Convolutional Network Representation for Visual Recognition ALI SHARIF RAZAVIAN Doctoral Thesis Stockholm, Sweden, 2017

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Convolutional Network Representationfor Visual Recognition
ALI SHARIF RAZAVIAN
Doctoral ThesisStockholm, Sweden, 2017

TRITA-CSC-A-2017:01ISSN-1653-5723ISRN-KTH/CSC/A–17/01–SEISBN-978-91-7729-213-5
Robotics, Perception and Learning Lab.School of Computer Science and Communication
KTH Royal Institute of TechnologySE-100 44 Stockholm, Sweden
Copyright © January 2017 by Ali Sharif Razavian except where otherwise stated.
Tryck: US-AB

iii
Abstract
Image representation is a key component in visual recognition systems. In visualrecognition problem, the solution or the model should be able to learn and infer thequality of certain visual semantics in the image. Therefore, it is important for the modelto represent the input image in a way that the semantics of interest can be inferredeasily and reliably. This thesis is written in the form of a compilation of publicationsand tries to look into the Convolutional Networks (CovnNets) representation in visualrecognition problems from an empirical perspective.
Convolutional Network is a special class of Neural Networks with a hierarchicalstructure where every layer’s output (except for the last layer) will be the input ofanother one. It was shown that ConvNets are powerful tools to learn a generic repre-sentation of an image. In this body of work, we first showed that this is indeed thecase and ConvNet representation with a simple classifier can outperform highly-tunedpipelines based on hand-crafted features. To be precise, we first trained a ConvNeton a large dataset, then for every image in another task with a small dataset, we feed-forward the image to the ConvNet and take the ConvNets activation on a certain layeras the image representation. Transferring the knowledge from the large dataset (sourcetask) to the small dataset (target task) proved to be effective and outperformed base-lines on a variety of tasks in visual recognition. We also evaluated the presence ofspatial visual semantics in ConvNet representation and observed that ConvNet retainssignificant spatial information despite the fact that it has never been explicitly trainedto preserve low-level semantics.
We then tried to investigate the factors that affect the transferability of these rep-resentations. We studied various factors on a diverse set of visual recognition tasksand found a consistent correlation between the effect of those factors and the similarityof the target task to the source task. This intuition alongside the experimental resultsprovides a guideline to improve the performance of visual recognition tasks using Con-vNet features. Finally, we addressed the task of visual instance retrieval specifically asan example of how these simple intuitions can increase the performance of the targettask massively.
Keywords: Convolutional Network, Visual Recognition, Transfer Learning.

iv
List of Papers
The thesis is based on the following papers:
[A] Ali Sharif Razavian, Hossein Azizpour, Josephine Sullivan, Stefan Carlsson.CNN Features off-the-shelf: an Astounding Baseline for Recognition. InIEEE Conference on Computer Vision and Pattern Recognition, Deep VisionWorkshop, 2014.
[B] Ali Sharif Razavian, Hossein Azizpour, Atsuto Maki, Josephine Sullivan, CarlHenrik Ek, Stefan Carlsson. Persistent Evidence of Local Image Properties inGeneric Convnets. In Scandinavian Conference on Image Analysis, 2015.
[C] Hossein Azizpour, Ali Sharif Razavian, Josephine Sullivan, Atsuto Maki, Ste-fan Carlsson. Factors of Transferability for a Generic Convnet Representation.In IEEE Transaction on Pattern Analysis and Machine Intelligence, 2016.1
This paper is an extension of the following award winning paper:
Hossein Azizpour, Ali Sharif Razavian, Josephine Sullivan, Atsuto Maki, Ste-fan Carlsson. From Generic to Specific Deep Representations for VisualRecognition. In IEEE Conference on Computer Vision and Pattern Recog-nition, Deep Vision Workshop, 2015.
[D] Ali Sharif Razavian, Josephine Sullivan, Stefan Carlsson, Atsuto Maki. VisualInstance Retrieval with Deep Convolutional Networks. In ITE Transactionson Media Technology and Applications, 2016.
This paper is an extension to the following one:
Ali Sharif Razavian, Josephine Sullivan, Atsuto Maki, Stefan Carlsson. ABaseline for Visual Instance Retrieval with Deep Convolutional Networks. InInternational Conference on Learning Representations Workshops, 2015.
In addition to the papers [A]-[D], the author of this thesis has contributed to the fol-lowing papers:
• Ali Sharif Razavian, Omid Aghazadeh, Josephine Sullivan and Stefan Carlsson, Es-timating Attention in Exhibitions Using Wearable Cameras. In International Con-ference on Pattern Recognition, 2014.
• Stefan Carlsson, Hossein Azizpour, Ali Sharif Razavian The Preimage of RectifierNetwork Activities. Submitted to International Conference on Learning Represen-tations, 2017.
1I designed some of the pipelines, network architectures and factors. Also, I performed the experiments forhundreds out of approximately a thousand reported results in this paper.

Contents
Contents v
I Introduction 1
1 Introduction 31 Tasks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42 Pipeline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63 Factors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2 Background 111 Descriptors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112 Encoding Methods . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143 Convolutional Networks . . . . . . . . . . . . . . . . . . . . . . . . . . 154 Comparison . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3 Summary of papers 19A CNN Features off-the-shelf: an Astounding Baseline for Recognition . . . 19B Persistent Evidence of Local Image Properties in Generic ConvNets . . . 21C Factors of Transferability for a Generic ConvNet Representation . . . . . 23D Visual Instance Retrieval with Deep Convolutional Networks . . . . . . . 25
4 Conclusion 27
References 29
II Included Publications 39
A CNN Features off-the-shelf: an Astounding Baseline for Recognition A11 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A22 Background and Outline . . . . . . . . . . . . . . . . . . . . . . . . . . A5
v

vi CONTENTS
3 Visual Classification . . . . . . . . . . . . . . . . . . . . . . . . . . . . A54 Visual Instance Retrieval . . . . . . . . . . . . . . . . . . . . . . . . . . A125 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A14References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A15
B Persistent Evidence of Local Image Properties in Generic ConvNets B11 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B22 Flow of information through a ConvNet . . . . . . . . . . . . . . . . . . B43 Experiment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B54 Semantic directions in representation space . . . . . . . . . . . . . . . . B11References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B12
C Factors of Transferability for a Generic ConvNet Representation C11 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . C22 Range of target tasks examined . . . . . . . . . . . . . . . . . . . . . . . C63 Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . C84 Optimized Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . C215 Implementation details . . . . . . . . . . . . . . . . . . . . . . . . . . . C226 Closing Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . C227 Acknowledgement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . C23References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . C23
D Visual Instance Retrieval with Deep Convolutional Networks D11 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . D22 Related work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . D43 The ConvNet representation of an image . . . . . . . . . . . . . . . . . . D44 Pipeline for measuring similarities of images . . . . . . . . . . . . . . . D65 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . D106 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . D13References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . D13

Part I
Introduction


Chapter 1
Introduction
Visual recognition is a family of tasks in computer vision that try to model and infer thestate of visual semantics in an image. To do so, models usually try to represent the inputimage in a way that relevant information is easily accessible to the inference module. Thereare numerous algorithms proposed to represent an image. Before 2012, the most successfulrepresentations were usually built upon well engineered and handcrafted modules describ-ing the image. The performance of models based on these handcrafted descriptors wasincreasing steadily and slowly. But in 2012, with the advent of large manually annotateddatasets and the increasing power of processors, a Convolutional Network (ConvNet) [60]won [58] the ImageNet challenge [85] and outperformed pipelines based on handcrafteddescriptors by a huge margin (see figure 1).
ConvNets are a family of feed forward deep neural networks that are trained in a super-vised and end-to-end fashion. Studies suggest that the magic associated with ConvNet is itsability to learn a good image representation from a large dataset [20, 10, 19, 71, 26, 17, 80].
This compilation thesis is comprised of four papers that are originally written to shedmore light on the general questions of "What should be expected from ConvNet represen-tation in visual recognition?" from an empirical perspective.
In paper A [80], we trained a ConvNet on a large dataset and used the ConvNet rep-resentation space to address a wide variety of visual recognition tasks. Our experimentssolidify the superiority of ConvNet representations over other representations based onhandcrafted descriptors. In paper B [79], we showed that the spatial information that per-sisted in the ConvNet representation space is reliable and easily accessible. In paper C [4],we studied the factors of transferability for a ConvNet representation. Finally, in paper D[81] we used the finding of the previous publications on the task of visual instance retrieval.
In all our experiments, we employed transfer learning. Transfer learning is a techniquethat aims to improve the performance of the task at hand (target task) by transferring theknowledge harvested from another task (source task). In all our experiments, we used largedatasets (e.g., ImageNet [85]) as the source tasks and relatively small yet frequently useddataset as the target task.
The structure of this chapter is as follows: We define the visual recognition tasks that
3

4 CHAPTER 1. INTRODUCTION
2007 2009 2011 2013 2015
10
20
30
40
50
60
70
80
90
RCNN [42]RCNN-FT [42]
RCNN-FT-VGGNet [42]ResNet [47]
AlexNet [58] Overfeat [89]
GoogLeNet [93] ResNet [47]
FV+hand-crafted features
UoCTTI(Competition)
DPM [36]
MultiKernel [96]
DPM-v4 [35]
DPM-v5 [43]
DPM+HSC [82]
Year
Perf
orm
ance
VOC07 (mAP) [29]ImageNet (Acc) [85]
Figure 1: Reported results for object detection on Pascal VOC07 [29] and ImageNet top-5classification [85] benchmarks. ConvNet based models (circle marks) have significantlyoutperformed pipelines based on handcrafted features (square marks).
we tackled in section 1. Our pipeline is explained in section 2 and the factors of transfer-ability that we studied in section 3. We summarize the discussion of this chapter in section4.
The next chapters are organized as following: In chapter 2, we brief the details of someof the most famous handcrafted features and common encodings. Then we continue thischapter by mentioning the important components of ConvNets and finally try to make aconnection between these two. Chapter 3 provides the summary of papers that this thesisis based upon. Finally in chapter 4 we conclude this thesis by providing a list of our con-tributions. The second part of this thesis contains full text of aforementioned publications.
1 Tasks
In our work, we studied the performance of ConvNet representations on a diverse set ofvisual recognition tasks. In some tasks, the model should infer about high-level visualsemantics while in some others low-level visual semantics like spatial information must bemodeled. Below is the list of tasks and their associated benchmarks:
Object Classification In this task, the model should infer about the presence or absenceof a specific category of object in the image (For example, whether there is a cat in theimage or not). Object classification is one of the core problems in computer vision. We

1. TASKS 5
used the highly cited benchmark of Pascal VOC 2007 dataset [29] as a benchmark for thistask.
Scene Classification tries to predict the category of the scene in an image. An objectclassifier can be helpful in narrowing down the set of possible scenes. For example, de-tecting multiple books in an image implies that the scene is most likely a bookstore or alibrary. But to exactly recognize the scene, the model should also be aware of the structureof these objects in the scene. We used MIT67 Indoor scene dataset [78] and SUN 397dataset [101] for our experiments on this task.
Fine Grained Classification is a narrow family of tasks in Object Classification wherethe objects of interest are visually similar. Unlike general object classification tasks incomputer vision, in this family of tasks the outline of the object is far less informativeand the model should be more aware of other families of features like color or texture(For example, the outlines of Sphinx and Cornish Rex are very similar but the texture oftheir skin is different). To evaluate this task, we considered the following benchmarks: Petdataset [73], CUB-200 bird dataset [100] and Flower dataset [68].
Attribute Detection tries to describe the content of an image in terms of attributes asopposed to nouns. If an object detector is based on attributes, it could still function tosome extent when encountering a new category of object. For example, a model may nothave seen any cup before but it can still tell whether it is round or cylindrical. We usedH3D human attributes dataset [13], Object attribute dataset [33] and SUN scene attributedataset [74] for this task.
Action Recognition tries to model the verb in an image. For example, a man cuttingvegetables is performing a different action than a man cooking them. In this task, objects,their spatiotemporal relation with each other and their pose are all important factors.1 Forevaluation, we used Pascal VOC12 action dataset [31] and Stanford Action40 dataset [103].
Visual Phrases describe an image in terms of phrases like "A man riding a horse" bycombining the words associated with visual concepts in the image. The same way that aphrase can be seen as an intermediate between a word and a sentence, a visual phrase taskcan also be viewed as the successor of the aforementioned tasks and the predecessor tovisual caption generators. We used Visual Phrases dataset [86] to evaluate this task.
Visual Instance Retrieval aims to retrieve images of the same instance of an object in areference set by sorting them according to their distance to the query image. This can beinterpreted as embedding images into a representation space where visually similar imageshave similar representation. One of the challenges in this task is that the definition of
1We excluded temporal information from our pipelines and only focused on the still-image action recognitiontasks for the sake of unified framework.

6 CHAPTER 1. INTRODUCTION
similarity is vague. Similarity can be related to the presence of a particular object, pattern,shape or a scene structure. A major difference between visual instance retrieval and othervisual recognition tasks is that retrieval tasks usually do not have a training set and sortingthe reference set usually has to be done on the fly. For evaluation, we used five standardbenchmarks in this field: Oxford building dataset [75], Paris Building dataset [76], OxfordSculpture dataset [3], Holidays dataset [52] and UKBench dataset [69].
Pose Estimation aims to find the spatial properties of the item of interest in an image.A model in this task should be sensitive to low-level visual semantics like spatial positionand orientation of an object of interest. Also, a model should be good enough to detect theobject of interest in the first place, but the standard benchmarks in this task usually take thelocalized item of interest as an input. For this task, we used Pascal VOC11 keypoints[30],Helen [59], IBUG [8] and LFPW [87] datasets.
Semantic Segmentation combines spatial and class information all together and assignslabels to each pixel. In this task, the model should be sensitive to both high-level classinformation from low-level spatial information in an image. High-level visual semanticsshould be as accurate as possible while the model is still sensitive to low-level spatialinformation. For evaluation, we used VOC 2012 semantic segmentation dataset [31].
2 Pipeline
Our approach to solve these tasks is by employing transfer learning. Transfer learningtries to incorporate the knowledge learned from one domain (source task) into another one(target task). The idea of transfer learning combined with neural networks is not new (e.g.,the work of Caruana (1998) [16]). But before 2012 in computer vision community, neuralnetworks were usually perceived to have a tendency toward over-fitting and therefore, notconsidered for transfer learning. The recent findings of [80] suggest that ConvNets trainedon large datasets learn a generic image representation and therefore, well suited for transferlearning in visual recognition. For all the categories of tasks that we studied, we stayedfaithful to the simple pipeline:
• Train a ConvNet on a large dataset (source task).
• For every image in the task at hand (target task):
– Feed each image to the pre-trained ConvNet.
– Take the mid-level response of the network as the vector representation of theimage.
– Normalize the vector.
• Train a linear model (SVM [21] or regression [48]) over the representations (For thetask of retrieval, sort reference images based on their distance to the query image inthe representation space).

3. FACTORS 7
• Measure the performance according to the task’s criteria.
This simple pipeline proved to be powerful and the reported performance was on a par(if not better) with heavily engineered pipelines based on handcrafted features. To improveon these results, we simply augment our training set by a simple, yet effective technique.We extracted multiple patches from the image and based on the objective of the tasks, weaggregated the model’s response. For classification tasks, we average the vectors of thetraining and the test sets. For pose estimation tasks, we apply bounding box regression tohave a higher resolution image and for retrieval, we compute the similarity between eachpatch in reference and query image.
It should be mentioned and highlighted that our simple off-the-shelf pipeline is by nomeans the most efficient pipeline. For example, while our simple pipeline resulted in theaccuracy of 67.1% on CUB dataset [98], the work of [14] reported 85.4% using a moresophisticated ConvNet-based pipeline. The reasons we used this simple pipeline are two-fold. First, we wanted to show the effectiveness of ConvNet representation and second, wecould build a unified framework to measure the importance of different ConvNet relatedfactors on the performance.
3 Factors
The use of ConvNet representations has proven to be more effective than handcrafted fea-tures over a wide variety of tasks [80], yet different ConvNets yield different performances.In the next part, we identified and studied the factors affecting the transferability of Con-vNet representation. We group these factors into two: Learning factors (see section 3.1)and post-learning factors (see section 3.2).
3.1 Learning Factors
Learning factors are the factors that are related to the training of the source task. Wedefined these factors as the following:
Network width Wider networks have more parameters in each layer while moderatelywide networks have fewer. Our finding suggests that wider networks tend to be morespecialized on the source task while moderately wide networks generalize better.
Network depth defines the number of layers that a network has. The deeper a network,the more linear transformations (followed by nonlinearity) will be applied to an image.We also observed that depth is a good regularizer and in general, deeper networks tend togeneralize better.
Early stopping is a regularization technique that avoids over-fitting by stopping thetraining procedure early. We observe that early stopping only helps when the networkon the source task also exhibits over-fitting (like the case of fine-tuning). Otherwise, itdoes not affect the performance of the target task.

8 CHAPTER 1. INTRODUCTION
Target task
FactorSource task xxxImageNet · · ·
FineGrainedrecognition · · ·
Instance xxxxxretrieval
Early stopping Don’t do it
Network depth As deep as possible
Network width Wider Moderately wide
Diversity/Density More classes better than more images per class
Fine-tuning Yes, more improvement with more labelled data
Dim. reduction Original dim Reduced dim
Rep. layer Later layers Earlier layers
Table 1: The relation between factors of transferability and the performance of the modelbased on transfered representation.
Source task’s training data is probably the most important factor in learning a genericrepresentation. We studied the training data from various points of view from the similarityof the objective in the source task to the target task, all the way to the density and diversityof the training data.
3.2 Post-learning Factors
Post-learning factors are the factors that should be considered when using a pre-trainedConvNet representation to target task.
Network Layer plays an important role on the performance of the target task. Earlylayers are more generic while later ones are more specific toward the source task.
Spatial Pooling is necessary to reduce the mid-layer representations’ size while preserv-ing some spatial consistency. This pooling, in particular, is useful when the presence ofspatial information is important (e.g., in retrieval tasks).
Dimensionality reduction We studied dimensionality reduction of the representationand observed that the representation for target tasks that are more distant to the source taskscan be more compressed. But in general, ConvNet representations can be compressed toan order of magnitude smaller footprint and still function as good.
Additional data We studied the effect of additional data from various points of view andour experiments suggest that additional data almost always helps.

4. SUMMARY 9
In our analysis, we found a consistent correlation between the similarity of source/targettasks and the effect of those factors. This intuition can be useful for the use of ConvNetrepresentations in other computer vision tasks. The summary of analysis is found in table1.
4 Summary
Our studies over a diverse family of visual recognition tasks solidified that indeed, Con-vNets trained on large datasets learn better-performing representations than the one basedon handcrafted features descriptors. Also, ConvNets encode both high-level and low-levelvisual semantics in their representations and these semantics are disentangled and linearlyaccessible. We also provided insight on how to more effectively use ConvNet representa-tion by defining factors that control the transferability of such representations. In chapter4, we explain our contributions in more details.


Chapter 2
Background
In the book "Computer Vision" [77], Prince defines a vision problem as “take a visual dataand use them to infer the state of the world”. He further describes a model as “a familyof possible relationships between the data and the state of the world”. The pipeline ofmapping between the input and the desired output or state of the world has gone throughchanges over time (See figure 1). In the rule-based era, no learning was involved in thepipeline but as the time went by, more and more machine learning was included in visualrecognition pipelines. Machine learning components generally perform better than intu-itive and hand-crafted components but they require more data and processing power. Whatall the pipelines have in common is that they repeatedly try to transform an image and rep-resent it in a form that is easier or more intuitive to make an inference on. A classical visualrecognition pipeline first tries to describe an image in terms of certain semantics that arebelieved to be informative like edges or colors. Then those descriptors are represented byaggregating them into a fixed length vector and the inference is made on those representa-tions. A deep ConvNet does not make any explicit assumption on what information shouldbe kept or discarded during each transformation. This chapter briefly describes some ofthe important components in visual recognition pipelines before the deep learning triumphin 2012 [58, 85] including some of the most commonly used hand-crafted features in sec-tion 1 and their associated encodings in section 2. Then we explain some of the importantcomponents of Convolutional Networks in section 3 and finally try to make a connectionbetween the two in section 4.
1 Descriptors
In this section, we brief four descriptors (SIFT [65], HOG [23], GIST [70] and SCD [9]).These descriptors have been the most frequently used hand-crafted descriptors in the do-main they are designed for. SIFT, HOG and SCD are histogram-based descriptors. Theirperformance are generally on par with other families of descriptors (e.g., Local DescriptorLearning [90]) while their simplicity and intuitiveness made them favorable to other de-scriptors. These descriptors aggregate the response of a certain filter over a large region
11

12 CHAPTER 2. BACKGROUND
InputHand-
designed program
Output
InputHand-
designed descriptor
Mappingfrom
features
InputHand-
designed descriptor
Encoding
Output
Mappingfrom
encodingOutput
Rule-based System
Simple CV pipeline
Classic CV pipeline
Input Simple features ….
More complex features
OutputDeep Learning
Figure 1: The history of visual recognition pipelines from rule-based times to the deeplearning era. Gray color indicates that the parameters of those components will be deter-mined according to some learning procedure on a dataset. This schematic is a recurringtheme in many recent talks. Our figure is most similar to Yoshua Bengio’s 2014 talk inKnowledge Discovery and Data Mining (KDD).
in the image by simply computing the histogram of the response. For cases where theresponse is continuous, some quantization has to be computed.
SIFT [65] or scale invariant feature descriptor and its variations like SURF [7], ORB[83] and BRIEF [15] are widely used in variety of computer vision task from classificationto regression, retrieval and registration.
SIFT is the most commonly used hand-crafted feature descriptor. SIFT descriptor com-putes the histogram of image orientation for the 16×16 pixel areas around the interestpoints. The orientations (from the range 0◦ to 360◦) are then quantized into 8 bins. Fi-nally, a histogram for every non-overlapping grid of 4×4 is computed. At the end, a16×16 pixel region is described in a 4×4 grid of 8 dimensional histogram which can beviewed as a 128-D vector per region of interest. To find the interest points, SIFT computesthe response of the image over K difference of Gaussian kernels with increasing scale andpicks the extrema in this X×Y×K volume.
SIFT algorithm estimates these points by approximating a local quadratic function tothe subvoxel around the extrema. This way, interest points will have a sub-pixel res-olution. Although SIFT-based models have recently been outperformed by ConvNet-based pipelines for certain tasks like classification [80, 17, 71, 26, 106] and regression

1. DESCRIPTORS 13
Figure 2: Left: HOG descriptor for a pedestrian image with overlapping grid of 2×2 asdisplayed in green and blue squares. HOG algorithm extracts gradient histogram fromeach cell as described in section 1. Middle: The visualization of HOG descriptors forthe image. In each cell, the brightness of the segment lines correlates with the strengthof the gradient in the same direction. The images on the left and middle are taken from[39]. Right: Visualization of SIFT descriptors. SIFT descriptors divide the area aroundthe interest points into a grid of 4×4 and extract the histogram of orientation as describedin section 1. SIFT visualization image is taken from [95].
[79, 27, 42, 63, 107, 105, 62], their sub-pixel resolution interest point gives them advan-tages on many other tasks e.g., registration [109, 65].
HOG [23] or Histogram of Oriented Gradient, is also a collection of normalized his-togram and is generally viewed as a global descriptor. HOG computes the histogram oforiented gradient for small overlapping cells of 6×6 and returns a descriptor for each cell.These gradients are then quantized into 9 bins of 0◦ to 180◦. The final descriptor is theproduct of concatenating all the cell descriptors. There are many extensions to HOG aswell like PHOG [12], HOG-3D [57] and Histogram of Sparse Coding [82].
HOG descriptor in nature is similar to SIFT [65] but it has higher resolution and per-forms better localized normalizations. HOG is more suited for detection tasks where thespatial structure of object should be preserved (e.g., pedestrian detection).1
GIST [70] is another gradient based global descriptor. GIST divides the image into gridsof 4×4 and computes a 32D feature for each cell by convolving Gabor filters at 4 scales
1There are different implementations of SIFT and HOG with different parameters. We took the details from[77].

14 CHAPTER 2. BACKGROUND
and 8 orientations. These 16 vectors are then concatenated into a single 512 vector. Thiscompact descriptor collects statistics about the gradients in each region of the image whilepreserving some spatial structure. This property is useful for categorizing different scenes.
SCD [9] or Shape Context Descriptor has been built upon the idea that for many classes,an object can be described with its silhouette. Shape Context descriptors, similar to SIFTand HOG, collect local information into a histogram but unlike those, the histogram iscollected in a polar coordinate system as opposed to the Cartesian one. Also, instead ofgradient, Shape Context models the distribution of the relative position of the interest pointto other points that are sampled along the contours of the object.
2 Encoding Methods
Encoding methods try to embed the feature descriptors into a representation space by anon-linear transformation. In this chapter, we brief two families of encoding methodsthat have appeared frequently in computer vision. We briefly describe dictionary basedmethods and deformable part-based models.
Dictionary-Based Encodings In dictionary based encodings, a set of bases C ⊂ Rdcalled codebooks or dictionary is learned (d is the dimension of the descriptors) so that eachdescriptor x can be approximated by these codebooks: x ≈
∑c∈C αcc. (α coefficients
are usually non-negative and add up to 1). In histogram encoding [92] each descriptor isassigned to its nearest codebook and a histogram of those assignments will be collected foreach image. The representation of a descriptor with its nearest codebook loses information.To address this problem, the size of dictionary is usually considered to be big.
VLAD [53] or Vector of Locally Aggregated Descriptors divides the descriptor spaceinto Voronoi cells based on its codebook and tries to preserve the information in eachVoronoi cell. To do so, VLAD aggregate the difference of assignments between descrip-tors and the assigned dictionary. Fisher Vectors (FV) [51] try to model both first and secondorder information about the distribution of descriptors in each cluster. Many different nor-malization and pooling methods have been proposed for these encodings. FV have provento be the most successful of these family of encodings for large-scale image classification.
Deformable Part Models [38] are a family of the detector and have been built aroundthe idea that an object can be recognized by detecting its parts and their spatial relationswith each other. The work of Felzenszwalb et al. [37] is one of the most important class ofalgorithms in this family that uses HOG pyramid as an input. DPMs try to learn the mostdiscriminative parts among different categories. In other word, it implicitly and simultane-ously encodes features into parts and infers about the content of the image based on thoseparts.

3. CONVOLUTIONAL NETWORKS 15
Image:19x19
S1:19x19x12
C1:21x21x8
S2:21x21x38
C2:13x13x19
S3:13x13x35
C3:7x7x23
S4:3x3x11
C4:1x10
Image:32x32
Conv:28x28x6
Sub:14x14x6
Conv:10x10x16
Sub:5x5x16
FC:120
FC:84
FC:10
Image:224x224x3
Conv:55x55x96
Sub:27x27x96
Conv:27x27x128
Sub:13x13x128
FC:4096
FC:4096
FC:1000
Conv:13x13x384
Conv:13x13x384
Conv:13x13x256
Sub:7x7x256
Figure 3: Left: Hierarchical network structure of the Neocognitron as displayed inFukushima et al. (1983) [41]. S stands for simple layer and C for complex layer. Middle:LeNet-5 architecture as displayed in Lecun et al. (1998) [61]. LeNet substituted Simplelayers with Convolution operation and Sub-sampling instead of Complex Layer. FC standsfor fully connected layer. Right: AlexNet architecture as displayed in Krizhevsky et al.(2012) [58]. The structure of AlexNet is very similar to LeNet. Except AlexNet hasmore layers and trained with different regularizer on bigger and more training samples.
3 Convolutional Networks
Convolutional Network or ConvNet is an important class of supervised pattern recognitionmodels. It has been developed in the field of Artificial Neural Network and after 2012, hasreemerged as a crucial component in various computer vision tasks including classification[58, 91, 89, 93, 47, 71, 80, 17, 26, 55, 106, 42], regression [79, 27, 42, 63, 107, 105, 62],retrieval [81, 80, 2, 6, 99, 104, 5, 94, 1] and multi-model alignments [102, 18, 54, 67].
ConvNet [60, 61] was developed in late 1980s in Bell labs to address the task ofdigit recognition. The architecture of the proposed model (LeNet) was influenced bythe work of Neocognitron [41, 40], a hierarchical network for pattern recognition.Neocognitron itself was inspired by the psychological model of visual system by No-bel prize winners Hubel and Wiesel [49]. Neocognitron is composed of two types ofneurons, Simple (S) neurons with small field of view, transform the input of the previouslayer into a new representation space.

16 CHAPTER 2. BACKGROUND
Every S layer then is followed by a Complex (C) layer whose primary function is to"condense" the previous layers. The architecture of Neocognitron is displayed in figure3.
LeNet, elevated the structure of Neocognitron with at least two major changes:LeNet replaced the Complex neurons with max pooling function. By doing so, it elimi-nated all the parameters between S and C layers. LeNet also imposed parameter sharingamong neurons of a layer and reduced the number of parameters between C and S layersdrastically (see figure 3).
ConvNets are mostly trained according to error back-propagation algorithm [84]. Inback-propagation algorithm, the prediction of the model for the data batch is defined as y =f(x; θ). In this definition, f is the model that maps input x to output y using parametersθ. Then, the Loss function L measures error of prediction (E) w.r.t. the ground truth τaccording to equation 2.1.
E = L(τ,y) = L(τ, f(x; θ)) (2.1)
The gradient descent algorithm updates the parameters of model iteratively based onequation 2.2. This algorithm repeatedly updates the t dimensional vector of θ by adding avector proportional to the gradient of the loss function ∇θL but in the opposite direction.Parameter η controls the size of this residual.
θnew = θold − η∇θL(τ, f(x; θ)) (2.2)
∇θL = 〈 ∂L∂θ1
, . . . ,∂L∂θt〉
A feed forward Neural Network can be written recursively as
f(x; θ) = fL(fL−1(. . . f l(. . . f1(x; θ1) . . . ); θl) . . . )θL−1); θL)) (2.3)
where l is the index of a layer ranging from 1 to L and f l is usually a linear functionfollowed by a nonlinearity. Error Back-propagation algorithm applies chain rule to updatethe parameters according to equation 2.4.
∇θlL = ∂L∂θl
=
δl︷ ︸︸ ︷∂L∂fL
∂fL
∂fL−1 . . .∂f l+1
∂f l∂f l
∂θl(2.4)
As reflected in equation 2.4, δl can be computed recursively according to equation 2.5
δl = δl+1.∂f l+1
∂f l(2.5)
δL = ∂L∂fL
= ∇yL(τ,y)
It can be seen that the back-propagation algorithm is linear w.r.t. the size of dataset. InConvNet model, f is defined as a convolution operation: f(x; θ) = [x ∗ θ]+ where [.]+ isa nonlinear transformation usually in the form of [.]+ = max(., 0).

4. COMPARISON 17
One advantage of the convolution operation is that it can operate on a big image sizewith few parameters. For example the first layer of AlexNet [58] transforms images froma 150k (=224×224×3) dimensional input space into a 145k (=50×50×48) dimensionalhidden representation space with only 17k parameters that are highly correlated to oneanother. ConvNets benefit greatly from large and diverse datasets. This combination ofmassive data and small parameters regulates the model to a high degree.2 Beside sharedparameters and large datasets, ConvNets are usually further regularized by other techniqueslike `2 regularizations [58], Dropout [58, 22] or batch normalizations [50].
4 Comparison
After the ImageNet competition in 2012 [58], Gradient-based Neural Networks in generaland ConvNets in particular reemerged into computer vision pipelines. Collobert and We-ston (2008) [20] and Bengio et al. (2011) [10] speculated that the magic of deep modelsare that their representations are generic. Ciregan et al.[19], Oquab et al. (2013) [71] andDonahue and Jia et al. (2013) [26] showed that ConvNets “ pre-training on one differ-ent set greatly improves performance on quite different sets.” [88]. Razavian et al. (2014)[80] showed that Deep Convolutional Network trained on large datasets “can extract usefulfeatures from quite diverse off-training-set images, yielding better results than traditional,widely used features such as SIFT [65] on many vision tasks”[88].
There has been much speculation on why these models perform so well. First layer’stransformation seems to capture edges, textures and colors similar to hand-crafted features.The work of [97] showed that HOG features are noisy and they can map many different im-age patches to the same point in the HOG feature space. This is not the case for ConvNetswhere an image can be reconstructed almost perfectly from the early layers’ response mapof a ConvNet [66]. In fact, the empirical results in [97] showed that given only HOGfeatures, humans and DPMs perform almost as good.
Another interesting comparison is between DPMs and ConvNets [44]. In this work,Girshick et al. suggested that DPMs can be viewed as a special class of ConvNets witha certain generalization of the pooling layers. This implies that if HOG pyramids werenot noisy, a DPM on HOG can be viewed as a shallow ConvNet with different learningprocedure.
Dictionary based encodings usually learn their bases with an unsupervised density es-timation method (e.g., K-means or GMM) while ConvNet in each transformation realignsthe represented data manifold according to its objective.
It has been assumed [11, 45] that ConvNets simultaneously flatten and align the datamanifold. This explanation is justified by many experimental results in the field. For exam-ple, deeper ConvNets with their piecewise linear manifold functions can provide better ap-proximations to this process. Also in this explanations, the representation space should besmooth [11] or in other word, similar images should have similar representations [79, 81].
2The winner of 2014 ImageNet Competition GoogLeNet [93] had roughly 7M parameters and was trainedon 1M images of 256×256 pixels each. In other word, 1 parameter for every 9k input pixels.

18 CHAPTER 2. BACKGROUND
2000 2005 2010 20151k
10k
100k
1M
10M
MIT67[78]
SUN397[101]
Places[108]
VOC05[32]
VOC12[28]
Caltech101[34]
Caltech256[46]
ImageNet3M[25]
ImageNet11M[24]
MNIST[61]
ImageNet[85]
Year
Size
challengedataset
Figure 4: The size of dataset annotations over time. It is interesting to see that PietroPerona of Caltech and his student Fei-Fei Li (later professor in Stanford) were five yearsahead of the rest of vision community in grasping the importance of annotated data incomputer vision and investing on it.
Closing discussion A major drawback of ConvNets over well engineered models wasthat ConvNets require large datasets and immense processing power for training. The find-ing of [4] suggests that both density and diversity of datasets affect the quality of the rep-resentation space. While deep learning community had MNIST dataset [61], a massivelyannotated dataset of natural images was not around before 2009 (see figure 4). With theadvancements in the processor industry, in 2012 deep learning reemerged in visual recog-nition. In 2013 and 2014, the works of [71, 26, 17, 80] showed that ConvNet representationoutperforms baselines on small datasets with the help of a large dataset (ImageNet [25]).Those findings eliminated the last obstacle for ConvNet-based pipelines to take over thevisual recognition tasks.

Chapter 3
Summary of papers
A CNN Features off-the-shelf: an Astounding Baseline forRecognition
Studies suggest that ConvNets are powerful tools to learn the representation [20, 10, 19,71, 26, 17]. In this paper, we tried to put those findings in practice and showed that in fact,this is the case. In this work, we studied the performance of ConvNet representations on aset of fourteen different visual recognition tasks.
Our simple pipeline is as follows. First we trained a Convolutional Network (Overfeat[89]) on a large dataset (ImageNet[85]). Then for every image in a visual recognition task,we fed the image forward to the network and took the `2 normalized vector of neural ac-tivities of a certain layer as the image representations. For every task (except for visualinstance retrieval tasks) we trained a linear SVM [21] on the training set and reported theperformance on the test set (see figure 1). For visual instance retrieval, we measured theperformance based on the `2 distance of representation vectors.
This simple pipeline proved to be effective and competitive to highly-tuned pipelines
ImageDense Patch
Sampling
Clustering/Pooling Contexualization
CNN Representation
SVMExtraction: SIFT, C-
SIFT, LBP, HOG
Figure 1: Comparison of our pipeline (top) vs an example of a highly tuned and well-engineered pipeline (bottom) for the task of fine-grained classification. Our simple pipelineproved to be effective and competitive to every other pipeline on a diverse set of tasks.
19
20 CHAPTER 3. SUMMARY OF PAPERS
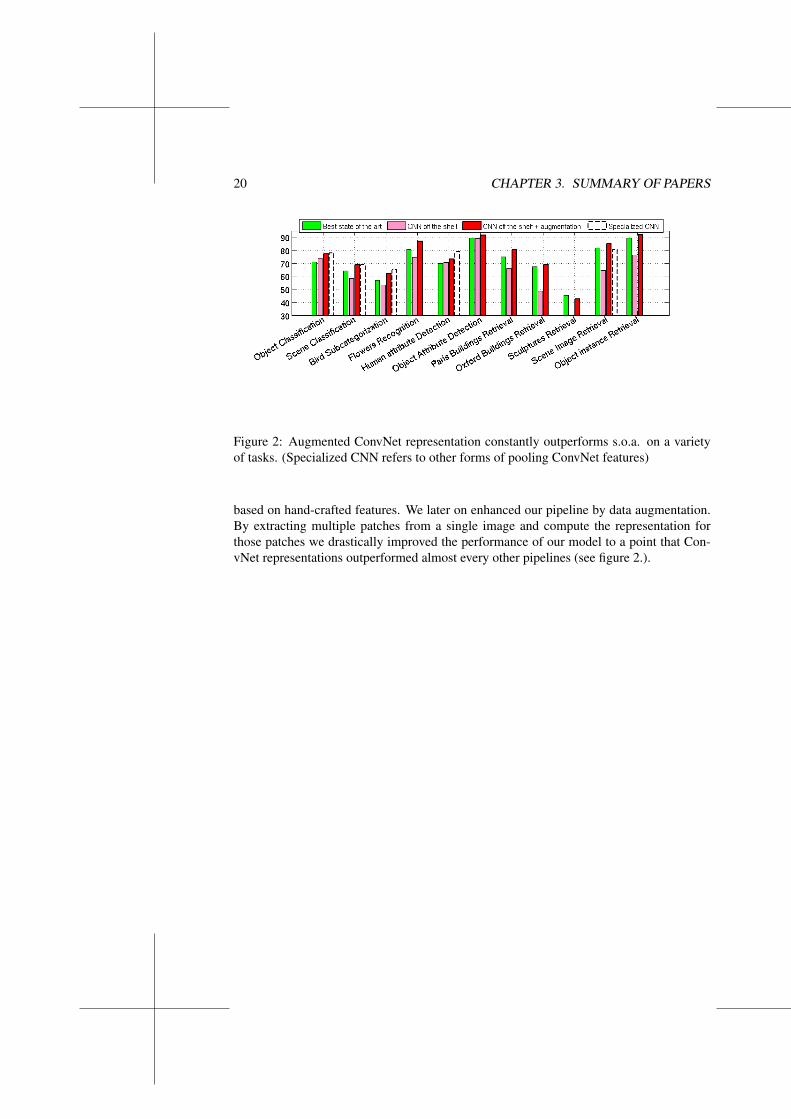
Figure 2: Augmented ConvNet representation constantly outperforms s.o.a. on a varietyof tasks. (Specialized CNN refers to other forms of pooling ConvNet features)
based on hand-crafted features. We later on enhanced our pipeline by data augmentation.By extracting multiple patches from a single image and compute the representation forthose patches we drastically improved the performance of our model to a point that Con-vNet representations outperformed almost every other pipelines (see figure 2.).

B. PERSISTENT EVIDENCE OF LOCAL IMAGE PROPERTIES IN GENERICCONVNETS 21
B Persistent Evidence of Local Image Properties in GenericConvNets
Although a generic ConvNet has never been explicitly trained to preserve spatial seman-tics, previous studies suggest that generic ConvNet representation trained for the task ofclassification is still sensitive to spatial semantics (i.e., the position of the object of interestin the image) [72]. In this work, we tried to measure the reliability of spatial semantics ina generic ConvNet representation.
To do so, we evaluated the ConvNet representation performance on four families oftasks that require local spatial semantics. We again chose our simplistic pipeline (i.e., onerepresentation per image and a linear mapping from representation to output) to tacklethese tasks. The families of tasks that we studied are 1) 2D landmark estimation, 2) 2Dkeypoint prediction, 3) RGB reconstruction and 4) Semantic Segmentation.
The qualitative and quantitative results on the aforementioned tasks suggest that Con-vNet representation retain significant spatial semantics (see figure 3 for an example on task1). In order to enhance the quality of our estimations, we employed the simple techniqueof data augmentation (extracting multiple patches per image instead of one) combined witha bounding box regression.
Our studies confirm that both low-level spatial semantics and high-level class seman-tics co-exist in ConvNet representation and they are accessible almost independently. Wefurther expanded our experiments and tried to move image representations in the represen-tation space along the directions that have meaningful interpretations for us.
Figure 3: Left: ground truth landmarks. Middle: estimated landmarks from a singleimage representation. The prediction is reliable enough to apply bounding box regressionfor further enhancements. Right: fine-tuned landmarks after bounding box regression.Our simple augmentation technique improves to the performance of landmarks to a pointwhere it is comparable to the highly tuned baselines based on hand-crafted features.

22 CHAPTER 3. SUMMARY OF PAPERS
To be precise, given an image, we extracted the image representation first, then movedthe representation along the direction that correlates the most with "gender" or "pose"and visualize the modified representation. Our observation suggests that changing a high-level representation according to a high-level semantic can be translated to the pixel-level-change that carries the same meaning to human subjects. Our findings can be viewedas evidence for a theory that ConvNets may disentangle different underlying factors thatgenerate the image.
male −→ female
right in-plane rot. −→ left in-plane rot.
Figure 4: Center column: We extract the ConvNet representation of an image (A facein this example) and reconstruct the image from the representation. We can also movethe representation vector in the direction of high-level semantics and revisualizes it (Othercolumns). By moving the image representation along the gender direction, we see thatthe corresponding visualization changes accordingly. Top row: Masculinity in ConvNetrepresentation space correlates with facial hair, triangular faces, and thick eyebrows. Fem-ininity is visualized with rounder faces, more makeups, and thinner eyebrows. Bottomrow: Visualization of the in-plane rotation of the face. Modifying the image according tospatial semantics also corresponds to the expected changes in the reconstructed image.

C. FACTORS OF TRANSFERABILITY FOR A GENERIC CONVNETREPRESENTATION 23
C Factors of Transferability for a Generic ConvNet Representation
The use of Artificial Neural Networks (ANN) in general for transfer learning is not new.But before 2012, Neural Networks in visual recognition were generally considered to beprune to over-fitting and therefore, few works had been done to the study of factors thataffect the transferability in visual recognition.
Recent studies suggest that ConvNet (a special family of Neural Networks) based rep-resentation should be considered as the primary choice for visual recognition [80]. Yet, theperformance of these models depends heavily on the factors that upon them, the ConvNetis trained or used.
In this work, we follow the pipeline proposed in [80] where the ConvNet is trained on asource task, then the activity of a certain layer of the ConvNet will be treated as the vectorrepresentation of the image in the target task. This work tries to corner out several factorsthat affect this transferability of the representation space from the source task to the targettask. We divided the factors into two groups: 1) Learning factors involving the training ofthe ConvNet on the source task including: ConvNet architecture (depth and width), Sourcedata and early stopping. 2) Post-learning factors that exploit source ConvNet for the targettask including: The choice of layer, spatial pooling, dimensionality reduction and the useof extra data in different ways on both source and target task (see figure 5).
Target
image
Source
ConvNet
Target ConvNet
RepresentationSVM
Target
label
layer?dim. reduction?
spatial pooling?fine-tuning?
Backprop with Source images & labelsRandom ConvNet Source ConvNet
network architecture?source task? early stopping?
⇓
Training of Source ConvNet from scratch
Exploit Source ConvNet for Target Task
Figure 5: Factors of transferability for a generic ConvNet from the source task to the targettask. Top: learning factors, Bottom: post-learning factors.

24 CHAPTER 3. SUMMARY OF PAPERS
VOC
MIT
SCENESU
N
SceneAtt
ObjAtt
Hum
anAtt
Petbreed
BirdSubord
Flowers
VOCAction
StfdAction
Vis.Phrase
Holidays
UKB
Oxford
Paris
Sculpture30
405060708090100
Best non-ConvNet Deep Standard Deep Optimal
Figure 6: The reported performance over 17 datasets in wide variety of tasks. Optimizingthe factors of transferability can reduce the relative error by up to 50%.
In our study, we observed a consistent pattern in the relation between the effect ofthese factors on the performance of the target tasks and the similarity between the sourceand target task. We performed our experiments over a diverse set of visual recognitiontasks, datasets, network architectures and models and showed that just by choosing theoptimal settings on these factors, the relative error on the target task can be improved byup to 50% (see figure 6).

D. VISUAL INSTANCE RETRIEVAL WITH DEEP CONVOLUTIONAL NETWORKS25
D Visual Instance Retrieval with Deep Convolutional Networks
In this paper, we tackled the task of visual instance retrieval specifically. In this task, areference set is provided and the model should be able to sort this reference set based ontheir relevance to a query image. The relevancy is usually defined as the presence of aparticular visual semantic of the query image in the reference image set (e.g., the presenceof a particular object or scene or shape of interest). In another word, the model should learnan embedding space where the representation of the relevant images ends up close to oneanother. A major challenge in this task is that the item of interest can appear in differentviewpoints. lightings, scales etc.
In this work, using a multi-scale scheme, we proposed a pipeline that tries to preservecertain spatial consistency while being less variant toward the change in position and scaleof the item of interest. We used five datasets to test our pipeline and showed that “genericConvNet image representations can outperform other state-of-the-art methods if they areextracted appropriately.”
This work, as well as the parallel work of Babenko et al. [6, 5], were among the first touse ConvNet representations for the task of retrieval.
Figure 7: The items of interest in visual instance retrieval can vary in many aspects,namely: viewpoints, lightings, scales and locations. A good model should be able tohandle those variations.


Chapter 4
Conclusion
Over the last years, the part of computer vision community focused on recognition haveshifted their focus from hand-crafted features to the deep ConvNet representations. Thepublications in this thesis were written to address some of the important questions in thispath. We addressed series of tasks, but the most significant contribution of this thesis isthat we showed a deep ConvNet trained on ImageNet learns a generic image representationthat can be transferred to a wide variety of visual recognition domains. Based on this, weconcluded that:
“From now on, deep learning with Convolutional Networks has to be consid-ered as the primary candidate in essentially any visual recognition task.”
In more details, the contributions of this thesis are listed below:
• In paper A, we systematically evaluated the performance of ConvNet representationson a wide variety of visual recognition tasks and showed that simple pipelines withConvNet representations can outperform highly-tuned baselines with hand-craftedfeatures. Our diverse experiments solidify and justify the superiority of ConvNetrepresentations over hand-crafted ones for visual recognition tasks.
• In paper B, we measured the spatial information in generic ConvNet representa-tions. It was shown that ConvNet representation trained for classifications preservessome spatial information [72, 64]. We evaluated the quality of this low-level visualsemantics and observed that ConvNets retain rich spatial semantics that are welldisentangled from the high-level ones.
• In paper C, we studied the factors involved in training and using ConvNets that affectthe transferability of ConvNet representations. By defining and studying a diverseset of factors over a large number of target tasks, this work provides intuitions onhow one can take advantage of these factors to optimize the performance of a visualrecognition model.
27

28 CHAPTER 4. CONCLUSION
• In paper D, we focused on the task of visual instance retrieval. We provided a singlepipeline that outperforms every other pipeline based on hand-crafted features onall the datasets. Our work was among the first to successfully use the ConvNetrepresentation for the task of instance retrieval.
• Last but not least, our vision of a unified pipeline based on an off-the-shelf repre-sentation that outperforms a wide variety of baselines over different datasets andobjective has permeated the computer vision field (e.g., [56] in natural languageprocessing).
Future work. Computer vision will probably remain a challenging problem in the com-ing years. Although ConvNets are sitting unchallenged at the core of visual recognitionmodels, there is a large body of ongoing work trying to improve the performance of Con-vNets which only means they are not perfect yet. Despite all the great works that have beendone recently in embedding structures into ConvNets, still it is safe to say that a ConvNetis only as good as the dataset it is trained on and many semantics are hard to annotate.Some of this semantics are low-level ones that are simply left behind. For example, to thebest of our knowledge, there has not been a large dataset that addresses the problem ofspecular/transparent surfaces yet. Or, some other semantics are too abstract to annotate. Avisual model may be able to reliably detect most of the objects in an image but we probablyhave to wait for a model that can tell us why "Starry Night" of Van Gogh feels so gloomyyet soothing. There are efforts in computer vision community to address these challengesby creating synthetic datasets or harvesting abstract semantics from other modes of data(texts for example). But to see how well those efforts would pay off, we just have to wait.

References
[1] Giuseppe Amato, Fabrizio Falchi, Claudio Gennaro, and Fausto Rabitti. Yfcc100m-hnfc6: A large-scale deep features benchmark for similarity search. In InternationalConference on Similarity Search and Applications, pages 196–209, 2016.
[2] Relja Arandjelovic, Petr Gronat, Akihiko Torii, Tomas Pajdla, and Josef Sivic.Netvlad: Cnn architecture for weakly supervised place recognition. Proceedingsof the Conference on Computer Vision and Pattern Recognition, 2016.
[3] Relja Arandjelovic and Andrew Zisserman. Smooth object retrieval using a bag ofboundaries. In Proceedings of the International Conference on Computer Vision,pages 375–382, 2011.
[4] Hossein Azizpour, Ali S Razavian, Josephine Sullivan, Atsuto Maki, and StefanCarlsson. Factors of transferability for a generic convnet representation. IEEETransactions on Pattern Analysis and Machine Intelligence, 2015.
[5] Artem Babenko and Victor Lempitsky. Aggregating local deep features for imageretrieval. In Proceedings of the International Conference on Computer Vision, pages1269–1277, 2015.
[6] Artem Babenko, Anton Slesarev, Alexandr Chigorin, and Victor Lempitsky. Neuralcodes for image retrieval. In Proceedings of the European Conference on ComputerVision, pages 584–599, 2014.
[7] Herbert Bay, Tinne Tuytelaars, and Luc Van Gool. Surf: Speeded up robust features.In Proceedings of the European Conference on Computer Vision, pages 404–417,2006.
[8] Peter N Belhumeur, David W Jacobs, David J Kriegman, and Neeraj Kumar. Local-izing parts of faces using a consensus of exemplars. IEEE Transactions on PatternAnalysis and Machine Intelligence, 35(12):2930–2940, 2013.
[9] Serge Belongie, Jitendra Malik, and Jan Puzicha. Shape context: A new descrip-tor for shape matching and object recognition. In Advances in Neural InformationProcessing Systems, volume 2, page 3, 2000.
29

30 REFERENCES
[10] Yoshua Bengio, Frédéric Bastien, Arnaud Bergeron, Nicolas Boulanger-Lewandowski, Thomas M Breuel, Youssouf Chherawala, Moustapha Cisse, Myr-iam Côté, Dumitru Erhan, Jeremy Eustache, et al. Deep learners benefit more fromout-of-distribution examples. In International Conference on Artificial Intelligenceand Statistics, pages 164–172, 2011.
[11] Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: Areview and new perspectives. IEEE Transactions on Pattern Analysis and MachineIntelligence, 35(8):1798–1828, 2013.
[12] Anna Bosch, Andrew Zisserman, and Xavier Munoz. Representing shape with aspatial pyramid kernel. In Proceedings of ACM international conference on Imageand video retrieval, pages 401–408, 2007.
[13] Lubomir Bourdev, Subhransu Maji, and Jitendra Malik. Describing people: Aposelet-based approach to attribute classification. In Proceedings of the Interna-tional Conference on Computer Vision, pages 1543–1550, 2011.
[14] Steve Branson, Grant Van Horn, Serge Belongie, and Pietro Perona. Bird speciescategorization using pose normalized deep convolutional nets. Proceedings of theBritish Machine Vision Conference, 2014.
[15] Michael Calonder, Vincent Lepetit, Christoph Strecha, and Pascal Fua. Brief: Bi-nary robust independent elementary features. In Proceedings of the European Con-ference on Computer Vision, pages 778–792, 2010.
[16] Rich Caruana. Multitask learning. In Learning to learn, pages 95–133. Springer,1998.
[17] Ken Chatfield, Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Returnof the devil in the details: Delving deep into convolutional nets. Proceedings of theBritish Machine Vision Conference, 2014.
[18] Xinlei Chen and C Lawrence Zitnick. Mind’s eye: A recurrent visual representationfor image caption generation. In Proceedings of the Conference on Computer Visionand Pattern Recognition, pages 2422–2431, 2015.
[19] Dan Ciregan, Ueli Meier, and Jürgen Schmidhuber. Multi-column deep neural net-works for image classification. In Proceedings of the Conference on Computer Vi-sion and Pattern Recognition, pages 3642–3649, 2012.
[20] Ronan Collobert and Jason Weston. A unified architecture for natural languageprocessing: Deep neural networks with multitask learning. In Proceedings of theInternational Conference on Machine Learning, pages 160–167, 2008.
[21] Corinna Cortes and Vladimir Vapnik. Support-vector networks. Machine learning,20(3):273–297, 1995.

31
[22] George E Dahl, Tara N Sainath, and Geoffrey E Hinton. Improving deep neuralnetworks for lvcsr using rectified linear units and dropout. In IEEE InternationalConference on Acoustics, Speech and Signal Processing, pages 8609–8613, 2013.
[23] Navneet Dalal and Bill Triggs. Histograms of oriented gradients for human detec-tion. In Proceedings of the Conference on Computer Vision and Pattern Recognition,volume 1, pages 886–893, 2005.
[24] Jia Deng, Alexander C Berg, Kai Li, and Li Fei-Fei. What does classifying morethan 10,000 image categories tell us? In Proceedings of the European Conferenceon Computer Vision, pages 71–84, 2010.
[25] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet:A large-scale hierarchical image database. In Proceedings of the Conference onComputer Vision and Pattern Recognition, pages 248–255, 2009.
[26] Jeff Donahue, Yangqing Jia, Oriol Vinyals, Judy Hoffman, Ning Zhang, Eric Tzeng,and Trevor Darrell. Decaf: A deep convolutional activation feature for generic visualrecognition. In Proceedings of the International Conference on Machine Learning,pages 647–655, 2014.
[27] David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from asingle image using a multi-scale deep network. In Advances in Neural InformationProcessing Systems, pages 2366–2374, 2014.
[28] Mark Everingham, SM Ali Eslami, Luc Van Gool, Christopher KI Williams, JohnWinn, and Andrew Zisserman. The pascal visual object classes challenge: A retro-spective. Proceedings of the International Conference on Computer Vision, 111(1):98–136, 2015.
[29] Mark Everingham, Luc Van Gool, Chris K. I. Williams, JohnWinn, and Andrew Zisserman. The PASCAL Visual ObjectClasses Challenge 2007 (VOC2007) Results. http://www.pascal-network.org/challenges/VOC/voc2007/workshop/index.html.
[30] Mark Everingham, Luc Van Gool, Chris K. I. Williams, JohnWinn, and Andrew Zisserman. The PASCAL Visual ObjectClasses Challenge 2011 (VOC2011) Results. http://www.pascal-network.org/challenges/VOC/voc2011/workshop/index.html.
[31] Mark Everingham, Luc Van Gool, Chris K. I. Williams, JohnWinn, and Andrew Zisserman. The PASCAL Visual ObjectClasses Challenge 2012 (VOC2012) Results. http://www.pascal-network.org/challenges/VOC/voc2012/workshop/index.html.
[32] Mark Everingham, Andrew Zisserman, Christopher KI Williams, Luc Van Gool,Moray Allan, Christopher M Bishop, Olivier Chapelle, Navneet Dalal, Thomas De-selaers, Gyuri Dorkó, et al. The 2005 pascal visual object classes challenge. In

32 REFERENCES
Machine Learning Challenges. Evaluating Predictive Uncertainty, Visual ObjectClassification, and Recognising Tectual Entailment, pages 117–176. Springer, 2006.
[33] Ali Farhadi, Ian Endres, Derek Hoiem, and David Forsyth. Describing objects bytheir attributes. In Proceedings of the Conference on Computer Vision and PatternRecognition, pages 1778–1785, 2009.
[34] Li Fei-Fei, Rob Fergus, and Pietro Perona. One-shot learning of object categories.IEEE Transactions on Pattern Analysis and Machine Intelligence, 28(4):594–611,2006.
[35] Pedro Felzenszwalb, Ross Girshick, and David McAllester. Discriminativelytrained deformable part models, release 4. http://people.cs.uchicago.edu/ pff/latent-release4/.
[36] Pedro Felzenszwalb, David McAllester, and Deva Ramanan. A discriminativelytrained, multiscale, deformable part model. In Computer Vision and Pattern Recog-nition, 2008. CVPR 2008. IEEE Conference on, pages 1–8. IEEE, 2008.
[37] Pedro F Felzenszwalb, Ross B Girshick, David McAllester, and Deva Ramanan. Ob-ject detection with discriminatively trained part-based models. IEEE Transactionson Pattern Analysis and Machine Intelligence, 32(9):1627–1645, 2010.
[38] Martin A Fischler and Robert A Elschlager. The representation and matching ofpictorial structures. IEEE Transactions on computers, 22(1):67–92, 1973.
[39] Efstathios P Fotiadis, Mario Garzón, and Antonio Barrientos. Human detectionfrom a mobile robot using fusion of laser and vision information. Sensors, 13(9):11603–11635, 2013.
[40] Kunihiko Fukushima. Neocognitron: A hierarchical neural network capable of vi-sual pattern recognition. Neural networks, 1(2):119–130, 1988.
[41] Kunihiko Fukushima, Sei Miyake, and Takayuki Ito. Neocognitron: A neural net-work model for a mechanism of visual pattern recognition. IEEE Transactions onSystems, Man, and Cybernetics, (5):826–834, 1983.
[42] Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hier-archies for accurate object detection and semantic segmentation. In Proceedings ofthe Conference on Computer Vision and Pattern Recognition, pages 580–587, 2014.
[43] Ross Girshick, Pedro Felzenszwalb, and David McAllester. Discriminativelytrained deformable part models, release 5. http://people.cs.uchicago.edu/ rbg/latent-release5/.
[44] Ross Girshick, Forrest Iandola, Trevor Darrell, and Jitendra Malik. Deformable partmodels are convolutional neural networks. In Proceedings of the Conference onComputer Vision and Pattern Recognition, pages 437–446, 2015.

33
[45] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley,Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. InAdvances in Neural Information Processing Systems, pages 2672–2680, 2014.
[46] Gregory Griffin, Alex Holub, and Pietro Perona. Caltech-256 object categorydataset. 2007.
[47] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learningfor image recognition. arXiv preprint arXiv:1512.03385, 2015.
[48] Arthur E Hoerl and Robert W Kennard. Ridge regression: Biased estimation fornonorthogonal problems. Technometrics, 12(1):55–67, 1970.
[49] David H Hubel and Torsten N Wiesel. Receptive fields, binocular interaction andfunctional architecture in the cat’s visual cortex. The Journal of physiology, 160(1):106–154, 1962.
[50] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep net-work training by reducing internal covariate shift. Proceedings of the InternationalConference on Machine Learning, 2015.
[51] Tommi S Jaakkola, David Haussler, et al. Exploiting generative models in dis-criminative classifiers. Advances in Neural Information Processing Systems, pages487–493, 1999.
[52] Herve Jegou, Matthijs Douze, and Cordelia Schmid. Hamming embedding andweak geometric consistency for large scale image search. In Proceedings of theEuropean Conference on Computer Vision, pages 304–317. Springer, 2008.
[53] Hervé Jégou, Matthijs Douze, Cordelia Schmid, and Patrick Pérez. Aggregating lo-cal descriptors into a compact image representation. In Proceedings of the Confer-ence on Computer Vision and Pattern Recognition, pages 3304–3311. IEEE, 2010.
[54] Andrej Karpathy and Li Fei-Fei. Deep visual-semantic alignments for generatingimage descriptions. In Proceedings of the Conference on Computer Vision and Pat-tern Recognition, pages 3128–3137, 2015.
[55] Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Suk-thankar, and Li Fei-Fei. Large-scale video classification with convolutional neu-ral networks. In Proceedings of the Conference on Computer Vision and PatternRecognition, pages 1725–1732, 2014.
[56] Yoon Kim. Convolutional neural networks for sentence classification. Proceedingsof the 2014 Conference on Empirical Methods in Natural Language Processing,2014.
[57] Alexander Klaser, Marcin Marszałek, and Cordelia Schmid. A spatio-temporal de-scriptor based on 3d-gradients. In Proceedings of the British Machine Vision Con-ference, pages 275–1, 2008.

34 REFERENCES
[58] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classificationwith deep convolutional neural networks. In Advances in Neural Information Pro-cessing Systems, pages 1097–1105, 2012.
[59] Vuong Le, Jonathan Brandt, Zhe Lin, Lubomir Bourdev, and Thomas S Huang.Interactive facial feature localization. In Proceedings of the European Conferenceon Computer Vision, pages 679–692. Springer, 2012.
[60] Yann LeCun, Bernhard Boser, John S Denker, Donnie Henderson, Richard EHoward, Wayne Hubbard, and Lawrence D Jackel. Backpropagation applied tohandwritten zip code recognition. Neural computation, 1(4):541–551, 1989.
[61] Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-basedlearning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
[62] Sergey Levine, Chelsea Finn, Trevor Darrell, and Pieter Abbeel. End-to-end trainingof deep visuomotor policies. Journal of Machine Learning Research, 17(39):1–40,2016.
[63] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networksfor semantic segmentation. In Proceedings of the Conference on Computer Visionand Pattern Recognition, pages 3431–3440, 2015.
[64] Jonathan L Long, Ning Zhang, and Trevor Darrell. Do convnets learn correspon-dence? In Advances in Neural Information Processing Systems, pages 1601–1609,2014.
[65] David G Lowe. Distinctive image features from scale-invariant keypoints. Interna-tional journal of computer vision, 60(2):91–110, 2004.
[66] Aravindh Mahendran and Andrea Vedaldi. Understanding deep image representa-tions by inverting them. In Proceedings of the Conference on Computer Vision andPattern Recognition, pages 5188–5196. IEEE, 2015.
[67] Mateusz Malinowski, Marcus Rohrbach, and Mario Fritz. Ask your neurons: Aneural-based approach to answering questions about images. In Proceedings of theInternational Conference on Computer Vision, pages 1–9, 2015.
[68] Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification overa large number of classes. In Computer Vision, Graphics & Image Processing, 2008.ICVGIP’08. Sixth Indian Conference on, pages 722–729. IEEE, 2008.
[69] David Nister and Henrik Stewenius. Scalable recognition with a vocabulary tree.In Proceedings of the Conference on Computer Vision and Pattern Recognition,volume 2, pages 2161–2168, 2006.

35
[70] Aude Oliva and Antonio Torralba. Modeling the shape of the scene: A holisticrepresentation of the spatial envelope. International journal of computer vision, 42(3):145–175, 2001.
[71] Maxime Oquab, Leon Bottou, Ivan Laptev, and Josef Sivic. Learning and trans-ferring mid-level image representations using convolutional neural networks. InProceedings of the Conference on Computer Vision and Pattern Recognition, pages1717–1724, 2014.
[72] Maxime Oquab, Léon Bottou, Ivan Laptev, and Josef Sivic. Is object localizationfor free?-weakly-supervised learning with convolutional neural networks. In Pro-ceedings of the Conference on Computer Vision and Pattern Recognition, pages685–694, 2015.
[73] Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats anddogs. In Proceedings of the Conference on Computer Vision and Pattern Recogni-tion, pages 3498–3505, 2012.
[74] Genevieve Patterson and James Hays. Sun attribute database: Discovering, an-notating, and recognizing scene attributes. In Proceedings of the Conference onComputer Vision and Pattern Recognition, pages 2751–2758, 2012.
[75] James Philbin, Ondrej Chum, Michael Isard, Josef Sivic, and Andrew Zisserman.Object retrieval with large vocabularies and fast spatial matching. In Proceedings ofthe Conference on Computer Vision and Pattern Recognition, pages 1–8, 2007.
[76] James Philbin, Ondrej Chum, Michael Isard, Josef Sivic, and Andrew Zisserman.Lost in quantization: Improving particular object retrieval in large scale imagedatabases. In Proceedings of the Conference on Computer Vision and Pattern Recog-nition, pages 1–8, 2008.
[77] Simon JD Prince. Computer vision: models, learning, and inference. CambridgeUniversity Press, 2012.
[78] Ariadna Quattoni and Antonio Torralba. Recognizing indoor scenes. In Proceedingsof the Conference on Computer Vision and Pattern Recognition, pages 413–420,2009.
[79] Ali S Razavian, Hossein Azizpour, Atsuto Maki, Josephine Sullivan, Carl HenrikEk, and Stefan Carlsson. Persistent evidence of local image properties in genericconvnets. In Scandinavian Conference on Image Analysis, pages 249–262. Springer,2015.
[80] Ali S Razavian, Hossein Azizpour, Josephine Sullivan, and Stefan Carlsson. Cnnfeatures off-the-shelf: an astounding baseline for recognition. In Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition Workshops, pages806–813, 2014.

36 REFERENCES
[81] Ali S Razavian, Josephine Sullivan, Stefan Carlsson, and Atsuto Maki. [paper]visual instance retrieval with deep convolutional networks. ITE Transactions onMedia Technology and Applications, 4(3):251–258, 2016.
[82] Xiaofeng Ren and Deva Ramanan. Histograms of sparse codes for object detection.In Proceedings of the Conference on Computer Vision and Pattern Recognition,pages 3246–3253, 2013.
[83] Ethan Rublee, Vincent Rabaud, Kurt Konolige, and Gary Bradski. Orb: An effi-cient alternative to sift or surf. In Proceedings of the International Conference onComputer Vision, pages 2564–2571, 2011.
[84] David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning represen-tations by back-propagating errors. Nature, 1986.
[85] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma,Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Ima-genet large scale visual recognition challenge. International Journal of ComputerVision, 115(3):211–252, 2015.
[86] Mohammad Amin Sadeghi and Ali Farhadi. Recognition using visual phrases. InProceedings of the Conference on Computer Vision and Pattern Recognition, pages1745–1752. IEEE, 2011.
[87] Christos Sagonas, Georgios Tzimiropoulos, Stefanos Zafeiriou, and Maja Pantic. Asemi-automatic methodology for facial landmark annotation. In Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition Workshops, pages896–903, 2013.
[88] Jürgen Schmidhuber. Deep learning in neural networks: An overview. Neural Net-works, 61:85–117, 2015.
[89] Pierre Sermanet, David Eigen, Xiang Zhang, Michaël Mathieu, Rob Fergus, andYann LeCun. Overfeat: Integrated recognition, localization and detection usingconvolutional networks. arXiv preprint arXiv:1312.6229, 2013.
[90] Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Learning local featuredescriptors using convex optimisation. IEEE Transactions on Pattern Analysis andMachine Intelligence, 36(8):1573–1585, 2014.
[91] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks forlarge-scale image recognition. International Conference on Learning Representa-tions, 2015.
[92] Josef Sivic and Andrew Zisserman. Video google: A text retrieval approach to objectmatching in videos. In Proceedings of the International Conference on ComputerVision, pages 1470–1477. IEEE, 2003.

37
[93] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, DragomirAnguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Goingdeeper with convolutions. In Proceedings of the Conference on Computer Visionand Pattern Recognition, pages 1–9, 2015.
[94] Giorgos Tolias, Ronan Sicre, and Hervé Jégou. Particular object retrieval with inte-gral max-pooling of cnn activations. International Conference on Learning Repre-sentations, 2016.
[95] Andrea Vedaldi and Brian Fulkerson. Vlfeat: An open and portable library of com-puter vision algorithms. In Proceedings of the 18th ACM international conferenceon Multimedia, pages 1469–1472, 2010.
[96] Andrea Vedaldi, Varun Gulshan, Manik Varma, and Andrew Zisserman. Multiplekernels for object detection. In Proceedings of the International Conference onComputer Vision, pages 606–613, 2009.
[97] Carl Vondrick, Aditya Khosla, Tomasz Malisiewicz, and Antonio Torralba. Hog-gles: Visualizing object detection features. In Proceedings of the InternationalConference on Computer Vision, pages 1–8, 2013.
[98] Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie.The caltech-ucsd birds-200-2011 dataset. 2011.
[99] Ji Wan, Dayong Wang, Steven Chu Hong Hoi, Pengcheng Wu, Jianke Zhu, Yong-dong Zhang, and Jintao Li. Deep learning for content-based image retrieval: Acomprehensive study. In Proceedings of the 22nd ACM international conference onMultimedia, pages 157–166, 2014.
[100] Peter Welinder, Steve Branson, Takeshi Mita, Catherine Wah, Florian Schroff, SergeBelongie, and Pietro Perona. Caltech-ucsd birds 200. 2010.
[101] Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba.Sun database: Large-scale scene recognition from abbey to zoo. In Proceedingsof the Conference on Computer Vision and Pattern Recognition, pages 3485–3492,2010.
[102] Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, RuslanSalakhutdinov, Richard S Zemel, and Yoshua Bengio. Show, attend and tell: Neuralimage caption generation with visual attention. arXiv preprint arXiv:1502.03044, 2(3):5, 2015.
[103] Bangpeng Yao, Xiaoye Jiang, Aditya Khosla, Andy Lai Lin, Leonidas Guibas, andLi Fei-Fei. Human action recognition by learning bases of action attributes andparts. In Proceedings of the International Conference on Computer Vision, pages1331–1338, 2011.

38 REFERENCES
[104] Joe Yue-Hei Ng, Fan Yang, and Larry S Davis. Exploiting local features from deepnetworks for image retrieval. In Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition Workshops, pages 53–61, 2015.
[105] Jure Zbontar and Yann LeCun. Computing the stereo matching cost with a convo-lutional neural network. In Proceedings of the Conference on Computer Vision andPattern Recognition, pages 1592–1599, 2015.
[106] Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutionalnetworks. In Proceedings of the European Conference on Computer Vision, pages818–833. Springer, 2014.
[107] Ning Zhang, Manohar Paluri, Marc’Aurelio Ranzato, Trevor Darrell, and LubomirBourdev. Panda: Pose aligned networks for deep attribute modeling. In Proceedingsof the Conference on Computer Vision and Pattern Recognition, pages 1637–1644,2014.
[108] Bolei Zhou, Agata Lapedriza, Jianxiong Xiao, Antonio Torralba, and Aude Oliva.Learning deep features for scene recognition using places database. In Advances inNeural Information Processing Systems, pages 487–495, 2014.
[109] Barbara Zitova and Jan Flusser. Image registration methods: a survey. Image andvision computing, 21(11):977–1000, 2003.
Related Documents











