Chap6. Organizing Files for Performance

Chap6. Organizing Files for Performance. Chapter Objectives(1) Look at several approaches to data compression Look at storage compaction as a simple.
Dec 18, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Chap6. Organizing Files for Performance

Chapter Objectives(1)
Look at several approaches to data compression
Look at storage compaction as a simple way of reusing space in a file
Develop a procedure for deleting fixed-length records that allows vacated file space to be reused
dynamically
Illustrate the use of linked lists and stacks to manage an avail list
Consider several approaches to the problem of deleting variable-length records
Introduce the concepts associated with the terms internal fragmentation and external
fragmentation

Chapter Objectives(2)
Outline some placement strategies associated with the reuse of space in a variable-length record
file
Provide an introduction to the idea underlying a binary search
Undertake an examination of the limitations of binary searching
Develop a keysort procedure for sorting larger files; investigate the costs associated with keysort
Introduce the concept of a pinned record

Contents
6.1 Data compression
6.2 Reclaiming space in files
6.3 Finding things quickly: An Introduction to internal sorting and binary searching
6.4 Keysorting

Data Compression(1)
Reasons for data compression
less storage
transmitting faster, decreasing access time
processing faster sequentially

Data Compression(2):Using a different notation
Fixed-Length fields are good candidates
Decrease the # of bits by finding a more compact notationex) original state field notation is 16bits, but we can encode with 6bit notation because of the # of
all states are 50
Cons. unreadable by human cost in encoding time decoding modules => increase the complexity of s/w=> used for particular application

Data Compression(3):Suppressing repeating sequences
Run-length encoding algorithm
read through pixels, copying pixel values to file in sequence, except the same pixel
value occurs more than once in succession
when the same value occurs more than once in succession, substitute the following
three bytes
special run-length code indicator((ex) ff)
pixel value repeated
the number of times that value is repeated
– ex) 22 23 24 24 24 24 24 24 24 25 26 26 26 26 26 26 25 24
22 23 ff 24 07 25 ff 26 06 25 24

Data Compression(3):Suppressing repeating sequences
Run-length encoding (cont’d)
example of redundancy reduction
cons.
– not guarantee any particular amount of space savings
– under some circumstances, compressed image is larger than
original image
– Why? Can you prevent this?

Data Compression(4):Assigning variable-length codes
Morse code: oldest & most common scheme of variable-length code
Some values occur more frequently than others
that value should take the least amount of space
Huffman coding
base on probability of occurrence
– determine probabilities of each value occurring
– build binary tree with search path for each value
– more frequently occurring values are given shorter search paths in tree

Data Compression(5):Assigning variable-length codes
Huffman coding Letter: a b c d e f g
Prob: 0.4 0.1 0.1 0.1 0.1 0.1 0.1
Code: 1 010 011 0000 0001 0010 0011
ex) the string “abde”
101000000001

d(0000) e(0001) f(0010) g(0011)
b(010) c(011)
a(1)
Huffman Tree
0
0001
000 001

Data Compression(6):Irreversible compression techniques
Some information can be sacrificed
Less common in data files
Shrinking raster image
400-by-400 pixels to 100-by-100 pixels
1 pixel for every 16 pixels
Speech compression
voice coding (the lost information is of no little or no value)

Compression in UNIX
System V
pack & unpack use Huffman codes
after compress file, appends “.z” to end of packed file
Berkeley UNIX
compress & uncompress use Lempel-Ziv method
after compress file, appends “.Z” to end of compressed file

Record Deletion and Storage Compaction Storage compaction
record deletion : just marks each deleted record
reclamation of all deleted records

Deleting Fixed-length Records for Reclaiming Space Dynamically(1)
Reuse the space from deleted records as soon as possible deleted records must be marked in special way we could find the deleted space
To make record reuse quickly, we need a way to know immediately if there are empty slots in the file a way to jump directly to one of those slots if they exist=> Linked lists or Stacks for avail list* avail list : a list that is made up of deleted records

Deleting Fixed-length Records for Reclaiming Space Dynamically(2)
Linked List
Stack

Deleting Fixed-length Records for Reclaiming Space Dynamically(3)
Linking and stacking deleted records
arranging and rearranging links are used to make one available record slot
point to the next
second field of deleted record points to next record
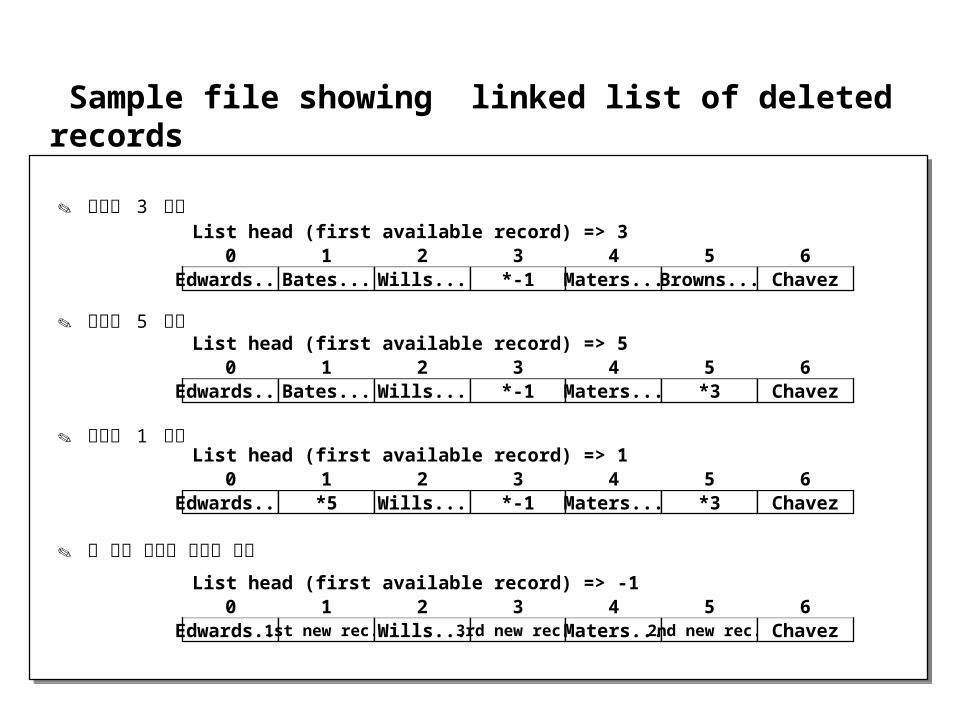
Sample file showing linked list of deleted records
Edwards...
레코드 3 삭제
레코드 5 삭제
레코드 1 삭제
세 개의 새로운 레코드 삽입
레코드 3 삭제
레코드 5 삭제
레코드 1 삭제
세 개의 새로운 레코드 삽입
Edwards... Bates... Wills... *-1 Maters... Browns... Chavez0 1 2 3 4 5 6
List head (first available record) => 3
Edwards... Bates... Wills... *-1 Maters... *3 Chavez0 1 2 3 4 5 6
List head (first available record) => 5
Edwards... *5 Wills... *-1 Maters... *3 Chavez0 1 2 3 4 5 6
List head (first available record) => 1
Edwards... 1st new rec.. Wills... 3rd new rec.. Maters... 2nd new rec.. Chavez0 1 2 3 4 5 6
List head (first available record) => -1

Deleting Variable-length Records
Avail list of variable-length records
it has byte count of record at beginning of each record
use byte offset instead of RRN
Adding and removing records
in adding records, search through avail list for right size (=>big enough)
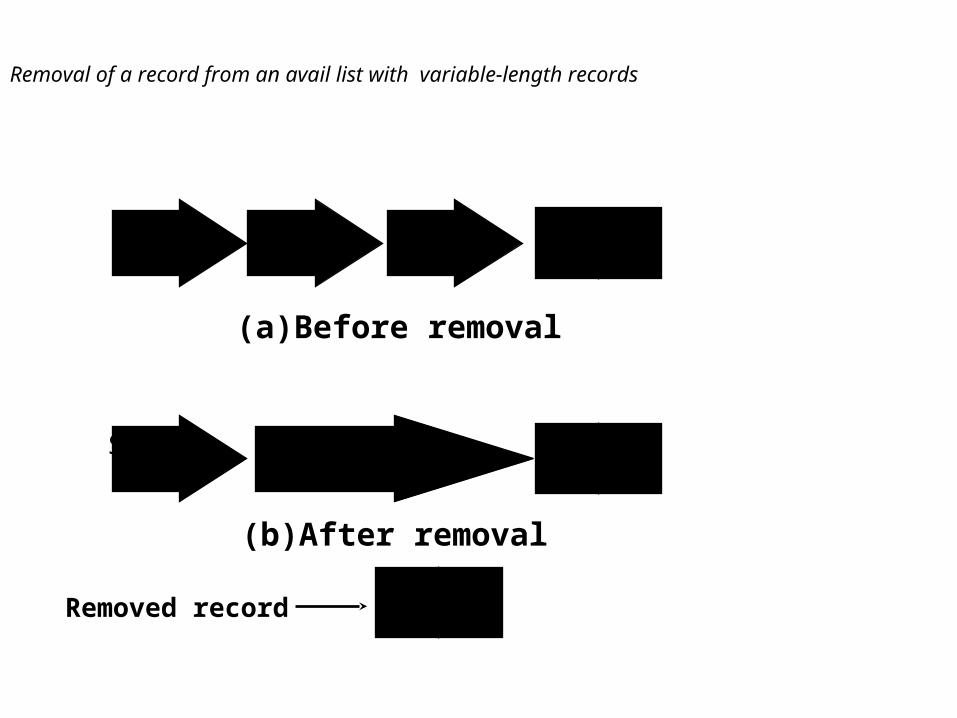
Size47
Size38
Size72
Size68
-1
Size47
Size68
-1Size38
Size72
New Link
Removed record
(a)Before removal
(b)After removal
Removal of a record from an avail list with variable-length records

Storage Fragmentation
Internal fragmentation (in fixed-length record)
waste space within a record
in variable-length records, minimize wasted space by doing away with internal
fragmentation
External fragmentation (in variable-length record)
unused space outside or between individual records
three possible solutions
storage compaction
coalescing the holes: a single, larger record slot
minimizing fragmentation by adopting placement strategy
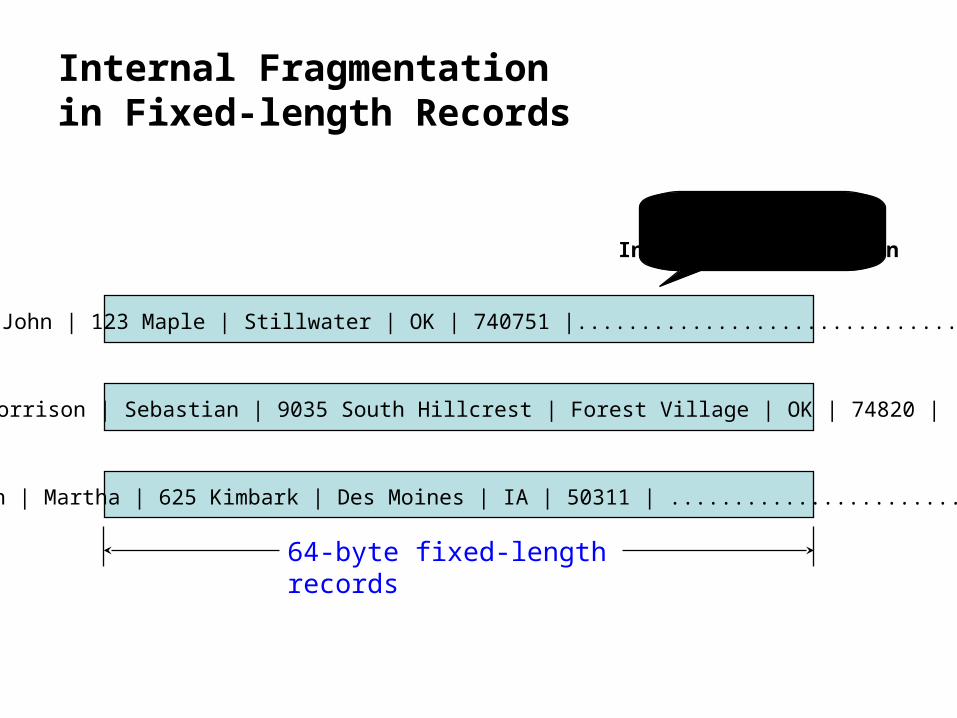
Internal Fragmentationin Fixed-length Records
Ames | John | 123 Maple | Stillwater | OK | 740751 |...................................
Morrison | Sebastian | 9035 South Hillcrest | Forest Village | OK | 74820 |
Brown | Martha | 625 Kimbark | Des Moines | IA | 50311 | .........................
64-byte fixed-length records
Unused space ->
Internal fragmentation

External Fragmentationin Variable-length Records
40 Ames | Jone | 123 Maple | Stillwater | OK | 740751 | 64 Morrison | Sebastian |
9035 South Hillcrest | Forest Village | OK | 74820 | 45 Brown | Martha | 625 Kimb
bark | Des Moines | IA | 50311 |
Record[1] Record[2]
Record[3]
ex) Delete Record[2] and Insert New Record[i] : 12-byte unused space
52 Adams | Kits | 3301 Washington D.C | Forest Village | IA | 43563 |
External fragmentation
recordlength
Record[i]

Placement Strategies
First-fit
select the first available record slot
suitable when lost space is due to internal fragmentation
Best-fit
select the available record slot closest in size
avail list in ascending order
suitable when lost space is due to internal fragmentation
Worst-fit
select the largest record slot
avail list in descending order
suitable when lost space is due to external fragmentation

Finding Things Quickly(1)
Goal: Minimize the number of disk accesses Finding things in simple field and record files may have many seeks Binary search algorithm for fixed-sized record
int BinarySearch(FixedRecordFile &file, RecType &obj, KeyType &key)// binary search for key.{
int low = 0; int high = file.NumRecs() - 1;while (low <= high){
int guess = (high - low)/2;file.ReadByRRN(obj, guess);if(obj.Key () == key) return 1; // record foundif(obj.Key() < key) high = guess - 1; // search before guesselse low = guess + 1; // search after guess
}return 0; // loop ended without finding key
}

Classes and Methods for Binary Search
Class KeyType {public
int operator == (KeyType &);
int operator < (KeyType &);
};
class RecType {public: KeyType Key();};
class FixedRecordFile{public:
int NumRecs();
int ReadByRRN (RecType & Record, int RRN);
};

Finding Things Quickly(2)
Binary search vs. Sequential search
binary search
– O(log n)
– list is sorted by key
sequential search
– O(n)

Finding Things Quickly(3)
Sorting a disk file in RAM
read the entire file from disk to memory
use internal sort (=sort in memory)
– UNIX sort utility uses internal sort
Limitations of binary search & internal sort
binary search requires more than one or two access c.f.) single access
by RRN
keeping a file sorted is very expensive
an internal sort works only on small files
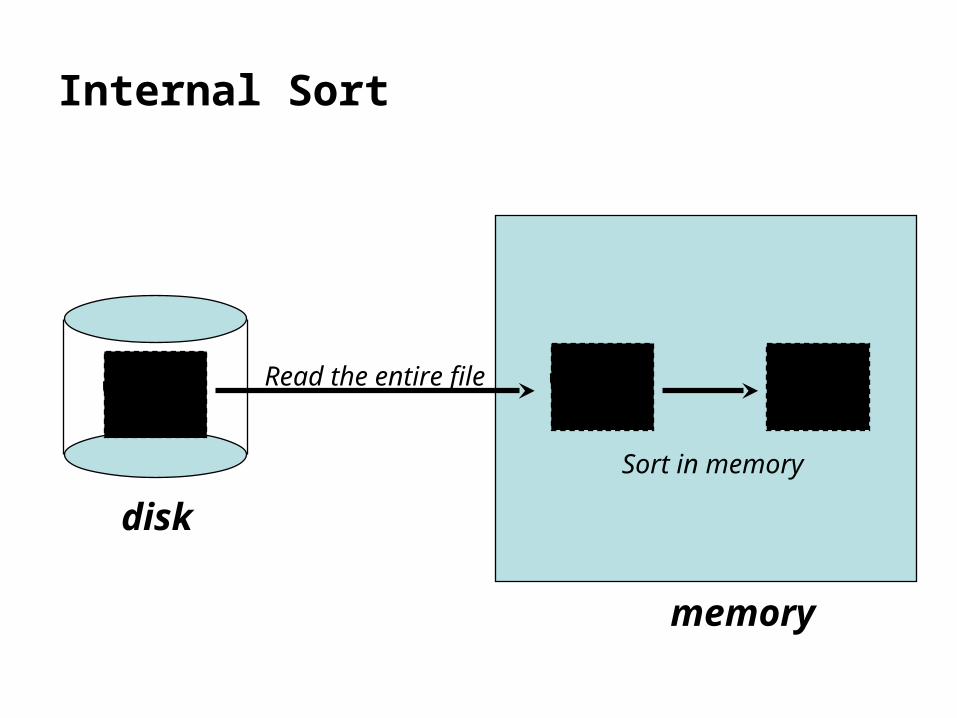
Internal Sort
unsortedfile
unsortedfile
sortedfile
Read the entire file
Sort in memory
disk
memory

Key Sorting & Its Limitations
So called, “tag sort” : sorted thing is “key” only Sorting procedure
Read only the keys into memory Sort the keys Rearrange the records in file by the sorted keys
Advantage less RAM than internal sort
Disadvantages(=Limitations) reading records in disk twice is required a lot of seeking for records for constructing a new(sorted) file

12
3
k
HARRISON
KELLOG
HARRIS
BELL
.
.
.
.
Harrison|Susan|387 Eastern....
Kellog|Bill|17 Maple....
Harris|Margaret|4343 West....
Bell|Robert|8912 Hill....
KEY RRN Records
In RAM On secondary storage
k3
1
2
HARRISON
KELLOG
HARRIS
BELL
.
.
.
.
Harrison|Susan|387 Eastern....
Kellog|Bill|17 Maple....
Harris|Margaret|4343 West....
Bell|Robert|8912 Hill....
KEY RRN Records
Conceptualview
after sortingkeys
in RAM
Conceptualview
beforesorting
KEYNODES array

Pseudocode for keysort(1) Program: keysort
open input file as IN_FILE create output file as OUT_FILE
read header record from IN_FILE and write a copy to OUT_FILE REC_COUNT := record count from header record /* read in records; set up KEYNODES array */ for i := 1 to REC_COUNT
read record from IN_FILE into BUFFER extract canonical key and place it in KEYNODES[i].KEY KEYNODES[i].KEY = i
(continued....)

Pseudocode for keysort(2)
/* sort KEYNODES[].KEY, thereby ordering RRNs correspondingly */
sort(KEYNODES, REC_COUNT)
/* read in records according to sorted order, and write them out in this
order */
for i := 1 to REC_COUNT
seek in IN_FILE to record with RRN of KEYNODES[I].RRN write BUFFER contents to OUT_FILE
close IN_FILE and OUT_FILE end PROGRAM
Two Solutions:why bother to write the file back?
Write out sorted KEYNODES[] array without writing records back in sorted order
KEYNODES[] array is used as index file
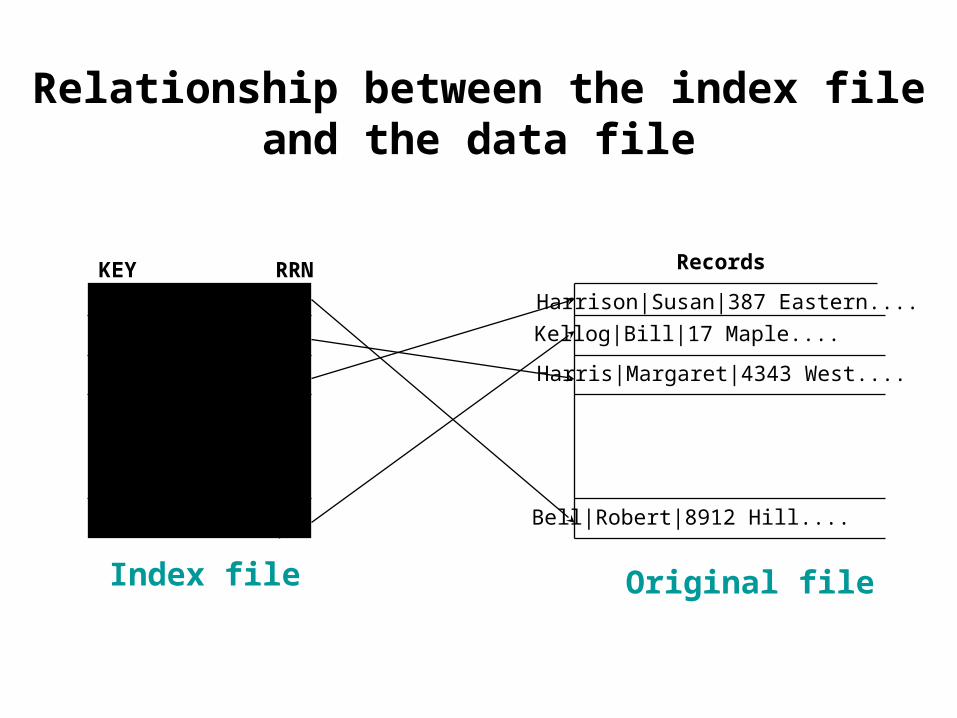
k3
1
2
HARRISON
KELLOG
HARRIS
BELL
.
.
.
.
Harrison|Susan|387 Eastern....
Kellog|Bill|17 Maple....
Harris|Margaret|4343 West....
Bell|Robert|8912 Hill....
KEY RRN Records
Index file Original file
Relationship between the index file and the data file

Pinned records(1)
Records that are referenced to physical location of themselves by other records
Not free to alter physical location of records for avoiding dangling references
Pinned records make sorting more difficult and sometimes impossible
solution: use index file, while keeping actual data file in original order
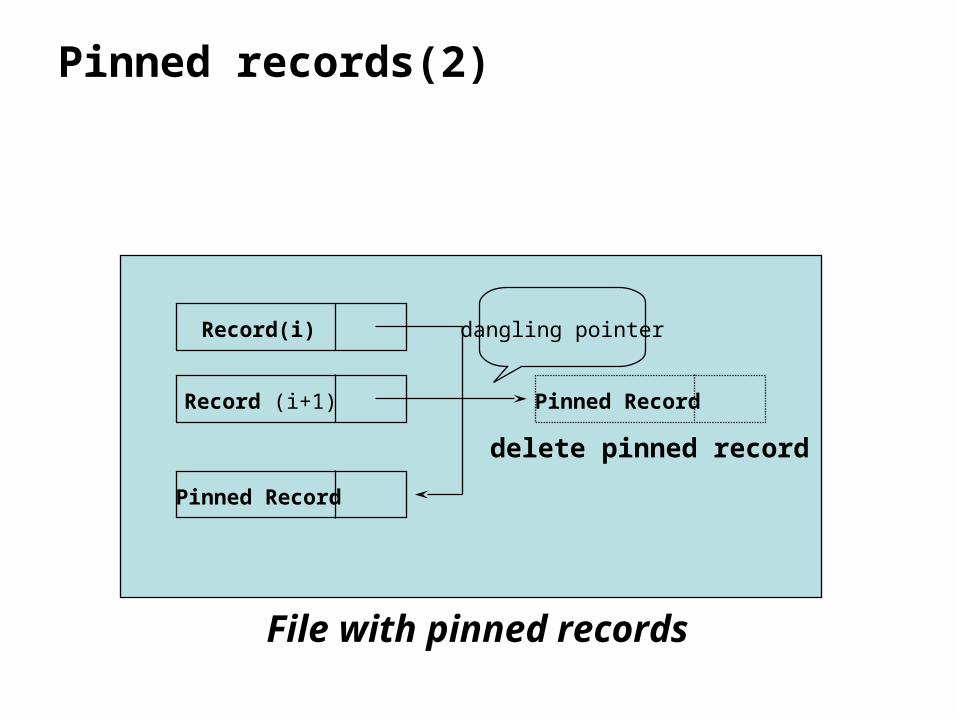
Pinned records(2)
File with pinned records
Record(i)
Pinned Record
Record (i+1) Pinned Record
delete pinned record
dangling pointer

Let’s Review !!!
6.1 Data compression
6.2 Reclaiming space in files
6.3 Finding things quickly: An Introduction to internal sorting and binary searching
6.4 Keysorting
Related Documents











