Intelligent Data Analysis 10 (2006) 163–182 163 IOS Press Combining advantages of new chromosome representation scheme and multi-objective genetic algorithms for better clustering Emin Erkan Korkmaz a , Jun Du b , Reda Alhajj b,c,∗ and Ken Barker b a Department of Computer Engineering, Yeditepe University, Kadikoy, Istanbul, Turkey E-mail: [email protected] b Department of Computer Science, University of Calgary, Calgary, Alberta, Canada E-mail: {jundu,alhajj,barker}@cpsc.ucalgary.ca c Department of Computer Science, Global University, Beirut, Lebanon Received 24 May 2005 Revised 12 July 2005 Accepted 25 September 2005 Abstract. Various methods have been proposed to utilize Genetic Algorithms (GA) in handling the clustering problem. GA work on encoded strings, namely chromosomes, and the representation of different clusters as a linear structure is an important issue about the usage of GA in this domain. In this paper, we present a novel encoding scheme that uses links to identify clusters in a partition. Particularly, we restrict the links so that objects to be clustered form a linear pseudo-graph. A one-to-one mapping is thus achieved between the genotype and phenotype spaces. The other feature of the proposed approach is the use of multiple objectives in the process. One of the two objectives we use is to minimize the Total Within Cluster Variation (TWCV), identical to the one used by other k-means clustering approaches. However, unlike other k-means methods, number of clusters is not required specified in advance. Combined with a second objective, minimizing the number of clusters in a partition, our approach obtains the optimal partitions for all the possible numbers of clusters in the Pareto Optimal set returned by a single GA run. The performance of the proposed approach has been tested using two well-known data sets, namely Iris Data and Ruspini Data. The obtained results are compared with the output of the classical Group Number Encoding and it has been observed that a clear improvement has been achieved with the new representation. Keywords: Clustering, genetic algorithms, linkage-encoding, k-means, multi-objective 1. Introduction Clustering can be described as the grouping of a set of data cases or objects so that objects that fall into the same class are more similar to each other than to objects of other clusters. Unsupervised clustering of data has received the attention of many researchers. The developed techniques in the area can be used effectively in a variety of disciplines, ranging from computer science topics like image processing and knowledge discovery to market research and molecular biology [3,8]. They may be classified into ∗ Corresponding author. Tel.: +1 403 210 9453; Fax: +1 403 284 4707; E-mail: [email protected]. 1088-467X/06/$17.00 © 2006 – IOS Press and the authors. All rights reserved

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Intelligent Data Analysis 10 (2006) 163–182 163IOS Press
Combining advantages of new chromosomerepresentation scheme and multi-objectivegenetic algorithms for better clustering
Emin Erkan Korkmaza, Jun Dub, Reda Alhajjb,c,∗ and Ken BarkerbaDepartment of Computer Engineering, Yeditepe University, Kadikoy, Istanbul, TurkeyE-mail: [email protected] of Computer Science, University of Calgary, Calgary, Alberta, CanadaE-mail: {jundu,alhajj,barker}@cpsc.ucalgary.cacDepartment of Computer Science, Global University, Beirut, Lebanon
Received 24 May 2005
Revised 12 July 2005
Accepted 25 September 2005
Abstract. Various methods have been proposed to utilize Genetic Algorithms (GA) in handling the clustering problem. GAwork on encoded strings, namely chromosomes, and the representation of different clusters as a linear structure is an importantissue about the usage of GA in this domain. In this paper, we present a novel encoding scheme that uses links to identifyclusters in a partition. Particularly, we restrict the links so that objects to be clustered form a linear pseudo-graph. A one-to-onemapping is thus achieved between the genotype and phenotype spaces. The other feature of the proposed approach is the use ofmultiple objectives in the process. One of the two objectives we use is to minimize the Total Within Cluster Variation (TWCV),identical to the one used by other k-means clustering approaches. However, unlike other k-means methods, number of clustersis not required specified in advance. Combined with a second objective, minimizing the number of clusters in a partition, ourapproach obtains the optimal partitions for all the possible numbers of clusters in the Pareto Optimal set returned by a single GArun. The performance of the proposed approach has been tested using two well-known data sets, namely Iris Data and RuspiniData. The obtained results are compared with the output of the classical Group Number Encoding and it has been observed thata clear improvement has been achieved with the new representation.
Keywords: Clustering, genetic algorithms, linkage-encoding, k-means, multi-objective
1. Introduction
Clustering can be described as the grouping of a set of data cases or objects so that objects that fall intothe same class are more similar to each other than to objects of other clusters. Unsupervised clusteringof data has received the attention of many researchers. The developed techniques in the area can beused effectively in a variety of disciplines, ranging from computer science topics like image processingand knowledge discovery to market research and molecular biology [3,8]. They may be classified into
∗Corresponding author. Tel.: +1 403 210 9453; Fax: +1 403 284 4707; E-mail: [email protected].
1088-467X/06/$17.00 © 2006 – IOS Press and the authors. All rights reserved

164 E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme
different categories, including hierarchical clustering, grid-based methods, partitioning and methodsbased on co-occurrence of categorical data [3].
As genetic algorithm (GA) has been successfully used to solve many optimization and search prob-lems [13,18], different techniques have been proposed for using GA to search for the optimal clusteringof a given data set. However, the existing techniques have some drawbacks, and redundancy seems tobe a problem for the representations used [10]. Ensuring the validity of the chromosomes that appearthroughout the search is another problematic issue for GA usage [23]. Lastly, the number of clusters hasto be specified beforehand in many of the proposed methods [23], i.e., the usage of GA is limited withthe k-clustering problem where the number of clusters is known.
In this paper, a new scheme is proposed for encoding clustering solutions into chromosomes. Theproposed representation forms a linked-list structure for objects in the same cluster. The genetic operatorsmodify the chromosomes by altering the links. Also, we deal with the partitional clustering problem byusing a multi-objective GA [19] to minimize Total Within Cluster Variation (TWCV), together with thenumber of clusters. TWCV [23] is a measure which denotes the sum of the average distance of clusterelements to cluster center. If this measure is used as the sole objective in the search, GA will tend toreduce the size of the clusters and eventually will form clusters with single elements where the variationturns out to be zero. Hence, traditionally, a prior specified number of clusters is needed for GA basedk-clustering approaches treating TWCV as the single objective function. The other objective effectivelyhandles this.
The new representation proposed in this paper is able to encode the solution space in fixed-lengthchromosomes. It enables an efficient exploration of the solution space. Together with the use of multi-objective GA, this approach can be extended to deal with the general clustering problem where theoptimum number of clusters is unknown. The Pareto Optimal set [19], obtained at the end of the runprovides solutions with the optimum TWCV for various potential numbers of clusters.
Two well-known data sets Iris Data [5] and Ruspini Data [30] have been used in the experiments todemonstrate the usefulness and effectiveness of the proposed approach. These data sets have been widelyused as benchmark problems for testing different techniques, and the corresponding optimal clusteringis known. Hence, it is easy to evaluate the performance of a clustering method by using these data sets.The results obtained on these data sets are compared with the output of the classical Group NumberEncoding [21]; a clear improvement has been achieved with the new representation.
The rest of the paper is organized as follows. Previous work in the area is presented in Section 2. Theapplication of multi-objective GA to the clustering problem and the objective functions used are discussedin Section 3. The design of the new encoding scheme is introduced in Section 4. The experimentalresults obtained on two well-known data sets are reported in Section 5. Section 6 is the conclusions.
2. Related work
Clustering is an important issue in explanatory data analysis. It can also be considered as one of themost challenging problems in unsupervised learning since the aim is finding structure in a collectionof unlabeled data. As mentioned in Section 1, there are many different approaches to the problem.For instance, hierarchical clustering builds a tree of clusters, namely a hierarchy where sibling clusterspartition the elements contained by their common parent [20,22].
Partitioning methods form another approach where algorithms are used to divide data into subsets.Checking all possible subset organizations would have an exponential complexity. Hence, the key pointis to use a heuristic or an optimization method to find a good partitioning. Different alternatives exist

E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme 165
for modeling the partitioning problem. In probabilistic clustering, data is assumed to be a sampleindependently drawn from several probability distributions [25]. Approaches based on the definition ofan objective function, also exist. The objective function is to be used in searching for the best partition.K-medoids [22,26] and K-means [9,17] are two well known examples of this approach. The two methodsdiffer in the way they represent a cluster. K-medoids represent a cluster with its most appropriate element.However, K-means uses the centroid to represent a cluster. The centroid is defined to be the mean ofthe elements in a cluster. It is also possible to partition the data based on the notion of density. In thisapproach, a cluster is defined to be a dense connected component. This definition makes the approachmore successful compared to other partitioning methods, when the clusters to be induced have irregularshapes [16].
A possibly different approach to the clustering problem is formed by the grid-based methods wherethe focus is on space-partitioning rather than data-partitioning [32]. Some other clustering methods havealso been developed based on the idea of co-occurrence of categorical data [12,14,16].
The application of GA to the problem can be considered in the framework of the partitioning approach.GA works on encoded strings, namely chromosomes. The representation of different clusters as a linearstructure seems to be the most central concern about the usage of the method. Mainly, two differentschemes are used for the representation of the clustering problems in the field of GA. The first oneallocates each object to a different gene of a chromosome and the value of the gene indicates its cluster.Group Number Encoding presented in [21] is a classical example of this scheme. Similarly, in [4], amatrix is used where rows denote clusters and columns denote objects. An entry of the matrix c ij is oneif the jth object is in cluster i.
In the second scheme, objects are represented by gene values and the position of a gene specifies itscluster. The Permutation with Separators encoding [21] is an example of this scheme where certainintegers are used to denote the boundaries of clusters in the permutation.
The approaches presented above can only be used for the k-clustering problem, where the number ofclusters should be provided beforehand. The validity of the chromosomes seems to be another potentialproblem during the search. For instance, each column in the matrix representation should have a singleone, since each object will be assigned to a single class. This can be easily violated throughout a geneticoperation. Mechanisms are needed to repair the invalid chromosomes. Lastly, redundancy is anotherissue that needs to be taken into consideration because more than one chromosome can correspond tothe same clustering with the used schemes. For instance, in the Group Number Encoding, redundancyis quite high. Having the value of the gene determines its cluster introduces the effect of numbering theclusters. However, the order of the clusters formed is not significant in the solution space. The resultis having more than one chromosome representing the same clustering, and this affects the efficiency ofGA.
An attempt to overcome the mentioned drawbacks can be found in [11], which adapted the AugmentedGroup Number Encoding so that it can be applied to the general clustering problem. However, therepresentation used cannot encode different number of clusters in a fixed length chromosome. Thus, avariable length representation [7] is used to encode the different number of clusters that might appearthroughout the search. This new representation is also used with multi-objective GA on the problem ofAssembly Line Design [28].
On the other side, GA is also used to increase the search power of other clustering methods. Theclassical K-means [16] algorithm has been widely used in different clustering applications. It is wellknown that the initialization process in the algorithm might lead to a local optimum [1]. In [24], a geneticbased approach is proposed to overcome this drawback. The method is based on encoding cluster centers

166 E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme
of the classic k-means algorithm as genes of the chromosome. Hence, the task of the GA is to find outthe appropriate cluster centers which will minimize the clustering metric. Also, GA is used to determinethe initial seed values in [2]. Another similar approach is presented in [15], where GA is employed tooptimize some functions used in cluster analysis. A different approach can be found in [31] where theGA is used to search clustering rules. Each rule includes a set of intervals, where each interval is for adifferent feature. The aim is to eliminate the drawbacks of the classical minimization approaches, andbe able to obtain clusters which can have large differences in their sizes, densities or geometries.
The new approach proposed in this paper, shares some common properties with the work of [23], whichalso tries to minimize TWCV by using GA. However, it uses the classic Group Number Encoding as therepresentation of the clusters. Hence, it can only be used with the k-clustering problem. Also, the GAused in the search has a single objective which is minimizing TWCV as noted above. We overcome thesedrawbacks by combining the advantages of a new novel representation scheme for the chromosomes andmulti-objective GA; the immediate outcome is better clustering.
3. Multiobjective GA for clustering
Many optimization problems are multi-objective by nature. The classical approach to such problems isto use a single objective function which is obtained by a linear combination (weighted sum) of multipleobjectives. Another approach is to treat different objectives as different constraints and use thresholdsand penalties during the search. However, the usage of weights and penalties has been clearly provedproblematic in the domain of GA. In [29], it is shown that GA search is very sensitive to even smallchanges in the penalty function or weighting factors used. Also, GA has been modified to deal withmulti-objective problems without the need of penalty functions and weighting schemes. An effectivemethod named Niched Pareto Genetic Algorithm is presented in [19]. The method is based on the notionof Pareto Domination which is used during the selection operation. An element is considered to bePareto-dominant over another one only if it is superior in terms of all the objectives used. Hence, insteadof a single solution, a set of Pareto-optimal solutions is obtained at the end of the search. None of theelements in this set would be Pareto-dominant over other elements. Also another effective operationcalled niching is defined in [19]. This operation applies a pressure on the search to spread the geneticpopulation along the pareto optimal surface.
In our approach, the Niched Pareto Genetic Algorithm described in [19] is used in order to minimizethe following two objectives.
1. Total within cluster variation (TWCV), which has been effectively used for the k-clustering problem.2. Number of clusters.
The formal definition of TWCV is given in [23] as follows. Let the clustering problem be partitioningn objects, each has d different properties, into k different groups. So, each object can be representedas a vector with dimension d, and the collection of these objects would be a matrix X, where entry x ij
denotes the jth property of the ith object. Then, another matrix W can be defined as:
wik ={
1, if ith pattern belongs to kth cluster.0, otherwise
(1)
The following two properties will hold for the new matrix; wij ∈ {0, 1} and∑K
k=1 wij = 1, where K isthe total number of clusters.

E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme 167
Let ck = {ck1, ck2 . . . , ckd} denote the center of the kth cluster, then
ckj =∑n
i=1 wikxij∑ni=1 wik
. (2)
The within-cluster variation (WCV) of the kth cluster can be defined as
S(k)(W ) =n∑
i=1
wik
d∑j=1
(xij − ckj)2 (3)
Lastly, TWCV is defined as
S(W ) =K∑
k=1
S(k) =K∑
k=1
n∑i=1
wik
d∑j=1
(xij − ckj)2 (4)
So, the objective is to find W which will minimize S(W ). TWCV is an effective objective function forthe k-clustering problem. However, using TWCV alone is impossible for the general clustering problem.Comparing TWCVs for partitions of different sizes would be misleading. It is more probable for TWCVto decrease as the number of clusters increases. Hence, a GA using TWCV only tends to find solutionswith smaller clusters and larger partition sizes. This bias causes the GA search to end up with clustersconsisting of single objects – TWCV for such trivial partition is zero.
We argue that additional objectives are needed to offset the bias towards trivial clustering. It isstraightforward to set another objective as to favor more coarse-grained clustering, which is to minimizethe partition size. It is apparent, given two different partition sizes, the smaller the partition size is, thesmaller (or equal when duplicated data points exist in a dataset) the minimum TWCV for that partitionsize is. Therefore, targeting these two objectives in GA could lead to solutions for all different partitionsizes in the Pareto optimal set.
4. Linked-List representation for genetic clustering
As mentioned in the previous sections, the most straightforward and the most widely used encod-ing scheme is Group Number Encoding [21]. In this scheme, the value of each gene represents themembership of an object to one of the clusters. Let the set of objects to be clustered in k groups beO = {o1, o2, . . . , on}. Since one gene is reserved for each object, the length of the chromosomes willbe n. Let V be a function denoting the value of a gene in a chromosome. If C = {g1, g2, . . . , gn} isa chromosome in the population, where ∀gi ∈ C, 1 � V (gi) � k, then V (gi) will denote the clusternumber for object oi. Two objects, oi and oj will be in the same cluster if and only if V (gi) = V (gj).
For example, the sample chromosome 2316736211 would encode the clustering solution where thefirst object is in cluster 2, the second in 3 and so on. However, it is possible to have multiple distinctchromosomes for the same solution with this encoding. In a clustering process, the naming or the orderingof the clusters is irrelevant. For instance, renaming cluster 2 to cluster 5 in chromosome 2316736211creates a new chromosome 5316736511. However, both chromosomes are mapping to the same clusteringsolution. The drawbacks of this traditional encoding are presented in [10], and it is pointed out in [27] thatthis encoding is against the minimal redundancy principles set for encoding scheme design. The remedyproposed in [10] is to use a length variable encoding scheme. It reduces redundancy of chromosome

168 E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme
population, but in the meantime it adds redundancy inside a chromosome; it needs more genes to encodea solution than traditional encoding. The other deficiency of the length variable encoding is that it cannottake advantage of conventional simple crossover and mutation operators. This gives advantage to theLinear Linkage Encoding presented in this section; it is a fixed length encoding scheme without any typeof redundancy.
4.1. Linkage encoding scheme
Under linkage encoding scheme, although each gene still stores an integer, the value of the geneno longer directly denotes the membership of an object but its fellowship – this is the fundamentaldifference between the group number encoding and the linkage encoding. Each gene is a link from anobject to another object of the same cluster. Given n objects, any partition on them can be described as achromosome of length n. Two objects are in the same group if either object can be directed to the otherobject via the links. Without any constraint, the state of redundancy is just as bad as that of the groupnumber encoding because the number of feasible chromosomes is still nn.
4.2. Linear linkage (LL) encoding scheme
Linear linkage encoding is a restricted linkage encoding. Let the n genes be indexed inside achromosome from 1 to n. The value of each gene in LL chromosome denotes the index of a fellow genewhere the objects that corresponding to these two genes would be in the same cluster. We can also treatthe stored index as an out-link from a node, and if a gene stores its own index, it depicts an ending node.To qualify an unrestricted linkage chromosome as a valid linear linkage encoding chromosome, thereare two constraints the chromosome must comply to:
1. The integer value stored in each gene is greater than or equal to its index but less than or equal to n.2. No two genes in the chromosome have the same value with the exception that at most two genes
can have the same integer value if the integer is the index of an ending node.
Formally, let the sets of objects to be clustered be O = {o1, o2, . . . , on} and let C = {g1, g2, . . . , gn} bea sample chromosome in the population. Assume V is a function that denotes the value of a gene and Iis the function which returns its index. Then, the following two properties hold for the LL encoding.
∀gi ∈ C [I(gi) � V (gi) � n] .(5)
∀gi, gj ∈ C[V (gi) = V (gj) =⇒ (i = j)
∨((i > j)) ∧ (V (gi) = I(gi))(6)
∨((i < j) ∧ (V (gj) = I(gj))].
The boolean function (ϕ : OXO �→ {True, False}), which would determine if two given objects are inthe same cluster or not, can be recursively defined. If o i and oj are two objects where i < j, then
ϕ(oi, oj) ={
[V (gi) = I(gj)]∨∃gk[(i < k < j) ∧ ϕ(oi, ok) ∧ V (gk) = I(gj)]
(7)
Linear linkage encoding gets its name because objects in a cluster construct a pseudo linear path withthe only loop allowed being a self loop link to mark the last node. It can be represented by the labeledoriented pseudo (LOP) graph.

E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme 169
A LOP graph is a labeled directed graph G(V, E), where V(G) = {v1, v2, . . . , vn}. A composition ofG is a partition of V(G) into disjointed oriented pseudo path graphs G1,G2, . . . ,Gm with the followingproperties:
1. Disjoint paths:⋃m
i=1 V(Gi) = V(G) and for i = j,V(G i)⋂V(Gj) = ∅
2. Non-backward oriented edges: If there is an edge e directed from vertex v l to vk, then l � k.3. Balanced connectivity:
(a) |E(G)| = |V(G)|(b) Each Gi must have only one ending node with a self referencing directed edge exists. The
ending node has an indegree of 2 and an outdegree of 1.(c) Each Gi must have only one starting node whose indegree is 0 and outdegree is 1.(d) All other |V(Gi)| − 2 vertexes in Gi have both their indegree and outdegree equal to 1.
Theorem 1. Given a set of objects S , there is one to one mapping between the chromosomes of LLencoding and the possible partition schemes.
In order to prove this theorem the following lemmas are used.
Lemma 1. Linear linkage encoding is an implementation of the LOP graph.Proof: First, each gene in LL has only one out-link; this causes the object represented by a gene
to belong to only one cluster induced from connections formed by out-links. Therefore, LL encodingrepresents disjoint partition. Hence, the first property of LOP is satisfied. Also, the first constraint ofLL encoding is equivalent to the second property of LOP graph. Lastly, the second constraint of LLencoding ensures the balanced connectivity property of LOP graph.
Lemma 2. Given a set of objects S , there exists one and only one composition of LOP graph G(V, E)for each partition scheme of S , where |V| = |S|.
Proof: Let the objects in S be indexed from 1 to n, and consider a partition scheme on S. Assume thatthe objects in each cluster are ordered in ascending order and each object is directed to the next higherindexed object in the cluster. In addition, a self referencing link is added on the last object of each cluster.This leads to LOP graph. Therefore, there exists at least one composition of G for each partition.
Note that, there is only one possible ascending order within clusters for a possible partition scheme.Thus, there exists only one composition of G for each partition. Reversely, a LOP graph represents onlya single partition scheme by definition.
Based on Lemmas 1 and 2, it can be claimed that LL encoding makes a one-to-one mapping betweenthe chromosomes and clustering solutions.
Corollary: The number of chromosomes corresponding to all possible partition schemes is given bythe nth Bell number.
The number of ways a set of n elements can be partitioned into non-empty subsets is called a Bellnumber [6]. According to Theorem 1, there is one-to-one correspondence between the chromosomes ofLL encoding and the possible partition schemes. Hence, the number of chromosomes in considerationwould be denoted by the nth Bell number B(n), too. Compared to LL encoding scheme, traditionalgroup number encoding demands GA to work in a solution space of nn
B(n) times larger. When n is 10,nn
B(n) is about 105.Although LL encoding keeps only fellowship in genes, it also implies the membership of each object.
Since each cluster must have one starting node and one ending node, both nodes can be used to identifya cluster. In practice, ending node is treated as the membership identifier for clusters because it is easierto detect. Apparently, finding the membership of an object in LL encoding requires only linear time.

170 E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme
Table 1Chromosome and partition mapping
Non-linear linkage Non-LL chromosomes without Linear linkage Partitions(5)chromosomes(27) backward out-links(6) chromosomes(5)(1,2,3) (1,2,3) (1,2,3) (a)(b)(c)(1,2,2) (1,3,2) (1,3,3) (1,3,3) (1,3,3) (a)(bc)(1,2,1) (3,2,1) (3,2,3) (3,2,3) (3,2,3) (ac)(b)(1,1,3) (2,1,3) (2,2,3) (2,2,3) (2,2,3) (ab)(c)(1,1,1) (1,1,2) (1,3,1) (2,3,3) (3,3,3) (2,3,3) (abc)(2,1,1) (2,1,2) (2,2,1)(2,2,2) (2,3,1) (2,3,2)(2,3,3) (3,1,1) (3,1,2)(3,1,3) (3,2,2) (3,3,1)(3,3,2) (3,3,3)
4.3. Initialization
The initial population should include diverse chromosomes. It is intuitive to achieve this goal bygenerating random chromosomes, which means each gene in a chromosome is assigned an integerrandomly selected from the range 1 to n, where n is the number of objects to be clustered. However,the chromosomes generated this way may violate the restrictions of linear linkage encoding. Table 1illustrates what would happen if we use this approach to initialize the population. Suppose we are to findthe optimal partition of three objects a, b, and c. The first column in Table 1 includes all the 27 differentchromosomes. Only five of them survive in the third column if the linear linkage encoding restrictionsare applied. And a one-to-one mapping exists between the third and fourth columns, where the actualpartition schemes of the objects are presented.
From Table 1, it can be easily concluded that the partition scheme {(abc)} will dominate the initialpopulation produced this way. Based on the first LL encoding constraint, each integer should be betweenits index and the maximum integer index number, inclusive. Therefore, a chromosome generator forcreating each gene based on this constraint would be a better choice for diversity.
Note that, the chromosomes produced this way still would not be fully complied with the constraintslaid for linear linkage encoding. Obviously, backward links are prevented with this generator, butmultiple nodes can link to the same node, violating the second constraint. The last chromosome inthe second column of Table 1 is such an example. Generally, this chromosome generator will producechromosomes tending to have small number of clusters. We did a test to generate a number of partitionschemes for 100 objects using this generator. Almost all partitions have sizes ranging from 1 to 10. Itis possible to introduce an extra control mechanism to prevent multiple links to a node. However, wesimply inject a set of chromosomes representing extremely small and big partition sizes in the initialpopulation. The experimental results demonstrate that this is a sufficient way to obtain the diversityneeded for an efficient search.
4.4. Chromosome recovery
Note that multiple links are allowed during the initialization process. Later, we will see backwardlinks in a chromosome emerge in the process of the mutation operation. Therefore, a recovery process isneeded after the constructors, and later other GA operators are employed to rectify a chromosome intoits legitimate format.

E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme 171
0
5
10
15
20
25
30
2 4 6 8 10 12 14 16 18 20
Aver
age
TWC
V
Number of Clusters
"Number Encoding""Linkage Encoding"
Fig. 1. Comparison of Linkage Encoding and Group Number Encoding on Iris-data.
The Rectifying algorithm used for the recovery process involves two correction steps. First, backwardlinks are eliminated from a chromosome. Then, multiple links to a node (except for the ending nodes)are replaced with one link in and one link out. The actual algorithm is given next:
Rectify(){for (each node i){//eliminate backward linkswhile (the out-link of node i is a backward out-link)let the target node of this backward out-link be node jif (node j is not an ending node)
let node i have the same link as node j}
172 E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme
0
2
4
6
8
10
12
14
2 4 6 8 10 12 14 16 18 20
Aver
age
TWC
V
Number of Clusters
"Number Encoding""Linkage Encoding"
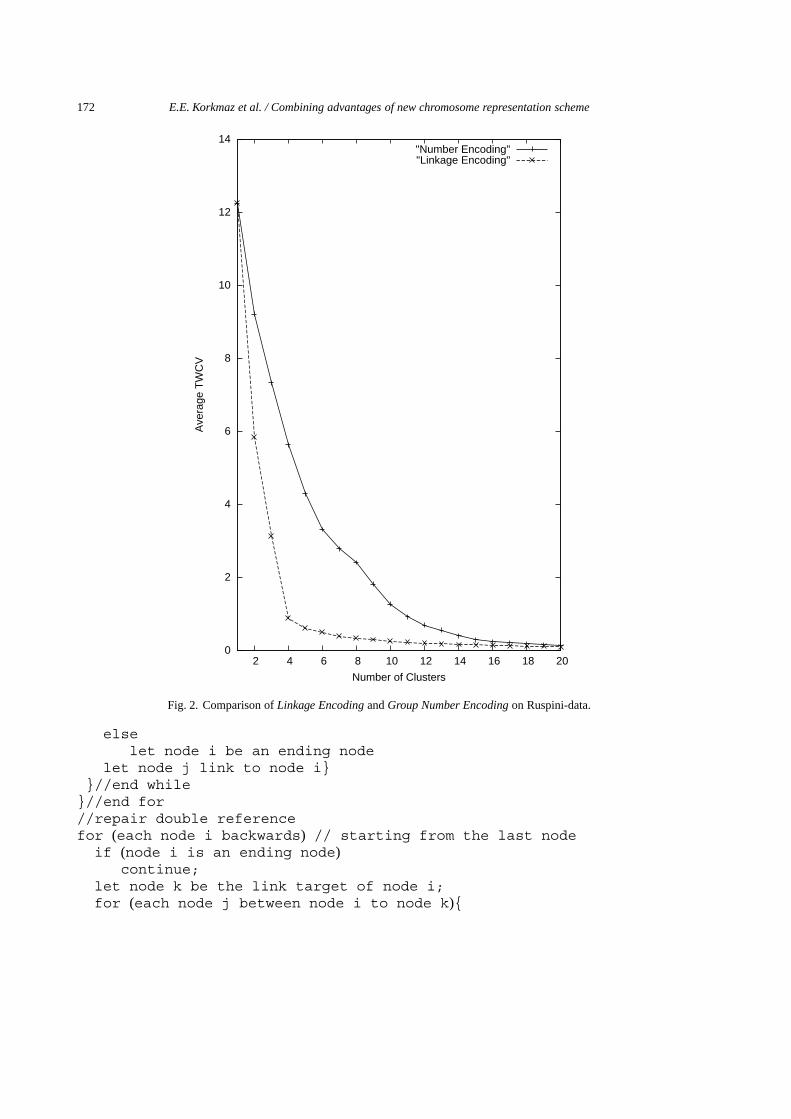
Fig. 2. Comparison of Linkage Encoding and Group Number Encoding on Ruspini-data.
elselet node i be an ending node
let node j link to node i}}//end while
}//end for//repair double referencefor (each node i backwards) // starting from the last nodeif (node i is an ending node)
continue;let node k be the link target of node i;for (each node j between node i to node k){

E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme 173
0
20
40
60
80
100
120
140
160
0 20 40 60 80 100 120
Attr
ibut
e-2
Attribute-1
Fig. 3. The best TWCV values obtained when the number of clusters is 3.
if (both node i and j link to node k){let node i links to node j;
break;
}
}//end for
}//end for
}//end Rectify

174 E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme
0
20
40
60
80
100
120
140
160
0 20 40 60 80 100 120
Attr
ibut
e-2
Attribute-1
Fig. 4. The best TWCV values obtained when the number of clusters is 4.
4.5. Selection
The selection process is very similar to that of Niched Pareto GA described in [19]. A chromosome issaid to be fitter or to dominate another one when it is superior to the latter in terms of all the objectivefunctions used. If only a part of the objective values of one chromosome are better than the other’s,neither chromosome is deemed dominant to the other. A chromosome can be compared to a set ofchromosomes. It is dominated by the set if any individual in the set is fitter than it. Otherwise, thechromosome is not dominated by the set.
When two randomly selected chromosomes competing for a spot in the parent pool, they are notdirectly compared with each other. Rather, each is compared to a comparison set of chromosomes

E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme 175
0
20
40
60
80
100
120
140
160
0 20 40 60 80 100 120
Attr
ibut
e-2
Attribute-1
Fig. 5. The best TWCV values obtained when the number of clusters is 5.
sampled from the current generation. If one of the competing chromosomes, say A, is dominated bythe comparison set and the other chromosome, say B, is not dominated, then B advances to the parentpool. However, when both A and B are either dominated or not dominated by the set, the niche count ofeach chromosome is compared. The chromosome with the smaller niche count gets advantage. Nichecount is an indicator of the solution density around a chromosome in a certain solution population. Thisapproach encourages even distribution of solutions in the GA population [19].
In each generation, the Pareto dominant set is achieved through a search in the whole population.Every individual is compared with the rest. If a chromosome is not dominated by the rest, it is copied tothe Pareto dominant set. The Pareto dominant set of the last generation contains the optimal solution.

176 E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5 10 15 20 25 30 35 40 45 50
Stan
dard
Dev
iatio
n
Number of Clusters
"Number Encoding""Linkage Encoding"
Fig. 6. The standard deviation of Linkage Encoding and Group Number Encoding on Iris-data.
4.6. Crossover
Since LL encoding represents solutions in a fixed length chromosome, it is very handy to use traditionalGA crossover operator. In our experiments, one point crossover is adapted. The operation both allowsdifferent clusters to exchange partial contents and also may split a cluster into two.
4.7. Mutation
Classical mutation operation would modify the value of a gene, one at a time. When the classicalGroup Number Encoding is applied to the clustering problem, such mutation causes a reassigning of only

E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme 177
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
5 10 15 20 25 30
Stan
dard
Dev
iatio
n
Number of Clusters
"Number Encoding""Linkage Encoding"
Fig. 7. The standard deviation of Linkage Encoding and Group Number Encoding on Ruspini-data.
a single object. However, if this approach is applied to the linear linkage encoding, a group of objectscould be moved to a different cluster.
This classical mutation was implemented for LL-encoding and the test results were not encouraging.With the classical mutation, the out-link of a node is very likely to change to a different one, but the newout-link might still point to the same cluster. This results in no change in the chromosome after beingrectified, and hence lessens the affect of the mutation during the search. The solution is to make surethat the mutated gene gains a link to a different cluster instead of just a different node. Also, when themutated gene is again assigned to its original cluster, that cluster is split into two. Hence, the mutationmight have two different effects on the chromosome; a sub-group of objects can be moved to a newcluster or a cluster can be split into two. This new mutation method changes the membership of set ofobjects rather than just a single object; we call it grafting mutation. It is described next:

178 E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme
0
5
10
15
20
25
30
2 4 6 8 10 12 14 16 18 20
Min
imum
TC
WV
Number of Clusters
"Number Encoding""Linkage Encoding"
Fig. 8. The minimum TWCV values obtained by Linkage Encoding and Group Number Encoding on Iris-data.
Grafting mutation:
1. Select a gene (a node) g from the chromosome at random. Let g be in cluster C i. Find the endingnode e of cluster C .
2. Pick a random number m from 1 to k, where k is the number of clusters in the partition scheme.3. If m = k, then make g an ending node. Ci is thus split into two clusters with exception that if the
selected g is the ending node already, the splitting will not occur.4. If m < k, then make g an ending node. Again, Ci is divided into two clusters, one ending with g
and one with e. Either link g or e to the mth ending node that exists to its right (loop). Thus, a partof Ci is grafted to another cluster.

E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme 179
Table 2Genetic parameters used for the experiments
Parameter ValueNumber of Experiments 10Number of Generations 2000population size (Iris) 800population size (Ruspini) 500Niche Comparison Size (selection) 5Nitch Radius 5Nitch Count Size 25Crossover Rate 0.9Mutation Rate 0.2
5. Experimental results
In this section, we report the result of our experiments on two widely used data sets, namely Iris andRuspini. The former is a real dataset recording 150 observations of the three species (Setosa, Versicolor,and Virginica) of iris flowers, all described in four features. The latter is an artificial dataset of twoattributes. Its 75 data points naturally form 4 clusters. Originally data points in both datasets are sortedso that the clusters are easily perceived. To obtain unbiased result, we reorganized the datasets and allthe data points are randomly placed. In addition, data standardization process is applied to the datasetto neutralize the effects brought by data attributes of disparage magnitude. We divide each data elementby the maximum value of its dimension to scale all data elements ranging from 0 to 1.
The proposed representation is compared with the classic Group Number Encoding scheme. In ourexperiments, two GAs are developed. Apart from the encoding schemes, all GA operators are kept thesame as described in Section 4. The genetic parameters are fixed for all GA runs and they are presentedin Table 2.
The comparison of the two methods are presented in Figs 1 and 2. Note that the multi-objective GAtries to minimize TWCV for all possible number of clusters. For the Iris data set, the possible numberof clusters ranges from 1 to 150. The single cluster is the case where all instances are placed into thesame cluster, and each instance is considered as a separate cluster when number of clusters increasesto 150. This range is between 1 and 75 for the Ruspini dataset since the number of instances is 75 inthis domain. In Figs 1 and 2, TWCV values obtained by the two methods are presented up to only 20clusters. Note that the optimal number of clusters for Iris and Ruspini is 3 and 4, respectively. Hence,TWCV values obtained for smaller number of clusters is of more interest. It is obvious from the figuresthat the Linkage Encoding clearly dominates the classical approach.
More interestingly, the TWCV values found by the Linkage Encoding rapidly increases for clusternumbers smaller than the optimal clustering. For instance, in Fig. 1, the change in TWCV is quite stabledown to 3 clusters. However, there is a considerable leap between TWCV values of 2 and 3 clusters.We observe a similar leap in Fig. 2 between 3 and 4 clusters this time. On the other hand, we do notdiscern such a clear indication for the Group Number Encoding presented in the same figures. Hence, itis possible to derive conclusions about the optimum number of clusters by considering the pareto optimalset obtained at the end of the GA search. In both data sets the optimum clusters are well separated fromothers. We realize that in a domain where the cluster borders are not very clear, the leap at the optimumnumber of clusters may not be as clear as the result obtained in these two domains.
Note that Ruspini dataset has only two attributes. It is easy to display the clusters obtained on thisdata set as two-dimensional diagrams. In Figs 3, 4 and 5, the best partitions obtained by the Linkage

180 E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme
0
2
4
6
8
10
12
14
2 4 6 8 10 12 14 16 18 20
Min
imum
TC
WV
Number of Clusters
"Number Encoding""Linkage Encoding"
Fig. 9. The minimum TWCV values obtained by Linkage Encoding and Group Number Encoding on Ruspini-data.
encoding are presented for 3, 4 and 5 clusters, respectively. From the figures, it can be easily realized thatthe natural partition of the data set is formed by four clusters (Fig. 4). However, the partitions obtainedwhen the number of clusters is decreased to 3 or increased to 5 are also plausible. When the number ofclusters is 3, two of the clusters that appear in the natural solution merge into a single cluster (Fig. 3).On the other hand, one of the clusters in the natural solution splits into two when the number of clustersis 5. In this case, a new cluster is created with the elements that seem to be a bit more separate comparedto the other elements in the original class (Fig. 5).
The deviation that appears throughout different runs is another important indicator about the GAperformance. In Figs 6 and 7, the standard deviation of the Linkage Encoding and the Group NumberEncoding are compared. As seen in the figures, the deviation with the classical encoding is quite highcompared to the new scheme. On the contrast, a more consistent output set is obtained with the newly

E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme 181
proposed scheme.The notion of statistical significance gains importance when the average of the experimental results is
used in comparing the two methods. The difference between the means is a necessary but not a sufficientcondition for the verification of a performance increase. Statistical tests are crucially needed, especiallywhen the number of experiments is not very large. One-tailed Student’s t-test has been used to verifythe performance increase obtained in both of the problem sets. The test is applied to the first 20 partitionschemes, since the method proposed dominates the classical approach in this part of the solution set. Ithas been observed that the performance increase obtained is statistically significant with a confidenceinterval of 99% for both sets.
In general, clustering is an off-line process. Therefore, even though an approach is superior to anotherone in terms of the average output it produces, the success of the method could still be questioned if thetwo approaches do not differ in terms of the best solution they can find. It is essential to compare theminimum TWCV values obtained by the two schemes. In Figs 8 and 9 this comparison is presented forboth data sets, and it has been observed that the new encoding is superior in terms of the best solution itcan find throughout different experiments.
6. Conclusions
In this paper, a new encoding scheme is proposed for the application of GA to the clustering problem.This new scheme has been successfully used with the multi-objective GA which is a powerful optimizationtechnique. The results obtained on two well-known data sets provide a good insight about the importanceand effectiveness of the new scheme. These results are compared with the output of classical GroupNumber Encoding. The analysis carried out clearly notifies that the new scheme is more advantageous.Although some extra processes are needed in order to keep the redundancy low, it has been observed thatthe computational cost of these processes is not significant.
The leap in TWCV after the optimum number of clusters seems to be an important issue about theproposed technique. The experiments demonstrate that it is expected to observe such a leap for datasetswith well separated clusters. It would be interesting to observe the change in TWCV, in domains wherecluster borders are not clear. In such domains, probably it would not be possible to directly observe theoptimum number of clusters. However, an automatic analysis of the change in TWCV values might behelpful to determine the optimum point.
References
[1] A. Pen, J. Lozano and J. Larran, An empirical comparison of four initialization methods for the k-means algorithm,Pattern Recognition Letters 20(10) (1999), 1027–1040.
[2] G.P. Babu and M.N. Murty, A near-optimal initial seed value selection in k-means algorithm using a genetic algorithm,Pattern Recognition Letters 14(10) (1993), 763–769.
[3] P. Berkhin, Survey of clustering data mining techniques, Technical report, Accrue Software, San Jose, CA, 2002.[4] J. Bezdek and S. Boggavarapu, Genetic algorithm guided clustering, Proc. 1st IEEE Conf. on Evolutionary Computation,
1994, 34–39.[5] C.L. Blake and C.J. Merz, UCI repository of machine learning databases, 2000.[6] A. Bremner, Reviews: The Book of Numbers, by John Horton Conway and Richard K. Guy, American Mathematical
Monthly 104(9) (November 1997), 884–.[7] D.S. Burke, K.A. De Jong and J.J. Grefenstette, Connie Loggia Ramsey, and Annie S. Wu. Putting more genetics into
genetic algorithms, Evolutionary Computation 6(4) (Winter 1998), 387–410.[8] Rowena Marie Cole, Clustering with genetic algorithms, Master’s thesis, Nedlands 6907, Australia, 1998.

182 E.E. Korkmaz et al. / Combining advantages of new chromosome representation scheme
[9] I. Dhillon, J. Fan and Y. Guan, Efficient clustering of very large document collections, in: Data Mining for Scientific andEngineering Applications, R. Grossman, C. Kamath and R. Naburu, eds, Kluwer Academic Publishers, 2001.
[10] E. Falkenauer, Genetic Algorithms and Grouping Problems, John Wiley & Sons, 1998.[11] E. Falkenauer, A new representation and operators for genetic algorithms applied to grouping problems, Evolutionary
Computation 2(2) (1994), 123–144.[12] D. Gibson, J.M. Kleinberg and P. Raghavan, Clustering categorical data: An approach based on dynamical systems,
VLDB Journal: Very Large Data Bases 8(3–4) (February 2000), 222–236. Electronic edition.[13] D.E. Goldberg, Genetic Algorithms in Search, Optimization, and Machine Learning, Addison-Wesley, Reading, Mass.,
1989. An introductory textbook and guide to current research. Contains examples, exercises, and sample programs aswell as proofs of most of the major GA theorems on crossover and implicit parallelism.
[14] S. Guha, R. Rastogi and K. Shim, CURE: an efficient clustering algorithm for large databases, In Laura Haas and AshutoshTiwary, editors, Proceedings of the 1998 ACM SIGMOD International Conference on Management of Data: June 1–4,1998, Seattle, Washington, USA, Volume 27(2) of SIGMOD Record (ACM Special Interest Group on Management ofData), 73–84, New York, NY 10036, USA, 1998. ACM Press.
[15] L.O. Hall, I.B. Ozyurt and J.C. Bezdek, Clustering with a genetically optimized approach, IEEE Trans. on EvolutionaryComputation 3(2) (1999), 103–112.
[16] J. Han and M. Kamer, Data Mining: Concepts and Techniques, Morgan Kaufmann, 2001.[17] J. Hartigan, Clustering Algorithms, Wiley, 1975.[18] J. Holland, Adaptation in Natural and Artificial Systems, University of Michigan Press, 1975.[19] J. Horn, N. Nafpliotis and D.E. Goldberg, A Niched Pareto Genetic Algorithm for Multiobjective Optimization, (Vol. 1),
In Proceedings of the First IEEE Conference on Evolutionary Computation, IEEE World Congress on ComputationalIntelligence, Piscataway, New Jersey, 1994. IEEE Service Center, 82–87.
[20] A.K. Jain and R.C. Dubes, Algorithms for Clustering Data, Prentice Hall International, 1988.[21] D.A. Jones and M.A. Beltramo. Solving partitioning problems with genetic algorithms, in: Proceedings of the 4th
International Conference on Genetic Algorithms, L.B. Belew and R.K. Booker, eds, San Diego, CA, July 1991. MorganKaufmann, 442–449.
[22] L. Kaufman and P.J. Rousseeuw, Finding Groups in Data, John Wiley & Sons, 1990.[23] K. Krishna and M. Murty, Genetic k-means algorithm, IEEE Transactions on Systems, Man, and Cybernetics – PartB:
Cybernetics 29(3) (1999), 433–439.[24] U. Maulik and S. Bandyopadhyay, Genetic algorithm-based clustering technique, Pattern Recognition 33 (2000), 1455–
1465.[25] G.J. McLachlan and K.E. Basford, Chapters 1 and 2, In McLachlan and Basford, editors, Mixture models: inference and
applications to clustering, Marcel Dekker, Inc., 1988, 1–69.[26] R. Ng and J. Han, Efficient and effective clustering method for spatial data mining, In Proc. of 1994 Int’l Conf. on Very
Large Data Bases (VLDB’94), September 1994, 144–155.[27] N.J. Radcliffe, Forma analysis and random respectful recombination, in: Proceedings of the 4th International Conference
on Genetic Algorithms, L.B. Belew and R.K. Booker, eds, San Diego, CA, July 1991. Morgan Kaufmann, 222–229.[28] B. Rekiek, P. de Lit, F. Pellichero, T. L’Eglise, P. Fouda, E. Falkenauer and A. Delchambre, A multiple objective grouping
genetic algorithm for assembly line design, Journal of Intelligent Manufacturing 12(5–6) (2001), 467–485.[29] J.T. Richardson, M.R. Palmer, G. Liepina and M. Hilliard, Some guidlines for genetic algorithms with penalty functions,
In Proc. of the 3rd Int. Conf. on Genetic Algorithms, Morgan Kaufman, 1989.[30] E.H. Ruspini, Numerical methods for fuzzy clustering, Inform. Sci. 2(3) (1970), 19–150.[31] I. Sarafis, A.M.S. Zalzala and P. Trinder, A genetic rule-based data clustering toolkit, in: Proceedings of the 2002
Congress on Evolutionary Computation CEC2002, D.B. Fogel, M.A. El-Sharkawi, X. Yao, G. Greenwood, H. Iba, P.Marrow and M. Shackleton, eds, IEEE Press, 2002, pp. 1238–1243.
[32] E. Schikuta and M. Erhart, BANG-Clustering: A novel grid-clustering algorithm for huge data sets, Lecture Notes inComputer Science 1451 (1998), 867.
Related Documents











