COPPE/UFRJ COPPE/UFRJ DESCOBERTA DE CONHECIMENTO EM UM PROGRAMA DE GESTÃO DE BENEFÍCIO DE MEDICAMENTOS Valmir Santos Sobral Dissertação de Mestrado apresentada ao Programa de Pós-graduação em Engenharia Civil, COPPE, da Universidade Federal do Rio de Janeiro, como parte dos requisitos necessários à obtenção do título de Mestre em Engenharia Civil. Orientador: Nelson Francisco Favilla Ebecken Rio de Janeiro JANEIRO de 2009

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

COPPE/UFRJCOPPE/UFRJ
DESCOBERTA DE CONHECIMENTO EM UM PROGRAMA DE GESTÃO DE
BENEFÍCIO DE MEDICAMENTOS
Valmir Santos Sobral
Dissertação de Mestrado apresentada ao
Programa de Pós-graduação em Engenharia
Civil, COPPE, da Universidade Federal do Rio
de Janeiro, como parte dos requisitos necessários
à obtenção do título de Mestre em Engenharia
Civil.
Orientador: Nelson Francisco Favilla Ebecken
Rio de Janeiro
JANEIRO de 2009

Livros Grátis
http://www.livrosgratis.com.br
Milhares de livros grátis para download.

DESCOBERTA DE CONHECIMENTO EM UM PROGRAMA DE GESTÃO DE
BENEFICIO DE MEDICAMENTOS
Valmir Santos Sobral
DISSERTAÇÃO SUBMETIDA AO CORPO DOCENTE DO INSTITUTO ALBERTO
LUIZ COIMBRA DE PÓS-GRADUAÇÃO E PESQUISA DE ENGENHARIA
(COPPE) DA UNIVERSIDADE FEDERAL DO RIO DE JANEIRO COMO PARTE
DOS REQUISITOS NECESSÁRIOS PARA A OBTENÇÃO DO GRAU DE MESTRE
EM CIÊNCIAS EM ENGENHARIA CIVIL.
Aprovada por:
________________________________________________
Prof. Nelson Francisco Favilla Ebecken, Dsc.
________________________________________________ Prof. Alexandre Gonçalves Evsukoff, Dr.
________________________________________________ Prof. Elton Fernandes, Ph.D.
RIO DE JANEIRO, RJ - BRASIL
JANEIRO DE 2009

iii
Sobral, Valmir Santos
Descoberta de Conhecimento em um Programa de
Gestão de Beneficio de Medicamentos / Valmir Santos
Sobral. - Rio de Janeiro: UFRJ/COPPE, 2009.
IX, 49 p.: il.; 29,7 cm.
Orientador: Nelson Francisco Favilla Ebecken
Dissertação (mestrado) – UFRJ/ COPPE/ Programa de
Engenharia Civil, 2008.
Referencias Bibliográficas: p. 50-41.
1. Mineração de dados. 2. Regras de Associação.
3.Gestão de Medicamentos. I. Ebecken, Nelson Francisco
Favilla. II. Universidade Federal do Rio de Janeiro,
COPPE, Programa de Engenharia Civil. III. Titulo.

iv
Agradecimentos
Aos meus pais José Freire Sobral e Maria José Santos Sobral e a minha avó Maria
Petronila Cruz.
Ao Professor Dsc. Nelson Ebecken pela paciência e na ajuda da realização de um
sonho.
Ao meu inestimável amigo Humberto Rubens Maciel Pereira.
Ao Amigo Martius Vicente Rodriguez y Rodriguez pelo estimulo na obtenção do
conhecimento.
As Dras. Angélica de Oliveira Gonçalves, Karla Costa Kurtz e Maria Tereza Castro
Telles e ao Dr. Frederico Araújo de Lucena, especialistas técnicos que contribuíram
com suas análises.

v
Resumo da Dissertação apresentada à COPPE/UFRJ como parte dos requisitos
necessários para a obtenção do grau de Mestre em Ciências (M.Sc.)
DESCOBERTA DE CONHECIMENTO EM UM PROGRAMA DE GESTÃO DE
BENEFICIO DE MEDICAMENTOS
Valmir Santos Sobral
Janeiro/2009
Orientador: Nelson Francisco Favilla Ebecken
Programa: Engenharia Civil
Os custos em saúde estão em uma curva de ascendência e algumas Operadoras de
Plano de Saúde oferecem aos seus beneficiários um Programa de Beneficio farmácia
cujo objetivo é facilitar a aquisição de medicamento para que a saúde seja restabelecida
e desta forma também minimizar os custos do tratamento da doença. As organizações
que prestam serviços em saúde estão usando as técnicas Data Mining como ferramenta
de auxilio na gestão. Na utilização da técnica de Data Mining, os algoritmos de
extração de regras de associação, constituem um ferramental bastante importante que
tem o objetivo de identificar o conhecimento em grandes bases de dados. O objetivo
deste trabalho foi a explicitação de conhecimento em base de dados de compra de
medicamentos, em Programa de beneficio de medicamentos em uma operadora de
plano de saúde, através da classe terapêutica.

vi
Abstract of Dissertation presented to COPPE/UFRJ as a partial fulfillment of the
requirements for the degree of Master of Science (D.Sc.)
DISCOVERY OF KNOWLEDGE IN ONE PROGRAM OF MANAGEMENT OF
BENEFIT OF MEDICINES
Valmir Santos Sobral
January/2009
Advisor: Nelson Francisco Favilla Ebecken
Department: Civil Engineering
Health costs are in an ascending curve and some health plano companies offer theur
beneficiaries a pharmacy benefit program whose goal is to make the acquisition of
medicine easy, so that health is restored and therefore treatment costs are reduced as
well. The companies which render service in health are using data mining techniques as
a management support tool. By doing so, the algorithms of association rules extraction
form a quite important instrument that aims at identifying knowledge in large database.
Our work is to obtain rules of utilization of these medications through the therapeutical
class.

vii
SUMÁRIO
1. INTRODUÇÃO..........................................................................................................1
1.1 Objetivo.....................................................................................................................1
1.2 Organização da Dissertação..............................................................................2
1.3 Kdd e Mineração de Dados ...............................................................................2
2 - APLICAÇÕES DE DATA MINING EM SAÚDE ............. ...................................4
2.1 Descoberta de Regras de Associação de Doenças Relacionadas com
Síndrome Metabólica.....................................................................................................5
2.2 Desenvolvimento de Algoritmos Preditivos de Custos em Saúde .................5
2.3 Detecção de Fraudes .........................................................................................6
2.4 Metodologia para Identificar Pagamentos Além do Esperado nas Empresas
de Seguro Saúde. ............................................................................................................6
3 - CONTEXTO DO NEGÓCIO ..................................................................................7
3.1 AMS - Assistência Multidisciplinar de Saúde ................................................7
3.2 Apresentação ......................................................................................................8
3.3 Programa de Beneficio Farmácia ...................................................................10
3.4 PBMs – Empresas Independentes de Gerenciamento do Programa de
Benefício Farmacêutico. ..............................................................................................12
3.5 Confidencialidade dos Dados ..........................................................................15
3.6 Implementação do Programa de Beneficio de Medicamentos na
PETROBRAS ...............................................................................................................16
3.7 Ciclo da Utilização do Benefício Farmácia ....................................................18

viii
3.8 O Problema.......................................................................................................20
4 - O PROCESSO DE DESCOBERTA DO CONHECIMENTO ...........................21
4.1 Regras de Associação .......................................................................................21
4.2 Formalização do Problema .............................................................................23
4.3 Interessabilidade das Regras...........................................................................25
5 – O ESTUDO DE CASO...........................................................................................27
5.1 Descrição dos Dados.........................................................................................27
5.2 Estatística dos Dados .......................................................................................31
5.3 Resultados e Análises .......................................................................................34
5.4 Seleção das Regras Obtidas.............................................................................34
5.5 Análise dos Resultados.....................................................................................37
6 - CONCLUSÕES.......................................................................................................46
6.1 Trabalhos Futuros............................................................................................49
REFERÊNCIAS BIBLIOGRÁFICAS.......................................................................48
ANEXOS.......................................................................................................................50

ix
LISTA DE FIGURAS
Figura 1 - Ciclo do PBM.................................................Erro! Indicador não definido.
Figura 2 - Criação de diagrama para uso na técnica de Regra de Associação...............62
Figura 3 - Seleção do diretório de dados........................................................................63
Figura 4 - Nome da tabela criada ...................................................................................63
Figura 5 - Biblioteca para carga dos dados ....................................................................64
Figura 6 - Propriedades da tabela criada........................................................................64
Figura 7 - Definição das variáveis para uso na técnica de Regra de Associação...........65
Figura 8 - Seleção de variável........................................................................................65
Figura 9 - Seleção para uso em redes não supervisionadas ...........................................66
Figura 10 - Definição da finalidade da tabela (Transação) ............................................66
Figura 11 - Construção do diagrama – Seleção da tabela de dados ...............................67
Figura 12 - Construção do diagrama – Seleção da técnica – Regra de Associação.......70
Figura 13 - Input de parâmetros da técnica de Regra de Associação.............................71
Figura 14 - Matriz de regras geradas..............................................................................72
Figura 15 - Gráfico Suporte x Confiança.......................................................................73
Figura 16 - Algumas informações estatísticas ...............................................................74

x
Figura 17 - Regras produzidas .......................................................................................75

xi
LISTA DE TABELAS
Tabela 1 - Benefícios farmacêuticos - Vantagens e desvantagens.................................14
Tabela 2 - Doenças de maior freqüência segundo o Ministério da Saúde .....................17
Tabela 3 - Atributos utilizados no estudo ......................................................................27
Tabela 4 - Faixas etárias segundo ANS .........................................................................27
Tabela 5 - Limites de compra.........................................................................................28
Tabela 6 - Domínio do tipo de beneficiários..................................................................28
Tabela 7 - Domínio do campo sexo ...............................................................................29
Tabela 8 - Atributos e respectivas descrições ................................................................30
Tabela 9 - Faias etárias de beneficiários que adquiriam medicamentos .......................32
Tabela 10 - Beneficiários e itens comprados .................................................................32
Tabela 11 - Beneficiários por faixa salarial ...................................................................33
Tabela 12 - Itens comprados por classe terapeutica.......................................................33
Tabela 13 - Classe terapêutica X faixa etária.................................................................34
Tabela 14 - Resumo - parte 1 .........................................................................................33
Tabela 15 - Resumo - Parte 2.........................................................................................35
Tabela 16 - Descrição dos atributos da análise ..............................................................36
Tabela 17 - Regra 1 ........................................................................................................37

xii
Tabela 18 - Regra 2 ........................................................................................................38
Tabela 19 - Regra 3 ........................................................................................................37
Tabela 20 - Regra 4 ........................................................................................................39
Tabela 21 - Regra 5 ........................................................................................................40
Tabela 22 - Regra 6 ........................................................................................................41
Tabela 23 - Regra 7 ........................................................................................................41
Tabela 24 - Regra 8 ........................................................................................................42
Tabela 25 - Regra 9 ........................................................................................................44
Tabela 26 - Regra 10 ......................................................................................................45

1
1 - INTRODUÇÃO
Segundo MAGALHÃES (2006), o aumento crescente no número de
informações e a capacidade de armazenamento em mídia digital, principalmente nas
organizações em suas operações diárias geram e coletam grandes volumes de dados, não
são capazes de processá-las em sua plenitude para obtenção de conhecimentos, pois as
informações úteis estão implícitas e são de difícil compreensão.
Segundo KENNETH (1998), obter conhecimentos em base de dados é uma área
de pesquisa crescente que atrai esforços de pesquisadores e investimentos nas
Organizações na busca de identificar informações importantes que as possibilitem
entender as demandas e o consumo dos clientes para obtenção de vantagens
competitivas.
Segundo MAGALHÃES (2006) o processo de transformar os dados em
informações que possam auxiliar à tomada de decisões é de extrema complexidade. As
organizações precisam identificar quais são as informações importantes e utilizá-las em
seu processo de tomada de decisões para se manterem competitivas. Portanto a
automação de técnicas de análises de dados é de fundamental importância.
1.1 Objetivo
O objetivo principal deste trabalho é a descoberta de regras de consumo de
medicamento a partir da classe terapêutica dos mesmos. Para tal utilizamos os dados de
compras dos medicamentos efetuados pelos beneficiários, a partir da implementação de
um programa de beneficio de medicamentos, em uma operadora de plano de saúde na
modalidade de autogestão usando uma empresa de PBM (Pharmacy Benefits
Management).
Com base nos dados de compra de medicamentos, o objetivo é identificar regras
de associação através de alguns atributos de compra para subsidiar a gestão do
programa de beneficio de medicamentos, melhorar a governança e identificar padrões
de consumo.

2
Periodicamente a lista de medicamento deve ser revisada, seja para exclusão ou
inclusão de novos medicamentos. Neste contexto a aplicação do conhecimento obtido a
partir das regras identificadas é de fundamental relevância na qualidade das decisões a
serem tomadas.
1.2 Organização da Dissertação
Este trabalho está organizado da seguinte forma:
No capítulo 1, apresentação do trabalho.
No capítulo 2, descrição de algumas aplicações de data mining em saúde.
No capítulo 3 é apresentado o contexto do negócio, o problema e o processo de
implementação de uma PBM.
No capítulo 4 um resumo da obtenção da descoberta de conhecimento em data
mining, a técnica utilizada - Regras de Associação, Formalização do problema e a
interessabilidade das regras.
No capítulo 5 é apresentado o estudo do caso, descrição dos dados, resultados
obtidos e o método usado para interessabilidade de seleção das regras.
A conclusão do trabalho é apresentada no capítulo 6 assim como a indicação de
possíveis estudos futuros.
1.3 Kdd e Mineração de Dados
O termo "Descoberta de Conhecimento em Base de Dados" (KDD – Knowledge
Discovery in Databases) foi utilizado em 1989 para referir-se ao processo total de
procurar conhecimentos em dados, com a aplicação de técnicas de Data Mining.
Inicialmente, foram designados vários nomes à noção de achar padrões úteis em dados

3
brutos, tais como Data Mining, Extração de Conhecimento, Descoberta de Informação,
Mineração de Dados e Processamento do Padrão de Dado. Pode-se, então, afirmar que
KDD refere-se ao processo completo da descoberta de conhecimento, enquanto que
Data Mining é uma de suas etapas voltada a aplicar algoritmos específicos e a produzir
padrões sobre uma base de dados, segundo FAYYAD (1996).
Mineração de Dados é uma área de pesquisa multidisciplinar, incluindo a
tecnologia de banco de dados, inteligência artificial, aprendizado de máquina, redes
neurais, estatística, reconhecimento de padrões, sistemas baseados em conhecimento,
recuperação da informação, computação de alto desempenho e visualização de dados,
segundo AMO (2003).

4
2 - APLICAÇÕES DE DATA MINING EM SAÚDE
O DM é aplicado em uma grande variedade de áreas, entre elas, pode-se citar:
vendas e marketing, bancos, saúde, telecomunicações, seguros, análise de vendas para
promoções, análise de perfil e comportamento de consumidores, detecção de fraudes,
etc. IBM (1996).
BALLENGER (1999) cita algumas vantagens obtidas com o uso de DM em
aplicações na saúde:
• Reduzir custos, respondendo a perguntas, tais como: quais tratamentos
são mais eficientes e, dentre esses, quais são os mais baratos?
• Melhorar a qualidade no atendimento, através da avaliação dos médicos e
dos recursos empregados.
• Detectar fraudes: verificando se os médicos estão solicitando um número
excessivo de exames e quais exames estão sendo solicitados por
diagnóstico.
Nas próximas seções apresentam-se alguns casos de aplicações de Data Mining
na área de saúde.

5
2.1 Descoberta de Regras de Associação de Doenças Relacionadas com
Síndrome Metabólica
Desde 1980, a hipertensão arterial e diabetes mellitus na síndrome metabólica,
estavam entre as dez principais causas de morte todos os anos em Taiwan. Foi efetuada
uma pesquisa para estudar as doenças relacionadas com a síndrome metabólica, usando
a técnica de regras de associação, para compreender a associação entre diabetes
mellitus, hipertensão e hiperlipidemia com doenças associadas a síndrome metabólica.
A técnica utilizada encontrou e confirmou a relação entre as doenças. Foi
descoberto também que a diabetes está relacionado a doenças bucais e cegueira e que
pacientes com síndrome metabólica têm maior ligação com doenças hepáticas do que os
pacientes com diabetes mellitus.
O estudo foi realizado no Departamento de Gestão da Informação da
Universidade Yuan Zé, Taiwan e publicado em 2008 no Congresso Mundial de
Inteligência Computacional. Chan, CHIEN-LUNG et al. (2008)
2.2 Desenvolvimento de Algoritmos Preditivos de Custos em Saúde
O aumento dos custos dos cuidados de saúde é um dos problemas mais
importantes do mundo. Por conseguinte, prever com precisão estes custos é um
importante primeiro passo na resolução deste problema.
Para tal foi utilizada de técnicas de arvores de classificação e de clusterização
para desenvolvimento de modelos preditivos de custos em uma seguradora de saúde. As
técnicas utilizadas geraram modelos preditivos com bastante precisão para predição de
custos futuros dos beneficiários.
O estudo foi conduzido por BERTSIMAS et al (2008) em uma seguradora de
saúde com 800.000 registros de utilização de procedimentos médicos.

6
2.3 Detecção de Fraudes
Projeto de mineração de dados desenvolvido por pesquisadores da Universidade
de Changhua de Taiwan para detecção de casos abusivos ou fraudulentos nos sistemas
de saúde, SILVA SANTOS (2007)
2.4 Metodologia para Identificar Pagamentos Além do Esperado nas
Empresas de Seguro Saúde
O seguro privado de saúde estima o reembolso com a despesa em saúde nos
Estados Unidos para 2010 em um trilhão de dólares para 2010 com mais de duzentas
milhões de vidas seguradas. Foi elaborada uma metodologia para minimizar os
pagamentos de reembolso errados ou além do previsto foram utilizadas técnicas de
modelagem preditiva e de regra de associação para identificar padrões de pagamentos
aos diversos prestadores de saúde, além do esperado nas contas médicas. Com a
metodologia as seguradoras minimizam custos e oferecem seguros saúde mais cessíveis.
Os pesquisadores ANAND e KHOTS (2008) da Seguradora West Asset
Management elaboraram a metodologia.

7
3 - CONTEXTO DO NEGÓCIO
3.1 AMS - Assistência Multidisciplinar de Saúde
O setor de saúde suplementar no Brasil reúne mais de duas mil empresas
operadoras de planos de saúde, milhares de médicos, dentistas e outros profissionais,
hospitais, laboratórios e clínicas. Toda essa rede prestadora de serviços de saúde atende
a mais de 37 milhões de consumidores que utilizam planos privados de assistência à
saúde para realizar consultas, exames ou internações e tem seu funcionamento
regulamentado pela lei 9656 e normatizado e fiscalizado pela ANS (Agência Nacional
de Saúde Suplementar).
A Agência Nacional de Saúde Suplementar - ANS é uma agência reguladora,
vinculada ao Ministério da Saúde, que trabalha para promover o equilíbrio nas relações
entre esses segmentos para construir, em parceria com a sociedade, um mercado sólido,
equilibrado e socialmente justo.
Segundo a ANS, as Operadoras de Planos de Assistência à Saúde são as
empresas e entidades que atuam no setor de saúde suplementar oferecendo aos
consumidores os planos de assistência à saúde.
O presente trabalho está inserido no contexto da saúde, na descoberta de
conhecimento a partir da utilização do Programa de benéfico farmácia da AMS
(Assistência Multidisciplinar de Saúde – Plano de Saúde de Autogestão da Petrobras
com o propósito de subsidiar a gestão do benefício, obtendo informações sobre os
medicamentos prescritos pela rede credenciada ou por profissionais não associados e
identificar grupos de usuários, em função da utilização dos medicamentos por classe
terapêutica, para desenvolver Programas preventivos de saúde.

8
3.2 Apresentação
Em cinqüenta e cinco anos de atividades, a Petrobras se transformou na maior
empresa brasileira e uma das principais empresas de energia em todo o mundo.
Uma conquista que não se deve apenas à competência da força de trabalho, mas
também a uma política de recursos humanos agressiva na defesa do bem-estar dos
empregados e de suas famílias, instrumento básico para a tranqüilidade no
desenvolvimento das atividades.
Entre os vários benefícios que compõem a política de recursos humanos, a
Assistência Multidisciplinar de Saúde - AMS - se firmou como um dos mais
importantes.
O Programa de Assistência Multidisciplinar de Saúde – AMS é um benefício
empresarial, gerenciado e operacionalizado pela Petrobras (Autogestão), oferecido na
modalidade de co-participação, sem fins lucrativos que foi criado em 1975 por decisão
da Diretoria Executiva, para atender às necessidades de saúde dos empregados,
aposentados, pensionistas e seus dependentes para assegurar a todos os beneficiários
uma abrangente assistência à saúde, com qualidade comprovada, substituindo com
vantagens, um plano ou seguro saúde, privado em que a mensalidade é muito superior e
de cobertura menos abrangente. Algumas das vantagens e diferenciais em relação ao
mercado:
1. Acesso aos serviços de saúde, sem carência;
2. Ampla Rede de Credenciados;
3. Assistência Domiciliar;
4. Cobertura de doenças pré-existentes, infecto-contagiosas;
5. Cobertura de Próteses;
6. Psicoterapia;
7. Transplantes;
8. Tratamento de Dependência Química;
9. Tratamento Odontológico;

9
A Petrobras está presente em todo o território nacional e para oferecer
atendimento de qualidade a todos os beneficiários tem uma ampla rede credenciada com
mais de 22000 credenciados (Hospitais, Clínicas, Laboratórios, Consultórios médicos,
Consultórios odontológicos, etc.) em diversas especialidades (Cardiologia, Clinico
Geral, Cirurgia vascular, Implantodontia, Neurologia, etc.) e atendendo, no mínimo, ao
conjunto de procedimentos obrigatórios estabelecidos pela ANS.
BENEFICIÁRIOS
São funcionários, aposentados com os seus dependentes que, atendendo ao
regulamento de elegibilidade, estejam inscritos na AMS.
Os tipos de beneficiários que podem ser inscritos na AMS são:
• Empregados
• Aposentados
• Filhos e Filhas até completarem 21 anos ou se universitários até os 24
anos
• Filhos e Filhas entre 21 e 33 anos (não sendo universitários)
• Cônjuge/Companheira(o)
• Enteadas (os)
• Filhos (as) adotivos (as)
• Pais e Mães (cuja inclusão foi permitida até Dezembro/1997)
A Petrobrás também oferece outros quatro programas em complemento a este
beneficio:
• PAD – Programa de Assistência Domiciliar – Programa que permite a
prestação de cuidados na cada do beneficiário, permitindo conforto,
qualidade e segurança.

10
• PASA - Programa de Avaliação de Saúde dos Aposentados – Programa
tem o objetivo de estimular a prevenção da saúde dos aposentados
• PAE – Programa de Assistência Especial – Programa para atender as
necessidades educacionais e assistenciais dos beneficiários que
necessitam de atendimento especial.
• Benefício farmácia - É um programa que prevê condições especiais para
atender as necessidades de aquisição de alguns medicamentos, em
farmácias credenciadas pela gerenciadora contratada e distribuídas na
maior parte do território nacional.
3.3 Programa de Beneficio Farmácia
Segundo VIANNA (2003), no âmbito da saúde privada, a assistência
farmacêutica tem por objetivo corroborar com a manutenção da saúde dos beneficiários,
que já se beneficiam dos demais programas de saúde. Estudos demonstram que o
favorecimento de condições para que indivíduos permaneçam aderentes aos tratamentos
propostos contribui para a moderação da utilização dos serviços médicos e hospitalares,
o que, conseqüentemente, leva a uma redução de custos, além de proporcionar maior
bem-estar ao usuário.
A não aderência ao tratamento medicamentoso é um dos fatores mais incisivos
no aumento dos custos com saúde, já que leva ao aumento do número de consultas
médicas e das hospitalizações. Além disso, um paciente que não toma medicamento
pode parecer refratário ao tratamento, experimentar uma piora na sua condição física, o
que pode levar o médico a suspeitar de erro no diagnóstico inicial e a prescrever outros
medicamentos, às vezes mais potentes, porém, com maiores efeitos colaterais do que o
anteriormente prescrito.
A maioria dos países tem direcionado atenção especial aos seus sistemas de
saúde cujo objetivo maior é cumprir com o princípio de acesso universal aos serviços de
saúde como direito de todos os indivíduos.

11
Segundo MOSEGUI (2003) as operadoras de saúde pesquisam novas ofertas de
benefícios, assistência e gerenciamento de farmacêuticos, objetivando não só a melhoria
da qualidade de vida, mas também a redução dos custos assistenciais com os seus
beneficiários. Desta forma a disponibilização de medicamentos quando associado a
programas de assistência farmacêutica e gerenciamento de doenças o acesso aos
medicamentos pode promover aumentos reais na qualidade e expectativa de vida dos
beneficiários e diminuição nas despesas dos custos assistenciais da operadora, devido a
continuidade no tratamento farmacológico adequado.
Segundo VIANNA (2003) a grande maioria das operadoras oferece o programa
de beneficio farmácia em função de uma das 03 modalidades:
Farmácias próprias - Nesta modalidade a operadora possui uma rede de
farmácias próprias o que permite, maior controle de custo, acesso imediato após a
prescrição médica aos medicamentos pelos beneficiários sem burocracia e acesso dos
médicos aos farmacêuticos. O custo operacional pode ser alto caso o número de
prescrições seja baixo, operações em regiões geográficas distantes podem ser inviáveis
devido ao custo de dispensação.
Farmácias contratadas - Nesta modalidade a operadora contrata uma ou mais
redes de farmácias, o reembolso é negociado entre a operadora e as redes, por
medicamento dispensado ou por usuário por mês (custo capitado). A rede de farmácias
negociam com os atacadistas ou com as indústrias farmacêuticas redução no preço dos
medicamentos. Algumas operadoras oferecem esta facilidade mesmo tendo rede de
farmácias próprias para seus beneficiários.

12
3.4 Pbms - Empresas Independentes de Gerenciamento do Programa
de Benefício Farmacêutico.
Segundo LIMA et al (2008), o sistema PBM surgiu na década de 1970 nos EUA
quando os empregadores foram pressionados pelos sindicatos para que incluíssem o
beneficio em medicamentos entre os direitos trabalhistas. Entre a década de 1980 e 1990
a parcela de medicamentos adquiridos nesta modalidade cresceu de 20% para pouco
mais de 50%.
Segundo MIRANDA (2003) dados da PCMA (Pharmaceutical Care
Management Association) foram atendidos 190 milhões de beneficiários com cerca de
dois bilhões de prescrições processadas ao ano e uma movimentação de US$ 164
bilhões por 170 empresas de PBMs nos EUA.
Segundo MOSEGUI (2003) as PBM´s são empresas que gerenciam o programa
de beneficio farmacêutico, desoneram as operadoras da operação do programa,
processam os pedidos de aquisição de medicamentos, verificam elegibilidade dos
beneficiários, reembolsam as farmácia e negociam contratos para obtenção de descontos
junto a industria farmacêutica, distribuidoras de medicamentos e redes de farmácias.
A modalidade mais comum de custeio da aquisição do medicamento é aquela em
que o beneficiário e a operadora ou empregador contribuem com parte do preço do
medicamento. A contribuição financeira do beneficiário é denominada de co-
participação e funciona como fator inibidor de abuso na utilização de medicamentos.
O pagamento poderá ocorrer no momento da aquisição do medicamento ou
descontados na folha de pagamento. A co-participação da operadora poderá variar de
0% a 100% e o beneficiário contribuirá com o percentual do complemento para 100%
do valor do medicamento.
As PBM´s oferecem os seguintes serviços:
• Negociação com as redes de farmácias ou com farmácias independentes para
que se tornem suas afiliadas para que possam dispor de uma rede bastante

13
numerosa e de abrangência bastante dispersa para que o acesso dos beneficiários
seja facilitado.
• A possibilidade de não haver desembolso no momento da aquisição dos
medicamentos. Posteriormente os valores a serem faturados serão enviados a
operadora para efetuar o pagamento. Algumas operadoras assumem o valor total
da fatura e outras subsidiam o valor e descontam parte dos beneficiários.
• Disponibilizam facilidade de comunicação com as farmácias para verificação de
elegibilidade dos beneficiários e controle dos medicamentos prescritos. Esta
facilidade é feita através de conexão entre o sistema da farmácia e o da PBM,
uso de POS (point of sale), contato telefônico ou através de formulários em
papel.
• Periodicamente enviam diversos tipos de relatórios as operadoras contendo as
informações que possibilitam a operadora gerenciar a qualidade do beneficio
oferecido para coibir o uso desnecessário de medicamentos, controle da
sinistralidade, perfis de prescrição e de venda de medicamentos, incentivo aos
medicamentos genéricos.
• Participam junto com as operadoras na elaboração e da revisão da lista de
medicamentos que será contemplada no programa, mantendo-as atualizadas
conforme as novas necessidades identificadas ou conforme as normatizações do
setor farmacêutico.
• Elaboram programas de adesão e de gerenciamento de doenças crônicas,
inclusive com a utilização de técnicas de data mining, informam as operadoras
sobre os beneficiários que não dão continuidade a prescrição médica, criam
programas de educação e incentivam mudanças de estilo de vida.
• Serviços de call centers ativos com o objetivo contatar aos beneficiários para
informá-los da utilização dos medicamentos e obter informações de saúde e de
estilo de vida.

14
A tabela 1 apresenta uma comparação entre os tipos de benefício farmacêutico
descrevendo as vantagens, desvantagens e Perfil da operadora.
Tabela 1 - Benefícios farmacêuticos - Vantagens e desvantagens
Modelo de Beneficio Vantagens Desvantagens Perfil da operadora
Farmácias próprias Maior controle do
custo e do serviço
prestado
Escolha limitada pelo
usuário
Adequado para
operadoras com
abrangência local ou
regional e para
aquelas que não
podem ser muito
oneradas com o
beneficio farmácia
Redes contratadas Maior controle dos
custos
Escolha limitada pelo
usuário
PBM´s Maior escolha por
parte do usuário
devida a abrangência
da rede.
Maior poder de
negociação com a
indústria para
obtenção de
descontos.
Menor controle de
custo
Ideal para operadoras
com abrangência
nacional, que podem
arcar com os custos
do beneficio
terceirizado
Fonte: EDGE (1997)
Segundo VIANNA (2003) as iniciativas de oferecer programa de beneficio
farmacêutico no Brasil estão limitadas a poucas operadoras devido a não existir
qualquer regulamentação pela ANS. As iniciativas são de grande variabilidade na oferta
do benefício e nos mecanismos de controles de custo e de fraude. O não gerenciamento
correto pode implicar na utilização indevida dos medicamentos distorcendo o principio
do benefício e desta forma contribuir nos custos assistências das operadoras.

15
Segundo VIANNA (2003), no Brasil, existe grande margem para negociação de
descontos entre Operadoras com os distribuidores e varejistas. De cada R$ 100,00 pagos
pelo consumidor pelo medicamento, a indústria fica com R$ 42,60; o varejo com R$
30,00; o distribuidor com R$ 12,60; R$ 10,30 para ICMS; R$ 2,10 para PIS/COFINS;
R$ 1,00 para frete e R$ 1,40 é custo de financiamento de vendas. Portanto as operadoras
que oferecem o benéfico por meio de farmácias próprias têm condições de obter
redução sobre o custo total do medicamento, parcelas dos distribuidores e varejistas. As
PBMs que tem parcerias com os grandes distribuidores podem obter descontos com a
indústria e varejistas.
3.5 Confidencialidade dos Dados
Em 1998 duas redes de farmácias nos EUA enviaram dados de consumo de
medicamentos de beneficiários de um programa de beneficio de farmácia para a
empresa Elensys de database marketing. A empresa enviou correspondência lembrando
aos beneficiários, sem o consentimento destes, da necessidade de compra dos
medicamentos utilizados e do lançamento de novos medicamentos para suas doenças
JAMA (2000).
Em 1999 foi publicado a HIPAA (Health Insurance Portability and
Accountability Act) pelo Congresso do EUA, regulamentando que dados dos pacientes
não podem ser identificados individualmente em formato eletrônico pelas empresas
envolvidas na atenção a saúde dos beneficiários. Não pode haver conflitos de interesses,
acesso indevido a dados dos pacientes e uso inadequado da segurança de informação
entre as partes interessadas. Políticas especificas de uso especifico em Programas de
Beneficio de Medicamentos foram criadas que permitem o uso adequado e seguro
destas informações por estas empresas, JAMA (2000).
No Brasil o manuseio indevido, posse, divulgação, comercialização de dados
médicos dos pacientes é considerado crime e violação dos direitos constitucionais dos
cidadãos.

16
3.6 Implementação do Programa de Beneficio de Medicamentos na
PETROBRAS
Para implementar o Programa de beneficio de medicamentos, foi designado um
grupo de pessoas para que elaborassem a melhor alternativa e os requisitos técnicos e
administrativos do referido Programa.
A escolha da Petrobras para implementar um Programa de benefício de
medicamentos foi junto com uma operadora de PBM e com o relatório produzido pelo
grupo iniciou um processo licitatório para contratação da operadora de PBM para
implementação do programa.
A Petrobras se baseou em dados obtidos do Ministério da Saúde para selecionar quais
são as doenças crônicas de maior freqüência na população brasileira para então elaborar
a lista de medicamentos que terão subsídios da Petrobras.
A tabela 2 apresenta as doenças de maior freqüência, conforme o Ministério da
Saúde, que terão subsídios.

17
Tabela 2 - Doenças de maior freqüência segundo o Ministério da Saúde
Doença Descrição
Hipertensão arterial sistêmica Doença cardiovascular caracterizada por
elevação dos níveis pressóricos arteriais
Insuficiência coronariana Deficiência de circulação nas artérias
coronárias
Hipertrigliceridemia Doença causada pela alteração da Diabetes
mellitus
Distúrbios do colesterol Doenças causadas pela alteração do colesterol.
Epilepsia Grupo de doenças do sistema nervoso central
que se manifesta através de convulsões
Depressão Doença psiquiátrica caracterizada por alteração
do estado humoral, manifestando-se com sinais
e sintomas de tristeza, lassidão, desejo de
morte.
Diabetes mellitus Elevação da glicemia em função de mal
funcionamento pancreático
Ainda como resultado do trabalho os próximos itens foram definidos para
escopo do benefício:
• Definição de valor para o limite máximo de compra mensal por grupo
familiar em função da faixa salarial do Beneficiário titular.
• Definição de um número mínimo de farmácias em função da quantidade
de beneficiários residentes em um determinado município.
• Definição de quais dados dos beneficiários será enviada para o banco de
dados da PBM para verificação da elegibilidade (Código do beneficiário,
faixa etária, faixa salarial, sexo).

18
• Definição de atualizações diárias dos beneficiários com direito a
utilização do benefício.
• Definição da lista de medicamentos contendo: medicamento,
apresentação, quantidade, faixa etária e sexo.
Os tipos do custeio dos medicamentos adquiridos no Programa de Benefício
Farmácia são:
• Subsídio Integral pela Petrobras - Medicamentos de alto custo, que já são
subsidiados pela empresa (utilizados no tratamento de doenças
oncológicas, onco-hematológicas, mielo displásicas, hepáticas, renais
crônicas e da AIDS).
• Subsídio Parcial – Medicamentos para tratamento das doenças crônicas
elencadas que terão subsídio parcial pela Petrobras, cabendo ao
Beneficiário Titular a complementação da participação.
• Custeio Integral – Medicamentos que constam da lista e medicamentos
que não constam da lista que serão integralmente custeados pelo
Beneficiário.
3.7 Ciclo da Utilização do Benefício Farmácia
O beneficiário se dirige a farmácia e apresenta o cartão de identificação da AMS
junto com um documento de identidade com foto e a receita médica com o carimbo e a
assinatura do profissional solicitante. O atendente confere os documentos apresentados,
acessa o sistema da PBM para checar a elegibilidade do beneficiário e se o
medicamento prescrito se encontra na lista de medicamentos estabelecidos pela
Petrobras, digita o valor do medicamento para verificação do saldo disponível conforme
limite máximo de compra mensal definido para cada grupo familiar. Caso o saldo

19
disponível não seja suficiente para a compra do medicamento o beneficiário poderá
efetuar a complementação do valor necessário.
Conforme data definida no contrato assinado com a operadora os dados das
compras serão enviados a Petrobras para processamento, análise e posterior débito na
folha de pagamento e pagamento das compras realizadas.
Periodicamente, a PBM envia relatórios estatísticos de compra dos
medicamentos e epidemiológicos para análise dos perfis de compra, indicadores da
saúde dos beneficiários e manutenção atualizada da lista de medicamentos.
A PBM de posse da informação de compra dos beneficiários negocia com a
industria, distribuidores e varejistas descontos e oferta dos medicamentos.
O laboratório negocia com os varejistas a oferta de medicamentos e junto aos
profissionais de saúde faz divulgação dos medicamentos a serem prescritos que lhe
sejam vantajosos.
Figura 1 - Ciclo do PBM

20
3.8 O Problema
Obter informações a partir dos dados de utilização da compra de medicamentos
que possam subsidiar ações de gestão no que se refere a adesão dos beneficiários ao
programa de medicamentos e descobrir padrões de utilização de medicamentos através
da classe terapêutica.

21
4 - O PROCESSO DE DESCOBERTA DO CONHECIMENTO
O desenvolvimento de sistemas de KDD está relacionado com diversos
domínios de aplicações: marketing, análises corporativas, astronomia, medicina,
biologia, entre outros. Existem diversas tarefas de KDD que são, principalmente,
dependentes do domínio da aplicação e do interesse do usuário; cada tarefa de KDD
extrai um tipo diferente de conhecimento do banco de dados e pode requerer um
algoritmo diferente para cada tarefa.
Segundo FELDENS (1996), fundamenta-se no fato de que as grandes bases de
dados podem ser uma fonte de conhecimento útil, porém não explicitamente
representado, cujo objetivo do KDD é desenvolver e validar técnicas, metodologias e
ferramentas capazes de extrair o conhecimento implícito nesses dados e representá-lo de
forma acessível aos usuários.
De acordo com SOUZA FILHO (2004) dentre estes algoritmos as regras de
associação são utilizadas para descobrir associações e correlações existentes entre os
dados que atendam a critérios estabelecidos que podem ser objetivos ou subjetivos,
servindo para determinar se uma regra de associação encontrada é interessante ou não.
Neste estudo será dada ênfase no método de Regras de Associação.

22
4.1 Regras de Associação
Regras de Associação é a técnica que tem por objetivo a identificação de
relacionamentos existentes entre os eventos representados numa base de dados. Esta
técnica também é conhecida como análise de cesta de compras, devido a sua principal
utilização, que é estabelecer relações entre os produtos a partir das cestas de compras
dos clientes, segundo SILVA SANTOS (2007). Uma regra de associação tem a forma X
=> Y que indica que a ocorrência do evento X implica no evento C.
Conforme inicialmente proposto por AGRAWAL (1993), uma regra de
associação ou afinidade de grupos visa a combinar itens importantes, tal que, a presença
de um item em uma determinada transação pressupõe a de outro na mesma transação.
Desse modo, o objetivo das regras de associação é encontrar tendências que possam ser
usadas para entender e explorar padrões de comportamento dos dados.
As aplicações de técnicas de regras de associação têm seu uso difundido em
diversas áreas, mas seu uso é mais difundido na área de marketing em que se pretende
descobrir as associações existentes entre produtos vendidos. As grandes redes varejistas
estudam as compras dos clientes para descobrir quais as vendas que são normalmente
realizadas ao mesmo tempo, denominando este estudo de market basket analysis. As
bases de dados envolvidas nestes processos são muito grandes, sendo assim, é
necessário que sejam utilizados algoritmos rápidos e eficientes.
Segundo DILLY (1995) uma regra de associação é uma expressão representada
na forma X => Y (X implica em Y), em que X e Y são conjuntos de itens da base de
dados; X é o antecedente da regra (lado esquerdo) e Y é o conseqüente da regra (lado
direito) e pode envolver qualquer número de itens em cada lado da regra.
A tarefa associação tem a premissa básica de encontrar elementos que implicam
na presença de outros elementos em uma mesma transação, ou seja, encontrar
relacionamentos ou padrões freqüentes entre conjuntos de dados com um determinado
grau de certeza. Este grau de certeza de uma regra é definido por dois fatores: o fator de
suporte e o fator de confiança.

23
De acordo com AGRAWAL et al. (1993), considerando que os conjuntos de
itens X e Y estão sendo analisados, o suporte é definido como a fração de registros que
satisfaz a união dos itens no conseqüente (Y) e no antecedente (X), correspondendo à
significância estatística da regra e a confiança é expressa pelo percentual de registros
que satisfaz o antecedente (X) e o conseqüente (Y), medindo a força da regra ou sua
precisão. Estes fatores limitam a quantidade de regras que serão extraídas e descrevem a
qualidade delas.
Para AGRAWAL et al. (1997), o problema das regras de associação é encontrar
todas as regras de associação que possuem o suporte e confiança acima de um
determinado valor mínimo, pois, na prática os usuários normalmente estão interessados
somente em um determinado subconjunto de associações.
4.2 Formalização do problema
O problema pode ser formalizado como se segue. Seja I = {I1, I2, I3, ..., Im} um
conjunto de atributos binários chamados itens e seja T uma base de dados de transações,
onde cada t é representada por um vetor binário, com t[k] = 1 se t indica a compra do
item Ik e t[k] = 0, ausência da compra. Existe uma dupla na base de dados para cada
transação. Seja X um conjunto de itens em I. É dito que a transação t satisfaz X se, para
todos os itens Ik em X, T[k] = 1.
Uma regra de associação é uma implicação da forma X => Y, onde X ⊂ I, Y ⊂ I,
e X ∩ Y = ∅. A regra X => Y é válida no conjunto de transações T, com o grau de
confiança c, se c% das transações em T que contêm X também contêm Y. A regra X =>
Y tem suporte s em T, se s% das transações em T contêm X ∪ Y. Se as condições forem
satisfeitas, c% representará o fator de confiança e s% o fator de suporte.
Em algumas literaturas o lado esquerdo da regra (se a regra é X=>Y, o lado
esquerdo é X) é denominado de antecedente e o lado direito de conseqüente (Y).

24
Dado o conjunto de transações I, há o interesse em gerar todas as regras que
satisfaçam certas restrições de duas diferentes formas:
• Restrições Sintáticas: Estas restrições envolvem restrições sobre itens que
podem aparecer numa regra. Por exemplo, pode haver interesse apenas em
regras que tenham um item Ix específico aparecendo no conseqüente, ou regras
que tenham um item Iy aparecendo no antecedente. Combinações das restrições
acima também são possíveis. Podem ser solicitadas todas as regras que tenham
itens de algum conjunto X de itens predefinido aparecendo no conseqüente, e
itens de algum outro conjunto Y aparecendo no antecedente.
• Restrições de Suporte: Estas restrições se referem ao número de transações em I
que suportam a regra. O suporte para uma regra é definido como a fração de
transações em I que satisfazem a união de itens no conseqüente e antecedente da
regra. Suporte não deve ser confundido com confiança. Enquanto confiança é
uma medida da força da regra, suporte corresponde à significância estatística.
Além da significância estatística, outra motivação para restrições de suporte vem
do fato de usualmente haver interesse apenas em regras com suporte acima de
algum limiar mínimo por razões do negócio. Se o suporte não é extenso o
suficiente, significa que a regra não merece consideração ou que é simplesmente
menos preferida.
Nesta formulação, o problema de mineração de regras pode ser decomposto em
dois problemas:
• Gerar todas as combinações de itens que tenham suporte a transação fracionária
acima de um certo limiar denominado minsuporte. Denominando estas
combinações extenso conjunto de itens, e todas as outras combinações, que não
atingem o limiar, de pequeno conjunto de itens. Restrições sintáticas
posteriormente restringem as combinações admissíveis. Por exemplo, se apenas
regras envolvendo um item Ix no antecedente são de interesse, então é suficiente
gerar apenas aquelas combinações que contém Ix.

25
• Para um dado extenso conjunto de itens Y = I1, I2, I3, ... Ik, gerar todas as
regras (no máximo k regras) que usam itens do conjunto I1,I2, I3, ..., Ik, .O
antecedente de cada uma destas regras será um subconjunto X de Y tal que X
tem k – 1 itens, e o conseqüente será o item Y – X. Para gerar uma regra X Þ Ij |
c, onde X = I1, I2, ..., Ij-1 Ij+1 ...Ik, toma o suporte de Y e divide-o pelo suporte
de X. Se a razão é maior que c então a regra é satisfeita com fator de confiança
c; caso contrário não. As regras obtidas a partir de Y devem satisfazer a restrição
de suporte porque Y satisfaz a restrição de suporte e Y é a união dos itens no
conseqüente e antecedente de toda regra.
Um dos algoritmos mais referenciados para este método é o Apriori, nas diversas
variações, tais como, o AprioriTid, DHP e Partition.
4.3 Interessabilidade das Regras
Segundo SOUZA (2004), as regras de associação têm sua aplicação comprovada
em diversas aplicações práticas, mas produzem um grande número de regras, muitas das
quais não são interessantes e os usuários/especialistas tem dificuldade em analisar cada
regra obtida para encontrar as mais interessantes e para solucionar este problema foram
desenvolvidas diversas aproximações para encontrar as regras mais interessantes de um
conjunto de regras obtidas.
Segundo SOUZA (2004), a determinação do conjunto de regras de associação
interessantes obtidas pode ser facilitada pela análise de interessabilidade que consiste
em encontrar regras que são interessantes e úteis aos usuários/especialistas, de acordo
com os critérios definidos. Diversas pesquisas que utilizaram técnicas de Mineração de
Dados mostram que podemos medir a interessabilidade de uma regra usando medidas
objetivas e subjetivas:
As medidas objetivas consistem em analisar a estrutura das regras, a
performance preditiva e a significância estatística obtidas no suporte e confiança.

26
Devido aos resultados obtidos com as medidas objetivas não serem suficientes
para determinar a interessabilidade de uma regra descoberta o estudo de medidas
subjetivas são necessários para melhor classificação. As duas principais medidas
subjetivas de interessabilidade são:
• Inesperabilidade: As regras são interessantes se elas são desconhecidas do
usuário ou contradizem ao existente conhecimento do usuário (ou esperado);
• Acionabilidade: As regras são interessantes se os usuários podem acionar
alguma atividade que produza benefício.
As regras interessantes podem ser classificadas dentro de três categorias:
• Regras que são ambas inesperadas e acionáveis;
• Regras que são inesperadas, mas não são acionáveis, e
• Regras que são acionáveis, mas esperadas.
Segundo LIMA DE SOUZA (2008) as regras de associação têm sua
interessabilidade avaliada em função de duas métricas: O suporte, que é a freqüência
com que os dados aparecem no conjunto de dados, e a confiança que indica a
probabilidade de associação entre os dados selecionados. Com base nos resultados são
tomadas decisões de negócios e podem ser traçadas novas estratégias de atuação.
No presente estudo usaremos como métricas de interessabilidade: Suporte e
Confiança.

27
5 - O ESTUDO DE CASO
Neste capitulo são apresentados detalhes do estudo de caso realizado.
Inicialmente é apresentada uma descrição dos dados utilizados seguida de uma
estatística básica e dos resultados obtidos com a técnica de regras de associação.
5.1 Descrição dos dados
A base de dados utilizada para aplicação da técnica de regras de associação
continha 06 atributos e um total de 361.892 registros referentes à compra de
medicamentos pelos beneficiários do Programa de Beneficio de Medicamentos da AMS
de abril de 2007 à agosto de 2008.
Na tabela 3 estão relacionados os atributos que foram utilizados neste estudo na
utilização da técnica de regras de associação estão relacionados e para cada um a
descrição de seu significado
Tabela 3 - Atributos utilizados no estudo
Atributo Descrição do atributo
Código do Beneficiário
Identificação única do beneficiário que adquiriu o medicamento
Sexo Sexo do Beneficiário
Faixa etária Faixa etária do Beneficiário
Faixa Salarial Faixa Salarial do beneficiário
Código da Classe Código da classe terapêutica do medicamento
Código do Tipo do Beneficiário Código da classe do beneficiário
A tabela 4 relaciona o domínio das faixas etárias utilizada, referência da ANS, obtida a partir da base de dados dos beneficiários cadastrados na AMS.

28
Tabela 4 - Faixas etárias segundo ANS
Faixa etária Descrição
0-18 Faixa 1
19-23 Faixa 2
24 – 28 Faixa 3
29 – 33 Faixa 4
34 – 38 Faixa 5
39 – 43 Faixa 6
44 – 48 Faixa 7
49 – 53 Faixa 8
54 – 58 Faixa 9
Acima de 58 Faixa acima 58 A tabela 5 relaciona o domínio das faixas salariais obtida a partir da base de dados dos beneficiários cadastrados na AMS e para cada faixa o limite de compra mensal por grupo familiar. Tabela 5 - Limites de compra
Faixa salarial Valor Limite de compra
1 754,43 120,00
2 1.392,79 240,00
3 2.785,58 480,00
4 5.571,17 800,00
5 11.142,34 800,00
6 acima de 11.142,35 800,00
A tabela 6, relaciona o domínio dos tipos de beneficiários obtida a partir da base de dados dos beneficiários cadastrados na AMS Tabela 6 - Domínio do tipo de beneficiários
TITULAR APOSENTADO
TITULAR ATIVO
TITULAR CURATELADO
TITULAR PENSIONISTA
TITULAR TUTELADO
DEPENDENTE DE APOSENTADO
DEPENDENTE DE ATIVO
DEPENDENTE DE CURATELADO
DEPENDENTE DE PENSIONISTA
DEPENDENTE DE TUTELADO

29
A tabela 7 apresenta os domínio dos códigos de sexo utilizados Tabela 7 - Domínio do campo sexo Sexo Descrição
F Feminino
M Masculino
Diariamente a PBM envia arquivo no formato txt, em layout previamente combinado, os dados das compras realizadas adquiridas no dia anterior.

30
Na tabela 8 estão descritos os atributos e a sua descrição Tabela 8 - Atributos e respectivas descrições Atributo Descrição Código do Beneficiário Código único do beneficiário
adquirente do medicamento Código da Faixa etária Código da faixa etária do beneficiário
que adquiriu o medicamento Código da Faixa salarial Código da faixa salarial do
beneficiário que adquiriu o medicamento
Código do Sexo Código do sexo do beneficiário que adquiriu o medicamento
Data da compra Data de compra do medicamento pelo beneficiário
CNPJ do local da compra CNPJ da farmácia que vendeu o medicamento
Sigla Estado do local da compra Sigla do estado da federação no qual foi realizada a venda
Município do local da compra Nome do município no qual a venda foi realizada.
Bairro do local da compra Nome do bairro no qual a venda foi realizada
Profissional prescritor Nome do profissional que prescreveu o medicamento
Código do registro profissional (CRM / CRO) Sigla do conselho de classe do profissional que prescreveu o medicamento
Número do registro profissional Número de registro do profissional que prescreveu o medicamento
Tipo do medicamento Indica se o medicamento é de marca ou genérico
Código da classe terapêutica Código da classe terapêutica do medicamento
Nome do medicamento Nome do medicamento adquirido pelo beneficiário
Quantidade adquirida Quantidade de medicamento adquirida Valor do medicamento Valor do medicamento adquirido ICMS Valor do ICMS do medicamento Apresentação Apresentação do medicamento
adquirido. ( Ex. Caixa com 12 drágeas)
O arquivo de origem contem informações sobre aquisições de medicamentos.
Entretanto, foi considerado que para diminuir a pulverização de regras, deveria ser feito
estudo utilizando-se a classe terapêutica do medicamento. Isto deve-se também ao fato

31
de que a classe terapêutica é uma forma de agrupamento de medicamento muito
utilizada pelos especialistas.
Os dados recebidos em arquivo no formato TXT foram carregados para uma
planilha Excel e complementados com a descrição da classe terapêutica (anexo yy) e
tipo do beneficiário (tabela xx) para obter a complementação do registro para submissão
ao processo de regra de associação.
Os dados da compra acrescidos da descrição da classe terapêutica e do tipo do
beneficiário foram carregados para uma planilha Excel, em folders diferentes e utilizou-
se a função PROCV para a complementação do registro. A partir do registro completo a
planilha resultante foi exportada para o formato txt para processamento na ferramenta
de análise.
5.2 Estatística dos dados
A seguir apresentaremos algumas estatísticas referente a utilização do Programa
de Benefício de Medicamentos.
A tabela 9 apresenta as faixas etárias dos beneficiários que adquiriram
medicamentos, a quantidade de beneficiários distintos em cada faixa etária, o percentual
destes beneficiários, a quantidade de itens comprados e o percentual de itens
comprados. Observe que nas 03 últimas faixas, Faixa etária entre 49 e 53, Faixa etária
entre 54 e 58 e Faixa etária acima de 58 apresentam uma concentração de 80,55% de
dos medicamentos comprados e uma concentração de 58,45% dos beneficiários.

32
Tabela 9 – Faias etárias de beneficiários que adquiriam medicamentos Faixa etária Quantidade de
beneficiários distintos
% de benefici
ários distintos
Quantidade de itens
comprados
% de itens comprados
Faixa etária entre 00 e 18 2.816 9,02 9.599 2,65
Faixa etária entre 19 e 23 1.258 4,03 4.760 1,31
Faixa etária entre 24 e 28 1.278 4,09 4.569 1,26
Faixa etária entre 29 e 33 1.361 4,36 6.372 1,76
Faixa etária entre 34 e 38 1.268 4,06 6.620 1,83
Faixa etária entre 39 e 43 1.791 5,73 11.073 3,06
Faixa etária entre 44 e 48 3.205 10,26 27.410 7,57
Faixa etária entre 49 e 53 3.939 12,61 42.761 11,81
Faixa etária entre 54 e 58 3.754 12,02 52.662 14,55
Faixa etária acima de 58 10.564 33,82 196.156 54,19
Total 31.234 100,00 361.982 100,00
A tabela 10 apresenta a quantidade de beneficiários por sexo que adquiriram
medicamentos, a quantidade de beneficiários distintos em cada faixa etária, o percentual
destes beneficiários, a quantidade de itens comprados e o percentual de itens
comprados.
Tabela 10 – Beneficiários e itens comprados
Sexo
Quantidade de beneficiários
distintos
% de beneficiários
distintos
Quantidade de itens
comprados % de itens comprados
Feminimo 14.926 47,79 146.404 40,45
Masculino 16.308 52,21 215.578 59,55
Total 31.234 100,00 361.982 100,00
A tabela 11 apresenta a quantidade de beneficiários por faixa salarial que
adquiriram medicamentos, a quantidade de beneficiários distintos em cada faixa etária,
o percentual destes beneficiários, a quantidade de itens comprados e o percentual de
itens comprados. Observe que as Faixas 4 e 5 apresentam uma concentração de 68,36%
dos medicamentos comprados e uma concentração de 74,13% dos beneficiáros que
adquiriram medicamentos no Programa.

33
Tabela 11 – Beneficiários por faixa salarial
Faixa salarial Quantidade de beneficiários distintos
% de beneficiários distintos
Quantidade de itens comprados
% de itens comprados
1 69 0,22 1.679 0,46
2 298 0,95 5.400 1,49
3 3.665 11,73 46.587 12,87
4 10.531 33,72 123.553 34,13
5 12.623 40,41 138.386 38,23
6 4.048 12,96 46.377 12,81
Total 31.234 100,00 361.982 100,00
A tabela 12 apresenta a quantidade de itens comprados por Classe terapêutica e o
percentual de cada item. Observe a classe terapêutica Sistema Cardiovascular concentra
46,71% dos medicamentos comprados.
Tabela 12 – Itens comprados por classe terapêutica
CLASSE TERAPEUTICA TOTAL PERCENTUAL
SISTEMA CARDIOVASCULAR 169.069 46,71
SISTEMA NERVOSO CENTRAL 59.935 16,56
APARELHO DIGESTO E METABOLISMO 51.636 14,26
SANGUE/ORGAOS HEMATOPOETICOS 23.036 6,36
SISTEMA MUSCULO/ESQUELETICO 13.938 3,85
ANTIINFECCIOSOS SISTEMICOS 12.620 3,49
HORMONIOS SISTEMICOS EXCLUINDO HORMONIOS SEXUAIS 8.867 2,45
APARELHO RESPIRATORIO 8.710 2,41
SISTEMA GENITURINARIO/HORMONIOS SEXUAIS 6.082 1,68
ORGAOS DO SENSORIO 4.145 1,15
DERMATOLOGICOS 1.855 0,51
ANTINEOPLASICOS/IMUNOMODULADORES 1.274 0,35
PARASITOLOGIA 815 0,23
Total geral 361.982 100,00

34
Na tabela 13 apresenta a distribuição de medicamentos por Classe terapêutica
por Faixa etária dos Beneficiários. Podemos concluir que 58,45% dos beneficiários que
utilizaram o Programa conforme apresentado na tabela 9, adquiriram 46,71%
medicamentos da classe terapeutica Sistema Cardiovascular.
Tabela 13 – Classe terapêutica x faixa etária Classe terapeutica FAIXA
1
FAIXA
2
FAIXA
3
FAIXA
4
FAIXA
5
FAIXA
6
FAIXA
7
FAIXA
8
FAIXA
9
FAIXA
ACIMA
58
Total
geral
Percentual
SISTEMA CARDIOVASCULAR 811 809 478 858 1.529 3.201 10.344 19.438 26.874 104.727 169.069 46,71
APARELHO DIGESTO E METABOLISMO 1.002 508 633 842 658 1.275 3.274 5.603 7.745 30.096 51.636 14,26
SISTEMA NERVOSO CENTRAL 2.647 1.551 1.482 1.866 1.891 3.399 7.352 8.860 8.016 22.871 59.935 16,56
SANGUE/ORGAOS HEMATOPOETICOS 58 91 20 44 125 259 925 2.131 3.218 16.165 23.036 6,36
SISTEMA MUSCULO/ESQUELETICO 545 394 360 490 516 655 1.397 1.718 1.892 5.971 13.938 3,85
HORMONIOS SISTEMICOS EXCLUINDO HORMONIOS SEXUAIS
664 202 219 304 303 360 844 960 1.140 3.871
8.867 2,45 ANTIINFECCIOSOS SISTEMICOS 1.641 509 577 832 717 886 1.290 1.597 1.222 3.349
12.620 3,49 APARELHO RESPIRATORIO 1.612 218 244 413 400 425 786 807 768 3.037
8.710 2,41 ORGAOS DO SENSORIO 83 28 39 59 49 69 244 333 593 2.648
4.145 1,15 SISTEMA GENITURINARIO/HORMONIOS SEXUAIS
177 319 395 444 280 333 516 770 744 2.104
6.082 1,68 ANTINEOPLASICOS/IMUNOMODULADORES 18 7 2 63 6 55 146 171 164 642
1.274 0,35 DERMATOLOGICOS 124 105 93 113 95 86 203 275 211 550
1.855 0,51 PARASITOLOGIA 217 19 27 44 51 70 89 98 75 125
815 0,23
Total geral 9.599 4.760 4.569 6.372 6.620 11.073 27.410 42.761 52.662 196.156 361.982 100,00
5.3 Resultados e análises
Para início da execução do software de extração de regras são necessários que
determinados parâmetros sejam inicializados. Os parâmetros que foram definidos para
execução do modelo estão apresentados na Tabela 14.
O número ma´ximo de regras que o software de extração de regras poderia gerar
seria de 1.000.000, o suporte mínimo 0,01% e a confiança mínima 1%.

35
Tabela 14 – Resumo – parte 1
Suporte mínimo 0,01%
Confiança mínima 1%
Número máximo de regras 1.000.000
A tabela 15 apresenta os resultados alcançados com os parâmetros estabelecidos
na Tabela 14.
Tabela 15 – Resumo – Parte 2
Regras produzidas 68.358
Confiana esperada máx 22,59
Confiana esperada mín 0,54
Confiança mínima 1,01
Confiança máxima 99,86
Suporte mínimo 0,52
Suporte máximo 9,67
Lift mínimo 0,09
Lift máximo 9,99
A tabela 15 sumariza algumas informações obtidas no processamento para
descoberta de regras. A seguir estão descritos os significados dos termos utilizados
nesta tabela.
Confiança esperada – É igual ao número de transações “conseqüentes”, ou seja,
regras obtidas, dividido pelo número total de transações.
Suporte – É a freqüência que uma dada combinação ocorre.
Confiança – É o percentual de casos nos quais dado um “antecedente” ocorre um
“consequente”. Conforme descrito na seção 4.2.
LIFT – É igual a confiança dividido pela Confiança esperada.

36
5.4 Seleção das regras obtidas
Para avaliação das regras obtidas no software de mineração realizamos a
exportação para o formato XLS (planilha Excel) com o objetivo de facilitar o manuseio
pelos especialistas que avaliariam o resultado obtido. O arquivo exportado tinha um
total de 68.358 regras e os atributos do arquivo gerado estão descritos na tabela 16.
Tabela 16 – Descrição dos atributos da análise
ATRIBUTO DESCRIÇÃO
SET_SIZE Numero de itens na regra
EXP_CONF Percentual da confiança esperada que é o número de transações "conseqüentes" dividido pelo total de transações
CONF Percentual da confiança que é o número de transações "antecedentes" dividido pelo total de transações
SUPPORT Percentual do suporte que é o número total de transações que qualificam a regra
LIFT É a razão entre a confiança esperada pela confiança
COUNT Número total de transações da regra
RULE É o texto da regra
No EXCEL o arquivo CSV foi carregado, aplicado o critério de classificação por
ordem decrescente de Suporte e também a facilidade de filtro para selecionar as regras
que tinham Confiança acima de 70.00. Utilizamos as métricas de confiança e suporte
como determinação de medidas objetivas da interessabilidade.
Também foram obtidas algumas regras duplicadas, isto é, quando para uma
mesma regra havia a inversão entre o conseqüente e antecedente, ou seja, o antecedente
passava a ser o conseqüente e o conseqüente o antecedente. A eliminação automática
destas regras não era objeto deste trabalho.
Foram geradas três planilhas com 100 registros diferentes em cada uma, para
serem entregue aos especialistas para avaliação do resultado produzido.

37
5.5 Análise dos Resultados
Do total de 68.358 regras extraídas selecionamos 10 regras representativas para
as quais apresentamos as análises dos especialistas, ações para cada uma, características
dimensionais e a análise de interessabilidade.
Conforme apresentado na tabela 13 há uma prevalência de doenças associadas a
problemas cardiovasculares, 46,71% de itens comprados, o que é característica da faixa
etária dos beneficiários que adquiriam os medicamentos, que conforme apresentado na
tabela 9, 58,45% dos beneficiários que adquiriram medicamentos têem idade maior ou
igual a 49 anos.
Regra 1 – MASCULINO & ANTAGONISTAS RECEPTORES ADP- INIBIDORES PLAQUETARIOS ==> TITULAR APOSENTADOS & NITRITOS E NITRATOS.
A tabela 17 apresenta as características dimensionais encontradas na regra 1.
Com esta regra obtivemos suporte 0,66 e confiança 74,91 que são valores altos que
demonstram a interessabilidade da mesma para o estudo de caso.
Tabela 17 – Regra 1
Variável Conteúdo Confiança 74,91 Suporte 0,66 LIFT 4,38 COUNT 196
A análise da regra efetuada por um especialista concluiu que é uma intervenção
farmacológica para terapia antiplaquetária (indicada para inibir avanço das doenças
cardiovasculares) associada a nitritos e nitratos. A informação mostra a conduta
terapêutica que está sendo utilizado para pacientes do sexo masculino aposentados com
risco para eventos patológicos cardiovasculares (IAM, Angina, AVCi).
O especialista classificou esta regra como acionável e esperada.

38
Regra 2 - MASCULINO & INIBIDORES REDUTASE HMG-COA &
BETABLOQUEADORES PUROS ==> TITULAR APOSENTADO & INIBIDORES
CICLO-OX INIBIDORES AGREGACAO PLAQUETARIA & ANTAGONISTAS
RECEPTORES ADP- INIBIDORES PLAQUETARIOS.
A tabela 18 apresenta as características dimensionais encontradas na regra 2.
Com esta regra obtivemos suporte 0,58 e confiança 74,90 que são valores altos que
demonstram a interessabilidade da mesma para o estudo de caso.
Tabela 18 – Regra 2
Variável Conteúdo Confiança 74,90 Suporte 0,58 LIFT 5,39 COUNT 165
A análise da regra efetuada por um especialista concluiu que além da situação
anterior, relatada na regra 1, há ainda a associação de betabloqueadores puros e
medicamento para controle de dislipidemia o que demonstra a intervenção terapêutica
diante da existência de múltiplos fatores de riscos associados para o desenvolvimento de
doenças cardiovasculares em pacientes do sexo masculino aposentados.
O especialista classificou esta regra como acionável e esperada.
Regra 3 - FAIXA ACIMA 58 & DEPENDENTE DE APOSENTADO &
ANTIDIABETICOS SULFONILUREIA ==> FEMININO & ANTIDIABETICOS
BIGUANIDAS.
A tabela 19 apresenta as características dimensionais encontradas na regra 2.
Com esta regra obtivemos suporte 0,54 e confiança 72,22 que são valores altos que
demonstram a interessabilidade da mesma para o estudo de caso.

39
Tabela 19 – Regra 3
Variável Conteúdo Confiança 72,22 Suporte 0,54 LIFT 4,47 COUNT 190
A análise da regra efetuada por um especialista concluiu que esta regra aplicada
ao sexo feminino demonstra grau de confiabilidade para compra de medicamentos
apenas para diabetes, incluindo para faixa etária acima de 58 anos.
Em função das regras geradas e combinadas com o conhecimento técnico dos
especialistas para a regra acima é possível estabelecer ações para melhorar a qualidade
de vida dos beneficiários identificados na regra e diminuição do custo assistencial e de
aquisição de medicamentos.
O especialista classificou esta regra como acionável e esperada.
Regra 4 - TITULAR PENSIONISTA & BETABLOQUEADORES PUROS ==>
FEMININO
A tabela 20 apresenta as características dimensionais encontradas na regra 4.
Com esta regra obtivemos suporte 0,83 e confiança 99,23 que são valores altos que
demonstram a interessabilidade da mesma para o estudo de caso.
Tabela 20 – Regra 4
Variável Conteúdo Confiança 99,23 Suporte 0,83 LIFT 2,08 COUNT 360
A análise da regra efetuada por um especialista concluiu que esta regra informa
que o uso de betabloqueadores por mulheres pensionistas, encontram-se numa faixa
etária maior. O uso de betabloqueadores é compatível com o quadro de hipertensão

40
arterial que é freqüente neste faixa etária. Os betabloqueadores também são indicados
para doenças cardiovasculares que no sexo feminino são mais frequentes após a
menopausa.
As ações propostas pelo especialista são: Oferecer descontos para este
medicamento e estimular o controle dos fatores de risco (sedentarismo, tabagismo,
etilismo, obesidade e etc.) para doenças cardiovasculares.
O especialista classificou esta regra como acionável e esperada.
Regra 5 - TITULAR PENSIONISTA & FAIXA ACIMA 58 &
BETABLOQUEADORES PUROS ==> FEMININO
A tabela 21 apresenta as características dimensionais encontradas na regra 5.
Com esta regra obtivemos suporte 0,69 e confiança 99,54 que são valores altos que
demonstram a interessabilidade da mesma para o estudo de caso.
Tabela 21 – Regra 5
Variável Conteúdo Confiança 99,54 Suporte 0,69 LIFT 2,08 COUNT 217
A análise da regra efetuada por um especialista concluiu que esta regra informa
que o uso de betabloqueadores por mulheres acima de 58 anos é compatível com quadro
de hipertensão arterial que é frequente nesta faixa etária. Os betabloqueadores também
são indicados para doenças cardiovasculares que no sexo feminino são mais freqüentes
após a menopausa.
As ações propostas pelo especialista são: Oferecer descontos para este
medicamento e estimular o controle dos fatores de risco (sedentarismo, tabagismo,
etilismo, obesidade e etc.) para doenças cardiovasculares.
O especialista classificou esta regra como acionável e esperada.

41
Regra 6 - MASCULINO & FAIXA ENTRE 00 E 18 & ANTIREUMATICOS NAO
ESTEROIDES PUROS ==> DEPENDENTE DE TITULAR
A tabela 22 apresenta as características dimensionais encontradas na regra 6.
Com esta regra obtivemos suporte 0,59 e confiança 99,46 que são valores altos que
demonstram a interessabilidade da mesma para o estudo de caso.
Tabela 22 – Regra 6
Variável Conteúdo Confiança 99,46 Suporte 0,59 LIFT 2,12 COUNT 184
A análise da regra efetuada por um especialista concluiu que esta regra dá a
informação do uso de antireumáticos não esteróides em menores de 18 anos o que pode
estar relacionado ao uso de anti-inflamatórios por conta de possíveis eventos
traumáticos comuns nesta faixa etária ou relacionado ao tratamento de febre reumática
cuja incidência é mais freqüente nesta faixa etária.
A ação proposta pelo especialista é oferecer descontos para este medicamento.
O especialista classificou esta regra como acionável e esperada.
Regra 7 - TITULAR PENSIONISTA & INIBIDORES REDUTASE HMG-
COA & FAIXA ACIMA 58 ==> FEMININO
A tabela 23 apresenta as características dimensionais encontradas na regra 7.
Com esta regra obtivemos suporte 1,15 e confiança 99,17 que são valores altos que
demonstram a interessabilidade da mesma para o estudo de caso.
Tabela 23 – Regra 7
Variável Conteúdo Confiança 99,17 Suporte 1,15 LIFT 2,08 COUNT 360

42
A análise da regra efetuada por um especialista concluiu que esta regra é
compatível com a epidemiologia da hipercolesterolemia que é mais freqüente em
pacientes com faixa etária acima de 58 anos em ambos os sexos. Os inibidores da
redutas e HMG-CoA reduzem o colesterol.
As ações propostas pelo especialista são: Oferecer descontos para este
medicamento e estimular o controle dos fatores de risco (sedentarismo, tabagismo,
etilismo, obesidade e etc.) para doenças cardiovasculares.
O especialista classificou esta regra como acionável e esperada.
Regra 8 - MASCULINO & FAIXA ACIMA 58 & ANTAGONISTAS RECEPTORES
ADP- INIBIDORES PLAQUETARIOS ==> TITULAR APOSENTADO &
INIBIDORES REDUTASE HMG-COA & BETABLOQUEADORES PUROS.
A tabela 24 apresenta as características dimensionais encontradas na regra 8.
Com esta regra obtivemos suporte 1,28 e confiança 74,58 que são valores altos que
demonstram a interessabilidade da mesma para o estudo de caso.
Tabela 24 – Regra 8
Variável Conteúdo Confiança 74,58 Suporte 1,28 LIFT 4,36 COUNT 246
A análise da regra efetuada por um especialista concluiu que esta regra
caracteriza uma intervenção farmacológica para terapia antiplaquetária (indicada para
inibir avanço das doenças cardiovasculares), combinado com antagonistas receptores
ADP (terapia antiplaquetária). A informação mostra a conduta terapêutica que está
sendo utilizado para pacientes do sexo masculino aposentados com risco para eventos
patológicos cardiovasculares (IAM, Angina, AVCi), há ainda a associação de
betabloqueadores puros e medicamento para controle de dislipidemia. Com grau de
confiabilidade de 74.90% demonstrando a intervenção terapêutica diante da existência

43
de múltiplos fatores de riscos associados para o desenvolvimento de doenças
cardiovasculares em pacientes do sexo masculino aposentados.
As ações propostas pelo especialista são:
a) Identificar os pacientes com esse perfil e incluí-los em Programa de
Gerenciamento com o objetivo de analisar a ocorrência de eventos cardiovasculares
prévios e fazer follow up para comprovar a efetividade dessa associação;
b) Fornecer gratuitamente ou aumentar o subsídio dos medicamentos para
estimular a adesão ao tratamento entre os pacientes do sexo masculino aposentados
pertencentes a esse grupo de risco;
c) Propor programa de reabilitação cardíaca para o grupo, tendo em vista o grau
de adesão ao tratamento;
d) Analisar o impacto nos custos com procedimentos terapêuticos do grupo
assistido;
e) Propor ações de prevenção para reduzir a exposição aos fatores de risco para o
desenvolvimento de doenças cardiovasculares;
f) Avaliar os protocolos utilizados pelos médicos assistentes;
g) Negociar descontos maiores nos preços dos medicamentos envolvidos nessa
associação de grupos terapêuticos para os pacientes do sexo masculino.
h) Selecionar as associações terapêuticas mais efetivas e mais utilizadas;
i) Negociar padronização com a rede credenciada do uso de
O especialista classificou esta regra como acionável e esperada.
Regra 9 - TITULAR APOSENTADO & ANTAGONISTAS RECEPTORES ADP-
INIBIDORES PLAQUETARIOS ==> MASCULINO & INIBIDORES REDUTASE
HMG-COA & INIBIDORES CICLO-OX INIBIDORES AGREGACAO
PLAQUETARIA & BETABLOQUEADORES PUROS

44
A tabela 25 apresenta as características dimensionais encontradas na regra 9.
Com esta regra obtivemos suporte 1,99 e confiança 74,79 que são valores altos que
demonstram a interessabilidade da mesma para o estudo de caso.
Tabela 25 – Regra 9
Variável Conteúdo Confiança 74,79 Suporte 1,99 LIFT 4,37 COUNT 165
A análise da regra efetuada por um especialista concluiu que esta regra
caracteriza, além da situação anterior encontrada na regra 8, a associação de
betabloqueadores puros e medicamento para controle de dislipidemia.
Todas as ações mencionadas para a regra 8, poderão ser aplicadas aqui também.
Podendo-se acrescentar:
a) programa de orientação nutricional ;
b) definição de política de alimentação saudável na Companhia;
c) Estimular o combate ao sedentarismo;
O especialista classificou esta regra como acionável e esperada.
Regra 10 - TITULAR APOSENTADO & INIBIDORES CICLO-OX INIBIDORES
AGREGACAO PLAQUETARIA & BETABLOQUEADORES PUROS ==>
NITRITOS E NITRATOS & MASCULINO
A tabela 26 apresenta as características dimensionais encontradas na regra 10.
Com esta regra obtivemos suporte 0,93 e confiança 74,48 que são valores altos que
demonstram a interessabilidade da mesma para o estudo de caso.

45
Tabela 26 – Regra 10
Variável Conteúdo Confiança 74,48 Suporte 0,93 LIFT 4,35 COUNT 171
A análise da regra efetuada por um especialista concluiu que esta regra
caracteriza associação terapêutica utilizada para pacientes diabéticos com dislipidemia.
Todas as ações mencionadas para a regra 9, poderão ser aplicadas aqui também.
O especialista classificou esta regra como acionável e esperada.

46
6 - CONCLUSÕES
O objetivo deste trabalho foi a descoberta de regras de consumo de
medicamentos a partir da classe terapêutica dos mesmos. Para tal utilizamos os dados de
compras dos medicamentos efetuados pelos beneficiários, a partir da implementação de
um programa de beneficio de medicamentos, em uma operadora de plano de saúde na
modalidade de autogestão usando uma empresa de PBM.
Foi utilizada a técnica de regras de associação é a técnica que tem por objetivo a
identificação de relacionamentos existentes entre os eventos representados numa base
de dados para a descoberta das regras de consumo à partir da classe terapêutica dos
medicamentos.
Os dados diários de compra de medicamentos foram compilados em uma única
planilha. Desta planilha foram extraídos 06 atributos, totalizando 361.892 registros que
foram submetidos para avaliação no software de mineração de dados que produziu um
total de 68.358 regras de associação.
As regras de associação tem sua aplicação comprovada em diversas aplicações
práticas mas produzem um grande número de regras, algumas interessantes e outras não
e os usuários/especialistas tem dificuldade em cada regra obtida para encontrar as mais
interessantes. Para determinar a interessabilidade de uma regra diversas pesquisas
mostram que podemos usar medidas objetivas e subjetivas.
As regras de associação têm sua interessabilidade avaliada em função de 02
métricas objetivas: O suporte, que é a freqüência com que os dados aparecem no
conjunto de dados, e a confiança que indica a probabilidade de associação entre os
dados selecionados.
As duas principais medidas subjetivas de interessabilidade são a inesperabilidade
(são regras interessantes e desconhecidas ou que contradizem o conhecimento do
especialista/usuário) e a acionabilidade (são regras interessantes se o
especialista/usuário podem efetuar alguma ação que produza benefício).

47
Do total de 68.358 regras obtidas no software de mineração dividimos em 03
conjuntos, exportados para 03 planilhas, que foram entregues a 03 especialistas médicos
para análise.
Cada planilha foi classificada em ordem decrescente de Suporte e Confiança e
somente as 100 primeiras regras foram analisadas.
Houve uma dificuldade, algumas regras apareciam repetidas, isto é, algumas
vezes havia uma inversão entre o antecedente (lado esquerdo) e o conseqüente (lado
direito) da regras. O antecedente tornava-se conseqüente e o conseqüente tornava-se
antecedente. Quando isto acontecia uma das regras era eliminada manualmente.
Segundo os especialistas no conjunto analisado havia somente regras acionáveis
não havendo nenhuma regra inesperada.
Este estudo permitiu explicitar informações que subsidiarão a Gestão do
Programa de Medicamentos e também o estabelecimento de vínculos com a utilização
de procedimentos médicos complementares. Abaixo algumas conclusões:
a) Identificar os beneficiários que utilizem medicamentos associados a eventos
cardiovasculares e incluí-los em Programa de Gerenciamento com o objetivo de analisar
a ocorrência prévia destes eventos e fazer o acompanhamento para comprovar a
efetividade dessa associação;
b) Fornecer gratuitamente ou aumentar o subsídio dos medicamentos para
estimular a adesão ao tratamento entre os pacientes do sexo masculino aposentados
pertencentes a esse grupo de risco;
c) Propor programa de reabilitação cardíaca, com o objetivo de aumentar a
adesão ao tratamento;
d) Analisar o impacto nos custos com procedimentos terapêuticos aos diversos
grupos de beneficiários identificados;
e) Propor ações de prevenção para reduzir a exposição aos fatores de risco para o
desenvolvimento de doenças cardiovasculares;
f) Avaliar os protocolos utilizados pelos médicos assistentes;

48
g) Negociar descontos maiores nos preços dos medicamentos envolvidos nessa
associação de grupos terapêuticos para os pacientes do sexo masculino.
h) Possibilitar a seleção das associações terapêuticas mais efetivas e mais
utilizadas e negociar padronização com rede credenciada
i) Negociar maior índice de descontos para os medicamentos envolvidos na
associação.
j) Implementar programa de orientação nutricional ;
k) Definir política de alimentação saudável na Companhia;
l) Estimular programa de combate ao sedentarismo;
A utilização da técnica de regra de associação trouxe benefícios pois a partir do
uso das medidas de insteressabilidade explicitou associações de regras esperadas e
acionáveis que contribuirão na Gestão do Benefício trazendo melhorias de qualidade de
vida para os beneficiários e otimização de custos para o plano.

49
6.1 Trabalhos Futuros
Efetuar estudos para desenvolver modelos preventivos com o uso de técnicas de
data mining, com os dados de utilização de procedimentos médicos, utilização de
medicamentos, dados dos ambientes de trabalho e de exames periódicos de saúde anual
com o objetivo de antecipar necessidades de tratamentos, melhora da qualidade de vida,
otimização de custos para o plano e análise considerando um conjunto maior de regras
buscando por regras que sejam inesperadas e acionáveis.

50
REFERÊNCIAS BIBLIOGRÁFICAS
AGRAWAL, R. & R. Srikant (1993) Fast algorithms for mining association rules in large databases. In Proceedings of the 20th International Conference on Very Large Databases, pp. 487–499. Disponível em: <http://www.almaden.ibm.com/u/ragrawal/pubs.htm>. Acesso em Mar 2008. AGRAWAL, R. & R. Srikant (1997) et al. Mining Association Rules With Item Constraints. Disponível em: < http://www.aaai.org/Papers/KDD/1997/KDD97-011.pdf>. Acesso em Mar 2008. AMO, S (2003). Técnicas de Mineração de Dados, Universidade Federal de Uberlândia, MG. Disponível em: < http://www.deamo.prof.ufu.br/arquivos/JAI-cap5.pdf>. Acesso em Set 2008. ANAND, A. KHOTS, D. “A data mining framework for identifying claim overpayments for the health insurance industry”, Proceedings of the 3rd INFORMS Workshop on Data Mining and Health Informatics (DM-HI 2008), J. Li, D. Aleman, R. Sikora, eds, 2008. BERTSIMAS, D, et al. ”Algorithmic Prediction of Health-Care Costs” OPERATIONS RESEARCH Vol. 56, No. 6, November-December 2008, pp. 1382-1392 CHAN, Chien-Lung, CHIEN-WEI Chen; BAW-JHIUNE, Liu. “Discovery of association rules in Metabolic Syndrome related diseases”, Neural Networks, 2008. IJCNN 2008. (IEEE World Congress on Computational Intelligence). IEEE International Joint Conference on Volume , Issue , 1-8 June 2008 Page(s):856 - 862 Digital Object Identifier 10.1109/IJCNN.2008.4633898. Disponivel em: <http://ieeexplore.ieee.org/xpl/freeabs_all.jsp?arnumber=4633898.>. Acesso em Jan 2009. DILLY , R. Data Mining - an introduction . Parallel Computer Centre - Queen's University of Belfast. Dezembro, 1995. FAYYAD, Usama, PIATETSKY-SHAPIRO, Gregory, SMYTH, Padhraic. From data mining to knowledge discovery: an overview. In: Advances in Knowledge Discovery and Data Mining, AAAI Press / The MIT Press, MIT, Cambridge, Massachusets, and London, England, 1996, p.1-34. FELDENS, M. A.; CASTILHO, J. M. V. de (1996). Descoberta de Conhecimento Aplicada à Detecção de Anomalias em Bases de Dados: Trabalho Individual, PPGC-UFRGS, Rio Grande do Sul, RS.

51
FILHO, H. Souza (2004). Extração de Regras de Associação de um Banco de Dados Relacional, M. Sc, COPPE/UFRJ, Rio de Janeiro, RJ, Brasil. FILHO, J. Rodrigues (2001). Data Mining: Conceitos, Técnicas e Aplicação. Msc, Escola Politécnica da Universidade Federal de São Paulo, São Paulo, SP, Brasil. IBM. IBM'S data mining technology. White Paper, 1996. JAMA – Uses and abuses of prescriptiondrug information in Pharmacy benefits management programs, Bernard Lo; Ann Alpers. Disponivel em <http://jama.ama-assn.org/cgi/content/full/283/6/801> Acesso em Dez 2009. KENNETH S. Lubel (1998). Data Mining: A New Way to Find Answers, Disponível em <http://faculty.ed.umuc.edu/~meinkej/inss690/lubel.htm>. Acesso em Dez 2007. MAGALHAES, L. H.; ARBEX, M. A. Data mining - extração e exploração de conhecimento. Disponível em < http://www.viannajr.edu.br/site/menu/publicacoes/publicacao_tecnologos/artigos/edicao1/200615801.pdf>. Acesso em Jun 2008. MIRANDA, Claúdio da Rocha. Gerenciamento de custos em planos de assistência à saúde – Projeto ANS/PNUD, 2003. SANTOS, R. Silva,2007, Ambiente para extração de informações através da Mineração das Bases de Dados do Sistema Único de Saúde, D.Sc., UNIFESP, São Paulo, SP, Brasil, 2007. SOUZA, F. T.,2004, Predição de escorregamentos das encostas do município do Rio de Janeiro através de técnicas de mineração de dados, D. Sc, COPPE/UFRJ, Rio de Janeiro, Brasil. SOUZA, S. L.,2008, Evasão no ensino superior: Um estudo utilizando a mineração de dados como ferramenta de gestão do conhecimento em um banco de dados referente a graduação em Engenharia, M. Sc, COPPE/UFRJ, Rio de Janeiro, RJ, Brasil.

52
ANEXOS ANEXO A – TABELA CLASSE TERAPEUTICA X FAIXA SALARIAL
Fx_Salarial
1 2 3 4 5 6 Total
Desc_Classe_Terapeutica
AGENTES ANTI-ALERGICOS NASAIS . 1 2 3 4 . 10
AGENTES ANTIINFLAMATORIOS INTESTINAIS . . 23 29 41 11 104
AGENTES IMUNOSSUPRESSORES . . 6 32 100 13 151
AGENTES POUPADORES POTASSIO PURO 21 16 500 832 1055 197 2621
AGENTES POUPADORES POTASSIO+TIAZIDAS COM 2 23 195 779 788 302 2089
AGENTES SISTEMICOS P/INFECCOES FUNGICAS 1 39 197 575 623 150 1585
AMEBICIDAS 1 . 4 13 5 1 24
AMINOGLICOSIDEOS . . 15 20 18 10 63
ANALGESICO NAO NARCOTICO/ANTIPIRETICO 37 108 1135 2581 2567 778 7206
ANALGESICOS NARCOTICOS 2 2 46 145 89 21 305
ANESTESICOS LOCAIS TOPICOS . 2 4 9 12 5 32
ANTAGONISTA RECEPTORES H2 30 2 121 423 330 130 1036
ANTAGONISTAS ANGIOTENSINA II ASSOCIADOS 77 412 2455 6361 7287 2216 18808
ANTAGONISTAS CALCIO C/ ATIVIDADE CEREBRAL 10 . 24 106 88 31 259
ANTAGONISTAS CALCIO PUROS 121 358 2592 6740 6604 2237 18652
ANTAGONISTAS CALCIO+BETABLOQUEADORES COMBINADOS 1 16 141 376 323 48 905
ANTAGONISTAS PUROS ANGIOTENSINA II 70 300 2297 6806 7617 2586 19676
ANTAGONISTAS RECEPTORES ADP- INIBIDORES PLAQUETARIOS 41 111 919 2842 2870 1072 7855
ANTI-ASMATICOS/ ANTILEUCOTRIENOS SISTEMICOS . . 94 244 344 129 811
ANTI-HISTAMINICOS SISTEMICOS 6 41 386 1147 1226 302 3108
ANTIACIDOS PUROS . . 9 14 8 8 39
ANTIACNEICOS SISTEMICOS . . 11 12 36 6 65
ANTIACNEICOS TOPICOS . 2 8 39 56 24 129
ANTIARRITMICOS CARDIACOS 11 4 311 384 498 187 1395
ANTIBIOTICOS GINECOLOGICOS . 1 11 29 17 3 61
ANTIBIOTICOS TOPICOS PUROS/SULFONAMIDAS 1 3 32 51 53 23 163
ANTICOAGULANTES NAO INJETAVEIS 10 11 316 513 597 265 1712
ANTICOLINERGICOS PURO INALANTES 1 4 82 188 186 23 484
ANTICONVULSIVANTES INCLUINDO ANTIEPILEPTICOS 99 326 2462 5968 7320 2280 18455

53
Fx_Salarial
1 2 3 4 5 6 Total
ANTIDEPRESSIVOS EXCLUINDO PLANTAS 34 121 1852 4751 7089 3342 17189
ANTIDIABETICOS BIGUANIDAS 28 159 1412 3805 4148 1327 10879
ANTIDIABETICOS INIBIDORES ALFA-GLUCOSIDADE 1 70 175 754 954 131 2085
ANTIDIABETICOS SULFONILUREIA 46 245 1435 3406 3905 878 9915
ANTIDIABETICOS TIAZOLIDINEDIONAS 31 71 302 1106 1591 660 3761
ANTIESPASMODICOS ASSOCIADOS C/OUTROS PRODUTOS . . . 4 2 . 6
ANTIESPASMODICOS+ANTICOLINERGICOS PUROS 2 6 26 73 71 12 190
ANTIFLATULENTOS PUROS/CARMINATIVOS 35 29 219 647 727 181 1838
ANTIFUNGICOS DERMATOLOGICOS SISTEMICOS . . 2 6 2 . 10
ANTIFUNGICOS DERMATOLOGICOS TOPICOS 5 8 127 213 252 72 677
ANTIFUNGICOS GINECOLOGICOS 3 16 127 316 340 101 903
ANTIFUNGICOS TOPICOS COURO CABELUDO . 1 12 46 54 24 137
ANTIGOTOSOS . 5 184 703 924 416 2232
ANTIHELMINTICOS EXCETO P 1C 10 7 107 313 269 85 791
ANTIHEMORROIDARIOS SEM CORTICOIDE 3 1 42 90 109 58 303
ANTIHIPERTENSIVOS PURO-ACAO CENTRAL 12 110 401 1003 733 223 2482
ANTIHIPERTENSIVOS PURO-ACAO PERIFERICA 20 90 494 680 499 92 1875
ANTIINFECCIOSOS OFTALMOLOGICOS . 1 29 73 68 26 197
ANTIINFLAMATORIOS OFTALMOLOGICOS + ANTIINFECCIOSOS . . 9 23 21 4 57
ANTIINFLAMATORIOS OFTALMOLOGICOS NAO ESTEROIDES . 8 28 57 52 27 172
ANTIINFLAMATORIOS RESPIRATORIOS NAO ESTEROIDAIS SISTEMICOS . . 1 13 14 3 31
ANTIMETABOLITOS . . 2 20 31 5 58
ANTIPARKINSONIANOS . . 163 218 316 105 802
ANTIPSICOTICOS ATIPICOS . 13 175 502 527 260 1477
ANTIPSICOTICOS CONVENCIONAIS 2 12 68 187 135 74 478
ANTIREUMATICOS NAO ESTEROIDES PUROS 44 127 1114 2370 2132 474 6261
ANTIREUMATICOS NAO ESTEROIDES- COXIBS 13 62 497 1206 1234 374 3386
ANTIREUMATICOS RUBEFAC. TOPICOS 9 12 95 172 221 54 563
ANTISEPTICOS GINECOLOGICOS . . 1 11 6 1 19
ANTITUSSIGENOS PUROS . . 25 50 60 15 150
ANTIVIRAIS EXCETO PRODUTOS ANTI-HIV . 6 15 56 77 13 167

54
Fx_Salarial
1 2 3 4 5 6 Total
ANTIVIRAIS OFTALMOLOGICOS . . 3 4 1 . 8
ANTIVIRAIS TOPICOS 1 19 37 107 97 21 282
ASSOCIACOES ANTIESPASMODICOS/ANALGESICOS 26 33 195 478 358 85 1175
ASSOCIACOES C/ ANTIHIPERTENSIVOS E/OU DIURETICOS 20 13 461 1141 1104 349 3088
ASSOCIACOES CORTICOSTEROIDES SISTEMICOS 2 8 106 239 215 65 635
ASSOCIACOES DE ESTROGENOS/PROGESTERONAS . . 18 74 175 11 278
ASSOCIACOES DE TRIMETOPRIMA E SIMILARES 2 8 71 226 157 64 528
BETABLOQUEADORES PUROS 73 350 2838 8365 8766 2769 23161
BISFOSF. O REGULADOR CALCIO OSSEO 8 16 72 241 314 173 824
CARDIOGLICOSIDEOS PUROS 1 9 280 506 486 185 1467
CEFALOSPORINAS INJETAVEIS . . 7 24 20 3 54
CEFALOSPORINAS ORAIS 5 13 404 1060 1040 308 2830
CITOSTATICOS ANTI-ANDROGENICOS . . 48 107 51 36 242
CITOSTATICOS ANTI-ESTROGENEOS . . 38 81 206 79 404
COMBINACOES DE ANTIDIABETICOS SULFONILUREIAS+BIGUANIDAS 60 47 334 967 886 212 2506
CORTICOIDES - INALANTES 1 8 63 155 132 34 393
CORTICOIDES TOPICOS PUROS . 1 62 95 112 33 303
CORTICOSTEROIDES COM ANTIMICOTICOS . 4 4 11 12 2 33
CORTICOSTEROIDES INJETAVEIS PUROS . . 4 9 14 2 29
CORTICOSTEROIDES NASAIS COM ANTIINFECCIOSOS . . 12 21 19 11 63
CORTICOSTEROIDES OFTALMOLOGICOS . 2 5 17 27 7 58
CORTICOSTEROIDES ORAIS PUROS 5 37 496 1322 1481 452 3793
CORTICOSTEROIDES OTICOS ASSOCIADOS C/ANTIINFECCIOSOS 1 1 15 42 48 12 119
DIURETICOS DE ALCA PUROS 36 30 681 1189 1316 360 3612
ESTABILIZADORES DO HUMOR . 1 81 214 240 130 666
ESTIMULANTES B2 C- ACAO INALATORIA . 1 15 36 22 7 81
ESTIMULANTES B2 COM CORTICOIDES -INALANTES 5 26 251 621 456 188 1547
ESTIMULANTES B2 L -ACAO INALATORIA . 3 38 118 92 16 267
ESTIMULANTES B2-SISTEMICOS 2 5 67 201 169 42 486
ESTROGENEOS CITOSTATICOS . . 7 3 7 3 20
ESTROGENIOS EXCLUINDO G3A,G3E,G3F . 5 23 66 69 26 189

55
Fx_Salarial
1 2 3 4 5 6 Total
EXPECTORANTES 1 3 113 237 195 42 591
FIBRATOS 15 7 275 814 946 249 2306
FLUORQUINOLONAS ORAIS . 30 395 915 962 278 2580
GASTROPROCINETICOS 10 17 296 955 932 306 2516
HIPNOTICOS/SEDATIVOS NAO BARBITURICOS PUROS . . 87 257 364 117 825
INIBIDORES AROMATASE CITOSTATICOS . 4 30 111 165 64 374
INIBIDORES CICLO-OX INIBIDORES AGREGACAO PLAQUETARIA 70 178 1524 4466 5290 1941 13469
INIBIDORES DA BOMBA ACIDA 67 196 1446 3708 4299 1493 11209
INIBIDORES DA ECA ASSOCIADOS C/ ANTIHIPERTENSIVOS ANTAGONISTAS 6 60 302 708 727 127 1930
INIBIDORES DA ECA ASSOCIADOS C/ ANTIHIPERTENSIVOS DIURETICOS . 2 104 402 560 135 1203
INIBIDORES DA NUCLEASE TRANSCRIPTASE REVERSA . . . . . 2 2
INIBIDORES ENZIMA CONVERSORA DE ANGIOTENSINA PUROS 46 139 1500 3941 4377 1562 11565
INIBIDORES PROLACTINA . . 3 14 64 13 94
INIBIDORES REDUTASE HMG-COA 137 408 3519 10462 13793 5592 33911
INSULINA HUMANA+ANALOGOS ACAO INTERMEDIARIA 1 17 107 173 176 25 499
INSULINA HUMANA+ANALOGOS ACAO PROLONGADA . 10 73 283 384 151 901
INSULINA HUMANA+ANALOGOS- ACAO INTERMEDIARIA+RAPIDA . . 12 23 86 12 133
INSULINA HUMANA+ANALOGOS- ACAO RAPIDA . 2 44 201 317 94 658
LAXANTES ENEMAS . 1 11 29 22 1 64
LUBRIFICANTES OCULARES/LAGRIMAS ARTIFICIAIS . 1 11 8 12 3 35
MACROLIDEOS E SIMILARES 3 12 154 378 451 116 1114
MOD SENSOM GASTRO-INTEST . . 8 22 41 17 88
NEUROTONICOS E OUTROS . 3 25 51 74 28 181
NITRITOS E NITRATOS 51 110 866 2136 2293 594 6050
OUTROS ANTIDIABETICOS ORAIS 17 . 51 370 492 337 1267
OUTROS ANTISEPTCOS URINARIOS . . 42 49 55 50 196
OUTROS HORMONIOS CONTRACEPTIVOS SISTEMICOS . 2 28 136 93 36 295
OUTROS HORMONIOS SEXUAIS E PRODUTOS SIMILARES . . 52 127 156 58 393

56
Fx_Salarial
1 2 3 4 5 6 Total
OUTROS PRODUTOS CARDIOVASCULARES . 1 10 200 66 62 339
PENICILINAS INJETAVEIS AMPLO ESPECTRO 2 1 18 17 14 2 54
PENICILINAS ORAIS AMPLO ESPECTRO 17 46 506 1284 1320 354 3527
POUPADORES POTASSIO+DIURETICOS ALCA COMB . 1 13 59 69 4 146
PREPARACOES BIFASICAS . 7 65 187 191 59 509
PREPARADOS ANTIGLAUCOMATOSOS E MIOTICOS SISTEMICOS 8 19 108 256 188 68 647
PREPARADOS ANTIGLAUCOMATOSOS E MIOTICOS TOPICOS 8 47 431 994 951 374 2805
PREPARADOS DE TIREOIDE 21 53 542 1585 1631 578 4410
PREPARADOS MONOFASICOS C/ESTROGENOS <50MCG . 2 3 13 12 6 36
PREPARADOS P/TRATAMENTO CONJUTIVITES NAO ESPECIFICADAS 7 2 7 17 12 2 47
PRODUTOS ANTI-ALZHEIMER INIBIDORES COLINESTERASE . 17 101 284 256 92 750
PRODUTOS ORAIS SO C/PROGESTERONA . 1 29 103 109 19 261
PRODUTOS P/DOENCAS DA PROSTATA 7 10 130 496 595 257 1495
PRODUTOS P/INCONTINENCIA URINARIA . . 3 15 4 . 22
PROGESTOGENEOS . . . 4 6 . 10
PROGESTOGENIOS EXCLUINDO G3A,G3F . . 6 3 5 . 14
PSICOESTIMULANTES . . 7 75 236 46 364
RELAXANTES MUSCULARES ACAO CENTRAL 6 16 98 222 251 79 672
SUBSTITUTOS ORAIS ELETROLITICOS . . 27 89 76 15 207
SUPLEMENTOS MINERAIS/CALCIO . 2 24 101 121 28 276
SUPLEMENTOS MINERAIS/POTASSIO 1 4 26 84 123 46 284
TERAPIA CORONARIANA EXCLUINDO ANTAGONISTAS CALCIO+NITRITOS . 48 295 527 471 133 1474
TETRACICLINAS E ASSOCIACOES . . 28 31 43 14 116
TIAZIDAS+ANALOGOS PUROS 30 73 849 2564 2927 1046 7489
TODAS OUTRAS PREPARACOES ANTIENXAQUECA . . 2 16 4 . 22
TODOS OUTROS ANTINEOPLASICOS . . 5 5 4 1 15
TODOS OUTROS ANTI-ASMATICOS E BRONCODILATADORES INALATORIOS . 4 34 140 100 24 302
TODOS OUTROS PRODUTOS P/TRATAMENTO DE FERIDAS . . 7 17 20 12 56

57
Fx_Salarial
1 2 3 4 5 6 Total
TRANQUILIZANTES 19 181 1430 3858 4130 1210 10828
TRICOMONICIDAS SISTEMICOS 4 8 102 329 341 105 889
TRICOMONICIDAS TOPICOS 1 11 69 159 146 42 428
TRIPTANICOS ANTIENXAQUECA 2 . 18 53 166 116 355
VASOPROTETORES SISTEMICOS 5 16 88 426 502 109 1146
VASOTERAPIA CEREBRAL E PERIFERICA EXCLUINDO ANTAGONISTAS CALCIO 13 7 100 381 388 228 1117
XANTINICOS-SISTEMICOS 16 19 55 108 165 23 386

58
ANEXO B – CLASSE TERAPEUTICA X SEXO
Sexo
F M Total
Desc_Classe_Terapeutica
AGENTES ANTI-ALERGICOS NASAIS 3 7 10
AGENTES ANTIINFLAMATORIOS INTESTINAIS 48 56 104
AGENTES IMUNOSSUPRESSORES 84 67 151
AGENTES POUPADORES POTASSIO PURO 1009 1612 2621
AGENTES POUPADORES POTASSIO+TIAZIDAS COM 858 1231 2089
AGENTES SISTEMICOS P/INFECCOES FUNGICAS 762 823 1585
AMEBICIDAS 12 12 24
AMINOGLICOSIDEOS 26 37 63
ANALGESICO NAO NARCOTICO/ANTIPIRETICO 3127 4079 7206
ANALGESICOS NARCOTICOS 118 187 305
ANESTESICOS LOCAIS TOPICOS 15 17 32
ANTAGONISTA RECEPTORES H2 437 599 1036
ANTAGONISTAS ANGIOTENSINA II ASSOCIADOS 6873 11935 18808
ANTAGONISTAS CALCIO C/ ATIVIDADE CEREBRAL 148 111 259
ANTAGONISTAS CALCIO PUROS 6797 11855 18652
ANTAGONISTAS CALCIO+BETABLOQUEADORES COMBINADOS 301 604 905
ANTAGONISTAS PUROS ANGIOTENSINA II 7460 12216 19676
ANTAGONISTAS RECEPTORES ADP- INIBIDORES PLAQUETARIO S 2360 5495 7855
ANTI-ASMATICOS/ ANTILEUCOTRIENOS SISTEMICOS 372 439 811
ANTI-HISTAMINICOS SISTEMICOS 1416 1692 3108
ANTIACIDOS PUROS 16 23 39
ANTIACNEICOS SISTEMICOS 15 50 65
ANTIACNEICOS TOPICOS 77 52 129
ANTIARRITMICOS CARDIACOS 550 845 1395
ANTIBIOTICOS GINECOLOGICOS 40 21 61
ANTIBIOTICOS TOPICOS PUROS/SULFONAMIDAS 68 95 163
ANTICOAGULANTES NAO INJETAVEIS 671 1041 1712
ANTICOLINERGICOS PURO INALANTES 232 252 484
ANTICONVULSIVANTES INCLUINDO ANTIEPILEPTICOS 8910 9545 18455
ANTIDEPRESSIVOS EXCLUINDO PLANTAS 9065 8124 17189

59
Sexo
F M Total
ANTIDIABETICOS BIGUANIDAS 4041 6838 10879
ANTIDIABETICOS INIBIDORES ALFA-GLUCOSIDADE 788 1297 2085
ANTIDIABETICOS SULFONILUREIA 3545 6370 9915
ANTIDIABETICOS TIAZOLIDINEDIONAS 1232 2529 3761
ANTIESPASMODICOS ASSOCIADOS C/OUTROS PRODUTOS . 6 6
ANTIESPASMODICOS+ANTICOLINERGICOS PUROS 99 91 190
ANTIFLATULENTOS PUROS/CARMINATIVOS 956 882 1838
ANTIFUNGICOS DERMATOLOGICOS SISTEMICOS 3 7 10
ANTIFUNGICOS DERMATOLOGICOS TOPICOS 238 439 677
ANTIFUNGICOS GINECOLOGICOS 666 237 903
ANTIFUNGICOS TOPICOS COURO CABELUDO 57 80 137
ANTIGOTOSOS 381 1851 2232
ANTIHELMINTICOS EXCETO P 1C 366 425 791
ANTIHEMORROIDARIOS SEM CORTICOIDE 110 193 303
ANTIHIPERTENSIVOS PURO-ACAO CENTRAL 1155 1327 2482
ANTIHIPERTENSIVOS PURO-ACAO PERIFERICA 752 1123 1875
ANTIINFECCIOSOS OFTALMOLOGICOS 77 120 197
ANTIINFLAMATORIOS OFTALMOLOGICOS + ANTIINFECCIOSOS 25 32 57
ANTIINFLAMATORIOS OFTALMOLOGICOS NAO ESTEROIDES 72 100 172
ANTIINFLAMATORIOS RESPIRATORIOS NAO ESTEROIDAIS SISTEMICOS 11 20 31
ANTIMETABOLITOS 27 31 58
ANTIPARKINSONIANOS 352 450 802
ANTIPSICOTICOS ATIPICOS 741 736 1477
ANTIPSICOTICOS CONVENCIONAIS 224 254 478
ANTIREUMATICOS NAO ESTEROIDES PUROS 2779 3482 6261
ANTIREUMATICOS NAO ESTEROIDES- COXIBS 1447 1939 3386
ANTIREUMATICOS RUBEFAC. TOPICOS 271 292 563
ANTISEPTICOS GINECOLOGICOS 4 15 19
ANTITUSSIGENOS PUROS 81 69 150
ANTIVIRAIS EXCETO PRODUTOS ANTI-HIV 68 99 167
ANTIVIRAIS OFTALMOLOGICOS 5 3 8
ANTIVIRAIS TOPICOS 131 151 282

60
Sexo
F M Total
ASSOCIACOES ANTIESPASMODICOS/ANALGESICOS 541 634 1175
ASSOCIACOES C/ ANTIHIPERTENSIVOS E/OU DIURETICOS 1177 1911 3088
ASSOCIACOES CORTICOSTEROIDES SISTEMICOS 273 362 635
ASSOCIACOES DE ESTROGENOS/PROGESTERONAS 191 87 278
ASSOCIACOES DE TRIMETOPRIMA E SIMILARES 234 294 528
BETABLOQUEADORES PUROS 8104 15057 23161
BISFOSF. O REGULADOR CALCIO OSSEO 568 256 824
CARDIOGLICOSIDEOS PUROS 577 890 1467
CEFALOSPORINAS INJETAVEIS 26 28 54
CEFALOSPORINAS ORAIS 1241 1589 2830
CITOSTATICOS ANTI-ANDROGENICOS 27 215 242
CITOSTATICOS ANTI-ESTROGENEOS 349 55 404
COMBINACOES DE ANTIDIABETICOS SULFONILUREIAS+BIGUAN IDAS 940 1566 2506
CORTICOIDES - INALANTES 199 194 393
CORTICOIDES TOPICOS PUROS 118 185 303
CORTICOSTEROIDES COM ANTIMICOTICOS 17 16 33
CORTICOSTEROIDES INJETAVEIS PUROS 18 11 29
CORTICOSTEROIDES NASAIS COM ANTIINFECCIOSOS 23 40 63
CORTICOSTEROIDES OFTALMOLOGICOS 26 32 58
CORTICOSTEROIDES ORAIS PUROS 1664 2129 3793
CORTICOSTEROIDES OTICOS ASSOCIADOS C/ANTIINFECCIOSO S 46 73 119
DIURETICOS DE ALCA PUROS 1422 2190 3612
ESTABILIZADORES DO HUMOR 259 407 666
ESTIMULANTES B2 C- ACAO INALATORIA 38 43 81
ESTIMULANTES B2 COM CORTICOIDES -INALANTES 673 874 1547
ESTIMULANTES B2 L -ACAO INALATORIA 121 146 267
ESTIMULANTES B2-SISTEMICOS 227 259 486
ESTROGENEOS CITOSTATICOS . 20 20
ESTROGENIOS EXCLUINDO G3A,G3E,G3F 122 67 189
EXPECTORANTES 240 351 591
FIBRATOS 640 1666 2306
FLUORQUINOLONAS ORAIS 1155 1425 2580

61
Sexo
F M Total
GASTROPROCINETICOS 1236 1280 2516
HIPNOTICOS/SEDATIVOS NAO BARBITURICOS PUROS 388 437 825
INIBIDORES AROMATASE CITOSTATICOS 292 82 374
INIBIDORES CICLO-OX INIBIDORES AGREGACAO PLAQUETARI A 4280 9189 13469
INIBIDORES DA BOMBA ACIDA 5123 6086 11209
INIBIDORES DA ECA ASSOCIADOS C/ ANTIHIPERTENSIVOS ANTAGONISTAS 633 1297 1930
INIBIDORES DA ECA ASSOCIADOS C/ ANTIHIPERTENSIVOS DIURETICOS 369 834 1203
INIBIDORES DA NUCLEASE TRANSCRIPTASE REVERSA . 2 2
INIBIDORES ENZIMA CONVERSORA DE ANGIOTENSINA PUROS 3807 7758 11565
INIBIDORES PROLACTINA 36 58 94
INIBIDORES REDUTASE HMG-COA 12762 21149 33911
INSULINA HUMANA+ANALOGOS ACAO INTERMEDIARIA 184 315 499
INSULINA HUMANA+ANALOGOS ACAO PROLONGADA 400 501 901
INSULINA HUMANA+ANALOGOS- ACAO INTERMEDIARIA+RAPIDA 44 89 133
INSULINA HUMANA+ANALOGOS- ACAO RAPIDA 284 374 658
LAXANTES ENEMAS 35 29 64
LUBRIFICANTES OCULARES/LAGRIMAS ARTIFICIAIS 18 17 35
MACROLIDEOS E SIMILARES 507 607 1114
MOD SENSOM GASTRO-INTEST 47 41 88
NEUROTONICOS E OUTROS 92 89 181
NITRITOS E NITRATOS 1976 4074 6050
OUTROS ANTIDIABETICOS ORAIS 348 919 1267
OUTROS ANTISEPTCOS URINARIOS 126 70 196
OUTROS HORMONIOS CONTRACEPTIVOS SISTEMICOS 231 64 295
OUTROS HORMONIOS SEXUAIS E PRODUTOS SIMILARES 289 104 393
OUTROS PRODUTOS CARDIOVASCULARES 49 290 339
PENICILINAS INJETAVEIS AMPLO ESPECTRO 26 28 54
PENICILINAS ORAIS AMPLO ESPECTRO 1537 1990 3527
POUPADORES POTASSIO+DIURETICOS ALCA COMB 33 113 146
PREPARACOES BIFASICAS 394 115 509
PREPARADOS ANTIGLAUCOMATOSOS E MIOTICOS SISTEMICOS 223 424 647

62
Sexo
F M Total
PREPARADOS ANTIGLAUCOMATOSOS E MIOTICOS TOPICOS 956 1849 2805
PREPARADOS DE TIREOIDE 2562 1848 4410
PREPARADOS MONOFASICOS C/ESTROGENOS <50MCG 32 4 36
PREPARADOS P/TRATAMENTO CONJUTIVITES NAO ESPECIFICA DAS 25 22 47
PRODUTOS ANTI-ALZHEIMER INIBIDORES COLINESTERASE 406 344 750
PRODUTOS ORAIS SO C/PROGESTERONA 187 74 261
PRODUTOS P/DOENCAS DA PROSTATA 122 1373 1495
PRODUTOS P/INCONTINENCIA URINARIA 17 5 22
PROGESTOGENEOS 9 1 10
PROGESTOGENIOS EXCLUINDO G3A,G3F 7 7 14
PSICOESTIMULANTES 160 204 364
RELAXANTES MUSCULARES ACAO CENTRAL 334 338 672
SUBSTITUTOS ORAIS ELETROLITICOS 101 106 207
SUPLEMENTOS MINERAIS/CALCIO 161 115 276
SUPLEMENTOS MINERAIS/POTASSIO 119 165 284
TERAPIA CORONARIANA EXCLUINDO ANTAGONISTAS CALCIO+NITRITOS 450 1024 1474
TETRACICLINAS E ASSOCIACOES 47 69 116
TIAZIDAS+ANALOGOS PUROS 3159 4330 7489
TODAS OUTRAS PREPARACOES ANTIENXAQUECA 9 13 22
TODOS OUTROS ANTINEOPLASICOS 12 3 15
TODOS OUTROS ANTI-ASMATICOS E BRONCODILATADORES INALATORIOS 121 181 302
TODOS OUTROS PRODUTOS P/TRATAMENTO DE FERIDAS 28 28 56
TRANQUILIZANTES 5633 5195 10828
TRICOMONICIDAS SISTEMICOS 460 429 889
TRICOMONICIDAS TOPICOS 322 106 428
TRIPTANICOS ANTIENXAQUECA 206 149 355
VASOPROTETORES SISTEMICOS 557 589 1146
VASOTERAPIA CEREBRAL E PERIFERICA EXCLUINDO ANTAGONISTAS CALCIO 439 678 1117
XANTINICOS-SISTEMICOS 164 222 386

63

64
ANEXO C - Telas do SAS
A ferramenta utilizada para a descoberta de regras na base de dados de utilização
do benefício farmácia foi o SAS (Statistical Analsys System – SAS Institute inc.
www.sas.com).
Este anexo descreve o processo realizado no SAS, executado após a preparação
descrita na sessão 5.1, para a descoberta de regras.
Inicialmente é necessário definir a estrutura para o SAS trabalhar. A figura
abaixo mostra a interface de trabalho do SAS Enterprise Miner versão 5.3.
Figura 2 - Criação de diagrama para uso na técnica de Regra de Associação
Nas figuras seguintes é mostrado passo a passo como realizar e interpretar uma
análise de associação dentro do Software.
O primeiro passo é fazer a definição da tabela analítica (Flat Table) que servirá
de insumo para a criação das regras de associação. Na janela de definições do projeto
(figura 3), clicando com o botão direito no menu “Data Source” e selecionando

65
“Create Data Source”, será aberto um wizard para a definição da tabela. Este wizard
está detalhado nas figuras 3 a 10.
Figura 3 - Seleção do diretório de dados
A figura 3 apresenta a opção de seleção do repositório de dados onde
se encontra a tabela de dados. Este repositório é um arquivo na visão do
sistema operacional.
Figura 4 - Nome da tabela criada

66
O repositório é semelhante a uma biblioteca e é composto por várias tabelas. A
figura 4 apresenta a seleção da flat table analítica, que é parte deste
repositório.
Figura 5 – Biblioteca para carga dos dados
A figura 5 apresenta o passo no qual, opcionalmente, é incluída uma
definição de library SAS, apontando o local físico onde se encontra a flat –
uma pasta no sistema operacional.
Figura 6 – Propriedades da tabela criada
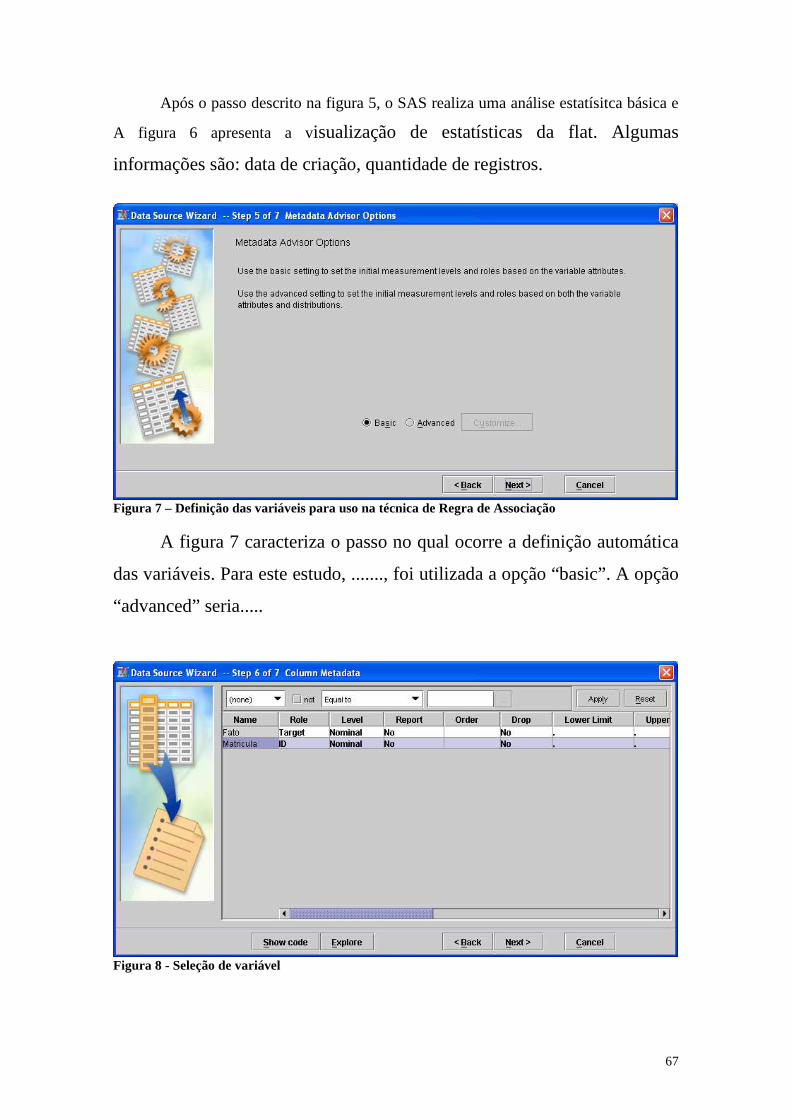
67
Após o passo descrito na figura 5, o SAS realiza uma análise estatísitca básica e
A figura 6 apresenta a visualização de estatísticas da flat. Algumas
informações são: data de criação, quantidade de registros.
Figura 7 – Definição das variáveis para uso na técnica de Regra de Associação
A figura 7 caracteriza o passo no qual ocorre a definição automática
das variáveis. Para este estudo, ......., foi utilizada a opção “basic”. A opção
“advanced” seria.....
Figura 8 - Seleção de variável

68
A figura 8 é o passo no qual ocorre a seleção das variáveis que consiste na
escolha do conjunto que será analisado dentro do conjunto total de campos
disponíveis no arquivo carregado. Especificamente a figura 8 mostra a
seleção da variável “matrícula”.
Figura 9 – Seleção para uso em redes não supervisionadas
A figura 9 é o passo no qual ocorre a definição do custo/ganho de
cada decisão tomada. Não se aplica no contexto de Análise de associação.
Figura 10 – Definição da finalidade da tabela (Transação)

69
A figura 10 é o passo no qual ocorre a definição da finalidade de uma
tabela analítica. Para análise de associação a tabela deve ser definida como
Transaction.
Figura 11 – Construção do diagrama – Seleção da tabela de dados

70
Figura 12 – Construção do diagrama – Seleção da técnica – Regra de Associação
Neste passo, após a definição da tabela, é necessário colocá-la na área de
trabalho (figura 11). O nó Association, também deve estar na área de trabalho e uma
ligação deve ser criada entre o ícone da tabela e do nó Association (figura 12).

71
Figura 13 – Input de parâmetros da técnica de Regra de Associação
Clicando sobre o nó Association, é possível parametrizá-lo através da janela de
propriedades à esquerda da área de trabalho (figura 13). É possível especificar a
quantidade de regras, restrições para se criar uma regra e a complexidade das regras
criadas. Depois de definidas as propriedades do nó, clique sobre ele com o botão direito
e selecione a opção “Run” para executar o modelo de associação e criar as regras.
Depois o processo terminar, selecione a opção “Results” para ver os resultados da
análise.

72
As figuras 14 a 17 mostram os resultados gerados pelo SAS Enterprise Miner
5.3 para a análise de associação.
Figura 14 – Matriz de regras geradas
A figura 14 mostra, em uma matriz, a estatística confiança (confidence) de todas
as regras que foram geradas. Como pode ser visto na legenda, pontos mais próximos do
azul indicam confiança mais baixa, e pontos vermelhos indicam maior confiança. Os
eixos X e Y, respectivamente “Mão direita da regra” e “Mão esquerda da regra”,
facilitam encontrar todas as regras ligadas a determinado produto. A “mão esquerda”
pode ser interpretada como a causa e a “mão direita” como a conseqüência de uma
regra. Por exemplo, veja a regra abaixo:
Se comprou produto A => 60% também comprou produto B
Mão esquerda Mão direita confiança

73
Figura 15 - Gráfico Suporte x Confiança
A figura 15 mostra um gráfico de pontos (Scatter Plot), onde cada ponto
representa uma regra, sendo o eixo X a confiança e o eixo Y o suporte daquela regra. A
cor do ponto mostra a quantidade de itens que compões a regra, de acordo com a
legenda. Geralmente as melhores regras são aquelas que apresentam alto suporte e alta
confiança.

74
Figura 16 – Algumas informações estatísticas
A figura 16 mostra uma cópia da tela do SAS contendo estatísticas gerais sobre
as regras produzidas.
Os valores mínimo, máximo e médio para as variaveis:
EXP_CONF – Confiança esperada
CONF – Confiança
SUPPORT – Suporte
LIFT – Razão entre a Confiança e Confiança esperada.

75
Figura 17 – Regras produzidas
A figura 17 mostra a descrição completa de cada regra, junto com as estatísticas
específicas.

Livros Grátis( http://www.livrosgratis.com.br )
Milhares de Livros para Download: Baixar livros de AdministraçãoBaixar livros de AgronomiaBaixar livros de ArquiteturaBaixar livros de ArtesBaixar livros de AstronomiaBaixar livros de Biologia GeralBaixar livros de Ciência da ComputaçãoBaixar livros de Ciência da InformaçãoBaixar livros de Ciência PolíticaBaixar livros de Ciências da SaúdeBaixar livros de ComunicaçãoBaixar livros do Conselho Nacional de Educação - CNEBaixar livros de Defesa civilBaixar livros de DireitoBaixar livros de Direitos humanosBaixar livros de EconomiaBaixar livros de Economia DomésticaBaixar livros de EducaçãoBaixar livros de Educação - TrânsitoBaixar livros de Educação FísicaBaixar livros de Engenharia AeroespacialBaixar livros de FarmáciaBaixar livros de FilosofiaBaixar livros de FísicaBaixar livros de GeociênciasBaixar livros de GeografiaBaixar livros de HistóriaBaixar livros de Línguas

Baixar livros de LiteraturaBaixar livros de Literatura de CordelBaixar livros de Literatura InfantilBaixar livros de MatemáticaBaixar livros de MedicinaBaixar livros de Medicina VeterináriaBaixar livros de Meio AmbienteBaixar livros de MeteorologiaBaixar Monografias e TCCBaixar livros MultidisciplinarBaixar livros de MúsicaBaixar livros de PsicologiaBaixar livros de QuímicaBaixar livros de Saúde ColetivaBaixar livros de Serviço SocialBaixar livros de SociologiaBaixar livros de TeologiaBaixar livros de TrabalhoBaixar livros de Turismo
Related Documents











