23 Chapter 2 Classical Machine- Learning Paradigms for Data Mining We are drowning in information but starved for knowledge. John Naisbitt Megatrends: Ten New Directions Transforming Our Lives Data mining flourishes because the information influx in ubiquitous applications calls for data management, pattern recognition and classification, and knowledge discovery. Cyberinfrastructures generate peta-scale data sets for daily monitoring and pattern profiling in cybersecurity models. To facilitate the application of data- mining techniques in cybersecurity protection systems, we comprehensively study the classic data-mining and machine-learning paradigms. In this chapter, we intro- duce the fundamental concepts of machine learning in Section 2.1. We categorize classic machine-learning methods into supervised learning and unsupervised learn- ing, and present the respective methodologies, which will be used in cybersecurity techniques. In Section 2.2, we highlight a variety of techniques, such as resampling, feature selection, cost-effective learning, and performance evaluation metrics, that can be used to improve and evaluate the quality of machine-learning methods in mining cyberinfrastructure data. Since malicious behaviors occur either rarely or infrequently among cyberinfrastructures, classic machine-learning techniques must adopt machine-learning techniques to perform unbalanced learning accu- rately. In Section 2.3, we address several challenges that arise when we apply the

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

23
Chapter 2
ClassicalMachine-LearningParadigmsforDataMining
Wearedrowningininformationbutstarvedforknowledge.
John NaisbittMegatrends: Ten New Directions Transforming Our Lives
Dataminingflourishesbecausetheinformationinfluxinubiquitousapplicationscallsfordatamanagement,patternrecognitionandclassification,andknowledgediscovery.Cyberinfrastructuresgeneratepeta-scaledatasetsfordailymonitoringandpatternprofilingincybersecuritymodels.Tofacilitatetheapplicationofdata-miningtechniquesincybersecurityprotectionsystems,wecomprehensivelystudytheclassicdata-miningandmachine-learningparadigms.Inthischapter,weintro-ducethefundamentalconceptsofmachinelearninginSection2.1.Wecategorizeclassicmachine-learningmethodsintosupervisedlearningandunsupervisedlearn-ing,andpresenttherespectivemethodologies,whichwillbeusedincybersecuritytechniques.InSection2.2,wehighlightavarietyoftechniques,suchasresampling,featureselection,cost-effectivelearning,andperformanceevaluationmetrics,thatcanbeusedtoimproveandevaluatethequalityofmachine-learningmethodsinmining cyberinfrastructure data. Since malicious behaviors occur either rarelyor infrequently among cyberinfrastructures, classicmachine-learning techniquesmust adopt machine-learning techniques to perform unbalanced learning accu-rately.InSection2.3,weaddressseveralchallengesthatarisewhenweapplythe

24 ◾ Data Mining and Machine Learning in Cybersecurity
classicdata-miningandmachine-learningmethodstodiscoveringcyberinfrastruc-tures.Finally,wesummarizetheemergingresearchdirectionsinmachinelearningforcybersecurityinSection2.4.
2.1 MachineLearningMachine learning is the computational process of automatically inferring andgeneralizinga learningmodel fromsampledata.Learningmodelsuse statisticalfunctions or rules to describe the dependences among data and causalities andcorrelationsbetweeninputandoutput(Jainetal.,2000).Theoretically,givenanobserveddatasetX,asetofparametersθ,andalearningmodelf (θ),amachine-learningmethod isusedtominimize the learningerrorsE(f (θ),X ),betweenthe learningmodelf (θ)andthegroundtruth.Withoutlossofgeneralization,weobtainthelearningerrorsusingthedifferencebetweenthepredictedoutputf (θ )andtheobservedsampledata,whereθ isthesetofapproximatedparametersderivedfrom theoptimizationprocedures forminimizationof theobjective functionoflearningerrors.Machine-learningmethodsdifferentiatefromeachotherbecauseoftheselectionofthelearningmodelf (θ),theparametersθ,andtheexpressionoflearningerrorE(f (θ),X ).
To make a clear representation in the following review, we start with somenotationsusedinthebook.GivenatrainingdatasetSwithmsamples(|S|=m),ddimensionalfeaturespaceF,andal-dimensionalclasslabelsetC={C1,…,Cl},wehavepairedsamplesandtargetlabelsS={(xi,yi)},i=1,…,m,andF={f1,f2,…,fd},wherexi∈Xisaninstanceandyi∈Yistheclasslabelofinstancexi.
2.1.1 Fundamentals of Supervised Machine-Learning MethodsInsupervisedmachinelearning,analgorithmisfedsampledatathatarelabeledinmeaningfulways.Thealgorithmusesthelabeledsamplesfortrainingandobtainsamodel.Then,thetrainedmachine-learningmodelcanlabelthedatapointsthathaveneverbeenusedbythealgorithm.Theobjectiveofusingasupervisedmachine-learningalgorithmistoobtainthehighestclassificationaccuracy.Themostpopu-larsupervisedmachine-learningmethodsincludeartificialneuralnetwork(ANN),supportvectormachine(SVM),decisiontrees,Bayesiannetworks(BNs),k-nearestneighbor(KNN),andthehiddenMarkovmodel(HMM).
2.1.1.1 Association Rule Classification
Anassociationrulecanbeseenasanextensionofthecorrelationpropertytomorethantwodimensions, since itcanfindassociated isomorphismsamongmultipleattributes.Weexplainthebasicsofassociationrulesasfollows.

Classical Machine-Learning Paradigms for Data Mining ◾ 25
LetE = {I1, I2,...,Ik} be a set of items andD be adatabase consistingofNtransactionsT1,T2,...,TN.EachtransactionTj,∀1≤j≤NisasetofitemssuchthatTj⊆E.WepresentanassociationruleABwiththefollowingconstraints:
1.∃Tj,A,B∈Tj, 2.A⊆E,B⊆E,and 3.A∩B ∈φ.
In theabove rule,A (left-hand sideof rule) is called theantecedentof the rule,andB(right-handsideofrule)iscalledtheprecedentoftherule.Sincemanysuchrulesmaybepresentedinthedatabase,twointerestingnessmeasures,supportandconfidence, are provided for association rules. Support indicates the percentageof data in the database that shows the correlation, and confidence indicates theconditionalprobabilityofaprecedentiftheantecedenthasalreadyoccurred.Usingthenotationsabove,wedefinethesupportandconfidencebelow
Support A B
T A B TN
i i( )# | ,
,⇒ =∈
Confidence A B
T A B TT A Ti i
i i( )
# | ,# |
.⇒ =∈
∈
Anassociationruleisconsideredstrongifthesupportandconfidenceofarulearegreaterthanuser-specifiedminimumsupportandminimumconfidencethresholds.
Let theaboveAdescribe frequentpatternsofattribute-valuepairs,and letBdescribeclasslabels.Then,associationrulescanconducteffectiveclassificationofA.Associationruleshaveadvantagesinelucidatinginterestingrelationships,suchascausalitybetweenthesubsetsofitems(attributes)andclasslabels.Strongassocia-tionrulescanclassifyfrequentpatternsofattribute-valuepairsintovariousclasslabels. However, elucidation of all interesting relationships by rules can lead tocomputationalcomplexity,evenformoderate-sizeddatasets.Confiningandprun-ingtherulespacecanguideassociationruleminingatafastspeed.
2.1.1.2 Artificial Neural Network
AnANN is amachine-learningmodel that transforms inputs intooutputs thatmatchtargets,throughnonlinearinformationprocessinginaconnectedgroupofartificialneurons(asshowninFigure2.1),whichmakeupthelayersof“hidden”units.TheactivityofeachhiddenunitandoutputŶ isdeterminedbythecomposi-tionofitsinputXandasetofneuronweightsW:Ŷ=f (X,W ),whereWreferstothematrixofweightvectorsofhiddenlayers.Forexample,Figure2.1presentsanANNstructurewithfourinputs,oneoutput,andtwohiddenlayers.W 1andW 2

26 ◾ Data Mining and Machine Learning in Cybersecurity
areweightvectorsforlayer1andlayer2,respectively.Layer1hasthreeneurons,andlayer2hastwoneurons.
WhenANNisusedasasupervisedmachine-learningmethod,effortsaremadetodetermineasetofweightstominimizetheclassificationerror.Onewell-knownmethodthatiscommontomanylearningparadigmsistheleastmean-squarecon-vergence.TheobjectiveofANNistominimizetheerrorsbetweenthegroundtruthYandtheexpectedoutputf(X;W )ofANNasE(X )=( f(X;W )−Y )2.ThebehaviorofanANNdependsonboththeweightsandthetransferfunctionTf ,whicharespecifiedfortheconnectionsbetweenneurons.Forexample,inFigure2.1,thenetactivationatthejthneuronoflayer1canbepresentedas
y T x wj f i ji
i
1 1= ⋅⎛
⎝⎜
⎞
⎠⎟∑ .
(2.1)
Subsequently,thenetactivationatthekthneuronoflayer2canbepresentedas
y T y wk f j kj
j
2 1 2= ⋅⎛
⎝⎜⎜
⎞
⎠⎟⎟∑ .
(2.2)
Thistransferfunctiontypicallyfallsintooneofthreecategories:linear(orramp),threshold,orsigmoid.Usingthelinearfunction,theoutputofTfisproportionaltotheweightedoutput.Usingthethresholdmethod,theoutputofTfdependsonwhetherthetotalinputisgreaterthanorlessthanaspecifiedthresholdvalue.Usingthesigmoidfunction,theoutputofTfvariescontinuouslybutnotlinearly,astheinputchanges.Theoutputofthesigmoidfunctionbearsagreaterresemblancetorealneuronsthando linearor thresholdunits. Inanyapplicationof these threefunctions,wemustconsiderroughapproximations.
Layer 1
Layer 2
Output f (X,W )
W1
W2
{xi}Inputs X
w1ji
w2kj
y1j
y2ky1
j–1
y1j–2 y2
k–1
Figure2.1 Exampleofatwo-layerANNframework.

Classical Machine-Learning Paradigms for Data Mining ◾ 27
ANNencompassesdiversetypesoflearningalgorithms,themostpopularofwhich include feed-forward back-propagation (BP), radial basis function (RBF)networks,andself-organizingmap(SOM).SOMANNisanunsupervisedlearn-ingtechnique,andwediscussitinSection2.1.2.4.
In feed-forward BP ANN, information is transformed from an input layerthroughhidden layers to anoutput layer in a straightforwarddirectionwithoutany loop included inthestructureofnetwork(e.g.,Figure2.1). In feed-forwardBPANN,wetraintheANNstructureas follows.First,we feed inputdata tothenetworkand theactivations for each levelofneurons are cascaded forward.WecomparethedesiredoutputandrealoutputtoupdateBPANNstructure,e.g.,weightsindifferentlayers,layer-by-layerinadirectionofBPfromtheoutputlayertotheinputlayer.
RBFANNhasonlyonehiddenlayerandusesalinearcombinationofnonlin-earRBFsinthetransferfunctionTf .Forinstance,wecanexpresstheoutputofaRBFANNasfollows:
f X W w T X ci f i
i
n
, ,( ) = ⋅ −( )=
∑1
(2.3)
wherewiandciaretheweightandcentervectorsforneuroninisthenumberofneuronsinthehiddenlayer
Typically,thecentervectorscanbefoundbyusingk-meansorKNN.ThenormfunctioncanbeEuclideandistance,andthetransferfunctionTfcanbeGaussianfunction.
ANNmethodsperformwellforclassifyingorpredictinglatentvariablesthatare difficult to measure and solving nonlinear classification problems and areinsensitive to outliers. ANN models implicitly define the relationships betweeninputandoutput,and,thus,offersolutionsfortediouspatternrecognitionprob-lems,especiallywhenusershavenoideawhattherelationshipbetweenvariablesis.ANNmaygenerateclassificationresultsthatarehardertointerpretthanthoseresultsobtainedfromtheclassificationmethodsthatassumefunctionalrelation-shipsbetweendatapoints,suchasusingassociaterules.However,ANNmethodsaredatadependent,suchthattheANNperformancecanimprovewithincreasingsampledatasize.
2.1.1.3 Support Vector Machines
GivendatapointsXinanndimensionalfeaturespace,SVMseparatesthesedatapointswithann−1dimensionalhyperplane.InSVM,theobjectiveistoclassifythedatapointswiththehyperplanethathasthemaximumdistancetothenearest

28 ◾ Data Mining and Machine Learning in Cybersecurity
datapointoneachside.Subsequently,suchalinearclassifierisalsocalledthemaxi-mummarginclassifier.AsshowninFigure2.2a,anyhyperplanecanbewrittenasthesetofpointsXsatisfyingwTx+b=0,wherethevectorwisanormalvectorperpendiculartothehyperplaneandbistheoffsetofthehyperplanewTx+b=0fromtheoriginalpointalongthedirectionofw.
GivenlabelsofdatapointsXfortwoclasses:class1andclass2,wepresentthelabelsasY=+1andY=−1.Meanwhile,givenapairof(wT,b),weclassifydataXintoclass1orclass2accordingthesignof thefunction f(x)= sign(wTx+b),asshowninFigure2.2a.Thus,thelinearseparabilityofthedataXinthesetwoclassescanbeexpressedinthecombinationalequationasy ·(wTx+b)≥1.Inaddition,thedistancefromdatapointtotheseparatorhyperplanewTx+b=0canbecomputedasr=(wTx+b)/w,andthedatapointsclosesttothehyperplanearecalledsupportvectors.Thedistancebetweensupportvectorsiscalledthemarginoftheseparator(Figure 2.2b). Linear SVM is solved by formulating the quadratic optimizationproblemasfollows:
arg min ,
( ) .
,w b
T
w
y w x b
12
1
2⎛⎝⎜
⎞⎠⎟
+ ≥s.t. (2.4)
Usingkernel functions,nonlinearSVMis formulated into the sameproblemaslinearSVMbymappingtheoriginalfeaturespacetoahigher-dimensionalfeaturespacewherethetrainingsetisseparablebyusingkernelfunctions.NonlinearSVMissolvedbyusingasoftmargintoseparateclassesorbyaddingslackvariables,asshowninEquation2.4.
SVMisbetterthanANNforachievingglobaloptimizationandcontrollingthe overfitting problem by selecting suitable support vectors for classification.
Class 1
(a) (b)
Class 2wTx + b ≥ 0
wTx + b ≤ 0
wTx + b = 0
Support vectors
Figure2.2 SVMclassification.(a)HyperplaneinSVM.(b)SupportvectorinSVM.

Classical Machine-Learning Paradigms for Data Mining ◾ 29
SVMcanfindlinear,nonlinear,andcomplexclassificationboundariesaccurately,evenwithasmalltrainingsamplesize.SVMisextensivelyemployedformulti-typedataby incorporatingkernel functions tomapdata spaces.However, selectingkernelfunctionsandfine-tuningthecorrespondingparametersusingSVMarestill trial-and-error procedures. SVM is fast, but its running time quadrupleswhenasampledatasizedoubles.
Unfortunately, SVM algorithms root in binary classification. To solvemulti-classclassificationproblems,multiplebinary-classSVMscanbecom-binedbyclassifyingeachclassandalltheotherclassesorclassifyingeachpairofclasses.
2.1.1.4 Decision Trees
Adecisiontreeisatree-likestructuralmodelthathasleaves,whichrepresentclas-sificationsordecisions,andbranches,whichrepresenttheconjunctionsoffeaturesthat lead to those classifications.Abinarydecision tree is shown inFigure2.3,whereCistherootnodeofthetree,Ai(i=1,2)aretheleaves(terminalnodes)ofthetree,andBj(j=1,2,3,4)arebranches(decisionpoint)ofthetree.
Treeclassificationofaninputvectorisperformedbytraversingthetreebegin-ningattherootnode,andendingattheleaf.Eachnodeofthetreecomputesaninequalitybasedon a single input variable.Each leaf is assigned to aparticularclass.Each inequality that is used to split the input space is onlybasedononeinputvariable.Lineardecisiontreesaresimilartobinarydecisiontrees,exceptthattheinequalitycomputedateachnodetakesonanarbitrarylinearformthatmaydependonmultiplevariables.Withthedifferentselectionsofsplittingcriteria,clas-sificationandregressiontreesandothertreemodelsaredeveloped.
AsshowninFigure2.3,adecisiontreedependsonif–thenrules,butrequiresnoparametersandnometrics.Thissimpleandinterpretablestructureallowsdeci-siontreestosolvemulti-typeattributeproblems.Decisiontreescanalsomanagemissingvaluesornoisedata.However,theycannotguaranteetheoptimalaccu-racythatothermachine-learningmethodscan.Althoughdecisiontreesareeasy
B2
No NoYes Yes
Yes NoRoot node C
B1
A1 A2
B4B3
Figure2.3 Samplestructureofadecisiontree.

30 ◾ Data Mining and Machine Learning in Cybersecurity
tolearnandimplement,theydonotseemtobepopularmethodsofintrusiondetection.Apossiblereasonforthelackofpopularityisthatseekingthesmallestdecisiontree,whichisconsistentwithasetoftrainingexamples,isknowntobeNP-hard.
2.1.1.5 Bayesian Network
TheBN,alsocalledthebeliefnetwork,usesfactoredjointprobabilitydistributioninagraphicalmodelfordecisionsaboutuncertainvariables.TheBNclassifierisbasedontheBayesrulethatgivesahypothesisHofclassesanddatax,wehave,then
P H x
P x H P HP x
||
,( ) =( ) ( )
( ) (2.5)
whereP(H ) denotes prior probability of each class without information about a
variablexP(H |x)denotesposteriorprobabilityofvariablexoverthepossibleclassesP(x |H)denotestheconditionalprobabilityofxgivenlikelihoodH
As shown inFigure2.4,BNsarepresentedwithnodes representing randomvariablesandarcsrepresentingprobabilisticdependenciesbetweenvariables,andconditionalprobabilitiesencodingthestrengthofthedependencies,whileuncon-nectednodes refer tovariables thatare independentofeachother.Eachnode isassociatedwithaprobabilityfunctioncorrespondingtothenode’sparentvariables.Thenode always computes posterior probabilities givenproof of theparents for
x1
x5
x2
x4 x6
x3
Figure2.4 Bayesnetworkwithsamplefactoredjointdistribution.

Classical Machine-Learning Paradigms for Data Mining ◾ 31
theselectednodes.Forexample,inFigure2.4,thefactoredjointprobabilityofthenetworkiscomputedas
p(x1,x2,x3,x4,x5,x6)=p(x6|x5)p(x5|x3,x2)p(x4|x2,x1)p(x3|x1)p(x2|x1)p(x1),where
p(·)denotesprobabilityofavariablep(·|·)denotesconditionalprobabilityofvariables
NaïveBayes isa simpleBNmodel thatassumesallvariablesare independent.UsingtheBayesruleforNaïveBayesclassification,weneedtofindthemaximumlikelihoodhypothesis,whichdeterminestheclasslabel,foreachtestingdatax.GivenobserveddataxandagroupofclasslabelsC={cj},aNaïveBayesclassifiercanbesolvedbymaximumaposterioriprobability(MAP)hypothesisforthedataasfollows:
arg max ( ) ( ).
c Cj j
j
P x c P c∈
(2.6)
NaïveBayes is efficient for inference tasks.However,NaïveBayes isbasedonastrongindependenceassumptionofthevariablesinvolved.Surprisingly,themethodgivesgoodresultseveniftheindependenceassumptionisviolated.
2.1.1.6 Hidden Markov Model
Intheprevioussections,wehavediscussedmachine-learningmethodsfordatasetsthatconsistofindependentandidenticallydistributed(iid)samplesfromsamplespace.Insomecases,datamaybesequential,andthesequencesmayhavecorrela-tion.To solve the sequential learningproblems, adynamicBNmethod,HMMhasbeenproposedforsupervisedlearningofthesequentialpatterns,e.g.,speechrecognition(Rabiner,1989).
In HMM, the observed samples yt, t = 1,…,T, have an unobserved state xtat time t (as shown inFigure2.5).Figure2.5 shows the general architecture ofanHMM.Eachnoderepresentsarandomvariablewiththehiddenstatextandobservedvalueytattimet.InHMM,itisassumedthatstatexthasaprobabilitydistributionovertheobservedsamplesytandthatthesequenceofobservedsamplesembedinformationaboutthesequenceofstates.Statistically,HMMisbasedontheMarkovpropertythatthecurrenttruestatextisconditionedonlyonthevalueofthehiddenvariablext−1butisindependentofthepastandfuturestates.Similarly,
x0 x1 x2 x3 x4 Hiddenstates
Observationsy4y3y2y1
Figure2.5 ArchitectureofHMM.

32 ◾ Data Mining and Machine Learning in Cybersecurity
theobservationytonlydependsonthehiddenstatext.ThemostfamoussolutiontoHMMistheBaum−Welchalgorithm,whichderivesthemaximumlikelihoodestimateoftheparametersoftheHMMgivenadatasetofoutputsequences.
LetusformulatetheHMMusingtheabovenotationsasfollows.GiventhatY andXarethefixedobservedsamplesandstatethesequenceoflengthTdefinedabove,Y = (y1,…,yT)andX=(x1,…,xT),then,wehavethestatesetSandtheobservabledatasetO,S=(s1,…,sM)andO=(o1,…,oN).LetusdefineAasthestatetransitionarray[Ai,j],i =1,…,M,j=1,…,M,whereeachelementAi,jrepresentstheprobabilityofstatetransformationfromsitosj.Thetransformationcanbecalculatedasfollows:
A x s x si j t j t i, | .= = =−prob( )1 (2.7)
LetusdefineBastheobservationarray[Bj,k],j=1,…,M,k=1,…,N,whereeachelement Bjk represents the probability of the observation ok has the state sj. Theobservationarraycanthenbecalculatedasfollows:
B y o x sj k t k t j, | .= = =prob( ) (2.8)
Letusdefineπastheinitialprobabilityarray[πt],t=1,…,T,whereπtrepresentstheprobabilitythattheobservationythasthestatesi,i=1,…,πcanbeexpressedas
πi ix s= =prob( )1 . (2.9)
WethendefineanHMMusingtheabovedefinitions,asfollows:
λ π= ( )A B, , . (2.10)
Theaboveanalysisistheevaluationoftheprobabilityofobservations,whichcanbesummarizedinthealgorithminfourstepsasfollows:
Step 1.Initializefort=1,accordingtotheinitialstatedistributionπ.Step 2.DeducttheobservationvalueattimetcorrespondingtoEquation2.8.Step 3.Deductthenewstateattimet+1accordingtoEquation2.9.Step 4.IterateSteps2through4untilt=T.
Given the HMM described in Equation 2.10, we can predict the probabilityofobservationsY for a specific state sequenceX and theprobabilityof the statesequenceXas
prob( ) prob( )Y X y xt t
t
T
| , | , ,λ λ==
∏1
(2.11)
and
prob( )X A A AT T| .λ π= ⋅ ⋅ −1 12 23 1… (2.12)

Classical Machine-Learning Paradigms for Data Mining ◾ 33
Then,weobtaintheprobabilityofobservationsequenceYforstatesequenceXasfollows:
prob prob probY Y X X
X
| | , | .λ λ λ( ) = ( ) ⋅ ( )∑ (2.13)
Usersaregenerallymoreinterestedinpredictingthehiddenstatesequenceforagivenobservationsequence.ThisdecodingprocesshasafamoussolutionknownastheViterbialgorithm,whichusesthemaximizedprobabilityateachsteptoobtainthemostprobable state sequence for thepartialobservation sequence.GivenanHMMmodelλ,wecanfindthemaximumprobabilityofthestatesequence(x1,…,xt)fortheobservationsequence( y1,…,yt)attimetasfollows:
ρ λt
x xt i ti x x s y y
t( ) max , , , , , | .
,...= ( ( = ))
−1 11 1prob … …
(2.14)
TheViterbialgorithmfollowsthestepslistedbelow:
Step 1.Initializethestatefort=1,accordingtotheinitialstatedistributionπ:
ρ π1 1 11 0( ) ( ), , ( ) .i B y i M ii i= ≤ ≤ =ψ (2.15)
Step 2.Deducttheobservationvalueattimetcorrespondingtothefollowingequation:
ρ ρt
it ij j tj i A B y t T j M( ) max ( ) ( ), , ,[ ]= ≤ ≤ ≤ ≤2 1
(2.16)
and
ψ ρti
t ijj i A t T j M( ) arg max ( ) , , .[ ]= ≤ ≤ ≤ ≤−1 2 1 (2.17)
Step 3.IterateSteps2through4untilt=T.
HMMcansolvesequentialsupervisedlearningproblems.ItisanelegantandsoundmethodtoclassifyorpredictthehiddenstateoftheobservedsequenceswithahighdegreeofaccuracywhendatafittheMarkovproperty.However,whenthetruerela-tionshipbetweenhiddensequentialstatesdoesnotfittheproposedHMMstruc-ture,HMMwillresult inpoorclassificationorprediction.Meanwhile,HMMsuffers from large training data sets and complex computation, especially whensequences are long and have many labels. The assumption of the independencybetweenthehistoricalstates,orfuturestatesandthecurrentstatesalsohampersthedevelopmentofHMMinachievinggoodclassificationorpredictionaccuracy.ForfurtherdiscussionandadetailedanalysisoftheabovealgorithmsinHMM,readersshouldrefertoRoweisandGhahramani(1999)andDietterich(2002).

34 ◾ Data Mining and Machine Learning in Cybersecurity
2.1.1.7 Kalman Filter
UnlikeHMM,theKalmanfilterperformsbasedontheassumptionthatthetruestateisdependentonandevolvedfromthepreviousstate.Thisstatetransitionisexpressedasfollows:
x A x B u w w N Qt t t t t t t t= + +−1 0, , ,( )∼ (2.18)
y H x v v N Rt t t t t t= + , , ,( )∼ 0 (2.19)
whereAtisthestatetransitionarraybetweenstatesxtandxt−1attimetandt−1BtreferstothecontrolmodelforcontrolvectorutwtpresentstheprocessnoiseHt is the observation transition array between the hidden state xt and the
observationytattimetvtdenotesthemeasurementnoiseinobservationQtdenotesthevarianceofnoiseofhiddenstatextRtdenotesthevarianceofnoiseofobservationyt
AsshowninEquations2.18and2.19,theKalmanmodelrecursivelyestimatesthepres-entcurrentsystematicstatextbasedonthepreviousstatext−1andpresentobservationyt.
TheKalmanfilterestimatestheposteriorstateusingaminimummean-squareerrorestimator.TwophasesareincludedinKalmanfilteralgorithms:aprioriesti-matephase,inwhichthecurrentstateisestimatedfromthepreviousstate,andaposterioriestimatephase,inwhichthecurrentaprioriestimateiscombinedwithcurrentobservationinformationtorefinethestateestimate.Intheaprioriestimatephase,themodelisassumedtobeperfectandwithoutprocessnoise,andtheerrorcovarianceofthenextstateisestimated.Intheposterioriestimatephase,againfactor,calledKalmangain,iscomputedtocorrectstateestimationandminimizetheerrorcovariance.TheaboveispresentedindetailinFigure2.6.
ThemostemployedKalmanfiltersincludethebasicKalmanfilter,theextendedKalmanfilter, theunscentedKalmanfilter, and theStratonovich–Kalman–Bucyfilter(Dietterich,2002).TheKalmanfilterenablestheonlinecontinuousestimationofstatevectorsforupdatingobservations.Implicatively,theKalmanfilterusesallthehistoricalandcurrentinformationforstateprediction,whichresultsinthesmoothinterpretationandestimationofstates.However,theaccuracyoftheKalmanfiltermostreliesontheassumptionthatnoisesandinitial stateshavenormaldistribu-tions.Thelossofthenormalityassumptioncanresultinbiasedestimators.
2.1.1.8 Bootstrap, Bagging, and AdaBoost
Incomplexmachine-learningscenarios,asinglemachine-learningalgorithmcan-notguarantee satisfactoryaccuracy.Researchers attempt to ensembleagroupof

Classical Machine-Learning Paradigms for Data Mining ◾ 35
learningalgorithmstoimprovethelearningperformanceoversinglealgorithms.Inthenextsections,wewillintroduceseveralpopularensemblelearningmethods,includingrandomforest,bagging,bootstrap,andAdaBoost.
Bootstrapismostemployedtoyieldamoreinformativeestimateofageneralstatistics, suchasbiasandvarianceofanestimator.Given sample setX= {xi},i=1,…,m,asetofparametersθ,andalearningmodelf (θ),amachine-learningmethodminimizesthelearningerrorsE( f (θ),X ).Inbootstrap,mdatapointsareselectedrandomlywithreplacementsfromdatasetX.ByrepeatingthissamplingprocessindependentlyBtimes,weobtainBBootstrapsamplesets.Theparametersinfunctionf (θ)canbeestimatedbyeachsampleset,andweobtainasetofboot-strapestimate{θ j},j=1,…,B.Then,theestimateonbootstrapsamplesis
ˆ ˆ θ θB
j
j
B
==
∑1
.
(2.20)
AsthebootstrapselectssamplesrepeatedlyfromX,eachdatasamplehas1/mprob-abilityofbeingchosenineachselection.Whenmisbigenough,theprobabilitythatxiisselectedmboottimesisPoissondistributionwithmeanunity.Wecanobtainitsunbiasedestimateofparametersθ statisticallyoversampledataX.Then,wecanobtainthebootstrapestimateoftheparameterbiasat
biasb B( ) ,θ θ θ= −ˆ ˆ (2.21)
A prior estimation phase:
Step 2. Estimation of the error covariance ofthe next state
Step 4. Correction of the state estimation
Step 5. Correction of error covariance of thenext state
Step 1. Estimation of the next state
Step 3. Kalman Gain
Posterior estimation phase:Measurement
update
Timeupdate
ˆ ˆx(t|t–1) = At . x(t–1|t–1) + Bt . ut
Kt = Pt . HT . (H . Pt . HT + Vt . R .VTt)–1
ˆ ˆ ˆxt|t = xt|t–1 + Kt . [yt – Ht . xt|t–1]
P(t|t–1) = At . P(t–1|t–1) . AtT +Qt–1
Figure2.6 WorkflowofKalmanfilter.

36 ◾ Data Mining and Machine Learning in Cybersecurity
andthebootstrapestimateoftheparametervariance,
var ( ) .b j
j
B
Bθ θ θ= −( )
=∑1 2
1
ˆ ˆ
(2.22)
Bootstrapaggregating(bagging)aimstosampledatasetsforanensembleofclas-sifiers. In bagging, m′ < m data points are selected randomly with replacementfrom thedata setX.Repeating this samplingprocessmultiple times,weobtaindifferenttrainingsamplesetsforeachmemberoftheensembleofclassifiers.Thefinaldecisionistheaverageofthemember-modeldecisionsbyvoting.Baggingiscommonlyusedtoimprovethestabilityofdecisiontreesorothermachine-learningmodels.However,baggingcanresult inredundantandlostinformationbecauseofreplacement.
Boostingisusedtoboostastrongmachine-learningalgorithmwithanarbi-trarilyhighaccuracybyusingaweightedtrainingdataset.Boostingalgorithmsstartbyfindingaweakmachine-learningalgorithmthatperformsbetterthanran-domguessing.Then,memberclassifiersareintegratedintoanaccurateclassificationensembleoverthemostinformativesubsetofthetrainingdata.Boostingmodifiesbaggingintwoways:weightingthesampleandweightingthevote.Boostingcanresultinhigheraccuracythanbaggingwhenadatasetisnoisefree,althoughbag-gingstaysmorerobustinnoisydata.
Adaptiveboosting (AdaBoost) is themostpopular variantofboosting algo-rithms.GiventrainingdatasetSwithmexamples(|S|=m),andanl-dimensionalclasslabelsetC={C1,…,Cl },wehaveapaireddatasetS={(xi,yi )},i=1,…,m,wherexi∈Xisaninstanceandyi∈Yandyi∈Cformtheclasslabelofsamplexi.We assign a sample weight wt(i), t = 1,…T, to each sample xi to determine itsprobabilityofbeingselectedasthetrainingsetforamemberclassifieratiterativestept.Thisweightwillberaisedifthesampleisnotaccuratelyclassified.Likewise,itwillbeloweredifthesampleisaccuratelyclassified.Inthisway,boostingwillselectthemostinformativeordifficultsamplesovereachiterativestepk.AdaBoostalgorithmscanbesummarizedinthefollowingsteps(asshowninFigure2.7):
Step 1.Initializethesampleweightw1(i)=1/m,i=1,…,m.Step 2.Traintheweaklearnerht:X→YbytheweightedsamplesStdefinedby
wt(i)andS,wherehtisassignedlabel+1whenht(xi)=yi,else−1.Step 3. Calculate the learning error of ht by εt t
i h x yw i
t i i=
≠∑ ( ): ( )( )
and the
weightαt=(1/2)ln[(1−εt)/εt].Step 4.Updatesampleweightsoverthetrainingset:wt+1(i)=(wt(i)exp(−wt yiht(xi)))/
Zt,whereZtdenotesthenormalizationfactortoensurethatwt(i)isadistribution.Step 5.IterateSteps2through4untilt=T,weightedvotingamongtheensemble
ofclassifiers:H x h xt tt
T( ) ( )= ⎛
⎝⎜⎞⎠⎟=∑sign α
1.

Classical Machine-Learning Paradigms for Data Mining ◾ 37
Intheabovesteps,αtmeasurestheconfidencewhenassigningthosesamplestotheclassifierhtatstept.
AdaBoost offers accurate machine-learning results without overfitting prob-lems that are common in machine-learning algorithms. AdaBoost is simple forimplementationandhasasolidtheoreticalbackgroundandgoodgeneralization.Therefore, AdaBoost has been employed for various learning tasks, e.g., featureselection. However, Adaboost can only guarantee suboptimal learning solutionsaftergreedylearning.ReadersshouldrefertoFreundandSchapire(1999),Breiman(1996),andFreundandSchapire(1997)forabetterunderstandingoftheunderly-ingtheoryandalgorithmsofAdaBoost.
2.1.1.9 Random Forest
The random forest algorithm is the most popular bagging ensemble classifier(Breiman, 2001). Random forest consists of manydecision trees.The output ofrandomforestisdecidedbythevotesgivenbyallindividualtrees.Eachdecisiontreeisbuiltbyclassifyingthebootstrapsamplesoftheinputdatausingatreealgo-rithm.Then,everytreewillbeusedtoclassifytestingdata.Eachtreehasadecisiontolabelanytestingdata.Thislabeliscalledavote.Finally,theforestdecidestheclassificationresultofthetestingdataaftercollectingthemostvotesamongtrees.
Let us review the random forests using some definitions given by Breiman(2001). Given a forest consisting of K trees {T1,…,TK}, a random vector θk isgenerated for the kth tree, k = 1,…,K. The vectors {θk} are iid random vectorsfortreemodeling.Thesevectorsaredefinedintreeconstruction.Forinstance,inrandomselection,thesevectorsarecomposedofrandomintegersrandomlyselectedfrom{1,…,N}whereNisthesplitnumber.Usingtrainingdatasetandthevectors{θk},atreegrowsandcastsaunitvoteforthemostpopularclassatinputx.Wepresentthekthtreeclassifierasf (x,θk)andobtainarandomforestconsistingofthecollectionofthosetrees,{f (x,θk)},k=1,…,K.
{w2(i)} {wt(i)}{wT(i)}
Update learner{ht(xi)}
Update data S1 Update data St–1
Sample S = {xi}Update data ST–1… …
Figure2.7 WorkflowofAdaBoost.

38 ◾ Data Mining and Machine Learning in Cybersecurity
Theaccuracyofrandomforestdependsonthestrengthoftheindividualtreesandameasureofthedependencebetweenthetrees.Moreover,therandomforestalgorithmusesbootstraptoavoidbiasesintreebuilding,suchthatcrossvalidation(CV)isnotneededintrainingandtesting.However,randomforestsuffersfromtheclassimbalanceduetothemaximizationofthepredictionaccuracyinitsalgo-rithm.Tree-basedmethodshaveahighvariance.Thehierarchicalstructureoftreescanproduceanunstableresult.Theaverageofmanytrees,e.g.,usingbagging,canimprovestabilityofensemblelearningalgorithms.
2.1.2 Popular Unsupervised Machine-Learning Methods
2.1.2.1 k-Means Clustering
Clusteringistheassignmentofobjectsintogroups(calledclusters)sothatobjectsfromthesameclusteraremoresimilartoeachotherthanobjectsfromdifferentclusters.Thesamenessoftheobjectsisusuallydeterminedbythedistancebetweentheobjectsovermultipledimensionsofthedataset.Clusteringiswidelyusedinvariousdomainslikebioinformatics,textmining,patternrecognition,andimageanalysis.Clustering isanapproachofunsupervised learningwhereexamplesareunlabeled,i.e.,theyarenotpre-classified.
k-MeansclusteringpartitionsthegivendatapointsXintokclusters,inwhicheachdatapointismoresimilartoitsclustercentroidthantotheotherclustercen-troids.Thek-meansclusteringalgorithmgenerallyconsistsofthestepsdescribedasfollows:
Step 1.Selectthekinitialclustercentroids,c1,c2,c3…,ck.Step 2.AssigneachinstancexinStotheclusterthathasacentroidnearesttox.Step 3.Recomputeeachcluster’scentroidbasedonwhichelementsarecontained
init.Step 4.RepeatSteps2through3untilconvergenceisachieved.
Twokey issues are important for the successful implementationof thek-meansmethod:theclusternumberkforpartitioningandthedistancemetric.Euclideandistance is the most employed metric in k-means clustering. Unless the clusternumberk isknownbeforeclustering,noevaluationmethodscanguarantee theselectedkisoptimal.However,researchershavetriedtousestability,accuracy,andothermetricstoevaluateclusteringperformance.
2.1.2.2 Expectation Maximum
Theexpectationmaximization (EM)method isdesigned to search for themax-imum likelihood estimates of the parameters in a probabilistic model. The EMmethodsassumethatparametricstatisticalmodels,suchastheGaussianmixture

Classical Machine-Learning Paradigms for Data Mining ◾ 39
model(GMM),candescribethedistributionofasetofdatapoints.Forexample,whenthehistogramofthedatapointsisregardedasanestimateoftheprobabilitydensityfunction(PDF),theparametersofthefunctioncanbeestimatedbyusingthehistogram.
Correspondingly,inEM,theexpectation(E)stepandthemaximization(M)stepareperformediteratively.TheEstepcomputesanexpectationoftheloglikeli-hoodwithrespecttothecurrentestimateofthedistributionforthelatentvariables,andMstepcomputestheparametersthatmaximizetheexpectedlog likelihoodfoundontheEstep.TheseparametersarethenusedtodeterminethedistributionofthelatentvariablesinthenextEstep.Thetwostepsaredescribedasfollows:
Step 1.(Expectationstep)Givensampledataxandundiscoveredormisseddataz,theexpectedloglikelihoodfunctionofparametersθcanbeestimatedbyθt:
f E L x ztθ θ θ( ) = [ ]log ( ; , ) . (2.23)
Step 2. (Maximization step) Using the estimated parameter at step t, themaximumlikelihoodfunctionoftheparameterscanbeobtainedthrough
θ θ θθ
t tf+ = ( )( )1 arg max . (2.24)
In the above, themaximum likelihood function is determinedby themarginalprobabilitydistributionoftheobserveddataL(θ;x).Inthefollowing,weformulatetheEMmathematicallyanddescribetheiterationstepsindepth.
GivenasetofdatapointsS={x1,…,xm},wedescribethemixtureofPDFsasfollows:
p x p xi j j i j
j
K
( ) ( ; ).==
∑α θ1
(2.25)
In the above,αj is theproportionof the jthdensity in themixturemodel, andα j
j
K
=∑ =1
1.pj(xi;θj)isthejthdensityfunctionwithparametersetθj.TheGMMisthemostemployed,andhastwoparameters,meanμiandcovarianceΣj,suchthatθj=(μj,Σj).Ifweassumethatθ j
t istheestimatedvalueofparameters(μj,Σj)atthet-thstep,thenθ j
t+1canbeobtainediteratively.TheEMalgorithmframeworkfollows:
α jt
ijt
i
m
ra+
=
= ∑1
1
1 , (2.26)
ua x
ajt
ijt
ji
m
ijt
j
m+ =
=
=∑∑
1 1
1
,
(2.27)

40 ◾ Data Mining and Machine Learning in Cybersecurity
=−( ) −( )⎡
⎣⎢⎤⎦⎥=
=
+ ∑∑
∑a x u x u
a
ijt
i
m
i jt
i jt T
ijt
i
mj
t1
1
1,
(2.28)
aa p x u
a p x uijt i j i
tit
i j it
it
i
m=⋅ ( )
⋅ ( )=∑
; ,
; ,.
Σ
Σ1
(2.29)
These equations state that the estimated parameters of the density function areupdated according to the weighted average of the data point values where theweightsaretheweightsfromtheEstepforthispartition.TheEMcyclestartsataninitialsettingofθ j uj j
0 0 0= ∑( ), andupdatestheparametersusingEquations2.26through2.29iteratively.TheEMalgorithmconvergesuntilitsestimatedparam-eterscannotchange.
TheEMalgorithmcanresultinahighdegreeoflearningaccuracywhengivendatasetshavethesamedistributionastheassumption.Otherwise,theclusteringaccuracyislowbecausethemodelisbiased.
2.1.2.3 k-Nearest Neighbor
In KNN, each data point is assigned the label that has the highest confidenceamongthekdatapointsnearesttothequerypoint.AsshowninFigure2.8,k=5,thequerypointXquery,isclassifiedtothenegativeclasswithaconfidenceof3/5,becausetherearethreenegativeandtwopositivepointsinsidethecircle.Thenumbersofnearestneighbors(k)andthedistancemeasurearekeycomponentsfortheKNNalgorithm.TheselectionofthenumberkshouldbebasedonaCVoveranum-berofksettings.Generally,alargernumberkreducestheeffectofdatanoiseon
++
+
Xquery
+–
–
–
–
–
–
Figure2.8 KNNclassification(k=5).

Classical Machine-Learning Paradigms for Data Mining ◾ 41
classification,whileitmayblurthedistinctionbetweenclasses.Agoodrule-of-thumbisthatkshouldbelessthanthesquarerootofthetotalnumberoftrainingpatterns.Intwo-classclassificationproblems,kshouldbeselectedamongoddnumberstoavoidtiedvotes.
The most employed distance metric is Euclidean distance. Given two datapointsinndimensionalfeaturespace:x1=(x11,…,x1n)andx2=(x21,…,x2n),theEuclideandistancebetweenthesepointsisgivenby
dist x x x xi i
i
n
1 2 1 22
1
0 5
, ..
( ) = −( )⎛
⎝⎜⎜
⎞
⎠⎟⎟
=∑
(2.30)
Because KNN does not need to train parameters for learning while it remainspowerfulforclassification,itiseasytoimplementandinterpret.However,KNNclassificationistimeconsumingandstorageintensive.
2.1.2.4 SOM ANN
SOMANN,alsoknownasKohonen,characterizesANNinvisualizinglow-dimen-sionalviewsofhigh-dimensionaldatabypreservingneighborhoodpropertiesoftheinputdata.Forexample,atwo-dimensionalSOMconsistsof lattices.Eachlatticecorresponds to oneneuron.Each lattice contains a vector ofweights of the samedimensionastheinputvectors,andnoneuronsconnectwitheachother.Eachweightofalatticecorrespondstoanelementoftheinputvector.TheobjectiveofSOMANNistooptimizetheareaoflatticetoresemblethedatafortheclassthattheinputvectorbelongsto.TheSOMANNalgorithmsconsistofthefollowingsteps:
Step 1.Initializeneuronweights.Step 2.Selectavectorrandomlyfromtrainingdataforthelattice.Step 3.Findtheneuronthathastheweightsmostmatchingtheinputvector.Step 4.Findtheneurons inside theneighborhoodof thematchedneurons in
Step3Step 5.Fine-tunetheweightofeachneighboringneuronobtainedinStep4to
increasethesimilarityoftheseneuronsandtheinputvectorStep 6.IterativelyrunSteps1through5untilconvergence
SOMANNformsasemanticmapwheresimilarsamplesaremappedclosetogetheranddissimilarsamplesaremappedfurtherapart.WecanvisualizethesimilaritybytheEuclideandistancebetweenweightvectorsofneighboringcells.SOMpreservesthetopologicalrelationshipsbetweeninputvectors.
2.1.2.5 Principal Components Analysis
Theprincipalcomponentsanalysis(PCA)representstherawdatainalowerdimen-sional feature space to convey the maximum useful information. The extracted

42 ◾ Data Mining and Machine Learning in Cybersecurity
principalfeaturecomponentsarelocatedinthedimensionsthatrepresentthevari-abilityofthedata.Givendataset{x1,…,xn}ind-dimensionalfeaturespace,weputthesedatapointsinmatrixXwitheachrowpresentingadatapointandeachcol-umndenotingafeature.WepresentthematrixXasX=[x1,…,xn]T,andtransposeasT.Then,weadjustthedatapointstobecenteredaroundzerobyX−X−,whereX−denotesthematrixinspacen×d,witheachrowpresentingthemeanofallrowsinmatrixX.SuchanoperationensuresthatthePCAresultwillnotbeskewedduetothedifferencebetweenfeatures.
Then,anempiricalcovariancematrixofX−X−canbeobtainedbyC=(1/d)∑(X −X− )(X−X− )T.AfterweobtaintheempiricalcovariancematrixofX−X−,wethenobtainamatrixV,V=[v1,…,vd],ofeigenvectorsinspaced,whichconsistsofasetofdprincipalcomponentsinddimensions.Eacheigenvectorvi,i=1,…,m,inmatrixVcorrespondstoaneigenvalueλiinthediagonalmatrixD,whereD=V −1CVandDij=λi,ifi=j;elseDij=0.Finally,werankeigenvaluesandreorganizethecorrespondingeigenvectorssuchthatwecanfindthesignificanceofvariancealongthedifferentorthogonaldirections(denotedbyeigenvectors).Then,wecanpresenttheithprincipalcomponentoreigenvectorviasfollows:
v X X X X v v vi
vj j
T= − − −( )=
∑arg max .( ) ( )1
(2.31)
Intheaboveequation,(X−X−)vjcapturestheamountofvarianceprojectedalongthedirectionofvj.Thisvarianceisalsodenotedbythecorrespondingeigenvalueλi.TheapplicationofthePCAmethodcanbesummarizedinfourstepsasfollows:
Step 1.Subtractthemeanineachofthedimensionstoproduceadatasetwithameanofzero.
Step 2.Calculatethecovariancematrix.Step 3.Calculatetheeigenvectorsandeigenvaluesofthecovariancematrix.Step 4.Ranktheeigenvectorsbyeigenvaluesfromhighesttolowesttogetthe
componentsinorderofsignificance.
AsshowninFigure2.9,v1andv2arethefirstandsecondprincipalcomponentsobtainedbyPCA.λ1andλ2are thecorrespondingfirstandsecondeigenvalues.Theprincipalcomponentsareorthogonalinfeaturespace,whilev1representstheoriginalvarianceinthedatasetandv2representstheremainingvariance.
PCA projects original data on a lower dimensional data space while retain-ingdatavarianceasmuchaspossible.PCAcanextractuncorrelated features todescribe theembedded statistical informationofdata sets.PCAhasassumptionthatinputdatadistributecontinuouslyandnormally,althoughnon-normallydis-tributeddatamayalsoresultingoodprojection.However,whendataspreadinacomplicatedmanifold,PCAcanfail.PCAprovideslittlevisualizationimplicationsofthefeaturesintheoriginaldatasets.

Classical Machine-Learning Paradigms for Data Mining ◾ 43
2.1.2.6 Subspace Clustering
Inclusteringmethods,e.g.,k-means,similarobjectsaregroupedbymeasuringthedistancebetweenthem.Forhigh-dimensionaldata,objectsaredispersedinspaceanddistance,asthemeasureof“sameness”becomesmeaningless(referredasthe“curseofdimensionality”).Irrelevantdimensionsactasnoise,maskingtheclustersinagivendataset.Inordertoreducethenumberofdimensions,feature transformation (e.g., PCA in the next section) combines some attri-butestoproduceanewattribute.However,sincedimensionsarenotessentiallyeliminated, subspace clustering is not useful for clustering high-dimensionaldatawithanumberofirrelevantattributes.Featureselectionisusedtofindthesubsetthatcontainsthemostrelevantattributes.However,eventhissubsetmayhaveirrelevantattributesforsomeclusters.Inaddition,overlappingclusterswillbeignored.
Subspaceclustering,whichperformsalocalizationsearchandfocusesononlyasubsetofdimensions, isaneffectivetechniqueinsuchcases.Thistechniqueissimilar to feature selection, except that instead of searching the entire data set,thesubspacesearchislocalized.Thelocalizationofthesearchmakesitpossibletofindclusters frommultipleandoverlapping subspaces.Themotivation forusingsubspaceclusteringistoremovethedatathatarenotcoherentwiththeclustereddata.Thesedatacanbefoundbyplottingdatainthehistogramchartswiththedimensionsascoordinatereferences.
Subspaceclusteringalgorithmscanbecategorizedastop-downorbottom-up.Therearevariousbottom-up searchmethods likeCLIQUE,MAFIA,cell-basedclustering, CLTree, and density-based optimal projective clustering. All of themethodsusetheaprioristyleapproach.Inthisstyle, ifthereare“n”unitsin“s”
4v2 v1
λ1 λ2
3
2
13 975
Figure2.9 ExampleofPCAapplicationinatwo-dimensionalGaussianmixturedataset.

44 ◾ Data Mining and Machine Learning in Cybersecurity
dimensions,thenthe s-dimensionaldatawillbeprojectedin(s−1)dimensions.CLIQUEformsacluster,anditdiscardsthedataintheclusterthatarerepeatedduringinput.Theclusterthatisformedisrepresentedusingthedisjunctivenor-mal form (DNF). ENCLUS inherits all the characteristics of CLIQUE, exceptthatitusesentropytoevaluatetheclusters.MAFIAinheritsallthecharacteristicsofCLIQUE, and it introduces anewconcept calledparallelism.Thecell-basedclusteringmethodfixesall theefficiencyproblemsofthepreviousmethods,anditusesanindexstructuretoretrievedatafromtheclusters.TheCLTreemethodevaluatesbyconsideringeachclusterseparately,unlikethepreviousmethods.Inthedensity-basedmethod,theMonteCarloalgorithmisusedtofindthesubsetofdataclustersthatarenotincoherencewithotherdatainthecluster.Intop-downsubspacesearchmethods,wehavedifferenttypesofmethodssuchasPROCLUS,ORCLUS,FINDIT,andCOSA.ReadersshouldrefertoL.Parsons,E.Haque,andH.Liu(2004)fordetails.
2.2 ImprovementsonMachine-LearningMethodsAs discussed above, given a sample data set, a machine-learning algorithm canoutputaclasslabel.Themachine-learningmethodshavehypothesisthatthereexistunknownfunctionsforagivensampledataset.Usingthegiventrainingdataset,afamilyofhypothesescanbebuilt,andthenfunctionscanbetrained.Amachine-learning model can be applied on the new data for classification or prediction.Theseclassicmachine-learningmethodshavecommondrawbackswhenappliedincybersecurityapplications.Forexample,classicmachine-learningmethodscannotuseanomalydetectionorothercyberdefenseanalysisanddecisionproceduresduetospecificproblemsembeddedinthecybernetworkdata,e.g., imbalancedclassdistributionsofnormalandanomalydata.
2.2.1 New Machine-Learning AlgorithmsVariousnewlearningalgorithmshavebeenproposedtoclassifyimbalanceddatasets. The objective of these algorithms is to ensure the classification methodsachieveoptimalperformanceonunseendata.Therepresentativesofthemethodsincludeone-class learners,ensemblemethods,andcost-sensitive learners.One-classlearnersaretrainedtorecognizesamplesfromoneclasswhilerejectingsam-plesfromanotherclass.Inthetrainingprocess,one-classdataareusedprimarilytoidentifytheminorityclasssuccessfully.One-classlearnersarenotstable,andtheperformanceofone-classlearnersisstronglyaffectedbytheparametersandkernelused.
Cost-sensitive learners maximize a loss function associated with a data-based cost matrix in which misclassification costs are different, e.g., the costs

Classical Machine-Learning Paradigms for Data Mining ◾ 45
for classification results in confusion matrix in Figure 2.10. In the confusionmatrix, TP denotes true positive, TN denotes true negative, FP denotes falsepositive,andFNdenotesfalsenegative.Thecost-sensitivemethodsimprovetheclassificationperformance in imbalanced learning,although it is assumedthatthecostmatrixisavailable.Ensemblemachinelearningintegratestheclassifica-tionresultsofvariousclassifiersintooneclassificationresultinasuitablefashion,suchasbyvoting.Thismethodattemptstogeneralizethetaskbytrainingindi-vidualclassifiersusingrandomlyselectedsubsetsofthedataset.Aslongaseachdatasubsetisdifferent,ensemblemethodscanprovideagooddiscoveryofthemachine-learningtask.
Twomethods,baggingandboosting,resamplethedatasetinensembleclassifiers.Inthebaggingensemble,eachclassifieristrainedusingadifferentbootstrapofthedata set. (Section 2.1.1.9 contains a detailed explanation of the bagging, boost-ing,andbootstrapmethods.)Theaveragebootstrapcontainsroughly62%ofthesamplesintheoriginaldata.Onceeachclassifieristrained,thefinalclassificationresultisdeterminedbycountingthemajorityofclassifiers’votes.Baggingperformswellwhenindividualclassifierscanidentifylargedifferencesintheclassificationsinthetrainingdata.
Boostingisusedtoweightthemostdifficultsamplesthatareeasilymisclassi-fied.Inboosting,theprobabilityofmisclassificationisincreased,orviceversafortheseriesofclassifiers.Ensemblemethodscanbevalidonlyifthereisdisagreementamongclassifiers.Acombinationofclassifierscannotguaranteebetterperformancethananindividualclassifier.
Additionally, researchers attempt to apply semi-supervised machine-learningmethodstocombatchallengesinusinglabeleddatasetsforsupervisedlearning,suchastimeconsumption,expensiveness,limitationofexpertise,andtheaccuracyoflabelsincollectinglabeleddata.Especially,semi-supervisedlearninghasapplica-tionsincyberanomalydetection(Lakhinaetal.,2004).Reinforcedlearningisabranchofmachinelearning,whichconsidersthefeedbackfromthefinitestatesinanenvironmenttoadaptactionsintheenvironment.Reinforcedlearningmethodsparticularlyhaveapplicationsinmultiagentenvironmentsincyberinfrastructures.Werecommend(Kaelblingetal.,1996;Chapelleetal.,2006)formoredetailedanalysesofsemi-supervisedlearning.
True+
+
–
–
TP
Test
FN
FP
TN
Figure2.10 Confusionmatrixformachine-learningperformanceevaluation.

46 ◾ Data Mining and Machine Learning in Cybersecurity
2.2.2 ResamplingAs shown in Section 2.1.1.8, bootstrap, bagging, and AdaBoost are supervisedmachine-learningmethodsthatuseresampling.Similarly,otherresamplingmeth-odsaredesigned to improveclassifieraccuracieswhenused inconjunctionwithalgorithmsfortrainingclassifiers.Forexample,resamplingiscommonlyusedforimbalancedlearning.Resamplingaddssamplestominorityclassesorreducessam-plesinmajorityclassesinimbalanceddatasetsbyusingartificialmechanisms.Theresamplingdatadistributionisclosertoabalanceddatadistribution.
Resamplingmethodscanbeclassifiedintothefollowinggroups:randomovers-ampling and undersampling, informed undersampling, and synthetic samplingwithdatageneration.Undersamplingisperformedbyreducingsamplesinthemajor-ityclass.Thistechniquemaymissimportantinformationpertainingtothemajorityclass.Oversamplingreplicatestheminoritysamples,whichcausesoverfitting.Thesyntheticsamplingmethodgeneratessyntheticdatasamplesfortheminorityclassbyusingclusteringmethods,suchasfindingthenearestneighborstothecurrentminority samples. This method may increase overlap between classes. Althoughnoneofthesemethodsisperfect,studieshaveshownthatsamplingmethodscanimprovetheoverallclassificationperformanceofclassifiersoverunbalanceddatasets(H.HeandE.A.Garcia,2009).
2.2.3 Feature Selection MethodsImbalanced data is commonly accompanied by high-dimensional feature space.Among the high-dimensional features, the existence of many noisy features canhinder and downgrade classifier performance. In the last few years, feature selec-tionandsubspacemethodshavebeenproposedandevaluatedtosolvethisproblem.Featuresubsetselectionmethodsareusedtoselectasmallfeaturesubsetamonghigh-dimensionalfeaturesaccordingtofeatureselectionmetrics.Ithasbeendemonstratedthat feature selectionmethodsperformbetter thanclassificationalgorithmswhenimbalanceddatahavethecharacteristicsofhigh-dimensionalfeaturespace.
Featureselectionmethodscanbedividedintotwocategories,featurescalarselec-tion,whichselectsfeatures individually,andfeaturevectorselection,whichselectsfeaturesbasedonthemutualcorrelationbetweenfeatures.Featurescalarselectionhastheadvantageofcomputationsimplificationandmaynotbeeffectiveforadatasetwithmutuallycorrelatedfeatures.Featurevectorselectionmethodsselectthebestfeaturevectorcombinations.
Featurevectorselectionmethodscanbefurtherdividedintowrapperandfilter-basedmethods.Wrappersusemachine-learningmethods,suchasblackbox,andselect the features that aremost relevant, so that the learningmethodperformsoptimally. The search strategies include exhaustive search, beam search, branchandbound,geneticalgorithms,greedysearchmethods,andsoon.Whenwrappersareused,theselectedfeaturesarepronetooverfittingthedata.Inthefilter-based

Classical Machine-Learning Paradigms for Data Mining ◾ 47
featureselectionmethod,thefeatureiscorrelatedwithaclassoffeaturesanditscorrespondingfeaturesubset.
Usingacorrelationmeasureleadstoanoptimalsolutioninfeatureselection.Thus,themethodfocusesontwoissues:thecorrelationmeasurecriteriaandthefeature selection algorithm. The correlation criteria can be Pearson’s correlationcoefficient (PCC),mutual information (MI), andother relevantcriterions.PCCisameasureoflineardependencybetweenvariablesandfeatures.Itisversatiletocontinuousorbinaryvariables.
MIcanmeasurenonlineardependency,whichmeasurestheirrelevanceofindi-vidualvariablesusingtheKullback-leiblerdivergence.However,MIisharderthanPCCtoestimate,especiallyforcontinuousdata.Atypicalfilter-basedfeatureselec-tionmethodissequentialforwardfloatingselection(SFFS),whichfindsthebestapproximationsolutionwithregardtothenumberofselectedfeatures.SFFSstartsfromanemptyfeatureselectionpoolandincreasesthepoolusingthelocaloptimalfeature set in two steps: inclusionandconditional exclusion steps.Theheuristicbasis of theSFFS algorithm is the assumption that the feature selection criteriaaremonotonicwiththechangeoffeaturesizeandfeaturesetinformation.SFFSapproximatestheoptimalsolutionatanaffordablecomputationalcost.
2.2.4 Evaluation MethodsThe traditional classification metrics include classification accuracy and error,definedasfollows:
accuracy TP TN
=+# # ,S
(2.32)
error accuracy= −1 . (2.33)
Themetricsaresensitivetothechangeinthedatasetandareeffectivewhendataarenotbalanced.Forexample,wehaveadatasetthathasadistributioninwhich95%ofsamplesarenegativeand5%ofsamplesarepositive.If5ofagiventestdatasetof100samplesarepositiveand95samplesarenegative,then,evenifalltestresultsareclassifiedasnegative,theaccuracyis95%.ThisvalueispreservedwhenthenumberofTNincreaseswhilethenumberofTPdecreasesthesameamount.Whenthepositiveresultismoreimportantforresearchers,theabovemetricscan-notprovidetheexactinformationoftheclasslabels.
Tocomprehensivelyevaluateimbalancedlearning,especiallyforminorityclassi-fication,othermetricsareusedincludingprecision,recall,F-score,Q-score,G-mean,receiveroperatingcharacteristics(ROC),areasunderreceiveroperatingcharacter-istics,precisionrecallcurves,andcostcurves.Themetricsaredefinedasfollows:
Precision TP
TP FP=
+#
# #,
(2.34)

48 ◾ Data Mining and Machine Learning in Cybersecurity
Recall TP
TP FN=
+#
# #,
(2.35)
F -score Recall Precision
Recall Precision=
+ ⋅ ⋅⋅ ⋅
( ) ,1 2
2β
β (2.36)
or
F -score TP
TP FN FP=
+ ⋅+ ⋅ + ⋅ +
( )( )
## # #
,11
2
2 2β
β β (2.37)
and
G -mean TPTP FN
TNTN FP
=+
⋅+
## #
## #
. (2.38)
Precision,as showninEquation2.34,measures theexactnessofpositive labeling,thecoverageofthecorrectpositivelabelsamongallpositive-labeledsamples.Recall,asshowninEquation2.36,measuresthecompletenessofpositivelabeling,theper-centage of the correctly labeledpositive samples among all positive class samples.Precisionissensitivetodatadistribution,whilerecallisnot(asshownintheconfu-sionmatrix inFigure2.10).Recalldoesnotreflecthowmanysamplesare labeledpositive incorrectly, and precision does not provide any information about howmanypositive samplesare labeled incorrectly.F-measurecombines theabove twometricsandassignstheweightedimportanceoneitherprecisionorrecallusingthecoefficientβ.Consequently,theF-measureprovidesmoreinsightintotheaccuracyofaclassifierthanrecallandprecision,whileremainingsensitivetodatadistribution.TheG-meanevaluatestheinductivebiasoftheclassifierusingtheratioofpositivetonegativeaccuracy.
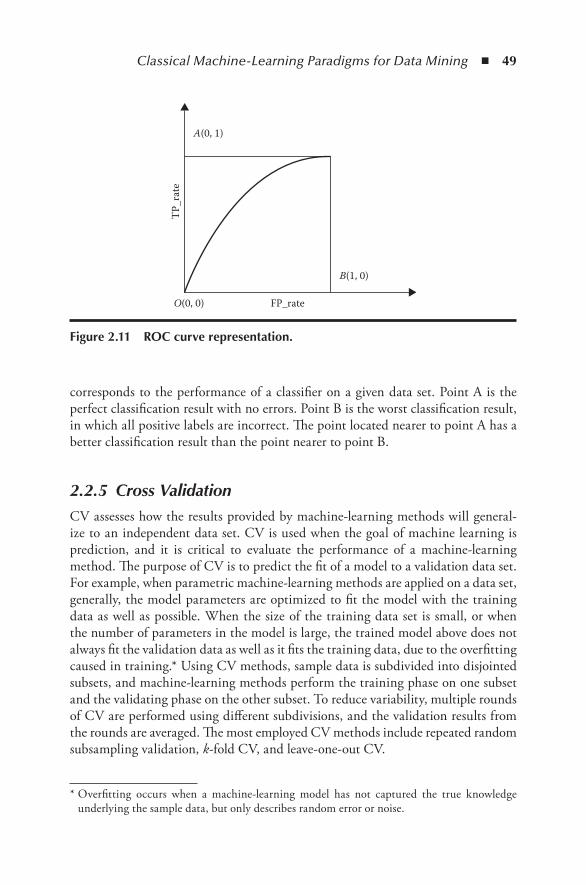
ROC curves provide more insight into the relative balance between thegains(truepositive)andcosts(falsepositive)ofclassificationonagivendataset.TwoevaluationmetricsareusedinROCcurvesasfollows:
TP TP
rate =# ,Smi
(2.39)
FP FPrate =
# .Sma (2.40)
AsshowninFigure2.11,ROCcurvesarecomposedofthecombinationalvaluesofTPrateandFPrate.EachpointontheROCcurve(thegray lineinFigure2.11)
Classical Machine-Learning Paradigms for Data Mining ◾ 49
correspondstotheperformanceofaclassifieronagivendataset.PointAistheperfectclassificationresultwithnoerrors.PointBistheworstclassificationresult,inwhichallpositivelabelsareincorrect.ThepointlocatednearertopointAhasabetterclassificationresultthanthepointnearertopointB.
2.2.5 Cross ValidationCVassesseshowtheresultsprovidedbymachine-learningmethodswillgeneral-izetoanindependentdataset.CVisusedwhenthegoalofmachinelearningisprediction, and it is critical to evaluate the performance of a machine-learningmethod.ThepurposeofCVistopredictthefitofamodeltoavalidationdataset.Forexample,whenparametricmachine-learningmethodsareappliedonadataset,generally,themodelparametersareoptimizedtofitthemodelwiththetrainingdataaswellaspossible.Whenthesizeofthetrainingdatasetissmall,orwhenthenumberofparametersinthemodelislarge,thetrainedmodelabovedoesnotalwaysfitthevalidationdataaswellasitfitsthetrainingdata,duetotheoverfittingcausedintraining.*UsingCVmethods,sampledataissubdividedintodisjointedsubsets,andmachine-learningmethodsperformthetrainingphaseononesubsetandthevalidatingphaseontheothersubset.Toreducevariability,multipleroundsofCVareperformedusingdifferentsubdivisions,andthevalidationresultsfromtheroundsareaveraged.ThemostemployedCVmethodsincluderepeatedrandomsubsamplingvalidation,k-foldCV,andleave-one-outCV.
* Overfitting occurs when a machine-learning model has not captured the true knowledgeunderlyingthesampledata,butonlydescribesrandomerrorornoise.
O(0, 0) FP_rate
TP_r
ate
A(0, 1)
B(1, 0)
Figure2.11 ROCcurverepresentation.

50 ◾ Data Mining and Machine Learning in Cybersecurity
2.3 ChallengesMachinelearningfordata-miningapplicationsincybersecurityfacechallengesduetotheamountandcomplexityofgrowingdataincyberinfrastructures.Intrusions(e.g.,networkanomalies)aremovingtargetsandaredifficulttodetectpreciselyandinapredefinedway.Meanwhile, large falsealarmsmakeanalysisoverwhelmingduetothelackoflabelsforintrusion.
2.3.1 Challenges in Data MiningThechallengesareclassifiedintofourareasfordata-miningapplicationsincyberse-curity:modelinglarge-scalenetworks,intrusiondiscovery,networkdynamics,andprivacypreservingindatamining.
2.3.1.1 Modeling Large-Scale Networks
Modelingacyberinfrastructureischallenging,asmanycommongraphmeasuresare difficult to compute for theunderlying networks. It is difficult to build theexplanatorymodelofnetworksduetotherequirementsforaccuratelearningandprediction: Realistic networks at different scales are simulated for testing algo-rithmsfordefense,andanomaliesthatdonotconformtothemodelandpotentiallyrepresentanintrusionorothernetworkproblemaredetected.
Anetworkmodelcanbeextractedpartiallyandamenablyforadvancedanaly-sis,andanetworkcanbebuiltinareal-world,meaningfulwaybutmaynotfollowthe assumption of iid random variables.Moreover, challenges exist in the com-putation of graphic measures in the network model. Examples of these graphicmodelshavethedynamicnetworkoftelecommunications,e-mailcommunicationnetworks throughwhichviruses spread,andthenetworkofhyperlinksbetweenWebsites.Oneexampleofagraphicmeasureisthegraphdiameter,i.e.,thegreat-estdistancebetweentwonodesinagraph.Thecomputationdifficultiescallforadata-miningmodelthatdiscoversthenatureofrealdatausingasimplermodel.
2.3.1.2 Discovery of Threats
Data-miningcyberinfrastructureforthediscoveryofthreatssuffersfromthesheervolumeandheterogeneousnetworkdata,thedynamicchangeofthreats,andthesevere imbalanced classes of normal and anomalous behaviors. The above chal-lengescallforthemethodsthatcanaggregateinformationdynamicallyandlocallyandacrossthenetworkstodetectcomplexmultistageattacksandpredictpotentialandrarethreatsbasedonthebehavioranalysisofnetworkeventdata.Themostemployedmethodsfordetectingmaliciouscodeorbehavioruserule-basedorsta-tisticalmodelstoidentifythreatsinreal-time,usingadaptivethreatdetectionwithtemporaldatamodelingandmissingdata.Thesamplingofbig-scalenetworkdata

Classical Machine-Learning Paradigms for Data Mining ◾ 51
hastobeadaptivetotheuncertaintyofphysicalchangesofnetworks,maliciouscode,andmaliciousbehavior.Adaptiveanddynamicmodelingisnecessaryforthetemporallyevolvingdatastructureandfeatures.
2.3.1.3 Network Dynamics and Cyber Attacks
Manycyberattacksspreadmalwaretovulnerablecomputers.Duetothecondi-tionstriggeringthemalware,themalwaremayinfectcomputersinanetworkinvaryingdegrees.Oncethecyberdefendersdetectthemalware,thespreadofmal-wareinfectionsisinvestigatedtobuildtheprotectionsystem.Noveldata-miningmethodsarenecessarytopredictfutureattacksbyconstantlyevolvingmalwareandlaunchdefensescorrespondingly.However,thedetailedstructureofthenetworkisunknown,limitingtheknowledgeofinfectionevolution.
2.3.1.4 Privacy Preservation in Data Mining
Data-miningtechniquesarecriticalfordiscoveringintrusionsincybersecuritysys-tems.However,dataminingcanalsobeusedmaliciouslyincyberinfrastructurestobreachprivacy.Inprinciple,themorecompletedataisavailablefordatamining,themoreaccuratetheminingresultthatwillbeobtained.However,thecompre-hensiveandaccuratedatamayalsoraiseprivacybreachissues.Furthermore,thedata-miningresultcanpotentially revealprivate information.Privacypreservingdatamining(PPDM)protectsprivatedatafrombeingstolenormisusedbymali-cioususers,whileallowingtheotherdatatobeextractedforuse.
2.3.2 Challenges in Machine Learning (Supervised Learning and Unsupervised Learning)
Machinelearningfaceschallengesthatarecommonforresearchersinanyapplica-tion.First,itisdifficulttoselectagoodmachine-learningalgorithmthatisamena-bleforthenewdatabythecomparativeevaluationofmachine-learningmethods.Insufficientknowledgeabouttheperformanceofthegivenmachine-learningmeth-odsindifferentdatasetsmakessuchevaluationdifficult.Second,thereisnowaytoprovidetheexactquantityrequirementfortrainingdataandvalidationdata.Nomethodsexisttodemonstratethatagivenmachine-learningmethodcanconverge.
Third, the relationship between the stability of machine-learning methodsand theiroptimal settingsofparametershasnotbeenestablished.For example,theselectionofaclusternumberk ink-meansclusteringisempirical.Normally,researchersbelievethebestkshouldbeaccompaniedbythestableperformanceofthek-meansinavailabledata.Whenthedataisnotenoughtoreflectthegroundtruthinthedatadistribution,theselectednumberkiswrong.Meanwhile,anotherquestionarisesevenifthiskreflectsthesmallsampledatawell:Whatistherelationbetweenthesampledatadistributionandthetruedatadistribution.

52 ◾ Data Mining and Machine Learning in Cybersecurity
Incybersecurity,machinelearningisformulatedtoclassifyeventdataintonor-maloranomalyclasses.Machinelearninghastwoformulationsaccordingtotheclassificationobjectives.Inthefirstformulation,machinelearningdetectsanomalypatternsbyemployinga learningmechanismandclassifyingnewnetworkeventdataintonormaloranomalyclasses.Inversely,inthesecondformulation,machinelearningdetectsnormalpatterns.Thefirstimplementationofmachinelearningismostemployedinmisusedetectionwhilethesecondismostemployedinanomalydetection.Asoneofthemostusedmethodsindata-miningapplicationsincyber-security, machine learning faces pertinent challenges as stated in Section 2.3.1.Machinelearningalsofacesthefollowingobstacles:onlinelearningmethodsforthedynamicmodelingofnetworkdataandmalware,modelingdatawithskewedclassdistributionstohandlerareeventdetection,andfeatureselection/extractionfordatawithevolvingcharacteristics.
2.3.2.1 Online Learning Methods for Dynamic Modeling of Network Data
The most employed method for finding the temporal or sequential patterns ofan audit data stream is to slide a window across the audit trace and deter-minewhethertheshortsequencewithintheslidingwindowisanomalousornot.Sequencesofthe samewindowsizeareused in trainingand testing.Thepri-marydifficultywithusingthismethodisselectingtheappropriatewindowsizeforanomalydetectionusingagoodlearningmethodinsteadoftrial-and-error.
Information-theoretic measures have been proposed to describe the regular-ityofanauditdatasetanddeterminethebestslidingwindowsizebasedontheconditional entropy and information cost measures. However, a simple traineddetectorbasedoninstancecannotbegeneralized,andtheconditionalentropydoesnotaffecttheappropriatewindowsize.Consequently,agoodlearningmethodisneededtofindtheoptimumwindowsizeforsequencelearninginanomalydetec-tionanddynamicmodelinginnetwork.
2.3.2.2 Modeling Data with Skewed Class Distributions to Handle Rare Event Detection
There is a fundamental asymmetry in anomaly detection problems: normalactivity iscommon,and intrusiveactivity in thenetwork is typicallya smallfractionofthetotalnetworkdata.Oneoftenfacesatrainingsetconsistingofahandfulofattackexamplesandplentyofnormalexamples,ornoattackexam-pleatall.Standardmachine-learningclassificationmethodshavebeenfoundtobebiasedtowardrecognizingthemajorityclassinanimbalanceddataset.Because classic learning algorithms have the assumption that data distributeequallyamongclasses,theminingaccuracycanberepresentedbytheoverallclassificationaccuracyacrosstheclassesofdata.Theseclassificationalgorithms

Classical Machine-Learning Paradigms for Data Mining ◾ 53
generalizewell to the overall predictive accuracy of trainingdatawhendataequallydistributeacrossclasses.
Whenadatasetishighlyskewed,aclassifierattemptstoclassifyboththemajor-ityandminoritysamplesintothemajorityclassforbetterclassificationaccuracyoverallsamples.Ithasbeenshownthathighpredictiveaccuracyoverallsamplescannotguaranteethecorrectclassificationofminoritysamples.Becauseofthelackofattackexamples,improvedimbalancedmachine-learningapproachesareneededto generate ameaningful andgeneral classificationof the intrusivebehavior forintrusiondetection.Classificationshouldbefocusedtowardclassifyingtheminor-itybehaviorasattackoranomalous.
2.3.2.3 Feature Extraction for Data with Evolving Characteristics
Inanomalydetection,therearemanydifferentlevelsatwhichanintrusiondetectionsystem(IDS)canmonitoractivitiesinacomputersystem.Anomaliesmaybeunde-tectableatonelevelofgranularityorabstractionbuteasytodetectatanotherlevel.Forexample,awormattackmightescapedetectionatthelevelofasinglehost,butbedetectablewhenthetrafficofthewholenetworkisobservedandanalyzed.Oneofthebiggestchallengesinanomalydetectionistochoosefeatures(i.e.,attributes)thatbestcharacterizetheuserorsystemusagepatternssothatintrusivebehaviorwillbeperceived,whereasnonintrusiveactivitieswillnotbeclassifiedasanomalous.
Evenatacertainlevelofmonitoringgranularity,oneoftenfacesalargenumberoffeaturesrepresentingthemonitoredobject’sbehavior.Forinstance,anetworkconnectioncanbecharacterizedwithnumerousattributes,includingbasicfeaturessuchassourceanddestinationIPs,ports,protocols,andothersecondaryattributes.Meanwhile,anaudittrailusuallyconsistsofsequencesofcategoricalsymbolsgen-eratedfromalargediscretealphabet.Aprogrammayissueseveralhundreduniquesystemcalls.Thehighdimensionalityofthedataorthelargealphabetsizegivesrisetoalargehypothesissearchspace.This,inturn,notonlyincreasesthecomplexityoftheproblemoflearningnormalbehavior,butalsocanleadtolargeclassificationerrors.Therefore,selectingrelevantfeaturesandeliminatingredundantfeaturesisvitaltotheeffectivenessofthemachine-learningtechniqueemployed.Likeothermachine-learningapplications,anomalydetectionoftenneedsanexperttousehisorherdomainknowledgetoselectrelevantfeaturesmanually.
2.4 ResearchDirectionsAsshownintheaboveliteraturereview,asignificantamountofresearchhasbeendoneincybersecurityusingmachine-learninganddata-miningmethods.However,manyfundamentalproblemsawaitsolutions,andthecomplexityofcybersecurityproblemspresentnewresearchchallengesinthedomainsofmachinelearninganddatamining.Thecomplexityofmanylearningproblemsincybersecuritygoeswellbeyondthecapabilitiesofcurrentmachine-learningmethods.

54 ◾ Data Mining and Machine Learning in Cybersecurity
Inthecybersecurityarea,themachine-learningtechnologiesthatarebeingusedarenotadequatetohandlechallengesfromthehugeamountofdynamicandseverelyimbalancednetworkdata.Machine-learningtechnologiesshouldberevolutionizedsothattheirpotentialcanbeleveragedtoaddressthosechallengesincybersecurity.Webrieflydiscussseveralaspectsforthefutureresearchdirectionsinthisdomain.
2.4.1 Understanding the Fundamental Problems of Machine-Learning Methods in Cybersecurity
Mostoftheresearcheffortsinmachine-learningapplicationsincybersecurityfocusonspecificmachine-learningalgorithmsandcasestudies;onlyalimitednumberofprincipalandconsequencetheorieshavebeeninvestigated.Wehavediscussedsev-eral fundamentalproblemsexistinginmachine-learningmethods,andsimilarly,fundamentalquestionsawaitanswersinthechallengesposedinSection2.3.Forexample,animbalancedlearningproblemexistsincybersecurity.
Thefollowingarethecriticalquestionsthatremainunansweredinthisdomain.First,what assumptionsmake imbalanced learningalgorithmsworkbetter thanalgorithmsthatlearnfromtheoriginaldistribution?Second,towhatdegreeshoulddatabebalancedsuchthatordinarymachine-learningmethodsworkwell?Third,givenimbalanceddata,whatistheoptimalsolutionforanimbalancedmachine-learningmethod,andhowcanwedefinethebestperformancemetricforimbal-anced learning? Fourth, is there theoretical evaluation of different imbalancedlearning methods, such as between resampling and cost-effective learning. Theanswerstothesequestionscanvastlyimproveresults.
2.4.2 Incremental Learning in CyberinfrastructuresTheoretically,thereisaninadequateunderstandingofthecharacteristicsandnor-malbehaviorofanattack.Withoutthisinformation,itisdifficulttodetectexcur-sionsfromthenorm.However,cyberinfrastructurecontainsahugeamountofdatastreamingcontinuouslyanddynamically.Thesedataarerequiredforincrementallearning. Dynamic information challenges machine-learning modeling, whereas“time”addsimportantinformationfortheunderstandingandlearningofanoma-lies.Newmachine-learningprinciples,methodologies, algorithms, and tools arerequiredforsuchdynamicmodelingtotransformrawdataintotheusefulinforma-tionabouttheirownnormalandanomalybehaviors.
2.4.3 Feature Selection/Extraction for Data with Evolving Characteristics
Feature selection/extraction methods partially solve the problems that cyber-security encounters with imbalanced data sets. However, the existing featureselection/extraction methods extract static information without perturbation.

Classical Machine-Learning Paradigms for Data Mining ◾ 55
Cyberinfrastructureischaracterizedwithalargeamountofevolvingdynamicinfor-mation.Thisevolvinginformationrequiresfeatureselection/extraction,notonlytoreducethedimensionalityformachinelearning,butalsotocapturetheevolvingcharacteristics.Todiscovertheevolvingpatternsindata,machine-learningmeth-odshavetobecombinedintofeatureselection.Newmachine-learningandfeature-selectiontechniquesarerequiredtoindentifycontinuousbehaviorindata.
2.4.4 Privacy-Preserving Data MiningPPDMtechniquesaddressconcernsthatthebroaduseofdataminingwillthreatentheprivacyofindividuals,industries,andevencountries.Meanwhile,PPDMopensopportunities fordataminingtoprotectprivatedata fromdisclosure.Theinter-actionbetween legallyprotecteddataanddatamininghasneverbeenexplored.PPDMisrelativelynewandhasnotbeenadoptedinreal-worldapplications.Atthispoint,itisnotclearhowmuchorlittleprivateinformationdata-miningmethodscandisclose.Thus,machine-learninganddata-miningmethodsshouldbefunda-mentallyinvestigatedtoanswerthisquestion.Meanwhile,thedevelopedPPDMmethodsneedtobeevaluatedforresearcherstodeterminehowmuchprivacytheycanprotect.
2.5 SummaryInthischapter,weintroducedthefundamentalbackgroundofmachinelearningandprovidedabriefoverviewofmachine-learningformulationsandmethodsfordataminingincybersecurity.Wediscussedchallengingandcriticalproblemsthatoccurwhenmachine-learningmethodsareappliedinthehugeamountoftempo-ralandunbalancednetworkdata.Wehopethatourdiscussionsofthenatureofthenetworkdata,fundamentalproblemsexistinginmachinelearning,therecom-mendedsolutionsusedtoaddresstheproblems,andtheevaluationmethodsusedtoexploretheproblemswillserveasacomprehensiveresourceforresearchers inmachinelearning,datamining,andcybersecurity.Wealsohopethatourinsightsintothenewresearchareawillhelpguidepotentialresearchinthefuture.
ReferencesBreiman,L.Baggingpredictors.Machine Learning24(2)(1996):123–140.Breiman,L.Randomforests.Machine Learning45(1)(2001):5–32.Chapelle, O., B. Schölkopf, and A. Zien, eds. Semi-Supervised Learning. Cambridge,
MA:TheMITPress,2006.Dietterich,T.G.Machinelearningforsequentialdata:Areview.In:Proceedings of the Joint
IAPR International Workshop on Structural,Syntactic,and Statistical Pattern Recognition,WindsorandOntario,Canada,2002,pp.15–30.

56 ◾ Data Mining and Machine Learning in Cybersecurity
Freund,Y. andR.E.Schapire.Adecision-theoreticgeneralizationofon-line learningandan application to boosting. Journal of Computer and System Sciences 55 (1) (1997):119–139.
Freund,Y.andR.E.Schapire.Ashortintroductiontoboosting(inJapanese,translationbyNaokiAbe).Journal of Japanese Society for Artificial Intelligence14(5)(1999):771–780.
He,H.andE.A.Garcia.Learningfromimbalanceddata.IEEE Transactions on Knowledge and Data Engineering21(9)(2009):1263–1284.
Jain, A.K., R.P.W. Duin, and J. Mao. Statistical pattern recognition: A review. IEEE Transactions on Pattern Analysis and Machine Intelligence22(1)(2000):4–37.
Kaelbling,L.P.,M.L.Littman,andA.W.Moore.Reinforcementlearning:Asurvey.Journal of Artificial Intelligence Research4(1996):237–285.
Lakhina, A., M. Crovella, and C. Diot. Diagnosing network-wide traffic anomalies. In:Proceedings of the 2004 Conference on Applications,Technologies,Architectures,and Protocols for Computer Communications,Portland,OR,Vol.34,No.4,2004,pp.219–230.
Parsons,L.,E.Haque,andH.Liu.Subspaceclusteringforhighdimensionaldata:Areview.SIGKDD Exploration Newsletter6(1)(2004):90–105.
Rabiner,L.R.AtutorialonhiddenMarkovmodelsandselectedapplicationsinspeechrec-ognition.Proceedings of the IEEE77(2)(1989):257–286.
Roweis, S. and Z. Ghahramani. A unifying review of linear Gaussian models. Neural Computation11(2)(1999):305–345.
Related Documents











