R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1 Chapter 7: Eligibility Traces

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1
Chapter 7: Eligibility Traces
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 2
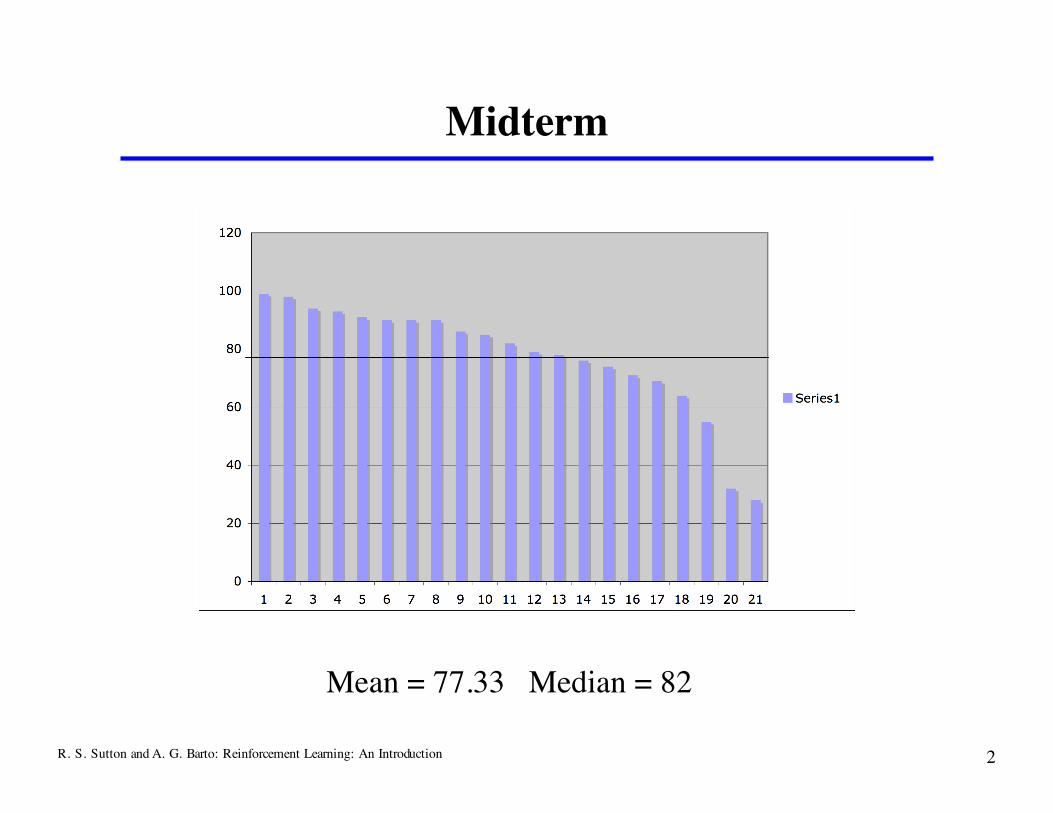
Midterm
Mean = 77.33 Median = 82

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 3
N-step TD Prediction
❐ Idea: Look farther into the future when you do TD backup(1, 2, 3, …, n steps)

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 4
❐ Monte Carlo:
❐ TD: Use V to estimate remaining return
❐ n-step TD: 2 step return:
n-step return:
Mathematics of N-step TD Prediction
T
tT
ttttrrrrR1
3
2
21
!!
+++ ++++= """ L
)( 11
)1(
++ +=ttttsVrR !
)( 2
2
21
)2(
+++ ++=tttttsVrrR !!
)(1
3
2
21
)(
ntt
n
nt
n
ttt
n
tsVrrrrR ++
!
+++ +++++= """" L

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 5
Learning with N-step Backups
❐ Backup (on-line or off-line):
❐ Error reduction property of n-step returns
❐ Using this, you can show that n-step methods converge
)()(max)(}|{max sVsVsVssREs
n
t
n
ts
!!
! " #$#=
n step return
Maximum error using n-step return Maximum error using V
!Vt(s
t) = " R
t
(n)# V
t(s
t)[ ]

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 6
Random Walk Examples
❐ How does 2-step TD work here?❐ How about 3-step TD?

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 7
A Larger Example
❐ Task: 19 staterandom walk
❐ Do you think thereis an optimal n (foreverything)?

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 8
Averaging N-step Returns
❐ n-step methods were introduced to help withTD(λ) understanding
❐ Idea: backup an average of several returns e.g. backup half of 2-step and half of 4-
step
❐ Called a complex backup Draw each component Label with the weights for that
component
)4()2(
2
1
2
1tt
avg
t RRR +=
One backup

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 9
Forward View of TD(λ)
❐ TD(λ) is a method foraveraging all n-step backups weight by λn-1 (time since
visitation) λ-return:
❐ Backup using λ-return:
Rt
!= (1" ! ) !
n "1
n=1
#
$ Rt
(n)
!Vt(s
t) = " R
t
#$ V
t(s
t)[ ]

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 10
λ-return Weighting Function

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 11
Relation to TD(0) and MC
❐ λ-return can be rewritten as:
❐ If λ = 1, you get MC:
❐ If λ = 0, you get TD(0)
Rt
!= (1" ! ) !
n"1
n=1
T" t"1
# Rt
(n)+ !
T"t"1Rt
Rt
!= (1"1) 1
n"1
n=1
T"t"1
# Rt
(n )+ 1
T" t"1Rt= R
t
Rt
!= (1" 0) 0
n"1
n=1
T"t"1
# Rt
(n )+ 0
T" t"1Rt= R
t
(1)
Until termination After termination
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 12
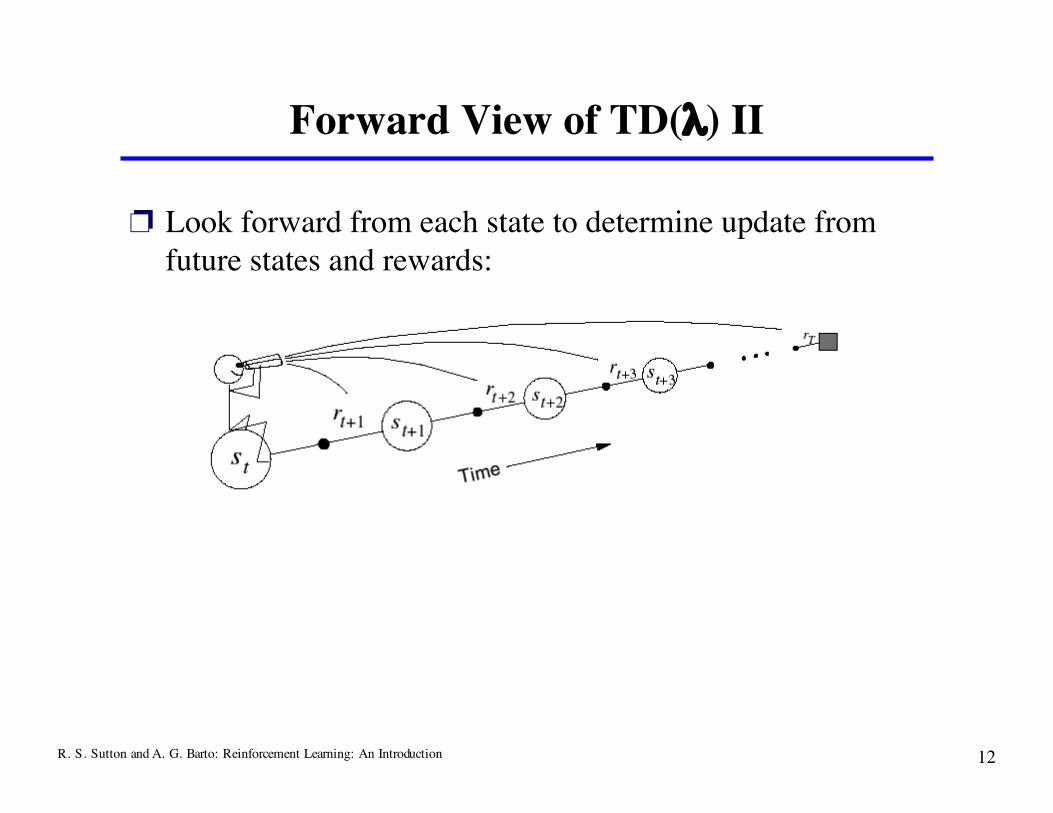
Forward View of TD(λ) II
❐ Look forward from each state to determine update fromfuture states and rewards:

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 13
λ-return on the Random Walk
❐ Same 19 state random walk as before❐ Why do you think intermediate values of λ are best?

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 14
Backward View of TD(λ)
❐ The forward view was for theory❐ The backward view is for mechanism
❐ New variable called eligibility trace On each step, decay all traces by γλ and increment the
trace for the current state by 1 Accumulating trace
+!")(set
et(s) =
!"et#1(s) if s $ s
t
!"et#1(s) +1 if s = s
t
% & '

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 15
On-line Tabular TD(λ)
Initialize V(s) arbitrarily and e(s) = 0, for all s !S
Repeat (for each episode) :
Initialize s
Repeat (for each step of episode) :
a" action given by # for s
Take action a, observe reward, r, and next state $ s
% " r +&V( $ s ) ' V (s)
e(s)" e(s) +1
For all s :
V(s) "V(s) +(%e(s)
e(s) "&)e(s)
s" $ s
Until s is terminal
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 16
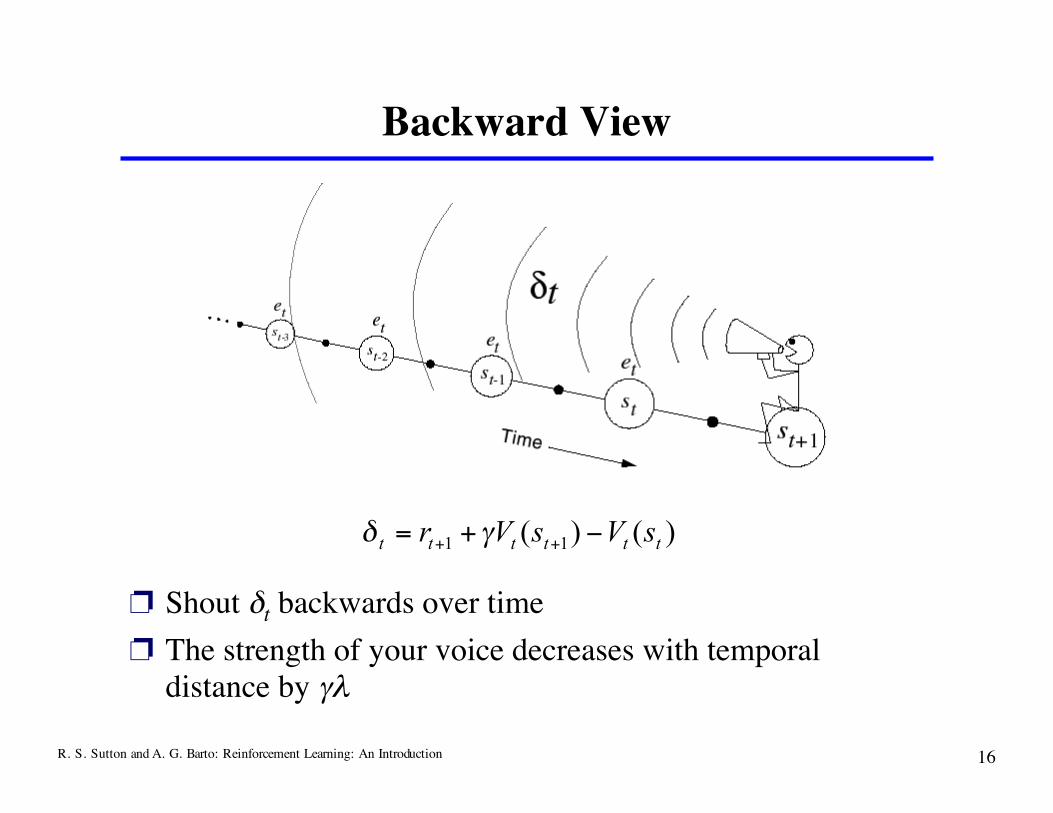
Backward View
❐ Shout δt backwards over time❐ The strength of your voice decreases with temporal
distance by γλ
)()( 11 ttttttsVsVr !+= ++ "#

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 17
Relation of Backwards View to MC & TD(0)
❐ Using update rule:
❐ As before, if you set λ to 0, you get to TD(0)❐ If you set λ to 1, you get MC but in a better way
Can apply TD(1) to continuing tasks Works incrementally and on-line (instead of waiting to
the end of the episode)
)()( sesVttt
!"=#
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 18
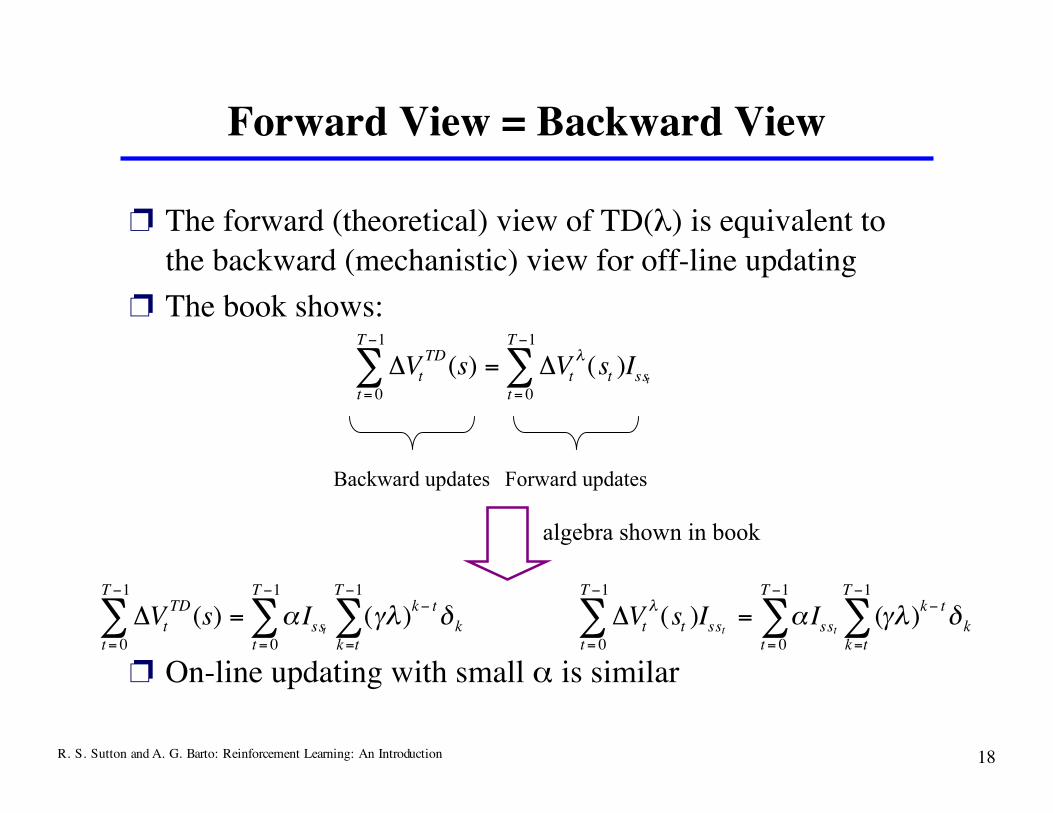
Forward View = Backward View
❐ The forward (theoretical) view of TD(λ) is equivalent tothe backward (mechanistic) view for off-line updating
❐ The book shows:
❐ On-line updating with small α is similar
!Vt
TD(s)
t= 0
T"1
# = $t= 0
T"1
# Isst
(%&)k" t'k
k=t
T"1
# !Vt
"(s
t)Isst
t= 0
T#1
$ = %t= 0
T#1
$ Isst
(&")k# t'k
k=t
T#1
$
!Vt
TD
(s)t= 0
T"1
# = !Vt
$(s
t)
t= 0
T"1
# Isst
Backward updates Forward updates
algebra shown in book
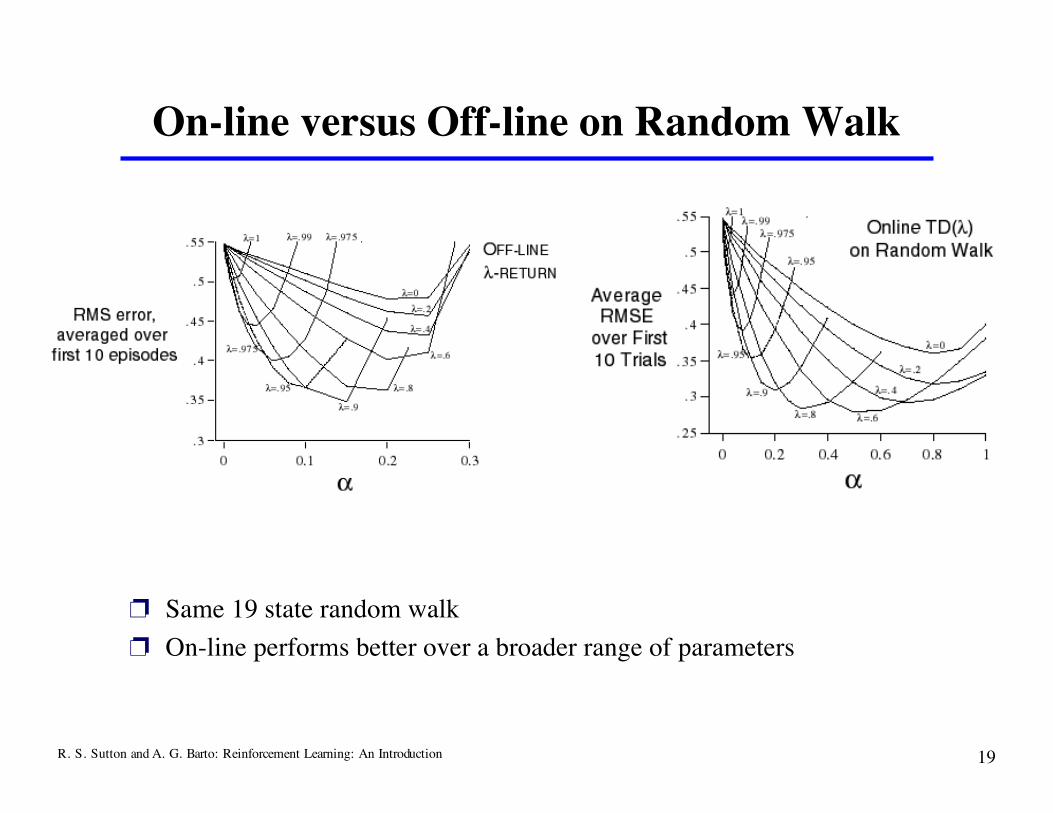
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 19
On-line versus Off-line on Random Walk
❐ Same 19 state random walk❐ On-line performs better over a broader range of parameters

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 20
Control: Sarsa(λ)
❐ Save eligibility for state-actionpairs instead of just states
et(s, a) =
!"et#1(s, a) +1 if s = s
t and a = a
t
!"et#1(s,a) otherwise
$ % &
Qt+1(s, a) = Q
t(s, a) +'(
tet(s, a)
(t
= rt+1 + !Q
t(s
t+1,at+1) #Qt(s
t, a
t)

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 21
Sarsa(λ) Algorithm
Initialize Q(s,a) arbitrarily and e(s, a) = 0, for all s, a
Repeat (for each episode) :
Initialize s, a
Repeat (for each step of episode) :
Take action a, observe r, ! s
Choose ! a from ! s using policy derived from Q (e.g. ? - greedy)
" # r +$Q( ! s , ! a ) %Q(s, a)
e(s,a)# e(s,a) +1
For all s,a :
Q(s, a)#Q(s, a) +&"e(s, a)
e(s, a) #$'e(s, a)
s# ! s ;a # ! a
Until s is terminal
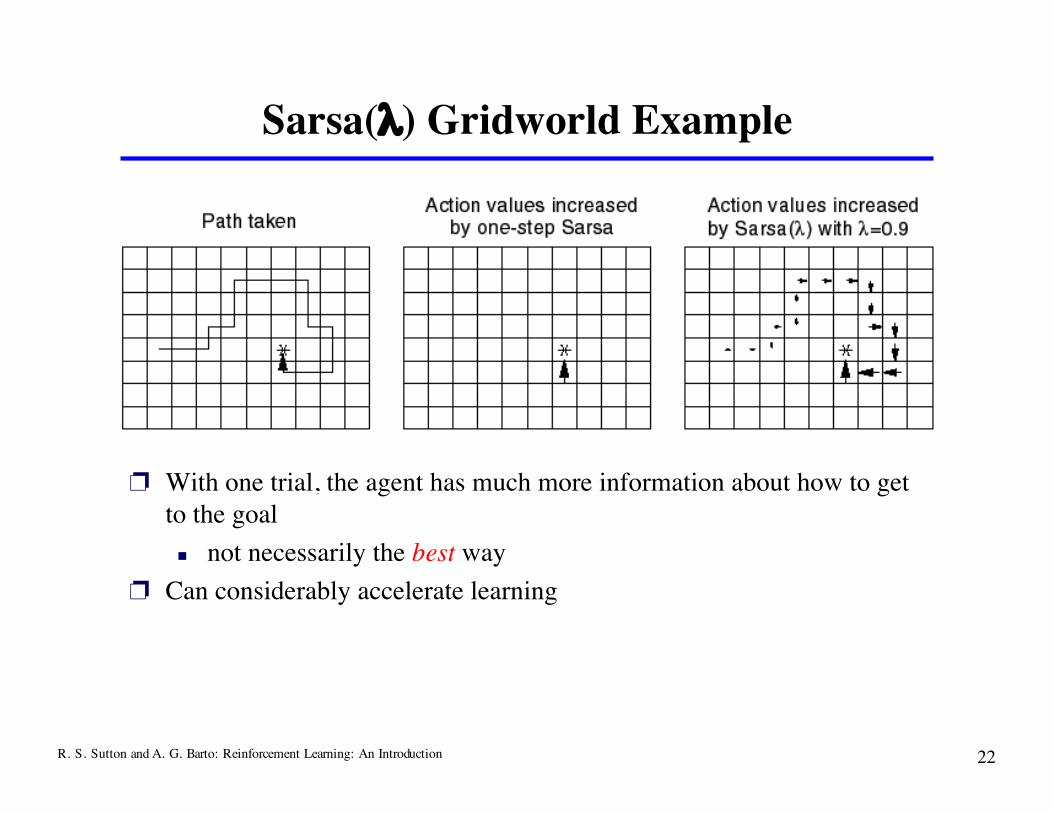
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 22
Sarsa(λ) Gridworld Example
❐ With one trial, the agent has much more information about how to getto the goal not necessarily the best way
❐ Can considerably accelerate learning

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 23
Three Approaches to Q(λ)
❐ How can we extend this to Q-learning?
❐ If you mark every state actionpair as eligible, you backupover non-greedy policy Watkins: Zero out
eligibility trace after a non-greedy action. Do maxwhen backing up at firstnon-greedy choice.
et(s, a) =
1 + !"et#1(s, a)
0
!"et#1(s,a)
if s = st, a = a
t,Q
t#1(st,a
t) = max
aQ
t#1(st, a)
if Qt#1(st
,at) $ max
aQ
t#1(st,a)
otherwise
%
& '
( '
Qt +1(s, a) = Q
t(s, a) +)*
te
t(s, a)
*t
= rt +1 + ! max + a
Qt(s
t +1, + a ) #Qt(s
t,a
t)

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 24
Watkins’s Q(λ)
Initialize Q(s,a) arbitrarily and e(s, a) = 0, for all s, a
Repeat (for each episode) :
Initialize s, a
Repeat (for each step of episode) :
Take action a, observe r, ! s
Choose ! a from ! s using policy derived from Q (e.g. ? - greedy)
a* " arg maxb Q( ! s , b) (if a ties for the max, then a* " ! a )
# " r +$Q( ! s , ! a ) %Q(s, a*)
e(s,a)" e(s,a) +1
For all s,a :
Q(s, a)"Q(s, a) +&#e(s, a)
If ! a = a*, then e(s, a) "$'e(s,a)
else e(s, a)" 0
s" ! s ;a " ! a
Until s is terminal

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 25
Peng’s Q(λ)
❐ Disadvantage to Watkins’smethod: Early in learning, the
eligibility trace will be“cut” (zeroed out)frequently resulting in littleadvantage to traces
❐ Peng: Backup max action except
at end Never cut traces
❐ Disadvantage: Complicated to implement

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 26
Naïve Q(λ)
❐ Idea: is it really a problem tobackup exploratory actions? Never zero traces Always backup max at
current action (unlike Pengor Watkins’s)
❐ Is this truly naïve?❐ Works well is preliminary
empirical studies
What is the backup diagram?

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 27
Comparison Task
From McGovern and Sutton (1997). Towards a better Q(λ)
❐ Compared Watkins’s, Peng’s, and Naïve (calledMcGovern’s here) Q(λ) on several tasks. See McGovern and Sutton (1997). Towards a Better Q(λ) for other tasks and results (stochastic tasks,continuing tasks, etc)
❐ Deterministic gridworld with obstacles 10x10 gridworld 25 randomly generated obstacles 30 runs α = 0.05, γ = 0.9, λ = 0.9, ε = 0.05, accumulating traces
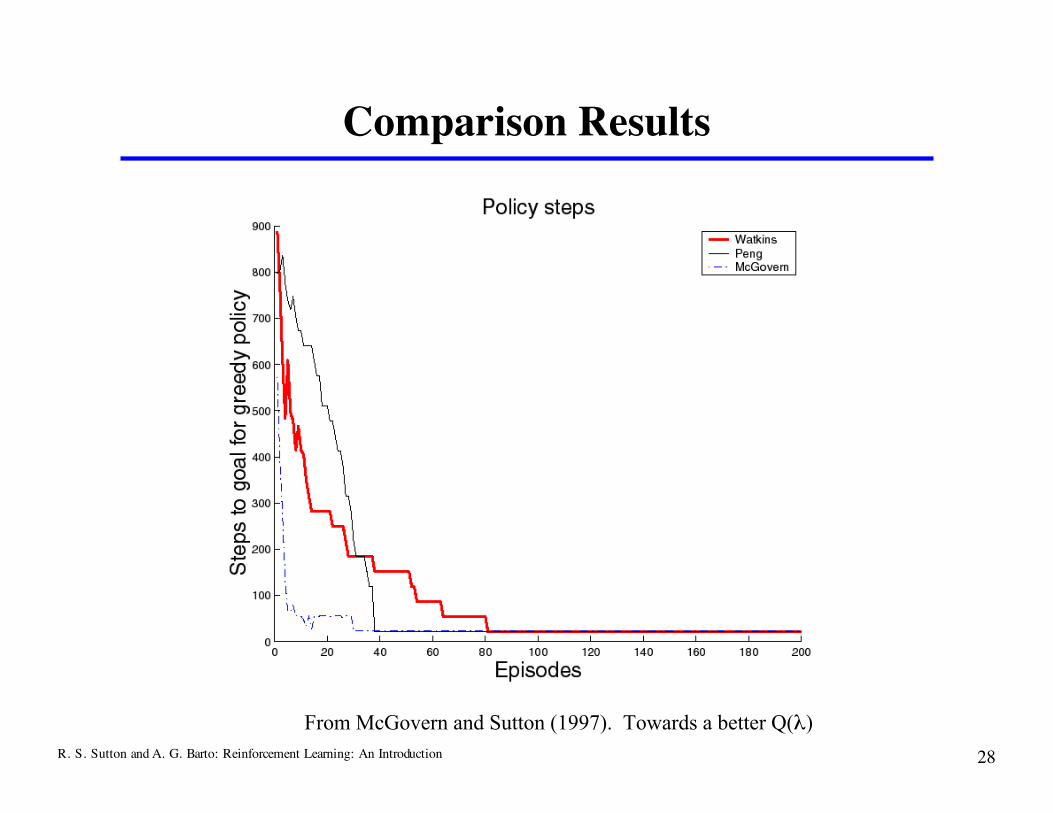
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 28
Comparison Results
From McGovern and Sutton (1997). Towards a better Q(λ)

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 29
Convergence of the Q(λ)’s
❐ None of the methods are proven to converge. Much extra credit if you can prove any of them.
❐ Watkins’s is thought to converge to Q*
❐ Peng’s is thought to converge to a mixture of Qπ and Q*
❐ Naïve - Q*?

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 30
Eligibility Traces for Actor-Critic Methods
❐ Critic: On-policy learning of Vπ. Use TD(λ) as describedbefore.
❐ Actor: Needs eligibility traces for each state-action pair.❐ We change the update equation:
❐ Can change the other actor-critic update:
pt+1(s, a) =pt(s,a) +!" t if a = at and s = st
pt (s, a) otherwise
# $ %
),(),(),(1 aseaspasptttt
!"+=+to
pt+1(s, a) =pt(s,a) +!" t 1# $ (s, a)[ ] if a = at and s = st
pt(s,a) otherwise
% & '
to ),(),(),(1 aseaspasptttt
!"+=+
et(s, a) =
!"et#1(s, a) +1 # $
t(st,a
t) if s = s
t and a = a
t
!"et#1(s, a) otherwise
% & '
where

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 31
Replacing Traces
❐ Using accumulating traces, frequently visited states canhave eligibilities greater than 1 This can be a problem for convergence
❐ Replacing traces: Instead of adding 1 when you visit astate, set that trace to 1
et(s) =
!"et#1(s) if s $ s
t
1 if s = st
% & '

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 32
Replacing Traces Example
❐ Same 19 state random walk task as before❐ Replacing traces perform better than accumulating traces over more
values of λ

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 33
Why Replacing Traces?
❐ Replacing traces can significantly speed learning
❐ They can make the system perform well for a broader set ofparameters
❐ Accumulating traces can do poorly on certain types of tasks
Why is this task particularly onerousfor accumulating traces?

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 34
More Replacing Traces
❐ Off-line replacing trace TD(1) is identical to first-visit MC
❐ Extension to action-values: When you revisit a state, what should you do with the
traces for the other actions? Singh and Sutton say to set them to zero:
et(s, a) =
1
0
!"et#1(s, a)
$
% &
' &
if s = st and a = a
t
if s = st and a ( a
t
if s ( st

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 35
Implementation Issues
❐ Could require much more computation But most eligibility traces are VERY close to zero
❐ If you implement it in Matlab, backup is only one line ofcode and is very fast (Matlab is optimized for matrices)

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 36
Variable λ
❐ Can generalize to variable λ
❐ Here λ is a function of time Could define
et(s) =
!"tet#1(s) if s $ s
t
!"tet#1(s) +1 if s = s
t
% & '
!""""t
ttts == or )(

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 37
Conclusions
❐ Provides efficient, incremental way to combine MC andTD Includes advantages of MC (can deal with lack of
Markov property) Includes advantages of TD (using TD error,
bootstrapping)❐ Can significantly speed learning❐ Does have a cost in computation

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 38
Something Here is Not Like the Other
Related Documents











