©2015 IBM Corporation @RomeoKienzler Cloud scale predictive DevOps automation using Apache Spark

Cloud scale predictive DevOps automation using Apache Spark: Velocity in Amsterdam - O'Reilly Conferences, 28 - 30, October 2015
Feb 14, 2017
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

©2015 IBM Corporation
@RomeoKienzler
Cloud scale predictive DevOps automation using Apache Spark

©2015 IBM Corporation
@RomeoKienzler
What you will learn• What Spark really is and what is means to your UseCases• How to use Spark in the Cloud• Basic programming in Scala• Basic programming in Python• Some functional programming• Some insights into Spark Streaming, MLLib, GraphX, Spark SQL (Shark)• Solve any data analytics problem of any size
2

©2015 IBM Corporation
@RomeoKienzler
Introductions
3

©2015 IBM Corporation
@RomeoKienzler
Excursion, Demo: What is the IBM Cloud about?
4

©2015 IBM Corporation
@RomeoKienzler
My Peers in US
5

©2015 IBM Corporation
@RomeoKienzler
What is our motivation?• Local or cloud development and deployment
Advantages of local development• Rapid development• Productivity• Excellent for proof of concept• Easy debugging
Disadvantages of local development• Time consuming for reproducing on a larger scale• Difficult for sharing quickly• Intense on hardware resource• Demanding skills for deployment and operations
6

©2015 IBM Corporation
@RomeoKienzler
What is spark
Spark is an open sourcein-memory
computing framework for distributed data processing
and iterative analysis
on massive data volumes
7

©2015 IBM Corporation
@RomeoKienzler
Spark Core Libraries
Spark Core
general compute engine, handles distributed task dispatching, scheduling
and basic I/O functions
Spark SQL
Spark Streaming
Mllib (machine learning)
GraphX (graph)
executes SQL
statements
performs streaming
analytics using micro-batches
common machine
learning and statistical algorithms
distributed graph
processing framework
8

©2015 IBM Corporation
@RomeoKienzler
Key reasons for interest in Spark Open Source
Fast
distributed data processing
Productive
Web Scale
•In-memory storage greatly reduces disk I/O•Up to 100x faster in memory, 10x faster on disk
•Largest project and one of the most active on Apache•Vibrant growing community of developers continuously improve code base and extend capabilities
•Fast adoption in the enterprise (IBM, Databricks, etc…)
•Fault tolerant, seamlessly recompute lost data from hardware failure•Scalable: easily increase number of worker nodes•Flexible job execution: Batch, Streaming, Interactive
•Easily handle Petabytes of data without special code handling•Compatible with existing Hadoop ecosystem
•Unified programming model across a range of use cases•Rich and expressive apis hide complexities of parallel computing and worker node management
•Support for Java, Scala, Python and R: less code written•Include a set of core libraries that enable various analytic methods: Spark SQL, Mllib, GraphX
9

©2015 IBM Corporation
@RomeoKienzler
Ecosystem of the IBM Analytics for Apache Spark as service
10

©2015 IBM Corporation
@RomeoKienzler
A Word about the Scala Programming language
‣Scala is Object oriented but also support functional programming style‣Bi-directional interoperability with Java‣Resources:
• Official web site: http://scala-lang.org• Excellent first steps site: http://www.artima.com/scalazine/articles/steps.html• Free e-books: http://readwrite.com/2011/04/30/5-free-b-books-and-tutorials-o
11

©2015 IBM Corporation
@RomeoKienzler
Spark Streaming‣“Spark Streaming is an extension of the core Spark API that enables scalable, high-
throughput, fault-tolerant stream processing of live data streams” (http://spark.apache.org/docs/latest/streaming-programming-guide.html)
‣Breakdown the Streaming data into smaller pieces which are then sent to the Spark Engine
12

©2015 IBM Corporation
@RomeoKienzler
Spark Streaming‣Provides connectors for multiple data sources:
- Kafka- Flume- Twitter- MQTT- ZeroMQ
‣Provides API to create custom connectors. Lots of examples available on Github and spark-packages.org
13

©2015 IBM Corporation
@RomeoKienzler
Introduction to Notebooks‣Notebooks allow creation of interactive executable documents that include rich
text with Markdown, executable code with Scala, Python or R, graphics with matplotlib
‣First idea: Matematica in the 80s‣Apache Spark provides multiple flavor APIs that can be executed with a REPL shell:
Scala, Python (PYSpark), R‣Multiple open-source implementations available:
- Jupyter: https://jupyter.org- Apache Zeppelin: http://zeppelin-project.org
14
©2015 IBM Corporation
@RomeoKienzler
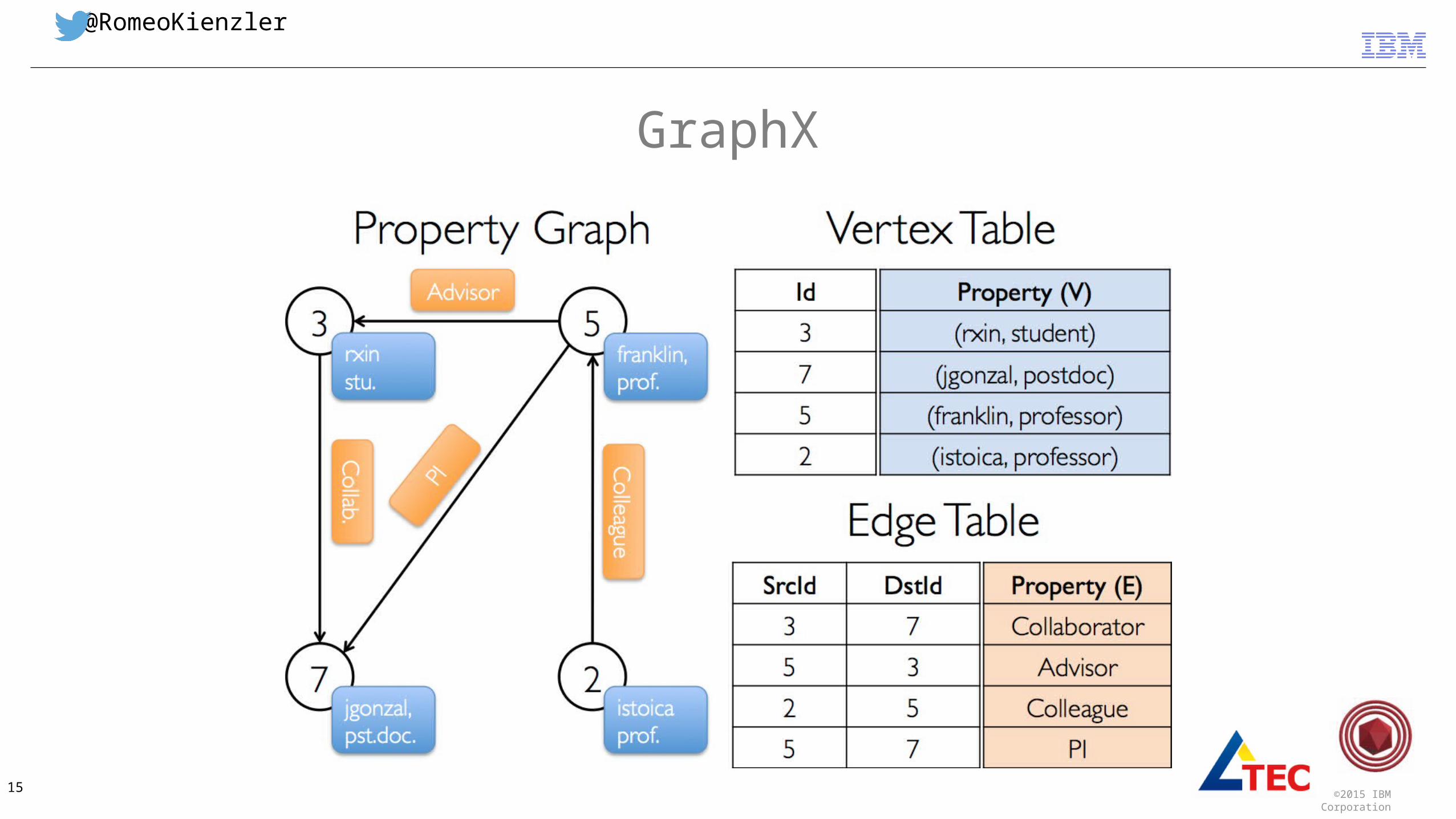
GraphX
15

©2015 IBM Corporation
@RomeoKienzler
GraphX
16
[0,0.38321138272637756,[[532,0.6149796534336811],[664,0.8356153428569336],[9,0.1570050826694932]]][1,0.18065772749938025,[[575,0.17536476465887452],[411,0.27954200550966013],[649,0.8039858806410443],[915,0.4486520294403563],[726,0.27371661315845497],[284,0.3189228134847226],[371,0.6743424877728893],[105,0.02948311591149355]]][2,0.8326535898442957,[[187,0.237892453843756],[433,0.4888193209543986]]][3,0.8486227788712039,[[10,0.42657104117967704],[911,0.5044620825940729],[471,0.7925728999064424],[144,0.2682384916510707]]][4,0.213144518747322,[[287,0.5153627230542949],[500,0.9610167165689496],[471,0.7384315544250067]]][5,0.13936158086656125,[[788,0.6207349427530987],[716,0.8224267617783542],[29,0.9599548358124281],[446,0.6890358757389514],[81,0.6200710121203236]]][6,0.18348506014555566,[[312,0.3572072639232693]]][7,0.4944948151337266,[[337,0.17081573705381814],[749,0.5357649236615107],[908,0.16851141164430072],[94,0.46547674836585895],[327,0.8010320866648896]]][8,0.8065548204216567,[[706,0.7232142181639899],[981,0.9877867134305364],[581,0.4675382627711474]]][9,0.721217368691803,[]][10,0.9039814039370966,[[983,0.4159992760397089],[163,0.850921982262316],[50,0.22098242172416915],[483,0.8338046999885983],[118,0.6589390317899275]]]

©2015 IBM Corporation
@RomeoKienzler
GraphX
17

©2015 IBM Corporation
@RomeoKienzler
Lab 1: Notebook walkthrough
‣https://developer.ibm.com/clouddataservices/start-developing-with-spark-and-notebooks/
‣http://bit.ly/ibmvelocity1‣Sign up on Bluemix http://ibm.biz/joinIBMCloud‣Create an Apache Starter boilerplate application‣Create notebooks either in python or scala or both‣Run basic commands and get familiar with notebooks
18

©2015 IBM Corporation
@RomeoKienzler
Break
19

©2015 IBM Corporation
@RomeoKienzler
Use-cases
Customer Behavior Analytics
Retail & Merchandising
Churn Reduction
Telco, Cable, Schools
Cyber Security
IT –Any Industry
Predictive Maintenance (IoT)
IT –Any Industry
Network Performance Optimization
IT –Any Industry
-Predict system failure before it happens
-Network intrusion detection-Fraud Detection-…
-Predict customer drop-offs/drop-outs
-Diagnose real-time device issues-…
-Refine strategy based on customer behaviour data-…
20
‣SETI use-case for astronomers, data scientist, mathematician and algorithm design.

©2015 IBM Corporation
@RomeoKienzler
IBM Spark @ SETI - Application Architecture
• Spark@SETI GitHub repository
• Python code modules for data access and analytics
• Jupyter notebooks• Documentation and links to
other relevant github repos• Standard GitHub Collaboration
functions
Import of signal data from SETI radio telescope data archives ~ 10 years Shared repository of SETI data in Object Store
•200M rows of signal event data•15M binary recordings of “signals of interest”
Collaborative environment for project team data scientists (NASA, SETI Institute, Penn State, IBM Research)
Actively analyzing over 4TB of signal data. Results have already been used by SETI to re-program the radio telescope observation sequence to include “new targets of interest”
21

©2015 IBM Corporation
@RomeoKienzler
Lab 2: Twitter Sentiment Analytics
‣https://developer.ibm.com/clouddataservices/sentiment-analysis-of-twitter-hashtags/
‣http://bit.ly/ibmvelocity2
22

©2015 IBM Corporation
@RomeoKienzler
Demo 1: MLLib
23

©2015 IBM Corporation
@RomeoKienzler
Challenge: Calculate and Plot Apache HTTPD response code distribution as bar charts
‣Download the access_log file from https://github.com/romeokienzler/developerWorks
‣http://bit.ly/ibmvelocity3‣Upload the file to the SWIFT Object Store (Hint: Have a look at Tutorial 1 - Load
Data.ipynb)‣Use what you have learned so far to do it yourself, either in Scala or Python‣ I’ll walk around and help you (Hint: Google for the WordCount example in Spark)
24

©2015 IBM Corporation
@RomeoKienzler
Thank You
25
Related Documents











