CRAY XC30 System 利用者講習会 2015/06/15 1

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

CRAY XC30 System
利用者講習会
2015/06/15 1

演習事前準備
2
演習用プログラム一式が /work/Samples/workshop2015 下に置いてあります。 各自、/work下の作業ディレクトリへコピーしてください。

Agenda
13:30 - 13:45 ・Cray XC30 システム概要
ハードウェア、ソフトウェア
13:45 - 14:00 ・Cray XC30 システムのサイト構成
ハードウェア、ソフトウェア
14:00 - 14:10 <休憩>
14:10 - 14:50 ・XC30 プログラミング環境
・演習
14:50 - 15:00 <休憩>
15:00 - 15:10 ・MPIとは
15:10 - 15:50 ・簡単なMPIプログラム
・演習
15:50 - 16:00 <休憩>
16:00 - 16:20 ・主要なMPI関数の説明
・演習
16:20 - 16:50 ・コードの書換えによる最適化
・演習
16:50 - 17:00 ・さらに進んだ使い方を学ぶ為には
17:00 - 17:30 ・質疑応答
3

XK System
With GPU
CRAY System Roadmap (XT~XC30)
6/5/2015 6/5/2015
Cray XT4
(2006)
Cray XT Infrastructure
Cray XT3
“Red Storm”
(2005) Cray XT5h
(2007)
Cray XT5
(2007)
XMT is based on
XT3
infrastructure.
Cray XE6
(2010)
Cray XC30
(2012)
• XMT2: fall 2011
• larger memory
• higher bandwidth
• enhanced RAS
• new performance features 4

CRAY XC30 System構成(1)
System,
SDB
システムディスク
SMW 管理用端末
FCスイッチ
貴学Network 4x QDR Infiniband
8Gbps Fibre Channel
1GbE or 10GbE
ノード数 360ノード
(720CPU, 5760コア)
理論ピーク性能
119.8TFLOPS
総主記憶容量 22.5TB
フロントエンドサービスノード
(ログインノード)
二次記憶装置
磁気ディスク装置
システム管理ノード
5
2014/12/25以降 ノード数 360ノード
(720CPU, 8640コア)
理論ピーク性能 359.4TFLOPS
総主記憶容量 45TB

System構成 (計算ノード)
ノード数 :360ノード(720CPU,5760コア) 総理論演算性能 :119.8TFLOPS
主記憶容量 :22.5TB
ノード仕様
CPU :Intel Xeon E5-2670 2.6GHz 8core CPU数 :2 CPU理論演算性能 :166.4GFLOPS ノード理論演算性能 :332.8GFLOPS ノード主記憶容量 :64GB
(8GB DDR3-1600 ECC DIMM x8) ノードメモリバンド幅 :102.4GB/s
6
360ノード(720CPU,8640コア)
359.4TFLOPS
47TB
Intel Xeon E5-2690 V3 2.6GHz 12core
499.2GFLOPS
998.4GFLOPS
128GB
16 GB DDR4-2133 ECC DIMM x8
136.4GB/s
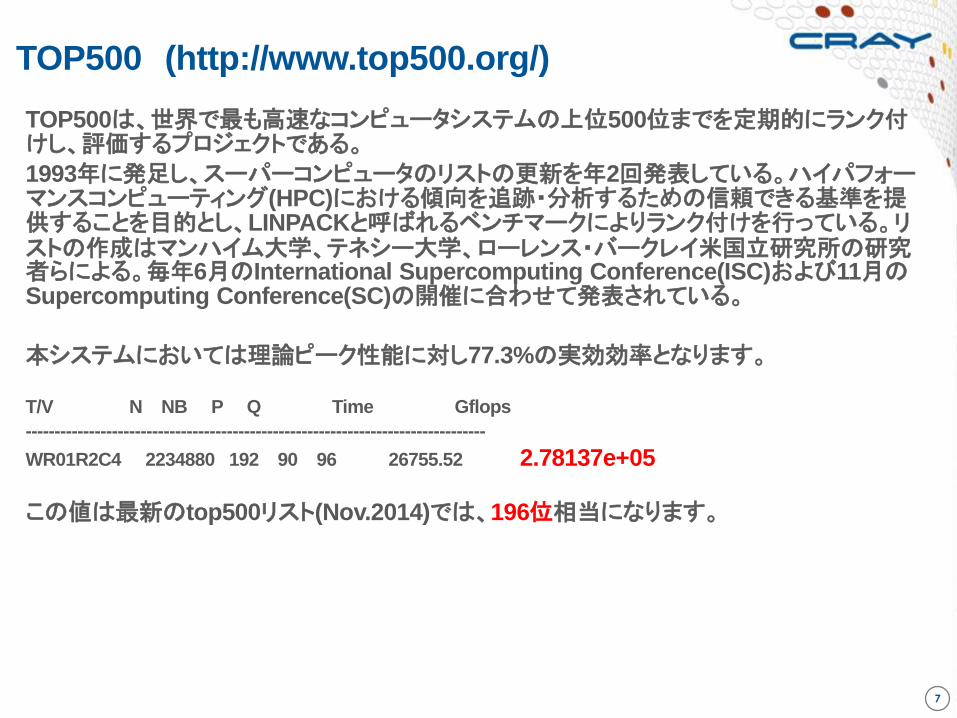
TOP500 (http://www.top500.org/)
7
TOP500は、世界で最も高速なコンピュータシステムの上位500位までを定期的にランク付けし、評価するプロジェクトである。
1993年に発足し、スーパーコンピュータのリストの更新を年2回発表している。ハイパフォーマンスコンピューティング(HPC)における傾向を追跡・分析するための信頼できる基準を提供することを目的とし、LINPACKと呼ばれるベンチマークによりランク付けを行っている。リストの作成はマンハイム大学、テネシー大学、ローレンス・バークレイ米国立研究所の研究者らによる。毎年6月のInternational Supercomputing Conference(ISC)および11月のSupercomputing Conference(SC)の開催に合わせて発表されている。
本システムにおいては理論ピーク性能に対し77.3%の実効効率となります。
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR01R2C4 2234880 192 90 96 26755.52 2.78137e+05
この値は最新のtop500リスト(Nov.2014)では、196位相当になります。

Cray XC30 System Cabinet
8

Cray XC30 Compute Cabinet
9

XC30 Chassis : Blower Cabinet
Blower Cabinet Exploded View Blower Assembly
Hot Swap Blower Assembly
N+1 configurations
Low pressure and velocity of air
Low noise (TN26-6 standard, 75 db/cabinet)
Blower Cabinet
10

Cray XC30システム 冷却
11

Cray XC30システムのパッケージング
1つのシャーシに16ブレードを搭載
合計64ノード(128 CPUソケット)を搭載
Aries間通信網はバックプレーン
1つのキャビネットに3シャーシ(192ノード)を搭載
Side-to-side冷却エアーフロー
前世代のCray XE6システムと比較して1.5倍のキャビネット幅で2倍のノード数を搭載
1つのブレードに4ノードを搭載
合計8つのCPUソケットを搭載
1つのAriesルータチップを搭載
ブレード構成
シャーシ構成
キャビネット構成
12

13

Cray XC30 Compute Blade (left side)
14

Cray XC30 IO Blade (left side)
15

Cray XC30計算ノードと高速ルータチップAries
16

Cray Network Evolution
SeaStar 25万コア対応のルーターチップ
高効率のルーティング、低コンテンション
Red Storm, Cray XT3/XT4/XT5/XT6システム
Gemini メッセージスループット100倍以上の改善
レイテンシ3倍以上の改善
PGAS, グローバルアドレッシング空間をサポート
スケーラビリティの改善100万コア以上
Cray XE6システム
Aries 高バンド幅、ホップ数低減、最大で10倍以上の改善
非常に効率の良いルーティングと低コンテンション
Electro-Optical シグナル
Cray XC30システム
17

Torus
Topology
Flattened Butterfly
Topology
All-to-All Links
Dragonfly Group
Encapsu
late
& A
dd
Glo
bal Lin
ks
階層型All-to-AllのDragonflyネットワークトポロジー
各端子間は直接接続
1シャーシー内で15通りのルーティングがあります
ホップカウント数は単一
グローバルな帯域幅を向上
トーラス・トポロジ
All-to-Allリンクを形成
システム全体を階層型のAll-to-Allで構成
本システムでは2階層
18

CRAY XC30 System概要
Cray XC30 シリーズは、次世代Aries インターコネクト、Dragonfly ネットワークトポロジ、Crayのスーパーコンピュータラインで初めて採用した高性能Intel Xeon プロセッサ、統合ストレージソリューション、さらにCray のOS、プログラミング環境などの先進的ソフトウエアから成る新世代スーパーコンピュータです。次世代プロセッサへのアップグレードや各種アクセラレータも利用可能とするCray のビジョン アダプティブスーパーコンピューティングを実現する画期的なシステムとなっております。
19

16 Aries connected
in backplane
“Rank-1”
Dragonfly Class-2 Topology ------JAIST System
4 nodes connect
to a single Aries
6 backplanes
connected with
copper wires in a
2-cabinet group:
“Rank-2”
Pairs of Aries
connect to a optical
fiber to interconnect
groups
“Rank-3”
Chassis
20

Dragonflyネットワークの優位性
• 新開発のAriesチップとAll-to-Allをベースにした新しいネットワークトポロジの採用。
• 前世代のCray XE6システムと比較してより高バンド幅、低レイテンシを実現。
• 実アプリケーションによる多数ノードを使用した全通信処理時に著しく性能が向上。
(通信性能は2ノード間の評価ではなく、全体通信性能の評価が重要)
~ 20倍の
All-to-All
バンド幅
21

System構成 (Storage)
22
DDN RAID S2A9900 Tier 3 1 2 1 3 4 5 6 7 8 P P
Tier 2 1 2 3 4 5 6 7 8 P P
1 Tier 1 2 1 3 4 5 6 7 8 P P
/work (200TB)
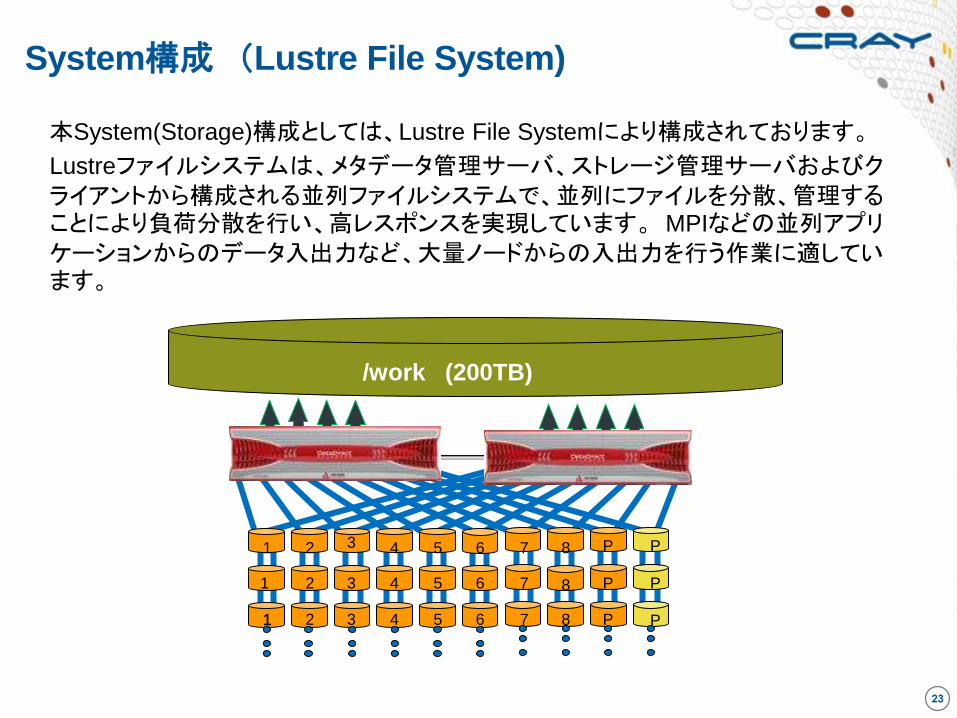
System構成 (Lustre File System)
本System(Storage)構成としては、Lustre File Systemにより構成されております。
Lustreファイルシステムは、メタデータ管理サーバ、ストレージ管理サーバおよびクライアントから構成される並列ファイルシステムで、並列にファイルを分散、管理することにより負荷分散を行い、高レスポンスを実現しています。 MPIなどの並列アプリケーションからのデータ入出力など、大量ノードからの入出力を行う作業に適しています。
23

/workの並列I/O性能
● /work (DDN-SFA12000, Lustre ファイルシステム)のIORベンチマークによる並列I/O性能は以下の通りです。
● 設定は api = POSIX, access = file-per-process
clients = 32 (1 per node)
repetitions = 3
xfersize = 1 MiB
blocksize = 64 GiB
aggregate filesize = 2048 GiB
Operation Max (MiB) Min (MiB) Mean (MiB) Std Dev Max (OPs) Min (OPs) Mean (OPs)
--------- --------- --------- ---------- ------- --------- --------- ----------
write 11234.56 6176.17 9536.07 2375.86 11234.56 6176.17 9536.07
read 10662.81 6742.32 9270.11 1790.50 10662.81 6742.32 9270.11
Max Write: 11234.56 MiB/sec (11780.29 MB/sec)
Max Read: 10662.81 MiB/sec (11180.76 MB/sec)
24

/xc30-workのI/O性能
● /xc30-work (ファイルサーバ上のNFS)のI/O性能は以下の通り write 88MB/s, read 106MB/s
● 性能測定にはbonnie++1.03eを使用
Writing with putc()...done
Writing intelligently...done
Rewriting...done
Reading with getc()...done
Reading intelligently...done
start 'em...done...done...done...
Create files in sequential order...done.
Stat files in sequential order...done.
Delete files in sequential order...done.
Create files in random order...done.
Stat files in random order...done.
Delete files in random order...done.
Version 1.03e ------Sequential Output------ --Sequential Input- --Random-
-Per Chr- --Block-- -Rewrite- -Per Chr- --Block-- --Seeks--
Machine Size K/sec %CP K/sec %CP K/sec %CP K/sec %CP K/sec %CP /sec %CP
xc30-0 63G 85778 85 88123 3 39613 3 87725 76 106167 4 293.1 0
------Sequential Create------ --------Random Create--------
-Create-- --Read--- -Delete-- -Create-- --Read--- -Delete--
files /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP
16 993 4 1275 0 237 1 228 1 865 1 473 2
xc30-0,63G,85778,85,88123,3,39613,3,87725,76,106167,4,293.1,0,16,993,4,1275,0,237,1,228,1,865,1,473,2
25
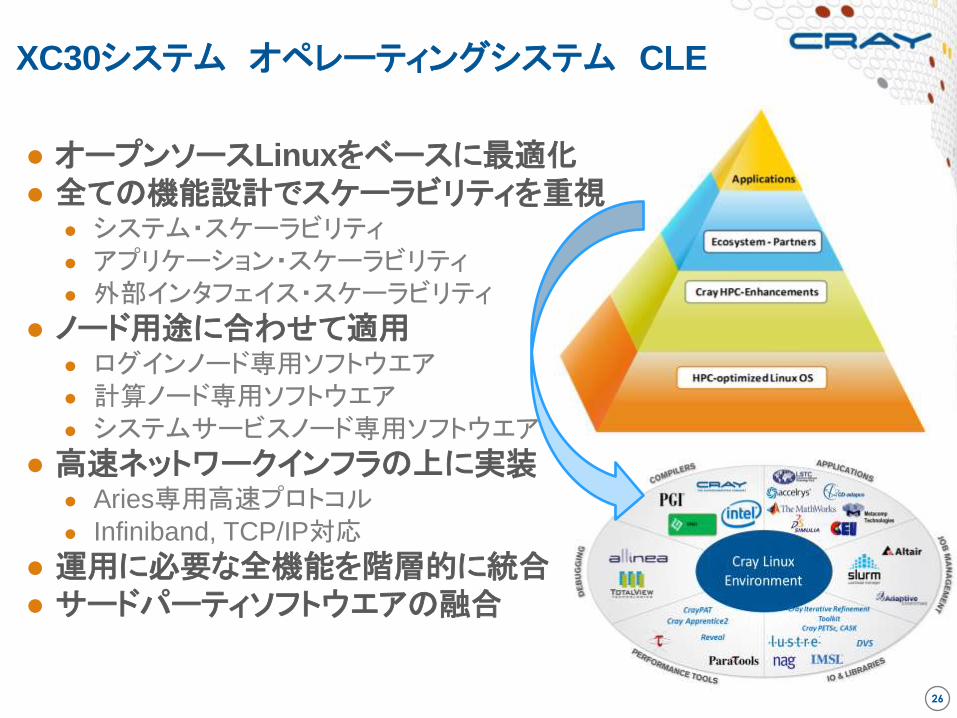
XC30システム オペレーティングシステム CLE
● オープンソースLinuxをベースに最適化
● 全ての機能設計でスケーラビリティを重視 ● システム・スケーラビリティ
● アプリケーション・スケーラビリティ
● 外部インタフェイス・スケーラビリティ
● ノード用途に合わせて適用 ● ログインノード専用ソフトウエア
● 計算ノード専用ソフトウエア
● システムサービスノード専用ソフトウエア
● 高速ネットワークインフラの上に実装 ● Aries専用高速プロトコル
● Infiniband, TCP/IP対応
● 運用に必要な全機能を階層的に統合
● サードパーティソフトウエアの融合
26

Crayプログラミング環境
Cray Programming Environment
• Cray コンパイラ
• Fortran
• C/C++
• Cray 科学数学ライブラリCSML
• 通信ライブラリ
• I/Oライブラリ
• 性能解析ツール
• プログラム最適化ツール
• Cray 開発ツールキット
• 最適化 Fortran, C, C++
• Cray fortran コンパイラ
• 自動最適化、自動並列化
• Fortran 2008 規格準拠
• coarray のフルサポート+デバッガによるサポート
• Cray C コンパイラ
• 自動最適化、自動並列化
• UPC のフルサポート+デバッガによるサポート
• OpenACC 1.0 準拠(Fortran, C)
• 以降も積極的な強化計画
• OpenACC 2.0
• OpenMP 4.0
• C++11
• inline assembly
• Intel Xeon Phi
27

Cray Programming Environment Distribution Focus on Differentiation and Productivity
Programming Languages
Fortran
C
C++
Chapel
Python
Compilers Programming
models I/O Libraries
Optimized Scientific
Libraries
Cray Compiling Environment
(CCE)
GNU
Distributed Memory (Cray MPT)
• MPI
• SHMEM
PGAS & Global View
• UPC (CCE)
• CAF (CCE)
• Chapel
NetCDF
HDF5
Cray Performance
Monitoring and Analysis Tool
LAPACK
ScaLAPCK
BLAS (libgoto)
Iterative Refinement
Toolkit
Cray Adaptive FFTs (CRAFFT)
FFTW
Cray PETSc (with CASK)
Cray Trilinos (with CASK)
Cray developed
#: Under development
Licensed ISV SW
3rd party packaging
Cray added value to 3rd party
Tools
Environment setup
Debuggers
Modules
lgdb
Debugging Support
Tools
• Fast Track Debugger (CCE w/ DDT)
• Abnormal Termination Processing
gdb
Performance Analysis
STAT
Cray Comparative Debugger#
Shared Memory
• OpenMP 3.0 (CCE & PGI ) Intel
28

ジョブ投入(実行)環境(バッチ・サブシステム)
● アプリケーションをバッチ・サブシステムに投入して実行する方法
インタラクティブ・セッションから、バッチ・サブシステム(PBS Pro)で、aprunコマンドを用いてジョブを実行する事が出来ます。
※ 具体的な利用方法は、後のプログラミング編でご説明いたします。
Database nodeLogin node
User application
yod
Fan outapplication
CPU inventorydetabase
CPU list Request CPU
User
Log-in andstart application
Userapplication
PCT
Compute nodecatamount/QK
Userapplication
PCT
Compute nodecatamount/QK
Userapplication
PCT
Compute nodecatamount/QK
Userapplication
PCT
Compute nodecatamount/QK
PBSProExecutor
PBSProScheduler
ComputePE
Allocator
PBSProServer
JobQueues
apinit
UNICOS/CL
apsheperd
User app
UNICOS/CLE
UNICOS/CLE
UNICOS/CLE
apinitapsheperd
User
app
apinitapsheperd
User
app
apinitapsheperd
User
app
apsched
apbridge
apwatch
app agent
Local apsys
aprun
29

/root
/opt /tmp /work/appli /workLibrary及びヘッダーファイル等用
一時領域 3rdベンダ・アプリケーション用
ユーザ一時領域用
ログイン・ノードのファイルシステムは、次の構成になっています。
30
/opt : 後述いたしますmoduleコマンドでCompilerやLibrary等が読み込まれる為、通常は直接パスで指定は不要です。

Cray XC30システムを使用する上での留意点
● 利用可能な一時ファイルシステム
/ work ファイルシステムがテンポラリとして利用可能
※利用の際は自分のユーザ名のディレクトリを作成
例: mkdir /work/testuser-name
● ログイン・ノード上にあるコンパイラでコンパイルし、生成した実行形式ファイルが、計算ノードで実行可能
● 計算ノード用の実行形式ファイルは、ログイン・ノードでは実行しない
● 計算ノードではホームディレクトリ( /home )が利用できないため,ジョブ実行に必要なファイルはすべて/work以下に置く
31

Cray XC30システムへログインする方法 ssh ユーザ名 @ xc30 Sample Program Directory xc30:/work/Samples/workshop2015 Queue Name SEMINAR

並列化プログラミング入門

● プログラミング環境
● MPIとは?
● 簡単なMPIプログラム
● 主要なMPI関数の説明
● 台形公式の数値積分
● さらに進んだ使い方を学ぶためには?
この講習で行う内容
34

プログラミング環境
35

● moduleコマンド概要 ● ソフトウエア開発・実行に必要な環境設定を動的に切り替えるためのコマンド
ツール
● Cray, IntelおよびGNUコンパイラのプログラミング環境
• Cray環境モジュール PrgEnv-cray: Crayコンパイラ(標準)
• Intel環境モジュール PrgEnv-intel: Intelコンパイラ
• GNU環境モジュール PrgEnv-gnu: GNUコンパイラ
● 一般ユーザのXCシステムログイン時の標準設定はCray環境
● 主なmoduleコマンド
プログラミング環境の選択- moduleコマンド
ロードされているmodule一覧表示
module list
使用できる全module一覧表示
module avail
moduleのロード、アンロード
module load [ module_name ]
module unload [ module_name ]
moduleのスイッチ (module_name1からmodule_name2へ)
module switch [ module_name1] [module_name2]
moduleのクリア(ロードされている全moduleのアンロード)
module purge
36

演習事前準備
37
演習用プログラム一式が /work/Samples/workshop2015 下に置いてあります。 各自、/work下の作業ディレクトリへコピーしてください。
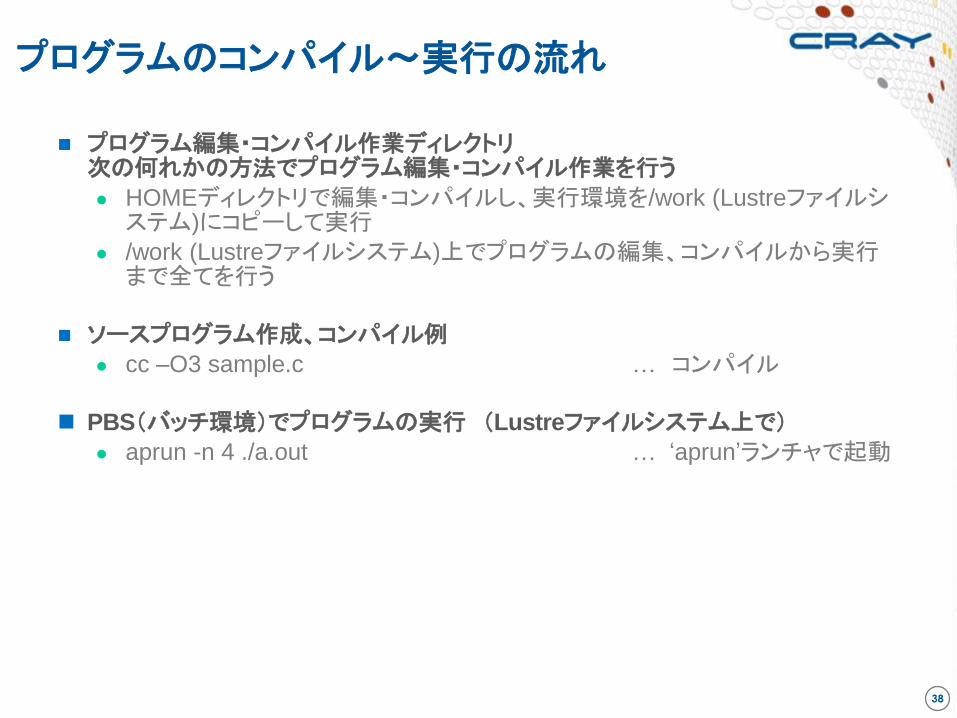
プログラム編集・コンパイル作業ディレクトリ 次の何れかの方法でプログラム編集・コンパイル作業を行う
● HOMEディレクトリで編集・コンパイルし、実行環境を/work (Lustreファイルシステム)にコピーして実行
● /work (Lustreファイルシステム)上でプログラムの編集、コンパイルから実行まで全てを行う
ソースプログラム作成、コンパイル例
● cc –O3 sample.c … コンパイル
PBS(バッチ環境)でプログラムの実行 (Lustreファイルシステム上で)
● aprun -n 4 ./a.out … ‘aprun’ランチャで起動
プログラムのコンパイル~実行の流れ
38

ログインノードでのテスト実行時の注意点
39
● 現在のログインノードのCPUは、計算ノードのCPUとは異なっています ● ログインノード:Intel Xeon E5-2670 (SandyBridge)
● 計算ノード :Intel Xeon E5-2690 v3 (Haswell)
● ログインノード上において前ページのようにデフォルト値でのコンパイルをおこなった場合、実行バイナリはHaswell用に生成されるため、ログインノードでは実行出来ません。
● ログインノード上でプログラムを実行したい場合には、以下のいずれかの方法をご利用ください。 ● moduleファイルの変更
● $ module swap craype-haswell craype-sandybridge
もしくは
● 以下のコンパイラオプションの明示的な指定(PrgEnv-crayの場合)
● -h cpu=sandybridge
● ただし、ログインノード上でのプログラムの実行は、ログインノードへの負荷を高め、他のユーザー様へのご迷惑となる場合がありますので、なるべくお控えください。

Fortran,C,C++コンパイラのコマンド名はftn, cc, CCに統一されています。
Cray, Intel,GNUのどのコンパイラ環境がロードされている場合でも、ftn/cc/CCコマンドでコンパイラを利用します。
例えばコンパイラ環境をCrayからGNUへswitchした場合、ccコマンドが内部で呼び出すコンパイラの切り替え(craycc → gcc)は自動的に行われます。
注意: • MPIプログラムをコンパイルする場合もftn, cc, CCを使用する。
• MPIライブラリは自動的にリンクされます。
(mpif90, mpicc, mpicxx などMPI専用ラッパーは使用しない)
• コンパイラ個別のmanページなどは、実際に起動するコマンド名を参照下さい。
(例: man crayftn )
コンパイラ名称について
コンパイラコマンド(ドライバ名)
PrgEnv-crayで実際に起動されるコマンド
PrgEnv-intelで実際に起動されるコマンド
PrgEnv-gnuで実際に起動されるコマンド
ftn crayftn ifort gfortran
cc craycc icc gcc
CC crayCC icpc g++
40

Crayコンパイラの最適化オプション
● Crayコンパイラの最適化オプション例
● よく利用される最適化オプション
ftn –O3 –hautothread,thread3,vector3,scalar3,fp3,omp,wp,pl=tmp sample.F90
オプション 意味
-O1|2|3 最適化レベルの設定
-hautothread 自動並列化
-hwp,pl=xxx xxx/を作業ディレクトリとし、プログラム全体の手続き間解析を行う
-h[no]omp OpenMPの使用・不使用
-hvector1|2|3 SIMDベクトル化レベルの設定
-hthread1|2|3 スレッド最適化レベルの設定
-hscalar1|2|3 スカラ最適化レベルの設定
-hfp1|2|3 浮動小数点演算最適化レベルの設定
41 コンパイラオプションの詳細は $ man craycc|crayCC|crayftn

Intelコンパイラの最適化オプション
● Intelコンパイラの最適化オプション例
● よく利用される最適化オプション
● デフォルトでcraype-haswellモジュールがロードされている場合は、”-xCORE-AVX2” オプションが有効になっています
ftn –O3 –parallel -ip sample.F90
オプション 意味
-O1|2|3 最適化レベルの設定
-parallel 自動並列化
-ip 単一ファイルの手続き間解析を行う
-ipo 複数ファイルに渡るプログラム全体の手続き間解析を行う
-openmp OpenMPの使用
42
コンパイラオプションの詳細は $ man icc/icpc/ifort

XC30並びに従来システム(XT5)での 主要なコンパイルオプションの違い
意味 CCE Intel GNU PGI(XT5)
コード生成対象命令セット
モジュールでの対応(craype-haswell)
-xSSE3, -xAVX,
-xCORE-AVX2
-msse3, -mavx,
-march=core-
avx2
-tp=core2,
-tp=nehalem
最適化レベル -O[1|2|3] -O[1|2|3] -O[1|2|3] -O[1|2|3]
OpenMP -O[no]omp (ftn)
-h[no]omp (cc/CC)
-openmp -fopenmp -mp=nonuma
自動並列化 -Oautothread (ftn)
-hautothread (cc/CC)
-parallel -Mconcur
ベクトル、SIMD化 -Ovector[1|2|3] (ftn)
-hvector[1|2|3] (cc/CC)
-vec -ftree-vectorize -Mvect
IPA最適化 -hwp,pl=/tmp -ipo -finline-functions -Mipa=fast
FORTRAN書式 -ffree, -ffixed -free, -fixed -ffree-form,
-ffixed-form
-Mfree, -Mfixed
Endian変換 -h byteswapio (ftn) -convert big_endian -fconvert -byteswapio
未初期化変数のゼロ初期化
-e0,z (ftn) -zero
43

aprun ジョブラウンチャ
● プログラムの起動コマンド aprun
● 計算ノードでプログラムを起動するための高機能なランチャーコマンド
● 多様なリソース指定オプション(後述)
● 利用例
● (aprunコマンドはバッチジョブの中から実行可能です)
● プログラムの実行 - バッチ処理
● ジョブスクリプトファイルの作成PBS指示行と実行するコマンド列を記述
● ジョブスクリプトファイルの記述例
● バッチジョブとして投入
$ aprun –n 24 ./a.out
#PBS –l mppwidth=24, walltime=1:00:00
#PBS –N Myjobname
cd $PBS_O_WORKDIR
ftn foo.f90
aprun –n 24 ./a.out
$ qsub my-job-script 44

$ aprun –n 1 ./a.out
$ aprun –n 24 ./a.out
$ aprun –n 1 –d 24 ./a.out
$ aprun –n 2 –d 12 ./a.out
$ aprun –n 4 –d 6 ./a.out
$ aprun –n 8 –d 3 ./a.out
● シリアルジョブ(1プロセスジョブ)
● MPI 24プロセスの並列ジョブ
● OpenMP 24スレッド並列ジョブ
● 2MPI x 12 OpenMP 並列ジョブ
● 4MPI x 6 OpenMP 並列ジョブ
● 8MPI x 3 OpenMP 並列ジョブ
● 注意:OpenMPを用いる場合は別途明示的なOMP_NUM_THREADSの指定が必要
ジョブ実行時のaprunパラメータ指定例 1ノードジョブ
45
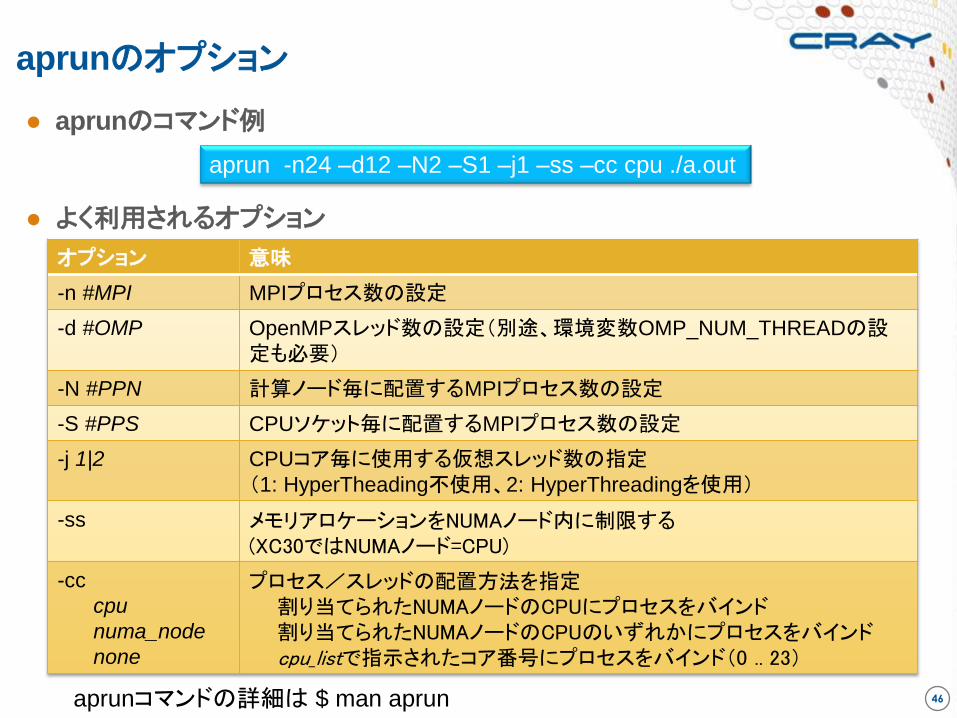
aprunのオプション
● aprunのコマンド例
● よく利用されるオプション
aprun -n24 –d12 –N2 –S1 –j1 –ss –cc cpu ./a.out
オプション 意味
-n #MPI MPIプロセス数の設定
-d #OMP OpenMPスレッド数の設定(別途、環境変数OMP_NUM_THREADの設定も必要)
-N #PPN 計算ノード毎に配置するMPIプロセス数の設定
-S #PPS CPUソケット毎に配置するMPIプロセス数の設定
-j 1|2 CPUコア毎に使用する仮想スレッド数の指定
(1: HyperTheading不使用、2: HyperThreadingを使用)
-ss メモリアロケーションをNUMAノード内に制限する (XC30ではNUMAノード=CPU)
-cc
cpu
numa_node
none
プロセス/スレッドの配置方法を指定 割り当てられたNUMAノードのCPUにプロセスをバインド 割り当てられたNUMAノードのCPUのいずれかにプロセスをバインド cpu_listで指示されたコア番号にプロセスをバインド(0 .. 23)
46 aprunコマンドの詳細は $ man aprun

PBSバッチシステム
基本的な利用方法
● バッチジョブのサブミット qsub [–q queue] script_file
● バッチジョブのモニタ ● 全ジョブの一覧表示 nqstat
● 個別ジョブ
qstat –f job_id
● バッチジョブの削除
qdel job_id
バッチジョブスクリプトの例
PBS Proの詳細に関しては http://www.pbspro.com
を参照のこと。
47
#!/bin/csh
#PBS –l mppwidth=24 ← PE数の上限が24
#PBS –N batch-job ← ジョブの名前をbatch-jobに設定
cd $PBS_O_WORKDIR ← バッチ投入ディレクトリへの移動
aprun –n 24 ./a.out

● 通常、計算ノードはバッチジョブ処理用に設定される ● プログラムはバッチジョブの中で実行する
● バッチジョブの中で複数のプログラムを実行する事も可能
● バッチジョブはPBS professionalのコマンドを用いてサブミットする
● qsub, nqstat(qstat), qdelなど
● サブミットされたジョブ ● ジョブの実行開始はPBSスケジューラによって管理される
● キューイングされた(実行開始待ちの)状態ではリソースは割り当てられていない。
● 実行開始時から実行終了時まで要求した計算ノードリソースを占有する。 → 計算ノードは他ジョブと共有されない
● qsubコマンドオプションやディレクティブでのリソース要求はスケジューラにフォワードされ、スケジューリングサーバによって具体的な割り当てが行われる → 一般のクラスタのようにノード名・ホスト名の指定は不要
XCでのバッチ処理
48

バッチジョブ用のコマンド
● ジョブの起動、ステータス確認、強制終了
● ジョブ起動 (qsub)
● ジョブステータス確認 (qstat)
● ジョブ強制終了 (qdel)
● ジョブ中で利用可能な主なPBS環境変数
$ qsub [バッチスクリプトファイル]
$ qstat –a
$ qdel [ジョブID番号]
PBS_O_WORKDIR ジョブを投入したカレントディレクトリ
PBS_O_HOME ホームディレクトリ
PBS_O_QUEUE バッチキュー名称
PBS_JOBID ジョブID
PBS_JOBNAME ジョブ名
49

ジョブを投入し、実行結果を得る
● qsubコマンドで、TINYキューへバッチスクリプトファイルrun.shを投入し、実行プログラムhello_single.exeの実行結果を出力ファイルHELLO.o*で確認する
● aprunコマンドにより、プログラムは計算ノードで実行される
$ qsub –q TINY run.sh
4662.sdb
$
#!/bin/bash
#PBS -N HELLO
#PBS -l mppwidth=1
#PBS -l walltime=00:05:00
#PBS -j oe
if [ ${PBS_O_WORKDIR} ]
then
cd ${PBS_O_WORKDIR}
fi
echo "Hello Single ..."
time -p aprun ./hello_single.exe
sleep 120
$ cat HELLO.o4662
Hello Single ...
Hello World
Application 17757 resources:
utime 0, stime 0
real 0.29
user 0.02
sys 0.01
$
50
スクリプトファイルrun.sh qsubコマンドによるジョブのサブミット
実行結果ファイルの出力例

qsubのオプション
● オプションはジョブスクリプトの指示行としてもコマンド引数としても指定可能
オプション 機能概要
-N ジョブ名 ジョブ名称
-e パス名 標準エラー出力を,’パス名’で指定したファイルに出力する
-o パス名 標準出力を,’パス名’で指定したファイルに出力する
-j eo
-j oe
標準出力と標準エラー出力をマージした結果を標準エラーに出力する
標準出力と標準エラー出力をマージした結果を標準出力に出力する
-l mppmem=size[GB|MB] プロセスあたりの最大メモリサイズを指定する
-l walltime=hh:mm:ss wall時間(経過時間)を指定する
-l mppwidth=pes MPIプロセス数を指定する(本システムではこの値だけが有効となる)
-l mppnppn=pes_per_node ノード内のプロセス数(例: MPIプロセス数)
-l mppdepth=depth ノード内で使用するスレッド数(例: OpenMPスレッド数)
-M メールアドレス メールを送るアドレス(のリスト)を指定する
-mb ジョブ開始時にメールで通知する. ※ -Mで送り先を指定
-me ジョブ終了時にメールで通知する. ※ -Mで送り先を指定
-r n 再実行を禁止する
-q キュー名 ジョブを投入するキュー名を指定する
51
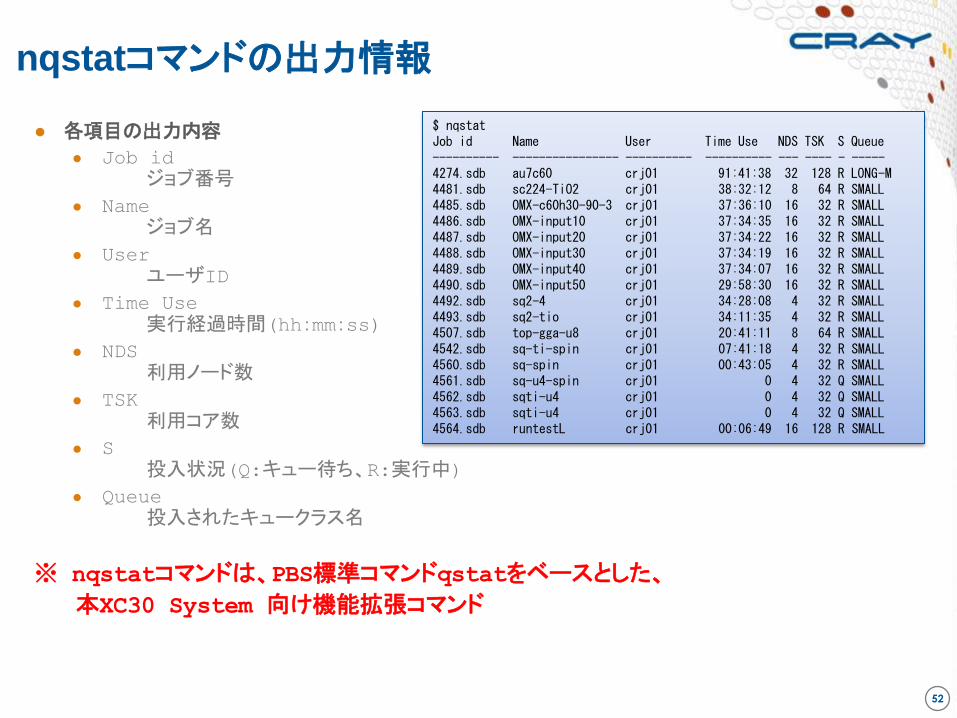
nqstatコマンドの出力情報
● 各項目の出力内容
● Job id
ジョブ番号
● Name
ジョブ名
● User
ユーザID
● Time Use
実行経過時間(hh:mm:ss)
● NDS
利用ノード数
● TSK
利用コア数
● S
投入状況(Q:キュー待ち、R:実行中)
● Queue
投入されたキュークラス名
※ nqstatコマンドは、PBS標準コマンドqstatをベースとした、
本XC30 System 向け機能拡張コマンド
$ nqstat Job id Name User Time Use NDS TSK S Queue ---------- ---------------- ---------- ---------- --- ---- - ----- 4274.sdb au7c60 crj01 91:41:38 32 128 R LONG-M 4481.sdb sc224-TiO2 crj01 38:32:12 8 64 R SMALL 4485.sdb OMX-c60h30-90-3 crj01 37:36:10 16 32 R SMALL 4486.sdb OMX-input10 crj01 37:34:35 16 32 R SMALL 4487.sdb OMX-input20 crj01 37:34:22 16 32 R SMALL 4488.sdb OMX-input30 crj01 37:34:19 16 32 R SMALL 4489.sdb OMX-input40 crj01 37:34:07 16 32 R SMALL 4490.sdb OMX-input50 crj01 29:58:30 16 32 R SMALL 4492.sdb sq2-4 crj01 34:28:08 4 32 R SMALL 4493.sdb sq2-tio crj01 34:11:35 4 32 R SMALL 4507.sdb top-gga-u8 crj01 20:41:11 8 64 R SMALL 4542.sdb sq-ti-spin crj01 07:41:18 4 32 R SMALL 4560.sdb sq-spin crj01 00:43:05 4 32 R SMALL 4561.sdb sq-u4-spin crj01 0 4 32 Q SMALL 4562.sdb sqti-u4 crj01 0 4 32 Q SMALL 4563.sdb sqti-u4 crj01 0 4 32 Q SMALL 4564.sdb runtestL crj01 00:06:49 16 128 R SMALL
52

キューイング中のバッチJobの停止は,以下のようにします。 1)Job番号の確認 $ nqstat
2)Jobの停止
$ qdel 1330
ジョブのキャンセル
$ nqstat Job id Name User Time Use NDS TSK S Queue ---------- ---------------- ---------- ---------- --- ---- - ----- 4268.sdb au4c60 crj01 46:20:51 8 64 R LONG-S 4274.sdb au7c60 crj01 01:06:43 32 128 R LONG-M 4309.sdb m_nal_e crj01 01:13:07 32 256 R MEDIUM 4317.sdb sip30 crj01 35:31:39 16 128 R SMALL 4318.sdb sip40 crj01 01:14:07 16 128 R SMALL 4376.sdb au4c60b1 crj01 00:55:32 13 104 R SMALL 4377.sdb k444 crj01 00:01:59 4 32 R SMALL 4378.sdb k444 crj01 00:01:28 4 32 R SMALL 4379.sdb k444 crj01 0 4 32 Q SMALL 1330.sdb MPI crj01 0 4 32 Q SMALL
53

バッチジョブスクリプト例
● 例(1):コンパイル・実行を行うバッチジョブ
● ジョブを投入するディレクトリにソースプログラム main.f90がある場合
● デフォルトのコンパイラはCrayコンパイラ。1コアを使用して計算実行
#PBS –N job1
#PBS –l mppwidth=1
#PBS –j oe
cd $PBS_O_WORKDIR
ftn main.f90
aprun –n 1 ./a.out > output.txt
#PBS –N job2
#PBS –l mppwidth=24
#PBS –j oe
cd $PBS_O_WORKDIR
ftn–h autothread main.f90
export OMP_NUM_THREADS=24
aprun–n 1 –d 24 –cc none ./a.out > output.txt
● 例(2) SMP並列(OpenMP,自動並列) ジョブの例
● 1ノード内の24コア 全てをスレッド並列( 24スレッド)に用いて a.outを実行
54

バッチジョブスクリプト例
● 例(3): 192 MPIプロセスのプログラムを実行
#PBS –N job3
#PBS –l mppwidth=192
#PBS –l mppnppn=24
#PBS –j oe
cd $PBS_O_WORKDIR
ftn main.f90
aprun –n 192 -N 24 ./a.out > output.txt
55

バッチジョブスクリプト例
● 例(4) : MPIとOpenMPを併用したマルチノードジョブ
● MPIプロセス総数192、1ノード内を2MPI x 12OpenMP (CPU1台に1MPI)
● OMP_NUM_THREADSとaprun –dの指定とが共に必要
#PBS –N job4
#PBS –l mppwidth=192
#PBS –l mppdepth=12
#PBS –l mppnppn=2
cd $PBS_O_WORKDIR
ftn –h omp –o my.mix main.f90
export OMP_NUM_THREADS=12
aprun –n 192 –S 1 –N 2 –d 12 ./my.mix > output.txt
56

バッチジョブスクリプト例
● 例(5) 投入キューを指定する例
● 投入するキューを明示的に指定する場合は - q オプションを使用する
● TINYキューにジョブを投入する場合の例
#PBS –N job5
#PBS –l mppwidth=1
#PBS –q TINY
#PBS –j oe
cd $PBS_O_WORKDIR
ftn –h list=a –o a.out foo.f90
aprun –n 1 ./a.out > output.txt
57

バッチジョブスクリプト例
● 例(6) ジョブ内でmoduleコマンドを使用する例
● バッチジョブ内でmoduleコマンドを利用するには利用するシェルに対応したinitスクリプトを読み込む必要がある
● initスクリプト $ ls /opt/modules/default/init/*sh
/opt/modules/default/init/bash /opt/modules/default/init/sh
/opt/modules/default/init/csh /opt/modules/default/init/tcsh
/opt/modules/default/init/ksh /opt/modules/default/init/zsh
● 以下はbashジョブスクリプトでの例
58
#PBS -N job6
#PBS -l mppwidth=1
#PBS -j oe
source /opt/modules/default/init/bash
module switch PrgEnv-cray PrgEnv-intel
module list
cd $PBS_O_WORKDIR
ftn -openmp main.f90

対話的ジョブの実行方法
● 対話的ジョブを実行するには qsubコマンドの対話セッションを利用
● 全ての計算ノードはバッチ処理用に構成されている
● 対話的なジョブセッションもバッチジョブとして実行される
● 対話的ジョブの起動(投入) $ qsub –I [ –l mppwidth=コア数] [ -l walltime=hh:mm:ss ] [ .. ]
L(エル)の小文字
● オプション -I 対話的なジョブセッションであることを指定 -l mppwidth=コア数 使用するコア数 -l walltime=hh:mm:ss 経過時間の上限。 hh:mm:ss の形式で指定 バッチジョブスケジューラ(PBS professional)が他のバッチと同様にスケジューリングを行い、リソースが提供可能な時点で開始される。
● 開始と同時にプロンプトが表示される。
● 対話的ジョブの中ではaprunコマンドを対話的に利用する事が可能
● 対話セッションの終了は ‘exit’ とキー入力→元のログインノードへ復帰する
59
注意事項:
P.44のaprunジョブランチャを利用しない限り,プロセスはログインノード上で実行されますので必ずaprunジョブランチャを利用してください。
また、ログインノード上では不用意に大量のリソースを必要とするようなプログラムを動作させないようお願いいたします。

対話的ジョブの実行 X11クライアントを端末に表示する場合
● X11クライアントを表示可能な端末からログインノードへログインする
$ ssh -Y xc
● Xオプションを指定して対話的ジョブの起動(投入)
$ qsub –I –X [ –l mppwidth=…]
● オプション -I 対話的なジョブセッションであることを指定 –X 現在のDISPLAY変数をジョブへひきつぐ
● -l mppwidth,-l walltimeなどは前ページの例と同様に指定
● 前ページと同様に、ジョブの開始と同時にプロンプトが表示されるので、X11クライアントが表示されることを確認して継続実行する
● 対話セッションの終了は ‘exit’ とキー入力
60

バッチジョブ関連コマンド:システムの稼働状況の確認
● XCシステムのノード稼働状況 (xtnodestat)
● Lustre ファイルシステム使用状況
● 計算ノードリソースの情報 (CPUクロック、コア数、メモリ)
$ xtnodestat
$ du -s [-h] /work/ユーザ名
$ xtprocadmin -a clockmhz,cores,availmem [-A]
61

PBSバッチシステム
● XC30キュークラスの構成情報
● 日本語 http://isc-w3.jaist.ac.jp/iscenter/index.php?id=745#c4142
● English http://isc-w3.jaist.ac.jp/iscenter/index.php?id=745&L=1#c4148
62

● プログラムの起動場所 ● プログラムの起動は/work (= Lustre ファイルシステム) 上でのみ可能 ● 計算ノードでは$HOMEはマウントされない
● 計算ノードのファイルシステム
● 計算ノードでは/tmpファイルシステムはユーザによる書き込み不可 ● ユーザーが利用可能なファイルシステムは/work ( Lustreファイルシステム)
のみ
● バイトオーダー(エンディアン) ● XCはリトルエンディアン(X86-64)
● 標準出力に関して ● PBSの標準出力はジョブ実行中ログインノード上の/var下に書き出される ● 標準出力が大量に書き出されるプログラムをそのまま実行するとログインノー
ド上の/varを溢れさせてしまう場合がある ● プログラムの標準出力は必ず/work (Lustreファイルシステム)へリダイレクトす
る(特に大量の出力の場合)
XCプログラミング・実行上の注意
63

計算ノードの大規模メモリ使用
● プログラムプロセスが使用可能な静的変数のサイズはディフォルトで合計2GBが上限 ● 4バイト単精度では array(500 000 000) 8バイト単精度では array(250 000 000)
● 回避法1:1プロセスで2GB以上の配列を使用する場合は動的に確保する ● Fortran: 配列変数をallocatable宣言+allocate文で実行時に動的確保 ● C: 同様に malloc()関数等を用いて動的領域確保
● 回避法2:コンパイラに用意されているオプションを使用する ● PrgEnv-crayの場合: -hpic –dynamic
● PrgEnv-intelの場合: -mcmodel=medium –shared-intel
● PrgEnv-gnuの場合: -mcmodel=medium
● Fortranプログラム例(回避策1の場合): program main
integer Giga
real, allocatable :: array(:)
Giga= 800000000
allocate (array(Giga))
array(Giga)=1.0
write (,) "the stored value is=", array(Giga)
deallocate(array)
stop
end
64

動的リンクの利用
● XC30のコンパイラはディフォルトで静的リンクを行う
● 以下の場合には動的リンクを行う ● 2GB以上の静的データ領域(BSS)の使用
● DLS(Dynamics Shared Library, lib***.so)としてのみ提供されるライブラリの使用
● 動的リンクのためには以下のコンパイルオプションを使用する ● Crayコンパイラ: -dynamic –hpic
● Intelコンパイラ: -dynamic –fpic –mcmodel=medium -shared-intel
● GCC: -dynamic –fpic –mcmodel=medium
● DSLとしてのみ提供されるライブラリを使う場合、ライブラリパスはCRAY_LD_LIBRARY_PATHで指定する ● 自分でDLSを作成し利用する場合や、XC30にインストールされていない任
意のライブラリを自身でインストールして使用する場合等
65

● 従来通り、libsci科学技術演算ライブラリが利用可能 ● cray-libsci モジュール (デフォルトでロード済み)
● 標準ルーチンとして、BLAS, LAPACK, BLACS, SCALAPACK , SuperLUライブラリを包含
● 詳細はman intro_libsciを参照
● 別途、fftw, netcdfモジュールも利用可能
● 使用時の注意 ● インクルードパス –I やライブラリパス –L の指定は不要
● cray-libsciモジュールを読み込めば、特にコンパイルオプション等を指定する事なく使える(MPIと同じ使い勝手)
● PrgEnv-intel環境においてIntel MKLを利用したい場合は、cray-libsciモジュールをunloadしておく
科学技術演算ライブラリの利用
66

● LIBSCI概要情報 . . . man libsci
● BLAS (Basic Linear Algebra Subroutines)
BLAS1 関数一覧 . . . man blas1
BLAS2 関数一覧 . . . man blas2
BLAS3 関数一覧 . . . man blas3
● LAPACK (Linear Algebra routines)
LAPACK関数概要 . . . man lapack
● LAPACKユーザーズガイド . . . http://www.netlib.org/lapack/lug/
● BLACS
BLACS概要、関数一覧 . . . man blacs
● FFTW (Fastest FFT in the West)
FFTW2 概要、使用方法 . . . man intro_fftw2
FFTW2 ユーザーズマニュアル(PDF)
. . . http://www.fftw.org/fftw2.pdf
FFTW3 概要、使用方法 . . . man intro_fftw3
FFTW3 ユーザーズマニュアル(PDF) . . . http://www.fftw.org/fftw3.pdf
● IRT (Iterative Refinement Toolkit)
Cray IRT 概要、関数一覧 . ... man intro_irt
● ScaLAPACK (parallel Linear Algebra routines)
ScaLAPACK概要 ... man intro_scalapack
ScaLAPACKユーザーズガイド
. . . http://www.netlib.org/scalapack/slug/
● SuperLU_DIST (sparse solvers)
SuperLU ユーザーズガイド . . . http://crd.lbl.gov/~xiaoye/SuperLU/superlu_ug.pdf
オンラインドキュメント . . . http://crd.lbl.gov/~xiaoye/SuperLU/superlu_dist_code_html/
CRAY LIBSCI 各種オンライン情報
Cray LIBSCI ライブラリオンラインマニュアル情報
67

MPIとは?
68

Argonne国立研究所で開発された、 分散メモリ型並列プログラミングライブラリの標準
明示的プロセッサ間通信
● SPMD (Single Program Multiple Data) モデル
● 各プロセスは排他的ローカルメモリを持つ
● FORTRAN, C/C++からライブラリルーチンとして呼出す
● 祖粒度の並列化に適し、スケーラビリティが高い
69

並列プログラミングモデル
1. 分散メモリ型(MPI, SHMEM, Co-Array/UPC) ● プログラムを明示的に並列化する
● 明示的な同期指示がない限りは非同期実行
● スケーラビリティが高い
● 主に、数百~数千CPUまでの処理
2. 共有メモリ型(自動並列、OpenMP) ● プログラミングが容易
● PE間で同期をとり、fork/joinを繰り返す
● スケーラビリティが低い
● 主に、~数十CPUまでの処理
70
共有メモリ型 分散メモリ型

簡単なMPIプログラム
71

4プロセッサでの実行例
72
$ make
cc -O3 -c -o hello.o hello.c
cc -O3 -o hello hello.o
$ qsub pbs
$ cat HELLO.o58189
Hello World from 0 of 4 procs.
Hello World from 2 of 4 procs.
Hello World from 1 of 4 procs.
Hello World from 3 of 4 procs.

4CPUでの実行例
73
$ make
cc -O3 -c -o sendrecv.o sendrecv.c
cc -O3 -o sendrecv sendrecv.o
$ qsub pbs
$ cat SENDRECV.o58190
NPROCS=4:MYRANK=1
NPROCS=4:MYRANK=2
NPROCS=4:MYRANK=3

● MPIプロセス間でのメッセージを送受信するための最も基本的な関数
MPI_Send(buf,length,type,dest,tag,comm) MPI_Recv(buf,length,type,src,tag,comm,istat)
● 送信側、受信側の両者で暗黙的同期が取られる
● 通信がデッドロックに陥らないように注意する
74

主要なMPI関数の説明
75

プロセスの同期と集団通信
● 全プロセスの同期
MPI_Barrier(comm)
● データのブロードキャスト
MPI_Bcast(buf,length,type,root,comm)
● データの集積計算
MPI_Reduce(sbuf,rbuf,length,type,op,root,comm)
● データの収集
MPI_Gather(sbuf,scount,stype,rbuf,rcount,rtype,root,comm)
● データの分散
MPI_Scatter(sbuf,scount,stype,rbuf,rcount,rtype,root,comm)
76

4CPUでの実行例
77
$ make
cc -O3 -c -o 1xn.o 1xn.c
cc -O3 -o 1xn 1xn.o
$ qsub pbs
$ cat 1XN.o58192
MYRANK=0: BUF=0.000000
MYRANK=1: BUF=0.000000
MYRANK=2: BUF=0.000000
MYRANK=3: BUF=0.000000
RBUF=6.000000

非同期通信とRMA
● 非同期送受信 MPI_Isend,MPI_Irecv,MPI_Wait
暗黙的同期が無いのでsend/recvより高速
データの整合性はユーザ制御
デッドロックの危険なし
● RMA(Remote Memory Access)通信 MPI_Win_Create,MPI_Win_Free,MPI_Win_Fence
MPI_Get,MPI_Put
他プロセスのメモリへ直接アクセスするため高速
78

プログラム中の時間計測(05.mpi_wtime)
● MPI_Wtime関数: MPIプログラムの経過時間を返します
MPI_Wtimeの粒度に関してはMPI_Wtickで
システムへ問い合わせる
79

台形公式の数値積分
80

台形公式数値積分の逐次プログラム
1. 積分区間[a:b]と分割数dを入力する。
2. 積分区間をd分割し、台形則を適用する。
3. 個々に計算した台形の面積を全て足し合わせ、積分値を求める。
4. 求めた積分値を出力する。
81

台形公式数値積分の逐次プログラム
82

台形公式数値積分(06-1.integral-single)
83
main()関数

台形公式数値積分(06-1.integral-single)
84
積分関数 integral()
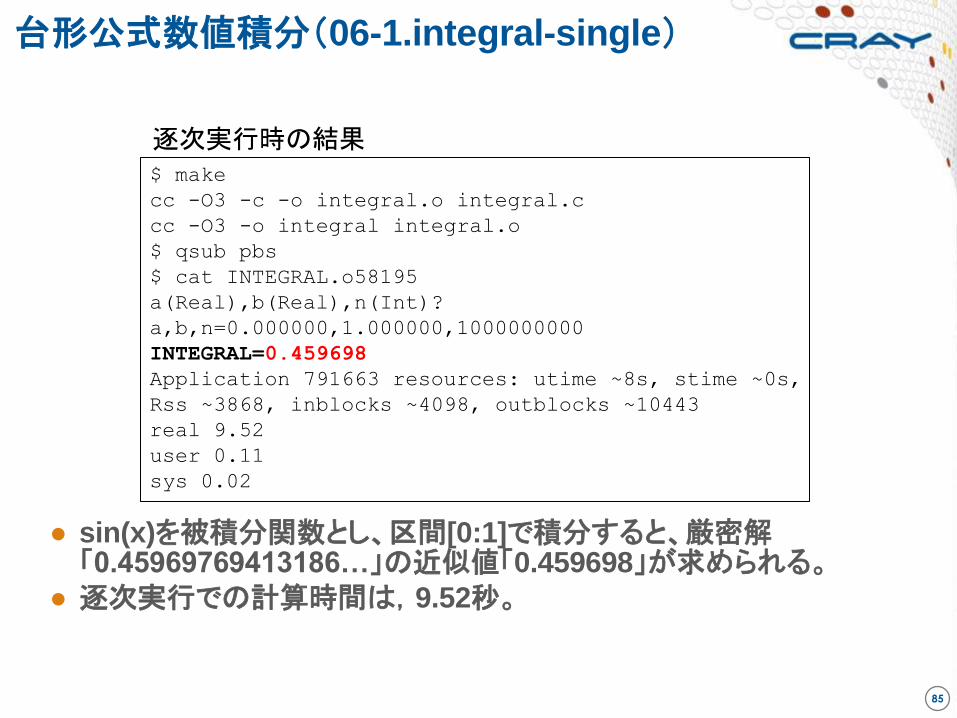
台形公式数値積分(06-1.integral-single)
● sin(x)を被積分関数とし、区間[0:1]で積分すると、厳密解「0.45969769413186…」の近似値「0.459698」が求められる。
● 逐次実行での計算時間は,9.52秒。
85
逐次実行時の結果
$ make
cc -O3 -c -o integral.o integral.c
cc -O3 -o integral integral.o
$ qsub pbs
$ cat INTEGRAL.o58195
a(Real),b(Real),n(Int)?
a,b,n=0.000000,1.000000,1000000000
INTEGRAL=0.459698
Application 791663 resources: utime ~8s, stime ~0s,
Rss ~3868, inblocks ~4098, outblocks ~10443
real 9.52
user 0.11
sys 0.02

台形公式数値積分の並列版
1. ランク0のPEで積分区間[a:b]と分割数nを入力する。
2. 積分区間をn分割し、その中で自分の担当する区間を決定する。
3. 各PEで担当する区間に対して、台形則を適用する。
4. 各PEで担当する区間に対しするローカルな積分値を求める。
5. 各PEで求めたローカルな積分値の総和により、全体の積分値を求める。
6. ランク0のPEで求めた積分値を出力する。
★
★
★
★ MPI向けの追加ロジック
86

台形公式数値積分の並列版
87

台形公式数値積分(06-2.integral-mpi)
88
main()関数

台形公式数値積分(06-2.integral-mpi)
89
main()関数の続き

台形公式数値積分(06-2.integral-mpi)
90
積分関数 integral():逐次実行版と内容が同じ

台形公式数値積分(06-2.integral-mpi)
91
領域分割関数 dist_range()

台形公式数値積分(06-2.integral-mpi)
92
領域分割関数 para_range()

台形公式数値積分(06-2.integral-mpi)
● sin(x)を被積分関数とし、区間[0:1]で積分すると、厳密解「0.45969769413186…」の近似値「0.459698」が求められる。
● 実行結果は厳密解に近い数値となっており、並列処理が正しく行われていることがわかる。
● 4並列実行での計算時間は、3.53秒。逐次実行(9.52秒)に比べ、約2.69倍の性能向上。
93
4並列実行時の結果 $ make
cc -O3 -c -o integral.o integral.c
cc -O3 -o integral integral.o
$ qsub pbs
$ cat INTEGRAL.o58197
a(Real),b(Real),n(Int)?
a,b,n=0.000000,1.000000,1000000000
INTEGRAL=0.459698
Application 791667 resources: utime ~9s, stime
~0s, Rss ~3868, inblocks ~6969, outblocks ~16594
real 3.53
user 0.19
sys 0.02

さらに進んだ使い方を学ぶには?
94

MPIプログラミングの情報源
● MPI公式Webページ ● http://www.mcs.anl.gov/research/projects/mpi/
● http://www.mpi-forum.org/
● サンプルプログラム ● http://www.mcs.anl.gov/research/projects/mpi/usingmpi2/
● 並列プログラミング入門(MPI編) ● http://www.hpci-office.jp/pages/seminar_text.html
● Netlib ● http://www.netlib.org/mpi/
● http://www.netlib.org/utk/papers/mpi-book/
● 書籍 ● 畑崎隆雄訳,実践MPI-2 メッセージパッシング・インターフェースの上級者向け機能
● W.Gropp et al.,”Using MPI 2nd. Ed.”, MIT press.
● P.S.Pacheco,”Parallel Programming with MPI”,
Morgan Kaufmann Pub.
95

96
付録: システムエラーメッセージと
対処法

デバックの前にできること
● プログラムが異常終了した際のエラーメッセージからある程度のエラー要因が特定でき、原因を特定することができます。
● ATP (Abnormal Termination Processing)モジュールを使用すると、異常終了時にはエラーメッセージの他にトレースバック情報が出力されます(後述)
● アボートプログラムの終了コードについて “exit code” から128を引いた数値がプログラムが受けたシグナル番号に相当 Application 448051 exit codes: 137 137-128=9 → SIGKILL (9)
● シグナル番号は ‘kill –l’コマンドで参照できます $ kill –l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL
5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE
9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2
13) SIGPIPE 14) SIGALRM 15) SIGTERM 17) SIGCHLD ( 詳細はman signal 参照 )
● 以降に比較的良く報告されるエラーメッセージについて原因とその対処方法を説明します
97

ATP(Abnormal Termination Processing)
● ATP(Abnormal Termination Processing)を使用すると、異常終了時にプログラムのトレースバック情報が自動的に出力されます。
● 使用方法: 1. atpモジュールをロードする(デフォルトでロード済み)
2. プログラムを再コンパイル(再リンク)する(atpモジュールが未ロードの場合のみ)
3. バッチスクリプト中で環境変数ATP_ENABLEDを1に設定する
4. プログラムを実行
5. 異常終了時にはトレースバック情報が表示され、同時にatp***.dotファイルが出力される
6. 出力されたatp***.dotファイルはstatviewコマンドにより可視化する事ができる(X11クライアントが表示できる環境で、statモジュールをロードする必要有)
$ statview atp***.dot
98
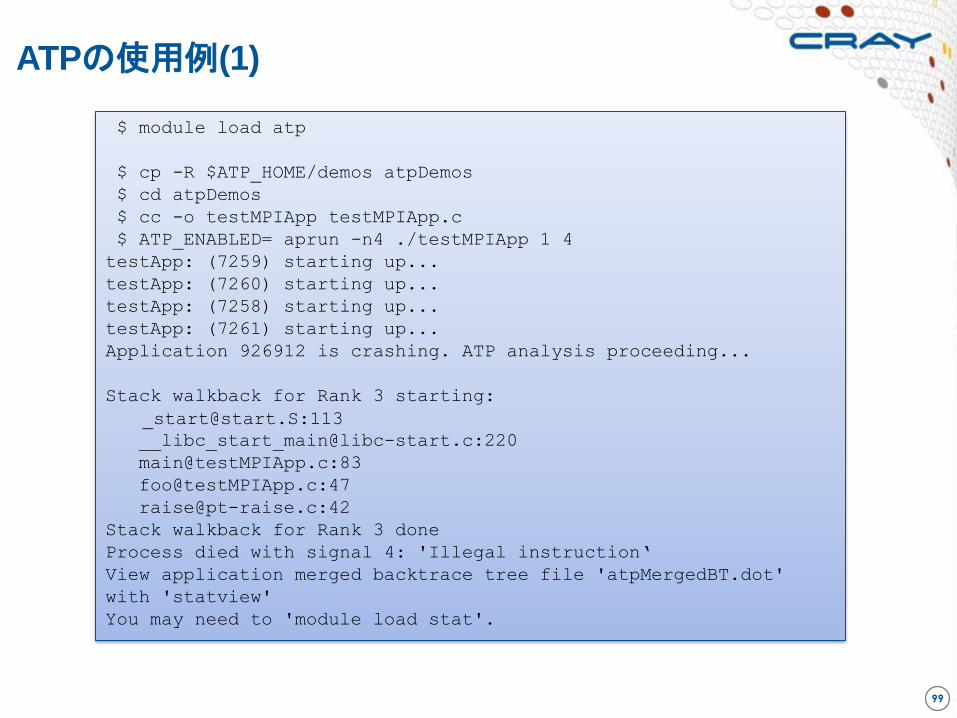
ATPの使用例(1)
$ module load atp
$ cp -R $ATP_HOME/demos atpDemos
$ cd atpDemos
$ cc -o testMPIApp testMPIApp.c
$ ATP_ENABLED= aprun -n4 ./testMPIApp 1 4
testApp: (7259) starting up...
testApp: (7260) starting up...
testApp: (7258) starting up...
testApp: (7261) starting up...
Application 926912 is crashing. ATP analysis proceeding...
Stack walkback for Rank 3 starting:
[email protected]:113 [email protected]:220
Stack walkback for Rank 3 done
Process died with signal 4: 'Illegal instruction‘
View application merged backtrace tree file 'atpMergedBT.dot'
with 'statview'
You may need to 'module load stat'.
99

ATPの使用例(2)
● statviewを使ってatp***.dotファイルを可視化した例
100

エラーメッセージ例 (1)
● aprun -n 4 ./a.out _pmii_daemon(SIGCHLD): PE 0 exit signal Killed
[NID 00078] 2009-04-26 20:48:08 Apid 448051: initiated application termination
[NID 00078] 2009-04-26 20:48:09 Apid 448051: OOM killer terminated this process.
Application 448051 exit codes: 137
Application 448051 resources: utime 0, stime 0
Command exited with non-zero status 137
● 原因
● プログラムのメモリ要求が実装メモリを越えたため、カーネルのOOM Killerにより強制終了された
● 解決方法 ● プログラムのメモリ使用量を見直す ● MPIプログラムであれば、領域分割の並列度を増やすことでプロセスあたりのメ
モリ量を減らす
101

エラーメッセージ例 (2)
● aprun ./a.out ./a.out: error while loading shared libraries: libm.so.6: cannot open shared object file: No such file or directory Application 613090 exit codes: 127
● 原因
1. コンパイラに icc, ifort, pgcc, pgf90,gcc等を直接使用し、実行ファイルを作成した場合にこのメッセージが出力される
2. 動的リンクが指定された実行ファイルを起動する際に環境変数CRAY_LD_LIBRARY_PATH, LD_LIBRARY_PATHの設定が不適切
● 解決方法
1. コンパイラは ftn, cc, CC を使用する。バックエンドコンパイラの起動コマンドを直接使用してプログラムを作成しない
2. 環境変数CRAY_LD_LIBRARY_PATH, LD_LIBRARY_PATHを明示的に設定してみる
102

エラーメッセージ例 (3)
● aprun -n 26 ./a.out Claim exceeds reservation's node-count
● 原因
● バッチスクリプトでPBSにリクエストしたリソースを超えて aprun のコア数指定を行っている。
● 解決方法 ● aprunの指定コア数 (-n)は PBSのリソース mppwidth=nn 以下を指定する
103
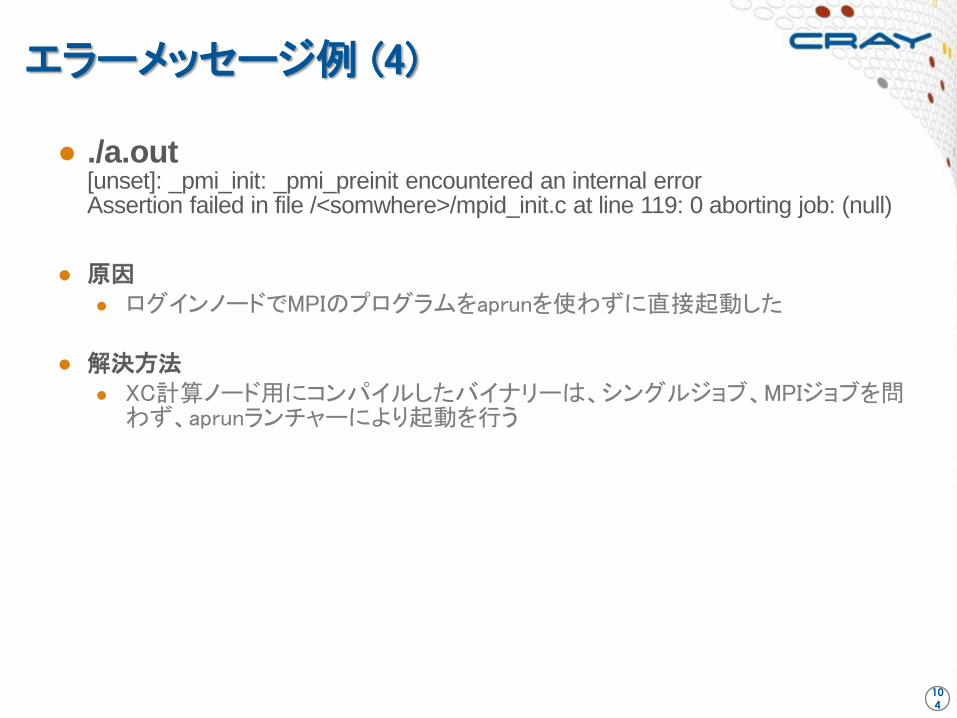
エラーメッセージ例 (4)
● ./a.out [unset]: _pmi_init: _pmi_preinit encountered an internal error Assertion failed in file /<somwhere>/mpid_init.c at line 119: 0 aborting job: (null)
● 原因
● ログインノードでMPIのプログラムをaprunを使わずに直接起動した
● 解決方法 ● XC計算ノード用にコンパイルしたバイナリーは、シングルジョブ、MPIジョブを問
わず、aprunランチャーにより起動を行う
104

エラーメッセージ例 (5)
● aprun –n 24 ./a.out Fatal error in MPI_Send: Invalid tag, error stack: MPI_Send(173): MPI_Send(buf=0x7fffffffca84, count=1, MPI_INTEGER, dest=0,
tag=-48, MPI_COMM_WORLD) failed MPI_Send(99).: Invalid tag, value is -48 aborting job:
● 原因
● MPI通信(MPI_Send)のパラメータである(tag)に不正な値が設定されている
● 解決方法 ● MPI通信のタグ変数が初期化されているかどうか、あるいは、タグに不正な値が
設定されていないかをチェックする。
105

エラーメッセージ例 (6)
● aprun –n 24 ./a.out aborting job: Fatal error in MPI_Wait: Message truncated, error stack: MPI_Wait(156).............................: MPI_Wait(request=0xa5ad40,
status0x7bf820) failed MPIDI_CRAY_ptldev_recv_event_handler(1629): Message truncated
● 原因
● MPI受信側(MPI_Recvなど)に用意されているバッファのサイズが送信データを格納するために充分なサイズが確保されていない恐れがある。このためデータがトランケートされる。
● 解決方法 ● MPIの送受信のメッセージサイズに対し充分な受信バッファが用意されているか
どうかチェックする。
106

エラーメッセージについて
● その他、MPIやジョブランチャーに関連したエラーメッセージについては、オンラインドキュメント “Cray Programming Environment User's Guide” 7. Debugging Code ● http://docs.cray.com/books/S-2529-116/S-2529-116.pdf
を参照ください
107

FORTRANプログラムメモリサイズの取得方法
108

FORTRANプログラムメモリサイズの取得
● 実行中のプログラムのメモリサイズを取得する方法 ● /proc/self/statusファイルから自プロセスのメモリ情報(VmHWM, VmRSS)を取
得
● VmHWM(ハイウォーターマーク)、VmRSS(現時点の消費量Resident Set Size)
subroutine print_hwm
parameter (lun=99)
character*80 line
integer(kind=8) hwm,rss
open(lun,file='/proc/self/status')
hwm=0
do while(.true.)
read(lun,'(a)',end=99) line
if (line(1:6).eq.'VmHWM:') read(line(8:80),*) hwm
if (line(1:6).eq.'VmRSS:') read(line(8:80),*) rss
enddo
99 close(lun)
print *,'HWM = ',hwm,'kB =',hwm*1024,'bytes'
print *,'RSS = ',rss,'kB =',rss*1024,'bytes'
return
end
109

付録:OpenMPによる並列化

● OpenMP指示行、自動並列化による並列化はノード内のみ
● XCではノード内24コアまで
● ノードをまたがる並列化はMPIにより明示的に行う
● スレッド数はaprunの-dオプションにより指定する
● OMP_NUM_THREADSと同じスレッド数を –dオプションで指定
● 両者の値が異なる場合、物理的なCPUコア数は-dオプションで指定する値で確保される
OpenMPと自動並列化
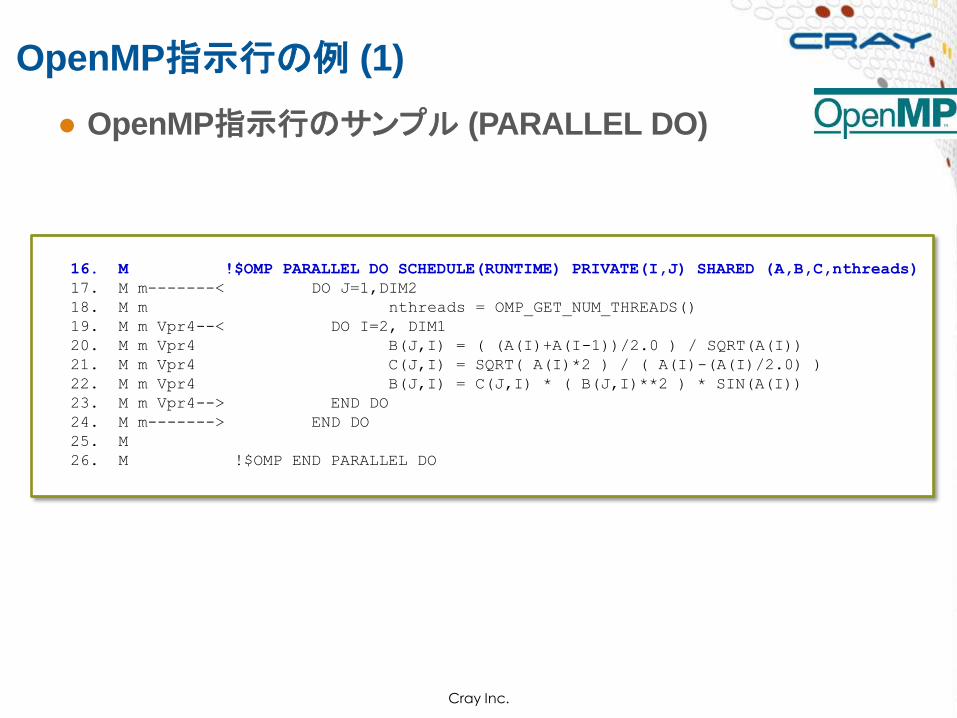
● OpenMP指示行のサンプル (PARALLEL DO)
OpenMP指示行の例 (1)
Cray Inc.
16. M !$OMP PARALLEL DO SCHEDULE(RUNTIME) PRIVATE(I,J) SHARED (A,B,C,nthreads)
17. M m-------< DO J=1,DIM2
18. M m nthreads = OMP_GET_NUM_THREADS()
19. M m Vpr4--< DO I=2, DIM1
20. M m Vpr4 B(J,I) = ( (A(I)+A(I-1))/2.0 ) / SQRT(A(I))
21. M m Vpr4 C(J,I) = SQRT( A(I)*2 ) / ( A(I)-(A(I)/2.0) )
22. M m Vpr4 B(J,I) = C(J,I) * ( B(J,I)**2 ) * SIN(A(I))
23. M m Vpr4--> END DO
24. M m-------> END DO
25. M
26. M !$OMP END PARALLEL DO

● OpenMPリダクション型ループ (総和,最大,最小)
OpenMP指示行の例 (2)
8. s=0.0d0
9. dmx=0.0d0
10. dmn=0.0d0
11. M !$OMP PARALLEL PRIVATE(i) SHARED(N,A) REDUCTION(+:s) &
12. M !$OMP REDUCTION(MAX:dmx) REDUCTION(min:dmn)
13. M !$OMP DO
14. M mVr4--< do i=1,n
15. M mVr4 s=s+a(i)
16. M mVr4 dmx = max(dmx,a(i))
17. M mVr4 dmn = min(dmx,a(i))
18. M mVr4--> end do
19. M !$OMP END DO NOWAIT
20. M !$OMP END PARALLEL

● OpenMP公式Webページ ● http://openmp.org/wp/
● OpenMP書籍 ● 「OpenMPによる並列プログラミングと数値解析」 丸善
OpenMPプログラミングの情報
Slide 114

115
Related Documents











