
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript


2 Ceph Tech Talks: CephFS
Agenda
● Recap: CephFS architecture
● What's new for Jewel?● Scrub/repair● Fine-grained authorization● RADOS namespace support in layouts● OpenStack Manila● Experimental multi-filesystem functionality
3 Ceph Tech Talks: CephFS
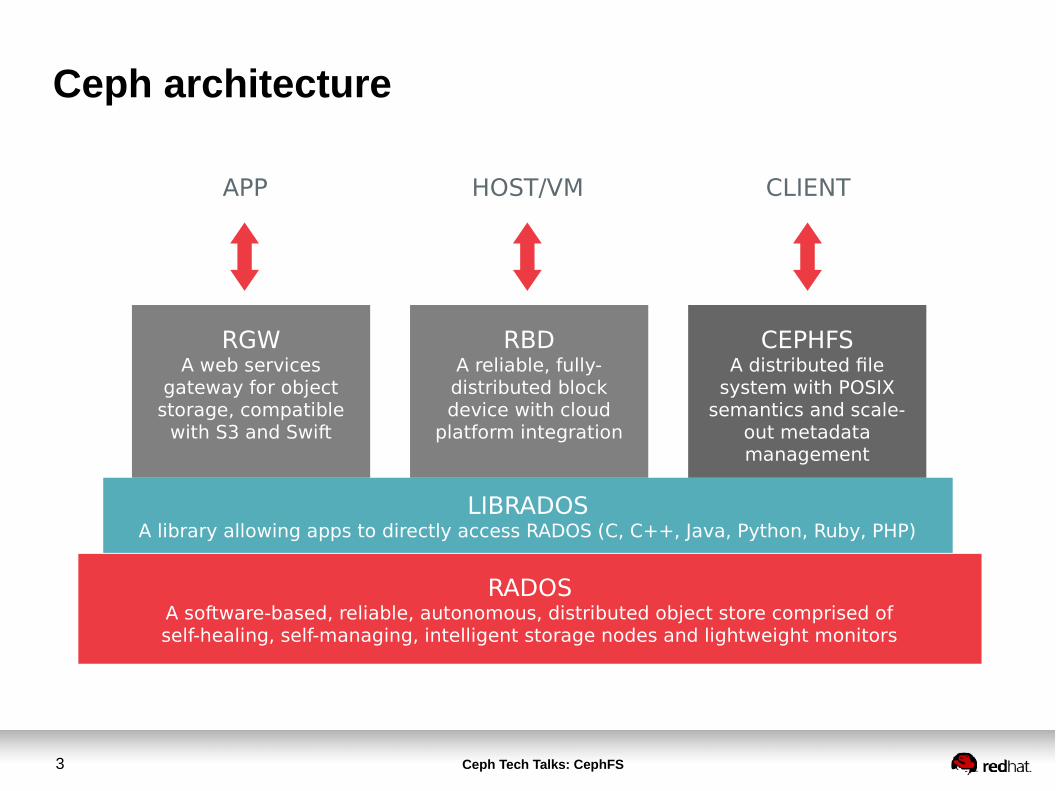
Ceph architecture
RGWA web services
gateway for object storage, compatible
with S3 and Swift
LIBRADOSA library allowing apps to directly access RADOS (C, C++, Java, Python, Ruby, PHP)
RADOSA software-based, reliable, autonomous, distributed object store comprised ofself-healing, self-managing, intelligent storage nodes and lightweight monitors
RBDA reliable, fully-distributed block device with cloud
platform integration
CEPHFSA distributed file
system with POSIX semantics and scale-
out metadata management
APP HOST/VM CLIENT

4 Ceph Tech Talks: CephFS
CephFS
● POSIX interface: drop in replacement for any local or network filesystem
● Scalable data: files stored directly in RADOS
● Scalable metadata: cluster of metadata servers
● Extra functionality: snapshots, recursive statistics
● Same storage backend as object (RGW) + block (RBD): no separate silo needed for file

5Ceph Tech Talks: CephFS
Components
Linux host
M M
M
Ceph server daemons
CephFS client
datametadata 0110
M
OSD
Monitor
MDS

6 Ceph Tech Talks: CephFS
Why build a distributed filesystem?
● Existing filesystem-using workloads aren't going away
● POSIX filesystems are a lingua-franca, for administrators as well as applications
● Interoperability with other storage systems in data lifecycle (e.g. backup, archival)
● New platform container “volumes” are filesystems
● Permissions, directories are actually useful concepts!

7 Ceph Tech Talks: CephFS
Why not build a distributed filesystem?
● Harder to scale than object stores, because entities (inodes, dentries, dirs) are related to one another, good locality needed for performance.
● Some filesystem-using applications are gratuitously inefficient (e.g. redundant “ls -l” calls, using files for IPC) due to local filesystem latency expectations
● Complexity resulting from stateful clients e.g. taking locks, opening files requires coordination and clients can interfere with one another's responsiveness.

8 Ceph Tech Talks: CephFS
CephFS in practice
ceph-deploy mds create myserver
ceph osd pool create fs_data
ceph osd pool create fs_metadata
ceph fs new myfs fs_metadata fs_data
mount -t ceph x.x.x.x:6789 /mnt/ceph

9Ceph Tech Talks: CephFS
Scrub and repair

10 Ceph Tech Talks: CephFS
Scrub/repair status
● In general, resilience and self-repair is RADOS's job: all CephFS data & metadata lives in RADOS objects
● CephFS scrub/repair is for handling disasters: serious software bugs, or permanently lost data in RADOS
● In Jewel, can now handle and recover from many forms of metadata damage (corruptions, deletions)
● Repair tools require expertise: primarily for use during (rare) support incidents, not everyday user activity

11 Ceph Tech Talks: CephFS
Scrub/repair: handling damage
● Fine-grained damage status (“damage ls”) instead of taking whole rank offline
● Detect damage during normal load of metadata, or during scrub
ceph tell mds.<id> damage ls
ceph tell mds.<id> damage rm
ceph mds 0 repaired
● Can repair damaged statistics online: other repairs happen offline (i.e. stop MDS and writing directly to metadata pool)

12 Ceph Tech Talks: CephFS
Scrub/repair: online scrub commands
● Forward scrub: traversing metadata from root downwards
ceph daemon mds.<id> scrub_path
ceph daemon mds.<id> scrub_path recursive
ceph daemon mds.<id> scrub_path repair
ceph daemon mds.<id> tag path
● These commands will give you success or failure info on completion, and emit cluster log messages about issues.

13 Ceph Tech Talks: CephFS
Scrub/repair: offline repair commands
● Backward scrub: iterating over all data objects and trying to relate them back to the metadata
● Potentially long running, but can run workers in parallel
● Find all the objects in files:● cephfsdatascan scan_extents
● Find (or insert) all the files into the metadata:● cephfsdatascan scan_inodes

14 Ceph Tech Talks: CephFS
Scrub/repair: parallel execution
● New functionality in RADOS to enable iterating over subsets of the overall set of objects in pool.
● Currently one must coordinate collection of workers by hand (or a short shell script)
● Example: invoke worker 3 of 10 like this:● cephfsdatascan scan_inodes –worker_n 3 –worker_m 10

15 Ceph Tech Talks: CephFS
Scrub/repair: caveats
● This is still disaster recovery functionality: don't run “repair” commands for fun.
● Not multi-MDS aware: commands operate directly on a single MDS's share of the metadata.
● Not yet auto-run in background like RADOS scrub

16Ceph Tech Talks: CephFS
Fine-grained authorisation

17 Ceph Tech Talks: CephFS
CephFS authorization
● Clients need to talk to MDS daemons, mons and OSDs.
● OSD auth caps enable limiting clients to use only particular data pools, but couldn't control which parts of filesystem metadata they saw
● New MDS auth caps enable limiting access by path and uid.

18 Ceph Tech Talks: CephFS
MDS auth caps
● Example: we created a dir `foodir` that has its layout set to pool `foopool`. We create a client key 'foo' that can only see metadata within that dir and data within that pool.
ceph auth getorcreate client.foo \
mds “allow rw path=/foodir” \
osd “allow rw pool=foopool” \
mon “allow r”
● Client must mount with “-r /foodir”, to treat that as its root (doesn't have capability to see the real root)

19Ceph Tech Talks: CephFS
RADOS namespaces in file layouts

20 Ceph Tech Talks: CephFS
RADOS namespaces
● Namespaces offer a cheaper way to divide up objects than pools.
● Pools consume physical resources (i.e. they create PGs), whereas namespaces are effectively just a prefix to object names.
● OSD auth caps can be limited by namespaces: when we need to isolate two clients (e.g. two cephfs clients) we can give them auth caps that allow access to different namespaces.

21 Ceph Tech Talks: CephFS
Namespaces in layouts
● Existing fields: pool, stripe_unit, stripe_count, object_size
● New field: pool_namespace● setfattr n ceph.file.layout.pool_namespace v <ns>
● setfattr n ceph.dir.layout.pool_namespace v <ns>
● As with setting layout.pool, the data gets written there, but the backtrace continues to be written to the default pool (and default namespace). Backtrace not accessed by client, so doesn't affect client side auth configuration.

22Ceph Tech Talks: CephFS
OpenStack Manila

23 Ceph Tech Talks: CephFS
Manila
● The OpenStack shared filesystem service
● Manila users request filesystem storage as shares which are provisioned by drivers
● CephFS driver implements shares as directories:
● Manila expects shares to be size-constrained, we use CephFS Quotas
● Client mount commands includes -r flag to treat the share dir as the root
● Capacity stats reported for that directory using rstats● Clients restricted to their directory and
pool/namespace using new auth caps
24 Ceph Tech Talks: CephFS
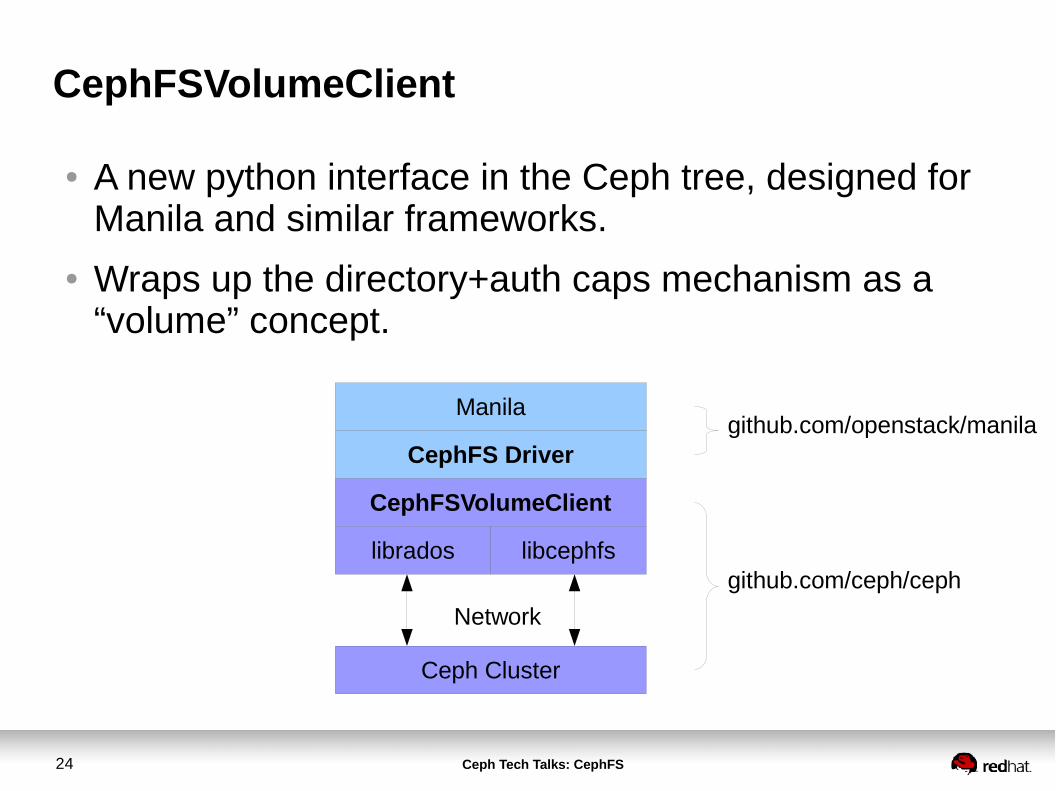
CephFSVolumeClient
● A new python interface in the Ceph tree, designed for Manila and similar frameworks.
● Wraps up the directory+auth caps mechanism as a “volume” concept.
Manila
CephFS Driver
CephFSVolumeClient
librados libcephfs
Ceph Cluster
Network
github.com/openstack/manila
github.com/ceph/ceph

25Ceph Tech Talks: CephFS
Experimental multi-filesystem functionality

26 Ceph Tech Talks: CephFS
Multiple filesystems
● Historical 1:1 mapping between Ceph cluster (RADOS) and Ceph filesystem (cluster of MDSs)
● Artificial limitation: no reason we can't have multiple CephFS filesystems, with multiple MDS clusters, all backed onto one RADOS cluster.
● Use case ideas:● Physically isolate workloads on separate MDS clusters
(vs. using dirs within one cluster)● Disaster recovery: recover into a new filesystem on the
same cluster, instead of trying to do in-place● Resilience: multiple filesystems become separate failure
domains in case of issues.

27 Ceph Tech Talks: CephFS
Multiple filesystems initial implementation
● You can now run “fs new” more than once (with different pools)
● Old clients get the default filesystem (you can configure which one that is)
● New userspace client config opt to select which filesystem should be mounted
● MDS daemons are all equal: any one may get used for any filesystem
● Switched off by default: must set a special flag to use this (like snapshots, inline data)

28 Ceph Tech Talks: CephFS
Multiple filesystems future work
● Enable use of RADOS namespaces (not just separate pools) for different filesystems to avoid needlessly creating more pools
● Authorization capabilities to limit MDS and clients to particular filesystems
● Enable selecting FS in kernel client
● Enable manually configured affinity of MDS daemons to filesystem(s)
● More user friendly FS selection in userspace client (filesystem name instead of ID)

29Ceph Tech Talks: CephFS
Wrap up

30 Ceph Tech Talks: CephFS
Tips for early adopters
http://ceph.com/resources/mailing-list-irc/
http://tracker.ceph.com/projects/ceph/issues
http://ceph.com/docs/master/rados/troubleshooting/log-and-debug/
● Does the most recent development release or kernel fix your issue?
● What is your configuration? MDS config, Ceph version, client version, kclient or fuse
● What is your workload?
● Can you reproduce with debug logging enabled?

31Ceph Tech Talks: CephFS
Questions?
Related Documents











