ConnectX-2 InfiniBand Management Queues: First Investigation of the New Support for Network Offloaded Collective Operations Richard L. Graham * , Steve Poole * , Pavel Shamis † , Gil Bloch † , Noam Bloch † , Hillel Chapman † , Michael Kagan † , Ariel Shahar † , Ishai Rabinovitz † , Gilad Shainer ‡ * Oak Ridge National Laboratory (ORNL), Oak Ridge, TN, USA Email: {rlgraham,spoole}@ornl.gov † Mellanox Technologies, Inc. Email: {pasha,gil,noam,hillel,michael,ariels,ishai}@mellanox.co.il ‡ Mellanox Technologies, Inc. Email: {shainer}@mellanox.com Abstract—This paper introduces the newly developed Infini- Band (IB) Management Queue capability, used by the Host Channel Adapter (HCA) to manage network task data flow dependancies, and progress the communications associated with such flows. These tasks include sends, receives, and the newly supported wait task, and are scheduled by the HCA based on a data dependency description provided by the user. This functionality is supported by the ConnectX-2 HCA, and provides the means for delegating collective communication management and progress to the HCA, also known as collective communication offload. This provides a means for overlapping collective communications managed by the HCA and compu- tation on the Central Processing Unit (CPU), thus making it possible to reduce the impact of system noise on parallel applications using collective operations. This paper further describes how this new capability can be used to implement scalable Message Passing Interface (MPI) collective operations, describing the high level details of how this new capability is used to implement the MPI Barrier collective operation, focusing on the latency sensitive performance aspects of this new capability. This paper concludes with small scale bench- mark experiments comparing implementations of the barrier collective operation, using the new network offload capabilities, with established point-to-point based implementations of these same algorithms, which manage the data flow using the central processing unit. These early results demonstrate the promise this new capability provides to improve the scalability of high- performance applications using collective communications. The latency of the HCA based implementation of the barrier is similar to that of the best performing point-to-point based im- plementation managed by the central processing unit, starting to outperform these as the number of processes involved in the collective operation increases. Keywords-InfiniBand; Offload; Collectives I. I NTRODUCTION CPU clock speeds have remained essentially constant over the last several years, resulting in the scale of CPU’s used in high-end system rapidly increasing to keep up with the performance boosts expected by Moore’s law. System size on the Top500 list [1] has changed rapidly, and in November 2009 the top ten systems averaged 134,893 cores, with five systems larger than 100, 000 cores. This rapid increase of system size and the associated increase in the number of compute elements used in a single user job increases the urgency of dealing with system characteristics that impede application scalability. Scientific simulation codes frequently use collective com- munications such as broadcasts, and data reductions. The ordered communication patterns used by high performance implementation of collective algorithms present an appli- cation scalability challenge. This is further magnified by application load imbalance, with different application pro- cesses entering a collective operation at different times and producing process skew, thus slowing the progress on those ranks already in the collective operation. System activity, also known as system noise [2], [3], which displaces appli- cation processes from the CPU also delays the participation of the displaced processes in the collective operation, further posing a scalability challenge. CORE-Direct functionality, recently added to the IB ConnectX-2 HCAs by Mellanox Technologies [4], pro- vides hardware support for offloading a sequence of data- dependent communications to the network. This functionality is well suited for supporting asyn- chronous MPI [5] collective operations. It provides hardware support for overlapping collective communications with ap- plication computation, which may be used to help improve application scalability. This paper briefly describes the InfiniBand CORE-Direct capabilities, and how these are used to develop scalable blocking and nonblocking asynchronous Barrier operations.

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

ConnectX-2 InfiniBand Management Queues: First Investigation of the New Supportfor Network Offloaded Collective Operations
Richard L. Graham∗, Steve Poole∗, Pavel Shamis†, Gil Bloch † ,Noam Bloch†, Hillel Chapman†, Michael Kagan†, Ariel Shahar†, Ishai Rabinovitz†, Gilad Shainer‡
∗ Oak Ridge National Laboratory (ORNL), Oak Ridge, TN, USAEmail: {rlgraham,spoole}@ornl.gov
† Mellanox Technologies, Inc.Email: {pasha,gil,noam,hillel,michael,ariels,ishai}@mellanox.co.il
‡ Mellanox Technologies, Inc.Email: {shainer}@mellanox.com
Abstract—This paper introduces the newly developed Infini-Band (IB) Management Queue capability, used by the HostChannel Adapter (HCA) to manage network task data flowdependancies, and progress the communications associatedwith such flows. These tasks include sends, receives, and thenewly supported wait task, and are scheduled by the HCAbased on a data dependency description provided by the user.This functionality is supported by the ConnectX-2 HCA, andprovides the means for delegating collective communicationmanagement and progress to the HCA, also known as collectivecommunication offload. This provides a means for overlappingcollective communications managed by the HCA and compu-tation on the Central Processing Unit (CPU), thus makingit possible to reduce the impact of system noise on parallelapplications using collective operations. This paper furtherdescribes how this new capability can be used to implementscalable Message Passing Interface (MPI) collective operations,describing the high level details of how this new capabilityis used to implement the MPI Barrier collective operation,focusing on the latency sensitive performance aspects of thisnew capability. This paper concludes with small scale bench-mark experiments comparing implementations of the barriercollective operation, using the new network offload capabilities,with established point-to-point based implementations of thesesame algorithms, which manage the data flow using the centralprocessing unit. These early results demonstrate the promisethis new capability provides to improve the scalability of high-performance applications using collective communications. Thelatency of the HCA based implementation of the barrier issimilar to that of the best performing point-to-point based im-plementation managed by the central processing unit, startingto outperform these as the number of processes involved in thecollective operation increases.
Keywords-InfiniBand; Offload; Collectives
I. INTRODUCTION
CPU clock speeds have remained essentially constant overthe last several years, resulting in the scale of CPU’s usedin high-end system rapidly increasing to keep up with theperformance boosts expected by Moore’s law. System size
on the Top500 list [1] has changed rapidly, and in November2009 the top ten systems averaged 134,893 cores, with fivesystems larger than 100, 000 cores. This rapid increase ofsystem size and the associated increase in the number ofcompute elements used in a single user job increases theurgency of dealing with system characteristics that impedeapplication scalability.
Scientific simulation codes frequently use collective com-munications such as broadcasts, and data reductions. Theordered communication patterns used by high performanceimplementation of collective algorithms present an appli-cation scalability challenge. This is further magnified byapplication load imbalance, with different application pro-cesses entering a collective operation at different times andproducing process skew, thus slowing the progress on thoseranks already in the collective operation. System activity,also known as system noise [2], [3], which displaces appli-cation processes from the CPU also delays the participationof the displaced processes in the collective operation, furtherposing a scalability challenge.
CORE-Direct functionality, recently added to the IBConnectX-2 HCAs by Mellanox Technologies [4], pro-vides hardware support for offloading a sequence of data-dependent communications to the network.
This functionality is well suited for supporting asyn-chronous MPI [5] collective operations. It provides hardwaresupport for overlapping collective communications with ap-plication computation, which may be used to help improveapplication scalability.
This paper briefly describes the InfiniBand CORE-Directcapabilities, and how these are used to develop scalableblocking and nonblocking asynchronous Barrier operations.

II. RELATED WORK
Work to delegate communication management, bothpoint-to-point and collective, to processing units other thanthe main CPU has already been done. A number of studiesexplored the benefits of HCA-based collective operationsincluding those described in references [6], [7], [8], [9], [10],[11]. Several analyses of HCA-based broadcast algorithmsare available in References [6], [7], [9]. Generally, theseall tend to use HCA-based packet forwarding as a meansof improving performance of the broadcast operation. Someof the benefits of offloading barrier, reduce and broadcastoperations to the HCA are described in References [8], [12],[10], and [9]. These showed that barrier and reduce oper-ations can benefit from reduced host involvement, efficientcommunication processing, and better tolerance to processskew. Keeping the data transfer paths relatively short inmulti-stage communication patterns is appealing as it offersa favorable payback for moving the work to the network.Even though much research has been done in this area, manyproblems are still to be solved. As such, these techniqueshave not gained wide acceptance.
Amongst all the previous HCA-based collective imple-mentations, only the effort from Quadrics [13] has beenlargely deployed in the Elan3/4 interconnects, enabling itswide utilization in Quadrics-based clusters. In this work, westudy the benefits of collective offload in another popularinterconnect technology, InfiniBand. This paper focuses onthe potential for overlapping communication with compu-tation with the new CORE-Direct functionality, using anonblocking barrier algorithm.
III. AN OVERVIEW OF INFINIBAND
The InfiniBand Architecture (IBA) [14] is an open spec-ification designed for interconnecting compute nodes, In-put/Output (I/O) nodes and devices in a system area network.It defines a communication architecture from the switch-based network fabric to transport layer communication in-terface for inter-processor communication. Processing nodesand I/O nodes are connected as end-nodes to the fabric bytwo kinds of channel adapters: Host Channel Adapters andTarget Channel Adapters. Most of the software drivers for In-finiBand are being developed under the Open Fabric Alliance(OFA) open source organization. OFA promotes the devel-opment of Remote Direct Memory Access (RDMA) [15]software solutions for both InfiniBand [14] and iWARP [16].The Linux version for the software package is referred toas OFED (OpenFabrics Enterprise Distribution), and theWindows version as Win-OF (Windows Open Fabrics).
Fig. 1 (left) illustrates the IBA specification of the IBcommunication stack. Two processes communicate througha pair of IB queues that are created on the HCAs. Thispair of send/receive queues is also referred to as a QueuePair (QP). A communication operation is initiated by posting
send, receive, read, write, or RDMA work queue elements(WQE) to the QP.
Figure 1. InfiniBand Communication Stack
Send WQEs are interpreted and processed by the HCA,which sends data on behalf of this WQE. The postedWQE’s are consumed in the order posted, and are eligiblefor processing as soon as they are posted to the queue.Communications may occur via send/receive type of op-erations, or using RDMA capabilities directly accessingremote memory. RDMA data transfers tend to have lowerlatency than send/receive data movement since the remotedata is accessed directly at the destination and can bypassremote queues management. RDMA’s operations using theImmediate Data option generate remote completion queueentries. However, these are usually avoided, as it is faster forthe receiver to poll a pre-define main memory address ratherthan poll HCA completion queues for RDMA completion.
On the receive side, data is delivered in the order inwhich it is sent. Send/receive packets are delivered to theappropriate QP, and are matched up with the appropriateWQE. The data delivered to the buffer is described inthe WQE. RDMA data is delivered directly to the addressspecified in the send operation without involving the receiveside queues.
Completion of a WQE results in a Completion QueueEntry (CQE) being posted to a Completion Queue (CQ). Theconsumer obtains this event by polling the completion queue.Multiple QP’s may share a CQ, thus offering good scalabil-ity characteristics for communications sharing completionqueues. Completion queues are actively polled to determineWQE completion. Except for very special circumstances,RDMA write operations do not generate remote completionentries, and therefore the completion queue can’t be reliedon for completion, and other means must be used to infersuch completion.
These communication capabilities may be used to im-plement collective operations. For example, if send/receivechannel operations are used, QP’s are created for each pair ofcommunicating processes. A single send CQ can be used for

send completion, as well as a single receive side CQ, keepingthe number of queues that must be polled to determinecompletion constant.
The recursive doubling algorithm used is describedin [17]. The algorithm for N=2L number of ranks has Lsteps. At each step l = 0, 1, ..., L − 1, each rank signals arank 2l ranks away, and waits on a signal from the samerank before proceeding to the next step in the algorithm.If the number of process M is not a power of two, andN is the largest power of two smaller than M , each rankr = N,N+1, ...,M−1, called an extra rank, is paired withthe rank r −N . The barrier algorithm for M ranks has aninitiation phase where each rank r = N,N + 1, ...,M − 1signals it’s partner r − N . After the recursive doublingalgorithm is executed with the N ranks, each rank pairedwith an extra rank signal their partner. We do not takeadvantage of IB’s multicast capabilities for the notificationphase of a barrier algorithm, as this is an unreliable protocol,and with the current CORE-Direct we can’t use the HCAalone to detect dropped packets.
As an example, the MPI Barrier collective operations,using a recursive doubling algorithm for four process isdescribed in Table I. Each rank communicates with twoother ranks. The algorithm implemented with IB verbs,using channel communication semantics is described inTable II. This includes only communications operations inthe performance critical path, which we will call criticalpath, omitting send completion which can be done asyn-chronously, independent of MPI Barrier completion. Thenotation “send QP i” used indicates a send posted to rank iusing the QP for communications with that rank, “recv QPi” corresponds to the receive posted from rank i, and “recvCQP i” corresponds to completing the receive from ranki, by polling the receive CQ associated with that queue.A single receive completion queue is often used to keepcompletion polling overhead constant. It is important to notethat posing network operations to the QP’s and polling forcompletion all use the CPU. As a result, the CPU cost forthis operation increases as the number of ranks participatingin the collective operation increases - logarithmically forthe recursive doubling barrier algorithm described here. Inaddition, the chaining of communication operations usedto achieve efficient collective operations magnifies skewdue to delay in individual ranks entering the collectiveoperation, making scalability of collective operations evenmore difficult. Such skew due to system activities, alsoknown as system-noise, is one of the well known obstaclesto large-scale application scalability.
To help deal with these sources of application scalability,new support has been added to Mellanox InfiniBand HCA’s.Support is provided for moving management of chainednetwork operations to the network card, keeping the amountof work the CPU needs to do in the collective operations totwo phases - the initiation and completion phases. Execution
proc 0 proc 1 proc 2 proc 3Exchange Exchange Exchange Exchangewith 1 with 0 with 3 with 2Exchange Exchange Exchange Exchangewith 2 with 3 with 0 with 1
Table ICOMMUNICATION PATTERN FOR A FOUR PROCESS RECURSIVE
DOUBLING BARRIER
proc 0 proc 1 proc 2 proc 3recv QP 1 recv QP 0 recv QP 3 recv QP 2send QP 1 send QP 0 send QP 3 send QP 2recv CQP 1 recv CQP 0 recv CQP 3 recv CQP 2recv QP 2 recv QP 3 recv QP 0 recv QP 1send QP 2 send QP 3 send QP 0 send QP 1recv CQP 2 recv CQP 3 recv CQP 0 recv CQP 1
Table IIIB CRITICAL PATH COMMUNICATIONS FOR A 4 PROCESS RECURSIVE
DOUBLING BARRIER
of these operations on the HCA minimizes the impactprocess skew on the collective operations, and reduces theimpact of system noise. The use of nonblocking collectivescan be used to minimize the impact of process skew. Thesupport added is described in detail in the following section.
IV. CONNETX-2: NEW SUPPORT FOR COMMUNICATIONMANAGEMENT OFFLOAD
Mellanox ConnectX-2 InfiniBand adapters include newhardware technology to support offloading communicationmanagement. The new technology defines a general purposemechanism for coordinating multiple network operations,such as issuing a send only after the data to be senthas arrived at the sender. In the design process care wastaken to ensure this supports effective implementation ofasynchronous collective communications (MPI, SHMEMand others) used by scientific applications. The goal ofthese enhancements is to relieve communication manage-ment workload from the CPU and to enhance the scala-bility of applications on ultra-scale computer systems. Toaccomplish this, ConnectX-2’s new technology includeshardware support for wait network tasks, Multiple WorkRequests (MWR), and Management Queues (MQs). Thefollowing sub-sections will describe this new support, andthe subsequent sections will describe how this may be usedto implement MPI collective operations.
A. SynchronizationTasks
The IBA defines several communication tasks, these in-clude send, receive, read, write, and atomic tasks. ConnectX-2 adds hardware support for cross QP synchronizationoperations - wait, send enable, and receive enable. The waittask takes as arguments a completion queue and the number

of completion tasks to wait for. The completions that areconsumed by the wait task may not be obtained by pollingon the completion queue, but are inferred from completionof this wait event. For example, a wait task may wait onthe completion of two receives from the QP associated withprocess X. Details of where the data was delivered can onlybe obtained by keeping track of the receive buffers postedto that QP and their order, and the number of completedreceives associated with the completion tasks.
This wait task provides a means of coordinating com-munication activities taking place simultaneously throughmultiple queue pairs. This enables one to string together aseries of network communication tasks, and coordinate them,using the wait task, to order the network traffic. For example,one can wait on receive completion for data sent using aQP associated with process X using a wait task, and thensend this data to process Y using the (perhaps different) QPassociated with the destination rank. This is a key ingredientneeded to offload collective operation management to theHCA.
The send enable and receive enable tasks enable a previ-ously posted send or receive task, respectively. This allowsone to postpone the processing of a send or receive task untilthese are enabled by the enable task posted to some otherqueue.
B. Multiple Work Requests
The Multiple Work Request is a linked list of InfiniBandcommunication tasks which the driver posts in order tothe queues specified by the individual work request. Thesetasks include the send, receive, and wait tasks. An MWRcompletion entry is posted after the task that is markedwith the flag MQE WR FLAG SIGNAL is processed bythe HCA, giving the user one more knob to use in settingup the communication patterns.
The MWR may be used to chain together a series ofnetwork operations, and manage the data dependenciesbetween the different phases in the algorithm. Once theMWR is started, the HCAs on the network progress thecommunication, without using the central processing unit.
C. Management Queues
The Management Queues are used to handle MWR’s. Thedriver supports two different types of MQs, one type is thehardware MQ, and the other is a software construct usedto post the ordered list of tasks in a MWR to multipleReliably Connected QPs. We will refer to this as a SoftwareMQ (SW-MQ), even though all network processing takesplace by hardware in the HCA. The rest of this section willdescribe the hardware MQ’s, as the software construct doesnot provide new IB functionality.
MQ’s and a unique MQ Completion Queue are created ina single step. This queue is polled to detect MQ completionentries. Network activity is initiated by posting an MWR
to an MQ, and its completion indicated by a CompletionQueue Entry (CQE) that is posted to the Management QueueCompletion queue (CMQ). Tasks issued are posted to thevarious QP’s and the MQ in order, with no interleavingof individual tasks from different MWR’s. Wait tasks areposted either to the QP specified in the task, or to thehardware MQ if the QP specified is NULL. A send/receivetask that follows a wait task posted to the MQ results intwo tasks being posted, a send/receive task is posted to theQP specified in the task, but is not enabled, that is the HCAwon’t process it until it is enabled, and needs to be enabledbefore the hardware can process them. The driver also postsa send/receive-enable task to the MQ after the appropriatewait task, which will then enable the send/receive task afterthe wait tasks have completed.
Once the MWR is posted to the HCA, progress on theMWR occurs asynchronously by the hardware. The centralprocessing unit is involved only in polling the CMQ forMWR completion.
The new capabilities exposed by the MQ, MWR, and waittask provide a powerful set of primitives that may be usedfor a variety of reasons. We have taken advantage of thesecapabilities to offload MPI collectives to the network.
V. MPI COLLECTIVE DESIGN - BASE DESIGN
The new Management-Queue, Multiple Work Request,and the wait task functionality added to ConnectX-2 isdesigned to support arbitrary communication patterns andto manage the data dependencies between tasks in thesepatterns. This was added specifically to support collectiveoperations. The intent is to offload the progression ofcollective operations to the HCA after the list of tasks issetup, with the CPU being involved again only in pollingfor communications completion.
The MPI design implemented in Open MPI aims toprovide high-performance support for the emerging non-blocking MPI collective operations, as well as support for theblocking collectives currently defined in the standard. It alsoaims to support progressing concurrent collective operationson the same or different MPI communicators.
The task lists, queue structure, and memory managementscheme used to support the implementation of MPI collec-tive operations are described in the next sub-sections.
A. Queue Structure
Each MPI communicator is assigned a different set ofqueues, to ensure independent progress. Figure 2 gives agraphical representation of the queue structure. Each com-municator has a single local MQ, and a corresponding CMQused to determine collective operation completion.
Each process allocates a single Reliably Connected QPfor each remote process with which it will communicate,with resource consumption scaling based on the collectiveoperation algorithms used. Receive completion is handled

Figure 2. Queue structure used to implement the MPI Collectives on aper communicator basis. Only three QP’s are shown, but in practice moreare used.
by the wait task posted to the hardware MQ, which doesnot generate a completion entry to a user poll-able queue.Therefore, we must keep track of the receive buffers postedto each QP, in order to keep track correctly of the pointer tothe received data, which may be used as input to subsequentsend tasks. Therefore, each QP is assigned a different receiveCQ, so that we can correctly distinguish between completionentries associated with different QP’s, and track data bufferscorrectly. We do not use Shared Receive Queues (SRQ), aswe need to keep track of which buffer is consumed by eachreceive operation, which we can’t do when using the SRQand hardware MQ, since don’t have access to the receivecompletion queue entry.
Send tasks are completed asynchronously, out of thecritical path. Since we can poll for send completion, andexamine completion context on an event by event basis, weuse as single completion queue.
B. Task Lists
MPI collective operations are implemented using an in-terdependent sequence of network operations executed byeach process in the communicator. Each process in a specificcollective operation executes a different sequence of networkoperations, with reduction operations also manipulating thedata being transferred. These local communication patternsform the basis for the MWR task list associated with eachprocess in the barrier collective operation. Table I givesa simple example of the communication patterns for eachprocess involved in a four process recursive doubling barrieralgorithm. At each phase of this algorithm, each processexchanges data with another rank in the communicator,sending to that rank a message to indicate it is participatingin the barrier operation and receiving a message from thesame partner indicating the same.
Several factors beyond the network traffic pattern in-fluence the MWR task lists posted to the MQ, and the
proc 0 proc 1 proc 2 proc 3MQ send to 1 MQ send to 0 MQ send to 3 MQ send to 2MQ recv wait MQ recv wait MQ recv wait MQ recv waitfrom 1 from 0 from 3 from 2MQ send to 2 MQ send to 3 MQ send to 0 MQ send to 1MQ recv wait MQ recv wait MQ recv wait MQ recv waitfrom 2 from 3 from 0 from 1
Table IIITASK LIST FOR A FOUR PROCESS RECURSIVE DOUBLING BARRIER.
corresponding queue pairs. Send completion at the verbslevel involves hardware level acknowledgement being sentfrom the receiver to the sender, resulting in send completionincluding this extra half network round trip latency. Receivecompletion is local, and includes only the time to transfer thedata from the source to the destination. While progressingcollective operations we really only care about receivecompletion, to ensure data has arrived before proceedingto the next step in the algorithm. In other words, MPI levelcollective algorithms may complete before the send tasksassociated with the collective operation have completed atthe IB level. Therefore, when creating the task list we donot include send wait events, but process send completionasynchronously, out of the critical path. In addition, to avoidReceiver-Not-Ready Negative Acknowledgements, we alsopre-post receive WQE’s, and as such don’t explicitly includethese in the task lists. However, we must keep track of thepre-posted receive buffers, to associate the correct receivebuffer with the send task that uses the data received.
Taking all of these details into account, the task list cor-responding to the four process barrier algorithm is describedin Table I and is given in Table III. The wait events are usedto ensure receive completion only. “MQ send to X” standsposting a send message to the QP associated with rank X.“MQ recv wait Y” corresponds to posting a wait event tothe hardware MQ and waiting on a receive to complete onthe QP associated with rank Y.
It should be noted that we use the channel semanticssend/receive operations, as opposed to RDMA operationsin the current implementation. In future work we willinvestigate using RDMA operations with Immediate Datato generate the completion queue entries needed for MWRprogress management.
C. Memory Management
The memory management scheme used is simple - largecollective operations are segmented to keep registered mem-ory requirements down, and allow for pipelining collectiveoperations. A memory pool of registered buffers is usedto provide the task buffers, with user data copied intoand out of the preallocated memory. Blocks of receivebuffers are pre-posted to each QP, to avoid the performancedegradation associated with the Receive-Not-Ready negativeacknowledgement state.

proc 0 proc 1 proc 2 proc 3MQ send to 1 MQ send to 0 MQ send to 3 MQ send to 2send enabled send enabled send enabled send enabledMQ send to 2 MQ send to 3 MQ send to 0 MQ send to 1send not send not send not send notenabled enabled enabled enabled
Table IVQUEUE PAIR TASK LIST FOR A FOUR PROCESS RECURSIVE DOUBLING
BARRIER.
proc 0 proc 1 proc 2 proc 3MQ recv wait MQ recv wait MQ recv wait MQ recv waitfrom 1 from 0 from 3 from 2send enable send enable send enable send enable1 0 3 2MQ recv wait MQ recv wait MQ recv wait MQ recv waitfrom 2 from 3 from 0 from 1
Table VMANAGEMENT QUEUE TASK LIST FOR A FOUR PROCESS RECURSIVE
DOUBLING BARRIER. COMPLETION OF THE LAST WAIT OPERATION ONTHE MQ SIGNALS MWR COMPLETION
Putting all the pieces together, Table IV describes the tasksposted to the queue pairs, and Table V describes the tasksposted to the management queue, for each of the four ranksparticipating in the barrier collective operation.
VI. MPI COLLECTIVE DESIGN - ENHANCED DESIGN
Using hardware management queues allows one to satisfydata flow dependencies between unrelated QPs, but addsthe overhead of generating additional QP tasks to satisfythese dependancies. Many of the same algorithms maybe implemented using only QP’s, but this may requireposting more tasks to a given QP to accomplish the correctsynchronization. We show this for the recursive doublingalgorithm below.
The software MQ can be initiated is such a way thatit is used to post ordered tasks to a set of QP’s, withoutinvolving the hardware MQ at all. In this way all sends thatare posted are posted as enabled, and the ordered completionof the network tasks is sufficient for satisfying the ordereddata dependencies. Therefore, we can use such MQ’s tofurther improve performance for some collective operations,and still have the HCA handle all communication progressissues, without any CPU involvement.
The recursive doubling barrier algorithm is suited for thisoptimization, as at each step in the process communicationinvolves only one QP. The communication pattern used isthe same as that described in Table III, but wait tasks specifywhich QP they should be posted to rather than posting thisto the hardware MQ. However, since there is no centralqueue ordering receive completions, each QP needs to makesure that all receive dependencies are satisfied for a givensend task it will execute. Table VI shows, for rank 0, the
QP 1 QP 2 QP 4send QP 1 wait CQP 1 wait CQP 1
send QP 2 wait CQP 2send QP 4wait CQP 4
Table VIQUEUE PAIR TASK LIST FOR RANK 0 IS AN EIGHT PROCESS RECURSIVE
DOUBLING BARRIER USING SW-MQ.
tasks posted to each queue pair for this barrier collectiveoperation to ensure the correct dependencies between tasksare satisfied. Rank 0 communicates with ranks 1, 2, and 4 inthis case. Multiple waits that reference the same completionentry, ”wait on receive completion for Completion QP 1”for example, are all posted through a single wait task. Thewait tasks takes a list of QP’s to which this wait will beposted.
VII. EARLY BENCHMARK RESULTS
This paper includes an early investigation of the newIB technology introduced with the ConnectX-2 HCAs. Thesupport for network offloading of communication manage-ment is explored using recursive doubling MPI Barrier()algorithms to look at raw performance characteristics. Thiscollective operation does not manipulate any user data, andtherefore the performance of implementations is latencydominated. This performance is determined mostly by thelatency through the MPI level barrier code, network latency,and in the case of the network offload support, the latencyof HCA queue management. We have also performed someinitial studies of MPI Broadcast(), MPI Allreduce(), as wellas nonblocking barrier (recently passing preliminary votesfor inclusion in the MPI-3 standard), but these are beyondthe scope of this paper, and will be reported on in future pa-pers. Since this hardware is very new, we have limited HCAaccess, and therefore are extremely limited with respect tothe size of the cluster that can be used for these experiments.
A. Hardware Setup
The performance measurements were all taken on aneight node, dual socket quad-core, 2.50 Gigahertz (GHz)Intel Xeon Quad-core E5420 with 16 gigabytes of memory.The system is running Red Hat Enterprise Linux Server5.2, kernel version 2.6.18-92.el5, and a dual port quaddata rate ConnectX-2 HCA and switch running Mellanoxfirmware version 2.6.8000. This is a pre-release version ofthe firmware, and provides the first working implementationfor the new MQ capability.
B. Software configuration
The prototype offloaded IB collectives are implementedwithin the Open MPI code base as a separate collectivecomponent using trunk version 1.5. The results reported here
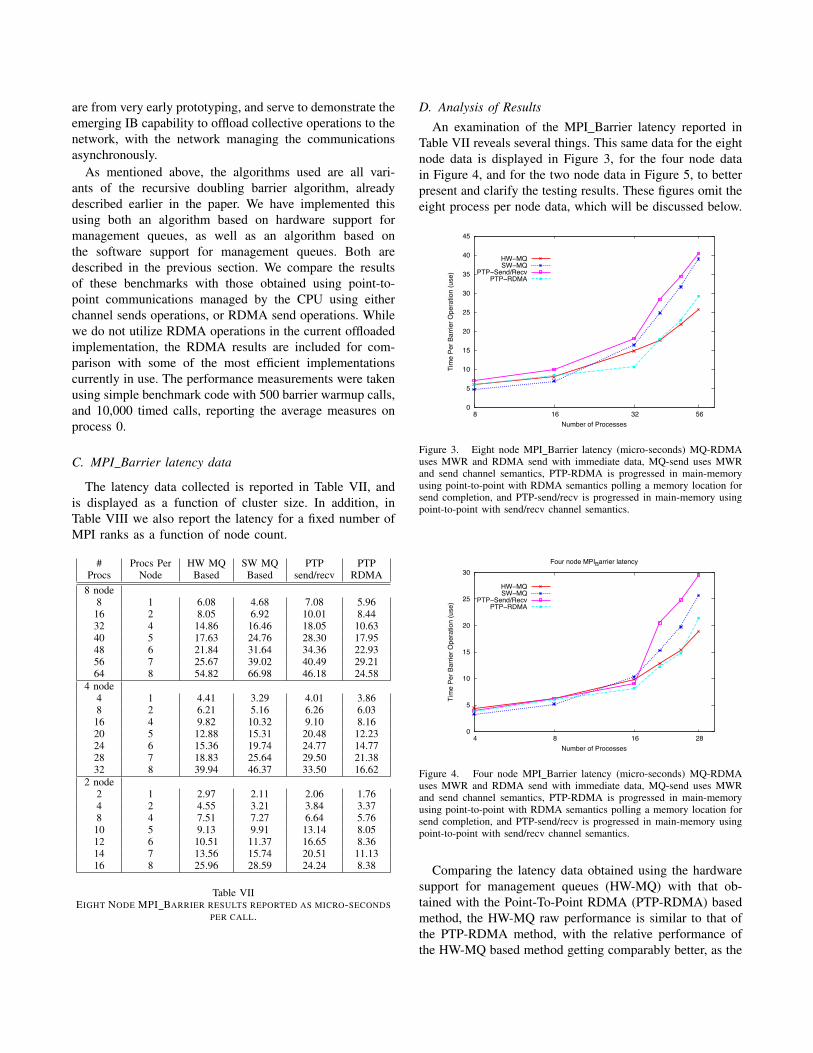
are from very early prototyping, and serve to demonstrate theemerging IB capability to offload collective operations to thenetwork, with the network managing the communicationsasynchronously.
As mentioned above, the algorithms used are all vari-ants of the recursive doubling barrier algorithm, alreadydescribed earlier in the paper. We have implemented thisusing both an algorithm based on hardware support formanagement queues, as well as an algorithm based onthe software support for management queues. Both aredescribed in the previous section. We compare the resultsof these benchmarks with those obtained using point-to-point communications managed by the CPU using eitherchannel sends operations, or RDMA send operations. Whilewe do not utilize RDMA operations in the current offloadedimplementation, the RDMA results are included for com-parison with some of the most efficient implementationscurrently in use. The performance measurements were takenusing simple benchmark code with 500 barrier warmup calls,and 10,000 timed calls, reporting the average measures onprocess 0.
C. MPI Barrier latency data
The latency data collected is reported in Table VII, andis displayed as a function of cluster size. In addition, inTable VIII we also report the latency for a fixed number ofMPI ranks as a function of node count.
# Procs Per HW MQ SW MQ PTP PTPProcs Node Based Based send/recv RDMA
8 node8 1 6.08 4.68 7.08 5.9616 2 8.05 6.92 10.01 8.4432 4 14.86 16.46 18.05 10.6340 5 17.63 24.76 28.30 17.9548 6 21.84 31.64 34.36 22.9356 7 25.67 39.02 40.49 29.2164 8 54.82 66.98 46.18 24.58
4 node4 1 4.41 3.29 4.01 3.868 2 6.21 5.16 6.26 6.0316 4 9.82 10.32 9.10 8.1620 5 12.88 15.31 20.48 12.2324 6 15.36 19.74 24.77 14.7728 7 18.83 25.64 29.50 21.3832 8 39.94 46.37 33.50 16.62
2 node2 1 2.97 2.11 2.06 1.764 2 4.55 3.21 3.84 3.378 4 7.51 7.27 6.64 5.7610 5 9.13 9.91 13.14 8.0512 6 10.51 11.37 16.65 8.3614 7 13.56 15.74 20.51 11.1316 8 25.96 28.59 24.24 8.38
Table VIIEIGHT NODE MPI BARRIER RESULTS REPORTED AS MICRO-SECONDS
PER CALL.
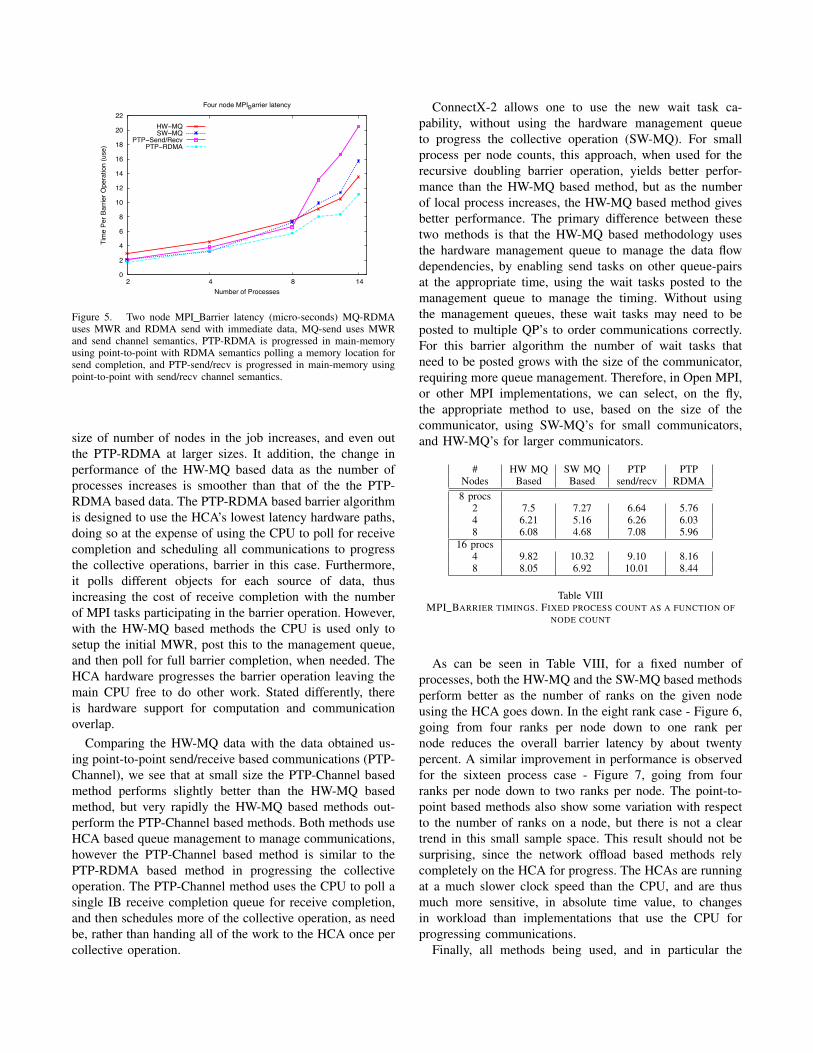
D. Analysis of Results
An examination of the MPI Barrier latency reported inTable VII reveals several things. This same data for the eightnode data is displayed in Figure 3, for the four node datain Figure 4, and for the two node data in Figure 5, to betterpresent and clarify the testing results. These figures omit theeight process per node data, which will be discussed below.
0
5
10
15
20
25
30
35
40
45
8 16 32 56
Tim
e Pe
r Bar
rier O
pera
tion
(use
)
Number of Processes
HW−MQSW−MQ
PTP−Send/RecvPTP−RDMA
Figure 3. Eight node MPI Barrier latency (micro-seconds) MQ-RDMAuses MWR and RDMA send with immediate data, MQ-send uses MWRand send channel semantics, PTP-RDMA is progressed in main-memoryusing point-to-point with RDMA semantics polling a memory location forsend completion, and PTP-send/recv is progressed in main-memory usingpoint-to-point with send/recv channel semantics.
0
5
10
15
20
25
30
4 8 16 28
Tim
e Pe
r Bar
rier O
pera
tion
(use
)
Number of Processes
Four node MPIBarrier latency
HW−MQSW−MQ
PTP−Send/RecvPTP−RDMA
Figure 4. Four node MPI Barrier latency (micro-seconds) MQ-RDMAuses MWR and RDMA send with immediate data, MQ-send uses MWRand send channel semantics, PTP-RDMA is progressed in main-memoryusing point-to-point with RDMA semantics polling a memory location forsend completion, and PTP-send/recv is progressed in main-memory usingpoint-to-point with send/recv channel semantics.
Comparing the latency data obtained using the hardwaresupport for management queues (HW-MQ) with that ob-tained with the Point-To-Point RDMA (PTP-RDMA) basedmethod, the HW-MQ raw performance is similar to that ofthe PTP-RDMA method, with the relative performance ofthe HW-MQ based method getting comparably better, as the
0
2
4
6
8
10
12
14
16
18
20
22
2 4 8 14
Tim
e Pe
r Bar
rier O
pera
tion
(use
)
Number of Processes
Four node MPIBarrier latency
HW−MQSW−MQ
PTP−Send/RecvPTP−RDMA
Figure 5. Two node MPI Barrier latency (micro-seconds) MQ-RDMAuses MWR and RDMA send with immediate data, MQ-send uses MWRand send channel semantics, PTP-RDMA is progressed in main-memoryusing point-to-point with RDMA semantics polling a memory location forsend completion, and PTP-send/recv is progressed in main-memory usingpoint-to-point with send/recv channel semantics.
size of number of nodes in the job increases, and even outthe PTP-RDMA at larger sizes. It addition, the change inperformance of the HW-MQ based data as the number ofprocesses increases is smoother than that of the the PTP-RDMA based data. The PTP-RDMA based barrier algorithmis designed to use the HCA’s lowest latency hardware paths,doing so at the expense of using the CPU to poll for receivecompletion and scheduling all communications to progressthe collective operations, barrier in this case. Furthermore,it polls different objects for each source of data, thusincreasing the cost of receive completion with the numberof MPI tasks participating in the barrier operation. However,with the HW-MQ based methods the CPU is used only tosetup the initial MWR, post this to the management queue,and then poll for full barrier completion, when needed. TheHCA hardware progresses the barrier operation leaving themain CPU free to do other work. Stated differently, thereis hardware support for computation and communicationoverlap.
Comparing the HW-MQ data with the data obtained us-ing point-to-point send/receive based communications (PTP-Channel), we see that at small size the PTP-Channel basedmethod performs slightly better than the HW-MQ basedmethod, but very rapidly the HW-MQ based methods out-perform the PTP-Channel based methods. Both methods useHCA based queue management to manage communications,however the PTP-Channel based method is similar to thePTP-RDMA based method in progressing the collectiveoperation. The PTP-Channel method uses the CPU to poll asingle IB receive completion queue for receive completion,and then schedules more of the collective operation, as needbe, rather than handing all of the work to the HCA once percollective operation.
ConnectX-2 allows one to use the new wait task ca-pability, without using the hardware management queueto progress the collective operation (SW-MQ). For smallprocess per node counts, this approach, when used for therecursive doubling barrier operation, yields better perfor-mance than the HW-MQ based method, but as the numberof local process increases, the HW-MQ based method givesbetter performance. The primary difference between thesetwo methods is that the HW-MQ based methodology usesthe hardware management queue to manage the data flowdependencies, by enabling send tasks on other queue-pairsat the appropriate time, using the wait tasks posted to themanagement queue to manage the timing. Without usingthe management queues, these wait tasks may need to beposted to multiple QP’s to order communications correctly.For this barrier algorithm the number of wait tasks thatneed to be posted grows with the size of the communicator,requiring more queue management. Therefore, in Open MPI,or other MPI implementations, we can select, on the fly,the appropriate method to use, based on the size of thecommunicator, using SW-MQ’s for small communicators,and HW-MQ’s for larger communicators.
# HW MQ SW MQ PTP PTPNodes Based Based send/recv RDMA8 procs
2 7.5 7.27 6.64 5.764 6.21 5.16 6.26 6.038 6.08 4.68 7.08 5.96
16 procs4 9.82 10.32 9.10 8.168 8.05 6.92 10.01 8.44
Table VIIIMPI BARRIER TIMINGS. FIXED PROCESS COUNT AS A FUNCTION OF
NODE COUNT
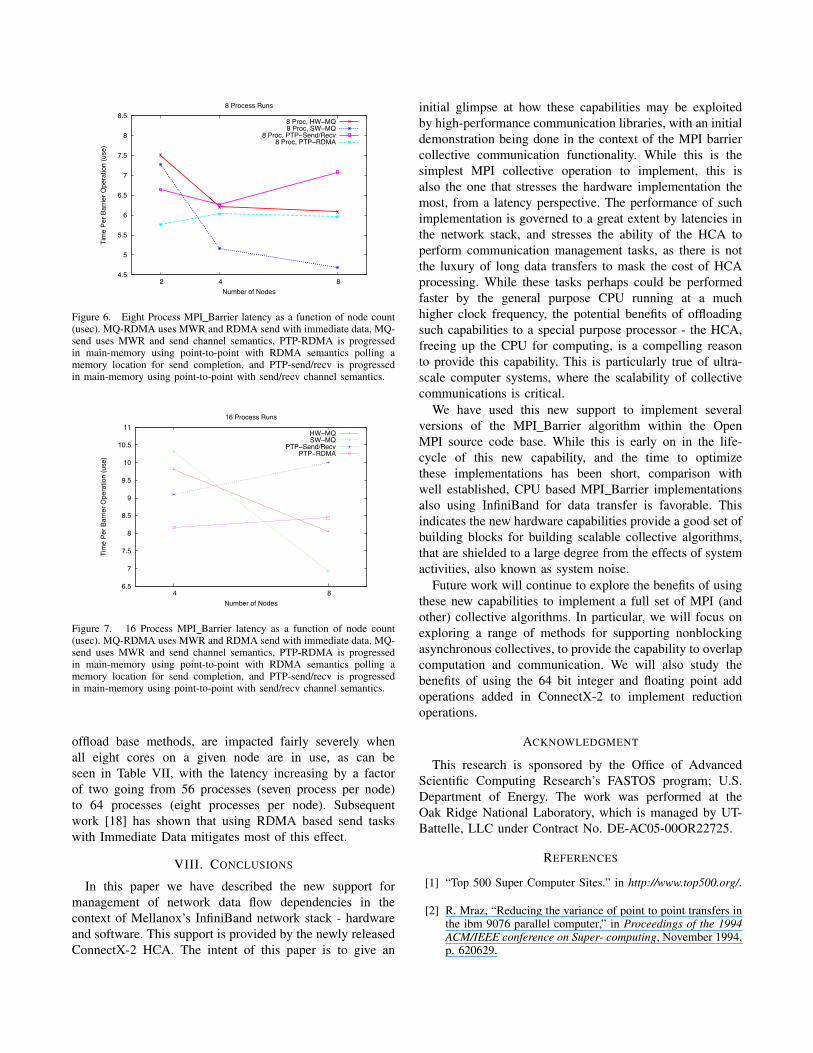
As can be seen in Table VIII, for a fixed number ofprocesses, both the HW-MQ and the SW-MQ based methodsperform better as the number of ranks on the given nodeusing the HCA goes down. In the eight rank case - Figure 6,going from four ranks per node down to one rank pernode reduces the overall barrier latency by about twentypercent. A similar improvement in performance is observedfor the sixteen process case - Figure 7, going from fourranks per node down to two ranks per node. The point-to-point based methods also show some variation with respectto the number of ranks on a node, but there is not a cleartrend in this small sample space. This result should not besurprising, since the network offload based methods relycompletely on the HCA for progress. The HCAs are runningat a much slower clock speed than the CPU, and are thusmuch more sensitive, in absolute time value, to changesin workload than implementations that use the CPU forprogressing communications.
Finally, all methods being used, and in particular the
4.5
5
5.5
6
6.5
7
7.5
8
8.5
2 4 8
Tim
e Pe
r Bar
rier O
pera
tion
(use
)
Number of Nodes
8 Process Runs
8 Proc, HW−MQ8 Proc, SW−MQ
8 Proc, PTP−Send/Recv8 Proc, PTP−RDMA
Figure 6. Eight Process MPI Barrier latency as a function of node count(usec). MQ-RDMA uses MWR and RDMA send with immediate data, MQ-send uses MWR and send channel semantics, PTP-RDMA is progressedin main-memory using point-to-point with RDMA semantics polling amemory location for send completion, and PTP-send/recv is progressedin main-memory using point-to-point with send/recv channel semantics.
6.5
7
7.5
8
8.5
9
9.5
10
10.5
11
4 8
Tim
e Pe
r Bar
rier O
pera
tion
(use
)
Number of Nodes
16 Process Runs
HW−MQSW−MQ
PTP−Send/RecvPTP−RDMA
Figure 7. 16 Process MPI Barrier latency as a function of node count(usec). MQ-RDMA uses MWR and RDMA send with immediate data, MQ-send uses MWR and send channel semantics, PTP-RDMA is progressedin main-memory using point-to-point with RDMA semantics polling amemory location for send completion, and PTP-send/recv is progressedin main-memory using point-to-point with send/recv channel semantics.
offload base methods, are impacted fairly severely whenall eight cores on a given node are in use, as can beseen in Table VII, with the latency increasing by a factorof two going from 56 processes (seven process per node)to 64 processes (eight processes per node). Subsequentwork [18] has shown that using RDMA based send taskswith Immediate Data mitigates most of this effect.
VIII. CONCLUSIONS
In this paper we have described the new support formanagement of network data flow dependencies in thecontext of Mellanox’s InfiniBand network stack - hardwareand software. This support is provided by the newly releasedConnectX-2 HCA. The intent of this paper is to give an
initial glimpse at how these capabilities may be exploitedby high-performance communication libraries, with an initialdemonstration being done in the context of the MPI barriercollective communication functionality. While this is thesimplest MPI collective operation to implement, this isalso the one that stresses the hardware implementation themost, from a latency perspective. The performance of suchimplementation is governed to a great extent by latencies inthe network stack, and stresses the ability of the HCA toperform communication management tasks, as there is notthe luxury of long data transfers to mask the cost of HCAprocessing. While these tasks perhaps could be performedfaster by the general purpose CPU running at a muchhigher clock frequency, the potential benefits of offloadingsuch capabilities to a special purpose processor - the HCA,freeing up the CPU for computing, is a compelling reasonto provide this capability. This is particularly true of ultra-scale computer systems, where the scalability of collectivecommunications is critical.
We have used this new support to implement severalversions of the MPI Barrier algorithm within the OpenMPI source code base. While this is early on in the life-cycle of this new capability, and the time to optimizethese implementations has been short, comparison withwell established, CPU based MPI Barrier implementationsalso using InfiniBand for data transfer is favorable. Thisindicates the new hardware capabilities provide a good set ofbuilding blocks for building scalable collective algorithms,that are shielded to a large degree from the effects of systemactivities, also known as system noise.
Future work will continue to explore the benefits of usingthese new capabilities to implement a full set of MPI (andother) collective algorithms. In particular, we will focus onexploring a range of methods for supporting nonblockingasynchronous collectives, to provide the capability to overlapcomputation and communication. We will also study thebenefits of using the 64 bit integer and floating point addoperations added in ConnectX-2 to implement reductionoperations.
ACKNOWLEDGMENT
This research is sponsored by the Office of AdvancedScientific Computing Research’s FASTOS program; U.S.Department of Energy. The work was performed at theOak Ridge National Laboratory, which is managed by UT-Battelle, LLC under Contract No. DE-AC05-00OR22725.
REFERENCES
[1] “Top 500 Super Computer Sites.” in http://www.top500.org/.
[2] R. Mraz, “Reducing the variance of point to point transfers inthe ibm 9076 parallel computer,” in Proceedings of the 1994ACM/IEEE conference on Super- computing, November 1994,p. 620629.

[3] F. Petrini, D. J. Kerbyson, and S. Pakin, “The case ofthe missing supercomputer performance: Achieving optimalperformance on the 8,192 processors of asci q,” in Proceed-ings of the 2003 ACM/IEEE conference on Supercomputing,November 2003, p. 55.
[4] “Mellanox Technologies,” http://www.mellanox.com/, 2008.[Online]. Available: http://www.mellanox.com/
[5] MPI: A Message-Passing Standard, Message Passing Inter-face Forum, June 2008.
[6] K. Verstoep, K. Langendoen, and H. E. Bal,“Efficient Reliable Multicast on Myrinet,” in theProceedings of the International Conference on ParallelProcessing ’96, 1996, pp. 156–165. [Online]. Available:citeseer.nj.nec.com/verstoep96efficient.html
[7] R. A. Bhoedjang, T. Ruhl, and H. E. Bal, “Efficient Multicaston Myrinet Using Link-Level Flow Control,” in 27th Inter-national Conference on Parallel Processing, 1998. [Online].Available: citeseer.nj.nec.com/bhoedjang98efficient.html
[8] D. Buntinas, D. K. Panda, and P. Sadayappan, “Fast NIC-Level Barrier over Myrinet/GM,” in Proceedings of Interna-tional Parallel and Distributed Processing Symposium, 2001.[Online]. Available: citeseer.nj.nec.com/buntinas01fast.html
[9] W. Yu, D. Buntinas, and D. K. Panda, “High Performanceand Reliable NIC-Based Multicast over Myrinet/GM-2,” inProceedings of the International Conference on Parallel Pro-cessing ’03, October 2003.
[10] A. Moody, J. Fernandez, F. Petrini, and D. Panda, “ScalableNIC-based Reduction on Large-Scale Clusters,” in SC ’03,November 2003.
[11] Y. Huang and P. K. McKinley, “Efficient collective operationswith ATM network interface support,” in ICPP, Vol. 1, 1996,pp. 34–43.
[12] D. Buntinas and D. K. Panda, “NIC-Based Reduction inMyrinet Clusters: Is It Beneficial?” in SAN-02 Workshop (inconjunction with HPCA), Feb. 2003.
[13] “Quadrics,” http://www.quadrics.com/.
[14] InfiniBand Trade Association, “The InfiniBand Architecture,”http://www.infinibandta.org/specs.
[15] RDMA Consortium, “An RDMA Protocol Specification,”http://www.rdmaconsortium.org.
[16] A. Romanow and S. Bailey, “An Overview of RDMAover IP,” in International Workshop on Protocols for Long-Distance Networks, (PFLDnet2003).
[17] R. L. Graham and G. Shipman, “MPI support for multi-core architectures: Optimized shared memory collectives,” inProceedings of the 15th European PVM/MPI Users’ GroupMeeting on Recent Advances in Parallel Virtual Machine andMessage Passing Interface. Berlin, Heidelberg: Springer-Verlag, 2008, pp. 130–140.
[18] R. L. Graham, S. Poole, P. Shamis, G. Bloch, N. Bloch,H. Chapman, M. Kagan, A. Shahar, I. Rabinovitz, andG. Shainer, “Overlapping computation and communication:Barrier algorithms and connectx-2 core-direct capabilities,”in Accepted to CAC, 2010.
Related Documents











