1 ÇOK DEĞİŞKENLİ İSTATİSTİK KONU: TEK VE ÇİFT YÖNLÜ ANOVA, TEK VE ÇİFT YÖNLÜ MANOVA, FAKTÖR ANALİZİ, DİSKRİMİNANT ANALİZİ, KÜMELEME ANALİZİ, LOJİSTİK REGRESYON ANALİZİ, TEMEL BİLEŞEN ANALİZİ’NİN VERİLER ÜZERİNDEN UYGULAMASI Burcu Aksoy 20110111072

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
ÇOK DEĞİŞKENLİ İSTATİSTİK
KONU: TEK VE ÇİFT YÖNLÜ ANOVA, TEK VE ÇİFT YÖNLÜ MANOVA, FAKTÖR
ANALİZİ, DİSKRİMİNANT ANALİZİ, KÜMELEME ANALİZİ, LOJİSTİK REGRESYON
ANALİZİ, TEMEL BİLEŞEN ANALİZİ’NİN VERİLER ÜZERİNDEN UYGULAMASI
Burcu Aksoy
20110111072

2
İçindekiler Tablosu 1.VARYANS ANALİZİ ...................................................................................................................... 4
1.1TEK YÖNLÜ ANOVA ..........................................................................................................................4
2.2 İKİ YÖNLÜ ANOVA ......................................................................................................................7
2. ÇOK DEĞİŞKENLİ VARYANS ANALİZİ ........................................................................................... 10
2.1 TEK YÖNLÜ MANOVA .................................................................................................................. 10
2.2 İKİ YÖNLÜ MANOVA ................................................................................................................ 10
3.FAKTÖR ANALİZİ ........................................................................................................................ 17
4.TEMEL BİLEŞENLER ANALİZİ ....................................................................................................... 29
5.DİSKRİMİNANT ANALİZİ ............................................................................................................. 34
6.LOJİSTİK REGRESYON ANALİZİ .................................................................................................... 40
7.KÜMELEME ANALİZİ .................................................................................................................. 49
1.1HİYERARŞİK KÜMELEME ANALİZİ ................................................................................................. 51
2.2 HİYERARŞİK OLMAYAN KÜMELEME ANALİZİ ........................................................................... 56
KAYNAKÇA ................................................................................................................................... 59

3
ANOVA ve MANOVA analizlerinde kullanılacak olan veriler aşağıdaki tabloda belirtilmiştir;
Yaş gruplarına ve cinsiyetlere bağlı olarak çeşitli durumlar altında çocuklardaki miyopluk
durumu araştırılmıştır.
DEĞİŞKENLER
AÇIKLAMA
MİYOPLUK: Çocuklarda miyopluk var mı, yok mu?
YAŞ: Çocukların yaşları
CİNSİYET: Çocukların cinsiyetleri
ODAKLAMA: Işığı kırma derecesi
EKSEN: Milimetre cinsinden eksen
uzunlukları
ÖN_ODA: Milimetre cinsinden ön oda derinliği
MERCEK: Milimetre cinsinden mercek kalınlığı
VITREUS_BOŞLUĞU: Viterüs boşluğu kalınlığı
AKTIVITE: Çocuğun okul dışında aktivitelere
harcadığı haftalık saat
KITAP: Çocuğun okul dışında haftalık kitap
okumaya ayırdığı saat
OYUN: Çocuğun okul dışında haftalık olarak
bilgisayar oyununa ayırdığı zaman
DERS: Çocuğun okul dışında ödev yapmaya
ayırdığı haftalık saat
TV: Çocuğun haftada kaç saat televizyon
izlediği
DIĞER: Bunlar dışında haftalık aktiviteye
harcadığı zaman
ANNE: Anne'de miyop var mı?
BABA: Baba'da miyop var mı?

4
1. VARYANS ANALİZİ
Varyans analizi genel olarak iki ya da daha fazla ortalama arasında fark olup olmadığının
test edilmesinde kullanılmaktadır. Varyans analizi yapılırken veri setinin özelliklerine göre
analize alınan bağımlı ve bağımsız değişkenlerin sayısına göre analizin türü değişmektedir.
Analize tabii tutulan tek bağımlı değişken olması durumunda ANOVA, birden fazla bağımlı
değişken olması durumunda MANOVA uygulanır.
1.1 TEK YÖNLÜ ANOVA
Tek yönlü ANOVA en basit Varyans analizidir. İki tane değişken vardır. Bunlardan birisi
kategorik özellik gösteren bağımsız değişkendir diğeri ise metrik özellik gösteren bağımlı
değişkendir. Tek Yönlü Anova’da iki temel varsayım vardır. Bu varsayımlara göre her bir grup
normal dağılımdan gelir ve grupların varyansları eşittir. Tek Yönlü Anova’da bağımlı değişken
ile her bir bağımsız değişkeni ayrı ayrı analize tabi tutar.
Normallik için;
𝐻0: Değişkenler normallik varsayımını sağlar.
𝐻1: Değişkenler normallik varsayımını sağlamaz.
Varyans Eşitliği için;
𝐻0: Varyanslar homojendir. 𝐻𝐴: Varyanslar homojen değildir.
Hipotezler bu şekilde kurulur ve uygun testler yapılır.
Örneğimiz için;
Çocukların cinsiyetlerinin mercek kalınlığı üzerinde değişiklik yaratıp yaratmadığını test etmek istiyoruz ama öncelikle gerekli varsayımların sağlanıp sağlanmadığına bakmak gerekir.
Bağımsız değişkenler: Mercek kalınlığı
Bağımlı değişkenler: Cinsiyet
NORMALLİK TESTİ:
Analizlerin yapılabilmesi için normallik varsayımına bakılması gerekir. Tüm değişkenler
için normalliğe bakarsak;

5
𝐻0: Değişkenler normallik varsayımını sağlar
𝐻1: Değişkenler normallik varsayımını sağlamaz
Hipotezlerimiz kurulduktan sonra Kolmogorov-Smirnov testinin sig. değerlerine göre
inceleme yaparsak;
Tests of Normality
Kolmogorov-Smirnov
a Shapiro-Wilk
Statistic df Sig. Statistic df Sig.
Işığı kırma derecesi ,111 618 ,000 ,893 618 ,000
uzunluk(mm) ,026 618 ,200* ,997 618 ,458
derinlik(mm) ,036 618 ,057 ,998 618 ,730
kalınlık(mm) ,030 618 ,200* ,997 618 ,277
kalınlık ,035 618 ,065 ,996 618 ,167
çocuğun okul dışında
aktivitelere harcadığı
haftalık saat
,152 618 ,000 ,931 618 ,000
çocuğun haftada kaç saat
televizyon izlediği
,139 618 ,000 ,932 618 ,000
bunlar dışında haftalık
aktiviteye harcadığı
zaman
,117 618 ,000 ,903 618 ,000
MİYOPLUK ,520 618 ,000 ,397 618 ,000
YAŞ ,435 618 ,000 ,648 618 ,000
CİNSİYET ,347 618 ,000 ,636 618 ,000
çocuğun okul dışında
haftalık kitap okumaya
ayırdığı saat
,182 618 ,000 ,832 618 ,000
çocuğun okul dışında
haftalık olarak bilgisayar
oyununa ayırdığı zaman
,253 618 ,000 ,670 618 ,000
çocuğun okul dışında
ödev yapmaya ayırdığı
haftalık saat
,272 618 ,000 ,673 618 ,000
anne'de miyop var mı? ,344 618 ,000 ,636 618 ,000
baba'da miyop var mı? ,342 618 ,000 ,637 618 ,000
a. Lilliefors Significance Correction
*. This is a lower bound of the true significance.
sig. > 0.05 olan değerler için 𝐻0 hipotezi kabul edilir ve bu değişkenlerin normallik
varsayımını sağladığı söylenebilir.

6
Uzunluk(mm)-Eksen Uzunluğu, derinlik(mm)-Ön Oda Derinliği, kalınlık(mm)-Mercek Kalınlığı,
kalınlık-Viterüs Boşluğu değişkenlerinin sig. Değerleri 0.05 ten büyük olduğu için bu
değişkenler normallik varsayımı sağlarlar. Diğer değişkenler normallik varsayımını
sağlamazlar. Ama bizim analize katacağımız değişkenler Normalliğe uyduğu için sorun yoktur
devam ediyoruz. Bunu yukarıdaki “Tests of Normality” tablosundan görebiliriz.
VARYANSLARIN EŞİTLİĞİ TESTİ:
Test of Homogeneity of Variances
Levene
Statistic df1 df2 Sig.
Işığı kırma derecesi ,317 1 616 ,573
uzunluk(mm) ,151 1 616 ,698
derinlik(mm) 1,866 1 616 ,172
kalınlık(mm) ,294 1 616 ,588
kalınlık ,124 1 616 ,725
Tabloda Tek Yönlü ANOVA’nın temel varsayımı olan varyansların homojenliği testinin sonucu
görülmektedir. Sig. değerleri 0.05’ten büyük olduğu için 𝐻0 hipotezi kabul edilir ve
varyansların homojen olduğu söylenebilir.
TANIMLAYICI İSTATİSTİKLER:
Yukarıda ki tabloda her bir grup için ortalama, standart sapma vs. gibi temel istatistiksel
veriler sunulmuştur.

7
ANOVA
kalınlık(mm)
Sum of
Squares df Mean Square F Sig.
Between Groups ,083 1 ,083 3,473 ,063
Within Groups 14,649 616 ,024
Total 14,732 617
ANOVA tablosunda mercek kalınlığının gruplar arasında bir farklılık yaratıp yaratmadığı test
edilmiştir.
𝐻0: Gruplar arasında farklılık yoktur.
𝐻1: Gruplar arasında farklılık vardır.
Sig. Değerlerine bakılarak yorum yapılır. Sig. Değeri 0.05 ten küçük olan değerler için 𝐻0
hipotezi red edilir. Bu durumda gruplar arasında mercek kalınlığının bir farklılık yaratmadığı
söylenebilir. Çünkü Sig. Değeri 0.05 ten büyük çıkmıştır.
1.2 İKİ YÖNLÜ ANOVA
Çocukların cinsiyetlerinin odaklama, eksen uzunluğu üzerinde değişiklik yaratıp yaratmadığını test
etmek istiyoruz, gerekli varsayımların kontrolü başta yapılmıştı.
İki bağımsız değişkenin, bir bağımlı değişkenin analizinde kullanılır.
Bağımsız değişkenler: Odaklama ve eksen uzunluğu
Bağımlı değişkenler: Cinsiyet

8
Descriptive Statistics
Dependent Variable:Işığı kırma derecesi
CİNSİYET YAŞ Mean Std. Deviation N
Erkek 5 ,44180 ,300680 10
6 ,83984 ,618086 215
7 ,84133 ,638934 63
8 ,40804 ,318484 23
9 -,10460 ,550410 5
Total ,78117 ,618670 316
Kız 5 ,62173 ,519592 11
6 ,85585 ,627567 241
7 ,78089 ,551904 19
8 ,62897 ,743550 30
9 1,36800 . 1
Total ,82177 ,633775 302
Total 5 ,53605 ,429128 21
6 ,84830 ,622482 456
7 ,82733 ,617109 82
8 ,53309 ,602879 53
9 ,14083 ,777037 6
Total ,80101 ,625918 618
Tabloda her bir grup için ortalama, standart sapma vs. gibi temel istatistiksel veriler
sunulmuştur. Bu sonuçlara göre erkek ve kızların gözlerinin ışığı kırma dereceleri ile ilgili
genel ortalamaları arasındaki fark dikkat çekmektedir.
Levene's Test of Equality of Error Variancesa
Dependent Variable:Işığı kırma derecesi
F df1 df2 Sig.
,652 9 608 ,753
Tests the null hypothesis that the error variance
of the dependent variable is equal across
groups.
a. Design: Intercept + CİNSİYET + YAŞ +
CİNSİYET * YAŞ

9
Sig. Değeri 0.05’ten büyük olduğu için varyansların eşitliği varsayımının sağlandığı görülebilir.
Tests of Between-Subjects Effects
Dependent Variable:Işığı kırma derecesi
Source
Type III Sum of
Squares df Mean Square F Sig.
Partial Eta
Squared
Intercept Hypothesis 28,897 1 28,897 42,650 ,000 ,776
Error 8,351 12,325 ,678a
CİNSİYET Hypothesis 2,165 1 2,165 5,015 ,031 ,119
Error 16,085 37,255 ,432b
YAŞ Hypothesis 6,772 4 1,693 2,762 ,174 ,734
Error 2,452 4 ,613c
CİNSİYET * YAŞ Hypothesis 2,452 4 ,613 1,620 ,168 ,011
Error 230,060 608 ,378d
a. ,228 MS(YAŞ) + ,772 MS(Error)
b. ,228 MS(CİNSİYET * YAŞ) + ,772 MS(Error)
c. MS(CİNSİYET * YAŞ)
d. MS(Error)
Cinsiyet satırı, cinsiyetin gözün ışığı kırma derecesi üzerindeki ana etkisini, yaş satırı yaşın
gözün ışığı kırma derecesi üzerindeki ana etkisini, cinsiyet*yaş satırı ise cinsiyet-yaş
etkileşiminin gözün ışığı kırma derecesi üzerindeki etkisini araştırır.
Bağımsız değişkenin bağımlı değişkene etkisinin anlamlı olup olmadığına sig. değerlerine
bakılarak karar verilir. Etki derecelerine ise Partial Eta Squared kısmından bakılır.
Sig. değeri 0.05 ten küçük olanlar bağımlı değişken üzerinde anlamlı bir etkiye sahiptir yani
bir tek cinsiyet değişkeni gözün ışığı kırma derecesi üzerinde anlamlı etkiye sahiptir.
CİNSİYET
Dependent Variable:Işığı kırma derecesi
CİNSİYET Mean Std. Error
95% Confidence Interval
Lower Bound Upper Bound
Erkek ,485 ,074 ,340 ,631
Kız ,851 ,134 ,589 1,114
Yukarıdaki tabloda erkek ve kızlar için gözün ışığı kırma derecesi ile ilgili ortalamalar, standart
hatalar ve güven aralıkları verilmektedir.

10
2. ÇOK DEĞİŞKENLİ VARYANS ANALİZİ
Birden çok bağımlı değişken bulunduğu zaman bu tür varyans analizi kullanılır.
2.1 TEK YÖNLÜ MANOVA
Tek yönlü MANOVA analizi ile bir bağımsız değişkenin, birden fazla bağımlı değişken
üzerindeki etkisi incelenmektedir. Varsayımları Anova’da ki ile aynıdır.
Örneğimiz için;
Bağımlı değişken: Eksen uzunluğu, ön oda derinliği
Bağımsız değişken: Yaş
Box's M 9,293
F ,732
df1 12
df2 3059,709
Sig. ,721
Tests the null
hypothesis that the
observed covariance
matrices of the
dependent variables
are equal across
groups.
a. Design: Intercept +
YAŞ
𝐻0: Bağımlı değişkenler arasındaki kovaryans matrisleri arasında fark yoktur.
𝐻1: Bağımlı değişkenler arasındaki kovaryans matrisleri arasında fark vardır.

11
Sig. değeri 0.05 ten büyük olduğu için 𝐻0 hipotezi kabul edilir. Temel varsayım olan
kovaryans eşitliği sağlanmıştır.
Levene's Test of Equality of Error Variancesa
F df1 df2 Sig.
uzunluk(mm) ,718 4 613 ,580
derinlik(mm) ,634 4 613 ,638
Tests the null hypothesis that the error variance of the dependent
variable is equal across groups.
a. Design: Intercept + YAŞ
Bir diğer varsayım olan, bağımlı değişkenlerdeki, gruplararası varyans eşitliği şartını test eder.
𝐻0: Gruplararası varyanslar homojendir. 𝐻𝐴: Gruplararası varyanslar homojen değildir.
Sig. değerleri 0.05’ ten büyük oldukları için 𝐻0 hipotezi kabul edilir. Varyans eşitliği varsayımı da sağlanmış olur ve uzunluk ve derinlik bağımlı değişkenlerinin her biri için varyans eşitliği vardır denilebilir.
Multivariate Testsc
Effect Value F Hypothesis df Error df Sig.
Partial Eta
Squared
Intercept Pillai's Trace ,995 58927,533a 2,000 612,000 ,000 ,995
Wilks' Lambda ,005 58927,533a 2,000 612,000 ,000 ,995
Hotelling's Trace 192,574 58927,533a 2,000 612,000 ,000 ,995
Roy's Largest Root 192,574 58927,533a 2,000 612,000 ,000 ,995
YAŞ Pillai's Trace ,063 4,984 8,000 1226,000 ,000 ,031
Wilks' Lambda ,937 5,057a 8,000 1224,000 ,000 ,032
Hotelling's Trace ,067 5,130 8,000 1222,000 ,000 ,032
Roy's Largest Root ,067 10,218b 4,000 613,000 ,000 ,063

12
Multivariate Testsc
Effect Value F Hypothesis df Error df Sig.
Partial Eta
Squared
Intercept Pillai's Trace ,995 58927,533a 2,000 612,000 ,000 ,995
Wilks' Lambda ,005 58927,533a 2,000 612,000 ,000 ,995
Hotelling's Trace 192,574 58927,533a 2,000 612,000 ,000 ,995
Roy's Largest Root 192,574 58927,533a 2,000 612,000 ,000 ,995
YAŞ Pillai's Trace ,063 4,984 8,000 1226,000 ,000 ,031
Wilks' Lambda ,937 5,057a 8,000 1224,000 ,000 ,032
Hotelling's Trace ,067 5,130 8,000 1222,000 ,000 ,032
Roy's Largest Root ,067 10,218b 4,000 613,000 ,000 ,063
a. Exact statistic
b. The statistic is an upper bound on F that yields a lower bound on the significance level.
c. Design: Intercept + YAŞ
Yaş bağımsız değişkeninin bağımlı değişkenler üzerindeki etksini anlamada yaş satırıyla
belirtilen kısıma bakmak önemlidir.
Pillai's Trace, Hotelling's Trace ve Roy's Largest Root testleri pozitif değerli testlerdir. Value
kısmındaki değerler arttıkça faktörün etkisinin modele katkısının arttığı düşünülebilir. Wilk’s
Lambda ise negatif değerli bir testtir. Value kısmındaki değer azaldıkça faktörün etkisinin
modele katkısının azaldığı düşünülebilir.
Sig. kolonu MANOVA temel hipotezini test eder. Değerler 0.05’ ten küçük olduğu için
faktörün en az iki grubu arasında bağımlı değişkenlerden en az birisinde anlamlı bir farklılık
vardır denilebilir.
𝐻0: Gruplar arasında farklılık yoktur.
𝐻1: Gruplar arasında farklılık vardır.
𝐻0 hipotezi red edildi. Yani yaş gruplarına göre eksen uzunluğu ve ön oda derinliğinde
gruplar arasında fark vardır denilebilir.

13
Tests of Between-Subjects Effects
Source Dependent Variable
Type III Sum of
Squares df Mean Square F Sig.
Partial Eta
Squared
Corrected Model uzunluk(mm) 14,866a 4 3,717 8,421 ,000 ,052
derinlik(mm) 1,255b 4 ,314 6,105 ,000 ,038
Intercept uzunluk(mm) 52012,178 1 52012,178 117845,461 ,000 ,995
derinlik(mm) 1330,581 1 1330,581 25896,504 ,000 ,977
YAŞ uzunluk(mm) 14,866 4 3,717 8,421 ,000 ,052
derinlik(mm) 1,255 4 ,314 6,105 ,000 ,038
Error uzunluk(mm) 270,553 613 ,441
derinlik(mm) 31,496 613 ,051
Total uzunluk(mm) 313058,376 618
derinlik(mm) 7947,223 618
Corrected Total uzunluk(mm) 285,419 617
derinlik(mm) 32,751 617
a. R Squared = ,052 (Adjusted R Squared = ,046)
b. R Squared = ,038 (Adjusted R Squared = ,032)
Yaş faktörünün hangi değişken üzerinde daha etkili olduğunu incelemek için bu tabloya bakılır. Yaş satırına ait sig. değerleri 0.05’ ten küçük olduğu için değişkenler anlamlı, yani etkilidir. Hangi değişkenin daha etkili olduğunu Partial Eta Squared değerlerine bakarak inceliyoruz. Eksen uzunluğu yaş üzerinde en etkilidir.

14
Multiple Comparisons
Tamhane
Dependent Variable (I) YAŞ (J) YAŞ
Mean
Difference (I-J) Std. Error Sig.
95% Confidence Interval
Lower Bound Upper Bound
uzunluk(mm) 5 6 -,1451 ,13512 ,969 -,5644 ,2743
7 -,4262 ,14987 ,073 -,8756 ,0232
8 -,5024* ,15333 ,023 -,9601 -,0446
9 -,9929 ,40438 ,388 -2,6994 ,7137
6 5 ,1451 ,13512 ,969 -,2743 ,5644
7 -,2812* ,07875 ,005 -,5060 -,0564
8 -,3573* ,08515 ,001 -,6035 -,1111
9 -,8478 ,38375 ,553 -2,6546 ,9590
7 5 ,4262 ,14987 ,073 -,0232 ,8756
6 ,2812* ,07875 ,005 ,0564 ,5060
8 -,0761 ,10702 ,999 -,3813 ,2291
9 -,5666 ,38919 ,894 -2,3400 1,2068
8 5 ,5024* ,15333 ,023 ,0446 ,9601
6 ,3573* ,08515 ,001 ,1111 ,6035
7 ,0761 ,10702 ,999 -,2291 ,3813
9 -,4905 ,39053 ,951 -2,2565 1,2755
9 5 ,9929 ,40438 ,388 -,7137 2,6994
6 ,8478 ,38375 ,553 -,9590 2,6546
7 ,5666 ,38919 ,894 -1,2068 2,3400
8 ,4905 ,39053 ,951 -1,2755 2,2565
derinlik(mm) 5 6 -,0397 ,05423 ,998 -,2086 ,1293
7 -,1227 ,05808 ,360 -,2990 ,0536
8 -,1535 ,06126 ,159 -,3370 ,0299
9 -,2451 ,15793 ,843 -,9064 ,4161
6 5 ,0397 ,05423 ,998 -,1293 ,2086
7 -,0830* ,02565 ,016 -,1562 -,0098
8 -,1139* ,03221 ,008 -,2072 -,0205
9 -,2055 ,14908 ,923 -,9088 ,4979
7 5 ,1227 ,05808 ,360 -,0536 ,2990
6 ,0830* ,02565 ,016 ,0098 ,1562
8 -,0308 ,03833 ,996 -,1404 ,0787
9 -,1224 ,15052 ,998 -,8167 ,5718
8 5 ,1535 ,06126 ,159 -,0299 ,3370
6 ,1139* ,03221 ,008 ,0205 ,2072
7 ,0308 ,03833 ,996 -,0787 ,1404
9 -,0916 ,15178 1,000 -,7786 ,5954

15
Bu tabloda bağımlı değişkenin her biri için, bağımsız değişkenlerin hangi grupları arasında
farklılık olduğu öğrenilir. Farklılık yaratan gruplar üzerinde * işareti ile belirlenmiştir, bu
farklılıkları belli etmek içinde sarı renkle vurguladık.
2.2 İKİ YÖNLÜ MANOVA
İki yönlü ANOVA ile tek yönlü MANOVA’ nın karışımı gibidir. İki bağımsız değişkenin, birden
fazla bağımlı değişken üzerindeki etkisi araştırılır.
Bağımsız değişkenler: Miyopluk ve Cinsiyet
Bağımlı değişkenler: Çocuğun haftada kaç saat televizyon izlediği, çocuğun okul dışında
aktivitelere harcadığı haftalık saat, bunlar dışında haftalık aktiviteye harcadığı zaman.
Box's Test of Equality
of Covariance
Matricesa
F 1,209
df1 18
df2 59175,943
Sig. ,243
Kovaryans matrislerinin eşitliğine bakmak istersek, sig. değer 0.05’ ten büyük olduğu için
kovaryans matrislerinin eşit olduğu sonucuna varabiliriz.
9 5 ,2451 ,15793 ,843 -,4161 ,9064
6 ,2055 ,14908 ,923 -,4979 ,9088
7 ,1224 ,15052 ,998 -,5718 ,8167
8 ,0916 ,15178 1,000 -,5954 ,7786
Based on observed means.
The error term is Mean Square(Error) = ,051.
*. The mean difference is significant at the ,05 level.

16
Levene's Test of Equality of Error Variancesa
F df1 df2 Sig.
çocuğun haftada kaç saat
televizyon izlediği
1,481 3 614 ,219
çocuğun okul dışında
aktivitelere harcadığı
haftalık saat
,459 3 614 ,711
bunlar dışında haftalık
aktiviteye harcadığı zaman
,200 3 614 ,896
Tests the null hypothesis that the error variance of the dependent variable is
equal across groups.
a. Design: Intercept + MİYOPLUK + CİNSİYET + MİYOPLUK * CİNSİYET
Sig. kolonundaki tüm değerler 0.05’ ten büyük varyanslar eşittir denilir dolayısıyla MANOVA’
nın temel varsayımları sağlanmış oldu.

17
Sig. sütununda 0.05’ ten küçük olan faktörleri değişkenler üzerinde etkilidir denilebilir. Bu
tabloya göre Miyopluk çocuğun okul dışında aktivitelere harcadığı haftalık saat üzerinde
etkilidir. Bir tek bu değişken etkili çıktığı için diğer değişkenlerle karşılaştırmaya ve hangisinin
etkili olduğunu araştırmaya gerek duyulmaz.
Multivariate Testsb
Effect Value F Hypothesis df Error df Sig.
Partial Eta
Squared
Intercept Pillai's Trace ,678 428,843a 3,000 612,000 ,000 ,678
Wilks' Lambda ,322 428,843a 3,000 612,000 ,000 ,678
Hotelling's Trace 2,102 428,843a 3,000 612,000 ,000 ,678
Roy's Largest Root 2,102 428,843a 3,000 612,000 ,000 ,678

18
Sig. kolonuna bakarsak, sadece miyopluğa ait sig. değerlerinin 0.05’ ten küçük olduğunu görüyoruz. Yani sadece miyop değişkeninin bağımsız değişkenler üzerindeki etkisi anlamlıdır.
3. FAKTÖR ANALİZİ
Faktör analizi, ayni yapıyı ölçen çok sayıda değişkenden, az sayıda ve tanımlanabilir nitelikte
anlamlı değişkenler elde etmeye yönelik çok değişkenli bir istatistiktir.
Faktör analizinde aralarında yüksek korelasyon olan değişkenler setinin bir araya getirilmesi
suretiyle faktör adı verilen genel değişkenlerin (faktörlerin) oluşturulması söz konusudur.
Burada amaç:
Değişken sayısını azaltmak,
Değişkenler arası ilişkilerdeki yapıyı ortaya çıkarmak, başka bir ifade ile değişkenleri
sınıflandırmaktır.
Faktör Analizinin Aşamaları:
1. Veri setinin faktör analizi için uygunluğunun değerlendirilmesi
1.1 Analizde kullanılan tüm değişkenler için korelasyon matrisinin oluşturulması.
1.2 Bartlett Tesi
1.3 KMO örneklem yeterliliği ölçütü
MİYOPLUK Pillai's Trace ,013 2,746a 3,000 612,000 ,042 ,013
Wilks' Lambda ,987 2,746a 3,000 612,000 ,042 ,013
Hotelling's Trace ,013 2,746a 3,000 612,000 ,042 ,013
Roy's Largest Root ,013 2,746a 3,000 612,000 ,042 ,013
CİNSİYET Pillai's Trace ,001 ,119a 3,000 612,000 ,949 ,001
Wilks' Lambda ,999 ,119a 3,000 612,000 ,949 ,001
Hotelling's Trace ,001 ,119a 3,000 612,000 ,949 ,001
Roy's Largest Root ,001 ,119a 3,000 612,000 ,949 ,001
MİYOPLUK * CİNSİYET Pillai's Trace ,006 1,224a 3,000 612,000 ,300 ,006
Wilks' Lambda ,994 1,224a 3,000 612,000 ,300 ,006
Hotelling's Trace ,006 1,224a 3,000 612,000 ,300 ,006
Roy's Largest Root ,006 1,224a 3,000 612,000 ,300 ,006
a. Exact statistic
b. Design: Intercept + MİYOPLUK + CİNSİYET + MİYOPLUK * CİNSİYET

19
2. Faktörlerin elde edilmesi
3. Faktörlerin rotasyonu
4. Faktörlerin isimlendirilmesi
İyi bir faktörleşme de ya da faktör dönüştürmede;
a. Değişken azaltma olmalı,
b. Üretilen yeni değişken ya da faktörler arasında ilişkisizlik sağlanmalı,
c. Ulaşılan sonuçlar, yani elde edilen faktörler anlamlı olmalıdır
Örneğimiz üzerinden uygulama yaparsak ;
Correlatio
n Matrixa
a. This
matrix is
not
positive
definite.
Hata korelasyon matrisinin negatif olduğunu gösterir. Korelasyon matrisi faktör analizinde yer alan değişkenler arasındaki ilişkiyi gösteren bir matristir. Bu tablodan değişkenler arasında ilişki olmadığını anlayabiliriz ve çocuklarda miyopluk araştırması için bu veri setimizde faktör analizini uygulayamayız. Bu yüzden faktör analizini başka bir veri üzerinden yapacağız. Veriyi tanıyacak olursak;
Sanığın fiziksel çekiciliği ve işlediği suçun türünün hukuki kararı nasıl etkilediğine dair bir araştırmadır. Jüri’lere sanığın durumuna uygun olarak 1-15 yıl arası bir hüküm giydirmesi istenmiştir. Jüriler bu kararı verirken sanıkların karakteristik özelliklerine göre 1-10 arasında puanlar vererek derecelendirme yapmışlardır.

20
A. dull exciting
1 2 3 4 5 6 7 8 9
B. nervous calm
1 2 3 4 5 6 7 8 9
C. dependent independent
1 2 3 4 5 6 7 8 9
D. insincere sincere
1 2 3 4 5 6 7 8 9
E. cold warm
1 2 3 4 5 6 7 8 9
F. physically attractive physically unattractive
1 2 3 4 5 6 7 8 9
G. cruel kind
1 2 3 4 5 6 7 8 9
H. unintelligent intelligent
1 2 3 4 5 6 7 8 9
I. weak strong
1 2 3 4 5 6 7 8 9
J. naive sophisticated
1 2 3 4 5 6 7 8 9
K. sad happy
1 2 3 4 5 6 7 8 9
L. unsociable sociable
1 2 3 4 5 6 7 8 9

21
DEĞİŞKENLER
AÇIKLAMA
1. crime İşlenen suç(1.00-Dolandırıcılık, 2.00-
Hırsızlık)
2. pa_manip fiziksel çekicilik sterotipi(1.00-Çekici
değil, 2.00-Çekici)
3. sex_def Kurbanın cinsiyeti(1.00-Kadın, 2.00-
Erkek)
4. sex_subj Sanığın cinsiyeti(1.00-Kadın, 2.00-
Erkek)
5. sentence Hüküm verilen yıl (1-15 yıl)
6. serious Ciddi
7. exciting Heyecanlı
8. calm Sakin
9. independ Bağımsız
10. sincere Samimi
11. warm Sıcak
12. phy_attr Fiziksel nitelikler
13. kind Kibar
14. intellig Zeki
15. strong Güçlü
16. sophist Sofist
17. happy Mutlu
18. sociable Sosyal

22
Faktör analizini bu veriler üzerinde uygulayalım.
KMO and Bartlett's Test
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. ,753
Bartlett's Test of Sphericity Approx. Chi-Square 1915,217
df 153
Sig. ,000
KMO Testi tablo da görüldüğü gibi %75,3 (,753)’tür. Veri setimizin faktör analizi için uygun
olduğunu söyleyebiliriz, 753>,50 ‘dir. KMO gibi Bartlett’te de bakmak önemlidir.
𝐻0: R=I
𝐻1: R≠I
Bartlett’s testi için sig. Değeri 0.05’ten küçük olduğu için 𝐻0 red edilir. Faktör analizi
yapılabilir.
İlk veri setimizde değişkenler arasında korelasyon güçlü olmadığı için faktör analizini
uygulayamamıştık.
FAKTÖR SAYISININ BELİRLENMESİ

23
Anti-Image değerlerinden 0.50’den büyük olan değişkenler önemli değişkenlerdir. Anti-Image
correlation değerleri 0.05’ten küçük olan sex_def ve sex_subj değişkenlerini (köşegen)
çıkarabiliriz.
Çıkarıp tekrar inceleme yaparsak;
KMO and Bartlett's Test
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. ,767
Bartlett's Test of Sphericity Approx. Chi-Square 1856,266
df 120
Sig. ,000
KMO Testi tablo da görüldüğü gibi %76,7 (,767)’ dir. Çok büyük bir fark olmasa da
değişkenler çıkarıldıktan sonra KMO değerinde artış olduğu görülmektedir.
Özdeğer istatistiği 1’den büyük olan faktörler anlamlı olarak belirlenir.
Öz değer istatistiği 1’den büyük olan 5 faktör söz konusudur. 1. Faktör toplam varyansın
%17,071 ini açıklamaktadır. Bunu en sağdaki Cumulative % sütununa bakarak görebiliriz. 1.
Ve 2. Faktörler birlikte toplam varyansın %33,145 ini açıklamaktadır. 6 faktör ise toplam
varyansın %66,315 ini açıklamaktadır.

24
Rotasyona tabi olacak faktör sayısını belirlerken faktör analizi çizgi grafiğinden de
yararlanabiliriz. Grafiğe göre de eğimin kaybolmaya başladığı noktaya göre faktör sayısını 6-7
faktör ile sınırlayabiliriz.
DEĞİŞKENLERİN ORTAK VARYANSI
Communalities
Initial Extraction
crime 1,000 ,701
pa_manip 1,000 ,876
sentence 1,000 ,752
serious 1,000 ,773
sincere 1,000 ,599
warm 1,000 ,742
phy_attr 1,000 ,892
kind 1,000 ,631
intellig 1,000 ,595
sophist 1,000 ,592
exciting 1,000 ,579
calm 1,000 ,690
independ 1,000 ,598
strong 1,000 ,581
happy 1,000 ,489
sociable 1,000 ,520
Extraction Method: Principal
Component Analysis.

25
Ortak varyans bir değişkenin analizde yer alan diğer değişkenlerle paylaştığı varyans
miktarıdır. Faktör analizinde düşük ortak varyansa sahip olan değişkenler analizden
çıkarılarak faktör analizi yeniden yapılabilir. Böylece hem KMO hem de açıklanan varyans
değeri istatistiği daha yüksek bir değere ulaşacaktır.
Communality değerleri 0,50 ‘den küçük değerleri analizden çıkarıp tekrar faktör analizi
yapılabilir fakat 0.50 den küçük değeri olan sadece bir değişken var ve oda çok ufak olmadığı
için göz ardı edilebilir. Çıkarmadan analize devam edelim.
Component Matrixa
Component
1 2 3 4 5
strong ,740 ,016 ,145 -,030 -,109
sophist ,737 -,175 ,020 -,114 -,059
phy_attr ,709 -,009 -,304 ,525 ,145
pa_manip ,702 -,087 -,308 ,523 ,080
intellig ,693 -,138 ,003 -,304 ,063
exciting ,668 -,270 ,015 ,196 ,143
happy ,617 ,026 ,131 -,206 ,220
sociable ,584 -,322 ,007 -,262 ,085
warm ,307 ,754 ,153 -,163 ,171
kind ,332 ,697 ,099 -,055 ,150
sincere ,266 ,658 ,297 -,004 ,080
serious -,028 -,370 ,764 ,176 ,145
sentence -,108 -,277 ,743 ,124 ,309
crime -,270 ,272 ,212 ,697 -,149
calm ,411 -,063 ,245 -,170 -,655
independ ,389 ,141 ,287 ,186 -,557
Extraction Method: Principal Component Analysis.
a. 5 components extracted.
Component Matrix hiç dönüşüm yapılmadan değişkenlerin faktörlere atandığı tabloyu
gösterir. Bizim için önemli olan dönüşüm işlemi yapıldıktan sonra değişkenlerin faktörlere
atanmasıdır. Dönüşümün amacı yorumlanabilir, anlamlı faktörler elde etmektir.

26
Varimax (Eğik) Döndürme için;
Rotated Component Matrixa
Component
1 2 3 4 5
crime -,755 ,223 ,125 ,208 ,151
intellig ,706 ,234 ,121 -,020 ,163
sociable ,673 ,219 -,071 ,062 ,104
sophist ,598 ,375 ,060 ,008 ,299
happy ,570 ,235 ,307 ,112 ,052
strong ,470 ,375 ,244 ,058 ,395
phy_attr ,148 ,917 ,108 -,126 ,040
pa_manip ,158 ,910 ,020 -,124 ,091
exciting ,421 ,601 -,022 ,166 ,108
warm ,093 -,016 ,850 -,098 ,020
kind ,053 ,093 ,779 -,110 ,033
sincere -,027 ,029 ,758 ,065 ,138
serious ,011 -,024 -,110 ,865 ,112
sentence -,005 -,085 -,013 ,860 -,066
calm ,265 -,042 -,013 -,022 ,786
independ -,031 ,184 ,165 ,057 ,730
Extraction Method: Principal Component Analysis.
Rotation Method: Varimax with Kaiser Normalization.
a. Rotation converged in 6 iterations.
Faktörleri isimleştirirsek;
1.Faktör-Ruhsal Özellikler
2.Faktör-Fiziksel Özellikler
3.Faktör-Davranışsal Özellikler
4.Faktör-Saldırganlık
5.Faktör-Sakinlik
1.Faktör 2.Faktör 3.Faktör 4.Faktör 5.Faktör
intellig phy_attr warm serious calm
sociable pa_manip kind sentence independ
sophist sincere
happy
strong

27
Quartimax (Dik) Döndürme için bakarsak;
Rotated Component Matrixa
Component
1 2 3 4 5
intellig ,760 ,093 ,048 -,046 ,070
sociable ,712 -,098 ,043 ,036 ,018
sophist ,706 ,036 ,209 -,015 ,217
crime -,637 ,153 ,399 ,237 ,236
happy ,627 ,282 ,083 ,091 -,026
strong ,605 ,225 ,239 ,041 ,326
exciting ,572 -,044 ,474 ,149 ,046
warm ,117 ,847 -,041 -,097 -,001
kind ,104 ,776 ,075 -,109 ,016
sincere ,031 ,759 ,030 ,069 ,131
phy_attr ,375 ,096 ,851 -,132 ,006
pa_manip ,385 ,009 ,841 -,131 ,057
serious ,045 -,114 -,034 ,863 ,107
sentence -,003 -,017 -,087 ,860 -,068
calm ,339 -,018 -,118 -,032 ,748
independ ,114 ,170 ,174 ,059 ,723
Extraction Method: Principal Component Analysis.
Rotation Method: Quartimax with Kaiser Normalization.
a. Rotation converged in 6 iterations.
Faktörleşme açısından bir farklılık olmadığı yukarıdaki tablodan görülebilir.
Not: Varimax (Eğik) döndürmede faktörler arasında korelasyon olduğu varsayılır, Quartimax
(Dik) döndürmede faktörler arası korelasyon olmadığı varsayılır.
FAKTÖRLER SKORLARI
Faktör analizine başlamadan önce 18 değişkenimiz vardı sonunda 5 faktöre indirgenmiş oldu.
Faktör sayısı kadarda faktör skoru elde edilmiş oldu.
Faktörlere göre işlenen suçları, kurban ve sanığın cinsiyetlerini incelemek istersek faktörleri
tek tek artandan azalana sıraya sokup bakabiliriz.

28
Faktör1’i azalan sıraya göre sıralarsak;
Faktör 2’yi azalan sıraya göre sıralarsak;

29
Faktör 3’ü azalan sıraya göre sıralarsak;
Faktör 4’ü azalan sıraya göre sıralarsak;

30
Faktör 5’i azalan sıraya göre sıralarsak;
4. TEMEL BİLEŞENLER ANALİZİ
Temel Bileşenler analizi genel olarak değişkenler arasındaki bağımlılık yapısının yok
edilmesi veya boyut yapısının indirgenmesi ve çok sayıda değişken kullanarak
gözlemler arasında bir endeks oluşturulmasında kullanılmaktadır.
Faktör analizinden tek farkı dönüşüm işlemler uygulanmaz çoklu bağlantıyı azaltmak
için sadece boyut indirgeme yapılır.
KMO and Bartlett's Test
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. ,767
Bartlett's Test of Sphericity Approx. Chi-Square 1856,266
df 120
Sig. ,000
KMO = ,767>0,05 olduğu için TBA uygulanabilir.
Barttlet =, 000<0,005 olduğu için Korelasyon matrisinin birim olmadığını söyleyebiliriz ve
değişkenler arası ilişkinin olduğu varsayımı sağlanmıştır.
31
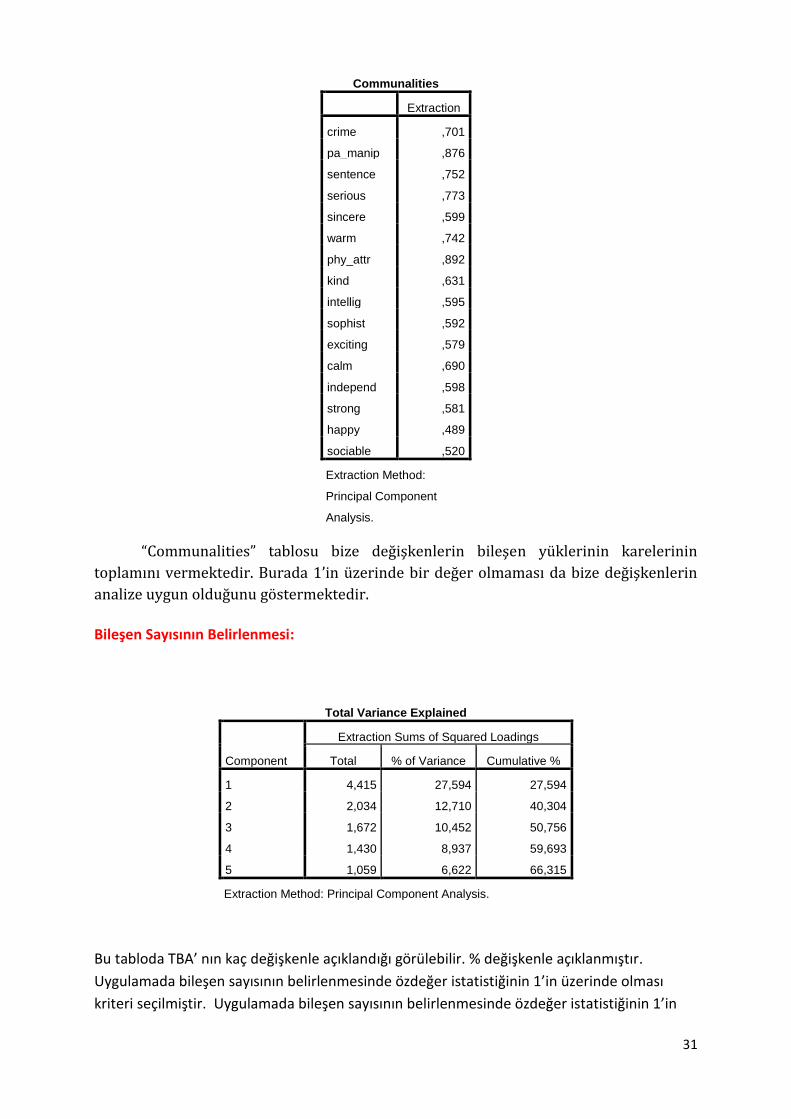
“Communalities” tablosu bize değişkenlerin bileşen yüklerinin karelerinin
toplamını vermektedir. Burada 1’in üzerinde bir değer olmaması da bize değişkenlerin
analize uygun olduğunu göstermektedir.
Bileşen Sayısının Belirlenmesi:
Bu tabloda TBA’ nın kaç değişkenle açıklandığı görülebilir. % değişkenle açıklanmıştır.
Uygulamada bileşen sayısının belirlenmesinde özdeğer istatistiğinin 1’in üzerinde olması
kriteri seçilmiştir. Uygulamada bileşen sayısının belirlenmesinde özdeğer istatistiğinin 1’in
Communalities
Extraction
crime ,701
pa_manip ,876
sentence ,752
serious ,773
sincere ,599
warm ,742
phy_attr ,892
kind ,631
intellig ,595
sophist ,592
exciting ,579
calm ,690
independ ,598
strong ,581
happy ,489
sociable ,520
Extraction Method:
Principal Component
Analysis.
Total Variance Explained
Component
Extraction Sums of Squared Loadings
Total % of Variance Cumulative %
1 4,415 27,594 27,594
2 2,034 12,710 40,304
3 1,672 10,452 50,756
4 1,430 8,937 59,693
5 1,059 6,622 66,315
Extraction Method: Principal Component Analysis.

32
üzerinde olması kriteri seçilmiştir. Buna göre SPSS’te 1 bileşen otomatik olarak oluşmuştur.
Bu bileşen tek başına toplam varyansın %66,3’ünü açıklamaktadır.
Bileşen sayısının belirlenmesinde bir diğer yöntem de “Scree Plot”tur. Grafikteki çizginin
eğiminin azaldığı nokta uygun bileşen sayısının belirlenmesinde değerlendirilmektedir.
Bileşen Matrislerinin İncelenmesi:
Component Matrixa
Component
1 2 3 4 5
strong ,740 ,016 ,145 -,030 -,109
sophist ,737 -,175 ,020 -,114 -,059
phy_attr ,709 -,009 -,304 ,525 ,145
pa_manip ,702 -,087 -,308 ,523 ,080
intellig ,693 -,138 ,003 -,304 ,063
exciting ,668 -,270 ,015 ,196 ,143
happy ,617 ,026 ,131 -,206 ,220
sociable ,584 -,322 ,007 -,262 ,085
warm ,307 ,754 ,153 -,163 ,171
kind ,332 ,697 ,099 -,055 ,150
sincere ,266 ,658 ,297 -,004 ,080
serious -,028 -,370 ,764 ,176 ,145

33
sentence -,108 -,277 ,743 ,124 ,309
crime -,270 ,272 ,212 ,697 -,149
calm ,411 -,063 ,245 -,170 -,655
independ ,389 ,141 ,287 ,186 -,557
Extraction Method: Principal Component Analysis.
a. 5 components extracted.
1.Temel Bileşen 2.Temel Bileşen 3.Temel Bileşen 4.Temel Bileşen 5.Temel Bileşen strong warm serious crime sentence sophist kind sentence phy_attr sincere
pa_manip intellig exciting happy
sociable
EXCEL’İN XLSTAT EKLENTİSİYLE TBA YAPARSAK:
The PRINCOMP Procedure
Varsayımların Testi :
H0: Korelasyon matrisi birim matristir. HA: Korelasyon matrisi birim matris değildir.
Summary Statistics:
Observations 320
Variables 14
Variable Observations Obs. with missing data Obs. without missing data Minimum Maximum Mean Std. deviation
sentence 320 0 320 0,000 15,000 5,447 3,338
serious 320 0 320 1,000 9,000 5,538 1,603
exciting 320 0 320 1,000 9,000 4,700 1,832
calm 320 0 320 1,000 9,000 6,313 2,172
independ 320 0 320 1,000 9,000 5,744 2,457
sincere 320 0 320 1,000 9,000 3,603 2,359
warm 320 0 320 1,000 8,000 3,613 2,046
phy_attr 320 0 320 1,000 9,000 5,134 3,200
kind 320 0 320 1,000 9,000 3,916 2,065
intellig 320 0 320 1,000 9,000 6,253 1,940
strong 320 0 320 1,000 9,000 5,681 1,982
sophist 320 0 320 1,000 9,000 5,766 1,941
happy 320 0 320 1,000 9,000 4,569 1,852
sociable 320 0 320 1,000 9,000 5,747 2,160

34
Bu tabloda temel istatistikleri gösterir ve her bir değişken için ortalama ve standart sapma değerleri
görülebilir.
Correlation matrix (Pearson (n)):
Values in bold are different from 0 with a significance level alpha=0,05
Eigen Values(Özdeğerler)
Bileşenden sonraki hızlı düşüş yukarıdaki bilgilere paralel olarak tek bileşeni işaret etmektedir.
0
0,5
1
1,5
2
2,5
3
3,5
4
4,5
F1 F2 F3 F4 F5 F6 F7 F8 F9 F10 F11 F12 F13 F14
Eige
nva
lue
axis
Scree plot
Variables sentence serious exciting calm independ sincere warm phy_attr kind intellig strong sophist happy sociable
sentence 1 0,550 0,032 -0,026 0,043 -0,018 -0,086 -0,144 -0,114 -0,029 -0,041 -0,064 0,033 -0,002
serious 0,550 1 0,099 0,081 0,021 0,005 -0,160 -0,118 -0,153 0,015 0,078 0,051 0,009 0,063
exciting 0,032 0,099 1 0,167 0,245 0,010 0,032 0,514 0,054 0,379 0,429 0,380 0,405 0,448
calm -0,026 0,081 0,167 1 0,295 0,081 0,072 0,094 0,078 0,262 0,306 0,325 0,210 0,243
independ 0,043 0,021 0,245 0,295 1 0,211 0,143 0,209 0,109 0,164 0,311 0,191 0,157 0,119
sincere -0,018 0,005 0,010 0,081 0,211 1 0,543 0,128 0,392 0,093 0,187 0,081 0,133 0,007
warm -0,086 -0,160 0,032 0,072 0,143 0,543 1 0,110 0,540 0,142 0,211 0,077 0,243 0,008
phy_attr -0,144 -0,118 0,514 0,094 0,209 0,128 0,110 1 0,184 0,359 0,392 0,423 0,292 0,282
kind -0,114 -0,153 0,054 0,078 0,109 0,392 0,540 0,184 1 0,152 0,264 0,132 0,250 0,019
intellig -0,029 0,015 0,379 0,262 0,164 0,093 0,142 0,359 0,152 1 0,515 0,524 0,414 0,350
strong -0,041 0,078 0,429 0,306 0,311 0,187 0,211 0,392 0,264 0,515 1 0,562 0,356 0,354
sophist -0,064 0,051 0,380 0,325 0,191 0,081 0,077 0,423 0,132 0,524 0,562 1 0,409 0,412
happy 0,033 0,009 0,405 0,210 0,157 0,133 0,243 0,292 0,250 0,414 0,356 0,409 1 0,381
sociable -0,002 0,063 0,448 0,243 0,119 0,007 0,008 0,282 0,019 0,350 0,354 0,412 0,381 1
F1 F2 F3 F4 F5 F6 F7 F8 F9 F10 F11 F12 F13 F14
Eigenvalue 3,937 2,008 1,525 1,047 0,911 0,754 0,647 0,585 0,542 0,487 0,461 0,405 0,356 0,336
Variability (%) 28,120 14,342 10,890 7,476 6,504 5,383 4,624 4,176 3,874 3,477 3,292 2,896 2,545 2,402
Cumulative % 28,120 42,461 53,352 60,827 67,331 72,714 77,339 81,515 85,389 88,865 92,157 95,053 97,598 100,000

35
Eigenvectors
1. 9. 11. Ve 14. temel bileşenlerde tüm değişkenler hemen hemen aynı etkiye sahipler. 2.
Temel bileşende sincere ve warm değişkenleri önemli oranda etkilidir. 3. Temel bileşende
sentence ve serious değişkenleri diğer değişkenlerden daha etkilidir. 4. bileşende calm ve
independend değişkenleri etkilidir. 5. Bileşende sadece independend değişkeni diğer
değişkenlerden daha önemli etkiye sahiptir. 6. Bileşende happy ve sociable değişkenleri daha
önemli etkiye sahiptir. Hepsini tek tek yazmaya gerek yoktur tabloda turuncu renk ile
vurgulanmış değerler her bir bileşende önemli olan değişkenlerdir.
5. DİSKRİMİNANT ANALİZİ
Ayırma analizi olarak ta bilinir, kategorik bağımlı değişkenler ile metrik bağımsız değişkenler
arasındaki ilişkileri tahmin etmeyi amaçlayan çok değişkenli istatistik tekniklerinden biridir.
Kullanım Amaçları;
Bir verinin hangi değişken grubuna gireceğine karar vermek için kullanılır.
Verilerin gruplara ayrılmasına yardımcı olur.
Bağımsız değişkenlerin aritmetik ortalamalarının gruplar arasında nasıl değiştiğini
tespit etmek için kullanılabilir.
Bağımlı değişkenin varyansının ne kadarının bağımsız değişkenler tarafından
açıklanabildiğini belirlemek için kullanılabilir.
Grupları ayırmada etkili olan ve olmayan değişkenleri belirlemek için kullanılabilir.
Verilerin tahmin edildiği gibi sınıflandırılıp sınıflandırılmadığını test etmek için
kullanılabilir.
Varsayımları;
Değişkenler çoklu normal dağılıma uymalıdır.
Eigenvectors: F1 F2 F3 F4 F5 F6 F7 F8 F9 F10 F11 F12 F13 F14
sentence -0,037 -0,287 0,605 -0,204 0,069 0,023 -0,221 0,001 -0,020 -0,038 0,496 0,312 0,289 0,162
serious 0,005 -0,357 0,572 -0,097 -0,021 -0,178 0,190 0,176 -0,005 0,059 -0,334 -0,302 -0,385 -0,288
exciting 0,331 -0,219 -0,077 -0,200 0,382 0,221 0,034 0,214 -0,043 -0,372 -0,361 0,115 -0,083 0,514
calm 0,225 -0,081 0,094 0,649 -0,355 0,161 0,074 0,433 -0,341 -0,176 0,068 0,067 0,107 -0,008
independ 0,213 0,031 0,177 0,567 0,529 0,165 -0,287 -0,284 0,225 0,130 0,074 -0,139 -0,192 -0,038
sincere 0,157 0,425 0,339 0,002 0,117 -0,036 0,507 -0,289 -0,312 0,096 -0,068 -0,231 0,316 0,245
warm 0,179 0,511 0,223 -0,115 -0,074 0,115 0,027 -0,073 -0,021 -0,236 -0,024 0,554 -0,435 -0,258
phy_attr 0,316 -0,009 -0,231 -0,187 0,482 -0,189 0,091 0,306 -0,363 0,108 0,333 -0,024 0,037 -0,432
kind 0,194 0,460 0,136 -0,161 -0,108 -0,032 -0,222 0,522 0,379 0,052 0,183 -0,390 -0,031 0,200
intellig 0,351 -0,093 -0,065 -0,065 -0,245 -0,335 -0,217 -0,402 -0,131 -0,539 0,210 -0,336 -0,119 0,009
strong 0,384 -0,032 0,035 0,081 -0,024 -0,375 0,011 -0,002 0,441 -0,035 -0,340 0,258 0,513 -0,246
sophist 0,368 -0,140 -0,094 0,034 -0,208 -0,334 0,070 -0,067 -0,034 0,570 0,104 0,249 -0,338 0,396
happy 0,328 -0,015 0,034 -0,260 -0,225 0,451 -0,451 -0,138 -0,285 0,336 -0,281 -0,109 0,171 -0,180
sociable 0,293 -0,229 -0,095 -0,112 -0,160 0,497 0,505 -0,123 0,404 -0,004 0,321 -0,093 -0,025 -0,148

36
Bütün gruplar için kovaryans matrisleri eşit olmalıdır.
Bağımsız değişkenler arasında çoklu bağlantı probleminin olmaması gerekir.
Örneğimiz üzerinde hırsızlık ve dolandırıcılık yapanlar üzerinde bir araştırma yapalım. Merak
ettiklerimiz çekici ve çekici olmayan insanları birbirinden ayıran özellikler, suç işleyen bir
insanın çekici ya da çekici olup olamayacağı, bağımsız değişkenlerin aritmetik ortalamalarının
gruplar arasında nasıl değiştiği, bağımlı değişkendeki varyansın ne kadarının bağımsız
değişkenler tarafından açıklandığı, çekici ve çekici olmayan grupları ayırmada etkili olan
değişkenleri belirlemek gibi konulardır.
Enter independents together yöntemiyle incelersek;
Test Results
Box's M 174,251
F Approx. 1,582
df1 105
df2 301098,626
Sig. ,000
Tests null hypothesis of equal
population covariance matrices.
𝐻0: Grupların kovaryans matrisleri eşittir. 𝐻𝐴: Grupların kovaryans matrisleri eşit değildir.
Box’s M testinin sig değeri = ,000 < 0,05 olduğundan dolayı 𝐻0 hipotezi red edilir. Yani gruplar kovaryans matrisleri açısından eşit değildir denilebilir.
Use stepwise method yöntemiyle incelersek;
Test Results
Box's M 13,536
F Approx. 1,335
df1 10
df2 462022,400
Sig. ,205
Tests null hypothesis of equal
population covariance matrices.

37
𝐻0: Grupların kovaryans matrisleri eşittir. 𝐻𝐴: Grupların kovaryans matrisleri eşit değildir.
Box’s M testinin sig değeri = ,205 > 0,05 olduğundan dolayı 𝐻0 hipotezi kabul edilir. Yani gruplar kovaryans matrisleri açısından eşittir.
Uygulamanın doğruluğu açısından stepwise methodu kullanmak uygun olacaktır zaten stepwise verilerde ki hatayı minimize edip kullanır ve daha uygun bir yöntemdir.
Korelasyon Matrisi
Çoklu bağlantı probleminin olup olmadığına korelasyon matrisine bakarak karar verebiliriz.
Eğer iki değişken arasındaki korelasyon 70 ten büyükse değişkenlerden birinin analiz dışında
tabi tutulması veya değişkenlerin birleştirilmesi yoluna gidebilir. Korelasyon matrisinden de
anlaşılacağı gibi değişkenler arasında çok yüksek sayılabilecek korelasyon yoktur.
Tests of Equality of Group Means
Wilks' Lambda F df1 df2 Sig.
serious ,989 3,328 1 311 ,069
exciting ,761 97,750 1 311 ,000
calm ,978 7,089 1 311 ,008
independ ,962 12,182 1 311 ,001
sincere ,995 1,623 1 311 ,204
warm ,996 1,285 1 311 ,258
phy_attr ,188 1342,800 1 311 ,000
kind ,990 3,089 1 311 ,080

38
intellig ,878 43,397 1 311 ,000
strong ,836 61,071 1 311 ,000
sophist ,802 76,884 1 311 ,000
happy ,929 23,738 1 311 ,000
sociable ,914 29,423 1 311 ,000
sentence ,982 5,799 1 311 ,017
Yukarıdaki ANOVA tablosu modele katkısı olan değişkenleri gösterir. Sig. değeri 0,05’ ten
küçük olanların modele anlamlı katkısı vardır. Sarı renk ile vurgulanmış olan değişkenler
anlamlı birer katkı sağlamazlar analizden çıkarılabilirler.
Diskriminant skorları ve gruplar arasındaki ilişkiye bu grafiğe bakarak karar verebiliriz,
açıklanan toplam varyansı gösterir. Canonical Correlation değeri 0,908’ dir. Bu değeri
yorumlayabilmek için karesini (0,9082 = 0,8244) alırız. Yani modelimiz bağımlı değişkendeki
varyansın %82’ sini açıklayabilmektedir.
Öz değer istatistiği ne kadar büyükse, bağımlı değişkendeki varyansın daha büyük bir kısmı o
fonksiyon tarafından açıklanacak demektir. Bizim örneğimizde öz değer istatistiği 4,707 olup,
fonksiyonumuzun iyi bir ayrımcılık sağladığını söyleyebiliriz.
Wilks' Lambda
Test of Function(s) Wilks' Lambda Chi-square df Sig.
1 ,175 538,201 4 ,000
Wilks’ Lambda istatistiği, ayırma skorlarındaki toplam varyansın gruplar arasındaki farklar
tarafından açıklanmayan kısmını gösterir. Yani toplam varyansın yaklaşık %17’ si gruplar
arasındaki farklar tarafından açıklanamamaktadır diyebiliriz.
Eigenvalues
Function Eigenvalue % of Variance Cumulative %
Canonical
Correlation
1 4,707a 100,0 100,0 ,908
a. First 1 canonical discriminant functions were used in the analysis.

39
Standardized Canonical
Discriminant Function
Coefficients
Function
1
calm ,133
phy_attr 1,005
kind -,194
sophist ,164
Yukarıdaki tabloda standartlaştırılmış ayırma fonksiyon katsayıları verilmiştir. Sonuçlara göre
çekici ve çekici olmama gruplarını ayırmada calm(sakinlik), phy_attr(fiziksel nitelikler),
kind(kibarlık), sophist(sofistlik) önemli ayırt edici bağımsız değişkenlerdir. Katsayıları sırasıyla
0,133 , 1,005 , -0,194 , 0,164 ‘tür. Bu katsayılar regresyon analizindeki beta katsayılarına
karşılık gelir.
Structure Matrix
Function
1
phy_attr ,958
sophist ,229
excitinga ,224
intelliga ,180
happya ,143
stronga ,131
sociablea ,121
independa ,098
calm ,070
kind ,046
sentencea -,043
seriousa ,012
Pooled within-groups
correlations between
discriminating variables and
standardized canonical
discriminant functions
Variables ordered by
absolute size of correlation
within function.
a. This variable not used in
the analysis.

40
Bu tabloda bağımsız değişkenlerin öneminin değerlendirilmesinde kullanılabilecek bir matrisi
gösterir.Sarı renkli olarak vurgulanmış olanlar analizlerde kullanılmamıştır. Structure Matrisi
her bir değişkenin ayırma fonksiyonu ile olan korelasyonunu gösterir. Burada her sütun bir
fonksiyonu gösterir.
Yapı matrisine göre ayırma fonksiyonu ile en yüksek korelasyona phy_attr (fiziksel nitelikler)
bağımsız değişkeni sahiptir.
Canonical Discriminant
Function Coefficients
Function
1
calm ,061
phy_attr ,721
kind -,094
sophist ,093
(Constant) -4,272
Unstandardized coefficients
Tabloda standardize olmayan diskriminant katsayıları yer alır. Çoklu regresyonda standardize
olmayan betalara karşılık gelir. Yeni sınıflandırma da kullanılabilecek gerçek tahmin modelini
oluşturmada kullanılır.
Ayırma fonksiyonu ;
𝑍 = −4,272 + 0,061(𝑐𝑎𝑙𝑚) + 0,721(𝑝ℎ𝑦_𝑎𝑡𝑡𝑟) − 0,094(𝑘𝑖𝑛𝑑) + 0,093(𝑠𝑜𝑝ℎ𝑖𝑠𝑡)
Functions at Group
Centroids
pa_manip
Function
1
Unattractive -2,184
Attractive 2,142
Unstandardized canonical
discriminant functions
evaluated at group means

41
Bu tabloda her bir grubun ortalama ayırma fonksiyon skorunu görebiliriz. Birinci grubun
ortalama değeri -2,184, ikinci grubun ortalama değeri 2,142’ dir.
AYIRMA ANALİZİNİN BAŞARISININ DEĞERLENDİRİLMESİ
Ayırma analizinde , analizin başarısı doğru sınıflandırma yüzdesidir. Yani doğru sınıflandırma
yüzdesi ne kadar yüksekse analiz o kadar başarılıdır.
Classification Resultsa
pa_manip
Predicted Group Membership
Total Unattractive Attractive
Original Count Unattractive 154 5 159
Attractive 6 154 160
% Unattractive 96,9 3,1 100,0
Attractive 3,8 96,3 100,0
a. 96,6% of original grouped cases correctly classified.
Yukarıdaki tabloda örnekleme dahil ettiğimiz değişkenlerin %96,6 sı doğru olarak
sınıflandırılmıştır.
Suç işleyen ve çekici olmayan 159 kişiden 154’ü doğru tahmin edilirken 5’ i yanlış
sınıflandırılmış, suç işleyen çekici olan 160 kişiden 154’ ü doğru sınıflandırılırken 6’ sı yanlış
sınıflandırılmıştır.
Örneğimizde çekici ve çekici olmayan insanları birbirinden ayıran özellikleri merak etmiştik.
Ayrıştırma analizi sonunda bunların calm, phy_attr, kind ve sophist değişkenleri olduğunu
gördük.
6. LOJİSTİK REGRESYON ANALİZİ
Bağımlı ve bağımsız değişken ayrımının yapıldığı çok değişkenli bir modelde, bağımlı değişken
nominal ölçekli bir değişken olduğunda EKK tekniğiyle elde edilen tahminler yetersiz
kalmaktadır. Yani tahmin edilen varyanslar artık minimum değildir.
Lojistik regresyon,ayırma işleminde diskriminant analizinin varsayımlarının sağlanmadığı
zamanlarda kullanılmalıdır.

42
Az önceki sanığın fiziksel çekiciliği ve işlediği suçun türünün hukuki kararı nasıl etkilediğine
dair bir araştırma diskriminant analizine uyduğu için lojistik regresyon uygulayamayız.
Lojistik regresyon için başka veri seti üzerinden devam edelim. 377 hasta üzerinde yapılan bir
şizofreni varlığına dair araştırma verimizi tanımlayacak olursak:
DEĞİŞKENLER AÇIKLAMA
1. Schizo: Şizofreni Teşhisi
2. L: Yalan ölçeği
3. F: F ölçeği
4. K: K ölçeği
5. Hs: Hastalık hastalığı
6. D: Depresyon
7. Hy: Histeri
8. Pd: Psikopati
9. Mf: Maskülenlik / Feminenlik
10. Pa: Paranoya
11. Pt: Psikasteni
12. Sc: Şizofreni
13. Ma: Hipomani
14. Si: İçe kapanıklık

43
Test Results
Box's M 28,170
F Approx. 4,568
df1 6
df2 28825,387
Sig. ,000
Tests null hypothesis of equal
population covariance matrices.
𝐻0: Grupların kovaryans matrisleri eşittir. 𝐻𝐴: Grupların kovaryans matrisleri eşit değildir.
Sig. değeri 0,05’ ten küçük olduğu için 𝐻0 hipotezi red edilir. Kovaryans matrislerinin eşit
olmadığı hipotezi kabul edilir ve verimizin dikriminant analizine uymadığı söylenebilir.
Bu yüzden lojistik regresyonu bu veri setine uygulayabiliriz.
Case Processing Summary
Unweighted Casesa N Percent
Selected Cases Included in Analysis 377 100,0
Missing Cases 0 ,0
Total 377 100,0
Unselected Cases 0 ,0
Total 377 100,0
a. If weight is in effect, see classification table for the total number of
cases.
Bu tablo veri setimiz hakkında bilgi verir. Görüldüğü gibi 377 gözlemimiz var ve hiç missing
değerimiz yoktur.
Dependent Variable Encoding
Original Value Internal Value
Şizofreni Yok 0
Kesin Şizofren 1
Bu Tabloda bağımlı değişkenin orijinal değerlerini gösterir.

44
Omnibus Tests of Model Coefficients
Chi-square df Sig.
Step 1 Step 46,168 13 ,000
Block 46,168 13 ,000
Model 46,168 13 ,000
Bu tabloda model katsayılarının anlamlılığını test eder.
H0: β1 = β2 = β3 … . = β14
H1: β1 ≠ β2 ≠ β3 … . ≠ β14
Block ve Model satırlarına ait sig. değerleri =0,000 < 0,05 olduğu için 𝐻0 red edilir ve
modeldeki katsayıların anlamlı olduğu söylenebilir.
Hosmer and Lemeshow Test
Step Chi-square df Sig.
1 3,607 8 ,891
H0: Model verileri iyi temsil eder.
H1: Model verileri iyi temsil etmemektedir.
Sig. = 0,891 > 0,05 olduğu için H0 kabul edilir ve kurulan lojistik modelin verileri iyi temsil
ettiği söylenebilir.
Classification Tablea
Observed
Predicted
Şizofreni Teşhisi Percentage
Correct Şizofreni Yok Kesin Şizofren
Step 1 Şizofreni Teşhisi Şizofreni Yok 331 4 98,8
Kesin Şizofren 36 6 14,3
Overall Percentage 89,4
a. The cut value is ,500

45
Aynı diskriminant analizindeki gibi değişkenlerin kaçının doğru atandığına bu tablodan
bakarak yorum yapabiliriz. Şizofreni olmayanları %98,8’i kesin şizofren olanların %14,3’ü
doğru atanmıştır. Toplamda da %89,4’ lük bir doğru atama oranı yakalanmıştır.
Doğru atama oranına Classification Tablosuna bakılmadan bu grafiğe bakarak ta karar
verebiliriz.
Variables in the Equation
B S.E. Wald df Sig. Exp(B)
Step 1a Mf ,009 ,017 ,306 1 ,580 1,009
L ,005 ,027 ,036 1 ,849 1,005
F ,024 ,021 1,396 1 ,237 1,025
K ,020 ,036 ,315 1 ,574 1,021
Hs -,021 ,032 ,439 1 ,508 ,979
D ,002 ,026 ,004 1 ,952 1,002
Hy -,003 ,031 ,008 1 ,928 ,997

46
Pd -,034 ,020 2,976 1 ,085 ,966
Pa ,033 ,020 2,727 1 ,099 1,034
Pt -,055 ,045 1,536 1 ,215 ,946
Sc ,045 ,038 1,349 1 ,245 1,046
Ma ,054 ,026 4,132 1 ,042 1,055
Si ,011 ,029 ,148 1 ,700 1,011
Constant -7,689 3,672 4,384 1 ,036 ,000
a. Variable(s) entered on step 1: Mf, L, F, K, Hs, D, Hy, Pd, Pa, Pt, Sc, Ma, Si.
Lojistik regresyon modelini kurmak içinde bu tablodan yararlanırız. Modeli yazarken β’lardan
yazıyoruz ve yorumlarken de 𝑒𝛽’ ya göre yapıyoruz.
p
1 − p= 𝑒^(−7,689 + 0,009𝑀𝑓 + 0,005𝐿 + 0,024𝐹 + 0,020𝐾 − 0,021𝐻𝑠 + 0,002𝐷
− 0,003𝐻𝑦 − 0,034𝑃𝑑 + 0,033𝑃𝑎 − 0,055𝑃𝑡 + 0,045𝑆𝑐 + 0,054𝑀𝑎
+ 0,011𝑆𝑖)
Lojistik regresyon modelimiz bu şekildedir.
Methodumuzu Forward Wald olarak değiştirirsek;
Classification Tablea,b
Observed
Predicted
Şizofreni Teşhisi Percentage
Correct Şizofreni Yok Kesin Şizofren
Step 0 Şizofreni Teşhisi Şizofreni Yok 335 0 100,0
Kesin Şizofren 42 0 ,0
Overall Percentage 88,9
a. Constant is included in the model.
b. The cut value is ,500
Hiçbir işlem yapılmadan önce değişkenlerin %89,9 unun doğru atanmış olduğunu görürüz.

47
Variables not in the Equation
Score df Sig.
Step 1 Variables Mf ,237 1 ,627
L ,285 1 ,593
K ,335 1 ,563
Hs 1,959 1 ,162
D 4,970 1 ,026
Hy 1,973 1 ,160
Pd 2,116 1 ,146
Pa ,905 1 ,341
Pt 2,946 1 ,086
Sc ,000 1 ,991
Ma 6,504 1 ,011
Si 2,396 1 ,122
Overall Statistics 19,627 12 ,074
Step 2 Variables Mf ,064 1 ,800
L 2,399 1 ,121
K 2,781 1 ,095
Hs 2,818 1 ,093
D 2,740 1 ,098
Hy 1,190 1 ,275
Pd 4,609 1 ,032
Pa ,310 1 ,578
Pt 5,048 1 ,025
Sc 1,161 1 ,281
Si ,890 1 ,346
Overall Statistics 13,472 11 ,264
Step 3 Variables Mf ,118 1 ,731
L ,499 1 ,480
K ,201 1 ,654
Hs ,349 1 ,555
D ,030 1 ,863
Hy ,064 1 ,801
Pd 1,523 1 ,217
Pa 2,775 1 ,096
Sc 1,712 1 ,191
Si ,527 1 ,468
Overall Statistics 8,512 10 ,579

48
Score değeri en büyük olan değişkenler modelimize giren ilk değişkenlerdir. Overall statistics’
e ait sig. değerleri modelde yer almayan değişkenlerin katsayılarının “0” olduğunu söyleyen
hipotezi test eder. Sig. değerleri 0,05’ ten büyük olduğu için bu değişkenlerin anlamsız
olduğunu söyleyebiliriz.
Tabloda 0,50 kritik değer ve tahmin edilen olasılıklar yardımıyla her adımdaki sınıflandırma
sonuçları verilmektedir.
Variables in the Equation
B S.E. Wald df Sig. Exp(B)
Step 1a F ,050 ,010 26,126 1 ,000 1,051
Constant -5,383 ,708 57,836 1 ,000 ,005
Step 2b F ,033 ,012 7,748 1 ,005 1,033
Ma ,042 ,017 6,343 1 ,012 1,043
Constant -6,879 ,973 49,989 1 ,000 ,001
Step 3c F ,049 ,014 12,184 1 ,000 1,050
Pt -,042 ,019 4,921 1 ,027 ,959
Ma ,051 ,018 8,318 1 ,004 1,053
Constant -6,118 1,016 36,287 1 ,000 ,002
a. Variable(s) entered on step 1: F.
b. Variable(s) entered on step 2: Ma.
c. Variable(s) entered on step 3: Pt.
Classification Tablea
Observed
Predicted
Şizofreni Teşhisi Percentage
Correct Şizofreni Yok Kesin Şizofren
Step 1 Şizofreni Teşhisi Şizofreni Yok 333 2 99,4
Kesin Şizofren 39 3 7,1

49
Modelde yer alan değişkenler 1. Adımda=F , 2.Adımda=F,Ma , 3.Adımda=F,Pt,Ma ‘
eklenmiştir ve işlemimiz 3 adımda tamamlanmıştır,analizimize bunlarla devam ediyoruz.
Tablodan genel doğru sınıflandırma oranlarının birinci adımda%89,1, ikinci adımda %88,6, 3. Adımda %89,9 olduğunu görebiliriz.
Model Summary
Step
-2 Log
likelihood
Cox & Snell R
Square
Nagelkerke R
Square
1 237,795a ,066 ,131
2 231,315b ,082 ,163
3 226,040b ,095 ,188
a. Estimation terminated at iteration number 5 because
parameter estimates changed by less than ,001.
b. Estimation terminated at iteration number 6 because
parameter estimates changed by less than ,001.
Bu tablodan bağımsız değişkenin bağımlı değişkenin % kaçını açıkladığını görebiliriz. Olasılık
esasına göre çoklu 𝑅2 istatistiğine benzemektedir.
1.Adımda 0,066 sını
2.Adımda 0,082 sini
3.Adımda 0,095 ini açıklar.
Overall Percentage 89,1
Step 2 Şizofreni Teşhisi Şizofreni Yok 333 2 99,4
Kesin Şizofren 41 1 2,4
Overall Percentage 88,6
Step 3 Şizofreni Teşhisi Şizofreni Yok 333 2 99,4
Kesin Şizofren 36 6 14,3
Overall Percentage 89,9
a. The cut value is ,500

50
Kaçıncı iterasyonda yakınsama sağladığına da bu grafikten inceleme yaparak söylemek
mümkündür.
1.Adım için 5. İterasyonda
2.Adım için 6. İterasyonda
3.Adım için 6. İterasyonda yakınsama sağlanmıştır.
Modelde yer alan değişkenler (son adıma göre) için Lojistik Regresyon modeli;
p
1 − p= 𝑒^(−6,118 + 0,049𝐹 − 0,042𝑃𝑡 + 0,051𝑀𝑎)
7. KÜMELEME ANALİZİ
Kümeleme analizinde amaç benzer olan değişkenleri gruplamaktır. Öncelikli amacı birey ya
da nesnelerin temel özelliklerini dikkate alarak onları gruplamaktır.

51
Kümeleme Analizinde Araştırma Planı:
1. Benzerlik Ölçümleri
2. Korelasyon Ölçümleri
3. Uzaklık Ölçümleri
4. Ortaklık Ölçümü
5. Verilerin Standartlaştırılması
6. Kümeleme Analizinde Varsayımlar
7. Bir Kümeleme Algoritması Seçme
8. Hiyerarşik Kümeleme
9. Küme Sayısının Belirlenmesi
10. Uzaklık Katsayıları
11. Ağaç Grafiği
12. Hiyerarşik Olmayan Kümeleme
13. Küme Analizini Düzenleme
14. Kümelerin Yorumlanması
15. Kümelerin Geçerliliği ve Profili
Kümeleme analizini uygulayacağımız veriyi tanıyalım;
Araştırmada 157 tüketiciye Kellogs’ markasına ait 15 kraker denetilmiş ve bunları
puanlamaları istenmiştir. [1-Hiç beğenmedim , 9-Çok beğendim şeklinde]
DEĞİŞKENLER AÇIKLAMA
R#1 1.Kraker için verilen puanlar
R#2 2.Kraker için verilen puanlar
R#3 3.Kraker için verilen puanlar
R#4 4.Kraker için verilen puanlar
R#5 5.Kraker için verilen puanlar
R#6 6.Kraker için verilen puanlar
R#7 7.Kraker için verilen puanlar
R#8 8.Kraker için verilen puanlar
R#9 9.Kraker için verilen puanlar
R#10 10.Kraker için verilen puanlar
AvgRtg Ortalama verilen puanlar
CITY Araştırmanın yapıldığı şehirler
GENDER Cinsiyet
AGE Yaş
Kümeleme analizini örnek üzerinde uygularsak;

52
Case Processing Summarya,b
Cases
Valid Missing Total
N Percent N Percent N Percent
157 100,0 0 ,0 157 100,0
a. Squared Euclidean Distance used
b. Ward Linkage
157 değişken için analizimiz yapılmıştır ve hiç kayıp gözlem değerimiz yoktur.
7.1 Hiyerarşik Kümeleme Analizi:
Kümeleme yöntemi olarak “Ward Linkage” ve uzaklık olarak “kareli öklit uzaklığı”
seçilmesiyle çıkan “Agglomeration Schedule” tablosu bize gözlemlerin birleştirilme
süreçlerini göstermektedir.
Agglomeration Schedule
Stage
Cluster Combined
Coefficients
Stage Cluster First Appears
Next Stage Cluster 1 Cluster 2 Cluster 1 Cluster 2
1 16 141 2,500 0 0 73
2 40 121 5,500 0 0 32
3 17 60 10,000 0 0 48
4 38 156 15,000 0 0 42
5 96 155 20,000 0 0 13
6 1 87 25,000 0 0 66
7 19 43 30,000 0 0 64
8 28 32 35,000 0 0 125
9 8 107 40,500 0 0 39
10 2 47 46,000 0 0 91
11 147 151 52,000 0 0 73
12 51 110 58,000 0 0 116
13 96 148 64,333 5 0 66
14 53 145 70,833 0 0 41
15 109 118 77,333 0 0 79
16 49 92 83,833 0 0 90
17 63 149 90,833 0 0 79
18 135 136 97,833 0 0 25
19 4 129 104,833 0 0 82
20 29 95 111,833 0 0 32
21 57 81 118,833 0 0 70

53
22 88 146 126,333 0 0 75
23 56 127 133,833 0 0 69
24 77 84 141,333 0 0 104
25 106 135 149,000 0 18 65
26 126 153 157,000 0 0 53
27 117 143 165,000 0 0 106
28 59 130 173,000 0 0 92
29 89 102 181,000 0 0 72
30 50 85 189,000 0 0 83
31 61 90 197,500 0 0 125
32 29 40 206,000 20 2 94
33 9 37 214,500 0 0 91
34 25 131 223,500 0 0 82
35 20 128 233,000 0 0 93
36 91 108 242,500 0 0 62
37 100 105 252,000 0 0 57
38 41 62 261,500 0 0 71
39 8 33 271,333 9 0 83
40 68 83 281,333 0 0 85
41 53 66 291,500 14 0 97
42 38 132 301,833 4 0 96
43 113 144 312,333 0 0 117
44 123 139 322,833 0 0 84
45 44 82 333,333 0 0 95
46 10 30 343,833 0 0 120
47 7 18 354,333 0 0 103
48 17 103 365,167 3 0 129
49 31 74 376,167 0 0 74
50 12 73 387,667 0 0 88
51 119 152 399,667 0 0 99
52 69 142 411,667 0 0 101
53 70 126 423,667 0 26 106
54 94 114 435,667 0 0 89
55 55 99 447,667 0 0 102
56 27 150 460,167 0 0 80
57 86 100 472,667 0 37 110
58 36 76 485,167 0 0 100
59 22 45 497,667 0 0 108
60 46 79 510,667 0 0 119
61 3 72 524,167 0 0 94
62 91 122 538,000 36 0 105
63 64 133 552,000 0 0 98
64 19 120 566,333 7 0 136

54
65 52 106 581,167 0 25 76
66 1 96 596,033 6 13 85
67 112 154 611,033 0 0 115
68 67 97 626,033 0 0 122
69 56 104 641,200 23 0 96
70 57 80 656,867 21 0 87
71 41 75 673,367 38 0 105
72 65 89 690,033 0 29 84
73 16 147 706,783 1 11 124
74 31 71 723,783 49 0 113
75 88 157 740,950 22 0 111
76 52 98 758,250 65 0 124
77 13 58 775,750 0 0 112
78 14 21 793,250 0 0 126
79 63 109 811,500 17 15 90
80 5 27 830,333 0 56 134
81 134 140 850,333 0 0 130
82 4 25 870,333 19 34 132
83 8 50 891,000 39 30 140
84 65 123 911,833 72 44 122
85 1 68 933,490 66 40 111
86 35 78 955,490 0 0 128
87 26 57 977,574 0 70 121
88 6 12 1000,074 0 50 104
89 94 116 1022,740 54 0 101
90 49 63 1045,490 16 79 128
91 2 9 1068,490 10 33 97
92 48 59 1091,824 0 28 117
93 20 124 1115,657 35 0 98
94 3 29 1139,490 61 32 120
95 44 54 1163,657 45 0 138
96 38 56 1188,490 42 69 131
97 2 53 1213,681 91 41 123
98 20 64 1239,148 93 63 141
99 115 119 1265,148 0 51 108
100 36 125 1291,314 58 0 114
101 69 94 1318,648 52 89 130
102 11 55 1346,648 0 55 127
103 7 138 1374,814 47 0 121
104 6 77 1403,714 88 24 113
105 41 91 1432,714 71 62 129
106 70 117 1461,914 53 27 135
107 24 39 1491,914 0 0 137

55
108 22 115 1522,214 59 99 137
109 15 42 1552,714 0 0 123
110 86 101 1583,964 57 0 118
111 1 88 1616,440 85 75 133
112 13 111 1651,607 77 0 119
113 6 31 1687,082 104 74 136
114 36 93 1725,165 100 0 126
115 112 137 1764,165 67 0 131
116 34 51 1804,165 0 12 138
117 48 113 1845,132 92 43 133
118 23 86 1886,682 0 110 132
119 13 46 1928,615 112 60 144
120 3 10 1971,782 94 46 127
121 7 26 2015,794 103 87 149
122 65 67 2061,937 84 68 140
123 2 15 2109,691 97 109 146
124 16 52 2158,308 73 76 135
125 28 61 2207,058 8 31 141
126 14 36 2257,808 78 114 142
127 3 11 2309,035 120 102 145
128 35 49 2360,535 86 90 144
129 17 41 2413,757 48 105 142
130 69 134 2467,757 101 81 143
131 38 112 2521,813 96 115 143
132 4 23 2576,568 82 118 134
133 1 48 2640,301 111 117 139
134 4 5 2716,829 132 80 148
135 16 70 2793,677 124 106 139
136 6 19 2871,378 113 64 147
137 22 24 2951,149 108 107 148
138 34 44 3035,316 116 95 150
139 1 16 3129,792 133 135 146
140 8 65 3224,816 83 122 145
141 20 28 3334,211 98 125 151
142 14 17 3449,255 126 129 149
143 38 69 3569,679 131 130 152
144 13 35 3698,963 119 128 147
145 3 8 3841,287 127 140 152
146 1 2 3986,109 139 123 153
147 6 13 4139,691 136 144 150
148 4 22 4297,808 134 137 151
149 7 14 4490,719 121 142 154
150 6 34 4696,677 147 138 155

56
151 4 20 4918,199 148 141 154
152 3 38 5170,233 145 143 153
153 1 3 5502,089 146 152 155
154 4 7 5860,545 151 149 156
155 1 6 6322,529 153 150 156
156 1 4 7355,414 155 154 0
Örneğin tabloya göre 1. kümedeki 16 ve 2. Kümedeki 141 numaralı değişkenlerin yakın
gözlemler olduğunu birleşerek 73. Aşamaya geçtiklerini göstermektedir. 73. Adımda ise 15 ve
147 numaralı değişkenlerin birleştiği ve 124. aşamaya geçtiği görülmektedir. 124. adımda ise
16 ve 52 numaralı değişkenlerin birleştiği ve 135. aşamaya geçtiği görülmektedir. Bu döngü,
yani birleşmeler tüm değişkenler için devam etmekte ve tamamlanmaktadır.
Dendogram İncelemesi:

57
Dendogram sonucuna Phoenix ve Philly eyaletlerine göre krakerlere verilen puanları 4 küme oluşturduğu görülmektedir.
7.2 Hiyerarşik Olmayan Kümeleme Analizi:
4 küme seçilerek yapılan K-means Kümele Analizi:
Değişkenlerin hangi kümeye atandıklarını gösterir.
Iteration Historya
Iteration
Change in Cluster Centers
1 2 3 4
1 6,812 6,754 7,409 6,688
2 ,326 ,675 1,068 1,190
3 ,360 ,387 ,309 ,952
4 ,115 ,670 ,258 ,575
5 ,000 ,656 ,225 ,183
6 ,114 ,337 ,000 ,000
7 ,000 ,341 ,204 ,000
8 ,000 ,251 ,134 ,000
9 ,000 ,000 ,000 ,000
a. Convergence achieved due to no or small change in
cluster centers. The maximum absolute coordinate change
for any center is ,000. The current iteration is 9. The
minimum distance between initial centers is 14,000.
Initial Cluster Centers
Cluster
1 2 3 4
1.Kraker 9 9 1 3
2.Kraker 9 1 1 9
3.Kraker 9 7 1 1
4.Kraker 9 8 1 6
5.Kraker 7 1 3 4
6.Kraker 9 5 6 2
7.Kraker 9 6 5 4
8.Kraker 9 4 3 9
9.Kraker 9 1 8 7
10.Kraker 9 9 2 9

58
Tekrarlama tablosudur,tekrarlama sayısını verir. 9 tekrarlamada 4 kümenin oluşturulduğunu
görebiliriz.
Final Cluster Centers
Cluster
1 2 3 4
1.Kraker 6 7 4 5
2.Kraker 7 4 2 6
3.Kraker 5 5 4 4
4.Kraker 6 6 4 7
5.Kraker 7 6 6 4
6.Kraker 7 6 6 5
7.Kraker 8 8 6 4
8.Kraker 7 4 6 6
9.Kraker 6 2 6 6
10.Kraker 8 7 7 8
Atamalar yapıldıktan sonra 10 değişkenin 4 kümedeki ortalamalarını verir. Örneğin; 1.
Krakeri en çok beğenen küme 2. Küme, 2.Krakeri beğenen küme ise 1. Kümedir.
Distances between Final Cluster Centers
Cluster 1 2 3 4
1 6,383 6,876 5,307
2 6,383 5,888 6,404
3 6,876 5,888 5,549
4 5,307 6,404 5,549
Bu tablo biribirne en yakın kümeleri gösterir. 1. Ve 4. Küme birbirlerine en yakın olan
kümelerdir. 1. Ve 3. Kümelerde birbirlerine en uzak olan kümelerdir.

59
ANOVA
Cluster Error
F Sig. Mean Square df Mean Square df
1.Kraker 49,198 3 4,336 153 11,345 ,000
2.Kraker 211,303 3 2,896 153 72,964 ,000
3.Kraker 31,709 3 4,870 153 6,510 ,000
4.Kraker 47,164 3 3,783 153 12,468 ,000
5.Kraker 63,392 3 3,269 153 19,390 ,000
6.Kraker 35,013 3 3,909 153 8,957 ,000
7.Kraker 106,110 3 2,667 153 39,781 ,000
8.Kraker 42,412 3 3,618 153 11,722 ,000
9.Kraker 93,059 3 3,158 153 29,471 ,000
10.Kraker 7,739 3 2,095 153 3,695 ,013
The F tests should be used only for descriptive purposes because the clusters have been chosen
to maximize the differences among cases in different clusters. The observed significance levels
are not corrected for this and thus cannot be interpreted as tests of the hypothesis that the cluster
means are equal.
Gruplar arasında fark olup olmadığına ANOVA tablosuna bakarak karar veririz.
H0 : 𝜇1 = 𝜇2 = 𝜇n H1: En az biri farklıdır. n=1,2,….,10
Her ne kadar Anova değişkenlerin kümeleme analizine uygunluğu amacıyla yapılmış olsa da,
kümeler oluşturulurken aralardaki benzerliği minimuma indiren yöntemler uygulanmaktadır.
Bu nedenle değişkenlerin tümünün ortalamaları arasındaki fark istatistiksel olarak (tüm
değişkenlerde sig.0,00<0,05, yani H0 red) anlamlıdır.
Number of Cases in each
Cluster
Cluster 1 66,000
2 20,000
3 36,000
4 35,000
Valid 157,000
Missing ,000
Hangi kümede kaç gözlem var onu gösterir;
1.Kümede 66 gözlem, 2.Kümede 20 gözlem, 3.Kümede 36 gözlem, 4. Kümede 35 gözlem
vardır.

60
Kaynakça
http://core.ecu.edu/psyc/wuenschk/spss/spss-Data.htm
http://psych.colorado.edu/~carey/Courses/PSYC7291/ClassDataSets.htm
http://www.psych.yorku.ca/lab/psy6140/ex/data.htm
Popper, Richard, Kroll, Jeff and Magidson, Jay. Sawtooth Software Proceedings,
2004.
Hosmer, D.W., Lemeshow, S. and Sturdivant, R.X. (2013) Applied Logistic
Regression: Third Edition.
Related Documents











