CONCURRENCY: PRACTICE AND EXPERIENCE, VOL. 5(6), 449-470 (SEPTEMBER 1993) Competitive neural networks on message-passing parallel computers MICHELE CECCARELLI, ALFRED0 PETROSIN0 AND ROBERTO VACCARO Istauto per la Ricerca sui Sirrenu' Informatici Paralleli, IRSIP - CNR Vii P. Castellin0 111,80128 Napoli, Ilaly SUMMARY The paper reports two techniques for parallelizing on a MIMD multicomputer a class of learning algorithms (competltfve learning) for aracial neuraI networks widely used in pattern recognition and understanding. The first technique presented, following the divide ef impem strategy, achieves O($ +lOgP) time for n neurons and P processors interconnected as a tree. A modification of the algorithm allows the application of a systolic technique With the processorshterconnected as a ring; this technique has the advantage that the communication time does not depend on the number of processors. The two techniques are also compared on the basis of predicted and measured performance on a transputer-based MIMD machine. As the number of processors grows the advantage of the systolic approach increases. On the contrary, the divide ef imperu approach is more advantageous in the retrieving phase. 1. INTRODUCTION Formal models of brain-like activities, better known as artificial neural networks (ANNs), have been in the limelight in recent years because of their wide applications in several different fields as computer vision, automatic target recognition and robot control[l]. In all such fields and generally in pattern recognition (PR) problems[2,3], the major challenge is the automatic classification of features of raw sensory data (images, speech, sonar and radar signals, etc.). Owing to their flexibility. modifiabilityand parallelism in computation, ANNs are very useful both applied to single PR tasks and viewed as components of a more complex pattern understanding or cognitive architecture. ANNs, indeed, show some characteristics which compete with classical clustering methods: the intrinsic parallelism which allows efficient simulation on parallel architectures and the design of special-purpose VLSI devices; the capability of a knowledge engine, e.g. the capability to learn by examples and generalize; the fault tolerance which is a fundamental requirement in PR. Moreover. the computational power required by ANNs must be sufficient to support extensive learning and testing on a great amount of data for real applications, e.g. speech processing, image analysis and compression. To date, ANNs can either be implemented in hardware on special-purpose VLSI chips and, consequently, be difficult to reconfigure. or be virtually implemented in software. The virtual implementation of ANNs allows fewer physical processors and interprocessor links to be used, offering both computational power to support large-scale ANN problems and flexibility for general-purposeapplications. It is clear that these virtual software implementationssuffer the limits in communication and computation presented by existing parallel platforms. 1040-3 108/93/060449-22$16.00 01993 by John Why & Sons. Ltd. Received 10 December 1991 Accepted I8 September 1992

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

CONCURRENCY: PRACTICE AND EXPERIENCE, VOL. 5(6), 449-470 (SEPTEMBER 1993)
Competitive neural networks on message-passing parallel computers MICHELE CECCARELLI, ALFRED0 PETROSIN0 AND ROBERTO VACCARO Istauto per la Ricerca sui Sirrenu' Informatici Paralleli, IRSIP - CNR Vii P. Castellin0 111,80128 Napoli, Ilaly
SUMMARY The paper reports two techniques for parallelizing on a MIMD multicomputer a class of learning algorithms (competltfve learning) for a rac ia l neuraI networks widely used in pattern recognition and understanding. The first technique presented, following the divide ef impem strategy, achieves O($ +lOgP) time for n neurons and P processors interconnected as a tree. A modification of the algorithm allows the application of a systolic technique With the processorshterconnected as a ring; this technique has the advantage that the communication time does not depend on the number of processors. The two techniques are also compared on the basis of predicted and measured performance on a transputer-based MIMD machine. As the number of processors grows the advantage of the systolic approach increases. On the contrary, the divide ef imperu approach is more advantageous in the retrieving phase.
1. INTRODUCTION
Formal models of brain-like activities, better known as artificial neural networks (ANNs), have been in the limelight in recent years because of their wide applications in several different fields as computer vision, automatic target recognition and robot control[l]. In all such fields and generally in pattern recognition (PR) problems[2,3], the major challenge is the automatic classification of features of raw sensory data (images, speech, sonar and radar signals, etc.).
Owing to their flexibility. modifiability and parallelism in computation, ANNs are very useful both applied to single PR tasks and viewed as components of a more complex pattern understanding or cognitive architecture.
ANNs, indeed, show some characteristics which compete with classical clustering methods: the intrinsic parallelism which allows efficient simulation on parallel architectures and the design of special-purpose VLSI devices; the capability of a knowledge engine, e.g. the capability to learn by examples and generalize; the fault tolerance which is a fundamental requirement in PR.
Moreover. the computational power required by A N N s must be sufficient to support extensive learning and testing on a great amount of data for real applications, e.g. speech processing, image analysis and compression. To date, A N N s can either be implemented in hardware on special-purpose VLSI chips and, consequently, be difficult to reconfigure. or be virtually implemented in software. The virtual implementation of ANNs allows fewer physical processors and interprocessor links to be used, offering both computational power to support large-scale ANN problems and flexibility for general-purpose applications. It is clear that these virtual software implementations suffer the limits in communication and computation presented by existing parallel platforms.
1040-3 108/93/060449-22$16.00 01993 by John Why & Sons. Ltd.
Received 10 December 1991 Accepted I8 September 1992

450 MICHELE CECCARELLI, ALFRED0 PETROSIN0 AND ROBERTO VACCARO
Thus it is fundamental to conceive methods as general as possible to detect and overcome bottlenecks and workload imbalances due to processing (learning and retrieving phases), memory space and communication time required by ANN implementations (see Reference 4 for a survey).
General approaches for implementing ANNs on coarse-grained MIMD machines assume that their computational requirements are usually restricted to matrix-vector products. Kung proposed a unified VLSI approach for implementing a wide number of A N N s using a programmable systolic array and formulated both retrieving and learning phases of generic ANN models as recursive matrix operations[S]. It is clear that this approach offers high flexibility and pipelinability when used for A N N s with local communication and layers of equal size[6]. Some problems arise when these conditions do not hold (i) when multilayer nets are considered for classification of large inputs (the output layer size is the smallest one) or for compression (the hidden layer size is the smallest one); (ii) when competitive or winner-takes-all learning rules are applied (the election of the winner requires a global communication).
In this paper we investigate two approaches to the software implementation of the competitive learning paradigm on message-passing parallel computers. Obermayer et aZ.[7] have studied this problem on a transputer ring developing a solution with O($ + 5 ) time for each training pattern, n being the number of elements of the neural lattice and P the number of processors used. Hodges et a1.[8] have considered a mesh connected multicomputer developing a parallel algorithm with O(5 + JP) time complexity.
The first approach reported follows the divide et impera strategy to solve the non- parallelizable global data control represented by the computation of the leader cell. The adopted interconnection network is a tree of processors. This strategy, together with the tree-connected architecture, ensures a balance of the workload and minimizes the communication time for the election of the leader cell. A modified version of the learning paradigm allows a second implementation on a systolic ring of processors; this implementation presents the advantage that the communication overhead does not depend on the number of processors. Experimental results which justify the adapted learning modality as regards the convergence and the topological ordering of the neurons, and show the influence of the network dimensionality and the number of processors on the learning procedures, will be reported.
Our theoretical results show that the overall time corresponding to each training pattern is O(; + logP) for the first approach and O(%) for the last one.
The plan of this paper is structured as follows: Section 2 describes the model under study; Section 3 shows the details of the parallelization approaches for a specific algorithm (the Kohonen model); Section 4 reports the theoretical and experimental results on very large nets and input data which are representative of real applications or biological modelling; last, in Section 5 some extensions of the parallelization approaches to other competitive learning models are sketched.
2. THE COMPETITIVE LEARNING MODEL
To introduce the competitive learning scheme we define how ANNs are usually represented. They are totally described by the weights wi,, 1 5 i j 5 n, n being the number of neurons, each weight representing the strength of the connection from neuron j to neuron i, and by an activation function f computed by every neuron.

COMPETITIVE NEURAL NETWORKS 45 1
The power of A N N s arises fiom the ability of inferencing distributed knowledge in such a way as to apply it entirely to the problem at hand. The knowledge acquisition or learning phase occurs by modifying the network strengths on the basis of samples of an unknown mapping. The retrieving phase involves the computation of all the neurons to recall the information storexi or infer the knowledge acquired.
A class of A N N s which is of great relevance is the one characterized by competitive learning (CL)[9]: the competition among neurons allows partition of, in a self-organizing way. the network in subareas, each one more receptive to a subset of training patterns. The biological evidence of this process can be found at the lowest level of the visual system, where an elementary neuron, called a ‘simple cell’, receives inputs over a small visual field and responds maximally to visual edges aligned to specific orientations, winning a competition among more neurons[lO]. The learning algorithms in the CL class are very similar to the clustering methods in statistical pattern recognition where the feature space is to be partitioned into clusters. Commonly used CL algorithms are adaptive resonance theory (ART)[ll], self-organizing feature map (SOFM)[12], neocognitron[13], and the CL based on geometrical sphere[l41.
The CL method can be described succinctly as follows:
1. Given a neural lattice, initialize the weights wi, j to small random values. 2. Present an input pattern x = ( X I . . . . A). 3. Compute the ‘matching’, usually a distance, between x and all the weight vectors,
wi = (w i ,~ ,w i~ , . . .,wid), i = 1,. . . ,n. 4. Select the index l of the best matching neuron and update wl in order to match more
closely the current input pattern x. 5. Go to step 2 until convergence.
At the end of the above procedure the different weight vectors. and consequently the corresponding neurons, tend to be tuned to different domains of the input space, i.e. the vectors wl, . . ., w, will represent the reference vectors of the input space.
In the sequel, when we treat implementation and design approaches and report theoretical and experimental results, we refer to one of the most common and used CL paradigms due to Kohonen: the SOFM (see Reference 15 for a review). However, the same considerations and results hold for other CL models with slight changes as shown in Section 5.
According to the Kohonen algorithm, the neurons are organized as a bidimensional grid. In this case the index 1 represents the co-ordinates of the winning neuron in the grid, the matching function is the Euclidean distance, and the updating in step 4, at the tth iteration, is given by
(1) wi(t + 1) =wi(t) + ~ ( t ) A l ( i . t ) ( ~ ( t ) - w&)) for i E I&)
wi(t + 1) = wi(t) for i $ I&),
where I&) is the neighborhood of the neuron l with radius o(t). and cr(t). 0 < a(t) I 1, is the learning rate; both a(t) and a(t) are slowly decreasing functions. Al(i,t) defines the amount of adaptation for neighboring neurons; it is often chosen equal to 1 or as a Gaussian-like function of the Euclidean distance between i and I with d a n c e proportional to a2(t), i.e. it reaches its maximum at i = 1 and decays towards zero when this distance increases.

452 MICHELE CECCARELLL ALFREDO PETROSIN0 AND ROBERTO VACCARO
The learning rule (1) tends to produce a topologically ordered neural network 'the w; vectors tend to be ordered according to their mutual Similarity, and the asymptotic local point density of the wi, in the average sense, is of the form f(p(x)), where f ( ) is some continuous, monotonically increasing function, and p(x) is a stationary probability density function of the input vectors', (Proposition 5.1[121).
This proposition has been proved for one-dimensional inputs [12], whereas, for arbitrary dimensions of the input and when the interaction A,(i,t) is a Gaussian function, Lo and Bavarian[16] have shown that each application of the rule (1) enforces the topological ordering. As regards the convergence properties, Ritter and Shulten[l7] proved that the following conditions
'are necessary and sujicient to guarantee with probability 1 convergence to an equilibrium state jY, for all initial values of the weights suftciently close to the equilibrium expectation ti'. A similar result was proved by Clark and Ravish- [18]. by considering just one weight vector. They stated the following theorem:
Theorem (Clark and Ravishankar)
If the training set includes more than one pattern, then for any sequence a(t).t = 0.1. ..., 0 < a(t) 5 1, the following conditions are equivalent:
(i) For any initial weight w(O), the weight vector w(t) converges in probability to the
(ii) For some initial weight w(0). the weight vector w(t) converges in probability to
(iii) The sequence a(t) converges to 0, but the series C a(t) diverges.
probabilistic centroid jY of the training set.
some value.
We remark that w(t) is said to converge in probability to a point z if, for every E > 0,
To show clearly the above properties, we draw in Figure 1 the results of the application of this learning procedure to a set of 500 training patterns chosen from a uniform distribution over a square shape, using an 8 x 8 network with bidimensional input. The weight vector associated to each neuron is depicted as a point in the x-y-plane; a straight line between the points corresponding to neighboring neurons is then drawn. The example in Figure 1 shows a succesful experiment; however, it is possibile that the network does not evolve to an ordered equilibrium state when inappropriate learning parameters a(t) and c(t) are used (Figure 2). In the sequel, according to experiments made by other authors[l6, 171 we always consider the interaction Ar(i,t) to be equal to 1.

mMPETlTIvENEuRALNETwoRKs 453
Figure 1. Results of succeJ training of an 8 X 8 neural nrap with formula (1) at the 6eginning of the process(a), after 1000 iteratwns (b), 2000 iterations (c) and3000 iterations (d). The sLnrJoriolrp
used the interactwn Al(i,t) = 1, a(t) = 0.1e-'/350 and a(t) = 4.0e-'/350
3. PARALLEL IMPLEMENTATIONS OF THE ALGORITHM
In the field of parallel simulation of ANN models two main guidelines can be isolated: the data partitioning approach @PA)[19] and the network partitioning approach (NPA)[20]. These approaches exploit respectively the inherent parallelism in the data procedng and in the neural processing. In the DPA simulation all the processors own the whole neural network and the set of training patterns is divided among them. At each iteration of the learning algorithm the weight changes are computed in parallel for each subset of the training patterns and then communicated among processors. On the contrary, for the NPA simulation, the neurons are divided among procesors. In scch a case the main goals are the workload balance and the reduction of the communication overhead. This is achieved with several strategies, depending on the particular ANN model adopted: recursive systolic matrix multiplication[5], vertical slicing[21] and structural mapping[22]. Since these two approaches exploit different kinds of parallelism at different levels they do not clash because, for very large ANN applications, they could be used together by running several NPA simuIations on different sets of data in order to optimize both the workload and the communication overhead[21]. Since NPA effectiveness is greatly dependent on the communication time, efficient methods for its application are of interest. We give two simulations of the CL model based on NPA using two Merent topologies of the processor network a tree and a ring as depicted in Figures 3 and 4.
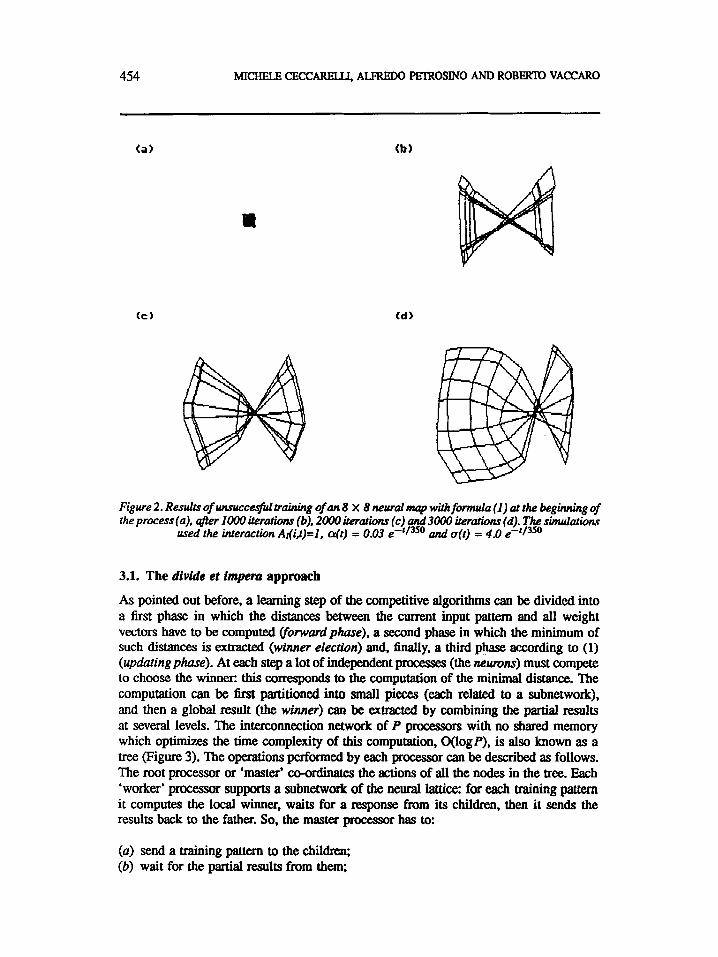
454 MICHELE CECCARELLI. ALFRED0 PElRosINO AND R O B m VACCARO
Figure 2. Results of unsuccesfultraining of an 8 x 8 neural map with f o d a ( I ) at the beginning of the process(a), after 1000 iterations (b), 2000 iteratwns (c) and3000 iterations (d). The simulatwns
used the interactwn Al(i.t)=I, a(t) = 0.03 e-‘l3’O and a(t) = 4.0
3.1. The divide ef impem approach
As pointed out before, a learning step of the competitive algorithms can be divided into a first phase in which the distances between the current input pattern and all weight vectors have to be computed vonvard p h e ) , a second phase in which the minimum of such distances is extracted (winner eZecrion) and, finally, a third phase amording to (1) (updutingphuse). At each step a lot of independent processes (the neurons) must compete to choose the winner: this corresponds to the computation of the minimal distance. The computation can be first partitioned into small pieces (each related to a subnetwork), and then a global result (the winner) can be extracted by combining the partial results at several levels. The interconnection network of P processors with no shared memory which optimizes the time complexity of this computation, O(logP), is also known as a tree (Figure 3). The operations performed by each pmessor can be described as follows. The root processor or ‘master’ co-ordinates the actions of all the nodes in the tree. Each ‘worker’ processor supports a subnetwork of the neural lattice: for each training pattern it computes the local winnw, waits for a response from its children, then it sends the results back to the father. So, the master processor has to:
(a) send a training pattern to the children; (b) wait for the partial results from them;
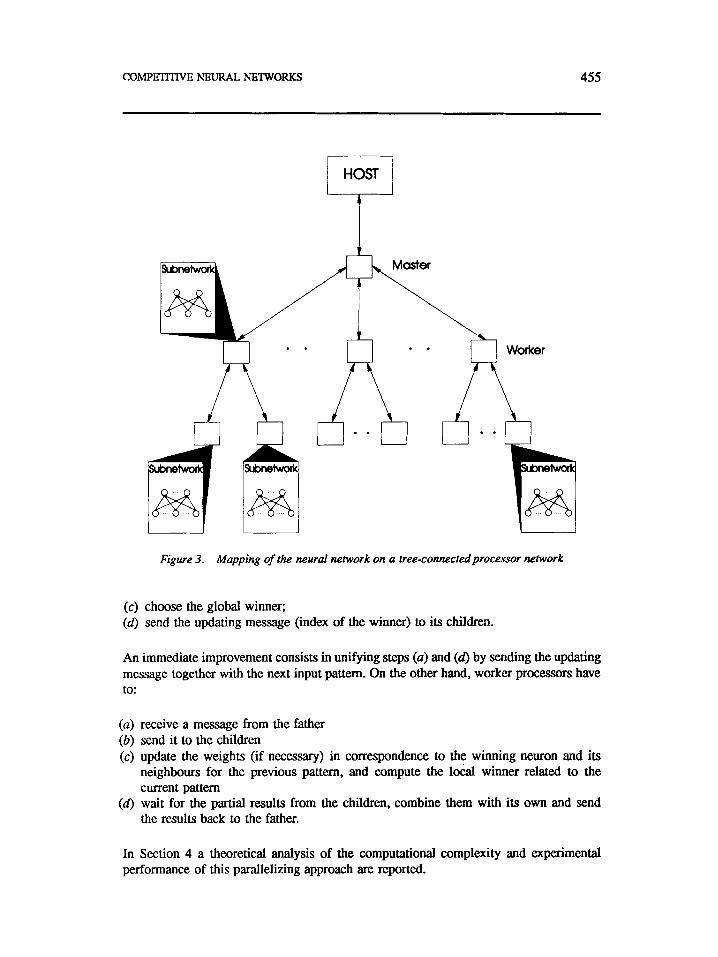
COMPETITIVE NEURAL NETWORKS 455
Figure 3. Mapping of the neural network on a tree-connected processor network
(c) choose the global winner; (6) send the updating message (index of the winner) to its children.
An immediate improvement consists in unifying steps (a) and (d) by sending the updating message together with the next input pattern. On the other hand, worker processors have to:
(a) receive a message from the father (b) send it to the children (c) update the weights (if necessary) in correspondence to the winning neuron and its
neighbours for the previous pattern, and compute the local winner related to the current pattern
(6) wait for the partial results from the children, combine them with its own and send the results back to the father.
In Section 4 a theoretical analysis of the computational complexity and experimental performance of this parallelizing approach are reported.

456 MICHELE CECCARELLT. ALFRED0 PETROSINO AND ROBERTO VACCARO
Element
Figure 4.
. . Element 7 2 Element
1
HOST
Mapping of the neural network on a systolic ring
3.2. The systolic approach If we have P processors and N sets of data, with P << N , it is possible to compute N minima in O(N) instead of O(N logP) by pipelining all such computations through the processor network: as soon as a processor terminates the comparisons related to the current data, it forwards the results and instantaneously begins the computations and the Comparisons related to the next data stream. We choose the ring as an adequate interconnection network for working in this way. Indeed, despite the filling of the pipe producing a greater constant factor in the time complexity of the algorithm, the ring architecture gains the advantages of greater scalability, a simpler VLSI implementation and a lower overhead due to the link handling.
To make this pipelined scheme applicable, the learning procedure under study needs to be modified: the updatings have to take place only after the presentation of all the training patterns (epoch). by applying the following rule:
Wi(t + 1) = Wi(t) + c a(t)(xk - Wi(t)) k
(3)
where t indicates the current epoch and the sum is over all patterns Xk for which i is the winner, or one of its neighbors. Moreover, we consider that the parameters a(f) and o(t) change after each epoch. The learning modality characterized by the application of ( 3 ) is called batch or epoch learning, whereas the application of (1) after the presentation of each pattern is called exuct or on-line learning. Let us assume for a moment that rule (1) is applied just to the winning neuron, i.e. there is no neighborhood interaction. By doing so, the on-line learning process tends to minimize the total error defined as

CDMPElTIlVE NEURAL "WORKS 457
where xl,. . .,XN are the training patterns and kj is the index of the winning neuron at the presentation of the pattern X j . Indeed, the on-line update (the second term in the right side of formula (1)) is proportional to VEj (the gradient of Ej). On the other hand, since the batch update (the second term on the right side of formula (3)) is proportional to V E , the learning by epoch is a form of gradient descent applied to E in such a way as to minimize the total error. If the learning rate a(t) is close to zero the movement in the weight space at the end of an epoch will be similar to the one obtained with a single batch update[23]. Specifically, let us introduce the function Sii, 1 5 i 5 n and 1 5 j 5 N:
1 if, at the presentation of xi, kj = i { 0 otherwise 6, =
The following closed form for the on-line learning holds
where 1 5 i 5 n. If a(?) + 0 the terms in a2(t),o13(t), . . . of the products above can be neglected obtaining the following approximated formula:
Although the formulae (3) and (5) are different (the values 6, in (5) depend on the order of the updates), the assumption a(t) + 0 makes the differences small. In this framework a useful upper bound on a(t) is a(t) < h; however, since in real applications the number of training patterns can be great, a small learning rate provides a slow learning process. In addition, if we take into consideration the effects produced by the use of the neighborhood interaction (more weight vectors are updated at the presentation of one pattern) and want to use a greater learning rate (fat learning), the values W i i can grow excessively, leading to the divergence of the algorithm. To prevent this situation a clever heuristic is the bounding of the weights, w,,,i,, 5 wii 5 w-; in such a case the convergence is reached in most cases, as will be reported in our experiments. Moreover, it must also be remarked that the batch learning sometimes fails to generate topologically ordered maps. Since the initial phase of the learning process is crucial for the creation of ordered maps[ 121, a method to make reliable the topological ordering could consist in running early iterations with the on-line learning before starting with the batch learning. Otherwise, a second alternative consists in suitably choosing the parameters a(t) and n(t). As regards the parameter a@), we observed for the experiment reported in Section 2 that good performance is achieved by using an exponential function for the learning rate, a(t) = aoe-"@, where the parameters 00 and p need an accurate tuning. For example, by fixing P = 350, we observed that the network evolves to ordered equilibrium states just for values of a0 in the interval [0.003,0.06]; other values of a0 generate non- ordered maps (see Figure 5). Moreover, better results can be obtained by choosing a(t) inversely proportional to p(t) where p( . ) is a polynomial in t. Figure 6 shows the weights

458 MICHELE CECC- ALFRED0 PETROSIN0 AND ROBERTO VACCARO
Figure 5. Final results (ajter 4000 iteratwns) of batch learning. The parameters are: o(t)=4.0 e-t/350 and &(I) = a0 e-t/350, with a0 = 0.075 (a), QO = 0.05 (b). a0 = 0.01 (c)
and = 0.002 (d)
produced by the batch learning with a(r) = A; this last choice turns out to guarantee good performance for a large set of experiments. Regarding the neighborhood radius a(r), an initial value greater than the side of the map and the use of an exponential decaying are sufficient to ensure the topological ordering.
To emphasize the similarity between formulae (3) and (5) for pattern recognition purposes, we tested both on-line and batch learning on a speak=-independent digit recognition task. The data base consists of 40 pronunciations of the ten digits spoken in Italian by 20 different male speakers. Ten speakers were randomly selected for training, while the remaining were used for testing. The patterns were constructed by extracting six melcep coefficients for every 10 ms of speech sampled at 8- The patterns so created were first segmented with adaptive thresholding on the energy per hime and then an alignment algorithm was applied to obtain fixed-length patterns of dimension 280. Figure 7 shows the curves of the MSE (mean square error) for 3000 iterations of both learning methodologies applied to a network of 80 neurons. After the training phase, the nets were partitioned in labelled subareas according to the excitation caused by the presentation of a pattern belonging to a given class. After this labelling, the 200 test patterns were provided to the trained nets for classification. For both learning methodologies, the percentage of right classification is about 98.2%.
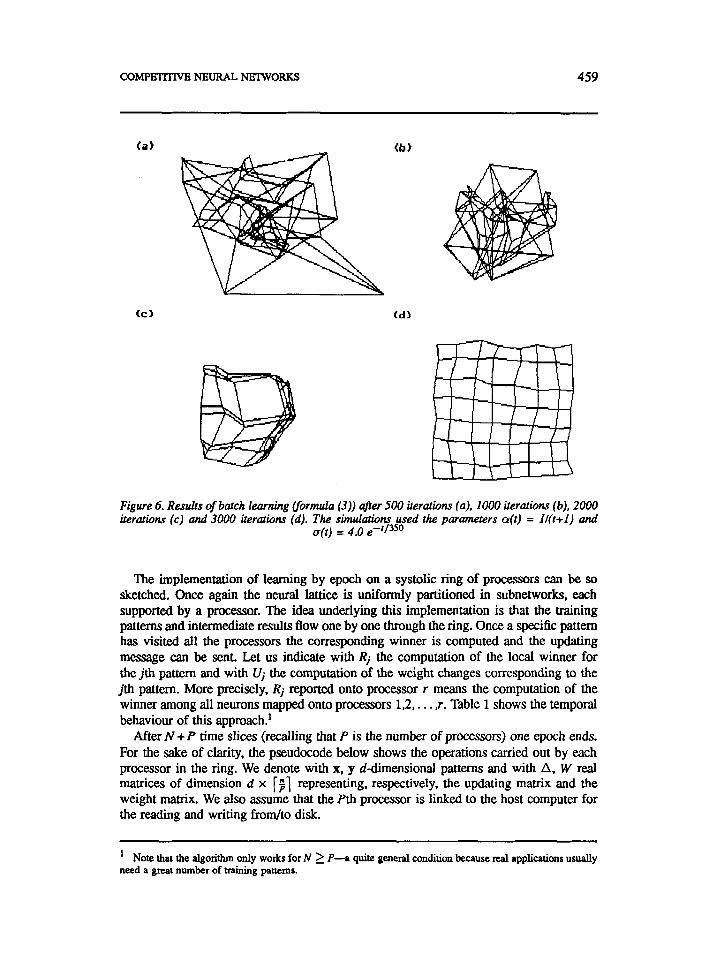
CoMPETrrlvE NEURAL NETWORKS 459
Figure 6. Results of batch learning (formula (3)) afer 500 iteratwns (a), 1000 iteratwns (b). 2000 iteratwns (c) and 3000 iteratwns (d). The skdatwns used the parameters a(t) = Il(t-+I) and
u(t) = 4.0 e-t/350
The implementation of learning by epoch on a systolic ring of processors can be so sketched. Once again the neural lattice is uniformly partitioned in subnetworks, each supported by a processor. The idea underlying this implementation is that the training patterns and intermediate results flow one by one through the ring. Once a specific pattern has visited a l l the processors the corresponding winner is computed and the updating message can be sent. Let us indicate with Rj the computation of the local winner for the jth pattern and with Uj the computation of the weight changes corresponding to the jth pattern. More precisely, Rj reported onto processor r means the computation of the winner among all neurons mapped onto processors 1,2,. . . ,r. Table 1 shows the temporal behaviour of this approach.'
After N + P time slices (recalling that P is the number of processors) one epoch ends. For the sake of clarity, the pseudocode below shows the operations carried out by each processor in the ring. We denote with x, y d-dimensional patterns and with A, W real matrices of dimension d x fa] representing, respectively, the updating matrix and the weight matrix. We also assume that the Pth processor is linked to the host computer for the reading and writing from/to disk.
' Note that the algorithm only worlrs for N 2 P 4 quite general condition because real applications usually need a great number of training patwms.

460 MICHELE CECCARELLI. ALFRED0 PETROSINO AND ROBERTO VACCARO
1.2
I . I
I
s ? 0.9
1 0
4 (I, 0.8
2
0.5
+ b a t c h l e a r n i n g
- on-line l e a r n i n g
I 1 I I I I I I I I I r I I
0 0 , 4 0 ,8 1 .2 1.6 2 2 , 4 2,8
L E A R N I N C S T E P S / / 1 0 0 0 1
Figure 7 . Mean square error (MSE) as ajbction of learning steps when 26Opatterns of dimension 280 and 80 neurons are considered. The parameters are a( t ) = l l( t+l) and a(t) = 9.0 e-r/soo
Table 1 . Temporal behavior for computing in pipeline minima and weight changes on a ring whenN 2 2P. 2 5 h 5 P - 1 and P 5 k 5 N - P
Time Proc. 1 Roc. 2 ... Proc. P
..

COMPETITIVE NEURAL "WORKS 46 1
procedure element (a) / /The operations carried out by the i-th processor for each epoch once the pipe is filled. The symbol - represents a dummy value.//
begin Initialize A to zero values for k := 1 to P
receive(x, candidate-winner, distance, -, -) Compute local-winner and local-distance if (local-distance < distance) then
candidate-winner := local-winner distance := local-distance
end if if (i = P) then
else
end if
send(next-pattern, -1, 00, x, candidate-winner)
send(x, candidate-winner, distance, -, -)
end for for k := 1 to N - P
receive(x, candidate-winner, distance, y, winner(y)) Compute local-winner and local-distance Compute the weight changes related to y and add them to A if (local-distance < distance) then
candidate-winner := local-winner distance := local-distance
end if if (i = P ) then
else
end if end for for k := 1 to P
send(next-pattern, -1, 00, x, candidate-winner)
send(x, candidate-winner, distance, y, winner(y))
receive(y, winner(y), -, -) Compute the weight changes related to y and add them to A if (i = P) then
send(next-pattern, -1, 00, -, -) else
sendfy, winner(y), -, -) end for Update the matrix of weights W
end procedure // W := W + A//
4. PERFORMANCE ANALYSIS In the following, we deal with the expected and experimental performance of the parallel algorithms of the CL model described in subsections 3.1 and 3.2. Specifically, we compute the worst-case time and space complexities of the algorithms and experimentally evaluate their performance on a target XvIIMD machine.

462 MICHELE CECCARELU. ALFRED0 PETROSIN0 AND ROBERTO VACCARO
4.1. Theoretical hues
Let us introduce the following parameters:
d = dimension of input n = number of neurons N = number of training patterns trr = time required to transfer 32 bits of information tm = time required by a multiplication trr = time required by an addition.
Let us consider the approach described in Section 3.1 (tree topology with the on-line learning). Since each processor needs to store the weight matrix and two input patterns, the space complexity is S'I~~EE M d[; l + 26. The total processing time for each iteration can be approximately2 broken down into the sum of the times required by the three phases in which the competitive learning algorithm can be decomposed. The time required by the forward computation is
n Tjow M N(2ta + t,) [-I d + Ndt, log P
The first term corresponds to the cornputation of the distances between weight vectors and patterns, while the second is the time necessary for the communication of the patterns along the tree. The time needed to compute the global winner among the processors is
P
TLn M Uvt, log P
Let us indicate with f the average size of the neighborhoodI(t). If I! is less than [;I, the time required by the updating phase is
otherwise the term above is to be substituted by N(3trr + t m ) d [ a l . The communication of the patterns along the tree is not considered because it is already
included in Tjoy as described in Section 3.1. The total time TTREE can be expressed as the sum of the tlmes T;.,,,,. TLh and T L .
As regards the systolic approach described in Section 3.2 (ring topology with batch learning), since each element process must store all the weight changes together with the weight matrix, the space complexity is SRING = 2dr;l + 2d. The total time can be expressed as TRING = TjLw + T& where:
n T/&,,, x N(2trr + rm)d[-l + Ndf , P
* We do not take into account the constant time due to the initializations. the calculations of the new learning rate and neighbohood size values.

COMPETITIVE NEURAL NETWORKS 463
The first term of 7'2 is due to the computation of the weight changes, while the third term corresponds to the weight matrix updating. The same considerations made above about 1 are valid. It is not diflicult to see that for this strategy the communication times required by the three phases of the learning process are independent of the number of processors. This implies that the technique adopted scales better than the tree topology.
4.2. Experimental issues The learning procedures (on-line and batch learning) described above were implemented on a massively MIMD parallel system, the Meiko Computing Surface, available at the Parallel Architectures and Artificial Intelligence laboratory of our Institute. Experiments were performed with up to 64 processors, each one constituted by a transputer Inmos T800 running at 20 MHz clock speed with 4 Mbyte of external local memory. Each processor is connected to four of its neighbor nodes by four bidirectional communication links. The implementations were carried out in Occam I1 using the OPS environment.
The overall processing time was measured by using the internal timer of the transputer linked to the host. There are some processes that at regular intervals save the state of the network on the disk and other processes that manage the communication with the host to read the input patterns from the disk. Considering the four links of each processor, we adopted for the approach in Subsection 3.1 the binary and ternary tree topologies.
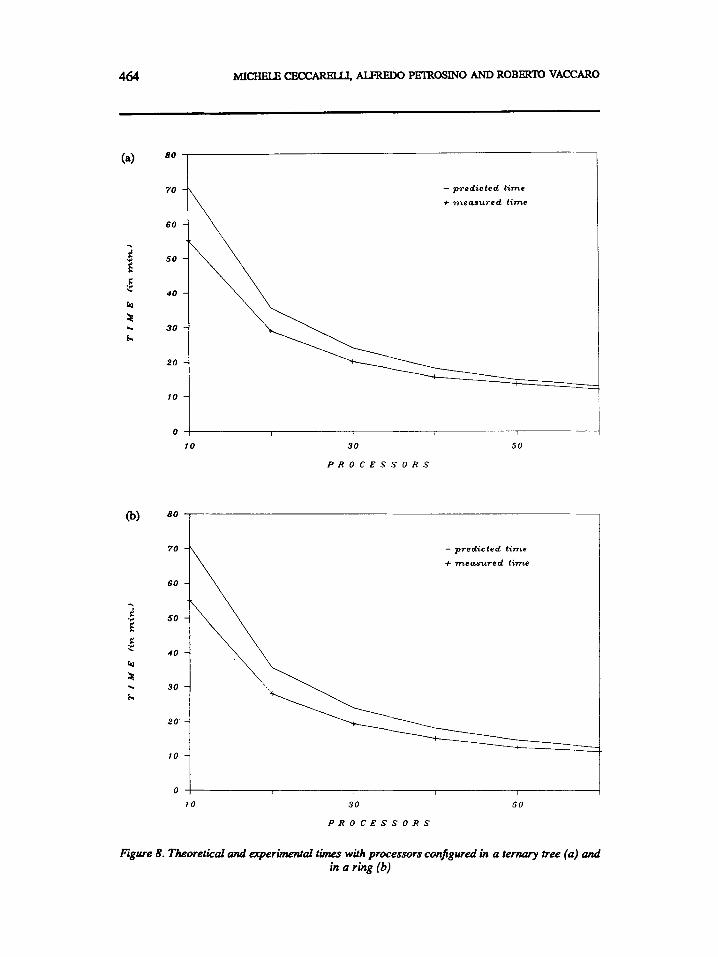
Our aim was first to compare the time estimated by the performance model with the measured time (Figures 8(a). (b)). This is meaningful when we want to improve our approaches and determine the consistency of our performance model. To fit as best as possible to the reality we took into account the real values of the parameters fm,fcr and t,[24, 253. We also considered the calculations due to the initializations and the array indexing.
It is useful and remarkable to show how the efficiency of our simulation depends on the number of processors adopted. Thus, we tested our implementations on large nets as required when the A N N s are applied to biological modelling and complex PR tasks, e.g. continuous speech processing and recognition, and real-time image compression.
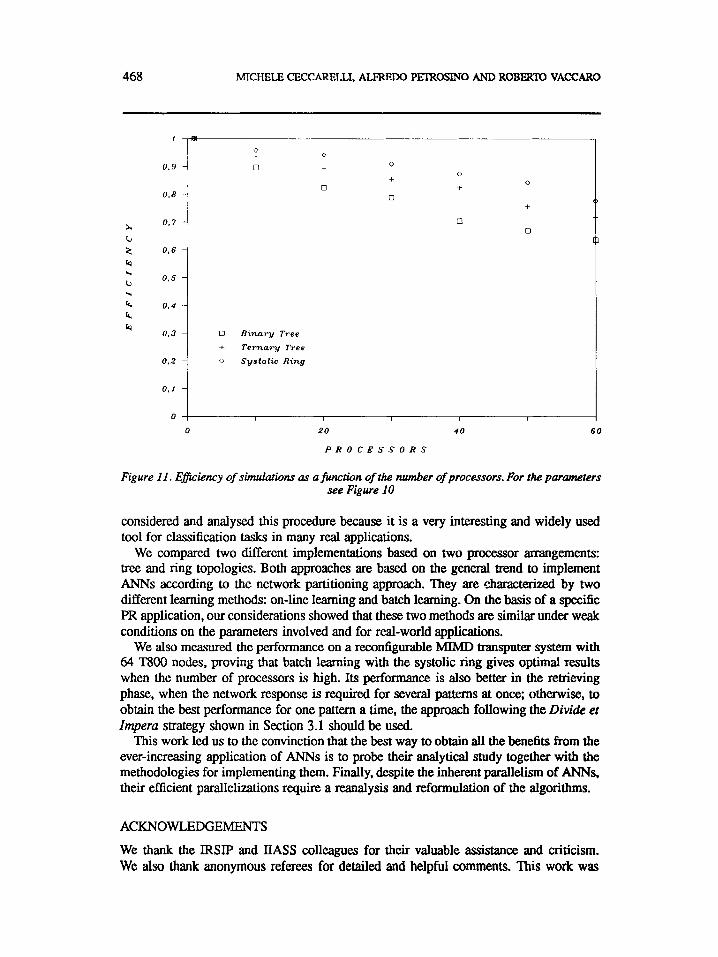
Figures 9(a)-(c) show the total processing times spent by all the simulations over three different problem sizes: 5000,10,000 and 15,000 neurons with the input dimension equal to 100 and SO00 adaptive steps. Figures 10 and 11 show, respectively, the speed-up and the efficiency achieved by our parallelizations for each processor topology adopted on the same problem size. The batch learning mapped onto the ring topology gives the best performance as we expected from the analysis of the preceding Section. For all the simulations the speed-up is approximately linear.
5. EXTENSIONS TO WHER MODELS As remarked in the Introduction the Kohonen model is a very general and useful CL procedure[l5]. It can be shown that several models involving lateral inhibition by a normalization of the weights and a Hebbian updating rule behave in the same manner[7, 26, 271. Some common models will be analysed in the following subsections.
5.1. Grossberg's adaptive resonance theory The adaptive resonance theory (ART) architecture[ 1 I] is a self-organizing neural network born to model the general cognitive process of hypothesis discovery. testing. classification
464 MICHEiLE CECCARELLI, ALFREDO PETROSIN0 AND ROBERTO VACCARO
10 -
0
80
I I I I lo 0 : 10 30 5 0
P R O C E S S O R S
80
70
60
50
40
30
20
10
0
- predicted time
10 30
P R O C E S S O R S
5 0
Figure 8. Theoretical and experimental times with processors configured in a ternary tree (a) and in a ring (b)

m M P m NEURAL NElwoRKs 465
and learning. It has been applied to a wide range of visual pattern recognition tasks as image segmentation, contour extraction, texture analysis, etc. The ART learning process is similar to the Kohonen rule, except that only the winning neuron updates its weight vector to match more closely the input pattern, by applying formula (1) with Al(i,r) = 1. Hence, for this simpler rule the same considerations made above about the convergence properties and the parallelkation holdC181.
Sf Fukushima’s neocognitron
The hierarchical architecture for pattern recognition developed by Fukushima, the neocognitron[l3]. is constituted by a cascade of processing stages each dedicated to the extraction of features from input patterns at different stages of the visual process. Each stage is divided into two layers: the S-layer, consisting of S-cells for feature extraction. and the C-layer, constituted by the C-cells for positional grouping of features. The connections from C-cells to S-cells can be updated, while the connections from S-cells to C-cells are fixed a priori. The units of an S-layer are divided into subgroups according to the feature to which they respond, and the connections incoming to cells in the same subgroup are homogeneous: they have the same weights and differ from each other just because they receive input from a spatially shifted region of the previous layer (a similar idea, for the time domain, is present in the TDNN mode1[28]). Essentially, the learning is carried out layer by layer by applying the Competitive learning principle: the cell which yields the maximum output is selected to have reinforced its input connections. The learning phase for each sublayer of the Neocognitron, that has to be receptive to specific features of training patterns. could be parallelized in the same way as reported in Section 3; each sublayer trained in this way is then replicated to be receptive to the same features but spatially located in different areas of the input patterns. Hence. for the learning procedure in each layer, the same considerations made in Sections 3 and 4 are still valid. Different and more efficient schemes for the parallelization of the whole architecture are obviously possible; however, this is beyond the aims of this paper, where we are mainly concerned in the parallelization of competitive learning algorithms.
5.3 Rumelhart and Zipser’s competitive learning
Rumelhart and Zipser developed in Reference 14 a hierarchical system whose layers are divided into a set of non-overlapping clusters each having cells which receive the same input and act in a competitive manner to become more sensitive to particular input stimuli. Since each unit in the cluster maximally responds when a particular feature is present in the input pattern, each cluster could be seen as a coding of the input pattern in a set of feature attribute values. Then, the major difference with the Kohonen rule is that the input patterns and the weight vectors are normalized (ci4i = 1) and there is no neighborhood interaction, i.e. the topological ordering is not preserved for the weight vectors after training.
5. DISCUSSION The aim of this paper was to present optimal parallelization techniques of a common learning p d u r e for neural networks on MIMD machines: the CL paradigm. We

466 MICHELE CECCARELLI, ALFRED0 PETROSIN0 AND ROBERTO VACCARO
10 -
8 -
6 -
4
30
0 + 0 +
v
1 1 I I
2 4
22
0 Binary Tree
+ Ternary Tree
0 Systolic Ring
0
+ 0
0
+ c
5 5 6o I-- 45 i
0 Binary Tree + Ternary Tree 0 Systolic Ring
40 1
30
20
l 5 i 8 0 + 0
10 I I I I I
10 30 5 0
P R O C E S S O R S
Figure 9. Total processing time for all topologies agakt number of processors. The parameters adopted were: 5000 (a), 10,000 (b) and 15,000 (c) neuronr, d = 100 aruj 5000 adaptive steps

CoMpEmZvE NEURAL NETWORKS 467
80
70
60 'E F c 50 4
+ 40 h
* 30
20
0 + 0
0 8
0 *
Binary Tree Ternary Tree Sgsto lic Ring
0 8
10
10 30 50
P R O C E S S O R S
Figwe 9. Part (c)
50
45
40
35
4 a 3O 9 4 25 4
4 4 20
15
10
5
0
0
0 Binary Tree
+ Ternary Tree
0 Systolic Ring
0 + 0
0 +
0
b
I I I I I I
20 40
P R O C E S S O R S
60
Figure 10. Speed-up for dl t0pOlOgieS ar a fwrction of the number of processors. The parameters of the simulatwn were: n = 10000. d = 100 and So00 adnprive steps
468 MICHELE CECCAFSLU, ALFREDO PEIROSINO AND ROBERTO VACCARO
0 0
,+ 0.7 - c, % 0,6 - 4
0.5 -
* 4 0.4 - 4 4
0.3 -
0.2 -
0 Binary Tree + Ternary Tree 0 Systolic Ring
n 0
0 O S 1
I
0 20 4 0 6 0
P R O C E S S O R S
Figure 11. EJiciency of simulatwns as a funcrion of the number of processors. For the parameters see Figure 10
considered and analysed this procedure because it is a very interesting and widely used tool for classification tasks in many real applications.
We compared two different implementations based on two processor arrangements: tree and ring topologies. Both approaches are based on the general trend to implement ANNs according to the network partitioning approach. They are characterized by two different learning methods: on-line learning and batch learning. On the basis of a specific PR application, our considerations showed that these two methods are similar under weak conditions on the parameters involved and for real-world applications.
We also measured the performance on a reconfigurable MIMD transputer system with 64 T800 nodes, proving that batch learning with the systolic ring gives optimal results when the number of processors is high. Its performance is also better in the retrieving phase, when the network response is required for several patterns at once; otherwise, to obtain the best performance for one pattern a time, the approach following the Divide et Impera strategy shown in Section 3.1 should be used.
This work led us to the convinction that the best way to obtain all the benefits from the ever-increasing application of ANNs is to probe their analytical study together with the methodologies for implementing them. Finally, despite the inherent parallelism of ANNs. their efficient parallelizations require a reanalysis and reformulation of the algorithms.
ACKNOWLEDGEMENTS
We thank the IRSIP and IIASS colleagues for their valuable assistance and criticism. We also thank anonymous referees for detailed and helpful comments. This work was

COMF%llTNENEURALNETWORKS 469
supported by National Council of Research (CNR), contract N. 91.02014.67, Progem Finalizzato ‘Robotica’.
REFERENCES
1. 2. 3. 4.
5.
6.
7.
8.
9.
10.
11.
12. 13.
14.
15. 16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
Y. H. Pao, Adaptive Pattern Recognition and Neural Networks, Addison Wesley, 1989. R. Duda and C. Hart, Pattern Classijication and Scene Analysis, Wiley, 1973. A. Jain and R. Dubes. Algorithms for Clustering Data. Prentice-Hall, 1988. T. Nordsfrom and B. Svensson, ‘Using and designing massively parallel computer for artificial neural networks’. J. Parallel Distrib. Cornput., 14(3). 260-285 (1992). S. Y. Kung and J. N. Hwang. ‘A unified systolic architecture for artificial neural networks’, J. Parallel Distrib. Comput., 6(2), 358-387 (1989). S. Y. Kung and J. N. Hwang, ‘Parallel architectures for d c i a l neural nets’, Proc. IEEE Internat. Coqf Neural Networks, 2, 165-172 (1990). K. O b a y e r . H. Ritter and K. Shulten, ‘Large-scale simulations of self-organizing neural networks on parallel computers: application to biological modelling’, Parallel Computing, 14(3), 381404 (1990). R. E. Hodges. C. Wu and C. J. Wang. ‘Parallelizing the self-organizing feature map on multiprocessor systems’. Paralkl Comput.. 17.812432 (1991). C. von der Malsburg, ‘Self-organization of orientation-sensitive cells in the striate cortex’, Kybernetik, 14. 85-100 (1973). D. H. Hubel and T. N. Wiesel, ‘Receptive fields, binocular interactions and functional architecture in the cat’s visual cortex’, J. Physwfogy, 60, 106-154 (1962). G. A. Carpenter and S. Grossberg, ‘A massively parallel architecture for a self-organizing neural pattern recognition machine’. CVGZP. 37,561 15 (1987). T. Kohonen, Self Organization and Associative Memory. Springer Verlag. Berlin, 1984. K. Fukushima. ‘Neocognitron: a self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position’, Bwlogical Cybernetics, 36,193-202 (1980). D. E. Rumelhart and D. Zipser, ‘Feature discovery by competitive learning’, Cognitive Science,
T. Kohonen, ‘The self-organizing map’, Proc IEEE, 78(9), 1464-1481 (1990). 2. P. Lo and B. Bavarian, ‘On the rate convergence in topology preserving neural networks’, Biological Cybernetics, 65(l). 55-63 (1991). K. R i m and H. Shulten, ‘Convergence properties of Kohonen’s topology preserving maps: fluctuations, stabfity, and dimension selection’. Biological Cyberwics, 60, pp. 59-71 (1988). D. Clark and K. Ravishankar. ‘A convergence theorem for Grossberg learning’, Neural Networks, 3. 87-92 (1990). D. A. Pomerleau. G. L. Gusciora, D. S. Touretzky and H. T. Kung, ‘Neural network simulation at Warp speed: How we got 17 million connections per second’, in IEEE Internut. Cot# on Neural Network, San Diego, CA, 1988, pp. 143-150. B. M. Fonest, D. Roweth. N. Stroud, D. J. Wallace and G. V. Wilson, ‘Implementing neural network models on parallel computers’. Comput. J., 30(5), 41-19 (1987). X. Zhang, M. Mckenna. J. P. Mesirov and D. L. walk. ‘The backpmpagation algorithm on grid and hypercube architectures’, Parallel Computing, 14.317-327 (1990). Y. Ghosh and K. Hwang. ‘Mapping neural networks onto message-passing multicomputers’. J. Parallel Distrib. Cornput., 6(2), 291-330 (1989). R. Battiti ‘First- and second-order methods for learning: between steepest descent and Newton’s method’, Neural Chmpur., 4(2A 141-166 (1992). D. May and R. Sheperd, The INMOS transputer’, in P a r a 1 Processing: state of the art report, Pergamon Infotech Ltd.. 1988. P. van Renterghem. Transputers for industrial applications’, Concurrency. l(2). 135-170 (1989). W. Banzhaf and H. Haken, ‘Learning in a competitive network’, Newd Networks, 3.423-435 (1990).
9.75-112 (1985).

470 MICHELE CEARELLI, ALFRED0 PElROSNO AND ROBERTO VACCARO
27. S. I. Amat-i, ‘Mathematical fundations of neurocomputing’. Proc. IEEE, 78(9), 143-1463 (1990).
28. K. J. Lang. A. H. Wai i l and G. E. Hinton, ‘A timedelay neural network architecture for isolated word recognition’, Neural Networks, 3.23-43 (1990).
29. M. CeccarelLi, A. Petrosino and R. Vaccm, ‘On parallelking self-organizing neural networks’. in Parallel Archirectures and Neural Networks ‘91. E. R. Caianiello (Ed.), World Scientific Publishing. Singapore, 1991.147-156.
Related Documents











