Computer-Based Video Self-Modeling to Teach Receptive Understanding of Prepositions by Students with Intellectual Disabilities Linda C. Mechling and Jenny R. Hunnicutt University of North Carolina Wilmington Abstract: This investigation examined the effects of computer-based video self-modeling on the receptive understanding of six prepositions by three students with a diagnosis of moderate intellectual disabilities. Using a multiple probe design across three sets of prepositions, video captions were paired with photographs on the computer in order to simulate and teach prepositional concepts. When students selected a target photograph on the computer screen, the corresponding self-modeling video segment was activated. Results indicate an increase in the number of photographs correctly selected with the computer-based program and that students were able to generalize receptive understanding of concepts to the activities “positioning self” and “positioning objects” measured during probe conditions. Implications are discussed with respect to teaching generalized use of specific language concepts using computer-based video instruction. Teaching language and communication skills is an important component of most curricu- lums for students with disabilities (Bufkin & Altman, 1999; Stephenson & Dowrick, 2000) and considered essential for daily social and learning activities (Snell & Brown, 2006). In- cluded in language skill instruction is the teaching of concepts such as object and pic- ture labeling, vocabulary (word meanings), and action words. Additionally, language in- struction includes teaching more abstract con- cepts such as prepositional relationships, pro- nouns, and adjectives. Functional use of each of these skills includes both the expressive and receptive understanding of concepts in every- day life. Traditionally, when teaching con- cepts such as prepositions, verbs, or object labels, students are presented with a verbal direction, “What is this?”, “What is he doing?” or “Where is the ____?” paired with the object or picture and a response prompting proce- dure (i.e. constant time delay, prompt and fade). Students have been taught in this man- ner to spontaneously label objects and pic- tures (Handleman, Powers, & Harris, 1984; Reagon, Higbee, & Endicott, 2006), label ac- tions and verbs (Johnson, Knowlton, Adams, & Swall, 1992; Stephens, & Ludy, 1975), and expressively describe the prepositional loca- tion of objects (King, Moors, & Fabrizio, 2003; Konstantareas, 1984; McGee, Krantz, & Mc- Clannahan, 1985; Mitchell, Evans, & Bernard, 1978; Sailor & Taman, 1972). In addition to expressive labeling, measures of receptive un- derstanding of concepts such as prepositions, has traditionally required the student to place objects in a particular position such as “in the box” (Alberto, Jobes, Sizemore, & Doran, 1980; Egel, Shafer, & Neef, 1984; Frisch & Schumaker, 1974; King et al.; Summers, Rin- cover, & Feldman, 1993). Receptive instruc- tion of prepositions has also included “posi- tioning self” whereby the student is instructed to place himself in a specific location in rela- tion to an object (Egel et al.; King et al.) or requiring the student to point to pictures rep- resenting target stimuli (i.e., from an array of four, touch the picture “under the table”) (Coleman & Anderson, 1979). With advancements in technology and its increasing availability and use in educational programs for students with disabilities, it may be time to re-evaluate instructional proce- Correspondence concerning this article should be addressed to Linda Mechling, University of North Carolina Wilmington, Department of Educa- tion of Young Children and Special Education, 601 S. College Road, Wilmington, NC 28404-5940. Education and Training in Autism and Developmental Disabilities, 2011, 46(3), 369 –385 © Division on Autism and Developmental Disabilities Video Self-Modeling / 369

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Computer-Based Video Self-Modeling to Teach ReceptiveUnderstanding of Prepositions by Students with Intellectual
Disabilities
Linda C. Mechling and Jenny R. HunnicuttUniversity of North Carolina Wilmington
Abstract: This investigation examined the effects of computer-based video self-modeling on the receptiveunderstanding of six prepositions by three students with a diagnosis of moderate intellectual disabilities. Usinga multiple probe design across three sets of prepositions, video captions were paired with photographs on thecomputer in order to simulate and teach prepositional concepts. When students selected a target photograph onthe computer screen, the corresponding self-modeling video segment was activated. Results indicate an increasein the number of photographs correctly selected with the computer-based program and that students were able togeneralize receptive understanding of concepts to the activities “positioning self” and “positioning objects”measured during probe conditions. Implications are discussed with respect to teaching generalized use of specificlanguage concepts using computer-based video instruction.
Teaching language and communication skillsis an important component of most curricu-lums for students with disabilities (Bufkin &Altman, 1999; Stephenson & Dowrick, 2000)and considered essential for daily social andlearning activities (Snell & Brown, 2006). In-cluded in language skill instruction is theteaching of concepts such as object and pic-ture labeling, vocabulary (word meanings),and action words. Additionally, language in-struction includes teaching more abstract con-cepts such as prepositional relationships, pro-nouns, and adjectives. Functional use of eachof these skills includes both the expressive andreceptive understanding of concepts in every-day life. Traditionally, when teaching con-cepts such as prepositions, verbs, or objectlabels, students are presented with a verbaldirection, “What is this?”, “What is he doing?”or “Where is the ____?” paired with the objector picture and a response prompting proce-dure (i.e. constant time delay, prompt andfade). Students have been taught in this man-
ner to spontaneously label objects and pic-tures (Handleman, Powers, & Harris, 1984;Reagon, Higbee, & Endicott, 2006), label ac-tions and verbs (Johnson, Knowlton, Adams,& Swall, 1992; Stephens, & Ludy, 1975), andexpressively describe the prepositional loca-tion of objects (King, Moors, & Fabrizio, 2003;Konstantareas, 1984; McGee, Krantz, & Mc-Clannahan, 1985; Mitchell, Evans, & Bernard,1978; Sailor & Taman, 1972). In addition toexpressive labeling, measures of receptive un-derstanding of concepts such as prepositions,has traditionally required the student to placeobjects in a particular position such as “in thebox” (Alberto, Jobes, Sizemore, & Doran,1980; Egel, Shafer, & Neef, 1984; Frisch &Schumaker, 1974; King et al.; Summers, Rin-cover, & Feldman, 1993). Receptive instruc-tion of prepositions has also included “posi-tioning self” whereby the student is instructedto place himself in a specific location in rela-tion to an object (Egel et al.; King et al.) orrequiring the student to point to pictures rep-resenting target stimuli (i.e., from an array offour, touch the picture “under the table”)(Coleman & Anderson, 1979).
With advancements in technology and itsincreasing availability and use in educationalprograms for students with disabilities, it maybe time to re-evaluate instructional proce-
Correspondence concerning this article shouldbe addressed to Linda Mechling, University ofNorth Carolina Wilmington, Department of Educa-tion of Young Children and Special Education, 601S. College Road, Wilmington, NC 28404-5940.
Education and Training in Autism and Developmental Disabilities, 2011, 46(3), 369–385© Division on Autism and Developmental Disabilities
Video Self-Modeling / 369

dures for teaching language concepts such asprepositions. One form of technology-basedinstruction is the use of video technology. Todate, video technology to teach language andcommunication skills, has primarily been usedin the form of video models and video self-models. With video modeling the student ob-serves another adult, sibling, and/or peer en-gaging in a skill and is later required toperform the skill. Communication skillstaught with video modeling have included so-cial initiations during play (Nikopoulos &Keenan, 2003; 2004) and conversationalspeech related to toys (Charlop & Milstein,1989; Taylor, Levin, & Jasper, 1999). In aninteresting comparison, Charlop-Christy, Le,and Freeman (2000) found that video model-ing led to faster acquisition of tasks (includingexpressive labeling of emotions, spontaneousgreetings, and conversational speech) thanuse of live (in vivo) models. When using videoself-modeling the target child or adult servesas the model in the video. Videos are createdby: a) editing out prompts provided by adults;c) editing out student errors made duringtaping; or c) only showing best case perfor-mances of a skill by the student on the video(Dowrick, 1999). Conversation skills (Shereret al., 2001); spontaneous requesting (Wert, &Neisworth, 2003); verbal social interactions(Buggey, 2005; and verbal responses to ques-tions (Buggey, Toombs, Gardener, & Cervetti,1999) have all been successfully taught to stu-dents with autism using video self-modeling.
While shown to have positive results, themajority of the studies to date evaluating videotechnology to teach communication and lan-guage to students with disabilities have fo-cused on social communication skills ratherthan specific language concepts (Ayres & Lan-gone, 2005; Bellini & Akullian, 2007; Delano,2007; Hitchcock, Dowrick, & Prater, 2003; Mc-Coy & Hermansen, 2007; Meharg & Wolters-dorf, 1990). Of those studies teaching a spe-cific language concept through videotechnology, Reagon et al. (2007) taught objectlabeling to three preschoolers diagnosed withautism by presenting photographs, text, andverbal prompts on DVDs. Although DVDswere created and presented on a DVD playerit does not appear that the study incorporatedthe features of animation and motion com-monly used with video-based instruction. Like-
wise, Moore and Calvert (2000) taught recep-tive recognition of noun labels using picturespresented on flash cards or still pictures pre-sented on a computer software program. An-imation and sound were used for reinforce-ment, but not for the actual representation ofthe concepts. Interestingly, the study foundthat the children with autism were more at-tentive, showed greater motivation to com-plete tasks, and acquired more vocabulary us-ing the computer based program than teacherdelivered instruction. In contrast to these twostudies, Mechling and Langone (2000) used acomputer-based program to present videocaptions paired with still photographs to teachphotograph recognition to represent commu-nication related concepts to two students withsevere intellectual disabilities.
While it is recognized that use of real mate-rials in real-life situations is an effective meansfor teaching language concepts (i.e., preposi-tions) to students with disabilities, creatingvideo-based instruction may provide an inter-esting medium for delivering instruction tostudents in a controlled environment with re-peated practice and limited distractions. Forexample, placing a block “in” or “under” abox (traditional method) may hold less moti-vational appeal when compared to a videosegment of a dog barking while sitting “in” adog house or a familiar peer crawling “under”a table while being chased by another peer.The alternative method of “positioning self”may also pose distracting difficulties when try-ing to manage students going “under” tablesand returning to their seats in a timely man-ner. In contrast, students may interact repeat-edly with a video based program by selectingphotographs on the screen and watching therelated action or concept being modeled inreal-life fashion. Such programs may furtherremove irrelevant stimuli that may be distract-ing to the student (Charlop-Christy et al.,2000) and can zoom in on salient features(i.e., dog in a dog house) thus reducing atten-tion to stimuli irrelevant to the task (Charlop-Christy et al.; Shipley-Benamou, Lutzker, &Taubman, 2002).
Video-based instruction may further pro-vide multiple teaching examples that may notbe available in the classroom. While researchsupports the use of multiple exemplars to pro-mote stimulus and response generalization
370 / Education and Training in Autism and Developmental Disabilities-September 2011

across untaught environments, materials, andpersons (Chadsey-Rusch & Halle, 1992;Hughes, 1992; Hupp, 1986), teachers mayfind themselves limited to a table and chairwhen teaching the concept “under” or jump-ing on a trampoline when teaching the con-cept “up.” Video technology provides a nearendless supply of teaching examples takenfrom real-life examples (i.e., local fireman“up” on a ladder).
The purpose of the current study was toevaluate computer-based video self-modelingand constant time delay as an instructionalprocedure for teaching prepositional con-cepts to students with a diagnosis of moderateintellectual disabilities. The investigation ad-dressed two research questions: (1) Wouldcomputer-based video self-modeling be effec-tive in teaching students to receptively identifypictures corresponding to prepositional con-cepts?; and (2) Would students generalize re-ceptive use of prepositions to untaught mate-rials, settings, and response topographies asmeasured by: (a) positioning self and; (b)positioning objects?
Method
Participants
Three students, one boy and two girls ages 7 to8 years with a diagnosis of moderate intellec-tual disability, participated in the study. Thestudents were selected based on their ages;identified Individualized Educational Pro-gram (IEP) objectives in the area of languagedevelopment; diagnosis; and entry level skills.Entry level skills included: (a) visual ability tosee photographs and video captions on thecomputer screen; (b) fine motor ability totouch the computer screen and to place smallobjects in various locations on a table; (c)gross motor ability to position self in relationto objects in the classroom; (d) ability to imi-tate a video model; and (e) attention to taskfor 10 minutes. All students attended a self-contained elementary classroom for studentswith moderate intellectual disabilities. Eachhad received computer assisted instructionand it was reported that each enjoyed workingon the computer, an interactive whiteboard,and watching videos.
Andrea was an 8 year, 11 month old female
diagnosed with a moderate intellectual dis-ability (IQ 50 Wechsler Intelligence Scale forChildren – Third edition: Wechsler, 1991)and cerebral palsy. Her composite score onthe Vineland Adapative Behavior Scale (Spar-row, Balla, & Cicchetti, 1984) was 60. She wasdelivered by C-section at birth, had breathingproblems, and experienced a decline in skillsat the age of 6-months. Her vision and hearingwere within normal limits and she receivedspeech, occupational, and physical therapies.Her gait was unsteady, however, she couldwalk, run, and swing with good leg pumping.Her fine motor skills were significantly im-paired making it difficult for her to completetasks such as writing letters or copying shapes.She demonstrated a right hand preference,but occasionally switched hands if not moni-tored. She was able to cut across paper, butneeded assistance for rotating paper. She wasalso able to isolate her index finger for key-boarding.
Andrea demonstrated significant difficultieswith speech production with weaknesses inoral motor skills. She had severe verbalapraxia characterized by Voicing Errors (i.e.,/b/ for /p/), Final Consonant Deletion (i.e.,/do/ for /dog/), Cluster Reduction (i.e.,/soon/ for /spoon/) and Fronting (i.e., /tey/for /key/) which most often appeared whenproducing words within phrases. She couldidentify 11 letter sounds and 7 sight words andfollowed along with a story being read whileneeding visual picture prompts to answercomprehension questions. She could rotecount to 20 with verbal prompts for the teensand recognized numerals to 10. She countedobjects with assistance with pointing to objectsas she counted. Behaviorally, she was de-scribed as cooperative and enjoyed attentionof both adults and peers. She greeted others,offered high-five’s and expressed wants andneeds by saying such things as “my turn.” Shestruggled with personal space issues and dem-onstrated some aggression towards certainpeers. Her teachers reported her as some-times being stubborn and she used visual cuessuch as photographs to assist with complianceand understanding of tasks. She also demon-strated anxiety and possible panic attacks (fa-cial expressions of panic, heart racing, andtrembling) and unusual responses to soundsand places she once liked (i.e., favorite restau-
Video Self-Modeling / 371

rant she later tried to escape from) and envi-ronments such as public and busy places (i.e.,grocery store, shopping center). At school sherefused to enter the cafeteria at times and wasobserved covering her ears even when no no-ticeably unusual sound was present. Her watchwas identified as a treasured possession andused for behavior reinforcement. She worepull ups and went to the restroom on a regularschedule. She undressed herself, but neededassistance with zipping and buttoning herpants. She also needed prompts to wash anddry her hands. She was semi-independent withlunchroom skills and could open her milkcarton and utensil package.
Andrea’s needs included identifying nu-merals above 10, rote counting to 30, count-ing up to 10 objects, understanding one toone correspondence, and increasing lettersound and sight word recognition. She wasworking on describing words, pairing adjec-tives and nouns in her speech, and use ofdescriptive words to describe items. Her com-munication needs also included combiningwords into phrases and short sentences, imita-tion of speech sounds and syllables, and imi-tation of familiar one and two syllable words.Her needs also included cutting within 1.5”line, writing letters of her first name, jumpingdown from a 15” height, remaining in as-signed areas within the classroom, and follow-ing verbal directions with no more than twoverbal prompts.
Vanessa was an 8 year, 2 month old femalediagnosed with a moderate intellectual dis-ability [IQ 49 Leiter International Perfor-mance Scale-Revised (Leiter-R): Roid &Miller, 1997] and her composite score on theAdaptive Behavior Evaluation Scale - SecondEdition (ABES-R2; McCarney & Arthaud,2006) was 42. At the time of birth she experi-enced persistent pulmonary hyper-tensionthat resulted in brain damage on the left side.She was diagnosed with hydrocephaly at 15months, and was currently equipped with herfourth shunt. She had mild hypotonicity glob-ally. Her vision and hearing were within nor-mal limits and she received speech, occupa-tional, and physical therapies. Gross motorskills indicated no delays and she was able totrace all letters independently, write the firstletter of her name independently, and cutwith children’s scissors. She demonstrated a
nasal voice, spoke combining words into sim-ple phrases, used some plurals, and namedverbs, but did not use correct grammar orcomplete sentences. She was able to read andmatch sight words, knew 13 letter sounds,could follow words in text by pointing as thestory was read, and rote count to 15. Behav-iorally, Vanessa was characterized as attention-seeking, defiant, easily distracted and off-task.She occasionally used profanity against peersand teachers, but was described as being verysocial and expressed a desire to talk with oth-ers by saying “Me?” or “Play with me?” She alsoexhibited a short attention span which causedher to quickly ask to do something different.She was able to use the restroom indepen-dently, but needed assistance buttoning herpants.
Vanessa’s needs included improvement onfunctional reading skills (including readingsight words upon request), saying lettersounds, answering literal questions about astory, writing her first name, and completing asentence by filling in the blank with a sightword. Her functional academic needs furtherincluded rote counting to 30, counting up to10 objects using 1:1 correspondence, andidentifying numerals in random order up tofifteen. She needed to continue to work onunderstanding the concept of categories, po-sitional words, and the appropriate use of“ing” endings to describe actions. Her needsalso included demonstration of appropriateschool/classroom behaviors including re-maining seated for up to fifteen minutes andindependently following directions upon thefirst request.
Jeremy was a 7 year, 11 month old malediagnosed with a moderate intellectual dis-ability (IQ 46 Wechsler Intelligence Scale forChildren – Third edition: Wechsler, 2001)and his composite score on the VinelandAdaptive Behavior Scale (Sparrow et al., 1984)was 48. He was born prematurely at 22 weeksgestation and he had a shunt, history of sei-zures, and hydrocephaly. His vision and hear-ing were within normal limits and he receivedspeech, occupational, and physical therapies.He had low muscle tone throughout his trunkand exhibited a weaker right side with hyper-tonia in his right upper extremity. When walk-ing he reduced the amount of stance on hisweaker right side. He ascended stairs with a
372 / Education and Training in Autism and Developmental Disabilities-September 2011

railing and was working on ascending stairsusing a mature step-over-step pattern whileholding the left railing. He required verbalencouragement for all playground activitiesand those which occurred on uneven terrain.He preferred to have his left hand held whenwalking. His right elbow and wrist remained ina flexed and abducted posture. His right handwas generally fisted with an indwelling thumb.He wore a left ankle foot orthotic and a thumbabductor with a wrist support brace whichassisted with his thumb to digit grasp. He wasunable to consistently grasp and release ob-jects, but could open his hand in order to tryto grossly grasp an item such as the edge ofthe table. He wrote his first name using his lefthand and required minimal cues to stay withinboundaries.
Jeremy was verbal and his speech was intel-ligible although he omitted verbs, preposi-tions and articles in his sentences and did notuse regular plurals or past tense. He initiatedconversations with others and formulatedmultiple word sentences, but sentences wereoften incomplete. He also exhibited some let-ter sound substitutions. Academically, heknew 14 letter sounds, was able to sound outthree letter words, could recognize 9 sightwords, and could answer comprehensionquestions after a passage was read to him. Heidentified numerals to 30, rote counted to 30,counted up to 12 objects, and could completean AB pattern. Behaviorally he was describedas inattentive, had difficulty following direc-tions, and was easily distracted. He also perse-verated on some topics of conversation andwould repeatedly ask questions such as, “why?”and “then what?” He was also described asbeing a joy to have in class, sweet, kind andrespectful. He also remembered names of ev-eryone he met and was highly interested inknowing what everyone was doing. He usedthe restroom independently, but needed re-minders to pull up his pants in the back. Healso needed assistance with snapping, button-ing, and zipping. He washed his hands inde-pendently, but was learning to dry them. Hisother needs included: categorization, learn-ing basic concepts and prepositions, answer-ing “when” questions, articulating appropriatesounds in single words and short phrases, andusing pronouns in speech. He was also work-ing on ascending three steps while holding a
railing with his left hand and using a step-over-step pattern. His academic needs includedrote counting to 50, identification of numeralsto 50, counting objects to 20, reading sen-tences containing sight words, filling in theblanks of sentences with sight words andsounding out words using phonemic aware-ness.
Setting and Instructional Arrangement
All computer-based video self-modeling ses-sions were conducted in the classroom at asmall table sectioned off behind a series ofdividers and screens. The student sat directlyin front of the laptop and the instructor sat tothe right of the student. The reliability datacollector sat behind and to the left of thestudent when present. Video recordings werealso made for reliability data collection pur-poses and the camera was positioned on atripod behind the student when used.
During “positioning of objects” generaliza-tion probe sessions the materials were placedon the same table within the classroom areaused during intervention and the student, in-structor, and reliability data collector were po-sitioned identically to that of the intervention.Generalization “positioning of self” probe ses-sions were held in the sectioned off area of theclassroom used during intervention, the hall-way outside of the classroom, and outdoors ina paved courtyard area.
Prepositions, Materials, and Equipment
Three pairs of prepositions (6 total) weretaught to each student using computer-basedvideo self-modeling and three different exem-plars were used to teach each preposition(Hupp, 1986). Students had not shown mas-tery or understanding of the prepositions dur-ing screenings prior to the study. The threepairs of prepositions were: (a) on/under, (b)in/next to, and (c) in front of/behind (Mc-Gee et al., 1985). Table 1 shows each prepo-sition and photograph exemplars used duringcomputer-based video self-modeling and stim-uli used during placement of objects and selfduring generalization sessions. Three differ-ent photographs of the target student demon-strating the preposition and three differentvideo self-modeling recordings were made for
Video Self-Modeling / 373

each of the six target prepositions for useduring photograph probe sessions and com-puter-based video self-modeling (Table 1).Photographs and video recordings were madeusing a Sony 800x digital video camera. Photo-graphs were downloaded onto a Dell Latitude300 laptop computer from the camera’s Memo-ryStick using the USB port. Video self-modelswere created by editing out teacher promptsfor placing or directing students to the correctposition representing each preposition. Whilethe student was engaged in the correct posi-tion, a still photograph was also taken. Videostreaming features of the camera alloweddownloading of video to the computer usingthe same USB port. Video recordings werethen edited using Windows Movie Maker andsaved onto the laptop computer. The instruc-tional programs were created using the soft-ware program PowerPoint (Microsoft). Three3in x 3in color photographs (one target andtwo distractors) were placed in a horizontalrow across the bottom of a slide. Studentsselected photographs on the computer screenby touching a Magic Touch touch screen(Keytec, Inc). The PowerPoint program wasprogrammed to advance to the next slide “ona click” when a student touched a target (cor-rect) photograph. The target photograph washyperlinked to a slide which automaticallyplayed the corresponding digital video record-
ing. The program remained on the photo-graph slide until the student touched the cor-rect photograph. Video recordingscorresponding to the target photographplayed approximately 5 seconds and thenstopped and the program automatically ad-vanced to the next slide containing three pho-tographs.
Response Definitions and Data Collection
During generalization probe sessions studentswere asked to place an object or themselves inone of 6 positions (on, under, in, next to, infront of, and behind) when presented with atask direction such as, “Put the cake on thetable.” Student responses were recorded as:(a) correct – student initiated the behaviorwithin 3s of the task direction and placedobject or self in correct position within 5s; (b)incorrect – student failed to initiate the behav-ior within 3s of presentation of the task direc-tion (latency error); (c) incorrect - studentfailed to place object or self in the correctposition within 5s of the task direction (dura-tion error); or (d) incorrect – student placedobject or self in an incorrect position (topog-raphy error). Correct placement of objectsand self was defined as placing the item within.5in. of the target position for objects and 4in.for self.
TABLE 1
Exemplars used for teaching prepositions during CBVI and for measuring generalization of skills.
CBVIGeneralizationPositioning Self Generalization Positioning Objects
On/under Beach towelTableBean bag chair
Beach towelTableBean bag chairNovel example:
Beach mat
Miniature doll and chairMiniature cake and tableMiniature doll and bunk bed
In/next to Laundry basketTunnelWagon
Laundry basketTunnelWagonNovel example:
Large box
Miniature pan and stove with ovenMiniature book and bookcaseMiniature dog and doghouse
In front of/Behind
Rocking chairThree sided screenCrate
Rocking chairThree sided screenCrateNovel example:
Round storage tub
Miniature doll and sofaMiniature pan and sinkMiniature doll and cabinet
374 / Education and Training in Autism and Developmental Disabilities-September 2011

During computer-based video self-modelingand CTD instruction student responses fortouching the correct photograph were re-corded as: (a) unprompted correct (initiatingand correctly touching the photograph within3s of the task direction); (b) prompted correct(touching the correct photograph within 3safter delivery of the controlling prompt (ges-ture) by the instructor); (c) unprompted in-correct (touching an incorrect photographwithin 3s of the instructor delivering the taskdirection); (d) prompted incorrect (touchingan incorrect photograph within 3s after theinstructor’s gesture prompt); or (e) no re-sponse (failure to initiate touching a photo-graph within 3s after the instructor’s gestureprompt).
Experimental Design
A multiple probe design (Gast & Ledford,2010) across three pairs of prepositions andreplicated across three students, was used toevaluate the effectiveness of computer-basedvideo self-modeling and constant time delayon the acquisition and generalization of re-ceptive comprehension of prepositions.
The order of experimental conditions was:(a) Positioning Objects Generalization Probecondition; (b) Positioning Self GeneralizationProbe condition; (c) Computer-based VideoSelf-Modeling and Constant Time Delay Dis-crimination Instruction with the first pair ofprepositions. Criterion for mastery of eachpair was defined as 80% correct respondingacross three sessions using 3s delay trials. Cri-terion was set at this level to allow for distract-ibility of the students and due to their youngage. The generalization probe conditionsserved to evaluate students’ abilities to dem-onstrate receptive comprehension of preposi-tions across untaught settings, requests, andmaterials. Following computer-based videoself-modeling with the first pair of preposi-tions, generalization probe conditions withobjects and self were repeated across all threepairs followed by computer-based video self-modeling with the second pair of preposi-tions. This sequence continued until all threepairs reached mastery level. Subsequent gen-eralization probe sessions of mastered pairs ofprepositions served as maintenance checks.
General Procedure
Probes were conducted to measure receptiveresponding to prepositions prior to computer-based video self-modeling and generalizationacross untrained stimuli and response topog-raphies following computer-based video self-modeling. All probe and computer-basedvideo self-modeling sessions were conductedin a one-to-one arrangement and procedureswere similar to those by Egel et al. (1984) forevaluating positioning of objects and position-ing self generalization conditions. Each probecondition was conducted for a minimum ofthree sessions or until responding stabilized.One to two sessions were implemented perday in the morning and/or afternoon forprobe and computer-based video self-model-ing conditions. Sessions were conducted 4-5days a week and lasted approximately 15 min-utes for probe sessions and 5 minutes for com-puter-based video self-modeling. Probe ses-sions with objects consisted of 18 trials, 3 trialsfor each of the 6 prepositions and positioningself probe sessions consisted of 24 trials due tothe inclusion of 1 trial per novel exemplar foreach preposition. Computer-based video self-modeling sessions consisted of 5 intermixedtrials for each of the 2 prepositions in the pair(10 total trials). During computer-based videoself-modeling sessions, trial sequences variedand prepositions were presented so that nomore than two consecutive trials for one prep-osition were presented at once.
Positioning Objects Generalization Probe Procedure
At the beginning of the investigation and fol-lowing mastering of a pair of prepositions us-ing computer-based video self-modeling, aminimum of three probe sessions were con-ducted to evaluate a student’s ability to gener-alize receptive understanding of prepositionsusing novel objects not depicted in computer-based video self-modeling. Sessions consistedof 18 intermixed trials, 3 trials for each prep-osition. One object was placed on the table infront of the student and the student was givena second object (Table 1). Each pair of objectswas used for more than one prepositional re-quest to ensure that students were attendingto the preposition and not receiving cues fromobjects. Three multiple exemplars were used
Video Self-Modeling / 375

for each prepositional pair (Table 1). By plac-ing only one object on the table and handingthe student only one object, student’s focuswas directed to the preposition rather thandifferences among object labels and multi-component directions. A general attentionalcue was provided and after an attentional re-sponse was obtained, the instructor presentedthe task direction, “Put ___ (behind) the ___,”and waited 3s for the student to initiate aresponse and 5s for the student to completethe behavior. The instructor delivered verbalpraise on a variable ratio schedule (VR-3) forattending, correct positioning, and attempt-ing to position objects. Incorrect or no re-sponses were ignored and the instructor pre-sented the next trial.
Positioning Self Generalization Probe Procedure
Following evaluation of positioning objects, aminimum of three probe sessions were con-ducted whereby the student was directed toposition him/herself in relationship to stimuliin the video self-models and a novel stimulusnot depicted in computer-based video self-modeling. Furniture and equipment exem-plars were used for more than one preposi-tional request to ensure that students wereattending to the preposition and not receivingpositional cues from stimuli. Three differentmultiple exemplars were used for each pair ofprepositions plus one novel exemplar (Table1). By placing only one piece of furniture orequipment in front of the student, focus wasdirected to the preposition rather than differ-ences among names of stimuli and requestswith multiple components. During these ses-sions the student was seated on a chair facingthe front of the object (i.e., rocking chair) anda general attentional cue was provided. Afteran attentional response was obtained, the taskdirection, “Go_____(under) the ____,” wasgiven by the instructor. The student was given3s to initiate a response and 5s to completethe behavior. The instructor delivered verbalpraise on a variable ratio schedule (VR-3) forattending and attempting to position self. In-correct or no response was ignored and theinstructor presented the next trial. Sessionsconsisted of 24 trials, 3 trials per prepositionusing target stimuli and 1 trial per novel stim-uli for each preposition.
Computer-Based Video Self-Modeling and CTDProcedure
Individual instruction with computer-basedvideo self-modeling and CTD began on thefirst pair of prepositions after a student’s datastabilized across the two probe conditions (po-sitioning objects and self). During instruc-tional trials, three photographs appeared onthe computer monitor (PowerPoint slide). Stu-dents were directed to look at the photo-graphs followed by the task direction, “Touch____(in).” During 0s trials the instructor im-mediately gestured to the correct photograph.Touching the photograph resulted in the Pow-erPoint program advancing to the next slidewhich showed a brief video of the studentmodeling the preposition corresponding tothe photograph. Sessions continued at 0s untilthe student reached 100% prompted correctresponses for touching the two target prepo-sitions across one session of 10 trials (5 trialsper preposition). Thereafter, a 3s prompt de-lay interval was inserted between the presen-tation of the task direction and delivery of thecontrolling prompt (gesture). Unpromptedcorrect and prompted correct responses (stu-dent touching correct photograph) resultedin playing of the video segment and verbalpraise. Unprompted incorrect, prompted cor-rect, and no responses resulted in the instruc-tor pointing to the correct photograph. Onthe next trial the student was presented withthe task direction for a second prepositionwithin the pair while viewing a new slide withthree photographs. Sessions consisted of 10intermixed trials, 5 trials for each preposition.Three different photograph exemplars andvideo segments were used for each preposi-tional pair (Table 1). Exemplars presentedthe prepositions within the pair and one otherpreposition using the same stimuli (e.g., pho-tographs of the student under, on, and besidethe bean bag chair). Criterion for mastery oneach pair was 80% unprompted correct re-sponding across three sessions. As criterionwas reached for each pair, generalizationprobe sessions were again conducted.
Reliability
Interobserver and procedural reliability databetween the instructor and observer were col-
376 / Education and Training in Autism and Developmental Disabilities-September 2011

lected on 20% of all probe and instructionalsessions with at least one session being con-ducted per condition. Interobserver reliabilityratings on student responses were analyzedusing the point-by-point method (total num-ber of agreements divided by total number ofagreements plus disagreements and multi-plied by 100). Mean interobserver agreementwhen recording student responses was 98.5%across all participants during computer-basedvideo self-modeling sessions (range � 90 -100), 94.2% during positioning self general-ization sessions (range � 83.3 – 100), and95.3% during positioning object generaliza-tion sessions (range � 88.9-100). Disagree-ment occurred most frequently for placingthe item within 4in. during positioning of selfand placing an object or self in the correctposition within 5s. Procedural reliability wasderived by dividing the number of observedinstructor behaviors by the number of oppor-tunities to emit the behavior and multiplyingby 100 (Billingsley, White, & Munson, 1980).The following instructor and computer behav-iors were evaluated: (a) advancement of slidesduring computer-based video self-modeling;(b) delivery of the controlling prompt (com-puter-based video self-modeling); (c) deliv-ery of reinforcement; (d) wait times; and (e)presenting correct materials during posi-tioning self and object generalization ses-sions. Procedural reliability was 96.5%across all participants during computer-based video self-modeling sessions and97.7% during generalization probe sessionsand conditions. Errors during computer-based video self-modeling instruction weredue to photograph slides being incorrectlylinked to video slides during initial sessionsand the instructor delivering the controllingprompt before 3 seconds. Errors duringgeneralization sessions were due to placingincorrect materials on the table during po-sitioning of objects.
Social Validity
After completion of the final generalizationsessions, teaching staff were interviewed in or-der to determine their opinion of the comput-er-based video self-modeling program. Theywere also asked at that time to informally ob-serve the three students throughout the
school day in order to report back to theinvestigator two weeks later on any use of thesix target prepositions by the students.
Results
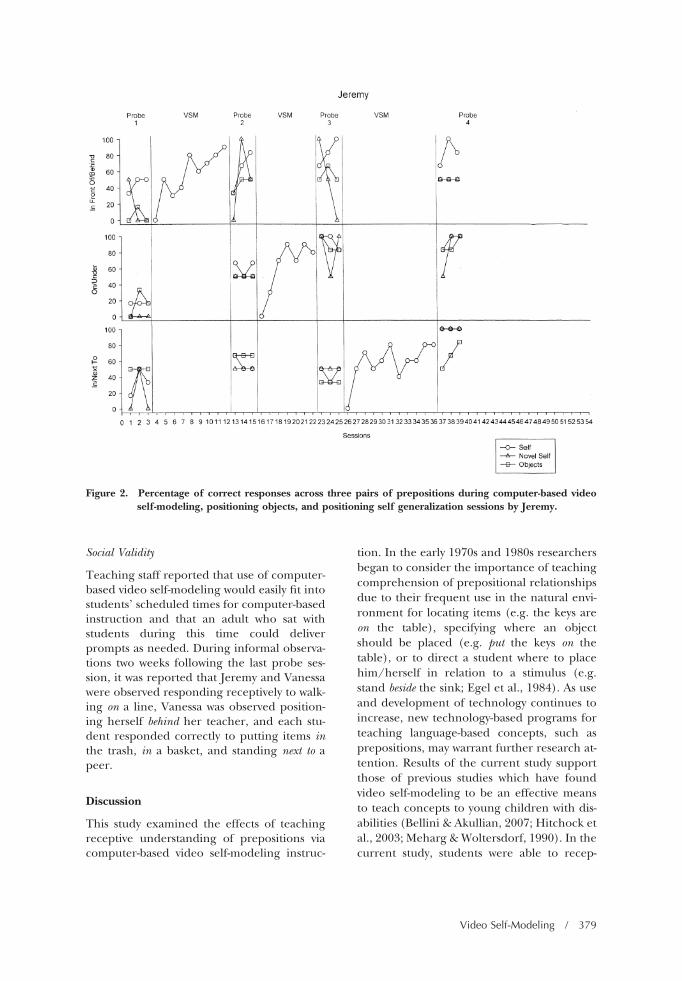
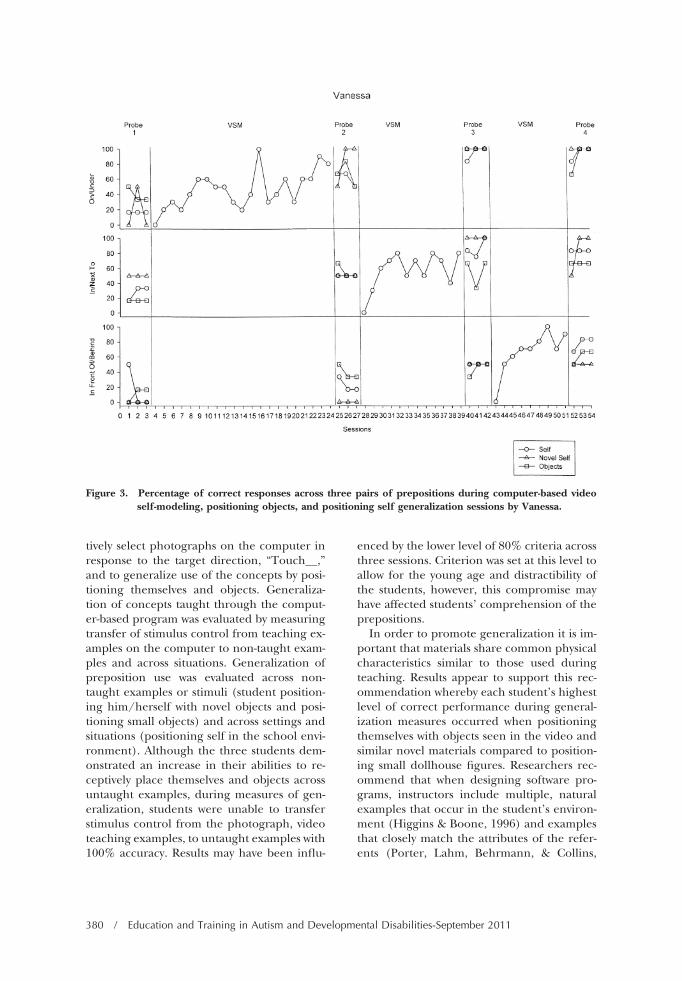
Figures 1-3 show the data for each student’sacquisition of receptive understanding ofprepositions. The graphic displays present thepercentage of photographs selected correctlyusing the computer-based video self-modelingprogram along with generalization of theprepositions to self and objects. Results dem-onstrate that the three students were taughtreceptive identification of photographs associ-ated with the six prepositions. Use of the com-puter-based program resulted in an increasein the level of performance (photograph se-lection) for each of the three participants al-though the number of sessions to criterionvaried across pairs for each student and acrossstudents. Vanessa required the greatest num-ber of sessions to criteria on her first pair ofprepositions (21), but required successivelyfewer trials on each of her remaining pairs.This may have reflected a need for her tolearn to respond to the computer-based pro-gram although the other two participants didnot follow this pattern. Both Andrea and Jer-emy required the least number of sessions tocriteria when presented with the pair on/un-der, but it should be recognized that they werebeginning to place themselves and objects inthese two positions prior to computer-basedvideo self-modeling instruction. No other pat-terns appear to exist between correct perfor-mance and prepositional pairs across thethree students when using the computer pro-gram.
Although positive changes occurred in thegeneralization of concepts to self and objects(Figures 1-3, Table 2), in comparison to probesessions prior to instruction, with the excep-tion of Vanessa and her third pair of preposi-tions (in front of/behind), students were ableto position themselves and objects with someaccuracy across each pair prior to computer-based video self-modeling instruction. In ad-dition, levels of generalization for positioningself and objects were below 100% for eachstudent with the exception of Jeremy and An-drea who demonstrated 100% correct place-ment of themselves on their third pair of prep-
Video Self-Modeling / 377
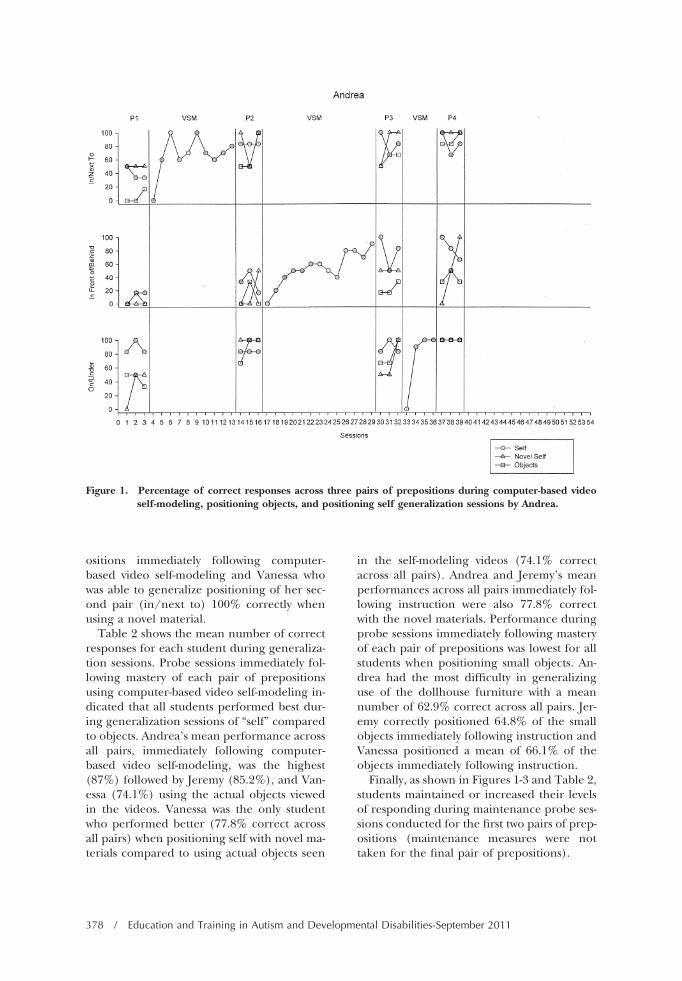
ositions immediately following computer-based video self-modeling and Vanessa whowas able to generalize positioning of her sec-ond pair (in/next to) 100% correctly whenusing a novel material.
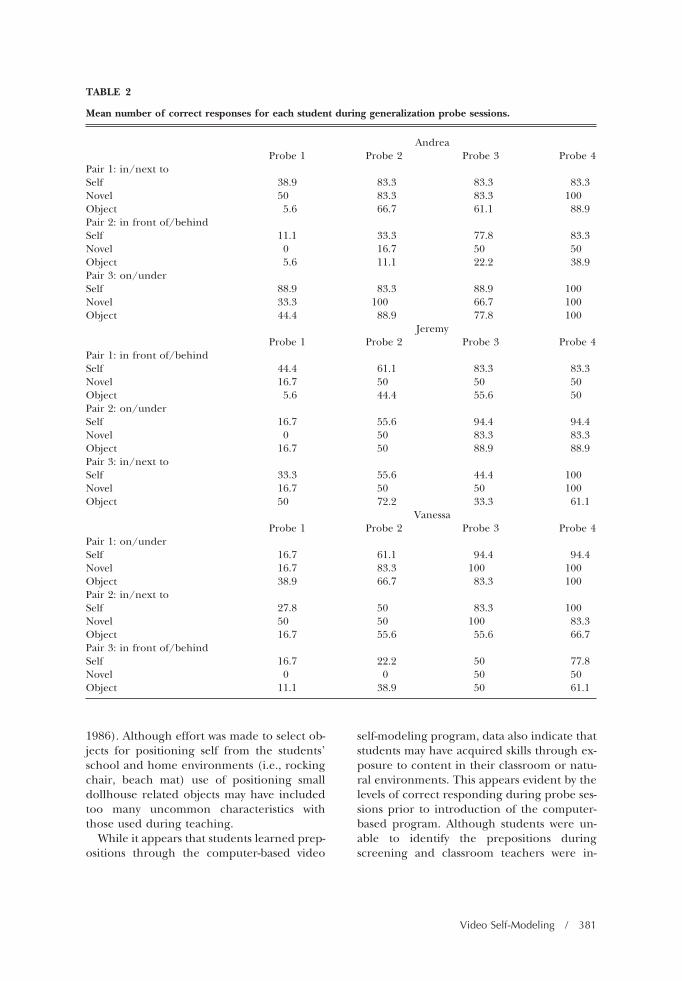
Table 2 shows the mean number of correctresponses for each student during generaliza-tion sessions. Probe sessions immediately fol-lowing mastery of each pair of prepositionsusing computer-based video self-modeling in-dicated that all students performed best dur-ing generalization sessions of “self” comparedto objects. Andrea’s mean performance acrossall pairs, immediately following computer-based video self-modeling, was the highest(87%) followed by Jeremy (85.2%), and Van-essa (74.1%) using the actual objects viewedin the videos. Vanessa was the only studentwho performed better (77.8% correct acrossall pairs) when positioning self with novel ma-terials compared to using actual objects seen
in the self-modeling videos (74.1% correctacross all pairs). Andrea and Jeremy’s meanperformances across all pairs immediately fol-lowing instruction were also 77.8% correctwith the novel materials. Performance duringprobe sessions immediately following masteryof each pair of prepositions was lowest for allstudents when positioning small objects. An-drea had the most difficulty in generalizinguse of the dollhouse furniture with a meannumber of 62.9% correct across all pairs. Jer-emy correctly positioned 64.8% of the smallobjects immediately following instruction andVanessa positioned a mean of 66.1% of theobjects immediately following instruction.
Finally, as shown in Figures 1-3 and Table 2,students maintained or increased their levelsof responding during maintenance probe ses-sions conducted for the first two pairs of prep-ositions (maintenance measures were nottaken for the final pair of prepositions).
Figure 1. Percentage of correct responses across three pairs of prepositions during computer-based videoself-modeling, positioning objects, and positioning self generalization sessions by Andrea.
378 / Education and Training in Autism and Developmental Disabilities-September 2011
Social Validity
Teaching staff reported that use of computer-based video self-modeling would easily fit intostudents’ scheduled times for computer-basedinstruction and that an adult who sat withstudents during this time could deliverprompts as needed. During informal observa-tions two weeks following the last probe ses-sion, it was reported that Jeremy and Vanessawere observed responding receptively to walk-ing on a line, Vanessa was observed position-ing herself behind her teacher, and each stu-dent responded correctly to putting items inthe trash, in a basket, and standing next to apeer.
Discussion
This study examined the effects of teachingreceptive understanding of prepositions viacomputer-based video self-modeling instruc-
tion. In the early 1970s and 1980s researchersbegan to consider the importance of teachingcomprehension of prepositional relationshipsdue to their frequent use in the natural envi-ronment for locating items (e.g. the keys areon the table), specifying where an objectshould be placed (e.g. put the keys on thetable), or to direct a student where to placehim/herself in relation to a stimulus (e.g.stand beside the sink; Egel et al., 1984). As useand development of technology continues toincrease, new technology-based programs forteaching language-based concepts, such asprepositions, may warrant further research at-tention. Results of the current study supportthose of previous studies which have foundvideo self-modeling to be an effective meansto teach concepts to young children with dis-abilities (Bellini & Akullian, 2007; Hitchock etal., 2003; Meharg & Woltersdorf, 1990). In thecurrent study, students were able to recep-
Figure 2. Percentage of correct responses across three pairs of prepositions during computer-based videoself-modeling, positioning objects, and positioning self generalization sessions by Jeremy.
Video Self-Modeling / 379
tively select photographs on the computer inresponse to the target direction, “Touch__,”and to generalize use of the concepts by posi-tioning themselves and objects. Generaliza-tion of concepts taught through the comput-er-based program was evaluated by measuringtransfer of stimulus control from teaching ex-amples on the computer to non-taught exam-ples and across situations. Generalization ofpreposition use was evaluated across non-taught examples or stimuli (student position-ing him/herself with novel objects and posi-tioning small objects) and across settings andsituations (positioning self in the school envi-ronment). Although the three students dem-onstrated an increase in their abilities to re-ceptively place themselves and objects acrossuntaught examples, during measures of gen-eralization, students were unable to transferstimulus control from the photograph, videoteaching examples, to untaught examples with100% accuracy. Results may have been influ-
enced by the lower level of 80% criteria acrossthree sessions. Criterion was set at this level toallow for the young age and distractibility ofthe students, however, this compromise mayhave affected students’ comprehension of theprepositions.
In order to promote generalization it is im-portant that materials share common physicalcharacteristics similar to those used duringteaching. Results appear to support this rec-ommendation whereby each student’s highestlevel of correct performance during general-ization measures occurred when positioningthemselves with objects seen in the video andsimilar novel materials compared to position-ing small dollhouse figures. Researchers rec-ommend that when designing software pro-grams, instructors include multiple, naturalexamples that occur in the student’s environ-ment (Higgins & Boone, 1996) and examplesthat closely match the attributes of the refer-ents (Porter, Lahm, Behrmann, & Collins,
Figure 3. Percentage of correct responses across three pairs of prepositions during computer-based videoself-modeling, positioning objects, and positioning self generalization sessions by Vanessa.
380 / Education and Training in Autism and Developmental Disabilities-September 2011
1986). Although effort was made to select ob-jects for positioning self from the students’school and home environments (i.e., rockingchair, beach mat) use of positioning smalldollhouse related objects may have includedtoo many uncommon characteristics withthose used during teaching.
While it appears that students learned prep-ositions through the computer-based video
self-modeling program, data also indicate thatstudents may have acquired skills through ex-posure to content in their classroom or natu-ral environments. This appears evident by thelevels of correct responding during probe ses-sions prior to introduction of the computer-based program. Although students were un-able to identify the prepositions duringscreening and classroom teachers were in-
TABLE 2
Mean number of correct responses for each student during generalization probe sessions.
AndreaProbe 1 Probe 2 Probe 3 Probe 4
Pair 1: in/next toSelf 38.9 83.3 83.3 83.3Novel 50 83.3 83.3 100Object 5.6 66.7 61.1 88.9Pair 2: in front of/behindSelf 11.1 33.3 77.8 83.3Novel 0 16.7 50 50Object 5.6 11.1 22.2 38.9Pair 3: on/underSelf 88.9 83.3 88.9 100Novel 33.3 100 66.7 100Object 44.4 88.9 77.8 100
JeremyProbe 1 Probe 2 Probe 3 Probe 4
Pair 1: in front of/behindSelf 44.4 61.1 83.3 83.3Novel 16.7 50 50 50Object 5.6 44.4 55.6 50Pair 2: on/underSelf 16.7 55.6 94.4 94.4Novel 0 50 83.3 83.3Object 16.7 50 88.9 88.9Pair 3: in/next toSelf 33.3 55.6 44.4 100Novel 16.7 50 50 100Object 50 72.2 33.3 61.1
VanessaProbe 1 Probe 2 Probe 3 Probe 4
Pair 1: on/underSelf 16.7 61.1 94.4 94.4Novel 16.7 83.3 100 100Object 38.9 66.7 83.3 100Pair 2: in/next toSelf 27.8 50 83.3 100Novel 50 50 100 83.3Object 16.7 55.6 55.6 66.7Pair 3: in front of/behindSelf 16.7 22.2 50 77.8Novel 0 0 50 50Object 11.1 38.9 50 61.1
Video Self-Modeling / 381

structed not to teach or reinforce use of thesix prepositions, it was impossible for the stu-dents to receive daily instruction in a“vacume” and students were likely indirectlyexposed to the prepositions in a variety ofunidentified means. Levels of performance in-creased for Jeremy during maintenance ses-sions with his first pair of prepositions whileAndrea showed increases across both her firstand second pairs and Vanessa showed in-creased in her first pair and during position-ing of self and objects with her second pair.
It should also be noted that some of theprepositions appeared to prompt a naturalresponse topography from the students. Forexample, students tended to go “in” the tun-nel and to sit “on” the rocking chair prior tocomputer-based video self-modeling instruc-tion. It is also possible that students’ correctpositioning of self during generalization ses-sions was due to imiation of the exact re-sponse topography seen in the video ratherthan receptively responding to the verbal di-rections (i.e., “go in the tunnel”). In otherwords, they may have seen the tunnel duringgeneralization sessions and recalled that theywent inside it on the video self-modeling re-cording. It was attempted to control this effectby providing two prepositional requests perobject (i.e., “in” and “next to” the tunnel) andone distracting photograph (i.e., “behind” thetunnel) during computer-based instruction.The study also included the conditions forpositioning self with novel objects and posi-tioning objects in relation to other objects inorder to control this effect and to measurestudents’ abilities to generalize responding toanother response mode (Egel et al., 1985).
A further limitation to the study and itsmeasures of generalization is that measureswere in controlled environments with onlyone stimuli present rather than in natural en-vironments where numerous materials anddemands for receptive use of prepositions arerequired. Future research may also want toevaluate receptive use of prepositions whenthere is a greater distance between the studentand the object to be used with the preposition.These scenarios may better represent the dailysituations in which students are functionallyrequired to use these concepts. Additionally,future research or applications of this proce-dure may wish to include a measure of expres-
sive understanding of the concepts by includ-ing questions such as, “Where is the dog?” or“Where are you?” during teaching and gener-alization sessions.
While available research and results fromthe current study support use of video, includ-ing video self-modeling, for teaching conceptsand skills to students with disabilities, limitedresearch exists comparing different types ofvideo. Of the comparative studies available,limited differences have been reported be-tween video approaches. Two studies evaluat-ing student preferences for types of video havehad mixed results. Mechling and Moser(2010) found that collectively three studentswith autism showed no clear preference be-tween watching themselves and others onvideo, however, individually one student indi-cated a preference for watching himself invideos and two students indicated a slight pref-erence for watching themselves perform rou-tine tasks. Mechling, Gast, and Cronin (2006)found that students with autism had a slightpreference for watching video captions ofthemselves interacting with preferred stimulicompared to video captions of preferred ac-tivities or events in their study which evaluatedthe effects of presenting high preferenceitems, paired with choice, via computer-basedvideo programming. Cihak and Schrader(2008) also reported that four adolescents intheir study comparing video modeling andvideo self-modeling reported that they pre-ferred to watch themselves performing tasksover adult models in the videos. In addition topreferences, others have evaluated the effectson task performance between types of video.Ayres and Langone (2007) evaluated subjec-tive point of view (perspective of the personwatching the video) and third-person perspec-tive (referred to as video modeling) with fourelementary age students with autism andfound no clear indication of superiority be-tween the two approaches in terms of acquisi-tion and generalization of skills with the few-est errors. In a study comparing videomodeling to video self-modeling with five chil-dren with autism, no overall difference in rateof acquisition of answering conversation ques-tions was found by Sherer and others (2001).Likewise, Cihak and Schrader found bothvideo modeling and video self-modeling to beeffective in teaching chained vocational tasks
382 / Education and Training in Autism and Developmental Disabilities-September 2011

to four adolescents with autism spectrum dis-order. However, individual differences did oc-cur with one participant performing more ef-fectively using video self-modeling and twoadditional participants acquiring skills moreefficiently using video self-modeling (no dif-ferences were found for the fourth partici-pant). A recent study further evaluated videomodeling, self-modeling and subjective pointof view with three students, ages 12-17 years,diagnosed with moderate intellectual disabili-ties (Van Laarhoven, Zurita, Johnson, Grider,& Grider, 2009). Findings suggest that twostudents performed best with video modelingwhile the third student completed more stepsof the tasks correctly when watching videowith a subjective point of view. However, theyreport significant differences in the time re-quired to create the video materials. Creationof the self-modeling videos required almosttwice the amount of time to create than theother two forms of video materials. Thereforeit may be necessary to further evaluate thebenefits of VSM in light of preparation time.For some students the benefit may justify theadditional preparation time, however, as sug-gested by Van Laarhoven et al., self-modelingmay be less cost effective in terms of outcomesand the amount of time required of teachersto prepare the materials. In the current study,the self-models were made by an instructorfirst pointing to where the child needed tostand and then the camera videotaped thestudent walking and standing in the targetlocation. The adult prompter could be editedout of the self-modeling video using the Sto-ryboard feature of Windows Movie Maker or bymerely capturing a video clip after the studentbegan to walk to the target location. This pro-cedure appeared to require little additionaltime to that of making a video model of some-one else demonstrating the target preposi-tion.
Further evaluation, in terms of effectivenessand efficiency for teaching prepositions,should be made between traditional ap-proaches (using real objects and pictures) tovideo technology. Early studies found person-alized photographs of students engaging inactivities to be an effective instructional pro-cedure (Parnell, 1978). Due to their positivefindings using personal photographs of stu-dents depicting the verbs in their language
books, Johnson and others (1992) recom-mended use of video technology to provide anelement of action that photographs could notprovide. Such an early comparison by Ste-phens and Ludy (1975) found motion picturesequences to be more effective than still pho-tographs and live demonstration for teachingverbs to 30 students with moderate intellec-tual disabilities. Issues that could be exploredby future research include comparing photo-graphs, live models, and video to teach con-cepts as well as further comparison of thedifferent types of video perspectives.
For purposes of experimental control, in-struction of prepositions in the current studyonly included the computer-based interven-tion. Practitioners will likely find it useful toteach such concepts with real-life, in-vivo in-struction concurrently with computer-basedinstruction. In such a concurrent arrange-ment, teachers may rely on computer-basedinstruction to deliver repetitive, independentpractice with multiple exemplars while provid-ing opportunities for in-vivo instruction tosupport acquisition and generalization ofskills (Ayres, Maguire, & McClimon, 2009).
Results of the current research producesevidence supporting video self-models toteach concepts such as prepositions. Now thatinstructors have the ability to create real lifesimulations through video technology, contin-ued research is needed to evaluate which fea-tures of video technology are most effectiveand efficient for teaching different popula-tions of students and whether the effects areinfluenced by the type of specific skills beingtaught.
References
Alberto, P., Jobes, N., Sizemore, A., & Doran, D.(1980). A comparison of individualand group in-struction across response tasks. Journal of the Asso-ciation for the Severely Handicapped, 5, 285–293.
Ayres, K. M., & Langone, J. (2007). A comparison ofvideo modeling perspectives for students with au-tism. Journal of Special Education Technology, 22,15–30.
Ayres, K. M., & Langone, J. (2005). Intervention andinstruction with video for student with autism: Areview of the literature. Education and Training inDevelopmental Disabilities, 40, 183–196.
Ayres, K. M., Maguire, A., & McClimon, D. (2009).Acquisition and generalization of chained tasks
Video Self-Modeling / 383

taught with computer based video instruction tochildren with autism. Education and Training inDevelopmental Disabilities, 44, 493–508.
Bellini, S., & Akullian, J. (2007). A meta-analysis ofvideo modeling and video self-modeling interven-tions for children and adolescents with autismspectrum disorders. Exceptional Children, 73, 264–287.
Billingsley, F. F., White, O. R., & Munson, R. (1980).Procedural reliability: A rational and an example.Behavioral Assessment, 2, 229–241.
Bufkin, L. J., & Altman, R. (1995). A developmentalstudy of nonverbal pragmatic communication instudents with and without mild mental retarda-tion. Education and Training in Mental Retardationand Developmental Disabilities, 30, 199–207.
Buggey, T. (2005). Video self-modeling applicationswith students with autism spectrum disorder in asmall private school setting. Focus on Autism andOther Developmental Disabilities, 20, 52–63.
Buggey, T., Toombs, K., Gardener, P., & Cervetti, M.(1999). Training responding behaviors in stu-dents with autism: Using videotaped self-model-ing. Journal of Positive Behavior Interventions, 1,205–214.
Chadsey-Rusch, J., & Halle, J. (1992). The applica-tion of general-case instruction to the requestingrepertoires of learners with severe disabilities.Journal of the Association for the Severely Handicapped,17, 121–132.
Charlop, M. H., & Milstein, J. P. (1989). Teachingautistic children conversational speech usingvideo modeling. Journal of Applied Behavior Analy-sis, 22, 275–285.
Charlop-Christy, M. H., Le, L., & Freeman, K. A.(2000). A comparison of video modeling with invivo modeling for teaching children with autism.Journal of Autism and Developmental Disorders, 30,537–552.
Cihak, D. F., & Schrader, L. (2008). Does the modelmatter? Comparing video self-modeling andvideo adult modeling for task acquisition andmaintenance by adolescents with autism spec-trum disorders. Journal of Special Education Tech-nology, 23(3), 9–20.
Coleman, R. O., & Anderson, D. E. (1979). En-hancement of language comprehension in devel-opmentally delayed children. Language, Speech,and Hearing Services in the Schools, 9, 241–253.
Delano, M. E. (2007). Video modeling interventionsfor individuals with autism. Remedial and SpecialEducation, 28, 33–42.
Dowrick, P. W. (1999). A review of self modelingand related interventions. Applied & PreventativePsychology, 8, 23–39.
Egel, A. L., Shafer, M. S., & Neef, N. A. (1984).Receptive acquisition and generalization of prep-ositional responding in autistic children: A com-
parison of two procedures. Analysis and Interven-tion in Developmental Disabilities, 4, 285–298.
Frisch, S. A., & Schumaker, J. B. (1974). Traininggeneralized receptive prepositions in retardedchildren. Journal of Applied Behavior Analysis, 7,611–621.
Gast, D. L. & Ledford, J. (2010) Multiple baselineand multiple probe designs. In D. L. Gast (Ed.).Single subject research methodology in behavioral sci-ences. New York: Routledge Publishers.
Handleman, J. S., Powers, M. D., & Harris, S. L.(1984). Teaching of labels: An analysis of con-crete and pictorial representations. American Jour-nal of Mental Deficiency, 88, 625–629.
Higgins, K., & Boone, R. (1996). Creating individu-alized computer-assisted instruction for studentswith autism using multimedia authoring software.Focus on Autism and Other developmental Disabilities,11, 69–78.
Hitchcock, C. H., Dowrick, P. W., & Prater, M.(2003). Video self-modeling intervention inschool-based settings. Remedial and Special Educa-tion, 24(1), 36–45.
Hughes, C. (1992). Teaching self-instruction utiliz-ing multiple exemplars to produce generalizedproblem-solving among individuals with severemental retardation. American Journal on MentalRetardation, 97, 302–314.
Hupp, S. C. (1986). Use of multiple exemplars inobject concept training: How many are sufficient?Analysis and Intervention in Developmental Disabili-ties, 6, 305–317.
Johnson, T. E. B., Knowlton, H. E., Adams, S. E., &Swall, A. R. (1992). The effects of personal pho-tographs on verbal responses to figural stimuli bystudents with moderate mental retardation: ABrunerian approach. Education and Training inMental Retardation, 27, 367–378.
King, A., Moors, A. L., & Fabrizio, M. A. (2003).Concurrently teaching multiple verbal operantsrelated to preposition use to a child with autism.Journal of Precision Teaching and Celeration, 19(1),38–40.
Konstantareas, M. M. (1984). Sign language as acommunication prosthesis with language-im-paired children. Journal of Autism and Developmen-tal Disorders, 14, 9–25.
McCarney, S. B., & Arthaud, T. J. (2006). Adaptivebehavior evaluation scale-Revised second edition: 4-12years. Columbus, MO: Hawthorne.
McCoy, K., & Hermansen, E. (2007). Video model-ing for individuals with autism: A review of modeltypes and effects. Education and Treatment of Chil-dren, 30, 183–213.
McGee, G. G., Krantz, Pl. J., & McClannahan, L. E.(1985). The facilitative effects of incidental teach-ing on preposition use by autistic children. Jour-nal of Applied Behavior Analysis, 18, 17–31.
384 / Education and Training in Autism and Developmental Disabilities-September 2011

Mechling, L. C., Gast, D. L., & Cronin, B. A. (2006).The effects of presenting high preference items,paired with choice, via computer-based video pro-gramming on task completion of students withautism. Focus on Autism and Other DevelopmentalDisabilities, 21, 7–13.
Mechling, L., & Langone, J. (2000). The effects of acomputer-based instructional program with videoanchors on the use of photographs for promptingaugmentative communication. Education andTraining in Mental Retardation and DevelopmentalDisabilities, 35, 90–105.
Mechling, L. C., & Moser, S. V. (2010). Assessmentof video preference of students with autism forwatching self, familiar adult, or familiar peer com-pleting preferred and daily/routine activities. Fo-cus on Autism and Developmental Disabilities, 25,76–84.
Meharg, S. S., & Woltersdorf, M. A. (1990). Thera-peutic use of videotape self-modeling: A review.Advanced Behaviorial Research Therapy, 12, 85–99.
Mitchell, M., Evans, C., & Bernard, J. (1978). Train-able children can learn adjectives, polars, andprepositions! Language, Speech, and Hearing Ser-vices in Schools, 8, 181–187.
Moore, M., & Calvert, S. (2000). Vocabulary acqui-sition for children with autism: Teacher or com-puter instruction. Journal of Autism and Develop-mental Disorders, 30, 359–362.
Nikopoulos, C. K., & Keenan, M. (2003). Promotingsocial initiation in children with autism usingvideo modeling. Behavioral Interventions, 18, 87–108.
Nikopoulos, C. K., & Keenan, M. (2004). Effects ofvideo modeling on social initiations by childrenwith autism. Journal of Applied Behavior Analysis, 37,93–96.
Parnell, M. K. (1978). Personalized photography: Atool in language development. Day Care and EarlyEducation, 6(2), 55–57.
Porter, L. K., Lahm, E. A., Behrmann, M. M., &Collins, A. A. (1986). Designing picture-basedsoftware for the cognitively young. Journal of theDivision for Early Childhood, 10, 231–239.
Reagon, K. A., Higbee, T. S., & Endicott, K. (2007).Using video instruction procedures with and with-out embedded text to teach object labeling topreschoolers with autism: A preliminary investiga-tion. Journal of Special Education Technology, 22(1),13–20.
Roid, G., & Miller, L. (1997). Leiter internationalperformance scale-revised. Chicago: Stoelting.
Sailor, W., & Taman, T. (1972). Stimulus factors inthe training of prepositional usage in three autis-
tic children. Journal of Applied Behavior Analysis, 5,183–190.
Sherer, M., Pierce, K. L., Paredes, S., Kisacky, K. L.,Ingersoll, B., & Schreibman, L. (2001). Enhanc-ing conversation skills in children with autism viavideo technology. Behavior Modification, 25, 140–158.
Shipley-Benamou, R., Lutzker, J. R., & Taubman, M.(2002). Teaching daily living skills to childrenwith autism through instructional video model-ing. Journal of Positive Behavior Interventions, 4,165–175.
Sparrow, S. S., Balla, D. A., & Cicchetti, D. V. (1984).Vineland adaptive behavior scales. Circle Pines, MN:American Guidance Service.
Snell, M., & Brown, F. (2006). Instruction of studentswith severe disabilities (6th ed.). Upper Saddle River,NJ: Merrill Prentice-Hall.
Stephens, W. E., & Ludy, I. E. (1975). Action-con-cept learning in retarded children using photo-graphic slides, motion picture sequences, and livedemonstrations. American Journal of Mental Defi-ciency, 80, 277–280.
Stephenson, J. R., & Dowrick, M. (2000). Parentpriorities in communication interventions foryoung students with severe disabilities. Educationand Training in Mental Retardation and Developmen-tal Disabilities, 35, 25–35.
Summers, J. A., Rincover, A., & Feldman, M. A.(1993). Comparison of extra- and within-stimulusprompting to teach prepositional discriminationsto preschool children with developmental disabil-ities. Journal of Behavioral Education, 3, 287–298.
Taylor, B. A., Levin, L., & Jasper, S. (1999). Increas-ing play-related statements in children with au-tism toward their siblings: Effects of video model-ing. Journal of Developmental and PhysicalDisabilities, 11, 253–264.
Van Laarhoven, T., Zurita, L. M., Johnson, J. W.,Grider, K. M., & Grider, K. L. (2009).Comparisonof self, other, and subjective video models forteaching daily living skills to individuals with de-velopmental disabilities. Education and Training inDevelopmental Disabilities, 44, 509–522.
Wechsler, D. (1991). Wechsler intelligence scale for chil-dren – Third edition. San Antonio, TX: Psycholog-ical Corporation.
Wert, B. Y., & Neisworth, J. T. (2003). Effects ofvideo self-modeling on spontaneous requesting inchildren with autism. Journal of Positive BehaviorInterventions, 5, 30–35.
Received: 1 March 2010Initial Acceptance: 5 May 2010Final Acceptance: 20 July 2010
Video Self-Modeling / 385
Related Documents











