Pergamon Computers chem. Engng Vol.22, No. 1-2, pp. 299-321, 1998 Copyright © 1997Elsevier Science Ltd Printedin GreatBritain. All tightsreserved PIh S0098-1354(96)00000-0 0098-1354/97 $17.00+0.00 Chemical plant fault diagnosis through a hybrid symbolic-connectionist machine learning approach* B. OzyurP, A. K. Sunol a*, M. C. Camurdan b, P. MogilP, L. O. Hall a a College of Engineering, University of South Florida, Tampa, FL 33620, U.S.A. b Department of Chemical Engineering, Bogaziqi University, Bebek, Istanbul, Ttirkiye. (Received 26 October 1994; revised 4 April 1996) Abstract A novel hybrid symbolic-connectionist approach to machine learning is introduced and applied to fault diagnosis of a hydrocarbon chlorination plant. The learning algorithm addresses the knowledge acquisition problem by developing and maintaining the knowledge base through instance based inductive learning. The performance of the learning system is discussed in terms of the knowledge extracted from example cases and its classification accuracy on the test cases. Results indicate that the introduced system is a promising alternative to neural networks for fault diagnosis and a complement to expert systems. © 1997 Elsevier Science Ltd 1. Introduction The advances in computer and electronic sciences permit highly automated processes, where reliable, on- line fault diagnosis systems, which will eliminate or reduce the human operator dependency in real time fault diagnosis, are possible. Fault is defined as the departure of an observed variable or calculated parameter from an acceptable range associated with that equipment (Himmelblau, 1978). Fault diagnosis is referred to as the recognition of the abnormal operation of the equipment. The fault diagnosis problem in chemical process industries is addressed through a portfolio of methods each having its advantages and disadvantages. The approaches can be divided into six categories as shown in Fig. 1, which are not mutually exclusive, i.e. for some of them there is no clear-cut boundary to separate one approach from others. The first category is the state-space approach, which is model based. Application of extended Kalman filter and/ or nonlinear estimator to identify process parameters indicative of process faults by deterioration of compo- nents (Watanabe and Himmelblau, 1983a,b,c is an * This work is dedicated to the memory of Professor David W. T. Rippin who has been a source of inspiration in process systems engineering. The fault diagnosis benchmark problem used goes back to a diploma project completed by one of his students at ETH in the early 1970s. * Author for correspondence. example of this approach). This approach needs exten- sive effort in process modeling and has computation time related problems, that limits their applicability. Statistical approaches are primarily empirical and successfully applied in practice. Both parametric and nonparametric approaches are widely used. Parametric statistical approach assumes, a priori, a distribution for the process data and is based on identification of the parameters for the distribution. On the other hand, a non- parametric approach uses a distance measure for group- ing the data used, (i.e., it performs data clustering). The major shortcoming of this approach is its requirement for large amounts of data. Another approach used for fault diagnosis is based on directed graphs. Different types of directed graphs can be used. The most fundamental of them are Information Flow Graphs (Fault Trees) (Himmelblau, 1978), which are capable of only qualitative diagnosis. Beside this shortcoming, the construction of fault trees needs detailed process knowledge and, therefore, they are not suitable for large systems. Another type of digraph based method is the Signed Directed Graphs method (SDG) which is based on qualitative reasoning. The method suffers from incompleteness and can result in ambiguous diagnoses. Yu and Lee (1991) have developed a framework for integrating quantitative process knowl- edge into a qualitative SDG model to address this problem. Wilcox and Himmelblau (1994a,b) suggested another digraph-based diagnostic method called the Possible Cause and Effect Graphs (PCEG) model. This 299

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Pergamon Computers chem. Engng Vol. 22, No. 1-2, pp. 299-321, 1998
Copyright © 1997 Elsevier Science Ltd Printed in Great Britain. All tights reserved
PIh S0098-1354(96)00000-0 0098-1354/97 $17.00+0.00
Chemical plant fault diagnosis through a hybrid symbolic-connectionist machine
learning approach*
B. OzyurP, A. K. Sunol a*, M. C. Camurdan b, P. MogilP, L. O. Hall a
a College of Engineering, University of South Florida, Tampa, FL 33620, U.S.A. b Department of Chemical Engineering, Bogaziqi University, Bebek, Istanbul, Ttirkiye.
(Received 26 October 1994; revised 4 April 1996)
Abstract
A novel hybrid symbolic-connectionist approach to machine learning is introduced and applied to fault diagnosis of a hydrocarbon chlorination plant. The learning algorithm addresses the knowledge acquisition problem by developing and maintaining the knowledge base through instance based inductive learning. The performance of the learning system is discussed in terms of the knowledge extracted from example cases and its classification accuracy on the test cases. Results indicate that the introduced system is a promising alternative to neural networks for fault diagnosis and a complement to expert systems. © 1997 Elsevier Science Ltd
1. Introduction
The advances in computer and electronic sciences permit highly automated processes, where reliable, on- line fault diagnosis systems, which will eliminate or reduce the human operator dependency in real time fault diagnosis, are possible.
Fault is defined as the departure of an observed variable or calculated parameter from an acceptable range associated with that equipment (Himmelblau, 1978). Fault diagnosis is referred to as the recognition of the abnormal operation of the equipment. The fault diagnosis problem in chemical process industries is addressed through a portfolio of methods each having its advantages and disadvantages. The approaches can be divided into six categories as shown in Fig. 1, which are not mutually exclusive, i.e. for some of them there is no clear-cut boundary to separate one approach from others.
The first category is the state-space approach, which is model based. Application of extended Kalman filter and/ or nonlinear estimator to identify process parameters indicative of process faults by deterioration of compo- nents (Watanabe and Himmelblau, 1983a,b,c is an
* This work is dedicated to the memory of Professor David W. T. Rippin who has been a source of inspiration in process systems engineering. The fault diagnosis benchmark problem used goes back to a diploma project completed by one of his students at ETH in the early 1970s. * Author for correspondence.
example of this approach). This approach needs exten- sive effort in process modeling and has computation time related problems, that limits their applicability.
Statistical approaches are primarily empirical and successfully applied in practice. Both parametric and nonparametric approaches are widely used. Parametric statistical approach assumes, a priori , a distribution for the process data and is based on identification of the parameters for the distribution. On the other hand, a non- parametric approach uses a distance measure for group- ing the data used, (i.e., it performs data clustering). The major shortcoming of this approach is its requirement for large amounts of data.
Another approach used for fault diagnosis is based on directed graphs. Different types of directed graphs can be used. The most fundamental of them are Information Flow Graphs (Fault Trees) (Himmelblau, 1978), which are capable of only qualitative diagnosis. Beside this shortcoming, the construction of fault trees needs detailed process knowledge and, therefore, they are not suitable for large systems. Another type of digraph based method is the Signed Directed Graphs method (SDG) which is based on qualitative reasoning. The method suffers from incompleteness and can result in ambiguous diagnoses. Yu and Lee (1991) have developed a framework for integrating quantitative process knowl- edge into a qualitative SDG model to address this problem. Wilcox and Himmelblau (1994a,b) suggested another digraph-based diagnostic method called the Possible Cause and Effect Graphs (PCEG) model. This
299

300 B. O'zYua'r et al.
Smte-$1mce Approach -iim~/nonlin~ rote mimaton -(=~aded) ~
l~oblam 8olullon I
I
Im,, S .m I N.,.,.nmm,,o,,k. p p r u ~ lApp r°scln I
-~ook,m,ux,,S
I [-++'+-+++-I • RBF m
ISTIbollc..(~onm~:lioniJt IA,',''%.
~ a a l t k 'I~mry
Tam)
Fig. 1. Fault diagnosis problem solution methods.
method allows a more accurate representation of uncer- tainty about the state of the process than is possible by the SDG model. It also allows inclusion of relatively unconstrained concept families and designation of certain statements as exogenous with respect to the implicit model of the process. Rule generation is possible with this method, but it has limited applicability especially for processes with hard real-time constraints and for highly complex processes.
Nowadays, there are two popular approaches for fault diagnosis. The first is the expert system approach. Various expert systems have been developed for chem- ical engineering fault diagnosis (Dvorak and Kuipers, 1991, Finch and Kramer, 1988, Kramer, 1987, Petti et al., 1990, Ramanathan et al., 1993). They usually use non-Boolean reasoning, since non-Boolean reasoning techniques increase the stability and sensitivity of the diagnosis in the presence of noise. Both shallow and deep knowledge models have been applied.
The expert systems used are usually rule based. Creation of the knowledge base is usually time consum- ing due to its incremental nature and requires many process experts with conflicting perspectives. Fur- thermore, expert systems are known to be diagnostically brittle under new conditions (inclusion of deep knowl- edge of the process in the knowledge base addresses this problem, but this brings the uniqueness of the knowl- edge problem into account). Any change in the operation conditions of the process can result in the invalidation of the rules integrated into an expert system and requires updating of the knowledge base, which is a tedious and elaborate task to do.
The second approach makes use of artificial neural networks (ANN). ANNs are non-model based tools that belong to pattern recognition methods. They are known to be noise tolerant; they are adaptive and they can generalize the knowledge. Backpropagation neural net- works have been widely used for diagnostic purposes (Hoskins et al., 1991, Ungar et al., 1990, Watanabe et al., 1989, Venkatasubramanian et al., 1990). Kramer and Leonard (1991) pointed out the limitations of back- propagation networks with linear activation functions, including the problems of novel fault classes, corrupted or missing data, extrapolation problems, etc. To over- come these problems, radial basis function networks can be used (Moody and Darken, 1989, Sorsa and Koivo, 1993). Main drawbacks of the ANN based methods are long training times, difficulty in symbolic knowledge extraction from the trained network, and the need for considerable training data. There are some attempts at symbolic knowledge extraction from backpropagation neural networks (Passino et al., 1989). There are also attempts at integration of expert systems and neural networks (multilayer perceptrons) for chemical engi- neering fault diagnosis (Becraft and Lee, 1993).
1.1. Inductive learning
Inductive learning can be defined as the capability of extracting decision making knowledge from the data with or without using background knowledge. The main premise in all inductive learning techniques is that, if patterns that account for the class membership of the known objects can be found, these same patterns will predict the class of a new unseen object. A classification

Hybrid symbolic-connectionist machine learning
task is the problem of finding a general classification rule that works well on the objects in a given training set. By the above assumption, this rule codifies regularities in the training set that will be useful when trying to classify an unseen object (Quinlan, 1990).
Purely symbolic inductive machine learning tech- niques have been used since the first symbolic learning system, ID3, (Interactive Dichotomizer) was introduced by Quinlan in 1979. ID3 is a decision tree based non- incremental learning algorithm that uses an information theoretic measure for construction of induction rules from examples. Over the recent years, non-incremental learning behavior of the ID3 improved by Schlimmer and Fisher (1986)'s ID4 and Utgoff (1988)'s ID5. Both of these systems require repetitive representation of training examples, unlike the ID3. Cheng et al. (1988) have developed an generalized version of ID3, namely GID3, which allows for the use of continuous variables and avoids the limitations of missing branches, which can occur whenever branches are created for attribute values that can only occur in the training set, and overspecialization, which occurs when branches are generated for every possible value of a given attribute, resulting in the generation of very specific rules, imposed by the ID3. All of these systems use only raw data. AQI1 (Michalski, 1980) and AQI5 (Michalski et al., 1986) incorporate background knowledge in addition to data.
In recent years, Saraiva and Stephanopoulos (1992) have developed a methodology following the ID3 (Quinlan, 1979, 1986) approach for the creation of a fully expanded decision tree and following the CART algorithm (Breiman et al., 1984) for the pruning and simplification of the resulting decision tree. Also, they extended the basic methodology to handle fuzzy class definitions and function learning formulations. A similar approach is used by Bakshi and Stephanopoulos (1994) for induction of real-time patterns from operating data for diagnosis and supervisory control.
A novel hybrid machine learning approach, Symbolic- Connectionist Network (SC-net) (Romaniuk, 1991), is introduced in this study as a diagnostic tool. SC-net is a connectionist expert system which combines the desir- able features of connectionist approaches like neural networks and expert systems, namely parallel and distributed representation of knowledge, fault tolerance, noise resistance, ability to deal with continuous inputs and outputs and symbolic knowledge processing of expert systems. It also enables symbolic knowledge extraction, their incorporation as natural language-like rules, and has no real-time problems in either training or diagnosis.
2. Symbolic-connectionist network (SC-net)
The SC-net learning system is based on a hybrid symbolic, connectionist architecture, which allows for knowledge encoding and extraction in the form of natural language-like rules. In order to deal with uncertainty in the user responses and in the example data
301
for learning itself, SC-net uses fuzzy logic (Zadeh, 1988).
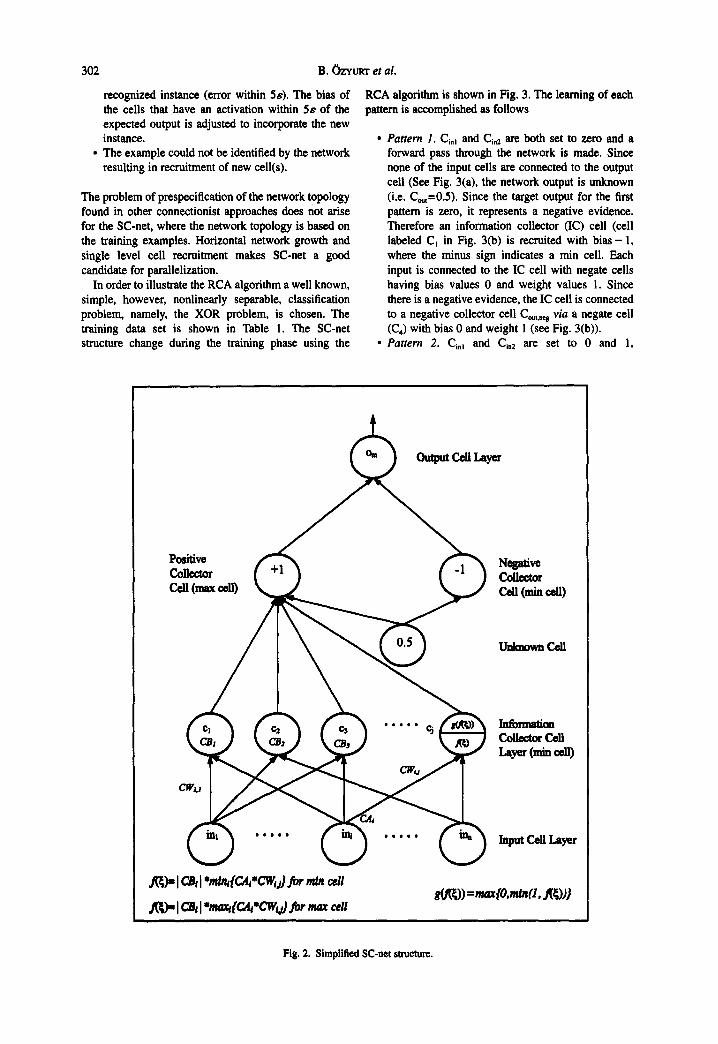
The SC-net network structure consists of simple cells modeling the fuzzy operators rain, max and sum. Every cell in the network contains a bias value CB~, which indicates what type of fuzzy function a cell models, and its absolute value represents an upper threshold value a cell can take on the activation, CAi. Cells are connected by links carrying link weights. A cell (7,. (with CA~) and another cell Cj (with CAj) are connected with a link carrying connection weight CW 0. Every cell C~ with a cell activation CAr (except for input cells) computes its new cell activation CA~ according to the formula
ICB,l*minjj,,{ CAy*CWij } if Ci is a min cell
ICBi*maxh,,{CA~*CW~j ] if C~ is a max cell
CA flCB~I*Zjj,,{CAj*CW~j} if Cj is a linear threshold cell i= 6 l 1 CA~ ..... +CA~.,.,.°- ~ if C~ is a final output cell
1 - CAj*CWij if Ci is a negate cell
(])
Oi=max(O,min(O,min(l,CAi)) where Oi is output for cell C~,
where the final output cell and negate cell formulas are special cases of the linear threshold cell formula. In the following three sections, the main algorithms used in SC-net are described (Romaniuk, 1991).
2.1. Recruitment of Cells Algorithm (RCA)
When SC-net is presented with a training set consist- ing of input and corresponding output information (i.e. in a supervised manner), then it invokes the Recruitment of Cells Algorithm (RCA). RCA generates a network to map the training set into a network representation. The details of the RCA algorithm are given in Appendix A.
The network generated consists of Input Cells, Information Collector (IC) cells, Negative Collector (NC) cells, Positive Collector (PC) Cells, Unknown (UK) Cells and Output Cells (see Fig. 2). Input Cells are responsible for input information representation. The positive and negative collector cells collect information for and against the presence of conclusion, respectively. These collector cells are connected to every output and IC cell, which combine the input information into an intermediate form. The UK cell always propagates a fixed activation of 0.5 and, therefore, acts on the positive and negative collector cells as a threshold, letting them propagate an activation representing the type of the evidence present (positive, negative or unknown).
Every training instance is presented to the network once, unlike the artificial neural networks, where for convergence many passes through the data are necessary. After the pass of the training instance, the actual and expected activations for every output are compared. Possible conditions resulting from this comparison are
• The example was correctly identified (error is below some tolerance limit 8 (for this study s<0.01)). No modifications are necessary.
• The example is similar to at least one previously
302 B. Ozyur, T et al.
recognized instance (error within 58). The bias of the cells that have an activation within 58 of the expected output is adjusted to incorporate the new instance.
• The example could not be identified by the network resulting in recruitment of new cell(s).
The problem of prespecification of the network topology found in other connectionist approaches does not arise for the SC-net, where the network topology is based on the training examples. Horizontal network growth and single level cell recruitment makes SC-net a good candidate for parallelization.
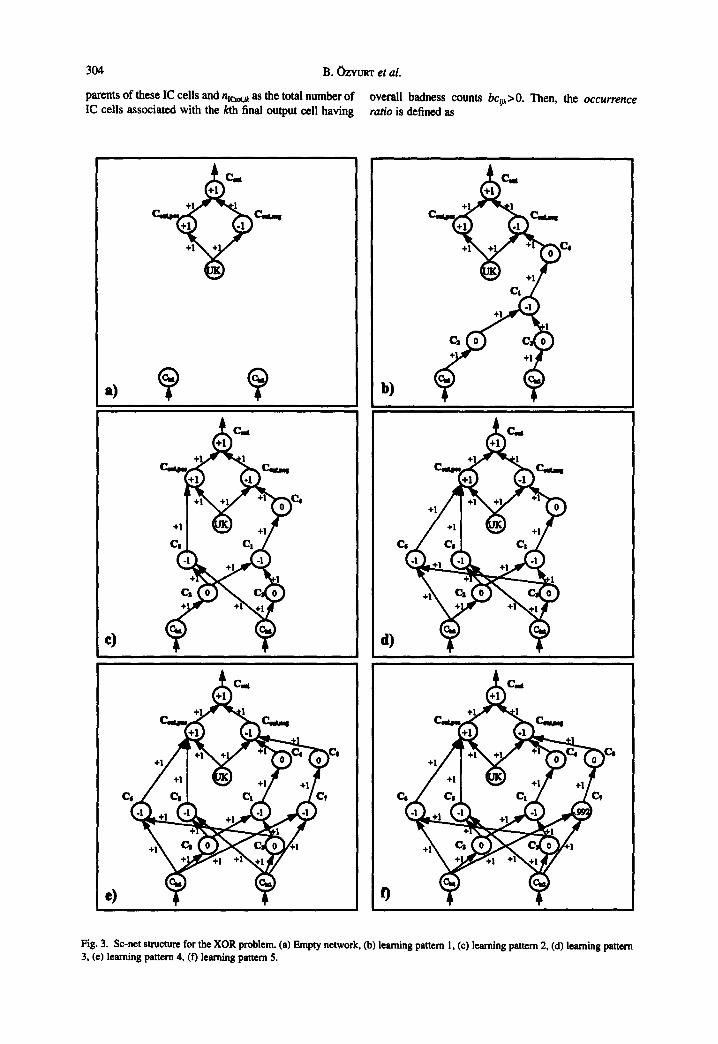
In order to illustrate the RCA algorithm a well known, simple, however, nonlinearly separable, classification problem, namely, the XOR problem, is chosen. The training data set is shown in Table 1. The SC-net structure change during the training phase using the
RCA algorithm is shown in Fig. 3. The learning of each pattern is accomplished as follows
• Pattern I. C~,, and C~n2 are both set to zero and a forward pass through the network is made. Since none of the input cells are connected to the output cell (See Fig. 3(a), the network output is unknown (i.e. Co~,=0.5). Since the target output for the first pattern is zero, it represents a negative evidence. Therefore an information collector (IC) cell (cell labeled Ci in Fig. 3(b) is recruited with b ias-1 , where the minus sign indicates a vain cell. Each input is connected to the IC cell with negate cells having bias values 0 and weight values 1. Since there is a negative evidence, the IC cell is connected to a negative collector cell Cout.~es via a negate cell (C4) with bias 0 and weight 1 (see Fig. 3(b)).
• Pattern 2. C~,, and C~ 2 are set to 0 and 1,
Output cen Layer
Positivo Co~or Coll (max ~II)
~eptive Collator cen (mix ¢..11)
Utdmown Coll
CWu
I n f o ~ o i l Collator Cell Layer (,,un cell)
Input CoH Layer
1(~)'1 cs, l *m~c~,*cw,.~ for mh, cell
~ 1 CS, I *mo~C~°CW,:) for max ceU
Fig. 2. Simplified SC-net slmcturc.

Hybrid symbolic--connectionist machine learning
Table 1. Training data for the XOR problem
Pattern number Input l(Ct.O Input 2(Ci.2) Output(Co~)
1 0 0 0 2 0 1 1 3 1 0 1 4 1 I 0 5 0.92 0.98 0.05
303
respectively, and a forward pass through the net- work is made. The network output is unknown (i.e. Co~t=0.5), since the pattern is not similar to the previously seen pattern. The target output for this pattern is 1.0, representing a positive evidence, therefore the newly recruited IC cell (C5) is connected directly to a positive collector cell C o ~ with a weight + 1. Input Ci.~ is connected to the IC cell C5 via the negation cell C2 with weight CWe.5= 1/(1 - Ci,0= 1, since Ci,i =0< 1/2, following the RCA algorithm given in Appendix A. Input C~.2 is connected to IC cell C 5 directly with weight CWi.2~=I/(Ci,2)=I, since Ci , )= l> l /2 (see Fig. 3(c)).
• Pattern 3. C~,t and C~,a are set to 1 and 0, respectively, and a forward pass through the net- work is made. Since the network output is unknown (i.e. C~, =0.5), IC cell C6 is recruited and connected to a positive collector cell C o ~ , similar to pattern 2 (see Fig. 3(d)).
• Pattern 4. Ci.. and C+,2 are both set to I and a forward pass through the network is made. Since the network output is unknown, a new IC cell C7 is recruited and connected to a negative collector cell Co,~.eg, similar to pattern 1 (see Fig. 3(e)).
• Pattern 5. Since the expected and actual output are within 5e (i.e. pattern 5 is similar to one of the patterns seen, namely pattern 4), the bias of IC cell C7 is adjusted (see Fig. 3(f)) using the formula
CB ~ = sgn(CBT)
*{ICB~I )(1 - [CBTl - }
= - { 1 I(l - 1 -0"05)1 } = - 0"992" 6
Note that the network grows linearly for the first four patterns, which are essential for the correct classifica- tion. In order to learn the last pattern, the network adjusts the activation value of the corresponding cell of the class to which the pattern belongs.
2.2. Global Attribute Covering algorithm (GAC)
The RCA's main disadvantage is that the network growth under worst case conditions is linear, resulting in large networks. The resulting large network (when compared to a backpropagation network) growth can
have serious effects on network simulation and training time, as well as increasing the memory requirements. This problem can be addressed by applying the Global Attribute Covering (GAC) algorithm. Given the RCA generated network as its input, GAC generates (except for contradictions and inconsistencies in the examples) an equivalent network, minimized in the number of cells and links that are used; as a side effect it allows the extraction of highly general and simple rules for explanation purposes.
In the first step of the GAC algorithm, all the inputs to the IC cells are disconnected, forcing them to propagate activations of 1.0. Since all IC cells fire, they will activate all the corresponding connected output cells. Since it is known when a concept should be activated for a given example (only if its IC cell has been selected for activation), one can determine those that fired but should not have, according to the given input assignment. Incorrectly activated IC cells enter into a conflict list. All links entering the IC cell as inputs will be considered as potential inhibitors for network minimization. By acti- vating certain links, one can prevent the cell from firing under the same input conditions.
In order to measure the quality of each incoming IC cell link for selection as a candidate for inhibition, a badness count is associated with it. The badness count is increased each time the link acts as a possible inhibitor. Finding the right set of links or punishment is accom- plished using a fitness measure that is based on a frequency of occurrence heuristic, which indicates the importance of the group of the links for every final output cell in terms of inhibiting the associated incor- rectly activated IC cells. The measure is composed of two individual measures, namely, badness ratio and occurrence ratio, defined as follows
Let
bcok = badness count of link j of the Rh IC cell connected to the kth final output cell. ob~k = overall badness count of the ith IC cell (i.e. the number of times the ith IC cell is incorrectly activated during iteration).
then the badness ratio is defined as
bcok br,jk= ~ k= 1,...,No. (2)
Let index i represent the links connected to the IC cells belonging to the kth final output cell and index j represent the IC cells connected to the kth final output cell. Also, defining nm,hjk as the number of IC cells inhibited by the group of links stemming from the
304 B. ~ U R ' r et al.
parents of these IC cells and n~c,o~t as the total number of overall badness counts bcuk>O. Then, the occurrence IC cells associated with the kth final output cell having ratio is defined as
+1 ~ +1 C + ~ C d
+I C 6 ~ Ci
e) d) ÷~
e) 0 ÷'~÷' Fig. 3. Sc-net structure for the XOR problem. (a) Empty network, (b) learning pattern 1, (c) learning pattern 2, (d) learning pattern 3, (e) learning pattern 4, (f) learning pattern 5.

Hybrid symbolic-connectionist machine learning
nlCnh.ik orok . . . . k= l,...,No. (3)
nlctot,k
The product of the badness and occurrence ratios is defined as the fitness ratio fr~ for the jth link of the IC . cell connected to the kth final output cell and used for the determination of the list of the links selected for inhibition (i.e. for connecting back) according to the equation .
max,j{frqk} k= 1 ..... No. (4)
The main purpose of the GAC algorithm is to obtain • a minimal network description both in the number of cells and links. Using the badness ratio only, one may yield a good set of inhibiting links. However, the • badness ratio does not take the size of the selected group into consideration, resulting in a decrease of pruned • links. To counteract this possibly detrimental behavior, the occurrence ratio is used. The fitness ratio combines the effects of both of these measures by taking their product.
After each iteration through the conflict vector, IC cells whose badness count has not been incremented are removed from the conflict vector. The upper bound for the number of iterations through the conflict vector is the number of all output cells.
The GAC algorithm stops when either the conflict vector is empty or when no more links are available to act as inhibitors, where the algorithm fails to find a minimal network. The second situation only arises when the training data includes inconsistencies.
2.2.1. Case study 1. In order to illustrate the effect of the GAC algorithm
on the final SC-net structure, a heptane-to-toluene aromatization example (Watanabe et al., 1989) is used. In this process, heptane is converted catalytically to toluene by a PI-feedback controlled heater-reactor system operating at near steady-state conditions. Hep- tane stored in the tank is fed to the reactor through process pump 1. In the reactor, a catalytic reaction
CTHI6"-*CTH 8 + 4H2 (5)
occurs. The reaction rate is controlled by the temperature in the reactor. Steam supplied to the heat exchanger in the reactor is recycled to the inlet of the heater via recycle pump 2. The outlet valve in the heater is controlled by the PI controller. The controlled variable is the reaction temperature, and the controller regulates the
305
temperature to the specified value. A lumped parameter dynamic model of the process is used to simulate 5 different faults which are categorized as
Deterioration of the catalyst performance due to physical and/or chemical deterioration of the cata- lyst causing a decrease in the frequency factor for the catalyst. Fouling of the heat exchanger surface in the reactor causing a decrease in the overall heat transfer coefficient. Fouling of the heat exchanger surface in the heater causing a decrease in the overall heat transfer coefficient. Partial plugging of the pipeline connected to pump 1 causing a decrease in the volumetric flowrate. Partial plugging of the pipeline connected to pump 2 causing a decrease in the volumetric flowrate.
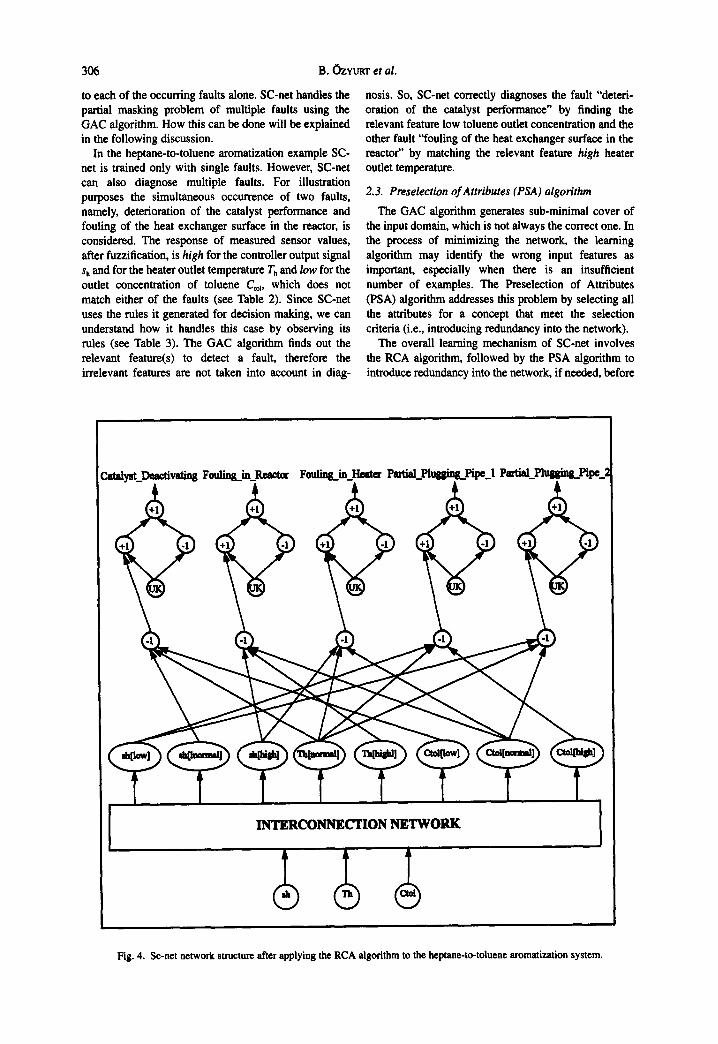
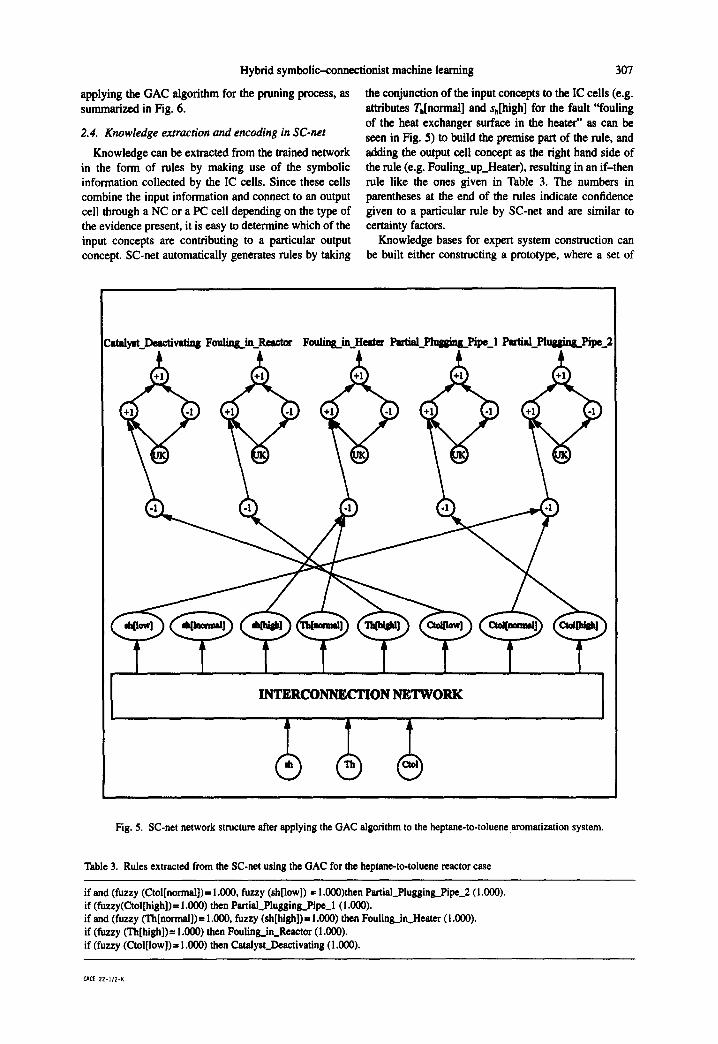
The existence of these five faults is diagnosed from measurements of the outlet concentration of toluene Cto~, the heater outlet temperature Th, and the controller output signal sh. The three continuous variables for the reactor system are converted into fuzzy linguistic variables to capture symbolic information in the sensor data to produce human expert favored rules. For the heater control signal Sh and toluene outlet concentration C,o~, three attributes, namely, low, normal and high, are used. For the heater outlet temperature Th, two attributes, namely, normal and high, are used. The training data set consisting of one instance per fault is given in Table 2. The final network structure resulting after applying the RCA algorithm is shown in Fig. 4. Here, for simplicity, the interconnections between the three input attributes and their respective attribute/value feature detector cells, are not shown. After applying the GAC algorithm the network structure reduces to the one in Fig. 5. From this structure, the SC-net easily generates classification rules as shown in Table 3.
2.2.2. Multiple faults. Simultaneous occurrence of faults is not unlikely in
chemical processes. Therefore, the ability of any diag- nostic system to detect multiple faults is an important characteristic of that system. Detection of multiple faults is more difficult than detection of single faults, since simultaneously occurring faults usually distort and mask each other's behavior, and because of that the resulting response of the process will be different than responses
Table 2. Training data for the heptane-to-toluene aromatiza- tion system
Fault description sh Th Ct~
CatalystDeactivating normal normal low Fouling.in_Reactor high high normal Fouling.in_Heater high normal normal Partial_Plugging..Pipe_ 1 low normal high Partial_Plugging._Pipe_2 low normal normal
306 B. OZYURT et al.
to each of the occurring faults alone. SC-net handles the partial masking problem of multiple faults using the GAC algorithm. How this can be done will be explained in the following discussion.
In the heptane-to-toluene aromatization example SC- net is trained only with single faults. However, SC-net can also diagnose multiple faults. For illustration purposes the simultaneous occurrence of two faults, namely, deterioration of the catalyst performance and fouling of the heat exchanger surface in the reactor, is considered. The response of measured sensor values, after fuzzification, is high for the controller output signal Sh and for the heater outlet temperature Th and low for the outlet concentration of toluene C, oj, which does not match either of the faults (see Table 2). Since SC-net uses the rules it generated for decision making, we can understand how it handles this case by observing its rules (see Table 3). The GAC algorithm finds out the relevant feature(s) to detect a fault, therefore the irrelevant features are not taken into account in diag-
nosis. So, SC-net correctly diagnoses the fault "deteri- oration of the catalyst performance" by finding the relevant feature low toluene outlet concentration and the other fault "fouling of the heat exchanger surface in the reactor" by matching the relevant feature high heater outlet temperature.
2.3. Preselection of Attributes (PSA) algorithm
The GAC algorithm generates sub-minimal cover of the input domain, which is not always the correct one. In the process of minimizing the network, the learning algorithm may identify the wrong input features as important, especially when there is an insufficient number of examples. The Preselection of Attributes (PSA) algorithm addresses this problem by selecting all the attributes for a concept that meet the selection criteria (i.e., introducing redundancy into the network).
The overall learning mechanism of SC-net involves the RCA algorithm, followed by the PSA algorithm to introduce redundancy into the network, if needed, before
Catalyst_Ikaedvati~ F o - " n ~ i n _ R ~ Fo-finLin_I'ka~ P ~ _ P l u g l ~ P i p c _ l P~ial_Pl "qBm~Pipej , h
INTERCONNECTION NETWORK
Fig. 4. Sc-net network structure after applying the RCA algorithm to the heptane-to-toluene aromatization system.
Hybrid symbolic-connectionist machine learning
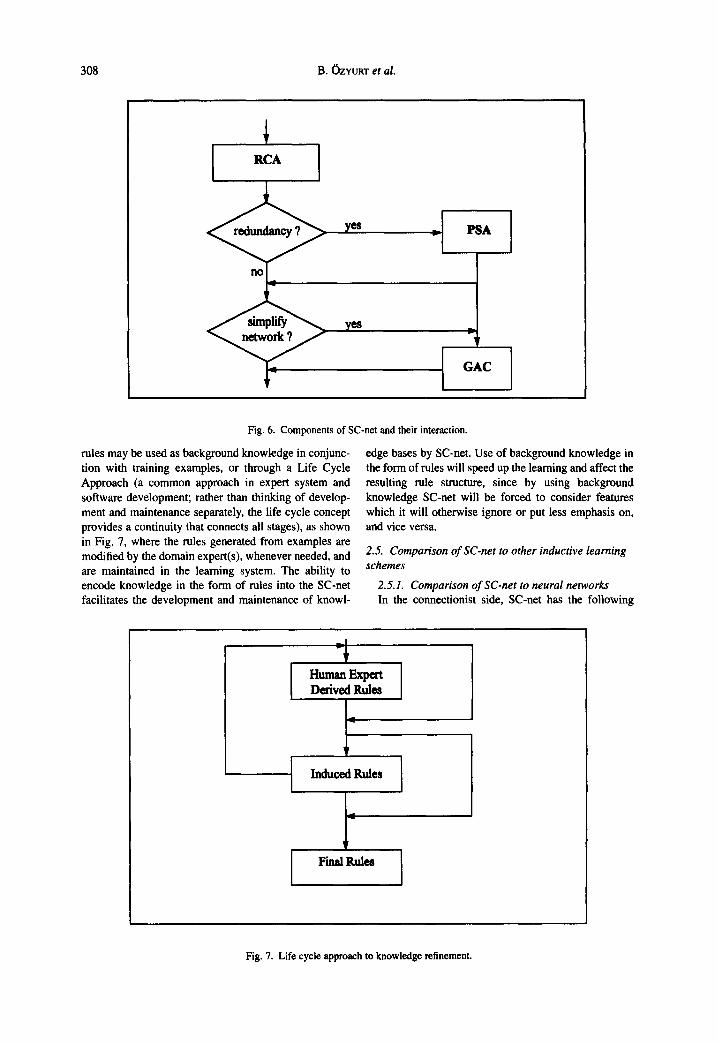
applying the GAC algorithm for the pruning process, as summarized in Fig. 6.
2.4. Knowledge extraction and encoding in SC-net
Knowledge can be extracted from the trained network in the form of rules by making use of the symbolic information collected by the IC cells. Since these cells combine the input information and connect to an output cell through a NC or a PC cell depending on the type of the evidence present, it is easy to determine which of the input concepts are contributing to a particular output concept. SC-net automatically generates rules by taking
307
the conjunction of the input concepts to the IC cells (e.g. attributes Th[normal] and sh[high] for the fault "fouling of the heat exchanger surface in the heater" as can be seen in Fig. 5) to build the premise part of the rule, and adding the output cell concept as the right hand side of the rule (e.g. Foulingup_Heater), resulting in an if-then rule like the ones given in Table 3. The numbers in parentheses at the end of the rules indicate confidence given to a particular rule by SC-net and are similar to certainty factors.
Knowledge bases for expert system construction can be built either constructing a prototype, where a set of
Fig. 5. SC-net network structure after applying the GAC algorithm to the heptane-to-toluene aromatization system.
Table 3. Rules extracted from the SC-net using the GAC for the heptane.to-toluene reactor case
if and (fuzzy (Ctol[normal])= 1.000, fuzzy (sh[low]) = 1.000)then Partial..Plugging_Pipe_2 (I ,000). if (fuzzy(Ctol[high])= 1.000) then Partial Plugging..Pipe_l (I.000). if and (fuzzy (Th[normal])= 1.000, fuzzy (sh[high])= 1.000) then Fouling_in_Heater (I.000). if (fuzzy (Th[high])= 1,000) then Fouling_in_Reactor (1.000). if (fuzzy (Ctol[Iow])= 1.000) then Catalyst_Deactivating (I .000).
CACE 22-]/2-K
308 B. Ozvuar et al.
RCA I
yes
yes
_I -I
PSA
GAC
Fig. 6. Components of SC-net and their interaction.
rules may be used as background knowledge in conjunc- tion with training examples, or through a Life Cycle Approach (a common approach in expert system and software development; rather than thinking of develop- ment and maintenance separately, the life cycle concept provides a continuity that connects all stages), as shown in Fig. 7, where the rules generated from examples are modified by the domain expert(s), whenever needed, and are maintained in the learning system. The ability to encode knowledge in the form of rules into the SC-net facilitates the development and maintenance of knowl-
edge bases by SC-net. Use of background knowledge in the form of rules will speed up the learning and affect the resulting rule structure, since by using background knowledge SC-net will be forced to consider features which it will otherwise ignore or put less emphasis on, and vice versa.
2.5, Comparison of SC-net to other inductive learning schemes
2.5.1. Comparison of SC-net to neural networks In the connectionist side, SC-net has the following
Human Expert Derived Rules [
d
Fig. 7. Life cycle approach to knowledge refinement.

Hybrid symbolic--connectionist machine learning
three desirable features of connectionist architectures like neural networks.
• A highly parallel and distributed representation of knowledge.
• Fault tolerance and noise resistance. • Ability to deal with continuous inputs and outputs.
In addition to these features, dynamic growth of SC-net via the RCA algorithm eliminates hidden layer neuron size problems encountered in purely connectionist architectures like common feedforward and backpropa- gation neural networks. SC-net is also capable of incremental learning, which is only possible for decision tree based methods by repetitive representation of training examples (Utgoff, 1988).
Fahlman and Lebiere (1990) proposed cascade- correlation learning architecture, which grows its hidden layer structure, one node per layer, and is designed for incremental learning. Training in cascade-correlation networks follows a gradient descent error minimization approach with a significant difference from the standard backpropagation algorithm. However, there are no means for symbolic knowledge extraction from learned cascade-correlation networks.
SC-net is not intended to be a substitute for artificial neural networks, which are good in learning continuous input-output mappings. However, SC-net was able to learn and classify two interleaved spirals, which is sometimes considered as a benchmark for neural net- work learning algorithms, since it is considered a very hard problem for backpropagation type algorithms (Lang
309
and Witbrock, 1988), as described in Romaniuk (1991). Also, in performance comparison studies of different inductive learning schemes on different domains, rang- ing from credit worthiness of credit applicants (Roma- niuk and Hall, 1989; Romaniuk, 1991) and soybean disease diagnosis (Romaniuk, 1991) to a real world application, namely, semiconductor wafer fault diag- nosis for the Harris Semiconductor Corporation at Melbourne, FL (Romaniuk, 1991), it has been shown that SC-net has either similar or slightly better perform- ance than Quickprop, a faster-learning version of backpropagation (Fahlman, 1988).
2.6. Comparison of SC-net to decision tree based methods
A decision tree is a recursive structure for expressing classification rules, where the tree consists of a test that has a set of mutually exclusive possible outcomes together with either a leaf or a subsidiary decision tree for each such outcome (Quinlan, 1990). Classification of an object is done by tracing out a path from the root of the decision tree to one of its leaves.
Decision tree based methods (e.g. ID3 (Quinlan, 1979, 1986), CART (Breiman et al., 1984), and C4.5 (Quinlan, 1993)) use heuristics based on information or entropy (Breiman et al., 1984; Quinlan, 1988), heuristics based on error (Breiman et al., 1984) or heuristics based on statistical significance (Hart, 1985; Mingers, 1989) to generate fully expanded decision trees. To remove unimportant or unsubstantiated portions of the fully expanded trees, for generation of a smaller decision tree with possibly better generalization properties, different
Fig. 8. Syschcm plant flowchart.

310 B. Ozvorrr et al.
Table 5. Syschem plant measurements used
Streamno. Temperature Pressure Flowrate Composition
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
t t
t
t t
t
• Initial measurements used for SC-net training. t Added measurements for better classification.
to learn incrementally from instances and generate rules. Learning in SC-net is accomplished through representa- tion of the training instances to the network once, from which SC-net dynamically grows to a distributed structure encoding the implicit knowledge in the training instances into an explicit representation from which rules are generated. How this was done is explained in previous sections on the main algorithms of SC-net.
pruning schemes are proposed. The most popular pruning techniques are, cost complexity pruning (Brei- man et al., 1984), minimum description length pruning (Quinlan and Rivest, 1989) and pessimistic pruning (Quinlan, 1987). Further details on decision tree based machine learning systems can be found in the above- mentioned publications.
SC-net is a connectionist expert system, which is able
Table 4. Syschem plant faults used in the case study
(1) Excessive heat loss from the vaporizer whose insulation may be damaged or wetted. (2) Cooling coil in the CSTR fouled and heat transfer resistance too high. (3) Condenser partially flooding. (4) PFR not operating abiabatically; cooling occurring and insulation possibly damaged. (5) Process in the condenser gaining heat, an unwanted chemical reaction possibly occurring within the condenser shell. (6) Reactants escaping from the PFR due to a leaking flanged head or joint. (7) Level of the reactants in the CSTR too high. (8) Gas entering into vaporizer feed resulting in further reaction. (9) Control valve controlling stream 8 not fully open.
(10) Loss of catalyst in PFR. (11) Hot spot formed in the middle of the catalyst bed in the PFR resulting in very high conversion. (12) Gross imbalance in the residence times of the reactants in the catalyst bed caused by channeling of gas through the bed in
PFR. (13) Excessive liquor level in the vaporizer possibly caused by a faulty controller system (FC5). (14) Desiccant in the drier saturated resulting in a need to regenerate the drier. (15) Desiccant quality becoming poor or massive corrosion occurring in the drier; unexpected reaction occurring with the process
gas. (16) Excessive resistance to cooling water flow through interstage cooler 1. (17) Stream 1 block valve is partially closed or is fouled causing an excessive resistance to flow. (18) Insulation damage results in excessive heat loss from stream 7. (19) Excessive resistance to cooling water flow and heat transfer within tubes of the condenser.
Hybrid symbolic-connectionist machine learning
In decision tree based approaches, attributes which include most information are selected via an information theoretic impurity (entropy) measure for splitting, and the process is repeated until there is no gain of information by splitting, or a predefined number of possible splits is reached.
Pruning in SC-net is accomplished using the GAC algorithm where the cells and links, which describe irrelevant microfeatures in the network for classification
311
and decision making, are disconnected. Whereas in the decision tree based methods, a sequence of pruned variants of the original tree is formed, and one of them is selected either on the basis of performance on a test set of unseen cases that were not used to construct the tree (Breiman et al., 1984), or on the basis of minimization of the total information required to specify the class of all training cases via a general rule (the pruned tree) and exceptions to the rule (Quinlan and Rivest, 1989).
ia) 1
~ 0 . 6 .m ,11 ,~ 114 H x ~
0 -
1000
S T R _ T O T _ F L O W ~ )
(b) I
|'T/ -3
OPEN CLOSED
. . .. ; ;
-25 -2 -15 -1 -05 0 Q5
CSTR_H BALANCE
°
1 1.5 2 25
ic) 1
g Q8
Q6
/ 0 " : : :
.8.~000 .4RXX~0 -350000 -250000 - ~ 0 K X ) -~000 50000 1RXX30
~EZ~T0,1~
• o / .
/
PFR ENERGY BALANCE
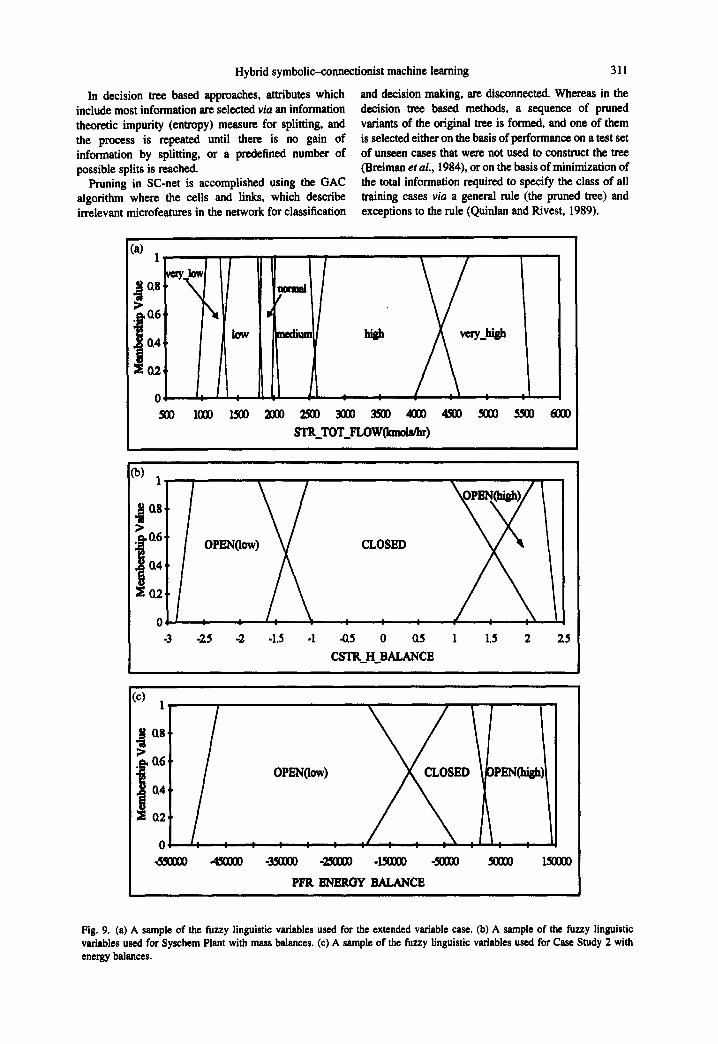
Fig. 9. (a) A sample of the fuzzy linguistic variables used for the extended variable case. (b) A sample of the fuzzy linguistic variables used for Syschem Plant with mass balances. (c) A sample of the fuzzy linguistic variables used for Case Study 2 with energy balances.

312 B. OZYUR'r et al.
SC-net has all the distinct features of decision trees, like ability to deal with continuous and discrete attributes, generalization, symbolic decision making knowledge extraction from data in the form of rules. Beside these features, SC-net has features which deci- sion tree based methods lack. SC-net is capable of incremental learning without need of repetitive repre- sentation of training instances. It has a distributed structure (i.e. its classification performance does not depend critically on any small part of the model. Some weights or links can be corrupted, or some cells can be discarded, without destroying the performance of SC- net). In contrast, decision trees are much more suscepti- ble to small changes (Quinlan, 1993). This property of SC-net is a direct consequence of its connectionist structure. In addition to this, SC-net can deal with non- mutually exclusive classes, whereas in decision tree based methods, classes should be mutually exclusive. The connectionist structure makes it a good candidate for parallelization. The ability to encode background
knowledge in the form of rules to SC-net facilitates the learning process and enables the use of available a priori knowledge about the case dealt with. SC-net is also able to deal with uncertainty both in the inputs as well as outputs. These additional features give SC-net a wider range of applicability than decision tree based machine learning techniques.
Comparison performance tests of SC-net with deci- sion tree-based methods like ID3 and GID3, on the same domains used for comparison studies with neural networks, have shown that SC-net favorably compares with these methods (Romaniuk, 1991; Perez et al., 1992).
2. 7. Comparison of SC-net to instance-based learning systems
Within the set of machine learning methods, SC-net most resembles instance-based learning methods (Shav- lik and Dietterich, 1990). The RCA algorithm of SC-net is, in general, similar to the exemplar model growth
Outlmt Cell Layer
Information Collector Cell Layer
V ~ = ' _ H ~ t _ ~ CSTR CoolinLCo~_Fouled P.esistsa~ to flow in Condenser
INTERCONNECTION NETWORK
Fig. 10. A representative network generated by SC-net for the Syschem plant fault diagnosis problem using an extended variable set.
Hybrid symbolic--connectionist machine learning 313
100
90
8O
70
3O
20
10
0.2% 0.7S% 0.7S% LS% ~ . ~ ~ k T A ) ~ ~ ~ G A ~
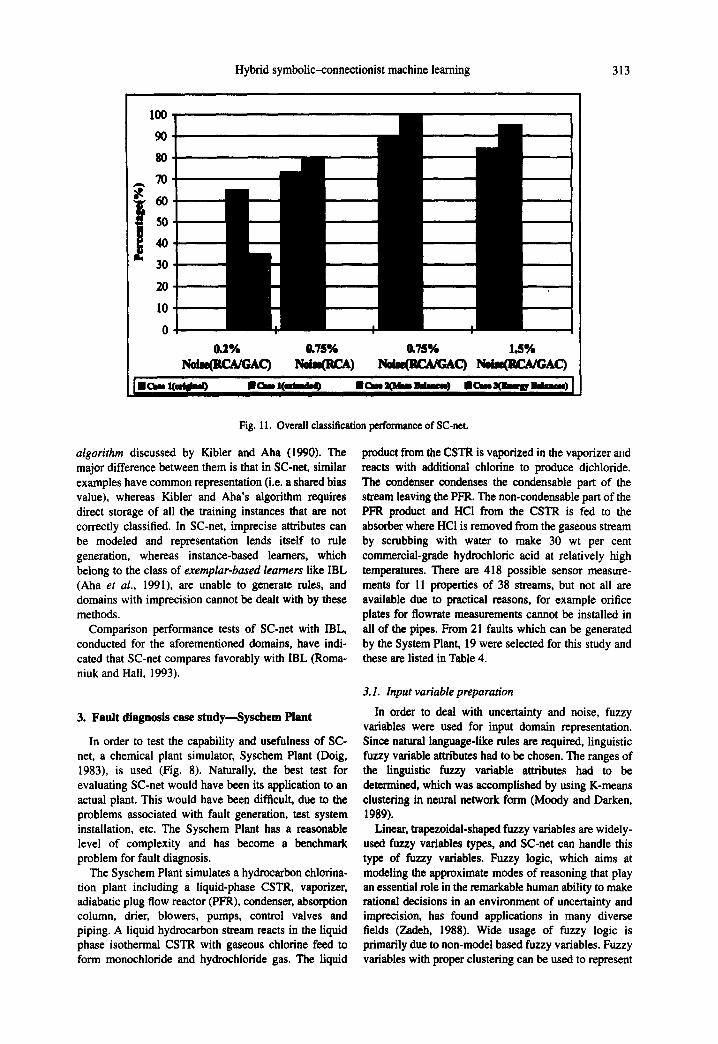
Fig. 11. Overall classification performance of SC-net.
algorithm discussed by Kibler and Aha (1990). The major difference between them is that in SC-net, similar examples have common representation (i.e. a shared bias value), whereas Kibler and Aha's algorithra requires direct storage of all the training instances that axe not correctly classified. In SC-net, imprecise attributes can be modeled and representation lends itself to rule generation, whereas instance-based learners, which belong to the class of exemplar-based learners like IBL (Aha et al., 1991), are unable to generate rules, and domains with imprecision cannot be dealt with by these methods.
Comparison performance tests of SC-net with IBL, conducted for the aforementioned domains, have indi- cated that SC-net compares favorably with IBL (Roma- niuk and Hall, 1993).
3. Fault diagnosis case study--Syschem Plant
In order to test the capability and usefulness of SC- net, a chemical plant simulator, Syscbem Plant (Doig, 1983), is used (Fig. 8). Naturally, the best test for evaluating SC-net would have been its application to an actual plant. This would have been difficult, due to the problems associated with fault generation, test system installation, etc. The Syschem Plant has a reasonable level of complexity and has become a benchmark problem for fault diagnosis.
The Syschem Plant simulates a hydrocarbon chlorina- tion plant including a liquid-phase CSTR, vaporizer, adiabatic plug flow reactor (PFR), condenser, absorption column, drier, blowers, pumps, control valves and piping. A liquid hydrocarbon stream reacts in the liquid phase isothermal CSTR with gaseous chlorine feed to form monochloride and hydrochloride gas. The liquid
product from the CSTR is vaporized in the vaporizer and reacts with additional chlorine to produce dichloride. The condenser condenses the condensable part of the stream leaving the PFR. The non-condensable part of the PFR product and HCI from the CSTR is fed to the absorber where HCI is removed from the gaseous stream by scrubbing with water to make 30 wt per cent commercial-grade hydrochloric acid at relatively high temperatures. There are 418 possible sensor measure- ments for 11 properties of 38 streams, but not all are available due to practical masons, for example orifice plates for flowrate measurements cannot be installed in all of the pipes. From 21 faults which can be generated by the System Plant, 19 were selected for this study and these are listed in Table 4.
3.1. Input variable preparation
In order to deal with uncertainty and noise, fuzzy variables were used for input domain representation. Since natural language-like rules are required, linguistic fuzzy variable attributes had to be chosen. The ranges of the linguistic fuzzy variable attributes had to be determined, which was accomplished by using K-means clustering in neural network form (Moody and Darken, 1989).
Linear, trapezoidal-shaped fuzzy variables are widely- used fuzzy variables types, and SC-net can handle this type of fuzzy variables. Fuzzy logic, which aims at modeling the approximate modes of reasoning that play an essential role in the remarkable human ability to make rational decisions in an environment of uncertainty and imprecision, has found applications in many diverse fields (Zadeh, 1988). Wide usage of fuzzy logic is primarily due to non-model based fuzzy variables. Fuzzy variables with proper clustering can be used to represent

314 B. &VI
any noisy process without need for the model equations and deep knowledge. Modeling is very cumbersome and time consuming for an industrial-sized process like Syschem Plant. It also needs detailed understanding of the process and, because of this, it is domain specific. Therefore, fuzzy reasoning seems to be a good alter- native to the modeling approach. However, determina- tion of the number and ranges of the fuzzy attributes
JRT et 01.
requires some distance measure and, for this purpose, usually euclidean distance is used. Available data is usually classified according to the distance between data points. Clustering is done depending on the assumption that similar patterns (in terms of distance between data points) should belong to the same group. For this study, fuzzy attribute numbers and ranges for each variable are determined using K-means clustering, in neural network
0 20 40 60 80 100
Percent Correctly Diwgnosed (“‘)
(b) Normd
Fmll19
Frlt18
Frit17
Fmltlb
Fad15
Fig. 12. (a) Classification performance of SC-net using an extended variable set for faults l-10. (b) Classification performance of SC-net using an extended variable set for fauits 1 l-19.

Hybrid symbolic-connectionist machine learning
Table 6. Rules extracted by SC-net using an extended variable set
315
if and (fuzzy (STR_I 2_TOT_FLOW[high]) = 1.000, fuzzy (STR_ 11 _H20_FLOW[normal]) = 1.000,fuzzy (STR_ 11 _HC2_FLOW- [normal]) = 1.000) then Resistance_to_flow_in_Condenser (1.000). if and (fuzzy (STR_I l_TOT_FLOW[normai])= 1.000, fuzzy (STR_9_TEMPERATURE[Iow])= 1.000) then Insulation_damage_ in_STR_7 (1.000). if (fuzzy (STR_I_PRESSURE[Iow])= 1.000) then Partially..closed_vaive_in_STR_l (I.000). if and (fuzzy (STR 20 H20_FLOW[normal])= 1.000, fuzzy (STR_3_HCL_FLOW[high])= 1.000)then Cooling..water_resis- tance_in_ISC 1 (1.000). if (fuzzy (STR_ 11_H20 FLOW[high]) = 1.000) then Unexpected rxn_Drier (1.000). if (fuzzy (STR_I l_H20_FLOW[very_high]) = 1.000) then Desiccant_saturated_in_Drier (1.000). if and (fuzzy (STR_20_H20_FLOW[normal])=I.000, fuzzy (STR_19_PRESSURE[normal])=I.000, fuzzy (STR_12_TOT_ FLOW[low])= 1.000, fuzzy (STR 10 TEMPERATURE[normal])= 1.000)then Vaporizer_liquor_level_high (1.000). if and (fuzzy (STR_20_H20_FLOW[Iow])=I.000, fuzzy (STR_lg_TOT_FLOW[normal])=l.000,fuzzy (STR_I_PRESSUR- E[normal]) = 1.000) then PFR_gas_channelling (1.000). if and (fuzzy(STR_! 8_TEMPERATURE[normal]) = 1.000, fuzzy(STR 11 HC2_FLOW[high]) = 1.000 fuzzy (STR_9 TEMPER- ATURE[normal])= 1.000) then PFR_hot_spot formation (1.000). if and (fuzzy (STR_19_TOT_FLOW[low])=I.000, fuzzy (STR_ll_H20_FLOW[normal])=l.000,fuzzy (STR 10 TEMPER- ATuRE[normal]) = 1.000) then PFR_catalyst_deactivating (1.000). if (fuzzy (STR_3_HC2_FLOW[high])= 1.000) then STR_8_valve_not..fully_open (1.000). if (fuzzy (STR_9_HCL_FLOW[high])= 1.000) then Further_rxn_in Vaporizer (1.000). if (fuzzy (STR_3_HC_FLOW[high]) = 1.000) then CSTR_reactant_level_high (1.000). if (fuzzy (STR_IS_TEMPERATURE[high])= 1.000) then PFR_leaking_flange (1.000). if and (fuzzy (STR_I2_TOT_FLOW[high])= 1.000, fuzzy (STR_II_HC2_FLOW[high])= 1.000)then Rxn_in_Condenser_Shell (1.ooo). if and (fuzzy (STR 19 TOT_FLOW[Iow])=I.000, fuzzy (STR_I0_TEMPERATURE[Iow])=I.000) then PFR not_adiabatic (1.000). if (fuzzy (STR_I I_TEMPERATURE[high]) = 1.000) then Condenser_Fouling (1.000). if and (fuzzy (STR 25 TOT_FLOW[high])=l.000, fuzzy (STR 3_HC_FLOW[normal])=l.000)then CSTR_Cooling_Coil_ Fouled ( 1.000). if and (fuzzy (STR_23 TOT_FLOW[high])=l.000, fuzzy (STR 18_TEMPERATURE[normal])=I.000) then Vaporizer_Heat_ Loss (1.000).
Table 7. Rules extracted by SC-net using mass balance equations
if and (fuzzy ABSR CL2 BALANCE[OPEN(high)])= 1.000,fuzzy CSTR_HC_BALANCE[OPEN(low)])= 1.000) then Resis- tance to flow in Condenser (1.000). if and (fuzzy (COND_HCL_BALANCE[CLOSED])= 1.000,fuzzy (PFR_CL2_BALANCE[OPEN(high)])= 1.000,fuzzy (CSTR_ HCL_BALANCE[CLOSED])= 1.000) then Insulation_damage_in_STR_7 (1.000). if and (fuzzy (DRIER_H_BALANCE[OPEN(high)])= 1.000,fuzzy (CSTR HCL_BALANCE[OPEN(high)])= 1.000) then Par- tially_closed_valve_in_STR_ 1 (1.000). if(fuzzy (DRIER_HCL_BALANCE[OPEN(high)])= !.000) then Unexpected_rxn in Drier (1.000). if (fuzzy(DRIER H20_BALANCE[OPEN(low)])= 1.000) then Desiccant_saturated_in_Drier (1.000). if and (fuzzy (VAPR_H20_BALANCE[CLOSED])= 1.000,fuzzy (COND_HCL_BALANCE[CLOSED])= 1.000,fuzzy (DRIER HBALANCE[OPEN(high)])= 1.000,fuzzy (ABSR_CL2-BALANCE[OPEN(high)D= 1.000) then Vaporizer_liquor_level_high (1.000). if and (fuzzy (VAPR_H20_BALANCE[CLOSED])= 1.000.fuzzy (PFR_HCL_BALANCE[OPEN(high)])= 1.000,fuzzy (ABSR_ CL2_BALANCE[CLOSED]) = 1.000) then PFR_gas_channelling (l.000). if and (fuzzy (VAPR_H_BALANCE[OPEN(Low)])= 1.000,fuzzy (ABSR_CL2_BALANCE(OPEN(high)])= 1.000) then PFR_ hotspot_formation (1.000). if and (fuzzy (VAPR_I-120_BALANCE[CLOSED]) = 1.000,fuzzy (PFR_HCL_BALANCE[OPEN(high)]) = 1.000,fuzzy (ABSR_ CL2_BALANCE[CLOSED]) = 1.000) then PFR_catalyst_deactivating (1.000). if (fuzzy (COND_HCL_BALANCE[OPEN(high)])= 1.000) then STR_8_valve_not fully_open (1.000). if (fuzzy (VAPR_HCL_BALANCE[OPEN(Iow)])= 1.000) then Further-rxn_in_Vaporizer (1.000). if (fuzzy (CSTR_HCL_BALANCE[OPEN(Iow)])= 1.000) then CSTR_reactant_level_high (I .000). if (fuzzy (PFR_H_BALANCE[OPEN(high)]) = 1.000) then PFR_leaking_flange (1.000). if (fuzzy (COND_HC2_BALANCE[OPEN(Iow)])= 1.000) then Rxn_in_Condenser..Shell (l.000). if and (fuzzy (PFR_HCL_BALANCE[OPEN(high)])= 1.000,fuzzy (ABSR CL2_BALANCE(OPEN(high)])= 1.000) then PFR_ not_adiabatic (1.000). if and (fuzzy (VAPR_H20_BALANCE[CLOSED])= 1.000,fuzzy (COND_HCL_BALANCE[CLOSED])= 1.000,fuzzy (DRIER_ H_BALANCE[OPEN(high)]) = 1.000,fuzzy (ABSR CL2 BALANCE[OPEN(high)])= 1.000) then Condenser_Fouling (l.000). if and (fuzzy (VAPR_H_BALANCE[CLOSED])= 1.000,fuzzy (CSTR_HC_BALANCE[OPEN(high)])= 1.000) then Vaporizer-_ Heat_Loss (1.000).

316 B. &ZYtn~T et al.
Table 8. Rules extracted by SC-net using energy balance equations
if and (fuzzy (VAPR_ENERGY_BALANCE[CLOSED]) = 1.000,fuzzy (PFR_ENERGY..BALANCE[OPEN(high)]) = 1.000) then Insulation_damage_in_STR_7 (1.000). if (fuzzy (DRIER_ENERGY_BALANCE[OPEN(high)]) = 1.000) then Unexpected_rxn_in Drier (1.000). if (fuzzy (DRIER_ENERGY_BALANCE[OPEN(low)]) = 1.000) then Desiccant_saturated_in_Drier (1.000) if and (fuzzy (VAPR_ENERGY_BALANCE[CLOSED]) = 1.000,fuzzy (PFR_ENERGY_BALANCE[OPEN(high)])--- 1.000) then PFR..catalyst_deactivating (1.000). if and (fuzzy (DRIERENERGY_BALANCE[CLOSED]) = 1.000,fuzzy (PFR_ENERGY_BALANCE[OPEN(Iow)]) = 1.000) then STR_8_valve_not fully_open (1.000). if and (fuzzy (VAPR_ENERGY_BALANCE[CLOSED])= 1.000,fuzzy (PFR_ENERGY_BALANCE[OPEN(high)])= 1.000) then PFR_ieaking_flange ( 1.000). if and (fuzzy (COND ENERGY BALANCE[OPEN[low)])= 1.000,fuzzy (PFR_ENERGY_BALANCE[CLOSED])= 1.000) then Rxn_in_Condenser..shell (1.000). if and (fuzzy (VAPR_ENERGY_BALANCE[CLOSED])= 1.000,fuzzy (PFR_ENERGY_BALANCE[OPEN(high)])= 1.000) then PFR_not_adiabatic (1.000). if (fuzzy (VAPR_ENERGY_BALANCE[OPEN(high)])= 1.000) then Vaporizer..Heat_Loss (1.000).
form. This is a hard competitive, unsupervised learning method, where every pattern is allowed to belong only to one cluster, i.e. no overlapping of the clusters is allowed. The neural network for K-means clustering has a layer of input neurons connected to a layer of output neurons. Each of the output neurons forms a cluster. The weights connecting the input neurons to an output neuron give the cluster coordinates.
For K-means clustering, the number of clusters should be set a priori. Therefore, the initial number of clusters should usually be overestimated, and several runs are necessary to find the number of clusters, i.e. attributes and attribute ranges. This procedure is repeated for each input variable with the input data collected from Syschem Plant and fuzzy variable files are created for SC-net training.
Different representations of the process information, mainly sensor measurements including measurement noise, are possible. The plant measurements can be used directly for SC-net training after clustering for identifica- tion of the fuzzy variables. These measurements can also be used in doing steady state mass and energy balances around each main unit. Our goal is not only to show the performance of a new machine learning tool on chemical process fault diagnosis, but also to extract knowledge from the examples presented, in the form of general, reliable, compact and natural language-like rules. The utility of mass and energy balances will result in rules more useful to domain experts and, as it will be explained later, they will support and fill the gaps left open by the rules generated using only process measure- ments. For the process measurement variables, attributes
/ k l 9 ~s t 18 U # 17 ~n# 16 • sk 15 ~sk 14 ~sk 1~ rank 13
~ 1 1
II~k7
l~nk$
lum#l
0 10 $0 40 $# 60 70 80
h r m t Cernmb, ~ (st) (0.2"/. r ~ t c w c , ~ c )
i i i
i
i
i i
N lOP
Fig. 13. Classification performance of SC-net using mass balances only.
Hybrid symbolic-connectionist machine learning 317
Fnlt 19
W~lt 19
fruit I-4
fruit 13
mO000000000000011 m
r J t n _ I i
m
F~It ?
0 10 20 .I0 40 $0 60 70 80 90 100
~ r m t Correctly ~ f'/O ~ 2"/. rwa~tc.Atc~ ¢~
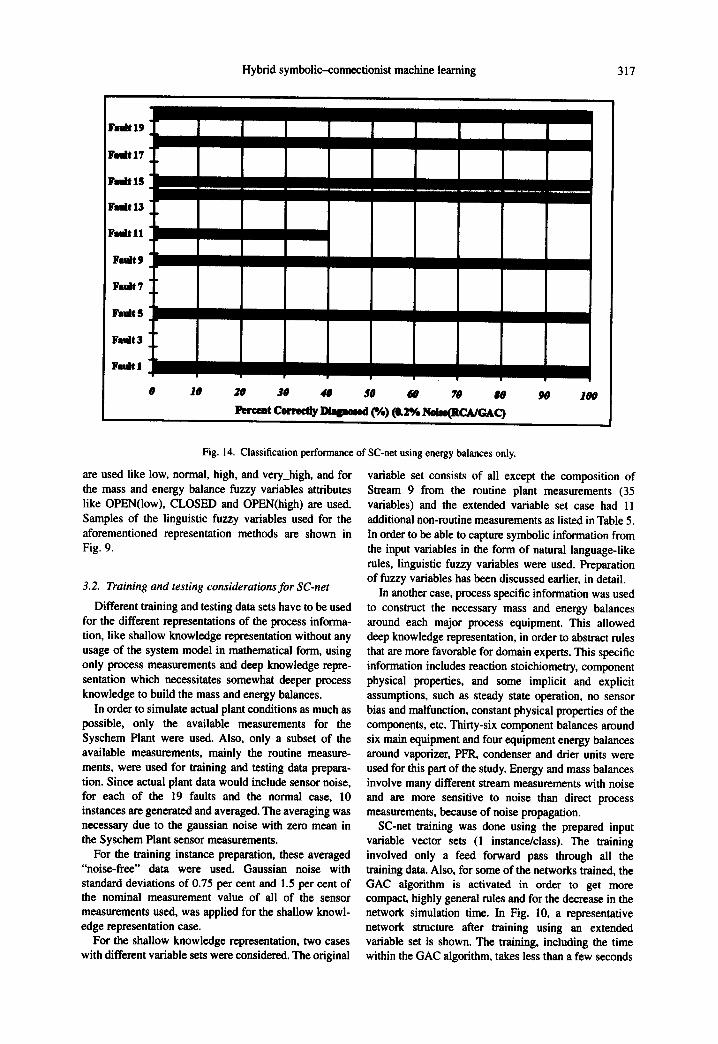
Fig. 14. Classification performance of SC-net using energy balances only.
are used like low, normal, high, and very_high, and for the mass and energy balance fuzzy variables attributes like OPEN(low), CLOSED and OPEN(high) are used. Samples of the linguistic fuzzy variables used for the aforementioned representation methods are shown in Fig. 9.
3.2. Training and testing considerations for SC-net
Different training and testing data sets have to be used for the different representations of the process informa- tion, like shallow knowledge representation without any usage of the system model in mathematical form, using only process measurements and deep knowledge repre- sentation which necessitates somewhat deeper process knowledge to build the mass and energy balances.
In order to simulate actual plant conditions as much as possible, only the available measurements for the Syschem Plant were used. Also, only a subset of the available measurements, mainly the routine measure- ments, were used for training and testing data prepara- tion. Since actual plant data would include sensor noise, for each of the 19 faults and the normal case, 10 instances are generated and averaged. The averaging was necessary due to the gaussian noise with zero mean in the Syschem Plant sensor measurements.
For the training instance preparation, these averaged "noise-free" data were used. Gaussian noise with standard deviations of 0.75 per cent and 1.5 per cent of the nominal measurement value of all of the sensor measurements used, was applied for the shallow knowl- edge representation case.
For the shallow knowledge representation, two cases with different variable sets were considered. The original
variable set consists of all except the composition of Stream 9 from the routine plant measurements (35 variables) and the extended variable set case had 11 additional non-routine measurements as listed in Table 5. In order to be able to capture symbolic information from the input variables in the form of natural language-like rules, linguistic fuzzy variables were used. Preparation of fuzzy variables has been discussed earlier, in detail.
In another case, process specific information was used to construct the necessary mass and energy balances around each major process equipment. This allowed deep knowledge representation, in order to abstract rules that are more favorable for domain experts. This specific information includes reaction stoichiometry, component physical properties, and some implicit and explicit assumptions, such as steady state operation, no sensor bias and malfunction, constant physical properties of the components, etc. Thirty-six component balances around six main equipment and four equipment energy balances around vaporizer, PFR, condenser and drier units were used for this part of the study. Energy and mass balances involve many different stream measurements with noise and are more sensitive to noise than direct process measurements, because of noise propagation.
SC-net training was done using the prepared input variable vector sets (1 instance/class). The training involved only a feed forward pass through all the training data. Also, for some of the networks trained, the GAC algorithm is activated in order to get more compact, highly general rules and for the decrease in the network simulation time. In Fig. 10, a representative network structure after training using an extended variable set is shown. The training, including the time within the GAC algorithm, takes less than a few seconds

318 B. OzYta~r et al.
on a moderately loaded Sun SPARC workstation. Test runs with 200 instances required even shorter computing time, where the training time for backpropagation neural networks with linear activation functions for all the process measurements was reported to be about 24 hours (Hoskins et al., 1991).
For the original set of variables, with 35 variables (Case 1), testing with 5 noisy instances/class (0.75 per cent noise) with RCA only resulted in 73 per cent correct diagnosis. For the extended variable set, the performance increased somewhat (80 per cent). For the RCA/GAC trained networks a reasonable increase in the testing performance was observed both in the original case (90 per cent) and the extended variable case (99 per cent). With 1.5 per cent noise, performance of the RCA/GAC trained network decreased slightly (85 per cent for original variables and 95 per cent for the extended variables). The testing performance of the SC-net is summarized in Fig. 11. As can be seen from Fig. 12, for the original variable case, the testing results indicate that the faults "Cooling Coil in the CSTR fouled" and "PFR not operating adiabatically" could not be identified (actually the fault "PFR not operating adiabatically" was mixed up with the other PFR faults), where for the extended variable case the performance of SC-net is nearly perfect, which indicates that SC-net is robust under sensor noise and can he used on-line in the field.
As was stated earlier, mass and energy balances are more sensitive than sensor measurements, and because of this 0.2 per cent noise is added to the process measurements used for mass and energy balances for testing purposes. The performance for the RCA/GAC trained network is about 65 per cent for the mass balances, only. The performance for the RCA/GAC trained system is 35 per cent for the case with only energy balances.
3.3. Comments on the rules extracted from different represehtations of process information
The rules generated by SC-net using the RCAJGAC listed in Tables 6-8 are quite general and simple. They indicate the most important and characteristic attributes causing the fault. For example, the rule generated for the fault "Insulation damage in Stream 7" using only shallow sensor measurements indicates that stream 9 has a low temperature. Due to heat loss in stream 7 temperature at the stream 9 (combining stream 7 and 8) upstream to the plug-flow reactor, decreases. The mass balance based rule shows an indirect linkage of the fault with a positively open chlorine balance around the PFR, which is due to the decreased reaction rate resulting from the loss of heat in the reactor inlet stream.
For the fault "Partially closed valve in Stream 1", the rule generated from the process measurements indicates low stream 1 pressure which is due to the reduced flowrate. However, the mass and energy balance based rules can only capture the indirect effects of this fault, since the fault is due to resistance of stream flow and can more directly be captured by pressure measurements or pressure balances.
Some of the rules generated share the same attributes, like the rules generated for the faults from process measurements only, "PFR hot spot formation" and "Further reaction in the condenser shell". They both have the attribute "Stream 11 hydrocarbon dichloride flow high" in common, which can result both from high conversion in the PFR due to hot spot formation or from further reaction in the condenser. However, the rule for the condenser fault additionally indicates high cooling water flowrate, since due to the exothermic reaction more cooling water will be needed for the condenser, which differentiates the faults from each other. The mass and energy balance based rules for these faults support this evidence.
Since the faults range from equipment leakages to parameter deterioration, mass and energy balances separately are not capable of identifying all of the faults. The best performance for the mass balance-based information only, for the faults involving reactions and leakages, can be concluded from Fig. 13, whereas using energy balance-based information only, faults involving heat losses and reactions can be identified from Fig. 14, which can also he seen from the contents of the rules generated. Some of the rules generated are the same, which means additional information is necessary for the correct diagnosis of these faults. That is the case especially for mass and energy balance-based rules. Therefore, combination of mass and energy balances with shallow knowledge information (i.e. process meas- urements) completes the picture.
4. Conclusions
For the extended variable case, performance of SC-net is nearly perfect, which indicates that SC-net is robust under sensor noise. Due to its unique properties like short training time and no network topology pre- specification, unlike neural networks, SC-net seems to be useful for identification problems. Beside these properties, its capability for symbolic knowledge proc- essing and knowledge extraction in the form of rules makes the diagnostic system introduced here favorable to neural networks in fault diagnosis.
The rules generated by SC-net are compact, readable and logical and they can be further refined, extended or modified by domain experts if and when additional information becomes available, or they can be used for educational purposes for operators, since they include extracted and generalised fault cause information. They can be used to construct the knowledge base of a domain-specific expert system. Stand-alone SC-net can effectively be used on-line as a diagnostic system for real time process monitoring, since the response time for novel instances is very short for SC-net.
Appendix
Recruitment of cells algorithm (RCA) Given the learn vector Vcf(ipl,ip2,...,ipM,tpl,tp2,...,to~ ) where it,,
tp are pth input and target output vectors, respectively.

Hybrid symbolic--connectionist machine learning
( l) Let CAmj=i ~ for i= l,...,M. (2) Feedforward pass using cell activation calculation for-
mulae given in equation (l) for all cells in network except the input cells.
(3) Compare target vector tp with the output of the network CAo. if It N -CAojl--<~r l = l,...,No then the pattern is learned. 1 Process next learn vector, if ip~ < ~ then
else for each 1 if It N - CAo.tl-<5~ • then
l if CAoj > ~ then
for all cells Cj connected to the positive collector cell of the final output cell CAoj do
if Iq, t - CAoj 1~5e then
for all Ci. i i = 1 .... M
ip~ ~ then if
1 connec t CAin J to C m with a weight CWI. "'~ = 7-
' l p i
if CBj>t N then
CB j=sgn( CBj)*{ ICBjl I(ICBjl - tpOI
319
recruit a negation cell, C., with bias CB.=0, and connect C~,j to C, with weight CW.. m = 1/(1 - ipi )
end for 1
if tp~--- ~ then
connect cell Cm to the positive collector cell Coj~,i~" with weight CW..ol,~,.~v= 1 and let CBM= - tpl.
I else if tpt <i then
else
CBj'=sgn(CB/)*{ ICBjI+ I(ICBjI~a tpOI )
end if end if
end for end if
1 ifCAo.l< ~ then
for all cells Cj connected to a negate cell, which is connected to the negative collector cell CAo. I do
if I(1 - CAj) - lvrl<5c then
if CBj>tp~ then
CBj=sgn(CBj){ICB/ I(l-'CBjl-te')l
else
CBj=sgn(CBj)*{ ICBjI+ II-ICBjl-tpOI
end if end if
end for end if
else
Recruit a new cell, C,.
recruit a negate cell C. with a bias CB,=0. Connect Cm to C. with a weight CW.. m = 1 and let C B . , = - ( 1 - I v 0 . Connect C. to the negative collector cell Co.~..~,~o with weight CW..oI..,. = 1.
end if end for
end if
(4). Stop The parameter a is used as a tuning factor and takes values ranging from one to infinity. If a is set to one then the just learned vector takes precedence over everything previous. On the other hand, if a is set to infinity then no change will occur as a result of the new learn vector. The tuning factor ot is set to 6 as default.
R e f e r e n c e s
Aha, D. W., Kibler, D. and Albert , M. K. (1991) Instance-based learning algorithms. Mach. Learn 6, 37-66.
Bakshi, B. R. and Stephanopoulos, G. (1994) Repre- sentation of process t rends- - IV. Induct ion of real- t ime patterns f rom operat ing data for diagnosis and supervisory control. Computers Chem. Engng 18, 303-332.
Becraft, W. R. and Lee, E L. (1993) A n integrated neural network/expert system approach for fault diagnosis. Computers Chem. Engng 17, 1001-1014.
Breiman, L., Friedman, J. H., Olsben, R. A. and Stone, C. J, (1984) Classification and Regression Trees. Wadsworth, CA.
Doig I. D., (1983) Fault detection and correction in a malfunctioning plant. C A C H E Corp., Austin, TX.
Dvorak, D. and Kuipers, B. (1991) Process moni tor ing and d i agnos i s - - a model based approach. IEEE Expert, 6, June, pp. 67-74.
Fahlman, S. E. and Lebiere, C. (1990) The cascade- correlat ion architecture for artificial intell igence. Tech. Report CMU-CS-90-100 , Depar tment of

320
Computer Science, Carnegie-Mellon University, Pittsburg, PA.
Fahlman, S. E. (1988) Faster-learning variations on backpropagation: An empirical study. Proceedings of the 1988 Connectionist Models Summer School Carnegie Mellon, 1, pp. 788-793.
Finch, E E. and Kramer, M. A. (1988) Narrowing diagnostic focus using functional decomposition. AIChE J. 34, 25-36.
Hart, A. E. (1985) Experience in the use of an inductive system in knowledge engineering. In Research and Development in Expert Systems, ed. Bramer, Cam- bridge University Press.
Himmelblau, D. M. (1978) Fault detection and diag- nosis in chemical and petrochemical processes. Chem. Eng. Monographs, vol. 8. Elsevier.
Hoskins, J. C., Kaliyur, K. M. and Himmelblau, D. M. (1991) Fault diagnosis in complex chemical plants using artificial neural networks. AIChE J. 37, 137-141.
Kibler, D. and Aha, D. W. (1990) Learning representa- tive exemplars of concepts: An initial case study. In Reading in Machine Learning, eds Shavlik, J. W. and Dietterich, T. G. Morgan Kaufman, Los Gatos, CA.
Kramer, M. A. (1987) Malfunction diagnosis using quantitative models with non-Boolean reasoning in expert system. AIChE J. 33, 130-140.
Kramer, M. A. and Leonard, J. A. (1991) Diagnosis using backpropagation neural networks analysis and criticism. Computers Chem. Engng 15, 1323-1338.
Lang, K. J. and Witbrock, M. J. (1988) Learning to tell two spirals apart. In Proceedings of the Con- nectionist Models Summer School 1988, eds Tour- etzky, Hinton and Sejnowski. Morgan Kaufman Publishers, Los Gatos, CA.
Michalski, R. S. (1980) Learning by being told and learning from examples: an experimental compar- ison of the two methods of knowledge acquisition in the context of developing an expert system for soybean disease diagnosis. International Journal of Policy Analysis and Information Systems 4, 125-161.
Michalski, R. S., Mozetic, I., Hong, J. and Lavrac, N. (1986) The multi-purpose incremental learning system AQ15 and its testing application to three medical domains. Proceedings of AAAI-86, Phil- adelphia, PA.
Mingers, J. (1989) An empirical comparison of selection methods for decision tree induction. Mach. Learn 3, 261-284.
Moody, J. and Darken, C. J. (1989) Fast learning in networks of locally-tuned processing units. Neur. Comput. 1, 281-294.
Passino, K. M., Sartori, M. A. and Antsaklis, P. J. (1989) Neural computing for numeric-to-symbolic conver- sion in control systems. IEEE Control Syst. Mag., April, pp. 44-51. (1989).
Perez, R. A., Hall, L. O., Romaniuk, S. G. and Lilkendey, J. T. (1992) Evaluation of machine learning tools using real manufacturing data. Int. J. of Expert Systems $, 299-317.
Petti, T. F., Klein, J. and Dhurjati, P. S. (1990) Diagnostic model processor: using deep knowledge for process fault diagnosis. AIChE J. 36, 565-575.
B. OzvuaT et al.
Quinlan J. R. (1979) Discovering rules by induction from large collection of examples. In Expert Systems in the Micro Electronic Age ed. Michie, Edinburgh University Press, Edinburgh.
Quinlan, J. R. (1986) Induction of decision trees. Mach. Learn 1, 81-106.
Quinlan, J. R. (1987) Simplifying decision trees. Int. J. Man-Machine Studies 27, 221-234.
Quinlan J. R. (1988) Decision trees and multi-valued attributes. In Machine Intelligence, Vol. 11, eds Hayes, Michie and Richards, Oxford University Press, Oxford.
Quinlan, J. R. (1990) Decision trees and decision making. IEEE Trans. Syst., Man Cybernet. 20, 339-346.
Quinlan J. R. (1993) C4.5: Programs in Machine Learning. Morgan Kanfman, San Mateo, CA.
Quinlan, J. R. and Rivest, R. L. (1989) Inferring decision trees using the minimum description length princi- ple. Information and Computation 80, 227-248.
Ramanathan, P., Kannan, S. and Davis, J. F. (1993) Use knowledge-based system programming toolkits to improve plant troubleshooting. Chem Eng. Progr. 89, 75-84.
Romaniuk S. G. (1991) Extracting knowledge from a hybrid symbolic-connectionist network Ph.D. The- sis, USE Department of Computer Engineering.
Romaniuk, S. G. and Hall, L. O. (1993) SC-net: a hybrid connectionist, symbolic system. Information Sci- ences 71, 223-268.
Romaniuk, S. G. and Hall, L. O. (1989) Decision making of credit-worthiness using a fuzzy connectionist model. INNC-90, 71, Paris, France.
Samiva, P. M. and Stephanopoulos, G. (1992) Con- tinuous process improvement through inductive and analogical learning. AIChE J. 38, 161-183.
Schlimmer, J. C. and Fisher, D. (1986) A case study of incremental concept induction. Proceedings of the Fifth National Conference of Artificial Intelli- gence.
Shavlik, J. W. and Dietterich, T. G. (1990) Readings in Machine Learning. Morgan Kaufman, San Mateo, CA.
Sorsa, T. and Koivo, H. N. (1993) Application of artificial neural networks in process fault diagnosis. Automatica 29, 843-849.
Ungar, L. H., A Powell, B. and Kamens, S. N. (1990) Adaptive networks for fault diagnosis and process control. Computers Chem. Engng 14, 561-573.
Utgoff P. E. (1988) ID5: an incremental ID3. Fifth International Conference On Machine Learning.
Venkatasubramanian, V., Vaidyanathan, R. and Yama- moto, Y. (1990) Process fault detection and diag- nosis using neural networks--I. Steady state proc- esses. Computers Chem. Engng 14, 699-712.
Watanabe, K. and Himmelblan, D. M. (1983) Fault diagnosis in nonlinear chemical processes--I. The- try . AIChE J. 29, 243-249.
Watanabe, K. and Himmelblau, D. M. (1983) Fault diagnosis in nonlinear chemical processes--II. Application to a chemical reactor. AIChE J. 29, 250-260.
Watanabe, K. and Himmelblau, D. M. (1983) Incipient fault diagnosis of nonlinear processes with multiple causes of faults. Chem. Eng. Sci. 39, 491
Watanabe, K., Matsuura, I., Abe, M., Kubota, M. and

Hybrid symbolic-connectionist machine learning
Himmelblau, D. M. (1989) Incipient fault diagnosis of chemical processes via artificial neural networks. AIChE J. 35, 1803-1812.
Wilcox, N. A. and M Himmeiblau, D. (1994) The possible cause and effect graphs (PCEG) model for fault diagnosis--I. Methodology. Computers Chem. Engng 18, 103-116.
Wilcox, N. A. and Himmelblau, D. M. (1994) The
321
possible cause and effect graphs (PCEG) model for fault diagnosis--II. Applications. Computers Chem. Engng 19, 117-127.
Yu, C. and Lee, C. (1991) Fault diagnosis based on qualitative/quantitative process knowledge. AlChE J. 37, 617-628.
Zadeh L. A. (1988) Fuzzy Logic, 1EEE Computer Mag., April, pp. 83-92.
Related Documents











