Inf Retrieval (2006) 9:613–631 DOI 10.1007/s10791-006-9007-3 Collection-based compound noun segmentation for Korean information retrieval In-Su Kang · Seung-Hoon Na · Jong-Hyeok Lee Received: 6 January 2005 / Accepted: 12 May 2006 / Published online: 1 September 2006 C Springer Science + Business Media, LLC 2006 Abstract Compound noun segmentation is a key first step in language processing for Korean. Thus far, most approaches require some form of human supervision, such as pre-existing dic- tionaries, segmented compound nouns, or heuristic rules. As a result, they suffer from the unknown word problem, which can be overcome by unsupervised approaches. However, pre- vious unsupervised methods normally do not consider all possible segmentation candidates, and/or rely on character-based segmentation clues such as bi-grams or all-length n-grams. So, they are prone to falling into a local solution. To overcome the problem, this paper proposes an unsupervised segmentation algorithm that searches the most likely segmentation result from all possible segmentation candidates using a word-based segmentation context. As word- based segmentation clues, a dictionary is automatically generated from a corpus. Experiments using three test collections show that our segmentation algorithm is successfully applied to Korean information retrieval, improving a dictionary-based longest-matching algorithm. Keywords Compound noun segmentation . Unsupervised method . Korean information retrieval 1. Introduction Unlike English, Korean does not use word boundaries within an Eojeol, a Korean spacing unit as well as a Korean syntactic unit. Generally, an Eojeol is composed of simple or I.-S. Kang () . S.-H. Na . J.-H. Lee Division of Electrical and Computer Engineering, Pohang University of Science and Technology (POSTECH), Advanced Information Technology Research Center (AITrc), PIRL 323, San 31, Hyoja-dong, Nam-gu, Pohang, 790-784, Republic of Korea e-mail: [email protected] S.-H. Na e-mail: [email protected] J.-H. Lee e-mail: [email protected] Springer

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Inf Retrieval (2006) 9:613–631
DOI 10.1007/s10791-006-9007-3
Collection-based compound noun segmentationfor Korean information retrieval
In-Su Kang · Seung-Hoon Na · Jong-Hyeok Lee
Received: 6 January 2005 / Accepted: 12 May 2006 / Published online: 1 September 2006C© Springer Science + Business Media, LLC 2006
Abstract Compound noun segmentation is a key first step in language processing for Korean.
Thus far, most approaches require some form of human supervision, such as pre-existing dic-
tionaries, segmented compound nouns, or heuristic rules. As a result, they suffer from the
unknown word problem, which can be overcome by unsupervised approaches. However, pre-
vious unsupervised methods normally do not consider all possible segmentation candidates,
and/or rely on character-based segmentation clues such as bi-grams or all-length n-grams. So,
they are prone to falling into a local solution. To overcome the problem, this paper proposes an
unsupervised segmentation algorithm that searches the most likely segmentation result from
all possible segmentation candidates using a word-based segmentation context. As word-
based segmentation clues, a dictionary is automatically generated from a corpus. Experiments
using three test collections show that our segmentation algorithm is successfully applied to
Korean information retrieval, improving a dictionary-based longest-matching algorithm.
Keywords Compound noun segmentation . Unsupervised method . Korean information
retrieval
1. Introduction
Unlike English, Korean does not use word boundaries within an Eojeol, a Korean spacing
unit as well as a Korean syntactic unit. Generally, an Eojeol is composed of simple or
I.-S. Kang (�) . S.-H. Na . J.-H. LeeDivision of Electrical and Computer Engineering, Pohang University of Science and Technology(POSTECH), Advanced Information Technology Research Center (AITrc), PIRL 323, San 31,Hyoja-dong, Nam-gu, Pohang, 790-784, Republic of Koreae-mail: [email protected]
S.-H. Nae-mail: [email protected]
J.-H. Leee-mail: [email protected]
Springer

614 Inf Retrieval (2006) 9:613–631
complex words followed by optional inflectional affixes. A complex word may consist of
many simple words or derived words. For example, an Eojeol ‘a-phu-li-kha-ki-a-mwun-cey-lul’ consists of a compound noun ‘a-phu-li-kha-ki-a-mwun-cey’ (African starvation problem)
and an accusative case marker lul. a-phu-li-kha-ki-a-mwun-cey is further decomposed into
three simple nouns a-phu-li-kha (Africa), ki-a (starvation), and mwun-cey (problem). Such
decomposition is crucial to identify source language words for transfer dictionary lookup
in machine translation, or to obtain index terms in information retrieval (IR). Thus, word
segmentation (more precisely, Eojeol segmentation) is a key first step in Korean language
processing.
In particular, decomposition of compound nouns is nontrivial in Korean (Kang, 1993,
1998; Choi, 1996; Jang and Myaeng, 1996; Park et al., 1996; Yun et al., 1997; Lee et al.,
1999; Shim, 1999; Yoon, 2001; Min et al., 2003; Park et al., 2004), since there may be
unknown component words and segmentation ambiguity in compound nouns. Today, due to
globalization, unknown words are growing faster than ever before, especially in nominals. To
attack the compound noun segmentation problem, practical and popular approaches rely on
dictionaries, a set of segmented compound nouns, and heuristics such as longest-matching
and/or least components preference. However, those supervised approaches typically suffer
from the unknown word problem, and cannot distinguish domain-oriented or corpus-directed
segmentation results from the others.
The problems inherent to supervised segmentation methods can be solved by unsuper-
vised statistical approaches, since they assume neither pre-existing dictionaries nor pre-
segmented corpora, and segment a compound noun using segmentation probabilities be-
tween two characters that are estimated from a raw corpus. For example, in order to segment
a character sequence w = c1 . . . cn , first, n − 1 segmentation probabilities between two ad-
jacent characters are calculated for each segmentation point. Next, w is segmented at a
critical segmentation point that has globally or locally the maximum segmentation proba-
bility. Then, each of two segmented sequences is iteratively segmented at its own critical
point.
However, many unsupervised approaches (Sproat and Shih, 1990; Lua and Gan, 1994;
Chen et al., 1997; Maosong et al., 1998; Shim, 1999; Ando and Lee, 2003) do not consider all
possible segmentation candidates,1 and simply rely on a one-dimensional character-based
segmentation context that is in most cases limited to only adjacent characters. So, they
are prone to falling into a local solution. Moreover, since they do not utilize word-based
context, certain threshold mechanisms are required to avoid under- or over-segmentation.
Currently, as far as we know, no systematic method has been proposed to determine threshold
values for segmentation decisions. Some other unsupervised methods (Ge et al., 1999; Huang
et al., 2002; Peng et al., 2002) attempt to select the best one from all possible segmentation
candidates based on the EM-algorithm. They use all-length n-gram statistics as segmentation
clues. However, all-length n-grams may not be sufficient in providing evidence for word
boundaries.
In order to deal with the problems of unsupervised statistical segmentation methods,
this article proposes a collection-based compound noun segmentation model that searches
the most likely segmentation candidate from all possible segmentation candidates using a
word-based segmentation context. A legal segment (or component) in a compound noun
is identified as an entry in a collection dictionary, which is composed of stems gathered
1 Theoretically, an n-character compound noun has 2n−1 segmentation candidates. In this paper, a segmentationcandidate is also called a segmentation result, and each component in a segmentation candidate is called asegment.
Springer

Inf Retrieval (2006) 9:613–631 615
from a target corpus. Stems are automatically obtained from Eojeols in a corpus by deleting
inflectional suffixes. In our approach, ‘collection-based’ means that our model relies on
only a given corpus, without using any other external resources. In other words, given a
corpus, our segmentation model is created from only the corpus, and then the segmentation
model is applied to segment the same corpus. This feature will be useful for domain-specific
applications where domain-specific dictionaries may be difficult to obtain. To demonstrate
the usefulness of our segmentation algorithm, this study evaluates the application of the
proposed segmentation method to Korean information retrieval.
The remainder of this article is organized as follows. Section 2 summarizes related works.
Section 3 describes a collection-based segmentation method as well as an automatic building
of a collection dictionary with a segmentation example. Sections 4 and 5 report the re-
sults of segmentation evaluations and retrieval experiments. Finally, concluding remarks
are given in Section 6. For representing Korean expressions, the Yale romanization2 is
used.
2. Related works
2.1. Overview
While Korean lacks a spacing unit within an Eojeol, Chinese and Japanese use no word de-
limiters in written text. Thus, much research has also been conducted on word segmentation
of the Chinese and Japanese languages. Previous studies can be classified into supervised and
unsupervised methods, according to whether human supervision about word boundaries is
required or not. However, since this paper handles a dictionary-less unsupervised approach,
only unsupervised methods using neither dictionaries nor pre-segmented corpora are re-
viewed. For supervised methods, other literatures (Wu and Tseng, 1995; Nie and Ren, 1999;
Ogawa and Matsuda, 1999; Ando and Lee, 2003) well summarize Chinese and Japanese
segmentation.
Most unsupervised segmentation methods for Chinese and Japanese depend on n-gram
statistics from raw corpora like bi-grams (Sproat and Shih, 1990; Lua and Gan, 1994; Chen
et al., 1997; Maosong et al., 1998) or all-length n-grams (Ge et al., 1999; Huang et al., 2002;
Peng et al., 2002; Ando and Lee, 2003). Bi-gram statistics are normally collected to compute
association probability like mutual information (MI) between adjacent two characters in text.
All-length n-gram statistics are used in the EM algorithm (Ge et al., 1999; Huang et al., 2002;
Peng et al., 2002) or in the TANGO algorithm (Ando and Lee, 2003). To resolve segmentation
ambiguity, all approaches except for the EM algorithm rely on empirical parameters such as
thresholds. EM-based segmentation depends on all-length n-gram statistics which may be
insufficient in providing evidence to identify word boundaries. Unlike the previous methods,
our algorithm uses stems and their frequencies obtained from a corpus as segmentation
clues.
2.2. Korean compound noun segmentation
Most researchers of Korean compound noun segmentation basically use a lexicon to iden-
tify segmentation candidates. To resolve segmentation ambiguity, they additionally utilize
2 The Yale romanization represents each morphophonemic element (which in most cases corresponds to ajamo, a letter of the Korean alphabet) by the same roman letter, irrelevant of its context (Wikipedia, 2006).
Springer

616 Inf Retrieval (2006) 9:613–631
heuristic rules (Kang, 1993, 1998; Choi, 1996; Yun et al., 1997), and/or statistics from
segmented compound nouns (Yun et al., 1997; Lee et al., 1999; Yoon, 2001). One example
of heuristic rules is that a 4-character compound noun tends to be more likely segmented
into 2 + 2 (two 2-character words) than 1 + 3 (1-character word and 3-character word) or
3 + 1. As statistical information used to resolve segmentation ambiguity, which is obtained
from a set of manually segmented compound nouns, Yun et al. (1997) rely on probabili-
ties that a simple word is used as a specifier, an intermediate, or a head in a compound
noun, and Lee et al. (1999) estimate probabilities for semantic association between ad-
jacent constituents in a compound noun, and Yoon (2001) use lexical probabilities to be
used in his min-max disambiguation procedure. In summary, most segmentation approaches
for Korean compound nouns can be classified into dictionary-based supervised approaches
with statistical disambiguation devices. So, they severely suffer from the unknown word
problem.
Some researchers proposed partially unsupervised segmentation methods for Korean
(Jang and Myaeng, 1996; Park et al., 1996; Shim, 1999). Jang and Myaeng (1996) rep-
resent a list of nouns (including compound nouns) obtained by POS-tagging a corpus
in the form of forward and backward tries, where each node corresponds to one char-
acter, and dummy nodes are inserted after common prefixes among nouns while match-
ing each noun forward and backward. For example, three compound nouns tay-hak-sayng-sen-kyo-hoy (a missionary party for university students), tay-hak-sayng (univer-
sity students), and kyo-hoy (a church) would generate forward and backward tries as
follows.
Forward trie: tay→hak→sayng→dummy→sen→kyo→hoy,
Backward trie: tay←hak←sayng←sen←dummy←kyo←hoy.
Then, a new compound noun is matched forward or backward over the two tries where
dummy nodes indicate segmentation points. However, Jang and Myaeng (1996) use heuristic
rules to resolve segmentation ambiguity.
Park et al. (1996) extract nouns from a corpus by a HMM model to build a noun
dictionary, from which all segmentation candidates of compound noun w in document
d are identified. Then, they select the best segmentation candidate corresponding to the
Kullback-Leibler divergence, which is calculated between distributions of each segmenta-
tion candidate s and document d, where each distribution is defined from term distributions
over a document collection. That is, they generate a segmentation candidate of which de-
composed terms are similar to document terms in d in terms of term distribution over a
document collection. So, their method assumes that for compound noun w in document
d , its correctly decomposed terms more likely appear in d than incorrectly decomposed
ones. Unfortunately, Park et al. (1996) did not evaluate segmentation accuracy, and they
reported the effect of segmentation on retrieval effectiveness using a small Korean test
collection.
For all adjacent character pairs (si , si +1) in a compound noun, Shim (1999) calculates its
segmentation strength as a linear combination of four kinds of mutual information (MI), which
can be informally rephrased as (1) a probability that si is followed by si +1 in a compound
noun, (2) a probability that there is a word boundary between si and si +1, (3) a probability
that a compound noun ends with a character si , and (4) a probability that a compound
noun starts with a character si +1. These probabilities can be collected from a raw corpus.
Using a threshold, Shim (1999) recursively segmented between characters. Unfortunately,
Springer

Inf Retrieval (2006) 9:613–631 617
he appealed to a dictionary to stop segmentation. For instance, if both segmented halves are
in a dictionary, segmentation stops.
In summary, previous unsupervised segmentation methods for Korean partially rely on
pre-existing dictionaries, heuristic rules, or threshold values. So, they require human labor
for dictionary maintenance, rule adaptation, and threshold tuning.
3. Collection-based compound noun segmentation
3.1. Building a collection dictionary
In our dictionary-less unsupervised approach to compound noun segmentation, we use word-
based context, compared to previous unsupervised methods that use character-based context.
Thus, a list of words should be acquired from a raw corpus C . For doing that in Korean,
one standard method is to use a morphological analyzer or a POS-tagger on C . Considering
that a raw corpus has in general a number of unknown words such as proper nouns, domain
jargons, technical terms, transliterated terms, acronyms, etc., morphological analysis is prone
to generate many spurious words.
The other method employs a list of inflectional suffixes to simply delete word end-
ings from an Eojeol to produce a stem. For example, the Eojeol ‘se-wul-ey-se-pwu-the-nun’ consists of a stem se-wul (Seoul) and a sequence of three inflectional suffixes ey-se(in), pwu-the (from), and nun (a topic marker). From that Eojeol, a stem se-wul (Seoul)
can be obtained by deleting the longest word ending ey-se-pwu-the-nun. Compared to
the former morphological analysis or tagging-based method that is highly dependent on
an open set of known words, this suffix-based method utilizes a closed set of suffixes.
In addition, this suffix-stripping technique is simple and fast. We adopt this method to
produce a collection dictionary using a list of our 7,434 Korean complex (inflectional)suffixes.3
3.2. Segmentation algorithm
Let us assume that we have a corpus C, which is viewed as a document collec-
tion in information retrieval. Now, we want to segment an n-character compound noun
w = c1 . . .ci . . .cn (ci is the i-th character), which is in C. As an alternative notation
for w = c1 . . .cn , we use c1n. First, a collection dictionary D is created from C us-
ing the suffix-based method described in Section 3.1. Note that an entry e in D is
a simple or complex word obtained from an Eojeol in C by deleting tailing function
words.
In order to find the most likely segmentation candidate S∗
of w , we should calculate the fol-
lowing Formula (1), where k-th segmentation candidate is represented as Sk = s1. . .s j . . .sm (k)
(s j is the j-th segment, m(k) ≤ n, and m(k) is the number of the last segment of Sk) of w .
Note that a segment covers one or more contiguous characters in w . In Formula (1), we in-
terpret P(Sk | C) as a probability that w is decomposed into s1, s2, . . ., and sm (k). In addition,
3A complex suffix consists of two or more base suffixes. For example, a complex suffix ‘ey-se-pwu-the-nun’consists of three base suffixes ‘ey-se’, ‘pwu-the’, and ‘nun’.
Springer

618 Inf Retrieval (2006) 9:613–631
occurrences of segments of a compound noun are assumed to be independent.
S∗ = argmaxSk=s1,...,sm(k)
P(Sk |C)
= argmaxSk=s1,...,sm(k)
m(k)∏i=1
P(si |C) (1)
However, Formula (1) tends to produce the segmentation candidate that has the smaller
number of segments. Generally, this can reflect well a heuristic of dictionary-based supervised
segmentation methods. In other words, if the other conditions are the same, a segmentation
candidate with the least number of segments is preferred. In unsupervised segmentation,
however, Formula (1) would divide the input string T into a few large segments. This means
that the naive application of Formula (1) may under-segment the input. We attempt to obviate
this problem by pruning unhelpful segmentation candidates from the search space using the
following two constraints.
Constraint 1: When the search space of a compound noun is enumerated in a top-down
two-way decomposition manner, do not further decompose a segment of which length is
smaller than K.
Constraint 2: When the search space of a compound noun is enumerated in a bottom-up
two-way combination manner, if a segment (XY) can be obtained from the concatenation
(X + Y) of two smaller segments (X and Y), do not generate the segment (XY) itself.
Figure 1 shows the pruned search space of a string ‘abcd’ for each of the two constraints.
In the left side, bold-faced segmentation candidates survive constraint 1 with K = 4, since
any of the segmentation candidates in the level 2 does not contain a segment of which length
is equal to or larger than 4. In the right side, only a + b + cd survive constraint 2 when the
collection dictionary contains a, b, ab, bc, cd, and abc. In cell (ii, 1), a segment ab is ignored
since the cell can be constructed by a + b though ab is in the collection dictionary. Cell
(ii, 2), however, can hold bc since any combination of smaller segments cannot create bc,
and bc is found in the collection dictionary. Thus, constraints 1 and 2 influence enumerating
the feasible set of hypotheses by hindering over-segmentation and under-segmentation of a
compound noun respectively.
Fig. 1 Example of applying two constraints to segmenting ‘abcd’
Springer

Inf Retrieval (2006) 9:613–631 619
In order to modify Formula (1) with the above constraints, we define a probability
δ using induction as in Formula (2), where the basis step deals with constraint 1 and
checking the value of β in the induction step reflects constraint 2. δ(cpq | C) means the
probability of the most likely segmentation candidate of cpq , a substring covering con-
tiguous characters of c1n from the p-th character to the q-th character. For example, for
c15 = kwuk-cey-wen-yu-ka (an international crude oil price), c35 is wen-yu-ka (an crude
oil price), and c55 is ka (price). A parameter K indicates a minimum character length of
the substring that is handled in the induction step. For example, K = 4 means that, for
a given input string, we do not try to segment any substrings of 2- or 3-character length
into smaller constituents, but 4- or more character sub-strings are decomposed if that is
possible.
Basis Step : (q − p + 1) < K
δ(cpq | C) = P(cpq | C)
σ(cpq ) = cpq
Induction Step : (q − p + 1) ≥ K (2)
r∗ = arg maxp≤r≤q−1
β(cpq , r, C)
δ(cpq | C) =(
P(cpq | C), ifβ(cpq , r∗, C) = 0
β(cpq , r∗, C), otherwise
)σ(cpq ) =
(cpq , ifβ(cpq , r∗, C) = 0
σ(cpr∗ ) + σ(c(r∗+1)q ), otherwise
)β(cpq , r, C) = δ(cpr | C)δ(c(r+1)q | C)
P(cpq | C), a probability that a character-string cpq is generated from C, is obtained from
maximum likelihood estimation as in Formula (3), where freq(x) means the frequency of xin C, and D is a collection dictionary.
P(cpq | C) = freq(cpq )∑c∈D freq(c)
(3)
The probability function β(cpq , r, C) calculates a probability that a character-string cpq
is decomposed into cpr and c(r+1)q in C. Using the recurrence relation of Formula (2), we
can efficiently calculate the probability of the most likely segmentation candidate S∗
for a
compound noun w = c1n as in Formula (4). To obtain S∗
from Formula (4), it is necessary
to store the best segmentation candidate at each step of Formula (2). For this, Formula (2)
maintains σ(cpq ) to store a partial segmentation result.
P(S∗ | C) = δ(c1n|C) (4)
3.3. Example
To exemplify the proposed segmentation algorithm, suppose that we want to segment a
compound noun kwuk-cey-wen-yu-ka (an international crude oil price), which occurs in cor-
pus C. Also, we assume that a collection dictionary is already built from C. To obtain the
Springer

620 Inf Retrieval (2006) 9:613–631
δ(kwuk-cey-wen-yu-ka|C)=1.34e-09
σ(kwuk-cey-wen-yu-ka)=σ(kwuk-
cey)+σ(wen-yu-ka)
β(kwuk-cey-wen-yu-ka,1,C)=1.12e-11
β(kwuk-cey-wen-yu-ka,2,C)=1.34e-09
β(kwuk-cey-wen-yu-ka,3,C)=1.66e-10
β(kwuk-cey-wen-yu-ka,4,C)=1.34e-09
δ(kwuk-cey-wen-yu|C)=1.39e-07
σ(kwuk-cey-wen-yu)=σ(kwuk-
cey)+σ(wen-yu)
β(kwuk-cey-wen-yu,1,C)=1.16e-09
β(kwuk-cey-wen-yu,2,C)=1.39e-07
β(kwuk-cey-wen-yu,3,C)=2.21e-09
δ(cey-wen-yu-ka|C)=1.18e-08
σ(cey-wen-yu-ka)=σ(cey)+
σ(wen-yu-ka)
β(cey-wen -yu-ka,2,C)=1.18e-08
β(cey-wen -yu-ka,3,C)=2.02e-10
β(cey-wen -yu-ka,4,C)=1.18e-08
δ(kwuk-cey-wen|C)=3.32e-06
σ(kwuk-cey-wen)=σ(kwuk-
cey)+σ(wen)
β(kwuk-cey-wen,1,C)=3.84e-09
β(kwuk-cey-wen,2,C)=3.32e-06
δ(cey-wen-yu|C)=1.23e-06
σ(cey-wen-yu)=σ(cey)+σ(wen-
yu)
β(cey-wen -yu,2,C)=1.23e-06
β(cey-wen -yu,3,C)=2.69e-09
δ(wen-yu-ka|C)=1.44e-06
σ(wen-yu-ka)=σ(wen-
yu)+σ(ka)
β(wen-yu-ka,3,C)=1.79e-07
β(wen-yu-ka,4,C)=1.44e-06
δ(kwuk-cey|C)=9.27e-04
σ(kwuk-cey)=kwuk-cey
P(kwuk-cey|C)=9.27e-04
δ(cey-wen |C)=4.05e-06
σ(cey-wen)=cey-wen
P(cey-wen|C)=4.05e-06
δ(wen-yu|C)=1.50e-04
σ(wen-yu)=wen-yu
P(wen-yu|C)=1.50e-04
δ(yu-ka|C)=5.00e-05
σ(yu-ka)=yu-ka
P(yu-ka|C)=5.00e-05
δ(kwuk|C)=9.48e -04
σ(kwuk)=kwuk
P(kwuk|C)=9.48e -04
δ(cey|C)=8.20e-03
σ(cey)=cey
P(cey|C)=8.20e-03
δ(wen|C)=3.59e-03
σ(wen)=wen
P(wen|C)=3.59e-03
δ(yu|C)=6.64e-04
σ(yu)=yu
P(yu|C)=6.64e-04
δ(ka|C)=9.62e-03
σ(ka)=ka
P(ka|C)=9.62e-03
Fig. 2 Calculation of δ(kwuk-cey-wen-yu-ka | d) and σ(kwuk-cey-wen-yu-ka) with K = 3
most probable segmentation of c15 = kwuk-cey-wen-yu-ka, we calculate δ(kwuk-cey-wen-yu-ka | C) using Formula (2). Note that the recurrence relation in Formula (2) is actually
implemented using a dynamic programming technique. So, the segmentation process pro-
ceeds in a bottom-up manner. Figure 2 shows all intermediate data in order to compute
δ(kwuk-cey-wen-yu-ka | C), with K = 3 in Formula (2).
The bottom two rows of Fig. 2 are computed from the basis step of Formula (2), and
the other rows from the induction step. For example, for a sub-string c34 = wen-yu (crude
oil), δ(wen-yu | C) is calculated as P(wen-yu | C) using the basis step, because the length of
the sub-string c34 = wen-yu is 2(= 4 − 3 + 1), which is less than the value of K(= 3). For
a sub-string c35 = wen-yu-ka, however, our induction step is fired. First, by the following
calculations, r∗ is set to 4, as follows.
r∗ = arg max3≤r ≤5−1
β(c35, r, C)
β(c35, 3, C) = δ(c33 | C)δ(c45 | C) = 3.59e−03 × 5.00e−05 = 1.79e−07
β(c35, 4, C) = δ(c34 | C)δ(c55 | C) = 1.50e−04 × 9.62e−03 = 1.44e−06
Next, δ(wen-yu-ka | C) is set to β(c35,4, C). During the calculation of δ(kwuk-cey-wen-yu-ka | C), σ(kwuk-cey-wen-yu-ka) is simultaneously accumulated as shown in Fig. 2. For
our example compound noun, the best segmentation candidate is as follows.
σ(kwuk-cey-wen-yu-ka)
= σ(kwuk-cey) + σ(wen-yu-ka)
= σ(kwuk-cey) + σ(wen-yu) + σ(ka))
= kwuk-cey + wen-yu + ka
Springer

Inf Retrieval (2006) 9:613–631 621
Table 1 A collection dictionary and an n-gram dictionary for segmentation evaluation
Number of tokens Number of types
Number of Eojeols 7,639,420 1,547,075
Collection dictionary (stems) 1,481,111 184,456
N-gram dictionary (all-length n-grams) 78,076,200 9,214,987
In this case, the decomposition kwuk-cey (international) + wen-yu (crude oil) + ka (price)
is correct.
4. Segmentation evaluation
4.1. Corpus, collection dictionary, and test set
In order to test our segmentation algorithm, we used the NTCIR-3 Korean corpus (Chen
et al., 2002) as a test collection. The corpus is a collection of 66,146 documents which are
newspaper articles published by the Korean Economic Daily in 1994. From this corpus, a
set of stems was automatically generated from Eojeols using the dictionary creation method
described in Section 3.1. As a result, a total of 184,456 stems constituted our collection
dictionary as shown in Table 1, where the number of Eojeols and the number of stems were
counted only for pure Korean Eojeols written in Hangul,4 excluding English words, numbers,
or any strings consisting of special characters. To compare word-based segmentation clues
with character-based ones, we created an n-gram dictionary that is composed of all-length
n-grams extracted from all Eojeols.
To create a test set, compound nouns were selected from the same corpus, since our
task was to segment all compound nouns within a particular corpus. First, from the corpus,
we randomly selected 886 documents, from which we extracted a total of 6,079 different
compound nouns of more than 3 characters. Then, the extracted compound nouns were
manually segmented to create our test set. For each test compound noun, we created two
types of answer sets: rigid and relaxed. Basically, each answer set consists of segmentation
answers that are semantically reasonable. A rigid answer set has a single segmentation answer,
while a relaxed answer set may have multiple segmentation answers. Segmentation answers
of rigid answer sets are composed of only simple nouns or affixes. That is, all derived nouns
in rigid answer sets were further decomposed into simple nouns and derivational affixes. A
relaxed answer set was obtained from its rigid answer set by creating another segmentation
answers in which simple derived nouns were considered as legal components. A relaxed
answer set thus includes its rigid answer set. By the simple derived noun, we mean a noun
consisting of a simple noun and an affix.
For example, for a compound noun pwuk-han-oy-mwu-pwu-tay-pyen-in (the spokesperson
for the Ministry of North Korea Foreign Affairs), two kinds of answer sets are as follows.
Rigid answer set: {pwuk-han (North Korea, a simple noun) + oy-mwu (foreign affairs, a simple
noun) + pwu (ministry, a suffix) + tay-pyen (speaking for, a simple noun)
+ in (person, a suffix)
}
4 Hangul is a primary writing system of Korean, which is alphabetic and phonetic.
Springer

622 Inf Retrieval (2006) 9:613–631
Relaxed answer set: {pwuk-han + oy-mwu + pwu + tay-pyen + in,
pwuk-han + oy-mwu-pwu (the Ministry of Foreign Affairs) + tay-pyen + in,
pwuk-han + oy-mwu + pwu + tay-pyen-in (spokesperson),
pwuk-han + oy-mwu-pwu + tay-pyen-in}
In the above, suffixes pwu and in are underlined. Compared to the rigid answer set, its
relaxed answer set includes three additional segmentation answers in which two simple
derived nouns oy-mwu-pwu and tay-pyen-in are not divided. Note that the relaxed answer set
does not include other segmentation answers composed of complex derived nouns such as
pwuk-han-oy-mwu-pwu (the Ministry of North Korea Foreign Affairs) or oy-mwu-pwu-tay-pyen-in (the spokesperson for the Ministry of Foreign Affairs).
Generally, simple derived words are not further decomposed in compound noun segmen-
tation. From the viewpoint of keyword extraction for information retrieval, however, it could
be crucial to identify stems of simple derived words to alleviate word mismatch problem.
Since the goal of this study is to develop a compound noun segmentation algorithm for
Korean information retrieval, we will investigate which answer set is more appropriate for
segmentation evaluation for IR.
4.2. Evaluation measures
To evaluate compound noun segmentation, we define two types of metrics: compound-noun-
level precision and segment-level recall/precision. The compound-noun-level measure cal-
culates how many compound nouns are correctly segmented, and it is defined as follows.
cPrecision =∑
w∈TestWords |Answer(w) ∩ Output(w)||TestWords|
In the above, TestWords is a set of test compound nouns. Answer(w) is a answer set for
test word w. Output(w) is a set of segmentation results for test word w, which is generated
by a compound noun segmentation program. In this paper, Output(w) has only the most
likely segmentation result for test word w. We consider a compound noun to be correctly
segmented, when all its segments are correct.
Segment-level measures are applied to segments to calculate how many segments are
correctly produced, and they are defined as follows. In the following, Segment(X) is a set of
segments extracted from X.
sRecall =∑
w∈TestWords |Segment(Answer(w)) ∩ Segment(Output(w))∑w∈TestWords |Segment(Answer(w))|
sPrecion =∑
w∈TestWords |Segment(Answer(w)) ∩ Segment(Output(w))∑w∈TestWords |Segment(Output(w))|
Note that for each of cPrecision, sRecall, and sPrecision, its rigid and relaxed versions
are defined according to whether Answer(w) in the above measures uses a rigid answer set
or a relaxed answer set described in Section 4.1.
Springer
Inf Retrieval (2006) 9:613–631 623
4.3. Evaluation results
As a baseline of compound noun segmentation, we used a commonly used left-to-rightlongest-matching algorithm which iteratively selects the leftmost longest dictionary word as
a segment. For example, for a compound noun se-wul-tay-kong-wen which has two segmen-
tation candidates (1) se-wul (Seoul) + tay-kong-wen (a large park), and (2) se-wul-tay (Seoul
national university) + kong-wen (a park), the left-to-right longest matching algorithm selects
the latter. As a manual dictionary for the baseline system, we used a list of 94,482 words
extracted from a dictionary of our laboratory’s Korean morphological analyzer (Kwon et al.,
1997).
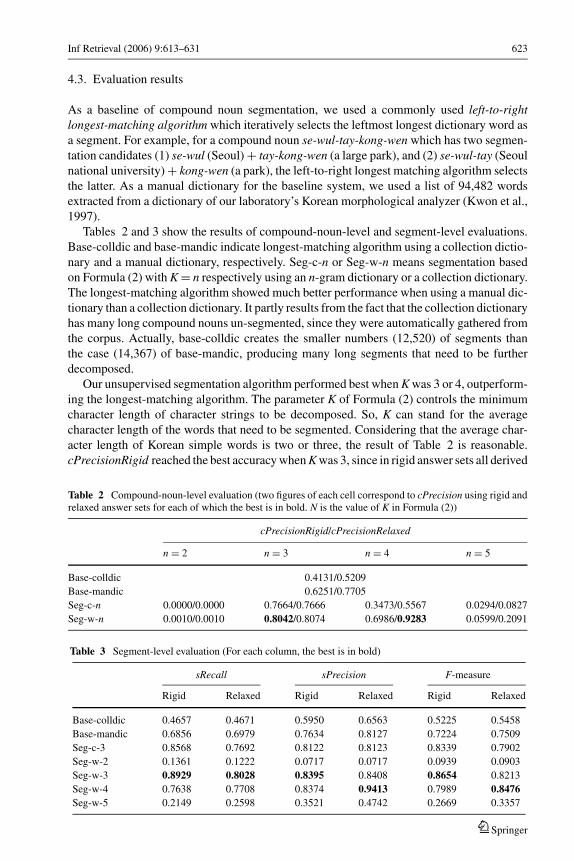
Tables 2 and 3 show the results of compound-noun-level and segment-level evaluations.
Base-colldic and base-mandic indicate longest-matching algorithm using a collection dictio-
nary and a manual dictionary, respectively. Seg-c-n or Seg-w-n means segmentation based
on Formula (2) with K = n respectively using an n-gram dictionary or a collection dictionary.
The longest-matching algorithm showed much better performance when using a manual dic-
tionary than a collection dictionary. It partly results from the fact that the collection dictionary
has many long compound nouns un-segmented, since they were automatically gathered from
the corpus. Actually, base-colldic creates the smaller numbers (12,520) of segments than
the case (14,367) of base-mandic, producing many long segments that need to be further
decomposed.
Our unsupervised segmentation algorithm performed best when K was 3 or 4, outperform-
ing the longest-matching algorithm. The parameter K of Formula (2) controls the minimum
character length of character strings to be decomposed. So, K can stand for the average
character length of the words that need to be segmented. Considering that the average char-
acter length of Korean simple words is two or three, the result of Table 2 is reasonable.
cPrecisionRigid reached the best accuracy when K was 3, since in rigid answer sets all derived
Table 2 Compound-noun-level evaluation (two figures of each cell correspond to cPrecision using rigid andrelaxed answer sets for each of which the best is in bold. N is the value of K in Formula (2))
cPrecisionRigid/cPrecisionRelaxed
n = 2 n = 3 n = 4 n = 5
Base-colldic 0.4131/0.5209
Base-mandic 0.6251/0.7705
Seg-c-n 0.0000/0.0000 0.7664/0.7666 0.3473/0.5567 0.0294/0.0827
Seg-w-n 0.0010/0.0010 0.8042/0.8074 0.6986/0.9283 0.0599/0.2091
Table 3 Segment-level evaluation (For each column, the best is in bold)
sRecall sPrecision F-measure
Rigid Relaxed Rigid Relaxed Rigid Relaxed
Base-colldic 0.4657 0.4671 0.5950 0.6563 0.5225 0.5458
Base-mandic 0.6856 0.6979 0.7634 0.8127 0.7224 0.7509
Seg-c-3 0.8568 0.7692 0.8122 0.8123 0.8339 0.7902
Seg-w-2 0.1361 0.1222 0.0717 0.0717 0.0939 0.0903
Seg-w-3 0.8929 0.8028 0.8395 0.8408 0.8654 0.8213
Seg-w-4 0.7638 0.7708 0.8374 0.9413 0.7989 0.8476Seg-w-5 0.2149 0.2598 0.3521 0.4742 0.2669 0.3357
Springer
624 Inf Retrieval (2006) 9:613–631
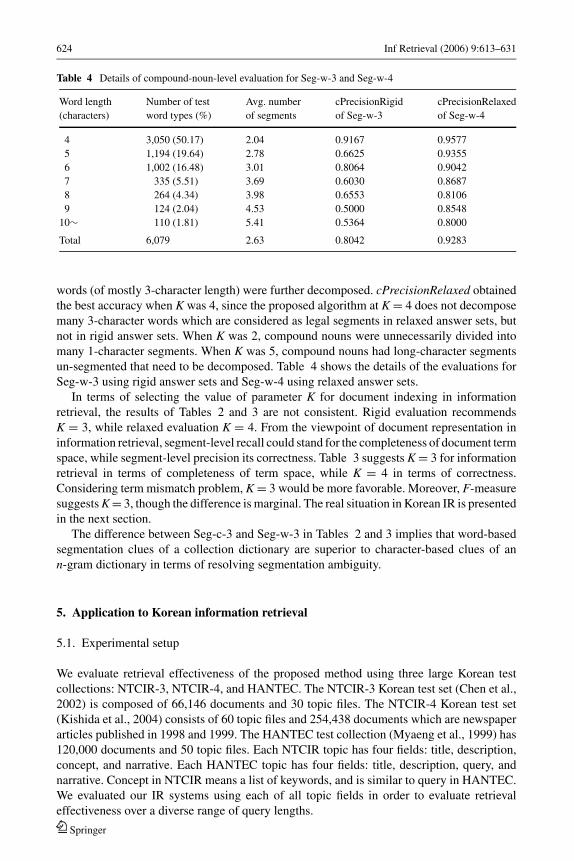
Table 4 Details of compound-noun-level evaluation for Seg-w-3 and Seg-w-4
Word length Number of test Avg. number cPrecisionRigid cPrecisionRelaxed
(characters) word types (%) of segments of Seg-w-3 of Seg-w-4
4 3,050 (50.17) 2.04 0.9167 0.9577
5 1,194 (19.64) 2.78 0.6625 0.9355
6 1,002 (16.48) 3.01 0.8064 0.9042
7 335 (5.51) 3.69 0.6030 0.8687
8 264 (4.34) 3.98 0.6553 0.8106
9 124 (2.04) 4.53 0.5000 0.8548
10∼ 110 (1.81) 5.41 0.5364 0.8000
Total 6,079 2.63 0.8042 0.9283
words (of mostly 3-character length) were further decomposed. cPrecisionRelaxed obtained
the best accuracy when K was 4, since the proposed algorithm at K = 4 does not decompose
many 3-character words which are considered as legal segments in relaxed answer sets, but
not in rigid answer sets. When K was 2, compound nouns were unnecessarily divided into
many 1-character segments. When K was 5, compound nouns had long-character segments
un-segmented that need to be decomposed. Table 4 shows the details of the evaluations for
Seg-w-3 using rigid answer sets and Seg-w-4 using relaxed answer sets.
In terms of selecting the value of parameter K for document indexing in information
retrieval, the results of Tables 2 and 3 are not consistent. Rigid evaluation recommends
K = 3, while relaxed evaluation K = 4. From the viewpoint of document representation in
information retrieval, segment-level recall could stand for the completeness of document term
space, while segment-level precision its correctness. Table 3 suggests K = 3 for information
retrieval in terms of completeness of term space, while K = 4 in terms of correctness.
Considering term mismatch problem, K = 3 would be more favorable. Moreover, F-measure
suggests K = 3, though the difference is marginal. The real situation in Korean IR is presented
in the next section.
The difference between Seg-c-3 and Seg-w-3 in Tables 2 and 3 implies that word-based
segmentation clues of a collection dictionary are superior to character-based clues of an
n-gram dictionary in terms of resolving segmentation ambiguity.
5. Application to Korean information retrieval
5.1. Experimental setup
We evaluate retrieval effectiveness of the proposed method using three large Korean test
collections: NTCIR-3, NTCIR-4, and HANTEC. The NTCIR-3 Korean test set (Chen et al.,
2002) is composed of 66,146 documents and 30 topic files. The NTCIR-4 Korean test set
(Kishida et al., 2004) consists of 60 topic files and 254,438 documents which are newspaper
articles published in 1998 and 1999. The HANTEC test collection (Myaeng et al., 1999) has
120,000 documents and 50 topic files. Each NTCIR topic has four fields: title, description,
concept, and narrative. Each HANTEC topic has four fields: title, description, query, and
narrative. Concept in NTCIR means a list of keywords, and is similar to query in HANTEC.
We evaluated our IR systems using each of all topic fields in order to evaluate retrieval
effectiveness over a diverse range of query lengths.
Springer

Inf Retrieval (2006) 9:613–631 625
In NTCIR, human assessors categorize the relevance of each document in a pool of se-
lected documents into four categories: “Highly Relevant”, “Relevant”, “Partially Relevant”,
and “Irrelevant”. However, since the well-known IR scoring program, TREC EVAL,5 adopts
binary relevance, NTCIR organizers divided the above four categories into two: rigid rele-
vance, and relaxed relevance. Rigid relevance considers “Highly Relevant” and “Relevant”
as relevant, and relaxed relevance regards “Highly Relevant”, “Relevant”, and “Partially Rel-
evant” as relevant. This paper used relaxed relevance as relevance judgments of the NTCIR
collections.
To create relevance judgments of HANTEC, two human assessors assign each document
five-degree relevance score. Higher score means higher relevance. There are 10 types of
relevance judgments: G1, G2, . . ., G5, L1, L2, . . ., and L5. G or L means using the lower or
higher one of scores from two assessors as relevance score, and each of 1, 2, . . ., 5 indicates
the cut-off score for creating binary relevance. For example, L2 regards 2 or all higher points
as relevant using lower scores from two assessors. In this paper, L2 was used as relevance
judgments of the HANTEC collection.
For the test document collection, a collection dictionary was constructed using the method
described in Section 3.1. Next, for each entry in a collection dictionary, our segmentation
algorithm from Section 3.2 was applied to produce its segmentation result. Then, each seg-
ment was used as an index term for document indexing. Query term extraction was basically
the same. For each Eojeol in a query, its longest inflectional suffix was deleted to produce a
query word w, which was segmented by the same segmentation algorithm using the collection
dictionary. Each segment of w corresponds to a query term.
As retrieval models, we used the language model based on Jelinek-Mercer (JM) smoothing
(Zhai and Lafferty, 2001) of which smoothing parameter λ was set to 0.75. For a statistical
significance test, the Wilcoxon signed rank test was used. A symbol ‘∗’ or ‘∗∗’ is attached
to the retrieval result that is statistically significant at a significance level of 0.05 or 0.01.
In addition, all retrieval results are reported using non-interpolated mean average precision
(MAP) which is computed by executing the TREC EVAL program.
5.2. Retrieval results
To see the effectiveness of the proposed algorithm on the NTCIR-4 collection, we compared
it with other index units as shown in Table 5. Eojeol-based, stem-based, and character-based
mean retrieval systems using Eojeols, stems, and character unigrams as index terms, respec-
tively. As described earlier, stems refer to entries in a collection dictionary. The character-
based model is equivalent to using the segmentation system which divides an n-character
stem into n characters, and it could show the lower-bound IR performance acquired from
segmentation. The other retrieval models in Table 5 indicate segment-based retrieval sys-
tems using as their index terms segments produced by segmentation systems in Table 3. In
Table 5, average term length, number of term types, and average term frequencies were cal-
culated only for pure Korean Eojeols written in Hangul, excluding English words, numbers,
or any strings consisting of special characters.
In Table 5, the difference between Eojeol-based and stem-based retrieval confirms that the
deletion of inflectional affixes from Eojeols substantially help to extract content terms from
documents in agglutinative languages like Korean. The fact that segmentation of stems using
a longest-matching algorithm outperforms stem-based retrieval implies that many stems in
5 ftp://ftp.cs.cornell.edu/pub/smart
Springer
626 Inf Retrieval (2006) 9:613–631
Table 5 Retrieval results for the NTCIR-4 collection (Avg. is the average over 4 different query types.% indicates the improvement over base-mandic)
Retrieval Avg. term Number of Avg. term Query type
system length term types frequency Title Desc. Conc. Narr. Avg.
Eojeol-based 3.12 3,694,106 11.92 0.2252 0.1245 0.2649 0.2263 0.2102
Stem-based 2.41 2,154,952 20.51 0.2917 0.2478 0.3202 0.3556 0.3038
Character-based 1.00 2,124 50125.90 0.2146 0.1927 0.2481 0.3178 0.2433
Base-mandic 1.85 834,937 69.08 0.3594 0.3490 0.3728 0.4523 0.3834
Base-colldic 1.77 482,633 124.95 0.3585 0.3353 0.3682 0.4306 0.3732
Seg-c-3 1.65 103,879 620.21 0.3948∗∗ 0.3668∗∗ 0.3957∗∗ 0.4608 0.4045
(9.85%) (5.10%) (6.14%) (1.88%) (5.50%)
Seg-w-2 1.21 76,160 1150.84 0.3267 0.2847 0.3500 0.3984 0.3400
Seg-w-3 1.67 87,632 727.94 0.4100 0.3947∗ 0.4055∗ 0.4706∗ 0.4202
(14.08%) (13.09%) (8.77%) (4.05%) (9.60%)
Seg-w-4 2.00 454,967 116.75 0.3836 0.3666 0.3909 0.4537 0.3987
(6.73%) (5.04%) (4.86%) (0.31%) (3.99%)
Seg-w-5 2.24 1,065,868 44.54 0.3342 0.3060 0.3436 0.3969 0.3452
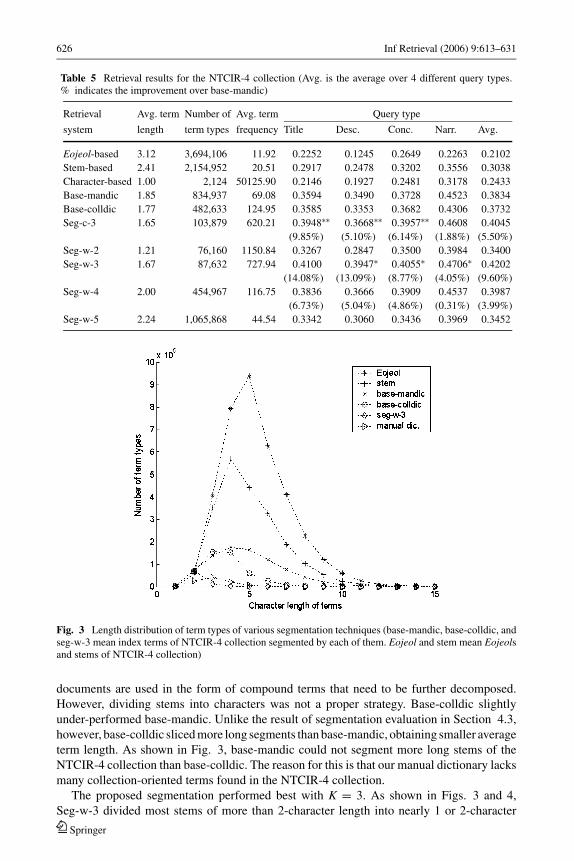
Fig. 3 Length distribution of term types of various segmentation techniques (base-mandic, base-colldic, andseg-w-3 mean index terms of NTCIR-4 collection segmented by each of them. Eojeol and stem mean Eojeolsand stems of NTCIR-4 collection)
documents are used in the form of compound terms that need to be further decomposed.
However, dividing stems into characters was not a proper strategy. Base-colldic slightly
under-performed base-mandic. Unlike the result of segmentation evaluation in Section 4.3,
however, base-colldic sliced more long segments than base-mandic, obtaining smaller average
term length. As shown in Fig. 3, base-mandic could not segment more long stems of the
NTCIR-4 collection than base-colldic. The reason for this is that our manual dictionary lacks
many collection-oriented terms found in the NTCIR-4 collection.
The proposed segmentation performed best with K = 3. As shown in Figs. 3 and 4,
Seg-w-3 divided most stems of more than 2-character length into nearly 1 or 2-character
Springer
Inf Retrieval (2006) 9:613–631 627
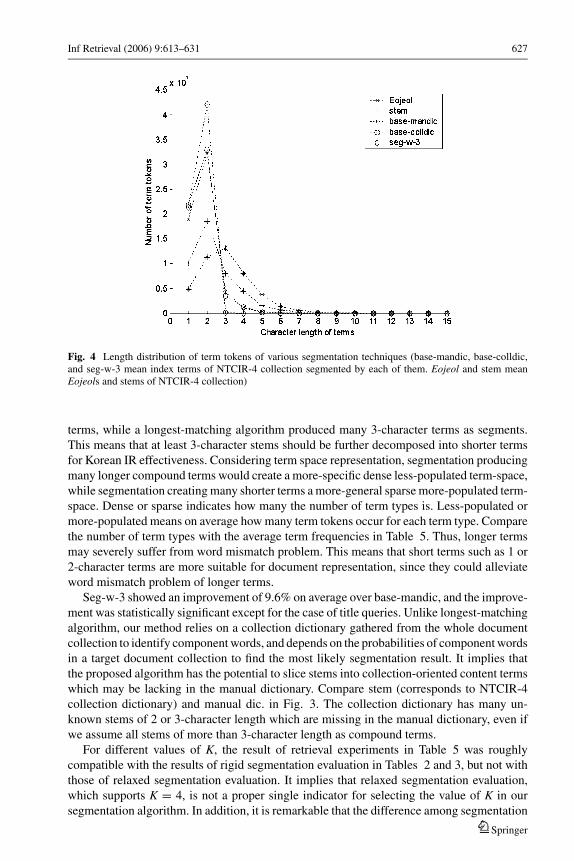
Fig. 4 Length distribution of term tokens of various segmentation techniques (base-mandic, base-colldic,and seg-w-3 mean index terms of NTCIR-4 collection segmented by each of them. Eojeol and stem meanEojeols and stems of NTCIR-4 collection)
terms, while a longest-matching algorithm produced many 3-character terms as segments.
This means that at least 3-character stems should be further decomposed into shorter terms
for Korean IR effectiveness. Considering term space representation, segmentation producing
many longer compound terms would create a more-specific dense less-populated term-space,
while segmentation creating many shorter terms a more-general sparse more-populated term-
space. Dense or sparse indicates how many the number of term types is. Less-populated or
more-populated means on average how many term tokens occur for each term type. Compare
the number of term types with the average term frequencies in Table 5. Thus, longer terms
may severely suffer from word mismatch problem. This means that short terms such as 1 or
2-character terms are more suitable for document representation, since they could alleviate
word mismatch problem of longer terms.
Seg-w-3 showed an improvement of 9.6% on average over base-mandic, and the improve-
ment was statistically significant except for the case of title queries. Unlike longest-matching
algorithm, our method relies on a collection dictionary gathered from the whole document
collection to identify component words, and depends on the probabilities of component words
in a target document collection to find the most likely segmentation result. It implies that
the proposed algorithm has the potential to slice stems into collection-oriented content terms
which may be lacking in the manual dictionary. Compare stem (corresponds to NTCIR-4
collection dictionary) and manual dic. in Fig. 3. The collection dictionary has many un-
known stems of 2 or 3-character length which are missing in the manual dictionary, even if
we assume all stems of more than 3-character length as compound terms.
For different values of K, the result of retrieval experiments in Table 5 was roughly
compatible with the results of rigid segmentation evaluation in Tables 2 and 3, but not with
those of relaxed segmentation evaluation. It implies that relaxed segmentation evaluation,
which supports K = 4, is not a proper single indicator for selecting the value of K in our
segmentation algorithm. In addition, it is remarkable that the difference among segmentation
Springer
628 Inf Retrieval (2006) 9:613–631
Table 6 Retrieval results for the HANTEC collection (Avg. is the average over 4 different querytypes. % indicates the improvement over base-mandic)
Title Desc. Query Narr. Avg.
Eojeol-based 0.0921 0.0774 0.1171 0.0885 0.0938
Stem-based 0.1447 0.1458 0.1644 0.1623 0.1543
Character-based 0.0775 0.1181 0.1562 0.1528 0.1262
Base-mandic 0.1775 0.2173 0.2292 0.2405 0.2161
Base-colldic 0.1579 0.1864 0.2140 0.2403 0.1997
Seg-c-3 0.1844∗∗ 0.2214 0.2147 0.2615∗∗ 0.2205
(3.89%) (1.89%) (−6.33%) (8.73%) (2.02%)
Seg-w-3 0.1767 0.2230 0.2384 0.2672∗∗ 0.2263
(−0.45%) (2.62%) (4.01%) (11.10%) (4.72%)
Seg-w-4 0.1735 0.2136 0.2326 0.2409 0.2152
(−2.25%) (−1.70%) (1.48%) (0.17%) (−0.45%)
performance is not directly proportional to the difference among retrieval effectiveness. For
example, Seg-w-2 and Seg-w-5 obtained 10.85 and 30.84% of Seg-w-3 in F-measure in
the case of rigid segmentation evaluation, while they attained up to 80.91 and 82.15% of
Seg-w-3 in mean average precision in the case of retrieval effectiveness. The reason for
this is as follows. Segmentation performance is absolutely determined by how many legal
component words or affixes are found. However, retrieval performance could be affected
by other factors such as co-occurrence of query terms and term weighting schemes. For
example, Seg-w-2 divides kwuk-cey-wen-yu-ka (an international crude oil price) into kwuk,
cey, wen, yu, and ka which are all illegal segments, but the use of kwuk, cey, wen, yu,
and ka as query terms could retrieve all documents containing any of legal components of
kwuk-cey-wen-yu-ka.
The fact that Seg-c-3 based on character-based segmentation clues performed less than
Seg-w-3 using word-based ones implies that segmentation based on word-based boundaries
is superior to the one based on character-based segmentation clues as well in the case of
IR effectiveness. Although Seg-c-3 did not employ on any resources such as a compiled
list of Korean suffixes, it outperformed substantially base-mandic. This means the proposed
algorithm itself is effective without using the suffix list.
To see the robustness of our method, we repeated the retrieval experiments of Table 5 for
two other Korean test collections: HANTEC and NTCIR-3. The retrieval results were roughly
consistent with that of Table 5. As shown in Tables 6 and 7, the proposed algorithm showed
the best performance with K = 3, and outperformed the dictionary-based segmentation (base-
mandic) by 4.72 and 23.37% for HANTEC and NTCIR-3 collections.
To see whether the retrieval system based on the proposed segmentation algorithm
parallels or outperforms current best practices, we have compared the performance of
our method with those of the best systems at recent NTCIR official evaluations. Table 8
shows such a comparison for title and description queries. At NTCIR-4 and NTCIR-5
evaluations, the submission of the retrieval results using title queries was mandatory for
all participants, and the use of description queries was mandatory for each of NTCIR-3,
NTCIR-4 and NTCIR-5 participation. For fair comparison, the retrieval results of seg-w-
3 in Table 8 were obtained after pseudo relevance feedback was performed. For pseudo
relevance feedback, we used model-based feedback with top 15 documents of initial re-
trieval (Na et al., 2005). Table 8 shows that our method parallels current NTCIR best
systems. Actually, NTCIR-5 best system was ours. That was based on the proposed
Springer
Inf Retrieval (2006) 9:613–631 629
Table 7 Retrieval results for the NTCIR-3 collection (Avg. is the average over 4 different query types.% indicates the improvement over base-mandic)
Title Desc. Conc. Narr. Avg.
Eojeol-based 0.1302 0.0382 0.1466 0.0771 0.0980
Stem-based 0.1804 0.1171 0.1974 0.1739 0.1672
Character-based 0.1807 0.1053 0.1859 0.1900 0.1655
Base-mandic 0.2337 0.1739 0.2689 0.2718 0.2371
Base-colldic 0.1996 0.1466 0.2237 0.2425 0.2031
Seg-c-3 0.2775∗ 0.1928∗∗ 0.2991 0.3086∗ 0.2695
(18.74%) (10.87%) (11.23%) (13.54%) (13.68%)
Seg-w-3 0.3101∗∗ 0.2119∗∗ 0.3222∗∗ 0.3257∗∗ 0.2925
(32.69%) (21.85%) (19.82%) (19.83%) (23.37%)
Seg-w-4 0.2297 0.1620 0.2640 0.2697 0.2314
(−1.71%) (−6.84%) (−1.82%) (−0.77%) (−2.41%)
Table 8 Comparison of thesystem based on the proposedalgorithm with recent NTCIRbest systems
Korean test set Method Title Desc.
NTCIR-3 Seg-w-3 0.3792 0.3241
NTCIR-3 Best system 0.3317 0.3602
NTCIR-4 Seg-w-3 0.5242 0.5267
NTCIR-4 Best system 0.5361 0.5097
NTCIR-5 Seg-w-3 0.5309 0.5638
NTCIR-5 Best system 0.5441 0.5680
segmentation algorithm and improved the performance a little with an additional combination
approach.
6. Conclusion
In this paper, we have proposed an unsupervised approach for Korean compound noun
segmentation. Compared with most previous unsupervised methods, our approach searches
the most likely segmentation candidate by considering all segmentation possibilities using
word-based segmentation clues. To summarize our method, first, a collection dictionary is
automatically built by generating stems from Eojeols in a corpus based on a set of complex
suffixes. Then, given a compound noun, its most probable segmentation candidate is deter-
mined by calculating the likelihood of each segmentation candidate based on the probabilities
of component words. Experiments showed that our segmentation algorithm is effective for
Korean information retrieval.
The proposed algorithm segments Eojeols of the Korean language into words based on
purely corpus statistics without the need for a pre-compiled dictionary. This feature would
be especially useful for the processing of domain-specific corpora such as patent documents,
genomic documents. We plan to apply our algorithm to patent retrieval or genomic data
retrieval. In addition, we want to apply this algorithm to other languages. For example,
segmenting Japanese Kanji sequences or Chinese noun-phrase chunks would be very similar
to segmenting Korean compound nouns.
Acknowledgments This work was supported by the KOSEF through the Advanced Information TechnologyResearch Center (AITrc) and by the BK21 project.
Springer

630 Inf Retrieval (2006) 9:613–631
References
Ando, R. K., & Lee, L. (2003). Mostly-unsupervised statistical segmentation of Japanese kanji sequences.Natural Language Engineering, 9(2), 127–149.
Chen, A., He, J., Xu, L., Gey, F. C., & Meggs, J. (1997). Chinese text retrieval without using a dictionary. InProceedings of the 20th Annual International ACM SIGIR Conference on Research and Development inInformation Retrieval (pp. 42–49).
Chen, K. H., Chen, H. H., Kando, N., Kuriyama, K., Lee, S. H., Myaeng, S. H., Kishida, K., Eguchi, K., &Kim, H. (2002). Overview of CLIR task at the 3rd NTCIR workshop. In Working Notes of the 3rd NTCIRWorkshop Meeting (pp. 1–38).
Choi, J. H. (1996). A division method of Korean compound noun by number of syllable. In Proceedings ofthe 8th Annual Conference on Hangul and Korean Language Information Processing (pp. 262–267) (inKorean).
Ge, X., Pratt, W., & Smyth, P. (1999). Discovering Chinese words from unsegmented text. In Proceedingsof the 22nd Annual International ACM SIGIR Conference on Research and Development in InformationRetrieval (pp. 271–272).
Huang, X., Peng, F., Schuurmans, D., & Cercone, N. ( 2002). Waterloo at NTCIR-3: Using self-supervisedword segmentation. In Working Notes of the 3rd NTCIR Workshop Meeting (pp. 159–163).
Jang, D. H., & Myaeng, S. H. ( 1996). A Korean compound noun analysis method for effective indexing.In Proceedings of the 8th Annual Conference on Hangul and Korean Language Information Processing(pp. 32–35) (in Korean).
Kang, S. S. ( 1993). Recognition of compound nouns for Korean morphological analysis. In Proceedings ofKSCS (The Korean Society for Cognitive Science) Annual Spring Conference (pp. 175–189) (in Korean).
Kang, S. S. (1998). Korean compound noun decomposition algorithm. Journal of the Korean InformationScience Society (KISS), 25(1), 172–182 (in Korean).
Kishida, K., Chen, K. H., LEE, S., Kuriyama, K., Kando, N., Chen, H. H., Myaeng, S. H., & Eguchi, K.(2004). Overview of CLIR task at the fourth NTCIR workshop. In Working Notes of the 4th NTCIRWorkshop Meeting (pp. 1–59).
Kwon, O. W., Lee, J. H., & Lee, G. B. (1997). Keyword extraction using an integrated method of CYK andViterbi algorithms in real Korean text. In Proceedings of the 17th International Conference on ComputerProcessing of Oriental Languages (pp. 418–421).
Lee, J. W., Zhang, B. T., & Kim, Y. T. ( 1999). Compound noun decomposition using a Markov model. InProceedings of the Machine Translation Summit VII (pp. 427–431).
Lua, K. T., & Gan, K. W. (1994). An application of information theory in Chinese word segmentation.Computer Processing of Chinese and Oriental Languages, 8(1), 115–123.
Maosong, S., Dayang, S., & Tsou, B. K. (1998). Chinese word segmentation without using lexicon and hand-crafted training data. In Proceedings of the 36th Annual Meeting of the Association for ComputationalLinguistics and the 17th International Conference on Computational Linguistics (COLING-ACL’98)(pp. 1265–1271).
Min, K. H., Wilson, W. H., & Moon, Y. J. (2003). Korean compound noun term analysis based on a chartparsing technique. In Proceedings of the 16th Australian Conference on Artificial Intelligence vol. 2903(pp. 186–195) (Lecture Notes in Artificial Intelligence).
Myaeng, S. H., Kim, J. Y., Lee, S. H., Jang, D. H., Seo, J. H., & Kim, H. ( 1999). Expansion of the Korean testcollection HANTEC. In Proceedings of the 4th Korea Science & Technology Infrastructure Workshop(in Korean).
Na, S. H., Kang, I. S., & Lee, J. H. (2005). POSTECH at NTCIR-5: Combining evidences of multiple termextractions for mono-lingual and cross-lingual retrieval in Korean and Japanese. In Working Notes of theFifth NTCIR Workshop Meeting (pp. 96–103).
Nie, J. Y., & Ren, F. (1999). Chinese information retrieval: Using characters or words? Information Processingand Management, 35(4), 443–462.
Ogawa, Y., & Matsuda, T. (1999). Overlapping statistical segmentation for effective indexing of Japanesetext. Information Processing and Management, 35(4), 463–480.
Park, H. R., Han, Y. S., Lee, K. H., & Choi, K. S. (1996). A probabilistic approach to compound noun indexingin Korean texts. In Proceedings of the 16th International Conference on Computational Linguistics(COLING’96) (pp. 514–518).
Park, S. B., Chang, J. H., & Zhang, B. T. (2004). Korean compound noun decomposition using syllabicinformation only. In Proceedings of the 5th International Conference on Intelligent Text Processing andComputational Linguistics vol. 2945 (pp. 143–154) (Lecture Notes in Computer Science).
Springer

Inf Retrieval (2006) 9:613–631 631
Peng, F., Huang, X., Schuurmans, D., Cercone, N., & Robertson, S. E. (2002). Using self-supervised wordsegmentation in chinese information retrieval. In Proceedings of the 25th Annual International ACMSIGIR Conference on Research and Development in Information Retrieval (pp. 271–272).
Shim, K. S. (1999). Segmentation of compound nouns using composite mutual information. In Proceedingsof the 3rd China-Korea Joint Symposium on Oriental Language Processing and Character Recognition(pp. 106–113).
Sproat, R., & Shih, C. (1990). A statistical method for finding word boundaries in Chinese text. ComputerProcessing of Chinese and Oriental Languages, 4(4), 336–351.
Wikipedia contributors (2006). Wikipedia the free encyclopedia. Available from http://en.wikipedia.org.Wu, Z., & Tseng, G. (1995). ACTS: An automatic Chinese text segmentation system for full text retrieval.
Journal of the American Society for Information Science, 46(2), 83–96.Yoon, J. T. (2001). Compound noun segmentation based on lexical data extracted from corpus. Natural
Language Engineering, 7(2), 167–185.Yun, B. H., Cho, M. J., & Rim, H. C. (1997). Segmenting Korean compound nouns using statistical information
and a preference rules. In Proceedings of Pacific Association for Computational Linguistics (pp. 345–350).Zhai, C., & Lafferty, J. ( 2001). A study of smoothing methods for language models applied to Ad Hoc
information retrieval. In Proceedings of the 24th Annual International ACM SIGIR Conference onResearch and Development in Information Retrieval (pp. 334–342).
Springer
Related Documents

![Korean Language (Level 1) - isi.snu.ac.krisi.snu.ac.kr/page/course/06_kl_01_Korean_Languages_1-6_2018__01... · published A Semantics for Korean Noun Phrases (2013) [in Korean]. Education](https://static.cupdf.com/doc/110x72/5adbc8a87f8b9aee348e7cc7/korean-language-level-1-isisnuackrisisnuackrpagecourse06kl01koreanlanguages1-6201801published.jpg)









