1 Dana Nau and Vikas Shivashankar: Lecture slides for Automated Planning and Ac0ng Updated 4/16/15 This work is licensed under a CreaBve Commons AEribuBonG NonCommercial G ShareAlike 4.0 InternaBonal License . Chapter 5 Delibera.on with Nondeterminis.c Domain Models Dana S. Nau and Vikas Shivashankar University of Maryland

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
This"work"is"licensed"under"a"CreaBve"Commons"AEribuBonGNonCommercialGShareAlike"4.0"InternaBonal"License."
Chapter(5((Delibera.on(with(Nondeterminis.c(Domain(
Models(
Dana S. Nau and Vikas Shivashankar
University of Maryland

2"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Introduc.on(! World seldom predictable
● corresponding deliberation models as a result always going to be incomplete ! Results in:
● Action failures ● Unexpected side effects of actions ● Exogenous events
! So far, been working with deterministic action models ● Each action, when applied in a particular state, results in only one state ● Formally: γ(s,a) returns a single state ● Doesn’t adequately support inherent uncertainty in domains
! Nondeterministic models provide more flexibility: ● An action, when applied in a state, may result in one among several possible
states ● γ(s,a) returns a set of states
! Nondeterministic models allow modeling uncertainty in planning domains
Ruofei Du
Ruofei Du
Ruofei Du
Ruofei Du

3"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Why(Model(Uncertainty?((! We’ve seen ways to handle these situations using deterministic models
● Generate plans for the nominal case ● Execute, and monitor ● Detect failure, and recover

4"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Why(Model(Uncertainty?(Answer: nondeterministic models have several advantages ! More accurate modeling ! Plan for uncertainty ahead of time, instead of during execution ! No nominal case in certain environments:
● Think of throwing a dice/tossing a coin ● Online payments where choice of payment left to user
! However, comes at a cost: ● More complicated, both conceptually and computationally ● Since you need to take all different possibilities into account
Ruofei Du
Ruofei Du
5"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
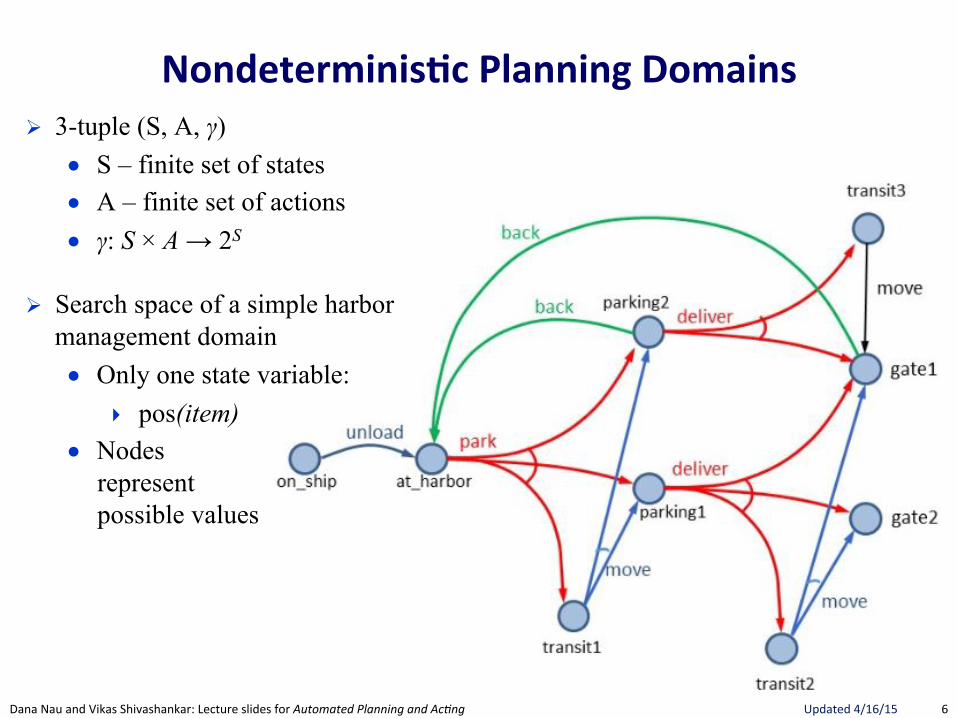
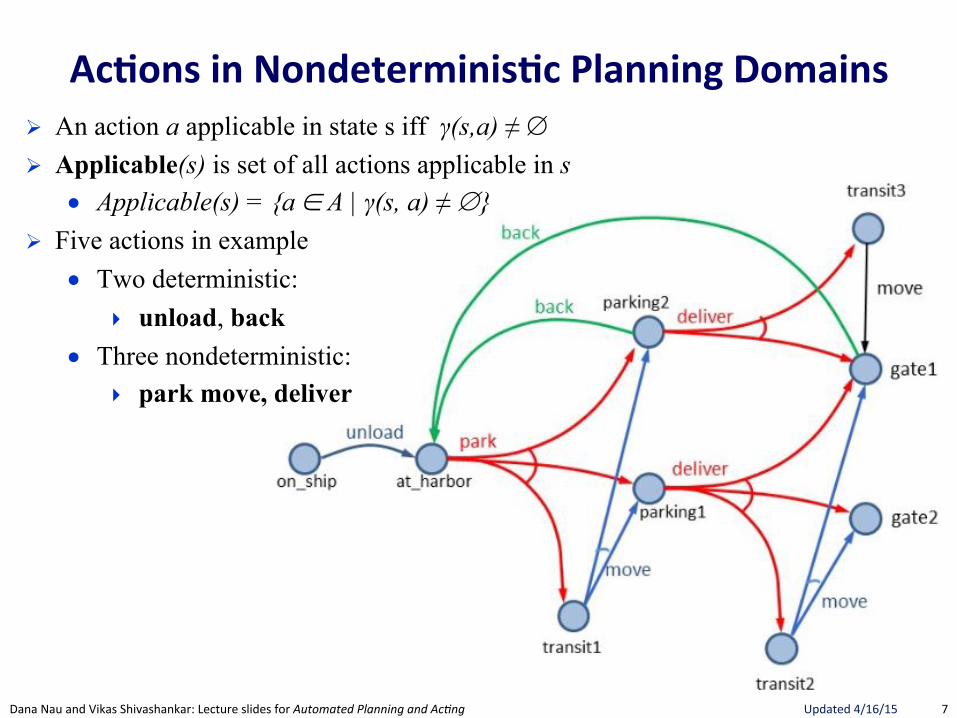
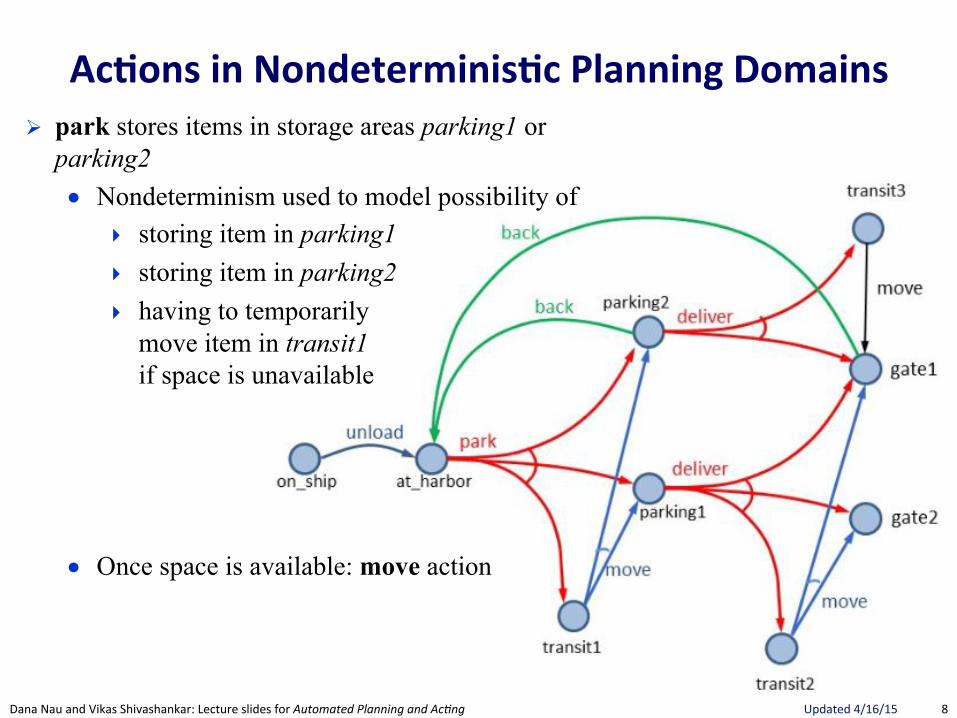
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
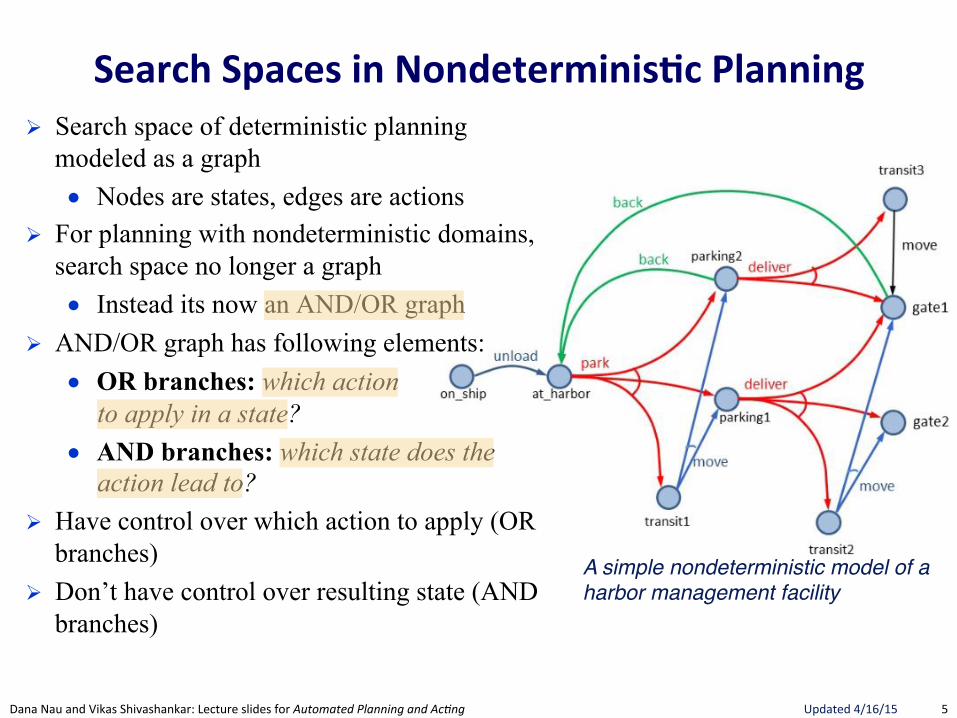
Search(Spaces(in(Nondeterminis.c(Planning(! Search space of deterministic planning
modeled as a graph ● Nodes are states, edges are actions
! For planning with nondeterministic domains, search space no longer a graph ● Instead its now an AND/OR graph
! AND/OR graph has following elements: ● OR branches: which action
to apply in a state? ● AND branches: which state does the
action lead to? ! Have control over which action to apply (OR
branches) ! Don’t have control over resulting state (AND
branches)
A simple nondeterministic model of a harbor management facility
Ruofei Du
Ruofei Du
Ruofei Du
6"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
Nondeterminis.c(Planning(Domains(! 3-tuple (S, A, γ)
● S – finite set of states ● A – finite set of actions ● γ: S × A → 2S
! Search space of a simple harbor management domain ● Only one state variable:
▸ pos(item) ● Nodes
represent possible values
7"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
Ac.ons(in(Nondeterminis.c(Planning(Domains(! An action a applicable in state s iff γ(s,a) ≠ ∅ ! Applicable(s) is set of all actions applicable in s
● Applicable(s) = {a ∈ A | γ(s, a) ≠ ∅} ! Five actions in example
● Two deterministic: ▸ unload, back
● Three nondeterministic: ▸ park move, deliver
8"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
Ac.ons(in(Nondeterminis.c(Planning(Domains(! park stores items in storage areas parking1 or
parking2 ● Nondeterminism used to model possibility of
▸ storing item in parking1 ▸ storing item in parking2 ▸ having to temporarily
move item in transit1 if space is unavailable
● Once space is available: move action

9"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
Plans(in(Nondeterminis.c(Domains(! Structure of plans must be different from
the deterministic case ● Previously, sequence of actions
! Doesn’t work here ● Why?
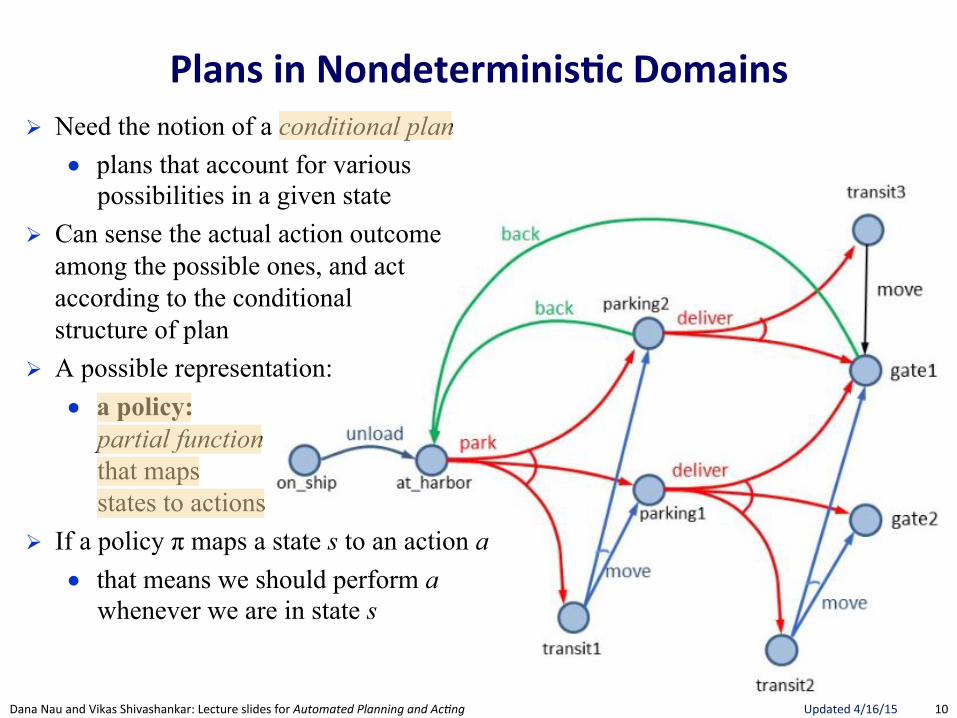
10"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
Plans(in(Nondeterminis.c(Domains(! Need the notion of a conditional plan
● plans that account for various possibilities in a given state
! Can sense the actual action outcome among the possible ones, and act according to the conditional structure of plan
! A possible representation: ● a policy:
partial function that maps states to actions
! If a policy π maps a state s to an action a ● that means we should perform a
whenever we are in state s
Ruofei Du
Ruofei Du
11"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
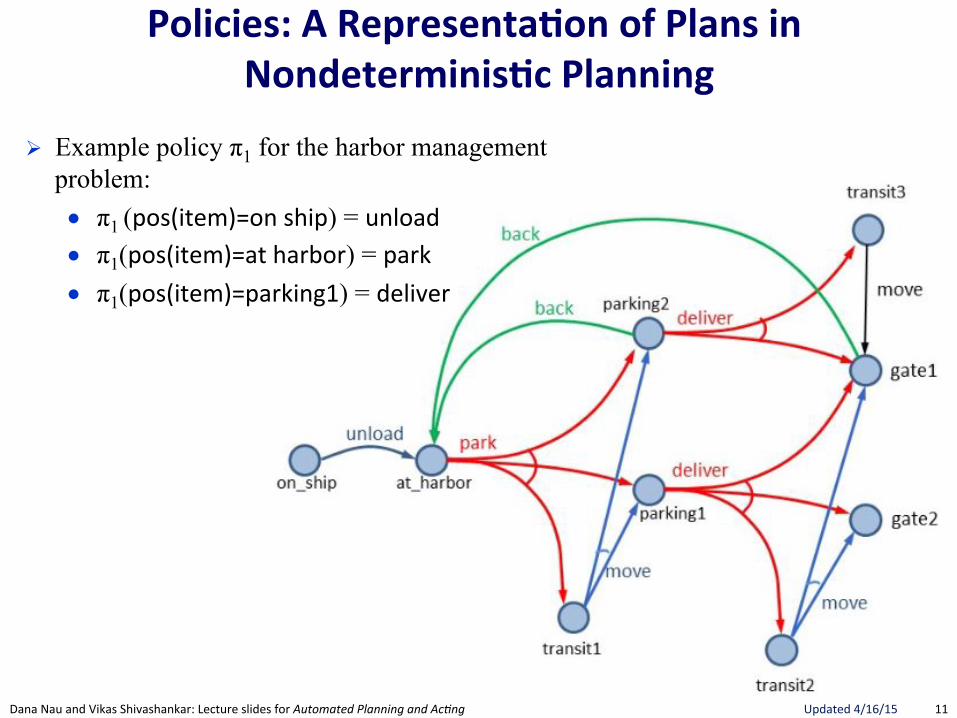
Policies:(A(Representa.on(of(Plans(in(Nondeterminis.c(Planning(
! Example policy π1 for the harbor management problem: ● π1 (pos(item)=on"ship) = unload"● π1(pos(item)=at"harbor) = park"● π1(pos(item)=parking1) = deliver"
12"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
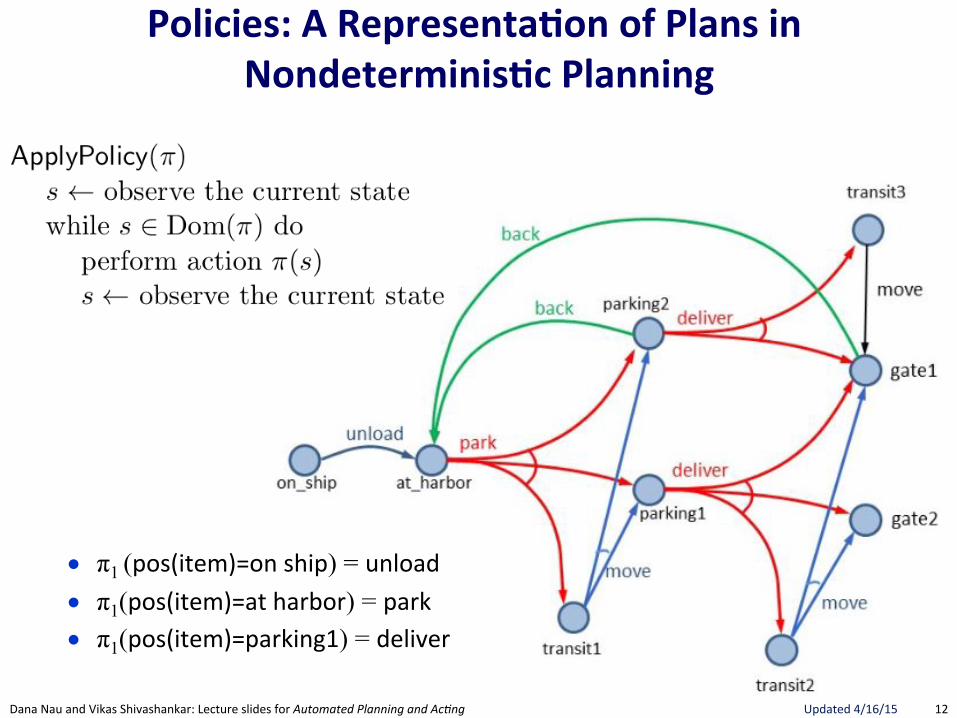
Policies:(A(Representa.on(of(Plans(in(Nondeterminis.c(Planning(
● π1 (pos(item)=on"ship) = unload"● π1(pos(item)=at"harbor) = park"● π1(pos(item)=parking1) = deliver"
13"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
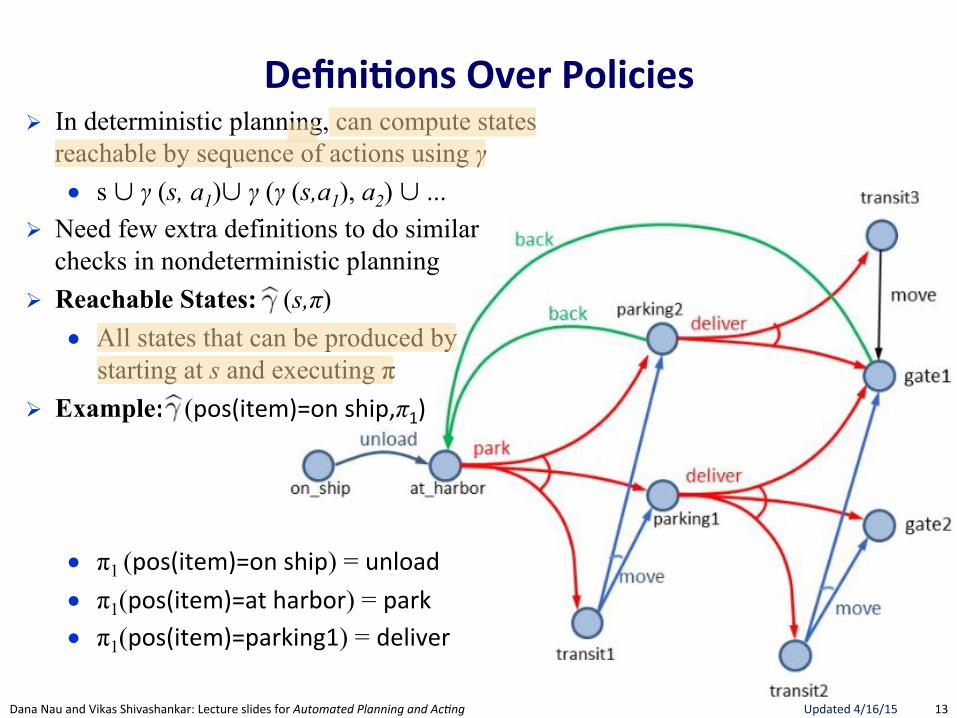
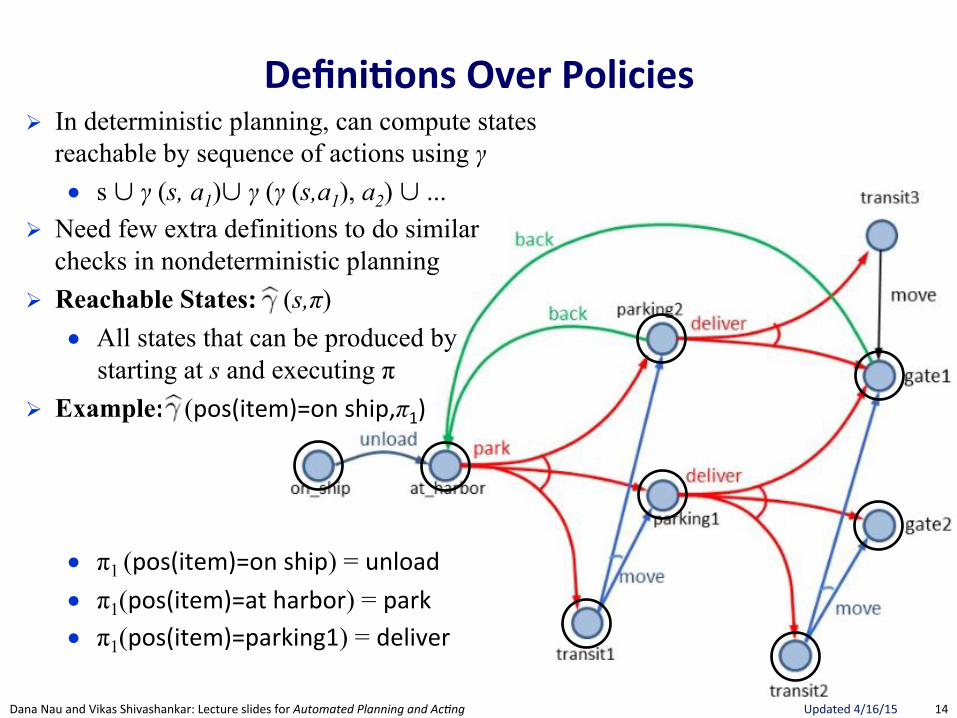
! In deterministic planning, can compute states reachable by sequence of actions using γ ● s ∪ γ (s, a1)∪ γ (γ (s,a1), a2) ∪ ...
! Need few extra definitions to do similar checks in nondeterministic planning
! Reachable States: (s,π) ● All states that can be produced by
starting at s and executing π ! Example: (pos(item)=on"ship,π1)
● π1 (pos(item)=on"ship) = unload"● π1(pos(item)=at"harbor) = park"● π1(pos(item)=parking1) = deliver"
Defini.ons(Over(Policies(
Ruofei Du
Ruofei Du
14"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
Defini.ons(Over(Policies(! In deterministic planning, can compute states
reachable by sequence of actions using γ ● s ∪ γ (s, a1)∪ γ (γ (s,a1), a2) ∪ ...
! Need few extra definitions to do similar checks in nondeterministic planning
! Reachable States: (s,π) ● All states that can be produced by
starting at s and executing π ! Example: (pos(item)=on"ship,π1)
● π1 (pos(item)=on"ship) = unload"● π1(pos(item)=at"harbor) = park"● π1(pos(item)=parking1) = deliver"
15"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
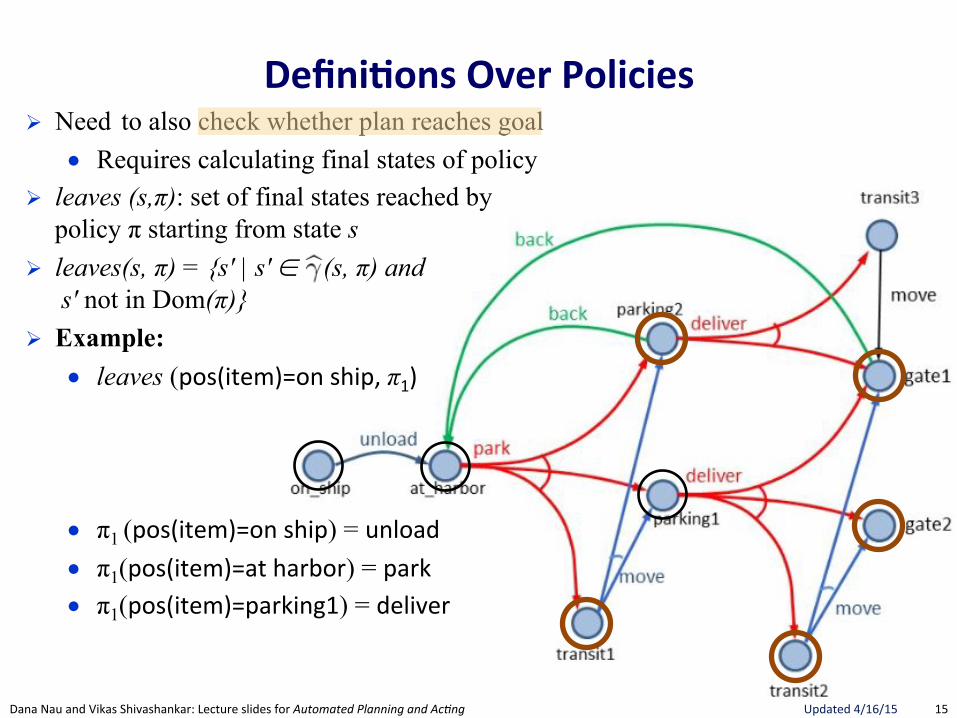
Defini.ons(Over(Policies(! Need to also check whether plan reaches goal
● Requires calculating final states of policy ! leaves (s,π): set of final states reached by
policy π starting from state s ! leaves(s, π) = {s′ | s′ ∈ ︎ (s, π) and
s′ not in Dom(π)} ! Example:
● leaves (pos(item)=on"ship,"π1)
● π1 (pos(item)=on"ship) = unload"● π1(pos(item)=at"harbor) = park"● π1(pos(item)=parking1) = deliver"
Ruofei Du

16"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Policies:(A(Representa.on(of(Plans(in(Nondeterminis.c(Planning(
! Reachability graph, Graph(s,π) ● Graph of all possible state transitions if we
execute π starting at s ● Graph(s,π) = { γ︎(s,π), E |
s′ ∈ γ︎(s, π), s′′ ∈ π(s′), and (s′,s′′) ∈ E}
● π1 (pos(item)=on"ship) = unload"● π1(pos(item)=at"harbor) = park"● π1(pos(item)=parking1) = deliver"
17"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Policies:(A(Representa.on(of(Plans(in(Nondeterminis.c(Planning(
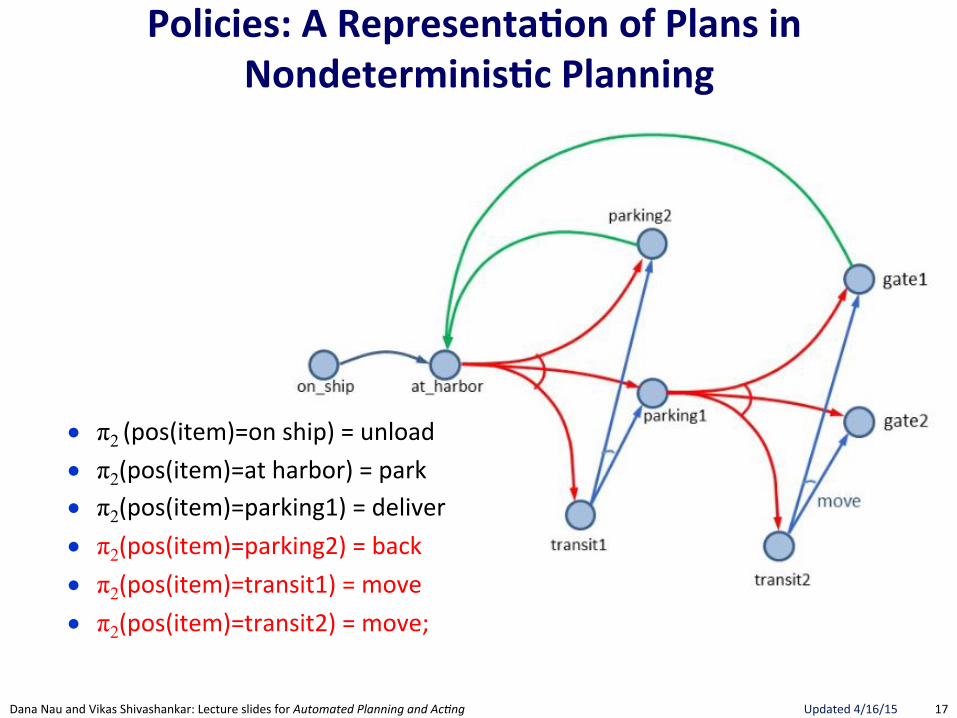
● π2"(pos(item)=on"ship)"="unload"
● π2(pos(item)=at"harbor)"="park"
● π2(pos(item)=parking1)"="deliver"
● π2(pos(item)=parking2)"="back"
● π2(pos(item)=transit1)"="move"
● π2(pos(item)=transit2)"="move;""
18"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Policies:(A(Representa.on(of(Plans(in(Nondeterminis.c(Planning(
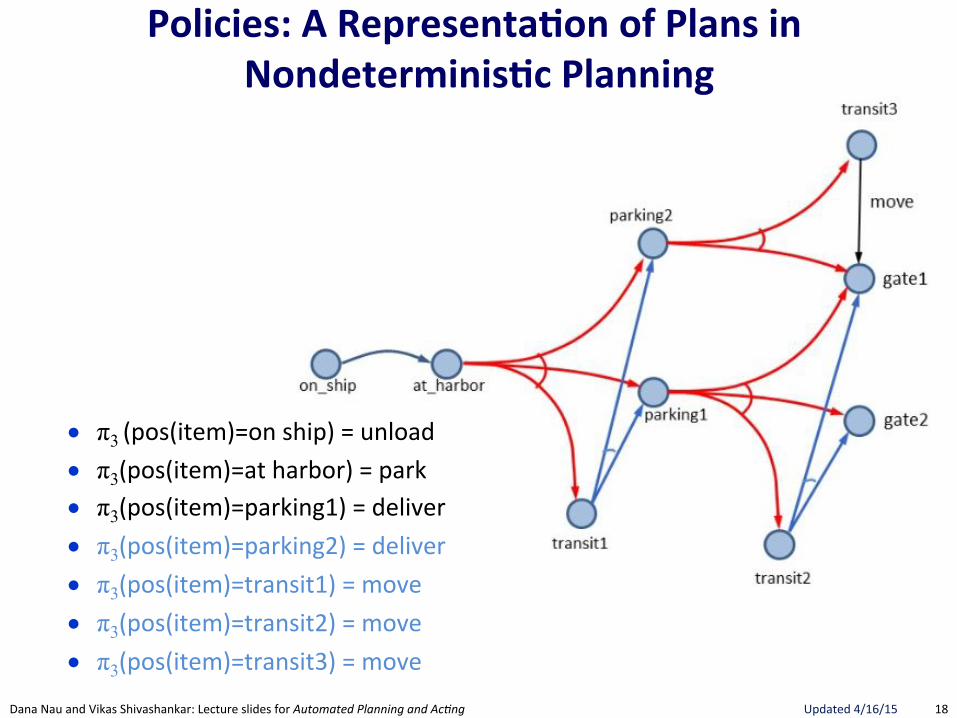
● π3"(pos(item)=on"ship)"="unload"
● π3(pos(item)=at"harbor)"="park"
● π3(pos(item)=parking1)"="deliver"
● π3(pos(item)=parking2)"="deliver"
● π3(pos(item)=transit1)"="move"
● π3(pos(item)=transit2)"="move"
● π3(pos(item)=transit3)"="move""

19"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Planning(Problems(and(Solu.ons(! Let Σ = (S,A,γ) be a planning domain ! A planning problem P is a 3-tuple P = (Σ,s0,Sg)
● s0 ∈ S is the initial state ● Sg ⊆ S is set of goal states
! Note: previous book had set of initial states S0
● Allowed uncertainty about initial state ● Current definition is equivalent
▸ Can easily translate one to the other • How?

20"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Planning(Problems(and(Solu.ons(! Let Σ = (S,A,γ) be a planning domain ! A planning problem P is a 3-tuple P = (Σ,s0,Sg)
● s0 ∈ S is the initial state ● Sg ⊆ S is set of goal states
! Note: previous book had set of initial states S0
● Allowed uncertainty about initial state ● Current definition is equivalent
▸ Can easily translate one to the other • How?
▸ Introduce a new start action such that γ (s0, start) = S0
! Solutions: not as straightforward to define as Deterministic Planning ● Based on actual action outcomes, might or might not achieve goal ● Can define different criteria of success – many types of solutions
21"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
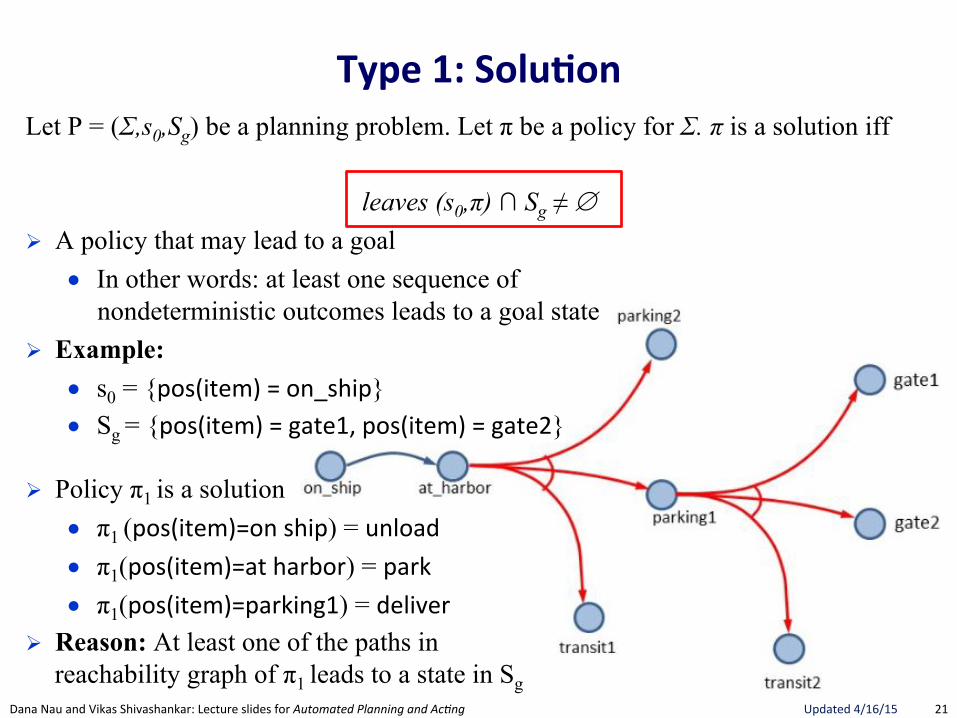
Type(1:(Solu.on(Let P = (Σ,s0,Sg) be a planning problem. Let π be a policy for Σ. π is a solution iff
leaves (s0,π) ∩ Sg ≠ ∅
! A policy that may lead to a goal ● In other words: at least one sequence of
nondeterministic outcomes leads to a goal state ! Example:
● s0 = {pos(item)"="on_ship} ● Sg = {pos(item)"="gate1,"pos(item)"="gate2}
! Policy π1 is a solution ● π1 (pos(item)=on"ship) = unload"● π1(pos(item)=at"harbor) = park"● π1(pos(item)=parking1) = deliver"
! Reason: At least one of the paths in reachability graph of π1 leads to a state in Sg
22"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
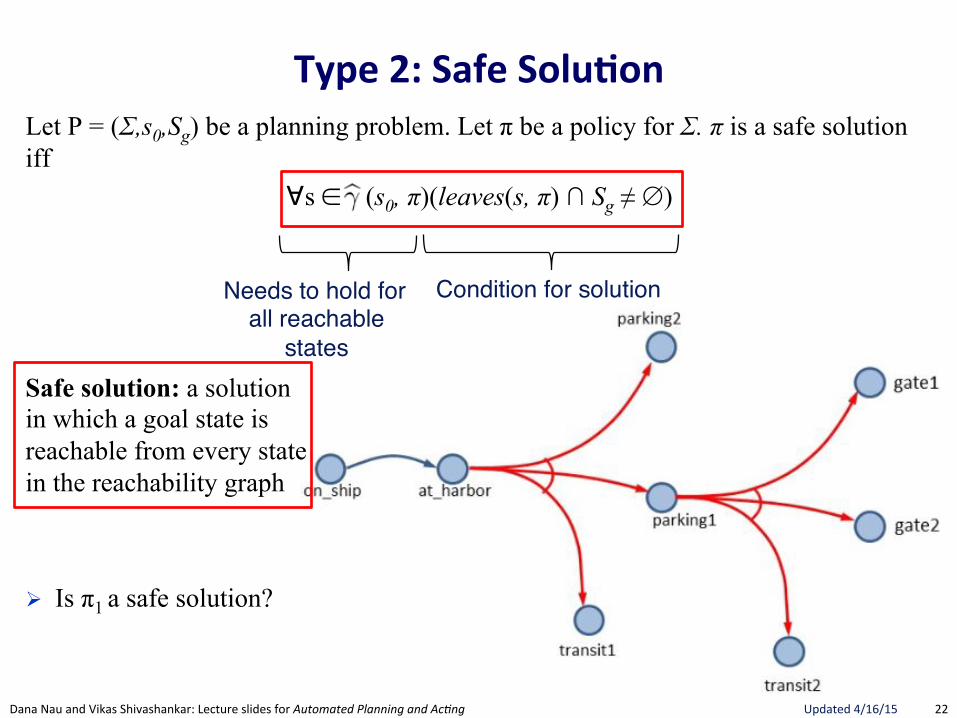
Type(2:(Safe(Solu.on(Let P = (Σ,s0,Sg) be a planning problem. Let π be a policy for Σ. π is a safe solution iff
∀s ∈ γ ︎(s0, π)(leaves(s, π) ∩ Sg ≠ ∅)
Safe solution: a solution in which a goal state is reachable from every state in the reachability graph
! Is π1 a safe solution?
Condition for solutionNeeds to hold for all reachable
states

23"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Type(2:(Safe(Solu.on(Let P = (Σ,s0,Sg) be a planning problem. Let π be a policy for Σ. π is a safe solution iff
∀s ∈ γ ︎(s0, π)(leaves(s, π) ∩ Sg ≠ ∅)
Safe solution: a solution in which a goal state is reachable from every state in the reachability graph
! Is π1 a safe solution? ● No
Condition for solutionNeeds to hold for all reachable
states

24"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Type(2:(Safe(Solu.on(Let P = (Σ,s0,Sg) be a planning problem. Let π be a policy for Σ. π is a safe solution iff
∀s ∈ γ ︎(s0, π)(leaves(s, π) ∩ Sg ≠ ∅)
Safe solution: a solution in which a goal state is reachable from every state in the reachability graph
! Is π2 a safe solution?
Condition for solutionNeeds to hold for all reachable
states

25"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Type(2:(Safe(Solu.on(Let P = (Σ,s0,Sg) be a planning problem. Let π be a policy for Σ. π is a safe solution iff
∀s ∈ γ ︎(s0, π)(leaves(s, π) ∩ Sg ≠ ∅)
Safe solution: a solution in which a goal state is reachable from every state in the reachability graph
! Is π2 a safe solution? ● Yes
Condition for solutionNeeds to hold for all reachable
states

26"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Type(2a:(Cyclic(Safe(Solu.ons(Let P = (Σ,s0,Sg) be a planning problem. Let π be a policy for Σ. π is a cyclic safe solution iff (1) leaves(s0, π) ⊆ Sg ∧ (2) (∀s ∈ γ ︎(s0, π)(leaves(s, π) ∩ Sg ≠ ∅)) (3) Graph(s0, π) is cyclic Meaning of Conditions: (1) No non-solution leaves (2) Safe solution (3) Reachability graph is cyclic Cyclic Safe solution: a safe solution with cycles ! π2 is a cyclic safe solution How does having cycles affect level of safety?

27"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Type(2a:(Cyclic(Safe(Solu.ons(Let P = (Σ,s0,Sg) be a planning problem. Let π be a policy for Σ. π is a cyclic safe solution iff (1) leaves(s0, π) ⊆ Sg ∧ (2) (∀s ∈ γ ︎(s0, π)(leaves(s, π) ∩ Sg ≠ ∅)) (3) Graph(s0, π) is cyclic Meaning of Conditions: (1) No non-solution leaves (2) Safe solution (3) Reachability graph is cyclic Cyclic Safe solution: a safe solution with cycles ! π2 is a cyclic safe solution How does having cycles affect level of safety? ! could go though cycle infinitely many times ! If execution gets out of loop eventually,
guaranteed to reach goal state

28"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Type(2b:(Acyclic(Safe(Solu.ons(Let P = (Σ,s0,Sg) be a planning problem. Let π be a policy for Σ. π is a acyclic safe solution iff (1) leaves(s0, π) ⊆ Sg ∧ (2) Graph(s0, π) is cyclic Meaning of Conditions: (1) No non-solution leaves (2) Reachability graph is acyclic Acyclic Safe Solution: a safe solution without cycles ! π3 is an acyclic safe solution ! Acyclic policy completely safe
● No matter what happens, guaranteed to eventually reach the goal

29"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Unsafe(Solu.ons(Let P = (Σ,s0,Sg) be a planning problem. Let π be a policy for Σ. π is an unsafe solution iff (1) (leaves(s0, π) ∩ Sg ≠ ∅) (2) ((∃s ∈ leaves(s0, π) | s is not in Sg) ∨ (∃s ∈ γ︎(s0,π) | leaves(s,π)=∅))
Either there is a non-solution leaf state
Or you get caught in an infinite loop
Both of these are bad events
30"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Summary(of(Solu.on(Types(Section 5.3 173
Figure 5.6: Di↵erent Kinds of Solutions: A Class Diagram
nondeterminism probabilistic
solutions weak solutions -unsafe solutions - improper solutionssafe solutions strong cyclic solutions proper solutions
cyclic safe solutions - -acyclic safe solutions strong solutions -
Table 5.1: Di↵erent Terminologies in the Literature
Notice that our terminology is di↵erent from the one used in previousliterature in nondeterministic and probabilistic planning. Table 5.1 summa-rizes the corresponding terminology used in planning with nondeterminismand in probabilistic planning literature. Our solutions and safe solutionsare called weak solutions and strong cyclic solutions, respectively, in liter-ature on planning in nondeterministic domains. In such literature indeed,strong solutions are also weak solutions, and this seems an improper use ofterminology. In probabilistic planning, improper solutions are our unsafe so-lutions, and our safe solutions are called proper, while there is no notion thatmakes a distinction between cyclic safe solutions and acyclic safe solutions,in spite of the di↵erent strength they provide .
5.3 And/Or Graph Search
A nondeterministic planning domain can be represented as an AND/ORgraph, in which each action leading from a state to a set of states is an “andnode” of the graph while the di↵erent actions applicable to a state represent“or-nodes”. In this section we present algorithms that search AND/ORr
Draft, not for distribution. March 24, 2015.
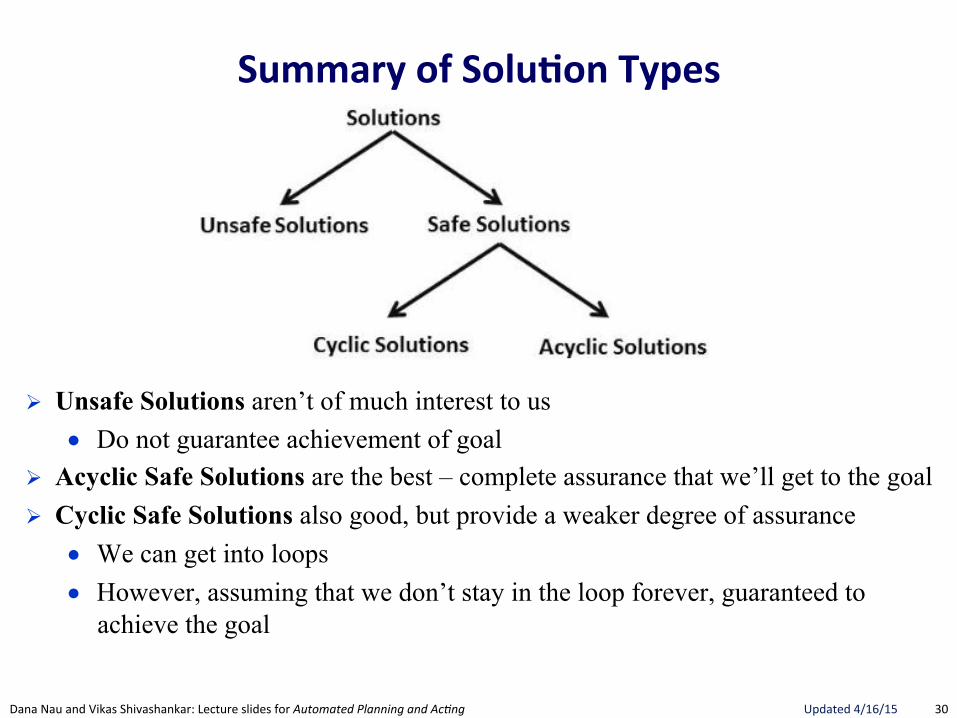
! Unsafe Solutions aren’t of much interest to us ● Do not guarantee achievement of goal
! Acyclic Safe Solutions are the best – complete assurance that we’ll get to the goal ! Cyclic Safe Solutions also good, but provide a weaker degree of assurance
● We can get into loops ● However, assuming that we don’t stay in the loop forever, guaranteed to
achieve the goal

31"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
SOLVING(NONDETERMINISTIC(PLANNING(PROBLEMS(

32"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
AND/OR(Graph(Search(Algorithms(! Nondeterministic planning search
spaces represented as AND/OR graphs ● nodes: states ● OR branches: actions applicable
in a state (consider 1) ● AND branches: successor states
from an state-action pair (consider ALL)
! Reachability graph of a solution policy includes one action at each OR branch and all of the action’s outcomes at each AND branch
! First set of planning algorithms will do AND/OR graph search ● Simple extensions of ForwardG
Search"from Chapter 2
ship
hbr
par1tr1
par2park
tr2g2 g1
del
tr3g1 hbr
delback
par1par2
move
unload

33"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
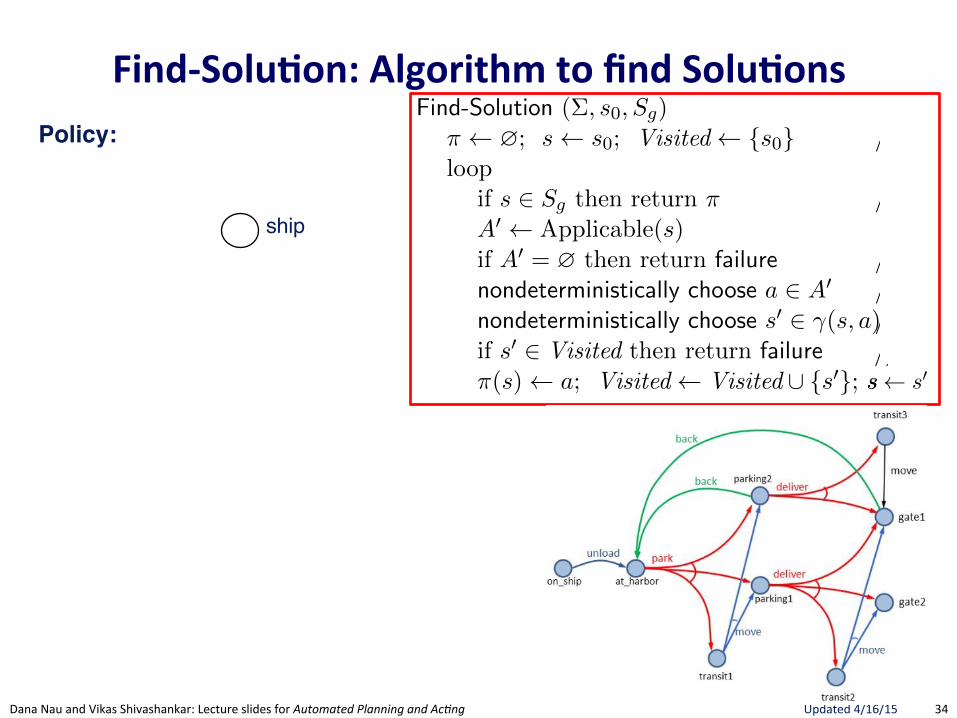
FindRSolu.on:(Algorithm(to(find(Solu.ons(32 Chapter 2
Forward-search (⌃, s0
, g)s s
0
; ⇡ hiloop
if s0
satisfies g then return ⇡A0 {a 2 A | a is applicable in s}if A0 = ? then return failurenondeterministically choose a 2 A0
s �(s, a); ⇡ ⇡.a
Figure 2.4: A nondeterministic forward-search planning algorithm.
enables us to discuss properties that are shared by all algorithms that do aforward search of the same search space, even though those algorithms maysearch the nodes of that tree in di↵erent orders. The rest of this sectiondiscuss several of those algorithms.
Finding a solution to a planning problem may require a huge computa-tional e↵ort; for an arbitrary CSV planning problem the task is PSPACE-equivalent [146]. To reduce the computational e↵ort, several of the searchalgorithms in this section incorporate heuristic techniques for selecting whichnode of the search space to visit next. Several of these techniques employ aheuristic function h(s) that returns an estimate of the minimum cost h⇤(s)of getting from s to a goal state; i.e.,
h(s) ⇡ h⇤(s) = min{cost(⇡) | �(s,⇡) satisfies g}. (2.7)
Some search algorithms require h to be admissible, i.e., they require 0 h(s) h⇤(s) for every state s (from which it follows that h(s) = 0 whenevers is a goal node). Section 2.5 describes several heuristic functions, someadmissible and some not.
Depth-first forward search. The DFFS algorithm shown in Figure 2.5attempts to construct a plan by searching forward from the initial state.Since most readers will already be familiar with depth-first search algo-rithms, the following discussion is relatively brief.
In line (ii), DFFS attempts to choose the best way to reach a goal node.For each applicable action a, DFFS evaluates the state �(s, a), and choosesthe action a for which �(s, a) has the smallest h-value.
In line (i), the condition �(s, a) 62 Visited is a cycle-checking test. Since⌃ has no infinite acyclic paths, this will restrict DFFS to a finite search space,
Draft, not for distribution. March 24, 2015.
174 Chapter 5
Find-Solution (⌃, s0
, Sg
)⇡ ?; s s
0
; Visited {s0
} // initializationloop
if s 2 Sg
then return ⇡ // goal testA0 Applicable(s)if A0 = ? then return failure // dead-end testnondeterministically choose a 2 A0 // branchingnondeterministically choose s0 2 �(s, a)// progressionif s0 2 Visited then return failure // loop check⇡(s) a; Visited Visited [ {s0}; s s0
Figure 5.7: Planning for Solutions by Forward-Search .
graphs to find solutions. The main goal of the following section is to showthe di↵erence in algorithms from deterministic domains. Most of them havemainly a didactic rather than practical objective.
5.3.1 Planning for Solutions by Forward Search
We first present a very simple algorithm that finds a solution by searchingthe AND/OR graph forward from initial state. Find-Solution (see Figure 5.7)is guaranteed to find a solution, which may be either safe or unsafe. It isa simple modification of the forward search algorithm Forward-search fordeterministic planning domains (see Chapter 2). Notice that the only sig-nificant di↵erence with Forward-search is in the ”progression” line, where wenondeterministically search for all possible states generated by the nonde-terministic �(s, a) that may result in more that one state.
Find-Solution simply search the AND/OR graph to find a path thatreaches the goal, without keeping track of which states are generated bywhich action. In this way Find-Solution ignores the real complexity of non-determinism in the domain. Since it does not keep track of the AND nodes(it deals with them in the same way as with the or nodes), it explores indi↵er-ently all generated states. Intuitively, Find-Solution has the same complexityas Forward-search.
The nondeterministic choices “nondeterministically choose a 2 A0” and“nondeterministically choose s0 2 �(s, a)” correspond to an abstraction forignoring the precise order in which the algorithm tries actions a among allthe applicable actions to state s and alternative states s0 among the states
Draft, not for distribution. March 24, 2015.
174 Chapter 5
Find-Solution (⌃, s0
, Sg
)⇡ ?; s s
0
; Visited {s0
} // initializationloop
if s 2 Sg
then return ⇡ // goal testA0 Applicable(s)if A0 = ? then return failure // dead-end testnondeterministically choose a 2 A0 // branchingnondeterministically choose s0 2 �(s, a)// progressionif s0 2 Visited then return failure // loop check⇡(s) a; Visited Visited [ {s0}; s s0
Figure 5.7: Planning for Solutions by Forward-Search .
graphs to find solutions. The main goal of the following section is to showthe di↵erence in algorithms from deterministic domains. Most of them havemainly a didactic rather than practical objective.
5.3.1 Planning for Solutions by Forward Search
We first present a very simple algorithm that finds a solution by searchingthe AND/OR graph forward from initial state. Find-Solution (see Figure 5.7)is guaranteed to find a solution, which may be either safe or unsafe. It isa simple modification of the forward search algorithm Forward-search fordeterministic planning domains (see Chapter 2). Notice that the only sig-nificant di↵erence with Forward-search is in the ”progression” line, where wenondeterministically search for all possible states generated by the nonde-terministic �(s, a) that may result in more that one state.
Find-Solution simply search the AND/OR graph to find a path thatreaches the goal, without keeping track of which states are generated bywhich action. In this way Find-Solution ignores the real complexity of non-determinism in the domain. Since it does not keep track of the AND nodes(it deals with them in the same way as with the or nodes), it explores indi↵er-ently all generated states. Intuitively, Find-Solution has the same complexityas Forward-search.
The nondeterministic choices “nondeterministically choose a 2 A0” and“nondeterministically choose s0 2 �(s, a)” correspond to an abstraction forignoring the precise order in which the algorithm tries actions a among allthe applicable actions to state s and alternative states s0 among the states
Draft, not for distribution. March 24, 2015.
Additional nondeterministicchoice to decide which action outcome to plan for next
Cycle-checking
Identical Algorithms except:
Deterministic Planning algorithm from Chapter 2
Nondeterministic Planningalgorithm
34"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
FindRSolu.on:(Algorithm(to(find(Solu.ons(
174 Chapter 5
Find-Solution (⌃, s0
, Sg
)⇡ ?; s s
0
; Visited {s0
} // initializationloop
if s 2 Sg
then return ⇡ // goal testA0 Applicable(s)if A0 = ? then return failure // dead-end testnondeterministically choose a 2 A0 // branchingnondeterministically choose s0 2 �(s, a)// progressionif s0 2 Visited then return failure // loop check⇡(s) a; Visited Visited [ {s0}; s s0
Figure 5.7: Planning for Solutions by Forward-Search .
graphs to find solutions. The main goal of the following section is to showthe di↵erence in algorithms from deterministic domains. Most of them havemainly a didactic rather than practical objective.
5.3.1 Planning for Solutions by Forward Search
We first present a very simple algorithm that finds a solution by searchingthe AND/OR graph forward from initial state. Find-Solution (see Figure 5.7)is guaranteed to find a solution, which may be either safe or unsafe. It isa simple modification of the forward search algorithm Forward-search fordeterministic planning domains (see Chapter 2). Notice that the only sig-nificant di↵erence with Forward-search is in the ”progression” line, where wenondeterministically search for all possible states generated by the nonde-terministic �(s, a) that may result in more that one state.
Find-Solution simply search the AND/OR graph to find a path thatreaches the goal, without keeping track of which states are generated bywhich action. In this way Find-Solution ignores the real complexity of non-determinism in the domain. Since it does not keep track of the AND nodes(it deals with them in the same way as with the or nodes), it explores indi↵er-ently all generated states. Intuitively, Find-Solution has the same complexityas Forward-search.
The nondeterministic choices “nondeterministically choose a 2 A0” and“nondeterministically choose s0 2 �(s, a)” correspond to an abstraction forignoring the precise order in which the algorithm tries actions a among allthe applicable actions to state s and alternative states s0 among the states
Draft, not for distribution. March 24, 2015.
174 Chapter 5
Find-Solution (⌃, s0
, Sg
)⇡ ?; s s
0
; Visited {s0
} // initializationloop
if s 2 Sg
then return ⇡ // goal testA0 Applicable(s)if A0 = ? then return failure // dead-end testnondeterministically choose a 2 A0 // branchingnondeterministically choose s0 2 �(s, a)// progressionif s0 2 Visited then return failure // loop check⇡(s) a; Visited Visited [ {s0}; s s0
Figure 5.7: Planning for Solutions by Forward-Search .
graphs to find solutions. The main goal of the following section is to showthe di↵erence in algorithms from deterministic domains. Most of them havemainly a didactic rather than practical objective.
5.3.1 Planning for Solutions by Forward Search
We first present a very simple algorithm that finds a solution by searchingthe AND/OR graph forward from initial state. Find-Solution (see Figure 5.7)is guaranteed to find a solution, which may be either safe or unsafe. It isa simple modification of the forward search algorithm Forward-search fordeterministic planning domains (see Chapter 2). Notice that the only sig-nificant di↵erence with Forward-search is in the ”progression” line, where wenondeterministically search for all possible states generated by the nonde-terministic �(s, a) that may result in more that one state.
Find-Solution simply search the AND/OR graph to find a path thatreaches the goal, without keeping track of which states are generated bywhich action. In this way Find-Solution ignores the real complexity of non-determinism in the domain. Since it does not keep track of the AND nodes(it deals with them in the same way as with the or nodes), it explores indi↵er-ently all generated states. Intuitively, Find-Solution has the same complexityas Forward-search.
The nondeterministic choices “nondeterministically choose a 2 A0” and“nondeterministically choose s0 2 �(s, a)” correspond to an abstraction forignoring the precise order in which the algorithm tries actions a among allthe applicable actions to state s and alternative states s0 among the states
Draft, not for distribution. March 24, 2015.
ship
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
Policy:
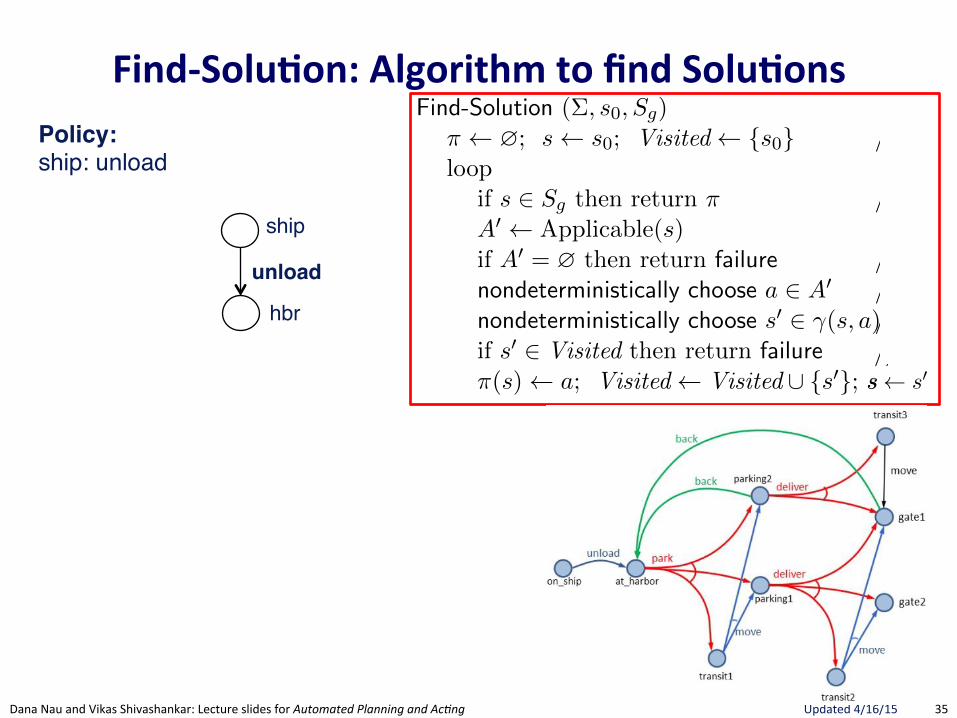
35"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
FindRSolu.on:(Algorithm(to(find(Solu.ons(
174 Chapter 5
Find-Solution (⌃, s0
, Sg
)⇡ ?; s s
0
; Visited {s0
} // initializationloop
if s 2 Sg
then return ⇡ // goal testA0 Applicable(s)if A0 = ? then return failure // dead-end testnondeterministically choose a 2 A0 // branchingnondeterministically choose s0 2 �(s, a)// progressionif s0 2 Visited then return failure // loop check⇡(s) a; Visited Visited [ {s0}; s s0
Figure 5.7: Planning for Solutions by Forward-Search .
graphs to find solutions. The main goal of the following section is to showthe di↵erence in algorithms from deterministic domains. Most of them havemainly a didactic rather than practical objective.
5.3.1 Planning for Solutions by Forward Search
We first present a very simple algorithm that finds a solution by searchingthe AND/OR graph forward from initial state. Find-Solution (see Figure 5.7)is guaranteed to find a solution, which may be either safe or unsafe. It isa simple modification of the forward search algorithm Forward-search fordeterministic planning domains (see Chapter 2). Notice that the only sig-nificant di↵erence with Forward-search is in the ”progression” line, where wenondeterministically search for all possible states generated by the nonde-terministic �(s, a) that may result in more that one state.
Find-Solution simply search the AND/OR graph to find a path thatreaches the goal, without keeping track of which states are generated bywhich action. In this way Find-Solution ignores the real complexity of non-determinism in the domain. Since it does not keep track of the AND nodes(it deals with them in the same way as with the or nodes), it explores indi↵er-ently all generated states. Intuitively, Find-Solution has the same complexityas Forward-search.
The nondeterministic choices “nondeterministically choose a 2 A0” and“nondeterministically choose s0 2 �(s, a)” correspond to an abstraction forignoring the precise order in which the algorithm tries actions a among allthe applicable actions to state s and alternative states s0 among the states
Draft, not for distribution. March 24, 2015.
174 Chapter 5
Find-Solution (⌃, s0
, Sg
)⇡ ?; s s
0
; Visited {s0
} // initializationloop
if s 2 Sg
then return ⇡ // goal testA0 Applicable(s)if A0 = ? then return failure // dead-end testnondeterministically choose a 2 A0 // branchingnondeterministically choose s0 2 �(s, a)// progressionif s0 2 Visited then return failure // loop check⇡(s) a; Visited Visited [ {s0}; s s0
Figure 5.7: Planning for Solutions by Forward-Search .
graphs to find solutions. The main goal of the following section is to showthe di↵erence in algorithms from deterministic domains. Most of them havemainly a didactic rather than practical objective.
5.3.1 Planning for Solutions by Forward Search
We first present a very simple algorithm that finds a solution by searchingthe AND/OR graph forward from initial state. Find-Solution (see Figure 5.7)is guaranteed to find a solution, which may be either safe or unsafe. It isa simple modification of the forward search algorithm Forward-search fordeterministic planning domains (see Chapter 2). Notice that the only sig-nificant di↵erence with Forward-search is in the ”progression” line, where wenondeterministically search for all possible states generated by the nonde-terministic �(s, a) that may result in more that one state.
Find-Solution simply search the AND/OR graph to find a path thatreaches the goal, without keeping track of which states are generated bywhich action. In this way Find-Solution ignores the real complexity of non-determinism in the domain. Since it does not keep track of the AND nodes(it deals with them in the same way as with the or nodes), it explores indi↵er-ently all generated states. Intuitively, Find-Solution has the same complexityas Forward-search.
The nondeterministic choices “nondeterministically choose a 2 A0” and“nondeterministically choose s0 2 �(s, a)” correspond to an abstraction forignoring the precise order in which the algorithm tries actions a among allthe applicable actions to state s and alternative states s0 among the states
Draft, not for distribution. March 24, 2015.
ship
hbr
unload
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
Policy:ship: unload
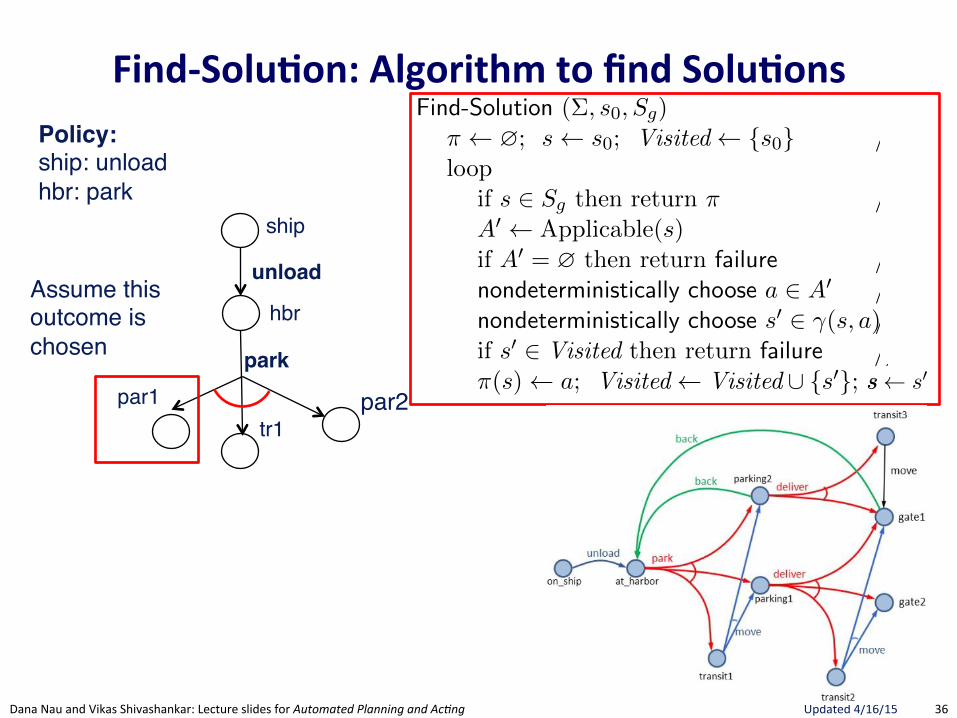
36"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
FindRSolu.on:(Algorithm(to(find(Solu.ons(
174 Chapter 5
Find-Solution (⌃, s0
, Sg
)⇡ ?; s s
0
; Visited {s0
} // initializationloop
if s 2 Sg
then return ⇡ // goal testA0 Applicable(s)if A0 = ? then return failure // dead-end testnondeterministically choose a 2 A0 // branchingnondeterministically choose s0 2 �(s, a)// progressionif s0 2 Visited then return failure // loop check⇡(s) a; Visited Visited [ {s0}; s s0
Figure 5.7: Planning for Solutions by Forward-Search .
graphs to find solutions. The main goal of the following section is to showthe di↵erence in algorithms from deterministic domains. Most of them havemainly a didactic rather than practical objective.
5.3.1 Planning for Solutions by Forward Search
We first present a very simple algorithm that finds a solution by searchingthe AND/OR graph forward from initial state. Find-Solution (see Figure 5.7)is guaranteed to find a solution, which may be either safe or unsafe. It isa simple modification of the forward search algorithm Forward-search fordeterministic planning domains (see Chapter 2). Notice that the only sig-nificant di↵erence with Forward-search is in the ”progression” line, where wenondeterministically search for all possible states generated by the nonde-terministic �(s, a) that may result in more that one state.
Find-Solution simply search the AND/OR graph to find a path thatreaches the goal, without keeping track of which states are generated bywhich action. In this way Find-Solution ignores the real complexity of non-determinism in the domain. Since it does not keep track of the AND nodes(it deals with them in the same way as with the or nodes), it explores indi↵er-ently all generated states. Intuitively, Find-Solution has the same complexityas Forward-search.
The nondeterministic choices “nondeterministically choose a 2 A0” and“nondeterministically choose s0 2 �(s, a)” correspond to an abstraction forignoring the precise order in which the algorithm tries actions a among allthe applicable actions to state s and alternative states s0 among the states
Draft, not for distribution. March 24, 2015.
174 Chapter 5
Find-Solution (⌃, s0
, Sg
)⇡ ?; s s
0
; Visited {s0
} // initializationloop
if s 2 Sg
then return ⇡ // goal testA0 Applicable(s)if A0 = ? then return failure // dead-end testnondeterministically choose a 2 A0 // branchingnondeterministically choose s0 2 �(s, a)// progressionif s0 2 Visited then return failure // loop check⇡(s) a; Visited Visited [ {s0}; s s0
Figure 5.7: Planning for Solutions by Forward-Search .
graphs to find solutions. The main goal of the following section is to showthe di↵erence in algorithms from deterministic domains. Most of them havemainly a didactic rather than practical objective.
5.3.1 Planning for Solutions by Forward Search
We first present a very simple algorithm that finds a solution by searchingthe AND/OR graph forward from initial state. Find-Solution (see Figure 5.7)is guaranteed to find a solution, which may be either safe or unsafe. It isa simple modification of the forward search algorithm Forward-search fordeterministic planning domains (see Chapter 2). Notice that the only sig-nificant di↵erence with Forward-search is in the ”progression” line, where wenondeterministically search for all possible states generated by the nonde-terministic �(s, a) that may result in more that one state.
Find-Solution simply search the AND/OR graph to find a path thatreaches the goal, without keeping track of which states are generated bywhich action. In this way Find-Solution ignores the real complexity of non-determinism in the domain. Since it does not keep track of the AND nodes(it deals with them in the same way as with the or nodes), it explores indi↵er-ently all generated states. Intuitively, Find-Solution has the same complexityas Forward-search.
The nondeterministic choices “nondeterministically choose a 2 A0” and“nondeterministically choose s0 2 �(s, a)” correspond to an abstraction forignoring the precise order in which the algorithm tries actions a among allthe applicable actions to state s and alternative states s0 among the states
Draft, not for distribution. March 24, 2015.
ship
hbr
par1tr1
par2park
unload
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
Policy:ship: unloadhbr: park
Assume thisoutcome is chosen
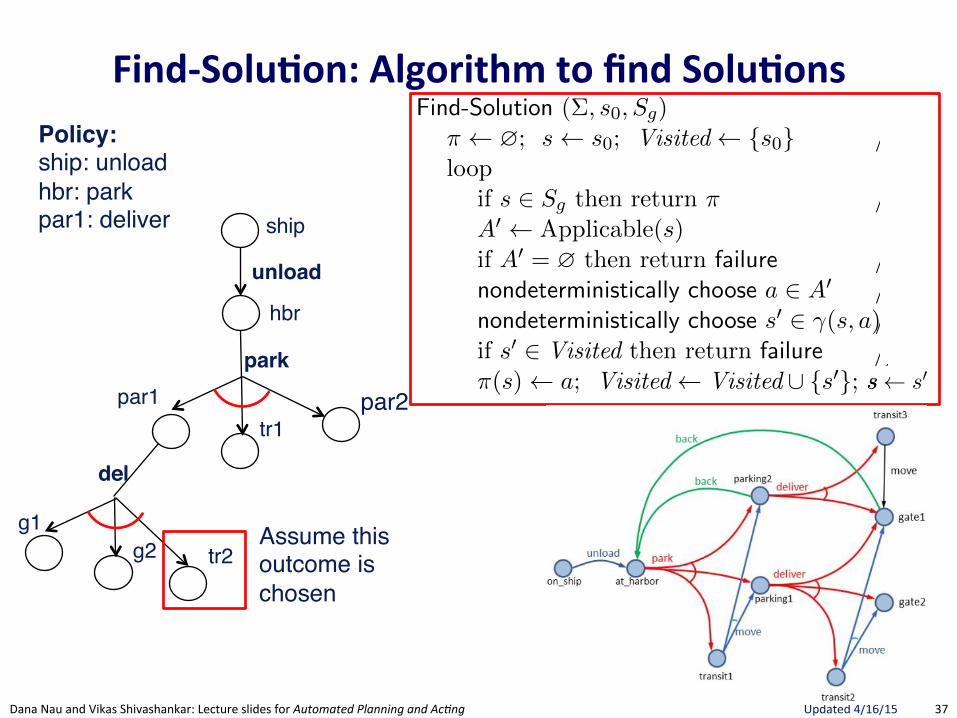
37"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
FindRSolu.on:(Algorithm(to(find(Solu.ons(
174 Chapter 5
Find-Solution (⌃, s0
, Sg
)⇡ ?; s s
0
; Visited {s0
} // initializationloop
if s 2 Sg
then return ⇡ // goal testA0 Applicable(s)if A0 = ? then return failure // dead-end testnondeterministically choose a 2 A0 // branchingnondeterministically choose s0 2 �(s, a)// progressionif s0 2 Visited then return failure // loop check⇡(s) a; Visited Visited [ {s0}; s s0
Figure 5.7: Planning for Solutions by Forward-Search .
graphs to find solutions. The main goal of the following section is to showthe di↵erence in algorithms from deterministic domains. Most of them havemainly a didactic rather than practical objective.
5.3.1 Planning for Solutions by Forward Search
We first present a very simple algorithm that finds a solution by searchingthe AND/OR graph forward from initial state. Find-Solution (see Figure 5.7)is guaranteed to find a solution, which may be either safe or unsafe. It isa simple modification of the forward search algorithm Forward-search fordeterministic planning domains (see Chapter 2). Notice that the only sig-nificant di↵erence with Forward-search is in the ”progression” line, where wenondeterministically search for all possible states generated by the nonde-terministic �(s, a) that may result in more that one state.
Find-Solution simply search the AND/OR graph to find a path thatreaches the goal, without keeping track of which states are generated bywhich action. In this way Find-Solution ignores the real complexity of non-determinism in the domain. Since it does not keep track of the AND nodes(it deals with them in the same way as with the or nodes), it explores indi↵er-ently all generated states. Intuitively, Find-Solution has the same complexityas Forward-search.
The nondeterministic choices “nondeterministically choose a 2 A0” and“nondeterministically choose s0 2 �(s, a)” correspond to an abstraction forignoring the precise order in which the algorithm tries actions a among allthe applicable actions to state s and alternative states s0 among the states
Draft, not for distribution. March 24, 2015.
174 Chapter 5
Find-Solution (⌃, s0
, Sg
)⇡ ?; s s
0
; Visited {s0
} // initializationloop
if s 2 Sg
then return ⇡ // goal testA0 Applicable(s)if A0 = ? then return failure // dead-end testnondeterministically choose a 2 A0 // branchingnondeterministically choose s0 2 �(s, a)// progressionif s0 2 Visited then return failure // loop check⇡(s) a; Visited Visited [ {s0}; s s0
Figure 5.7: Planning for Solutions by Forward-Search .
graphs to find solutions. The main goal of the following section is to showthe di↵erence in algorithms from deterministic domains. Most of them havemainly a didactic rather than practical objective.
5.3.1 Planning for Solutions by Forward Search
We first present a very simple algorithm that finds a solution by searchingthe AND/OR graph forward from initial state. Find-Solution (see Figure 5.7)is guaranteed to find a solution, which may be either safe or unsafe. It isa simple modification of the forward search algorithm Forward-search fordeterministic planning domains (see Chapter 2). Notice that the only sig-nificant di↵erence with Forward-search is in the ”progression” line, where wenondeterministically search for all possible states generated by the nonde-terministic �(s, a) that may result in more that one state.
Find-Solution simply search the AND/OR graph to find a path thatreaches the goal, without keeping track of which states are generated bywhich action. In this way Find-Solution ignores the real complexity of non-determinism in the domain. Since it does not keep track of the AND nodes(it deals with them in the same way as with the or nodes), it explores indi↵er-ently all generated states. Intuitively, Find-Solution has the same complexityas Forward-search.
The nondeterministic choices “nondeterministically choose a 2 A0” and“nondeterministically choose s0 2 �(s, a)” correspond to an abstraction forignoring the precise order in which the algorithm tries actions a among allthe applicable actions to state s and alternative states s0 among the states
Draft, not for distribution. March 24, 2015.
ship
hbr
par1tr1
par2park
unload
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
Policy:ship: unloadhbr: parkpar1: deliver
g1g2
del
tr2Assume thisoutcome is chosen

38"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
FindRSolu.on:(Algorithm(to(find(Solu.ons(
174 Chapter 5
Find-Solution (⌃, s0
, Sg
)⇡ ?; s s
0
; Visited {s0
} // initializationloop
if s 2 Sg
then return ⇡ // goal testA0 Applicable(s)if A0 = ? then return failure // dead-end testnondeterministically choose a 2 A0 // branchingnondeterministically choose s0 2 �(s, a)// progressionif s0 2 Visited then return failure // loop check⇡(s) a; Visited Visited [ {s0}; s s0
Figure 5.7: Planning for Solutions by Forward-Search .
graphs to find solutions. The main goal of the following section is to showthe di↵erence in algorithms from deterministic domains. Most of them havemainly a didactic rather than practical objective.
5.3.1 Planning for Solutions by Forward Search
We first present a very simple algorithm that finds a solution by searchingthe AND/OR graph forward from initial state. Find-Solution (see Figure 5.7)is guaranteed to find a solution, which may be either safe or unsafe. It isa simple modification of the forward search algorithm Forward-search fordeterministic planning domains (see Chapter 2). Notice that the only sig-nificant di↵erence with Forward-search is in the ”progression” line, where wenondeterministically search for all possible states generated by the nonde-terministic �(s, a) that may result in more that one state.
Find-Solution simply search the AND/OR graph to find a path thatreaches the goal, without keeping track of which states are generated bywhich action. In this way Find-Solution ignores the real complexity of non-determinism in the domain. Since it does not keep track of the AND nodes(it deals with them in the same way as with the or nodes), it explores indi↵er-ently all generated states. Intuitively, Find-Solution has the same complexityas Forward-search.
The nondeterministic choices “nondeterministically choose a 2 A0” and“nondeterministically choose s0 2 �(s, a)” correspond to an abstraction forignoring the precise order in which the algorithm tries actions a among allthe applicable actions to state s and alternative states s0 among the states
Draft, not for distribution. March 24, 2015.
174 Chapter 5
Find-Solution (⌃, s0
, Sg
)⇡ ?; s s
0
; Visited {s0
} // initializationloop
if s 2 Sg
then return ⇡ // goal testA0 Applicable(s)if A0 = ? then return failure // dead-end testnondeterministically choose a 2 A0 // branchingnondeterministically choose s0 2 �(s, a)// progressionif s0 2 Visited then return failure // loop check⇡(s) a; Visited Visited [ {s0}; s s0
Figure 5.7: Planning for Solutions by Forward-Search .
graphs to find solutions. The main goal of the following section is to showthe di↵erence in algorithms from deterministic domains. Most of them havemainly a didactic rather than practical objective.
5.3.1 Planning for Solutions by Forward Search
We first present a very simple algorithm that finds a solution by searchingthe AND/OR graph forward from initial state. Find-Solution (see Figure 5.7)is guaranteed to find a solution, which may be either safe or unsafe. It isa simple modification of the forward search algorithm Forward-search fordeterministic planning domains (see Chapter 2). Notice that the only sig-nificant di↵erence with Forward-search is in the ”progression” line, where wenondeterministically search for all possible states generated by the nonde-terministic �(s, a) that may result in more that one state.
Find-Solution simply search the AND/OR graph to find a path thatreaches the goal, without keeping track of which states are generated bywhich action. In this way Find-Solution ignores the real complexity of non-determinism in the domain. Since it does not keep track of the AND nodes(it deals with them in the same way as with the or nodes), it explores indi↵er-ently all generated states. Intuitively, Find-Solution has the same complexityas Forward-search.
The nondeterministic choices “nondeterministically choose a 2 A0” and“nondeterministically choose s0 2 �(s, a)” correspond to an abstraction forignoring the precise order in which the algorithm tries actions a among allthe applicable actions to state s and alternative states s0 among the states
Draft, not for distribution. March 24, 2015.
ship
hbr
par1tr1
par2park
unload
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
Policy:ship: unloadhbr: parkpar1: delivertr2: move
g1g2
del
tr2
g1 g2
move
Assume thisoutcome is chosen

39"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
FindRSolu.on:(Algorithm(to(find(Solu.ons(
174 Chapter 5
Find-Solution (⌃, s0
, Sg
)⇡ ?; s s
0
; Visited {s0
} // initializationloop
if s 2 Sg
then return ⇡ // goal testA0 Applicable(s)if A0 = ? then return failure // dead-end testnondeterministically choose a 2 A0 // branchingnondeterministically choose s0 2 �(s, a)// progressionif s0 2 Visited then return failure // loop check⇡(s) a; Visited Visited [ {s0}; s s0
Figure 5.7: Planning for Solutions by Forward-Search .
graphs to find solutions. The main goal of the following section is to showthe di↵erence in algorithms from deterministic domains. Most of them havemainly a didactic rather than practical objective.
5.3.1 Planning for Solutions by Forward Search
We first present a very simple algorithm that finds a solution by searchingthe AND/OR graph forward from initial state. Find-Solution (see Figure 5.7)is guaranteed to find a solution, which may be either safe or unsafe. It isa simple modification of the forward search algorithm Forward-search fordeterministic planning domains (see Chapter 2). Notice that the only sig-nificant di↵erence with Forward-search is in the ”progression” line, where wenondeterministically search for all possible states generated by the nonde-terministic �(s, a) that may result in more that one state.
Find-Solution simply search the AND/OR graph to find a path thatreaches the goal, without keeping track of which states are generated bywhich action. In this way Find-Solution ignores the real complexity of non-determinism in the domain. Since it does not keep track of the AND nodes(it deals with them in the same way as with the or nodes), it explores indi↵er-ently all generated states. Intuitively, Find-Solution has the same complexityas Forward-search.
The nondeterministic choices “nondeterministically choose a 2 A0” and“nondeterministically choose s0 2 �(s, a)” correspond to an abstraction forignoring the precise order in which the algorithm tries actions a among allthe applicable actions to state s and alternative states s0 among the states
Draft, not for distribution. March 24, 2015.
174 Chapter 5
Find-Solution (⌃, s0
, Sg
)⇡ ?; s s
0
; Visited {s0
} // initializationloop
if s 2 Sg
then return ⇡ // goal testA0 Applicable(s)if A0 = ? then return failure // dead-end testnondeterministically choose a 2 A0 // branchingnondeterministically choose s0 2 �(s, a)// progressionif s0 2 Visited then return failure // loop check⇡(s) a; Visited Visited [ {s0}; s s0
Figure 5.7: Planning for Solutions by Forward-Search .
graphs to find solutions. The main goal of the following section is to showthe di↵erence in algorithms from deterministic domains. Most of them havemainly a didactic rather than practical objective.
5.3.1 Planning for Solutions by Forward Search
We first present a very simple algorithm that finds a solution by searchingthe AND/OR graph forward from initial state. Find-Solution (see Figure 5.7)is guaranteed to find a solution, which may be either safe or unsafe. It isa simple modification of the forward search algorithm Forward-search fordeterministic planning domains (see Chapter 2). Notice that the only sig-nificant di↵erence with Forward-search is in the ”progression” line, where wenondeterministically search for all possible states generated by the nonde-terministic �(s, a) that may result in more that one state.
Find-Solution simply search the AND/OR graph to find a path thatreaches the goal, without keeping track of which states are generated bywhich action. In this way Find-Solution ignores the real complexity of non-determinism in the domain. Since it does not keep track of the AND nodes(it deals with them in the same way as with the or nodes), it explores indi↵er-ently all generated states. Intuitively, Find-Solution has the same complexityas Forward-search.
The nondeterministic choices “nondeterministically choose a 2 A0” and“nondeterministically choose s0 2 �(s, a)” correspond to an abstraction forignoring the precise order in which the algorithm tries actions a among allthe applicable actions to state s and alternative states s0 among the states
Draft, not for distribution. March 24, 2015.
ship
hbr
par1tr1
par2park
unload
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
Policy:ship: unloadhbr: parkpar1: delivertr2: move
g1g2
del
tr2
g1 g2
move
Reached a goal state.Terminate here.

40"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
FindRSolu.on:(Algorithm(to(find(Solu.ons(
174 Chapter 5
Find-Solution (⌃, s0
, Sg
)⇡ ?; s s
0
; Visited {s0
} // initializationloop
if s 2 Sg
then return ⇡ // goal testA0 Applicable(s)if A0 = ? then return failure // dead-end testnondeterministically choose a 2 A0 // branchingnondeterministically choose s0 2 �(s, a)// progressionif s0 2 Visited then return failure // loop check⇡(s) a; Visited Visited [ {s0}; s s0
Figure 5.7: Planning for Solutions by Forward-Search .
graphs to find solutions. The main goal of the following section is to showthe di↵erence in algorithms from deterministic domains. Most of them havemainly a didactic rather than practical objective.
5.3.1 Planning for Solutions by Forward Search
We first present a very simple algorithm that finds a solution by searchingthe AND/OR graph forward from initial state. Find-Solution (see Figure 5.7)is guaranteed to find a solution, which may be either safe or unsafe. It isa simple modification of the forward search algorithm Forward-search fordeterministic planning domains (see Chapter 2). Notice that the only sig-nificant di↵erence with Forward-search is in the ”progression” line, where wenondeterministically search for all possible states generated by the nonde-terministic �(s, a) that may result in more that one state.
Find-Solution simply search the AND/OR graph to find a path thatreaches the goal, without keeping track of which states are generated bywhich action. In this way Find-Solution ignores the real complexity of non-determinism in the domain. Since it does not keep track of the AND nodes(it deals with them in the same way as with the or nodes), it explores indi↵er-ently all generated states. Intuitively, Find-Solution has the same complexityas Forward-search.
The nondeterministic choices “nondeterministically choose a 2 A0” and“nondeterministically choose s0 2 �(s, a)” correspond to an abstraction forignoring the precise order in which the algorithm tries actions a among allthe applicable actions to state s and alternative states s0 among the states
Draft, not for distribution. March 24, 2015.
174 Chapter 5
Find-Solution (⌃, s0
, Sg
)⇡ ?; s s
0
; Visited {s0
} // initializationloop
if s 2 Sg
then return ⇡ // goal testA0 Applicable(s)if A0 = ? then return failure // dead-end testnondeterministically choose a 2 A0 // branchingnondeterministically choose s0 2 �(s, a)// progressionif s0 2 Visited then return failure // loop check⇡(s) a; Visited Visited [ {s0}; s s0
Figure 5.7: Planning for Solutions by Forward-Search .
graphs to find solutions. The main goal of the following section is to showthe di↵erence in algorithms from deterministic domains. Most of them havemainly a didactic rather than practical objective.
5.3.1 Planning for Solutions by Forward Search
We first present a very simple algorithm that finds a solution by searchingthe AND/OR graph forward from initial state. Find-Solution (see Figure 5.7)is guaranteed to find a solution, which may be either safe or unsafe. It isa simple modification of the forward search algorithm Forward-search fordeterministic planning domains (see Chapter 2). Notice that the only sig-nificant di↵erence with Forward-search is in the ”progression” line, where wenondeterministically search for all possible states generated by the nonde-terministic �(s, a) that may result in more that one state.
Find-Solution simply search the AND/OR graph to find a path thatreaches the goal, without keeping track of which states are generated bywhich action. In this way Find-Solution ignores the real complexity of non-determinism in the domain. Since it does not keep track of the AND nodes(it deals with them in the same way as with the or nodes), it explores indi↵er-ently all generated states. Intuitively, Find-Solution has the same complexityas Forward-search.
The nondeterministic choices “nondeterministically choose a 2 A0” and“nondeterministically choose s0 2 �(s, a)” correspond to an abstraction forignoring the precise order in which the algorithm tries actions a among allthe applicable actions to state s and alternative states s0 among the states
Draft, not for distribution. March 24, 2015.
ship
hbr
par1tr1
par2park
unload
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
Policy:ship: unloadhbr: parkpar1: delivertr2: move
g1g2
del
tr2
g1 g2
move
This policyis returned

41"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
FindRSolu.on:(Proper.es(! Finds a solution if one exists ! However, in most cases it will find unsafe solutions
● Because it only considers one outcome for each action
! Nondeterministic choice implemented using backtracking ● Two levels of backtracking
▸ Choosing an action ▸ Choosing an effect of that action
● Each sequence of choices corresponds to an execution trace of FindGSoluBon"
42"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
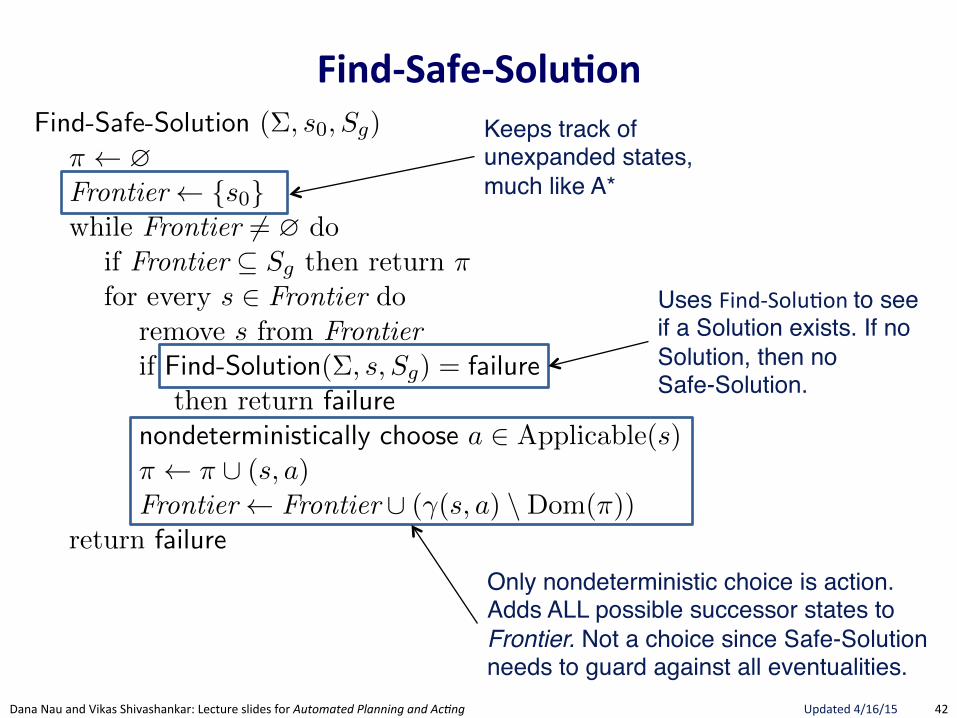
FindRSafeRSolu.on(
Section 5.3 175
Find-Safe-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Find-Solution(⌃, s, S
g
) = failure // nonterminating loopthen return failure
nondeterministically choose a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ (�(s, a) \Dom(⇡)) // expand
return failure
Figure 5.8: Planning for Safe Solutions by Forward-search.
resulting from applying a to s. The interpretation of the nondeterministicchoice of the state among the elements of the frontier is that Find-Solutioncreates several copies of a, one for each applicable action. Each time one ofthese copies has been made, the algorithm makes another nondeterministicchoice over the set of resulting states, thus creating further copies. Eachcopy corresponds to a di↵erent possible execution trace of Find-Solution.Therefore, for each state s and for each applicable action a we have anexecution trace of Find-Solution.
Example 5.14. Consider the planning problem P with domain ⌃ thenondeterministic domain described in Example 5.2, initial set of statesS0
= {on ship}, and goal states Sg
= {gate1, gate2}. Find-Solution proceedsforward from the initial state on ship, it finds initially only one applicableaction, i.e., unload, expands it into at harbor, one of the possible nondeter-ministic choices is s0 = parking1, wchich gets then expanded to gate2, and⇡1
(see Example 5.4) is generated in one of the possible nondeterministicexecution traces.
5.3.2 Planning for Safe Solutions by Forward Search
In Figure 5.8, we present a simple algorithm that finds safe solutions. Find-Safe-Solution exploits Find-Solution to plan for safe solutions. It succeeds ifall leaves are goal states, according to Definition 5.8.
Draft, not for distribution. March 24, 2015.
Keeps track ofunexpanded states,much like A*
Uses FindGSoluBon"to see if a Solution exists. If no Solution, then no Safe-Solution.
Only nondeterministic choice is action.Adds ALL possible successor states to Frontier. Not a choice since Safe-Solution needs to guard against all eventualities.

43"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRSafeRSolu.on(
Section 5.3 175
Find-Safe-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Find-Solution(⌃, s, S
g
) = failure // nonterminating loopthen return failure
nondeterministically choose a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ (�(s, a) \Dom(⇡)) // expand
return failure
Figure 5.8: Planning for Safe Solutions by Forward-search.
resulting from applying a to s. The interpretation of the nondeterministicchoice of the state among the elements of the frontier is that Find-Solutioncreates several copies of a, one for each applicable action. Each time one ofthese copies has been made, the algorithm makes another nondeterministicchoice over the set of resulting states, thus creating further copies. Eachcopy corresponds to a di↵erent possible execution trace of Find-Solution.Therefore, for each state s and for each applicable action a we have anexecution trace of Find-Solution.
Example 5.14. Consider the planning problem P with domain ⌃ thenondeterministic domain described in Example 5.2, initial set of statesS0
= {on ship}, and goal states Sg
= {gate1, gate2}. Find-Solution proceedsforward from the initial state on ship, it finds initially only one applicableaction, i.e., unload, expands it into at harbor, one of the possible nondeter-ministic choices is s0 = parking1, wchich gets then expanded to gate2, and⇡1
(see Example 5.4) is generated in one of the possible nondeterministicexecution traces.
5.3.2 Planning for Safe Solutions by Forward Search
In Figure 5.8, we present a simple algorithm that finds safe solutions. Find-Safe-Solution exploits Find-Solution to plan for safe solutions. It succeeds ifall leaves are goal states, according to Definition 5.8.
Draft, not for distribution. March 24, 2015.
ship
Policy:Frontier: ship
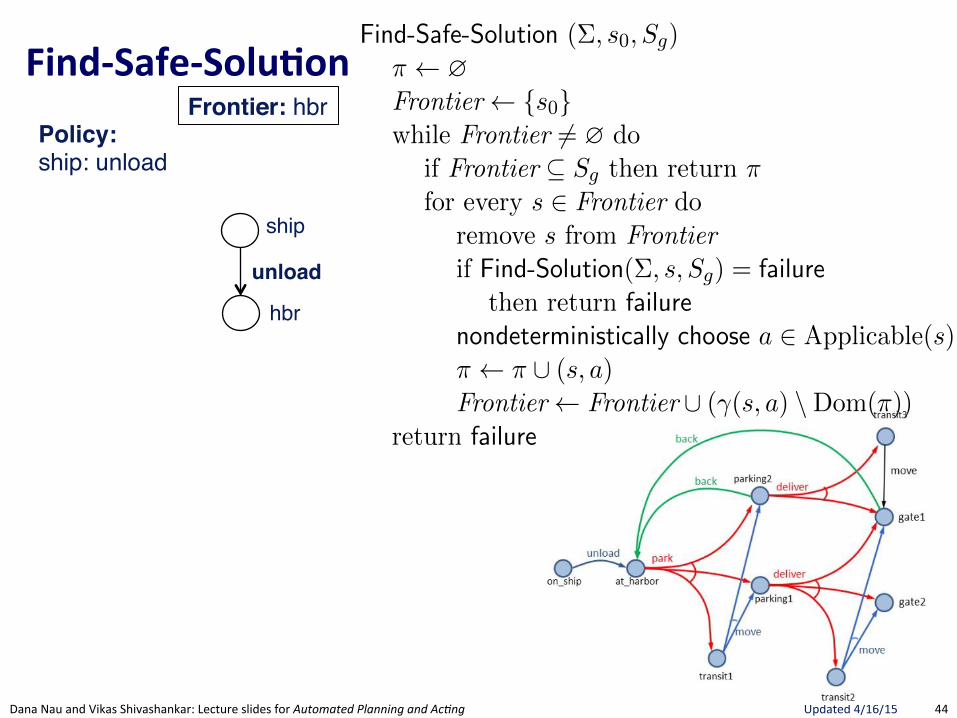
44"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRSafeRSolu.on(
Section 5.3 175
Find-Safe-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Find-Solution(⌃, s, S
g
) = failure // nonterminating loopthen return failure
nondeterministically choose a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ (�(s, a) \Dom(⇡)) // expand
return failure
Figure 5.8: Planning for Safe Solutions by Forward-search.
resulting from applying a to s. The interpretation of the nondeterministicchoice of the state among the elements of the frontier is that Find-Solutioncreates several copies of a, one for each applicable action. Each time one ofthese copies has been made, the algorithm makes another nondeterministicchoice over the set of resulting states, thus creating further copies. Eachcopy corresponds to a di↵erent possible execution trace of Find-Solution.Therefore, for each state s and for each applicable action a we have anexecution trace of Find-Solution.
Example 5.14. Consider the planning problem P with domain ⌃ thenondeterministic domain described in Example 5.2, initial set of statesS0
= {on ship}, and goal states Sg
= {gate1, gate2}. Find-Solution proceedsforward from the initial state on ship, it finds initially only one applicableaction, i.e., unload, expands it into at harbor, one of the possible nondeter-ministic choices is s0 = parking1, wchich gets then expanded to gate2, and⇡1
(see Example 5.4) is generated in one of the possible nondeterministicexecution traces.
5.3.2 Planning for Safe Solutions by Forward Search
In Figure 5.8, we present a simple algorithm that finds safe solutions. Find-Safe-Solution exploits Find-Solution to plan for safe solutions. It succeeds ifall leaves are goal states, according to Definition 5.8.
Draft, not for distribution. March 24, 2015.
ship
hbr
unload
Policy:ship: unload
Frontier: hbr
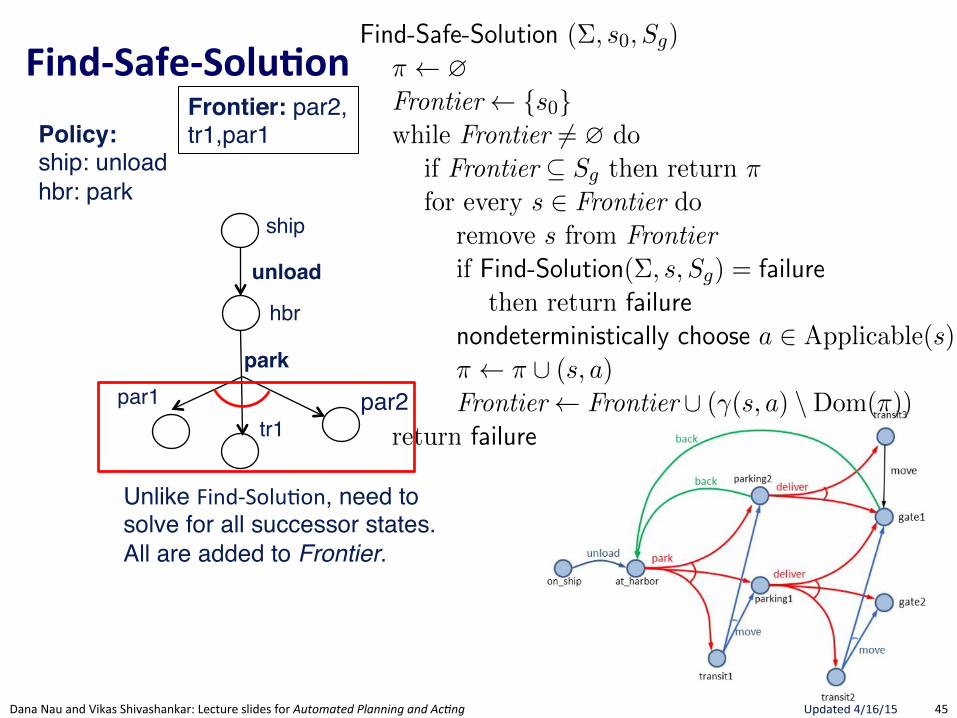
45"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRSafeRSolu.on(
Section 5.3 175
Find-Safe-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Find-Solution(⌃, s, S
g
) = failure // nonterminating loopthen return failure
nondeterministically choose a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ (�(s, a) \Dom(⇡)) // expand
return failure
Figure 5.8: Planning for Safe Solutions by Forward-search.
resulting from applying a to s. The interpretation of the nondeterministicchoice of the state among the elements of the frontier is that Find-Solutioncreates several copies of a, one for each applicable action. Each time one ofthese copies has been made, the algorithm makes another nondeterministicchoice over the set of resulting states, thus creating further copies. Eachcopy corresponds to a di↵erent possible execution trace of Find-Solution.Therefore, for each state s and for each applicable action a we have anexecution trace of Find-Solution.
Example 5.14. Consider the planning problem P with domain ⌃ thenondeterministic domain described in Example 5.2, initial set of statesS0
= {on ship}, and goal states Sg
= {gate1, gate2}. Find-Solution proceedsforward from the initial state on ship, it finds initially only one applicableaction, i.e., unload, expands it into at harbor, one of the possible nondeter-ministic choices is s0 = parking1, wchich gets then expanded to gate2, and⇡1
(see Example 5.4) is generated in one of the possible nondeterministicexecution traces.
5.3.2 Planning for Safe Solutions by Forward Search
In Figure 5.8, we present a simple algorithm that finds safe solutions. Find-Safe-Solution exploits Find-Solution to plan for safe solutions. It succeeds ifall leaves are goal states, according to Definition 5.8.
Draft, not for distribution. March 24, 2015.
Frontier: par2,tr1,par1
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park
Unlike FindGSoluBon, need tosolve for all successor states.All are added to Frontier.
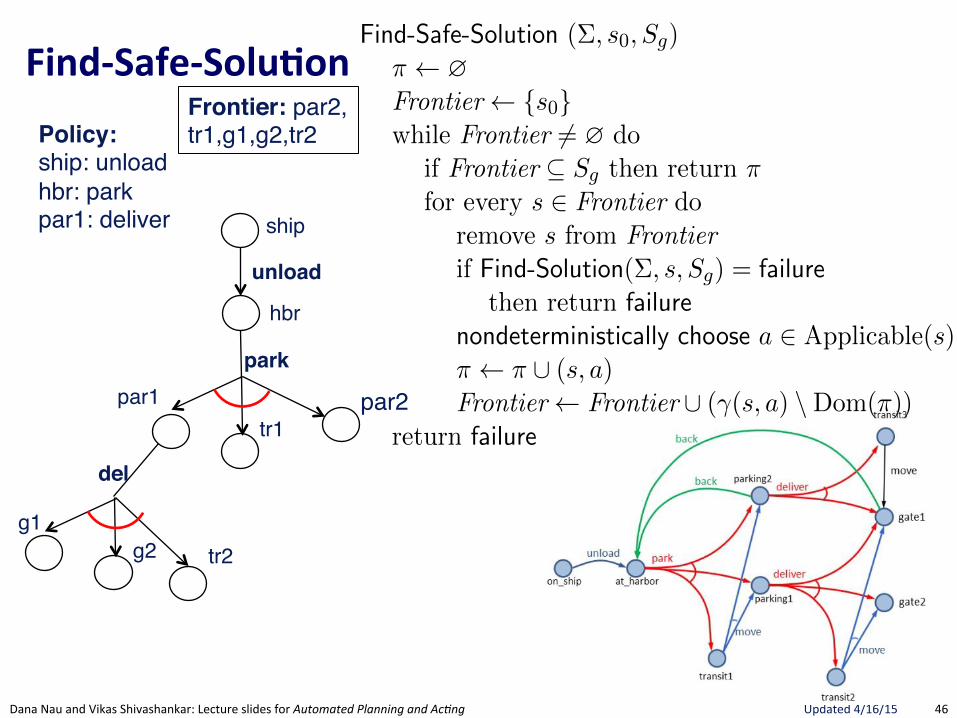
46"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRSafeRSolu.on(
Section 5.3 175
Find-Safe-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Find-Solution(⌃, s, S
g
) = failure // nonterminating loopthen return failure
nondeterministically choose a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ (�(s, a) \Dom(⇡)) // expand
return failure
Figure 5.8: Planning for Safe Solutions by Forward-search.
resulting from applying a to s. The interpretation of the nondeterministicchoice of the state among the elements of the frontier is that Find-Solutioncreates several copies of a, one for each applicable action. Each time one ofthese copies has been made, the algorithm makes another nondeterministicchoice over the set of resulting states, thus creating further copies. Eachcopy corresponds to a di↵erent possible execution trace of Find-Solution.Therefore, for each state s and for each applicable action a we have anexecution trace of Find-Solution.
Example 5.14. Consider the planning problem P with domain ⌃ thenondeterministic domain described in Example 5.2, initial set of statesS0
= {on ship}, and goal states Sg
= {gate1, gate2}. Find-Solution proceedsforward from the initial state on ship, it finds initially only one applicableaction, i.e., unload, expands it into at harbor, one of the possible nondeter-ministic choices is s0 = parking1, wchich gets then expanded to gate2, and⇡1
(see Example 5.4) is generated in one of the possible nondeterministicexecution traces.
5.3.2 Planning for Safe Solutions by Forward Search
In Figure 5.8, we present a simple algorithm that finds safe solutions. Find-Safe-Solution exploits Find-Solution to plan for safe solutions. It succeeds ifall leaves are goal states, according to Definition 5.8.
Draft, not for distribution. March 24, 2015.
Frontier: par2,tr1,g1,g2,tr2
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: deliver
g1g2
del
tr2
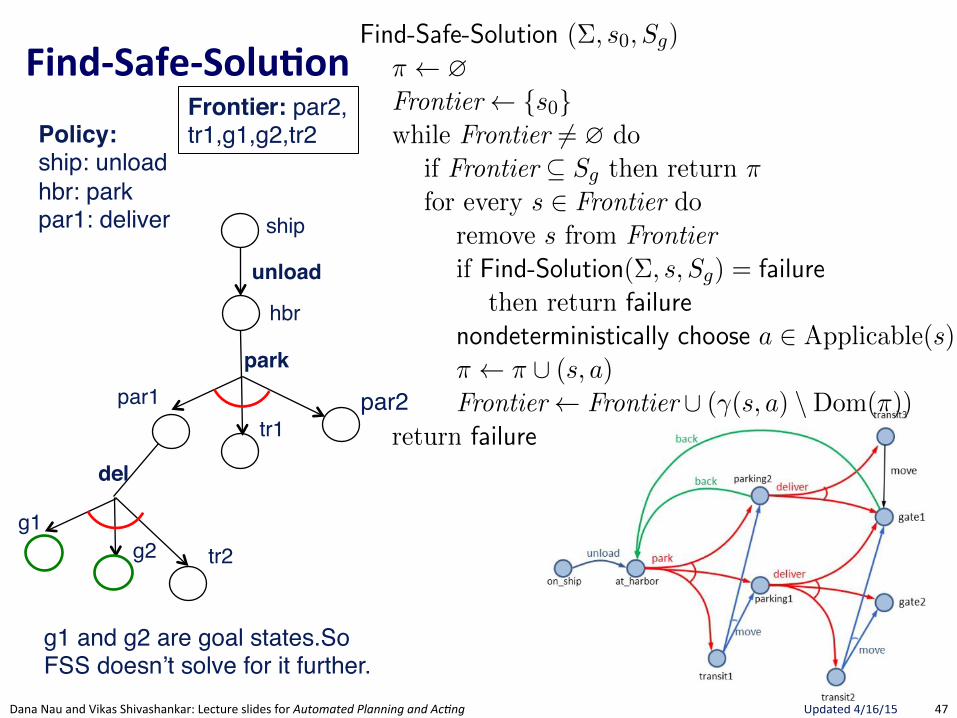
47"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRSafeRSolu.on(
Section 5.3 175
Find-Safe-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Find-Solution(⌃, s, S
g
) = failure // nonterminating loopthen return failure
nondeterministically choose a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ (�(s, a) \Dom(⇡)) // expand
return failure
Figure 5.8: Planning for Safe Solutions by Forward-search.
resulting from applying a to s. The interpretation of the nondeterministicchoice of the state among the elements of the frontier is that Find-Solutioncreates several copies of a, one for each applicable action. Each time one ofthese copies has been made, the algorithm makes another nondeterministicchoice over the set of resulting states, thus creating further copies. Eachcopy corresponds to a di↵erent possible execution trace of Find-Solution.Therefore, for each state s and for each applicable action a we have anexecution trace of Find-Solution.
Example 5.14. Consider the planning problem P with domain ⌃ thenondeterministic domain described in Example 5.2, initial set of statesS0
= {on ship}, and goal states Sg
= {gate1, gate2}. Find-Solution proceedsforward from the initial state on ship, it finds initially only one applicableaction, i.e., unload, expands it into at harbor, one of the possible nondeter-ministic choices is s0 = parking1, wchich gets then expanded to gate2, and⇡1
(see Example 5.4) is generated in one of the possible nondeterministicexecution traces.
5.3.2 Planning for Safe Solutions by Forward Search
In Figure 5.8, we present a simple algorithm that finds safe solutions. Find-Safe-Solution exploits Find-Solution to plan for safe solutions. It succeeds ifall leaves are goal states, according to Definition 5.8.
Draft, not for distribution. March 24, 2015.
Frontier: par2,tr1,g1,g2,tr2
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: deliver
g1g2
del
tr2
g1 and g2 are goal states.So FSS doesn’t solve for it further.

48"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRSafeRSolu.on(
Section 5.3 175
Find-Safe-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Find-Solution(⌃, s, S
g
) = failure // nonterminating loopthen return failure
nondeterministically choose a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ (�(s, a) \Dom(⇡)) // expand
return failure
Figure 5.8: Planning for Safe Solutions by Forward-search.
resulting from applying a to s. The interpretation of the nondeterministicchoice of the state among the elements of the frontier is that Find-Solutioncreates several copies of a, one for each applicable action. Each time one ofthese copies has been made, the algorithm makes another nondeterministicchoice over the set of resulting states, thus creating further copies. Eachcopy corresponds to a di↵erent possible execution trace of Find-Solution.Therefore, for each state s and for each applicable action a we have anexecution trace of Find-Solution.
Example 5.14. Consider the planning problem P with domain ⌃ thenondeterministic domain described in Example 5.2, initial set of statesS0
= {on ship}, and goal states Sg
= {gate1, gate2}. Find-Solution proceedsforward from the initial state on ship, it finds initially only one applicableaction, i.e., unload, expands it into at harbor, one of the possible nondeter-ministic choices is s0 = parking1, wchich gets then expanded to gate2, and⇡1
(see Example 5.4) is generated in one of the possible nondeterministicexecution traces.
5.3.2 Planning for Safe Solutions by Forward Search
In Figure 5.8, we present a simple algorithm that finds safe solutions. Find-Safe-Solution exploits Find-Solution to plan for safe solutions. It succeeds ifall leaves are goal states, according to Definition 5.8.
Draft, not for distribution. March 24, 2015.
Frontier: par2,tr1,g1,g2
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: delivertr2: move
g1g2
del
tr2
g1 g2
move
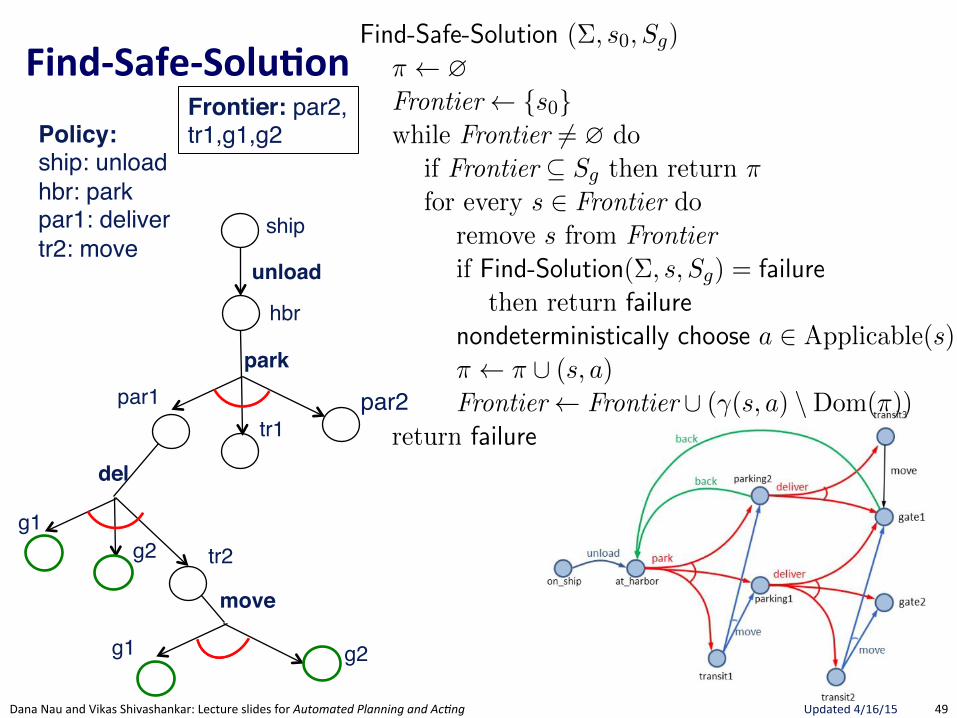
49"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRSafeRSolu.on(
Section 5.3 175
Find-Safe-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Find-Solution(⌃, s, S
g
) = failure // nonterminating loopthen return failure
nondeterministically choose a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ (�(s, a) \Dom(⇡)) // expand
return failure
Figure 5.8: Planning for Safe Solutions by Forward-search.
resulting from applying a to s. The interpretation of the nondeterministicchoice of the state among the elements of the frontier is that Find-Solutioncreates several copies of a, one for each applicable action. Each time one ofthese copies has been made, the algorithm makes another nondeterministicchoice over the set of resulting states, thus creating further copies. Eachcopy corresponds to a di↵erent possible execution trace of Find-Solution.Therefore, for each state s and for each applicable action a we have anexecution trace of Find-Solution.
Example 5.14. Consider the planning problem P with domain ⌃ thenondeterministic domain described in Example 5.2, initial set of statesS0
= {on ship}, and goal states Sg
= {gate1, gate2}. Find-Solution proceedsforward from the initial state on ship, it finds initially only one applicableaction, i.e., unload, expands it into at harbor, one of the possible nondeter-ministic choices is s0 = parking1, wchich gets then expanded to gate2, and⇡1
(see Example 5.4) is generated in one of the possible nondeterministicexecution traces.
5.3.2 Planning for Safe Solutions by Forward Search
In Figure 5.8, we present a simple algorithm that finds safe solutions. Find-Safe-Solution exploits Find-Solution to plan for safe solutions. It succeeds ifall leaves are goal states, according to Definition 5.8.
Draft, not for distribution. March 24, 2015.
Frontier: par2,tr1,g1,g2
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: delivertr2: move
g1g2
del
tr2
g1 g2
move

50"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRSafeRSolu.on(
Section 5.3 175
Find-Safe-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Find-Solution(⌃, s, S
g
) = failure // nonterminating loopthen return failure
nondeterministically choose a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ (�(s, a) \Dom(⇡)) // expand
return failure
Figure 5.8: Planning for Safe Solutions by Forward-search.
resulting from applying a to s. The interpretation of the nondeterministicchoice of the state among the elements of the frontier is that Find-Solutioncreates several copies of a, one for each applicable action. Each time one ofthese copies has been made, the algorithm makes another nondeterministicchoice over the set of resulting states, thus creating further copies. Eachcopy corresponds to a di↵erent possible execution trace of Find-Solution.Therefore, for each state s and for each applicable action a we have anexecution trace of Find-Solution.
Example 5.14. Consider the planning problem P with domain ⌃ thenondeterministic domain described in Example 5.2, initial set of statesS0
= {on ship}, and goal states Sg
= {gate1, gate2}. Find-Solution proceedsforward from the initial state on ship, it finds initially only one applicableaction, i.e., unload, expands it into at harbor, one of the possible nondeter-ministic choices is s0 = parking1, wchich gets then expanded to gate2, and⇡1
(see Example 5.4) is generated in one of the possible nondeterministicexecution traces.
5.3.2 Planning for Safe Solutions by Forward Search
In Figure 5.8, we present a simple algorithm that finds safe solutions. Find-Safe-Solution exploits Find-Solution to plan for safe solutions. It succeeds ifall leaves are goal states, according to Definition 5.8.
Draft, not for distribution. March 24, 2015.
Frontier:tr1,g1,g2
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: delivertr2: move par2: back
g1g2
del
tr2
g1 g2
move
hbrback

51"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRSafeRSolu.on(
Section 5.3 175
Find-Safe-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Find-Solution(⌃, s, S
g
) = failure // nonterminating loopthen return failure
nondeterministically choose a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ (�(s, a) \Dom(⇡)) // expand
return failure
Figure 5.8: Planning for Safe Solutions by Forward-search.
resulting from applying a to s. The interpretation of the nondeterministicchoice of the state among the elements of the frontier is that Find-Solutioncreates several copies of a, one for each applicable action. Each time one ofthese copies has been made, the algorithm makes another nondeterministicchoice over the set of resulting states, thus creating further copies. Eachcopy corresponds to a di↵erent possible execution trace of Find-Solution.Therefore, for each state s and for each applicable action a we have anexecution trace of Find-Solution.
Example 5.14. Consider the planning problem P with domain ⌃ thenondeterministic domain described in Example 5.2, initial set of statesS0
= {on ship}, and goal states Sg
= {gate1, gate2}. Find-Solution proceedsforward from the initial state on ship, it finds initially only one applicableaction, i.e., unload, expands it into at harbor, one of the possible nondeter-ministic choices is s0 = parking1, wchich gets then expanded to gate2, and⇡1
(see Example 5.4) is generated in one of the possible nondeterministicexecution traces.
5.3.2 Planning for Safe Solutions by Forward Search
In Figure 5.8, we present a simple algorithm that finds safe solutions. Find-Safe-Solution exploits Find-Solution to plan for safe solutions. It succeeds ifall leaves are goal states, according to Definition 5.8.
Draft, not for distribution. March 24, 2015.
Frontier:tr1,g1,g2
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: delivertr2: move par2: back
g1g2
del
tr2
g1 g2
move
hbrback

52"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRSafeRSolu.on(
Section 5.3 175
Find-Safe-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Find-Solution(⌃, s, S
g
) = failure // nonterminating loopthen return failure
nondeterministically choose a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ (�(s, a) \Dom(⇡)) // expand
return failure
Figure 5.8: Planning for Safe Solutions by Forward-search.
resulting from applying a to s. The interpretation of the nondeterministicchoice of the state among the elements of the frontier is that Find-Solutioncreates several copies of a, one for each applicable action. Each time one ofthese copies has been made, the algorithm makes another nondeterministicchoice over the set of resulting states, thus creating further copies. Eachcopy corresponds to a di↵erent possible execution trace of Find-Solution.Therefore, for each state s and for each applicable action a we have anexecution trace of Find-Solution.
Example 5.14. Consider the planning problem P with domain ⌃ thenondeterministic domain described in Example 5.2, initial set of statesS0
= {on ship}, and goal states Sg
= {gate1, gate2}. Find-Solution proceedsforward from the initial state on ship, it finds initially only one applicableaction, i.e., unload, expands it into at harbor, one of the possible nondeter-ministic choices is s0 = parking1, wchich gets then expanded to gate2, and⇡1
(see Example 5.4) is generated in one of the possible nondeterministicexecution traces.
5.3.2 Planning for Safe Solutions by Forward Search
In Figure 5.8, we present a simple algorithm that finds safe solutions. Find-Safe-Solution exploits Find-Solution to plan for safe solutions. It succeeds ifall leaves are goal states, according to Definition 5.8.
Draft, not for distribution. March 24, 2015.
Frontier: g1,g2
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: delivertr2: move par2: back tr1: move
g1g2
del
tr2
g1 g2
move
par1 par2
hbrback
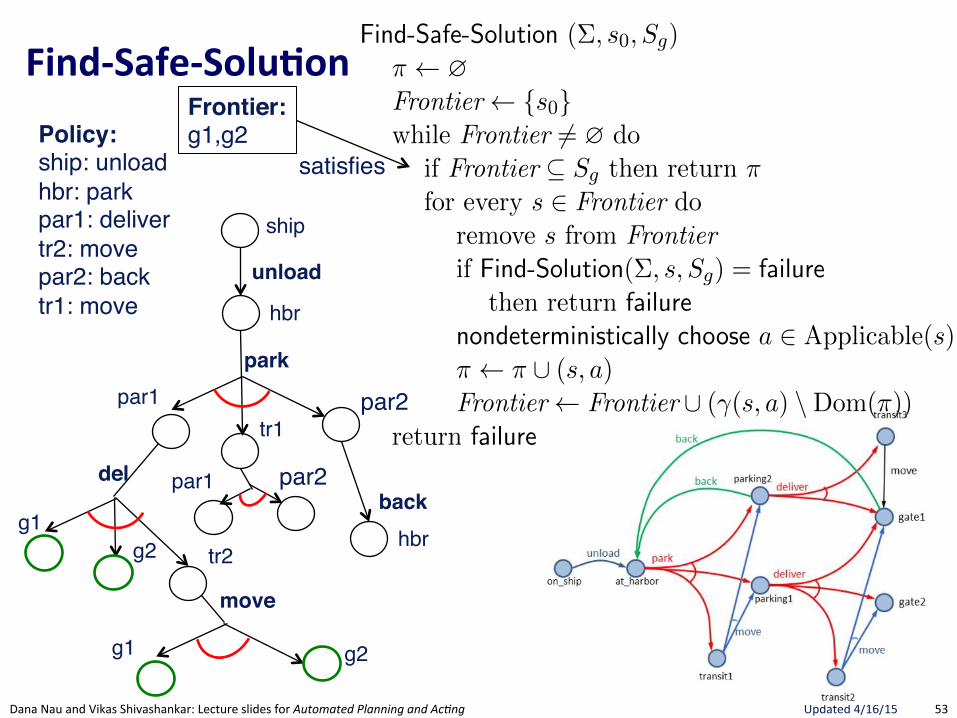
53"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRSafeRSolu.on(
Section 5.3 175
Find-Safe-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Find-Solution(⌃, s, S
g
) = failure // nonterminating loopthen return failure
nondeterministically choose a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ (�(s, a) \Dom(⇡)) // expand
return failure
Figure 5.8: Planning for Safe Solutions by Forward-search.
resulting from applying a to s. The interpretation of the nondeterministicchoice of the state among the elements of the frontier is that Find-Solutioncreates several copies of a, one for each applicable action. Each time one ofthese copies has been made, the algorithm makes another nondeterministicchoice over the set of resulting states, thus creating further copies. Eachcopy corresponds to a di↵erent possible execution trace of Find-Solution.Therefore, for each state s and for each applicable action a we have anexecution trace of Find-Solution.
Example 5.14. Consider the planning problem P with domain ⌃ thenondeterministic domain described in Example 5.2, initial set of statesS0
= {on ship}, and goal states Sg
= {gate1, gate2}. Find-Solution proceedsforward from the initial state on ship, it finds initially only one applicableaction, i.e., unload, expands it into at harbor, one of the possible nondeter-ministic choices is s0 = parking1, wchich gets then expanded to gate2, and⇡1
(see Example 5.4) is generated in one of the possible nondeterministicexecution traces.
5.3.2 Planning for Safe Solutions by Forward Search
In Figure 5.8, we present a simple algorithm that finds safe solutions. Find-Safe-Solution exploits Find-Solution to plan for safe solutions. It succeeds ifall leaves are goal states, according to Definition 5.8.
Draft, not for distribution. March 24, 2015.
Frontier: g1,g2
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: delivertr2: move par2: back tr1: move
g1g2
del
tr2
g1 g2
move
par1 par2
satisfies
hbrback
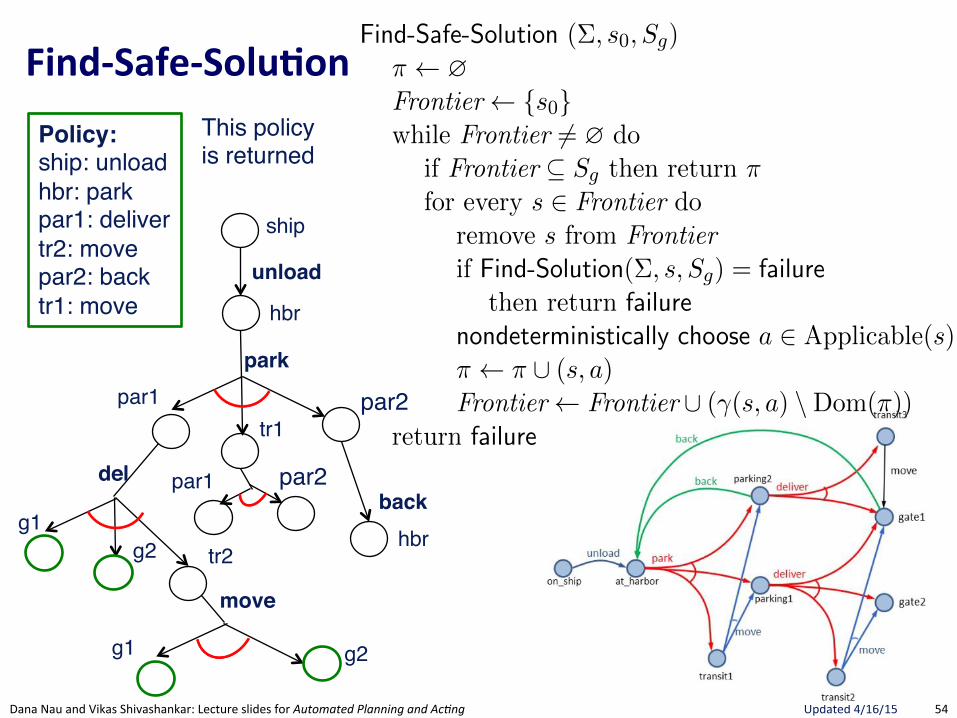
54"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRSafeRSolu.on(
Section 5.3 175
Find-Safe-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Find-Solution(⌃, s, S
g
) = failure // nonterminating loopthen return failure
nondeterministically choose a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ (�(s, a) \Dom(⇡)) // expand
return failure
Figure 5.8: Planning for Safe Solutions by Forward-search.
resulting from applying a to s. The interpretation of the nondeterministicchoice of the state among the elements of the frontier is that Find-Solutioncreates several copies of a, one for each applicable action. Each time one ofthese copies has been made, the algorithm makes another nondeterministicchoice over the set of resulting states, thus creating further copies. Eachcopy corresponds to a di↵erent possible execution trace of Find-Solution.Therefore, for each state s and for each applicable action a we have anexecution trace of Find-Solution.
Example 5.14. Consider the planning problem P with domain ⌃ thenondeterministic domain described in Example 5.2, initial set of statesS0
= {on ship}, and goal states Sg
= {gate1, gate2}. Find-Solution proceedsforward from the initial state on ship, it finds initially only one applicableaction, i.e., unload, expands it into at harbor, one of the possible nondeter-ministic choices is s0 = parking1, wchich gets then expanded to gate2, and⇡1
(see Example 5.4) is generated in one of the possible nondeterministicexecution traces.
5.3.2 Planning for Safe Solutions by Forward Search
In Figure 5.8, we present a simple algorithm that finds safe solutions. Find-Safe-Solution exploits Find-Solution to plan for safe solutions. It succeeds ifall leaves are goal states, according to Definition 5.8.
Draft, not for distribution. March 24, 2015.
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: delivertr2: move par2: back tr1: move
g1g2
del
tr2
g1 g2
move
par1 par2
This policyis returned
hbrback

55"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Proper.es(of(FindRSafeRSolu.on(! Guaranteed to find safe solution, if one exists ! Uses FindGSoluBon"as a subroutine to detect nonterminating loops

56"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
FindRAcyclicRSolu.on(
176 Chapter 5
Find-Acyclic-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Frontier \Dom(⇡) 6= ? // loop checking
then return failurechoose nondeterministically a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ �(s, a) // expand
return failure
Figure 5.9: Planning for Safe Acyclic Solutions by Forward-search.
While exploring the frontier, it calls Find-Solution in order to checkwhether the current policy contains cycles without possibility of termina-tion, i.e., whether it gets in a state where no action is applicable or wherethere is no path to the goal. Also Find-Safe-Solution is based on a nonde-terministic selection among the applicable actions. The nondeterministicchoice “nondeterministically choose a 2 Applicable(s)” is an abstraction forignoring the precise order in which the algorithm tries alternative applicableactions. Find-Safe-Solution launches therefore several execution traces, onefor each applicable action. Notice that, in the “expand” step, we eliminatefrom the frontier the states that lead back to the states already visited,i.e. those in Dom(⇡). These states represent cycles that the solution policygenerates. However, we can ignore them, since we check that there are nononterminating loops.
5.3.3 Planning for Safe Acyclic Solutions by Forward Search
Finally, we present in Figure 5.9 a simple algorithm that plans for acyclic safesolutions. Find-Acyclic-Solution terminates with success if all leaves are goalstates, according to Definition 5.11, but di↵erently from Find-Safe-Solution,it does not allow for loops. The “loop checking” step tests whether there isa state in the Frontier that is already in the domain of ⇡. Notice the maindi↵erence in the recursion over Find-Solution.
Draft, not for distribution. March 24, 2015.
Cycle check: makes sure that action applied in previousiteration didn’t lead to a state already considered by π
Similar toFindRSafeRSolu.on except:
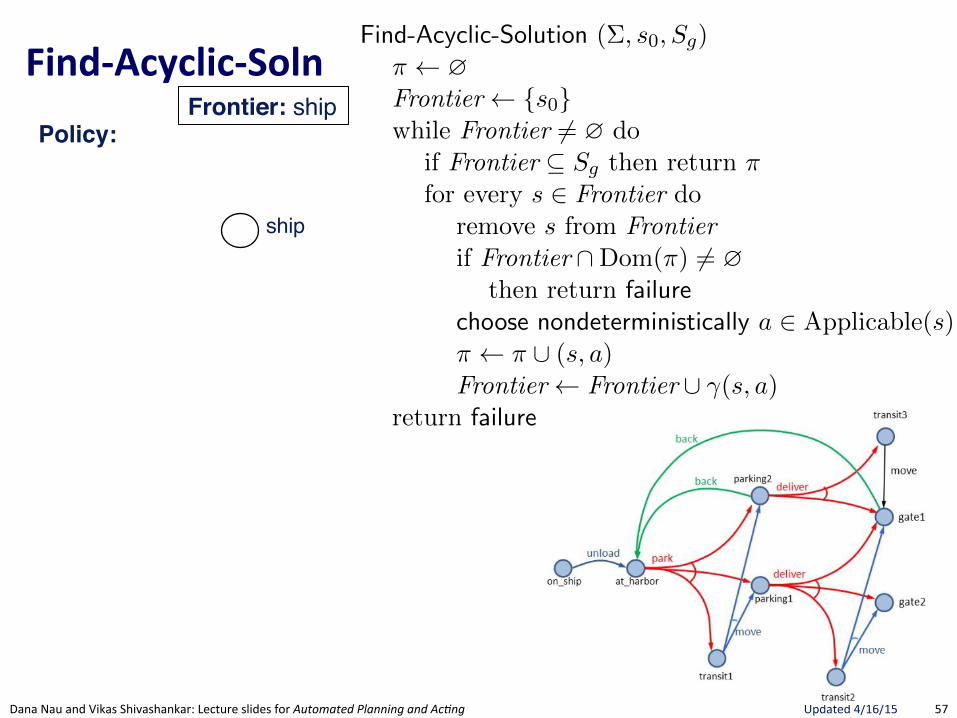
57"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRAcyclicRSoln(
ship
Policy:Frontier: ship
176 Chapter 5
Find-Acyclic-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Frontier \Dom(⇡) 6= ? // loop checking
then return failurechoose nondeterministically a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ �(s, a) // expand
return failure
Figure 5.9: Planning for Safe Acyclic Solutions by Forward-search.
While exploring the frontier, it calls Find-Solution in order to checkwhether the current policy contains cycles without possibility of termina-tion, i.e., whether it gets in a state where no action is applicable or wherethere is no path to the goal. Also Find-Safe-Solution is based on a nonde-terministic selection among the applicable actions. The nondeterministicchoice “nondeterministically choose a 2 Applicable(s)” is an abstraction forignoring the precise order in which the algorithm tries alternative applicableactions. Find-Safe-Solution launches therefore several execution traces, onefor each applicable action. Notice that, in the “expand” step, we eliminatefrom the frontier the states that lead back to the states already visited,i.e. those in Dom(⇡). These states represent cycles that the solution policygenerates. However, we can ignore them, since we check that there are nononterminating loops.
5.3.3 Planning for Safe Acyclic Solutions by Forward Search
Finally, we present in Figure 5.9 a simple algorithm that plans for acyclic safesolutions. Find-Acyclic-Solution terminates with success if all leaves are goalstates, according to Definition 5.11, but di↵erently from Find-Safe-Solution,it does not allow for loops. The “loop checking” step tests whether there isa state in the Frontier that is already in the domain of ⇡. Notice the maindi↵erence in the recursion over Find-Solution.
Draft, not for distribution. March 24, 2015.

58"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRAcyclicRSoln(
ship
hbr
unload
Policy:ship: unload
Frontier: hbr
176 Chapter 5
Find-Acyclic-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Frontier \Dom(⇡) 6= ? // loop checking
then return failurechoose nondeterministically a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ �(s, a) // expand
return failure
Figure 5.9: Planning for Safe Acyclic Solutions by Forward-search.
While exploring the frontier, it calls Find-Solution in order to checkwhether the current policy contains cycles without possibility of termina-tion, i.e., whether it gets in a state where no action is applicable or wherethere is no path to the goal. Also Find-Safe-Solution is based on a nonde-terministic selection among the applicable actions. The nondeterministicchoice “nondeterministically choose a 2 Applicable(s)” is an abstraction forignoring the precise order in which the algorithm tries alternative applicableactions. Find-Safe-Solution launches therefore several execution traces, onefor each applicable action. Notice that, in the “expand” step, we eliminatefrom the frontier the states that lead back to the states already visited,i.e. those in Dom(⇡). These states represent cycles that the solution policygenerates. However, we can ignore them, since we check that there are nononterminating loops.
5.3.3 Planning for Safe Acyclic Solutions by Forward Search
Finally, we present in Figure 5.9 a simple algorithm that plans for acyclic safesolutions. Find-Acyclic-Solution terminates with success if all leaves are goalstates, according to Definition 5.11, but di↵erently from Find-Safe-Solution,it does not allow for loops. The “loop checking” step tests whether there isa state in the Frontier that is already in the domain of ⇡. Notice the maindi↵erence in the recursion over Find-Solution.
Draft, not for distribution. March 24, 2015.
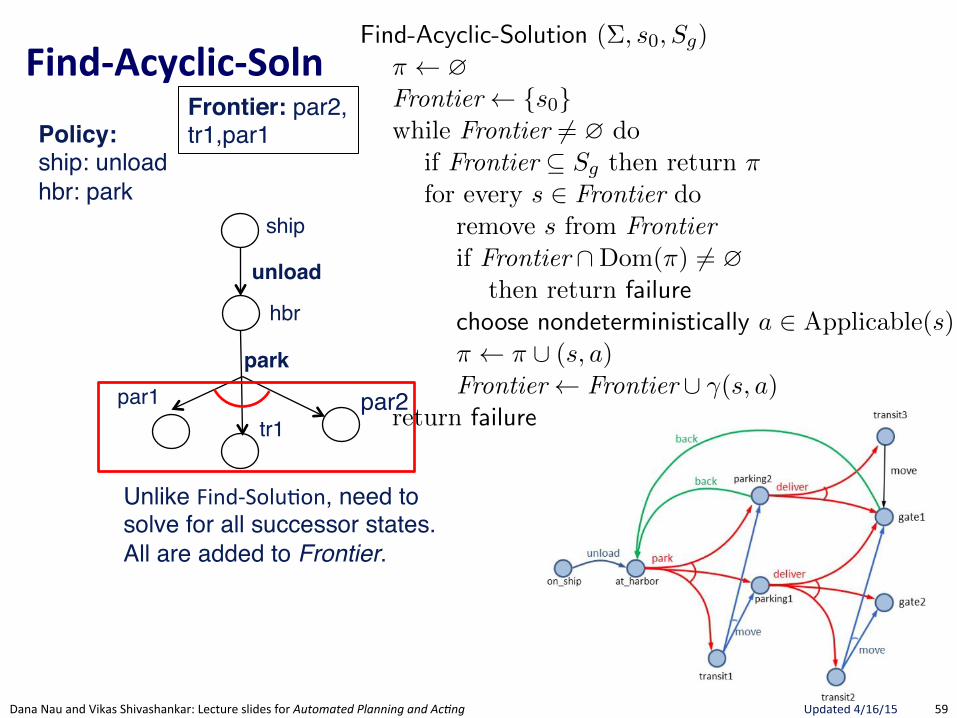
59"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRAcyclicRSoln(Frontier: par2,tr1,par1
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park
Unlike FindGSoluBon, need tosolve for all successor states.All are added to Frontier.
176 Chapter 5
Find-Acyclic-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Frontier \Dom(⇡) 6= ? // loop checking
then return failurechoose nondeterministically a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ �(s, a) // expand
return failure
Figure 5.9: Planning for Safe Acyclic Solutions by Forward-search.
While exploring the frontier, it calls Find-Solution in order to checkwhether the current policy contains cycles without possibility of termina-tion, i.e., whether it gets in a state where no action is applicable or wherethere is no path to the goal. Also Find-Safe-Solution is based on a nonde-terministic selection among the applicable actions. The nondeterministicchoice “nondeterministically choose a 2 Applicable(s)” is an abstraction forignoring the precise order in which the algorithm tries alternative applicableactions. Find-Safe-Solution launches therefore several execution traces, onefor each applicable action. Notice that, in the “expand” step, we eliminatefrom the frontier the states that lead back to the states already visited,i.e. those in Dom(⇡). These states represent cycles that the solution policygenerates. However, we can ignore them, since we check that there are nononterminating loops.
5.3.3 Planning for Safe Acyclic Solutions by Forward Search
Finally, we present in Figure 5.9 a simple algorithm that plans for acyclic safesolutions. Find-Acyclic-Solution terminates with success if all leaves are goalstates, according to Definition 5.11, but di↵erently from Find-Safe-Solution,it does not allow for loops. The “loop checking” step tests whether there isa state in the Frontier that is already in the domain of ⇡. Notice the maindi↵erence in the recursion over Find-Solution.
Draft, not for distribution. March 24, 2015.
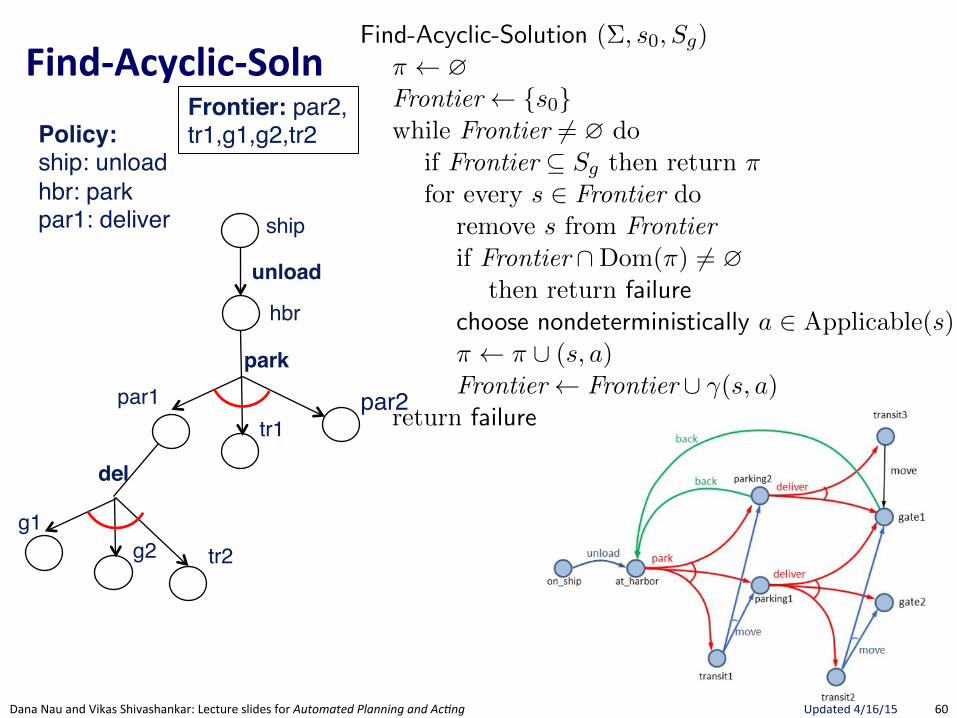
60"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRAcyclicRSoln(Frontier: par2,tr1,g1,g2,tr2
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: deliver
g1g2
del
tr2
176 Chapter 5
Find-Acyclic-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Frontier \Dom(⇡) 6= ? // loop checking
then return failurechoose nondeterministically a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ �(s, a) // expand
return failure
Figure 5.9: Planning for Safe Acyclic Solutions by Forward-search.
While exploring the frontier, it calls Find-Solution in order to checkwhether the current policy contains cycles without possibility of termina-tion, i.e., whether it gets in a state where no action is applicable or wherethere is no path to the goal. Also Find-Safe-Solution is based on a nonde-terministic selection among the applicable actions. The nondeterministicchoice “nondeterministically choose a 2 Applicable(s)” is an abstraction forignoring the precise order in which the algorithm tries alternative applicableactions. Find-Safe-Solution launches therefore several execution traces, onefor each applicable action. Notice that, in the “expand” step, we eliminatefrom the frontier the states that lead back to the states already visited,i.e. those in Dom(⇡). These states represent cycles that the solution policygenerates. However, we can ignore them, since we check that there are nononterminating loops.
5.3.3 Planning for Safe Acyclic Solutions by Forward Search
Finally, we present in Figure 5.9 a simple algorithm that plans for acyclic safesolutions. Find-Acyclic-Solution terminates with success if all leaves are goalstates, according to Definition 5.11, but di↵erently from Find-Safe-Solution,it does not allow for loops. The “loop checking” step tests whether there isa state in the Frontier that is already in the domain of ⇡. Notice the maindi↵erence in the recursion over Find-Solution.
Draft, not for distribution. March 24, 2015.

61"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRAcyclicRSoln(Frontier: par2,tr1,g1,g2,tr2
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: deliver
g1g2
del
tr2
g1 and g2 are goal states.So FSS doesn’t solve for it further.
176 Chapter 5
Find-Acyclic-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Frontier \Dom(⇡) 6= ? // loop checking
then return failurechoose nondeterministically a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ �(s, a) // expand
return failure
Figure 5.9: Planning for Safe Acyclic Solutions by Forward-search.
While exploring the frontier, it calls Find-Solution in order to checkwhether the current policy contains cycles without possibility of termina-tion, i.e., whether it gets in a state where no action is applicable or wherethere is no path to the goal. Also Find-Safe-Solution is based on a nonde-terministic selection among the applicable actions. The nondeterministicchoice “nondeterministically choose a 2 Applicable(s)” is an abstraction forignoring the precise order in which the algorithm tries alternative applicableactions. Find-Safe-Solution launches therefore several execution traces, onefor each applicable action. Notice that, in the “expand” step, we eliminatefrom the frontier the states that lead back to the states already visited,i.e. those in Dom(⇡). These states represent cycles that the solution policygenerates. However, we can ignore them, since we check that there are nononterminating loops.
5.3.3 Planning for Safe Acyclic Solutions by Forward Search
Finally, we present in Figure 5.9 a simple algorithm that plans for acyclic safesolutions. Find-Acyclic-Solution terminates with success if all leaves are goalstates, according to Definition 5.11, but di↵erently from Find-Safe-Solution,it does not allow for loops. The “loop checking” step tests whether there isa state in the Frontier that is already in the domain of ⇡. Notice the maindi↵erence in the recursion over Find-Solution.
Draft, not for distribution. March 24, 2015.

62"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRAcyclicRSoln(Frontier: par2,tr1,g1,g2
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: delivertr2: move
g1g2
del
tr2
g1 g2
move
176 Chapter 5
Find-Acyclic-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Frontier \Dom(⇡) 6= ? // loop checking
then return failurechoose nondeterministically a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ �(s, a) // expand
return failure
Figure 5.9: Planning for Safe Acyclic Solutions by Forward-search.
While exploring the frontier, it calls Find-Solution in order to checkwhether the current policy contains cycles without possibility of termina-tion, i.e., whether it gets in a state where no action is applicable or wherethere is no path to the goal. Also Find-Safe-Solution is based on a nonde-terministic selection among the applicable actions. The nondeterministicchoice “nondeterministically choose a 2 Applicable(s)” is an abstraction forignoring the precise order in which the algorithm tries alternative applicableactions. Find-Safe-Solution launches therefore several execution traces, onefor each applicable action. Notice that, in the “expand” step, we eliminatefrom the frontier the states that lead back to the states already visited,i.e. those in Dom(⇡). These states represent cycles that the solution policygenerates. However, we can ignore them, since we check that there are nononterminating loops.
5.3.3 Planning for Safe Acyclic Solutions by Forward Search
Finally, we present in Figure 5.9 a simple algorithm that plans for acyclic safesolutions. Find-Acyclic-Solution terminates with success if all leaves are goalstates, according to Definition 5.11, but di↵erently from Find-Safe-Solution,it does not allow for loops. The “loop checking” step tests whether there isa state in the Frontier that is already in the domain of ⇡. Notice the maindi↵erence in the recursion over Find-Solution.
Draft, not for distribution. March 24, 2015.

63"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRAcyclicRSoln(Frontier: par2,tr1,g1,g2
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: delivertr2: move
g1g2
del
tr2
g1 g2
move
176 Chapter 5
Find-Acyclic-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Frontier \Dom(⇡) 6= ? // loop checking
then return failurechoose nondeterministically a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ �(s, a) // expand
return failure
Figure 5.9: Planning for Safe Acyclic Solutions by Forward-search.
While exploring the frontier, it calls Find-Solution in order to checkwhether the current policy contains cycles without possibility of termina-tion, i.e., whether it gets in a state where no action is applicable or wherethere is no path to the goal. Also Find-Safe-Solution is based on a nonde-terministic selection among the applicable actions. The nondeterministicchoice “nondeterministically choose a 2 Applicable(s)” is an abstraction forignoring the precise order in which the algorithm tries alternative applicableactions. Find-Safe-Solution launches therefore several execution traces, onefor each applicable action. Notice that, in the “expand” step, we eliminatefrom the frontier the states that lead back to the states already visited,i.e. those in Dom(⇡). These states represent cycles that the solution policygenerates. However, we can ignore them, since we check that there are nononterminating loops.
5.3.3 Planning for Safe Acyclic Solutions by Forward Search
Finally, we present in Figure 5.9 a simple algorithm that plans for acyclic safesolutions. Find-Acyclic-Solution terminates with success if all leaves are goalstates, according to Definition 5.11, but di↵erently from Find-Safe-Solution,it does not allow for loops. The “loop checking” step tests whether there isa state in the Frontier that is already in the domain of ⇡. Notice the maindi↵erence in the recursion over Find-Solution.
Draft, not for distribution. March 24, 2015.

64"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRAcyclicRSoln(Frontier:tr1,g1,g2,tr3
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: delivertr2: move par2: deliver
g1g2
del
tr2
g1 g2
movetr3
del
g1
176 Chapter 5
Find-Acyclic-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Frontier \Dom(⇡) 6= ? // loop checking
then return failurechoose nondeterministically a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ �(s, a) // expand
return failure
Figure 5.9: Planning for Safe Acyclic Solutions by Forward-search.
While exploring the frontier, it calls Find-Solution in order to checkwhether the current policy contains cycles without possibility of termina-tion, i.e., whether it gets in a state where no action is applicable or wherethere is no path to the goal. Also Find-Safe-Solution is based on a nonde-terministic selection among the applicable actions. The nondeterministicchoice “nondeterministically choose a 2 Applicable(s)” is an abstraction forignoring the precise order in which the algorithm tries alternative applicableactions. Find-Safe-Solution launches therefore several execution traces, onefor each applicable action. Notice that, in the “expand” step, we eliminatefrom the frontier the states that lead back to the states already visited,i.e. those in Dom(⇡). These states represent cycles that the solution policygenerates. However, we can ignore them, since we check that there are nononterminating loops.
5.3.3 Planning for Safe Acyclic Solutions by Forward Search
Finally, we present in Figure 5.9 a simple algorithm that plans for acyclic safesolutions. Find-Acyclic-Solution terminates with success if all leaves are goalstates, according to Definition 5.11, but di↵erently from Find-Safe-Solution,it does not allow for loops. The “loop checking” step tests whether there isa state in the Frontier that is already in the domain of ⇡. Notice the maindi↵erence in the recursion over Find-Solution.
Draft, not for distribution. March 24, 2015.
Note: doesn’tconsider back(because it createsa cycle

65"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRAcyclicRSoln(Frontier:tr1,g1,g2
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: delivertr2: move par2: delivertr3: move
g1g2
del
tr2
g1 g2
movetr3
del
g1
g2move
176 Chapter 5
Find-Acyclic-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Frontier \Dom(⇡) 6= ? // loop checking
then return failurechoose nondeterministically a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ �(s, a) // expand
return failure
Figure 5.9: Planning for Safe Acyclic Solutions by Forward-search.
While exploring the frontier, it calls Find-Solution in order to checkwhether the current policy contains cycles without possibility of termina-tion, i.e., whether it gets in a state where no action is applicable or wherethere is no path to the goal. Also Find-Safe-Solution is based on a nonde-terministic selection among the applicable actions. The nondeterministicchoice “nondeterministically choose a 2 Applicable(s)” is an abstraction forignoring the precise order in which the algorithm tries alternative applicableactions. Find-Safe-Solution launches therefore several execution traces, onefor each applicable action. Notice that, in the “expand” step, we eliminatefrom the frontier the states that lead back to the states already visited,i.e. those in Dom(⇡). These states represent cycles that the solution policygenerates. However, we can ignore them, since we check that there are nononterminating loops.
5.3.3 Planning for Safe Acyclic Solutions by Forward Search
Finally, we present in Figure 5.9 a simple algorithm that plans for acyclic safesolutions. Find-Acyclic-Solution terminates with success if all leaves are goalstates, according to Definition 5.11, but di↵erently from Find-Safe-Solution,it does not allow for loops. The “loop checking” step tests whether there isa state in the Frontier that is already in the domain of ⇡. Notice the maindi↵erence in the recursion over Find-Solution.
Draft, not for distribution. March 24, 2015.
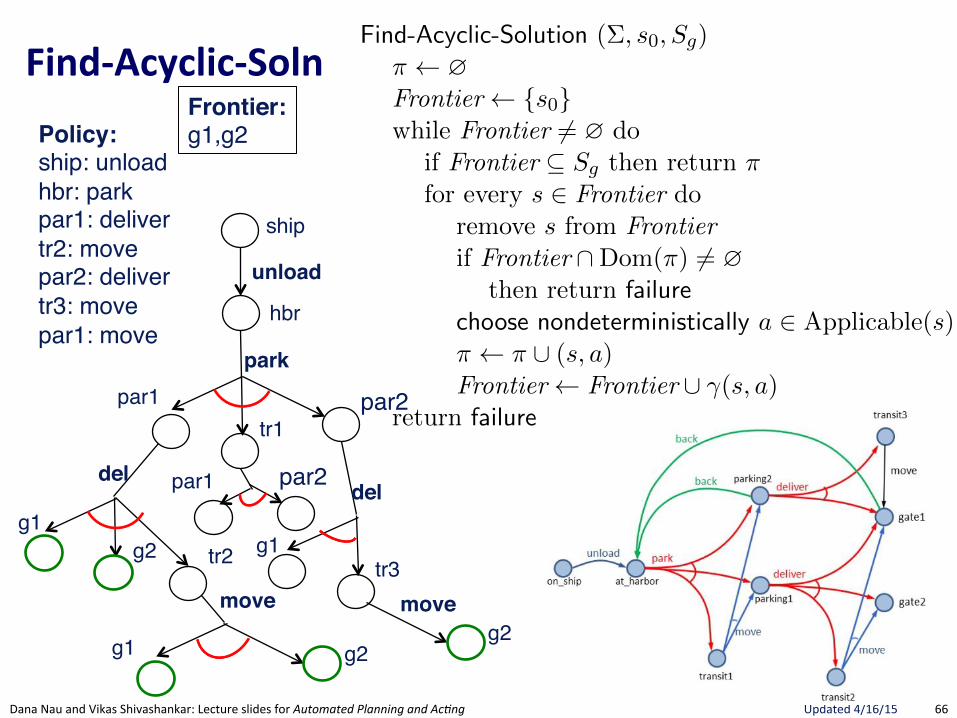
66"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRAcyclicRSoln(Frontier: g1,g2
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: delivertr2: move par2: delivertr3: move par1: move
g1g2
del
tr2
g1 g2
movetr3
del
g1
g2move
par1 par2
176 Chapter 5
Find-Acyclic-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Frontier \Dom(⇡) 6= ? // loop checking
then return failurechoose nondeterministically a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ �(s, a) // expand
return failure
Figure 5.9: Planning for Safe Acyclic Solutions by Forward-search.
While exploring the frontier, it calls Find-Solution in order to checkwhether the current policy contains cycles without possibility of termina-tion, i.e., whether it gets in a state where no action is applicable or wherethere is no path to the goal. Also Find-Safe-Solution is based on a nonde-terministic selection among the applicable actions. The nondeterministicchoice “nondeterministically choose a 2 Applicable(s)” is an abstraction forignoring the precise order in which the algorithm tries alternative applicableactions. Find-Safe-Solution launches therefore several execution traces, onefor each applicable action. Notice that, in the “expand” step, we eliminatefrom the frontier the states that lead back to the states already visited,i.e. those in Dom(⇡). These states represent cycles that the solution policygenerates. However, we can ignore them, since we check that there are nononterminating loops.
5.3.3 Planning for Safe Acyclic Solutions by Forward Search
Finally, we present in Figure 5.9 a simple algorithm that plans for acyclic safesolutions. Find-Acyclic-Solution terminates with success if all leaves are goalstates, according to Definition 5.11, but di↵erently from Find-Safe-Solution,it does not allow for loops. The “loop checking” step tests whether there isa state in the Frontier that is already in the domain of ⇡. Notice the maindi↵erence in the recursion over Find-Solution.
Draft, not for distribution. March 24, 2015.
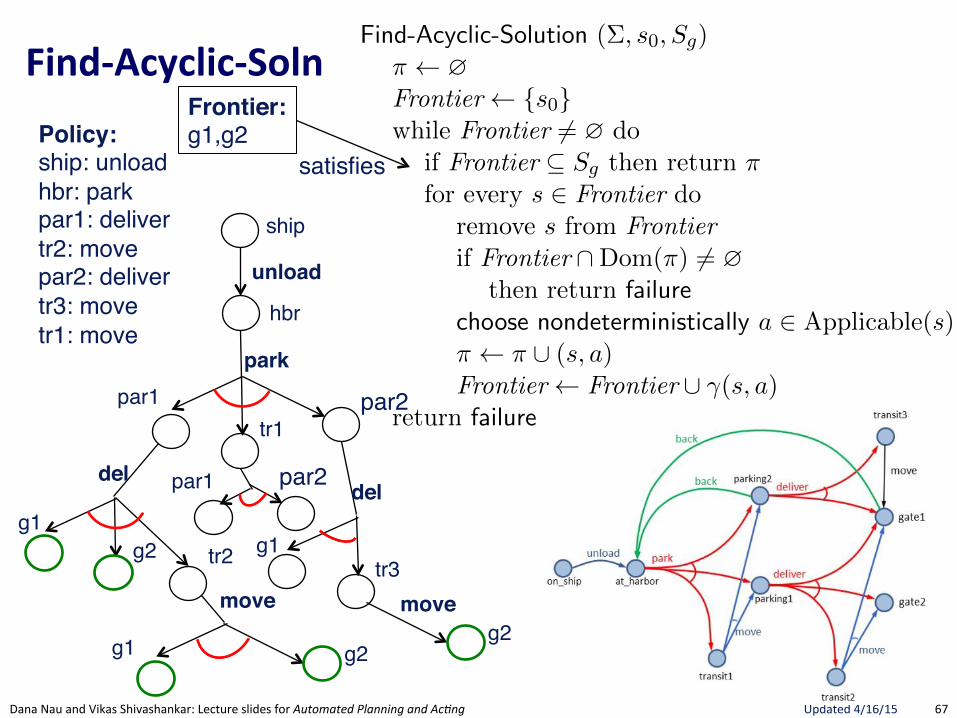
67"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRAcyclicRSoln(Frontier: g1,g2
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: delivertr2: move par2: delivertr3: move tr1: move
g1g2
del
tr2
g1 g2
movetr3
del
g1
g2move
par1 par2
satisfies
176 Chapter 5
Find-Acyclic-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Frontier \Dom(⇡) 6= ? // loop checking
then return failurechoose nondeterministically a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ �(s, a) // expand
return failure
Figure 5.9: Planning for Safe Acyclic Solutions by Forward-search.
While exploring the frontier, it calls Find-Solution in order to checkwhether the current policy contains cycles without possibility of termina-tion, i.e., whether it gets in a state where no action is applicable or wherethere is no path to the goal. Also Find-Safe-Solution is based on a nonde-terministic selection among the applicable actions. The nondeterministicchoice “nondeterministically choose a 2 Applicable(s)” is an abstraction forignoring the precise order in which the algorithm tries alternative applicableactions. Find-Safe-Solution launches therefore several execution traces, onefor each applicable action. Notice that, in the “expand” step, we eliminatefrom the frontier the states that lead back to the states already visited,i.e. those in Dom(⇡). These states represent cycles that the solution policygenerates. However, we can ignore them, since we check that there are nononterminating loops.
5.3.3 Planning for Safe Acyclic Solutions by Forward Search
Finally, we present in Figure 5.9 a simple algorithm that plans for acyclic safesolutions. Find-Acyclic-Solution terminates with success if all leaves are goalstates, according to Definition 5.11, but di↵erently from Find-Safe-Solution,it does not allow for loops. The “loop checking” step tests whether there isa state in the Frontier that is already in the domain of ⇡. Notice the maindi↵erence in the recursion over Find-Solution.
Draft, not for distribution. March 24, 2015.
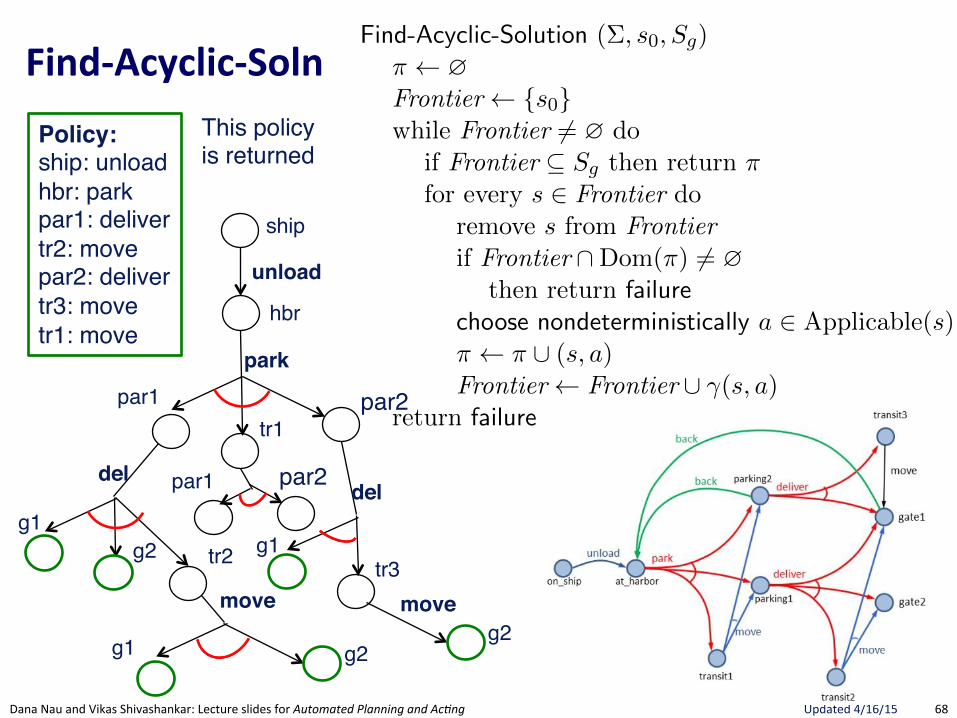
68"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
FindRAcyclicRSoln(
ship
hbr
par1tr1
par2park
unload
Policy:ship: unloadhbr: park par1: delivertr2: move par2: delivertr3: move tr1: move
g1g2
del
tr2
g1 g2
movetr3
del
g1
g2move
par1 par2
This policyis returned
176 Chapter 5
Find-Acyclic-Solution (⌃, s0
, Sg
)⇡ ?Frontier {s
0
}while Frontier 6= ? do
if Frontier ✓ Sg
then return ⇡ // goal reached by all leavesfor every s 2 Frontier do
remove s from Frontierif Frontier \Dom(⇡) 6= ? // loop checking
then return failurechoose nondeterministically a 2 Applicable(s) // select an action⇡ ⇡ [ (s, a)Frontier Frontier [ �(s, a) // expand
return failure
Figure 5.9: Planning for Safe Acyclic Solutions by Forward-search.
While exploring the frontier, it calls Find-Solution in order to checkwhether the current policy contains cycles without possibility of termina-tion, i.e., whether it gets in a state where no action is applicable or wherethere is no path to the goal. Also Find-Safe-Solution is based on a nonde-terministic selection among the applicable actions. The nondeterministicchoice “nondeterministically choose a 2 Applicable(s)” is an abstraction forignoring the precise order in which the algorithm tries alternative applicableactions. Find-Safe-Solution launches therefore several execution traces, onefor each applicable action. Notice that, in the “expand” step, we eliminatefrom the frontier the states that lead back to the states already visited,i.e. those in Dom(⇡). These states represent cycles that the solution policygenerates. However, we can ignore them, since we check that there are nononterminating loops.
5.3.3 Planning for Safe Acyclic Solutions by Forward Search
Finally, we present in Figure 5.9 a simple algorithm that plans for acyclic safesolutions. Find-Acyclic-Solution terminates with success if all leaves are goalstates, according to Definition 5.11, but di↵erently from Find-Safe-Solution,it does not allow for loops. The “loop checking” step tests whether there isa state in the Frontier that is already in the domain of ⇡. Notice the maindi↵erence in the recursion over Find-Solution.
Draft, not for distribution. March 24, 2015.

69"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Proper.es(of(FindRAcyclicRSolu.on(! Guarantees finding Acyclic Safe Solutions, if one exists ! Checks for cycles by seeing if any node in FronBer"is already in the domain of π

70"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Guided(Planning(For(Safe(Solu.ons(! Main motivation: finding possibly unsafe solutions much easier than finding safe
solutions ● FindGSoluBon"ignores AND/OR graph structure and just looks for a policy that
might achieve the goal ● FindGSafeGSoluBon needs to plan for all possible outcomes of actions
! We’ll now see an algorithm that computes safe solutions by starting from possibly unsafe solutions

71"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
GuidedRFindRSafeRSolu.on(192 Chapter 5
Guided-Find-Safe-Solution (⌃,s0
,Sg
)if s
0
2 Sg
then return(?)if Applicable(s
0
) = ? then return(failure)⇡ ?loop
Q leaves(s0
,⇡) \ Sg
if Q = ? then return(⇡)select arbitrarily s 2 Q⇡0 Find-Solution(⌃, s, S
g
)if ⇡0 6= failure then do
⇡ ⇡ [ {(s, a) 2 ⇡0 | s 62 Dom(⇡)}else for every s0 and a such that s 2 �(s0, a) do
⇡ ⇡ \ {(s0, a)}make a not applicable in s0
Figure 5.17: Guided Planning for a Safe Solution
in a nondeterministic domain ⌃ with initial state s0
and goal states Sg
. Ifa safe solution exists, it returns the safe solution ⇡.
The algorithm checks first if there are no applicable actions in s0
. If thisis the case, it returns failure.
In the loop, Q is the set of all non-goal leaf states reached by ⇡ from theinitial state. If there are no non-goal leaf states, then ⇡ is a safe solution.If there are instead non-goal leaf states reached by ⇡, then we have to goon with the loop. We select arbitrarily one of the non-goal leaf states, says, and find a (possibly unsafe) solution from initial state s with the routineFind-Solution, see previous section, Figure 5.7.
If a Find-Solution does not return failure, then ⇡0 is a (possibly unsafe)solution, and therefore we add to the current policy ⇡ all the pairs (s, a) ofthe (possibly unsafe) solution ⇡0 which do not have already a state s in ⇡.
If a (possibly unsafe) solution does not exists (the else part of the condi-tional) this means we are trapped in a loop or a dead-end without possibilityto get out. According to Definition 5.9 then this is not a safe solution. Wetherefore get rid from ⇡ of all the pairs (s0, a) that lead to dead-end states, and remember this making action a not applicable in s0. In this way, atthe next loop iteration, we will not have the possibility to get stuck in the
Draft, not for distribution. March 24, 2015.
Look at all the leaves of π. Safe solution requires a goal state to be reachable from every node.So plan from each non-solution leaf.
Incorporate solution π’ foundinto overall policy π
If solution not found from s, goals unreachable from s. Remove all elements of π that could result in s.

72"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
164 Chapter 5
Figure 5.1: A simple nondeterministic planning domain model
Definition 5.1. (Planning Domain) A nondeterministic planning do-main ⌃ is the tuple (S,A, �), where S is the finite set of states, A is thefinite set of actions, and � : S ⇥ A ! 2S is the state transition function.
An action a 2 A is executable in state s 2 S if and only if �(s, a) 6= ?:
Applicable(s) = {a 2 A | �(s, a) 6= ?}
Example 5.2. In Figure 5.1 we show a simple example of nondeterministicplanning domain model, inspired by the management facility for an harbour,where an item (e.g., a container, a car) is unloaded from the ship, storedin some storage area, possibly moved to transit areas while waiting to beparked, and delivered to gates where it is loaded on trucks. In this simpleexample we have just one state variable, pos(item), which can range overnine values: on ship, at harbor, parking1, parking2, transit1, transit2, transit3,
Draft, not for distribution. March 24, 2015.
EXAMPLE(

73"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Finding(Safe(Solu.ons(by(Determiniza.on(! Main idea underlying GuidedGFindGSafeGSoluBon:"
● Can use (possibly) unsafe solutions (using FindGSoluBon) to guide the search towards a safe solution
! Advantageous because we can temporarily focus on only one of the action’s outcomes ● Searching for paths rather than trees
! Determinization carries same idea even further ! I’ll explain how determinization works, and then how it compares with FindG
SoluBon"

74"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Determiniza.on(Techniques(! High-Level Approach:
● Transform nondeterministic model to a deterministic one ▸ Each nondeterministic action translates to
several deterministic actions, one for each possible successor state
● Use CSV planners to solve these problems ● Stitch solutions together into a policy
! Advantages: ● Deterministic planning problems efficiently
solvable ● Allows us to leverage all of the nice features
CSV planners bring in ▸ Heuristics, landmarks, etc
hbr
par1tr1
par2park
hbr
par1tr1
par2park1
park2park3

75"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
FindRSafeRSolu.onRbyRDeterminiza.on(
194 Chapter 5
Find-Safe-Solution-by-Determinization (⌃,s0
,Sg
)if s
0
2 Sg
then return(?)if Applicable(s
0
) = ? then return(failure)⇡ ?⌃d
mk-deterministic(⌃) // determinizationloop
Q leaves(s0
,⇡) \ Sg
if Q = ? then do⇡ ⇡ \ {(s, a) 2 ⇡ | s 62 b�(s
0
,⇡)} // clean policyreturn(⇡)
select s 2 Qp0 Forward-search (⌃
d
, s, Sg
) // classical plannerif p0 6= fail then do
⇡0 Plan2policy(p0, s) // plan2policy transformation⇡ ⇡ [ {(s, a) 2 ⇡0 | s 62 Dom(⇡)}
else for every s0 and a such that s 2 �(s0, a) do⇡ ⇡ \ {(s0, a)}make the actions in the determinization of a // action eliminationnot applicable in s0
Figure 5.18: Planning for Safe Solutions by Determinization
Draft, not for distribution. March 24, 2015.
Compute determinization of domain
If no non-solution leaf states, we’re done. Need to clean up policy to remove unreachable statesInvoke CSV planner on deterministic model
Transform deterministic plan into policy
Action elimination

76"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Plan2Policy(
Section 5.6 195
terministic domain ⌃d
rather than the Find-Solution on the nondeter-ministic domain ⌃. In general, we could apply any (e�cient) classicalplanner.
4. The plan2policy transformation step: We transform the se-quential plan p0 found by Forward-search into a policy (see routinePlan2policy in Figure 5.19), where �
d
(s, a) is the � of ⌃d
obtained bythe determinization of ⌃.
5. The action elimination step: We modify the deterministic domain⌃d
rather than the nondeterministic domain ⌃.
Plan2policy(p = ha1
, . . . , an
i,s)⇡ ?loop for i from 1 to n do
⇡ ⇡ [ (s, ai
)s �
d
(s, ai
)return ⇡
Figure 5.19: Transformation of a sequential plan into a corresponding policy
5.6 Online approaches with nondeterministicmodels
In Chapter 1 (see Section 1.2, and specifically Section 1.6.2) we introducedthe idea of interleaving planning and acting. One motivation is that, givena complete plan that is generated o↵-line, its execution seldom works asplanned. Interleaving is required because planning models are just approx-imations. Another motivation is the ability to deal with realistic large do-mains that cannot be addressed by purely o↵ line planning, i.e. by the twosequential steps planning then acting. This motivation is even stronger inthe case of nondeterministic domains, where planning algorithms need togenerate safe solutions by dealing with hundreds of state variables (a hugenumber of states) and the uncertainty due to nondeterministic actions.
Therefore, methods that interleave planning and acting are even morethe practical alternative to the problem of planning o↵-line with large statespaces in nondeterministic domains. The idea is that while o↵-line plannershave to find a large policy exploring a huge state space, if we interleave
Draft, not for distribution. March 24, 2015.
Relatively straightforward: transforms solution into a policy representation
Note: p needs to be an acyclic plan
To ensure this, Forward-Search (see previous slide) needs to return an acyclic plan

77"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Ac.on(Elimina.on(
194 Chapter 5
Find-Safe-Solution-by-Determinization (⌃,s0
,Sg
)if s
0
2 Sg
then return(?)if Applicable(s
0
) = ? then return(failure)⇡ ?⌃d
mk-deterministic(⌃) // determinizationloop
Q leaves(s0
,⇡) \ Sg
if Q = ? then do⇡ ⇡ \ {(s, a) 2 ⇡ | s 62 b�(s
0
,⇡)} // clean policyreturn(⇡)
select s 2 Qp0 Forward-search (⌃
d
, s, Sg
) // classical plannerif p0 6= fail then do
⇡0 Plan2policy(p0, s) // plan2policy transformation⇡ ⇡ [ {(s, a) 2 ⇡0 | s 62 Dom(⇡)}
else for every s0 and a such that s 2 �(s0, a) do⇡ ⇡ \ {(s0, a)}make the actions in the determinization of a // action eliminationnot applicable in s0
Figure 5.18: Planning for Safe Solutions by Determinization
Draft, not for distribution. March 24, 2015.
Fragment of FindGSafeGSoluBonGbyGDeterminizaBon that has to do with action elimination
Triggered if no deterministic solution from s
Informally it does the following:• Update π to ensure s is never reached• Ensure that no deterministic solution found in a future call to ForwardG
Search"returns a solution going through s

78"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Proper.es(of(FindRSafeRSolu.onRbyRDeterminiza.on(
! Finds safe solutions ! Any CSV planner can be plugged in
! Determinization needs to be done carefully ● Could potentially lead to an exponential blowup in the number of actions

79"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Online(Approaches(with(Nondeterminis.c(Models(! Interleaving planning and acting is
important ● Planning models are approximate –
execution seldom works out as planned ● Large problems mean long planning
time – need to interleave the two ! This motivation even more stronger in
nondeterministic domains ● Long time needed to generate safe
solutions when there are lots of state variables, actions etc
! Therefore interleaving planning and acting helps reduce complexity ● Instead of coming up with complete
policy, generate partial policy that tells us the next few actions to perform
196 Chapter 5
Figure 5.20: O↵-line vs. Run Time Search Spaces: Intuitions
acting and planning then we reduce significantly the search space. We needindeed to find a partial policy, e.g., the next few ”good” actions, apply allor some of them, and repeat these two interleaved planning and acting stepsfrom the state that has been actually reached. This is the great advantageof interleaving acting and planning, we know exactly which of the manypossible states has been actually reached, and the uncertainty as well as thesearch space gets reduced significantly.
Intuitively, the di↵erence in search space between planning o↵-line andinterleaving planing and acting is shown in Figure 5.20. In the case ofpurely o↵-line planning, uncertainty in the actual next state (and thereforethe number of states to search for) increases exponentially from the initialstate (the left vertex of the triangle) to the set of possible final states (theright part of the triangle) : the search space is depicted as the large triangle.In planning and acting, we plan just for a few next steps, then we act andwe know exactly in which state the application of actions results. We repeatthe interleaving of planning and acting until we reach a goal state. Thesearch space is reduced to the small sequence of triangles depicted in Figure5.20. Notice that there is a dii↵erence between the search space depicted inFigure 5.20 and the ones depicted in Figures 1.3 and 1.5, since here we haveuncertainty in the outcome of each action, and the basis of each red trianglerepresents all the possioble outcomes of an action rather than the di↵erentoutcome of the search for each di↵erent action in a deterministic domain.
A critical side of acting and planning algorithms is how to select “good”actions (i.e. actions that tend to lead to the goal) without exploring theentire search space. This is can be donewith estimations of distances fromand reachability conditions to the goal like in heuristic search and by learning
Draft, not for distribution. March 24, 2015.
Offline vs Runtime Search Spaces

80"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Issues(With(Interleaving(Planning(and(Ac.ng(! Need to identify good actions without exploring entire search space
● Can be done using heuristic estimates ! Handling Dead-ends:
● When lookahead is not enough, can get trapped in dead ends ▸ By planning fully, we would have found out about the dead-end ▸ E.g. if robot goes down a steep incline out of which it cannot come back
up ● Not a problem in safely explorable domains
▸ Goal states reachable from all situations
! Despite these issues, interleaving planning and acting an essential alternative to purely offline planning
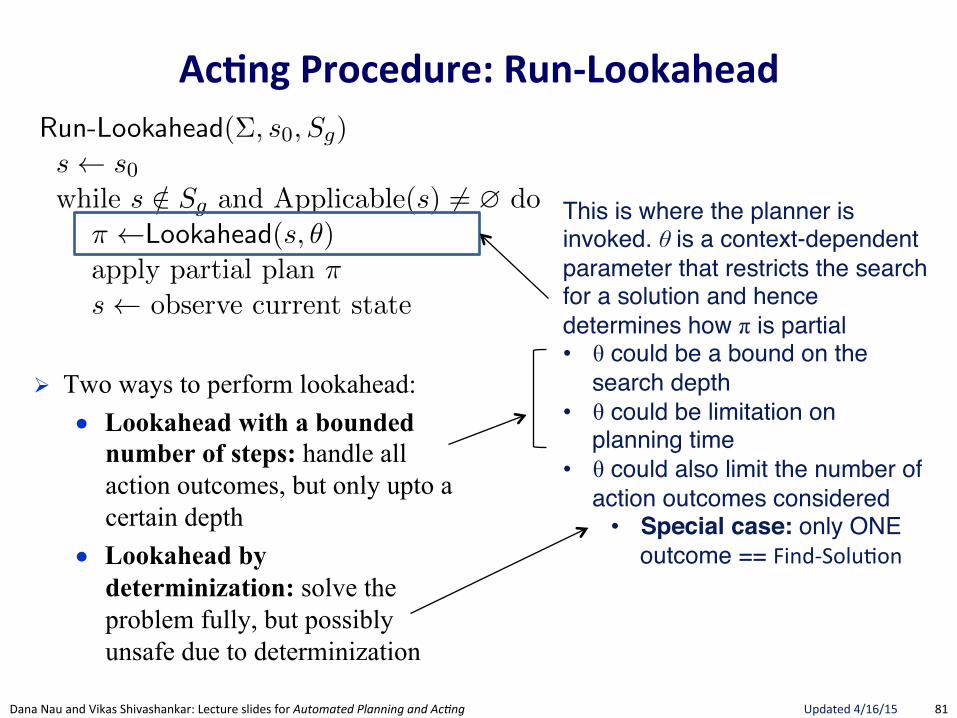
81"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
Ac.ng(Procedure:(RunRLookahead(
198 Chapter 5
Run-Lookahead(⌃, s0
, Sg
)s s
0
while s /2 Sg
and Applicable(s) 6= ? do⇡ Lookahead(s, ✓)apply partial plan ⇡s observe current state
Figure 5.21: Interleaving planning and execution by look-ahead
There are di↵erent ways in which the generated plan can be partialand di↵erent ways in planning and acting can be interleaved. Indeed theprocedure Run-Lookahead is parametric along two dimensions:
The first parametric dimension is in the call to the look-ahead planningstep, i.e., Lookahead(s, ✓). The parameter ✓ determines the way in which thegenerated plan ⇡ is partial. For instance, it can be partial since the lookaheadis bounded, i.e., the forward search is performed for a bounded number ofsteps without reaching the goal. In the simplest case, Lookahead(s, ✓) canlook ahead just one step, chose an action a (in this case ⇡ = a), and the nextapplication step applies a. This is the extreme case of interleaving in whichthe actor is as much reactive as possible. In general however, Lookahead(s, ✓)can look ahead for n � 1 steps. The greater is n, the more informed is thechoice on the partial plan to execute, while the drawback is that the costof the lookahead increases. In the extreme case in which it the lookaheadreaches the goal from the initial state s
0
, if acting along the found plansucceeds, then there is no actual interleaving.
However, there are other ways in which the generated plan is partial.For instance, Lookahead can consider a partial number of the outcomes of anon-deterministic action, i.e., just some of its possible outcomes of a non-deterministic action, and in this way the lookahead procedure can reachthe goal. Even if the goal is reached the plan is still partial since it isnot guaranteed that the execution will actually go through the consideredoutcomes of the actions, since they are not complete. In the extreme case,Lookahead can consider just one of the possible outcomes of an action, i.e.,look for a possibly unsafe solution to the goal, or in other words, pretendthat the domain model is deterministic. In this case the lookahead procedureis not bounded, but the plan is still partial. The policy ⇡ in this case canbe reduced to a sequential plan.
It is of course possible to combine the two types of partiality - bounded
Draft, not for distribution. March 24, 2015.
This is where the planner is invoked. θ is a context-dependent parameter that restricts the search for a solution and hence determines how π is partial• θ could be a bound on the
search depth• θ could be limitation on
planning time• θ could also limit the number of
action outcomes considered• Special case: only ONE
outcome == FindGSoluBon(
! Two ways to perform lookahead: ● Lookahead with a bounded
number of steps: handle all action outcomes, but only upto a certain depth
● Lookahead by determinization: solve the problem fully, but possibly unsafe due to determinization

82"Dana"Nau"and"Vikas"Shivashankar:"Lecture"slides"for!Automated!Planning!and!Ac0ng" Updated"4/16/15"
FFRReplan:(Lookahead(by(Determiniza.on(Section 5.6 199
FF-Replan (⌃, s, Sg
)while s /2 S
g
and Applicable(s) 6= ? doif ⇡
d
undefined for s then do⇡d
Forward-search (⌃d
, s, Sg
)apply action ⇡
d
(s)s observe resulting state
Figure 5.22: Online determinization planning and acting algorithm.
lookahead and partial numebr of outcomes, in any arbitrary way.The second parametric dimension is in the application of the partial plan
that has been generated, i.e., apply the partial plan ⇡. Independently of thelookahead, we can still execute ⇡ in a partial way. Suppose for instance thatwe have generated a sequential plan of length n, we can decide to applym n steps.
Two approaches to the design of a Lookahead procedure are presentednext:
• Lookahead by determinization
• Lookahead with a bounded number of steps
The former approach does not bound the search to a limited number ofsteps, but searches for a (possibly unsafe) solution to the goal. At executiontime, it checks whether the reached state corresponds to the one predictedby the (possibly unsafe) solution. The latter approach bounds the searchto a limited number of steps (in the simplest case just one step), selects anaction according to some heuristics, memorizes the results and performs avalue update to learn a better heuristics in possible future searches.
5.6.2 Lookahead by determinization
Lookahead can be realized by planning by determinazing the domain.. Al-gorithm FF-Replan (figure 5.22) illustrates a determinization relaxation in-troduced in Section 5.5.2, algorithm in Figure 5.18. The idea is to generatea path ⇡
d
from the current state to a goal for the all-outcomes of the de-terminized domain ⌃
d
using a deterministic planner, in this case Forward-search, but it could be any e�cient deterministic planner, like in the case ofthe o↵-line determinization algorithm in Figure 5.18. The actor acts using⇡d
until reaching a state s that is not in the domain of ⇡d
. At that point a
Draft, not for distribution. March 24, 2015.
Run Forward-Search on a determinized version ofthe problem.
Then start executing the (possibly unsafe) policy until we cannot execute it anymore
Properties:• If the domain is safely-explorable,
then FFGReplan will get to a goal state.• If the domain has dead-ends, then
no guarantees.
Related Documents











