Chapter 9

Chapter 9. HTTP Protocol: Text-based protocol vs TCP and many others Basically a couple of requests (GET and POST) and a much larger variety of replies.
Dec 27, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Chapter 9

HTTP Protocol:
Text-based protocol vs TCP and many others
Basically a couple of requests (GET and POST) and a much larger variety of replies (200 OK and more, over 40 in total).
Replies are divided into 5 groups:
Informational (1xx) Success (2xx) Redirection (3xx) Client Error (4xx) Server Error (5xx)
HTTP messages come with a plain text header with individual entries terminated by \r\n. The entire header is terminated by \r\n. It is followed by an optional contents.
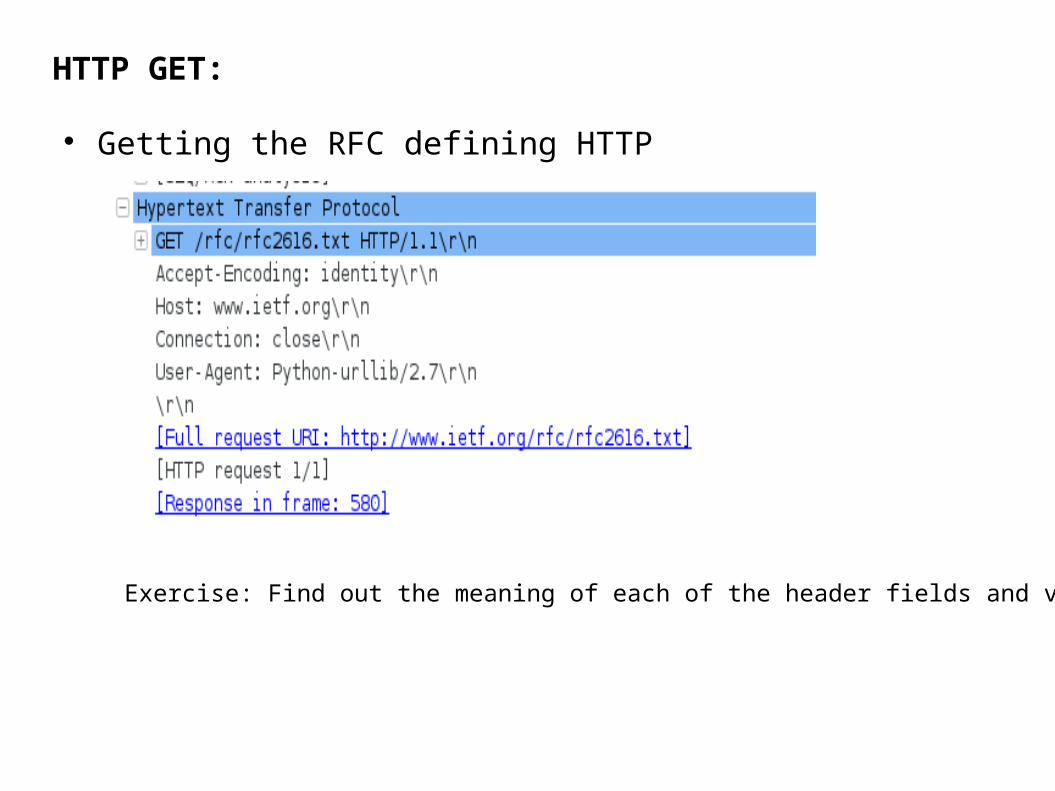
HTTP GET:
Getting the RFC defining HTTP
Exercise: Find out the meaning of each of the header fields and values.

HTTP 200 OK:
This is the response to the previous GET
Body to follow:

Reading the Header in Python:
The Python code that generates the previous traffic.
[pletcha@archimedes Spr14Homework]$ pythonPython 2.7.5 (default, Nov 12 2013, 16:18:42) [GCC 4.8.2 20131017 (Red Hat 4.8.2-1)] on linux2Type "help", "copyright", "credits" or "license" for more information.>>> import urllib,urllib2>>> url="http://www.ietf.org/rfc/rfc2616.txt">>> rawreply=urllib2.urlopen(url).read()

URL vs URI:
URIs identify a resource. URLs both identify and indicate how to fetch a resource.
For example:
Characters that are not alphanumerics on in the set “$-_.+!*'(),” must be expressed as %<ascii number in 2-digit hex>
http://example.com:8080/Nord%2FLB/logo?shape=square&dpi=96
host port path element script paramters

Parsing URLs:
Parsing methods
These break up a complex URL into its component parts
Given a URL, break it apart
>>> from urlparse import urlparse, urldefrag, parse_qs, parse_qsl
>>> from urlparse import urlparse, urldefrag, parse_qs, parse_qsl>>> p = urlparse('http://example.com:8080/Nord%2FLB/logo?shape=square&dpi=96')>>> pParseResult(scheme='http', netloc='example.com:8080', path='/Nord%2FLB/logo', params='', query='shape=square&dpi=96', fragment='')>>>
scheme://netloc/path;parameters?query#fragment NOTE: This is a tuple,not a dictionary
Example: 'path' could point to a servlet and the 'parameters' could tellus which version of the servlet to use – 1.1, 1.2, etc

Parsing Continued:
Suppose you want key-value pairs for everything
parse_qs vs parse_qsl: the latter preserves order in a dictionary by spitting out an ordered list (l)
Anchors are also part of a URL but not sent to the server. They are used by the client to locate a tag in the reply document.
You can split them off a URL using urldefrag():
>>> p.query'shape=square&dpi=96'>>> parse_qs(p.query){'shape': ['square'], 'dpi': ['96']}
>>> u = 'http://docs.python.org/library/urlparse.html#urlparse.urldefrag'>>> urldefrag(u)('http://docs.python.org/library/urlparse.html', 'urlparse.urldefrag')

Rebuilding a URL from a ParseResult:
It is always nice to go backwards.
Since the parse query is the only complicated thing we can build a query from scratch and then create a new ParseResult object with our query
>>> p.geturl()'http://example.com:8080/Nord%2FLB/logo?shape=square&dpi=96'
>>> import urllib>>> import urlparse>>> query=urllib.urlencode({'company':'Nord/LB','report': 'sales'})>>> query'report=sales&company=Nord%2FLB'>>> p = urlparse.ParseResult('https','example.com:8080','data/path',None,query,None)>>> p.geturl()'https://example.com:8080/data/path?report=sales&company=Nord%2FLB'

Relative URLs:
If a URL is “relative” then it is relative to some “base”.
The base is found from the URL used to fetch the page containing the relative link.
Relative URLs are particularly useful if an entire sub-tree of a website is moved to a new parent directory. All the relative links continue to function without any editing.

urlparse.urljoin():
urljoin() combines a relative URL with a base to give a single absolute URL.
>>> import urlparse>>> # a relative joined to a path that ends in / gets added on>>> urlparse.urljoin('http://www.python.org/psf/', 'grants')'http://www.python.org/psf/grants'>>> urlparse.urljoin('http://www.python.org/psf/', 'mission')'http://www.python.org/psf/mission'>>> # a relative joined to a path that does not end in / replaces>>> # the last part of the path>>> urlparse.urljoin('http://www.python.org/psf', 'grants')'http://www.python.org/grants'>>> # relatives can represent “current location” as '.'>>> urlparse.urljoin('http://www.python.org/psf/', './mission')'http://www.python.org/psf/mission'>>> urlparse.urljoin('http://www.python.org/psf', './mission')'http://www.python.org/mission'>>> # relatives can represent “parent of current” as '..'>>> urlparse.urljoin('http://www.python.org/psf/', '../news')'http://www.python.org/news'

urlparse.urljoin():
urljoin() combines a relative URL with a base to give a single absolute URL.
>>> # relatives won't take you out of the top level of the>>> # current website>>> urlparse.urljoin('http://www.python.org/psf', '../news')'http://www.python.org/../news'>>> # relatives that start with / start at the top level of this website>>> urlparse.urljoin('http://www.python.org/psf/', '/dev/')'http://www.python.org/dev/'>>> urlparse.urljoin('http://www.python.org/psf/mission/', '/dev/')'http://www.python.org/dev/'>>> # if the relative is an “absolut” then urljoin() simply replaces>>> # one absolute with another>>> urlparse.urljoin('http://www.python.org/psf/','http://yelp.com/')'http://yelp.com/'
Useful and implies we can always apply urljoin() to the current pathplus the next link

Easy Access to HTTP headers:
Every time we send off a GET or POST and get a reply we'd like to be able to see the headers.
urllib2 has an open() method that can be customized with handlers of your own devising.
You accomplish this by subclassing a couple of urllib2 and httplib classes and then overriding methods in this classes so that your methods are invoked instead of the default ones.
In order that the correct functionality actually occurs it is important that your methods also invoke the superclass methods.

Opening a link with your own opener:
>>> from verbose_http import VerboseHTTPHandler>>> import urllib, urllib2>>> opener = urllib2.build_opener(VerboseHTTPHandler)>>> opener.open('http://serendipomatic.org')--------------------------------------------------GET / HTTP/1.1Accept-Encoding: identityHost: serendipomatic.orgConnection: closeUser-Agent: Python-urllib/2.7-------------------- Response --------------------HTTP/1.1 200 OKDate: Mon, 24 Mar 2014 20:08:00 GMTServer: Apache/2.2.25 (Amazon)Vary: CookieSet-Cookie: csrftoken=HybJc4Gx5GgYsucjhF3f34aF7rMtzmcU; \ expires=Mon, 23-Mar-2015 20:08:00 GMT; Max-Age=31449600; Path=/Connection: closeTransfer-Encoding: chunkedContent-Type: text/html; charset=utf-8<addinfourl at 140151715103304 whose fp = \ <socket._fileobject object at 0x7f779f73e150>>

verbose_handler.py:
Replace standard open() with one of your own specialized to use your versions of the following object methods:
#!/usr/bin/env python# Foundations of Python Network Programming - Chapter 9 - verbose_http.py# HTTP request handler for urllib2 that prints requests and responses.
import StringIO, httplib, urllib2
# your VerboseHTTPHandler extends urllib2.HTTPHandlerclass VerboseHTTPHandler(urllib2.HTTPHandler): def http_open(self, req): # overrides HTTPHandler.http_open return self.do_open(VerboseHTTPConnection, req)

verbose_handler.py:
Replace standard open() with one of your own specialized to use your versions of the following object methods:
#!/usr/bin/env python# Foundations of Python Network Programming - Chapter 9 - verbose_http.py# HTTP request handler for urllib2 that prints requests and responses.
import StringIO, httplib, urllib2
class VerboseHTTPResponse(httplib.HTTPResponse): def _read_status(self): s = self.fp.read() print '-' * 20, 'Response', '-' * 20 print s.split('\r\n\r\n')[0] self.fp = StringIO.StringIO(s) return httplib.HTTPResponse._read_status(self)
class VerboseHTTPConnection(httplib.HTTPConnection): response_class = VerboseHTTPResponse def send(self, s): print '-' * 50 print s.strip() httplib.HTTPConnection.send(self, s)

GET:
In the begin there was only GET.
info is an object with many fields.
>>> from verbose_http import VerboseHTTPHandler>>> import urllib, urllib2>>> opener = urllib2.build_opener(VerboseHTTPHandler)>>> info = opener.open('http://www.ietf.org/rfc/rfc2616.txt')--------------------------------------------------GET /rfc/rfc2616.txt HTTP/1.1Accept-Encoding: identityHost: www.ietf.orgConnection: closeUser-Agent: Python-urllib/2.7
>>> info.code, info.msg(200, 'OK')>>> sorted(info.headers.keys())['accept-ranges', 'connection', 'content-length', 'content-type', 'date', 'etag', 'last-modified', 'server', 'vary']>>> info.headers['content-type']'text/plain'>>>

Why Host header?
Originally each IP address supported only one web server at port 80.
Over time we needed to put multiple sites at the same (IP,PortNum) pair.
So the httpd further demultiplexes the GET request using the Host header field to determine which website the request should be delivered to.
This is called virtual hosting.

GET (cont):
info is also set up to be read like a file starting to read right after the end of the header
>>> info.read(200)'\n\n\n\n\n\nNetwork Working Group R. Fielding\nRequest for Comments: 2616 UC Irvine\nObsoletes: 2068 '>>>

Return Codes:
200 range – things are OK
300 range – some kind of redirection
400 range – client problem (invalid URL, for exampe)
500 range – server problem

300s:
301 – Moved Permanently: the 'Location' header field has the new, permanent address.
303 – See Other: In response to an original POST or PUT, go to the 'Location' URL and issue a GET. The original request is considered to have succeeded.
304 – Not Modified: The request came with a page timestamp and the website hasn't changed since that time so the requester already has the most recent copy.
307 – Temporary Redirect: Like 303 but issue the original POST again.
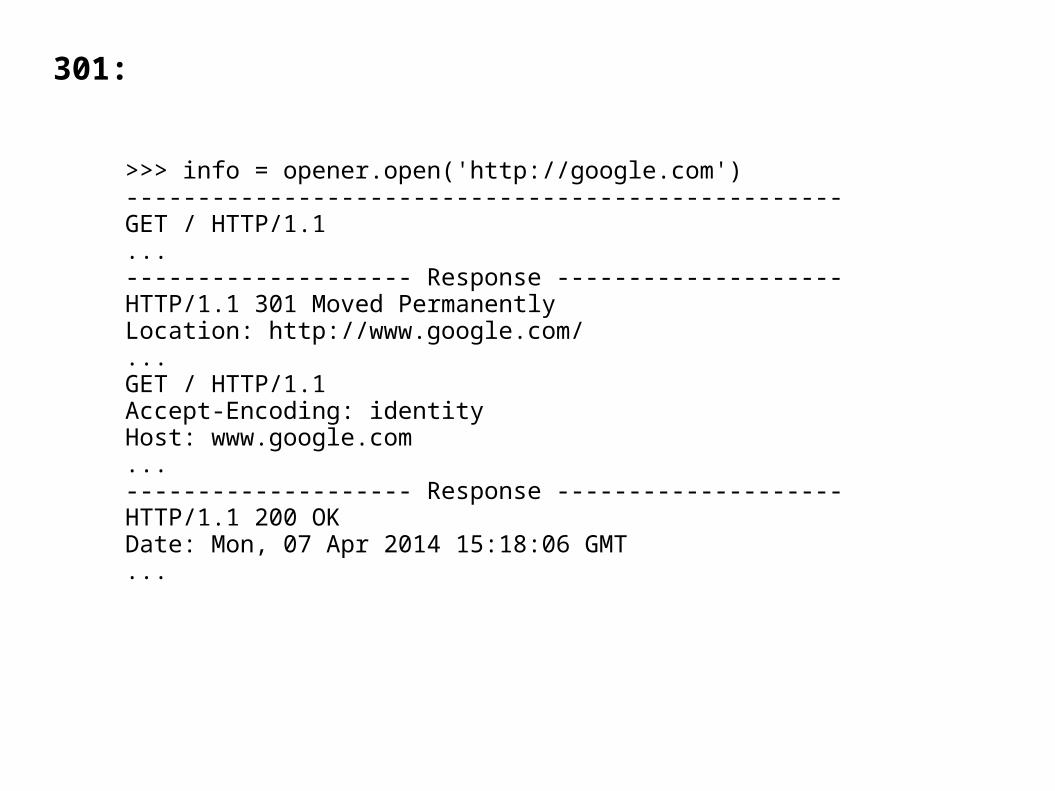
301:
>>> info = opener.open('http://google.com')--------------------------------------------------GET / HTTP/1.1...-------------------- Response --------------------HTTP/1.1 301 Moved PermanentlyLocation: http://www.google.com/...GET / HTTP/1.1Accept-Encoding: identityHost: www.google.com...-------------------- Response --------------------HTTP/1.1 200 OKDate: Mon, 07 Apr 2014 15:18:06 GMT...

301 (cont):
>>> info = opener.open('http://www.twitter.com')--------------------------------------------------GET / HTTP/1.1Accept-Encoding: identityHost: www.twitter.comConnection: closeUser-Agent: Python-urllib/2.7-------------------- Response --------------------HTTP/1.1 301 Moved Permanentlycontent-length: 0date: Mon, 07 Apr 2014 15:27:27 UTClocation: https://twitter.com/server: tfeset-cookie: guest_id=v1%3A139688444736565383; Domain=.twitter.com; Path=/; Expires=Wed, 06-Apr-2016 15:27:27 UTCConnection: close>>>
NOTE: This time urllib2 doesn't follow the redirect;perhaps because it is goingto a secure site.
NOTE: Obviously Google andTwitter have different opinions of'WWW'.

Handle You Own Redirect:
>>> class NoRedirectHandler(urllib2.HTTPRedirectHandler):... def http_error_302(self,req,fp,code,msg,headers):... return... http_error_301 = http_error_303 = http_error_307 = http_error_302... >>> no_redirect_opener = urllib2.build_opener(NoRedirectHandler)>>> no_redirect_opener.open('http://google.com')...urllib2.HTTPError: HTTP Error 301: Moved Permanently>>>

Title:
XXX

Title:
XXX
Related Documents











