Original article Comprehensive identification and characterization of novel cardiac genes in mouse Inju Park, Seong-Eui Hong, Tae-Wan Kim, Jiae Lee, Jungsu Oh, Eunyoung Choi, Cecil Han, Hoyong Lee, Do Han Kim, Chunghee Cho ⁎ Department of Life Science, Gwangju Institute of Science and Technology (GIST), Gwangju 500-712, Korea Received 25 February 2007; received in revised form 14 May 2007; accepted 15 May 2007 Available online 24 May 2007 Abstract Comprehensive understanding of the molecular and physiological events occurring in cardiac muscle requires identification of unknown genes expressed in this tissue. We analyzed the mouse cardiac muscle UniGene library containing 827 gene-oriented transcript clusters, predicting that 19% of these genes are unknown. We systematically identified 15 authentic novel genes abundantly expressed in cardiac muscle. Northern blot analysis revealed transcriptional characteristics of the genes, such as transcript size and presence of isoforms. Transfection assays performed using various cell lines including mouse cardiac muscle cells provided information on the cellular characteristics of the novel proteins. Using correlation analysis, we identified co-regulated genes from previously reported microarray data sets. Our in silico and in vitro data suggest that a number of the novel genes are implicated in calcium metabolism, mitochondrial functions and gene transcription. In particular, we obtained new and direct evidence that one of the novel proteins is a calcium-binding protein. Taken together, we identified and characterized a number of novel cardiac genes by integrative approach. Our inclusive data establish a firm basis for future investigation into the cardiac gene network and functions of these genes. © 2007 Elsevier Inc. All rights reserved. Keywords: Cardiac muscle; Gene expression; Microarray; Systems biology; Transcript; UniGene 1. Introduction The heart is central to the cardiovascular system. This muscular organ beats about 100,000 times rhythmically and spontaneously each day throughout a person's life. Complicated gene networks regulate the mechanism of heart contraction [1], and subtle changes in genes expressed in cardiac muscle can cause serious heart disease. A comprehensive understanding of the molecular and physiological events occurring in cardiac muscle requires identification and characterization of genes expressed in this tissue. To date, a number of high-throughput studies have investigated gene expression profile in heart tissues. Most of them have focused on differential gene expression when normal and disease conditions were compared [2–12]. Although these studies have provided important information on the expression profiles of a number of cardiac genes, the identities and characteristics of unknown cardiac genes with unassigned function are elusive. An inclusive approach to the discovery of novel genes ex- pressed in a given cell or tissue is the analysis of a database containing cell-specific or tissue-specific transcriptomes. The UniGene database provides information on tissue-specific gene cluster expression. The expressed sequence tags (ESTs) in UniGene are organized into clusters and each cluster is com- posed of sequences overlapping with at least one other member of the same cluster, but not with members of any other cluster. Thus, each cluster is likely to contain sequences corresponding to a single gene. Currently, UniGene is a large and widely used EST database and contains a large amount of unanalyzed information [13]. Furthermore, the UniGene database, combined with other computational bioinformatics databases, provides a great deal of information to assist in an understanding of Journal of Molecular and Cellular Cardiology 43 (2007) 93 – 106 www.elsevier.com/locate/yjmcc ⁎ Corresponding author. Tel.: +82 62 970 2490; fax: +82 62 970 2484. E-mail address: [email protected] (C. Cho). 0022-2828/$ - see front matter © 2007 Elsevier Inc. All rights reserved. doi:10.1016/j.yjmcc.2007.05.018

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Journal of Molecular and Cellular Cardiology 43 (2007) 93–106www.elsevier.com/locate/yjmcc
Original article
Comprehensive identification and characterization ofnovel cardiac genes in mouse
Inju Park, Seong-Eui Hong, Tae-Wan Kim, Jiae Lee, Jungsu Oh, Eunyoung Choi, Cecil Han,Hoyong Lee, Do Han Kim, Chunghee Cho ⁎
Department of Life Science, Gwangju Institute of Science and Technology (GIST), Gwangju 500-712, Korea
Received 25 February 2007; received in revised form 14 May 2007; accepted 15 May 2007Available online 24 May 2007
Abstract
Comprehensive understanding of the molecular and physiological events occurring in cardiac muscle requires identification of unknown genesexpressed in this tissue. We analyzed the mouse cardiac muscle UniGene library containing 827 gene-oriented transcript clusters, predicting that19% of these genes are unknown. We systematically identified 15 authentic novel genes abundantly expressed in cardiac muscle. Northern blotanalysis revealed transcriptional characteristics of the genes, such as transcript size and presence of isoforms. Transfection assays performed usingvarious cell lines including mouse cardiac muscle cells provided information on the cellular characteristics of the novel proteins. Using correlationanalysis, we identified co-regulated genes from previously reported microarray data sets. Our in silico and in vitro data suggest that a number ofthe novel genes are implicated in calcium metabolism, mitochondrial functions and gene transcription. In particular, we obtained new and directevidence that one of the novel proteins is a calcium-binding protein. Taken together, we identified and characterized a number of novel cardiacgenes by integrative approach. Our inclusive data establish a firm basis for future investigation into the cardiac gene network and functions ofthese genes.© 2007 Elsevier Inc. All rights reserved.
Keywords: Cardiac muscle; Gene expression; Microarray; Systems biology; Transcript; UniGene
1. Introduction
The heart is central to the cardiovascular system. Thismuscular organ beats about 100,000 times rhythmically andspontaneously each day throughout a person's life. Complicatedgene networks regulate the mechanism of heart contraction [1],and subtle changes in genes expressed in cardiac muscle cancause serious heart disease.
A comprehensive understanding of the molecular andphysiological events occurring in cardiac muscle requiresidentification and characterization of genes expressed in thistissue. To date, a number of high-throughput studies haveinvestigated gene expression profile in heart tissues. Most ofthem have focused on differential gene expression when normaland disease conditions were compared [2–12]. Although these
⁎ Corresponding author. Tel.: +82 62 970 2490; fax: +82 62 970 2484.E-mail address: [email protected] (C. Cho).
0022-2828/$ - see front matter © 2007 Elsevier Inc. All rights reserved.doi:10.1016/j.yjmcc.2007.05.018
studies have provided important information on the expressionprofiles of a number of cardiac genes, the identities andcharacteristics of unknown cardiac genes with unassignedfunction are elusive.
An inclusive approach to the discovery of novel genes ex-pressed in a given cell or tissue is the analysis of a databasecontaining cell-specific or tissue-specific transcriptomes. TheUniGene database provides information on tissue-specific genecluster expression. The expressed sequence tags (ESTs) inUniGene are organized into clusters and each cluster is com-posed of sequences overlapping with at least one other memberof the same cluster, but not with members of any other cluster.Thus, each cluster is likely to contain sequences correspondingto a single gene. Currently, UniGene is a large and widely usedEST database and contains a large amount of unanalyzedinformation [13]. Furthermore, the UniGene database, combinedwith other computational bioinformatics databases, provides agreat deal of information to assist in an understanding of

94 I. Park et al. / Journal of Molecular and Cellular Cardiology 43 (2007) 93–106
characteristics of genes. Such in silico gene identificationand analysis is a powerful tool of modern molecular biology[14–16].
Of 24 mouse heart and muscle libraries deposited in theUniGene data base at the National Center for BiotechnologyInformation (NCBI), we used the adult mouse cardiac musclelibrary (Li.8901) with 827 UniGene entries. Our analysisshowed that 671 entries are known genes. These genes hadpreviously been named and potential functions had beenassigned to the genes. The other 156 entries were potentiallynovel genes (unnamed genes with unknown or unassignedfunctions). We focused on these novel gene candidates. Initially,we examined whether these gene candidates are genuine novelgenes. Through various expression analyses, we soughtobvious, significant expression of these genes in mouse cardiacmuscle. With authentic genes, we used various in vitro and insilico analyses to obtain comprehensive expression informationat both the gene and protein levels. Our study, presented here, isunique in that we offer systematic identification of previouslyuncharacterized genes that show cardiac expression, providing anew basis for studies to uncover molecular mechanismsunderlying cardiac function.
2. Materials and methods
2.1. Reverse transcription-polymerase chain reaction(RT-PCR)
Total RNA samples were isolated from various tissues ofadult mice and from hearts of mice of different ages. Our workconformed to the Guide for the Care and Use of LaboratoryAnimals published by the US National Institutes of Health (NIHPublication No. 85-23, revised in 1996). Complementary DNAs(cDNAs) were synthesized by random hexamer and oligo(dT)(Promega), priming using Omniscript reverse transcriptase(QIAGEN). Gene-specific primers are listed in Table 1. ForPCR, the following conditions were used. The initial treatmentfor 5 min at 94 °C was followed by 30 cycles of 94 °C for 20 s,55 °C for 40 s and 72 °C for 1 min. The cDNA levels werecalibrated by glyceraldehyde-3-phosphate dehydrogenase(Gapdh).
2.2. Northern blot analysis
Total RNA and poly (A)+ RNA samples were incubated at65 °C for 5 min and separated on 1.2% (w/v) agarose gelscontaining 1.8% (w/v) formaldehyde. Separated RNAs weretransferred to Hybond-XL membrane (Amersham) using acapillary method. The RNA bands were crosslinked using theStratalinker reagent (Stratagene, La Jolla, CA). The blots werepre-hybridized with Rapid-Hyb buffer (Amersham) for 30 minat 68 °C and then hybridized with fresh buffer containing 25 ngof probes, derived from gene-specific PCR products, at 68 °Cfor 2 h. Probe DNA was labeled with [α-32P]dCTP (PerkinElmer) using NucTrap® Probe Purification Columns and thePrime-It random priming kit (Stratagene). The blot was rinsedtwice with 2× SSC/0.05% (w/v) SDS at room temperature for
10 min and twice with 0.1× SSC/0.1% (w/v) SDS at 68 °C for10 min. The blots were developed with Hyperfilm (Amersham),using intensifying screens, at −80 °C.
2.3. Cell culture and transient transfection
The atrially derived cardiac muscle cell line HL-1 (a gene-rous gift from Dr. W. C. Claycomb, Louisiana State UniversityMedical Center) was plated in gelatin/fibronectin-coated culturevessels and maintained in Claycomb medium (JRH Bios-ciences) supplemented with 10% (v/v) fetal bovine serum (JRH,Lot No. 3J0229, no heat inactivation), 0.1 mM norepinephrine,2 mM L-glutamine, 100 U/ml penicillin and 100 U/mlstreptomycin [17]. The C2C12 and COS-7 cell lines (ATCC,Manassas, VA) were routinely propagated in a growth mediumconsisting of Dulbecco's modified Eagle's medium (GIBCO)with 10% (v/v) fetal bovine serum (GIBCO), 100 U/ml ofpenicillin and 100 μg/ml of streptomycin. Cells were main-tained in a 95% humidified chamber at 37 °C with 5% (v/v)CO2. Full-length cDNAs of the novel genes were inserted intothe pEGFP-N2 vector (Clontech). The cloning was designed togenerate a C-terminal green fluorescent protein (GFP) fusion ineach fusion protein. Transient transfection of clones wasachieved using the Lipofectamine™ 2000 and Lipofectamine™LTX transfection reagents. As controls, cells were transfectedwith the cDNA-pEGFP construct of calnexin (NM_007597) orstained with a mitochondrion-selective probe, MitoTracker®(Molecular Probe™). After 18–36 h, cells on the coverslip werefixed with 4% (v/v) paraformaldehyde and mounted on slides.
2.4. Calcium overlay assay
A PCR product corresponding to the entire coding region ofthe Mm.20818 gene was generated using gene-specific primerswith a 5′ EcoHI site and a 3′ XhoI site. After restrictiondigestion, the amplified product was ligated into the pGEX-5X-2 vector (Pahmarcia). The resulting construct was expressed inE. coli BL21. The calcium overlay technique was previouslydescribed [18]. In brief, proteins were transferred from gels tonitrocellulose membranes. The membranes were then washedthree times in a buffer (60 mM KCl, 5 mM MgCl2, 10 mMimidazole–HCl, pH 6.8) for 30 min, followed by probing with45[Ca]Cl2 at concentrations of 0.2–2.0 μM for up to 1 h. Afterprobing, the membranes were washed in 67% (v/v) ethanol,dried and subjected to autoradiography with X-ray film for1–3 days at −80 °C.
2.5. In silico analysis
The cDNA sequences of novel genes were subjected toBLAST analysis using software available in the database ofNCBI Mouse Genome Resources. The University of CaliforniaSanta Cruz (UCSC) Genome Bioinformatics Center (availableon the World Wide Web at genome.ucsc.edu/) provides workingdraft assemblies for a large collection of genomes. The datainclude chromosomal locations, exon–intron structures andanalyses of comparative genomics. The programs Goblet (avail-
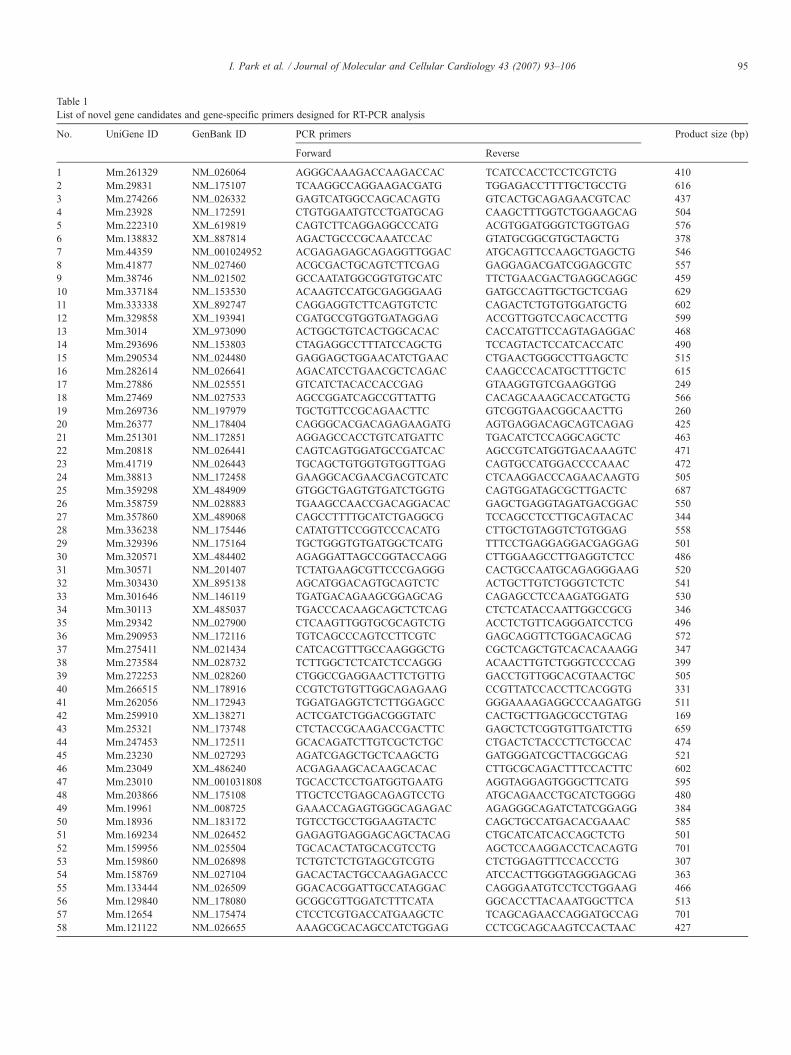
Table 1List of novel gene candidates and gene-specific primers designed for RT-PCR analysis
No. UniGene ID GenBank ID PCR primers Product size (bp)
Forward Reverse
1 Mm.261329 NM_026064 AGGGCAAAGACCAAGACCAC TCATCCACCTCCTCGTCTG 4102 Mm.29831 NM_175107 TCAAGGCCAGGAAGACGATG TGGAGACCTTTTGCTGCCTG 6163 Mm.274266 NM_026332 GAGTCATGGCCAGCACAGTG GTCACTGCAGAGAACGTCAC 4374 Mm.23928 NM_172591 CTGTGGAATGTCCTGATGCAG CAAGCTTTGGTCTGGAAGCAG 5045 Mm.222310 XM_619819 CAGTCTTCAGGAGGCCCATG ACGTGGATGGGTCTGGTGAG 5766 Mm.138832 XM_887814 AGACTGCCCGCAAATCCAC GTATGCGGCGTGCTAGCTG 3787 Mm.44359 NM_001024952 ACGAGAGAGCAGAGGTTGGAC ATGCAGTTCCAAGCTGAGCTG 5468 Mm.41877 NM_027460 ACGCGACTGCAGTCTTCGAG GAGGAGACGATCGGAGCGTC 5579 Mm.38746 NM_021502 GCCAATATGGCGGTGTGCATC TTCTGAACGACTGAGGCAGGC 45910 Mm.337184 NM_153530 ACAAGTCCATGCGAGGGAAG GATGCCAGTTGCTGCTCGAG 62911 Mm.333338 XM_892747 CAGGAGGTCTTCAGTGTCTC CAGACTCTGTGTGGATGCTG 60212 Mm.329858 XM_193941 CGATGCCGTGGTGATAGGAG ACCGTTGGTCCAGCACCTTG 59913 Mm.3014 XM_973090 ACTGGCTGTCACTGGCACAC CACCATGTTCCAGTAGAGGAC 46814 Mm.293696 NM_153803 CTAGAGGCCTTTATCCAGCTG TCCAGTACTCCATCACCATC 49015 Mm.290534 NM_024480 GAGGAGCTGGAACATCTGAAC CTGAACTGGGCCTTGAGCTC 51516 Mm.282614 NM_026641 AGACATCCTGAACGCTCAGAC CAAGCCCACATGCTTTGCTC 61517 Mm.27886 NM_025551 GTCATCTACACCACCGAG GTAAGGTGTCGAAGGTGG 24918 Mm.27469 NM_027533 AGCCGGATCAGCCGTTATTG CACAGCAAAGCACCATGCTG 56619 Mm.269736 NM_197979 TGCTGTTCCGCAGAACTTC GTCGGTGAACGGCAACTTG 26020 Mm.26377 NM_178404 CAGGGCACGACAGAGAAGATG AGTGAGGACAGCAGTCAGAG 42521 Mm.251301 NM_172851 AGGAGCCACCTGTCATGATTC TGACATCTCCAGGCAGCTC 46322 Mm.20818 NM_026441 CAGTCAGTGGATGCCGATCAC AGCCGTCATGGTGACAAAGTC 47123 Mm.41719 NM_026443 TGCAGCTGTGGTGTGGTTGAG CAGTGCCATGGACCCCAAAC 47224 Mm.38813 NM_172458 GAAGGCACGAACGACGTCATC CTCAAGGACCCAGAACAAGTG 50525 Mm.359298 XM_484909 GTGGCTGAGTGTGATCTGGTG CAGTGGATAGCGCTTGACTC 68726 Mm.358759 NM_028883 TGAAGCCAACCGACAGGACAC GAGCTGAGGTAGATGACGGAC 55027 Mm.357860 XM_489068 CAGCCTTTTGCATCTGAGGCG TCCAGCCTCCTTGCAGTACAC 34428 Mm.336238 NM_175446 CATATGTTCCGGTCCCACATG CTTGCTGTAGGTCTGTGGAG 55829 Mm.329396 NM_175164 TGCTGGGTGTGATGGCTCATG TTTCCTGAGGAGGACGAGGAG 50130 Mm.320571 XM_484402 AGAGGATTAGCCGGTACCAGG CTTGGAAGCCTTGAGGTCTCC 48631 Mm.30571 NM_201407 TCTATGAAGCGTTCCCGAGGG CACTGCCAATGCAGAGGGAAG 52032 Mm.303430 XM_895138 AGCATGGACAGTGCAGTCTC ACTGCTTGTCTGGGTCTCTC 54133 Mm.301646 NM_146119 TGATGACAGAAGCGGAGCAG CAGAGCCTCCAAGATGGATG 53034 Mm.30113 XM_485037 TGACCCACAAGCAGCTCTCAG CTCTCATACCAATTGGCCGCG 34635 Mm.29342 NM_027900 CTCAAGTTGGTGCGCAGTCTG ACCTCTGTTCAGGGATCCTCG 49636 Mm.290953 NM_172116 TGTCAGCCCAGTCCTTCGTC GAGCAGGTTCTGGACAGCAG 57237 Mm.275411 NM_021434 CATCACGTTTGCCAAGGGCTG CGCTCAGCTGTCACACAAAGG 34738 Mm.273584 NM_028732 TCTTGGCTCTCATCTCCAGGG ACAACTTGTCTGGGTCCCCAG 39939 Mm.272253 NM_028260 CTGGCCGAGGAACTTCTGTTG GACCTGTTGGCACGTAACTGC 50540 Mm.266515 NM_178916 CCGTCTGTGTTGGCAGAGAAG CCGTTATCCACCTTCACGGTG 33141 Mm.262056 NM_172943 TGGATGAGGTCTCTTGGAGCC GGGAAAAGAGGCCCAAGATGG 51142 Mm.259910 XM_138271 ACTCGATCTGGACGGGTATC CACTGCTTGAGCGCCTGTAG 16943 Mm.25321 NM_173748 CTCTACCGCAAGACCGACTTC GAGCTCTCGGTGTTGATCTTG 65944 Mm.247453 NM_172511 GCACAGATCTTGTCGCTCTGC CTGACTCTACCCTTCTGCCAC 47445 Mm.23230 NM_027293 AGATCGAGCTGCTCAAGCTG GATGGGATCGCTTACGGCAG 52146 Mm.23049 XM_486240 ACGAGAAGCACAAGCACAC CTTGCGCAGACTTTCCACTTC 60247 Mm.23010 NM_001031808 TGCACCTCCTGATGGTGAATG AGGTAGGAGTGGGCTTCATG 59548 Mm.203866 NM_175108 TTGCTCCTGAGCAGAGTCCTG ATGCAGAACCTGCATCTGGGG 48049 Mm.19961 NM_008725 GAAACCAGAGTGGGCAGAGAC AGAGGGCAGATCTATCGGAGG 38450 Mm.18936 NM_183172 TGTCCTGCCTGGAAGTACTC CAGCTGCCATGACACGAAAC 58551 Mm.169234 NM_026452 GAGAGTGAGGAGCAGCTACAG CTGCATCATCACCAGCTCTG 50152 Mm.159956 NM_025504 TGCACACTATGCACGTCCTG AGCTCCAAGGACCTCACAGTG 70153 Mm.159860 NM_026898 TCTGTCTCTGTAGCGTCGTG CTCTGGAGTTTCCACCCTG 30754 Mm.158769 NM_027104 GACACTACTGCCAAGAGACCC ATCCACTTGGGTAGGGAGCAG 36355 Mm.133444 NM_026509 GGACACGGATTGCCATAGGAC CAGGGAATGTCCTCCTGGAAG 46656 Mm.129840 NM_178080 GCGGCGTTGGATCTTTCATA GGCACCTTACAAATGGCTTCA 51357 Mm.12654 NM_175474 CTCCTCGTGACCATGAAGCTC TCAGCAGAACCAGGATGCCAG 70158 Mm.121122 NM_026655 AAAGCGCACAGCCATCTGGAG CCTCGCAGCAAGTCCACTAAC 427
95I. Park et al. / Journal of Molecular and Cellular Cardiology 43 (2007) 93–106
96 I. Park et al. / Journal of Molecular and Cellular Cardiology 43 (2007) 93–106
able on the World Wide Web at goblet.molgen.mpg.de/cgi-bin/GOblet.cgi) and AmiGO (available on the World Wide Web atgodatabase.org/cgi-bin/go.cgi) were used to predict gene onto-logy. Amino acid sequences deduced from cDNA sequences ofnovel genes were analyzed using several computational bioinfor-matics tools. The SignalP and TMHMM (available on the WorldWide Web at www.cbs.dtu.dk/services/) and InterProScan (avail-able on the World Wide Web at www.ebi.ac.uk/InterProScan/)programs were used.
2.6. Preprocessing of heart-Related microarray data andidentification of putative neighbor genes
Gene Expression Omnibus (GEO) is a public repository formicroarray studies, in which the novel genes are included in
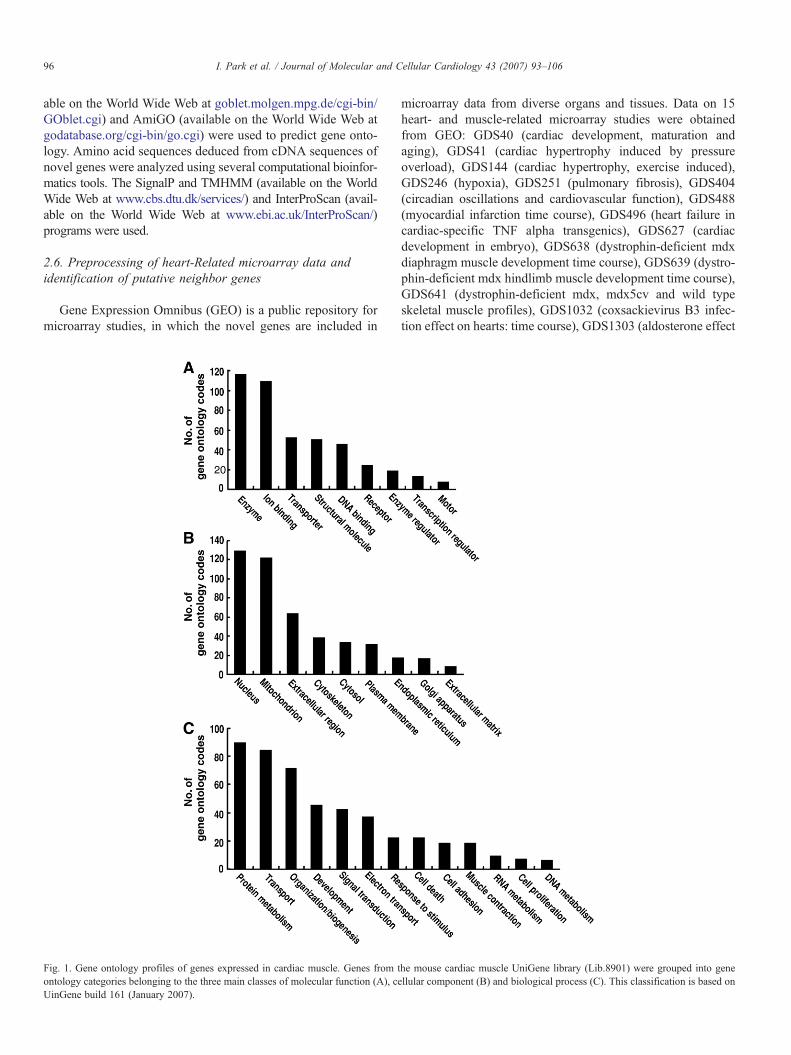
Fig. 1. Gene ontology profiles of genes expressed in cardiac muscle. Genes from tontology categories belonging to the three main classes of molecular function (A), ceUinGene build 161 (January 2007).
microarray data from diverse organs and tissues. Data on 15heart- and muscle-related microarray studies were obtainedfrom GEO: GDS40 (cardiac development, maturation andaging), GDS41 (cardiac hypertrophy induced by pressureoverload), GDS144 (cardiac hypertrophy, exercise induced),GDS246 (hypoxia), GDS251 (pulmonary fibrosis), GDS404(circadian oscillations and cardiovascular function), GDS488(myocardial infarction time course), GDS496 (heart failure incardiac-specific TNF alpha transgenics), GDS627 (cardiacdevelopment in embryo), GDS638 (dystrophin-deficient mdxdiaphragm muscle development time course), GDS639 (dystro-phin-deficient mdx hindlimb muscle development time course),GDS641 (dystrophin-deficient mdx, mdx5cv and wild typeskeletal muscle profiles), GDS1032 (coxsackievirus B3 infec-tion effect on hearts: time course), GDS1303 (aldosterone effect
he mouse cardiac muscle UniGene library (Lib.8901) were grouped into genellular component (B) and biological process (C). This classification is based on

Table 2Classification and selection of genes in the cardiac muscle UniGene library
Genes Number
Total entries 827Known 671
97I. Park et al. / Journal of Molecular and Cellular Cardiology 43 (2007) 93–106
on heart: time course) and GDS1306 (MAP kinase activationeffect on heart: time course). The redundant expression profilesfor any one gene were recalculated to obtain representativeexpression profiles. Then, UniGene identifiers were assignedusing chip information from GEO. To obtain a correlationcoefficient reflecting gene expression reliability across the 15microarray data sets, a procedure merging the data sets into asingle expression profile was followed. Here, we used a bypassto reject all genes having uneven distributions in the differentmicroarray studies and we obtained accurate correlationcoefficients as follows. Using the 15 heart-related microarraystudies, the Pearson's correlation coefficient (PCC) between theexpression levels of gene pairs was calculated to help identifynovel cardiac genes on the basis of tissue-specific co-expression.The formula used was:
r ¼nðXni¼0
XiYiÞ�Xni¼0
Xi
Xni¼0
Y iffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffinXni¼0
X 2i �
Xni¼0
ðX 2i Þ
" #nXni¼0
Y 2i �
Xni¼0
ðY 2i Þ
" #vuut
where r is PCC, X and Y are measures of gene expression and nrepresents the number of experiments from which data aretaken. The PCC values were calculated in two different con-texts. First, individual PCC values, from each microarray study,were calculated to reflect dynamic gene expression relation-ships under different heart-related conditions. Second, overallPCC values from integrated expression profiles across the 15microarray studies were calculated to obtain static gene ex-pression relationships in heart tissue. To validate the signifi-cance of PCC data, χ2 analyses were performed in comparisonwith randomly constructed expression profiles created byartificial, arbitrary selection of genes and experimental condi-tions in microarray data. P-values of b10−5 were consideredsignificant. The final selection criteria for genes with relatedexpression levels were as follows. First, the overall PCC,indicating a static functional gene relationship in the heart, wasN0.8. Second, a strong relationship, defined as a PCC N0.9, waspresent in at least 25% of the microarray studies. Third, theminimum PCC (N0.7) identifying a functional relationship wassatisfied in at least 75% of the microarray studies. Finally, atleast 50% of the PCC values from each microarray study wereN0.8 to support the notion that valid functional relationshipswere under study.
Unknown 156Full-length genes 110Genes with GO and domain/motif 58Genes with cardiac expression (RT-PCR) 41Genes with similar or higher expression level in heart,compared to other tissue (RT-PCR)
26
Genes with abundant expression (Northern blot) 15
Genes in the cardiac muscle UniGene library (as of January 2005) were class-ified into known and unknown genes. Of unknown genes, partial length geneswere excluded. Then, genes with gene ontology (GO) data, i.e. informationabout the molecular function, biological process and cellular component of geneproducts, or with known domains or motifs, were selected. These genes wereanalyzed in vitro to select authentic genes with abundant cardiac expression.
3. Results
3.1. The cardiac muscle library and in silico analysis to selectnovel gene candidates
Lib.8901, one of the UniGene libraries deposited in theUniGene database at NCBI (www.ncbi.nlm.nih.gov), is a col-lection of genes expressed in mouse cardiac muscle and con-tains 827 UniGene entries (as of January 2005). To gain aninsight into the characteristics of the cardiac muscle library, we
analyzed the genes in the library based on gene ontology codesthat provide information about cellular component, molecularfunction and biological process (Fig. 1). The overall gene onto-logy feature of these genes was similar to that of genome-widegenes in mouse [19], except for the notable expansion in thecategory of mitochondrial genes. This reflects the active aerobicmetabolism required for muscle contraction and is consistentwith the abundance (25%) of this organelle in the cardiacmuscle cells.
To identify and investigate novel genes expressed in cardiacmuscle, we sorted genes in the library based on the followingcriteria. Genes previously named with known or potentialfunctions were considered to be known genes, while unnamedgenes with unassigned functions were regarded to indicateunknown or novel genes. This classification of the 827 geneentries disclosed that 671 (81%) are known genes, and 156genes (19%) are unknown or novel (Tables 2 and 3). To selectmore principal and reliable genes, we further analyzed the 156genes whether they have mRNAs with poly (A). As a result, weidentified 110 gene entries with potential full-length transcriptsequences. Gene ontology data and indications of putativeprotein domains and motifs were also criteria for more effectiveselection of novel genes. Using these processes, the potential110 novel genes were narrowed down to 58 candidates. Thesegenes further analyzed in vitro (Tables 1–3).
3.2. Cardiac expression of the novel genes
To determine whether the candidates selected from the Uni-Gene library are true novel genes with cardiac expression, weperformed various expression analyses (Tables 1–3). RT-PCRanalysis showed that 41 of the 58 candidates are expressed withthe expected sizes in mouse heart. However, no PCR productswere detected for the other 17 candidates in the heart. Thus, theywere excluded from further analysis. It should be noted thatPCR was designed to be similar among the candidates in primerproperty and product size, and reaction condition was the samefor all the candidates. The 41 gene candidates were furtherexamined for tissue distribution using mouse cDNAs from
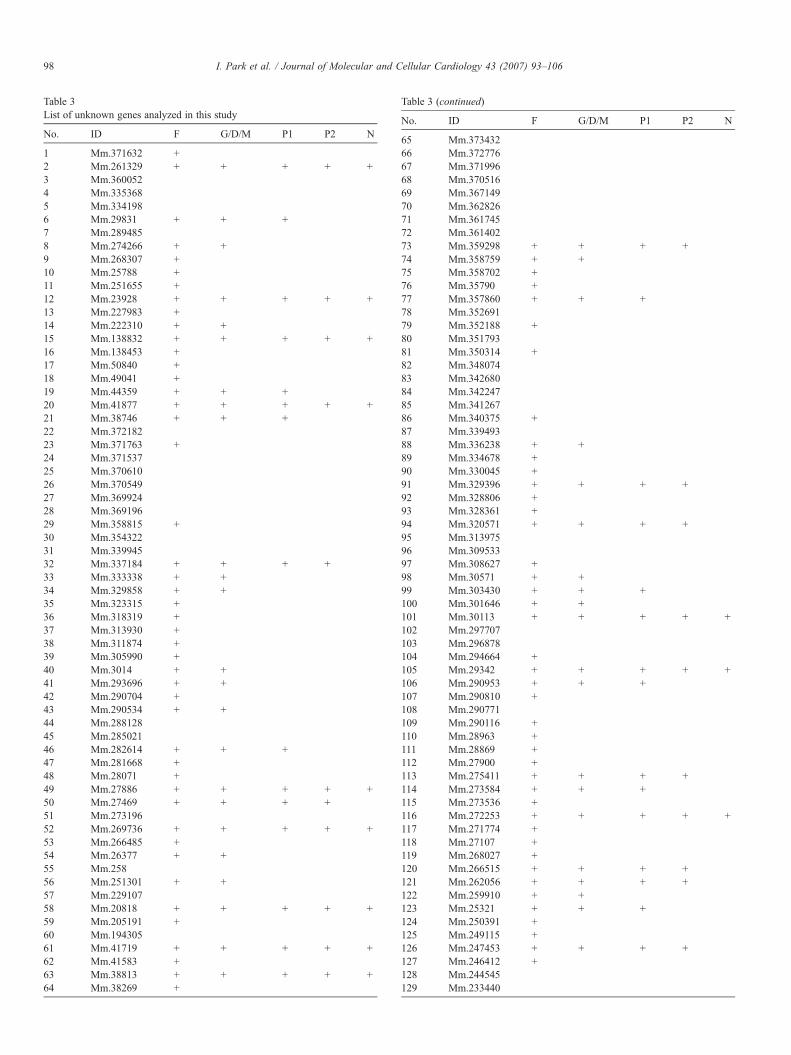
Table 3List of unknown genes analyzed in this study
No. ID F G/D/M P1 P2 N
1 Mm.371632 +2 Mm.261329 + + + + +3 Mm.3600524 Mm.3353685 Mm.3341986 Mm.29831 + + +7 Mm.2894858 Mm.274266 + +9 Mm.268307 +10 Mm.25788 +11 Mm.251655 +12 Mm.23928 + + + + +13 Mm.227983 +14 Mm.222310 + +15 Mm.138832 + + + + +16 Mm.138453 +17 Mm.50840 +18 Mm.49041 +19 Mm.44359 + + +20 Mm.41877 + + + + +21 Mm.38746 + + +22 Mm.37218223 Mm.371763 +24 Mm.37153725 Mm.37061026 Mm.37054927 Mm.36992428 Mm.36919629 Mm.358815 +30 Mm.35432231 Mm.33994532 Mm.337184 + + + +33 Mm.333338 + +34 Mm.329858 + +35 Mm.323315 +36 Mm.318319 +37 Mm.313930 +38 Mm.311874 +39 Mm.305990 +40 Mm.3014 + +41 Mm.293696 + +42 Mm.290704 +43 Mm.290534 + +44 Mm.28812845 Mm.28502146 Mm.282614 + + +47 Mm.281668 +48 Mm.28071 +49 Mm.27886 + + + + +50 Mm.27469 + + + +51 Mm.27319652 Mm.269736 + + + + +53 Mm.266485 +54 Mm.26377 + +55 Mm.25856 Mm.251301 + +57 Mm.22910758 Mm.20818 + + + + +59 Mm.205191 +60 Mm.19430561 Mm.41719 + + + + +62 Mm.41583 +63 Mm.38813 + + + + +64 Mm.38269 +
Table 3 (continued)
No. ID F G/D/M P1 P2 N
65 Mm.37343266 Mm.37277667 Mm.37199668 Mm.37051669 Mm.36714970 Mm.36282671 Mm.36174572 Mm.36140273 Mm.359298 + + + +74 Mm.358759 + +75 Mm.358702 +76 Mm.35790 +77 Mm.357860 + + +78 Mm.35269179 Mm.352188 +80 Mm.35179381 Mm.350314 +82 Mm.34807483 Mm.34268084 Mm.34224785 Mm.34126786 Mm.340375 +87 Mm.33949388 Mm.336238 + +89 Mm.334678 +90 Mm.330045 +91 Mm.329396 + + + +92 Mm.328806 +93 Mm.328361 +94 Mm.320571 + + + +95 Mm.31397596 Mm.30953397 Mm.308627 +98 Mm.30571 + +99 Mm.303430 + + +100 Mm.301646 + +101 Mm.30113 + + + + +102 Mm.297707103 Mm.296878104 Mm.294664 +105 Mm.29342 + + + + +106 Mm.290953 + + +107 Mm.290810 +108 Mm.290771109 Mm.290116 +110 Mm.28963 +111 Mm.28869 +112 Mm.27900 +113 Mm.275411 + + + +114 Mm.273584 + + +115 Mm.273536 +116 Mm.272253 + + + + +117 Mm.271774 +118 Mm.27107 +119 Mm.268027 +120 Mm.266515 + + + +121 Mm.262056 + + + +122 Mm.259910 + +123 Mm.25321 + + +124 Mm.250391 +125 Mm.249115 +126 Mm.247453 + + + +127 Mm.246412 +128 Mm.244545129 Mm.233440
98 I. Park et al. / Journal of Molecular and Cellular Cardiology 43 (2007) 93–106
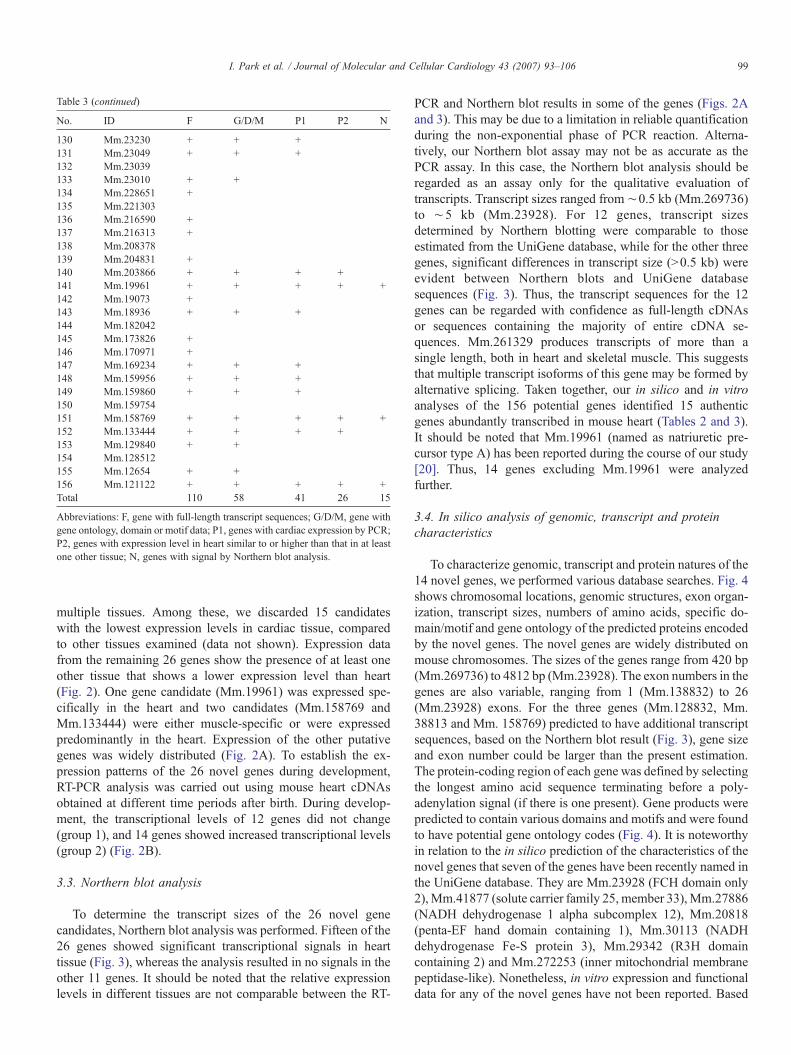
Table 3 (continued)
No. ID F G/D/M P1 P2 N
130 Mm.23230 + + +131 Mm.23049 + + +132 Mm.23039133 Mm.23010 + +134 Mm.228651 +135 Mm.221303136 Mm.216590 +137 Mm.216313 +138 Mm.208378139 Mm.204831 +140 Mm.203866 + + + +141 Mm.19961 + + + + +142 Mm.19073 +143 Mm.18936 + + +144 Mm.182042145 Mm.173826 +146 Mm.170971 +147 Mm.169234 + + +148 Mm.159956 + + +149 Mm.159860 + + +150 Mm.159754151 Mm.158769 + + + + +152 Mm.133444 + + + +153 Mm.129840 + +154 Mm.128512155 Mm.12654 + +156 Mm.121122 + + + + +Total 110 58 41 26 15
Abbreviations: F, gene with full-length transcript sequences; G/D/M, gene withgene ontology, domain or motif data; P1, genes with cardiac expression by PCR;P2, genes with expression level in heart similar to or higher than that in at leastone other tissue; N, genes with signal by Northern blot analysis.
99I. Park et al. / Journal of Molecular and Cellular Cardiology 43 (2007) 93–106
multiple tissues. Among these, we discarded 15 candidateswith the lowest expression levels in cardiac tissue, comparedto other tissues examined (data not shown). Expression datafrom the remaining 26 genes show the presence of at least oneother tissue that shows a lower expression level than heart(Fig. 2). One gene candidate (Mm.19961) was expressed spe-cifically in the heart and two candidates (Mm.158769 andMm.133444) were either muscle-specific or were expressedpredominantly in the heart. Expression of the other putativegenes was widely distributed (Fig. 2A). To establish the ex-pression patterns of the 26 novel genes during development,RT-PCR analysis was carried out using mouse heart cDNAsobtained at different time periods after birth. During develop-ment, the transcriptional levels of 12 genes did not change(group 1), and 14 genes showed increased transcriptional levels(group 2) (Fig. 2B).
3.3. Northern blot analysis
To determine the transcript sizes of the 26 novel genecandidates, Northern blot analysis was performed. Fifteen of the26 genes showed significant transcriptional signals in hearttissue (Fig. 3), whereas the analysis resulted in no signals in theother 11 genes. It should be noted that the relative expressionlevels in different tissues are not comparable between the RT-
PCR and Northern blot results in some of the genes (Figs. 2Aand 3). This may be due to a limitation in reliable quantificationduring the non-exponential phase of PCR reaction. Alterna-tively, our Northern blot assay may not be as accurate as thePCR assay. In this case, the Northern blot analysis should beregarded as an assay only for the qualitative evaluation oftranscripts. Transcript sizes ranged from ∼0.5 kb (Mm.269736)to ∼5 kb (Mm.23928). For 12 genes, transcript sizesdetermined by Northern blotting were comparable to thoseestimated from the UniGene database, while for the other threegenes, significant differences in transcript size (N0.5 kb) wereevident between Northern blots and UniGene databasesequences (Fig. 3). Thus, the transcript sequences for the 12genes can be regarded with confidence as full-length cDNAsor sequences containing the majority of entire cDNA se-quences. Mm.261329 produces transcripts of more than asingle length, both in heart and skeletal muscle. This suggeststhat multiple transcript isoforms of this gene may be formed byalternative splicing. Taken together, our in silico and in vitroanalyses of the 156 potential genes identified 15 authenticgenes abundantly transcribed in mouse heart (Tables 2 and 3).It should be noted that Mm.19961 (named as natriuretic pre-cursor type A) has been reported during the course of our study[20]. Thus, 14 genes excluding Mm.19961 were analyzedfurther.
3.4. In silico analysis of genomic, transcript and proteincharacteristics
To characterize genomic, transcript and protein natures of the14 novel genes, we performed various database searches. Fig. 4shows chromosomal locations, genomic structures, exon organ-ization, transcript sizes, numbers of amino acids, specific do-main/motif and gene ontology of the predicted proteins encodedby the novel genes. The novel genes are widely distributed onmouse chromosomes. The sizes of the genes range from 420 bp(Mm.269736) to 4812 bp (Mm.23928). The exon numbers in thegenes are also variable, ranging from 1 (Mm.138832) to 26(Mm.23928) exons. For the three genes (Mm.128832, Mm.38813 and Mm. 158769) predicted to have additional transcriptsequences, based on the Northern blot result (Fig. 3), gene sizeand exon number could be larger than the present estimation.The protein-coding region of each gene was defined by selectingthe longest amino acid sequence terminating before a poly-adenylation signal (if there is one present). Gene products werepredicted to contain various domains and motifs and were foundto have potential gene ontology codes (Fig. 4). It is noteworthyin relation to the in silico prediction of the characteristics of thenovel genes that seven of the genes have been recently named inthe UniGene database. They are Mm.23928 (FCH domain only2),Mm.41877 (solute carrier family 25, member 33),Mm.27886(NADH dehydrogenase 1 alpha subcomplex 12), Mm.20818(penta-EF hand domain containing 1), Mm.30113 (NADHdehydrogenase Fe-S protein 3), Mm.29342 (R3H domaincontaining 2) and Mm.272253 (inner mitochondrial membranepeptidase-like). Nonetheless, in vitro expression and functionaldata for any of the novel genes have not been reported. Based

Fig. 2. Tissue distribution and developmental expression patterns of 26 novel gene candidates. (A) Tissue distribution of the genes by RT-PCR analysis in varioustissues of adult male mice. B, brain; H, heart; K, kidney; Li, liver; Lu, lung; Ov, ovary; Sk, skeletal muscle; Sp, spleen; T, testis. (B) Expression of the candidates inheart during development. Gene expression was analyzed by PCR using cDNAs prepared from postnatal hearts obtained at different days during mouse development.Fifteen of these 26 genes, found to show significant Northern signals (Fig. 3) and thus, analyzed further in this study, are indicated by vertical bars. To insure the use ofthe equivalent amounts of cDNA templates among different tissues (A) and different developmental stages (B), template amounts were normalized prior to PCRreaction of the novel genes, based on the expression levels of the glyceraldehyde-3-phosphate dehydrogenase (Gapdh) gene.
100 I. Park et al. / Journal of Molecular and Cellular Cardiology 43 (2007) 93–106
on the in silico information, proteins encoded by the novel genesmight be implicated in calcium metabolism (Mm.261329 andMm.20818), mitochondrial functions (Mm.41877, Mm.27866,Mm.269736, Mm.41719, Mm.30113 and Mm.272253), tran-scription and/or nuclear activity (Mm.138832, Mm.38813 andMm.29342), cell structure (Mm.158769) and transmembranetransport (Mm.121122).
3.5. Expression and localization of the novel proteins
To explore the characteristics of the novel genes at theprotein and cellular levels [21], GFP-tagged full-length genesequences were transiently transfected into various cell linessuch as HL-1 (mouse cardiac muscle cells), C2C12 (mouseskeletal muscle myoblast cells) and COS-7 (monkey kidneycells) [17,22,23]. We observed GFP signals from most of thenovel genes, except for Mm.29342 (Fig. 5). The cDNA se-
quence for Mm.29342 may not code for a protein, or expressionof Mm.29342 could be highly transient, very low in amount ordelayed. Proteins tagged with GFP were found to distribute tovarious subcellular organelles, such as nucleus (Mm.261329,Mm.138832, Mm.41877, Mm.27886, Mm.269736, Mm.20818,Mm.38813 and Mm.30113), cytoplasm (Mm.261329,Mm.23928, Mm.41877, Mm.27886, Mm.269736, Mm.20818,Mm.41719, Mm.38813, Mm.30113, Mm.272253, Mm.158769and Mm.121122), mitochondria (Mm. 41719 and Mm.272253),cytoskeleton (Mm.30113) and endoplasmic reticulum(Mm.158769) (Fig. 5). It is important to note that localizationpatterns are highly consistent between cell types in the majorityof the genes. Another notable feature in the distribution patternsis that several gene products are located in more than onecompartment. We next compared bioinformatic information(Fig. 4) with the actual localizations of the gene products (Fig.5). The in silico information and localization data were
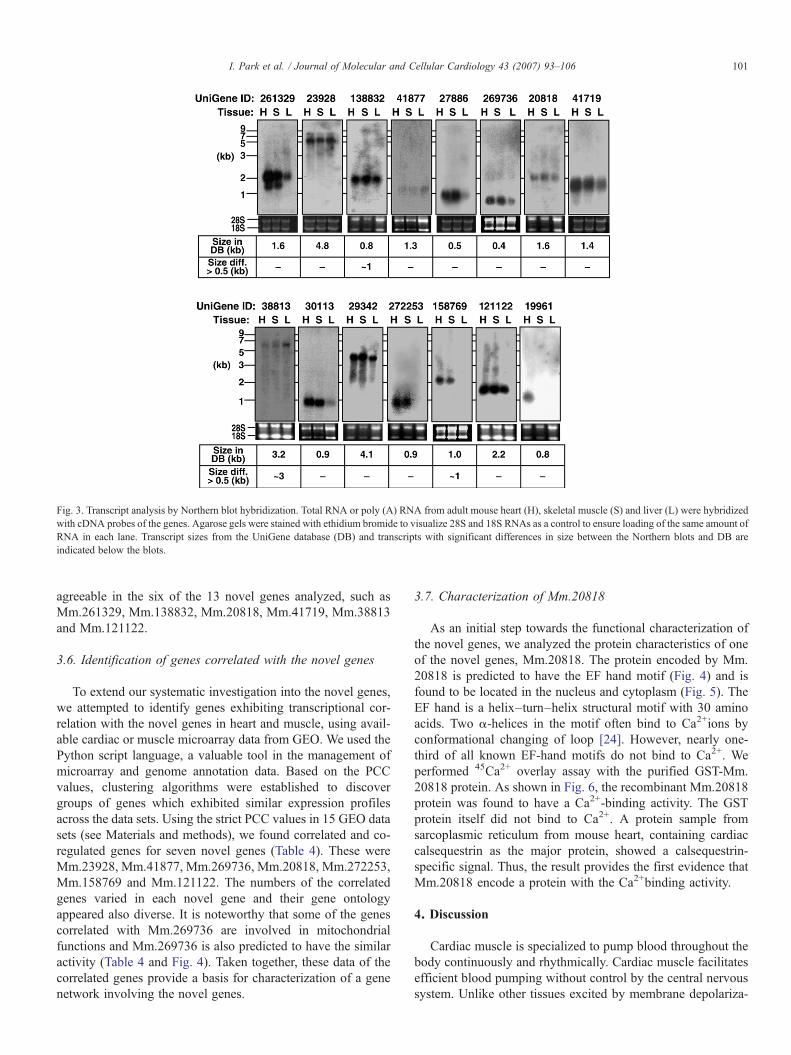
Fig. 3. Transcript analysis by Northern blot hybridization. Total RNA or poly (A) RNA from adult mouse heart (H), skeletal muscle (S) and liver (L) were hybridizedwith cDNA probes of the genes. Agarose gels were stained with ethidium bromide to visualize 28S and 18S RNAs as a control to ensure loading of the same amount ofRNA in each lane. Transcript sizes from the UniGene database (DB) and transcripts with significant differences in size between the Northern blots and DB areindicated below the blots.
101I. Park et al. / Journal of Molecular and Cellular Cardiology 43 (2007) 93–106
agreeable in the six of the 13 novel genes analyzed, such asMm.261329, Mm.138832, Mm.20818, Mm.41719, Mm.38813and Mm.121122.
3.6. Identification of genes correlated with the novel genes
To extend our systematic investigation into the novel genes,we attempted to identify genes exhibiting transcriptional cor-relation with the novel genes in heart and muscle, using avail-able cardiac or muscle microarray data from GEO. We used thePython script language, a valuable tool in the management ofmicroarray and genome annotation data. Based on the PCCvalues, clustering algorithms were established to discovergroups of genes which exhibited similar expression profilesacross the data sets. Using the strict PCC values in 15 GEO datasets (see Materials and methods), we found correlated and co-regulated genes for seven novel genes (Table 4). These wereMm.23928, Mm.41877, Mm.269736, Mm.20818, Mm.272253,Mm.158769 and Mm.121122. The numbers of the correlatedgenes varied in each novel gene and their gene ontologyappeared also diverse. It is noteworthy that some of the genescorrelated with Mm.269736 are involved in mitochondrialfunctions and Mm.269736 is also predicted to have the similaractivity (Table 4 and Fig. 4). Taken together, these data of thecorrelated genes provide a basis for characterization of a genenetwork involving the novel genes.
3.7. Characterization of Mm.20818
As an initial step towards the functional characterization ofthe novel genes, we analyzed the protein characteristics of oneof the novel genes, Mm.20818. The protein encoded by Mm.20818 is predicted to have the EF hand motif (Fig. 4) and isfound to be located in the nucleus and cytoplasm (Fig. 5). TheEF hand is a helix–turn–helix structural motif with 30 aminoacids. Two α-helices in the motif often bind to Ca2+ions byconformational changing of loop [24]. However, nearly one-third of all known EF-hand motifs do not bind to Ca2+. Weperformed 45Ca2+ overlay assay with the purified GST-Mm.20818 protein. As shown in Fig. 6, the recombinant Mm.20818protein was found to have a Ca2+-binding activity. The GSTprotein itself did not bind to Ca2+. A protein sample fromsarcoplasmic reticulum from mouse heart, containing cardiaccalsequestrin as the major protein, showed a calsequestrin-specific signal. Thus, the result provides the first evidence thatMm.20818 encode a protein with the Ca2+binding activity.
4. Discussion
Cardiac muscle is specialized to pump blood throughout thebody continuously and rhythmically. Cardiac muscle facilitatesefficient blood pumping without control by the central nervoussystem. Unlike other tissues excited by membrane depolariza-

Fig. 4. Genomic, transcript and protein characteristics of the novel genes in silico. The chromosomal locations of the novel genes, their structure and intron–exonorganization were determined by genome database searches. Vertical bars and connecting horizontal lines show exons and introns, respectively. The directions oftranscription are indicated by arrows. Coding regions were determined by selecting the longest open reading frames deduced from the cDNA sequences and thepredicted coding regions are shaded. Putative domains or motifs are indicated and shaded. FCH, Fes/CIP4 (Cdc42-interacting protein 4) homology domain; Mito_carr,mitochondrial carrier protein; Complex1_17_2 kDa, NADH dehydrogenase; FRQ1, Frequenin 1; Q9CZX4, mitochondrial 18 kDa protein (MTP18); KRAB,Krueppel-associated box; Complex1_30 kDa, NADH dehydrogenase; Encore_like_R3H, the R3H domain containing an invariant arginine and a highly conservedhistidine; Peptidase_S26, signal peptidase I; ABC transport, ATP-binding cassette.
102 I. Park et al. / Journal of Molecular and Cellular Cardiology 43 (2007) 93–106
tion, cardiac excitation and contraction coupling occurs uponpolarization. When the pacemaker produces an excitationsignal, the atria and ventricles contract sequentially. To maintainpumping at a constant rate, the heart provides its own energy.Many protein complexes are required for the physiological,energetic and mechanical cardiac functions. This suggests thatmany cardiac genes elaborately regulate cardiac behavior andfunction. To understand the heart in depth, identification of
systematic networks in cardiac regulation is required at both thegene and protein levels.
Our inclusive approach to the discovery of novel genes fromcardiac muscle uses databases and computational bioinfor-matics tools. UniGene provides information on gene-orientedclusters and also on tissue specificities of gene expression.UniGene is a powerful tool, offering an organized view of thetranscriptosome, with frequent updates and convenient linkages
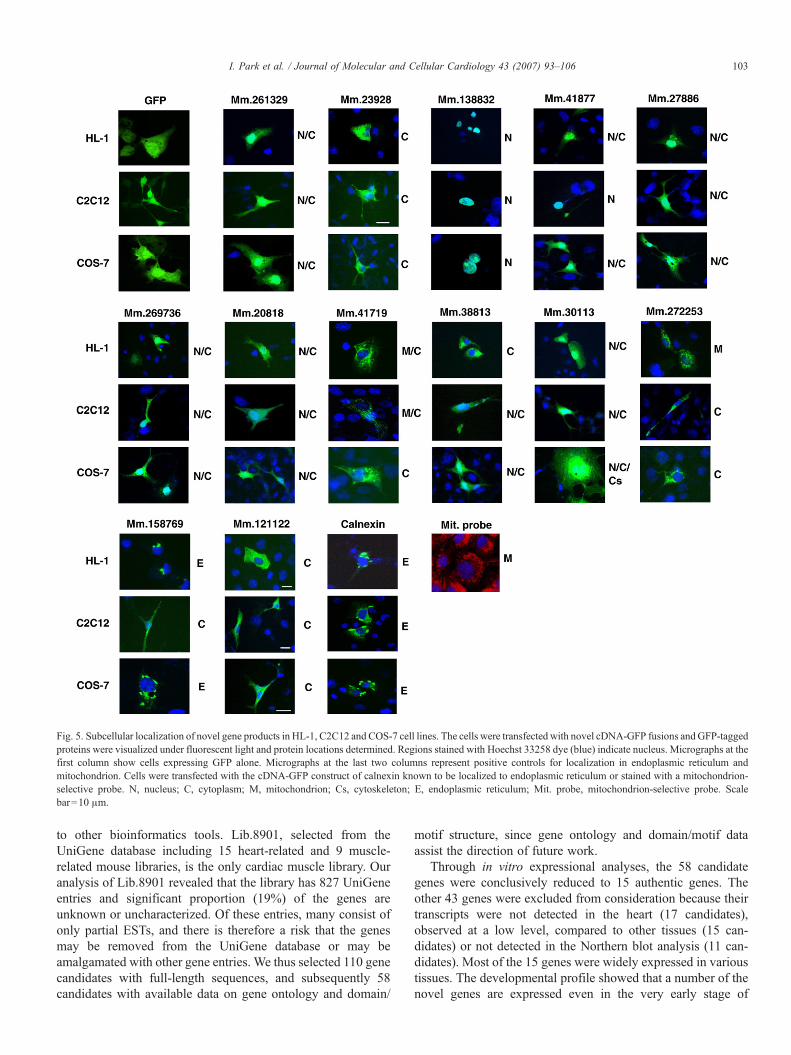
Fig. 5. Subcellular localization of novel gene products in HL-1, C2C12 and COS-7 cell lines. The cells were transfected with novel cDNA-GFP fusions andGFP-taggedproteins were visualized under fluorescent light and protein locations determined. Regions stained with Hoechst 33258 dye (blue) indicate nucleus. Micrographs at thefirst column show cells expressing GFP alone. Micrographs at the last two columns represent positive controls for localization in endoplasmic reticulum andmitochondrion. Cells were transfected with the cDNA-GFP construct of calnexin known to be localized to endoplasmic reticulum or stained with a mitochondrion-selective probe. N, nucleus; C, cytoplasm; M, mitochondrion; Cs, cytoskeleton; E, endoplasmic reticulum; Mit. probe, mitochondrion-selective probe. Scalebar=10 μm.
103I. Park et al. / Journal of Molecular and Cellular Cardiology 43 (2007) 93–106
to other bioinformatics tools. Lib.8901, selected from theUniGene database including 15 heart-related and 9 muscle-related mouse libraries, is the only cardiac muscle library. Ouranalysis of Lib.8901 revealed that the library has 827 UniGeneentries and significant proportion (19%) of the genes areunknown or uncharacterized. Of these entries, many consist ofonly partial ESTs, and there is therefore a risk that the genesmay be removed from the UniGene database or may beamalgamated with other gene entries. We thus selected 110 genecandidates with full-length sequences, and subsequently 58candidates with available data on gene ontology and domain/
motif structure, since gene ontology and domain/motif dataassist the direction of future work.
Through in vitro expressional analyses, the 58 candidategenes were conclusively reduced to 15 authentic genes. Theother 43 genes were excluded from consideration because theirtranscripts were not detected in the heart (17 candidates),observed at a low level, compared to other tissues (15 can-didates) or not detected in the Northern blot analysis (11 can-didates). Most of the 15 genes were widely expressed in varioustissues. The developmental profile showed that a number of thenovel genes are expressed even in the very early stage of
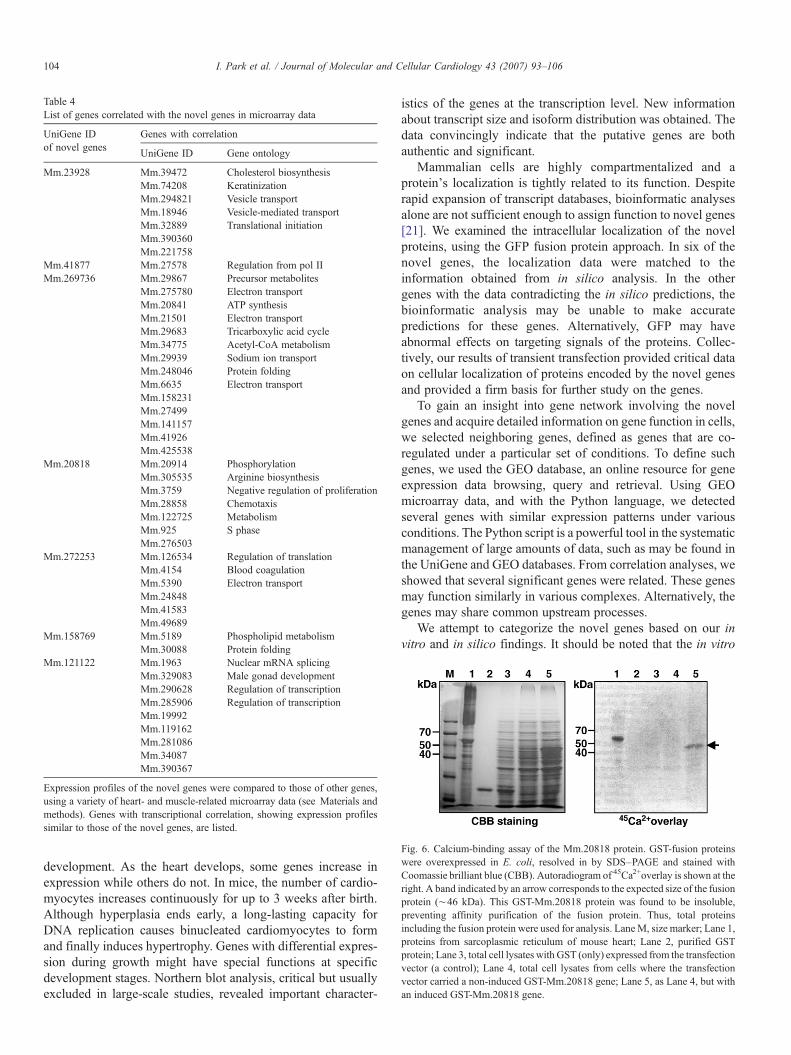
Table 4List of genes correlated with the novel genes in microarray data
UniGene IDof novel genes
Genes with correlation
UniGene ID Gene ontology
Mm.23928 Mm.39472 Cholesterol biosynthesisMm.74208 KeratinizationMm.294821 Vesicle transportMm.18946 Vesicle-mediated transportMm.32889 Translational initiationMm.390360Mm.221758
Mm.41877 Mm.27578 Regulation from pol IIMm.269736 Mm.29867 Precursor metabolites
Mm.275780 Electron transportMm.20841 ATP synthesisMm.21501 Electron transportMm.29683 Tricarboxylic acid cycleMm.34775 Acetyl-CoA metabolismMm.29939 Sodium ion transportMm.248046 Protein foldingMm.6635 Electron transportMm.158231Mm.27499Mm.141157Mm.41926Mm.425538
Mm.20818 Mm.20914 PhosphorylationMm.305535 Arginine biosynthesisMm.3759 Negative regulation of proliferationMm.28858 ChemotaxisMm.122725 MetabolismMm.925 S phaseMm.276503
Mm.272253 Mm.126534 Regulation of translationMm.4154 Blood coagulationMm.5390 Electron transportMm.24848Mm.41583Mm.49689
Mm.158769 Mm.5189 Phospholipid metabolismMm.30088 Protein folding
Mm.121122 Mm.1963 Nuclear mRNA splicingMm.329083 Male gonad developmentMm.290628 Regulation of transcriptionMm.285906 Regulation of transcriptionMm.19992Mm.119162Mm.281086Mm.34087Mm.390367
Expression profiles of the novel genes were compared to those of other genes,using a variety of heart- and muscle-related microarray data (see Materials andmethods). Genes with transcriptional correlation, showing expression profilessimilar to those of the novel genes, are listed.
Fig. 6. Calcium-binding assay of the Mm.20818 protein. GST-fusion proteinswere overexpressed in E. coli, resolved in by SDS–PAGE and stained withCoomassie brilliant blue (CBB). Autoradiogram of 45Ca2+overlay is shown at theright. A band indicated by an arrow corresponds to the expected size of the fusionprotein (∼46 kDa). This GST-Mm.20818 protein was found to be insoluble,preventing affinity purification of the fusion protein. Thus, total proteinsincluding the fusion protein were used for analysis. LaneM, size marker; Lane 1,proteins from sarcoplasmic reticulum of mouse heart; Lane 2, purified GSTprotein; Lane 3, total cell lysates with GST (only) expressed from the transfectionvector (a control); Lane 4, total cell lysates from cells where the transfectionvector carried a non-induced GST-Mm.20818 gene; Lane 5, as Lane 4, but withan induced GST-Mm.20818 gene.
104 I. Park et al. / Journal of Molecular and Cellular Cardiology 43 (2007) 93–106
development. As the heart develops, some genes increase inexpression while others do not. In mice, the number of cardio-myocytes increases continuously for up to 3 weeks after birth.Although hyperplasia ends early, a long-lasting capacity forDNA replication causes binucleated cardiomyocytes to formand finally induces hypertrophy. Genes with differential expres-sion during growth might have special functions at specificdevelopment stages. Northern blot analysis, critical but usuallyexcluded in large-scale studies, revealed important character-
istics of the genes at the transcription level. New informationabout transcript size and isoform distribution was obtained. Thedata convincingly indicate that the putative genes are bothauthentic and significant.
Mammalian cells are highly compartmentalized and aprotein's localization is tightly related to its function. Despiterapid expansion of transcript databases, bioinformatic analysesalone are not sufficient enough to assign function to novel genes[21]. We examined the intracellular localization of the novelproteins, using the GFP fusion protein approach. In six of thenovel genes, the localization data were matched to theinformation obtained from in silico analysis. In the othergenes with the data contradicting the in silico predictions, thebioinformatic analysis may be unable to make accuratepredictions for these genes. Alternatively, GFP may haveabnormal effects on targeting signals of the proteins. Collec-tively, our results of transient transfection provided critical dataon cellular localization of proteins encoded by the novel genesand provided a firm basis for further study on the genes.
To gain an insight into gene network involving the novelgenes and acquire detailed information on gene function in cells,we selected neighboring genes, defined as genes that are co-regulated under a particular set of conditions. To define suchgenes, we used the GEO database, an online resource for geneexpression data browsing, query and retrieval. Using GEOmicroarray data, and with the Python language, we detectedseveral genes with similar expression patterns under variousconditions. The Python script is a powerful tool in the systematicmanagement of large amounts of data, such as may be found inthe UniGene and GEO databases. From correlation analyses, weshowed that several significant genes were related. These genesmay function similarly in various complexes. Alternatively, thegenes may share common upstream processes.
We attempt to categorize the novel genes based on our invitro and in silico findings. It should be noted that the in vitro

105I. Park et al. / Journal of Molecular and Cellular Cardiology 43 (2007) 93–106
data confirm the bioinformatic predictions in some but not all ofthe novel genes and should extend the in silico data in futureinvestigations. The first group (Mm.261329 and Mm.20818)consists of potential calcium-binding proteins with EF-handmotifs. Indeed, we performed a Ca2+overlay assay with theMm.20818 protein and found for the first time that this novelprotein binds to Ca2+. Ca2+, present in all cellular compart-ments, plays an essential role in the regulation of a wide varietyof cellular functions in heart [25,26]. In muscle cells, the sar-coplasmic reticulum stores Ca2+, regulates intracellular Ca2+
levels and thus is central to excitation-contraction process [27].The novel genes may be involved in cardiac contraction orsignal transduction. Consistently, the human ortholog ofMm.261329 has been named as myosin regulatory light chainMRLC2. The second-group genes (Mm.41877, Mm.27886,Mm.269736, Mm.41719, Mm.30113 and Mm.272253) arelikely to be related with mitochondrial regulation. Mitochondriahave an important role in cardiac contraction; hence, thesegenes may be required for mitochondrial metabolism, perhapsas components of the electron transfer complex [28]. In fact, 4of them (Mm.41877, Mm.27886, Mm.30113 and Mm.272253)have been recently named as components localized inmitochondria in the UniGene database (see Results). Inaddition, the human homolog of Mm.269736 has been givena gene name, ubiquinol–cytochrome c reductase complex 7.2-kDa protein. However, they were found to be located in nucleusand/or cytoplasm in this study. Thus, to answer whether the insilico annotations are imprecise or the ability of the proteins tolocalize correctly is abolished in the GFP fusion proteins willrequire further investigation. The third-group genes (Mm.138832, Mm.38813 and Mm29342) may have functions in theareas of gene transcriptional regulation or nuclear integrity. Theother three novel genes should arguably not be clustered into agroup, as the genes share no obvious expression or computa-tional pattern. Two of them, Mm.158769 and Mm.121122, arepredicted to be implicated in cell structure and transmembranetransport, respectively.
In conclusion, identification of genes expressed in cardiacmuscle is crucial to understanding of the molecular basis ofcardiac function. Our systematic and integrative approachesexplored the genomic, transcriptional and protein expressioncharacteristics of these genes and correlated genes. Our full-scale study of novel cardiac genes should be a large resourceand a firm basis for future investigation into functional charac-terization of the genes, leading to the elucidation of variousmechanisms underlying cardiac function.
Acknowledgments
This work was supported by a grant from Korean SystemsBiology Research grant, M10503010001-06N0301-00110,from Korea Ministry of Science and Technology.
References
[1] SchaubMC, Hefti MA, ZauggM. Integration of calcium with the signalingnetwork in cardiac myocytes. J Mol Cell Cardiol 2006;41:183–214.
[2] Liew CC, Hwang DM, Wang RX, Ng SH, Dempsey A, Wen DH, et al.Construction of a human heart cDNA library and identification of car-diovascular based genes (CVBest). Mol Cell Biochem 1997;172:81–7.
[3] Bortoluzzi S, d'Alessi F, Danieli GA. A computational reconstruction ofthe adult human heart transcriptional profile. J Mol Cell Cardiol2000;32:1931–8.
[4] Plageman Jr TF, Yutzey KE. Microarray analysis of Tbx5-induced genesexpressed in the developing heart. Dev Dyn 2006;235:2868–80.
[5] Nanni L, Romualdi C, Maseri A, Lanfranchi G. Differential geneexpression profiling in genetic and multifactorial cardiovascular diseases.J Mol Cell Cardiol 2006;41:934–48.
[6] Roy S, Khanna S, Kuhn DE, Rink C, Williams WT, Zweier JL, et al.Transcriptome analysis of the ischemia-reperfused remodeling myocar-dium: temporal changes in inflammation and extracellular matrix. PhysiolGenomics 2006;25:364–74.
[7] Lamirault G, Gaborit N, Le Meur N, Chevalier C, Lande G, Demolombe S,et al. Gene expression profile associated with chronic atrial fibrillation andunderlying valvular heart disease in man. J Mol Cell Cardiol 2006;40:173–84.
[8] Kittleson MM, Hare JM. Molecular signature analysis: using themyocardial transcriptome as a biomarker in cardiovascular disease. TrendsCardiovasc Med 2005;15:130–8.
[9] Kittleson MM, Minhas KM, Irizarry RA, Ye SQ, Edness G, Breton E, et al.Gene expression analysis of ischemic and nonischemic cardiomyopathy:shared and distinct genes in the development of heart failure. PhysiolGenomics 2005;21:299–307.
[10] Ueno S, Ohki R, Hashimoto T, Takizawa T, Takeuchi K, Yamashita Y, et al.DNA microarray analysis of in vivo progression mechanism of heartfailure. Biochem Biophys Res Commun 2003;307:771–7.
[11] Anisimov SV, Boheler KR. Aging-associated changes in cardiac geneexpression: large scale transcriptome analysis. Adv Gerontol 2003;11:67–75.
[12] Zhao M, Chow A, Powers J, Fajardo G, Bernstein D. Microarray analysisof gene expression after transverse aortic constriction in mice. PhysiolGenomics 2004;19:93–105.
[13] Pontius JU, Wagner L, Schuler GD. National Center for BiotechnologyInformation. Bethesda, MA: National Library of Medicine, 2003.
[14] Hong S, Choi I, Woo JM, Oh J, Kim T, Choi E, et al. Identification andintegrative analysis of 28 novel genes specifically expressed anddevelopmentally regulated in murine spermatogenic cells. J Biol Chem2005;280:7685–93.
[15] Oh J, Lee J, Woo JM, Choi E, Park I, Han C, et al. Systematic iden-tification and integrative analysis of novel genes expressed specifi-cally or predominantly in mouse epididymis. BMC Genomics 2006;7:314.
[16] Lopez C, Jorge V, Piegu B, Mba C, Cortes D, Restrepo S, et al. A unigenecatalogue of 5700 expressed genes in cassava. Plant Mol Biol2004;56:541–54.
[17] Claycomb WC, Lanson Jr NA, Stallworth BS, Egeland DB, Delcarpio JB,Bahinski A, et al. HL-1 cells: a cardiac muscle cell line that contracts andretains phenotypic characteristics of the adult cardiomyocyte. Proc NatlAcad Sci U S A 1998;95:2979–84.
[18] Maruyama K, Mikawa T, Ebashi S. Detection of calcium binding proteinsby 45Ca autoradiography on nitrocellulose membrane after sodium dodecylsulfate gel electrophoresis. J Biol Chem 1984;95:511–9.
[19] Waterston RH, Lindblad-Toh K, Birney E, Rogers J, Abril JF, Agarwal P,et al. Initial sequencing and comparative analysis of the mouse genome.Nature 2002;420:520–62.
[20] Cea LB. Natriuretic peptide family: new aspects. Curr Med Chem2005;3:87–98.
[21] Simpson JC, Wellenreuther R, Poustka A, Pepperkok R, Wiemann S.Systematic subcellular localization of novel proteins identified by large-scale cDNA sequencing. EMBO Rep 2000;1:287–92.
[22] Sun L, Trausch-Azar JS, Ciechanover A, Schwartz AL. Ubiquitin-proteasome-mediated degradation, intracellular localization, and proteinsynthesis of MyoD and Id1 during muscle differentiation. J Biol Chem2005;280:26448–56.

106 I. Park et al. / Journal of Molecular and Cellular Cardiology 43 (2007) 93–106
[23] Barbosa MS, Wettstein FO. Identification and characterization of theCRPV E7 protein expressed in COS-7 cells. Virology 1988;165:134–40.
[24] Grabarek Z. Structural basis for diversity of the EF-hand calcium-bindingproteins. J Mol Biol 2006;359:509–25.
[25] Berridge MJ, Bootman MD, Roderick HL. Calcium signalling: dynamics,homeostasis and remodelling. Nat Rev, Mol Cell Biol 2003;4:517–29.
[26] Berridge MJ, Lipp P, Bootman MD. The versatility and universality ofcalcium signalling. Nat Rev, Mol Cell Biol 2000;1:11–21.
[27] Bers DM. Cardiac excitation–contraction coupling. Nature 2002;415:198–205.
[28] Chan DC. Mitochondria: dynamic organelles in disease, aging, anddevelopment. Cell 2006;125:1241–52.
Related Documents











