of the obtained signature).This makes it possible to reduce the security of this scheme to the one-waynessof the function f .
Reyzin and Reyzin propose to replace the subset selection function S by a cryp-tographic hash function H. The hash value h = H(m) is split into k parts ofequal length. Every part is interpreted as an integer and the collection of allthese integers is the subset that will be used to select the private key values to

40 Chapter 3. Efficiency of One-Time Signature Schemes
Algorithm 3.2 Lamport-Diffie one-time signature scheme with Winternitz im-provement (LDW)
Setup of system parameters
Select a OWF f mapping {0, 1}l to {0, 1}l. Let s be the fixed length of themessages to be signed (s = |m|). Select the system parameter g such that g|s.Key setup
1. Generate s/g + 1 random values x0, x1, . . . , xs/g with |xi| = l,2. let sk = {x0, x1, . . . , xs/g},3. compute pk = {f (2g−1)s/g(x0), f2g−1(x1), . . . f2g−1(xs/g)},4. publish pk as the one-time public key, keep sk as the one-time private key.
Signature generation
1. Split the message m into s/g parts, let these parts be m1,m2, . . . , ms/g,2. interpret each mj as an integer Ij ,
The signature of message m is
σ = Signsk (m) = {σ0, . . . , σs/g}
with{
σi = F 2g−1−Ii(xi) for 1 ≥ i ≥ s/gσ0 = F δ(x0) with δ =
∑i>0 Ii .
Signature verification
Given a public key pk = {v0, v1, . . . , vs/g} and a message-signature pair (m,σ),the verifier can verify the signature with the following procedure:
1. Split the message m into s/g parts, let these parts be m1,m2, . . . , ms/g,2. interpret each mj as an integer Ij ,3. verify the validity of the signature using
Verifypk (m,σ) = true if{
vi = F Ii(σi) for 1 ≥ i ≥ s/gv0 = F 2g−1−δ(σ0)with δ =
∑i>0 Ii

3.2 The HORS one-time signature scheme 41
be included in the signature. Reyzin and Reyzin have called this scheme HORSfor “Hash to Obtain Random Subset”; this algorithm is described in Alg. 3.3.
3.2.1 On the security of HORS
For the HORS scheme to be secure, it should be impossible to find two messagesm1 and m2 that result in the same subset of T . In general, for the scheme to besecure to sign up to r messages with a single public/private key pair, the hashfunction H has to be (r + 1, k) subset resilient.
Definition 3.1 ((r + 1, k) subset resilience). Suppose H is a constant lengthoutput function with |H| = s, and H(m) = 〈h1 , h2 , . . . , hk 〉 with |hi| = log2(t)(t = 2s/k). Let H(m) be the set of k elements {I1, I2, . . . , Ik} where Ij = Int(hj).The function H is called (r + 1) subset resilient if it satisfies the following con-dition: it should be infeasible to find r+1 messages m1,m2, . . . ,mr+1 such thatH(mr+1) ⊆ H(m1) ∪H(m2) ∪ · · · ∪ H(mr).
Note that subset resilience is a stronger assumption than pre-image resistance ofthe hash function H (see Def. 2.3 on p. 14).
For the rest of the security analysis we assume that the hash function H behaveslike a random oracle [9], and that the adversary obtained signatures on r randommessages using the same private key. The probability that an adversary is ableto forge a signature on a new message (without inverting the OWF f) is at most(rk/t)k. This is the probability that after rk elements of sk have been madepublic, k elements are chosen (at random) that are a subset of them.
Definition 3.2 (Security level of HORS). The security level of the HORSsignature scheme in combination with the hash function H, is defined as Σ =− log2(P ). Here, P is the probability of breaking the (r + 1, k) subset resilienceof the hash function H, assuming that H behaves like a random oracle. Thisprobability P is at most (rk/t)k .
The parameters k, t and s cannot be chosen independently, but have to satisfys = k log2(t). Using this, the probability can be rewritten as 2−Σ with
Σ = k(s/k − log2(k)− log2(r)
). (3.1)
This security level is shown in Fig. 3.1. As an example, for s = 160, k = 16 andr = 1 (and t = 1024), the security level is 96; for r = 4 the security level dropsto 64. Using Eq. 3.1 we can compute the number r of signatures we can generateper public key, while maintaining a security level Σ:
r = (1/k)2(s−Σ)/k . (3.2)

42 Chapter 3. Efficiency of One-Time Signature Schemes
Algorithm 3.3 The HORS one-time signature scheme
Setup of system parameters
Select a cryptographic hash function H with output length |H| = s and a OWFf mapping {0, 1}l to {0, 1}l. Select the system parameters k and t such thatk log2(t) = s.
Key setup
1. Generate t random values x1, x2, . . . , xt with |xi| = l,2. let sk = {x1, x2, . . . , xt},3. compute pk = {f(x1), f(x2), . . . , f(xt)},4. publish pk as the one-time public key, keep sk as the one-time private key.
Signature generation
1. Let h = H(m),2. split h into k substrings h1, h2, . . . , hk of length |hi| = log2(t),3. interpret each hj as an integer Ij .
The signature of message m is
σ = Signsk (m) = {xI1 , xI2 , . . . , xIk} .
Signature verification
Given a public key pk and a message-signature pair (m,σ), the verifier can verifythe signature with the following procedure:
1. Let h = H(m), σ = {σ1, σ2, . . . , σk}, and pk = {v1, v2, . . . , vt},2. split h into k substrings h1, h2, . . . , hk of length |hi| = log2(t),3. interpret each hj as an integer Ij ,4. verify the validity of the signature using
Verifypk (m,σ) = true if f(σj) = vIj for 1 ≤ j ≤ k .

3.3 Efficiency of one-time signature schemes 43
P
rk
Figure 3.1. Security level offered by the HORS scheme as a function of theparameters k and t (s = 160).
Finally, from Eq. (3.2) we can compute how many public keys we need to sign Smessages:
#pk = S/r = Sk2(Σ−s)/k . (3.3)
Figure 3.2 shows how the number of required public keys changes with the pa-rameter k if we use parameters s = 160, S = 216, and Σ = 40. We see thatthe number of public keys we need grows exponentially with k, but at the sametime the size t of each public key becomes smaller. Not that a security levelΣ = 40 is not sufficient with today’s hardware. As a practical example we willuse two different parameter sets with roughly the same security level: HORS-20 with (s, k, t, r) = (160, 20, 256, 1), providing Σ = 73.5, and HORS-18 with(s, k, t, r) = (162, 18, 512, 2), providing Σ = 68.9.
3.3 Efficiency of one-time signature schemes
All the one-time signature and public-key authentication schemes evaluated inthis chapter are based on a general OWF f . In order to be able to providealgebraic expressions for the cost (= power requirement) of these schemes weassume that:
– the input size of f is a multiple of l bits; we will refer to a group of l bits asone “block”;
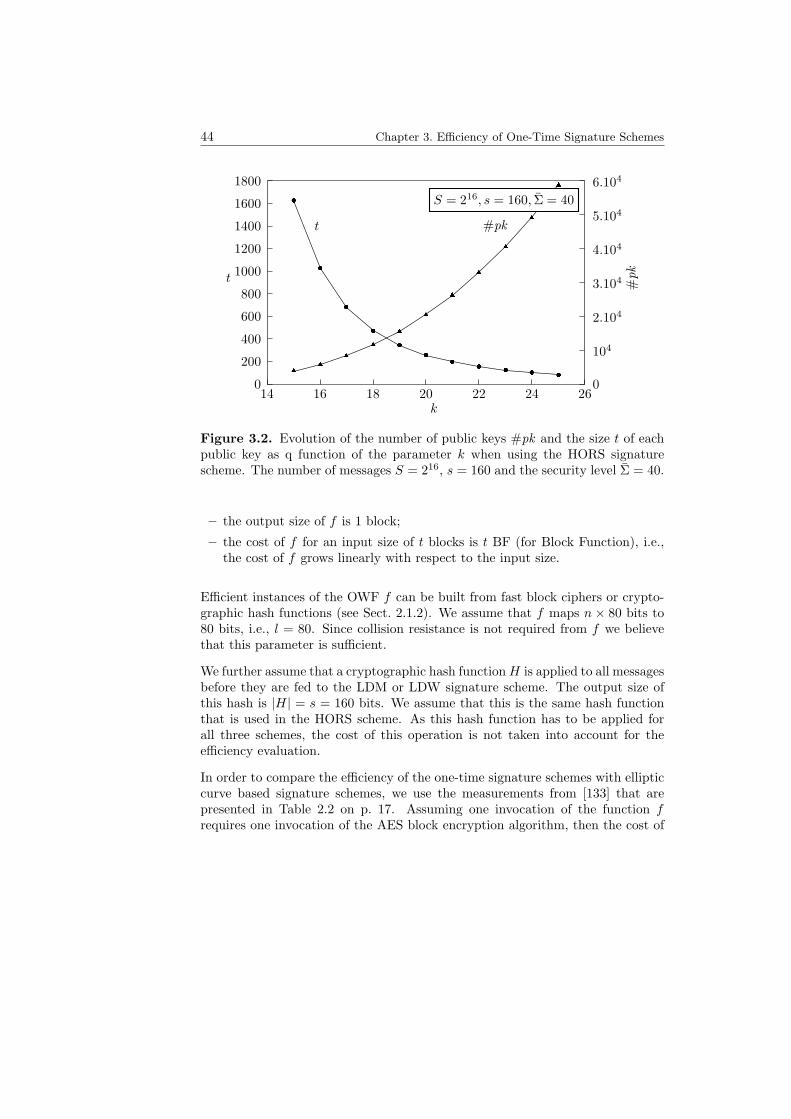
44 Chapter 3. Efficiency of One-Time Signature Schemes
t
#pk
k
t #pk
0
200
400
600
800
1000
1200
1400
1600
1800
14 16 18 20 22 24 26
�
�
�
�
�����
� �
0
104
2.104
3.104
4.104
5.104
6.104
����
�
�
�
�
�
�
�
S = 216, s = 160, Σ = 40
Figure 3.2. Evolution of the number of public keys #pk and the size t of eachpublic key as q function of the parameter k when using the HORS signaturescheme. The number of messages S = 216, s = 160 and the security level Σ = 40.
– the output size of f is 1 block;
– the cost of f for an input size of t blocks is t BF (for Block Function), i.e.,the cost of f grows linearly with respect to the input size.
Efficient instances of the OWF f can be built from fast block ciphers or crypto-graphic hash functions (see Sect. 2.1.2). We assume that f maps n × 80 bits to80 bits, i.e., l = 80. Since collision resistance is not required from f we believethat this parameter is sufficient.
We further assume that a cryptographic hash function H is applied to all messagesbefore they are fed to the LDM or LDW signature scheme. The output size ofthis hash is |H| = s = 160 bits. We assume that this is the same hash functionthat is used in the HORS scheme. As this hash function has to be applied forall three schemes, the cost of this operation is not taken into account for theefficiency evaluation.
In order to compare the efficiency of the one-time signature schemes with ellipticcurve based signature schemes, we use the measurements from [133] that arepresented in Table 2.2 on p. 17. Assuming one invocation of the function frequires one invocation of the AES block encryption algorithm, then the cost of

3.3 Efficiency of one-time signature schemes 45
an ECDSA verification (signature) is equal to the cost of 104 (7 ·103) invocationsof f .
Another important cost factor (certainly for one-time signature schemes) is thecommunication cost. A rigorous performance analysis of the popular Mica2 andMica2dot motes is presented in [2]. The authors show that the effective through-put available to applications on a Mica2 mote is only 4.6 kbits/s (a fraction of thenominal bandwidth of 19.2 kbits/s). In order to achieve this, the radio module ofthe mote requires 48 mW in receive mode and 54 mW in transmit mode. Thus,the mote uses 10.4 µJ/bit in receive mode and 11.7 µJ/bit in transmit mode.This results in the following assumptions we will use for the numeric evaluation:
– The size of the output of the hash function H is 160 bits (|H| = s = 160),– 1 block = 80 bits,– 1 BF = 16× 1.21 µJ = 19.36 µJ,– the transmission cost of 1 block = 936 µJ,– the receiving cost of 1 block = 832 µJ.
3.3.1 Efficiency of the LDM
Looking at Alg. 3.1, we see that the key setup requires s + dlog2(s)e BF. Thepublic and private key size is s+ dlog2(s)e blocks. Signature generation is “free”.Assuming a uniform distribution of the possible messages in the message space, onaverage the message and padded redundancy 〈m,w〉 will contain 50% zeros and50% ones. This means that the average signature size is 1
2 (s + dlog2(s)e) blocksand that verification requires 1
2 (s + dlog2(s)e) BF on average.
Note that the secret key sk = {x0, . . . , xm/t} can be generated with a goodpseudo-random generator using a single seed sk . The entropy of the output ofthe pseudo-random generator is at most |sk |, therefore we propose to use a seedwith size 2|xi|, i.e., 2 blocks. This means that storing the secret key only requiresa fraction of the total size of the private key. Obviously this is not true for thepublic key.
As a practical example, the total cost of signing a message, transmitting this mes-sage to the verifier and verifying the message is 148 mJ for the communicationsand 1.6 mJ for the computations, totalling about 150 mJ.
3.3.2 Efficiency of the LDW
Looking at Alg. 3.2, we see that the key setup requires 2(s/g)(2g − 1) BF. Thepublic and private key size is s/g + 1 blocks. The costs of signature generation

46 Chapter 3. Efficiency of One-Time Signature Schemes
and verification are both (s/g)(2g − 1) BF, independent of the message. Thesignature size is s/g + 1 blocks.
Notice that the computational cost grows exponentially with the group size g,while the communication cost only drops linearly with g. This indicates thatperformance gain, if any, will only be possible for small values of g. Table 3.1shows the total cost of a signature for different values of g. This cost includessignature generation, one signature verification and one transmission from senderto receiver. The minimum cost occurs for g = 4, i.e., signing 4 bits with asingle public/private key value pair. Using the LDW with g = 4 offers a 37%performance gain compared to the LDM.
Table 3.1. Cost of the LDW for different group sizes g (mJ).
group size g 1 2 3 4 5 6communications 285 143 96 72 58 49computations 6.20 9.29 14.46 23.23 38.41 65.05total 291 153 111 96 97 114
3.3.3 Efficiency of the HORS scheme
We assume that the system-wide parameter k is fixed, and is not included in thepublic/secret key. The cost of HORS can be summarized as follows:
– The key setup requires t evaluations of f , resulting in a total computationalcost of t BF. The public and private key size is t blocks.
– Signing requires no additional operations besides applying the hash functionto the message. The signature size is k blocks.
– Verifying requires a maximum of k BF if the signature is valid (if the signatureis invalid the verification process can be stopped earlier and the cost will beless).
For HORS-20 the total cost for signing a message, transmitting the signature tothe verifier and verifying the message is 452.6 mJ for the communications and387 µJ for the computations, totalling about 453 mJ. For HORS-18, this becomes905.2 mJ for the communications and 348 µJ for the computations, totallingabout 906 mJ. Note that the total cost is dominated by the transmission costwhich is 3 orders of magnitude larger than the computation cost.

3.4 One-time public key authentication 47
3.4 One-time public key authentication
Two obvious disadvantages of one-time signature schemes are the size of thepublic key and the fact that it can only be used a limited number of times. Allpossible verifiers need authenticated copies of these public keys, i.e., they needevidence that a particular public key is related to a particular user (see alsoSect. 2.2.2). For example, when using the LDM with s = 160 and l = 80, thetotal size of 1000 public keys is about 1.63 MBytes. One obvious mechanism toprovide authenticated copies of this public key set is to transfer the completeset to every verifier over some authenticated channel (e.g., using a traditionaldigital signature such as ECDSA). The disadvantage is that every verifier has tostore 1.63 Mbytes of data for every potential signer. Fortunately, there are moreefficient solutions.
3.4.1 Merkle trees
Merkle proposed the use of binary trees to reduce the authentication of a largenumber of public keys to the authentication of a single value, i.e., the root of thetree [110].
A Merkle tree is a complete binary tree with an l-bit value associated with eachnode such that each interior node value is a OWF of the node values of its children(Fig. 3.3). The N values that need to be authenticated are placed at the leavesof the tree. Usually these values need to be kept secret. In that case, the hashvalues of these secret values are placed at the leaves of the tree. The hash valuesleaf i = H(value) are called the leaves and the secret values are usually called theleaf pre-images. We will use the functions precalc(i) and leafcalc(i) to describethe process of creating the leaf pre-images and the leaves of the tree. The leavesare indexed from 0 to N − 1. The parent’s node value is calculated as a OWFf of the concatenation of the two child values. We use the following notation todescribe the tree nodes:
{leaf i = P [i, i] = leafcalc(i) ,
P [i, j] = f(P [i, (i + j − 1)/2], P [(i + j + 1)/2, j]
).
(3.4)
Since node P [i, j] is a function of leaf i, leaf i+1, . . . , leaf j , it can be used to au-thenticate these leaves. This implies that the whole tree is authenticated by thesingle root node of the tree. For example, root node P [1, 8] in Fig. 3.3 can be usedto authenticate the leaves 1 through 8. A particular leaf can be authenticatedwith respect to the root value and the authentication path of the leaf.

48 Chapter 3. Efficiency of One-Time Signature Schemes
P [1, 8]
P [1, 4]
P [1, 2]
leaf1
· · ·
leaf2
· · ·
P [3, 4]
leaf3
· · ·
leaf4
· · ·
P [5, 8]
P [5, 6]
leaf5
· · ·
leaf6
· · ·
P [7, 8]
leaf7
· · ·
leaf8
· · ·
1
Figure 3.3. Example Merkle hash tree with 8 leaves. The root node P [1, 8] canbe used to authenticate the complete tree.
Authentication paths
Let sibi be the value of the sibling of the node on height i on the path from theleaf to the root. A leaf has height 0, the OWF of two leaves has height 1, etc.,and the root has height H if the tree has 2H leaves. The authentication path isthen the set {sibi | 0 ≤ i ≤ H}. For example, the gray nodes in Fig. 3.3 makeup the authentication path for leaf leaf 3.
A leaf may be authenticated as follows: first apply the OWF to the leaf and itssibling sib0, then apply the OWF to the result and sib1, etc., all the way up to theroot. If the calculated root value is equal to the published root value, then theleaf value is accepted as authentic. This operation requires log2(N) invocationsof the OWF. For example, assume that we wish to authenticate leaf 3 to userU (Fig. 3.3). User U already obtained (out of band) an authenticated copy ofthe root node P [1, 8]. The minimum information we have to send to U is leaf 3
itself, leaf 4, P [1, 2] and P [5, 8]. These values (colored gray in Fig. 3.3) allow U torecreate the path from leaf 3 to the root node. Table 3.2 gives the authenticationpaths for a Merkle tree with 8 leaves. Note that most neighboring leaves share alarge portion of their authentication paths.
Authentication path generation
The goal of Merkle tree traversal is the sequential output of the leaf values andtheir authentication paths. In [110], Merkle presents a straightforward techniquethat requires a maximum of 2 log2(N) invocations of the OWF f per round, and

3.4 One-time public key authentication 49
Table 3.2. Authentication paths for a Merkle tree with 8 leaves (duplicateentries have been removed).
leaf authentication pathY1 P [1, 8] P [5, 8] P [3, 4] P [2, 2]Y2 P [1, 1]Y3 P [1, 2] P [4, 4]Y4 P [3, 3]Y5 P [1, 4] P [7, 8] P [6, 6]Y6 P [5, 5]Y7 P [5, 6] P [8, 8]Y8 P [7, 7]
requires a maximum storage of log22(N)/2 outputs of f . In [80], Jakobsson et
al. present an algorithm which allows a time-space trade-off. When storage isminimized, the algorithm requires about 2 log2(N)/ log2(log2(N)) invocations off , and a maximum storage of 1.5 log2
2(N)/ log2(log2(N)) outputs of f . Finally in[172], Szydlo presents an algorithm that requires 2 log2(N) time and a maximumstorage of 3 log2(N). All three Merkle tree traversal algorithms described herestart with the calculation of the tree root. During this root calculation, the initialinternal state of the algorithms are also calculated and stored in memory. Thisinitialization requires N − 1 invocations of f .1
3.4.2 One-way chains
In the three one-time signature schemes we have described, the public key iscomputed by applying the OWF f one or more times to the private key, which inturn is nothing more than a set of random values. Another way of authenticatingthese public keys is using one-way chains. Perrig suggests in [125] the use of theseone-way chains to authenticate the public keys that are used in the BiBa (Binsand Balls) one-time signature scheme, but this idea applies equally to othersignature schemes. This authentication mechanism is especially useful in thesetting of a single verifier, or a set of “synchronized” verifiers (i.e., verifiers whoall receive the same message-signature pairs at the same time). A typical exampleof the latter is broadcast authentication in wireless networks. All nodes withinrange of a sending node A have an authenticated copy of the root of the one-way chain used by A. Node A signs every message it broadcasts with a one-time
1The cost of this initial setup is not included in the time and storage requirements statedpreviously, since it is independent of the tree traversal algorithm that is used.

50 Chapter 3. Efficiency of One-Time Signature Schemes
signature scheme; this signature is verified by all receiving nodes at the same time.While Perrig uses time slots in which a particular public key is active [125], wemake an abstraction of these practical details and assume an ideal situation. Forthe LDM and the LDW a new public key becomes active after every signature,for the HORS scheme this happens after r signatures. Note that the private keythat was used for signature i becomes the public key for signature i + 1.
The private key of the LDM and HORS schemes consists of t random values, theprivate key in the LDW has one additional value x0: sk = {(x0), x1, x2, . . . , xt},where t depends on the specifics of the scheme. The public keys are com-puted by applying the OWF f one or more times to the private key: pk ={fβ(x0), fα(x1), fα(x2), . . . , fα(xt)}.The one-way chain generation process starts from the root private key skN ={(x(0,N)), x(1,N), x(2,N), . . . , x(t,N)}. The corresponding public key is computedaccording to the scheme: v(0,N) = fβ(x(0,N)) and v(i,N) = fα(x(i,N)) for all i > 0.All other public/private keys are computed recursively:
{v(0,j−1) = fβ(v(0,j)) for j = N → 2 ,
v(i,j−1) = fα(v(i,j)) for 1 ≤ i ≤ t and j = N → 2 .(3.5)
These one-way chains are depicted in Fig. 3.4. Every small dot in the horizontallines represent one invocation of f . The chains are computed beforehand fromleft to right, while they are used from right to left, i.e., the first public key thatwill be used is at the far right of the chains. The circles indicate the differentpublic keys. The currently active key is public key pk i. The bold dots representtwo consecutive signatures, and the arrows represent the verification process.
The signer stores the root private key in memory, i.e., the leftmost column inFig. 3.4. For signature i, the signer first computes the ith private key by applyingthe OWF (i−1)α or (i−1)β times. Using this active private key, the signer usesthe one-time signature signing algorithm to compute the signature.
The verification process works as follows: assume all verifiers have received anauthenticated copy of the first public key to be used, i.e., the far right column ofthe chains (pk1 = {(v(0,1)), v(1,1), v(2,1), . . . , v(t,1)}). A signature always consistsof values on the chains that are located to the left of the current public key. Notethat for the LDM and HORS schemes not all chains are used for every signature.This signature is verified according to the one-time signature verification process,i.e., by applying the function f until we have reached the currently active publickey. Once the signature has been verified, the verifier only keeps the leftmostknown values of the chains in memory, i.e., the last received valid signature. Thismeans that only for the first signature, a verifier has the actual public key (pk1)

3.4 One-time public key authentication 51
in memory. For all subsequent signatures, a verifier no longer has the actualactive public key in memory, but values on the chains that are to the right of thiskey (e.g., the rightmost bold dots in Fig. 3.4). When the next signature arrives(e.g., the leftmost bold dots in Fig. 3.4), the verifier applies the function f untilit reaches the known value on every chain (indicated by the arrows pointing toand originating from the currently active public key (pk i) values in Fig 3.4). Thearrows that point to pk i values indicate the actual signature verification process.The arrows that originate from pk i values depict the “public key” verificationprocess, i.e., following the chains until a known authenticated value is reached.Once this signature has been verified, again only the leftmost values of everychain are kept in memory. This process is repeated until the leftmost public key(pkN ) has been used.
The verifiers need one authenticated value on every chain to bootstrap the ver-ification process. A straightforward solution is to broadcast the first public keypk1 together with a traditional digital signature. Perrig suggests another solutionthat no longer requires the signer to broadcast a complete public key to every ver-ifier: new verifiers start collecting signatures as they are broadcast by the signer.Periodically the signer broadcasts a hash of a complete public key H(pks), ac-companied by a traditional digital signature. Once the recipients collect at leastone value of every one-way chain located to the left of this authenticated publickey, they can reconstruct this public key pks and validate the traditional signa-ture on it. The “coupon collector” problem [62] can be used to predict how longit will take on average before the recipients have at least one value of every chain:when we are collecting t different coupons, and we receive one random couponeach turn, it will take on average t ln(t) turns before we have collected all t dif-ferent coupons. In our case, a coupon is some value on a chain, and we requireat least one value on each chain. When using the LDW, a signature consists ofone value on half of the chains, thus it will take 2 ln(s/g +1) signatures to collecta value on each chain. In the HORS scheme, a signature consists of k out of tvalues. Assuming these k values are different, we require t ln(t)/k signatures tobootstrap the system. For the LDM every signature consists of exactly one valueon every chain; thus we need only a single signature to bootstrap.
Note that longer chains are only disadvantageous for the signer, and not forthe verifiers. The computational effort for signature generation grows for longerchains since the signer always has to start from the start of the chains. The signercould improve this by storing multiple intermediate private keys in memory. Thistechnique provides a means to exchange storage requirements for computationtime. For verifiers the length of the chains has no influence on the performance.
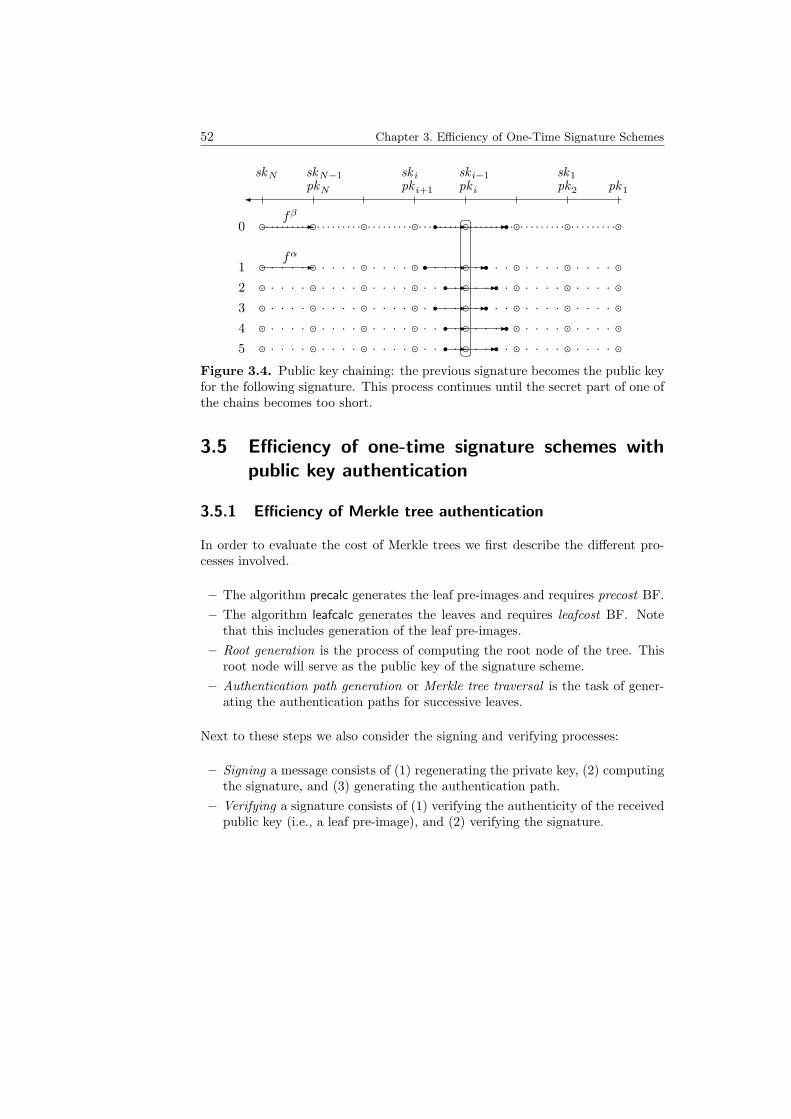
52 Chapter 3. Efficiency of One-Time Signature Schemes
¾pk ipk i+1
sk i−1sk ipkN
skN−1skN sk1pk2 pk1
p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p pp p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p pp p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p pp p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p pp p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p
c c c c c c c cc c c c c c c cc c c c c c c cc c c c c c c cc c c c c c c c-fα
p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p pc c c c c c c c-fβ
0
1
2
3
4
5
¤
£
¡
¢r -
r -
r -
r -
r -
r -
r-
r-
r-
r-
r-
r-
Figure 3.4. Public key chaining: the previous signature becomes the public keyfor the following signature. This process continues until the secret part of one ofthe chains becomes too short.
3.5 Efficiency of one-time signature schemes withpublic key authentication
3.5.1 Efficiency of Merkle tree authentication
In order to evaluate the cost of Merkle trees we first describe the different pro-cesses involved.
– The algorithm precalc generates the leaf pre-images and requires precost BF.– The algorithm leafcalc generates the leaves and requires leafcost BF. Note
that this includes generation of the leaf pre-images.– Root generation is the process of computing the root node of the tree. This
root node will serve as the public key of the signature scheme.– Authentication path generation or Merkle tree traversal is the task of gener-
ating the authentication paths for successive leaves.
Next to these steps we also consider the signing and verifying processes:
– Signing a message consists of (1) regenerating the private key, (2) computingthe signature, and (3) generating the authentication path.
– Verifying a signature consists of (1) verifying the authenticity of the receivedpublic key (i.e., a leaf pre-image), and (2) verifying the signature.

3.5 Efficiency of one-time signature schemes with public key authentication 53
Authentication path generation and verification cost
The fractal Merkle tree traversal algorithm presented in [80] by Jakobsson et al.allows a time-space trade-off. Briefly explained, the algorithm splits the originaltree into subtrees of height h ≤ H. These subtrees are constructed in sucha way that the root of one tree is at the same time a leaf of a tree above it,i.e., they are stacked on top of each other. Assuming h|H, let L = H/h bethe number of subtree levels. Exactly one such subtree for each level is kept inmemory and all these stacked subtrees together contain the authentication pathfor the leaf that is being authenticated at the moment. For each output of anauthentication path a second new subtree for each level is being constructed. Theconstruction is programmed in such a way that the new subtree will be finishedjust in time to be used to create the authentication path; at this moment the oldsubtree is discarded and the construction of a fresh subtree is initiated. Fractaltree traversal requires a maximum of 2(L − 1) evaluations of f per round, anda maximum space of 2L2h+1 + HL/2 memory units (each unit being the sizeof the output of f , i.e., 1 block). Note that according to our definition of f ,one evaluation here requires 2 BF. Taking into account the cost of generatingthe leaves (leafcost BF per leaf), the computational cost of fractal tree traversalbecomes (L − 1)(2 + leafcost) BF per round. The required space is minimizedusing h = log2(H) = log2(log2(N)). The authentication path generation costthen becomes
log2(N)log2(log2(N))
(2 + leafcost) BF per path. (3.6)
The root of the tree is computed at the initialisation phase of the fractal Merkletree traversal algorithm. This root generation process requires the computationof the N leaves and all nodes in the tree. By cleverly scheduling the order inwhich these nodes are computed, the memory requirements can be limited tolog2(N) + 1 blocks. The total root generation cost is
N(2 + leafcost)− 2 BF. (3.7)
Upon receipt of a leaf pre-image and the corresponding authentication path, therecipients have to compute nodes of the tree until they arrive at the root. Thetotal cost of this verification process is
2 log2(N) + (leafcost − precost) BF per path. (3.8)
Efficiency of the LDM using Merkle trees
We propose the following scheme to use Merkle trees for authentication of theLDM keys:

54 Chapter 3. Efficiency of One-Time Signature Schemes
– The private key consists of s + dlog2(s)e random values. These secret valuesare generated using a single seed value sk , requiring s+dlog2(s)e BF per secretkey. The public key values are computed as described in Sect. 3.1.1. Everypublic key is a leaf pre-image of the Merkle tree. Computing these leaf pre-images costs precost = 2(s+dlog2(s)e) BF. This includes s+dlog2(s)e BF forthe private key generation and s+ dlog2(s)e BF for the public key generationfrom the private key.
– The leaves themselves are the result of applying the OWF f to each of thepublic keys. This means that computing a leaf from a leaf pre-image costss + dlog2(s)e BF, and computing a leaf from scratch requires leafcost =3(s + dlog2(s)e) BF.
– The size of the tree is equal to the number S of signatures we wish to be ableto generate with this tree.
Key setup cost. Initially, the signer computes the root of the tree using theroot generation process. The cost of this process is given by Eq. (3.7). A copyof the resulting root value is transferred to the verifiers over an authenticatedchannel. The size of this public key is 1 block.
Cost of signing a message. The signer has to regenerate the private/publickey pair, compute the signature, and generate the authentication path for thisparticular public key. This requires (on average)2
precost +log2(S)
log2(log2(S))(2 + leafcost) BF. (3.9)
Cost of verifying a signature. The verifier has to check the validity of thesignature and of the public key (i.e., verifying the authentication path). Thisrequires (on average)
(s + dlog2(s)e)/2 + 2 log2(S) + (leafcost − precost) BF. (3.10)
Signature size. A signature consists of the public key that was used, thesignature itself, and the authentication path to authenticate the public key. Thetotal size of the signature is
s + dlog2(s)e+ (s + dlog2(s)e)/2 + log2(S) blocks. (3.11)
2Signature generation using the LDM is free (see Sect. 3.1.1).

3.5 Efficiency of one-time signature schemes with public key authentication 55
Efficiency of the LDW using Merkle trees
We propose the following scheme to use Merkle trees for authentication of theLDW keys:
– Using the Winternitz improvement with parameter g, the private key consistsof s/g random values. These secret values are generated using a single seedvalue sk , requiring s/g BF per secret key. The public key values are computedas described in Sect. 3.1.2. Every public key is a leaf pre-image of the Merkletree. Computing these leaf pre-images costs precost = (s/g)(2g+1 − 1) BF.This includes s/g BF for the private key generation and 2(s/g)(2g − 1) BFfor the public key generation from the private key.
– The leaves themselves are the result of applying the OWF f to each of thepublic keys. This means that computing a leaf from a leaf pre-image costss/g BF, and computing a leaf from scratch requires leafcost = (s/g)2g+1 BF.
– The size of the tree is equal to the number S of signatures we wish to be ableto generate with this tree.
Key setup cost. Initially, the signer computes the root of the tree using theroot generation process. The cost of this process is given by Eq. (3.7). A copyof the resulting root value is transferred to the verifiers over an authenticatedchannel. The size of this public key is 1 block.
Cost of signing a message. The signer has to regenerate the private/publickey pair, compute the signature, and generate the authentication path for thisparticular public key. This requires (on average)
precost + (s/g)(2g − 1) +log2(S)
log2(log2(S))(2 + leafcost) BF. (3.12)
Cost of verifying a signature. The verifier has to check the validity of thesignature and of the public key (i.e., verifying the authentication path). Thisrequires (on average)
(s/g)(2g − 1) + 2 log2(S) + (leafcost − precost) BF. (3.13)
Signature size. A signature consists of the public key that was used, thesignature itself, and the authentication path to authenticate the public key. Thetotal size of the signature is
2(s/g + 1) + log2(S) blocks. (3.14)

56 Chapter 3. Efficiency of One-Time Signature Schemes
Efficiency of the HORS scheme using Merkle trees
We propose the following scheme to use Merkle trees for authentication of theHORS public keys:
– In the HORS scheme the private key consists of t random values. Thesesecret values are generated using a random seed value sk . The public keysare computed as described in Sect. 3.2. Every public key is a leaf pre-imageof the Merkle tree. Computing these leaf pre-images costs precost = 2t BF(t BF for the secret key generation and t BF for the public key generation).
– The leaves themselves are the result of applying the OWF f to each of thepublic keys. This means that computing a leaf from a leaf pre-image costst BF, and computing a leaf from scratch requires leafcost = 3t BF.
– The size of the tree is equal to S/r, with S the number of signatures we wishto be able to authenticate with this tree, and r the number of signatures thatcan be placed using the same public key.
Key setup cost. Initially, the signer computes the root of the tree using theroot generation process. The cost of this process is given by Eq. (3.7). A copyof the resulting root value is transferred to the verifiers over an authenticatedchannel. The size of this public key is 1 block.
Cost of signing a message. The signer has to regenerate the private/publickey pair, compute the signature, and generate the authentication path for thisparticular public key. This requires3
precost +log(S/r)
log2(log2(S/r))(2 + leafcost) BF. (3.15)
Cost of verifying a signature. The verifier has to check the validity of thesignature and of the public key (i.e., verifying the authentication path). Thisrequires
k + 2 log2(S/r) + (leafcost − precost) BF. (3.16)
Signature size. A signature consists of the public key that was used, thesignature itself (k values), and the authentication path to authenticate the publickey. The total size of the signature is
t + k + log2(S/r) blocks. (3.17)3Signature generation using the HORS scheme is free (see Sect. 3.2).

3.5 Efficiency of one-time signature schemes with public key authentication 57
3.5.2 Efficiency of one-way chain authentication
One-way chains may seem more efficient than Merkle trees, as no authenticationpaths need to be computed, exchanged and verified. On the other hand, the useof one-way chains requires rather strict synchronization between the signer andthe verifiers, limiting the applications of this authentication mechanism.
The different processes involved are:
– One-way chain generation (key setup) is the process of generating all thehash chains. The output of this process is the root secret key skN and thefirst public key pk1 to be used by the verifiers.
– Active private key regeneration is the process of computing the currentlyactive private key.
– Signing a message consists of (1) regenerating the active private key and (2)generating the signature.
– Verifying a signature consists of verifying the received signature values bywalking down the chains until known values are reached (see Sect. 3.4.2).
One-way chain generation and verification
A private key consists of t + γ random values. For the LDM and HORS schemeγ = 0 and for the LDW γ = 1. These values are generated using a single seedvalue sk , requiring t+γ BF. From this root private key, the signer computes thechains. Assuming we wish to sign S messages with a single set of one-way chainsand assuming that a single private key can be used r times, the required lengthN of the chains is S/r. The total cost of the one-way chain generation processis
(t + γ) + N(tα + γβ) BF. (3.18)
When using one-way chains, the cost of regenerating the first private key is muchhigher than the cost of regenerating the last private key. This is because thesigner always starts from the root private key and works his way down the chainsuntil he reaches the active private key. The first active private key is to the farright of the chains (Fig. 3.4). Therefore, we compute the average cost of theprivate key regeneration process. In total, N private keys can be verified with asingle set of one-way chains. The cost of computing these N private keys consistsof computing the root private key and walking down the chains until the activekey is reached. The total cost of this process is
N(t + γ) +N(N − 1)
2(tα + γβ) BF.

58 Chapter 3. Efficiency of One-Time Signature Schemes
Assuming the signer keeps the active private key in memory until the r signaturesare generated, the average cost of private key regeneration per signature is
t + γ
r+
N − 12r
(tα + γβ) BF. (3.19)
The cost of signing a message is the cost of generating the active private key andusing this key to generate the signature. This last cost depends on the signaturescheme that is used.
Assume that the verifiers obtained an authenticated copy of the first public keypk1. Upon reception of a signature, the verifier has to walk down the chainsuntil he reaches a known authenticated value. Once the verifier has checkedthe authenticity of the received signature, he only keeps the leftmost values foreach chain (see Sect. 3.4.2). This way he will have to compute every value ineach chain exactly once, except for the root private key and possibly some othervalues close to this root private key. The total signature verification cost is atmost N(tα + γβ) BF or
(tα + γβ)/r BF (3.20)
per signature.
Efficiency of the LDM using one-way chains
The specific parameters for the LDM are γ = 0, the public key size t = s +dlog2(s)e, only one signature per key (r = 1 and N = S), and the OWF f isapplied once to compute the public key from the private key values (α = 1).Computing a signature from a private key is “free” (Sect. 3.3.1).
Key setup cost. The signer generates the root private key and the first publickey. A copy of this public key is transferred to the verifiers over an authenticatedchannel. The size of the public key is s+dlog2(s)e blocks. The cost of generatingthis public/private key pair is (Eq. (3.18))
(s + dlog2(s)e)(S + 1) BF. (3.21)
Cost of signing a message. The signer regenerates the active private key andcomputes the signature. On average, this requires (Eq. (3.19))
(s + dlog2(s)e)S + 1
2BF. (3.22)

3.5 Efficiency of one-time signature schemes with public key authentication 59
Cost of verifying a signature. On average, the verification of a single signa-ture requires (Eq. (3.20))
s + dlog2(s)e BF. (3.23)
Signature size. Public keys do not have to be transmitted when using one-waychains. Hence, the average signature size is
(s + dlog2(s)e)/2 blocks. (3.24)
Efficiency of the LDW using one-way chains
The specific parameters for the LDW are γ = 1, the public key size t+1 = s/g+1,only one signature per key (r = 1 and N = S), and the OWF f is appliedα = 2g − 1 or β = (2g − 1)s/g times to compute the public key from the privatekey values. Computing a signature from a private key requires (s/g)(2g − 1) BF(Sect. 3.3.2).
Key setup cost. The signer generates the root private key and the first publickey. A copy of this public key is transferred to the verifiers over an authenticatedchannel. The size of the public key is s/g + 1 blocks. The cost of generating thispublic/private key pair is (Eq. (3.18))
s/g + 1 + 2S(s/g)(2g − 1) BF. (3.25)
Cost of signing a message. The signer regenerates the active private key andcomputes the signature. On average, this requires (Eq. (3.19))
s/g + 1 + S(s/g)(2g − 1) BF. (3.26)
This includes both the private key generation cost and the signature generationcost. Note that the latter is much smaller than the former.
Cost of verifying a signature. On average, the verification of a single signa-ture requires (Eq. (3.20))
2(s/g)(2g − 1) BF. (3.27)
Signature size. Public keys do not have to be transmitted when using one-waychains. Hence, the signature size is
s/g + 1 blocks. (3.28)

60 Chapter 3. Efficiency of One-Time Signature Schemes
Efficiency of the HORS scheme using one-way chains
The specific parameters for the HORS scheme are γ = 0, the public key size t, rsignatures per key (N = S/r), and the OWF f is applied once to compute thepublic key from the private key values (α = 1). Computing a signature from aprivate key is free (Sect. 3.3.3).
Key setup cost. The signer generates the root private key and the first publickey. A copy of this public key is transferred to the verifiers over an authenticatedchannel. The size of the public key is t blocks. The cost of generating thispublic/private key pair is (Eq. (3.18))
t(1 + S/r) BF. (3.29)
Cost of signing a message. The signer regenerates the active private key andcomputes the signature. On average, this requires (Eq. (3.19))
(t/2r)(S/r + 1) BF. (3.30)
Cost of verifying a signature. On average, the verification of a single signa-ture requires (Eq. (3.20))
t/r BF. (3.31)
Signature size. Public keys do not have to be transmitted when using one-waychains. Hence, the signature size is (k log2(t) = s)
k blocks. (3.32)
Remarks
– It is possible to make signature generation more efficient. In Eq. (3.19)we assume that the signer first computes the complete active private key(consisting of t + γ values) and uses this private key to generate a signature(possibly consisting of less than t + γ values). For example, using the HORSscheme, the signature size k is always smaller than t. In this case it is moreefficient to compute the signature immediately from the root private key,without first computing the active private key. The performance gain whenusing this second technique is about a factor of t/k. The disadvantage of thisapproach is that the signer cannot schedule the demanding task of computingthe active private keys at his leisure.

3.6 Comparison 61
– Equation 3.19 shows that signature generation performance is improved by afactor of r2 (since N = S/r). This is because the chains are r times shorterand a single private key (computed only once) can be used r times. Thecombined effect is an improvement by a factor of r2.
3.6 Comparison
In order to compare the efficiency of the different one-time signature schemes, in-cluding the cost of communications, we will use assumptions presented in Sect. 3.3which are based on the measurements shown in Table 2.2. This table also allowsus to compare the one-time signature schemes with ECDSA. We have evaluatedthe energy cost per signature when we sign S messages with a single set of one-way chains or Merkle tree. The results in Fig. 3.5 up to Fig. 3.9 do not includethe cost of bootstrapping the system. We assume that the verifiers have alreadyobtained an authenticated copy of the public key material that they need. Fig-ure 3.10 shows an example scenario with 10 verifiers, and includes the cost ofbootstrapping the system. Table 3.4 show a summary of the efficiency of thedifferent one-time signature schemes.
Figure 3.5 shows how the energy cost per signature generation varies with thenumber of signatures. For Merkle based schemes, this cost includes the rootgeneration process (Eq. (3.7)) next to the cost of generating a signature andthe authentication path (Eq. (3.9), Eq. (3.12) and Eq. (3.15)). The cost of theroot generation process is divided over all S signatures. Because of the efficientauthentication path generation algorithm, the cost per signature only grows veryslowly with the number of signatures (∼ log2(S)/ log2(log2(S))). For schemesbased on one-way chains, the signing cost includes the overhead of computingthe first public key (i.e., the last values of the chains, Eq. (3.18)) next to the costof generating the signature (Eq. (3.22), Eq. (3.26) and Eq. (3.30)). In contrastto Merkle based schemes, the cost per signature grows linearly with respect toS. This is because of the inefficient private key generation process (Eq. (3.19)).The ECDSA does not suffer from any overhead and therefore the energy cost persignature is constant. The first column in Table 3.3 shows the signing cost of thedifferent schemes after the distances between the cost curves have stabilized (atS = 250). Note that the one-time cost curves continue rising, thus at some pointthe ECDSA will be the most efficient option. Obviously this operation pointshould never be used. For one-way chain based schemes the relative distancenever stabilizes.
Figure 3.6 shows the cost per signature verification as a function of the numberof signatures S. Looking at Eq. (3.10), Eq. (3.13) and Eq. (3.16), we see that the

62 Chapter 3. Efficiency of One-Time Signature Schemes
verification cost for Merkle based schemes grows with log2(S) because of the leafverification process (Eq. (3.8)). However, this cost is negligible compared to theconstant cost of verifying a signature, resulting in a near-constant verificationcost. One-way chain based schemes have a constant verification cost (Eq. (3.23),Eq. (3.27) and Eq. (3.31)). The ECDSA verification cost is also constant. Thesecond column in Table 3.3 shows the verification cost of the different schemesat S = 250.
Comparing Fig 3.5 with Fig. 3.6 we see that the verification cost is lower thanthe signature generation cost for all one-time signature schemes. For one-waychain base schemes this difference grows rapidly (∼ S), while for Merkle basedschemes the difference remains near-constant.
With respect to communications or signature size (Fig. 3.7) we see that ECDSAis most efficient as the signature size is only 320 bits and there is no overhead.The fact that we need to include the public key and the authentication path in asignature, makes Merkle based schemes (Eq. (3.11), Eq. (3.14) and Eq. (3.17)) lessefficient than one-way chain based schemes (Eq. (3.24), Eq. (3.28) and Eq. (3.32)).The HORS schemes have small signature sizes but relatively large public key sizes.Therefore, they are more efficient than both the LDM and the LDW when usingone-way chains, but less efficient than the LDM when using Merkle trees. Thethird column in Table 3.3 shows the communications cost in bits/signature of thedifferent schemes at S = 250.
Figures 3.8 and 3.9 show the total cost, computations and communications, forthe signer and the verifier. For the signer, i.e., the transmitter, the communi-cation cost is 11.7 mJ/kbit, while for the verifier it is 10.4 mJ/kbit. As thecommunication cost is near constant, we obtain shifted versions (with a differentshift for every scheme) of Fig 3.5 and Fig. 3.6 respectively. For the signer, wesee that the communications cost dominates for the Merkle based schemes. Forthe one-way chain based schemes the computational cost rapidly grows and startsdominating. For the verifier, the communications cost always dominates. For theECDSA, the computational cost is much larger than the cost of communications.
Figure 3.10 shows the total cost per signature for an example scenario. In thisscenario a single signer transmits signatures to 10 verifiers using a single broadcastmessage. The one-time schemes are bootstrapped using an ECDSA signature onthe root of the Merkle tree or on the first public key of the one-way chains.The cost of this bootstrapping process is divided over the S signatures. Becauseof the initialization and bootstrapping costs, the cost of the different schemesfirst decreases with the number of signatures. Depending on the scheme, thisdecrease levels out at around 50–75 signatures. Beyond this threshold the costper signature keeps increasing. The rate of increase depends on the signing costof the particular scheme. The most efficient solution for this particular setting

3.6 Comparison 63
50 100 150 200 2500
50
100
150
200
250
# signatures
mJ/
sign
atur
e
ECDSA
LDW with OWC
HORS−20 with OWCLDM with OWC HORS−18 with OWC
HORS−20 with Merkle
HORS−18 with Merkle
LDW with Merkle
LDM with Merkle
Figure 3.5. Signing efficiency of one-time signature schemes.
is HORS-18 using one-way chains with about 75 signatures per one-way chain.The last column in Table 3.3 shows the cost of the different schemes for S = 75signatures per Merkle tree or one-way chain. Using multiple instances of HORS-18 (including the bootstrapping cost) will yield a five-fold increase in efficiencycompared to using plain ECDSA. Figure 3.9 shows that ECDSA is less efficientthan HORS-18 for the verifier. This means that the efficiency difference betweenECDSA and HORS-18 will grow further in the case of more verifiers.
Summarizing we see that (1) one-way chains are most efficient for signature veri-fication, (2) ECDSA and Merkle trees are most efficient for signature generation,and (3) ECDSA is the best candidate with respect to communications costs. If wetake the average costs of all one-time signature schemes in Table 3.3, we obtain92.8 mJ/signature for signature generation, 10.4 mJ/signature for verificationand 8.9 mJ/signature for communications.4 This shows that signature genera-tion is about ten times more demanding than verification or communications.
4At a rounded 10 mJ/kbit.

64 Chapter 3. Efficiency of One-Time Signature Schemes
50 100 150 200 2500
50
100
150
200
250
# signatures
mJ/
sign
atur
e
LDW with Merkle LDW with OWC HORS−18 with Merkle HORS−20 with Merkle HORS−18/20 with OWC LDM with OWC LDM with Merkle
ECDSA
Figure 3.6. Verification efficiency of one-time signature schemes.
50 100 150 200 2500 (0)
10 (100)
20 (200)
30 (300)
40 (400)
# signatures
kbit
(mJ)
/ si
gnat
ure
HORS−20 with OWCHORS−18 with OWCECDSA
LDW with Merkle LDM with OWC
LDM with Merkle
HORS−20 with Merkle
LDW with OWC
HORS−18 with Merkle
Figure 3.7. Communication efficiency of one-time signature schemes. Theenergy cost (mJ/signature) is a rough approximation at 10 mJ/kbit.

3.6 Comparison 65
50 100 150 200 2500
100
200
300
400
500
600
# signatures
mJ/
sign
atur
e
HORS−18 with OWC
LDM with OWC
LDM with Merkle
LDW with OWC
ECDSA
HORS−18 with Merkle
LDW with Merkle
HORS−20 with Merkle
HORS−20 with OWC
Figure 3.8. Energy consumption of signer (communications and computations).
50 100 150 200 2500
100
200
300
400
500
600
# signatures
mJ/
sign
atur
e
HORS−20 with OWC HORS−18 with OWC
HORS−20 with MerkleLDM with MerkleECDSA LDW with Merkle
LDW with OWCLDM with OWC
HORS−18 with Merkle
Figure 3.9. Energy consumption of verifier (communications and computa-tions).

66 Chapter 3. Efficiency of One-Time Signature Schemes
0 200 400 600 800 1000 1200 1400 1600 1800 20000
1000
2000
3000
4000
5000
6000
# signatures
mJ/
sign
atur
eHORS−18 with Merkle
LDW with OWC
ECDSA
LDM with Merkle
HORS−18 with OWC
LDM with OWC
HORS−20 with Merkle
HORS−20 with OWC
LDW with Merkle
Figure 3.10. Overall energy consumption of one-time signature schemes. Thissetting assumes one signer and ten verifiers.
Table 3.3. Efficiency of one-time signature schemes.
Signing Verification Comms Total# signatures 250 250 250 75
[mJ] [mJ] [bit] [mJ]LDM with Merkle 42.3 5.19 20,797 2,509.2LDW with Merkle 138.9 25.09 7,197 1,226.7HORS-20 with Merkle 64.5 5.65 22,717 2,756.6HORS-18 with Merkle 123.7 10.53 42,957 5,202.0LDM with OWC ↑ 3.25 6,720 986.1LDW with OWC ↑ 23.23 3,280 1,540.6HORS-20 with OWC ↑ 4.96 1,600 488.1HORS-18 with OWC ↑ 5.61 1,440 408.3ECDSA 134.2 196.20 320 2,133.2
The entries are cost per signature.

3.7 Conclusions and future work 67
3.7 Conclusions and future work
In this chapter we have investigated the power consumption of several digitalsignature schemes. Our evaluation includes all aspects of using these schemes, i.e.,key generation, signature generation and verification, and communications. Wehave provided algebraic expressions for all these different aspects. Visualizationof these expressions shows that the optimal choice of algorithm depends on thespecific scenario. For example, if we require efficient signature generation, thenthe LDM using Merkle trees is the optimal choice. When we require efficientcommunications, then the ECDSA is the best option. However, the completesystem (signing, verifying and communications) is optimized when we use HORS-18. This chapter provides the necessary information to select the optimal schemefor any situation.

68 Chapter 3. Efficiency of One-Time Signature Schemes
Table 3.4. Summary of digital signature costs for message hash size s = 160.
LDMKey setup 168 BFSigning –Verification 84 BFPublic key size 168 blocksSignature size 84 blocksLDW (g=4)Key setup 1200 BFSigning 600 BFVerification 600 BFPublic key size 41 blocksSignature size 41 blocksHORS-18/20Key setup t BF = 512/256 BFSigning –Verification k BF = 18/20 BFPublic key size t blocks = 512/256 blocksSignature size k blocks = 18/20 blocksLDM using Merkle treesKey setup 506S BFSigning 336 + 506 log2(S)/ log2(log2(S)) BFVerification 84 + 168 + 2 log2(S) BFPublic key size 1 blockSignature size 168 + 84 + log2(S) blocksLDW using Merkle trees (g = 4)Key setup 1282S BFSigning 1240 + 1240 + 1282 log2(S)/ log2(log2(S)) BFVerification 40 + 1280 + 2 log2(S) BFPublic key size root node = 1 blockSignature size 41 + 41 + log2(S) blocksHORS-20 using Merkle trees
Continues on next page...
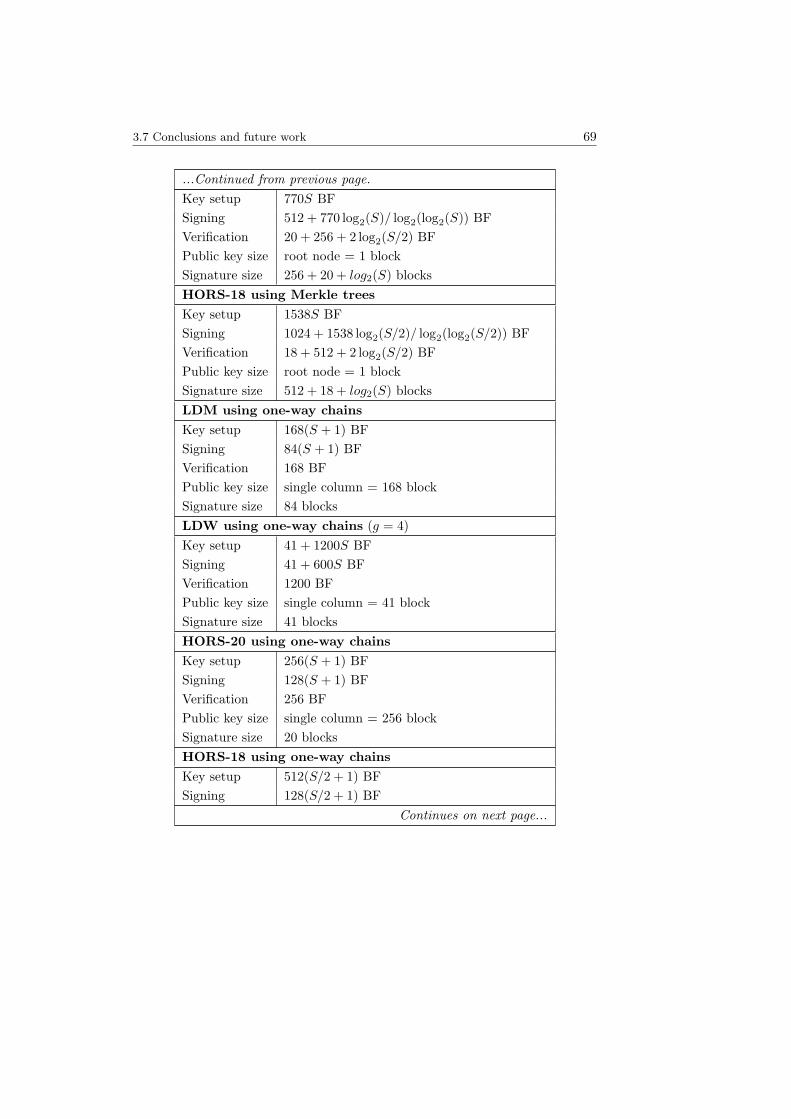
3.7 Conclusions and future work 69
...Continued from previous page.Key setup 770S BFSigning 512 + 770 log2(S)/ log2(log2(S)) BFVerification 20 + 256 + 2 log2(S/2) BFPublic key size root node = 1 blockSignature size 256 + 20 + log2(S) blocksHORS-18 using Merkle treesKey setup 1538S BFSigning 1024 + 1538 log2(S/2)/ log2(log2(S/2)) BFVerification 18 + 512 + 2 log2(S/2) BFPublic key size root node = 1 blockSignature size 512 + 18 + log2(S) blocksLDM using one-way chainsKey setup 168(S + 1) BFSigning 84(S + 1) BFVerification 168 BFPublic key size single column = 168 blockSignature size 84 blocksLDW using one-way chains (g = 4)Key setup 41 + 1200S BFSigning 41 + 600S BFVerification 1200 BFPublic key size single column = 41 blockSignature size 41 blocksHORS-20 using one-way chainsKey setup 256(S + 1) BFSigning 128(S + 1) BFVerification 256 BFPublic key size single column = 256 blockSignature size 20 blocksHORS-18 using one-way chainsKey setup 512(S/2 + 1) BFSigning 128(S/2 + 1) BF
Continues on next page...

70 Chapter 3. Efficiency of One-Time Signature Schemes
...Continued from previous page.Verification 256 BFPublic key size single column = 512 blockSignature size 18 blocks

Chapter 4
Efficient CooperativeSignatures
In the previous chapter we have shown that one-time signature schemes can bemore efficient than the ECDSA (in general the most efficient traditional signa-ture scheme). In this chapter we show that this can be further improved bycooperation. We propose a novel scheme that turns the Lamport-Diffie one-timesignature scheme into a one-time threshold signature scheme. In this scheme,multiple nodes can cooperate to jointly generate a signature on some message.We further show how this scheme can be used to create an authentication proto-col that forces multiple nodes to cooperate in order to be able to authenticate amessage. This prevents a single compromised or malicious node (or even a smallsubset of nodes) from sending authenticated messages. Moreover, our schemeis designed to work in the setting of power-constrained devices such as sensornodes: the low-power devices only use the efficient public operations of RSA orof the Rabin public key cryptosystem, or symmetric building blocks. To the bestof our knowledge no design has been proposed in the literature that can offersimilar properties.
Contributions in this chapter
This chapter extends the research results that were published in [158]. Thecontributions presented here are:
– We present the notion of one-time threshold signature schemes, and showhow they could be implemented.
71

72 Chapter 4. Efficient Cooperative Signatures
– We build a complete authentication mechanism on this threshold signaturescheme, that allows multiple nodes to jointly authenticate data packets insensor networks.
4.1 Threshold signatures
Definition 4.1 ((t, n) threshold signature scheme). A t out of n or (t, n)threshold signature scheme is a protocol that allows any subset of at least t parti-cipants1 out of n to generate a signature on behalf of the group, but that disallowsthe creation of a valid signature if fewer than t participants collaborate.
The basic property that any threshold signature scheme needs to provide is un-forgeability . Unforgeability means that any subset of less than t participantsshould not be able to create a valid signature, even if they collude. If one fore-sees that some participants might become corrupted, then the threshold signaturescheme should also be robust , meaning that corrupted participants cannot pre-vent uncorrupted participants from generating signatures. Note that a thresholdscheme always requires that more than half of the participants behave correctly,i.e., the threshold t is always larger than n/2. If more than half of the partici-pants are corrupted, they can cooperate and jointly sign some altered message,regardless of the threshold scheme that is used. For example, suppose there existsa threshold scheme that only requires 1/4 of the participants to behave honestlyto be unforgeable. Even if only 1/3 of the nodes are corrupted (thus 2/3 of thenodes are honest), they can still generate a forged signature on behalf of thegroup.
In 1987, Desmedt [43] first presented the notion of threshold signatures. Twoyears later, Desmedt and Frankel [44] presented the first (non-robust) thresholdElGamal scheme [57] based on Shamir’s secret sharing scheme [161] (i.e., poly-nomial interpolation over a finite field). Since this first proposal, the field ofthreshold signature schemes has been extensively studied (we refer to [76, 165]for an overview of the current state-of-the-art of threshold signature schemes).
We mention the most important additional properties that have been developedsince 1989. Threshold signature schemes with traceability [100] combine the ideaof multisignature schemes [78, 111] with threshold signatures to allow that indi-vidual signatures generated by the participants can be verified by a designatedclerk before they are combined into a group signature. This means that the
1Sometimes an alternative definition is used, in which at least t+1 participants are requiredto create a signature.

4.2 Threshold Lamport-Diffie signatures 73
clerk knows which participants have cooperated to create the threshold signa-ture. Threshold signature with (k, l) shared verification [177] can only be veri-fied by a colluding subset of at least k out of l verifiers. In a threshold scheme,the private key is usually distributed amongst the n participants using a secretsharing scheme. By exploiting the properties of the secret sharing scheme, thethreshold scheme can be further improved. Proactive schemes [69, 70] use sharerefreshing, which enables the participants to compute new shares from the oldones in collaboration without disclosing the group private key. Because the newshares are independent of the old ones, an adversary learns nothing by combiningnew shares with old ones. Participants can detect incorrect shares if verifiablesecret sharing schemes [61, 120] are used. Finally, share redistribution [39, 45]allows to alter the access structure of the secret sharing scheme from a (t, n) toa (t′, n′) scheme.
4.2 Threshold Lamport-Diffie signatures
The first threshold version we propose changes the basic Lamport-Diffie one-timesignature scheme into a threshold scheme. As we explained in Sect. 3.1 on p. 36,the basic Lamport-Diffie one-time signature scheme is based on a general OWFf . The secret key consists of two random values x0 and x1, while the publickey is the pair {f(x0), f(x1)}. The signature for a single bit b is xb. For m-bitmessages, m instances of this scheme are used.
In order to change this scheme into a threshold scheme, we employ Shamir’ssecret sharing scheme [161]. To implement a (t, n) threshold scheme, we choose apolynomial g of degree t−1 in a finite field such that g(0) equals the secret s. Thesize of the field should be larger than n. Each of the n participants is given a secretshare si = g(xi). The xi are made public. The reconstruction of the polynomialg requires any subset S of (at least) t distinct shares {sπS(1), sπS(2), . . . , sπS(t)}(for a given subset S of t out of n, πS : S → {1, 2, . . . , n} and |S| = t). Supposingthe polynomial g is chosen in the field GF (p), then the Lagrange interpolationthat yields g can be written as
g(x) =t∑
i=1
sπS(i)
t∏
j=1,j 6=i
(x− xπS(j))(xπS(i) − xπS(j))
(mod p) .
In our threshold Lamport-Diffie signature scheme, the public key is still the pair{f(x0), f(x1)}, while the pair of secret keys {x0, x1)} is distributed amongst then participants using two instances of Shamir’s secret sharing scheme. Every

74 Chapter 4. Efficient Cooperative Signatures
participant i has one share s0,i of x0 and one share s1,i of x1. The thresh-old signature for bit b is simply any subset Sb of (at least) t distinct shares{sb,πS(1), sb,πS(2), . . . , sb,πS(t)} (for a given subset S of t out of n, πS : S →{1, 2, . . . , n} and |S| = t). Verification of this signature consists of reconstructingthe secret xb using Lagrange interpolation of the shares and verifying whetherf(xb) is equal to the public key.
Discussion
– Any secret sharing scheme can be used instead of Shamir’s secret sharingscheme. However, since this is still a one-time signature scheme, advancedproperties such as proactive share refreshing do not offer any added value tothe scheme.
– The computational cost of signing is zero (selecting the correct share). Thecomputational cost of verification is equal to the cost of the reconstructionof the secret xb (when Shamir’s secret sharing scheme is used, this is the costof Lagrange interpolation of t points).
– This scheme cannot be used to extend the Winternitz improvement of theDiffie-Lamport one-time signature scheme (see next section).
4.3 Multi-signer Lamport-Diffie one-time signatureswith Winternitz improvement
The Winternitz improvement of the basic Lamport-Diffie one-time signaturescheme allows a time/memory tradeoff, i.e., it allows to reduce the storage re-quirements by using more CPU cycles. The OWF f is applied to the secret keyiteratively (see Sect. 3.1.2 on p. 37). We repeat the public key, private key and sig-nature equations for easy reference. The message M is split into m/t blocks of sizet bits. Let these parts be M1, . . . ,Mm/t. The secret key is sk = {x0, . . . , xm/t}.The public key is pk = {F (2t−1)m/t(x0), F 2t−1(x1), . . . F 2t−1(xm/t)}. The sig-nature Sign(M) = {s0, . . . , sm/t} with si = F 2t−1−Ii(xi) = F−Ii(yi) for i ≥ 1,while s0 = F
Pi≥1 Ii(x0), with Ii = Int(Mi).
Converting this scheme into a threshold scheme using the technique we describedin the previous section, would require every participant to have knowledge of ashare of all possible signature values. As these shares cannot be computed iter-atively (the iterative structure is obviously not maintained after the applicationof the secret sharing scheme), a participant will have to obtain and store a share

4.4 Cooperative threshold one-time signatures 75
of every possible signature value. This annihilates the time/memory tradeoff theLDW scheme offers.
Before presenting our second design that allows to create a threshold version ofthe LDW scheme, we briefly present a “multi-signer” solution using the Rabinfunction [107, Sect. 3.9] as a OWF. This is not a threshold scheme as it requiresall participants to collude to generate a valid signature. The scheme is based onthe observation that squaring modulo n with n the product of two large primes(f(x) = x2 (mod n = pq)) is a OWF with the following homomorphic property:when x = ab then f(x) = f(a)f(b). Instead of first generating a secret x andthen computing the shares, we first generate a random share si (1 < si < n− 1)for every participant and compute the secret x as x =
∏i si (mod n). We
repeat this for every value in the secret key sk = {x0, . . . , xm/t}, providing everyparticipant with m/t shares. Because of the homomorphic property of the OWF,every participant can generate his share of the signature by applying the one-timesignature scheme described above. The verifier needs to multiply all the signatureshares in order to reconstruct the multi-signer signature. After multiplying thesignature shares, the verification process is the same as in the normal LDWscheme. A similar scheme can be constructed using exponentiation modulo p asa OWF: f(x) = αx (mod p) with p prime, α a generator of Z∗p, and x ∈ Z∗p. ThisOWF has the following homomorphic property: when x = a + b then f(x) =f(a)f(b). The secret x is now computed from the shares as x =
∑i si (mod n).
The rest of the scheme remains the same. Note that the computational costof this scheme is much higher than the one based on the Rabin function. Adrawback of both schemes is the large key and signature size compared to thestandard LDW scheme.
4.4 Cooperative threshold one-time signatures
In this section, we present a construction that can be used to convert any One-Time Signature (OTS) scheme into a threshold one-time signature scheme. Thisconstruction differs radically from other threshold schemes in many ways. Mostimportantly, instead of sharing the secret key in a redundant way to all par-ticipants, every participant has its own one-time public/private key pair. Thecooperation is achieved by having each participant only sign a part of the message.The threshold property is achieved by applying an Error-Correcting Code (ECC)[101].
First the ECC is applied to the cryptographic hash of the message. Let H ′ =ECC (H) be the result of applying the error-correcting code ECC to the crypto-graphic hash H of the original message M . Let k be the number of participants

76 Chapter 4. Efficient Cooperative Signatures
in a group. Every participant is identified within the group with a serial numberi (1 ≤ i ≤ k). The strengthened hash H ′ is split into k parts H ′
1, . . . ,H′k. Every
participant i is assigned one of these parts to sign using the OTS scheme. Theparticipants submit their individual partial signatures to the verifier.
4.4.1 Signature generation
Signing 1: Apply a cryptographic hash to prevent forging
Without this step, our scheme cannot be secure because it is susceptible to ex-istential forgery (see Def. 2.7 on p. 23). Suppose our scheme is applied to themessage itself and not to a cryptographic hash of the message. If an adversaryis able to collect a large batch of partial signatures on different messages, he willbe able to recombine them in such a way that he obtains a valid signature on adifferent message (that was never signed by the group). The reason for this willbecome clear later on. In order to prevent this, a cryptographic hash function His applied to the message: H = H(m). In addition to the requirements stated inSect. 2.1.1 on p. 14, this cryptographic hash also has to provide:
Definition 4.2 (Partial collision resistance). It should be computationallyinfeasible to find two distinct inputs with a hash value that is partially the same.In other words, it should be infeasible to find two distinct inputs x and y suchthat Hi(x) = Hi(y), ∀i ∈ S, with S a subset of all the bit positions of the hashvalue and Hi(x) the bit at position i of H(x). Note that a function H can onlymeet this requirement if the size of S is sufficiently large, i.e., |S| > l, where l islarge enough to withstand the birthday paradox.
Obviously these are requirements are more difficult to achieve than the normal,non-partial versions. Assuming the hash function is a random oracle, it is suffi-cient to lengthen the output size of H to achieve these properties.
Signing 2: Apply an error-correcting code for robustness
Assume we use an error-correcting block code that encodes an information wordin a codeword that consists of ω code symbols. Representation in the binaryfield of the code symbols requires w bits. Let α be the number of times the ECCis applied to encode the complete cryptographic hash H, resulting in a totalof αω code symbols. The hash H is padded with random bits until its lengthis a multiple of the ECC’s information word bit-length. Further assume thatthe ECC can recover the original information word from a fraction k−b
k of the

4.4 Cooperative threshold one-time signatures 77
code symbols. There is only one requirement for the ECC: the number of codesymbols ω is a multiple of the number of participants k. When this requirementis fulfilled, it is possible to construct the shares in such a way that every shareH ′
i consists of ω/k code symbols of each of the α codewords. No codeword isused twice. This share construction protocol is deterministic and depends on theECC, the hash H, the number of participants k and the identity of the particularparticipant i: H ′
i = constructShare(H, i) (we assume that the ECC and k areparameters of the complete threshold signature scheme, and do not change frommessage to message). Figure 4.1 depicts this preparation phase of the signaturescheme.
The use of this constructShare algorithm provides the following property:
Property 4.1 (Robustness). The value H can be recovered from any subsetS of (at least) k − b distinct shares {H ′
πS(1),H′πS(2), . . . ,H
′πS(|S|)} (for a given
subset S of k − b out of k, πS : S → {1, 2, . . . , k} and |S| ≥ k − b).
Proof. Because of the construction of the shares, every H ′i contains ω/k code
symbols of every codeword. When k− b distinct shares are combined, we obtainexactly (k − b)ω/k code symbols of every codeword. This is enough informationto reconstruct the original information words using the ECC.
In other words, the scheme can protect against a maximum of b corrupted parti-cipants in the group. We use a concrete example to further clarify this. Supposewe have a group of k = 15 participants and use a cryptographic hash functionwith a 160-bit output. Further suppose that we want to be able to reconstruct avalid hash even if b = 3 out of the 15 participants refuse to cooperate. One error-correcting code that can achieve this property is a (45,27) Reed-Solomon codeover GF (26) [181]. This code operates in the q-ary alphabet (q = 26) and encodes27 information symbols into ω = 45 code symbols of bit-length w = 6, having afractional redundancy of 40%, and guarantees a 9 symbol-error-correcting capa-bility. Every participant will send a share consisting of ω/k = 3 code symbolsto the verifier. Together the 3 malicious participants cannot corrupt more than9 code symbols and hence the hash H can be recovered from the remaining 36code symbols. Adapting the scheme to the group size k and threshold b is simplya matter of selecting a suitable ECC.
Signing 3: Generating partial signatures
Assume participant i has computed his share H ′i = constructShare(H, i). Before
signing this share using the OTS scheme, the participant first adds a signature

78 Chapter 4. Efficient Cooperative Signatures
ECC (H ) = α code words
ω symbols
k users H′
5
H
Figure 4.1. Preparation phase of the cooperative threshold one-time signaturescheme.
identifier to his share. This signature identifier sid is used to link the par-tial signatures of the different participants with each other. Without this linkan adversary could collect partial signatures on different messages and try tocombine them to create a signature on a new message hash, i.e., this preventsexistential forgery by outsiders. This sid has to be the same for all the par-ticipants that are signing the same message and could be negotiated amongstthem when they are agreeing on the message that needs to be signed. The sidtogether with H ′
i are signed using the OTS scheme. Finally, participant i trans-mits 〈i ,M , sid ,SignOT i(sid ,H ′
i )〉 to the verifier. There is no need to transmit H ′i
as the verifier can construct this value himself using the constructShare algorithm.
Note that in many cases (depending on the k and b parameters, efficiency of theECC, etc.), the length of H ′
i together with sid is less than the bit-length of thehash H. This means that the computational cost of a partial signature is less thanthe cost of a normal individual signature, hence the name cooperative thresholdsignature. Further note that the signature identifier sid is only effective againstadversaries outside the group. The use of the cryptographic hash function H isstill required to protect against existential forgeries by colluding users inside thegroup (see Sect. 4.4.3). As such the use of the sid can be considered optional asthe cryptographic hash also protects against adversaries outside the group.
4.4.2 Signature verification
After receiving the multiple inputs 〈i ,M , sid ,SignOT i(sid ,H ′i )〉 from the partic-
ipating signers, the verifier uses the following protocol to verify the correctnessof the complete signature on the message M .

4.4 Cooperative threshold one-time signatures 79
Verification of individual input
In order to verify the validity of the individual inputs, the verifier first computesthe share this user was supposed to sign: H ′
i = constructShare(H(M), i). Next,he checks if the received OTS signature is a valid signature on 〈sid , H ′
i 〉. If so,the input of participant i is accepted as valid input for the threshold signature.Only one input of a particular participant is accepted.
Verification of threshold signature
After checking all the individual inputs, the verifier counts the number of validinputs with the same signature identifier sid on the same message M . If thiscount is less than k − b, the one-time threshold signature is invalid. If at leastk − b correct partial signatures were received, the collection of these individualinputs is accepted as a valid signature on message M .
If this verification process fails, the verifier concludes one of the following:
– Case 1: There are sufficient valid partial signatures with the same sid, buton different messages. This indicates miscommunication within the group onthe message to be signed, or a failed attempt to forge a signature by colludingparticipants within the group.
– Case 2: There are insufficient valid partial signatures. This indicates a De-nial of Service (DoS) attack by insiders or outsiders that have disrupted thecommunication between the signers and the verifier.
The verification scheme has the following property:
Property 4.2 (Traceability). The verifier knows the identities of the partici-pants that have submitted a valid partial signature (even if the resulting thresholdsignature is not valid).
Proof. This follows from the fact that every participant uses his own key pair tocompute the individual partial signatures.
This property prevents a colluding group of at least k − b participants fromanonymously forging a signature without taking any responsibility. In the caseof a failed forgery attempt (by less than k − b participants), the identities ofthe culprits and the message they attempted to sign can be presented to a thirdparty, the complete group, etc. If traceability is not desired, then extra measuresshould be taken to ensure that individual partial signatures are anonymized, i.e.,the public key that was used can be authenticated and related to the group ofparticipants, but not to an individual participant.

80 Chapter 4. Efficient Cooperative Signatures
4.4.3 Informal Security proof of our scheme
The verification process can only succeed if there are at least k − b distinctparticipants have provided a valid partial signature. This prevents any group ofless than k−b participants from generating a valid threshold signature. Note thatthe partial signatures are not anonymous and thus it is impossible to impersonatea participant and sign in his name.
Theorem 4.1. Assume the scheme is used without applying the cryptographichash H. An external adversary that has intercepted l threshold signatures (con-sisting of k valid partial signatures) on different messages, is not able to constructa signature on a different message M ′ (different from the l signed messages) suchthat this threshold signature will be accepted.
Proof. A threshold signature will only be accepted if at least k − b valid partialsignatures with the same sid arrive at the verifier. By changing the sid or sharethat is protected by a partial signature, the OTS signature in this partial sig-nature becomes invalid and it will be discarded by the verifier. This means theadversary cannot combine partial signatures carrying different sids. This leavesonly one strategy for the adversary: construct a message M ′ that is differentfrom M (for which the adversary has k valid partial signatures), such that atleast k − b shares (obtained by using the constructShare algorithm) are equal tothe shares of M . This is prevented by the robustness property of the scheme.
Theorem 4.2. Suppose the scheme is used without signature identifiers. Anexternal adversary who has intercepted l threshold signatures (consisting of kvalid partial signatures) on different messages, is not able to construct a signatureon a different message M ′ (different from the l signed messages) such that thisthreshold signature will be accepted.
Proof. By changing the share H ′i that is protected by a partial signature, the OTS
signature in this partial signature becomes invalid and it will be discarded by theverifier. This prevents the adversary from obtaining a valid partial signature ona share H ′ that is different from any of the shares H ′
i that he has intercepted.It does enable the adversary to combine partial signatures of different messages.In combining these partial signatures he is limited to the partial signatures hehas intercepted and he can only use a single share of every participant in everycombination. Every combination will result in a valid signature on a differentHi, i.e., the adversary is able to construct existential forgeries. However, theuse of the irreversibility cryptographic function H prevents the adversary fromconstructing a message M ′ that is mapped to any of the H’s for which he hasobtained a valid threshold signature

4.5 Application of our scheme in sensor networks 81
Theorem 4.3. Suppose the scheme is used without signature identifiers. A groupof k − b− 1 corrupted participants that can use another participant as a signingoracle cannot construct a valid threshold signature on a message M ′ that theyhave not submitted to the oracle. This signing oracle takes as input a messageM and produces a valid partial signature on this message.
Proof. The adversary (the group of corrupted participants) requires one addi-tional partial signature from the oracle to construct a valid threshold signature.Adversary strategy 1: the adversary computes valid partial signatures on k−b−1shares H ′
i of a message M ′ and tries to complete this set with a partial signatureon one additional share H ′ obtained from the oracle. As the oracle only acceptsmessages as input, the adversary has to construct a message M different fromM ′ that results in the same share H ′. This is prevented by the partial collisionresistance property (Def. 4.2) of the hash function H. Adversary strategy 2: theadversary first obtains a partial signature from the oracle on share H ′ of messageM . The adversary again has to construct a message M ′ different from M thatresults in the share H ′, which is prevented by partial collision resistance of thehash function.
4.5 Application of our scheme in sensor networks
The cooperative threshold one-time signature scheme presented in the previoussection was originally developed to provide efficient authentication in sensor net-works. In Chapter 2 we have shown that RSA and Rabin offer very efficient publickey encryption and signature verification. Our cooperative threshold one-timesignature scheme completes this with efficient cooperative signature generation.
We now describe how these efficient primitives can be used to provide strongauthentication for query-response conversations between a cluster of sensor nodes(a cell) and a query node that request data from the network. Note that in oursetting the low-power sensor nodes do not possess an asymmetric decryption(private) key, since we assume that the asymmetric decryption operation is toopower consuming.
4.5.1 Network operation
Our solution is designed with the following sensor network architecture in mind.The majority of the nodes in the sensor network, sensor nodes, measure what-ever property they are designed to measure (e.g., temperature, pressure, light

82 Chapter 4. Efficient Cooperative Signatures
intensity, etc.). These sensor nodes are organized in cells (sometimes referred toas clusters). One node in each cell will act as a cell manager. The cell manageris responsible for collecting information from the sensor nodes in its cell and for-warding it to a query node or sink node. A query node requests (pulls) a specificcell manager for an update, while a sink node is used when an event is triggeredby a sensor node and the update information is pushed to the sink node. Obvi-ously a single node can act as both a query and a sink node. Figure 4.2 shows anexample network topology with three cells. When a query node sends a requestto the cell manager to pull data from the sensors, the cell manager broadcaststhe request to the rest of its cell. Besides requests from query nodes, an updatecan be triggered by any sensor and forwarded to the cell manager. Sensors withina cell collect data, and locally process it resulting in a single response or updatethat is transmitted to a query (sink) node respectively. The response/update istransmitted to the query or sink node by the cell manager. The cell manager alsoensures that every node in its cell gets a copy of the final result. This architectureis commonly accepted [139].
In this scenario we assume that the query (sink) node is trusted. This is necessaryas the query (sink) node collects the data collected from the sensor network, andforwards it to the user.
Our solution provides the following security properties:
1. Query nodes can authenticate their requests.2. The confidentiality of the response or update data can be guaranteed (only
the query or sink node can read it).3. Sensors in a cell have to cooperate in order to authenticate the response or
update. This prevents a single malicious node in the network from providingthe query or sink nodes with incorrect information.
In order to achieve this, we assume that there is a protocol in place that ensuressecure intra-cell communications. Our scheme depends on the ability of the nodesto securely communicate with each other within a cell. It is of little use to protectthe confidentiality of the response to some query only between the cell managerand the query node – it also has to be protected while the cell is negotiating theresponse. Group key management schemes [138] could provide a solution here.When the sensor nodes enter or leave cells continuously because of node mobility,then the key management scheme we presented in Chapter 5 could be used. Wefurther assume the following PKI to be in place:
1. Every query and sink node has a private/public key pair for signing andanother pair for encryption, both accompanied by a certificate signed bysome third party.

4.5 Application of our scheme in sensor networks 83
query node
cell C
cell B
cell AH ′
2,SignOT
2(sid , H ′
2)
M
reqID ,Pubq(sid , res)
H ′
1,SignOT
1(sid , H ′
1)
Figure 4.2. Example sensor network with three cells. Every cell has one cellmanager node (black square).
2. Every sensor node has an authenticated copy of this third party’s public key.This enables the sensor node to verify the certificates of the query or sinknodes. Note that signature verification is an efficient operation.
3. Every sensor node has a number of private/public key pairs to be used withour cooperative threshold one-time signature scheme. In Sect. 4.5.3 we showhow these key pairs can be renewed.
4.5.2 Strong authentication between query nodes and cells
Using the proposed building blocks, implementing the authentication schemeitself is straightforward.
Authenticated requests
When a query node Q wishes to send an authenticated request req to a managernode M , it uses the following protocol:
Q −→ M : reqID , req ,SignRSAq(〈reqID , req〉) .
The reqID is incremented for every request and stored in memory by both thequery node and the manager nodes. Only requests with an reqID larger thanthe one in memory are accepted. The signature in combination with the reqID

84 Chapter 4. Efficient Cooperative Signatures
assure the manager node that the request is not a replay and that it originatedfrom a valid query node. If freshness of the request must be guaranteed, then athree-message challenge/response can be used:
Q −→ M : notify (1)Q ←− M : Nm (2)Q −→ M : req ,SignRSAq(req , Nm) (3)
Here the first message is only necessary to notify the manager node that thequery nodes wishes to send an authenticated request. In the push model towardsa sink node this message is not necessary.
Authenticated replies or updates
For this purpose we originally developed the cooperative threshold LDW signa-ture scheme. Obviously our scheme can be used in any low-power setting werea single device is not trusted to sign a message individually. As we explained,we assume that upon arrival of a valid request, the manager node broadcasts therequest to the cell, and the cell locally computes the best result from the collec-tive data. The manager ensure that all nodes in its cell know this final resultres. Once the final result is computed, the manager node replies to the requestwith the following message: 〈reqID ,Pubq(sid , res)〉. This message contains theidentity of the corresponding request and the encryption (with the query nodespublic key) of the final result and the sid that will be used for the cooperativesignatures.
All nodes in the cell employ the cooperative signature scheme in order to createthe partial signatures SignOT i(sid ,H ′
i) on the final result res. These partial sig-natures are transmitted by every node in the cell to the query node (see Fig. 4.2).The query node collects all partial signatures and verifies the correctness of thecomplete signature on the response res it received from the manager node. Notethat the sensor nodes do not transmit the response res to the query node. Thequery node uses the res it received from the manager node to verify all thepartial signatures. The result of this verification process might be used to dis-tinguish between honest nodes and possibly uncooperative sensor nodes. Whenour scheme is used in combination with a reputation scheme [30, 31, 32], thenthis information can be used as one of the inputs to recompute a sensor node’sreputation.

4.5 Application of our scheme in sensor networks 85
4.5.3 One-time secret key updates
Two important aspects in the use of one-time signature schemes are (1) gener-ating public keys, and (2) providing the verifier with an authenticated copy ofthese public keys. In our solution we efficiently solve this problem by reversing2
it: we let the verifier (query nodes) generate the private/public LDW key pairsand transmit an authenticated and encrypted version of the private keys to thesigners (sensor nodes). This has multiple advantages:
1. The computational burden of generating the random private keys and com-puting the corresponding public keys is off-loaded from the low-power sensornodes. When Merkle trees or one-way chains are used (Sect. 3.4), computingthe root node or the last column of the chains is also off-loaded from thesensor nodes.
2. The verifier automatically obtains an authenticated copy of the public key.3. The private key sk can be generated from an l-bit seed sk (this is not true for
the public key). This means that transmitting the private key to the signeris more efficient than transmitting the public key to the verifier. This is trueparticularly in this case where there is only one dedicated verifier.
4. It allows for an asymmetric protocol with respect to the communicationscost: the bulk of the messages travel from the (powerful) query node to thelow-power sensor nodes. As transmitting radio signals cost at least as muchenergy as receiving them [2], this off-loads the burden of communication fromthe sensors to the query node.
The disadvantage is that the secret key is known by two parties, but in thisscenario that is not an issue, as the query nodes are assumed to be trusted.
Secret key updates when using Public Key Chaining
When using public key chaining to authenticate public keys, the query node Qfirst generates n private keys sk i = {x0, x1, . . . , xm/t} from the random seeds sk i.When public key chaining is used, then the signer only needs the secret keys togenerate signatures that can be efficiently verified by all parties who have a copyof the public key. Protocol 4.1 shows the scheme we propose to transfer thesenew secret keys to the sensor S. First a symmetric session key K is establishedbetween the sensor node S and the query node Q. The signature in message (2)is required to provide the query node with proof that this session key K is really
2Normally the signer generates the key pair and the verifier obtains the public key in someway.

86 Chapter 4. Efficient Cooperative Signatures
Protocol 4.1 Secret key update protocol when using public key chaining
Pre-protocol setup:The query node Q prepares n fresh private/public key pairs (sk i, pk i) that areto be used by sensor node S. The private keys sk i are generated by the seedvalues sk i.
Conventions:Nq is a random nonce generated by Q. K is a random session key generatedby S. K1 and K2 are two distinct keys derived from the session key K. H isa cryptographic hash function.
Protocol messages:
Q −→ S : Nq (1)Q ←− S : Nq,Pubq(K),SignOT s(H(Nq,K)) (2)Q −→ S : EK1 [sk1, . . . , skn], MACK2 [sk1, . . . , skn] (3)
Result:Node S can now use the new secret keys to sign messages.
generated by sensor node S. In the last message, the query node transmits anencrypted set of new private keys, and authenticates them with a MAC. Boththe encryption key and authentication key are derived from the session key K.
Note that this protocol is only efficient if multiple secret keys are transferredusing the session key K since one signature is required in message (2). Even thesmall sensor nodes should be able to store multiple private keys simultaneouslysince only a single l-bit seed has to be stored per private key (the sensor nodesdo not need to store or compute public keys in this case). The query node hasto store the last column of all n key chains, i.e., all the public keys (see Fig. 3.4on p. 52).
Secret key updates when using Merkle trees
When using Merkle trees to authenticate the public keys, the query node Qfirst generates n private keys sk i = {x0, x1, . . . , xm/t} from the seeds sk i andcomputes the public keys pk i according to the LDW scheme. The hashes ofthese public keys h(pk i) are then placed at the leaves of a Merkle tree. Finallythe query node calculates the root of the tree and the initial internal state initof the tree traversal algorithm (Sect. 3.4.1 on p. 48). The sensor node requiresthe following information in order to sign messages and compute authentication

4.5 Application of our scheme in sensor networks 87
Protocol 4.2 Secret key update protocol when using Merkle trees
Pre-protocol setup:The query node Q prepares n fresh private/public key pairs (sk i, pk i) that areto be used by sensor node S. The private keys sk i are generated by the seedvalues sk i. The query node also computes all hashes h(pk i) of the public keysand the initial internal state init of the tree traversal algorithm.
Conventions:Nq is a random nonce generated by Q. K is a random session key generatedby S. K1 and K2 are two distinct keys derived from the session key K. H isa cryptographic hash function.
Protocol messages:
Q −→ S : Nq (1)Q ←− S : Nq,Pubq(K),SignOT s(H(Nq,K)) (2)Q −→ S : EK1 [{sk i, h(pk i)}1≤i≤n, init ], MACK2 [·] (3)
Result:Node S can now use the new secret keys to sign messages.
paths: the sk i’s, the h(pk i)’s and init . Note that both sk i and h(pk i) are shortbit-strings (compared to a complete private/public key pair) and that the size ofinit is maximized by 3 log2(n) l-bit values when using Szydlo’s [172] tree traversalalgorithm. Protocol 4.2 shows the protocol we propose to securely transfer thisinformation to the sensor nodes.
After successful completion of the private key update protocol the query nodeonly has to store the root of the Merkle tree in order to be able to verify signatures.When using Merkle trees, the sensor node has to regenerate the public key whensigning a message and include it in the signature as the verifier (i.e., the querynode) needs the public key to verify the validity of the signature.
Comparison
As we explained in Sect. 3.5.1 on p. 52, generating signatures when using publickey chaining requires multiple evaluations of the OWF f as the signer has to workhis way down the chains starting from the far left (Fig. 3.4 on p. 52). Publickey chaining requires that the verifier stores the complete current public key inmemory, i.e., one value for every chain.
The use of Merkle trees requires that the signer computes the public key and the

88 Chapter 4. Efficient Cooperative Signatures
authentication path, and includes both in the signature (Sect. 3.5.2 on p. 57).On the other hand, the verifier only needs to store the root of the tree. The sizeof message (3) of Protocol 4.2 when using Merkle trees will be about double thesize of this message when using public key chaining in Protocol 4.1.
The optimal choice depends on multiple factors such as the number of verifiers,relative cost of communications and computations, specific scenario in which theprotocol is used, etc.
4.6 Conclusions
To the best of our knowledge, the work presented in this chapter is the firstconstruction that allows to turn any one-time signature scheme into a thresholdsignature scheme. Next to this construction we have shown how it is possibleto build more efficient protocols using the asymmetric cost of certain primitivesand offloading demanding tasks to more powerful devices. This work should beextended with a formal security proof and a complete efficiency analysis such asthe one presented in Chapter 3.

Chapter 5
Dynamic Key Establishment
Establishing session keys between communicating parties is essential when usingsymmetric cryptographic primitives to protect confidentiality and integrity. Inthis chapter, we propose a key management scheme that is based only on efficientsymmetric cryptographic primitives, and does not rely on public key cryptogra-phy. The scheme extends key pre-distribution schemes to the setting of dynamicad hoc networks. At all times, a node maintains pairwise keys with all nodesin its neighborhood. As nodes wander through the network, their neighborhoodchanges and the keys are updated to reflect this change in environment. Theexisting pairwise keys are used to establish keys with new neighbors.
Contributions in this chapter
– We present a fully autonomous, efficient key management scheme for low-power mobile ad hoc networks. Our scheme only requires the use of efficientcryptographic primitives and does not depend on the use of the more powerconsuming public key cryptosystems. The scheme is not dependent on anymanager nodes that operate as key distribution centers.
– We show how the key establishment scheme can be integrated with ad hocrouting protocols, in particular the DSR protocol.
– We show how the keys that have been established, can be used to secure adhoc routing protocols, in particular the DSR protocol.
– We evaluate the efficiency of the protocol both using an analytical model andthrough simulations.
– We evaluate how the security of our scheme changes with various parameters.
89

90 Chapter 5. Dynamic Key Establishment
5.1 Secure Neighborhood Discovery protocol
Our protocol is based on the observation that in many scenarios nodes wanderthrough a network rather than jump from one end of the network to the other.This means that our scheme works nicely in the setting of DSNs, but is not suitedfor networks where nodes do jump from one geographical location to another (e.g.,when the users carry their devices around and turn them on and off).
The goal of Neighborhood Discovery is to (1) provide nodes with knowledgeof their 1-hop neighborhood, (2) establish pairwise link keys between all nodeswithin a neighborhood, and (3) establish broadcast keys with the 1-hop neighbors.Having these symmetric keys in place ensures that it is possible to find a pathbetween any two nodes in which every hop can be secured using a symmetric key.
5.1.1 Neighborhood
Every node is surrounded by its neighborhood. The neighborhood of node W isthe collection of all nodes that W can reach in h or fewer hops. We call h theradius of the neighborhood. In Fig. 5.1 we depict the neighborhood of node Was it travels through the network. At time t1, W ’s neighborhood (with radius1) contains only two nodes. Obviously, as W moves, its neighborhood changes:at time t3 the neighborhood of W has completely changed and now contains 4nodes.
We assume that there are always a couple of nodes within radio range. Themore nodes that are in range, the more flexible and secure the NeighborhoodDiscovery protocol becomes. For DSNs this is usually the case as measurementsof one sensor are not very accurate and they are combined with results of othersensors in the vicinity to get a more reliable result. Also, robustness is achievedthrough numbers and not quality. Individual sensor nodes die, but functionalityis maintained by neighboring sensors.
Because of the limited memory of the nodes, we assume that every node onlykeeps security related information on the nodes in its neighborhood. The follow-ing information is stored:
– the identities of the nodes in the neighborhood;– shared secret keys with every node in the neighborhood;– keying material of a group key scheme: used to secure broadcast messages;– keying material of the broadcast groups of its neighbors (= neighborhood
of radius 1): used to verify or decrypt broadcast messages sent by theseneighbors.

5.1 Secure Neighborhood Discovery protocol 91
5.1.2 Bootstrapping the system: key pre-distribution
We assume that all nodes share symmetric keys with at least one of its neighbors.A number of key pre-distribution schemes have been proposed that can achievethis goal [37, 56, 58]. If for some reason the key pre-distribution scheme fails tosetup at least one shared key between some node and its neighbors, this nodewill be excluded from the network.
We assume that the initial set of deployed nodes are owned by a single entityor, if there are different owners, they share the initial secret information thatis used by the key pre-distribution scheme that sets up initial keys. In otherwords, the world of sensor nodes is split into two groups: nodes that are partof the network (included in the key pre-distribution scheme) and nodes that areoutside of this network (all other nodes). Nodes can be added to the networkif the key pre-distribution scheme allows this. A trivial example is the use of asingle master key: nodes that possess this key are in the network, others are out.In order to add a node, the owner just installs the master key.
5.1.3 Dynamic Neighborhood Discovery
Keeping an up-to-date view of the neighborhood
The neighborhood is discovered by periodically (every ∆T milliseconds) broad-casting a JOIN request to the neighborhood. If some new node receives thisrequest, it will answer with its identity. Nodes that are already part of the neigh-borhood send an updated view of their own neighborhood to the initiator of therequest. When the initiator of the JOIN request sees that a new node has arrivedin its neighborhood, it will initiate the process of setting up a link key with thenewly arrived node. In fig. 5.1 node W (the black square) initiates a Neighbor-hood Discovery process by sending JOIN requests at times t1, t2, t3 and t4. Thecircle around W indicates its neighborhood at these times. For the NeighborhoodDiscovery protocol to operate correctly, two consecutive (in time) neighborhoodsshould share at least one node. If not, node W has no node with which it sharesa link key in its new neighborhood, and has no means of setting up link keys withits new members. The time interval ∆T between two consecutive JOIN requestsis a parameter of the system and is dependent on how dynamic the network is:high mobility requires a small ∆T , while an almost static network can operatewith less frequent neighborhood updates.

92 Chapter 5. Dynamic Key Establishment
C
A
B
W
t1 t2 t3 t4
Neighbourhood of W at time t3
Figure 5.1. Evolution of node W ’s neighborhood as it travels through thenetwork. The circles indicate the current neighborhood of W . For simplicity, theother nodes of the network are assumed to be static between t1 and t4.
Setting up link keys
As a result of the key pre-distribution scheme, all nodes share a symmetric keywith at least one of their neighbors. We build on this to bootstrap the Neigh-borhood Discovery protocol. We use trust transitivity to authenticate nodes wedon’t yet share a key with: if A shares a key with B and B shares a key with C,then A and C can use their trust relationship with B to set up a secret sharedkey. We refer to section 5.2 for the details of our protocol to set up these linkkeys. As more link keys are installed, these nodes can also participate in theprocess of setting up link keys with other nodes. This process continues untilevery node shares a secret link key with all nodes in its neighborhood.
Setting up broadcast keys
Once all link keys have been established in the neighborhood, they can be used toset up a broadcast key with the 1-hop neighbors. We will not discuss the details ofthe exact implementation of setting up these broadcast keys, but group key man-agement schemes, where every node is the group manager for its neighborhood,are suited for this task [106, 138].

5.2 Establishing link keys 93
5.2 Establishing link keys
In this section, we describe the protocol to establish link keys between two nodes.It is primarily used to set up new link keys within a neighborhood. Its seconduse is establishing link keys to provide end-to-end security between nodes thatare not within the same neighborhood. The mechanism is exactly the same inboth cases.
5.2.1 Normal operation
Suppose node S wishes to establish a link key kSR between itself and node R.Since S and R do not yet share a secret key, we will use the keys shared betweenthe intermediate nodes to securely set up a route between S and R. We assumethat the routing scheme has provided S with one or more routes to R and viceversa. For now, we also assume that for at least one of these routes between Sand R all intermediate nodes have established link keys with their neighbors onthe route. We will call such a route a “trusted route”.
Node S initiates the key establishment protocol by sending a request to nodeR. When R receives this request for a link key, it checks how many routes thereare between itself and S. Then it generates the link key kSR that will be usedbetween R and S. Using the information R has about the number of routes to Sit uses a (m,n) secret sharing mechanism (for example Shamir’s secret sharingusing polynomials [161]) to split the secret into shares. Node R now sends eachof the shares to S using a different route provided by the routing mechanism. Asroutes may already be broken before the shares reach the initiator of the request,the parameters of the secret sharing mechanism should be chosen in such a waythat the secret can still be reconstructed by the initiator S even if some sharesare lost.
The shares are encrypted hop-by-hop using the already established link keys onthe route between S and R. Using hop-by-hop encryption we prevent nodesoutside the network from learning any of the shares. Using the secret sharingscheme we further limit the number of nodes that may learn the link key betweenS and R. For example, in Fig. 5.2 only node C is able to reconstruct the secretkSR because all routes between S and R pass through it. Obviously, if only oneroute is available, then all nodes on this route will learn the link key between Sand R. In this case node R can notify S that it is impossible to securely set upa key at this time and wait for the network to reconfigure, and multiple routesthat do not intersect appear. Here, mobility can help to provide more security.

94 Chapter 5. Dynamic Key Establishment
F
S
A
C
B
E
D
R
Figure 5.2. Multiple routes that can be used to establish a link key betweennodes S and R. Since all routes pass through node C, C is able to compute thelink key between S and R.
5.2.2 Exceptional operation
In the previous description we assumed that there is at least one trusted routebetween S and R on which all intermediate nodes share a link key that canbe used to secure the communication over this route. In the early stage of thenetwork (right after deployment) however, it is possible that no such route existsbetween a node and one or more nodes in its neighborhood. Suppose that nodesS and C share a link key (because of the key pre-distribution scheme) and nodesB and C (see Fig. 5.2). If the neighborhood radius h ≥ 2 then our schemerequires that nodes S and B establish a link key if possible.
In this case, S will send a message to B including a request to establish a link key,together with a list of nodes with which S already shares a link key. Node B willlook for nodes in this list with which it also shares a link key (in our example C).Now B will contact node C with a request to establish a link key between S andB. Node C will play the role of temporary Key Distribution Center (KDC) toaid nodes B and S to establish a pairwise link key. Any secure key establishmentprotocol involving a KDC [107, Chapter 12] can be used to fulfill this task. Notethat the scheme can be made more secure by requiring multiple nodes to playthe role of KDC. This prevents an adversary that has corrupted a single nodefrom introducing more corrupted nodes.
This scheme is only used within a node’s neighborhood, and probably only rightafter the initial deployment. Once all nodes have established link keys with theirentire neighborhood, the probability that there is no trusted route between twonodes is very low (see Sect. 5.4).

5.3 Implementation based on DSR 95
5.3 Implementation based on DSR
We will now show how our key management scheme can be added to the DSRprotocol [89] and how DSR can be secured with the link and broadcast keys ourscheme provides. We have selected DSR because it is a well known on demandrouting scheme that is suited for dynamic ad hoc networks.
Dynamic Source Routing (DSR)
When a node has a packet to send to some destination for which it has no route inits route cache, the node initiates a Route Discovery to find a route. The initiatorof the Route Discovery broadcasts a Route Request (RREQ) packet. This packethas the following format: 〈SourceAddr, DestAddr, List of intermediate nodes,ReqID〉. The “list of intermediate nodes” is initially empty. When some nodereceives a RREQ packet, it appends its identity to the list of intermediate nodes,and broadcasts the new RREQ packet. When the request reaches its targetnode, this node sends a Route Reply (RREP) packet back to the initiator ofthe request. This packet with the following format 〈Reversed list of intermediatenodes = route to SourceAddr, SourceAddr, ReqID〉 is routed through the reversedlist of intermediate nodes. Upon receiving a RREP packet, the initiator adds theroute in this RREP to its route cache. Multiple routes may be available afterreceiving multiple valid RREP packets containing different routes. DSR usessource routing: when sending a packet, the originator includes the completesequence of nodes through which the packet is to be forwarded. Note that thisis a very rudimentary description of DSR, for a detailed description we refer to[89] and Sect. 6.4.1 on p. 119.
Authenticated Dynamic Source Routing (AuthDSR)
A straightforward way to authenticate the RREQ and RREP packets is to add ahop-by-hop MAC to these packets: every node on the route adds a MAC usingthe broadcast keys that are established by the Neighborhood Discovery protocol.The Route Reply packets are unicast and are thus protected by the link keys thatare established within a neighborhood. We add incremented counters to preventreplay attacks. If we wish to prevent attackers from learning the topology of thenetwork by eavesdropping on these routing packets, we can also encrypt themusing a symmetric cipher and the broadcast keys for RREQ packets, or the linkkeys for RREP packets. We will refer to this authenticated DSR implementationas AuthDSR.

96 Chapter 5. Dynamic Key Establishment
Establishing link keys using AuthDSR
Suppose that node S wishes to establish a link key with node R. Node S initiatesthe protocol by sending a RREQ packet targeted at R that includes a request toestablish a link key. Node R can determine the number of routes to S by countingthe RREQ packets (containing different routes) it receives during some intervalτ that were initiated by S. During this interval τ it does not immediately answerthese RREQ packets, but stores them in memory. After the delay τ it generatesa secret key kSR, applies the secret sharing scheme, adds one of the shares toeach of the RREQ packets, and transmits them.
5.4 Performance evaluation
In this section we analyze the computational and communication cost of ourscheme. The overhead of our scheme arises from updating the broadcast groupsas nodes wander through the network and setting up link keys with the currentneighborhood.
5.4.1 Analytic model and simulations
In this section we answer the following questions: “What is the average numberof nodes in the overlap?”, “What is the probability that there is at least one nodein this overlap?”, and “How long does it initially take before a node can establishlink keys with its neighborhood?”
We employ both an analytical model and simulations to evaluate the performanceof the scheme. Figure 5.3 shows the model we use for our analysis:
– The nodes are placed on a discrete two-dimensional grid mapped on a torus(Fig. 5.3). The transmission range of a node is equal to the distance betweentwo neighboring grid points.
– Only a fraction ρ of the grid points are occupied by nodes.– The network evolves synchronously with a global discrete clock. At every
clock tick all nodes move with an equal probability to one of the four neigh-boring grid points on the torus.
– We follow a node W that has been added to the system after all other nodeswere deployed. This means that this node’s 1-hop neighbors are all the nodeslocated on one of the four neighboring grid points, or on the grid point onwhich node W itself is located, i.e., there are 5 possible locations for its 1-hopneighbors. Thus, the total number of 1-hop neighbors of node W is 5ρ.

5.4 Performance evaluation 97
Selecting a torus for the space model has the advantage that the nodes do notdisperse because of their movements, i.e., the node density ρ is constant through-out time. This model has been simulated using a Java implementation. For thesimulations we have used a torus with 250 × 250 grid points, i.e., 250 possiblelocations in the x direction and 250 grid points in the y direction (Fig. 5.3). Thesimulation uses a very elementary key distribution scheme in which every nodereceives a random selection of 25 different keys out of a pool of 5000 keys. Usingthis scheme, the probability ps that any two nodes share a key is approximately1/10. The simulation results are the average of 1000 independent runs of thesimulator.
The number of nodes within a neighborhood with radius h is
α = ρ(2h2 + 2h + 1) . (5.1)
Without loss of generality, assume that node W moves as shown in Fig. 5.3. Allother nodes move to one of the neighboring grid points at random. After allthe nodes have moved, some nodes will certainly still be in the neighborhood ofnode W , others will still be in the neighborhood with probability 1/2 and otherswith probability 1/4. The total average number of nodes in the overlap of twoconsecutive neighborhoods is
β = ρ((2h2 − 2h + 1) + (4h− 2)(1/2) + 2(1/4)
)= ρ(2h2 + 1/2) . (5.2)
This means that the average number of new nodes entering the neighborhood is
δ = α− β = ρ(2h + 1/2) . (5.3)
The probability that there is at least one node in the overlap is
Po = 1− “Probability no nodes in overlap”
= 1−∏
∀i
“Node i not in overlap”
= 1−∏
∀i
(1− “Node i in overlap”)
= 1− (1− ρ)2h2−2h+1(1− (1/2)ρ)4h−2(1− (1/4)ρ)2 . (5.4)
Figure 5.4 shows this probability for different neighborhood radii h and differentnode densities ρ.
Assuming that nodes share a key due to the key pre-distribution scheme with aprobability ps, then the probability that a node does not share such a key withany of its neighbors after t clock ticks (turns) is
Pti = (1− ps)α+tδ . (5.5)

98 Chapter 5. Dynamic Key Establishment
Initially a node has α neighbors and every clock tick δ new/old nodes enter/leaveits neighborhood. Note that this is only an approximation, as not all nodesentering the neighborhood are necessarily “new” in the sense that they have notbeen in the neighborhood before. Only true new nodes give a new opportunity toestablishing link keys. Figure 5.5 shows this probability for ρ = 1/3, ps = 1/10and different neighborhood radii h.
From Pi(t) we can compute the expected number of turns T a node will beisolated from the rest of the network, i.e., how many turns it takes before a nodeestablishes the first link key with another node. The probability that a node willbe able to establish its first key in turn t is equal to the probability that the nodeis still isolated after t− 1 turns times the probability that it shares at least onekey with the new nodes that enter at turn t:
Pts = Pt−1
i × (1− (1− ps)δ
)
= (1− ps)α+(t−1)δ(1− (1− ps)δ
)
= (1− ps)α+(t−1)δ − (1− ps)α+tδ
= Pt−1i − Pt
i .
The expected number of turns T a node will be isolated from the rest of thenetwork is
T =∞∑
t=0
tPts
=∞∑
t=0
t(1− ps)α+(t−1)δ(1− (1− ps)δ
)
= (1− ps)α(1− (1− ps)δ
) ∞∑t=0
t(1− ps)(t−1)δ
= (1− ps)α(1− (1− ps)δ
)−1. (5.6)
Table 5.1 show the results for different neighborhood radii (ρ = 1/3 and ps =1/10). We see that the simulation predicts longer isolation times (the last columnshows the quotient of the two results). This is due to the fact that the analyticalmodel assumes that δ new nodes enter the neighborhood every turn. While this isa good approximation for the first couple of turns (see Fig. 5.5), fewer and fewertruly new nodes will enter the neighborhood for later turns. This also explainswhy the theoretical model becomes better for larger neighborhood radii.

5.4 Performance evaluation 99
Table 5.1. Expected number of turns before a node is no longer isolated (ρ = 1/3and ps = 1/10).
Neighborhood Theoretic model Simulations Deviationradius h (turns) (turns) (fraction)
2 4.33 7.132 1.653 2.04 3.23 1.584 0.92 1.304 1.42
W
x
y
Figure 5.3. Network model. Nodes move on the grid of the torus. The emptysquares indicate the positions of nodes that are located within the black square’sneighborhood with radius h = 3.
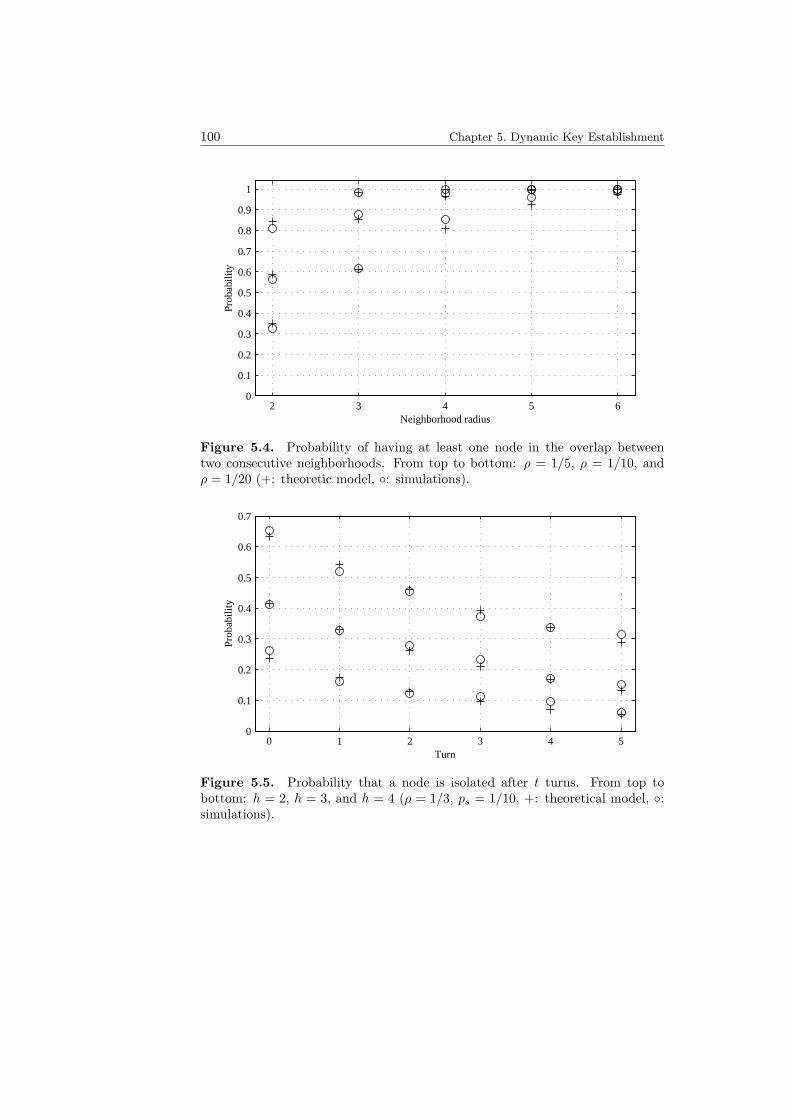
100 Chapter 5. Dynamic Key Establishment
2 3 4 5 60
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Neighborhood radius
Prob
abili
ty
Figure 5.4. Probability of having at least one node in the overlap betweentwo consecutive neighborhoods. From top to bottom: ρ = 1/5, ρ = 1/10, andρ = 1/20 (+: theoretic model, ◦: simulations).
0 1 2 3 4 50
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Prob
abili
ty
Turn
Figure 5.5. Probability that a node is isolated after t turns. From top tobottom: h = 2, h = 3, and h = 4 (ρ = 1/3, ps = 1/10, +: theoretical model, ◦:simulations).

5.4 Performance evaluation 101
5.4.2 Efficiency of the scheme
Establishing link keys
Using our model with node density ρ, the number of disjoint routes is limited to4ρ as each route will have to go through one of the four neighboring grid pointson the torus. In the efficiency evaluation of the key establishment scheme weassume that for a new node that enters node W ’s neighborhood, we transmit asingle share over each of these 4ρ disjoint routes between the new node and W .Therefore, a node density ρ implies the use of a (m, b4ρc) secret sharing scheme.A second assumption we make is that the average length l of these routes isequal to two times the neighborhood radius h. This assumption is based on thefact that new nodes will most likely enter the neighborhood at the border. Theshortest path from the border of a neighborhood to its center requires h−1 hopsin our model. We feel that a factor 2 allows enough “detour” space for the other,longer routes.
Using these assumption, the cost of the link key establishment protocol can besummarized as follows:
– Computations: A single share needs to be encrypted and decrypted 2(h− 1)times on a path of length 2h = hops.
– Communications: The encrypted share is transmitted and received by 2(h−1)nodes on a path of length 2h = hops.
For example, using the numbers in Table 2.2 on p. 17 (with AES key scheduling),and assuming ρ = 1.25, a (4, 5) secret sharing scheme, 80 bit shares, and aneighborhood radius h = 3, the total computational cost is 136 µJ, and thetotal communications cost is 5 × 5 × 80 bits = 44.2 mJ. In comparison, thecost of signing a message with ECDSA, transferring it over a single route, andverifying it is 330.4 mJ for the computations and 5× 320 bits = 35.4 mJ for thecommunications.
Updating the broadcast group
The cost of group key management schemes depends on the size of the group andon the number of members that enter or leave the group. The broadcast groupof a particular node is limited to its 1-hop neighbors. In our model the numberof 1-hop neighbors is α1 = 5ρ (Eq. 5.1), and the average number of nodes thatenter or leave this group is δ1 = 2.5ρ (Eq. 5.3).

102 Chapter 5. Dynamic Key Establishment
Table 5.2. Efficiency of the EHBT scheme.
Operation CostSingle join computations 1 + 4(d + 1) BFSingle join sending cost (d + 1)(|K|+ |I|) bitSingle join receive cost (d + 1)|K|+ (dα1 + 1)|I| bitSingle leave computations 3d BFSingle leave sending cost d|K|+ |I| bitSingle leave receive cost α1(d|K|+ |I|) bit
One efficient group key management scheme is the Efficient Hierarchical BinaryTree (EHBT) scheme [138]. This scheme uses key indices to allow efficient keyupdates. We assume the size of a key index is one fifth of the size of a key(|I| = (1/5)|K|). Assuming that hashing, encrypting and decrypting a singleblock requires 1 BF the total computational cost can summarized as follows(d = log2(α1)).
Using the same assumptions as for the link key establishment efficiency evalu-ation, the total cost of updating the broadcast keys for one join plus one leaveoperation is 639 µJ for the computations, 577 bits = 6.75 mJ for the sendingcost, and 1, 994 bits = 20.7 mJ for the receiving cost. Per turn, nodes leaveand join the neighborhood δ1 times. This results in a total cost of 87.8 mJ. Incomparison, using ECDSA to broadcast a single signed message to the 5ρ 1-hopneighbors costs 1385 mJ.
5.5 Security analysis
In this section, we analyze the security of both our key management mechanism(Secure Neighborhood Discovery) and our secure routing scheme (AuthDSR).
5.5.1 Informal analysis of the Secure Neighborhood Discovery
When a sensor node has been compromised (for example by extracting the keysfrom its memory module), the adversary can utilize these captured keys to launchattacks. If this is somehow detected and reported, then this node can be excludedfrom the system. Excluding a node S from the network can be achieved by asking

5.5 Security analysis 103
every node in the current neighborhood of S to delete all keying material relatedto S and establish fresh broadcast keys.
If a compromised node stays in the network undetected, then this node cancommunicate and set up trust relationships with all the nodes in its neighborhood.This means that the compromised node can decrypt all messages that are routedthrough it and that it can ask nodes to forward messages and hence activelytake part in the network. However, knowledge of the keying material of node Sdoes not enable an attacker to learn the link keys shared between other nodesin the neighborhood (nor in the rest of the network obviously) since these areestablished using secret sharing over multiple paths. Moreover, a compromisednode cannot broaden the neighborhood it shares keys with, it can only change it.While wandering through the network, nodes entering the compromised node’sneighborhood will establish keys with it, and nodes leaving the neighborhoodwill remove related keying material and exclude it from their broadcast group.This effectively limits the amount of data that is revealed to the adversary aftercompromising a sensor node.
5.5.2 Informal analysis of AuthDSR
Multiple attacks on different routing protocols for ad hoc networks and sensornetworks have been proposed in the literature (an overview can be found in [91]).We now briefly discuss how our protocol copes with the most important attackson routing protocols for ad hoc networks.
AuthDSR authenticates every routing packet with a MAC using the broadcastkeys for RREQ packets and the pairwise link keys shared between nodes for theRREP packets. Replay of these messages is prevented by including incrementingcounter values in the input for the MAC. Authenticating the routing packetsprevents an “outsider” (attacker without knowledge of any keys) from disruptingthe routing process. An attacker that has compromised one or more nodes canactively take part in the routing process and hence try to disrupt it by replaying,changing or spoofing routing packets. However, our scheme can minimize the im-pact of these attacks. First, since routing packets are authenticated and cannotbe replayed, the adversary can only launch an attack within the limited neigh-borhood of the compromised node (since it only possesses keying material relatedto its neighborhood). Again, this zone cannot be broadened but only shifted toanother set of nodes. Second, because the attacks are localized within a smallzone, they are likely to be detected by the surrounding honest nodes. Third,once the malicious node has been detected, the Secure Neighborhood Discoveryprocess can be used to exclude it from the network.

104 Chapter 5. Dynamic Key Establishment
The attack that is most difficult to detect and prevent is the Wormhole attack[72]. In the wormhole attack, two distant malicious nodes try to convince thenetwork that they are only a single hop apart. In order to achieve this, theyuse an out-of-band low latency link that is invisible to the sensor network. Thiswormhole can attract nodes to route traffic through it and hence through themalicious nodes. For an outside adversary, the wormhole attack is not applicablesince nodes will only accept routing packets from the nodes with which it sharesa broadcast key. This means that an adversary cannot forward some RREQpacket through the wormhole and replay it to the target node (the node corre-sponding to the DestAddr in the RREQ packet). An inside adversary will haveto compromise at least two sensor nodes to create a wormhole in our scheme (wewill call these two compromised nodes the wormhole’s entry point and terminus).Our AuthDSR protocol in itself cannot prevent this attack as the adversary willbe able to forward an RREQ packet (coming from node S and directed at R)through the wormhole, compute a valid MAC on it at the wormhole’s terminusand broadcast it to the target node R. The RREP packet from R can again beforwarded through the wormhole, a MAC using the link key shared between Sand the wormhole’s entry point can be added, and a valid RREQ containing theroute through the wormhole can be delivered to S. However, successfully cre-ating a wormhole does not compromise the link key that is established betweennodes S and R because of the use of secret shares that do not pass through thewormhole. This reduces the wormhole attack to a sinkhole attack. In a sinkholeattack a malicious node tries to attract packets from its neighbors and then dropsthem. This behavior can be detected, and the malicious nodes can be excludedfrom the network.
5.5.3 Evolution of compromised link keys
In this section we discuss the evolution of compromised link keys in time. Ob-viously, this evolution depends on a large number of assumptions. Nevertheless,we believe that this evaluation gives valuable insights into the dynamics of ourscheme.
Assumptions
We assume that the attacker can eavesdrop on every transmission (global eaves-dropper) and a fraction c of the link keys is compromised at some moment intime tc after the initial deployment phase. We assume that every link key isequally likely to be compromised at any moment in time. In order to simplifythe calculations we assume a symmetric network in which every node has exactly

5.5 Security analysis 105
α nodes in its neighborhood. The total number of nodes in the network is β. Alink key is established using n randomly chosen paths, and a (m,n) secret sharingscheme (at least m shares must be known to compute the link key). We assumethat the average length of these paths is twice the neighborhood radius (l = 2h)as normally nodes will enter the neighborhood at the border. As the nodes in thenetwork move, old link keys are discarded and new link keys are established. Weassume a discrete time t that grows by ‘1’ every time this happens. Finally, letf(t) be the fraction of compromised link keys at time t. We assume that thesecompromised keys are distributed uniformly in the network, i.e., if a fractionf(t) of the link keys is compromised, then the probability that any link key iscompromised is f(t).
Evolution of compromised link keys
After the initial deployment phase, every node will share a link key with its kneighbors, resulting in a total of αβ link keys. At time tc the attacker learnsa fraction c of these link keys (for example by compromising a fraction c ofthe nodes), providing her with knowledge of cαβ of these link keys, meaningf(tc) = c. We assume that an adversary cannot make clones of nodes he hascompromised and that the number of nodes in the network is constant. If anadversary could make clones of compromised nodes, then he can always makethe fraction c of known link keys larger than the safety threshold (see below) bycreating sufficient clones.
A new link key that is established using the (m,n) secret sharing scheme will beknown to the attacker if at least m path of length l contain at least one knownlink key. If a fraction f(t) of all link keys is known to the attacker, then theprobability that the attacker will learn the new link key is
P (t) =n∑
i=m
(n
i
)pi(1− p)n−i with p = 1− (1− f(t))l. (5.7)
There are αβ link keys in the system. Every time one of them is replaced by anew one, the fraction f of compromised link keys changes as follows:
f(t + 1) =αβ − 1
αβf(t) +
1αβ
P (t). (5.8)
It is easy to verify that, if P (t) < f(t) (independent of αβ) then f(t + 1) < f(t).However, the network size does determine the rate of change of f . Note that thereare only three possible states for the system: continual increase of the fractionof compromised link keys, continual decrease, or no change (P (t) = f(t)). In the

106 Chapter 5. Dynamic Key Establishment
Table 5.3. Maximum supported compromised link keys for several configura-tions.
(m,n)-scheme (4, 5) (4, 5) (3, 5)path length l = 5 l = 6 l = 5max. supported f 10% 8% 4%
last state, the fraction of compromised link keys is fixed on f(tc) = c. Withoutany additional external changes, the system will stay in one state, i.e., if thefraction decreases at time tc + 1, it keeps decreasing.
Table 5.3 shows the influence of different parameters on the maximum supportedfraction (safety threshold) of compromised link keys. Both longer paths (largercells) and more robust secret sharing schemes make it easier for the attacker tocompromise new link keys. This shows that there is a clear trade off betweensecurity (small cells, secret sharing schemes with m ≈ n) and robustness (largecells, secret sharing schemes with large n/m ratio).
5.6 Conclusions
In this chapter, we have proposed a key establishment scheme for dynamic adhoc networks. The scheme ensures that nodes share secret pairwise keys and abroadcast key with their neighborhood at all times. These keys are continuouslyupdated as the nodes move through the network. We have shown how these keyscan be used to create a secure implementation of the DSR protocol and how ourscheme can be integrated with DSR. We have evaluated the efficiency of theprotocol both using an analytical model and through simulations. Finally, weevaluated how the security of our scheme changes with various parameters. Thissecurity analysis could be approved by using a more detailed statistical approachsimilar to the one used in the efficiency evaluation.

Chapter 6
Privacy in Ad Hoc Networks
In this chapter we consider mechanisms to provide anonymity in wireless mobilead hoc networks. We describe an anonymous on demand routing protocol forMANETs that is secure against both nodes that actively participate in the net-work and a passive global adversary who monitors all network traffic. As this isa rather recent research topic, it is possible to give a complete overview of thecurrent state of the art in the chapter. As this topic differs quite a bit from theprevious chapters, we have also tried to situate the research field of anonymity inMANETs in the broader research field of anonymity in general. Therefore, thischapter has its own introduction and contains an extended overview of existingwork.
Contributions in this chapter
This chapter extends the research results that were published in [157]. Thecontributions presented here are:
– This chapter gives an overview of the state of the art of existing anonymousrouting schemes for ad hoc networks.
– We show the strengths and weaknesses of these schemes, with respect to boththe anonymity they offer and their efficiency.
– We describe a novel anonymous routing scheme that has better performancewhile providing a higher level of anonymity.
– We give a detailed analysis of the level of anonymity that can be offered bypadding schemes.
107

108 Chapter 6. Privacy in Ad Hoc Networks
– We show how it is possible to hide routes by allowing limited broadcast andshow how to select time-to-live values in order to achieve optimal performancewith respect to anonymity.
In joint work with Dıaz et al. [48, 50] we introduce an information theoretic modelthat can be used to measure the degree of anonymity provided by schemes foranonymous connections. Although we do not describe those research results inthis thesis, we do employ similar techniques to evaluate the anonymity providedby our anonymous on demand routing protocol in Sect. 6.6.
Note on encryption
Throughout this chapter we assume that symmetric encryption a message corre-spond to authenticated encryption. This means that after successful decryptionof an encrypted message, the receiver is assured that the plaintext has not beenaltered by an adversary who has no knowledge of the secret key that was usedfor the encryption. This could be achieved by the following construction [12]:〈Ek1 [m, MACk2 [m]]〉, where keys k1 and k2 are derived from a single secret keyk. Another possibility is to use modes of operation designed for this purpose,such as OCB [148], Counter with CBC-MAC (CCM) [179] and EAX [13].
6.1 Introduction
6.1.1 Privacy in a digitized world
The means of communications and long-term data storage have radically changedwith the advent of cheap electronic devices, ubiquitous Internet access and cellphone coverage. Fifty years ago, big centralized databases consisted of microfilmrecordings securely stored in government or private buildings. Nowadays, withcomputer hard drive prices ranging around 0.50e per Gigabyte and processingpower growing exponentially, it has become practical to massively store informa-tion on just about anything and retrieve relevant portions of it in real time. Forexample, retailers now track your shopping habits via your supermarket savingscard, credit card companies are able to trace your shopping and travel habits,and phone operators log your calling patterns in databases, etc.
As more and more services are available through the Internet, it becomes eveneasier and cheaper for companies to track your daily habits: spyware monitorsthe web sites you visit, commercial banners on web sites trace your preferences,

6.1 Introduction 109
Google reads the email you receive on your Google email account, etc. Nextto these companies that are driven by economical reasons, your Internet ServiceProvider (ISP) is obliged by law to store all the traffic information of their userson their network [59].
It is clear that moving from government-controlled, centralized microfilm databa-ses to digital online databases has a major impact on personal privacy. Not onlycan these databases be controlled by unknown and possibly dishonest parties,without correct security measures these online databases can become availableto anybody. As these privacy issues became apparent, many researchers havefocussed on techniques to better protect the privacy of users. A large part of thisresearch is focussed on hiding the sender-receiver relationship of traffic on theInternet. If you browse the Internet without any measures to protect your pri-vacy, your ISP can eavesdrop on all the data you generate (emails you downloadfrom the server, web pages you browse, chat sessions, etc.). Using encryption(e.g., when using a SSL connection) prevents the ISP from learning the con-tent of the web pages you visit, but it does not hide the Universal ResourceLocators (URLs) you have visited. In some cases (e.g., when visiting the website http://www.alcoholics-anonymous.org), even this URL may reveal pri-vate information. In Sect. 6.3 we discuss techniques that provide anonymousconnections in wired networks such as the Internet.
Today many people own a mobile phone and use it daily. Similar to your ISP,your Mobile Communication Service Provider (MCSP) is obliged by law to storeyour cell phone records. These phone records include the Base Station (BS)that was used to set up the call. The location of this BS thus fixes the user’slocation within the range of that BS. Moreover, when an ISP is requested totrack somebody in real-time, they can use triangulation techniques over multipleBSs to locate somebody within a couple of meters. One real life example of theuse of this location information by law enforcement is the case of the New YorkTimes journalist Jayson Blair [17]. In May 2003, Blair was forced to resign asa reporter for The New York Times after investigations had revealed that Blairfalsified his whereabouts. The investigators used the reporter’s cell phone recordsto trace his whereabouts and discovered that Blair had claimed to be reportingfrom West Virginia or Maryland while he was still in New York. Location dataextrapolated from BS records is frequently used in criminal cases. In cases likethis, MCSPs will not release a user’s phone record without a court order. Bycontrast, in the Blair situation no criminal proceeding was involved. He was usinga cell phone issued by his employer and The New York Times merely requestedto view its own records. These examples show that it is very likely that manyservice providers, such as ISPs and MCSPs, will be forced by law to store andprovide a certain amount of private data regarding their users in specific cases.

110 Chapter 6. Privacy in Ad Hoc Networks
At the time of writing this thesis, service providers are not forced to use anymechanism that supports exactly this legal requirement. Today service providersare obliged to store traffic over a period of time [59] and we have to trust themonly to reveal this data in those cases the law specifies. Some research has beendirected at conditional anonymity, where a third party is involved to reveal partsof the stored data. In these systems, the data is anonymized by the user incooperation with a third party and stored by the service provider. The data canonly be revealed if the service provider and this third party cooperate. A detailedsurvey of these techniques can be found in [40].
With the advent of MANETs, where mobile nodes exchange data with othernodes without continuous supervision of the user, the privacy risks are evengreater. With traditional wired networks such as the Internet, the amount oftraffic a normal user can capture (in addition to his own traffic) is limited tohis broadcast domain. For most access technologies (regular model, AsymmetricDigital Subscriber Line (ADSL) or cable) your broadcast domain is limited toyour home network. When connected to a LAN (for example when connectingthrough a wireless AP), your broadcast domain is extended to all hosts connectedto this LAN. This means that in practice only ISPs, whose networks your traffictraverses, can see your traffic, and your privacy is not at risk with respect toother users. In multi-hop MANETs, your data is transferred through other users’devices and your “broadcast domain” is unknown and changes continuously. Thismeans that personal data now becomes available to many other users of thesystem that you don’t know or trust. For example, Jakobsson and Wetzel showed[82] that users carrying Bluetooth devices today can be traced as these devicescontinuously use a single unique device identity that is included in every message.This identifier can be picked up by strategically placed tracker devices in airports,train stations, etc.
In MANETs there is no service provider that we can trust to protect our privatedata: we will have to rely on technical solutions, usually referred to as PrivacyEnhancing Techniques (PETs), to protect our privacy.
6.1.2 Anonymity at different layers
Goldberg [66] observes that it is not possible to add anonymity at a higher layerof the protocol stack, if a lower layer does not offer anonymity. In this re-spect there is a subtle difference between anonymity and confidentiality. Whenproviding confidentiality between two communicating parties at one layer, thisautomatically protects all the higher layers in the system. For example, all traf-fic transfered over an IPsec tunnel will be protected, independent of the type oftraffic (HTML, email, etc.). For anonymity this is not the case for two reasons:

6.2 Anonymity: definitions and requirements 111
1. Anonymous connections require encrypted channels, but not necessarily be-tween the two end points (this is explained further below). This implies thatidentifiable data at higher layers may become available to intermediate nodes.
2. Anonymity of the sender towards the receiver is a valid notion, while confiden-tiality towards the receiver is not. An encrypted channel always terminatesat some point and presents its contents in plaintext to the receiver. For ananonymous channel it may be required to hide even the identity of the senderto the receiver.
Both reasons clearly indicate that anonymous channels require anonymity atevery layer in the system, in contrast to confidential channels.
In this chapter we present mechanisms that provide anonymity up to the networklayer in the Open Systems Interconnection (OSI) model. Due to the very differentnature of the physical, data link and network layers of MANETs compared towired networks, existing PETs at these layers for wired networks do not directlyapply to MANETs. At higher layers in the OSI model, the difference betweenwired networks and MANETs disappears and existing PETs will apply to bothwired networks and MANETs. Building blocks that can be used to provideanonymity at the application layer have been surveyed in the first stage of theAnonymity and Privacy in Electronic Services (APES) project [4]. We refer to[51] for comprehensive list of these building blocks.
6.2 Anonymity: definitions and requirements
Before discussing specific anonymity mechanisms, we first give some generic ano-nymity definitions and requirements, and present some assumptions we make onthe model we are working in (i.e., the network and adversary model). An ex-tended model to describe anonymity properties has been developed in the courseof the APES project. We give a brief summary of the most important notionsand refer to [153] for a detailed description.
6.2.1 Definitions
Pfitzmann and Kohntopp started work on standardising terminology on anony-mity in 2000 [129]. This is ongoing work, first by Pfitzmann and Kohntopp, andlater by Pfitzmann and Hansen [128]. We adopt their definitions.
Definition 6.1 (Identity). An identity is any subset of attributes of an indi-vidual which distinguishes this individual (from all other individuals) within any

112 Chapter 6. Privacy in Ad Hoc Networks
set of individuals. So usually there is no such thing as “the identity”, but severalof them.
We assume that every node in the network has a long-term identifier (S for thesender, D for the destination and Ni for intermediate nodes). This identifieris one of the identities of a node. Another identity we take into account is thelocation of a node.
Definition 6.2 (Anonymity). Anonymity is the state of being not identifiablewithin a set of subjects, the anonymity set.
Definition 6.3 (Unlinkability). Unlinkability of two or more Items of Interest(IOIs) (e.g., nodes, messages, events, actions, etc.) means that within the sys-tem, from the attacker’s perspective, these IOIs are no more and no less relatedafter his observation than they are prior to his observations.
The IOIs of interest here are sending and receiving messages. In this case, anony-mity may be defined as unlinkability of an IOI and any identifier (ID) of a node.More specifically, we can describe the anonymity of an IOI as not being linkableto any ID, and the anonymity of an ID as not being linkable to any IOI.
6.2.2 Adversary model
An adversary is a real life person who interacts with the system he wishes toattack through one or more physical devices. As the adversary shares all hisknowledge with his devices and vice versa, the term “adversary” is used for both.
Initially, an adversary has knowledge of all the parameters of the network suchas the protocols used by legitimate entities, public keys and certificates, etc. Theonly knowledge that differentiates an adversary from a legitimate entity in thesystem is the knowledge of secrets used in cryptographic algorithms, e.g., sharedsymmetric keys and private keys.
An adversary has the following limitations:
1. An adversary cannot perform unbounded computations.2. An adversary has limited data storage space and bounded access times to his
stored data.
In consequence of the above limitations, we assume that an adversary cannotbreak any of the cryptographic primitives we use in this thesis. More precisely,

6.2 Anonymity: definitions and requirements 113
we assume that all the properties we describe in Chapter 2 hold when theseprimitives are attacked by our adversary.
We classify adversaries according to three criteria: an external versus an inter-nal adversary according to his network membership status; a passive versus anactive adversary according to his behavior; and a local versus a global adversaryaccording to his scope. We also consider the possibility that different adversariescooperate and share their knowledge and resources. Combination of the threecriteria results in eight possible adversary models.
External versus internal adversary model
In ad hoc networks, unattended nodes with inadequate physical protection aresusceptible to being captured and compromised. Measures that provide tam-per resistance could help to prevent node compromise [3]. However, the relatedresearch is addressing physical properties of the network nodes. As this is a net-work security research work, we will not consider this design choice. Instead, weassume that once an adversary has compromised a node, all records stored inthis node’s memory are known to the adversary. These records include privatekeys, routing tables, etc.
An internal adversary is an adversary who has compromised one or more nodesand has learned all data records stored on these nodes. In contrast, an externaladversary has not compromised any nodes. Once an adversary has compromiseda node, we assume that he has either taken over control of the compromised nodeor that he has control over one ore more exact copies of this node.
Passive versus active adversary model
A passive adversary can monitor, intercept and record all traffic within its scope.If its an internal adversary, then he can combine this knowledge with all hehas learned from the compromised nodes. A passive adversary can only gatherknowledge on the network he attacks, and on the nodes of which this networksconsist.
An active adversary has additional capabilities next to those of a passive adver-sary. An active adversary can block, modify and insert messages within its scope(i.e., a local adversary can only send messages to nodes within range).
One capability of active adversaries that requires extra attention is the abilityto block and intercept messages at the same time, i.e., the adversary can inter-cept a message while preventing other nodes from receiving this message. It is

114 Chapter 6. Privacy in Ad Hoc Networks
EA
B
(a)
BE
′
EA
(b)
Figure 6.1. Two possible scenarios in which an adversary (E, or E and E′
combined) can intercept and block the message transmitted from A to B.
physically impossible to intercept radio signals and block them (with a jammingsignal) using a single radio antenna. However, Fig. 6.1 shows two possible attackscenarios that make this possible. In scenario (a) the adversary E uses a directiveantenna to transmit a jamming signal that blocks all messages received or sentby the victim B. Node E intercepts the messages transmitted by A using a sec-ond antenna. In scenario (b) the adversary uses two different nodes E and E′ toperform the attack. The adversary intercepts messages transmitted by A usingnode E. Node E′ transmits a jamming signal that blocks all messages receivedor sent by B. The adversary limits the jamming range of node E′ in order notto jam the intercepting node E.
Important adversary classes
The protocol we describe in this chapter has been developed with two distinctadversary models in mind.
The first adversary model is the external global passive adversary . This adversarycan observe and record all communications between all nodes in the network atany time. As he is a passive adversary, he is not capable of any active attackssuch as replaying previously recorded messages. Since he is an external attacker,he has no knowledge of any of the secrets used by the legitimate network nodes.For example when using an encrypted Secure Shell (SSH) connection, the Trans-mission Control Protocol (TCP) and Internet Protocol (IP) headers are not en-

6.2 Anonymity: definitions and requirements 115
crypted [7]. This means that this attacker will be able to derive for example theIP address and network port used by this SSH connection. This model impliesthat a node will not be able to hide the fact that it is the source of a new freshmessage and not forwarding a message that originated from some other node.
The second adversary model we protect against is the internal local active ad-versary . This adversary can perform active attacks within his local range andhas knowledge of the secrets stored in one or more compromised nodes. If thecompromised node keeps following the normal flow of the network protocols, thenhe will be able to stay in the network undetected indefinitely. This means thatwe assume that every node that is part of the network is a potential adversary.
Finally, we assume that both adversaries can locate the source of a specific radiotransmission. A possible means of achieving this is through triangulation.
6.2.3 Goals
Using the above definitions, we can now describe the two main properties wewant to achieve with our anonymity system:
1. Identifier anonymity of the source, destination or forwarding nodes meansthat a particular message is not linkable to the identifier of any source, des-tination or forwarding node respectively, and vice versa.
2. Location anonymity of the source, destination or forwarding nodes means thata particular message is not linkable to the position of any source, destinationor forwarding node respectively, and vice versa.
3. Identifier Relationship anonymity means that it is impossible to relate theidentifier of the source with the identifier of the destination. Note that Re-lationship anonymity is weaker than both source and destination anonymity(i.e., source and destination anonymity both imply Relationship anonymity).
4. Location Relationship anonymity means that it is impossible to relate thelocation of the source with the location of the destination.
The goals towards the external global passive adversary are to (1) prevent himfrom learning the relationship source–destination of messages (Identifier and Lo-cation Relationship anonymity), and (2) prevent him from learning which nodesare part of the path from the source to the final destination (Identifier and Lo-cation anonymity of the forwarding nodes).
The goals towards the internal local active adversary are: (1) a compromisednode should not be able to determine whether another node in the network is

116 Chapter 6. Privacy in Ad Hoc Networks
the source or the destination of a particular message (Identifier and Locationanonymity of the source and destination), and (2) a compromised node shouldnot be able to determine whether another node is part of a communication pathbetween two nodes (Identifier and Location anonymity of the forwarding nodes).
Another design goal of our protocol is to provide these anonymity propertieswhile staying as energy efficient as possible.
6.3 Anonymous connections in wired networks
In this section we briefly discuss existing technologies that provide communicationanonymity in wired networks such as the Internet. We assume that every devicethat is part of these networks has a network address. On the Internet this iscalled an IP address.
If one device sends a message to another device, then the IP address of both thesending device (source) and the receiving device (destination) is contained in thismessage according to the IP transfer protocol. The originating IP address is eitherthe IP address of the source itself, or of an intermediate device that has replacedthe real originating IP address with its own IP address. Possible intermediatedevices include a proxy, a firewall, or a Network Address Translation (NAT)box. In most cases the intermediate device is the access point of the sendingdevice’s intranet to the Internet (e.g., the NAT box that separates a corporateintranet from the Internet). Most intermediate devices will keep detailed logs ofall traffic they forward. These logs can be used to single out the IP address ofthe device (source or destination) responsible for a specific message at a specifictime. Consequently, in either case, the IP address can be linked to a group ofdevices, or to an individual device. Once the IP address is known, it usually isstraightforward to trace the user’s identity with the help of the ISPs involved.
Note that tracing a user’s identity from an IP address is not straightforward whena user has anonymous access to a device, e.g., when a user is using a hotspot, orsitting in an Internet cafe without proper registration. However, we assume thatan IP address constitutes identifiable information in the technical sense.
From the above argument it follows that we need to hide the sending device’sIP address from the receiver, or any other device, in order to provide an anony-mous connection. We consider a bidirectional communication session between asource and a destination. The source establishes the session, and from that pointon bidirectional communication is possible. During this communication session,only the source should know with whom he is communicating. Other entities

6.3 Anonymous connections in wired networks 117
in the network, including the destination, should not be able to discover who iscommunicating with whom.
6.3.1 Overview of existing technologies
In 1981, Chaum proposed the first mix design as a means of providing anonymousemail [38]. A mix can be seen as a black box with n inputs and m outputs. Thesein- and outputs are clients and hosts on the Internet. The goal of a mix is tomake it impossible to trace a message entering at one of the inputs to a messageleaving the mix at one of the outputs and vice versa. The adversary who isattacking the mix can see the content of all messages entering or leaving the mix,but not the internal state of the mix. A mix does so by changing the flow ofthe messages (by delaying and reordering) and altering their appearance (usingencryption and padding).
Since the original mix design by Chaum in 1981 [38], many mix designs havebeen proposed in the literature. These designs can be grouped into differentcategories:
Pool mixes: Pool mixes collect messages for some period of time, and storethem in their pool, i.e., an internal memory buffer of the mix. Messagesare forwarded (flushed from the pool) when the pool’s flushing condition isfulfilled. This threshold is usually time based (i.e., flush every s seconds),or based on the size of the pool (i.e., flush when the pool size has reached xmessages), or a combination of the two. The flushing strategy decides whichmessage(s) are flushed from the pool. A detailed taxonomy can be found in[152, 47]. Dıaz and Serjantov proposed a general model to represent poolmixes [49].
Continuous mixes: The first continuous mix design (also called Stop-and-Gomix) was proposed by Kesdogan et al. in 1998 [92]. In this design, the usersadd a random delay parameter to the header of their messages before sendingthem to the mix. The mix holds the message for the specified delay timebefore forwarding it. This is a continuous process as messages are forwardedas soon as their delay time has passed.
A single mix, even one that perfectly hides the link between incoming and outgo-ing messages, can only be trusted as far as its operator can be trusted. In order toincrease the anonymity provided by a mix, multiple mixes can be combined in amix network. As each mix on itself effectively protects the anonymity of its users,having a single trustworthy mix on the path is sufficient. A redundant mix net-work also makes the system more robust as the failure of one or more mixes does

118 Chapter 6. Privacy in Ad Hoc Networks
not necessarily result in a breakdown of the anonymous service. There are twoapproaches to establishing a mix network: cascades and free route networks. Ina cascade, the paths messages traverse are predefined. This approach is followedby for example Web Mixes [16] which was implemented as the web anonymizingproxy JAP [83]. In a free route network, users freely select their own path. Thispath can differ for every message. Examples of free route networks are OnionRouting [67, 140] and Mixmaster [114]. In these systems, the source preparesa layered request (called onion) that contains information for each mix on thepath to the receiver. This information is wrapped in a series of encrypted layers– one layer for each of the intermediate hops that is forwarding the onion. Tor,the second generation of onion routers [54], includes a number of improvementsand currently has a working implementation that everyone can use to join theTor-network [173].
Techniques such as Onion Routing and Tor are based on a number of dedicatedservers that host a mix implementation. In Crowds [141] however, the users them-selves are the intermediate entities that forward each others’ messages. Crowdsis targeted at client/server applications such as browsing the web. Requests (toweb pages) are forwarded within a “crowd” of participating users (called jon-dos) before being submitted to the intended recipient (the server hosting therequested web page). The identity of the user is not known to the host as theactual request comes from a random member of the crowd. The reply followsthe same path as the request but in reverse order. Briefly, the system works asfollows: when a user wishes to request a web page, he forwards this request toa randomly selected jondo. This jondo tosses a biased coin to decide whether tosubmit the request to the server, or to forward the request to another randomlyselected jondo. Each jondo on the path chooses to forward or submit the requestindependently. Communication between jondos is encrypted hop by hop (thefinal request to the server is submitted in plaintext for obvious reasons). Everyjondo can read the contents of the request (or reply) it forwards. However, ajondo cannot know whether his predecessor on the path was the originator of therequest or only forwarded it. Hordes [164] is similar to Crowds but uses multicastfor the reply, instead of routing the reply along the reversed request path.
As peer-to-peer systems became popular, techniques to provide anonymity forthese networks were proposed. These proposals include Tarzan [64], Pipenet[41], MorphMix [142, 143], Herbivore [65], GNUnet [15], P 5 (Peer-to-Peer Per-sonal Privacy Protocol) [163] and Cebolla [29]. A detailed description of thesetechniques can be found in [46].

6.4 Anonymous connections in mobile ad hoc networks 119
6.4 Anonymous connections in mobile ad hoc net-works
6.4.1 On demand routing protocols
In on demand routing protocols routes are created when they are required. Whena source wants to send a message to a destination, it invokes the route discoverymechanism of the protocol to find a path to the destination. This route remainsvalid until the destination becomes unreachable or until the route is no longerneeded.
On demand protocols (reactive) outperform table driven (proactive) routing pro-tocols in dynamic networks [27, 85, 103, 122], since they react quickly to the manychanges that may occur in node connectivity, while reducing routing overheadwhen the network becomes more stable. Table driven routing protocols becomeless efficient as the network becomes more dynamic, since the routing informationin the tables is only valid for a short period of time.
Well known examples of on demand routing protocols include DSR [87, 88, 89],the Ad hoc On-demand Distance Vector (AODV) routing protocol [122, 123, 149]and the Temporally Ordered Routing Algorithm (TORA) [119]. These routingprotocols differ in many aspects, but they all use the same Route Discoverymechanism. When a node needs to send to a destination for which it has noroute in its Routing Cache, it will invoke a route discovery. Figure 6.2 showsan example of a route discovery. To initiate a route discovery, S broadcasts aRoute Request (RREQ) message, which is received by all nodes currently withintransmission range of S. Each RREQ message identifies the source and target ofthe route discovery and also contains a unique identifier (request ID), determinedby the source of the request.
A node that receives a RREQ message, will add its own identity to the routerecord contained in the RREQ message and broadcast it. However, a node willdiscard the RREQ message if it recently saw another RREQ from the same sourcebearing the same request ID, or if it finds its own identity is already listed inthe route record contained in the RREQ message. A node receiving a RREQ forwhich it is the target of the route discovery will return a Route Reply (RREP)message to the source of the route discovery. Note that multiple routes can becreated by answering multiple RREQ messages. There are typically three optionsfrom which the target node, such as node D in Fig. 6.2, can select to return theRREP to the source S of the RREQ. First, D can examine its own Route Cachefor a route back to S and use it. D can also perform its own route discovery fora route to S, and piggyback the RREP on its own RREQ message for S. Finally,

120 Chapter 6. Privacy in Ad Hoc Networks
N2
S
2, S,D,N2
2, S,D
N1
2, S,D,N1
N3
N4
2, S,D
D
2, S,D
,N2, N4
2, S,D,N1 , N
3
Figure 6.2. Route discovery initiated by node S to destination D. Nodes onthe path add their identity to the RREQ before forwarding it. Every RREQcontains the source (S) and the target (D), and a unique identifier (“2”).
D can simply reverse the sequence of hops contained in the RREQ message anduse this as a route to S. Note that this last option requires bidirectional linksbetween nodes. This is a description of the basic route discovery protocol; theactual protocol descriptions of, for example, DSR, AODV and TORA includemany further improvements.
When the source node receives a RREP message in answer to its RREQ it storesthe route contained in the RREP in its Route Cache. Nodes apply source routingto transfer actual data. In source routing the complete route to the destination isincluded in the header of every DATA packet. For example, using the top routein Fig. 6.2, a typical packet sent from S to D will have the following content:〈S ,D ,N1 ,N2 , payload〉. This packet progresses through the network using hopby hop local broadcasts.
Some of the anonymous routing protocols we discuss in Sect. 6.4.3 will employ aslightly adapted version of this routing mechanism, which we refer to as short-lived table based routing. In short-lived table based routing, every node that ispart of a route stores both neighboring nodes on this route in its Route Cache.In Fig. 6.2 node N3 would store N1 as its predecessor and D as its successor forroute “2”. DATA packets can now be routed from S to D only by specifying theRoute ID. Routes in the Route Caches are discarded after a time-out or to makeroom for new routes. The mechanism to establish these routes is as describedabove using RREQ broadcasts; the RREP message however will in general notcontain a source route to the destination. Instead it contains a route ID thatshould be used to target a certain destination. A typical packet sent from S toD (see Fig. 6.2) will have the following content: 〈S ,D , 2 , payload〉. This packetprogresses through the network using hop by hop local broadcasts based on thelocal Route Caches of the intermediate nodes.

6.4 Anonymous connections in mobile ad hoc networks 121
6.4.2 A generic anonymous on demand routing protocol
From the above description it is clear that neither the Route Discovery pro-cess, nor Source Routing provides anonymity as the identities of all participatingnodes are contained in RREQ, RREP and DATA packets. In order to provideanonymity towards the adversary described in Sect. 6.2.2, an anonymous routingprotocol has to provide:
1. A trapdoor identifier that can only be recognized by the targeted node (andpossibly the source) and reveals no information to any other node. Thistrapdoor identifier replaces the normal target identity used in the RREQmessages.
2. Unrelated and fresh identifiers used by the forwarding nodes for every RREQ,RREP and DATA message they forward. This makes sure that no two routesare linkable to the same node, and that neighboring nodes do not learn theidentity of their neighbors (they cannot distinguish an old neighbor from anew node that has moved in). These identifiers are changed for every DATApacket.
3. Untraceable DATA packets that alter their appearance hop by hop.
In the next section we discuss how protocols published prior to our work try toachieve these goals.
6.4.3 Evaluation of state of the art
In this section we provide the state of the art of anonymous on demand routingprotocols that were proposed in the literature before our work. We indicate theirstrengths and weaknesses, and evaluate these protocols against the goals specifiedin Sect. 6.2.3.
For all protocol descriptions it is assumed that node S initiates a route requestto node D. This route request is generally broadcast in the entire network ordies out after a certain time to live. During the description of the protocols wefollow RREQ and RREP messages as they traverse a single path from S to Dwith intermediate nodes N1, N2, etc. and back (see Fig. 6.3).
ANODR: ANonymous On Demand Routing
Kong and Hong [96] assume in the description of ANODR that the source S anddestination D share a secret key kSD . Node S generates the trapdoor identifier

122 Chapter 6. Privacy in Ad Hoc Networks
〈EkSD[dest , kpr],Ekpr [dest ]〉 where dest is a public binary string that indicates that
“you are the destination”. Obviously, only the destination D who has knowledgeof the key kSD can open this identifier. After opening the identifier, D alsoobtains the symmetric key kpr. This key is later on used by D to prove to theforwarding nodes that he was indeed the intended destination (i.e., that he haspossession of the secret key kSD that was used to create the trapdoor identifier).
RREQ messages contain an onion-like structure called Trapdoor BoomerangOnion (TBO). This onion has the following form:
TBO i = Ek′i
[ni, Ek′i−1
[ni−1 . . . Ek′S [src]
]],
where src is a public binary string that indicates “you are the source”. Everyforwarding node Ni adds one layer to the onion using a fresh secret key k′i andnonce ni known only to node Ni (see Fig. 6.3). The forwarding node stores theseparameters together with the sequence number in their routing table. Everyforwarding node also includes a one-time public key pubi in the RREQ messagebefore forwarding it (replacing the public key pubi−1 of the previous hop). Thepublic key of the previous hop is stored in the routing table (see Fig. 6.4). Thesepublic keys will be used to setup a secret channel for the future RREP messages.The source S stores the pair (Ek′S [src], D) in a table in order to recognize futureRREP messages it receives in answer to this RREQ message.
The RREP message transmitted by node Ni to node Ni−1 consists of a fresh linkkey ki encrypted with the public key pubi−1 of node Ni−1. This link key is usedto encrypt the proof of the destination k′pr and TBO i−1. Node Ni transmits itsRREP message in response to a RREP message it received from node Ni+1. NodeNi uses its private key to decrypt Pubi(ki+1) contained in the RREP message itreceived, and uses ki+1 to decrypt the boomerang onion TBO i. It can now verifywhether this RREP message was intended for it or not by trying to open TBO i
using k′i and ni stored in its RREQ table (see Fig. 6.4). It also verifies the proofby checking whether Ek′pr
[dest ] ?= Ekpr [dest ]. If this succeeds, it strips away onelayer of the boomerang onion, creates the RREP message and transmits it to nodeNi−1. Node Ni also stores the link key that was retrieved from the RREP messagein its routing table (ki+1 in Fig. 6.4). Note that a RREP message does not containa unique identifier. The original source S of the route request recognizes itselfas the source because it sees the fixed string src after decrypting the receivedboomerang onion. It now uses Ek′S [src] to look up to which destination it hasjust obtained a route.
ANODR uses padding in RREQ and RREP messages to hide the number of hopsthese messages have traveled.

6.4 Anonymous connections in mobile ad hoc networks 123
N1 N2S D
EkS[src] Ek2
[
n2, Ek1[n1, EkS
[src]]]
Ek1[n1, EkS
[src]]
Figure 6.3. Trapdoor Boomerang Onion used in ANODR. Every node adds alayer to the onion when forwarding RREQ messages. It removes this layer againwhen forwarding RREP messages.
Data packets are routed using the key ki shared between two consecutive hops.This key is used to encrypt the payload and to generate a pseudo-random routepseudonym of the form f j(ki) for the jth packet that is forwarded.
Observations.
1. In order to open the trapdoor identifier included in a RREQ message, a nodehas to try all keys kSD it shares with other nodes (as there is no way for anode to know who the source of the RREQ was).
2. In [96] the authors first present the protocol without the use of one-timeasymmetric keys. These keys are only required to prevent a global eaves-dropper from tracing a RREP as it travels from the destination back to thesource. The protocol presented here is the protocol presented by the ANODRauthors to resist a global eavesdropper. When using the one-time asymmet-ric keys, the Trapdoor Boomerang Onion becomes redundant as forwardingnodes can already recognize a RREP message using their one-time privatekey. In fact, the ASR protocol is exactly the ANODR protocol presentedhere without the use of Trapdoor Boomerang Onions (and a slightly differentmechanism for data forwarding).
3. RREP packages carry no identifier that can be linked to the RREQ messages.This means that a node will have to try to decrypt every RREP message itreceives with every one-time private key it has in its routing table.
4. Every node forwarding a RREQ has to generate a fresh public key pair. Fordiscrete log and elliptic curve based schemes this is fairly efficient, but forRSA and Rabin this is a very costly operation.

124 Chapter 6. Privacy in Ad Hoc Networks
TBO i : Ek′i
[ni, Ek′i−1
[ni−1 . . . Ek′S [src]
]]
RREQ : seq, EkSD[dest , kpr], Ekpr [dest ], pubi,TBO i
RREP : Pubi−1(ki), Eki [k′pr,TBO i]
DATA : fβ(ki+1), Eki+1 [payload ]
RREQ table: : seq k′i ni priv i pubi−1
Routing table: : ki fα(ki) ki+1 fβ(ki+1)
Figure 6.4. ANODR Route Request and Reply messages transmitted by nodeNi, and elements stored in its routing table.
ASR: Anonymous Secure Routing
As we already mentioned, the functionality of ASR [186] is essentially the sameas that of ANODR without the use of TBOs.
The trapdoor identifier used in ASR is similar to the one used in ANODR:EkSD [D, kpr, U0], Ekpr [seq]. The only real difference is that D is the identity ofthe destination, while ANODR uses the system-wide destination indicator dest .Only the intended destination D can open this identifier as it is the only nodein possession of the shared key kSD . As in ANODR, the second part Ekpr [seq]allows D to generate a proof. The use of U0 is explained below.
ASR makes no use of onions that are built up as the RREQ progresses throughthe network, but instead relies on state information that is kept at the forwardingnodes. As in ANODR, every forwarding node includes a one-time public key pubi
in the RREQ message and stores the public key of the previous hop in its routingtable. Finally, the RREQ message also contains the random bit-strings U0 andUi that can be used (only) by the destination D to determine the number of hopsthe RREQ message has traversed.
The RREP message forwarded by node Ni consists of a fresh link key ki encryptedwith the public key pubi−1 of node Ni−1. This link key is used to encrypt thesequence number contained in the RREQ message and the destination’s proofk′pr. Every node that receives such a RREP message tries to decrypt the first
part with its secret key and verifies the proof (Ek′pr[seq] ?= Ekpr [seq]). If this
succeeds, the forwarding node generates a new RREP message and broadcasts

6.4 Anonymous connections in mobile ad hoc networks 125
RREQ : seq, EkSD[D, kpr, U0], Ekpr [seq], pubi, Ui
RREP : Pubi−1(ki), Eki[seq, k′pr]
DATA : N, MACki+1 [N ], Eki+1 [payload ]
RREQ table : seq priv i pubi−1
Routing table : ki ki+1
Figure 6.5. ASR Route Request and Reply messages, and elements stored inthe routing table by node Ni.
it. Finally, node Ni stores the link key it received from node Ni+1 and the linkkey it generated for the next hop Ni in its routing table.
Data transmission in ASR uses the secret key ki shared between two consecutivehops on the path. Data packets are encrypted hop-by-hop and are identified usinga small TAG. This TAG is of the form 〈N ,MACki [N ]〉 with N a non-decreasingnumber.
Observations.
1. In order to open the trapdoor identifier included in a RREQ message, a nodehas to try all keys kSD it shares with other nodes (as there is no way for anode to know who the source of the RREQ was).
2. RREP packages carry no identifier that can be linked to the RREQ messages.This means that a node will have to try to decrypt every RREP message itreceives with every one-time private key it has in its RREQ table.
3. The same argument holds for DATA packets, as the TAG contains no infor-mation to identify the correct verification key. This means that every nodethat receives a DATA packet will have to try to verify the TAG with everylink key ki in its current routing table.
4. Every node forwarding a RREQ packet has to generate a fresh public keypair. For discrete log and elliptic curve based schemes this is fairly efficient,but for RSA and Rabin this is a very costly operation.

126 Chapter 6. Privacy in Ad Hoc Networks
MASK
In MASK [183], nodes use different pseudonyms (Nym) when moving to a newlocation and establish a shared secret key kAB with each of their neighbors. Thiskey establishment is based on pairing [6, 23] and is a simple adaptation of thescheme of Balfanz et al. [5] to the mobile setting.
Using this shared key, neighboring nodes A and B compute Γ pairs of shared ses-sion keys LinkKeyγ
AB and link identifiers LinkIDγAB . Each node keeps a neighbor
table in which each entry contains the pseudonym of a neighbor, the pairwiseshared session keys and link identifiers (LinkKeyγ ,LinkIDγ) and the index γ ofthe pair that is currently in use. These pairs are used in sequence, i.e., the in-dex γ is increased for every message transmitted and received. New pairs aregenerated in batches of size Γ as required.
A RREQ message contains a unique identifier seq, the identity of the destinationD and the current pseudonym Nymi of the node forwarding or initiating theRREQ message. The forwarding node stores the pseudonym contained in theRREQ message it received from the previous hop in its reverse route table (seeFig. 6.6).
Upon reception of a RREQ message, the destination D prepares a RREP messageconsisting of the current link identifier LinkID corresponding to the pre-hop-pseudonym contained in the RREQ. The RREP also contains the identity of thedestination encrypted with the current session key LinkKey shared between Dand the receiving node. Forwarding nodes regenerate this RREP message withtheir own link keys and identifiers and store the received link identifiers in theirforwarding route table (see Fig. 6.6). The identity D of the destination is usedto link RREQ and RREP messages (i.e., to locate to link identity to be used toforward the RREP message). Finally nodes also keep a table with link identifiersfor which they are the final destination.
Data forwarding is based on the link identifiers and corresponding keys in theforwarding route tables. A data packet is reencrypted at every hop.
Observations.
1. The destination is revealed in RREQ messages.2. It requires strict synchronization between neighboring nodes at all time.3. Anonymity is strictly based on the use of pseudonyms. Pseudonyms only
offer privacy protection if they are changed rapidly and in an unpredictablemanner. The cost however of changing pseudonyms is high as it requires anode to reestablish keys with all its neighbors.

6.4 Anonymous connections in mobile ad hoc networks 127
RREQ : seq, D,Nymi
RREP : pre-LinkIDγ , Epre-LinkKeyγ [D]
DATA : next-LinkIDγ , Enext-LinkKeyγ [payload ]
RREQ (reverse) table : D Nymi−1
Routing (forward) table : D pre-LinkIDγ next-LinkIDγ
Figure 6.6. MASK Route Request and Reply messages, and elements stored inthe routing table by node Ni.
SDAR: Secure Distributed Anonymous Routing
In contrast to the previously presented protocols, SDAR [26] does not use tem-porary or continuously changing identities. Instead SDAR uses a single fixedidentity for every node. Every intermediate node inserts its identity as the sourceaddress of every message it broadcasts. These identities are indicated in Fig. 6.7using the following notation: idS |idR|message.
The source S first generates a fresh public/private key pair pubT /privT and asession key ksess. It uses this session key to encrypt information that will onlybe disclosed to the destination D: the source identity S, its public key pubS ,the one-time public/private key pair pubT /privT , a sequence number seqS gen-erated by S and finally a signature on all this data. SDAR uses a trapdooridentifier of the form PubD(D, ksess) which only D can open. A forwardingnode Ni simply appends the following information to the RREQ it received:PubT (id i, ki, seqi,Sign(·)). Here id i is the identity of node Ni, ki is a fresh linkkey, and seqi is a sequence number. The forwarding node stores the sequencenumber, the link key and the identity of the previous hop (i.e., the node it receivedthe RREQ from) in its RREQ table (see Fig. 6.7).
The destination opens the trapdoor identifier using his private key and retrievesthe session key ksess. With this key D decrypts the third part of the RREQmessage and retrieves the one-time private key privT . Using this private key, Dcan now open all data appended by the forwarding nodes and use this data togenerate the RREP message. This RREP message has an onion-like structurewith the outer-layer decryptable by the last forwarding node, etc. The inner-mostlayer is decryptable by the source S of the corresponding RREQ message. Thelayer intended for the source contains all sequence numbers and link keys of all

128 Chapter 6. Privacy in Ad Hoc Networks
intermediate nodes. As the RREP message traverses the network back to nodeS, every forwarding node adds the identity of the node it received the RREPmessage from in its routing table (idnext in Fig. 6.7).
Random padding in the RREQ messages prevents insiders from learning thenumber of hops the RREQ messages have traversed.
Data packets are onions generated by the source using the keys and sequencenumbers it retrieved from the RREP message. Forwarding nodes strip one layerof encryption and forward the message to the next node according to idnext foundin its routing table.
Observations.
1. SDAR route discovery is very inefficient as it requires every forwarding nodeto perform a public key decryption (of the trapdoor identifier PubD(D, ksess))and a public key encryption using pubT for every RREQ message. As RREQmessages are flooded over the entire network, this implies that every node inthe network has to perform a public key decryption and encryption for everyRREQ message that is launched in the network.
2. The identities of the forwarding nodes along a path are disclosed to thedestination. The destination needs these identities in order to be able toverify the signatures generated by the intermediate nodes (see also the nextobservation).
3. The destination only needs to obtain a public key of all intermediate nodeson a route (see previous observation).
Mix route
Jiang et al. [84] propose a mix network that runs on top of an existing ad hocrouting scheme. They assume that a number of the nodes in the ad hoc networkare mix routers that can be used by the other nodes.
In this solution routes terminate at these mix routers, and a fresh route is estab-lished to forward the message to the next mix router or to the final destination.This solution is equivalent to the solutions proposed for fixed wired networksas described in Sect. 6.3, the only difference being the difficulty of maintainingroutes due to node mobility.

6.4 Anonymous connections in mobile ad hoc networks 129
RREQ : id i| ∗ |pubT ,PubD(D, ksess),Eksess [S, pubS , pubT , privT , seqS ,Sign(·)],PubT (id1, k1, seq1,Sign(·)), . . . ,PubT (id i, ki, seqi,Sign(·))
RREP : id i|idprev|seqi−1, Eki−1
[seqi−2, Eki−2
[seqi−3 . . .
seqS , EkS[seq1, k1, seq2, k2, . . . , seqD, kD]
]]
DATA : id i|idnext|seqi+1,
Eki+1
[seqi+2, Eki+2
[seqi+3 . . . , seqD, EkD
[payload ]]]
RREQ table : seqi idprev ki
Routing table : seqi idprev idnext ki
Figure 6.7. SDAR Route Request and Reply messages, and elements stored inthe routing table by node Ni.
6.4.4 Comparison and evaluation
SDAR is by far the least efficient protocol as it requires both a public key decryp-tion (in order to open the trapdoor identifier), a public key encryption and signa-ture generation every time a node needs to process a RREQ message. ANODRand ASR do not require encryption or decryption, but require that every nodethat processes a RREQ message generates a fresh public key pair. As RREQsare flooded over the entire network, every node in the network needs to performthese public key operations for every RREQ that is released in the network. InMASK no public key operations are required during route establishment, insteada similar cost is paid because of the continuous process of establishing keys withina node’s neighborhood.
ANODR and ASR require a public key encryption and decryption for everyRREP a node processes. This cost is multiplied by the number of key pairsin a node’s routing table, as the RREP messages contain no identifier that canbe linked to the RREQ messages. This means that a node has to decrypt thereceived RREP message with all private keys in its routing table.
With respect to privacy protection, none of the described protocols offers anyprotection against an external global passive adversary as this adversary cantrivially trace both RREP packets and all consecutive DATA packets as they

130 Chapter 6. Privacy in Ad Hoc Networks
traverse the network. Although these packets alter their appearance at everyhop (because of the onion structure or because they are reencrypted at everyhop), the flow of these messages can be traced with high probability. This meansthat the attacker is able to correlate educated guesses on the path and quicklydiscover source-destination relationships by observing the message flows.
The use of mixing techniques and dummy traffic at every hop will improve theprivacy properties of these protocols, but these techniques can be applied in-dependent of the routing protocol that is used and are not considered part ofthe routing protocol. Moreover, mixing techniques are most effective with largetraffic densities. Ad hoc routing protocols often try to achieve a flat routingdistribution over all nodes in the network and thus make mixing a less effectivemeasure.
Table 6.1 on p. 131 shows a comparison of the different anonymous routing pro-tocols we evaluated and our own proposal, ARM.
6.5 ARM: efficient anonymous routing for mobile adhoc networks
ARM is an on demand short-lived table based routing protocol that achieves allthe anonymity goals stated in Sect. 6.2.3 while trying to be as efficient as possible.To achieve this we followed a design strategy that builds on the strengths ofthe protocols described in Sect. 6.4.3 and avoids the weaknesses. We also addnew ideas that make the protocol more robust against external global passiveadversaries.
We assume that every node in the network has a permanent identity that isknown by the other nodes in the network that wish to communicate with thisnode. Next, we assume that the source S and the targeted destination D sharea secret key kSD and a secret pseudonym NymSD . Finally, we assume that everynode establishes a broadcast key with its 1-hop neighborhood (this is only nec-essary for the additional protection against external global passive adversaries).One possible way to establish these broadcast keys securely and anonymously isdescribed in [183].
6.5.1 Trapdoor identifier
As we mentioned in Sect. 6.4.3, ANODR and ASR use RREQ messages witha trapdoor identifier of the form EkSD [dest , x], while the trapdoor identifier in

6.5 ARM: efficient anonymous routing for mobile ad hoc networks 131
Table 6.1. Comparison of different anonymous routing schemes.
AN
OD
R
ASR
MA
SK
SD
AR
AR
M
Privacy properties towards insiders
Identity privacy of source or destination√ √
SP (4)√
Identity privacy of forwarding nodes√ √ √
(5)√
Location privacy of source or destination (1)√ √ √ √
Privacy properties towards a global observer
Identity privacy of source or destination√ √
SP (2’)√
Identity privacy of forwarding nodes√ √ √
(2’)√
Location privacy of route (2) (3) (3) (2)√
Efficiency properties
Requires end-to-end shared keys√ √
— —√
Requires neighborhood keys — —√
—√
Requires public key operation on RREQ G G — D,E,S E
Requires public key operation on RREP nD,E nD,E — — —
Has efficient link between RREP/RREQ — —√ √ √
Size of state info per route 4/0 2/0 3/0 4/0 4/0
Size of state info per forwarded RREQ 3/2 1/2 2/0 3/0 4/0
G = key pair generation, D = decryption, E = encryption, S = sign, SP = source privacy.The state information size: number of items with size of a symmetric key/public key.
(1) Number of hops to source is known to the destination.
(2) Return path can be traced through the RREP packet and all subsequent DATApackets. Also, using mixing techniques for the RREP packets is non-trivial becauseof their unique size at every hop.
(2’) Same as (2), but since every packet contains the identity of the sender and theintended next hop, the identities of the sender and receiver are revealed.
(3) Return path can be traced through the RREP packet and all subsequent DATApackets. Mixing techniques are easier to apply compared to (2) since the RREPpackets have a fixed length.
(4) Destination learns the identities of all forwarding nodes on the path.
(5) Neighboring nodes on a path know the identity of the neighbor on that path (sincethey received a RREQ or RREP message from this neighbor).

132 Chapter 6. Privacy in Ad Hoc Networks
SDAR has the form PubD(D,x). In both cases x is data that is generated by thesource of the RREQ. This results in a performance penalty since every node thatreceives a RREQ message needs to decrypt this identifier with all keys it shareswith other nodes or with its private key.
We propose to use a trapdoor identifier that can be computed by both the senderand destination before the RREQ message arrives at the destination. This trap-door identifier can be thought of as a one-time pseudonym NymSD shared be-tween nodes S and D. Every node keeps a list of pseudonyms it shares withevery node it also shares a secret key kSD with. Different mechanisms can beused to synchronize the pseudonym shared between source and destination. Oneexample is the use of a synchronized counter c that is used to compute the validpseudonym as NymSD = EkSD
[c]. This counter is incremented by the sourcewith every RREQ it initiates. The destination needs to store two consecutivepseudonyms, the Nymi that is currently used and the next Nymi+1. The desti-nation advances this window when it receives a RREQ identified with Nymi+1.Another example is to assume a synchronized clock between source and destina-tion and use this clock to compute new pseudonyms after a certain time interval ina similar fashion as with the counter. Note that the pseudonym can be shortenedas no decryption is required. For example, when using the AES for encryption,the length of the resulting pseudonyms would be 256 bits (the block size of AES).These large pseudonyms can be truncated to fit a sufficient length, for example,80-bits.
6.5.2 Route discovery
First, S generates a fresh asymmetric key pair privD/pubD and a secret key kpr.Next, S generates a datagram infoD that can only be opened by node D thathas knowledge of the secret key kSD :
infoD = EkSD [D, kpr, privD, ttl init ], Ekpr [NymSD ] .
Here, ttl init is the initial value of the Time-to-Live (TTL) field. Next, S generatesa random pair of link identifiers (nS , kS) = (n0, k0) that will later on be usedto recognize RREP messages. Finally, S encrypts the pair of link identifierswith pubD and broadcasts the following RREQ message (NymSD also serves asa unique identifier for this RREQ message):
S −→ * : NymSD , ttl init , pubD, infoD,PubD(nS , kS) .
Each node Ni that receives a RREQ message first checks whether it is the targeteddestination of the received RREQ by verifying whether NymSD is in its current

6.5 ARM: efficient anonymous routing for mobile ad hoc networks 133
list of valid pseudonyms. If so, Ni tries to decrypt infoD and verifies whether thefirst part of the decryption is equal to its global identifier Ni. If this fails, thenode was not the targeted destination.
If Ni is not the targeted destination, the node checks whether NymSD has beenrecorded in its routing table. If so, the node discards the RREQ message. Oth-erwise, Ni stores (NymSD , ni−1, ki−1, Ekpr [NymSD ]) in its routing table. If thereceived ttl > 1 then the node decrements ttl , and generates a random pairof link identifiers (ni, ki), appends these to the already received encrypted linkidentifiers, encrypts everything with pubD, and broadcasts the following RREQmessage (if the received ttl = 1, no message is broadcast):
Ni −→ * : NymSD , ttl , pubD, infoD,PubD(. . . (PubD(ni−1, ki−1), ni, ki)) .
If Ni is the targeted destination, it stores the complete RREQ in memory andperforms the same steps as if it was not the targeted destination. This means thatthe destination D behaves exactly the same as all other nodes in the network.After it has forwarded one or more RREQ messages, the destination can prepareits reply message.
Design motivation
The RREQ message is designed with the following goal in mind. The cost for theintermediate nodes is minimized by moving the bulk of the computational cost tothe destination. This seems only fair as the two communicating end points arethe only beneficiaries and the intermediate hops are providing a service to them.Also, the destination can use the NymSD to identify the source and opt to ignorethe RREQ if it is not interested in communicating with the source. When thishappens, the cost for the intermediate nodes is minimal. The choice of publickey cryptosystem offers two options:
1. By using RSA or Rabin, the computation cost for the intermediate nodesis minimized as they are only required to perform a public key encryption(Sect. 2.2.5).
2. By using ECIES, the communication cost for the intermediate nodes is min-imized as ECIES offers very short cryptograms (320 bits compared to 1024bits for RSA or Rabin).

134 Chapter 6. Privacy in Ad Hoc Networks
DN1
N2
S
Figure 6.8. Hidden route from source S to destination D. The full arrowindicates an actual route between S and D, while the dashed arrows indicatesfake broadcasts that hide the actual path.
6.5.3 Route reply
Assume that the destination D has collected a number of RREQ messages thatwere targeted at it. First it decrypts the infoD field contained in one of theseRREQs (they all contain the same infoD) and obtains kpr, privD and ttl init .
Node D computes the number of hops a RREQ has traversed as h = ttl init −ttl . This hop count is useful to select the shortest route and to help with thedecryption of the link identifiers when padding is used (see Sect. 6.5.5).
Using privD, node D decrypts the link identifiers (ki, ni) for 0 ≤ i ≤ n (with(k0, n0) = (kS , nS)) that are contained within the received RREQs and selects aroute it wishes to use (for example based on the hop count). Since the destinationitself has also forwarded RREQ messages, it should discard routes that includelink identifiers that were generated by D itself in order to ensure loop-free routes.
For every route for which D wishes to generate a RREP message, D repeats thefollowing tasks:
First D generates n + 1 link keys si for 0 ≤ i ≤ n with s0 = sS . Link key si willbe shared between nodes Ni and Ni+1. Together with the link identifiers (ki, ni),node D constructs a route reply onion of the following form:
On = Ekn
[nn, sn, sn−1, kpr, Ekn−1
[nn−1, sn−1, sn−2, kpr, . . . EkS
[nS , sS , kpr]]]
.
In the case of only a single RREP message for a particular NymSD , D cangenerate a shorter RREQ message of the following form (the link key sharedbetween nodes Ni and Ni+1 is now h(ki)).
On = Ekn
[nn, h(kn−1), kpr, Ekn−1
[nn−1, h(kn−2), kpr, . . . EkS
[nS , kpr]]]
.

6.5 ARM: efficient anonymous routing for mobile ad hoc networks 135
After the construction of the reply onion, node D generates a random ttl (seeSect. 6.5.5) and broadcasts the following RREP message (〈NymSD , γ〉 serves asa unique identifier for this RREP message; the index γ is used to distinguishRREP messages that contain the same NymSD):
* ←− D : EkD∗ [NymSD , γ, ttl ],On
When only a single RREP is generated, the index γ is not required. The identifierand TTL field (i.e., the header) of the RREP message are encrypted with thecurrent broadcast key kD∗ of node D to hide them from a global passive adversary.
Each node Ni that receives a RREP message will perform one of two actions (a)or (b) (see below). Note that both actions are implemented in such a way thatthey both require an equal amount of time (in order to prevent timing analysis).The RREP contains identifier NymSD and index γ. First it verifies whether ithas forwarded a Route Request with identifier NymSD . If not, it proceeds withaction (b). Otherwise, the node checks whether it already received a Route Replywith the same identifier and index. If so, it again proceeds with action (b). Ifthis is the first time that it has seen a RREP with this particular index, thathas the same identifier as a RREQ it forwarded earlier, it decrypts the replyonion using ki and checks whether the first part of the decryption is equal toni. If so, node Ni is on the anonymous route. Node Ni now validates the proofof the destination by verifying that the decryption of Ekpr [NymSD ] (using kpr
retrieved from the RREP) is equal to NymSD . Note that node Ni uses NymSD
to retrieve 〈ni , ki ,Ekpr [NymSD ]〉 from its routing table. If the proof is valid, nodeNi proceeds with action (a); otherwise it discards the message.
(a) Node Ni strips one layer from the reply onion, generates a new random TTLvalue ttl and broadcasts the RREP message, encrypting the new header withits current broadcast key. Node Ni stores the secret keys (si, si−1) in itsrouting table. The first element is a secret key it shares with the next hopNi+1 in the route, while the second element is shares with the previous hopNi−1 in the route. We will use the notation kprev and knext, respectively, todenote these keys.
(b) Node Ni replaces the reply onion by random data of appropriate length,decrements ttl and broadcasts the RREP message, encrypting the headerwith its current broadcast key.
Design motivation
– Onion creation is efficient as it only requires symmetric encryption.

136 Chapter 6. Privacy in Ad Hoc Networks
– It is efficient for an intermediate node to check wether an onion is intendedfor it or not.
– We use a limited broadcast to hide the real route in a cloud of messages. Thetime-to-live value can be used to select the size of this cloud.
– The time-to-live value is encrypted with a node’s broadcast key. This is onlynecessary to protect against an external global passive adversary.
6.5.4 Data forwarding
Every RREP message with an identifier NymSD that arrives at the source Scontains a route to the destination D. When the RREP messages arrive at thesource S, they have the following form:
* ←− Nγ1 : EkN
γ1[NymSD , γ, ttl ], EkS
[nS , sγS ]
Index γ is used to indicate those fields that may differ for the different RREPmessages that return in response to a single RREQ message broadcast by thesource with identifier NymSD . Every link key sγ
S represents a different route tothe destination D.
Similar to sending RREQ messages, DATA messages will have a one-time identi-fier attached to them. This identifier allows a node on the route to recognize thefact that it is the next hop and that it should forward the message. The one-timeidentifier is computed using the secret key shared between consecutive hops inthe route and the counters c and c′ that are incremented per message receivedor sent on this route. The routing table of a node Ni consists of the followingelements:
kprev knext idprev = Ekprev [c] idnext = Eknext [c′]
Nodes that receive a message that is identified with one of the idprev’s in theirrouting table replace this identifier with idnext, reset the TTL field using thescheme in Sect. 6.5.5, and forward the message. After forwarding the message thenodes increment the counters c and c′. In order to change the appearance of themessages as they traverse the network, the identifier and TTL field are encryptedusing the nodes’ broadcast keys (similar to the forwarding of RREP messages),while the payload is re-encrypted at every hop using kprev for decryption andknext for encryption. The length of every data message is fixed (the message ispadded at the source if necessary).

6.5 ARM: efficient anonymous routing for mobile ad hoc networks 137
Nodes that receive a message with an identifier that does not appear in their rout-ing table replace the identifier and the message payload with a random number,decrement the TTL field and forward the message. Again the message identifierand TTL field are encrypted using the node’s broadcast key.
6.5.5 Padding and time-to-live schemes
Without randomized padding and time-to-live values, the length of routing mes-sages and the TTL value they contain reveals information to both the global ad-versary and to inside nodes participating in the routing process. In this sectionwe propose a possible strategy for both padding and time-to-live value selection.In the next two sections we analyze the privacy our scheme offers.
Time-to-live
For Route Request messages we propose not to use a TTL field for smallnetworks. For large networks, the cost of network-wide broadcast can be cutdown by using an safe estimate ttlest of the hop distance between source anddestination. If nodes have a clear idea of the hop distance to other nodes, thenthey should randomize the TTL value by adding a random value between zeroand some maximum to the required TTL size in order to reach the destination(ttl init = ttlest + ttl rand with 0 ≤ ttl rand ≤ tmax).
The TTL field in Route Reply and DATA messages is required in order tohide the actual path followed by these messages. Using a fixed TTL value wouldreveal the path to nodes inside the network that receive RREP or DATA messagesfrom their neighbors (as only nodes on the path will set the TTL value to thisfixed value and all other nodes decrement this value). We propose the followingpadding scheme to prevent this.
Every node on the path chooses a TTL value according to the probability dis-tribution in Fig. 6.10. This distribution has two important properties: (1) smallTTL values are favored, and (2) the probability rapidly decreases to reach zero atsome maximum TTL value ttlmax. Similar to the discussion on RREQ paddinglengths, node B that receives a RREP or DATA message from node A with acertain TTL value can compute the probability that it originated at node A. Theprobability that it did not originate at the node A is related to the surface of thearea underneath the probability distribution at the right side of the TTL valueit received. We see that using the distribution function we propose in Fig. 6.10,with high probability a node will select a TTL value that has a large area tothe right of it, while choosing a large TTL value (providing limited anonymity)

138 Chapter 6. Privacy in Ad Hoc Networks
is unlikely. We set a minimum TTL value in order to hide the path to a globalpassive adversary. Nodes receiving RREP or DATA messages that are not partof the path decrement the TTL before forwarding the message, as described inSect. 6.5.3 and Sect. 6.5.4.
Padding
Without padding the length of a Route Reply message would continuouslydecrease and hence reveal the number of hops the RREP still needs to travelin order to reach its target S. In order to prevent this, node D (the sourceof the RREP message) adds padding bits to the RREP before transmitting it.The length l of this padding is selected using a uniform probability distribution(lmin ≤ l ≤ lmax). Nodes forwarding a RREP message keep the length of themessage constant by right padding the RREP message before forwarding it tocompensate for length reduction created by the peeled off layer.
DATA messages are chopped into packets of equal length. The last packet ispadded if necessary.
The length of Route Request messages grows as they traverse the network.Without additional padding, the length of a RREQ message discloses the dis-tance the message has traveled. Moreover, the length of a fresh RREQ messagebroadcast by the source S is known to all nodes in the network (in contrast tothe initial length of a Route Reply message, which can vary).
We use a similar design philosophy for the padding scheme for RREQ as we usedfor the time-to-live scheme for RREP messages. The source randomly selects apadding length according to the probability distribution in Fig. 6.11. Note thata padding length of 5 means that the source adds random bits such that it seemsthat the RREQ message has already traveled 5 hops. Node B that receives aRREQ message from node A with a certain length can now compute the prob-ability that it originated at node A. The probability that it did not originateat the node A is equal to the surface of the area underneath the probabilitydistribution left of the actual length of the packet. We see that using the distri-bution function we propose in Fig. 6.11, with high probability a node will selecta padding length that has a large area to the left of it, while choosing a paddinglength close to zero (providing limited anonymity) is unlikely. Note that largepadding lengths offer higher privacy at a higher cost (since the message becomeslarger and needs to be encrypted at every forwarding hop). Nodes forwardingthe RREQ messages do not add any padding.

6.6 Analysis of the padding and time-to-live schemes 139
6.5.6 Variations
The first variation is to use no broadcast encryption for the RREP and DATApackets. The resulting scheme still hides the real route from insiders, but nolonger hides the route from an external global passive adversary. This is because aglobal adversary can trace the route using the TTL values (all nodes broadcastingpackets with the highest TTL value are on the route, the other nodes are justforwarding packets). Because of the limited view of the insiders, they cannotmake this analysis.
The second variation is to also drop the use of the limited broadcast of RREP andDATA packets (set the time-to-live to zero). This is obviously the most efficientversion, but now routes are also visible to insiders neighboring the route (as onlythey will receive the DATA and RREP packets).
6.6 Analysis of the padding and time-to-live schemes
6.6.1 Privacy offered by random TTL selection
We will now investigate how much privacy is offered by TTL value selectionaccording to a given probability distribution. Suppose that node B receivesa message with a TTL value t from its neighbor node A (see Fig. 6.9). Theadversary in this case is node B that has received the message from node A.
Let P be the discrete probability distribution of the TTL value selection, withvalues pt, where pt is the probability that a node selects an initial TTL value t(1 ≤ t ≤ tmax).
Assume that the adversary has a priori knowledge of the probabilities that somenode was the originator of the message that traverses route R. Let S be thisdiscrete probability distribution with values sR
Ni, where sR
Niis the a priori proba-
bility that node Ni is the originator of the message that traverses route R. Thisprobability distribution can vary for every message the adversary observes.
Definition 6.4 (Privacy offered by a TTL value equal to t). We definethe privacy of node A towards node B as the probability that node A was not theoriginator of the message with TTL value equal to t.
The probability that a message with a TTL value of t did originate at node A isgiven by the conditional probability P (A|B) with:
– event A: node A generates a message with TTL value t;

140 Chapter 6. Privacy in Ad Hoc Networks
B A
pad = l
ttl = t ttl = t + 1
pad = l − 1
ttl = t + 2
pad = l − 2
k1 k2 . . .
. . .
Figure 6.9. Evolution of padding and TTL values of a message. Node A receivesa RREQ message with padding length l, or a RREP or DATA message with TTLvalue t. This message could have originated from node A or from nodes furtheraway.
– event B: node B receives a message with TTL value t.
Using Bayes’ theorem we can rewrite P (A|B) as P (B|A)P (A)/P (B). One caneasily verify that P (B|A) = 1. The probability P (A) that A generates a messagewith TTL equal to t is equal to the product of the probability of A generatingthe message and the probability that it has a TTL value of t:
P (A) = sApt with sA =∑
∀R
sRA . (6.1)
We sum over all possible routes since all messages A sends will be received by itsneighbor node B.
The probability P (B) is the probability that some node in the network generateda message that resulted in a TTL value t when it reached node B. This can beexpressed as
P (B) =|NiB|R≤tmax−t∑
Ni,R
sNipt+h−1 with h = |NiB|R . (6.2)
Here, |AB|R is the hop distance between nodes A and B using route R. Notethat the hop distance between two nodes depends on the route R the messagefollows. The summation goes over all nodes and all routes that originate at thesenodes that pass through node A. The hop distance is limited since the TTL valuea node can select is limited to tmax.

6.6 Analysis of the padding and time-to-live schemes 141
Using Eq. (6.1) and Eq. (6.2) we can compute the privacy offered by a TTL valueequal to t as
Priv t = 1− P (A)P (B)
=P (B)− P (A)
P (B). (6.3)
This privacy depends on the probability distributions P and S. The former is asystem parameter, while the latter is the a priori knowledge the adversary has ofthe network (number of nodes, possible routes, probability of sending messages,etc.). At design time the a priori knowledge of the adversary is not known andwe need to make some assumptions to select the optimal probability distributionP.
We can now compute the average privacy of a node that generates messages withTTL values selected according to the probability distribution P as
Priv(P) =tmax∑t=1
ptPriv t . (6.4)
Equivalent to the average privacy, we can also compute the average “cost” ofa TTL distribution as (f(t) is function that indicates how fast the number ofnodes, that will forward a message originating from node A with a TTL value t,grows).
Cost(P) =tmax∑t=1
ptf(t) . (6.5)
The optimal distribution for the TTL value selection is the distribution thatmaximizes Priv(P)/Cost(P).
Selecting P
The first assumption we make is that all nodes are equally likely to generate amessage at any time. The second assumption we make is that routes with shortestpath length are selected amongst all possible routes. This last assumption meansthat a node with shortest hop distance h from node B has to generate a messagewith a TTL value equal to t+h− 1 in order for this message to arrive at node Bwith a TTL value of t. This also means that nodes that are closer to B than tonode A will never select a route that first passes A and then B. This also meansthat the message B receives from A could not have originated from a node withinB’s range, besides node A obviously. These assumptions are depicted in Fig. 6.9.The number of nodes that are at a 1 hop distance of node A is k1, the number

142 Chapter 6. Privacy in Ad Hoc Networks
of nodes at hop distance 2 is k2, etc. (k0 = 1, i.e. node A is the only node at hopdistance 0 from itself).
Let Kt be the number of nodes in the network that could have generated amessage that arrives at node B with a TTL value equal to t:
Kt =tmax−t∑
i=0
ki . (6.6)
Using these assumptions, we can rewrite P (A) (Eq. (6.1)) as
P (A) =1
Ktpt ,
and P (B) (Eq. (6.2)) as
P (B) = Pt =tmax∑
i=t
ki−t
Ktpt .
This results in a the following privacy measure (Eq. (6.3)):
Priv t =Pt − pt
Kt
Pt. (6.7)
If we further assume that the density of nodes is constant throughout the network,then ki grows linearly with i: ki = (1/2)C(2i−1) for i ≥ 1. Here C is the numberof nodes within transmission range of node A. As the hop distance grows, thenumber of nodes grows proportionally to the area difference of two concentriccircles with radii i and i− 1. The factor 1/2 is due to the fact that only half ofthe network should be counted, as nodes closer to B than to A can never be theoriginator of the message. Note that this is true for nodes that are scattered ona flat surface; if the nodes are located within a three dimensional space, then thenumber of nodes at a specific hop distance grows quadratically with the distance.
Using this assumption, Eq. (6.6) can be rewritten as
Kt = 1 + (1/2)Ctmax−t∑
i=1
(2i− 1) = 1 + (1/2)C(tmax − t)2 ,
and Eq. (6.5) can be rewritten as
Cost(P) =tmax∑t=1
ptt2 .

6.6 Analysis of the padding and time-to-live schemes 143
Table 6.2. Average privacy and privacy/cost ratio of two probability distri-butions P for TTL value selection. The numbers in boldface indicate maximalattainable values (β is a normalization factor).
P Param a Priv(P) Priv(P)/Cost(P)Exponential 0.22 0.56 0.28
pi = βai 0.59 0.82 0.150 0.72 0.066
Linear-0.1 0.74 0.15
pi = β + ai-0.071 0.81 0.12
Table 6.2 shows numerical results for two different classes of probability distri-butions: exponential (pi = βai) and linear (pi = β + ai). The number of 1-hopneighbors is fixed at C = 6 and tmax = 5. The normalization factor β needsto be chosen such that
∑i pi = 1. We see that the exponential distribution of-
fers the highest attainable privacy and the highest attainable privacy/cost ratio.For growing values of tmax both the linear and the exponential distribution offerlarger maximum privacy values, but at a lower privacy/cost ratio. For the lin-ear distribution, the maximum privacy/cost ratio decreases when tmax grows. Incontrast, the exponential distribution offers a constant maximum privacy/costratio, independent of tmax. This maximum is attained for a parameter selectiona = 0.22. The node density C of the network has a positive influence on theprivacy performance of the scheme as it lowers the probability that node A wasthe originator of the message.
Figure 6.10 shows the probability pi that a certain TTL value is selected, theprivacy Priv i and the (normalized) cost Cost i offered by this selection, and theaverage privacy offered by the exponential probability distribution P : pi = βai
with a = 0.35. We see that (except for the last couple of TTL values) the privacyoffered is independent of the TTL value that is selected. We also see that themost likely TTL values have the lowest cost.
6.6.2 Privacy offered by random padding selection
The evaluation of the privacy offered by random padding selection is very similarto the evaluation of the privacy offered by random time-to-live value selection.Assume the same situation as in Sect. 6.6.1, but now node B receives a messagefrom node A with a “length” l. The term “length” indicates how many hops thismessage seems to have traveled from the source. A message broadcast by the

144 Chapter 6. Privacy in Ad Hoc Networks
�����������������
�����������������
�����������������
�����������������
�����������������
�����������������
���������������������������������������������������
�����������������
����������������
����������������
������������������������������������������������
������������������������������������������������
� � � � � � � � � � � � � � � � �
���������������������������������������������������
��������������
��������������
�����������
�����������
�������������������
�����������������
�����������������
�����������������
�����������������
�����������������
���������������������������������������������������
�����������������
������������������������������������������������
������������������������������������������������
������������������������������������������������
� � � � � � � � � � � � � � � �
!�!!�!!�!!�!!�!!�!!�!!�!!�!!�!!�!!�!!�!!�!!�!!�!!�!
"�""�""�""�""�""�""�""�""�""�""�""�""�""�""�""�""�"
##############
$$$$$$$$$$$$$$
%%%%%%%%%%%
&&&&&&&&&&&
'()�)*�* +�+,�, -. /0 1122 3344 5�5
5�55�55�5
66667�77�77�77�77�7
8�88�88�88�88�8
9�99�99�99�99�9
:�::�::�::�::�:
;�;;�;;�;;�;;�;;�;
<�<<�<<�<<�<<�<<�<
=================
>>>>>>>>>>>>>>>>>
?????????????????
@@@@@@@@@@@@@@@@@
AAAAAAAAAAAAAAAAA
BBBBBBBBBBBBBBBBB
C�CC�CC�CC�CC�CC�CC�CC�CC�CC�CC�CC�CC�CC�CC�CC�CC�C
DDDDDDDDDDDDDDDDD
E�EE�EE�EE�EE�EE�EE�EE�EE�EE�EE�EE�EE�EE�EE�EE�E
F�FF�FF�FF�FF�FF�FF�FF�FF�FF�FF�FF�FF�FF�FF�FF�F
G�GG�GG�GG�GG�GG�GG�GG�GG�GG�GG�GG�GG�GG�GG�GG�G
H�HH�HH�HH�HH�HH�HH�HH�HH�HH�HH�HH�HH�HH�HH�HH�H
I�II�II�II�II�II�II�II�II�II�II�II�II�II�II�II�II�I
J�JJ�JJ�JJ�JJ�JJ�JJ�JJ�JJ�JJ�JJ�JJ�JJ�JJ�JJ�JJ�JJ�J
KKKKKKKKKKKKKK
LLLLLLLLLLLLLL
MMMMMMMMMMM
NNNNNNNNNNN
OPQ�QR�R S�ST�T UV WX YYZZ [[\\ ]�]
]�]]�]]�]
^^^^_�__�__�__�__�_
`�``�``�``�``�`
a�aa�aa�aa�aa�a
b�bb�bb�bb�bb�b
c�cc�cc�cc�cc�cc�c
d�dd�dd�dd�dd�dd�d
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1 2 3 4 5 6 7 8 9 10
pi,Priv
i,C
osti,Priv
(P)
ttl value
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1 2 3 4 5 6 7 8 9 10
pi,Priv
i,C
osti,Priv
(P)
ttl value
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1 2 3 4 5 6 7 8 9 10
pi,Priv
i,C
osti,Priv
(P)
ttl value
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1 2 3 4 5 6 7 8 9 10
pi,Priv
i,C
osti,Priv
(P)
ttl value
Figure 6.10. Privacy and cost of an exponential probability distribution forTTL value selection (pi = βai with a = 0.35). The first bar is the probabilitya TTL is selected, the second the privacy offered and the third the cost. Thehorizontal line is the average privacy offered by the distribution.
source S without any padding has length l = 0. A message that has traveled onehop from the source, or has padding length 1, has a total length of 1, etc. Withthese definitions, the events A and B become:
– event A: node A generates a message with padding length l;
– event B: node B receives a message with length l.
Let P be the discrete probability distribution of the padding length selection,with values pl, where pl is the probability that a node selects a padding length l(0 ≤ l ≤ lmax).
Definition 6.5 (Privacy offered by a padding length l). We define theprivacy of node A towards node B as the probability that node A was not theoriginator of the message with padding length l.
Using the same reasoning as in Sect. 6.6.1, we get the following practical measurefor the privacy offered by a particular message length l (see also Eq. (6.7)):
Priv l =Pl − pl
Kl
Pl, (6.8)

6.6 Analysis of the padding and time-to-live schemes 145
with
Pl =l∑
i=0
kl−i
Klpi and Kl =
l∑
i=0
ki .
Finally, the average privacy and cost measure of a particular distribution Pbecome (see Eq. (6.4) and Eq. (6.5)):
Priv(P) =l∑
l=0
plPriv l ,
and
Cost(P) =lmax∑
l=0
pl(1 + αl) .
Here, α is the ratio of the true length of a single padding block (in bits) to thelength of a RREQ without padding as it leaves the source. The length of a singlepadding block is approximately 1024 bits when using RSA, while the length ofan unpadded RREQ is approximately 3530 bits when using AES and |D| = 64,|k| = 80, |NymSD = 64|, and |ttl| = 10. This results in α ≈ 0.3.
Note that the cost only grows linearly with the padding length l; this is becausethis padding is only added once at the source.
Table 6.3 shows numerical results for exponential and linear probability distri-butions. The number of 1-hop neighbors is fixed at C = 6 and lmax = 4. We seethat the exponential distribution offers the highest attainable privacy. For grow-ing values of tmax both the linear and the exponential distribution offer largermaximum privacy values, but at a lower privacy/cost ratio. The node density Cof the network has a positive influence on the privacy performance of the schemeas it lowers the probability that node A was the originator of the message.
Figure 6.11 shows the probability pi that a certain padding length is selected, theprivacy Priv i and the (normalized) cost Cost i offered by this selection, and theaverage privacy offered by the exponential probability distribution P : pi = βai
with a = 1/0.35. We see that (except for the first couple of padding lengths) theprivacy offered is independent of the padding length that is selected. We alsosee that the most likely padding values have the highest cost (in contrast to theTTL scheme). Fortunately, the padding scheme is only used for RREQ messagesand not for the more common DATA packets.

146 Chapter 6. Privacy in Ad Hoc Networks
Table 6.3. Average privacy and privacy/cost ratio of two probability distribu-tions P for padding length selection. The numbers in boldface indicate maximalattainable values (β is a normalization factor).
P Param a Priv(P) Priv(P)/Cost(P)Exponential 1.16 0.77 0.46
pi = βai 1.70 (= 10.59 ) 0.82 0.44
0 0.72 0.45Linear
0.032 0.77 0.46pi = β + ai
0.071 0.81 0.44
�� ������������
������������
���������������
���������������
���������������������������������������������
���������������
����������������
����������������
������������������������������������������������
������������������������������������������������
� � � � � � � � � � � � � � � �
������������������������������������������������
����������������
����������������
����������������
����������������
�����������������
�����������������
�� ������������
������������
���������������
���������������
���������������������������������������������
���������������
������������������������������������������������
������������������������������������������������
������������������������������������������������
� � � � � � � � � � � � � � � �
!�!!�!!�!!�!!�!!�!!�!!�!!�!!�!!�!!�!!�!!�!!�!!�!
"�""�""�""�""�""�""�""�""�""�""�""�""�""�""�""�"
################
$$$$$$$$$$$$$$$$
%%%%%%%%%%%%%%%%
&&&&&&&&&&&&&&&&
'''''''''''''''''
(((((((((((((((((
)�)*�* +�++�+,�,,�, --.. //00 1122 3333
44445�55�55�56667�77�77�78�88�88�89�99�99�9:�::�::�:
;�;;�;;�;;�;;�;
<�<<�<<�<<�<<�<
=> ????????????
@@@@@@@@@@@@
AAAAAAAAAAAAAAA
BBBBBBBBBBBBBBB
C�CC�CC�CC�CC�CC�CC�CC�CC�CC�CC�CC�CC�CC�CC�C
DDDDDDDDDDDDDDD
E�EE�EE�EE�EE�EE�EE�EE�EE�EE�EE�EE�EE�EE�EE�EE�E
F�FF�FF�FF�FF�FF�FF�FF�FF�FF�FF�FF�FF�FF�FF�FF�F
G�GG�GG�GG�GG�GG�GG�GG�GG�GG�GG�GG�GG�GG�GG�GG�G
H�HH�HH�HH�HH�HH�HH�HH�HH�HH�HH�HH�HH�HH�HH�HH�H
I�II�II�II�II�II�II�II�II�II�II�II�II�II�II�II�I
J�JJ�JJ�JJ�JJ�JJ�JJ�JJ�JJ�JJ�JJ�JJ�JJ�JJ�JJ�JJ�J
KKKKKKKKKKKKKKKK
LLLLLLLLLLLLLLLL
MMMMMMMMMMMMMMMM
NNNNNNNNNNNNNNNN
OOOOOOOOOOOOOOOOO
PPPPPPPPPPPPPPPPP
Q�QR�R S�SS�ST�TT�T UUVV WWXX YYZZ [[[[
\\\\]�]]�]]�]^^^_�__�__�_`�``�``�`a�aa�aa�ab�bb�bb�b
c�cc�cc�cc�cc�c
d�dd�dd�dd�dd�d
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0 1 2 3 4 5 6 7 8 9
pi,Priv
i,C
osti,Priv
(P)
padding length
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0 1 2 3 4 5 6 7 8 9
pi,Priv
i,C
osti,Priv
(P)
padding length
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0 1 2 3 4 5 6 7 8 9
pi,Priv
i,C
osti,Priv
(P)
padding length
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0 1 2 3 4 5 6 7 8 9
pi,Priv
i,C
osti,Priv
(P)
padding length
Figure 6.11. Privacy and cost of an exponential probability distribution forpadding length selection (pi = βai with a = 1/0.35). The first bar is the proba-bility a padding length is selected, the second the privacy offered and the thirdthe cost. The horizontal line is the average privacy offered by the distribution.

6.7 Conclusions 147
6.6.3 Analysis of our protocol
Route Hiding
Our protocol effectively hides routes between sources and destinations, bothagainst a passive global adversary and nodes inside the network. Because ofthe probabilistic padding and TTL scheme we use, nodes inside the network willnot be able to determine whether the node they received a message from is thesource of this message or forwarding it. Nor can they tell which nodes are partof a route between two nodes. Nodes on a route are not able to tell which nodeis communicating with which other node by inspecting the messages they areforwarding. A passive global adversary will be able to learn which nodes arethe sources of fresh messages, but he will not be able to trace this message andlearn which nodes are forwarding the message and which node is the final des-tination. The probabilistic TTL scheme hides the actual path between sourceand destination in a “cloud” of possible paths as this message is forwarded byevery node that receives it (whether the node is on the path or not) until theTTL field finally reaches zero (see Fig. 6.8). Note that this scheme only works innetworks where every node is surrounded by multiple neighbors. In very sparsenetworks, hiding routes is very difficult, as there are only a limited number ofpossible routes an actual message could have followed.
Efficiency
Our protocol requires no cryptographic operations in order for nodes to be ableto recognize whether a message is targeted at them or not. Next to this, partic-ipating in the forwarding of a RREQ message only requires nodes to perform asingle public key encryption. When using Rabin or RSA with a small exponent,this can be implemented very efficiently [107]. Our probabilistic TTL schememakes it possible to hide the path between source and destination in a localizedcloud without flooding the entire network. Nodes that only participate in thehiding process only need to decrypt and encrypt the short message header usingtheir broadcast keys.
6.7 Conclusions
In this chapter we have described an anonymous on demand routing protocolfor wireless ad hoc networks. We have situated this research in the broaderfield of Privacy Enhancing Techniques (PETs). After an analysis of the current

148 Chapter 6. Privacy in Ad Hoc Networks
state of the art in anonymous ad hoc routing protocols, we have described ourown proposal, indicating the different design motivations. Finally, we provideda detailed analysis of the privacy offered by hiding routes in limited broadcastgroups, and padding messages.
Although we have given indicators for the efficiency of the current state of the art(including our own scheme), a detailed efficiency analysis is required to determinethe exact efficiency of each scheme. This evaluation could be based on a systemmodel like the one we presented in Chapter 5, or on simulations.

Chapter 7
Conclusions and FutureResearch
7.1 Conclusions
In this thesis we deal with security solutions for wireless mobile ad hoc networks.The emphasis is on efficient protocols that are targeted at resource constraineddevices.
We start by evaluating and comparing the efficiency of cryptographic primitives.We have collected a large number of power and timing measurements of blockciphers, stream ciphers, hash functions, digital signature schemes and public keyencryption systems. We can conclude that symmetric primitives are far moreefficient than public key cryptosystems (e.g., the energy cost of a single ECDSAsignature generation in a 160-bit field is equal to the cost of encrypting 111 KByteusing the AES block cipher). We further note that RSA and Rabin provide themost efficient public operations, but also the least efficient private operations.Elliptic curve based algorithms offer the most efficient private operations (theirpublic operations are about two times less efficient than their private operations)and have the additional advantage of smaller digital signature, ciphertext andkey sizes.
Motivated by the efficiency of symmetric primitives, we have evaluated the effi-ciency of one-time digital signature schemes that are based on a one-way function.This one-way function can be implemented using fast symmetric primitives suchas block ciphers or cryptographic hash functions. The disadvantage of one-time
149

150 Chapter 7. Conclusions and Future Research
signature schemes is the fact that a public key can be used only once. As allverifiers need an authenticated copy of the public keys, efficient solutions forpublic key authentication are required. We have evaluated three one-time signa-ture schemes (Lamport-Diffie with Winternitz improvement, Lamport-Diffie withMerkle improvement and the HORS signature scheme) in combination with twopublic key authentication mechanisms (Merkle trees and one-way chains). Ourevaluation includes both the computational and communications costs. The opti-mal solution depends on the scenario in which these schemes will be used (numberof verifiers, specific cost figures for computations and communications, etc.). Weshow that for the scenario of a single signer and 10 verifiers, the HORS schemeusing one-way chains for authentication yields a five-fold increase in efficiencycompared to using plain ECDSA.
Next, we have presented a construction of a cooperative threshold one-time sig-nature schemes, in which multiple users can cooperate to sign a message. First,we show how secret sharing schemes can be employed to construct threshold ver-sions of the basic Lamport-Diffie scheme and the Lamport-Diffie scheme withWinternitz improvement. Next, we present a general construction that can beused to convert any one-time signature scheme into a threshold one-time signa-ture scheme. In this scheme, the cost of the threshold signature is divided over allthe signers. Finally, we show how our scheme can be used to provide an efficientauthentication mechanism for distributed sensor networks.
Establishing session keys between communicating parties is essential when usingsymmetric cryptographic primitives to protect confidentiality and integrity. Wehave proposed a novel key management scheme that is targeted on dynamic adhoc networks and only relies on efficient symmetric cryptographic primitives. Thescheme is not dependent on any manager nodes that operate as key distributioncenters, rather it extends key pre-distribution schemes to the setting of dynamicad hoc networks. The scheme allows a node to maintain pairwise keys with allnodes in its neighborhood, and to establish a session key with any arbitrary nodein the network. We show how the key establishment scheme can be integratedwith ad hoc routing protocols, in particular the DSR protocol. We show how thekeys, that have been established, can be used to secure ad hoc routing protocols.We evaluate the efficiency of the protocol both using an analytical model andthrough simulations, and show how the security of our scheme changes withvarious parameters.
Finally, we have described the state of the art in anonymous routing schemesfor ad hoc networks, analyzed the strengths and weaknesses of these schemes.We have presented a novel anonymous routing scheme for ad hoc networks thatoutperforms existing proposals with respect to both efficiency and anonymity. Wehave discussed how it is possible to hide routes by allowing limited broadcast,

7.2 Future work 151
and how to select time-to-live and padding values in order to achieve optimalperformance for anonymity.
7.2 Future work
Providing security for mobile ad hoc networks is an interesting and challengingresearch area with many unsolved problems.
Intensive use of cryptography on the resource constrained devices that makeup ad hoc networks, and in particular sensor networks, requires primitives withultra-low power budgets. As we have seen in the first chapter, this can onlytruly be achieved using dedicated hardware implementations. Further researchon novel designs of symmetric primitives should be targeted at secure ciphersthat allow very low-power implementations in hardware. This design task ismade a little easier because the cipher only has to support the low transmissionspeeds of the constrained devices (10–100 kbit/s). Advances in mathematicsand hardware design could further improve existing implementations of Ellipticand Hyperelliptic curve cryptosystems. Promising new designs of asymmetriccryptosystems, such as Multivariate Quadratic schemes, could also lead to moreefficient solutions. Another important issue the hardware designs should takeinto account is tamper resistance and protection against side-channel attacks. Inmany scenarios, the nodes will be left unprotected (e.g., sensor nodes in publicbuildings, hostile environments, etc.). This means that we have to assume thatan adversary will be able to capture one or more nodes.
Radio Frequency Identification (RFID) tags are a rapidly emerging technologywith many applications. Today, they have already started to replace bar codesin the back end of large distribution centers. Other applications include incorpo-ration of personal medical information through RFID implants, and automaticdetection of traffic signs through RFID tags buried underneath the road surface.In many situations there is a risk when using these tags without taking the nec-essary precautions. In particular, the privacy of users carrying RFID tags is atrisk, falsified tags could lead to dangerous situations, etc. Due to the ultra-lowcosts of RFID tags, they are and will be even more constrained compared tosensor nodes. Providing security on these devices will require careful review ofthe risks involved, and the new designs of cryptographic primitives and protocols,specifically tailored to the realm of RFID tags.
We have shown that one-time signature schemes can be more efficient than El-liptic curve based cryptosystems. Our efficiency evaluations show that the maincost of using these schemes is due to the authentication mechanism of the one-

152 Chapter 7. Conclusions and Future Research
time public keys. Research on more efficient authentication mechanisms couldlead to further improvements of the efficiency advantage of these schemes.
Research should also be targeted at cooperation. We have shown that it is possi-ble to distribute the load of signing a message over multiple parties. Cooperationis a logical solution in networks with thousands of low power nodes. One exampleof cooperation that has received a large amount of attention is multi-hop rout-ing. Future research should investigate how cooperation could be used for otherdemanding tasks. In particular in sensor networks, where all nodes are ownedby the same entity, cooperation is a viable solution. In other networks, wheredifferent nodes are owned by different users, cooperation becomes more difficultbecause of trust issues involved. For these networks, future research will indicatewhether the additional effort to resolve these trust issues does not surpass theadvantage of the cooperation.
As wireless networks evolve from isolated ad hoc networks towards true ubiq-uitous computing, privacy issues will become very important. Today, researchshould already be targeted at envisioning scenarios of these future networks andthe privacy risks they present. Once these risks are well known, research shouldbe targeted at resolving them. Digital credentials are a particularly promisingtechnology that could resolve many privacy related issues. Therefore, future re-search should be targeted at efficient implementations of credential systems andlight-weight protocols built on top of them.
In the near future, multi-hop ad hoc networks could be used to create urban meshnetworks and car to car networks. These networks will be used to offer manydifferent services to the users by different operators. Today, a mobile phoneuser pays his operator, and additional services are charged on top of the normalphone bill. In the future, probably there will be different operators and serviceproviders, and a user will be able to use any of the services offered by them,using the same device and Subscriber Identity Module (SIM) card. Not only willthis require new solutions to protect the user’s privacy, but also new solutionsto offer payment mechanisms to the service providers. Maybe the demand foranonymous payment mechanisms will inspire new research towards digital cashsystems. Transparent switching between mobile operators might also lead to therequirement of a PKI for mobile communications. Without this PKI, mobileoperators would be forced to share the keys stored in the SIM cards with thirdparties (i.e., other mobile operators and service providers); this is something thatis not likely to happen.

Bibliography
[1] M. Abdalla, M. Bellare, and P. Rogaway, “The oracle Diffie-Hellman as-sumptions and an analysis of DHIES,” in Topics in Cryptology – RSAConference Cryptographers’ Track (RSA-CT 2001), vol. 2020 of LectureNotes in Computer Science, pp. 143–158, Springer-Verlag, 2001.
[2] G. Anastasi, A. Falchi, A. Passarella, M. Conti, and E. Gregori, “Perfor-mance measurements of motes sensor networks,” in Proceedings of the 7thInternational Symposium on Modeling Analysis and Simulation of Wirelessand Mobile Systems (MSWiM 2004), pp. 174–181, ACM Press, 2004.
[3] R. Anderson and M. Kuhn, “Tamper resistance–a cautionary note,” inProceedings of the 2nd USENIX Workshop on Electronic Commerce, pp. 1–11, USENIX Association, 1996.
[4] “Anonymity and Privacy in Electronic Services (APES), IWT/STWWProject.” 〈https://www.cosic.esat.kuleuven.ac.be/apes/〉.
[5] D. Balfanz, G. Durfee, N. Shankar, D. K. Smetters, J. Staddon, and H. C.Wong, “Secret handshakes from pairing-based key agreements,” in Proceed-ings of the 2003 IEEE Symposium on Security and Privacy, pp. 180–196,IEEE, 2003.
[6] P. S. L. M. Barreto, H. Y. Kim, B. Lynn, and M. Scott, “Efficient al-gorithms for pairing-based cryptosystems,” in Advances in Cryptology -CRYPTO 2002, vol. 2442 of Lecture Notes in Computer Science, pp. 354–368, Springer-Verlag, 2002.
[7] D. J. Barrett, R. E. Silverman, and R. G. Byrnes, SSH, The Secure Shell:The Definitive Guide, Second Edition. O’Reilly, 2005.
[8] L. Batina, J. Lano, N. Mentens, B. Preneel, I. Verbauwhede, and S. B. Ors,“Energy, performance, area versus security trade-offs for stream ciphers,”in ECRYPT Workshops – The State of the Art of Stream Ciphers (SASC2004), pp. 302–310, 2004.
[9] M. Bellare and P. Rogaway, “Random oracles are practical: A paradigm for
153

154 Bibliography
designing efficient protocols,” in Proceedings of the 1th ACM Conferenceon Computer and Communications Security (CCS 1993), pp. 62–73, ACMPress, 1993.
[10] M. Bellare and P. Rogaway, “Optimal asymmetric encryption,” in Advancesin Cryptology - EUROCRYPT 1994, vol. 950 of Lecture Notes in ComputerScience, pp. 92–111, Springer-Verlag, 1995.
[11] M. Bellare and P. Rogaway, “The exact security of digital signatures:How to sign with RSA and Rabin,” in Advances in Cryptology - EURO-CRYPT 1996, vol. 1070 of Lecture Notes in Computer Science, pp. 399–414,Springer-Verlag, 1996.
[12] M. Bellare and C. Namprempre, “Authenticated encryption: Relationsamong notions and analysis of the generic composition paradigm,” in Ad-vances in Cryptology - ASIACRYPT 2000, vol. 1976 of Lecture Notes inComputer Science, pp. 531–545, Springer-Verlag, 2000.
[13] M. Bellare, P. Rogaway, and D. Wagner, “The EAX mode of operation,”in Fast Software Encryption (FSE 2004), vol. 3017 of Lecture Notes inComputer Science, pp. 389–407, Springer-Verlag, 2004.
[14] F. Bennett, D. Clarke, J. B. Evans, A. Hopper, A. Jones, and D. Leask,“Piconet: embedded mobile networking,” IEEE Personal Communications,vol. 4, no. 5, pp. 8–15, 1997.
[15] K. Bennett and C. Grothoff, “GAP – practical anonymous networking,” inPrivacy Enhancing Technologies (PET 2003), vol. 2760 of Lecture Notes inComputer Science, pp. 141–160, Springer-Verlag, 2003.
[16] O. Berthold, H. Federrath, and S. Kopsell, “Web MIXes: A system foranonymous and unobservable internet access,” in Designing Privacy En-hancing Technologies, International Workshop on Design Issues in Anony-mity and Unobservability, vol. 2009 of Lecture Notes in Computer Science,pp. 115–129, Springer-Verlag, 2001.
[17] J. Blair, Burning Down My Masters’ House: My Life at the New YorkTimes. New Millennium, 2004.
[18] I. F. Blake, G. Seroussi, and N. P. Smart, Elliptic Curves in Cryptography.Cambridge University Press, 1999.
[19] D. Bleichenbacher and U. M. Maurer, “Directed acyclic graphs, one-way functions and digital signatures,” in Advances in Cryptology -CRYPTO 1994, vol. 839 of Lecture Notes in Computer Science, pp. 75–82, Springer-Verlag, 1994.
[20] D. Bleichenbacher and U. M. Maurer, “On the efficiency of one-time digitalsignatures,” in Advances in Cryptology - ASIACRYPT 1996, vol. 1163 ofLecture Notes in Computer Science, pp. 145–158, Springer-Verlag, 1996.

Bibliography 155
[21] D. Bleichenbacher and U. Maurer, “Optimal tree-based one-time digitalsignature schemes,” in Proceedings of the 13th Annual Symposium on The-oretical Aspects of Computer Science (STACS ’96), vol. 1046 of LectureNotes in Computer Science, pp. 363–374, Springer-Verlag, 1996.
[22] R. Blom, “An optimal class of symmetric key generation systems,” in Ad-vances in Cryptology - EUROCRYPT 1984, vol. 209 of Lecture Notes inComputer Science, pp. 335–338, Springer-Verlag, 1985.
[23] D. Boneh and M. K. Franklin, “Identity-based encryption from the Weilpairing,” in Advances in Cryptology - CRYPTO 2001, vol. 2139 of LectureNotes in Computer Science, pp. 213–229, Springer-Verlag, 2001.
[24] N. Borisov, I. Goldberg, and D. Wagner, “Intercepting mobile commu-nications: The insecurity of 802.11,” in Proceedings of the 7th AnnualInternational Conference on Mobile Computing and Networking (MOBI-COM 2001), pp. 180–189, ACM Press, 2001.
[25] J. N. E. Bos and D. Chaum, “Provably unforgeable signatures,” in Advancesin Cryptology - CRYPTO 1992, vol. 740 of Lecture Notes in ComputerScience, pp. 1–14, Springer-Verlag, 1993.
[26] A. Boukerche, K. El-Khatib, L. Xu, and L. Korba, “A novel solution forachieving anonymity in wireless ad hoc networks,” in Proceedings of the 1stACM International Workshop on Performance Evaluation of Wireless Adhoc, Sensor, and Ubiquitous Networks, pp. 30–38, ACM Press, 2004.
[27] J. Broch, D. A. Maltz, D. B. Johnson, Y.-C. Hu, and J. G. Jetcheva,“A performance comparison of multi-hop wireless ad hoc network routingprotocols,” in Proceedings of the 4th Annual International Conference onMobile Computing and Networking (MOBICOM 1998), pp. 85–97, ACMPress, 1998.
[28] M. Brown, D. Cheung, D. Hankerson, J. Hernandez, M. Kirkup, andA. Menezes, “PGP in constrained wireless devices,” in Proceedings of the9th USENIX Security Symposium, pp. 247–261, USENIX Association, 2000.
[29] Z. Brown, “Cebolla: Pragmatic IP anonymity,” in Proceedings of the 2002Ottawa Linux Symposium, 2002.
[30] S. Buchegger and J.-Y. Le Boudec, “Nodes bearing grudges: Towards rout-ing security, fairness, and robustness in mobile ad hoc networks,” in Pro-ceedings of 10th Euromicro Workshop on Parallel, Distributed and Network-Based Processing (PDP 2002), pp. 403–410, IEEE, 2002.
[31] S. Buchegger and J.-Y. Le Boudec, “The effect of rumor spreading in rep-utation systems for mobile ad-hoc networks,” in Proceedings of Modelingand Optimization in Mobile, Ad Hoc and Wireless Networks (WiOpt 2003),2003.

156 Bibliography
[32] S. Buchegger and J.-Y. Le Boudec, “Performance analysis of the CON-FIDANT protocol (cooperation of nodes–fairness in dynamic ad-hoc net-works),” in Proceedings of the 3rd ACM Interational Symposium on MobileAd Hoc Networking and Computing (MOBIHOC 2002), pp. 226–236, ACMPress, 2002.
[33] L. Buttyan and J.-P. Hubaux, “Nuglets: A virtual currency to stimulatecooperation in self-organized mobile ad hoc networks,” Technical ReportDSC/2001/001, Department of Communication Systems, Swiss Federal In-stitute of Technology, 2001.
[34] L. Buttyan and J.-P. Hubaux, “Stimulating cooperation in self-organizingmobile ad hoc networks,” Mobile Networks and Applications, vol. 8, no. 5,pp. 579–592, 2003.
[35] D. W. Carman, P. S. Kruus, and B. J. Matt, “Constraints and approachesfor distributed sensor network security (draft),” technical report #00-010,NAI Labs, 2000.
[36] D. W. Carman, B. J. Matt, and G. H. Cirincione, “Energy-efficient andlow-latency key management for sensor networks,” in Proceedings of the23rd Army Science Conference (ASC 2002), 2002.
[37] H. Chan, A. Perrig, and D. Song, “Random key predistribution schemes forsensor networks,” in Proceedings of the 2003 IEEE Symposium on Securityand Privacy, pp. 197–213, IEEE, 2003.
[38] D. L. Chaum, “Untraceable electronic mail, return addresses, and digitalpseudonyms,” Communications of the ACM, vol. 24, no. 2, pp. 84–88, 1981.
[39] L. Chen, D. Gollman, and C. J. Mitchell, “Key escrow in mutually mis-trusting domains,” in Proceedings of the International Security ProtocolsWorkshop 1996, vol. 1189 of Lecture Notes in Computer Science, pp. 139–153, 1997.
[40] J. Claessens, C. Dıaz, S. Nikova, V. Naessens, B. de Win, C. Goemans,S. Seys, M. Loncke, J. Dumortier, B. De Decker, and B. Preneel, “Tech-nologies for controlled anonymity,” Anonymity and Privacy in ElectronicServices (APES), Deliverable 10, IWT/STWW, 2003.
[41] W. Dai, “Pipenet 1.1,” 1996.[42] H. Deng, A. Mukherjee, and D. P. Agrawal, “Threshold and identity-based
key management and authentication for wireless ad hoc networks,” in Pro-ceedings of the IEEE International Conference on Information Technology:Coding and Computing (ITCC 2004), vol. 1, pp. 107–111, IEEE, 2004.
[43] Y. Desmedt, “Society and group oriented cryptography: a new concept,”in Advances in Cryptology - CRYPTO 1987, vol. 293 of Lecture Notes inComputer Science, pp. 120–127, 1988.

Bibliography 157
[44] Y. Desmedt and Y. Frankel, “Threshold cryptosystems,” in Advances inCryptology - CRYPTO 1989, vol. 435 of Lecture Notes in Computer Science,pp. 307–315, 1990.
[45] Y. Desmedt and S. Jajodia, “Redistributing secret shares to new accessstructures and its applications,” Technical Report ISSE TR-97-01, GeorgeMason University, 1997.
[46] C. Dıaz, V. Naessens, S. Nikova, B. D. Decker, and B. Preneel, “Toolsfor technologies and applications of controlled anonymity,” Anonymity andPrivacy in Electronic Services (APES), Deliverable 11, IWT/STWW, 2004.
[47] C. Dıaz and B. Preneel, “Taxonomy of mixes and dummy traffic,” in Work-ing Conference on Privacy and Anonymity in Networked and DistributedSystems, pp. 215–230, Kluwer Academic Publishers, 2004.
[48] C. Dıaz, J. Claessens, S. Seys, and B. Preneel, “Information theory andanonymity,” in Proceedings of the 23rd Symposium on Information Theoryin the Benelux, pp. 179–186, 2002.
[49] C. Dıaz and A. Serjantov, “Generalising mixes,” in Privacy EnhancingTechnologies (PET 2003), vol. 2760 of Lecture Notes in Computer Science,pp. 18–31, Springer-Verlag, 2003.
[50] C. Dıaz, S. Seys, J. Claessens, and B. Preneel, “Towards measuring anony-mity,” in Privacy Enhancing Technologies (PET 2002), vol. 2482 of LectureNotes in Computer Science, pp. 54–68, Springer-Verlag, 2003.
[51] C. Dıaz, S. Seys, B. de Win, V. Naessens, C. Goemans, J. Claessens, B. DeDecker, J. Dumortier, and B. Preneel, “Technologies overview,” Anonymityand Privacy in Electronic Services (APES), Deliverable 3, IWT/STWW,2001.
[52] W. Diffie and M. Hellman, “Multiuser cryptographic techniques,” in Pro-ceedings of AFIPS 1976 NCC, pp. 109–112, AFIPS Press, 1976.
[53] W. Diffie and M. Hellman, “New directions in cryptography,” IEEE Trans-actions on Information Theory, vol. 22, no. 6, pp. 644–654, 1976.
[54] R. Dingledine, N. Mathewson, and P. Syverson, “Tor: The second-generation onion router,” in Proceedings of the 13th USENIX Security Sym-posium, pp. 303–320, USENIX Association, 2004.
[55] H. Dobbertin, A. Bosselaers, and B. Preneel, “RIPEMD-160: A strength-ened version of RIPEMD,” in Fast Software Encryption (FSE 1996),vol. 1039 of Lecture Notes in Computer Science, pp. 71–82, Springer-Verlag,1996.
[56] W. Du, J. Deng, Y. S. Han, P. K. Varshney, J. Katz, and A. Khalili, “Apairwise key pre-distribution scheme for wireless sensor networks,” ACM

158 Bibliography
Transactions on Information and System Security (TISSEC), vol. 8, no. 2,pp. 228–258, 2005.
[57] T. ElGamal, “A public key cryptosystem and signature scheme based ondiscrete logarithms,” IEEE Transactions on Information Theory, vol. 31,pp. 469–472, 1985.
[58] L. Eschenauer and V. D. Gligor, “A key-management scheme for distributedsensor networks,” in Proceedings of the 9th ACM Conference on Computerand Communications Security (CCS 2002), pp. 41–47, ACM Press, 2002.
[59] “European Union directive on privacy and electronic communications (Di-rective 2002/58/EC),” 2002.
[60] S. Even, O. Goldreich, and S. Micali, “On-line/off-line digital signatures,”in Advances in Cryptology - CRYPTO 1989, vol. 435 of Lecture Notes inComputer Science, pp. 263–275, Springer-Verlag, 1990.
[61] P. Feldman, “A practical scheme for non-interactive verifiable secret shar-ing,” in Proceedings of the 28th IEEE Symposium on the Foundations ofComputer Science, pp. 427–437, IEEE, 1987.
[62] M. Finkelstein, H. G. Tucker, and J. A. Veeh, “Confidence intervals forthe number of unseen types,” Statistics and Probability Letters, vol. 37,pp. 423–430, 1998.
[63] S. Fluhrer, I. Mantin, and A. Shamir, “Weaknesses in the key schedulingalgorithm of RC4,” in Proceeding of the 8th International Annual Workshopon Selected Areas in Cryptography (SAC 2001), vol. 2259 of Lecture Notesin Computer Science, pp. 1–24, Springer-Verlag, 2001.
[64] M. J. Freedman and R. Morris, “Tarzan: A peer-to-peer anonymizing net-work layer,” in Proceedings of the 9th ACM Conference on Computer andCommunications Security (CCS 2002), pp. 193–206, ACM Press, 2002.
[65] S. Goel, M. Robson, M. Polte, and E. G. Sirer, “Herbivore: A scalableand efficient protocol for anonymous communication,” Technical Report2003-1890, Cornell University, Ithaca, NY, USA, 2003.
[66] I. Goldberg, A Pseudonymous Communications Infrastructure for the In-ternet. PhD thesis, University of California at Berkeley, 2000.
[67] D. M. Goldschlag, M. G. Reed, and P. F. Syverson, “Hiding routing infor-mation,” in Information Hiding (IH 1996), vol. 1174 of Lecture Notes inComputer Science, pp. 137–150, Springer-Verlag, 1996.
[68] N. Gura, A. Patel, and A. Wander, “Comparing elliptic curve cryptogra-phy and RSA on 8-bit CPUs,” in Cryptographic Hardware and EmbeddedSystems (CHES 2004), vol. 3156 of Lecture Notes in Computer Science,pp. 119–132, 2004.

Bibliography 159
[69] A. Herzberg, M. Jakobsson, S. Jarecki, H. Krawczyk, and M. Yung, “Proac-tive public key and signature systems,” in Proceedings of the 4th ACM Con-ference on Computer and Communications Security (CCS 1997), pp. 100–110, ACM Press, 1997.
[70] A. Herzberg, S. Jarecki, H. Krawczyk, and M. Yung, “Proactive secretsharing or: How to cope with perpetual leakage,” in Advances in Cryptology- CRYPTO 1995, vol. 963 of Lecture Notes in Computer Science, pp. 457–469, Springer-Verlag, 1995.
[71] Y.-C. Hu, D. B. Johnson, and A. Perrig, “SEAD: Secure efficient distancevector routing for mobile wireless ad hoc networks,” in Proceedings of the4th IEEE Workshop on Mobile Computing Systems and Applications (WM-CSA 2002), pp. 3–13, IEEE, 2001.
[72] Y.-C. Hu, A. Perrig, and D. B. Johnson, “Wormhole detection in wirelessad hoc networks,” Technical Report TR01-384, Department of ComputerScience, Rice University, 2001.
[73] Y.-C. Hu, A. Perrig, and D. B. Johnson, “Ariadne: A secure on-demandrouting protocol for ad hoc networks,” in Proceedings of the 8th AnnualInternational Conference on Mobile Computing and Networking (MOBI-COM 2002), pp. 12–23, ACM Press, 2002.
[74] Y.-C. Hu, A. Perrig, and D. B. Johnson, “Packet leashes: A defense againstwormhole attacks in wireless networks,” in Proceedings of the 22nd AnnualJoint Conference of the IEEE Computer and Communications Societies(INFOCOM 2003), pp. 1976–1986, IEEE, 2003.
[75] J.-P. Hubaux, L. Buttyan, and S. Capkun, “The quest for security in mobilead hoc networks,” in Proceedings of the 2nd ACM Interational Symposiumon Mobile Ad Hoc Networking and Computing (MOBIHOC 2001), pp. 146–155, ACM Press, 2001.
[76] M.-S. Hwang and T.-Y. Chang, “Threshold signatures: Current statusand key issues,” International Journal of Network Security, vol. 1, no. 3,pp. 123–137, 2005.
[77] T. Ichikawa, T. Kasuya, and M. Matsui, “Hardware evaluation of the AESfinalists,” in Proceedings of the third AES Candidate Conference, 2000.
[78] K. Itakura and K. Nakamura, “A public-key cryptosystem suitable for dig-ital multisignatures,” NEC Research and Development, vol. 71, pp. 1–8,1983.
[79] M. Jakobsson, J.-P. Hubaux, and L. Buttyan, “A micro-payment schemeencouraging collaboration in multi-hop cellular networks,” in FinancialCryptography (FC 2003), vol. 2742 of Lecture Notes in Computer Science,pp. 15–33, Springer-Verlag, 2003.

160 Bibliography
[80] M. Jakobsson, T. Leighton, S. Micali, and M. Szydlo, “Fractal Merkle treerepresentation and traversal,” in Topics in Cryptology – RSA ConferenceCryptographers’ Track (RSA-CT 2003), vol. 2612 of Lecture Notes in Com-puter Science, pp. 314–326, Springer-Verlag, 2003.
[81] M. Jakobsson and D. Pointcheval, “Mutual authentication for low-powermobile devices,” in Financial Cryptography (FC 2001), vol. 2339 of LectureNotes in Computer Science, pp. 178–195, Springer-Verlag, 2001.
[82] M. Jakobsson and S. Wetzel, “Security weaknesses in Bluetooth,” in Topicsin Cryptology – RSA Conference Cryptographers’ Track (RSA-CT 2001),vol. 2020 of Lecture Notes in Computer Science, pp. 176–191, Springer-Verlag, 2001.
[83] “JAP – anonymity & privacy.” 〈http://anon.inf.tu-dresden.de/〉.[84] S. Jiang, N. Vaidya, and W. Zhao, “A mix route algorithm for mix-net
in wireless ad hoc networks,” in Proceedings of the 1st IEEE InternationalConference on Mobile Ad-hoc and Sensor Systems (MASS 2004), pp. 406–415, IEEE, 2004.
[85] P. Johansson, T. Larsson, N. Hedman, B. Mielczarek, and M. Degermark,“Scenario-based performance analysis of routing protocols for mobile ad-hoc networks,” in Proceedings of the 5th Annual International Conferenceon Mobile Computing and Networking (MOBICOM 1999), pp. 195–206,ACM Press, 1999.
[86] D. Johnson and A. Menezes, “The elliptic curve digital signature algo-rithm (ECDSA),” technical report CORR 99-34, Departement of Combi-natorics & Optimizations, University of Waterloo, Canada, 1999. Updated:2000/02/24.
[87] D. B. Johnson, “Routing in ad hoc networks of mobile hosts,” in Proceedingsof the 1th IEEE Workshop on Mobile Computing Systems and Applications(WMCSA 1994), pp. 158–163, IEEE, 1994.
[88] D. B. Johnson and D. A. Maltz, “Dynamic source routing in ad hoc wirelessnetworks,” in Mobile Computing, vol. 353 of The Kluwer International Se-ries in Engineering and Computer Science, pp. 153–181, Kluwer AcademicPublishers, 1996.
[89] D. B. Johnson, D. A. Maltz, and Y.-C. Hu, “The dynamic source routingprotocol for mobile ad hoc networks (DSR),” Internet Draft, IETF MANETWorking Group, 2004. draft-ietf-manet-dsr-10.txt, work in progress.
[90] J. M. Kahn, R. H. Katz, and K. S. J. Pister, “Next century challenges:Mobile networking for ‘smart dust’,” in Proceedings of the 5th AnnualInternational Conference on Mobile Computing and Networking (MOBI-COM 1999), pp. 483–492, ACM Press, 1999.

Bibliography 161
[91] C. Karlof and D. Wagner, “Secure routing in sensor networks: Attacks andcountermeasures,” in Proceedings of the 1st IEEE International Workshopon Sensor Network Protocols and Applications, pp. 113–127, IEEE, 2003.
[92] D. Kesdogan, J. Egner, and R. Buschkes, “Stop-and-go MIXes: Provid-ing probabilistic anonymity in an open system,” in Information Hiding(IH 1998), vol. 1525 of Lecture Notes in Computer Science, pp. 83–98,Springer-Verlag, 1998.
[93] A. Khalili, J. Katz, and W. A. Arbaugh, “Toward secure key distribution intruly ad-hoc networks,” in Proceedings of the 2003 Symposium on Applica-tions and the Internet Workshops (SAINT 2003 Workshops), pp. 342–346,IEEE, 2003.
[94] P. Kitsos, G. Kostopoulos, N. Sklavos, and O. Koufopavlou, “Hardwareimplementation of the RC4 stream cipher,” in Proceedings of the 46th IEEEMidwest Symposium on Circuits & Systems, pp. 27–30, 2003.
[95] L. Kohnfelder, “Towards a practical public-key cryptosystem,” Master’sthesis, Massachusetts Institute of Technology, MA, USA, 1978.
[96] J. Kong and X. Hong, “ANODR: anonymous on demand routing with un-traceable routes for mobile ad-hoc networks,” in Proceedings of the 4thACM International Symposium on Mobile Ad hoc Networking and Com-puting (MOBIHOC 2003), pp. 291–302, ACM Press, 2003.
[97] H. Kuo and I. Verbauwhede, “Architectural optimization for a1.82 Gbits/sec VLSI implementation of the AES Rijndael algorithm,” inCryptographic Hardware and Embedded Systems (CHES 2001), vol. 2162 ofLecture Notes in Computer Science, pp. 51–64, Springer-Verlag, 2001.
[98] L. Lamport, “Constructing digital signatures from a one-way function,”Technical Report CSL-98, SRI International, 1979.
[99] A. K. Lenstra and E. R. Verheul, “Selecting cryptographic key sizes,” Jour-nal of Cryptology, vol. 14, no. 4, pp. 255–293, 2001.
[100] C. M. Li, T. Hwang, and N. Y. Lee, “Threshold-multisignature schemeswhere suspected forgery implies traceability of adversarial shareholders,”in Advances in Cryptology - EUROCRYPT 1994, vol. 950 of Lecture Notesin Computer Science, pp. 194–204, 1995.
[101] S. Lin and D. J. Costello, Jr., Error Control Coding: Fundamentals andApplications. Prentice Hall, 1983.
[102] R. J. Lipton and R. Ostrovsky, “Micro-payments via efficient coin-flipping,”in Financial Cryptography (FC 1998), vol. 1465 of Lecture Notes in Com-puter Science, pp. 1–15, Springer-Verlag, 1998.
[103] D. A. Maltz, J. Broch, J. G. Jetcheva, and D. B. Johnson, “The effectsof on-demand behavior in routing protocols for multi-hop wireless ad hoc

162 Bibliography
networks,” IEEE Journal on Selected Areas in Communications, vol. 17,no. 8, pp. 1439–1453, 1999.
[104] W. Mao, Modern Cryptography – Theory & Practice. Prentice Hall PTR,2004.
[105] S. Marti, T. Giuli, K. Lai, and M. Baker, “Mitigating routing misbehaviorin ad hoc networks,” in Proceedings of the 6th Annual International Con-ference on Mobile Computing and Networking (MOBICOM 2000), pp. 255–265, ACM Press, 2000.
[106] D. A. McGrew and A. T. Sherman, “Key establishment in large dynamicgroups using one-way function trees,” Technical Report 755, TIS Labs atNetwork Associates, Glenwood, MD, USA, 1998.
[107] A. J. Menezes, P. C. van Oorschot, and S. A. Vanstone, Handbook of AppliedCryptography. CRC Press, 1997.
[108] R. C. Merkle, Secrecy, Authentication and Public Key Systems. UMI Re-search Press, 1982.
[109] R. C. Merkle, “A digital signature based on a conventional encryptionfunction,” in Advances in Cryptology - CRYPTO 1987, vol. 293 of LectureNotes in Computer Science, pp. 369–378, Springer-Verlag, 1987.
[110] R. C. Merkle, “A certified digital signature,” in Advances in Cryptology -CRYPTO 1989, vol. 435 of Lecture Notes in Computer Science, pp. 218–238, Springer-Verlag, 1990.
[111] S. Micali, K. Ohta, and L. Reyzin, “Accountable-subgroup multisigna-tures,” in Proceedings of the 8th ACM Conference on Computer and Com-munications Security (CCS 2001), pp. 245–254, ACM Press, 2001.
[112] S. Micali and R. L. Rivest, “Micropayments revisited,” in Topics in Cryp-tology – RSA Conference Cryptographers’ Track (RSA-CT 2002), vol. 2271of Lecture Notes in Computer Science, pp. 149–163, Springer-Verlag, 2002.
[113] P. Michiardi and R. Molva, “Core: a collaborative reputation mechanismto enforce node cooperation in mobile ad hoc networks,” in Proceedingsof the 6th Joint Working Conference on Communications and MultimediaSecurity, vol. 228 of IFIP Conference Proceedings, pp. 107–121, Kluwer,2002.
[114] U. Moller, L. Cottrell, P. Palfrader, and L. Sassaman, “Mixmaster protocol– version 2,” Internet Draft, Internet Engineering Task Force, 2004.
[115] “MUGI pseudorandom number generator,” Self-evaluation Report 1.1, Hi-tachi, Ltd., 2001.
[116] “MUGI pseudorandom number generator,” Specification 1.2, Hitachi, Ltd.,2001.

Bibliography 163
[117] P. Papadimitratos and Z. J. Haas, “Secure link state routing for mobilead hoc networks,” in 2003 Symposium on Applications and the InternetWorkshops (SAINT 2003 Workshops), pp. 379–383, IEEE, 2003.
[118] P. Papadimitratos and Z. J. Haas, “Secure routing for ad hoc networks,”in Communication Networks and Distributed Systems Modeling and Simu-lation Conference (CNDS ’02), SCS, 2002.
[119] V. D. Park and M. S. Corson, “A highly adaptive distributed routing al-gorithm for mobile wireless networks,” in Proceedings of the 16th AnnualJoint Conference of the IEEE Computer and Communications Societies(INFOCOM 1997), pp. 1405–1413, IEEE, 1997.
[120] T. Pedersen, “Non-interactive and information-theoretic secure verifiablesecret sharing,” in Advances in Cryptology - CRYPTO 1991, vol. 576 ofLecture Notes in Computer Science, pp. 129–140, Springer-Verlag, 1991.
[121] C. E. Perkins, Ad Hoc Networking. Addison-Wesley, 2001.[122] C. E. Perkins and E. M. Royer, “Ad hoc on-demand distance vector rout-
ing,” in Proceedings of the 2nd IEEE Workshop on Mobile Computing Sys-tems and Applications (WMCSA 1999), pp. 90–100, IEEE, 1999.
[123] C. E. Perkins, E. M. Royer, and S. Das, “Ad hoc on demand distance vector(AODV) routing,” IETF RFC 3561, Internet Engineering Task Force, 2003.
[124] A. Perrig, R. Szewczyk, V. Wen, D. Culler, and J. D. Tygar, “SPINS:Security protocols for sensor networks,” in Proceedings of the 7th AnnualInternational Conference on Mobile Computing and Networking (MOBI-COM 2001), pp. 189–199, ACM Press, 2001.
[125] A. Perrig, “The BiBa one-time signature and broadcast authentication pro-tocol,” in Proceedings of the 8th ACM Conference on Computer and Com-munications Security (CCS 2001), ACM Press, 2001.
[126] A. Perrig, R. Canetti, D. Song, and J. D. Tygar, “Efficient and securesource authentication for multicast,” in Proceedings of the Network andDistributed System Security Symposium (NDSS 2001), pp. 35–46, 2001.
[127] A. Perrig and J. D. Tygar, Secure Broadcast Communication in Wired andWireless Networks. Kluwer Academic Publishers, 2003.
[128] A. Pfitzmann and M. Hansen, “Anonymity, unlinkability, unobservability,pseudonymity, and identity management – A consolidated proposal for ter-minology,” 2005. Version 0.23. 〈http://dud.inf.tu-dresden.de/Anon_Terminology.shtml〉.
[129] A. Pfitzmann and M. Kohntopp, “Anonymity, unobserability andpseudonymity – A proposal for terminology,” in Designing Privacy Enhanc-ing Technologies, vol. 2009 of Lecture Notes in Computer Science, pp. 1–9,Springer-Verlag, 2001.

164 Bibliography
[130] J. Pieprzyk, T. Hardjono, and J. Seberry, Fundamentals of Computer Se-curity. Springer-Verlag, 2003.
[131] J. Pieprzyk, H. Wang, and C. Xing, “Multiple-time signature schemesagainst adaptive chosen message attacks.,” in Selected Areas in Cryptogra-phy (SAC 2003), vol. 3006 of Lecture Notes in Computer Science, pp. 88–100, Springer-Verlag, 2004.
[132] “PKCS #1 version 2.1: RSA cryptography standard,” Public-Key Crypto-graphy Standard 1, RSA Laboratories, 2002.
[133] N. R. Potlapally, S. Ravi, A. Raghunathan, and N. K. Jha, “Analyzingthe energy consumption of security protocols,” in Proceedings of the 2003International Symposium on Low Power Electronics and Design (ISLPED2003), pp. 30–35, 2003.
[134] B. Preneel, B. V. Rompay, S. B. Ors, A. Biryukov, L. Granboulan, E. Dot-tax, M. Dichtl, M. Schafheutle, P. Serf, S. Pyka, E. Biham, E. Barkan,O. Dunkelman, J. Stolin, M. Ciet, J.-J. Quisquater, F. Sica, H. Raddum,and M. Parker, “Performance of optimized implementations of the NESSIEprimitives,” Deliverable D21, NESSIE Project, 2002.
[135] J. M. Rabaey, J. Ammer, J. da Silva, D. Patel, and S. Roundy, “PicoRadiosupports ad hoc ultra-low power wireless networking,” IEEE ComputerMagazine, vol. 33, no. 7, pp. 42–48, 2000.
[136] M. O. Rabin, “Digitalized signatures,” Foundations of Secure Computation,pp. 155–168, 1978.
[137] M. O. Rabin, “Digitized signatures and public-key functions as intractibleas factorization,” Technical Report LCS/TR-212, MIT Laboratory forComputer Science, 1979.
[138] S. Rafaeli, L. Mathy, and D. Hutchison, “EHBT: An efficient protocolfor group key management,” in Proceedings of the Third InternationalCOST264 Workshop (NGC 2001), vol. 2233 of Lecture Notes in ComputerScience, pp. 159–171, Springer-Verlag, 2001.
[139] C. S. Raghavendra, K. M. Sivalingam, and T. Znati, eds., Wireless SensorNetworks. Kluwer Academic Publishers, 2004.
[140] M. G. Reed and P. F. S. en D. M. Goldschlag, “Anonymous connectionsand onion routing,” IEEE Journal on Selected Areas in Communications,Special Issue on Copyright and Privacy Protection, vol. 16, no. 4, pp. 482–494, 1998.
[141] M. K. Reiter and A. D. Rubin, “Crowds: Anonymity for Web Transac-tions,” ACM Transactions on Information and System Security (TISSEC),vol. 1, no. 1, pp. 66–92, 1998.

Bibliography 165
[142] M. Rennhard and B. Plattner, “Introducing MorphMix: Peer-to-peer basedanonymous internet usage with collusion detection,” in Proceedings of the2002 ACM workshop on Privacy in the Electronic Society (WPES 2002),pp. 91–102, ACM Press, 2002.
[143] M. Rennhard and B. Plattner, “Practical anonymity for the masses withmorphmix,” in Financial Cryptography (FC 2004), vol. 3110 of LectureNotes in Computer Science, pp. 223–250, Springer-Verlag, 2004.
[144] L. Reyzin and N. Reyzin, “Better than BiBa: Short one-time signatureswith fast signing and verifying,” in Proceedings of the 7th Australian Con-ference on Information Security and Privacy, vol. 2384 of Lecture Notes inComputer Science, pp. 144–153, Springer-Verlag, 2002.
[145] R. L. Rivest, “The RC4 encryption algorithm,” 1992.[146] R. L. Rivest and A. Shamir, “PayWord and MicroMint: Two simple mi-
cropayment schemes,” in Security Protocols Workshop, vol. 1189 of LectureNotes in Computer Science, pp. 69–87, Springer-Verlag, 1996.
[147] R. L. Rivest, A. Shamir, and L. M. Adleman, “A method for obtainingdigital signatures and public-key cryptosystems,” Communications of theACM, vol. 21, pp. 120–126, 1978.
[148] P. Rogaway, M. Bellare, and J. Black, “OCB: A block-cipher mode ofoperation for efficient authenticated encryption,” ACM Transactions onInformation and System Security (TISSEC), vol. 6, no. 3, pp. 365–403,2003.
[149] E. M. Royer and C. E. Perkins, “An implementation study of the AODVrouting protocol,” in Proceedings of the IEEE Wireless Communicationsand Networking Conference (WCNC 2000), pp. 1003–1008, IEEE, 2000.
[150] A. Satoh and S. Morioka, “Unified hardware architecture for 128-bit blockciphers AES and camellia,” in Cryptographic Hardware and EmbeddedSystems (CHES 2003), vol. 2779 of Lecture Notes in Computer Science,pp. 304–318, Springer-Verlag, 2003.
[151] “SEC 2: Recommended elliptic curve domain parameters,” Version 1.0,Standards for Efficient Cryptography Group, 2000.
[152] A. Serjantov, R. Dingledine, and P. Syverson, “From a trickle to a flood:Active attacks on several mix types,” in Information Hiding (IH 2002),vol. 2578 of Lecture Notes in Computer Science, pp. 36–52, Springer-Verlag,2002.
[153] S. Seys, C. Dıaz, B. de Win, V. Naessens, C. Goemans, J. Claessens,W. Moreau, B. De Decker, J. Dumortier, and B. Preneel, “Requirementstudy of different applications,” Anonymity and Privacy in Electronic Ser-vices (APES), Deliverable 2, IWT/STWW, 2001.

166 Bibliography
[154] S. Seys and B. Preneel, “Securing ad hoc networks: Master-slave-masterchains to prevent denial of service attacks,” Internal Report STS–0101,K.U.Leuven/SCD, 2001.
[155] S. Seys and B. Preneel, “Key establishment and authentication suite tocounter DoS attacks in distributed sensor networks,” Internal Report STS–0201, K.U.Leuven/SCD, 2002.
[156] S. Seys and B. Preneel, “Authenticated and efficient key management forwireless ad hoc networks,” in Proceedings of the 24th Symposium on Infor-mation Theory in the Benelux, pp. 195–202, 2003.
[157] S. Seys and B. Preneel, “ARM: Anonymous routing protocol for mobile adhoc networks,” in IEEE International Workshop on Pervasive Computingand Ad Hoc Communications (PCAC 2006), p. 6, IEEE, 2005.
[158] S. Seys and B. Preneel, “Efficient cooperative signatures: A novel authen-tication scheme for sensor networks,” in 2nd International Conference onSecurity in Pervasive Computing (SPC 2005), vol. 3450 of Lecture Notesin Computer Science, pp. 86–100, Springer-Verlag, 2005.
[159] S. Seys and B. Preneel, “Power consumption evaluation of efficient digitalsignature schemes for low power devices,” in IEEE International Confer-ence on Wireless and Mobile Computing, Networking and Communications(WIMOB 2005), pp. 79–86, IEEE, 2005.
[160] S. Seys and B. Preneel, “The wandering nodes: Key management for low-power mobile ad hoc networks,” in Proceedings of the 25th IEEE Interna-tional Conference on Distributed Computing Systems - Workshops (ICDCS2005 Workshops), pp. 916–922, IEEE, 2005.
[161] A. Shamir, “How to share a secret,” Communications of the ACM, vol. 22,pp. 612–613, 1979.
[162] C. E. Shannon, “A mathematical theory of communication,” Bell SystemTechnical Journal, vol. 27, pp. 379–423, 1948. Reprinted with corrections.
[163] R. Sherwood, B. Bhattacharjee, and A. Srinivasan, “P 5: A protocol forscalable anonymous communication,” in Proceedings of the 2002 IEEESymposium on Security and Privacy, pp. 839–876, IEEE, 2002.
[164] C. Shields and B. N. Levine, “A protocol for anonymous communicationover the Internet,” in Proceedings of the 7th ACM Conference on Computerand Communications Security (CCS 2000), pp. 33–42, ACM Press, 2000.
[165] V. Shoup, “Practical threshold signatures,” in Advances in Cryptology- EUROCRYPT 2000, vol. 1870 of Lecture Notes in Computer Science,pp. 207–220, 2000.
[166] V. Shoup, “A proposal for an ISO standard for public key encryption,”Version 2.1, IBM Zurich research lab, 2001.

Bibliography 167
[167] B. R. Smith, S. Murthy, and J. J. Garcia-Luna-Aceves, “Securing distance-vector routing protocols,” in Proceedings of the 1997 Symposium on Net-work and Distributed System Security, pp. 85–92, IEEE, 1997.
[168] F. Stajano, “The resurrecting duckling – what next?,” in Proceedings ofthe 8th International Workshop on Security Protocols, vol. 2133 of LectureNotes in Computer Science, pp. 204–214, Springer-Verlag, 2000.
[169] F. Stajano and R. Anderson, “The resurrecting duckling: Security issues inad-hoc wireless networks,” in Proceedings of the 7th International Workshopon Security Protocols, vol. 1796 of Lecture Notes in Computer Science,pp. 172–194, Springer-Verlag, 1999.
[170] A. Stubblefield, J. Ioannidis, and A. D. Rubin, “Using the Fluhrer, Mantinand Shamir attack to break WEP,” Technical Report TD-4ZCPZZ (Revi-sion 2), AT&T Labs, 2001.
[171] R. Szewczyk and A. Ferencz, “Power evaluation of smartdust remote sen-sors,” CS252 project report, Berkeley Wireless Research Center, 2000.
[172] M. Szydlo, “Merkle tree traversal in log space and time,” in Advances inCryptology - EUROCRYPT 2004, vol. 3027 of Lecture Notes in ComputerScience, pp. 541–554, Springer-Verlag, 2004.
[173] “Tor: An anonymous internet communication system.” 〈http://tor.eff.org/〉.
[174] University of California, “Wireless integrated network sensors (WINS).”〈http://www.janet.ucla.edu/WINS/〉.
[175] S. Vaudenay, “One-time identification with low memory,” in Proceedings ofEUROCODE 1992, no. 339 in CISM Courses and Lectures, pp. 217–228,Springer-Verlag, 1992.
[176] I. Verbauwhede, A. Hodjat, D. Hwang, and B.-C. Lai, “Security for ambientintelligent systems,” in Ambient Intelligence, pp. 199–221, Springer-Verlag,2003.
[177] C. T. Wang, C. C. Chang, and C. H. Lin, “Generalization of thresholdsignature and authenticated encryption for group communications,” IEICETransactions on Fundamentals, vol. E83-A, no. 6, pp. 1228–1237, 2000.
[178] D. Watanabe, S. Furuya, K. Takaragi, H. Yoshida, and B. Preneel, “Anew keystream generator MUGI,” in Fast Software Encryption (FSE 2002),vol. 2365 of Lecture Notes in Computer Science, pp. 179–194, Springer-Verlag, 2002.
[179] D. Whiting, R. Housley, and N. Ferguson, “Counter with CBC-MAC(CCM),” IETF RFC 3610, Internet Engineering Task Force, 2003.
[180] M. J. Wiener, “Performance comparison of public-key cryptosystems,” RSALaboratories’ CryptoBytes, vol. 4, no. 1, pp. 1+3–5, 1998.

168 Bibliography
[181] S. G. Wilson, Digital Modulation and Coding. Prentice Hall, 1996.[182] C. Wolf, Multivariate Quadratic Polynomials in Public Key Cryptography.
PhD thesis, Katholieke Universiteit Leuven, 2005.[183] Y. Zhang, W. Liu, and W. Lou, “Anonymous communications in mobile ad
hoc networks,” in Proceedings of the 24th Annual Joint Conference of theIEEE Computer and Communications Societies (INFOCOM 2005), vol. 3,pp. 1940–1951, IEEE, 2005.
[184] S. Zhong, J. Chen, and Y. R. Yang, “Sprite: A simple, cheat-proof, credit-based system for mobile ad-hoc networks,” in Proceedings of the 22nd An-nual Joint Conference of the IEEE Computer and Communications Soci-eties (INFOCOM 2003), pp. 1987–1997, 2003.
[185] L. Zhou and Z. Haas, “Securing ad hoc networks,” IEEE Network Magazine– Special Issue on Network Security, vol. 13, no. 6, pp. 24–30, 1999.
[186] B. Zhu, Z. Wan, M. S. Kankanhalli, F. Bao, and R. H. Deng, “Anony-mous secure routing in mobile ad-hoc networks,” in Proceedings of the29th Annual IEEE International Conference on Local Computer Networks(LCN 2004), pp. 102–108, IEEE, 2004.
[187] P. Zimmermann, The Official PGP User’s Guide. MIT Press, 1995.

Index
A5/1, 18adversary
external global passive, 114internal local active, 115model, 112
AES, 15ANODR, 121anonymity, 112AODV, 119ARM, 130ASR, 124authentication path, 48
generation, 48, 53
block cipher, 13Bluetooth, 18
certificate, 20Certification Authority, 21collision resistance, 14
partial, 76cooperative one-time signatures, 75–
81Crowds, 118
DHIES, 27digital signature scheme, 20DSA, 25, 29DSN, see sensor networkDSR, 95, 119
authenticated (AuthDSR), 95
E0, 18
ECDSA, 27, 29ECIES, 27, 29EHBT, 101elliptic curves, 27encryption scheme, 12existential forgery, 23
forgeability, 72
group key management, 92, 101GSM, 18
hash function, 14Hordes, 118HORS, 39, 46, 56, 60
identity, 111incentives, 7
JAP, 117
key pre-distribution, 4, 91
Lamport-Diffie signature, 36LDM, 37, 38, 45, 53, 58
threshold scheme, 73LDW, 37, 45, 55, 59
multi-signer scheme, 74
MAC, see Message AuthenticationCode
MANET, 1MASK, 126Merkle (improvement), see LDM
169

170 Index
Merkle tree, 47, 52Message Authentication Code, 12mix, 117
continuous mix, 117pool mix, 117
Mixmaster, 118MUGI, 18
neighborhood, 90
one-time signatures, 36one-way chains, 49, 57one-way function, 19, 43Onion Routing, 118
padding, 138privacy offered by, 143
pre-image resistance, 14proactive secret sharing, 73PSEC, 27public key cryptography, 19Public Key Infrastructure, 21
Rabin, 24, 29RC4, 18reputation scheme, 7RFID, 151Rijndael, see AESRIPEMD, 18robustness, 72, 77routing protocol, 119RSA, 22, 29
SDAR, 127second pre-image resistance, 14sensor network, 2, 81SHA, 18Shamir’s secret sharing, 73, 93stream cipher, 14symmetric primitives, 12
tamper resistance, 113threshold signature scheme, 72
time-to-live, 137privacy offered by, 139
Tor, 117TORA, 119traceability, 72, 79trapdoor identifier, 130TTL, see time-to-live
unlinkability, 112
verifiable secret sharing, 73
Winternitz, see LDW

List of Publications
Lecture Notes in Computer Science
1. C. Dıaz, S. Seys, J. Claessens and B. Preneel, “Towards measuring ano-nymity,” Proceedings of Privacy Enhancing Technologies, 2nd InternationalWorkshop, PET 2002, Lecture Notes in Computer Science 2482, R. Dingle-dine, P. F. Syverson, Eds., Springer-Verlag, pp. 54–68, 2003.
2. S. Seys and B. Preneel, “Efficient Cooperative Signatures: A Novel Authen-tication Scheme for Sensor Networks,” 2nd International Conference on Se-curity in Pervasive Computing, Lecture Notes in Computer Science 3450, D.Hutter, M. Ullmann, Eds., Springer-Verlag, pp. 86–100, 2005.
International Conferences
1. S. Seys and B. Preneel, “Power Consumption Evaluation of Efficient Digi-tal Signature Schemes for Low Power Devices,” IEEE International Confer-ence on Wireless and Mobile Computing, Networking and Communications(WIMOB 2005), IEEE, pp. 79–86, 2005.
2. S. Seys and B. Preneel, “The Wandering Nodes: Key Management for Low-power Mobile Ad Hoc Networks,” Proceedings of the 25th IEEE InternationalConference on Distributed Computing Systems - Workshops (ICDCS 2005Workshops), IEEE, pp. 916–922, 2005.
3. S. Seys and B. Preneel, “ARM: Anonymous Routing Protocol for MobileAd hoc Networks,” Proceedings of the 20th IEEE International Conferenceon Advanced Information Networking and Applications - Workshops (AINA2006 Workshops), IEEE, pp. 133–137, 2006.
Part or chapter of a book
1. S. Seys and B. Preneel, “Cryptologie,” Kluwer Handboek Security, Kluwer,pp. 89–138, 2002.
171

172 List of Publications
2. S. Seys, D. Singelee and B. Preneel, “Security in Wireless PAN Mesh Net-works,” Security in Wireless Mesh Networks, Auerbach Publications, CRCPress, 2006. [to be published]
Journals (national level)
1. S. Seys and B. Preneel, “Network Security: Fixed Networks,” Revue HFTijdschrift 2004(4), pp. 15–24, 2004.
2. S. Seys, D. Singelee and B. Preneel, “Wireless Network Security,” Revue HFTijdschrift 2004(4), pp. 25–35, 2004.
3. S. Seys, “Security Architecture for Wireless Ad hoc Networks,” Revue HFTijdschrift 2005(1), pp. 8–10, 2005.
National Conferences
1. C. Dıaz, J. Claessens, S. Seys and B. Preneel, “Information Theory and Ano-nymity,” Proceedings of the 23rd Symposium on Information Theory in theBenelux, B. Macq, J. Quisquater, Eds., Werkgemeenschap voor Informatie-en Communicatietheorie, pp. 179–186, 2002.
2. S. Seys and B. Preneel, “Authenticated and efficient key management forwireless ad hoc networks,” Proceedings of the 24th Symposium on Informa-tion Theory in the Benelux, Werkgemeenschap voor Informatie- en Commu-nicatietheorie, pp. 195–202, 2003.
3. S. Seys, “Security Architecture for Wireless Ad hoc Networks,” Proceedingsof the 12th URSI Forum 2004, M. Blondel, M. Wuilpart, Eds., pp. 10–12,2004.
Internal Reports
1. S. Seys and B. Preneel, “Securing Ad Hoc Networks: Master-Slave-MasterChains to Prevent Denial of Service Attacks.,” COSIC internal report, 15pages, 2001.
2. S. Seys, B. Preneel, “Key Establishment and Authentication Suite to CounterDoS Attacks in Distributed Sensor Networks,” COSIC internal report, 15pages, 2002.

Stefaan Seys was born on March 2, 1977 in Schoten, Belgium. He received thedegree of Master in Electrical Engineering (Burgerlijk Ingenieur Elektrotechniek)from the K.U.Leuven, Belgium, in July 2000. His Masters’ thesis dealt with thetopic of Quantum Computing. In August 2000, Stefaan started working in theresearch group COSIC (Computer Security and Industrial Cryptography) at theDepartment of Electrical Engineering (ESAT) of the K.U.Leuven. The first fouryears of his research were sponsored by a grant of the IWT (Institute for thePromotion of Innovation by Science and Technology in Flanders).
Related Documents











