Classification of place of articulation in unvoiced stops with spectro-temporal surface modeling V. Karjigi , P. Rao Dept. of Electrical Engineering, Indian Institute of Technology Bombay, Powai, Mumbai 400076, India Received 8 December 2011; received in revised form 12 March 2012; accepted 23 April 2012 Available online 1 June 2012 Chairman:Hung-Chi Yang Presenter: Yue-Fong Guo Advisor: Dr. Yeou-Jiunn Chen Date: 2013.3.20

Classification of place of articulation in unvoiced stops with spectro-temporal surface modeling V. Karjigi, P. Rao Dept. of Electrical Engineering, Indian.
Dec 27, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Classification of place of articulation
in unvoiced stops with spectro-temporal surface
modeling
V. Karjigi , P. RaoDept. of Electrical Engineering, Indian Institute of Technology
Bombay, Powai, Mumbai 400076, India Received 8 December 2011; received in revised form 12 March 2012;
accepted 23 April 2012 Available online 1 June 2012
Chairman:Hung-Chi YangPresenter: Yue-Fong GuoAdvisor: Dr. Yeou-Jiunn ChenDate: 2013.3.20
Outline
• Introduction
• MFCC
• 2D-DCT
• Polynomial surface
Outline
• GMM
• Results
• Conclusion

Introduction
• Automatic speech recognition (ASR) system
• The goal is the lexical content of the human voice is converted to a computer-readable input
• Attempt to identify or confirm issue voice speaker rather than the content of the terms contained therein

Introduction
• Automatic speech recognition (ASR) system • Acoustics feature• Signal processing and feature extraction• Mel frequency cepstral coefficients (MFCC)
• Acoustics model• Statistically speech model• Gaussian mixture model (GMM)

MFCC
• Mel frequency cepstral coefficients (MFCC)
• MFCC takes human perception sensitivity with respect to frequencies into consideration, and therefore are best for speech/speaker recognition.
MFCC
1.Pre-emphasis
• The speech signal s(n) is sent to a high-pass filter
2.Frame blocking
3.Hamming windowing
• Each frame has to be multiplied with a hamming window in order to keep the continuity of the first and the last points in the frame

MFCC
4. Fast Fourier Transform or FFT
• The time domain signal into a frequency domain
5.Triangular Bandpass Filters
• Smooth the magnitude spectrum such that the harmonics are flattened in order to obtain the envelop of the spectrum with harmonics.
6.Discrete cosine transform or DCT

MFCC
7.Log energy
• The energy within a frame is also an important feature that can be easily obtained
8.Delta cepstrum
• Actually used in speech recognition, we usually coupled differential cepstrum parameters to show the changes of the the cepstrum parameters of the time

2D-DCT
• 2D-DCT modeling

Polynomial surface
• Polynomial surface modeling

Polynomial surface
• Polynomial surface modeling

Polynomial surface
• Polynomial surface modeling
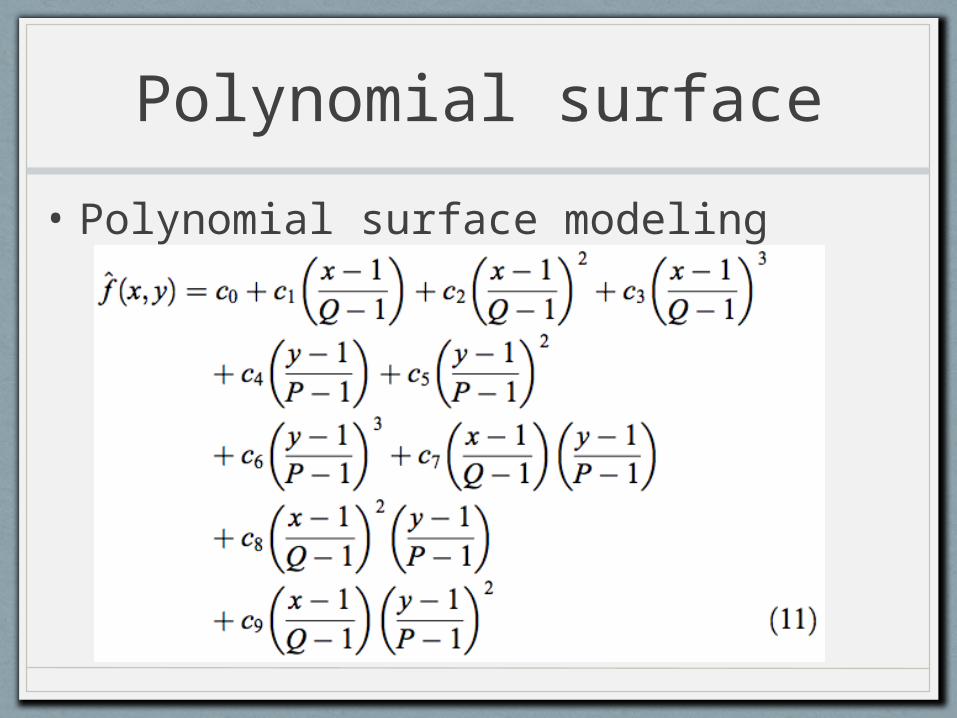
Polynomial surface
• Polynomial surface modeling

GMM
• Gaussian mixture model (GMM)
• Is an effective tool for data modeling and pattern classification
• Speaker acoustic characteristics for clustering, and then each group of acoustic characteristics described with a Gaussian density distribution

Databases
• Databases• Evaluated on two distinct datasets • American English continuous speech as provided
in the TIMIT database • Marathi words database specially created for the
purpose
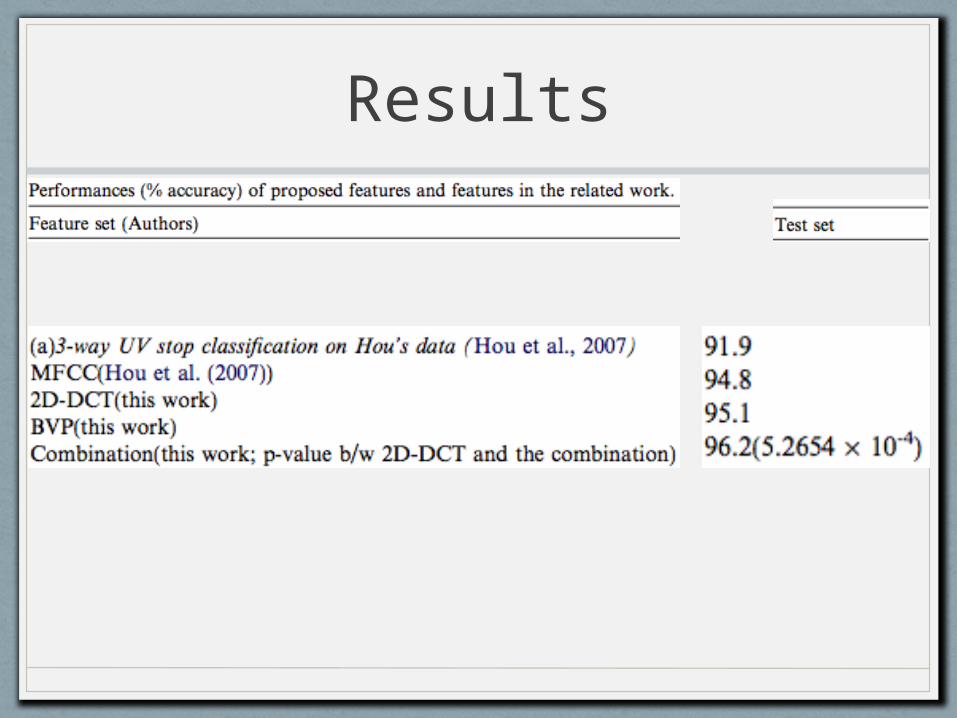
Results

Conclusion
• A comparison of performance with published results on the same task revealed that the spectro-temporal feature systems tested in this work improve upon the best previous systems’ performances in terms of classification accuracies on the specified datasets.
The End
Related Documents











