Computer Vision Group University of California Berkeley 1 Scale-Invariant Random Fields for Mid-level Vision Xiaofeng Ren, Charless Fowlkes and Jitendra Malik University of California at Berkeley

Computer Vision Group University of California Berkeley 1 Scale-Invariant Random Fields for Mid-level Vision Xiaofeng Ren, Charless Fowlkes and Jitendra.
Dec 21, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Computer Vision GroupUniversity of California Berkeley
1
Scale-Invariant Random Fieldsfor
Mid-level Vision
Xiaofeng Ren, Charless Fowlkes and Jitendra Malik
University of California at Berkeley

Computer Vision GroupUniversity of California Berkeley
2
Overview• Scale Invariance in Natural Images• A Scale-Invariant Representation from bottom-up
using Constrained Delaunay Triangulation (CDT)• Scale-Invariant Models for Contour Completion
– A baseline local model
– A global model using Conditional Random Fields (CRF)
– Results and Quantitative Evaluations
• Extensions of the CDT/CRF Framework– Image segmentation
– Figure/ground organization
– Finding people in a single image

Computer Vision GroupUniversity of California Berkeley
3
Overview• Scale Invariance in Natural Images• A Scale-Invariant Representation from bottom-up
using Constrained Delaunay Triangulation (CDT)• Scale-Invariant Models for Contour Completion
– A baseline local model
– A global model using Conditional Random Fields (CRF)
– Results and Quantitative Evaluations
• Extensions of the CDT/CRF Framework– Image segmentation
– Figure/ground organization
– Finding people in a single image

Computer Vision GroupUniversity of California Berkeley
4
Scale Invariance• An intuitive understanding
• A mathematical characterization
… …
or ?
or ?
X1
X2
FX1( · ) = F( · ; s1)
FX2( · ) = F( · ; s2)
Computer Vision GroupUniversity of California Berkeley
5
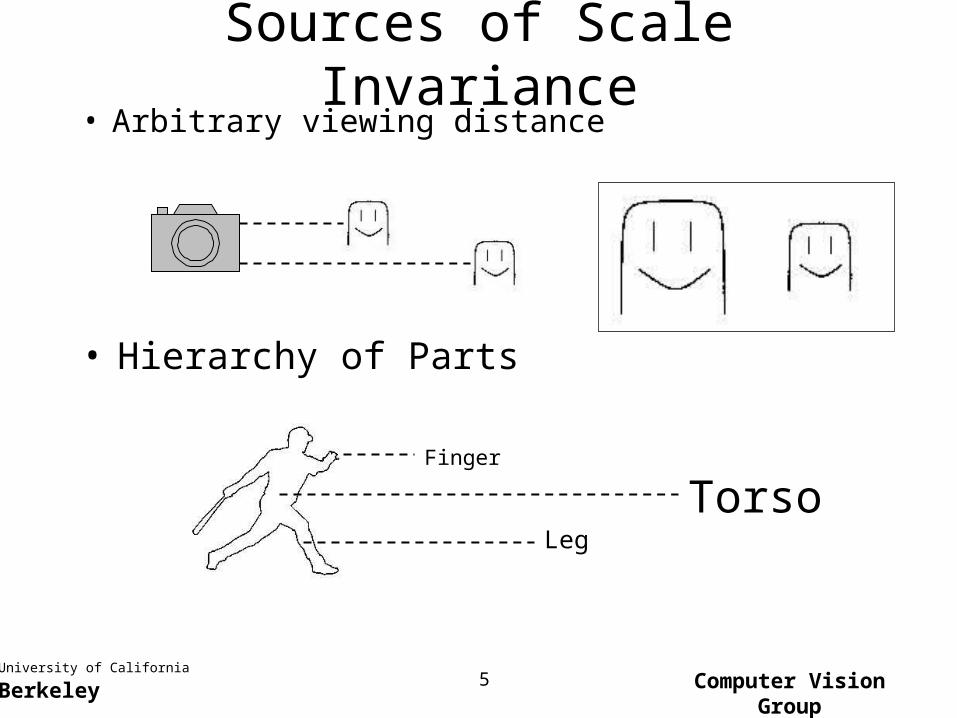
Sources of Scale Invariance• Arbitrary viewing distance
• Hierarchy of Parts
Finger
LegTorso

Computer Vision GroupUniversity of California Berkeley
6
Scale Invariance in Natural Images• Scale Space Theory and Gaussian Pyramids
– Witkin, Lindenberg, Koenderink, …
• Empirical Studies: Power Laws in Natural Images– Power spectra (Ruderman, 1994)
– Wavelet coefficients (e.g. Simoncelli)
– Probabilistic Models (e.g. Mumford)
– Power laws in the statistics
of boundary contours
[Ren and Malik 2002]

Computer Vision GroupUniversity of California Berkeley
7
How to Handle Scale Invariance?• Top-down Search
• Bottom-up Scale Selection– Scale space (e.g. zero crossing of the Laplacian)
– Lowe’s SIFT operator
– Our boundary-oriented approach based on piecewise approximation of edges and constrained Delaunay triangulation (CDT)
… 1 2 3 4 5 6 …

Computer Vision GroupUniversity of California Berkeley
8
Overview• Scale Invariance in Natural Images• A Scale-Invariant Representation from bottom-up
using Constrained Delaunay Triangulation (CDT)• Scale-Invariant Models for Contour Completion
– A baseline local model
– A global model using Conditional Random Fields (CRF)
– Results and Quantitative Evaluations
• Extensions of the CDT/CRF Framework– Image segmentation
– Figure/ground organization
– Finding people in a single image

Computer Vision GroupUniversity of California Berkeley
9
Low-level Contour Detection• Use Pb (probability of boundary) as input
– Combines local brightness, texture and color cues
– Trained from human-marked segmentation boundaries
– Outperforms existing local boundary detectors including Canny
• Canny’s hysteresis thresholding
• Use Pb (probability of boundary) as input – Combines local brightness, texture and color cues
– Trained from human-marked segmentation boundaries
– Outperforms existing local boundary detectors including Canny
• Canny’s hysteresis thresholding
[Martin, Fowlkes & Malik 02]

Computer Vision GroupUniversity of California Berkeley
10
Piecewise Linear Approximation• Recursively split the boundaries until each piece is
approximately straight• Recursively split the boundaries until each piece is
approximately straight
Computer Vision GroupUniversity of California Berkeley
11
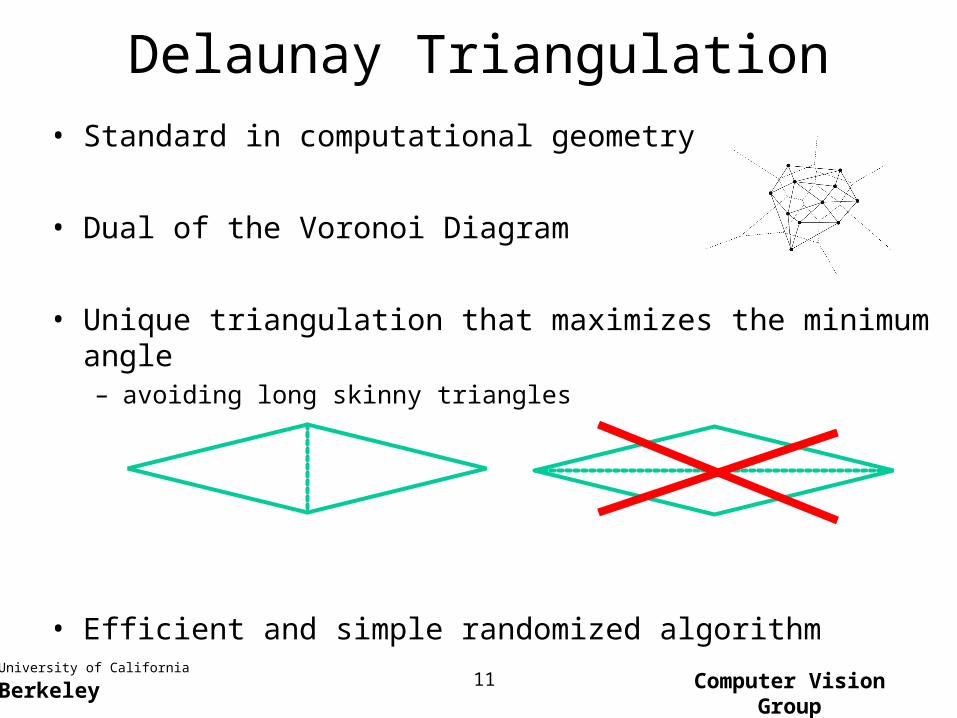
Delaunay Triangulation
• Standard in computational geometry
• Dual of the Voronoi Diagram
• Unique triangulation that maximizes the minimum angle– avoiding long skinny triangles
• Efficient and simple randomized algorithm
• Standard in computational geometry
• Dual of the Voronoi Diagram
• Unique triangulation that maximizes the minimum angle– avoiding long skinny triangles
• Efficient and simple randomized algorithm
Computer Vision GroupUniversity of California Berkeley
12
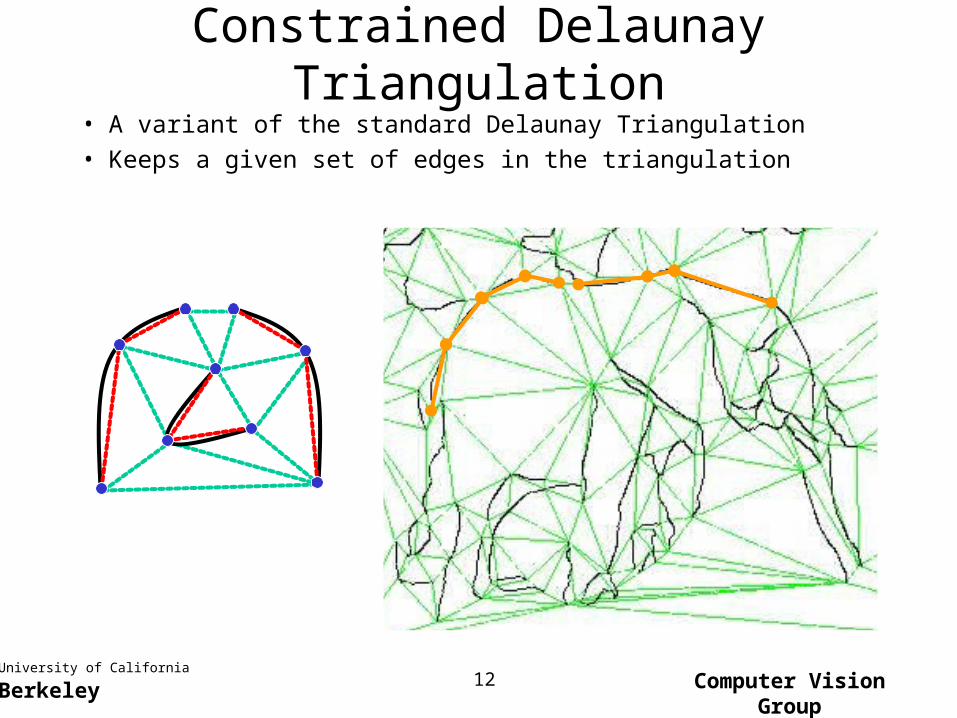
Constrained Delaunay Triangulation
• A variant of the standard Delaunay Triangulation
• Keeps a given set of edges in the triangulation
• A variant of the standard Delaunay Triangulation
• Keeps a given set of edges in the triangulation

Computer Vision GroupUniversity of California Berkeley
13
“Gap-Filling” Property of CDT• A typical scenario of contour completion• A typical scenario of contour completion
low contrast
high contrasthigh contrast
• CDT picks the “right” edge, completing the gap• CDT picks the “right” edge, completing the gap

Computer Vision GroupUniversity of California Berkeley
14

Computer Vision GroupUniversity of California Berkeley
15
The CDT Graph
scale-invariant
fast to compute
<1000 edges
completes gaps
little loss of
structure

Computer Vision GroupUniversity of California Berkeley
16
Berkeley Segmentation Dataset
[Martin et al, ICCV 2001]1,000 images, >14,000 segmentations

Computer Vision GroupUniversity of California Berkeley
17
Evaluating Boundary Operators• Precision-Recall Curves
– threshold the output boundary map
– bipartite matching with the groundtruth
• Precision-Recall Curves– threshold the output boundary map
– bipartite matching with the groundtruth
m pixels on human-marked boundaries
n detected pixels above a given threshold
k matched pairs
Precision = k/n, percentage of true positives
Recall = k/m, percentage of groundtruth being detected
• Project CDT edges back to the pixel-grid• Project CDT edges back to the pixel-grid
Computer Vision GroupUniversity of California Berkeley
18
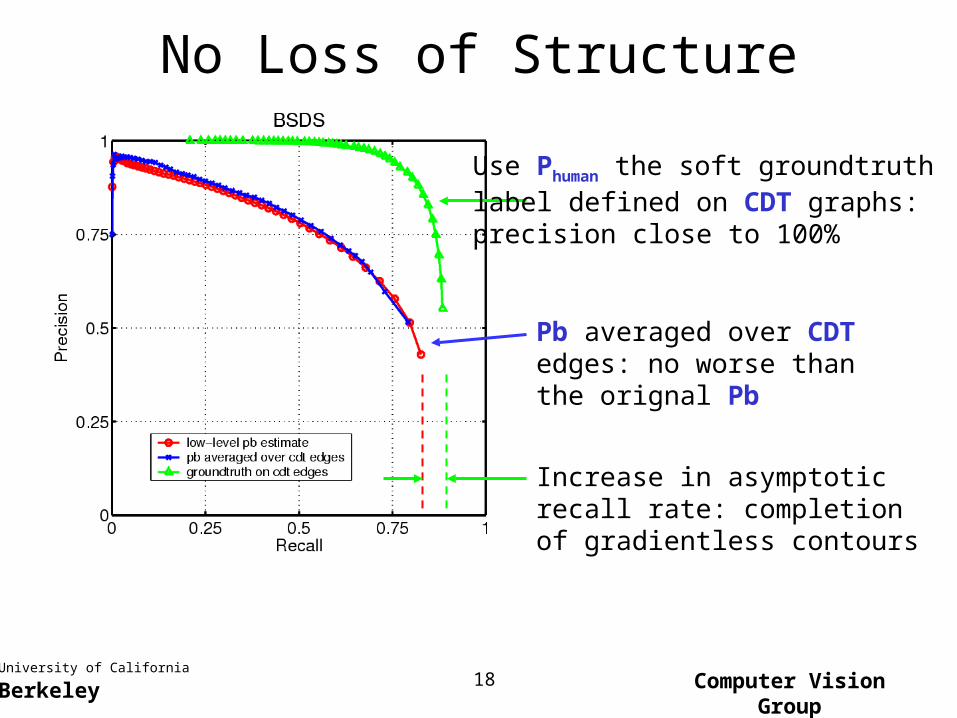
No Loss of Structure
Use Phuman the soft groundtruthlabel defined on CDT graphs:precision close to 100%
Pb averaged over CDT edges: no worse than the orignal Pb
Increase in asymptotic recall rate: completion of gradientless contours
Computer Vision GroupUniversity of California Berkeley
19
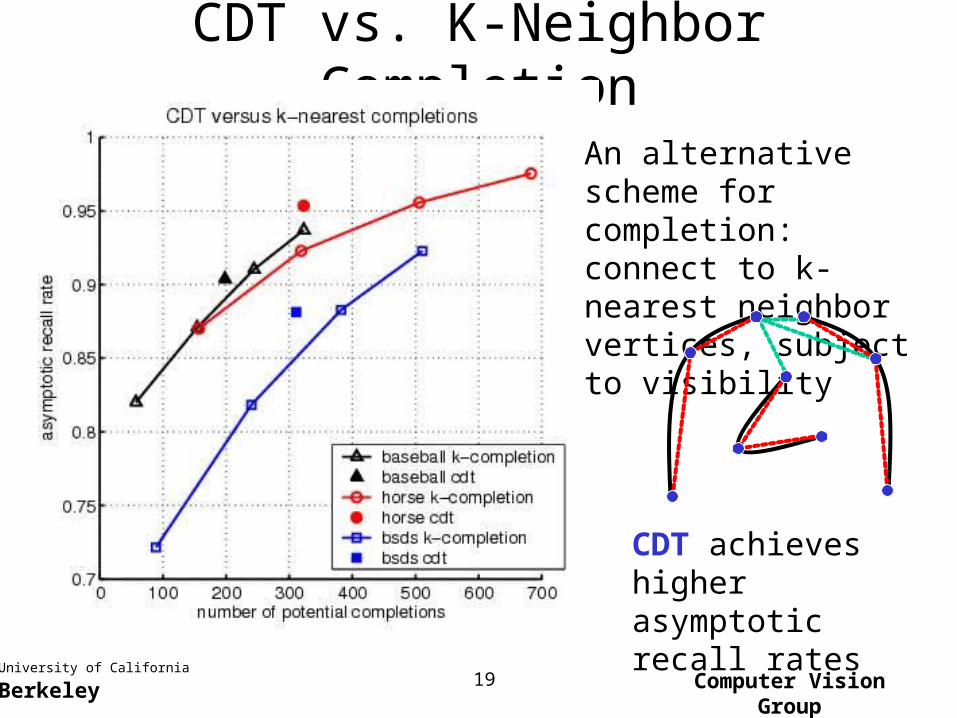
CDT vs. K-Neighbor Completion
An alternative scheme for completion: connect to k-nearest neighbor vertices, subject to visibility
CDT achieves higher asymptotic recall rates

Computer Vision GroupUniversity of California Berkeley
20
The CDT Graph
scale-invariant
fast to compute
<1000 edges
completes gaps
little loss of
structure

Computer Vision GroupUniversity of California Berkeley
21
“Superpixels”• Idea: use oversegmentation as preprocessing and
work with homogenous regions instead of pixels.
• Empirical Validation [Ren and Malik 2003]
How much do we lose when we go from pixels to superpixels?

Computer Vision GroupUniversity of California Berkeley
22
So the CDT graph is nice to work with…
We can develop sophisticated models
on top of the CDT graph, e.g.
for Mid-level vision

Computer Vision GroupUniversity of California Berkeley
23
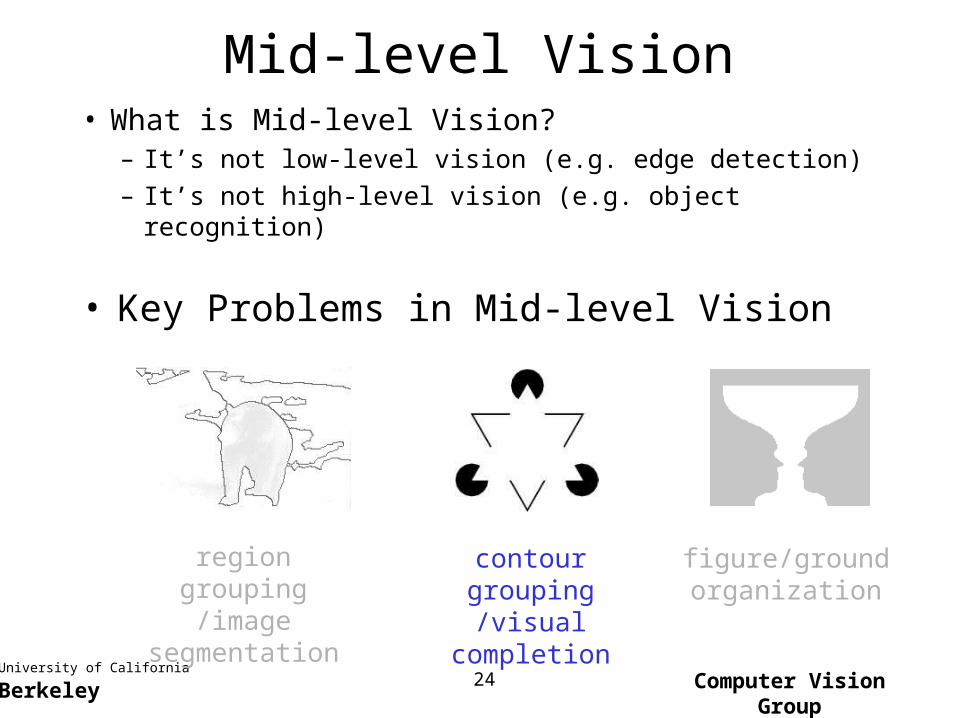
Mid-level Vision• What is Mid-level Vision?
– It’s not low-level vision (e.g. edge detection)
– It’s not high-level vision (e.g. object recognition)
region grouping/image segmentation
contour grouping/visual completion
figure/groundorganization
• Key Problems in Mid-level Vision
Computer Vision GroupUniversity of California Berkeley
24
Mid-level Vision• What is Mid-level Vision?
– It’s not low-level vision (e.g. edge detection)
– It’s not high-level vision (e.g. object recognition)
region grouping/image segmentation
contour grouping/visual completion
figure/groundorganization
• Key Problems in Mid-level Vision

Computer Vision GroupUniversity of California Berkeley
25
Boundary Detection• Edge detection: 20 years after Canny• Edge detection: 20 years after Canny
• Pb (Probability of Boundary): learning to combine brightness, color and texture contrasts
• Pb (Probability of Boundary): learning to combine brightness, color and texture contrasts
• There is psychophysical evidence that we might have been approaching the limit of local edge detection
• There is psychophysical evidence that we might have been approaching the limit of local edge detection

Computer Vision GroupUniversity of California Berkeley
26
Curvilinear Continuity• Boundaries are smooth in nature
• A number of associated phenomena– Good continuation
– Visual completion
– Illusory contours
• Well studied in human vision– Wertheimer, Kanizsa, von der Heydt, Kellman,
Field, Geisler, …
• Extensively explored in computer vision– Shashua, Zucker, Mumford, Williams, Jacobs,
Elder, Jermyn, Wang, …
• Is the net effect of completion positive? Or negative? Lack of quantitative evaluation
• Boundaries are smooth in nature
• A number of associated phenomena– Good continuation
– Visual completion
– Illusory contours
• Well studied in human vision– Wertheimer, Kanizsa, von der Heydt, Kellman,
Field, Geisler, …
• Extensively explored in computer vision– Shashua, Zucker, Mumford, Williams, Jacobs,
Elder, Jermyn, Wang, …
• Is the net effect of completion positive? Or negative? Lack of quantitative evaluation

Computer Vision GroupUniversity of California Berkeley
27
Overview• Scale Invariance in Natural Images• A Scale-Invariant Representation from bottom-up
using Constrained Delaunay Triangulation (CDT)• Scale-Invariant Models for Contour Completion
– A baseline local model
– A global model using Conditional Random Fields (CRF)
– Results and Quantitative Evaluations
• Extensions of the CDT/CRF Framework– Image segmentation
– Figure/ground organization
– Finding people in a single image

Computer Vision GroupUniversity of California Berkeley
28
Inference on the CDT Graph
Xe
Xe
Xe
Xe
Xe
Xe
Xe
Xe
Xe
XeXeXe
Xe
Xe
Xe
Xe
Xe
Xe
Local inference:
XeXe
Global inference:
Computer Vision GroupUniversity of California Berkeley
29
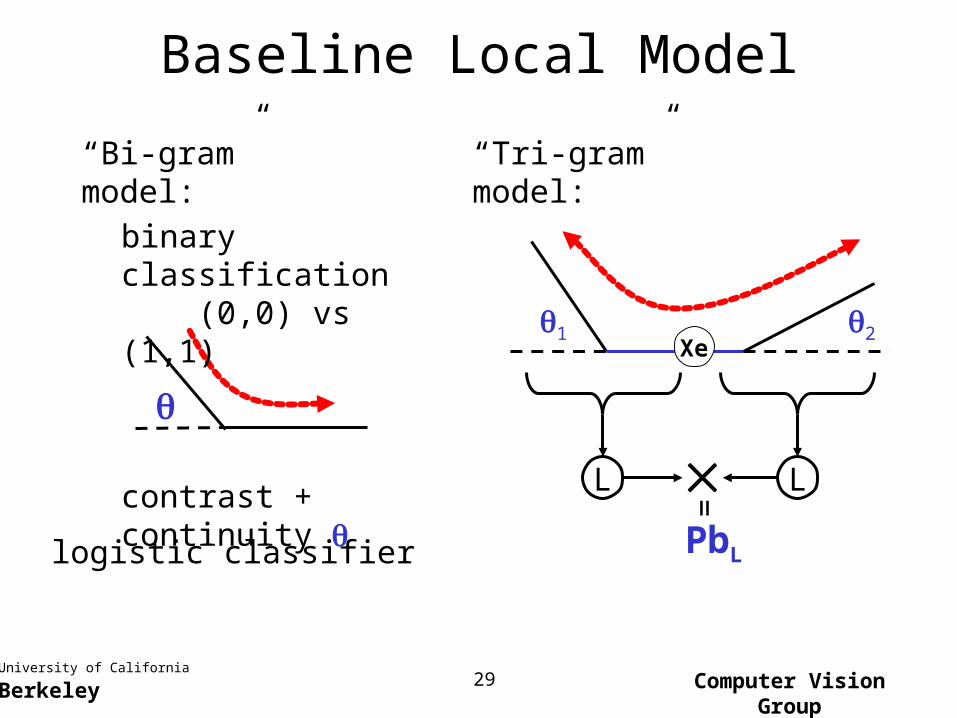
Baseline Local Model
“Bi-gram” model:
contrast + continuity
binary classification (0,0) vs (1,1)
logistic classifier
“Tri-gram” model:
1 2
L LPbL
=
Xe

Computer Vision GroupUniversity of California Berkeley
30
For each edge i, define a set of features{g1,g2,…,gh}
Potential function exp(i) at edge i
hhi ggg 2211expexp
For each junction j, define a set of features{f1,f2,…,fk}
Potential function exp(j) at juncion j
kkj fff 2211expexp
X={X1,X2,…,Xm}
[Pietra, Pietra & Lafferty 97][Lafferty, McCallum & Pereira 01]
Conditional Random Fields

Computer Vision GroupUniversity of California Berkeley
31
X={X1,X2,…,Xm}
Conditional Random Fields
Potential function on edges {exp(i)}
Potential function on junctions {exp(j)}
This defines a probability distribution over X:
Z
XX
XPj
ji
i exp
X j
ji
i XXZ expwhere
Estimate P(Xi|) an undirected graphical model with potential functions in the exponential family
Computer Vision GroupUniversity of California Berkeley
32
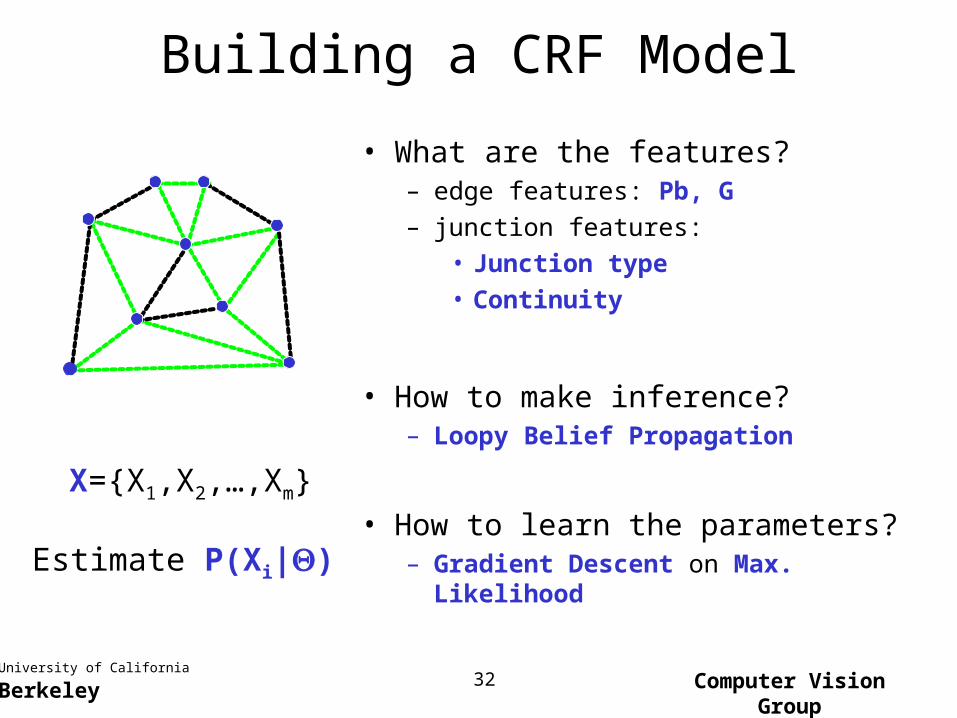
Building a CRF Model
• What are the features?– edge features: Pb, G
– junction features:
• Junction type
• Continuity
• How to make inference?– Loopy Belief Propagation
• How to learn the parameters?– Gradient Descent on Max. Likelihood
• What are the features?– edge features: Pb, G
– junction features:
• Junction type
• Continuity
• How to make inference?– Loopy Belief Propagation
• How to learn the parameters?– Gradient Descent on Max. Likelihood
X={X1,X2,…,Xm}
Estimate P(Xi|)

Computer Vision GroupUniversity of California Berkeley
33
Junctions and Continuity• Junction types (degg,degc):• Junction types (degg,degc):
baXf cgba degdeg),(
degg=1,degc=0 degg=0,degc=2 degg=1,degc=2
• Continuity term for degree-2 junctions• Continuity term for degree-2 junctions
degg+degc=2
),(),( exp baba f
2degdeg exp cgg
degg=0,degc=0

Computer Vision GroupUniversity of California Berkeley
34
Inference w/ Belief Propagation
• Loopy Belief Propagation
– just like belief propagation
– iterates message passing until convergence
– lack of theoretical foundations and known to have convergence issues
– however becoming popular in practice
– typically applied on pixel-grid
• Works well on CDT graphs– converges fast (<10 iterations)
– produces empirically sound results
• Loopy Belief Propagation
– just like belief propagation
– iterates message passing until convergence
– lack of theoretical foundations and known to have convergence issues
– however becoming popular in practice
– typically applied on pixel-grid
• Works well on CDT graphs– converges fast (<10 iterations)
– produces empirically sound results

Computer Vision GroupUniversity of California Berkeley
35
Maximum Likelihood Learning
• Maximum-likelihood estimation in CRFLet denote the groundtruth labeling on the CDT graph
• Maximum-likelihood estimation in CRFLet denote the groundtruth labeling on the CDT graph
XXq
qtt
ti
iss
s XfXgZ
XL~factor edge
exp1~
Xtqqt
t ZFfXL exp
1~~log
factor
• Many possible optimization techniques– gradient descent, iterative scaling, conjugate gradient, …
• Gradient descent works well
• Many possible optimization techniques– gradient descent, iterative scaling, conjugate gradient, …
• Gradient descent works well
X~
)|()(~
XPtXPt ff

Computer Vision GroupUniversity of California Berkeley
36
Interpreting the Parameters
=2.46 =0.87 =1.14 =0.01
=-0.59
=-0.98
Line endings and junctions are rare
Completed edges are weak

Computer Vision GroupUniversity of California Berkeley
37
Quantitative Evaluation
• Baseball player dataset [Mori et al 04]
– 30 news photos of baseball players in various poses, 15 training and 15 testing
• Horse dataset [Borenstein & Ullman 02]
– 350 images of standing horses facing left, 175 training and 175 testing
• Berkeley Segmentation Dataset [Martin et al 01]
– 300 Corel images of various natural scenes and ~2500 segmentations, 200 training and 100 testing
• Baseball player dataset [Mori et al 04]
– 30 news photos of baseball players in various poses, 15 training and 15 testing
• Horse dataset [Borenstein & Ullman 02]
– 350 images of standing horses facing left, 175 training and 175 testing
• Berkeley Segmentation Dataset [Martin et al 01]
– 300 Corel images of various natural scenes and ~2500 segmentations, 200 training and 100 testing

Computer Vision GroupUniversity of California Berkeley
38
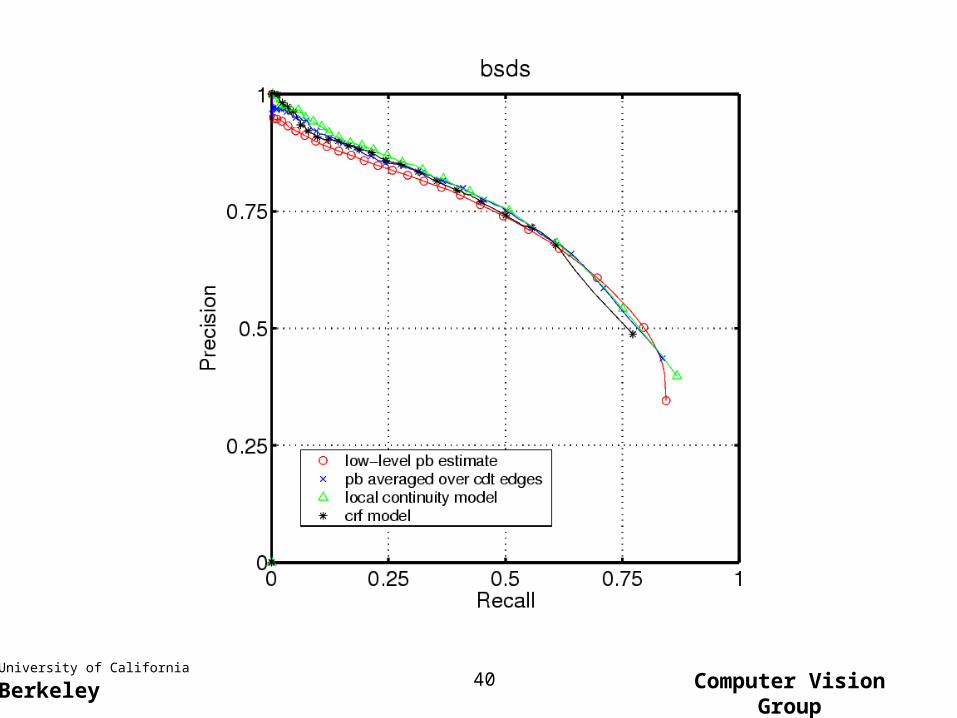
Continuity improves boundary detection in both low-recall and high-recall ranges
Global inference helps; mostly in low-recall/high-precision
Roughly speaking,
CRF>Local>CDT only>Pb

Computer Vision GroupUniversity of California Berkeley
39
Computer Vision GroupUniversity of California Berkeley
40

Computer Vision GroupUniversity of California Berkeley
41
Image Pb Local Global

Computer Vision GroupUniversity of California Berkeley
42
Image Pb Local Global

Computer Vision GroupUniversity of California Berkeley
43
Image Pb Local Global

Computer Vision GroupUniversity of California Berkeley
44
Conclusion I• Constrained Delaunay Triangulation is a scale-invariant
discretization of images with little loss of structure;• Constrained Delaunay Triangulation is a scale-invariant
discretization of images with little loss of structure;
• Moving from 100,000 pixels to <1000 edges, CDT achieves great statistical and computational efficiency;
• Moving from 100,000 pixels to <1000 edges, CDT achieves great statistical and computational efficiency;
• Curvilinear Continuity improves boundary detection;
– the local model of continuity is simple yet very effective
– global inference of continuity further improves performance
– Conditional Random Fields w/ loopy belief propagation works well on CDT graphs
• Curvilinear Continuity improves boundary detection;
– the local model of continuity is simple yet very effective
– global inference of continuity further improves performance
– Conditional Random Fields w/ loopy belief propagation works well on CDT graphs
• Mid-level vision is useful.• Mid-level vision is useful.

Computer Vision GroupUniversity of California Berkeley
45
Overview• Scale Invariance in Natural Images• A Scale-Invariant Representation from bottom-up
using Constrained Delaunay Triangulation (CDT)• Scale-Invariant Models for Contour Completion
– A baseline local model
– A global model using Conditional Random Fields (CRF)
– Results and Quantitative Evaluations
• Extensions of the CDT/CRF Framework– Image segmentation
– Figure/ground organization
– Finding people in a single image

Computer Vision GroupUniversity of California Berkeley
46
Overview• Scale Invariance in Natural Images• A Scale-Invariant Representation from bottom-up
using Constrained Delaunay Triangulation (CDT)• Scale-Invariant Models for Contour Completion
– A baseline local model
– A global model using Conditional Random Fields (CRF)
– Results and Quantitative Evaluations
• Extensions of the CDT/CRF Framework– Image segmentation
– Figure/ground organization
– Finding people in a single image

Computer Vision GroupUniversity of California Berkeley
47
Summary
CRF
Conditional Random Fields on triangulated images, trained to integrate low/mid/high-level grouping cues

Computer Vision GroupUniversity of California Berkeley
48
Inference on the CDT Graph
Xe
Xe
Xe
Xe
Xe
Xe
Xe
Xe
Xe
XeXeXe
Xe
Xe
Xe
Xe
Xe
Xe
Yt
Yt
Yt
Yt
Yt
Yt
Yt
Yt
YtYt
Z
Contour variables {Xe}
Region variables {Yt}
Object variable {Z}
Integrating {Xe},{Yt} and{Z}: low/mid/high-level cues
Xe
Xe
Xe
Xe
Xe
Xe
Xe
Xe
Xe
XeXeXe
Xe
Xe
Xe
Xe
Xe
Xe
Yt
Yt
Yt
Yt
Yt
Yt
Yt
Yt
YtYt
Z

Computer Vision GroupUniversity of California Berkeley
49
Grouping Cues• Low-level Cues
– Edge energy along edge e
– Brightness/texture similarity between two regions s and t
• Mid-level Cues– Edge collinearity and junction frequency at
vertex V
– Consistency between edge e and two adjoining regions s and t
• High-level Cues– Texture similarity of region t to exemplars
– Compatibility of region support with pose
– Compatibility of local edge shape with pose
• Low-level Cues– Edge energy along edge e
– Brightness/texture similarity between two regions s and t
• Mid-level Cues– Edge collinearity and junction frequency at
vertex V
– Consistency between edge e and two adjoining regions s and t
• High-level Cues– Texture similarity of region t to exemplars
– Compatibility of region support with pose
– Compatibility of local edge shape with pose
L1(Xe|I)L2(Ys,Yt|I)
M1(XV|I)
M2(Xe,Ys,Yt)
H1(Yt|I)H2(Yt,Z|I)H3(Xe,Z|I)

Computer Vision GroupUniversity of California Berkeley
50
Conditional Random Fields for Cue Integration
,,|,exp),(
1,,, IZYXE
IZIZYXP
ts
tse
e IYYLIXLE,
21 |,|
ts
etsV
V XYYMIXM,
21 ,,|
e
et
tt
t IZXHIZYHIYH |,|,| 321
Estimate the marginal posteriors of X, Y and Z
Computer Vision GroupUniversity of California Berkeley
51
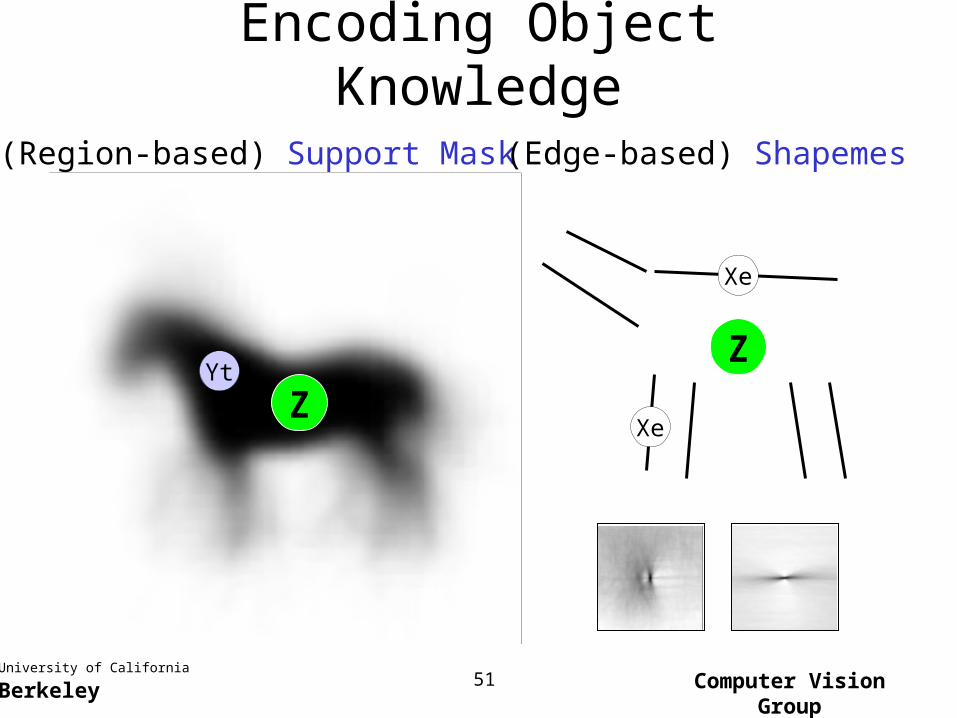
Encoding Object Knowledge
(Region-based) Support Mask
Yt
Z
(Edge-based) Shapemes
Xe
Z
Xe

Computer Vision GroupUniversity of California Berkeley
52
H3(Xe,Z|I): local shape and pose
distribution ON(x,y,i)
shapeme j(vertical pairs) distribution ON(x,y,j)
Let S(x,y) be the shapeme at image location (x,y); (xo,yo) be the object location in Z. Compute average log likelihood SON(e,Z) as:
eyx
oo yxSyyxxONe ,
),(,,log1
eOFFOFF
eONONe
XZeS
XZeSIZXH
),(
),(|,3
Then we have:
SOFF(e,Z) is defined similarly.
shapeme i(horizontal line)
Computer Vision GroupUniversity of California Berkeley
53

Computer Vision GroupUniversity of California Berkeley
54

Computer Vision GroupUniversity of California Berkeley
55
Results
Input Input Pb Output Contour Output Figure

Computer Vision GroupUniversity of California Berkeley
56
Input Input Pb Output Contour Output Figure

Computer Vision GroupUniversity of California Berkeley
57
Input Input Pb Output Contour Output Figure

Computer Vision GroupUniversity of California Berkeley
58
Conclusion II• Constrained Delaunay Triangulation provides a scale-
invariant discrete structure which enables efficient probabilistic inference.
• Conditional random fields combine joint contour and region grouping and can be efficiently trained.
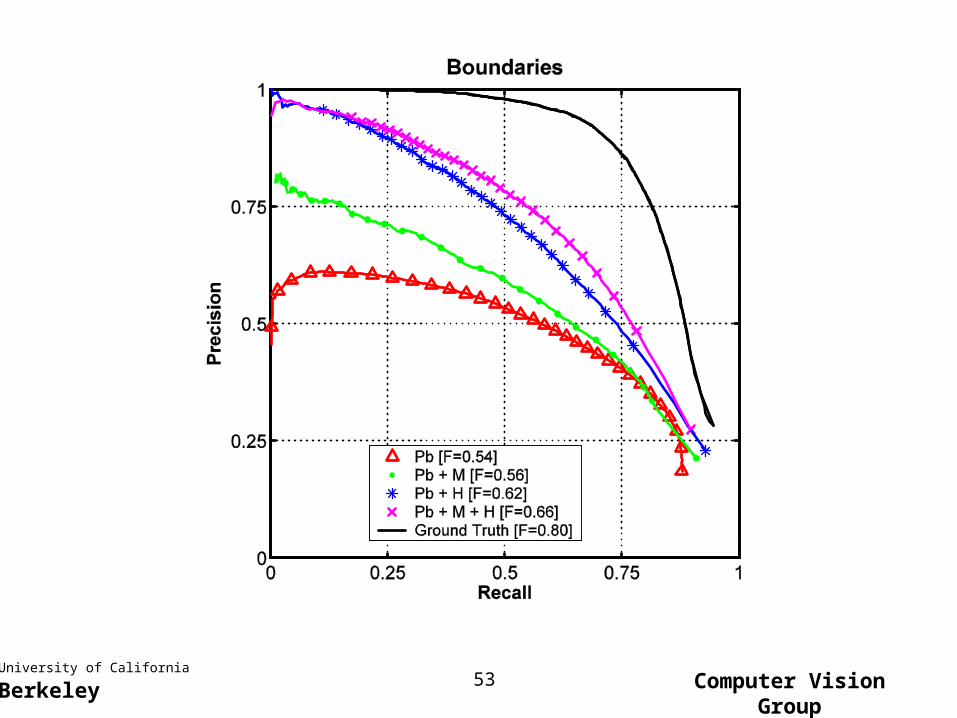
• Mid-level cues are useful for figure/ground segmentation, even when object-specific cues are present.
• Constrained Delaunay Triangulation provides a scale-invariant discrete structure which enables efficient probabilistic inference.
• Conditional random fields combine joint contour and region grouping and can be efficiently trained.
• Mid-level cues are useful for figure/ground segmentation, even when object-specific cues are present.

Computer Vision GroupUniversity of California Berkeley
59
Overview• Scale Invariance in Natural Images• A Scale-Invariant Representation from bottom-up
using Constrained Delaunay Triangulation (CDT)• Scale-Invariant Models for Contour Completion
– A baseline local model
– A global model using Conditional Random Fields (CRF)
– Results and Quantitative Evaluations
• Extensions of the CDT/CRF Framework– Image segmentation
– Figure/ground organization
– Finding people in a single image

Computer Vision GroupUniversity of California Berkeley
60
Figure/Ground Organization
• A classical problem in Gestalt psychology– [Rubin 1921]
• “Perceptual organization after grouping”
• Gestalt principles for figure/ground– surroundedness, size, convexity, parallelism, symmetry,
lower-region, common fate, familiar configuration, …
• Very few computational studies[Hinton 86], [von der Heydt 93], …
• A classical problem in Gestalt psychology– [Rubin 1921]
• “Perceptual organization after grouping”
• Gestalt principles for figure/ground– surroundedness, size, convexity, parallelism, symmetry,
lower-region, common fate, familiar configuration, …
• Very few computational studies[Hinton 86], [von der Heydt 93], …

Computer Vision GroupUniversity of California Berkeley
61
Shapemes: Prototypical Shapes
local figure/ground cues: size/convexity, parallelism, …
Computer Vision GroupUniversity of California Berkeley
62
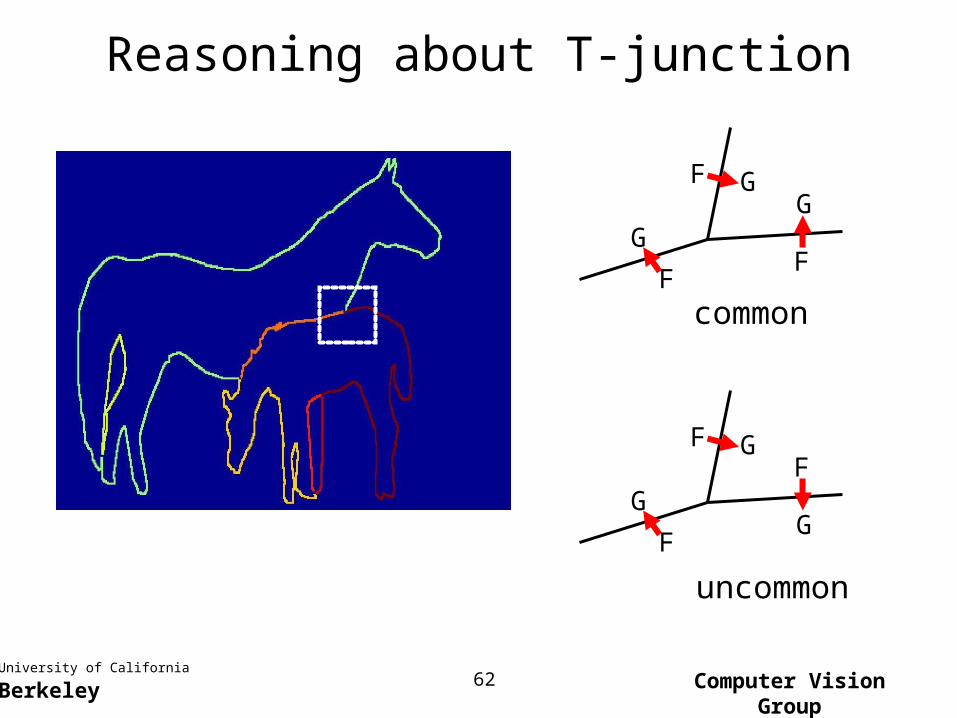
Reasoning about T-junction
F
G
F
F
GG
common
F
G
F
G
GF
uncommon
Computer Vision GroupUniversity of California Berkeley
63
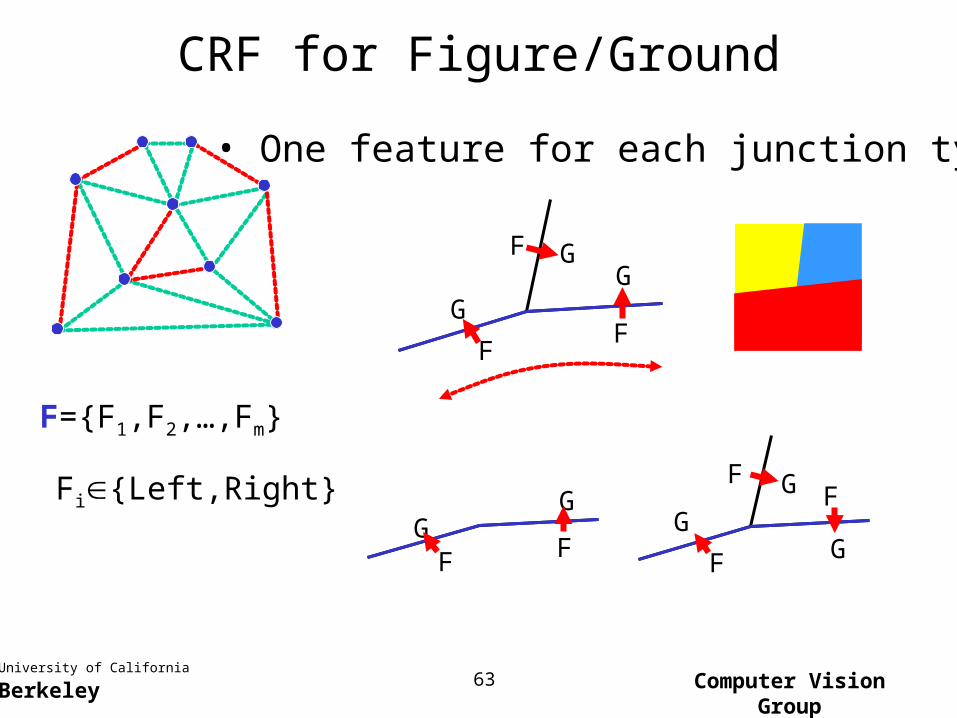
CRF for Figure/Ground
F={F1,F2,…,Fm}
Fi{Left,Right}
• One feature for each junction type
F
G
F
F
GG
F
G
F
G
G F
FG
F
G

Computer Vision GroupUniversity of California Berkeley
64
Results on Natural Images
• Chance error rate
• Baseline size/convexity
• Local model w/ shapemes
• Using human segmentations:– Averaging local cues on human-marked
boundaries
– CRF w/ junction type and continuity
• Using low-level edges– Averaging local cues
– CRF w/ junction type and continuity
• Dataset inconsistency
• Chance error rate
• Baseline size/convexity
• Local model w/ shapemes
• Using human segmentations:– Averaging local cues on human-marked
boundaries
– CRF w/ junction type and continuity
• Using low-level edges– Averaging local cues
– CRF w/ junction type and continuity
• Dataset inconsistency
50%
44%
36%
29%
22%
34%
32%
12%
50%
44%
36%
29%
22%
34%
32%
12%

Computer Vision GroupUniversity of California Berkeley
65

Computer Vision GroupUniversity of California Berkeley
66

Computer Vision GroupUniversity of California Berkeley
67
Overview• Scale Invariance in Natural Images• A Scale-Invariant Representation from bottom-up
using Constrained Delaunay Triangulation (CDT)• Scale-Invariant Models for Contour Completion
– A baseline local model
– A global model using Conditional Random Fields (CRF)
– Results and Quantitative Evaluations
• Extensions of the CDT/CRF Framework– Image segmentation
– Figure/ground organization
– Finding people in a single image

Computer Vision GroupUniversity of California Berkeley
68
Finding People
The Challenges: pose, clothing, lighting, , clutter, …
The Setting: single image, no pose restriction
Approaches:• Top-down holistic template matching• Assembly of 2D parts from bottom-up
The Assembly Problem:• Dynamic programming on tree-model• Brute-force search / pruning• Sampling

Computer Vision GroupUniversity of California Berkeley
69
Our Pipeline• Preprocessing with Constrained Delaunay Triangulation
• Detecting Candidate Parts using Parallelism
• Learning Pairwise Constraints between Parts
• Assembling Parts by Integer Quadratic Programming (IQP)
• Preprocessing with Constrained Delaunay Triangulation
• Detecting Candidate Parts using Parallelism
• Learning Pairwise Constraints between Parts
• Assembling Parts by Integer Quadratic Programming (IQP)
Computer Vision GroupUniversity of California Berkeley
70
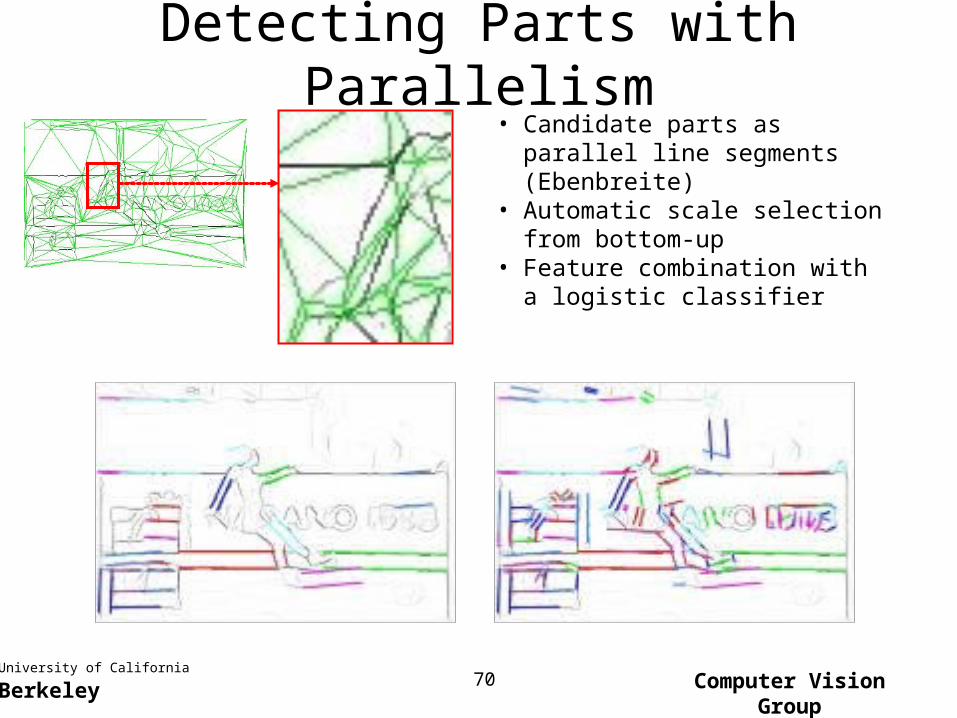
Detecting Parts with Parallelism• Candidate parts as parallel
line segments (Ebenbreite) • Automatic scale selection
from bottom-up• Feature combination with a
logistic classifier
• Candidate parts as parallel line segments (Ebenbreite)
• Automatic scale selection from bottom-up
• Feature combination with a logistic classifier

Computer Vision GroupUniversity of California Berkeley
71
Assembly as Assignment
Candidates {Ci} Parts {Lj}
(Lj1,Ci1=(Lj1))
(Lj2,Ci2=(Lj2))
Cost for a partial assignment {(Lj1,Ci1), (Lj2,Ci2)}:
assignment
2
)22)(11( 2,1
2,1)22(),11(
kijij jj
k
jjk
ijijkf
H

Computer Vision GroupUniversity of California Berkeley
72

Computer Vision GroupUniversity of California Berkeley
73

Computer Vision GroupUniversity of California Berkeley
74

Computer Vision GroupUniversity of California Berkeley
75
Conclusion (again)• Scale-invariance is a key issue in vision and we develop
a scale-invariant representation using Constrained Delaunay Triangulation (CDT).
• The CDT graph is a superpixel representation with little loss of structure and enables efficient training and testing of probabilistic models.
• On top of the CDT graph we use Conditional Random Fields (CRF) to solve mid-level vision problems including contour completion, image segmentation and figure/ground organization.
• By quantitative evaluation on large datasets of natural images, we show that our CRF models significantly improve performance.
• Scale-invariance is a key issue in vision and we develop a scale-invariant representation using Constrained Delaunay Triangulation (CDT).
• The CDT graph is a superpixel representation with little loss of structure and enables efficient training and testing of probabilistic models.
• On top of the CDT graph we use Conditional Random Fields (CRF) to solve mid-level vision problems including contour completion, image segmentation and figure/ground organization.
• By quantitative evaluation on large datasets of natural images, we show that our CRF models significantly improve performance.

Computer Vision GroupUniversity of California Berkeley
76
Thank You

Computer Vision GroupUniversity of California Berkeley
77

Computer Vision GroupUniversity of California Berkeley
78

Computer Vision GroupUniversity of California Berkeley
79

Computer Vision GroupUniversity of California Berkeley
80
Contour Geometry• First-Order Markov Model
– [Mumford 94, Williams & Jacobs 95]
– Curvature: white noise ( independent from position to position )
– Tangent t(s): random walk
– Markov assumption: the tangent at the next position, t(s+1), only depends on the current tangent t(s)
• First-Order Markov Model
– [Mumford 94, Williams & Jacobs 95]
– Curvature: white noise ( independent from position to position )
– Tangent t(s): random walk
– Markov assumption: the tangent at the next position, t(s+1), only depends on the current tangent t(s)
t(s)
t(s+1)
s
s+1

Computer Vision GroupUniversity of California Berkeley
81
Contours are Smooth
P( t(s+1) | t(s) )
marginal distribution of tangent change
t(s)
t(s+1)
s
s+1

Computer Vision GroupUniversity of California Berkeley
82
Testing the Markov Assumption
Segment the contours at high-curvature positions

Computer Vision GroupUniversity of California Berkeley
83
Prediction: Exponential
• If the first-order Markov assumption holds…• At every step, there is a constant probability p that a high curvature
event will occur
• High curvature events are independent from step to step
– Let L be the length of a segment between high-curvature points
– P( L>=k ) = (1-p)k
– P( L=k ) = p(1-p)k
– L has an exponential distribution
• If the first-order Markov assumption holds…• At every step, there is a constant probability p that a high curvature
event will occur
• High curvature events are independent from step to step
– Let L be the length of a segment between high-curvature points
– P( L>=k ) = (1-p)k
– P( L=k ) = p(1-p)k
– L has an exponential distribution

Computer Vision GroupUniversity of California Berkeley
84
Empirical: Power Law
Contour segment length L
Pro
babi
lit
y62.1)length(
1.Prob

Computer Vision GroupUniversity of California Berkeley
85
Scale Invariance of CDT
Related Documents











