CHAPTER 6 CHAPTER 6 Naive Bayes Models for Classification

CHAPTER 6 Naive Bayes Models for Classification. QUESTION????
Dec 13, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

CHAPTER 6CHAPTER 6
Naive Bayes Models for Classification

QUESTION????QUESTION????
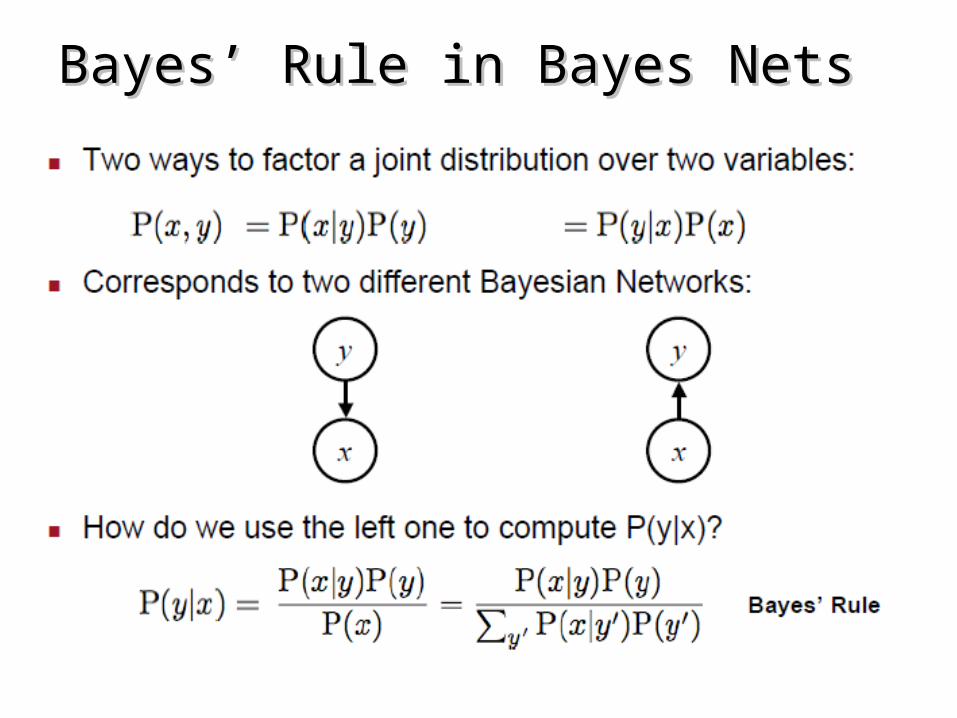
Bayes’ Rule in Bayes NetsBayes’ Rule in Bayes Nets

Combining EvidenceCombining Evidence

General Naïve BayesGeneral Naïve Bayes

Modeling with Naïve BayesModeling with Naïve Bayes

What to do with Naïve Bayes?What to do with Naïve Bayes?1. Create a Naïve Bayes model:
We need local probability estimates Could elicit them from a human Better: Estimate them from observations! This is called parameter estimation, or more generally learning
2. Use a Naïve Bayes model to estimate probability of causes given observations of effects: This is a specific kind of probabilistic inference Requires just a simple computation (next slide) From this we can also get the most likely cause, which is called prediction, or classification These are the basic tasks of machine learning!

Building Naïve Bayes ModelsBuilding Naïve Bayes Models
• What do we need to specify a Bayesian Network? Directed acyclic graph (DAG) Conditional probability tables (CPDs)
• How do we build a Naïve Bayes model?• We know the graph structure already (Why?)• Estimates of local conditional probability tables
(CPTs) P(C), the prior over causes P(E|C) for each evidence variable These typically come from observed data These probabilities are collectively called the
parameters of the model and denoted by θ

Review: Parameter EstimationReview: Parameter Estimation

A Spam FilterA Spam Filter

BaselinesBaselines• First task: get a baseline
Baselines are very simple “straw man” procedures
Help determine how hard the task is Help know what a “good” accuracy is
• Weak baseline: most frequent label classifier Gives all test instances whatever label was most
common in the training set E.g. for spam filtering, might label everything as
ham Accuracy might be very high if the problem is
skewed• For real research, usually use previous work as a (strong)
baseline

Naïve Bayes for TextNaïve Bayes for Text

Example: Spam FilteringExample: Spam Filtering
• Raw probabilities don’t affect the posteriors; relative probabilities (odds ratios) do:

Generalization and OverfittingGeneralization and Overfitting• Relative frequency parameters will overfit the training data!
Unlikely that every occurrence of “minute” is 100% spam Unlikely that every occurrence of “seriously” is 100% ham What about the words that don’t occur in the training set? In general, we can’t go around giving unseen events zero
probability
• As an extreme case, imagine using the entire email as the only feature Would get the training data perfect (if deterministic labeling) Wouldn’t generalize at all Just making the bag-of-words assumption gives us some generalization, but isn’t enough
• To generalize better: we need to smooth or regularize the estimates

Estimation: SmoothingEstimation: Smoothing• Problems with maximum likelihood estimates:
– If I flip a coin once, and it’s heads, what’s the
estimate for P(heads)?– What if I flip it 50 times with 27 heads?– What if I flip 10M times with 8M heads?
• Basic idea:– We have some prior expectation about
parameters (here, the probability of heads)– Given little evidence, we should skew towards prior– Given a lot of evidence, we should listen to the
data

Estimation: SmoothingEstimation: Smoothing

Estimation: Laplace SmoothingEstimation: Laplace Smoothing

Estimation: Laplace SmoothingEstimation: Laplace Smoothing

Estimation: Linear InterpolationEstimation: Linear Interpolation

Real NB: Smoothing

Spam ExampleSpam Example
Related Documents











