Eur. J. Biochem. 224, 999-1009 (1994) 0 FEBS 1994 Characterization of a bean (Phaseolus vulgaris L.) malic-enzyme gene Michael H. WALTER’, Jacqueline GRIMA-PETTENATP and Catherine FEUILLET2 ’ Institut fur Pflanzenphysiologie (260), Universitat Hohenheim, Stuttgart, Germany * Centre Physiologie et Biologie VegCtale, URA CNRS 1457, UniversitC Paul Sabatier, Toulouse, France (Received April 29/July 20, 1994) - EJB 94 0611/2 We have isolated a genomic clone encoding a plant NADP+-dependent malic enzyme (NADP- ME). This clone, isolated from bean (Phaseolus vulgaris L.), covers the entire gene (exons, introns) and 5’-flanking regions. DNA sequencing defines 20 exons spanning approximately 4.5 kb, which range over 48-235 bp in size. All 19 introns are fairly small (79-391 bp). The first intron resides in the S’hntranslated leader sequence. Introns 10, 11 and 16 are located at positions identical to a rat malic-enzyme gene. In the promoter region, a TATA box (TATATATA) is easily recognized 41 bp upstream of a single transcription-initiation site. Two potential cis-acting elements with homology to elements from plant genes, activated by UV light and fungal elicitors, were identified at posi- tions -153 and -312, respectively. Southern-blot analysis suggests a single gene copy, but also other distantly related genes, in the bean genome. The deduced NADP-ME protein of 589 amino acids exhibits features consistent with a cytoplasmic location. We describe the organization of the NADP-ME protein into functional domains located on separate exons. The evolution of malic- enzyme genes coding for isoforms in different cellular compartments of plants and animals is dis- cussed. Malic enzyme [L-malate : NAD(P)-oxidoreductase (de- carboxylating)] catalyzes the oxidative decarboxylation of malate to pymvate, generating reducing equivalents [NAD(P)H] and CO,. NAD+-dependent-malic-enzyme iso- forms (NAD-ME) and isoforms using NADP’ as a coenzyme (NADP-ME) are localized in different cellular compartments in both animals and plants [ l , 21. Another form of NAD-ME, which, like NADP-ME, can also decarboxylate oxaloacetate is found predominantly in bacteria [3]. Malic enzyme is widely distributed and its activity is particularly high in spe- cific metabolic situations. For example, it plays an important role in lipogenesis in mammalian liver, where a strictly cyto- solic NADP-ME is linked to the generation of NADPH for fatty acid biosynthesis [l]. Plants usually express nuclear genes for cytosolic NADP- MEs and mitochondria1 NAD-MEs [2-51. A particular use of NADP-ME has evolved in C, plants such as maize, which employ a chloroplastic NADP-ME in a special mode of pho- tosynthetic carbon fixation [6]. CO, is fixed into malate in mesophyll cells, shuttled into neighbouring bundle-sheath cells and released there from malate through chloroplastic Correspondence to M. H. Walter, Universitat Hohenheim, Insti- Fax: +49 711 459 3751. Abbreviations. NAD-ME, NAD+ -dependent malic enzyme ; NADP-ME, NADP+-dependent malic enzyme; CAM, crassulacean- acid metabolism. Enzymes. NAD+ -dependent malic enzyme, oxaloacetate decar- boxylating (EC 1.1 .I .38) ; NAD +-dependent malic enzyme (EC 1 .I .1.39) ; NADP+-dependent malic enzyme, oxaloacetate decarbox- ylating (EC 1.1.1.40). Note. The nucleotide sequences reported in this paper have been submitted to the GenbankEMBL Data Bank and are available under accession number X80051. tut fur Pflanzenphysiologie (260), D-70593 Stuttgart, Germany NADP-ME in order to be refixed by ribulose-1,s-bisphos- phate carboxylase. Primary carbon fixation into malate and CO, release from malate is also operative in crassulacean- acid-metabolism (CAM) plants. Nocturnal fixation is fol- lowed by efflux of malate from temporary vacuolar storage into the cytoplasm and release of CO, through the action of a cytosolic NADP-ME during the day [7]. Thus, NADP-ME functions primarily as a decarboxylase in these special cases, while it serves important functions as an oxidoreductase in other metabolic processes. These other housekeeping func- tions of cytosolic NADP-MEs in C3, C, and CAM plants have been studied in less detail than the special and promi- nent uses described above [3-5, 8-11]. A role in the main- tenance of the intracellular pH has been proposed [12]. The universal presence of malic enzyme in plants and in animals suggests a broad function, which is likely anaplerotic [4, 51. Reserves of CO, and NAD(P)H stored in malate are readily accessible by conversion into pyruvate through NAD(P)-ME activity (or malate dehydrogenase activity) and can be chan- nelled into diverse metabolic pathways. The primary sequences of NADP-MEs from C4, C, and CAM plants [13-181, as well as from animal sources [19, 201 have recently been deduced from cDNA clones, includ- ing a sequence from the C, plant bean (Phaseolus vulgaris L.), which was earlier erroneously identified as a NADP- dependent cinnamyl-alcohol dehydrogenase [ 17, 181. Identi- ties in amino acid sequences of 73-79% to other plant NADP-MEs and additional information provided in this re- port leave no doubt about the true identity of this cDNA as a bean malic-enzyme clone (cPvMEl). We have now used the cPvMEl cDNA to isolate a geno- mic clone containing a malic-enzyme gene from I? vulgaris L. We report here the first complete structural features of a malic-enzyme gene from a higher organism and its 5’-flank-

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Eur. J. Biochem. 224, 999-1009 (1994) 0 FEBS 1994
Characterization of a bean (Phaseolus vulgaris L.) malic-enzyme gene Michael H. WALTER’, Jacqueline GRIMA-PETTENATP and Catherine FEUILLET2 ’ Institut fur Pflanzenphysiologie (260), Universitat Hohenheim, Stuttgart, Germany * Centre Physiologie et Biologie VegCtale, URA CNRS 1457, UniversitC Paul Sabatier, Toulouse, France
(Received April 29/July 20, 1994) - EJB 94 0611/2
We have isolated a genomic clone encoding a plant NADP+-dependent malic enzyme (NADP- ME). This clone, isolated from bean (Phaseolus vulgaris L.), covers the entire gene (exons, introns) and 5’-flanking regions. DNA sequencing defines 20 exons spanning approximately 4.5 kb, which range over 48-235 bp in size. All 19 introns are fairly small (79-391 bp). The first intron resides in the S’hntranslated leader sequence. Introns 10, 11 and 16 are located at positions identical to a rat malic-enzyme gene. In the promoter region, a TATA box (TATATATA) is easily recognized 41 bp upstream of a single transcription-initiation site. Two potential cis-acting elements with homology to elements from plant genes, activated by UV light and fungal elicitors, were identified at posi- tions -153 and -312, respectively. Southern-blot analysis suggests a single gene copy, but also other distantly related genes, in the bean genome. The deduced NADP-ME protein of 589 amino acids exhibits features consistent with a cytoplasmic location. We describe the organization of the NADP-ME protein into functional domains located on separate exons. The evolution of malic- enzyme genes coding for isoforms in different cellular compartments of plants and animals is dis- cussed.
Malic enzyme [L-malate : NAD(P)-oxidoreductase (de- carboxylating)] catalyzes the oxidative decarboxylation of malate to pymvate, generating reducing equivalents [NAD(P)H] and CO,. NAD+-dependent-malic-enzyme iso- forms (NAD-ME) and isoforms using NADP’ as a coenzyme (NADP-ME) are localized in different cellular compartments in both animals and plants [ l , 21. Another form of NAD-ME, which, like NADP-ME, can also decarboxylate oxaloacetate is found predominantly in bacteria [3]. Malic enzyme is widely distributed and its activity is particularly high in spe- cific metabolic situations. For example, it plays an important role in lipogenesis in mammalian liver, where a strictly cyto- solic NADP-ME is linked to the generation of NADPH for fatty acid biosynthesis [l].
Plants usually express nuclear genes for cytosolic NADP- MEs and mitochondria1 NAD-MEs [2-51. A particular use of NADP-ME has evolved in C, plants such as maize, which employ a chloroplastic NADP-ME in a special mode of pho- tosynthetic carbon fixation [6]. CO, is fixed into malate in mesophyll cells, shuttled into neighbouring bundle-sheath cells and released there from malate through chloroplastic
Correspondence to M. H. Walter, Universitat Hohenheim, Insti-
Fax: +49 711 459 3751. Abbreviations. NAD-ME, NAD+ -dependent malic enzyme ;
NADP-ME, NADP+-dependent malic enzyme; CAM, crassulacean- acid metabolism.
Enzymes. NAD+ -dependent malic enzyme, oxaloacetate decar- boxylating (EC 1.1 .I .38) ; NAD +-dependent malic enzyme (EC 1 . I .1.39) ; NADP+-dependent malic enzyme, oxaloacetate decarbox- ylating (EC 1.1.1.40).
Note. The nucleotide sequences reported in this paper have been submitted to the GenbankEMBL Data Bank and are available under accession number X80051.
tut fur Pflanzenphysiologie (260), D-70593 Stuttgart, Germany
NADP-ME in order to be refixed by ribulose-1,s-bisphos- phate carboxylase. Primary carbon fixation into malate and CO, release from malate is also operative in crassulacean- acid-metabolism (CAM) plants. Nocturnal fixation is fol- lowed by efflux of malate from temporary vacuolar storage into the cytoplasm and release of CO, through the action of a cytosolic NADP-ME during the day [7]. Thus, NADP-ME functions primarily as a decarboxylase in these special cases, while it serves important functions as an oxidoreductase in other metabolic processes. These other housekeeping func- tions of cytosolic NADP-MEs in C3, C, and CAM plants have been studied in less detail than the special and promi- nent uses described above [3-5, 8-11]. A role in the main- tenance of the intracellular pH has been proposed [12]. The universal presence of malic enzyme in plants and in animals suggests a broad function, which is likely anaplerotic [4, 51. Reserves of CO, and NAD(P)H stored in malate are readily accessible by conversion into pyruvate through NAD(P)-ME activity (or malate dehydrogenase activity) and can be chan- nelled into diverse metabolic pathways.
The primary sequences of NADP-MEs from C4, C, and CAM plants [13-181, as well as from animal sources [19, 201 have recently been deduced from cDNA clones, includ- ing a sequence from the C, plant bean (Phaseolus vulgaris L.), which was earlier erroneously identified as a NADP- dependent cinnamyl-alcohol dehydrogenase [ 17, 181. Identi- ties in amino acid sequences of 73-79% to other plant NADP-MEs and additional information provided in this re- port leave no doubt about the true identity of this cDNA as a bean malic-enzyme clone (cPvMEl).
We have now used the cPvMEl cDNA to isolate a geno- mic clone containing a malic-enzyme gene from I? vulgaris L. We report here the first complete structural features of a malic-enzyme gene from a higher organism and its 5’-flank-

1000
ing sequence. Alignment of the deduced NADP-ME protein with published sequences strongly suggests that the gene en- codes a cytosolic NADP-ME. The promoter contains two pu- tative cis-regulatory elements, homologous to elements from plant genes activated by elicitors from pathogenic fungi. Ge- nomic blot analysis indicates a single copy but also other distantly related NAD(P)-ME genes in the bean genome, which may encode isoforms of distinct cellular location.
MATERIALS AND METHODS Plant material
Genomic DNA from I? vulgaris L. cv. Processor R, a fungus-resistant isoline [21], was used for genomic-library construction. Genomic DNA was also isolated from cv. Pro- cessor s, a fungus-susceptible isoline [21] and from cv. La Victoire. Poly(A)-rich RNA was obtained from leaves of a local Processor cultivar.
Genomic library High-molecular-mass genomic DNA was purified
through a CsCl gradient, partially digested with MboI, and size-fractionated in a sucrose gradient. The fraction of 10- 40 kb was cloned into the BamHI site of the phage vector A EMBL3 (Genofit). 1.8X lo6 recombinant phages were ampli- fied once to obtain a permanent library.
Isolation of a genomic clone
A total of approximately 1 .8X106 phage plaques were screened in several rounds using, as a probe, a 1.4-kb EcoRI fragment (cPvMEl a) covering coding sequences and the 3'- untranslated region of the cPvMEl cDNA [17, 181. Screen- ings were performed with the Escherichia coli strain P2392 as host. Hybridization was in 50% formamide, 5X NaCl/Cit (1X NaCl/Cit is 0.15 M NaC1, 15 mM sodium citrate, pH 8.0), 1 X Denhardt's solution, 0.1% SDS, 5 mM EDTA and 100 yg/ml degraded salmon sperm DNA at 42°C. The single positive clone isolated was carried through three rounds of purification. Recombinant 2-phage DNA was iso- lated and digested with various restriction enzymes and com- binations thereof. Electrophoretic separations of DNA frag- ments were blotted in duplicate and the blots hybridized separately with either the cPvMEla probe or the 550-bp cPvMEl b probe covering 5'-untranslated and adjacent cod- ing regions [17, 181. A restriction map and the orientation of the gene on the genomic clone was obtained by this analysis.
Subcloning and DNA sequence analysis Based on the mapping of the insert of the A -phage clone,
overlapping subfragments were selected, isolated and cloned into the plasmid vector pBS +/- (Stratagene). Double- stranded DNA sequencing by the dideoxy-chain-termination method was performed on the plasmid subclones and on de- letion clones thereof using T7 DNA-polymerase (Pharmacia LKB Biotechnology). The nested-deletion clones were gen- erated by a double-stranded nested-deletion kit (Pharmacia LKB Biotechnology). This strategy was complemented by the use of several synthetic oligonucleotides to obtain se- quence overlaps and second strand sequence data. The 1-kb region upstream of the transcription start site, the leader and parts of coding and intron regions were sequenced on both
strands. In addition, repeated independent sequence runs using 7-deaza dGTP and 7-deaza dITP (Pharmacia LKB Bio- technology) were used for sequence confirmation. Sequences were analyzed using the Heidelberg Unix Sequence Analysis Resources program package of the Deutsches Krebsfor- schungszentrum, Heidelberg, Germany. Identity/similarity scores were calculated using the GAP routine.
Primer-extension analysis
A 20-bp synthetic oligodeoxynucleotide primer (5'-CT- GGCTACAGAGAAGGTCCA-3', MWG-Biotechnology), which is complementary to the mRNA sequence in exon 2 at positions +289 to +308 was endlabeled with 150 pC'i [ y - 32P]ATP (3000 Ci/mmol) by T4 polynucleotide kinase (Phar- macia LKB Biotechnology). The labeled primer was prrcipi- tated with 2.5 vol. EtOH in 1.5 M ammonium acetate and 60 yg glycogen carrier (Boehringer Mannheim). Purified primer (200000 cpm) was mixed with 10 yg poly(A)-rich RNA in 20 mM Tris/HCl, pH 7.5, 5 mM MgC1, and 50 mM KCI. Po- ly(A)-rich RNA was obtained from bean leaves induced for NADP-ME mRNA by treatment with 10 mM reduced gluta- thione for 15 h. The annealing mixture was heated to 70°C for 10 min and slowly cooled to 37°C within 4 h. The exten- sion reaction was carried out by adjusting the mixture to 50 mM Tris/HCl, pH 8.0, 10 mM MgCl,, 10 mM dithiotrei- tol, 2mM dNTPs, 70U RNAguard (Pharmacia LKB Bio- technology), 0.1 mg/ml acetylated BSA (New England Bio- labs) and adding 60 U avian myeloblastosis virus reverse transcriptase (Pharmacia LKB Biotechnology) in a final vol- ume of 50 y1. The reaction was allowed to proceed for 60 min at 42°C. The reaction products were purified by ethanol precipitation and separated on a sequencing gel. The exten- sion products were visualized by autoradiography. A se- quencing product of a known size and a sequencing reaction using the extension primer were run in parallel as a reference to determine the size of the extension product.
Genomic DNA-blot analysis Genomic DNA was isolated from bean leaves using a
published procedure [22] with the inclusion of a separation step on a CsCl gradient. After restriction and electrophoresis, DNA was blotted to Gene Screen Plus membranes (NEN- Dupont) and hybridized in 1 M NaC1, 1 % SDS, 10% dextran sulfate and 100 yg/ml salmon sperm DNA at 65 "C overnight with the '*P-labeled cDNA probe (cPvMElb). Washes at different stringencies (OSXNaCl/Cit, 0.1 % SDS, 35 "C, 30 min, low stringency; 0.1 X NaCKit, 0.1% SDS, 6O"C, 1 h, moderate stringency) were performed successively. Ge- nome equivalents of bean genomic and cloned DNA were calculated on the basis of a bean genome size of 1.7 X 1 O9 bp ~ 3 1 .
RESULTS Isolation of a bean malic-enzyme gene
The bean genomic phage library was screened with a bean malic-enzyme cDNA fragment (cPvMEla) [17, 181. A single positive clone (gPvMEl) was isolated and further characterized by restriction mapping. The use of different cDNA fragments from the 3' and the 5' regions (cPvMEla, cPvMEl b, respectively) as probes in the mapping analysis revealed the orientation of the gene on the 18-kb A-phage

1001
H -- 4.1 kb -- H-- 2.6 kb --H A S E E -- 3.2 kb - E EE B H H E E S
II I I , I I I I I h i J h d 1 kb
‘ B ATG
I
TGA
-1m -500 + 1 I II 111 IV v VI VII Vlll IX x XI XI1 Xlll XIV xv XVI xvll XVlll XIX xx I I
- - - - - - - - - - - - - 4 L - - - _ _ - -
r - - Box II Box I .(la.*. . x . *..* .It* ‘ C CCACCACACACA ACTAGTCCACCC
- 312 - 153 - 41 +l - 100 bp
Fig. 1. Restriction map (A), exodintron organization (B) and promoter features (C) of LA? f! vulgaris PvME- gene. (A) Restriction map of the insert of the gPvMEl genomic clone from A EMBL3. Restriction enzymes are abbreviated as follows: B, BamHI; E, EcoRI; H, HindIII; S, SaZI. (B) Scheme of the gene structure of the PvMEl gene. Boxes filled black are coding exons, boxes stippled dark are non-coding exons, boxes stippled light are 5’-flanking promoter sequences, open boxes are introns. Exons are numbered by roman numerals. The transcription-initiation site is numbered + 1. Translational start and stop codons are indicated. The nucleotide sequence of this pad of the insert has been fully determined (see Fig. 2) . (C) Enlargement of leader and proximal promoter regions to show the TATA box and two potential cis-acting sequence elements (box I and box 11). Asterisks above the sequence of these elements indicate matches with a consensus sequence (see text).
insert and indicated that an entire gene including S’-flanking sequences was contained on the gPvMEl clone (Fig. 1A). Suitable overlapping insert fragments were subcloned into plasmid vectors for a more detailed restriction analysis and for DNA sequencing.
Exodintron organization and nucleotide sequence of the I! vulgaris ME1 gene
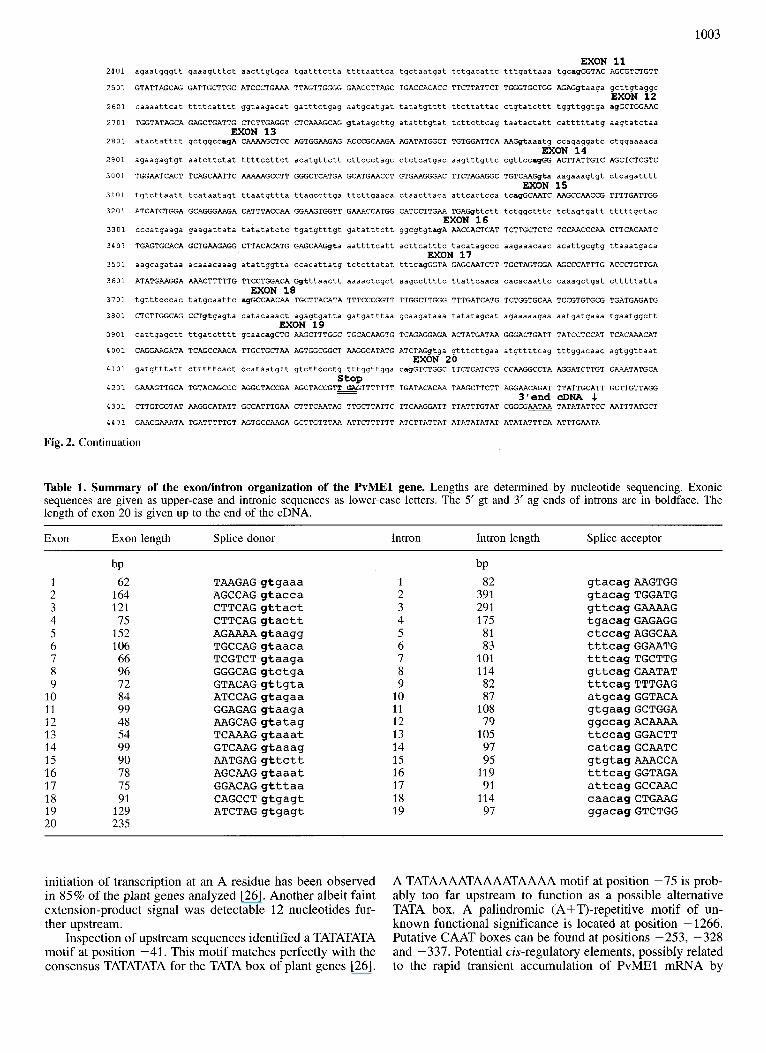
Of the 18-kb 1-phage insert, a total of 7153 bp DNA sequence, covering exons, introns and flanking sequences of the P. vulgaris (Pv) ME1 gene has been determined (Fig. 1B). The full nucleotide sequence is shown in Fig. 2. Comparison of genomic and cDNA sequence [17, 181 indi- cated that the PvMEl gene is highly split, consisting of 20 exons and 19 introns. All exons and introns are fairly small, ranging over 48-235 bp (exons) and 79-391 bp (introns). A summary of their sizes and exodintron boundary se- quences is listed in Table 1. A schematic presentation is given in Fig. 1B. As shown in Table 1, all exodintron boundaries conformed to the known GT/AG donor/acceptor- site rule valid in both plants and animals [24]. Upon closer inspection, a preference for AG/GT at the 5‘ exodintron splice junction is seen in 16 out of 19 introns in accordance with the AG/GTAAG consensus [25]. Similarly, 10 out of 19 PvMEl introns contain the CAG/G motif at the 3’ introd exon splice junction, identical to part of the TGCAG/G con- sensus for plant genes [25]. All introns are AT rich, as has been shown to be essential for the splicing of dicot introns [25]. The first intron resides in the untranslated leader se- quence 18 nucleotides upstream of the ATG translational start codon. Exon 1 is therefore a 5’ noncoding exon.
In the 19 exons of the coding region, only seven nucleo- tide exchanges were identified compared to the cDNA [17, 181. They are located at positions 1408 (C to A), 2170 (A to G), 2171 (C to A), 2173 (T to C), 2723 (G to C) 4171 (A to C) and 4172 (A to C) (numberings refer to Fig. 2). They result in five exchanges in the deduced amino acid sequence. Such a low frequency of differences in the nucleotide se- quence can probably be attributed to differences in cultivars between cDNA library ( R vulgaris L., cv. Canadian Wonder) and genomic library (P vulgaris L. cv. Processor). Thus, it is likely that the cDNA described [17, 181 represents a tran- script of the PvMEl gene characterized in this report. The lack of nucleotide exchanges in the 5’-untranslated and 3’- untranslated regions, which could lead to altered mRNA regulation and/or stability supports this view. The S’-un- translated leader comprises 162 bp, 82 bp of which are intron sequences. The size of the 3’-untranslated sequence cannot be given with certainty, since the cDNA did not contain a poly(A) tail [17, 181. The sequence AATAA starting 13 bp upstream from the 3’ end of the cDNA (Fig. 2) may consti- tute a polyadenylation signal. We have no evidence for the use of alternate polyadenylation signals, which would result in mRNAs of different lengths.
Transcription-initiation site and promoter sequences The transcription-initiation site of the PvMEl gene was
defined by a primer-extension experiment. The primer an- nealed to bean poly(A)-rich RNA was extended to a 226-bp cDNA fragment on the bean RNA template, which places the transcription initiation site at an A numbered +l in the PvMEl gene nucleotide sequence presented in Fig. 2. The

1002
-2664 AAGC TTTTAACCTC AAATGGATGA CCAATTCTTG AGTAAGGACT TTGTGTTTGA AAGGTTGAAA
-2600 ACCAAAAACT GTTTGAAATT CCGACAAAAT TGAACACAAG AAAATATATT ATATTTAATT AAATAGGTTG AACATAGAAG ACACCTTTGT CTATGAATGT
-2500 GAACATATTA TATTGTTCAA ACAAACAATA ACACCATTAA ATATTTACAG TTTTTTTTCT AGTAAAAAAA ATATGTATTT AAAGTAATCT TAGAAACTAG
-2400 ATAATTATGT TAAAGTTATT TAAATTGTTC TTCTCCAGGT GCATTTCTAC ATTTTTTTTT TTATAAAAGT TCTCATGTTA GGCATCACAA TGCAACTTGT
-2300 CATCTCAGCA AGGCTGACAC CTCAAGTAAC AACAATCATC TGCCATCACA TGAAAAAAAG TATTATTAAA RAAAAGAAAA AGAAAGAAAA AACAAARATA
-2200 TGGGGGGACT AGACCAAAAC CCACATGTTA ACRAAAACGA TACATAGGTA GACTATACCT ATTCATAAAG AATTCTAAAA ACAGACTAGA TGGAAGTCTA
-2100 TTATACCAAT GAAATGATTC TCTATGAATG AACCCTAAAT TAGCCAACTT ATCAGCACAT GCATTCCCCT CCCGAAAAAT ATGAGTAACC CTAAACCTGA
-2000 TTGTCCCACA GTAATTAAGA CAAGAATTCC ATCGATTACG AAGCATCCAC GGAACATTAG TCCTAGACGC AGCACAAACA AAGACCGAAT CACATTCAAG
-1900 C C ~ C A T T T GTAAGTCCCA TCTTTTGAGC TTCCTCCATA TAAGTAAAGT ATTGTACATA ATTAATATAT CATTAGTATA TTTTATTTAG GTCTTATTGA
-1800 CCATTATGAT TATTTTTGTG GTTTGGTTTT ATTCATTAAA TATAATATTA AACTTAACTT TTAAAATATG GTAAATTATT AATTATTTTT CTTTACACTG
-1700 GGGTTATTAT AAGTATATGT AATGTCTTAA ATCATAAATT TATTTTATTG TTGCATAGTT TAAATTGAAT ATGTTCTTAA TATTTATTTT TTTATTAAAT
-1600 TATTAAAATC ACGTTCATTA GTTTTTAAGA GTTAATTCAG TTAAAATTGA TATATTAGTA TAATAAAAAA AAAGCAAGTC ATTTGTGGTC TCTCAAAATT
-1500 CCCATAATAA AAAATTAATA TTTATTAACT ATTTTTAAAA TATGAACCAT TGGTCATAAT CACTATTGAG GAAATTTATT AGCAATAAGT AAAATATCTT
-1400 TATATAAGGA AAATTAGTAA TTACAATTAT TTAATTTTAA GATTTATTAA GTTAAATTAT ACGAGGTTAG CCTAAATCTA AATTAATTTT AAAAATTAAC
-1300 ACACTATATG TACTACATTA ATTGATATCA TAACTAATAT ATATATATAT ATATATATAT TACATTAGTT ATTAATTAAA AATTAATTAT TTTTTGTTTA
-1200 ATTAAATTTG CGAGTTTGAC GGTGAATGTG TGAAGGGAAT GAGCACATTT AAAGAGACAT GTAATAATAT TCCTTTCTAA ATAAGTTATT AATATTTTAT
-1100 TTGGAAGTCA ACTAAAGGAA GTTGAGAATC TCGAAGGTTG TTTTTTATTA AACTTTTCTC TTTAATAATA ATTTTTTCGT ACGCAATATT GTTTAAAGAT
-1000 ATAATCTGAA TCAACATGTG TTGGTAGATA TTATTATTTT AATATATTAA TTTTGAAAAA GAGACACTAT TATTATTTTA GTTTCAATAA TTAATATATT
-900 GACATAAAAG ACTGAAATTA CATAATTATA AATGAAACCA AAATTGCAAC TAAACATTAT TTTAGAGAAA GAAACATTTA ATAACCCCTT ATAAAAAACT
-800 TTTTTTTTCA CAAATAGTTA TTTCAAACTT TAATTTATTC TTAATTGGTT CTTCAATTTT ATCCTCTCTA CAGGACACCT CAAACTTGAA TTTGTTTTAA
-700 TTGATTTTAA AAATTTATCT TTTATTATAA AATAGATATT TAACTACATC AGATTATAAC CTGTCTAGAA TTTAGGGTTT AAAATTTAAG TTTTAATATT
-600 TAGATTTAGG GTTAGAGTTA GGGTTAGGGT TAAAGTAACA TTTTTTTTTT GAAGGTAGAA TGAGAAAGGG GCATGTTGTA TTAAATTGAA TAGAATAAAG
-500 ATGTGAACTT TTTCTCTCTC TTAACCATTT TGCCCCAGCA GCAGTGGTTA GATGAGCAGG GCAATATTGA CTCTTGAACA AAACGCGGAG AATCTGCAGA
-400 GCTTCTTTTC AAAATCTTCA CTTAAATCTT CCGCCAAGTC AATATGATGT GGCTCAATAG GCTCAATAGA CACAATATTA GTACTCTGCC ACcAcAcAcA
-300 AAAGTAATTT CCTTTCTCAT TCTTATTTTG AATTACTATT TCTTTAACAA TGAATGCTAT GAGATTAAAA AARAAATGTT GTTGGGTGGT ACCTAGGAGA
-200 CAGCGAAGGA CTAAAATTTC TTCCATCATT TGATTATTAC GCGTGCCACT AGTCCACCCT CATCTCCATT CAACATTGAA ACTAACTCAT TTTTGTCACG
-100 TAACAAAACA GACCAAAGTA AAAGGTATAA AAATAAAATA AAAAGTTGTC TTGAGAGCTT N N M A G A T TCATTCCAAG GTTGTTTCGG ACACATACCA
1 AACTCGCATT CTGTTTTCCT CTGCTTGTTG TTGTTTTTGT CTGCGTAGGT GCAAAGTAAG AGgtgaaaat cattgcttg cactgcattca ttgcttatgt
BOX 2
BOX 1
TATA
EXON 1 2 5' end cDNA
EXON 2 M e t 101 ggctacatga acctgtcttt aatttaatct tcattgttgt acayAAGTTG TTGGCAGTGA TCATCGAG CATTTCCTTG AAGGAGAACG GTGGTGAGGT
201 TTCTGTGAAG AAGGATTATA GCAATGGTGG GGGTGTGAGG GACTTGTATG GCGAGGACAG TGCCACAGAG GATCATCTTA TCACTCCATG GACCTTCTCT
301 GTAGCCAGyt accactactt aacatttgac atgtcgaaaa agacaacatg gaatttgtct qttgtagctt ttatatattt ggatctgtqt tcatttatct
401 gtcatcctat taatggagtt tcattttcgg ctatgccaga ctagttttct ggccatctct aaaaaatgga gaaatttttg tcacatttca tggcattctt
501 ggattatgtg tggtttggag tactgggttt qgtagataac cagtatgtgg tggagttatt tgataatqta atgctttatq agattattct gtagacttgt
601 aatgtgcgat ctgcagagtt ttttgtgttt caataaaatg tttgatttac ttgcttagag tttggtgtgg taatcaagca tttgcaattt tgtgtacagT EXON 3
701 GGATGCAGTT TGCTGAGAGA TCCACGTTAC AACAAAGGGC TGGCCTTTAC TGAGGGAGAG AGAGATGCTC ATTACTTGCG TGGCCTTTTG CCCCCATCTG
801 TCTTCAATCA GGAACTTCAG yttacttgct tcttagtatc acattcagtt actttattta tgtaaggaaa aaacttgaac tcaatttcgg tgttccaqta
901 ttgttctgta attagaacgt gattttcatq ttgataatat acgtaataaa acttgcata atgttgtccac atgaaactcc tattttgctc agagaacagt
1001 taccaaaaca cttgaaattg catctaactt tatcctctat acaaatggta tgctagaggc tgtgcaatct gaggattttt ggctaatttc ccttggtatt
1101 ttaatgttca gGAAAAGAGG TTGATGCACA ATCTTCGCCA GTATGAGGTT CCTCTGCATA GGTACATGGC CTTGATGGAT CTTCAGgtac tttctgaatt
1201 ctaactcatc ccatqtaaag tgcatatacc atgcagtact ctctttttaa aaattgggtt ttatgagtac atatatgtac agtatgctag tgtaaggaac
1301 atgtaaccaa gaactattgc tacgqagttt ctcactgtct ctgatatttc tctattqaca YGAGAGGAAT GAAAGGCTGT TCTACAAGCT TCTGATCGAT
1401 AATGTTGAGG AACTGCTTCC TGTTGTTTAC ACTCCAACGG TTGGAGAAGC ATGCCAGAAA TACGGAAGCA TTTTTAGGCG TCCTCAGGGT CTTTATATCA
EXON 4
EXON 5
EXON 6 1501 GTTTGAAAGA AAAgtaaggc ttttttcatg gcactgctcc tgtatqtttt ttcactaagc atttgagaaa tactaaqtgt tttgaattct tcayAGGcAA
1601 GATCCTTGAA GTACTGAAAA ACTGGCCAGA AAAGAGTATT CAAGTTATTG TTGTGACCGA TGGTGAGCGT ATATTAGGAC TGGGAGATCT TGGCTGCCAG EXON 7
1701 ytaacaaaat aaagtqctag tctcttaaat ctgcattata aacaaagaca attatgataa cattttttct aaattgtttt cagGGAATGG GAATTCCGGT
1801 TGGGAAACTT TCTCTCTATA CTGCTTTAGG AGGTGTTCGC CCTTCGTCTg taagaactac ttaatgctgt tttttctatt cccttttcct ttccctaatt
1901 catagtttat caaatattaa tttgctatat qtgatattct atgatttcag TGCTTGCCTG TTACCATTGA TGTTGGCACA AACAATGAGA AGTTGCTGAA
2001 TGATGAGTTT TACATTGGGC TTAGACAAAG GCGTGCAACT GGGCAGgtct gatcatcctt ggcaatacat gcataaaaaa taatgctcat tttttaacta
2101 cagttagtga gtgtgtgatg ttttattCCg ttaacatgat aattgtttqt tgtggttcay GAATATGCGG AGCTTCTAGA CGAGTTTATG CGTGCAGTTA
2201 AGCAGAACTA TGGAGAGAAA GTTCTCGTAC AGgttgtata tcagattcaa cacctgcagt gqctatggtt tacttgagtt tgttgtttta ctaattttgt
2301 tgattctttt tcagTTTGAG GATTTCGCCA ATCATAATGC ATTTGATCTG C T G G W T ACAGCTCATC TCATCTTGTT TTCAACGATG ATATCCAGgt
EXON 8
EXON 9
EXON 10
Fig.2. Nucleotide sequence of the I? vulgaris PvMEl gene. Sequences of the 5'-flanking region, exons and introns are shown. In the promoter region, two potential cis-acting elements are in boldface and underlined, the TATA box is in boldface. The transcription-initi ation site is numbered +l. Exons are numbered (1-20). Intervening sequences are given in lower-case letters with 5' gt and 3' ag ends shown in bold letters. Translational start and stop signals are indicated by boldface and are double underlined. A putative polyadenylation signal AATAA is underlined. The ends of the cDNA are indicated.
1003
2401 agaatgggtt gaaagtttct aacttgtgca tgatttctta ttttaattca
2 5 0 1 GTATTAGCAG GATTGCTTGC ATCCCTGAAA TTAGTTGGGG GAACCTTAGC
2601 caaaattcat ttttcatttt ggtaagacat gatttctgag aatgcatgat
2701 TGGTATAGCA GAGCTGATTG CTCTTGAGGT CTCAAAGCAG gtatagcttg EXON 13
2801 atactatttt gctggccagA CAAAAGCTCC AGTGGAAGAG ACCCGCAAGA
2901 agaagagtgt aatcttctat ttttccttct acatgttctt cttccctagc
3001 TGGAATCACT TCAGCAATTC AAAAAGCCTT GGGCTCATGA GCATGAACCT
3101 tgtcttaatt tcataatagt ttaatgttta ttagccttga ttcttgaaca
3201 ATCATCTGGA GCAGGGAAGA CATTTACCAA GGAAGTGGTT GAAACCATGG
3301 cccatgaaga gaagattata tatatatctc tgatgtttgt gatatttctt
3401 TGAGTGCACA GCTGAAGAGG CTTACACATG GAGCAAGgta aattttcatt
3501 aagcagataa acaaacaaag atattggtta ccacattatg tctcttatat
3601 ATATGAAGGA AAACTTTTTG TTCCTGGACA Ggtttaactt aaaactcgct
3701 tgtttcccac tatgcaattc agGCCAACAA TGCTTACATA TTTCCCGGTT
3801 CTCTTGGCAG CCTgtgagta catacaaact agagtgatta gatgatttaa
3901 cattgagctt ttgatctttt gcaacagCTG AAGCTTTGGC TGCACAAGTG
4001 CAGGAAGATA TCAGCCAACA TTGCTGCTAA AGTGGCGGCT AAGGCATATG
4101 gatgtttatt ctttttcact ccataatgtt gtcttccctg tttggttgga
4201 GAAAGTTGCA TGTACAGCCC AGGCTACCGA AGCTACCGTWTTTTTTT
4301 CTTGTGGTAT AAGGCATATT GCCATTTGAA CTTTCAATAG TTGCTTATTC
4401 GAACGAAATA TGATTTTTGT AGTGCCAAGA GCTTGTTTAA ATTCTTTTTT
EXON 18
EXON 19
stop -
Fig. 2. Continuation
tgctaatgat tctgacattc
TGACCACACC TTCTTATTCT
tatatgtttt ttcttattac
atatttgtat tcttcttcag
AGATATGGCT TGTGGATTCA
ctctcatgac aagtttgttc
GTGAAGGGAC TTCTAGAGGC
ctaacttaca attcactcca
CATCCTTGAA TGAGgttctt
ggcgtgtagA AACCACTCAT
acttcatttc tacatagccc EXON 17
tttcagGGTA GAGCAATCTT
aagccttttc ttattcaaca
TTGGCTTGGG TTTGATCATG
gcaagataaa tatatagcat
TCAGAGGAGA ACTATGATAA
ATCTAGgtga gtttcttgaa
cagGTCTGGC TTCTCATCTG
TGATACACAA TAAGCTTCTT
TTCAAGGATT TTATTTGTAT
ATCTTATTAT ATATATATAT
EXON 16
EXON 20
EXON 11 tttgattaaa tgcagGGTAC AGCGTCTGTT
TGGGTGCTGG AGAGgtaaga gcttgtaggc EXON 12
ctgtatcttt tggttggtga agGCTGGAAC
taatactatt catttttatg aagtatctaa
AAGgtaaatg ccagaggatc ctggaaaaca
cgttccagGG ACTTATTGTC AGCTCTCGTC EXON 14
TGTCAAGgta aagaaagtgt ctcagatttt EXON 15
tcagGCAATC AAGCCAACCG TTTTGATTGG
tctggctttc tctagtgatt tttttgctac
TCTTGCTCTC TCCAACCCAA CTTCACAATC
aagaaacaac acattgcgtg ttaaatgaca
TGCTAGTGGA AGCCCATTTG ACCCTGTTGA
cacacaattc caaagctgat ctttttatta
TCTGGTGCAA TCCGTGTGCG TGATGAGATG
agaaaaagaa aatgatgaaa tgaatggctt
GGGACTGATT TATCCTCCAT TCACAAACAT
atgttttcag tttggacaac agtggttaat
CCAAGGCCTA AGGATCTTGT CAAATATGCA
AGGAACAGAT TTATTGCATT GCTTGTTAGG
CGGGG* TATATATTCC AATTTATGCT
ATATATTTCA ATTTGAATA
3'end cDNA .1
Table 1. Summary of the exodintron organization of the PvMEl gene. Lengths are determined by nucleotide sequencing. Exonic sequences are given as upper-case and intronic sequences as lower-case letters. The 5' gt and 3' ag ends of introns are in boldface. The length of exon 20 is given up to the end of the cDNA.
Exon Exon length Splice donor Intron Intron length Splice acceptor
1 2 3 4 5 6 7 8 9
10 11 12 13 14 15 16 17 18 19 20
bP 62
164 121 75
152 106 66 96 72 84 99 48 54 99 90 78 75 91
129 235
T A A G A G g t g a a a A G C C A G g t a c c a C T T C A G g t t a c t C T T C A G g t a c t t AGAAAA gtaagg T G C C A G g t a a c a T C G T C T g t a a g a G G G C A G g t c t g a G T A C A G g t t g t a A T C C A G g t a g a a G G A G A G g t a a g a A A G C A G g t a t a g T C A A A G g t a a a t G T C A A G g t a a a g A A T G A G g t t c t t AGCAAG gtaaat G G A C A G g t t t a a C A G C C T g t g a g t A T C T A G g t g a g t
1 2 3 4 5 6 7 8 9
10 11 12 13 14 15 16 17 18 19
bP 82
391 291 175 81 83
101 114 82 87
108 79
105 97 95
119 91
114 97
g t a c a g A A G T G G g t a c a g T G G A T G gttcag GAAAAG t g a c a g G A G A G G c t c c a g A G G C A A t t t c a g G G A A T G t t t cag TGCTTG g t t c a g G A A T A T t t t c a g T T T G A G a t g c a g G G T A C A g t g a a g G C T G G A ggccag ACAAAA t t c c a g G G A C T T c a t c a g G C A A T C g tg tag AAACCA t t t c a g G G T A G A a t t c a g G C C A A C c a a c a g C T G A A G g g a c a g G T C T G G
initiation of transcription at an A residue has been observed in 85% of the plant genes analyzed [26]. Another albeit faint extension-product signal was detectable 12 nucleotides fur- ther upstream.
Inspection of upstream sequences identified a TATATATA motif at position -41. This motif matches perfectly with the consensus TATATATA for the TATA box of plant genes [26].
A TATAAAATAAAATAAAA motif at position -75 is prob- ably too far upstream to function as a possible alternative TATA box. A palindromic (A+T)-repetitive motif of un- known functional significance is located at position - 1266. Putative CAAT boxes can be found at positions -253, -328 and -337. Potential cis-regulatory elements, possibly related to the rapid transient accumulation of PvMEl mRNA by

1004
1 1 1 1 1
33 29 35 91 80 1
123 119 125 181 11 0 88
213 209 215 271 260 178
302 298 304 361 349 2 67
3 92 388 394 451 439 355
481 4 7 7 483 54 0 528 445
57 1 567 51 1 63 0 618 535
U T f GQLVTPW? I SVASGYTL I RD?HHN:<GIAFTF.KCRY LRSI L D F TT I SQQl QFKKI-VN]. 1 ~aYaLrLoKYTAMNE' -EKKERLt . ' (
M . S E E L F V M P W f i ? S V A - r G Y ~ L ~ P H ~ ~ ~ I ~ ~ T E E ~ ~ G I ~ ' ~ I f iC-I.LPDP.VLrQr'LQIKK~~-~~>RQY€?P!.Qh\! QETL'Eh!.F\' - - -f432iU\?RRRHTHQRGY LLTRD?HLNKDI kFTi.FERQ3L:"I HGLI PP: I VNQE I QV!.R\'I KNFK Rl.h'SCFPRY I.! I.Vrll,QCIXI\TKI ?Y
TATEDtiY T'rP'dSVSVASGYSLLPH~h'K~IAF''1'EKElFLRGI LPP\WNHTI Q V ~ ? I S l ~ O Y 3 V P L Q h Y C A T ~ l _ ? L Q Q R ~ ~ l F'S
1 I 1 .1 11 . * 1 T *. _...* . . = - - . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
A . EXON 5 . A
. ' . EXON 6 . A
EXON 7
..................................................... . . . . . . . . . . . . . . . . . . . . . . . . . . . * *
T . EXON 8 . . . TF . EXON 9 . .. . EXON 10 . A A
TALGGVRPSSCLPVTIDVGTNNEKLL-NDEFYIGLRQRRATGQEYAELLDE~VKQNYGEKVLVQFEDFANHNAFDLLEKYSSSHLVF
TACGGVNPQQCLPITLDVGTENEELL-KDPLY IGLRGRRVRGPEYDAFLDEMAAS~~KYGMNCLIGFEDFANLNAFRLLNKYRNKYCTF *.*** * * * * * . * * * * * * * * . ** *. .****.. *..* * * . ...................................
A A
v* . . EXON 11 . .* EXON 1 2 V. T . EXON 13 . T . EXON 1 4 .
*. *.*.**.*****.* . * . * * . * ........................... ....................... - -
A* A * A
. . EXON 15 . . V . EXON 1 6 . T* . EXON 17 . AHEHEPVKGLLEAVKAIKPTVLIGSSGAGKTFTKEWETMASLNEKPLILALSNPTSQSECTAEEAYTWSKGRAIFASGSPFDPV-EYEG AHEHEPITTLIDAVQAIKPTVLIGTSGKGKQFTKEVVEAMRNINAKPLILALSNPTSQSECTAEEAYTWSQGHAIFASGSPFDPV-EYEG AHEHEPVKGLLEVVKAIKPLVLIGTSGVGKTFTKEVIEAMASFNEKPLILRLSNPTSQSECTAEEAYTWGKGKAIFASGSPFDPV-EYEG AHDHEPVNEFLDAIkTIRPTVLIGSSGTGQTFTKE~TMSSLNEKPIILALSNPTSQSECTAEQAYTWSEGRAIFASGSPFKPV-EYNG AHEHEPLKTLYDAVQSIKPTVLIGTSGVGRTFTKEIIEAMSSFNERPIIFSLSNPTSHSECTAEQAYT~SQGRSIFASGSPFAPV-EYEG AHEHEEMKNLEAIVQKIKPTALIGVRAIGGAFTEQILKDMAAFNERPIIFALSNPTSKAECSAEECYKVTKGRP\IFASGSPFDPVTLPDG .......... .................. * .~ . * .~ * . * . . * * * * * * *t*.**..*** * . . * * * * * * t i * * . . * *
A A * T . EXON 18 . 7 . . EXON 19 .
... * * ** . * . ** . .**. . * .........*....... *. . .*. . .** .**..*. ** . ....**....* ... * A A
EXON 20 . DLVKYAESCMYSPGYRSYR------------------- p . . v DLVKFAESCMYNPTYRSFR------------------- M.c. NLVQHAESCMYSPAYRYYR------------------- P . d . NLVAYAESCMYSPKYRIYR------------------- F.t. DLVKYAENCMYTPVYRIYR------------------- 2.m. NKEEFVSSQMYSTNYDQILPDCYSWPEEVQKIQTKVNQ R . n . ...........
P.V. M.c. P.d . F.t. 2.m.
P.V. M.c. P.d . F.t. 2.m. R . n .
P.V. M.c. P.d. F.t. 2 . m . R . n .
P.V. M.c. P.d. F.t. 2.m. R.n.
P . V . M.c. P . d . F.t. 2.m. R . n .
P.V. M.c. P.d. F . t . Z . m . R . n .
P . V . M.c. P.d. F.t. 2 . m . R . n .
Fig. 3. Alignment of amino acid sequences and domain structure of NADP-ME proteins. Five plant NADP-ME sequences (P.v., P. vuTguris; M.c., M. cristullinum [16]; 6 d., P. deltoides x P trichocarpu 1151; Et., F: tri'nervia 1141; Z.m. Z. mays [13]) are-compared with one animal sequence (R.n., Ruttus norvegicus [19, 20]), for which exodintron structural data are available [20]. The P.v. sequence is deduced from the genomic sequence (Fig. 2) and amino acid exchanges found in the cDNA-derived protein 117, 181 are given above the sequence. The alignment was performed using the program MULTALIGN in the HUSAR program package and further optimized by eye. Predicted cleavage sites in F. t. and Z. m. NADP-ME precursors are indicated by vertical arrows [14]. Intron positions in the P. v. genz are shown by arrowheads above the sequences, intron positions in the R. n. gene are indicated by arrowheads below the sequence. Amino acid sequences are assigned to exons, as defined in Fig. 2. Strictly conserved residues are indicated by asterisks and conservative substitutions by dots. Intron positions conserved between the P.v. and the R. n. genes are marked by asterisks. Stretches attributed functional importance are underlined. Single amino acids of putative functional relevance are in boldface.
treatment of bean cell cultures with fungal elicitor [17, 181 are located at positions -153 and -312. The element AC- TAGTCCACCC at position -153 matches, in 9 out of 12 positions, the consensus sequence TIACTc/,ACCTAc/,Cc/, in
UV-light and fungal-elicitor-induced plant genes of the phe- nylpropanoid pathway [27]. Similarly, at position -312. the (A+C)-rich motif CCACCACACACA matches a second consensus motif (CCAA/,CA/TAACC/TCC) in 9 out of 12 posi-
1005
LOW MODERATE STRINGENCY STRINGENCY
H H H E E E E E H H H E E E E E
C 4.1 kb C 3.2 kb
c 2.6 kb
a b c a b c cloned I x 2x
a b c a
C 0.4 kb
b cloned I X 2x
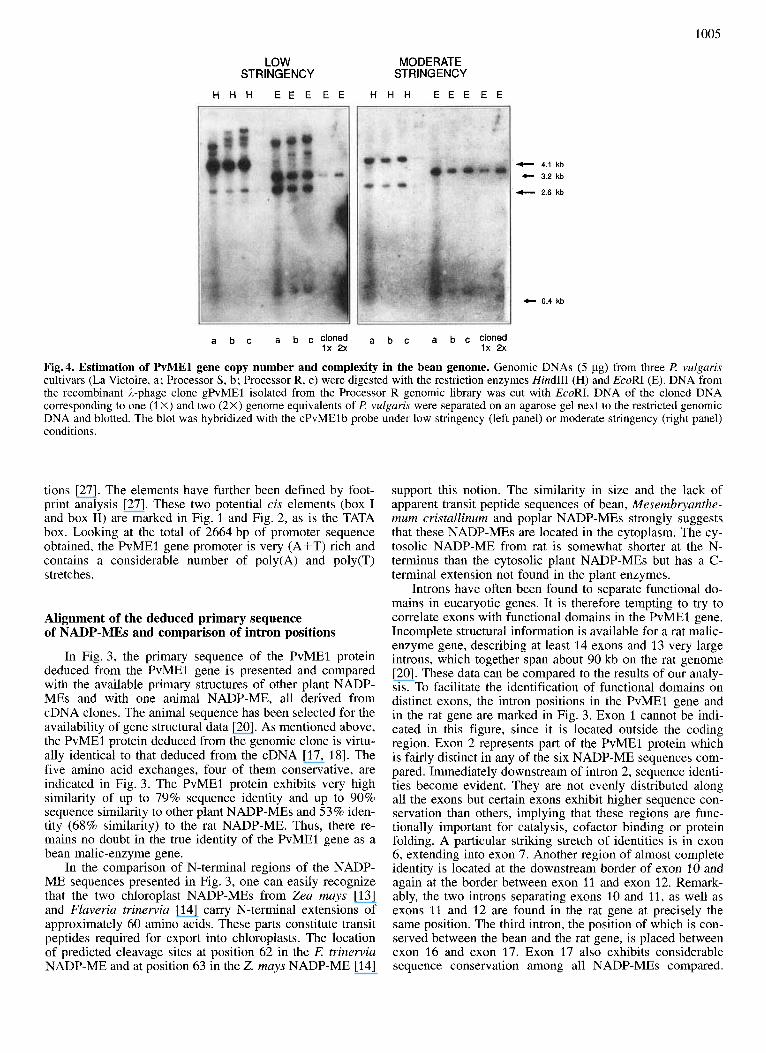
Fig.4. Estimation of PvMEl gene copy number and complexity in the bean genome. Genomic DNAs (5 pg) from three P. vulgaris cultivars (La Victoire, a ; Processor S, b ; Processor R, c) were digested with the restriction enzymes Hind111 (H) and EcoRI (E). DNA from the recombinant A-phage clone gPvMEl isolated from the Processor R genomic library was cut with EcoRI. DNA of the cloned DNA corresponding to one (1 X) and two (2X) genome equivalents of P. vulgaris were separated on an agarose gel next to the restricted genomic DNA and blotted. The blot was hybridized with the cPvMEl b probe under low stringency (left panel) or moderate stringency (right panel) conditions.
tions [27]. The elements have further been defined by foot- print analysis [27]. These two potential cis elements (box I and box 11) are marked in Fig. 1 and Fig. 2, as is the TATA box. Looking at the total of 2664 bp of promoter sequence obtained, the PvMEl gene promoter is very (A+T) rich and contains a considerable number of poly(A) and poly(T) stretches.
Alignment of the deduced primary sequence of NADP-MEs and comparison of intron positions
In Fig. 3, the primary sequence of the PvMEl protein deduced from the PvMEl gene is presented and compared with the available primary structures of other plant NADP- MEs and with one animal NADP-ME, all derived from cDNA clones. The animal sequence has been selected for the availability of gene structural data [20]. As mentioned above, the PvMEl protein deduced from the genomic clone is virtu- ally identical to that deduced from the cDNA [17, 181. The five amino acid exchanges, four of them conservative, are indicated in Fig. 3. The PvMEl protein exhibits very high similarity of up to 79% sequence identity and up to 90% sequence similarity to other plant NADP-MEs and 53% iden- tity (68% similarity) to the rat NADP-ME. Thus, there re- mains no doubt in the true identity of the PvMEl gene as a bean malic-enzyme gene.
In the comparison of N-terminal regions of the NADP- ME sequences presented in Fig. 3, one can easily recognize that the two chloroplast NADP-MEs from Zea muys [13] and Flaveria trinewia [14] carry N-terminal extensions of approximately 60 amino acids. These parts constitute transit peptides required for export into chloroplasts. The location of predicted cleavage sites at position 62 in the E trinewia NADP-ME and at position 63 in the Z. mays NADP-ME [14]
support this notion. The similarity in size and the lack of apparent transit peptide sequences of bean, Mesembiyanthe- mum cristallinum and poplar NADP-MEs strongly suggests that these NADP-MEs are located in the cytoplasm. The cy- tosolic NADP-ME from rat is somewhat shorter at the N- terminus than the cytosolic plant NADP-MEs but has a C- terminal extension not found in the plant enzymes.
Introns have often been found to separate functional do- mains in eucaryotic genes. It is therefore tempting to try to correlate exons with functional domains in the PvMEl gene. Incomplete structural information is available for a rat malic- enzyme gene, describing at least 14 exons and 13 very large introns, which together span about 90 kb on the rat genome [20]. These data can be compared to the results of our analy- sis. To facilitate the identification of functional domains on distinct exons, the intron positions in the PvMEl gene and in the rat gene are marked in Fig. 3. Exon 1 cannot be indi- cated in this figure, since it is located outside the coding region. Exon 2 represents part of the PvMEl protein which is fairly distinct in any of the six NADP-ME sequences com- pared. Immediately downstream of intron 2, sequence identi- ties become evident. They are not evenly distributed along all the exons but certain exons exhibit higher sequence con- servation than others, implying that these regions are func- tionally important for catalysis, cofactor binding or protein folding. A particular striking stretch of identities is in exon 6, extending into exon 7. Another region of almost complete identity is located at the downstream border of exon 10 and again at the border between exon 11 and exon 12. Remark- ably, the two introns separating exons 10 and 11, as well as exons 11 and 12 are found in the rat gene at precisely the same position. The third intron, the position of which is con- served between the bean and the rat gene, is placed between exon 16 and exon 17. Exon 17 also exhibits considerable sequence conservation among all NADP-MEs compared.

1006
Towards the C-terminus (exons 18-20) there is less struc- tural conservation among the different NADP-ME pro- teins.
Estimation of gene copy number
To assess the copy number and the complexity of malic- enzyme genes in t! vulgaris DNA blots with genomic DNA from three different bean cultivars and with DNA from the genomic clone were prepared. The DNAs were cut with two different restriction enzymes (EcoRI and HindIII), which have known recognition sites in the cloned DNA (Fig. 1). The DNA concentrations for one and two genome equiva- lents of the bean genome were calculated and an EcoRI di- gest of cloned DNA was run alongside with appropriate amounts of genomic DNA in an electrophoretic separation. After hybridization with the cPvMElb probe, the blot was first subjected to low stringency washing conditions, ana- lyzed by autoradiography, then subjected to moderate strin- gency washings and again analyzed for autoradiographic sig- nals (Fig. 4). Under moderate stringency conditions, signals at fragment sizes of 2.6 kb and 4.1 kb were obtained with the HindIII digest for all three bean cultivars. The EcoRI digest gave two bands of 3.2 kb and 0.4 kb in the three genomic DNAs and in the cloned DNA. This simple hybridization pattern is suggestive of a single-copy gene, since all the frag- ments observed can be accounted for by the cloned DNA. The very small EcoRI fragment expected (0.2 kb) could not be detected, probably because it did not yield a signal of sufficient strength. Comparison of signal intensities of geno- mic and cloned DNA applied at one and two genome equiva- lents suggests one or two NADP-ME geneshaploid genome. It is concluded that there is probably only a single copy of this NADP-ME gene encoding the cytosolic enzyme in a haploid genome off! vulgaris L. Analysis of the blot after washing under low stringency conditions indicates additional hybridization signals and hence genes (Fig. 4). These signals may originate from other more distantly related copies, such as the gene(s) for mitochondrial NAD-ME or other NAD(P)- ME genes. Human and plant mitochondrial NAD-MEs have considerable sequence similarity to NADP-MEs coding for cytosolic and chloroplastic enzymes in other organisms [ 28, 291 and such a relationship can also be expected within a single organism.
DISCUSSION We have cloned a gene locus from €! vulgaris L. encod-
ing a malic enzyme (PvME1). The features of the deduced enzyme protein are consistent with the action of the protein in the cytoplasm. Our results represent the first characteriza- tion of plant malic-enzyme genomic sequences. Data from genomic Southern-blot experiments suggest that the PvMEl gene is a single-copy gene. A malic-enzyme gene locus has recently been assigned to linkage group D4 containing ribu- lose-1,5-bisphosphate carboxylase in a RFLP-based linkage map of t ! vulgaris L. [30]. It is not known whether or not this locus corresponds to the PvMEl gene described here. The PvMEl gene is highly split and consists of 20 exons and 19 introns. Structural information on malic-enzyme genes such as the information provided in this paper is useful to follow the evolution of malic-enzyme gene loci between spe- cies and of genes for different isoforms within species as well as for the definition of functional domains.
The first type of comparison can be performed on the basis of cDNA-derived primary sequences of NAD(P)-VIES available from several plant and animal species and also from procaryotic organisms. In the compilation of plant NADP- ME sequences and a rat NADP-ME sequence shown in Fig. 3, a considerable degree of sequence identity (53% Iden- tity, 68% similarity) without gaps is evident between the bean and the rat sequences. This statement can be extended to the comparison of the animal sequence with other plant NADP-ME sequences all belonging to the E. C. 1.1.1.40 class. The first photosynthetic plant NAD-ME of the El. C. 1.1.1.39 class from the dicotyledoneous NAD-ME-type C, plant amaranth has recently been characterized at the cDNA level [29]. It appears to be a distinct malic enzyme as judged by several criteria including specific localization to the mito- chondria of bundle-sheath cells and a low score of identity with plant NADP-MEs (PvME1, 40%, but human mito- chondrial NAD-ME, 41 %). The N-terminus of the NAD-ME precursor protein contains a mitochondrial transit peptide with a characteristic amino acid composition [29, 311. None of the known features for mitochondrial-targeting peptides [31] are found at the N-termini of the presumably cytosolic NADP-MEs shown in Fig. 3, consistent with the predicted cytoplasmic location.
Additional NAD(P)-ME proteins from non-plant species have been characterized, and we have calculated their iden- titykmilarity values to the bean NADP-ME. Among them are a domestic duck cytosolic NADP-ME (54% identity/70% similarity) [32], a human mitochondrial NAD-ME (38% identity/68% similarity) [28] and a parasitic nematode (Asca- ris suum) mitochondrial NAD-ME (45 % identity/63 % 4imi- larity) [33]. A malic-enzyme protein from E. coli (44% iden- tity/63% similarity) [34] and a NAD-ME from the thermo- philic bacterium Bacillus stearothermophilus (27% identity/ 52% similarity) [35] exhibit lower but still significant se- quence similarities. The further reduced similarity in the B. stearothermophilus protein as compared to the E. coli en- zyme may be connected with its affiliation to the E. C . 1.1.1.38 class and/or with the increased thermostability of this malic enzyme. The considerable degree of similarity be- tween the NAD(P)-ME proteins analyzed so far supports the view that they all originate from a common ancestor. In plants, the nuclear gene for cytosolic NADP-ME may have been duplicated and individual copies may have evolved into nuclear genes encoding isoforms for catalysis in mito- chondria or in the chloroplasts of C, plants. For chloroplast NADP-MEs, such a theory is supported by the finding of a different codon bias in the transit peptide compared to the mature NADP-ME protein [13]. This suggests the addition of the transit-peptide region to an existing region for the mature protein [13]. The isoforms may have optimized their catalytic activity for the particular compartment in which they act. Kinetic parameters of enzyme activity seem to be different between cytosolic and chloroplastic enzymes [5]. However, from the comparison of plant chloroplastic and cytosolic NADP-MEs, particular stretches of amino acids that can be assigned to chloroplast enzymes are not immediately appar- ent (Fig. 3). A more definitive statement has to await the availability of structural information for different isoforms from a single plant species.
A comparison of gene and promoter structures of the PvMEl gene encoding a protein with cytoplasmic location in a C, plant with other plant NAD(P)-ME genes coding for cytosolic, mitochondrial and chloroplastic isoforms is not yet possible. This information should provide insight into the

1007
specific roles of the various isoforms. It may also provide information on the evolution of C, and CAM plants. Accord- ing to our genomic Southern-blot data, there are additional, distantly related NAD(P)-ME genes in the genome of the C, plant bean. They may correspond to genes for additional cytosolic forms, mitochondria1 forms or possibly to genes for chloroplastic forms such as described for C, plants. C, photosynthesis evolved independently in different plant fami- lies [13, 361. Transition states between C, and C, photosyn- thesis are being analyzed in the genus Flaveria. Initial results show a correlation of NADP-ME transcript levels in leaves with the particular state of transition from C, to C, plants [37]. Therefore, if separate genes for chloroplastic isoforms exist in C, plants, they may still have to acquire suitable promotor sequences for high levels of light-dependent ex- pression in leaves. Facultative CAM plants are capable of shifting from C, photosynthesis to CAM under conditions of high salt or drought. For example, M. cristallinum activates a gene for cytosolic NADP-ME upon salt stress [16]. Two or three NADP-ME gene copies are suggested by Southern-blot experiments in this plant with additional distantly related copies present [16]. This implies additional NADP-ME gene(s) for cytosolic NADP-ME involved in CAM. How- ever, in view of the highly split nature of the PvMEl gene, multiple signals may also have arisen as a consequence of a very large gene with many introns. At present it cannot be excluded that CAM-specific regulatory features have been added to an existing gene for cytosolic NADP-ME in the facultative CAM plant M. cristallinum and that these features are responsible for the observed expression in response to salt stress [16].
Functional domains in mature malic enzyme proteins have tentatively been assigned in previous reports by targeting stretches of high amino acid sequence identity or similarity [13, 16, 29, 331. Information on the organization of the sequence into separate exons can now be added from our study and from a partial characterization of a rat malic- enzyme gene [20]. Functional domains have often been found to be localized on distinct exons. Exon 2, as defined by the PvMEl gene analysis, seems to be a plant-specific exon, since identities to the rat sequence are not found (Fig. 3). In the center of exon 5, a stretch of highly conserved amino acids (positions 132 - 145, numbering here and below refers to PvME1) has been assigned to NADP binding on the basis of homologies to a goose fatty acid synthetase [13, 161. Since this region does not contain the characteristic amino- acid-sequence motif typically associated with NAD(P)-bind- ing sites, another function seems to be more likely. More recently, this region has been implied in malate binding and a particular role has been ascribed to the cysteine at position 145 [33]. This cysteine residue has been changed into a ser- ine in a duck liver NADP-ME modified by oligonucleotide- directed mutagenesis [32]. A considerable decrease in cata- lytic efficiency in the mutant enzyme argues for its role in the proper binding of malate. However, an involvement in the binding of bivalent metal ions could not be excluded [32].
Two other amino acid stretches, highlighted by striking sequence conservation, are located at positions 185 - 199 and 336-348. Both regions contain the GXGXXG motif of re- current glycine residues characteristic of NAD(P)-binding sites, except for a single conservative replacement in the rat sequence. The first putative NADP-binding site is located on a single exon (exon 6). The second site is separated by intron 11 and split into exon 11 and exon 12. Interestingly, this intron position is conserved in the rat gene as is the position
bordering exon 11 towards the N-terminus (Fig. 3), further supporting the functional importance of this region. Attempts to clearly identify the residues involved in the discrimination between NAD and NADP in NAD(P)-MEs have so far been unsuccessful [28, 331. The presence of an arginine residue at position 364 has been correlated with NADP specificity comparing two NAD-MEs and two NADP-MEs from mam- mals and bacteria [33]. The arginine residue is also found in the plant NADP-MEs (Fig. 3) but is non-conservatively replaced by a valine residue in duck liver NADP-ME [32]. The NAD-specific enzymes investigated contain cysteine or glutamine at this position [33], but in the plant NAD-ME recently characterized there is an arginine residue located at this site [29]. Thus, the role of particular amino acids in co- enzyme specificity remains to be established by site-directed mutagenesis and analysis of mutant enzymes. Such a study has been successfully undertaken in NAD-specific yeast al- cohol dehydrogenases [38].
A number of special amino acids including cysteine, his- tidine and arginine have been shown to be essential for catal- ysis by specific chemical modifications of enzyme prepara- tions [39-421. Four cysteine residues (Cys145, Cys199, Cys223 and Cys452) are invariant in the NADP-MEs ana- lyzed (Fig. 3) and three are located in regions of putative functional significance. The existence of a sulfhydryl group at or near the NADP-binding site has been demonstrated [39]. Additional experiments provided evidence for two proximal active-site thiol groups [40]. Protection by NADP of enzyme inactivation imposed by addition of maleimides indicates that both residues are at or near the NADP-binding site(s). Most likely, these proximal residues are Cysl99 and Cys223 (Fig. 3), since Cys145 has been ascribed a function in malate binding (see above). Six strictly conserved arginine residues are found in the six NADP-MEs analyzed, two of which are in the putative NADP-binding sites and may corre- spond to the functional arginine residues [42]. Only two in- variant histidine residues can be identified (His393, His395), which are separated by a single acidic amino acid (Fig. 3) and may possibly correspond to essential histidine residues
The promoter and the 5’-untranslated leader sequences of the PvMEl gene are very (A+T) rich, as is common for plant gene promoters. The TATA box is easily identified at position -41 upstream from a single transcription-initiation site. As expected, structural features of the promoter of a rat malic-enzyme gene do not match with the corresponding plant gene. The rat gene promoter resembles other complex mammalian housekeeping promoters in that it is GC-rich and has multiple transcription-initiation sites [20, 431. The latter result is in accord with the absence in the rat gene of TATA and CAAT boxes in the vicinity of transcription-initiation sites, which are necessary for precise and efficient initiation of transcription. Due to their wide distribution in many tis- sues, plant malic enzymes seem to be involved in many housekeeping functions similar to animals cells. However, the gene for cytosolic malic enzyme from the C, plant l? vulgaris, described in this report, exhibits novel regulatory characteristics in that it is responsive to an elicitor from a fungal pathogen. This has been shown by the analysis of bean cell cultures [17, 181 and suggests an involvement of plant cytosolic NADP-ME in pathogen-related and stress-re- lated defenses. Inspection of the PvMEl promoter sequence identifies two elements with homology to cis-regulatory- binding and trans-factor-binding regions in plant genes acti- vated by UV light and a fungal elicitor [27]. Their location
~411.

1008
and distance from each other is reminiscent of the position of these elements in other plant gene promoters activated by these two stimuli. It is, therefore, conceivable that these elements are involved in the activation of the PvMEl gene by a fungal elicitor. Fusions of the PvMEl promoter to the P-glucuronidase reporter gene have been initiated in our lab- oratory and are being analyzed for responsiveness of the pro- moter to external stimuli.
This research has been supported in part by the Vater und Sohn Eiselen Stiftung, Ulm, Germany in a grant awarded to Dieter Hess and by the Commission of the European Communities (ECLAIR, AGRE0021). We thank Dieter Hess and Alain M. Boudet for support and Alain M. Boudet for critically reading the manuscript. The skilled technical assistance of Jutta Babo is gratefully acknowl- edged. We also thank Joachim Schroder for useful discussions and Wolfgang Staiber for photographic work.
REFERENCES 1. Frenkel, R. (1975) Regulation and physiological function of ma-
lic enzyme, Cur% Topics Cell. Regul. 9, 157-181. 2. Ivanishchev, V. V. & Kurganov, B. I. (1992) Enzymes of malate
metabolism - characteristics, regulation of activity, and bio- logical roles, Biokhimiya 57, 441 -447.
3. Artus, N. N. & Edwards, G. E. (1985) NAD-malic enzyme from plants, FEBS Lett. 182, 225-233.
4. Wedding, R. T. (1989) Malic enzymes of higher plants. Charac- teristics, regulation, and physiological function, Plant Physiol. 90, 367-371.
5. Edwards, G. E. & Andreo, C. S. (1992) NADP-malic enzyme from plants, Phytochemistry 31, 1845 - 1857.
6. Hatch, M. D. (1987) C, photosynthesis: a unique blend of modi- fied biochemistry, anatomy and ultrastructure, Biochim. Bio-
7. Ting, I. P. (1985) Crassulacean acid metabolism, Annu. Rev. Plant Physiol. 36, 595-622.
8. Pupillo, P. & Bossi, P. (1979) Two forms of NADP-dependent malic enzyme in expanding maize leaves, Planta (Berlin) 144, 283 -289.
9. Scagliarini, S., Pupillo, P. & Valenti, V. (1988) Isoforms of NADP-dependent malic enzyme in tissues of the greening maize leaf, J. Exp. Bot. 39, 11 09 - 11 19.
10. Fathi, M. & Schnarrenberger, K. (1990) Purification by immu- noadsorption and immunochemical properties of NADP-de- pendent malic enzymes from leaves of C,, C, and Crassula- cean acid metabolism plants, Plant Physiol. 92, 710-717.
11. Goodenough, P. W., Prosser, I. M. & Young, K. (1985) NADP- linked malic enzyme and malate metabolism in ageing tomato fruit, Phytochemistry 24, 1157-1162.
12. Davies, D. D. (1986) The fine control of cytosolic pH, Physiol. Plant. 67, 702-706.
13. Rothermel, B. A. & Nelson, T. (1989) Primary structure of the maize NADP-dependent malic enzyme, J. Biol. Chem. 264, 19587 - 19592.
14. Borsch, D. & Westhoff, P. (1990) Primary structure of NADP- dependent malic enzyme in the dicotyledonous C, plant Fla- veria trinervia, FEBS Lett. 273, 111-115.
15. Van Doorsselaere, J., Villaroel, R., van Montagu, M. & InzC, D. (1991) Nucleotide sequence of a cDNA encoding malic en- zyme from poplar, Plant Physiol. 96, 1385-1386.
16. Cushman, J. C. (1992) Characterization and expression of a NADP-malic enzyme cDNA induced by salt stress from the facultative crassulacean acid metabolism plant, Mesembryan- themum crystallinum, Eur: J. Biochem. 208, 259-266.
17. Walter, M. H., Grima-Pettenati, J., Grand, C., Boudet, A. M. & Lamb, C. J. (1 988) Cinnamyl-alcohol dehydrogenase, a mo- lecular marker specific for lignin synthesis : cDNA cloning and mRNA induction by fungal elicitor, Proc. Natl. Acad. Sci. USA 85, 5546-5550.
phys. Acta 895, 81 -106.
18. Walter, M. H., Grima-Pettenati, J., Grand, C., Boudet, A. M. & Lamb, C. J. (1990) Extensive sequence similarity of the bean CAD4 “cinnamyl-alcohol dehydrogenase” to a maize malic enzyme, Plant Mol. Biol. 15, 525-526.
19. Magnuson, M. M., Morioka, H., Tecce, M. F. & Nikodem, V. M. (1986) Coding nucleotide sequence of rat liver malic enzyme mRNA, J. Biol. Chem. 261, 1183-1186.
20. Morioka, H., Magnuson, M. A., Mitsuhashi, T., Song, M.-K. H., Rall, J. E. & Nikodem, V. M. (1989) Structural characteriza- tion of the rat malic-enzyme gene, Proc. Natl Acad. Sci. USA 86,4912-4916.
21. Sharma, R. C., Barthe, J. P., Lafitte, C. & TouzC, A. (1986) Adsorption in vitro de l’endopolygalacturonase sCcretCe par Colletotrichum lindemuthianum sur des parois de deux IignCes de haricots isoginiques rksistants et sensibles 2 l’anthracnose, Can. J. Bot. 64, 2903-2908.
22. Dellaporta, S. L., Wood, J. & Hicks, J. B. (1983) A plant DNA minipreparation: version 11, Plant Mol. Biol. Rep. 1, 19 -21.
23. Talbot, D. R., Adang, M. J. L., Slightom, J. & Hall, T. C. ( 1 984) Size and organization of a multigene family encoding phitseo- lin, the major seed storage protein of Phaseolus vulgaris L., Mol. Gen. Genet. 198, 42-49.
24. Brown, J. W. S. (1986) A catalogue of splice junction and puta- tive branch point sequences from plant introns, Nucleic Acids Res. 14, 9549-9559.
25. Goodall, G. J. & Filipowicz, W. (1991) Different effects of in- tron nucleotide composition and secondary structure on pre- mRNA splicing in monocot and dicot plants, EMBO J . 10, 263552644,
26. Joshi, C. P. (1987) An inspection of the domain between puta- tive TATA box and translation start site in 79 plant genes, Nucleic Acids Res. 15, 6643-6653.
27. Lois, R., Dietrich, A., Hahlbrock, K. & Schulz, W. (1989) A phenylalanine ammonia-lyase gene from parsley: Structure, regulation and identification of elicitor and light responsive cis-acting elements, EMBO J. 8, 1641 -1648.
28. Loeber, G., Infantes, A. A., Maurer-Fogy, I., Krystek, E. & Dworkin, M. B. (1991) Human NAD+-dependent mito- chondrial malic enzyme. cDNA cloning, primary structure, and expression in Escherichia coli, J. Biol. Chem. 266, 3016- 3021.
29. Long, J. J., Wang, J.-L. & Berry, J. 0. (1994) Cloning and analysis of the C, photosynthetic NAD-dependent malic en- zyme of amaranth mitochondria, J. Biol. Chem. 269, 2827- 2833.
30. Nodari, R. O., Tsai, S. M., Gilbertson, R. L. & Gepts, P. (1993) Towards an integrated linkage map of common bean 2. Devel- opment of an RFLP-based linkage map, Theor: Appl. Genet. 85, 513-520.
31. Von Heijne, G., Steppuhn, J. & Herrmann, R. G. (1989) Domain structure of mitochondria1 and chloroplast targeting peptides, Eur: J. Biochem. 180, 535-545.
32. Hsu, R. Y., Glynias, M. J., Satterlee, J., Feeney, R., Clarke, A. R., Emery, D. C., Roe, B. A., Wilson, R. K., Goodridge, A. G. & Holbrook, J. J. (1992) Duck liver malic enzyme. Expres- sion in Escherichia coli and characterization of the wild-type enzyme and site-directed mutants, Biochem. J. 284, 869- 876.
33. Kulkarni, G., Cook, P. F. & Harris, B. G. (1993) Cloning and nucleotide sequence of a full-length cDNA encoding As#-aris mum malic enzyme, Arch. Biochem. Biophys. 300, 231 --237.
34. Mahajan, S. K., Chu, C. C., Willis, D. K., Templin, A. & Clark, A. J. (1990) Physical analysis of spontaneous and mutagen- induced mutants of Escherichia coli K-12 expressing DNA exonuclease VIII activity, Genetics 125, 261 -273.
35. Kobayashi, K., Doi, S., Negoro, S., Urabe, I. & Okada, H. (1989) Structure and properties of malic enzyme from Bacil- lus steurothermophilus, J. Biol. Chem. 264, 3200-3205.
36. Brown, R. H. & Bouton, J. H. (1993) Physiology and genetics of interspecific hybrids between photosynthetic types, Annu. Rev. Plant Physiol. Plant Mol. Biol. 44, 435-456.
37. Rajeevan, M. S., Bassett, C. L. & Hughes, D. W. (1991) Isola- tion and characterization of cDNA clones for NADP-malic

1009
enzyme from leaves of Flaveria: transcript abundance distin- guishes C,, C,-C, and C, photosynthetic types, Plant Mol. Biol. 17, 371-383.
38. Fan, F., Lerenzen, J. A. & Plapp, B. V. (1991) An aspartate residue in yeast alcohol dehydrogenase I determines the speci- ficity for coenzyme, Biochemistry 30, 6397-6401.
39. Drincovich, M. F. & Andreo, C. S. (1992) A study on the inacti- vation of maize leaves NADP-malic enzyme by 3-bromopyru- vate, Phytochemistry 31, 1883-1888.
40. Drincovich, M. F., Spampinato, C. P. & Andreo, C. S. (1992) Evidence for the existence of two essential and proximal cys-
teinyl residues in NADP-malic enzyme from maize leaves, Plant Physiol. 100, 2035-2040.
41. Jawali, N. & Bhagwat, A. S. (1 987) Presence of essential histi- dine residues in NADP-malic enzyme from maize, Phyto- chemistry 26, 1859- 1862.
42. Rao, S. R., Kamath, B. G. & Bhagwat, A. S. (1991) Chemical modification of the functional arginine residue(s) of malic en- zyme from Zea mays, Phytochemistry 30, 431 -435.
43. Morioka, H., Tennyson, G. E. & Nikodem, V. M. (1988) Struc- tural and functional analysis of the rat malic-enzyme gene promoter, Mol. Cell. Biol. 8, 3542-3545.
Related Documents











