1 CHƢƠNG III Phân tích cú pháp Mục tiêu: -Nắm đƣợc vai trò của giai đoạn phân tích cú pháp - Văn phạm phi ngữ cảnh (context- free grammar),cách phân tích cú pháp từ dƣới lên- từ trên xuống (top-down and bottom-up parsing) -Bộ phân tích cú pháp LR CuuDuongThanCong.com https://fb.com/tailieudientucntt

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
CHƢƠNG IIIPhân tích cú pháp
Mục tiêu:
-Nắm đƣợc vai trò của giai đoạn phân tích cú pháp
- Văn phạm phi ngữ cảnh (context- free grammar),cách phân tích cú pháp từ dƣới lên- từ trên xuống (top-down and bottom-up parsing)
-Bộ phân tích cú pháp LR
CuuDuongThanCong.com https://fb.com/tailieudientucntt

2
Vai trò của bộ phân tích cú pháp
• Đây là giai đoạn thứ 2 của quá trình biên dịch
• Nhiệm vụ chính: Nhận chuỗi các token từ bộ phân tích từ vựng và xác định chuỗi đó có đƣợc sinh ra bởi văn phạm của ngôn ngữ nguồn không
Source
program
Lexical
analyzerGet next
token
TokenParser
Symbol
table
Parse
tree
Rest of
front end
CuuDuongThanCong.com https://fb.com/tailieudientucntt

3
• Các phƣơng pháp phân tích cú pháp (PTCP) chia làm hai loại: Phân tích từ trên xuống (top- down parsing) và phân tích từ dƣới lên (bottom- up parsing)
• Trong quá trình biên dịch xuất hiện nhiều lỗi trong giai đoạn PTCP do đó bộ phân tích cú pháp phải phát hiện và thông báo lỗi chính xác cho ngƣời lập trình đồng thơi không làm chậm những chƣơng trình đƣợc viết đúng
CuuDuongThanCong.com https://fb.com/tailieudientucntt

4
Văn phạm phi ngữ cảnh
• Để định nghĩa cấu trúc của ngôn ngữ lập trình ta dùng văn phạm phi ngữ cảnh (Context-free grammars) hay gọi tắt là một văn phạm
• Một văn phạm bao gồm:
- Các kí hiệu kết thúc (terminals): Chính là các token
- Các kí hiệu chƣa kết thúc (nonterminals): Là các biến kí hiệu tập các xâu kí tự
- Các luật sinh (productions): Xác định cách thức hình thành các xâu từ các kí hiệu kết thúc và chƣa kết thúc
- Một kí tự bắt đầu (start symbol)
CuuDuongThanCong.com https://fb.com/tailieudientucntt

5
Ví dụ 3.1: Văn phạm sau định nghĩa các biểu thức số học đơn giản
E E A E | (E) | -E | id
A + | - | * | / |
Trong đó E, A là các kí tự chƣa kết thúc (E còn là kí tự bắt đầu), các kí tự còn lại là các kí tự kết thúc
CuuDuongThanCong.com https://fb.com/tailieudientucntt

6
• Dẫn xuất (derivation): Ta nói Anếu A là một luật sinh ( đọc là dẫn xuất hoặc suy ra)
• Nếu 1 2 ...... n thì ta nói rằng
1 dẫn xuất n
• Kí hiệu: * là dẫn xuất 0 bƣớc, + là dẫn xuất 1 bƣớc
• Cho văn phạm G với kí tự bắt đầu là S, L(G) là ngôn ngữ đƣợc sinh bởi G. Mọi xâu trong L(G) chỉ chứa các kí hiệu kết thúc của G
CuuDuongThanCong.com https://fb.com/tailieudientucntt

7
• Ta nói một xâu w L(G) nếu và chỉ nếu S +
w, w đƣợc gọi là một câu (sentence) của văn phạm G
• Một ngôn ngữ đƣợc sinh bởi văn phạm phi ngữ cảnh đƣợc gọi là ngôn ngữ phi ngữ cảnh (context- free language)
• Hai văn phạm đƣợc gọi là tƣơng đƣơng nếu sinh ra cùng một ngôn ngữ
• Nếu S * ( có thể chứa kí hiệu chƣa kết thúc) thí ta nói là một dạng câu (sentence form) của G. Một câu là một dạng câu không chứa kí hiệu chƣa kết thúcCuuDuongThanCong.com https://fb.com/tailieudientucntt

8
Ví dụ 3.2: Xâu –(id+id) là một câu của văn phạm trong ví dụ 3.1 vì
E -E -(E) -(E+E) -(id+E) (id+id)
• Một dẫn xuất đƣợc gọi là trái nhất (leftmost) nếu tại mỗi bƣớc kí hiệu chƣa kết thúc ngoài cùng bên trái đƣợc thay thế, kí hiệu lm. Nếu S *lm thì đƣợc gọi là dạng câu trái
• Tƣơng tự ta có dẫn xuất phải nhất (rightmost) hay còn gọi là dẫn xuất chính tắc, kí hiệu rm
CuuDuongThanCong.com https://fb.com/tailieudientucntt

9
• Cây phân tích cú pháp (parse tree) là dạng biểu diễn hình học của dẫn xuất. Ví dụ parse tree cho biểu thức –(id+id) là:
E
E
(
-
)E
E
|
id
E
|
id
+
CuuDuongThanCong.com https://fb.com/tailieudientucntt

10
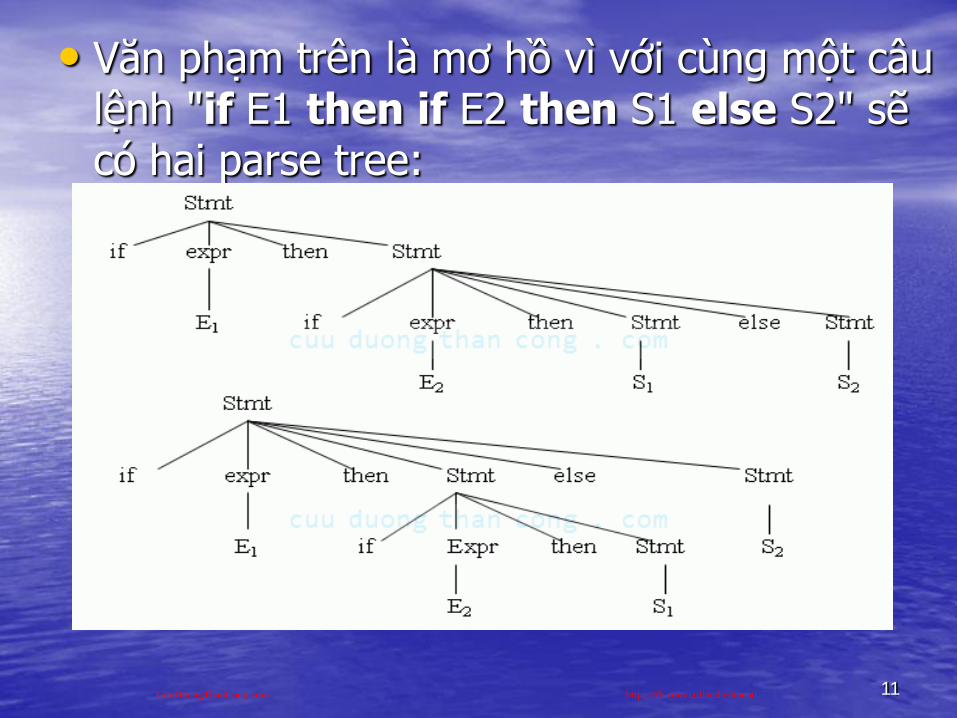
• Tính mơ hồ của văn phạm (ambiguity): Một văn phạm sinh ra nhiều hơn một parse tree cho một câu đƣợc gọi là văn phạm mơ hồ. Nói cách khác một văn phạm mơ hồ sẽ sinh ra nhiều hơn một dẫn xuất trái nhất hoặc dẫn xuất phải nhất cho cùng một câu.
• Loại bỏ sự mơ hồ của văn phạm: Ta xét ví dụ văn phạm sau
Stmt if expr then stmt
| if expr then stmt else stmt| other
CuuDuongThanCong.com https://fb.com/tailieudientucntt
11
• Văn phạm trên là mơ hồ vì với cùng một câu lệnh "if E1 then if E2 then S1 else S2" sẽ có hai parse tree:
CuuDuongThanCong.com https://fb.com/tailieudientucntt

12
• Ðể loại bỏ sự mơ hồ này ta đƣa ra qui tắc "Khớp mỗi else với một then chƣa khớp gần nhất trƣớc đó". Với qui tắc này, ta viết lại văn phạm trên nhƣ sau :
Stmt matched_stmt | unmatched_stmt
matched_stmt if expr thenmatched_stmt else
matched_stmt
| other
unmatched_stmt if expr then Stmt
| if expr thenmatched_stmt else
unmatched_stmtCuuDuongThanCong.com https://fb.com/tailieudientucntt

13
• Loại bỏ đệ qui trái: Một văn phạm đƣợc gọi là đệ qui trái (left recursion) nếu tồn tại một dẫn xuất có dạng A + A (A là 1 kí hiệu chƣa kết thúc, là một xâu).
• Các phƣơng pháp phân tích từ trên xuống không thể xử lí văn phạm đệ qui trái, do đó cần phải biến đổi văn phạm để loại bỏ các đệ qui trái
• Ðệ qui trái có hai loại :
Loại trực tiếp: Có dạng A + A
Loại gián tiếp: Gây ra do dẫn xuất của hai hoặc nhiều bƣớc CuuDuongThanCong.com https://fb.com/tailieudientucntt

14
• Với đệ qui trái trực tiếp: Ta nhóm các luật sinh thành
A A 1 | A 2 |..... | A m | 1 | 2 |.....|
n
Thay luật sinh trên bởi các luật sinh sau:
A 1A' | 2A' |..... | nA'
A' 1A' | 2A' |..... | mA' |
Ví dụ 3.3: Thay luật sinh A A | bởi
A A'
A' A' |
CuuDuongThanCong.com https://fb.com/tailieudientucntt
15
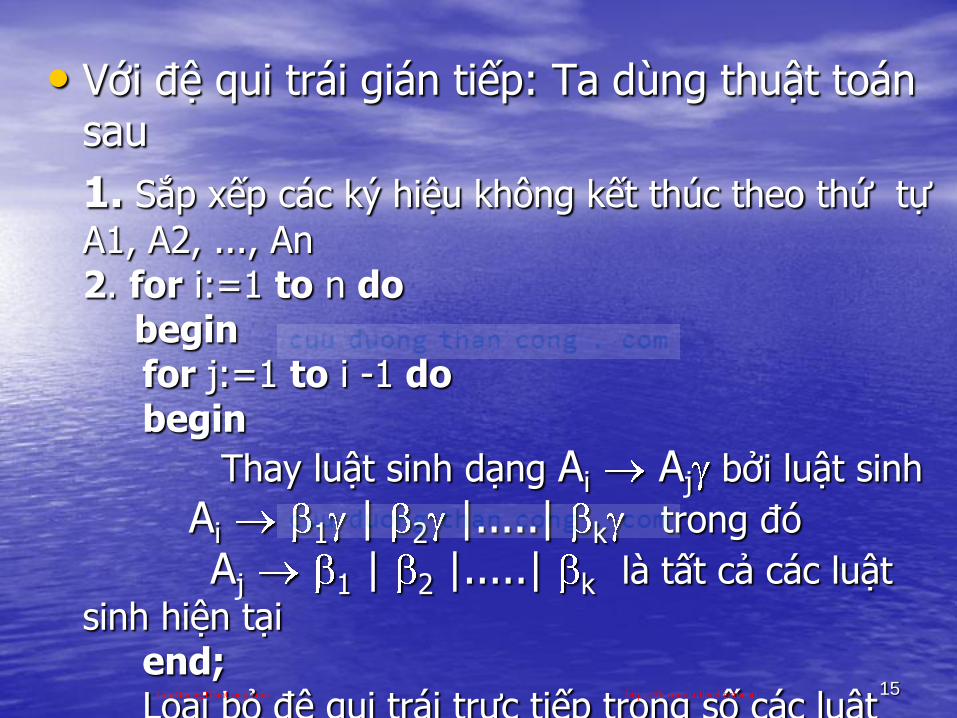
• Với đệ qui trái gián tiếp: Ta dùng thuật toán sau
1. Sắp xếp các ký hiệu không kết thúc theo thứ tự
A1, A2, ..., An2. for i:=1 to n do
beginfor j:=1 to i -1 dobegin
Thay luật sinh dạng Ai Aj bởi luật sinh
Ai 1 | 2 |.....| k trong đó
Aj 1 | 2 |.....| k là tất cả các luật
sinh hiện tạiend;Loại bỏ đệ qui trái trực tiếp trong số các luật
sinh Ai
CuuDuongThanCong.com https://fb.com/tailieudientucntt

16
• Tạo ra nhân tố trái (left factoring) là một phép biến đổi văn phạm rất có ích để có đƣợc một văn phạm thuận tiện cho việc phân tích dự đoán
• Ý tƣởng cơ bản là khi không rõ luật sinh nào trong hai luật sinh khả triển có thể dùng để khai triển một ký hiệu chƣa kết thúc A, chúng ta có thể viết lại các A- luật sinh nhằm "hoãn" lại việc quyết định cho đến khi thấy đủ yếu tố cho một lựa chọn đúng.
CuuDuongThanCong.com https://fb.com/tailieudientucntt

17
Ví dụ 3.3: Ta có hai luật sinh
stmt if expr then stmt else stmt| if expr then stmt
Sau khi đọc token if, ta không thể ngay lập tức quyết định sẽ dùng luật sinh nào để mở rộng stmt
• Cách tạo nhân tố trái: Giả sử có luật sinh
A 1 | 2 |..... | n | ( là tiền
tố chung dài nhất của các luật sinh,
không bắt đầu bởi )Luật sinh trên đƣợc biến đổi thành:
A A' |
A' | |..... |
CuuDuongThanCong.com https://fb.com/tailieudientucntt

18
Phân tích cú pháp từ trên xuống
• Phân tích cú pháp (PTCP) từ trên xuống đƣợc xem nhƣ một cố gắng tìm kiếm một dẫn xuất trái nhất cho chuỗi nhập. Nó cũng có thể xem nhƣ một cố gắng xây dựng cây phân tích cú pháp bắt đầu từ nút gốc và phát sinh dần xuống lá
• PTCP từ trên xuống đơn giản hơn PTCP từ dƣới lên nhƣng bị giới hạn về mặt hiệu quả
• Có một số kĩ thuật PTCP từ trên xuống nhƣ: PTCP đệ qui lùi, PTCP đoán trƣớc, PTCP đoán trƣớc đệ qui. Ta sẽ xét trƣờng
CuuDuongThanCong.com https://fb.com/tailieudientucntt
19
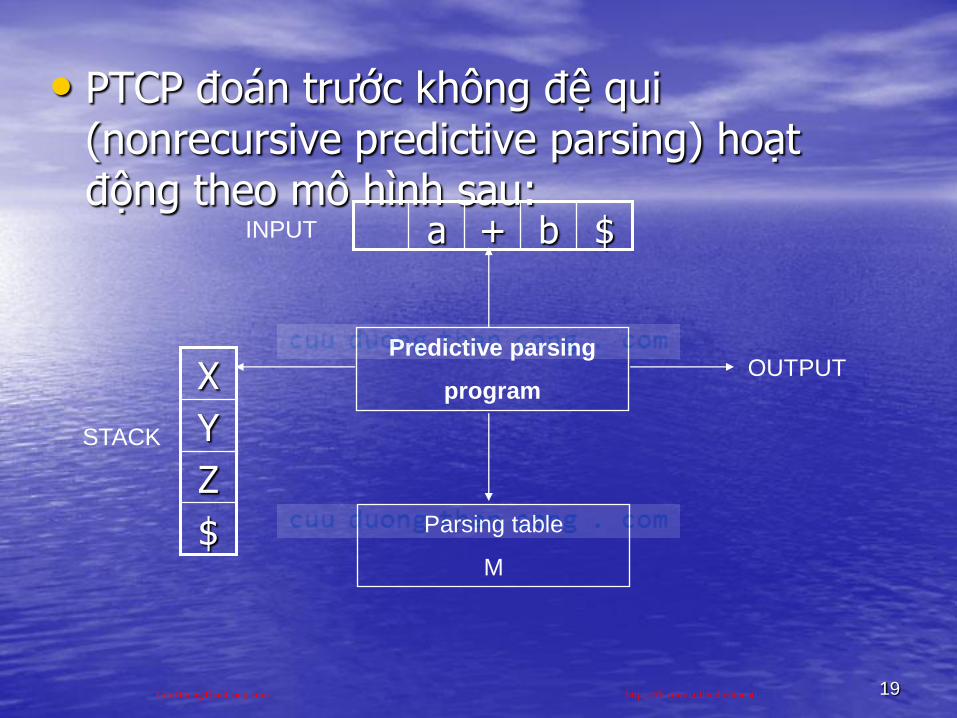
• PTCP đoán trƣớc không đệ qui (nonrecursive predictive parsing) hoạt động theo mô hình sau:
$
Z
Y
XPredictive parsing
program
Parsing table
M
OUTPUT
INPUT
STACK
$b+a
CuuDuongThanCong.com https://fb.com/tailieudientucntt

20
• INPUT là bộ đệm chứa chuỗi cần phân tích, kết thúc bởi ký hiệu $
• STACK chứa một chuỗi các ký hiệu văn phạm với ký hiệu $ nằm ở đáy STACK. Khởi đầu STACK chứa kí hiệu bắt đầu S trên đỉnh
• Parsing table M là một mảng hai chiều dạng M[A,a], trong đó A là ký hiệu chƣa kết thúc, a là ký hiệu kết thúc hoặc $.
• Bộ phân tích cú pháp đƣợc điều khiển bởi Predictive parsing program
CuuDuongThanCong.com https://fb.com/tailieudientucntt

21
• Predictive parsing program hoạt động nhƣ sau: Chƣơng trình xét ký hiệu X trên đỉnh Stack và ký hiệu nhập hiện hành a
1. Nếu X = a = $ thì quá trình PTCP kết thúc thành công
2. Nếu X = a $, đẩy X ra khỏi Stack và đọc ký hiệu nhập tiếp theo.
3. Nếu X là ký hiệu chƣa kết thúc thì chƣơng trình truy xuất đến phần tử M[X,a] trong Parsing table M:
- Nếu M[X,a] là một luật sinh có dạng X UYV thì đẩy X ra khỏi đỉnh Stack và đẩy V, Y, U vào Stack (với U trên đỉnh Stack), đồng thời bộ xuất ra OUTPUT luật sinh X UYV
- Nếu M[X,a] = error, gọi chƣơng trình phục hồi lỗi.
CuuDuongThanCong.com https://fb.com/tailieudientucntt

22
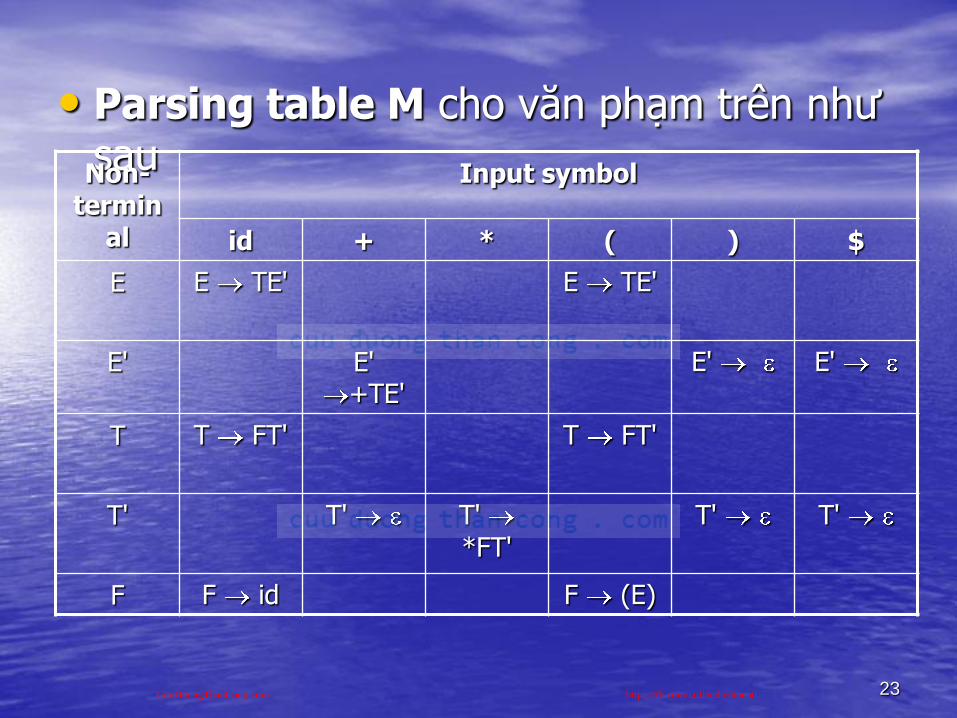
Ví dụ 3.4: Xét văn phạm
E E+T | TT T*F | FF (E) | id
Loại bỏ đệ qui trái ta thu đƣợc
E TE'E' +TE' | T FT'T' *FT' | F (E) | id
Giả sử xâu input nhập vào là id+id*id
CuuDuongThanCong.com https://fb.com/tailieudientucntt
23
• Parsing table M cho văn phạm trên nhƣ sauNon-
terminal
Input symbol
id + * ( ) $
E E TE' E TE'
E' E' +TE'
E' E'
T T FT' T FT'
T' T' T' *FT'
T' T'
F F id F (E)
CuuDuongThanCong.com https://fb.com/tailieudientucntt
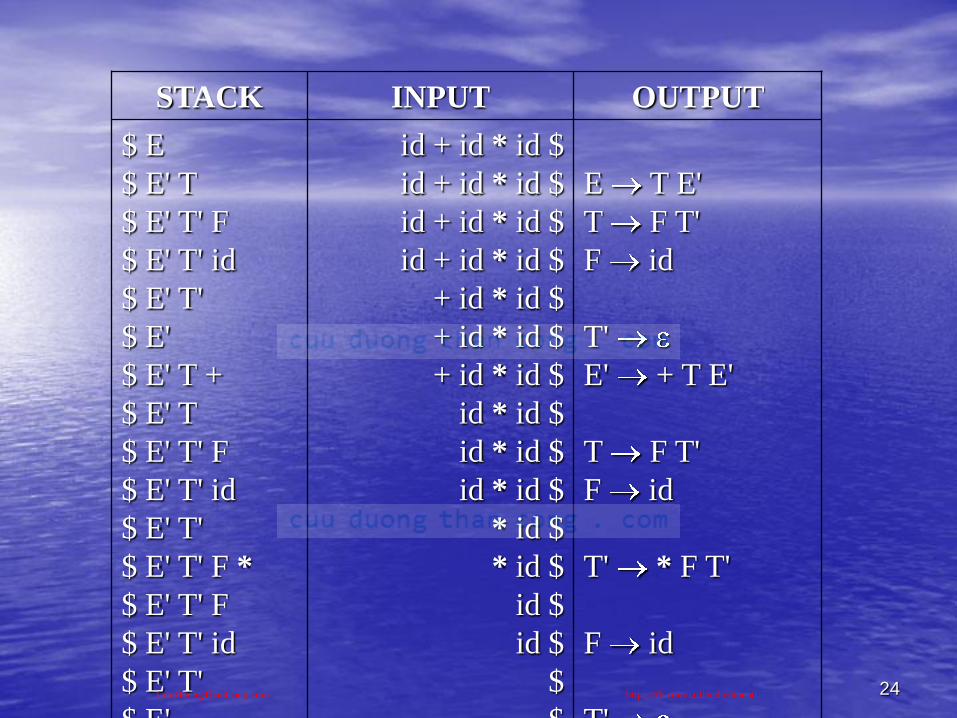
24
STACK INPUT OUTPUT
$ E
$ E' T
$ E' T' F
$ E' T' id
$ E' T'
$ E'
$ E' T +
$ E' T
$ E' T' F
$ E' T' id
$ E' T'
$ E' T' F *
$ E' T' F
$ E' T' id
$ E' T'
$ E'
id + id * id $
id + id * id $
id + id * id $
id + id * id $
+ id * id $
+ id * id $
+ id * id $
id * id $
id * id $
id * id $
* id $
* id $
id $
id $
$
$
E T E'
T F T'
F id
T'
E' + T E'
T F T'
F id
T' * F T'
F id
T'CuuDuongThanCong.com https://fb.com/tailieudientucntt

25
• Hàm FIRST và FOLLOW: Là các hàm xác định các tập hợp cho phép xây dựng bảng phân tích M và phục hồi lỗi
• Nếu là một xâu thì FIRST( ) là tập hợp các ký hiệu kết thúc mà nó bắt đầu một chuỗi dẫn xuất từ . Nếu * thì thuộc FIRST( )
• Nếu A là một kí hiệu chƣa kết thúc thì FOLLOW(A) là tập các kí hiệu kết thúc mà nó xuất hiện ngay bên phải A trong một dạng câu . Nếu S * A thì $ thuộc FOLLOW(A)
CuuDuongThanCong.com https://fb.com/tailieudientucntt

26
• Qui tắc tính các tập hợp FOLLOW
1. Đặt $ vào FOLLOW(S) (S là kí hiệu bắt đầu)
2. Nếu A B thì mọi phần tử thuộc FIRST( ) ngoại trừ đều thuộc FOLLOW(B)
3. Nếu A B hoặc A B và * thì mọi phần tử thuộc FOLLOW(A) đều thuộc FOLLOW(B)
CuuDuongThanCong.com https://fb.com/tailieudientucntt

27
Ví dụ 3.5: Xét văn phạm
E TE'
E' +TE' | T FT'T' *FT' | F (E) | id
Khi đó:
FIRST(E) = FIRST(T) = FIRST(F) = { (, id }FIRST(E') = {+, }FIRST(T') = {*, }FOLLOW(E) = FOLLOW(E') = { $, ) }FOLLOW(T) = FOLLOW(T') = { +, ), $ }FOLLOW(F) = {*,+, ), $ }
CuuDuongThanCong.com https://fb.com/tailieudientucntt

28
• Thuật giải xây dựng Parsing table M của văn phạm G:
1. Với mỗi luật sinh A của văn phạm, thực hiện bƣớc 2 và 3
2. Với mỗi ký hiệu kết thúc a FIRST( ), thêm A vào M[A,a]
3. Nếu FIRST( ) thì đƣa luật sinh A vào M[A,b] với mỗi ký hiệu kết thúc b FOLLOW(A). Nếu FIRST( ) và $ FOLLOW(A) thì đƣa luật sinh A vào M[A,$].
4. Ô còn trống trong bảng tƣơng ứng với lỗi (error).
CuuDuongThanCong.com https://fb.com/tailieudientucntt

29
Phân tích cú pháp từ dƣới lên
• Giới thiệu một kiểu phân tích cú pháp từ dƣới lên tổng quát gọi là phân tích cú pháp Shift –Reduce
• Một phƣơng pháp tổng quát hơn của kỹ thuật Shift - Reduce là phân tích cú pháp LR (LR parsing) sẽ đƣợc thảo luận
• Shift –Reduce parsing sẽ cố gắng xây dựng một parse tree cho một xâu nhập vào từ nút lá lên nút gốc. Nói cách khác ta "reducing" từng bƣớc xâu nhập vào đến khi thu đƣợc kí hiệu bắt đầu của văn phạm
CuuDuongThanCong.com https://fb.com/tailieudientucntt
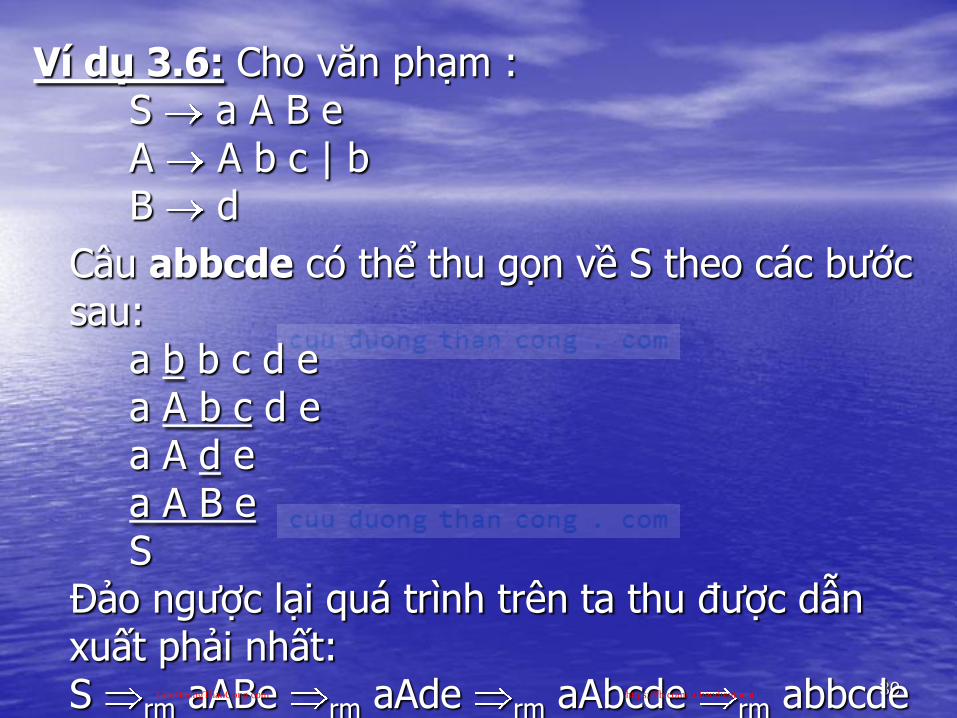
30
Ví dụ 3.6: Cho văn phạm :S a A B eA A b c | bB d
Câu abbcde có thể thu gọn về S theo các bƣớc sau:
a b b c d ea A b c d ea A d ea A B eS
Đảo ngƣợc lại quá trình trên ta thu đƣợc dẫn xuất phải nhất:S rm aABe rm aAde rm aAbcde rm abbcdeCuuDuongThanCong.com https://fb.com/tailieudientucntt

31
• Handles: Handle của một right-sentential form là một luật sinh A , một xâu sao cho = và S *
rm A rm . Đôi khi ta còn gọi là một handle, xâu bên phải chỉ chứa các kí hiệu kết thúc
• Nếu một văn phạm là không mơ hồ thì với mỗi right-sentential form có duy nhất một handle của nó
Ví dụ 3.7: Trong dẫn xuất S rm aABe rm
aAde rm aAbcde rm abbcde các handle đƣợc gạch chân
CuuDuongThanCong.com https://fb.com/tailieudientucntt

32
Ví dụ 3.8: Xét văn phạm mơ hồ
E E + E | E * E | (E) | id
Với cùng một biểu thức id+id*id sẽ có hai dẫn xuất phải nhất (các handle đƣợc gạch chân). Cùng một right sentence form E+E*id3 trong trƣờng hợp đầu id3 là handle còn trƣờng hợp thứ 2 handle là E+E
E rm E + E
rm E + E * E
rm E + E * id3
rm E + id2 * id3
rm id1 + id2 * id3
E rm E * E
rm E * id3
rm E + E * id3
rm E + id2 * id3
rm id1 + id2 * id3
CuuDuongThanCong.com https://fb.com/tailieudientucntt

33
• Biểu diễn stack của shift- reduce parsing
STACK INPUT ACTION
$$ id1
$ E$ E +$ E + id2
$ E + E$ E + E *$ E + E* id3
$ E + E * E$ E + E$ E
id1 + id2 * id3
$+ id2 * id3 $+ id2 * id3 $
id2 * id3 $* id3 $* id3 $
id3 $$$$
$
shiftreduce by E idshiftshiftreduce by E idshiftshiftreduce by E idreduce by E E *Ereduce by E E +Eaccept
CuuDuongThanCong.com https://fb.com/tailieudientucntt

34
Phân tích cú pháp LR (LR parser)• LR(k) là một kỹ thuật phân tích cú pháp từ
dƣới lên hiệu quả, có thể sử dụng để phân tích một lớp rộng các văn phạm phi ngữ cảnh.
- L(Left-to-right): Duyệt chuỗi nhập từ trái sang phải
- R(Rightmost derivation): Xây dựng chuỗi dẫn xuất phải nhất đảo ngƣợc
- k:Số lƣợng ký hiệu lookahead tại mỗi thời điểm, dùng để đƣa ra quyết định phân tích. Khi không đề cập đến k, chúng ta hiểu ngầm là k = 1
CuuDuongThanCong.com https://fb.com/tailieudientucntt

35
• Ƣu điểm của LR:
- Có thể nhận biết hầu nhƣ tất cả các ngôn ngữ
lập trình đƣợc tạo ra bởi văn phạm phi ngữ cảnh
- Phƣơng pháp phân tích cú pháp LR là phƣơng pháp tổng quát của phƣơng pháp shift-reduce không quay lui
- Lớp văn phạm có thể dùng phƣơng pháp LR là một lớp rộng lớn hơn lớp văn phạm có thể sử dụng phƣơng pháp dự đoán
- Có thể xác định lỗi cú pháp nhanh ngay trong khi duyệt dòng nhập từ trái sang phải
• Nhƣợc điểm của LR:
- Xây dựng LR parser khá phức tạpCuuDuongThanCong.com https://fb.com/tailieudientucntt
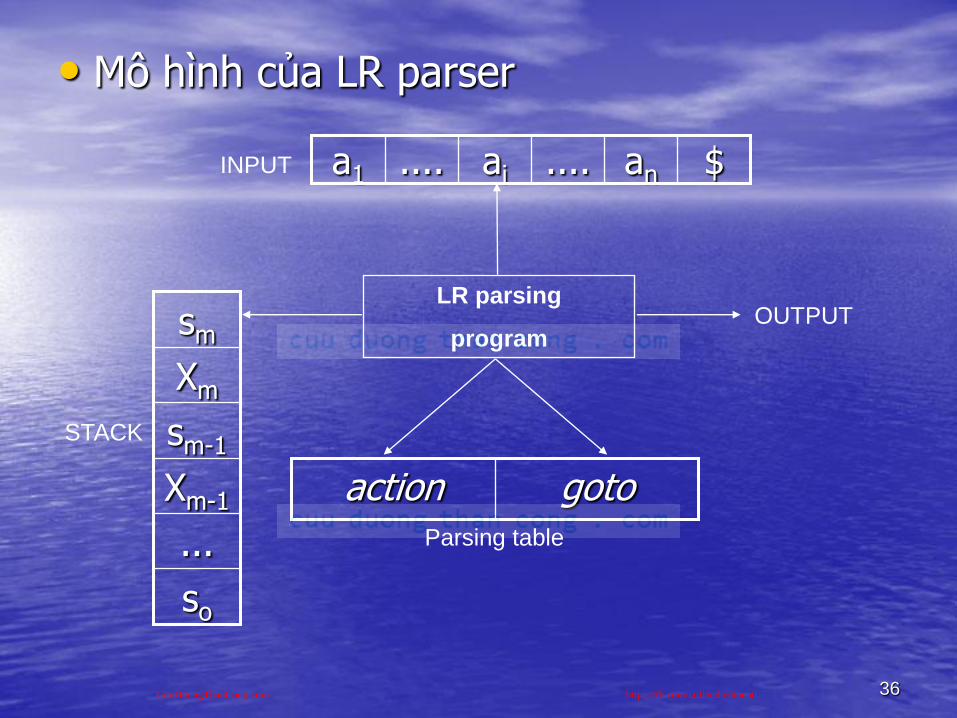
36
• Mô hình của LR parser
LR parsing
programOUTPUT
INPUT
STACK
so
...
Xm-1
sm-1
Xm
sm
$an....ai....a1
gotoactionParsing table
CuuDuongThanCong.com https://fb.com/tailieudientucntt

37
• STACK lƣu chuỗi s0 X1 s1 X2 s2... Xm sm
trong đó sm nằm trên đỉnh STACK một ký hiệu văn phạm, si là một trạng thái tóm tắt thông tin chứa trong STACK bên dƣới nó
• Parsing table bao gồm 2 phần : Hàm action và hàm goto
- action[sm, ai] có thể có một trong 4 giá trị :
1. shift s: Đẩy s, trong đó s là một trạng
thái
2. reduce: Thu gọn bằng luật sinh A
3. accept: Chấp nhậnCuuDuongThanCong.com https://fb.com/tailieudientucntt

38
• Cấu hình (configuration) của một bộ phân tích cú pháp LR là một cặp thành phần(s0 X1 s1 X2 s2... Xm sm, ai ai+1 ... an $). Cấu hình biểu diễn right- sentential form X1 X2... Xmai ai+1 ... an
• Sự thay đổi cấu hình theo hàm action nhƣ sau:
- Nếu action[sm, ai] = shift s, cấu hình chuyển thành
(s0 X1 s1 X2 s2... Xm sm ai s, ai+1 ... an $), trong đó
s=action[sm, ai]
- Nếu action[sm, ai] = reduce A , cấu hình chuyển thành
(s X s X s ... X s A s, a a ... a $), trong đó CuuDuongThanCong.com https://fb.com/tailieudientucntt
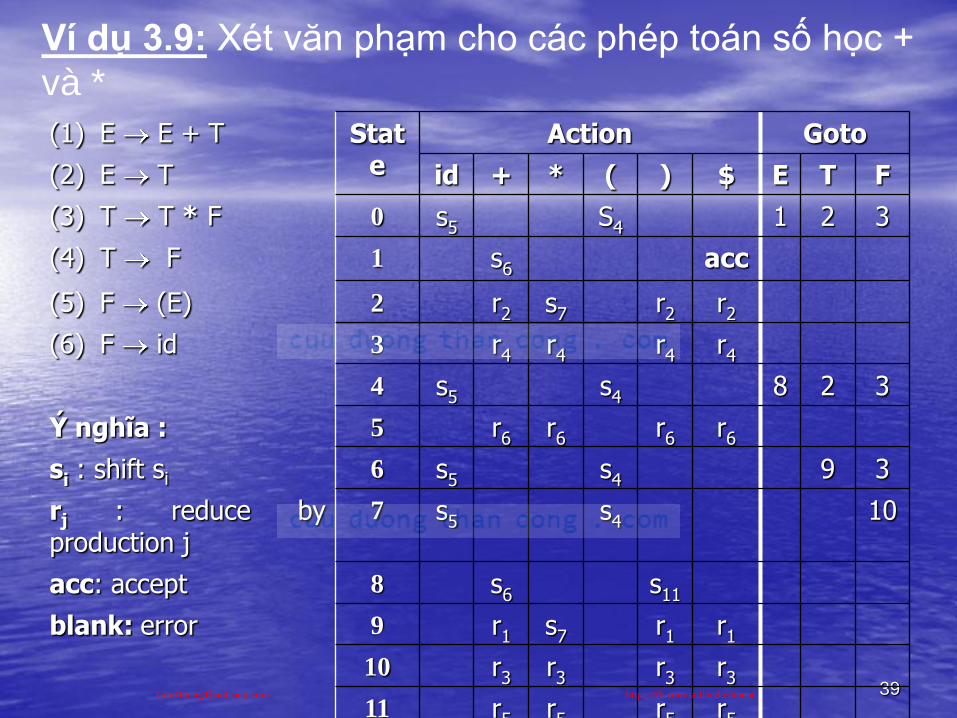
39
(1) E E + T State
Action Goto
(2) E T id + * ( ) $ E T F
(3) T T * F 0 s5 S4 1 2 3
(4) T F 1 s6 acc
(5) F (E) 2 r2 s7 r2 r2
(6) F id 3 r4 r4 r4 r4
4 s5 s4 8 2 3
Ý nghĩa : 5 r6 r6 r6 r6
si : shift si 6 s5 s4 9 3
rj : reduce byproduction j
7 s5 s4 10
acc: accept 8 s6 s11
blank: error 9 r1 s7 r1 r1
10 r3 r3 r3 r3
11 r5 r5 r5 r5
Ví dụ 3.9: Xét văn phạm cho các phép toán số học +
và *
CuuDuongThanCong.com https://fb.com/tailieudientucntt
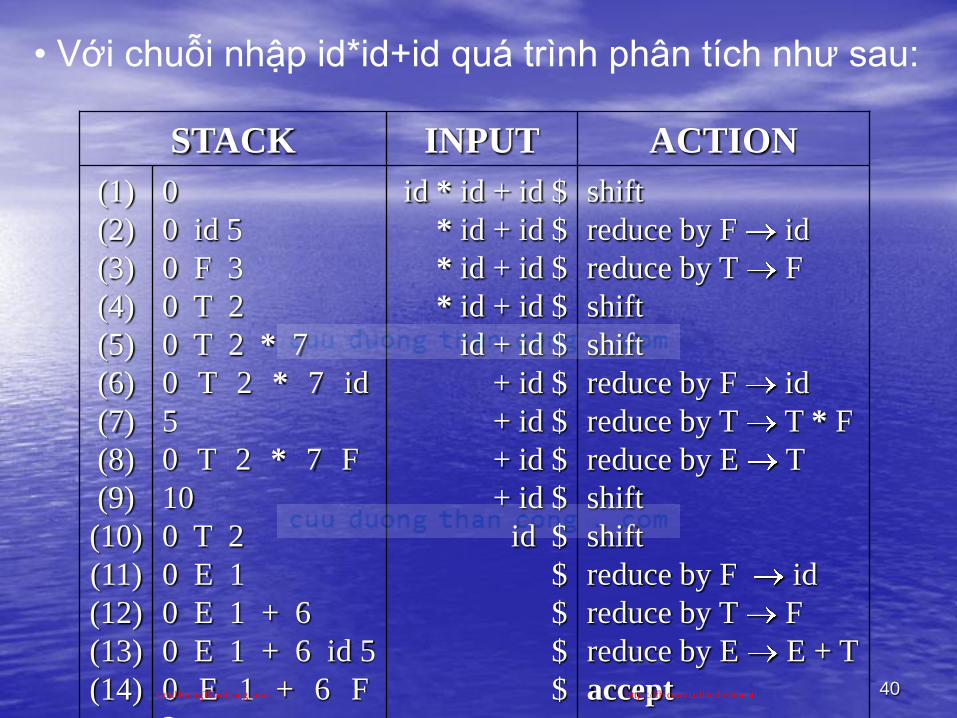
40
STACK INPUT ACTION
(1)
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
(12)
(13)
(14)
0
0 id 5
0 F 3
0 T 2
0 T 2 * 7
0 T 2 * 7 id
5
0 T 2 * 7 F
10
0 T 2
0 E 1
0 E 1 + 6
0 E 1 + 6 id 5
0 E 1 + 6 F
3
id * id + id $
* id + id $
* id + id $
* id + id $
id + id $
+ id $
+ id $
+ id $
+ id $
id $
$
$
$
$
shift
reduce by F id
reduce by T F
shift
shift
reduce by F id
reduce by T T * F
reduce by E T
shift
shift
reduce by F id
reduce by T F
reduce by E E + T
accept
• Với chuỗi nhập id*id+id quá trình phân tích như sau:
CuuDuongThanCong.com https://fb.com/tailieudientucntt

41
Xây dựng SLR parsing table
• Có 3 phƣơng pháp xây dựng một bảng phân tích cú pháp LR từ văn phạm là Simple LR (SLR), Canonical LR và Lookahead- LR (LALR), các phƣơng pháp khác nhau về tính hiệu quả cũng nhƣ tính dễ cài đặt
• Phƣơng pháp SLR, là phƣơng pháp yếu nhất nếu tính theo số lƣợng văn phạm có thể xây dựng thành công, nhƣng đây lại là phƣơng pháp dễ cài đặt nhất
• Một văn phạm có thể xây dựng đƣợc SLR parser đƣợc gọi là một văn phạm SLR
CuuDuongThanCong.com https://fb.com/tailieudientucntt

42
• Một mục LR(0) (hoặc item) của một văn phạm G là một luật sinh của G với một dấu chấm tại vị trí nào đó trong vế phải
Ví dụ 3.10: Luật sinh A XYZ có 4 mục
nhƣ sau:
A .XYZ
A X.YZ
A XY.Z
A XYZ.
• Luật sinh A chỉ tạo ra một mục A .
CuuDuongThanCong.com https://fb.com/tailieudientucntt

43
• Văn phạm tăng cƣờng (Augmented Grammar): G là một văn phạm với ký hiệu bắt đầu S, thêm một ký hiệu bắt đầu mới S'
và luật sinh S' S để đƣợc văn phạm mới
G' gọi là văn phạm tăng cƣờng
• Phép toán bao đóng (Closure): Giả sử I là một tập các mục của văn phạm G thì bao đóng closure(I) là tập các mục đƣợc xây dựng từ I nhƣ sau:
1. Tất cả các mục của I đƣợc thêm vào closure(I).
2. Nếu A .B closure(I) và B là một luật sinh thì thêm B . vào closure(I) nếu nó chƣa có trong đó. Lặp lại bƣớc này cho đến khi không thể thêm vào closure(I) đƣợc nữa
CuuDuongThanCong.com https://fb.com/tailieudientucntt

44
Ví dụ 3.11: Xét văn phạm tăng cƣờng
E' E
E E + T | T
T T * F | F
F (E) | id
Nếu I= {E' · E} thì closure(I) bao gồm các
mục sau:E' · EE · E + TE · TT · T * FT · FF · (E)F · idCuuDuongThanCong.com https://fb.com/tailieudientucntt
45
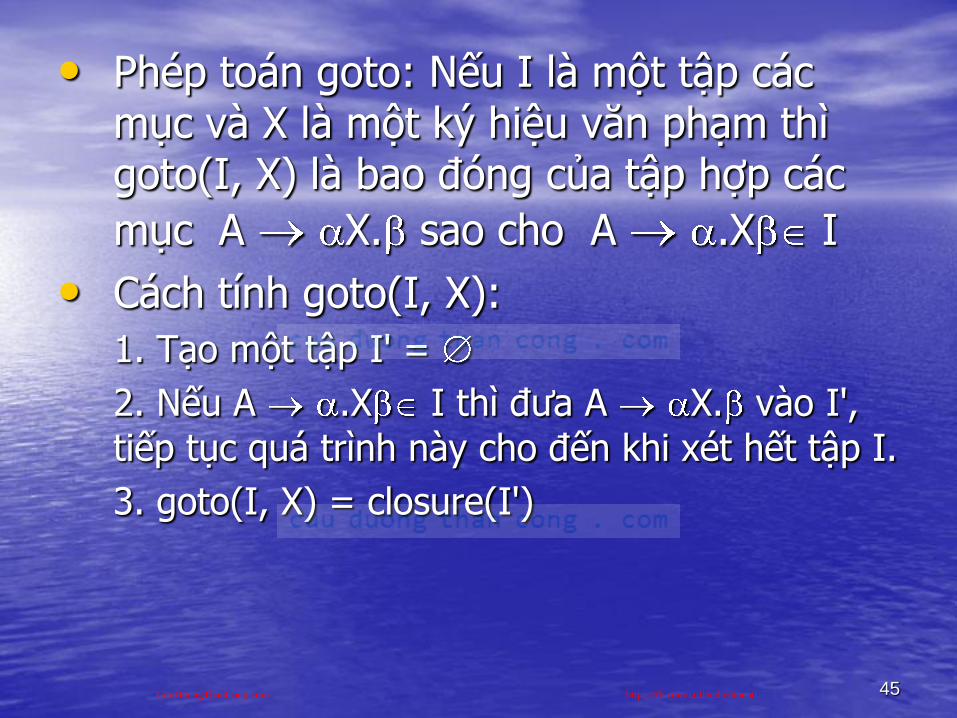
• Phép toán goto: Nếu I là một tập các mục và X là một ký hiệu văn phạm thì goto(I, X) là bao đóng của tập hợp các
mục A X. sao cho A .X I
• Cách tính goto(I, X):
1. Tạo một tập I' =
2. Nếu A .X I thì đƣa A X. vào I', tiếp tục quá trình này cho đến khi xét hết tập I.
3. goto(I, X) = closure(I')
CuuDuongThanCong.com https://fb.com/tailieudientucntt

46
Ví dụ 3.12: Giả sử I = {E' E., E E . + T}
Ta có I' = { E E + . T}
goto (I, +) = closure(I') bao gồm các mục :
E E + . T
T . T * F
T . F
F . (E)
F . id
CuuDuongThanCong.com https://fb.com/tailieudientucntt

47
• Giải thuật xây dựng họ tập hợp các mục LR(0) (kí hiệu là C) của văn phạm G'
procedure Item (G')
begin
C := {closure({ S' .S}) };
repeat
For Với mỗi tập các mục I C và mỗi ký hiệu văn phạm X sao cho goto (I, X) và
goto(I, X) C thì thêm goto(I, X) vào C;
until Không còn tập hợp mục nào có thể thêm vào C;
end;
CuuDuongThanCong.com https://fb.com/tailieudientucntt
48
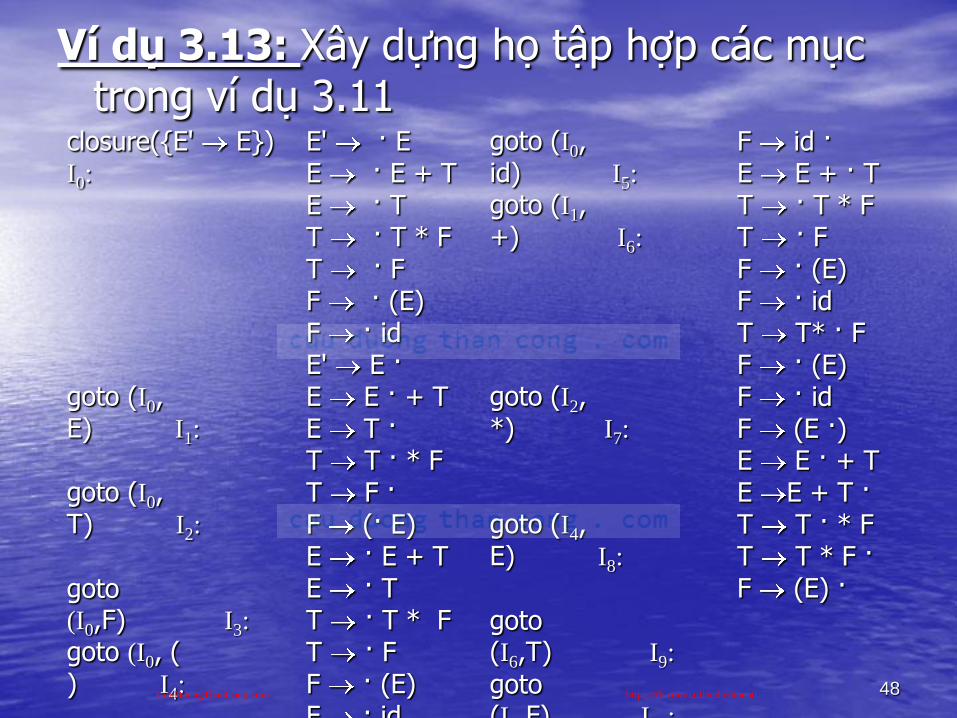
Ví dụ 3.13: Xây dựng họ tập hợp các mục trong ví dụ 3.11
closure({E' E}) I0:
goto (I0, E) I1:
goto (I0, T) I2:
goto (I0,F) I3:
goto (I0, ( ) I4:
E' · EE · E + TE · TT · T * FT · F F · (E)F · idE' E ·E E · + TE T ·T T · * FT F ·F (· E)E · E + TE · TT · T * FT · FF · (E)F · id
goto (I0, id) I5:
goto (I1, +) I6:
goto (I2, *) I7:
goto (I4, E) I8:
goto (I6,T) I9:
goto (I7,F) I10:
F id ·E E + · TT · T * FT · FF · (E)F · idT T* · FF · (E)F · idF (E ·)E E · + TE E + T ·T T · * FT T * F ·F (E) ·
CuuDuongThanCong.com https://fb.com/tailieudientucntt

49
• Xây dựng SLR parsing table
1. Xây dựng họ tập hợp các mục của G': C = { I0, I1, ..., In }
2. Trạng thái i đƣợc xây dựng từ Ii .Các action tƣơng ứng trạng thái i xác định nhƣ sau:
a) Nếu A .a Ii và goto (Ii, a) = Ij thì action[i, a] = "shift j",
a là ký hiệu kết thúc
b) Nếu A . Ii thì action[i, a] = "reduce (A )", với mọi a FOLLOW(A), A S'
c) Nếu S' S · Ii thì action[i, $] = "accept".
Nếu một action đụng độ đƣợc sinh ra bởi các luật trên, ta nói văn phạm không phải là SLR(1). Giải thuật thất bạiCuuDuongThanCong.com https://fb.com/tailieudientucntt

50
Xây dựng bảng phân tích LR chính tắc
• LR chính tắc (canonical LR) là kĩ thuật chung nhất để xây dựng LR parsing table cho một văn phạm
• Một mục LR(1) (item) là một cặp [A . , a] trong đó A là một luật sinh,
a- là kí tự lookahead là một kí hiệu kết thúc hoặc $
• Nếu thì a không có ý nghĩa nhƣng nếu = thì việc reduce theo luật A chỉ
đƣợc thực hiện nếu kí tự đọc vào tiếp theo là a
CuuDuongThanCong.com https://fb.com/tailieudientucntt

51
• Phép toán bao đóng (Closure): Giả sử I là một tập các mục LR(1) của văn phạm G thì bao đóng closure(I) là tập các mục đƣợc xây dựng từ I nhƣ sau:
1. Tất cả các mục của I đƣợc thêm vào closure(I).
2. Nếu [A .B , a] closure(I), B là một luật sinh và b FIRST( a) thì thêm [B . , b]vào closure(I) nếu nó chƣa có trong đó. Lặp lại bƣớc này cho đến khi không thể thêm vào closure(I) đƣợc nữa
• Phép toán goto: Nếu I là một tập các mục và X là một ký hiệu văn phạm thì goto(I, X) là bao đóng của tập hợp các mục [A
X. , a] sao cho [A .X , a] ICuuDuongThanCong.com https://fb.com/tailieudientucntt

52
• Giải thuật xây dựng họ tập hợp các mục LR(1) (kí hiệu là C) của văn phạm G'
procedure Item (G')
begin
C := {closure({[ S' .S, $]})};
repeat
For Với mỗi tập các mục I C và mỗi ký hiệu văn phạm X sao cho goto (I, X) và
goto(I, X) C thì thêm goto(I, X) vào C;
until Không còn tập hợp mục nào có thể thêm vào C;
end;
CuuDuongThanCong.com https://fb.com/tailieudientucntt

53
closure({S' S}) I0:
goto (I0, S) I1:
goto (I0, C) I2:
goto (I0, c) I :
S' · S, $S · CC, $C · cC, c/dC · d, c/dS' S ·, $
S C ·C, $C · cC, $C · d, $
C c ·C, c/dC · cC, c/dC · d, c/d
goto (I0, d ) I4:
goto (I2, C) I5:
goto (I2, c) I6:
goto (I2, d) I7:
goto (I ,
C d ·, c/d
S CC ·, $
C c · C, $C · cC, $C · d, $
C d ·, $
C cC ·, c/d
C cC ·, $
Ví dụ 3.14: Xây dựng họ tập hợp các mục LR(1) cho văn phạm dƣới đây
S' S
(1) S CC(2) C cC (3) C d
CuuDuongThanCong.com https://fb.com/tailieudientucntt
54
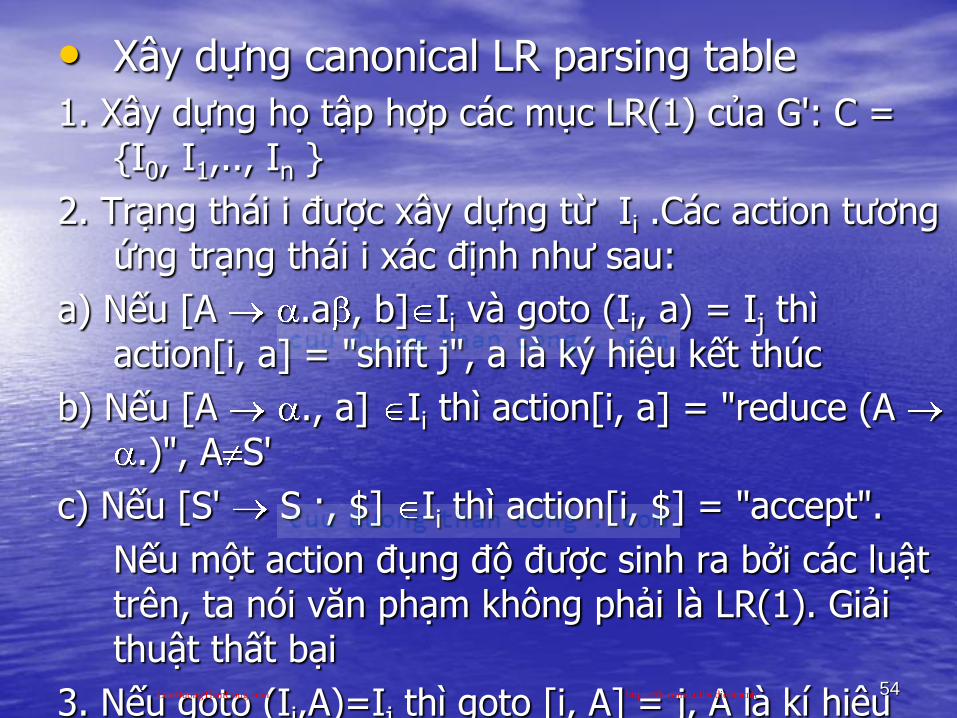
• Xây dựng canonical LR parsing table
1. Xây dựng họ tập hợp các mục LR(1) của G': C = {I0, I1,.., In }
2. Trạng thái i đƣợc xây dựng từ Ii .Các action tƣơng ứng trạng thái i xác định nhƣ sau:
a) Nếu [A .a , b] Ii và goto (Ii, a) = Ij thì action[i, a] = "shift j", a là ký hiệu kết thúc
b) Nếu [A ., a] Ii thì action[i, a] = "reduce (A .)", A S'
c) Nếu [S' S ·, $] Ii thì action[i, $] = "accept".
Nếu một action đụng độ đƣợc sinh ra bởi các luật trên, ta nói văn phạm không phải là LR(1). Giải thuật thất bại
3. Nếu goto (Ii,A)=Ij thì goto [i, A] = j, A là kí hiệu chƣa kết thúc
CuuDuongThanCong.com https://fb.com/tailieudientucntt
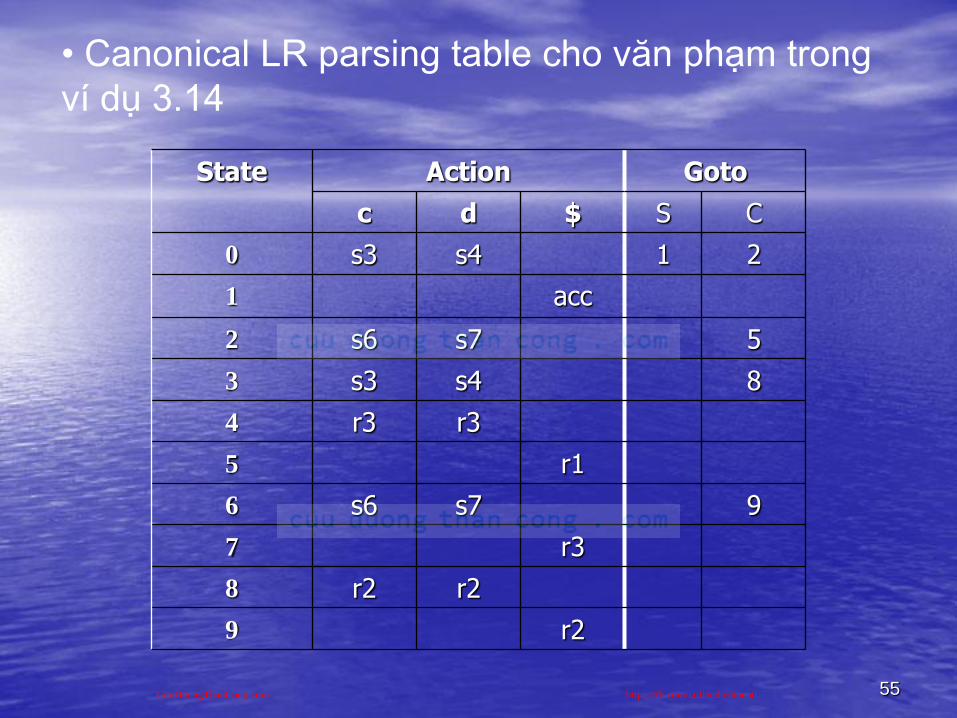
55
State Action Goto
c d $ S C
0 s3 s4 1 2
1 acc
2 s6 s7 5
3 s3 s4 8
4 r3 r3
5 r1
6 s6 s7 9
7 r3
8 r2 r2
9 r2
• Canonical LR parsing table cho văn phạm trong
ví dụ 3.14
CuuDuongThanCong.com https://fb.com/tailieudientucntt

56
• LALR là phƣơng pháp canonical parsing trong đó các trạng thái đƣợc nhóm lại với nhau nhờ đó bảng phân tich cấu trúc có kích thƣớc nhỏ hơn (có thể so sánh với SLR)
• Hạt nhân (core) của một tập hợp mục LR(1) có dạng {[A . , a]}, trong đó A là một luật sinh và a là ký hiệu kết thúc có hạt nhân (core) là tập hợp {A . }.
• Trong họ tập hợp các mục LR(1) C = {I0, I1,..., In} có thể có các tập hợp các mục có chung một hạt nhân.
Xây dựng bảng phân tích LALR
CuuDuongThanCong.com https://fb.com/tailieudientucntt

57
• Xây dựng LALR parsing table
1. Xây dựng họ tập hợp các mục LR(1) của G': C = {I0, I1,.., In }
2. Nhóm các mục có cùng core trong C đƣợc C' = {J0, J1,.., Jm }
3. Trạng thái i đƣợc xây dựng từ Ji .Các action tƣơng ứng trạng thái i xác định tƣơng tự nhƣ canonical LR
Nếu một action đụng độ đƣợc sinh ra bởi các luật trên, ta nói văn phạm không phải là LALR(1). Giải thuật thất bại
3. Xây dựng bảng goto : Giả sử J = I1 I2 . Ik . Vì I1, I2, ... Ik có chung hạt nhân nên goto (I1,X), goto (I2,X), ..., goto (Ik,X) cũng có chung hạt nhân.
Ðặt K bằng hợp tất cả các tập hợp có chung hạt CuuDuongThanCong.com https://fb.com/tailieudientucntt
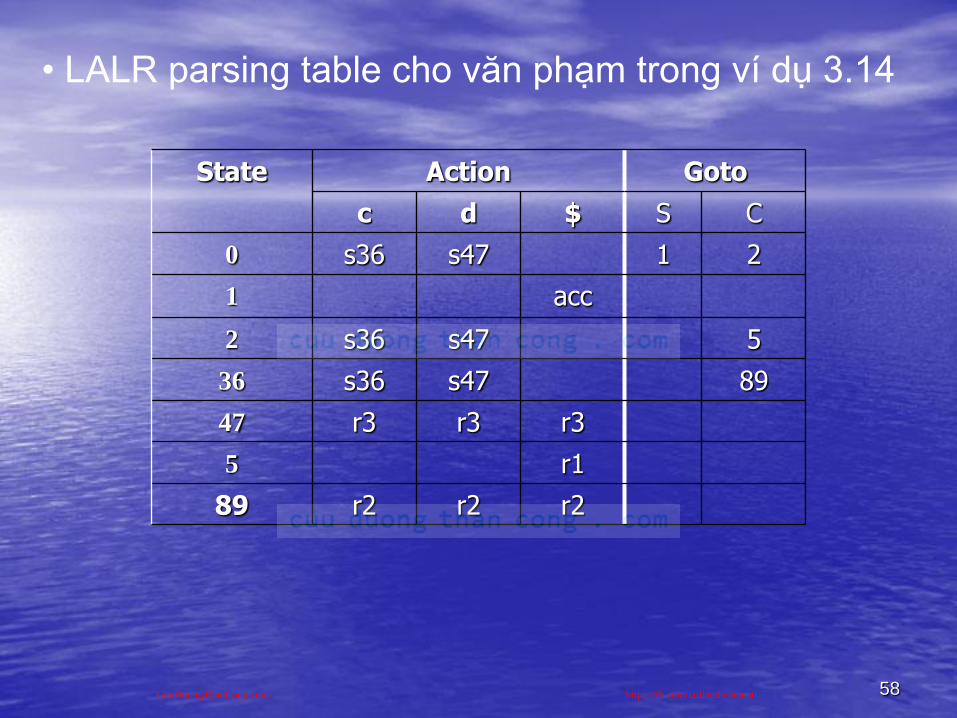
58
State Action Goto
c d $ S C
0 s36 s47 1 2
1 acc
2 s36 s47 5
36 s36 s47 89
47 r3 r3 r3
5 r1
89 r2 r2 r2
• LALR parsing table cho văn phạm trong ví dụ 3.14
CuuDuongThanCong.com https://fb.com/tailieudientucntt

59
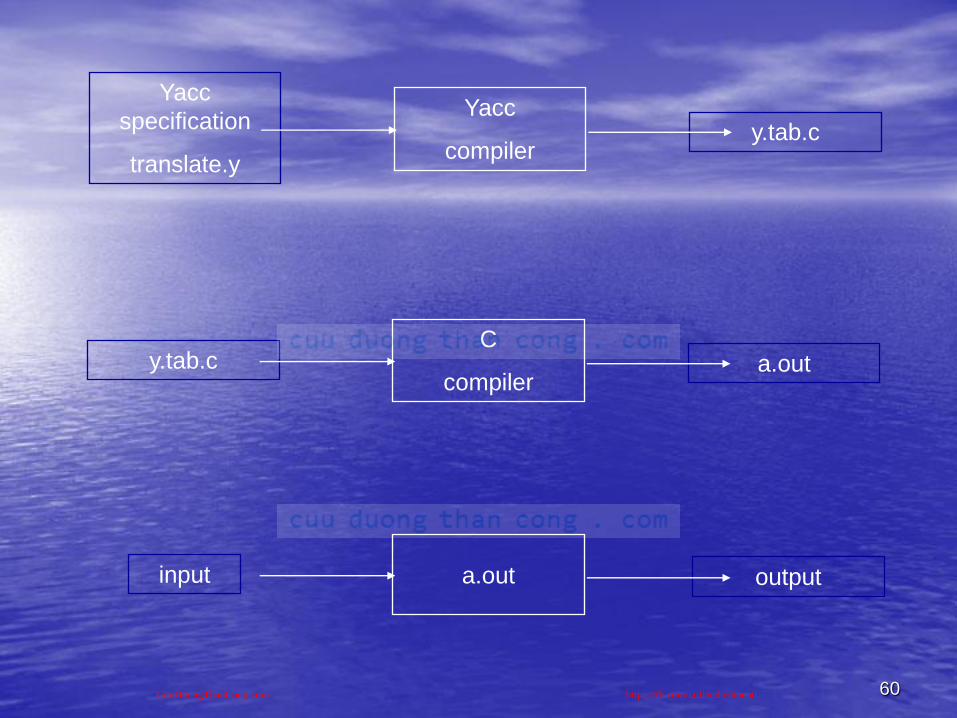
Công cụ phân tích cú pháp Yacc
• Giống nhƣ Lex, Yacc (yet another compiler compiler) là câu lệnh sẵn có của UNIX và là một công cụ hữu hiệu cho phép xây dựng bộ phân tích cú pháp một cách tự động
• Yacc đƣợc tạo bởi S. C. Johnson vào những năm đầu của thập kỉ 70
• Yacc sử dụng phƣơng pháp LALR
CuuDuongThanCong.com https://fb.com/tailieudientucntt
60
Yacc
specification
translate.y
Yacc
compilery.tab.c
y.tab.cC
compilera.out
input a.out output
CuuDuongThanCong.com https://fb.com/tailieudientucntt
Related Documents











