72150272 홍홍홍

Computations have to be distributed !
Dec 17, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

2015-1 학기 운영체제특론 Paper Re-view
MapReduce : Simplified Data Process-ing on Large Clusters Jeffrey Dean and Sanjay Ghemawat (Google, Inc.)

INDEX CONTENT
01. Introduction
02. Programming Model
03. Implementation
04. Refinements
05. Performance
06. Conclusions

01. Introduc-tion

IntroductionWhy need the data process system?
Web request logs
Crawled docu-mentsShopping, finan-cial, etc. Contents
Video, audio, picture, etc.
SNS
Computations have to be dis-tributed !
MapReduce : Simplified Data Processing on Large Clusters

IntroductionDesign
Express the simple com-
putations
Hides the messy details in a library
Use the map and reduce
(parallelization, fault-tolerance, data distribution,load balancing)
primitives present in Lisp and many
otherfunctional languages
MapReduce is a programming model and an associated imple-mentation for processing and generating large data sets.
MapReduce : Simplified Data Processing on Large Clusters

02. Programming Model
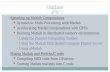
Programming ModelMap, Reduce Concept
Map
Reduce
Each logical “record” in our input
Produces a set of intermediate key/value pairs
Accepts an intermediate key I and a set of values for that key
Merges together these values that shared the same key
MapReduce : Simplified Data Processing on Large Clusters

Programming ModelExample – counting the number of occurrences of each word
Create intermediate key/value pair
Input : <document name, contents>Output : <word, 1>
Sum all values
Input : <word, list of counts>Output : <word, result>
MapReduce : Simplified Data Processing on Large Clusters

Programming ModelExample – counting the number of occurrences of each word
MapReduce : Simplified Data Processing on Large Clusters

Programming ModelMore Examples
Example Key/value pair
Distributed Grep map -> matched linereduce -> just pass
Count of URL Access Frequency
map -> <URL , 1>reduce -> <URL , total count>
Reverse Web-Link Graph map -> <target , source>reduce -> <target , list(source)>
Term-Vector per Hostmap -> <hostname , term vector> #term vector = a list of <word, frequency>reduce -> <hostname , term vector>
Inverted Index map -> a sequence of <word , document ID>reduce -> <word , list(document ID)>
Distributed Sort map -> <key , record>reduce -> just pass
MapReduce : Simplified Data Processing on Large Clusters

03. Implementa-tion

ImplementationImplementation Environment
dual-processor x86 processors running Linux, with 2-4GB of memory per machine.
1.
100 MB/sec or 1 GB/sec at the machine bandwidth.2.
A cluster consists of hundreds or thousands of machines (Machine failures are common)
3.
Storage is provided by inexpensive IDE disks4.
MapReduce : Simplified Data Processing on Large Clusters

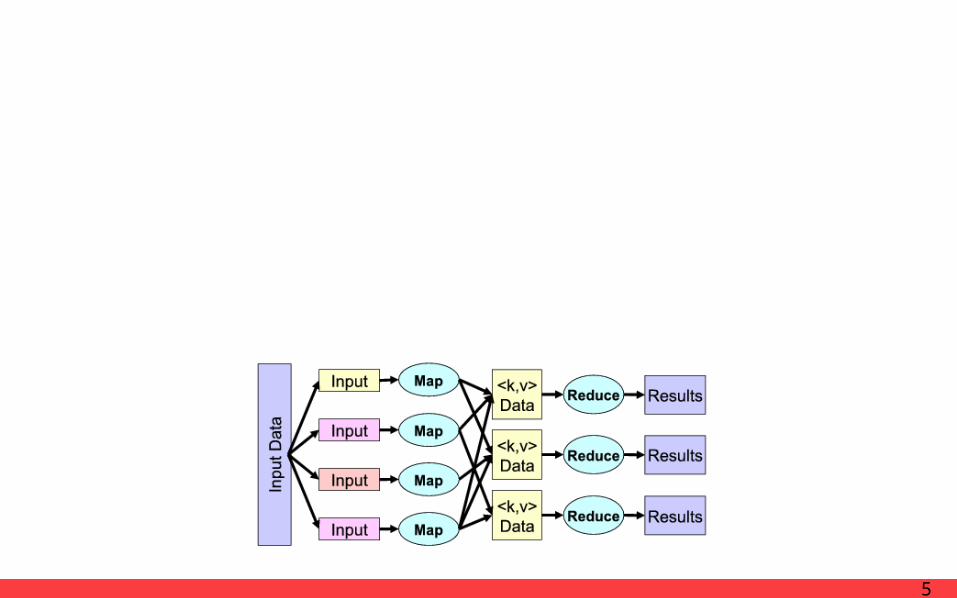
ImplementationExecution Overview
MapReduce : Simplified Data Processing on Large Clusters
ImplementationExecution Overview · Splits the input files
into M pieces
· Starts up many copies
MapReduce : Simplified Data Processing on Large Clusters

ImplementationExecution Overview
· One is the master
· Master assigned map/reduce task
MapReduce : Simplified Data Processing on Large Clusters
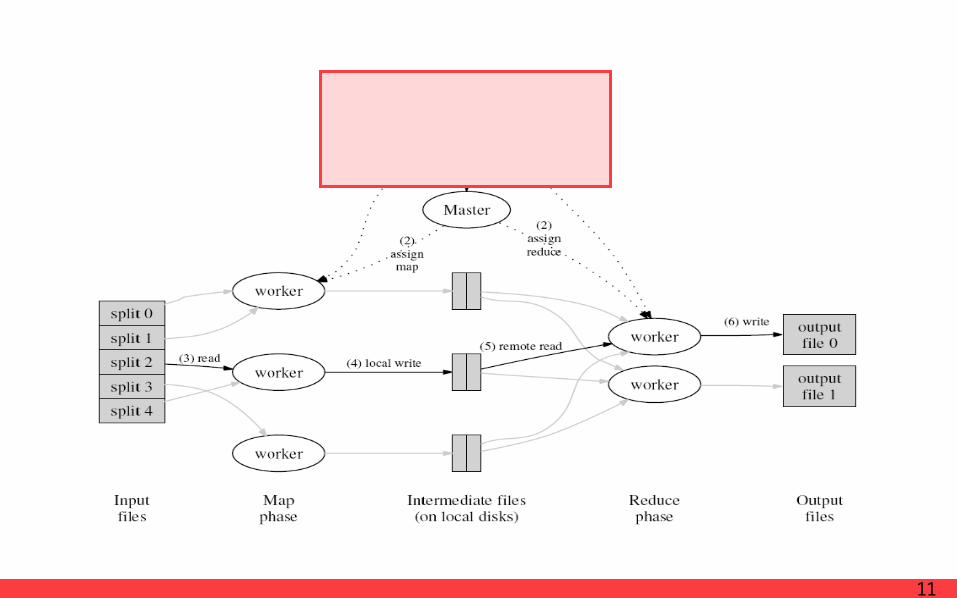
ImplementationExecution Overview
· Reads the contents of input split.
· Parses key/value pairs
· Producing intermediate key/value pairs
· Intermediate key/value pairs are buffered in memory
MapReduce : Simplified Data Processing on Large Clusters

ImplementationExecution Overview
· Buffered pairs are written to local disk
· Partitioned into R regions by the partitioning func-tion
· Passed back to the master
MapReduce : Simplified Data Processing on Large Clusters

ImplementationExecution Overview
· Read the buffered data from the local disks of the map workers
· Sorts the data by the intermediate keys
· All of the same key are grouped together
MapReduce : Simplified Data Processing on Large Clusters
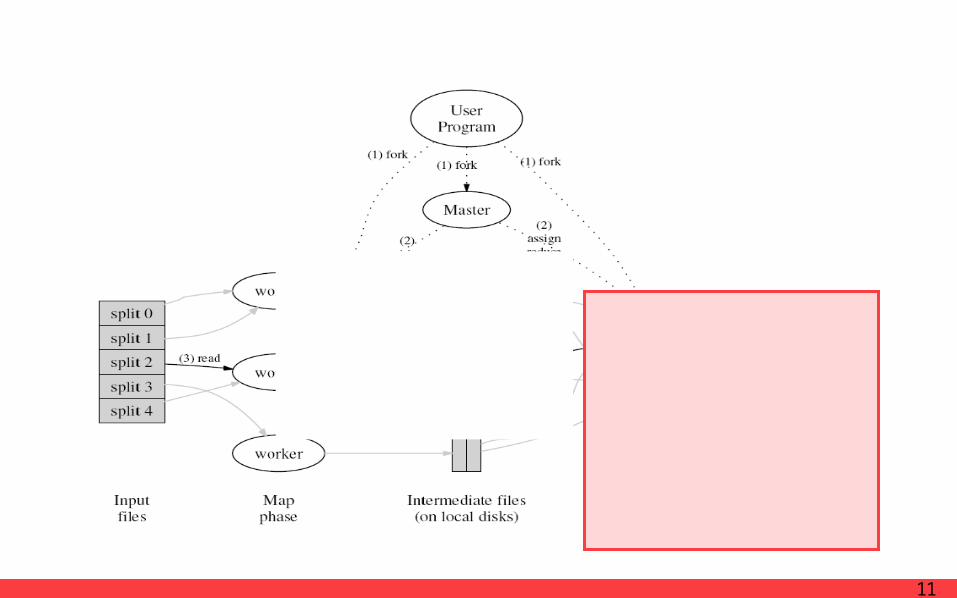
ImplementationExecution Overview
· Appended to a final output file
· Returns back to the user code
MapReduce : Simplified Data Processing on Large Clusters

ImplementationFault Tolerance
Master
Worker
Worker
ping
Master assigned task to another worker (idle state)
Map tasks are re-executed(output is stored on the local disk(s))
Reduce tasks do not need(output is stored in a global file system)
Master write periodic checkpoints
If the master task dies,A new copy can be started from the last checkpointed state
If there is only a single master,Aborts the computation
checkpoint
The vast majority of map & re-duce operators are determinis-tic.Input values produces the same out-put.
Each in-progress task writes its output to private temporary files
Worker sends a message to the master and includes the names
Worker
TempFile
R
Master
MapReduce : Simplified Data Processing on Large Clusters
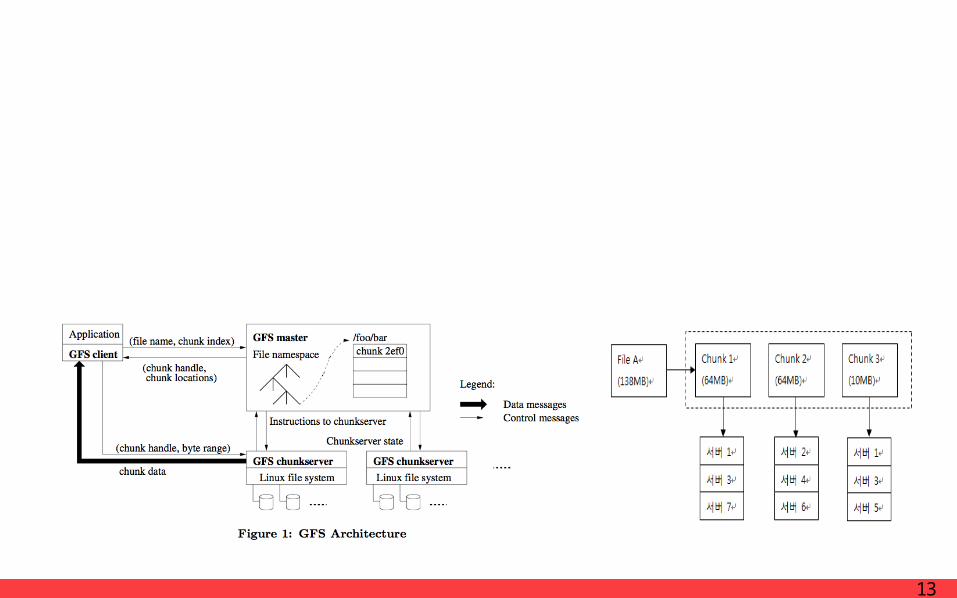
ImplementationLocality
Network bandwidth is a scarce resource
Input data(managed by GFS) is stored on the local disks of the machines that make up our cluster.
MapReduce : Simplified Data Processing on Large Clusters
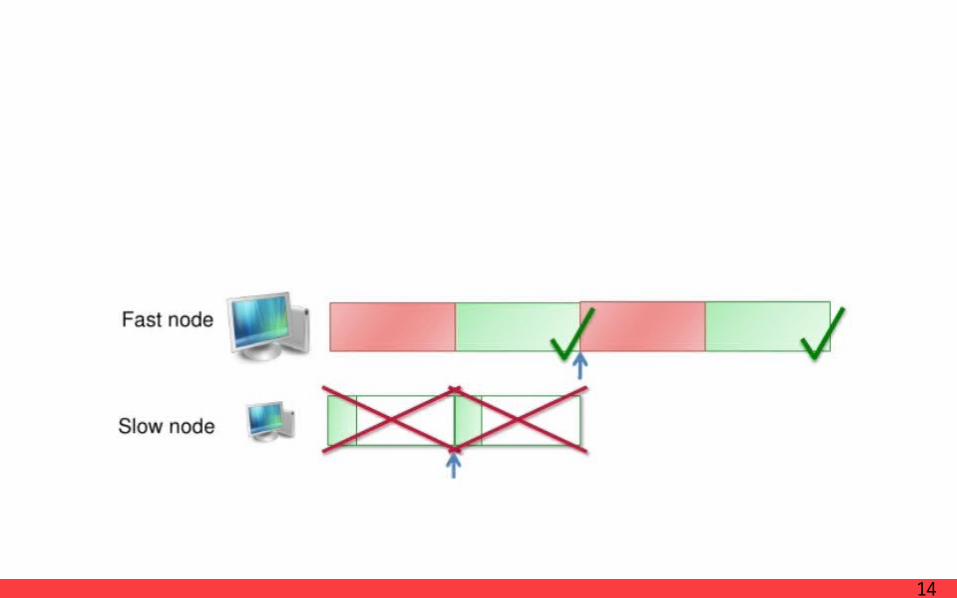
ImplementationBackup Tasks
When a MapReduce operation is close to completion,The master schedules backup executions of the remaining in-progress tasks.
Lengthens the total time taken for a MapReduce operation is a “strag-gler”
* stragglerA machine that takes an unusually long time to complete one of the last few map or reduce tasks in the computation.
MapReduce : Simplified Data Processing on Large Clusters

04. Refine-ments
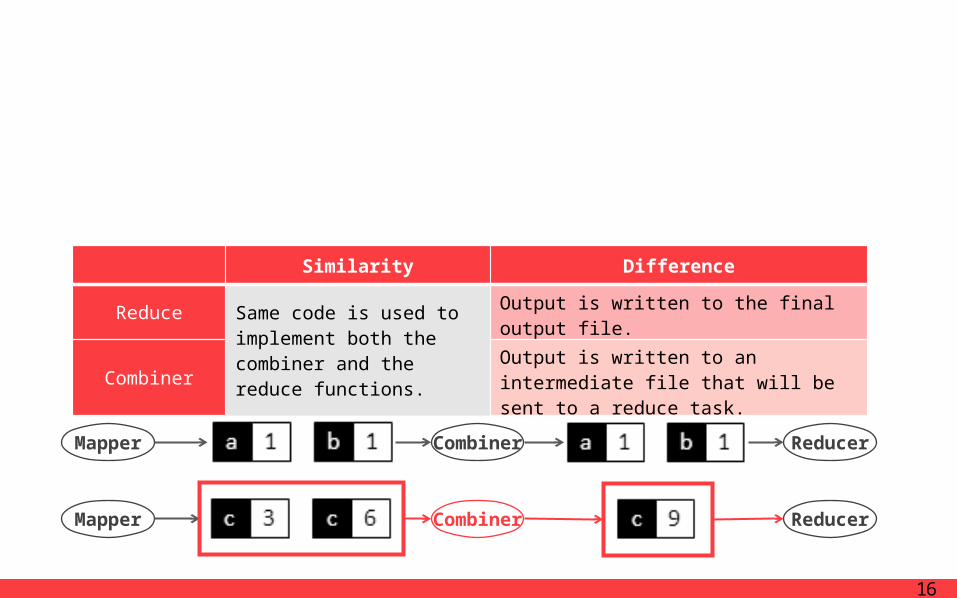
RefinementsCombiner Function
In some cases, there is significant repetition in the intermediate keys produced by each map task and the user specified reduce function is commutative and asso-ciative.
Combiner function that does partial merging of this data before it is sent over the network. Similarity Difference
Reduce Same code is used to im-plement both the com-biner and the reduce functions.
Output is written to the final output file.
CombinerOutput is written to an intermediate file that will be sent to a reduce task.
Mapper Combiner
ReducerMapper Combiner
Reducer
MapReduce : Simplified Data Processing on Large Clusters

RefinementsSkipping Bad Records
Problem : Such bugs prevent a MapReduce operation from completing.
WorkerSignal han-
dler
MasterSequence number N
UPD packetSequence Number NLocal vari-
able
Record N
Solution :
If the user code generates a signal
MapReduce : Simplified Data Processing on Large Clusters

RefinementsStatus Information
User can predict · how long the computation will take, · whether or not more resources should be added to the computa-tion.
Information is useful · when attempting to diagnose bugs in the user code.
· # of completed task · # of in-progress, · bytes of input,
· bytes of intermediate data, · bytes of output, · processing rates,
· which workers have failed, · when they failed.
Master runs an internal HTTP server and exports a set of status pages for human.
MapReduce : Simplified Data Processing on Large Clusters

RefinementsAnother
basic : Hash(key) mod RUpgrade : Hash(Hostname(URLkey)) mod R
Intermediate key/value pairs are processed in increasing key order.
Partitioning Function
Ordering Guarantees
MapReduce library provides a counter facility to count occurrences ofvarious events.
Counters
Each input type implementation knows how to split itself into meaningful ranges.
Input and Output Types
MapReduce : Simplified Data Processing on Large Clusters

05. Perfor-mance

PerformanceGrep
*Scans1TB records*The pattern occurs in 92,337 records.*Input is split into 64MB pieces (M=15000)*Output is placed in one file (R=1)
The rate gradually picks up as more machines are assigned to this MapReduce computation.
Peaks at over 30GB/s when 1764 workers have been assigned.
As the map tasks finish, the rate starts drop-ping and hits zero about 80sec.
The entire computation takes approximately 150sec from start to finish.
looking for a particular pattern
MapReduce : Simplified Data Processing on Large Clusters

PerformanceGrep – looking for a particular pattern
*Scans1TB records*The pattern occurs in 92,337 records.*Input is split into 64MB pieces (M=15000)*Output is placed in one file (R=1)
The rate gradually picks up as more machines are assigned to this MapReduce compu-tation.
Peaks at over 30GB/s when 1764 workers have been assigned.
As the map tasks finish, the rate starts drop-ping and hits zero about 80sec.
The entire computation takes approximately 150sec from start to finish.
MapReduce : Simplified Data Processing on Large Clusters

PerformanceGrep – looking for a particular pattern
*Scans1TB records*The pattern occurs in 92,337 records.*Input is split into 64MB pieces (M=15000)*Output is placed in one file (R=1)
The rate gradually picks up as more machines are assigned to this MapReduce computation.
Peaks at over 30GB/s when 1764 work-ers have been assigned.
As the map tasks finish, the rate starts drop-ping and hits zero about 80sec.
The entire computation takes approximately 150sec from start to finish.
MapReduce : Simplified Data Processing on Large Clusters

PerformanceGrep – looking for a particular pattern
*Scans1TB records*The pattern occurs in 92,337 records.*Input is split into 64MB pieces (M=15000)*Output is placed in one file (R=1)
The rate gradually picks up as more machines are assigned to this MapReduce computation.
Peaks at over 30GB/s when 1764 workers have been assigned.
As the map tasks finish, the rate starts dropping and hits zero about 80sec.
The entire computation takes approximately 150sec from start to finish.
MapReduce : Simplified Data Processing on Large Clusters
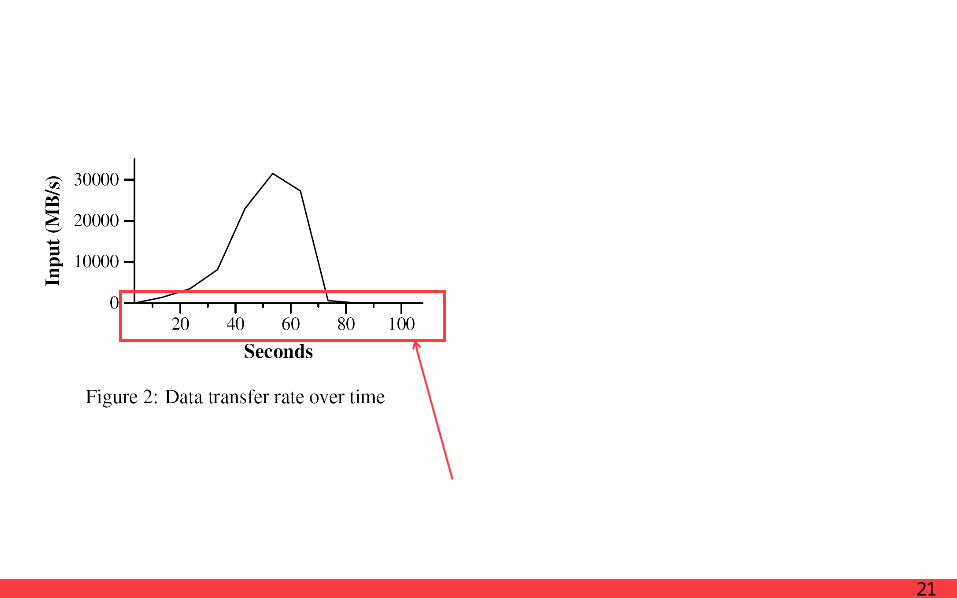
PerformanceGrep – looking for a particular pattern
*Scans1TB records*The pattern occurs in 92,337 records.*Input is split into 64MB pieces (M=15000)*Output is placed in one file (R=1)
The rate gradually picks up as more machines are assigned to this MapReduce computation.
Peaks at over 30GB/s when 1764 workers have been assigned.
As the map tasks finish, the rate starts drop-ping and hits zero about 80sec.
The entire computation takes approximately 150sec from start to fin-ish.
MapReduce : Simplified Data Processing on Large Clusters

PerformanceSort
Sorts approximately 1TB of data
MapReduce : Simplified Data Processing on Large Clusters

PerformanceSort – Normal execution
The rate peaks at about 13GB/s
Dies off fairly quickly since all map tasks finish before 200 sec
The input rate is less than for grep
[ ]Shows the rate at which input is read
MapReduce : Simplified Data Processing on Large Clusters

PerformanceSort – Normal execution
Shuffling starts as soon as the first map task completes.
The first hump in the graph is for the first batch of approximately 1700 reduce tasks.
Roughly 300 seconds into the computation, Start shuffling data for the remaining reduce tasks.
All of the shuffling is done about 600 sec
[ ]Shows the rate at which data is sent over the network
MapReduce : Simplified Data Processing on Large Clusters
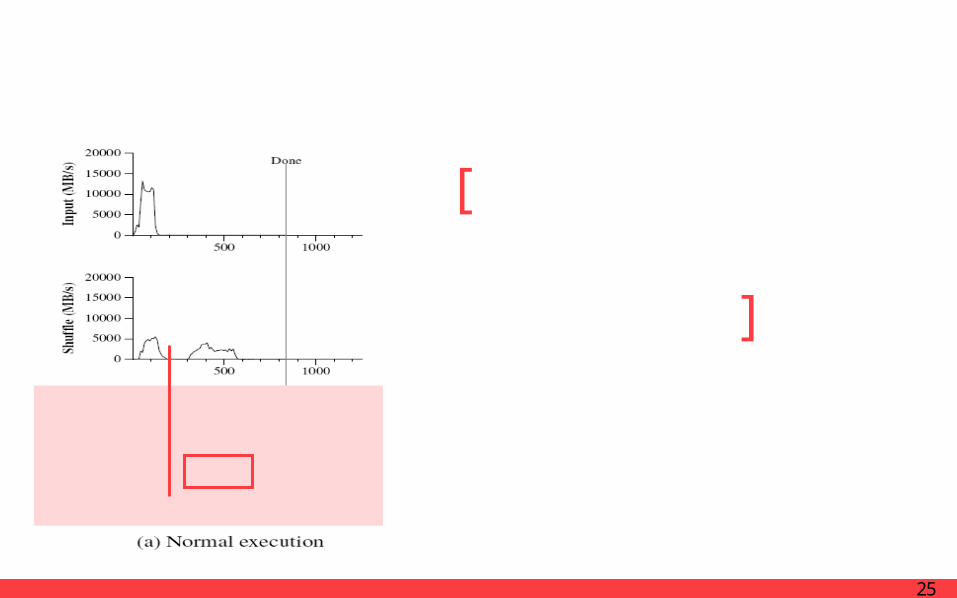
PerformanceSort – Normal execution
There is a delay between the end of the first shuffling period and the start of the writing period
The writes continue at a rate of about 2-4GB/s
Complete time : writes-850 sec / entire-891 sec
Output < Shuffle rate < Input rate
[ ]Shows the rate at data is written to the final
output files
MapReduce : Simplified Data Processing on Large Clusters
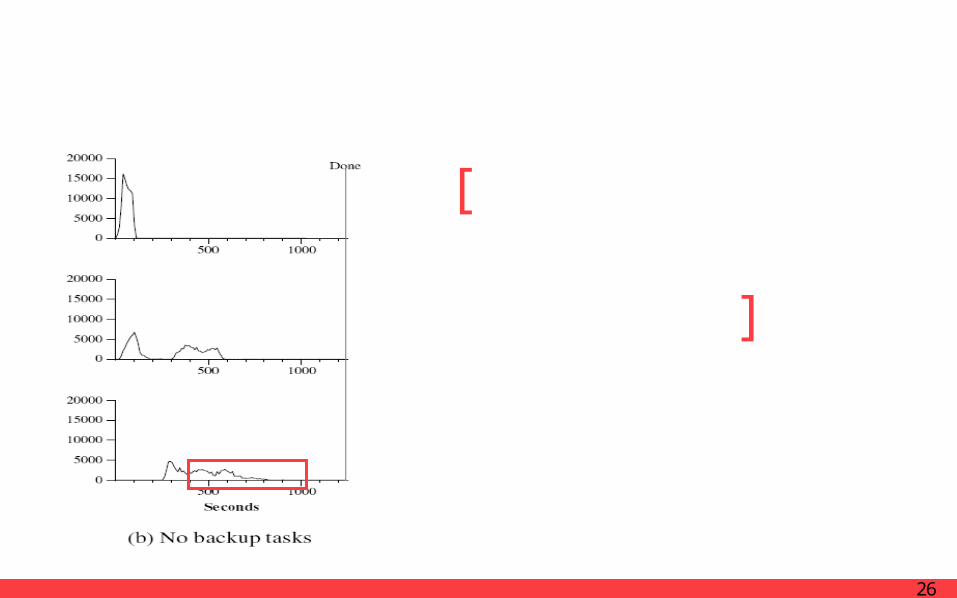
PerformanceEffect of Backup Tasks
Similar to that shown in (a)Normal execu-tion
After 960 seconds, all except 5 of the reduce tasks are com-pleted
Stragglers don’t finish until 300 seconds later
The entire computation takes 1283 sec-onds, an increase of 44% in elapsed time.
[ ]Show an execution of the sort with backup tasks disabled
MapReduce : Simplified Data Processing on Large Clusters

PerformanceMachine Failures
The underlying cluster scheduler immediately restarted new worker processes on these ma-chines.
The worker deaths show up as a negative in-put rate since some previously completed map work disappears and needs to be re-done.
The re-execution of this map work happens relatively quickly.
The entire computation finishes in 933 sec-onds including startup overhead(increase of 5% over the normal execution time)
[ ]killed 200 worker processes several minutes
MapReduce : Simplified Data Processing on Large Clusters

06. Conclusions

ExperienceLarge-Scale Indexing
Rewrite of the production indexing system that produces the data structures used for the Google web search service.
A large setof documents
Stored as a setof GFS files
Runs indexing process
Provided several benefits
Retrieved by crawling system
Documents are more than 20TB
Runs as a sequence of 5 to 10 MapReduce
The indexing code is simpler, smaller, and easier to understand.
It can keep conceptually unrelated computations separate.This makes it easy to change the indexing process.
The indexing process has become much easier to operate, because most of the problems are dealt with automatically the MapReduce library
MapReduce : Simplified Data Processing on Large Clusters

ConclusionsSuccess to several reasons
The model is easy to useIt hides the details of parallelization, fault-tolerance, locality optimization, and load balancing.
Large Variety of problems are easily expressibleIt is used for the generation of data for Google’s pro-duction web search service, for sorting, for data min-ing, for machine learning, and many other systems.
Developed that scales to large clusters of machinesThe implementation makes efficient use of these ma-chine resources and therefore is suitable for use on many of the large computational problems encoun-tered at Google.
MapReduce : Simplified Data Processing on Large Clusters

ReferenceReference documents
[1] Jeffrey Dean and Sanjay Chemawat, MapReduce: Simplified Data Processing on Large Clusters, 2004
[2] Sanjay Chemawat, Howard Gobioff, and Shun-Tak Leung, The Google File System, 2003
[3] Matei Zaharia, Andy Konwinski, Anthouny D. Joseph, Randy Kats, Ion Stoica, Improving MapReduce Performance in Heterogeneous Environ-ments
[4] terms.naver.com
[5] www.wikipedia.org
[6] etc.
MapReduce : Simplified Data Processing on Large Clusters

Thank You
Related Documents