Chia-Hui Chang, Shao-Chen Lui Dept. of Computer Science and Information Engineering National Central University IEPAD: Information Extraction Based on Pattern Discovery WWW10 ’01

Chia-Hui Chang, Shao-Chen Lui Dept. of Computer Science and Information Engineering National Central University IEPAD: Information Extraction Based on.
Dec 27, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Chia-Hui Chang, Shao-Chen LuiDept. of Computer Science and
Information EngineeringNational Central University
IEPAD: Information Extraction Based on Pattern Discovery
WWW10 ’01
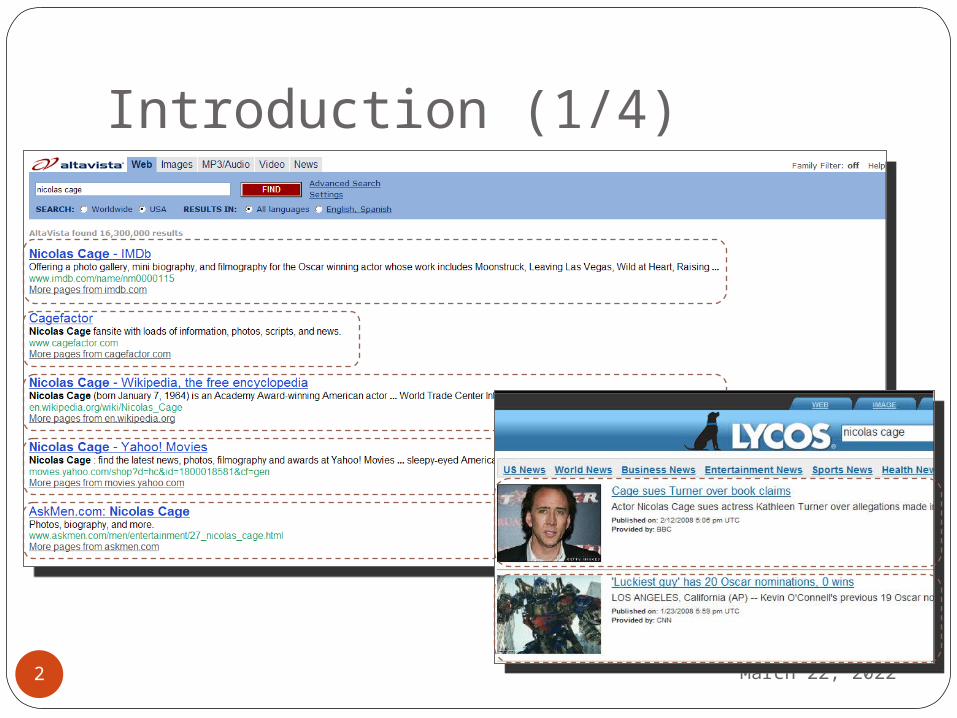
Introduction (1/4)
April 19, 20232

Introduction (2/4)
April 19, 2023
Great need for value-added service that integrates information from multiple sourcesCustomizable Web information gathering robots/crawlersComparison-shopping agentsMeta-search enginesNewsbots
Suppose the data has been collected from different Web sites…Write extractor program to extract the contents of the
Web pages Observe the extraction rules in person Write programs for each Web site
Since the format of Web pages is often subject to change, maintaining the wrapper can be expensive and impractical
→ labor-intensive !
3

Introduction (3/4)
April 19, 2023
Related worksTools that can generate wrappers automatically
Machine learning techniques to summarize extraction rules
Ex: WIEN, Softmealy, StalkerDesigner must manually label the beginning and the
end of the training examples for generating the rulesManual labeling is time-consuming and not efficient
enoughFully automate wrapper construction
Without users’ training examplesEx: One-tag separator approach (Embley et al.)
Discover record boundaries in Web documents by identifying candidate separator tags using five independent heuristics
Problem arises when the separator tag is used elsewhere among a record other than the boundary
4

Introduction (4/4)
April 19, 20235
Eliminate human intervention by pattern mining
Motivation is from the observation that useful information in a Web page is often placed in a structure having a particular alignment and orderEx: Web pages produced by search engines
generally present search results in regular and repetitive patterns
Mining repetitive patterns may discover the extraction rules for wrappers

System Overview (1/3)
April 19, 20236
The system IEPAD includes three components :An extraction rule generator
accepts an input Web pageA graphical user interface
Called pattern viewerShows repetitive patterns discovered
An extractor module Extracts desired information from similar Web pages
according to the extraction rule chosen by the user

System Overview (2/3)
April 19, 20237
Extraction rule generator includes :TranslatorPAT tree constructorPattern discovererPattern validatorExtraction rule composer
The results of rule extractor are extraction rules discovered in a Web page

System Overview (3/3)
April 19, 20238
1. User submits an HTML page
2. Receive and translate into a string of abstract representations
3. Receives the binary file to construct a PAT tree
4. Pattern discoverer uses the PAT tree to discover repetitive patterns, called maximal repeats
5. Filters out undesired patternsand produces candidate patterns6. Rule composer revises
each candidate pattern to form an extraction rule in regular expression

Extraction Rule Generator (1/2)
April 19, 20239
Desired information in a Web page is often placed in a structure having a particular alignment and forms repetitive patternsMay constitute the extraction rules for
wrappersRepetitive patterns : Any substring that
occurs at least twice in the encoded token stringInclude too many patterns fitting this requisiteDefine maximal repeats to uniquely identify
the longest pattern

Extraction Rule Generator (2/2)
Necessary for identifying the well used and popular term repeats
Maximal repeats have to be further verified by the validator to filter interesting ones
April 19, 202310

Translator (1/2)HTML page → token string 包含兩種 token
Tag tokenHtml(<tag_name>)
TEXT token兩個 tag 之間的 non-tag 文字內容當成單一個 tokenText(_)
April 19, 202311

Translator (2/2)Example – Congo code
April 19, 202312 1 2 3 4 5 6 7 8 9 10 11 12
13 14
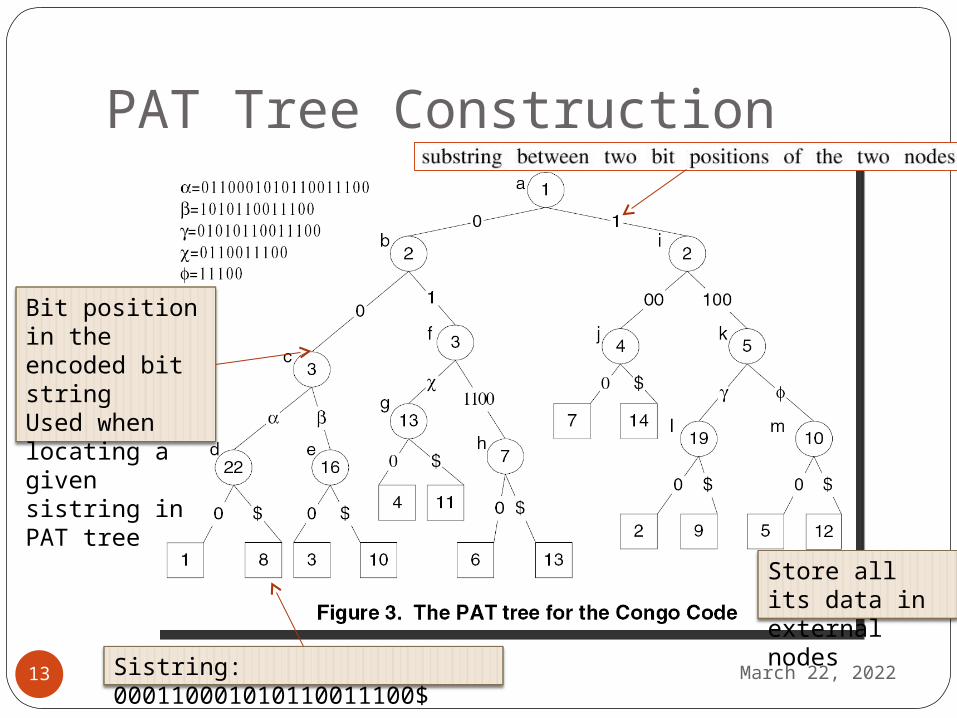
PAT Tree Construction
April 19, 202313 Sistring: 000110001010110011100$
Bit position in the encoded bit stringUsed when locating a given sistring in PAT tree
Store all its data in external nodes

Pattern Discoverer (1/2)
April 19, 202314

Pattern Discoverer (2/2)
不只記下 maximal repeats , 還要記下它們的 occurrence counts, reference positions, pattern length
Ex: 想找出所有長度 > 3 tokens 的 patterns , 因為每個 token 以 3 bits encoded , 所以只需檢察 index bit > 3*3=9 的 internal nodesd,e,g,l,m其中又只有 d 符合 left diverse , maximal
repeat 為 April 19, 202315

Pattern Validator (1/2)A typical web page usually contains a large
number of maximal repeatsNot all useful!
Validator 使用 3 criteria 來決定哪些 maximal repeats are useful
RegularityMeasured by computing the standard
deviation of the interval between two adjacent occurrences then be devided by the mean of sequence April 19, 202316
0

Pattern Validator (2/2)
April 19, 202317
1
large
利用 3 thresholds 濾掉不符合的 maximal repeats沒有包含 Text token 的也會濾掉
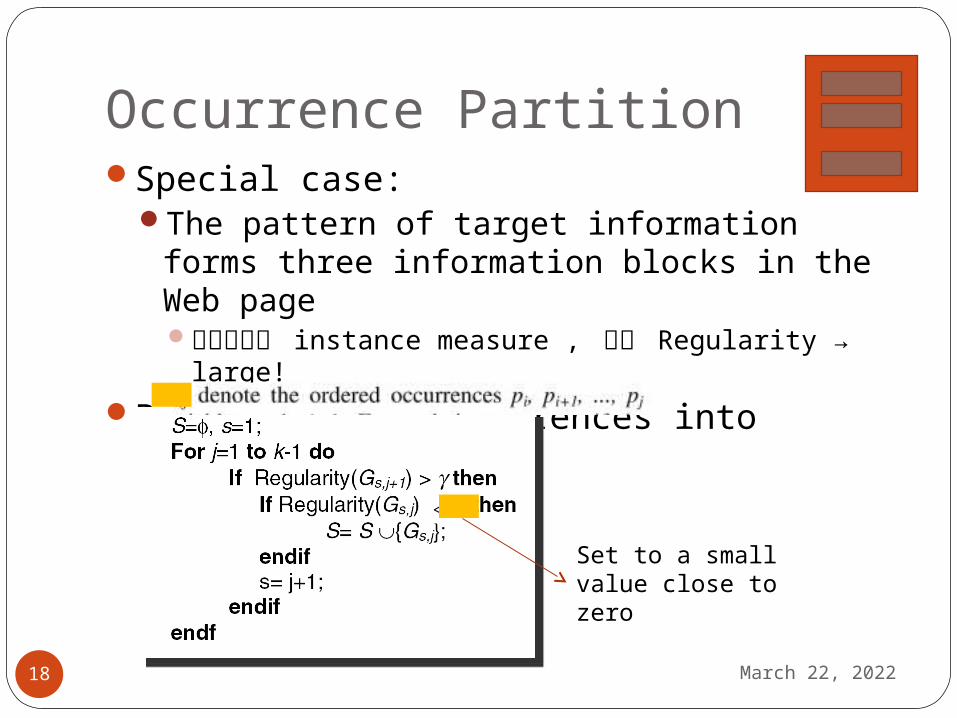
Occurrence PartitionSpecial case:
The pattern of target information forms three information blocks in the Web page因為用所有 instance measure , 所以 Regularity →
large!
Partition the occurrences into segments
April 19, 202318
<
Set to a small value close to zero

Rule Composer
April 19, 202319
Find a good representation of the critical common features of multiple strings
Suppose “adc” is the discovered pattern for token string “adcwbdadcxbadcxbdadcb”
Multiple alignment for strings The extraction pattern can be
generalized as “adc[w|x]b[d|-]” 假設 records 是連續的 , 若 alternatives 超過 10 個 , 仍使用
maximal repeats Center String Algorithm
Approximation, reduce time complexity Another problem
產生出 pattern: “c1c2c3...cn”, 實際上是“ cjcj+1cj+2...cnc1c2...cj–1”
考慮 cj 為首的 records, 並檢查是否“ cjcj+1cj+2...cnc1c2...cj–1” 為正確 pattern

The Extractor (1/2)
April 19, 202320
1. 2 patterns discovered
2. Shows the detail measures of the selected pattern

The Extractor (2/2)
April 19, 202321
3. The selected pattern is then forwarded to the extractor for pattern recognition and extractionSearching in a PAT is fast, since every subtree of a PAT tree has all its sistrings with a common prefix→ efficient, linear-time
PAT tree constructed already
Pattern-matching algorithm or finite state machine for extraction rule (regular expression)
else
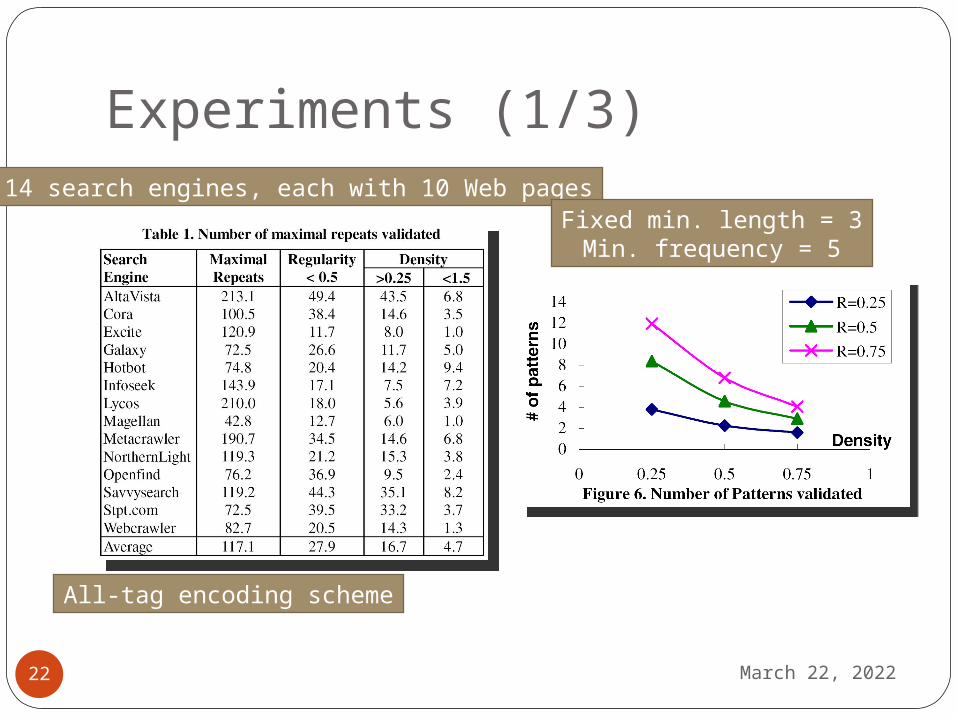
Experiments (1/3)
April 19, 202322
14 search engines, each with 10 Web pages
All-tag encoding scheme
Fixed min. length = 3Min. frequency = 5

Experiments (2/3)
April 19, 202323 recall precision
Encoding Scheme
0.4%
A pattern may contain only a portion of the
data record

Experiments (3/3)
April 19, 202324
Occurrence partition
Multiple string alignment
Lycos → 92%

SummaryPresented an unsupervised approach for
pattern discovery in the encoded token string of Web pages
Discovered maximal repeats are filtered by the measure regularity and compactness
Regularity higher than threshold → occurrence partition
Multiple string alignment is applied to patterns to generalize multiple recordsExpress the extraction rules in regular expressions
High retrieval rate and accuracy rateNo human intervention and training examplesTakes only 3 minutes to extract 140 pages →
quick and efficient!
April 19, 202325
Related Documents











