© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Oleg Avdeev, AdRoll October 2015 CMP310 Building Robust Data Pipelines Using Containers and Spot Instances

(CMP310) Data Processing Pipelines Using Containers & Spot Instances
Jan 09, 2017
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Oleg Avdeev, AdRoll
October 2015
CMP310
Building Robust Data Pipelines
Using Containers and Spot Instances

Lessons we learned from
• Building a new data-heavy product
• On a tight timeline
• On budget (just 6 people)
Solution:
• Leverage AWS and Docker to build a no-frills data
pipeline

AdRoll Prospecting Product
Find new customers based on your
existing customers’ behavior
• hundreds of TB of data
• billions of cookies
• ~20 000 ML models

Requirements
• Robust
• Language-agnostic
• Easy to debug
• Easy to deploy new jobs

Running things

Docker
• Solves deployment problem
• Solves libraries problem**by sweeping it under the rug
• Hip
• Great tooling

DockerfileFROM ubuntu:14.04
# Install dependencies
RUN apt-get update && apt-get install -y\
libcurl4-gnutls-dev \
libJudy-dev \
libcmph-dev \
libz-dev \
libpcre3 \
sudo \
make \
git \
clang-3.5 gcc \
python2.7 \
python-boto \
python-pip
RUN pip install awscli
RUN apt-get install -y jq indent libjson-c-dev python-ply
COPY . /opt/prospecting/trailmatch
# Compile TrailDB
WORKDIR /opt/prospecting/trailmatch/deps/traildb
RUN make

Running containers
• Swarm
• Mesos/Mesosphere/Marathon
• Amazon ECS
• Custom scheduler

Queue service (Quentin)
• Finds an instance to run container on
• Maintains a queue when no instances available
• Feed queue metrics to CloudWatch
• Capture container stdout/stderr
• UI to debug failuresCloudWatch
Quentin (queue)
Auto Scaling

Queue service (Quentin)

Elastic scaling

Lessons learned
• Scale based on job backlog size
• Multiple instance pools / Auto Scaling groups
• Use Elastic Load Balancing for health checks
• Lifecycle hooks
You don’t really need: data aware scheduling and HA
Nice to have: job profiling

Job Dependencies

50 years ago

Today
Many solutions:
• Chronos
• Airflow
• Jenkins/Buildbot
• Luigi

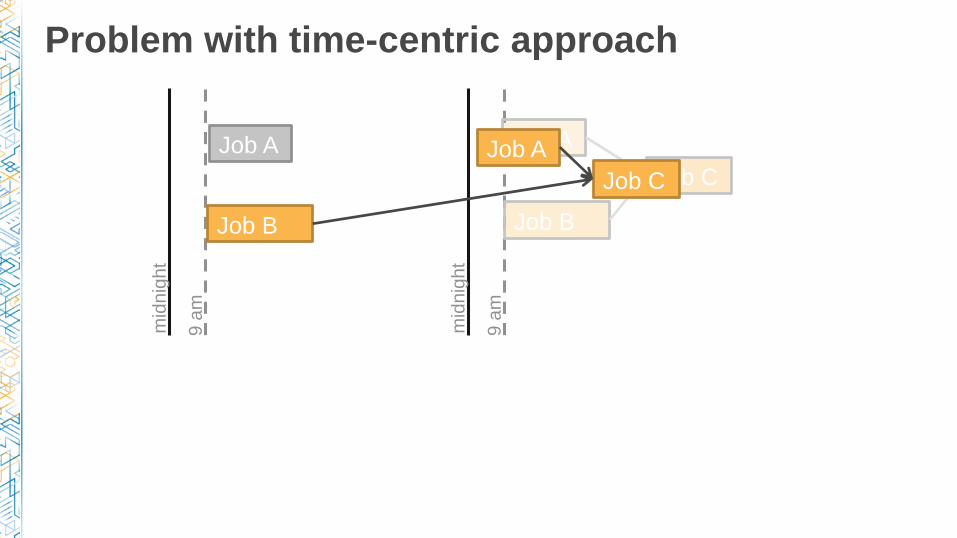
Problem with time-centric approach
Job A
9 a
m
mid
nig
ht
9 a
m
mid
nig
ht
Job C
Job B
Job A
Job C
Job B
9 a
m
mid
nig
ht
Job A
Job C
Job B
Problem with time-centric approach
Job A
9 a
m
mid
nig
ht
Job C
Job B
Job A

Problem with time-centric approach
Job A
9 a
m
mid
nig
ht
9 a
m
mid
nig
ht
Job C
Job B
Job C
Job A
Job C
Job B

Solution
Job A
9 a
m
mid
nig
ht
9 a
m
mid
nig
ht
Job C
Job B
• Basically, make(1)
• Time/date is just another explicit parameter
• Jobs are triggered based on file existence/timestamp
D=2015-10-09
D=2015-10-09D=2015-10-09
Job A
Job C
Job B

Luigigithub.com/spotify/luigi
• Dependency management based on data inputs/outputs
• Has S3/Postgres/Hadoop support out of the box
• Extensible in Python
• Has (pretty primitive) UI


Luigi
class PivotRunner(luigi.Task):
blob_path = luigi.Parameter()
out_path = luigi.Parameter()
segments = luigi.Parameter()
def requires(self):
return BlobTask(blob_path=self.blob_path)
def output(self):
return luigi.s3.S3Target(self.out_path)
def run(self):
q = {
"cmdline" : ["pivot %s {%s}" % (self.out_path, self.segments)],
"image": 'docker:5000/pivot:latest',
"caps" : "type=r3.4xlarge"
}
quentin.run_queries('pivot', [json.dumps(q)], max_retries=1)

Lessons learned
Not a hard problem, but easily complicated:
• Jobs depend on data (not other jobs)
• Time-based scheduling can be added later
• Idempotent jobs (ideally)
• Transactional success flag (_SUCCESS in s3)
• Useful to have: dynamic dependency graphs

Saving Money

Spot Instances
• Can be really cheap
• But availability varies
• Requires rest of the pipeline to be robust re: failures and
restarts

Spot Instances

Spot Instances

Lessons learned
• Hedge risks – use multiple instance types
• Multiple regions if you can
• Have a pool of On-Demand instances
• Still worth it

Putting It All Together

Putting it all together
Dependency management
Resource management
Deployment

Misc notes
• “Files in S3” is the only abstraction you really need
• No need in distributed FS, pulling from Amazon S3
scales well
• Keep jobs small (minutes to hours)
• Storing data efficiently helps a lot
• Using bigger instances

Daily numbers
• Hundreds of biggest Spot instances launched and killed
• 30 TB RAM in the cluster (peak)
• 100s of containers (1min to 6hr per container)
• Hundreds of billions of log lines analyzed
• Using R, C, Erlang, D, Python, Lua, JavaScript, and a
custom DSL

Remember to complete
your evaluations!

Related Documents











