Concurrent Markov Decision Processes Mausam, Daniel S. Weld University of Washington Seattle

Concurrent Markov Decision Processes Mausam, Daniel S. Weld University of Washington Seattle.
Dec 19, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Concurrent Markov Decision Processes
Mausam, Daniel S. WeldUniversity of WashingtonSeattle

Planning
Environment
Percepts Actions
What action next?

Motivation
Two features of real world planning domains : Concurrency (widely studied in the Classical
Planning literature) Some instruments may warm up Others may perform their tasks Others may shutdown to save power.
Uncertainty (widely studied in the MDP literature) All actions (pick up the rock, send data etc.) have a
probability of failure. Need both!

Probabilistic Planning
Probabilistic Planning typically modeled as Markov Decision Processes.
Traditional MDPs assume a “single action per decision epoch”.
Solving Concurrent MDPs in the naïve way incurs exponential blowups in running times.

Outline of the talk
MDPs Concurrent MDPs Present sound pruning rules to reduce
the blowup. Present sampling techniques to obtain
orders of magnitude speedups. Experiments Conclusions and Future Work

Markov Decision Process
S : a set of states, factored into Boolean variables.A : a set of actionsPr (S£ A£ S! [0,1]): the transition modelC (A! R) : the cost modeldiscount factor (2)s0 : the start stateG : a set of absorbing goals

GOAL of an MDP
Find a policy (S ! A) which:minimises expected discounted cost of reaching a goal for an infinite horizonfor a fully observable Markov decision process.

Bellman Backup
Define J*(s) {optimal cost} as the minimum expected cost to reach a goal from this state.
Given an estimate of J* function (say Jn) Backup Jn function at state s to calculate a new
estimate (Jn+1) as follows
Value IterationPerform Bellman updates at all states in each iteration.Stop when costs have converged at all states.

Min
Bellman Backup
a1
a2
a3
s
Jn
Jn
Jn
Jn
Jn
Jn
Jn
Qn+1(s,a)
Jn+1(s)
Ap(s)

Min
RTDP Trial
a1
a2
a3
s
Jn
Jn
Jn
Jn
Jn
Jn
Jn
Qn+1(s,a)
Jn+1(s)
Ap(s)
amin = a2
Goal

Real Time Dynamic Programming(Barto, Bradtke and Singh’95)
Trial : Simulate greedy policy;
Perform Bellman backup on visited states
Repeat RTDP Trials until cost function converges Anytime behaviour Only expands reachable state space Complete convergence is slow
Labeled RTDP (Bonet & Geffner’03) Admissible, if started with admissible cost function. Monotonic; converges quickly

Concurrent MDPs
Redefining the Applicability function
Ap : S!P(P(A)) Inheriting mutex
definitions from Classical planning: Conflicting preconditions Conflicting effects Interfering preconditions
and effects
a1 : if p1 set x1
a2 : if : p1 set x1
a1 : set x1 (pr=0.5)a2 : toggle x1 (pr=0.5)
a1 : if p1 set x1
a2 : toggle p1 (pr=0.5)

Concurrent MDPs (contd)
Ap(s) = {Ac µ A | All actions in Ac are individually applicable in s.
No two actions in Ac are mutex.
}
) The actions in Ac don’t interact with each other. Hence,

Concurrent MDPs (contd)
Cost ModelC : P(A)! R
Typically, C(Ac) < a2 AcC({a})
Time componentResource component
(if C(Ac) = … then optimal sequential policy is optimal for concurrent MDP)

Jn
Jn
Jn
Jn
Jn
Bellman Backup (Concurrent MDP)
a2
a1,a2
a3
sJn+1(s)
Ap(s)
a1
a1,a
3
a2,a3
a1,a2,a3
Jn
Jn
Jn
Jn
Jn
Jn JnJn
Jn
Jn
Jn
Jn
Jn
Min
Exponential blowup to calculate a
Bellman Backup!

Outline of the talk
MDPs Concurrent MDPs Present sound pruning rules to reduce
the blowup. Present sampling techniques to obtain
orders of magnitude speedups. Experiments Conclusions and Future Work

Combo skipping (proven sound pruning rule)
If d Jn(s)e < 1-kQn(s,{a1}) + func(Ac,)
Then prune Ac for state s in this backup.
Use Qn(s,Aprev) as an
upper bound of Jn(s).
Choose a1 as the action with maximum Qn(s,
{a1}) to obtain maximum pruning.
Skips a combination only for current iteration

Combo elimination (proven sound pruning rule)
If b Q*(s,Ac)c > d J*(s)e then eliminate Ac from applicability set of state s.
Eliminates the combination Ac from applicable list of s for all subsequent iterations.
Use Qn(s,Ac) as a
lower bound of Q*(s,Ac).
Use J*sing(s) (the optimal cost for single-action
MDP asan upper bound of J*(s).

Pruned RTDP
RTDP with modified Bellman Backups.Combo-skippingCombo-elimination
Guarantees:Convergence Optimality

Experiments
Domains NASA Rover Domain Factory Domain Switchboard domain
Cost function Time Component 0.2 Resource Component 0.8
State variables : 20-30 Avg(Ap(s)) : 170 -
12287

Speedups in Rover domain

Stochastic Bellman Backups
Sample a subset of combinations for a Bellman Backup.
Intuition : Actions with low Q-values have high likelihood
to be in the optimal combination. Sampling Distribution :
(i) Calculate all single action Q-values.(ii) Bias towards choosing combinations
containing actions with low Q-values.
Best combinations for this state in the previous iteration (memoization).

Sampled RTDP
Non-monotonicInadmissible
) Convergence, Optimality not proven.Heuristics
Complete backup phase (labeling).Run Pruned RTDP with value function
from Sampled RTDP (after scaling).
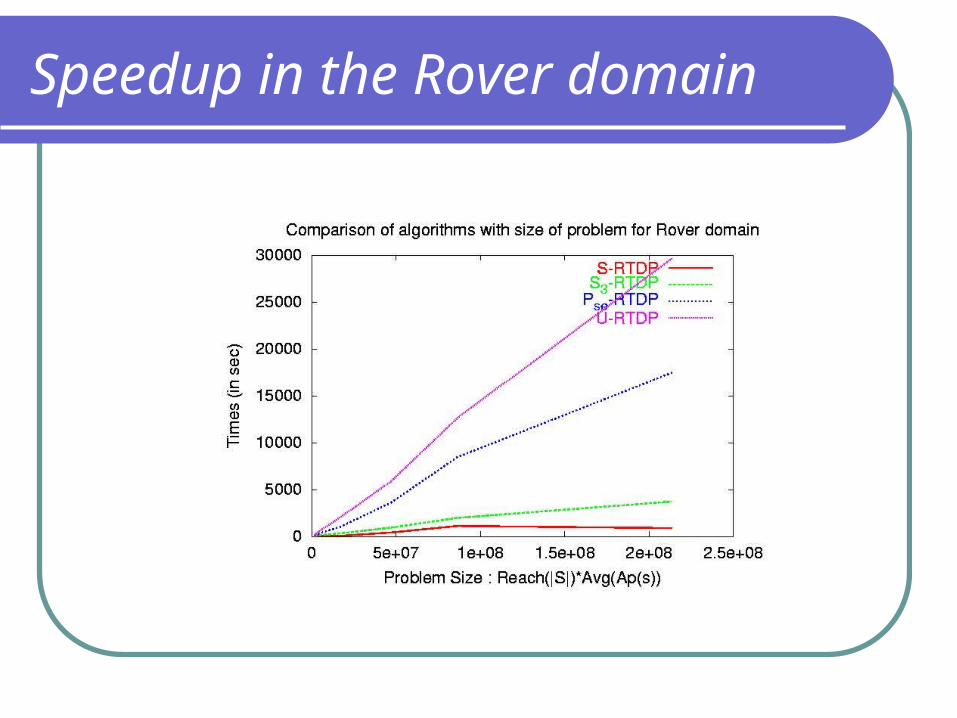
Speedup in the Rover domain

Close to optimal solutionsProblem J*(s0) (S-
RTDP)J*(s0) (Optimal)
Error
Rover1 10.7538 10.7535 <0.01%
Rover2 10.7535 10.7535 0
Rover3 11.0016 11.0016 0
Rover4 12.7490 12.7461 0.02%
Rover5 7.3163 7.3163 0
Rover6 10.5063 10.5063 0
Rover7 12.9343 12.9246 0.08%
Art1 4.5137 4.5137 0
Art2 6.3847 6.3847 0
Art3 6.5583 6.5583 0
Fact1 15.0859 15.0338 0.35%
Fact2 14.1414 14.0329 0.77%
Fact3 16.3771 16.3412 0.22%
Fact4 15.8588 15.8588 0
Fact5 9.0314 8.9844 0.56%

Speedup vs. Concurrency
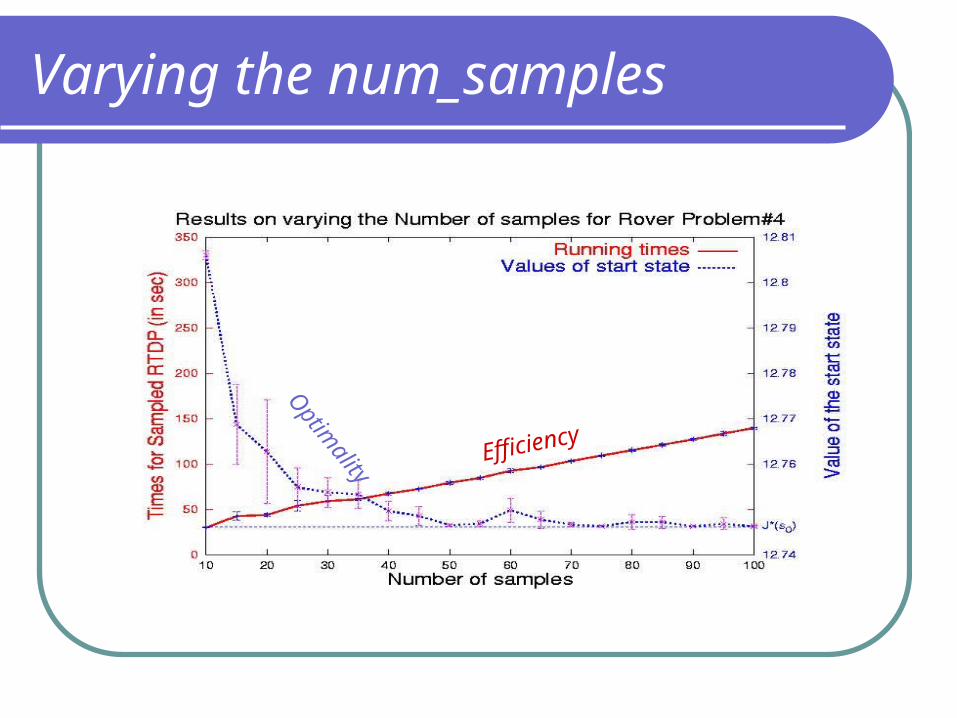
Varying the num_samples
Optim
ality
Efficiency

Contributions
Modeled Concurrent MDPs Sound, optimal pruning methods
Combo-skippingCombo-elimination
Fast sampling approachesClose to optimal solutionHeuristics to improve optimality
Our techniques are general and can be applied to any algorithm – VI, LAO*, etc.

Related Work
Factorial MDPs (Mealeau etal’98, Singh & Cohn’98)
Multiagent planning (Guestrin, Koller, Parr’01)
Concurrent Markov Options (Rohanimanesh & Mahadevan’01)
Generate, test and debug paradigm (Younes & Simmons’04)
Parallelization of sequential plans (Edelkamp’03, Nigenda & Kambhampati’03)

Future Work
Find error bounds, prove convergence for Sampled RTDP
Concurrent Reinforcement LearningModeling durative actions
(Concurrent Probabilistic Temporal Planning) Initial Results – Mausam & Weld’04,
(AAAI Workshop on MDPs)

Concurrent Probabilistic Temporal Planning (CPTP)
Concurrent MDP
CPTP
Our solution (AAAI Workshop on MDPs)Model CPTP as a Concurrent MDP in an
augmented state space.Present admissible heuristics to speed up the
search and manage the state space blowup.
Related Documents











