
CHEP – Mumbai, February 2006 The LCG Service Challenges Focus on SC3 Re-run; Outlook for 2006 Jamie Shiers, LCG Service Manager.
Dec 30, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript


CHEP – Mumbai, February CHEP – Mumbai, February 20062006
The LCG Service ChallengesThe LCG Service ChallengesFocus on SC3 Re-run; Outlook for 2006Focus on SC3 Re-run; Outlook for 2006
Jamie Shiers, LCG Service ManagerJamie Shiers, LCG Service Manager


Abstract
The LCG Service Challenges are aimed at achieving the goal of a production quality world-wide Grid that meets the requirements of the LHC experiments in terms of functionality and scale.
This talk highlights the main goals of the Service Challenge programme, significant milestones as well as the key services that have been validated in production by the LHC experiments.
The LCG Service Challenge programme currently involves both the 4 LHC experiments as well as many sites, including the Tier0, all Tier1s as well as a number of key Tier2s, allowing all primary data flows to be demonstrated.
The functionality so far addresses all primary offline Use Cases of the experiments except for analysis, the latter being addressed in the final challenge - scheduled to run from April until September 2006 - prior to delivery of the full production Worldwide LHC Computing Service.

Timeline - 2006January SC3 disk repeat – nominal
rates capped at 150MB/sJuly Tape Throughput
tests at full nominal rates!
February CHEP w/s – T1-T1 Use Cases, SC3 disk – tape repeat (50MB/s, 5 drives)
August T2 Milestones – debugging of tape results if needed
March Detailed plan for SC4 service agreed (M/W + DM service enhancements)
September
LHCC review – rerun of tape tests if required?
April SC4 disk – disk (nominal) and disk – tape (reduced) throughput tests
October WLCG Service Officially opened. Capacity continues to build up.
May Deployment of new m/w release and services across sites
November 1st WLCG ‘conference’All sites have network / tape h/w in production(?)
June Start of SC4 productionTests by experiments of ‘T1 Use Cases’ ‘Tier2 workshop’ – identification of key Use Cases and Milestones for T2
December ‘Final’ service / middleware review leading to early 2007 upgrades for LHC data taking??
O/S
Upg
rade
? S
omet
ime
befo
re A
pril
200
7!

SC3 -> SC4 Schedule February 2006
Rerun of SC3 disk – disk transfers (max 150MB/s X 7 days) Transfers with FTD, either triggered via AliEn jobs or scheduled T0 -> T1 (CCIN2P3, CNAF, Grid.Ka, RAL)
March 2006 T0-T1 “loop-back” tests at 2 x nominal rate (CERN) Run bulk production @ T1,T2 (simulation+reconstruction jobs) and send data back
to CERN (We get ready with proof@caf)
April 2006 T0-T1 disk-disk (nominal rates) disk-tape (50-75MB/s) First Push out (T0 -> T1) of simulated data, reconstruction at T1 (First tests with proof@caf)
July 2006 T0-T1 disk-tape (nominal rates) T1-T1, T1-T2, T2-T1 and other rates TBD according to CTDRs Second chance to push out the data Reconstruction at CERN and remote centres
September 2006 Scheduled analysis challenge Unscheduled challenge (target T2’s?)

June 12-14 2006 “Tier2” Workshop
Focus on analysis Use Cases and Tier2s in particular
List of Tier2s reasonably well established
Try to attract as many as possible!
Need experiments to help broadcast information on this!
Some 20+ already active – target of 40 by September 2006!
Still many to bring up to speed – re-use experience of existing sites!
Important to understand key data flows How experiments will decide which data goes where Where does a Tier2 archive its MC data? Where does it download the relevant Analysis data? The models have evolved significantly over the past year!
Two-three day workshop followed by 1-2 days of tutorials
Bri
ngi
ng
rem
ain
ing
site
s in
to p
lay:
Iden
tify
ing
rem
ain
ing
Use
Cas
es
Track on Distributed Data Analysis
DIAL
ProdSys
BOSS
Ganga
Analysis Systems
PROOF
CRAB
Submission Systems
DIRACPANDA
Bookkeeping Systems
JobMon
BOSS BbK
Monitoring Systems
DashBoard
JobMon
BOSS
MonaLisa
Data Access Systems
xrootd
SAM
Miscellaneous
Go4
ARDA
Grid Simulations
AJAX Analysis

Data Analysis Systems
ALICE ATLAS CMS LHCb
PROOF DIALGANGA
CRABPROOF
GANGA
All systems support, or plan to support, parallelism Except for PROOF all systems achieve parallelism via job
splitting and serial batch submission (job level parallelism)
The different analysis systems presented, categorized by experiment:
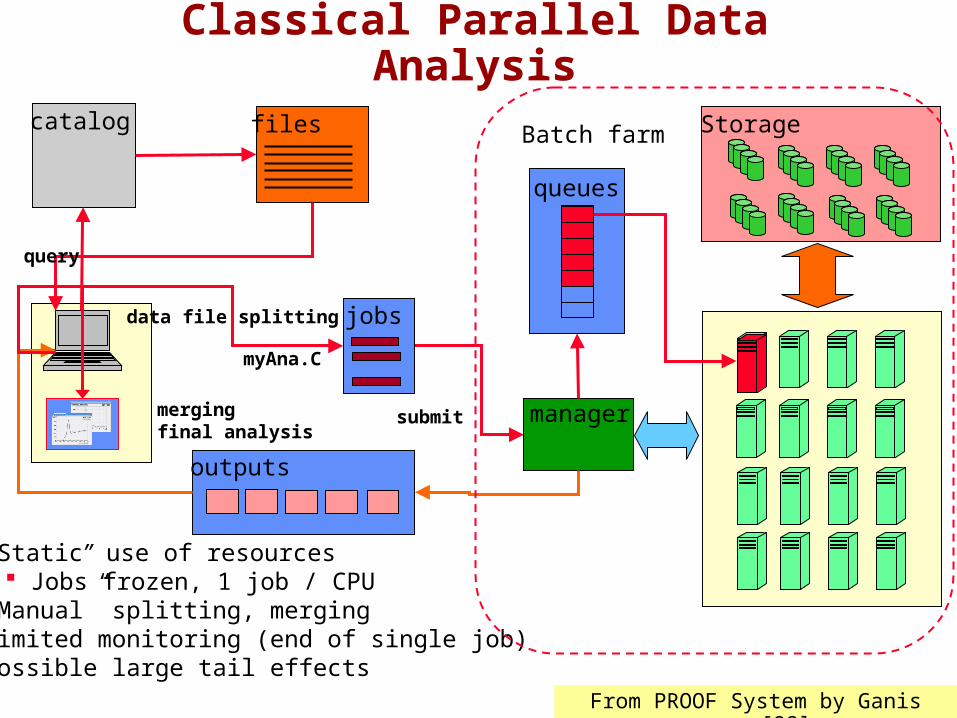
Classical Parallel Data Analysis
StorageBatch farm
queues
manager
outputs
catalog
“Static” use of resources Jobs frozen, 1 job / CPU
“Manual” splitting, merging Limited monitoring (end of single job) Possible large tail effects
submit
files
jobsdata file splitting
myAna.C
mergingfinal analysis
query
From PROOF System by Ganis [98]
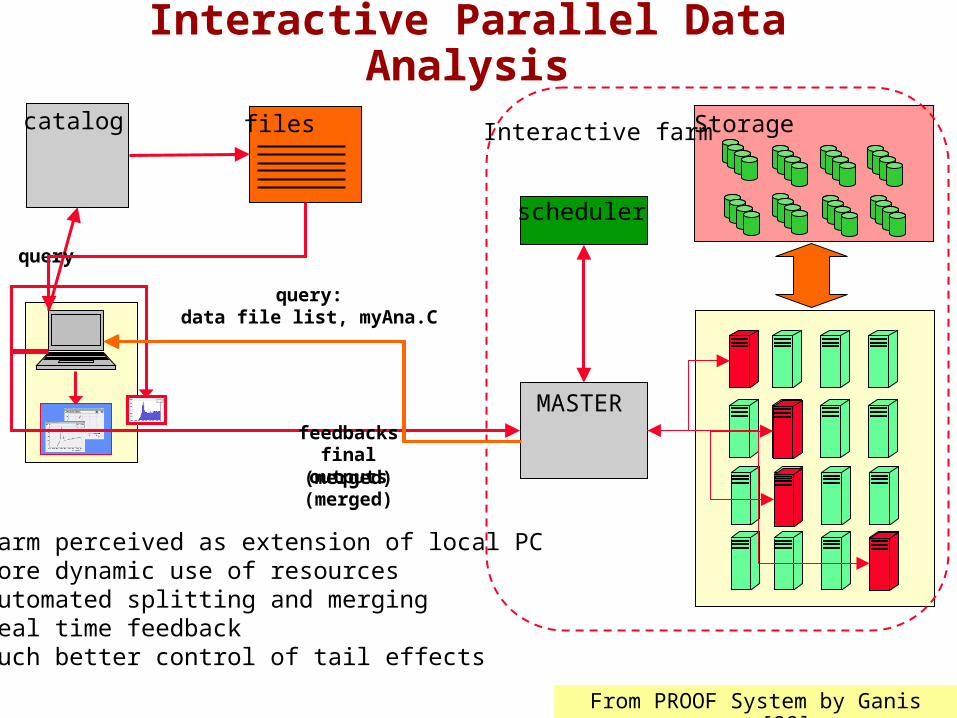
Interactive Parallel Data Analysis
catalog StorageInteractive farm
scheduler
query
Farm perceived as extension of local PC More dynamic use of resources Automated splitting and merging Real time feedback Much better control of tail effects
MASTER
query:data file list, myAna.C
files
final outputs(merged)
feedbacks
(merged)
From PROOF System by Ganis [98]
Related Documents











