1 ClusterSim: A Java-Based Parallel Discrete-Event Simulation Tool for Cluster Computing Luís F. W. Góes 1 , Luiz E. S. Ramos 2 , Carlos A. P. S. Martins 3 Graduation Program in Electrical Engineering, Pontifical Catholic University of Minas Gerais Av. Dom José Gaspar 500, Belo Horizonte, MG, Brazil 1 {[email protected] } 2 {[email protected] } 3 {[email protected] } Abstract – In this paper, we present the proposal and implementation of a Java-based parallel discrete-event simulation tool for cluster computing called ClusterSim (Cluster Simulation Tool). The ClusterSim supports visual modeling and simulation of clusters and their workloads for performance analysis. A cluster is composed of single or multi-processed nodes, parallel job schedulers, network topologies and technologies. A workload is represented by users that submit jobs composed of tasks described by probability distributions and their internal structure (CPU, I/O and MPI instructions). Our main objectives in this paper: to present the proposal and implementations of the software architecture and simulation model of ClusterSim; to verify and validate ClusterSim; to analyze ClusterSim by means of a case study. Our main contributions are: the proposal and implementation of ClusterSim with an hybrid workload model, a graphical environment, the modeling of heterogeneous clusters and a statistical and performance module. Keywords: Cluster Computing, Discrete-Event Simulation, Parallel Job Scheduling, Network Topologies and Technologies, Performance Analysis.

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
ClusterSim: A Java-Based Parallel Discrete-Event Simulation Tool
for Cluster Computing
Luís F. W. Góes1, Luiz E. S. Ramos2, Carlos A. P. S. Martins3
Graduation Program in Electrical Engineering, Pontifical Catholic University of Minas Gerais
Av. Dom José Gaspar 500, Belo Horizonte, MG, Brazil
1{[email protected]} 2{[email protected]} 3{[email protected]}
Abstract – In this paper, we present the proposal and implementation of a Java-based parallel
discrete-event simulation tool for cluster computing called ClusterSim (Cluster Simulation Tool).
The ClusterSim supports visual modeling and simulation of clusters and their workloads for
performance analysis. A cluster is composed of single or multi-processed nodes, parallel job
schedulers, network topologies and technologies. A workload is represented by users that submit
jobs composed of tasks described by probability distributions and their internal structure (CPU,
I/O and MPI instructions). Our main objectives in this paper: to present the proposal and
implementations of the software architecture and simulation model of ClusterSim; to verify and
validate ClusterSim; to analyze ClusterSim by means of a case study. Our main contributions
are: the proposal and implementation of ClusterSim with an hybrid workload model, a graphical
environment, the modeling of heterogeneous clusters and a statistical and performance module.
Keywords: Cluster Computing, Discrete-Event Simulation, Parallel Job Scheduling, Network
Topologies and Technologies, Performance Analysis.

2
1 Introduction
Nowadays, clusters of workstations are widely used in academic, industrial and commercial
areas. Usually built with “commodity-off-the-shelf” hardware components and freeware or
shareware available in the web, they are a low cost and high performance alternative to
supercomputers [8] [13]. The performance analysis of different parallel job scheduling
algorithms, interconnection networks and topologies, heterogeneous nodes and parallel jobs on
real clusters requires: a long time to develop and change software; a high financial cost to acquire
new hardware; a controllable and stable environment; less intrusive performance analysis tools
etc. On the other hand, analytical modeling for the performance analysis of clusters requires too
much simplifications and assumptions [3].
Thus, simulation appears as a performance analysis technique less expensive (financial cost)
than measurement and more accurate than analytical modeling to evaluate the performance of a
cluster. It allows a more detailed, flexible and controlled environment. So, researchers can
compare a lot of clusters configurations under a wide variety of workloads [3] [9]. Further, there
are many available types of tools that aid in the development of simulations: simulation libraries
(SimJava [10] [11], JSDESLib [8] etc.), languages (SIMSCRIPT [9], SLAM [9] etc.) and
application specific simulation tools (Gridsim [3], Simgrid [4], SRGSim [1] etc.).
In this paper, we present the proposal and implementation of the Cluster Simulation Tool
(ClusterSim) that is used to model clusters and their workloads through a graphical environment,
and evaluate their performance using simulation. It is an evolution of our RJSSim simulation tool
[7]. The main objectives of this paper are: to present the proposal and implementation of the
software architecture and simulation model of ClusterSim; to verify and validate ClusterSim; to
analyze ClusterSim by means of a case study. The main goals of this paper are: the proposal and

3
implementation of ClusterSim with an hybrid workload model, a graphical environment, the
modeling of heterogeneous clusters and a statistical and performance module.
In this paper, we introduce the Cluster Simulation Tool (ClusterSim) and relate it to other
related works in sections 3 and 2 respectively. In section 4, we verify and validate ClusterSim by
means of manual executions and experimental tests. Section 5 presents the simulation results
and the performance analysis in a case study using ClusterSim. Finally, in section 6 we highlight
our conclusions and future works.
2 Related Work
In the last years, simulation has been used as a powerful technique for performance analysis of
computer systems [5] [18] [19]. Generally, researchers build simplified specific purpose
simulation tools and do not describe them in detail or do not make available the source code
and/or binaries. In parallel, network, cluster and grid computing simulation, we find some works
that make available their simulation tools and documentation [1] [2] [3] [4] [12] [14] [16] [17].
Among all the found works, the simulation tool developed for the Schark Group (SRGSim)
[1] has the closest relation with ClusterSim, because it supports the simulation of clusters with
different parallel job scheduling algorithms, network topologies and parallel CPU, I/O and
Communication-bounded jobs. Moreover, we will analyze others two grid computing simulation
tools (GridSim [3] and Simgrid [4]) that present some interesting features like modeling of
multiple users and heterogeneous nodes, a graphical environment, Direct Acyclic Graph (DAG)
scheduling etc. Other simulation tools can be found in [15] [17].
The GridSim is a Java-based simulation toolkit, developed in the Monash University in
Melbourne. It supports modeling and discrete-event simulation of heterogeneous grids, such as
single and multiprocessors, shared and distributed memory machines, and parallel and distributed

4
job scheduling. The main features of the GridSim are: modeling of space- or time- shared
architectures, a graphical environment for visual modeling, support of various parallel job
algorithm models, jobs are CPU- and I/O-bounded, co-existence of multiples distributed users,
distributed scheduling, etc. The network model used in GridSim is simplified and jobs cannot
exchange messages, besides the parameters of the jobs are described by constants (it is not
possible to use a trace or a probabilistic model) [3] [16].
The Simgrid is a C++-based simulation tool developed in the University of California in San
Diego. It simulates job scheduling in time shared architectures, in which a workload can be
represented by constants or traces. The DAGSim is a simulator constructed in top of the SimGrid
that allows the representation of jobs by means of a DAG. The main features of the
Simgrid/DAGSim are: DAG scheduling, support to different network topologies, prediction with
behavior of arbitrary error and support to trace-driven simulation. In the simulation model of the
Simgrid, jobs are CPU-bounded and can be submitted by only one user. Moreover the Simgrid
does not have a graphical environment to model the grid architecture and it uses simple
mechanisms of statistical analysis [4].
The SRGSim is a Java-based discrete-event simulation tool developed in the University of
California. It simulates some classes of parallel job scheduling (dynamic and static scheduling),
architectures (cluster of computers, multiprocessors etc.) and jobs through probabilistic models,
constants and DAGs. The main features of the SRGSim are: to provide a DAG editor, jobs are
described by traces, probabilistic models or DAGs, jobs are CPU-, I/O- and Communication-
bounded, support to some network topologies and it has a parallel and distributed
implementation. The SRGSim has only a text interface and does not have a multithreading
implementation. Moreover, it does not support heterogeneous nodes and mechanisms that
simulate the MPI communication functions [1].

5
In spite of the SRGSim has a detailed probabilistic workload simulation model, its model
does not allow a detailed structural description of a job, through loop structures, different
communication functions etc. Moreover, the workload probabilistic description is less
representative, but it requires less simulation time. Thus, the structural description of the
workload makes ClusterSim more representative and with a graphical environment, it becomes
an easy-of-use tool. As well as the SRGSim, the ClusterSim implements CPU, I/O and
Communication functions that allows the definition of different communications patterns,
algorithms models and granularity.
Related with the architecture, such as in the Gridsim, the ClusterSim supports heterogeneous
nodes. But it also allow the configuration of interconnection networks through different
parameters as topology, latency etc, as SRGSim and Simgrid. Finally, the ClusterSim tool has a
statistical and performance module that supplies data about the main metrics to the performance
analysis of a cluster.
3 Cluster Simulation Tool (ClusterSim)
The ClusterSim is a Java-based parallel discrete-event simulation tool for cluster computing. It
supports visual modeling and simulation of clusters and their workloads for performance
analysis. A cluster is composed of single or multi-processed nodes, parallel job schedulers,
network topologies and technologies. A workload is represented by users that submit jobs
composed of tasks described by probability distributions and their internal structure. The main
features of ClusterSim are:
• It provides a graphical environment to model clusters and their workloads.
• Its source code is available and its classes are extensible, providing a mechanism to
implement new job scheduling algorithms, network topologies etc.

6
• A job is represented by some probability distributions and its internal structure (loop
structures, CPU, I/O and MPI (communication) instructions). Thus, any parallel
algorithm model and communication pattern can be simulated.
• It supports the modeling of clusters and heterogeneous or homogeneous nodes.
• Simulation entities (architectures and users) are independent threads, providing
parallelism.
• The most part of collective and point-to-point MPI (Message Passing Interface)
functions are supported.
• A network is represented by its topology (bus, switch etc.), latency, bandwidth,
protocol overhead, error rate and maximum segment size.
• It supports different parallel job scheduling algorithms (space sharing, gang scheduling,
etc.) and node scheduling algorithms (first-come-first-served (FCFS), etc.).
• It provides a statistical and performance module that calculates some metrics (mean
nodes utilization, mean simulation time, mean jobs response time etc.).
• It supports some probability distributions (Normal, Exponential, Erlang Hyper-
Exponential, Uniform etc.) to represent the parallelism degree of the jobs and the inter-
arrival time between jobs submissions.
• Simulation time and seed can be specified.
3.1 Architecture of the ClusterSim
The architecture of the ClusterSim is divided in three layers: graphical environment, entities and
core (Fig.1). The first layer allows the modeling and simulation of clusters and their workloads
by means of a graphical environment. Moreover, it provides statistical and performance data
about each executed simulation. The second layer is composed of three entities: user, cluster and
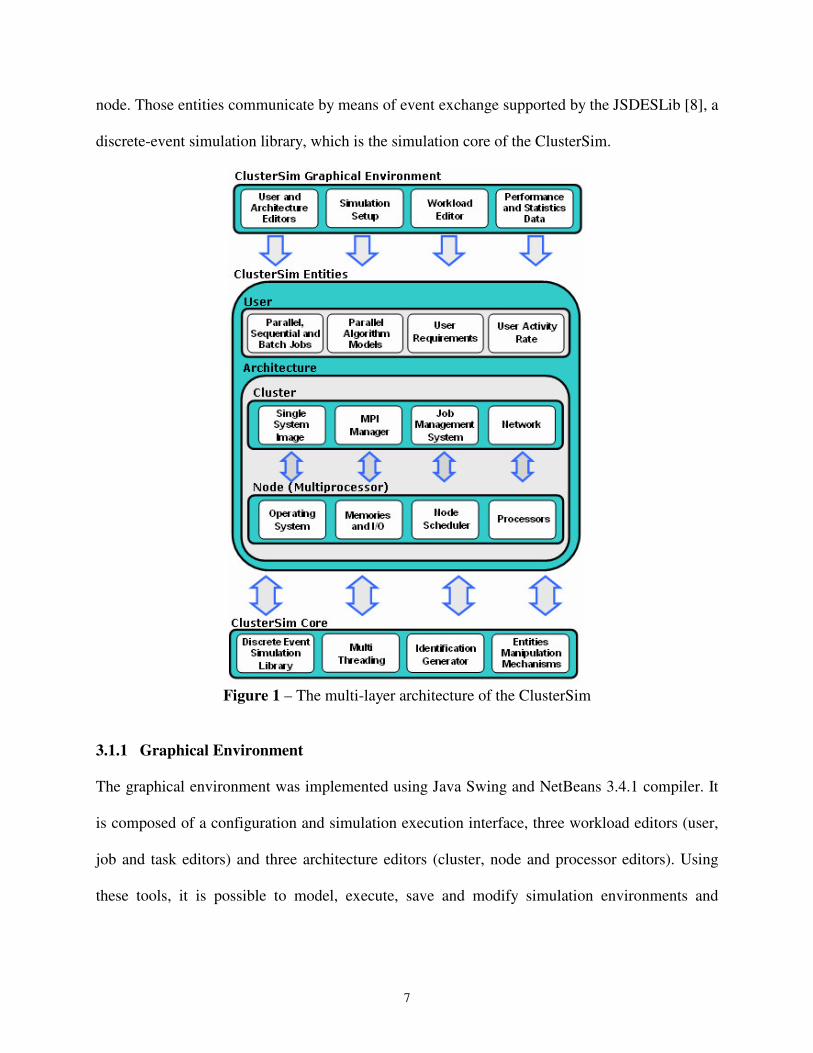
7
node. Those entities communicate by means of event exchange supported by the JSDESLib [8], a
discrete-event simulation library, which is the simulation core of the ClusterSim.
Figure 1 – The multi-layer architecture of the ClusterSim
3.1.1 Graphical Environment
The graphical environment was implemented using Java Swing and NetBeans 3.4.1 compiler. It
is composed of a configuration and simulation execution interface, three workload editors (user,
job and task editors) and three architecture editors (cluster, node and processor editors). Using
these tools, it is possible to model, execute, save and modify simulation environments and

8
experiments (Fig. 2). As well as the ClusterSim editors, the simulation model is divided between
workload and architecture.
Figure 2 – Main interface of the graphical environment
Based on the related works, we chose a hybrid workload model using probability
distributions to represent some parameters (parallelism degree and inter-arrival time) and the
internal structure description of the jobs. The use of execution time as a parameter, in spite of
being found on execution logs, it is valid only to a certain workload and architecture. Moreover,
it is influenced by many factors like load, nodes processing power, network overhead etc. Thus,
the execution time of a job must be calculated during a simulation, according to the simulated
workload and architecture.
Instead of execution time, we model a job by means of its internal structure description. This
approach has many advantages: i) real jobs can be represented directly, without modification in
their structures; ii) the execution time of a job is dynamically calculated and is influenced only by
the simulated environment; iii) the job’s behavior is more deterministic; iv) many parallel
algorithm models and communication patterns can be implemented.
Unlike the execution time, the parallelism degree is generally indicated by the user that
submits the job. Thus, it is not influenced by execution time factors. So, the parallelism degree of
job can be represented by a probability distribution.

9
To avoid long execution traces, the jobs inter-arrival time is also represented by a probability
distribution. Moreover, exponential and Erlang hyper-exponential distributions are widely used
in the academic community to represent the jobs inter-arrival time [18] [19].
Figure 3 – Job and task editors
To model a workload, three editors are necessary: user, job and task editors. In the user
editor, it is necessary to specify: the number of jobs to be submitted, the inter-arrival time
distribution and the jobs types. For each job type, its submission probability must be specified.
The sum of those probabilities must be equal to 100%. The jobs types are selected through Monte
Carlo's method, where a random number between 0 and 1 is raffled, indicating the job to be
submitted. For each new instance of a submitted job type, new values are sampled for the
parallelism degree of each task and inter-arrival time.
The job editor (Fig. 3) allows the specification of a job through a graph, in which each node
is a task and each edge represents the communication between two tasks. Starting from the job
editor, it is possible to edit each task activating the task editor (Fig. 3). In the task editor the
CPU, E/S and MPI instructions are inserted in instruction blocks and the distribution of the
parallelism degree is specified. Each instruction has the option of being automatically
parallelized according to the parallelism degree of the task. For instance, suppose a parallel job
that follows the process farm model. It would be modeled with two nodes: the master task
(parallelism degree equal to 1) and the slave tasks (parallelism degree equal to n). If the

10
parallelization option was activated in CPU instructions of a slave, the number of CPU
instructions to each slave would be equal to the total number of CPU instructions divided by the
parallelism degree n. Thus, it is possible to verify the speedup achieved by the parallelization of a
job, without implement a different job for each parallelism degree.
A cluster is composed of homogeneous or heterogeneous nodes, networks, job management
systems, single system image, message-passing managers and distributed shared memory. Each
node has a memory hierarchy, I/O devices, one or more processors and an operating system. In
our architecture model, a cluster is represented basically by a parallel job scheduler, a network
and nodes.
erheadProtocolOvMSS
eMessageSizverheadO ×
= (Equation 1)
( ) ( )610 Bandwidth
ErrorRateOverheadeMessageSizLatencyonTimeTransmissi
×+×++= 1
(Equation 2)
The scheduler implements parallel job scheduling algorithms as space sharing, backfilling,
gang scheduling etc. The network is represented by the following parameters: latency (ns),
bandwidth (MB/s), protocol overhead (bytes), error rate (%), maximum segment size - MSS
(bytes) and topology (Fig. 4). Some topologies are supported, among them we highlight: bus and
switch. The equations 1 and 2 show the relationship among the network parameters for the
calculation of the message transmission time between two nodes.
In our model, each node is represented by the following modules: scheduler, primary and
secondary memory transfer rate and processors. The scheduler implements basic scheduling
algorithms like Round-Robin and FCFS. Besides, it implements algorithms that guarantee the
correct operation of the parallel job scheduling algorithms of the cluster. The primary memory
transfer rate is used by the MPI manager, when receiving and sending data. The secondary

11
memory transfer rate is used to calculate the time spent in the readings and writings of the I/O
instructions.
FrequencynstructionCyclesPerIstructionsNumberOfIneElapsedTim
1××= (Equation 3)
A node has one or more processors, in which each processor is represented by the clock
frequency and the number of cycles per instruction (CPI). To calculate the elapsed time to
execute n instructions of a program, the processor uses the Equation 3.
3.1.1.1 Statistical and Performance Module
For each executed simulation, the statistical and performance module of ClusterSim creates a log
with the calculation of several metrics. The main calculated metrics are: mean jobs and tasks
response time; wait, submission, start and end time of each task; mean jobs slowdown; mean
nodes utilization; mean jobs reaction time and others.
3.1.2 ClusterSim’s Entities
Each entity has specific functions in a simulation environment. The user entity is responsible for
submitting a certain number of jobs to the cluster following a pattern of arrival interval. Besides,
each job type has a specific probability of being submitted to the cluster entity. This submission
is made through the generation of a job arrival event. When the cluster receives this event, it
should decide to which nodes the tasks of a job should be directed. So, there is a job management
system scheduler that implements certain parallel job scheduling algorithms. Other important
classes belonging to the cluster entity are: MPI manager, single system image and network.
The single system image works as an operating system of the cluster, receiving and directing
events to the responsible classes for the event treatment. Besides, it generates periodically the end
of time slice event to indicate to the node schedulers that another time slice ended.

12
To support message-passing among tasks, the network and MPI manager classes implement
certain basic communication mechanisms. As soon as a task executes a MPI function
(MPI_Send(), MPI_Barrier() etc.), the MPI manager interprets the function and if it is a sending
function, it calls the network class, which generates a message arrival event. The time spent for
the message transmission from a node to another depends on the topology, network technology
and contention parameters. When a message arrival event arrives at its destiny, the MPI manager
generates a unblock task event, if the task is waiting. Otherwise, the message is stored in a
message queue. When receiving an end of job event, the cluster scheduler should remove the
execution job. The Fig. 4 shows the events exchange diagram of the ClusterSim, detailing the
interaction among the user, cluster and node entities. To simplify the diagram, some classes were
omitted.
Figure 4 – Events exchange diagram of the ClusterSim
A cluster entity is composed of several node entities. When receiving a job arrival event, by
means of the node scheduler class, the node entity puts the tasks destined to it into a queue. On
each clock tick, the scheduler is called to execute tasks in the processors of the node. As each
task is composed of CPU, E/S and MPI instructions, at the end of each one of those macro
instructions an event is generated. A quantum is attributed to each task. When a task finishes, the
processor should generate an end of quantum event for the node scheduler to execute the

13
necessary actions (to change priorities, to remove the task from the head’s queue etc.). When the
processor executes all the instructions of a task, an end of task event is generated for the node
scheduler.
3.1.3 ClusterSim’s Core
The core is composed of the JSDESLib (Java Simple Discrete Event Simulation Library), a
multithread discrete-event simulation library in Java, developed by our group, which has as the
main objective to simplify the development of discrete-event simulation tools [8].
4 Verification and Validation of the ClusterSim
To verify and test the ClusterSim, we simulated a simple workload composed of two jobs and
compare with the analytical analysis or manual execution of the same workload. In Figure 5,
each graph represents a job, where the nodes are the tasks and the edges indicate exchange of
messages between the tasks. The value in each node and edge indicates the time spent in seconds
to perform the processing (CPU instructions) and communication. For example, Job 2 represents
a farm of processes or tasks, in which the master task sends data to the slaves. So, they process
these data and return them for the master process. As the ClusterSim does not use the execution
time as an entry parameter, the execution time of the jobs was converted in CPU instructions and
sent bytes.
Figure 5 – Jobs used as the workload in ClusterSim´s verification: (a) Job 1; (b) Job 2
As an example, we create a cluster composed of 4 homogeneous nodes and one bus network,
with the variation of the parallel job scheduling algorithms (gang scheduling, round-robin and

14
FCFS (first-come-first-served). The messages sent to the bus are queued and sent one by one
according to the arrival order.
In Figures 6, 7 and 8, we can observe the manual execution of the workload, step by step, for
each parallel job scheduling algorithm. Each line represents the jobs’ tasks execution along the
time in a node. It is important to highlight that the interconnection network is a shared resource
and allows that only one message is sent on each moment.
Figure 6 – Jobs execution diagram using the Round-Robin algorithm
The round-robin algorithm presented the shorter execution time, therefore it allows a bigger
concurrency between the tasks of different jobs, that is, when a task of the Job 1 is
communicating, a task of the Job 2 can use the processor. The FCFS allows that only one job is
executed for each time in the cluster, therefore the resources are less utilized and the jobs have a
higher reaction time.
Figure 7 – Jobs execution diagram using the FCFS algorithm

15
Finally, the gang scheduling algorithm used a time slice equal to 5 seconds and presented a
better result than FCFS, but worse than round-robin. The gang scheduling achieves high
performance in the scheduling of jobs with low granularity. The used jobs communicate few
times with high granularity. In despite of this, the total execution time was shorter than FCFS,
therefore gang scheduling allows the concurrency between jobs, increasing resources utilization.
Figure 8 – Jobs execution diagram using the Gang Scheduling algorithm
Table 1 shows the response time of each job obtained in the simulations. As observed, the
values are identical to the obtained ones using the manual method of execution in Figs. 6, 7 and
8. Thus, we verify the correct functioning of the main functionalities and parts of the ClusterSim
tool. Among these functionalities and parts we highlight: generation, sorting and delivery of
events; calculation of transmission time and execution time (processor, network, MPI manager
and other classes); scheduling algorithms; point-to-point communication functions; CPU
instructions etc.
Table 1 – Response time in seconds of each job obtained in the simulation Algorithm
Job Gang Scheduling Round-Robin FCFS
J1 65 60 45 J2 55 60 75
The other functionalities and parts did not verified in this example, as MPI collective
functions, I/O instructions, other network topologies and technologies etc., had been verified
exhaustively by means of more specific manual and analytical tests.

16
After the verification of the functionalities and classes of the ClusterSim, we did some real
experiments for the validation of the processing and communication parts the simulation model.
We decided to validate the most primitive or basic functionalities of the ClusterSim: the
processing time calculation and the MPI_RSend() function.
To validate the processing time calculation, we instrumented the code of a sequential image
convolution application by means of the PAPI (Performance Application Programming Interface)
library. The convolution application is characterized by intense mathematical calculation using
matrixes. PAPI library uses hardware counters to measure with high precision the operations did
by the processor and memory cache, for example, number of instructions, cache accesses etc.
After code instrumentation, we executed the application with a 2048 x a 2048 image and 11
x 11 mask for 10 iterations, in a processor Intel Pentium III 1 GHz. Using an arithmetic mean, we
extract the following metrics necessary for the simulation:
• Cycles per Instruction (CPI) = 0.9997105
• Number of Executed Instructions = 13328512173
• Total Response Time = 14.2053876 seconds
For the simulation, we created a machine with a processor with a mean frequency of 938
MHz (real frequency) and CPI of 0.9997105. Then we created a workload (job) that executed
13328512173 CPU instructions to simulate the convolution application. After the simulation
execution, the ClusterSim calculated the response time of the application as 14.2053876 seconds,
as the measured one. Therefore, we validated the processing part of the ClusterSim. It is
important to highlight that if we use heterogeneous workloads, the CPI could vary. It would be
necessary to execute different applications and to calculate a mean CPI to increase the precision
of the simulation.

17
Related with the communication part, we chose to validate the most primitive MPI function,
the MPI_Rsend (), on which all the other functions (point-to-point and collective ones) are based.
Thus, we created one network benchmark to calculate the bandwidth, latency and transmission
time of messages with different sizes based in the MPI_RSend (). Then we executed the
benchmark in a cluster composed of two nodes connected through a half-duplex Fast Ethernet
switch. Through the benchmark, that sends 100 equal messages to give greater confidence in the
measures, the latency and the bandwidth were calculated with the minimum and the geometric
mean of the executions (Table 2).
Table 2 – Latency and Bandwidth of the Fast Ethernet network Metric Latency Bandwidth
Minimum 0.000179 s 11.0516 MBps Geometric Mean 0.000243 s 10.15504 MBps
After calculate these metrics, we model a cluster in the simulation tool and create a workload
model similar to the benchmark, varying the message size between 0 bytes and 256 Kbytes
(power of 2 variations) in the simulation and in the cluster of computers. The obtained results
(transmission time) with the values of the latency, minimum and mean bandwidth are shown in
Table 3 (we did not show some of the message sizes).
Analyzing Table 3, using the mean of the differences between the measured and simulated
values, we found 5.51% (minimum) and 4.34% (average), with a standard deviation of 5.42 and
4.92 respectively.
Table 3 – Transmission time per message size Message
Size Minimum Geometric Mean
Simulation(s) Real(s) Difference(%) Simulation(s) Real(s) Difference(%) 1 1.79E-04 1.83E-04 1.87 2.43E-04 2.39E-04 1.74 8 1.80E-04 1.83E-04 1.52 2.44E-04 2.40E-04 1.42
64 1.85E-04 1.95E-04 4.99 2.49E-04 2.52E-04 1.26 512 2.25E-04 2.40E-04 5.91 2.93E-04 3.00E-04 2.14 4K 5.60E-04 6.47E-04 13.35 6.58E-04 7.28E-04 9.58
32K 0.00326 0.003144 3.70 0.003596 0.003561 0.99 256K 0.024845 0.025836 3.84 0.027086 0.029566 8.39

18
Thus, we can say that the simulation of the MPI_RSend() function was validated with real
experiments involving one benchmark. We considered the mean difference of 5% as an
acceptable one, therefore the simulation model is simplified, not leading in account: the
protocols stacks, the processing of the same ones, possible interventions of the operating system,
intermediate cache memory, copies in buffers and other details of a real system. As the
MPI_Rsend() function serves as a base for all the other sending functions executed by the MPI,
therefore the validation of the same one indicates the validation of the other MPI sending
collective functions and the communication part in their lower levels.
5. Simulation Results
To analyze the use of ClusterSim, we modeled, simulated and analyzed a case study composed of
12 workloads and 12 clusters. Due to the limited number of pages, we will only show the
analysis based on one metric: mean nodes utilization.
5.1 Simulation Setup
5.1.1 Clusters The clusters are composed of 16 nodes and a front-end node interconnected by a Fast Ethernet
switch. Each node has a Pentium III 1 Ghz (0.938 GHz real frequency) processor. In Table 4, we
show the main values of the clusters features, obtained from benchmarks and performance
libraries (Sandra 2003, PAPI 2.3 etc.).
Table 4 - Clusters features and their respective values. Characteristic Value Characteristic Value
Number of Processors 16 + 1 Network Fast Ethernet Processor Frequency 0.938 GHz Network Latency 0.000179 s
Cycles per Instruction 0.9997105 Max. Segment Size 1460 bytes Primary Memory
Transfer Rate 11.146 MB/s Network Bandwidth (Max. Throughput)
11.0516 MBps
Secondary Memory Transfer Rate 23.0 MB/s Protocol Overhead 58 bytes

19
The main difference of each cluster from another is the parallel job scheduling algorithm.
Each one has a variation of the gang scheduling algorithm. A gang scheduling algorithm is
composed of a packing scheme, a re-packing scheme, a multiprogramming level and a queue
policy. To represent the tasks allocation to the processors along the time, a matrix was proposed
by Ousterhout, in which the columns are processors and lines are time slices (Table 5) [5] [18].
During each time slice, the tasks of each job should execute simultaneously in their respective
processors [5] [18].
Table 5 – Ousterhout Matrix Processor 1 Processor 2 Processor 3 Processor 4
Slice 1 Job 1 Job 1 Job 1 Job 2 Slice 2 Job 3 Job 3 Job 3 Slice 3 Job 4 Job 4 Job 5 Job 5 Slice 4 Job 6 Job 6 Job 6 Job 6
Each time slice creates an illusion of a machine dedicated to the jobs fit in the same slice.
The number of time slices determines the multiprogramming level or the number of dedicated
virtual machines [5] [18].
Table 6 – Variations of the gang scheduling algorithm for each cluster
Clusters Packing Scheme Re-Packing Scheme Multiprogram-
ming Level Queue Policy
C 01 First Fit Alternative Scheduling Limited FCFS C 02 First Fit Alternative Scheduling Limited SJF C 03 First Fit Slot Unification Limited FCFS C 04 First Fit Slot Unification Limited SJF C 05 First Fit Alternative Scheduling Unlimited X C 06 First Fit Slot Unification Unlimited X C 07 Best Fit Alternative Scheduling Limited FCFS C 08 Best Fit Alternative Scheduling Limited SJF C 09 Best Fit Slot Unification Limited FCFS C 10 Best Fit Slot Unification Limited SJF C 11 Best Fit Alternative Scheduling Unlimited X C 12 Best Fit Slot Unification Unlimited X
Along the time, new jobs are inserted at the Ousterhout matrix, while other jobs are removed
as soon as they finish their execution. It implies in fragmentation of jobs in time slices, that is,

20
the time slices do not utilize all the available processors. By means of packing schemes, jobs are
allocated to processors (inserted in the Ousterhout) to minimize the jobs fragmentation. After
fragmentation, some re-packing schemes can be used, as alternative scheduling and slot
unification [5] [19].
In Table 6, we observe the variations of the gang scheduling algorithm for each cluster. The
multiprogramming level was limited in 3. When the multiprogramming level is unlimited, it does
not make sense to use a wait queue. Because, as soon as a job arrives, it will always fit to the
matrix. The description of these algorithms, schemes and policies can be found in [5].
5.1.2 Workloads
In ClusterSim, a workload is composed of a jobs set represented by: their types, internal
structures, submission probabilities and inter-arrival time distributions. Due to the lack of
information about the internal structure of the jobs, we decided to create a synthetic set of jobs
[5] [6] [8]. In the workload jobs, at each one of the iterations, the master task sends a different
message to each slave task. On their turn, they process a certain number of instructions,
according to the previously defined granularity, and then they return a message to the master task.
The total number of instructions that is to be processed by the job and the size of the messages
are divided equally among the slave tasks.
With regard to the parallelism degree, which is represented by a probability distribution, we
considered jobs between 1 and 4 tasks as low parallelism degree and between 5 and 16 as high
parallelism degree. As usual, we used a uniform distribution to represent the parallelism degree.
Combining the parallelism level, number of instructions and granularity characteristics, we had 8
different basic job types.

21
There are two main aspects through which a job can influence in a gang scheduling: space
and time [5]. In our case, space is related with the parallelism degree and time with the: number
of instructions, granularity and the other factors. Then we combine these orthogonal aspects to
form 4 workload types. In the first type, the most predominant are the jobs with a high
parallelism degree and a structure that leads to a high execution time. In the second type, jobs
with a high parallelism level and a low execution time predominate. The third one has the
majority of jobs with a low parallelism degree and a high execution time. In the last workload,
jobs with a low parallelism degree and a low execution time prevail. For each workload we
varied the predominance level between 60%, 80% and 100% (homogeneous). For example, a
workload named HH60 is a workload composed of 60% of jobs with a high execution time and a
high parallelism degree, and the other 40% is composed of the opposite workload (low execution
time and parallelism degree). So, we created 12 workloads to test the 12 clusters: HH60, 80 and
100; HL60, 80 and 100; LH60, 80 and 100; LL60, 80 and 100.
In all workloads we used a total number of jobs equal to 100 and the inter-arrival represented
by an Erlang hyper-exponential distribution. To simulate a heavy load, we divided the inter-
arrival time by a load factor equal to 100. This value was obtained through experimental tests.
Each one of the 12 clusters was tested with each workload, using 10 different simulation
seeds. The selected seeds were: 51, 173, 19, 531, 211, 739, 413, 967, 733 and 13. So we made a
total of 1440 (12 clusters X 12 workloads X 10 seeds) simulations.
5.2 Results Presentation and Analysis
In this section, we present and analyze the performance of the clusters and their gang scheduling
algorithms. To analyze them, we compare clusters in which a gang scheduling component or part
is varied and the others are fixed.

22
In Fig. 9, we present the mean nodes utilization for all workloads and clusters. Considering
the packing schemes (Fig. 10(a)), when the multiprogramming level is unlimited, the first fit is
better for HL and LH workloads.
Figure 9 – Mean nodes utilization for all clusters and workloads.
At a first moment, the best fit scheme finds the best slot for a job, but at long term, this
decision may prevent new jobs from entering in more appropriate slots. In the case of HL and LH
workloads, this chance increases, because the long jobs (with a low parallelism degree) that
remain after the execution of short jobs (with a high parallelism degree) will probably occupy
columns in common, thus, making it difficult to defragment the matrix. On the other hand, the
first fit initially makes the matrix more fragmented. Besides, it increases the multiprogramming
level. But at long term, it will make it easier to defragment the matrix, because the jobs will have
fewer columns in common. In the other cases, the best fit scheme presents a slightly better
performance. In general, both packing schemes have an equivalent performance. The same
happens to the re-packing schemes (Fig. 10 (b)).
Regarding the multiprogramming level, we reached two conclusions: the unlimited is better
for HH and LL workloads (Fig. 10 (c)), but it is very bad for HL and LH workloads (Fig. 10 (d)).
With an unlimited multiprogramming level, for each new job that does not fit to the matrix, a
new slot is created. At the end of the simulation, as the load is high, a big number of lines was
created. In this case, the big jobs are the long ones. So when small jobs terminate, the idle space
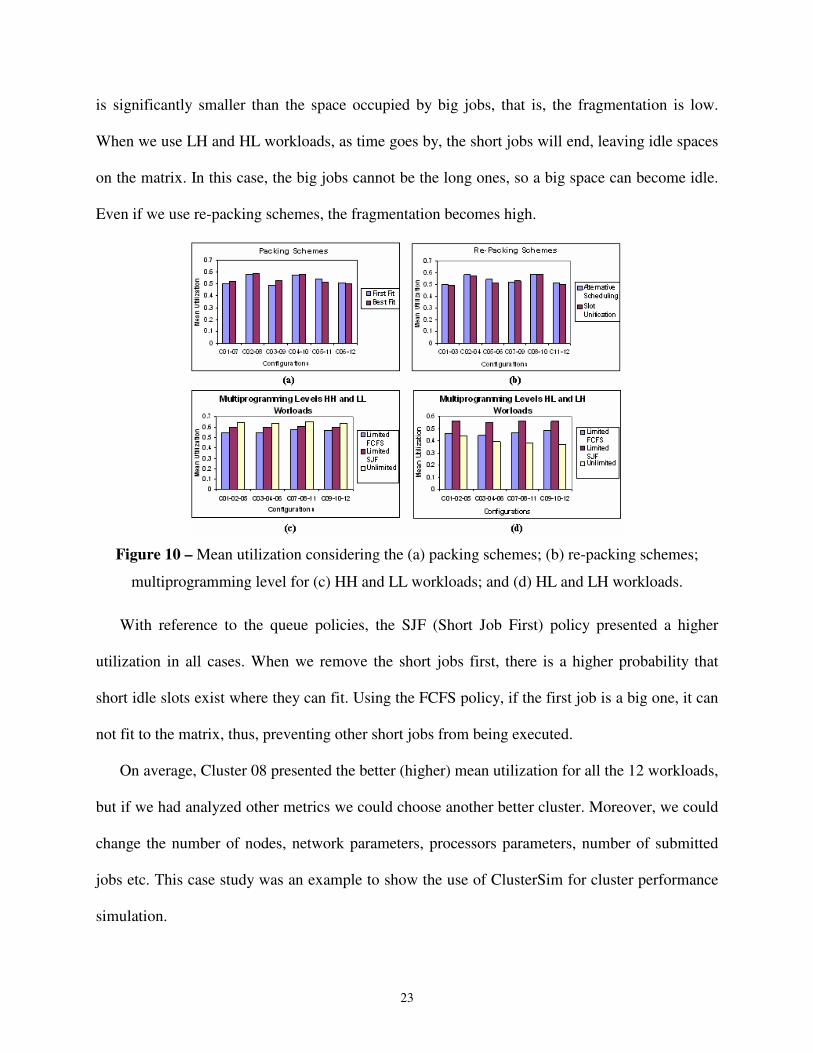
23
is significantly smaller than the space occupied by big jobs, that is, the fragmentation is low.
When we use LH and HL workloads, as time goes by, the short jobs will end, leaving idle spaces
on the matrix. In this case, the big jobs cannot be the long ones, so a big space can become idle.
Even if we use re-packing schemes, the fragmentation becomes high.
Figure 10 – Mean utilization considering the (a) packing schemes; (b) re-packing schemes;
multiprogramming level for (c) HH and LL workloads; and (d) HL and LH workloads.
With reference to the queue policies, the SJF (Short Job First) policy presented a higher
utilization in all cases. When we remove the short jobs first, there is a higher probability that
short idle slots exist where they can fit. Using the FCFS policy, if the first job is a big one, it can
not fit to the matrix, thus, preventing other short jobs from being executed.
On average, Cluster 08 presented the better (higher) mean utilization for all the 12 workloads,
but if we had analyzed other metrics we could choose another better cluster. Moreover, we could
change the number of nodes, network parameters, processors parameters, number of submitted
jobs etc. This case study was an example to show the use of ClusterSim for cluster performance
simulation.

24
6 Conclusions
In this paper, we proposed, implemented, verified, validated and analyzed the simulation tool
ClusterSim. It has a graphical environment that facilitates the modeling and creation of clusters
and workloads (parallel jobs and users) to analyze their performance by means of simulation. Its
hybrid workload model (probabilistic model and structural description) allows the representation
of real parallel jobs (instructions, loops etc.). Moreover it makes the simulation more
deterministic than an only-probabilistic model. The verification and validation of ClusterSim by
means of manual execution and experimental tests showed that ClusterSim provides mechanisms
to repeat and modify some parameters of real experiments under a controllable and trustful
environment. As shown in our case study, we can create synthetic workloads and evaluate the
performance of different cluster configurations.
Built in Java and with its source code available, the classes of ClusterSim can be extended,
allowing the creation of new network topologies, parallel job scheduling algorithms, etc.
The main contributions of this paper are: the definition, proposal, implementation,
verification, validation and analysis of the ClusterSim. The main features of ClusterSim are: an
hybrid workload model, a graphical environment, the modeling of heterogeneous clusters and a
statistical and performance module. As future works we can highlight: to implement a network
topology editor, support to distributed simulation, simulation of grid architectures, generation
of statistical and performance graphics etc. More information, source code and documentation of
the ClusterSim will be available on: http://o_cabra.sites.uol.com.br/clustersim/clustersim.html.
References
[1] Bodhanwala, H. et al., "A General Purpose Discrete Event Simulator", Symposium on Performance Analysis of
Computer and Telecommunication Systems, Orlando, USA, 2001.
[2] Breslau, L. et all, “Advances in Network Simulation”, IEEE Computer, Vol. 33 (5), pp. 59-67, May 2000.

25
[3] Buyya, R. and Murshed, M., “GridSim: A Toolkit for the Modeling and Simulation of Distributed Resource
Management and Scheduling for Grid Computing”, The Journal of Concurrency and Computation: Practice and
Experience, Volume 14, Issue 13-15, Pages: 1175-1220, Wiley Press, USA, November - December 2002..
[4] Casanova, H., “Simgrid: a Toolkit for the Simulation of Application Scheduling”, 3rd IEEE/ACM International
Symposium on Cluster Computing and the Grid, Los Angeles, 2001.
[5] Feitelson, D. G. “Packing Schemes for Gang Scheduling”, Workshop on Job Scheduling Strategies for Parallel
Processing, pp. 89-110, 1996.
[6] Feitelson, D., “Workload Modeling for Performance Analysis”, Performance Analysis of Complex Systems:
Techniques and Tools, pp. 114-141, 2002.
[7] Góes, L. F. W., Martins, C. A. P. S., “RJSSim: A Reconfigurable Job Scheduling Simulator for Parallel
Processing Learning”, 33rd ASEE/IEEE Frontiers in Education Conference, Colorado, pp. F3C3-8, 2003.
[8] Góes, L. F. W., Martins, C. A. P. S.: Proposal and Development of a Reconfigurable Parallel Job Scheduling
Algorithm. Master’s Thesis. Belo Horizonte, Brazil (2004) (in portuguese)
[9] Law, A.M., Kelton, W.D.,“Simulation Modeling and Analysis”, McGraw-Hill, 1991.
[10] Low, Y.H. et al., “Survey of Languages and Runtime Libraries for Parallel Discrete-Event Simulation”, IEEE
Computer Simulation, pp. 170-186, 1999.
[11] MacNab, R. and Howell, F.W., “Using Java for Discrete Event Simulation”, 12th UK Performance Engineering
Workshop, Edinburgh, pp. 219-228, 1996.
[12] Prakash, S. and Bagrodia, R.L., “MPI-SIM: Using Parallel Simulation to Evaluate MPI Programs”, Winter
Simulation Conference (WSC98), pp. 467-474, 1998.
[13] Ramos, L. E. S., Góes, L. F. W., Martins, C. A. P. S., “Teaching And Learning Parallel Processing Through
Performance Analysis Using Prober”, 32nd ASEE/IEEE Frontiers in Education Conference, Boston, pp. S2F13-18
2002.
[14] Rosenblum, M., Bugnion, E., Devine, S., Herrod, S. A. “Using the SimOS Machine Simulator to Study
Complex Computer Systems”, ACM TOMACS Special Issue on Computer Simulation, pp. 78-103, 1997.
[15] A Collection of Modeling and Simulation Resources on the Internet
URL: www.idsia.ch/%7Eandrea/sim/simindex.html
[16] Sulistio, A., Yeo, C.S. and Buyya, R., “Visual Modeler for Grid Modeling and Simulation Toolkit”, Technical
Report, Grid Computing and Distributed Systems (GRIDS) Lab, Dept. of Computer Science and Software
Engineering, The University of Melbourne, Australia, 2002.
[17] Sulistio, A., Yeo, C.S. and Buyya, R., “A Taxonomy of Computer-based Simulations and its Mapping to
Parallel and Distributed Systems Simulation Tools”, International Journal of Software: Practice and Experience,
Wiley Press, 2004.
[18] Zhang, Y., H. Franke, Moreira, E.J., Sivasubramaniam, A. “Improving Parallel Job Scheduling by Combining
Gang Scheduling and Backfilling Techniques”, IEEE International Parallel and Distributed Processing Symposium,
pp. 133, 2000.
[19] Zhou, B. B., Mackerras, P., Johnson C. W., Walsh, D. “An Efficient Resource Allocation Scheme for Gang
Scheduling”, 1st IEEE Computer Society International Workshop on Cluster Computing, pp. 187-194, 1999.
Related Documents











