UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática MS Jaime Carlos Porras Cerrón [email protected] 87 Capítulo IV DISTRIBUCIONES MUESTRALES "Es mucho mejor una respuesta aproximada a la pregunta correcta, la cual es comúnmente vaga, que la respuesta correcta a la pregunta errónea, la cual siempre puede hacerse de una forma precisa." John W. Tukey Introducción El desarrollo del análisis estadístico comprende el manejo de ciertos conceptos que servirán para afianzar el entendimiento de técnicas cada vez más complejas. En el análisis estadístico es muy importante conocer la teoría correspondiente a las distribuciones muestrales de una media, de una varianza, una proporción, de diferencia de medias, de diferencia de proporciones, etc. Esto permitirá un mejor entendimiento de los intervalos de confianza y pruebas de hipótesis. En la aplicación de algunos conceptos se tiene que hacer uso de programas estadísticos como R o Minitab. El presente capitulo tiene como objetivo fundamental desarrollar algunos conceptos y teoremas importantes en estadística, los cuales serán presentados desde un punto de vista aplicativo. En cursos posteriores de la carrera se complementará esta teoría con el respectivo desarrollo matemático. 1. Muestra Aleatoria Se dice que un conjunto de n variables aleatorias (v.a.) n X X X ..., , , 2 1 forman una muestra aleatoria (m.a.) de tamaño n seleccionada de la población en estudio, si verifica las siguientes relaciones entre sus elementos: a) Las v.a. n X X X ..., , , 2 1 son independientes. b) Todas las v.a. i X tienen la misma distribución de probabilidad, esto es: i X X F x F x PX x 1, 2, , i n . Es decir las v.a. i X 1, 2, , i n son independientes e idénticamente distribuidas (i,i.d.) con la misma distribución de probabilidad que tenga la población. Si el muestreo es con reemplazo o de una población infinita (conceptual), las condiciones a) y b) se satisfacen exactamente. Si la selección es sin reemplazo la condición de independencia no se cumple, pues la probabilidad de selección no se mantiene constante. A esta muestra se la refiere como muestra aleatoria simple. La parte fundamental de la definición de la m.a. es el significado de las variables aleatorias n X X X ..., , , 2 1 . La variable aleatoria i X de la muestra denota el valor numérico del i-ésimo elemento muestreado. Después que la muestra ha sido seleccionada, los valores actuales de n X X X ..., , , 2 1 son conocidos y usualmente estos valores se denotan por 1 , ..., n x x .

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
87
Capítulo IV
DISTRIBUCIONES MUESTRALES "Es mucho mejor una respuesta aproximada a la pregunta correcta, la cual es
comúnmente vaga, que la respuesta correcta a la pregunta errónea, la cual siempre puede hacerse de una forma precisa."
John W. Tukey
Introducción El desarrollo del análisis estadístico comprende el manejo de ciertos conceptos que servirán para afianzar el entendimiento de técnicas cada vez más complejas. En el análisis estadístico es muy importante conocer la teoría correspondiente a las distribuciones muestrales de una media, de una varianza, una proporción, de diferencia de medias, de diferencia de proporciones, etc. Esto permitirá un mejor entendimiento de los intervalos de confianza y pruebas de hipótesis. En la aplicación de algunos conceptos se tiene que hacer uso de programas estadísticos como R o Minitab. El presente capitulo tiene como objetivo fundamental desarrollar algunos conceptos y teoremas importantes en estadística, los cuales serán presentados desde un punto de vista aplicativo. En cursos posteriores de la carrera se complementará esta teoría con el respectivo desarrollo matemático.
1. Muestra Aleatoria
Se dice que un conjunto de n variables aleatorias (v.a.) nXXX ...,,, 21 forman
una muestra aleatoria (m.a.) de tamaño n seleccionada de la población en estudio, si verifica las siguientes relaciones entre sus elementos:
a) Las v.a. nXXX ...,,, 21 son independientes.
b) Todas las v.a. iX tienen la misma distribución de probabilidad, esto es:
iX XF x F x P X x 1,2, ,i n .
Es decir las v.a. iX 1,2, ,i n son independientes e idénticamente distribuidas
(i,i.d.) con la misma distribución de probabilidad que tenga la población. Si el muestreo es con reemplazo o de una población infinita (conceptual),
las condiciones a) y b) se satisfacen exactamente. Si la selección es sin reemplazo la condición de independencia no se
cumple, pues la probabilidad de selección no se mantiene constante. A esta muestra se la refiere como muestra aleatoria simple.
La parte fundamental de la definición de la m.a. es el significado de las
variables aleatorias nXXX ...,,, 21 . La variable aleatoria iX de la muestra
denota el valor numérico del i-ésimo elemento muestreado. Después que la
muestra ha sido seleccionada, los valores actuales de nXXX ...,,, 21 son
conocidos y usualmente estos valores se denotan por 1, ..., nx x .

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
88
Ejemplo. Los pesos de un artículo tienen distribución normal con media 2 Kg. y varianza
1.5 kg2. Si se extrae una muestra aleatoria de tamaño 10 ( 1021 ...,,, XXX ).
a) Halle 1 3 5 9 4.5P X X X X
1 3 5 9Y X X X X
( ) 2 2 2 2 4Y E Y 2 1.5 1.5 1.5 1.5 6Y
4.5 4
1 0.2041 0.41916
Y
Y
YP P Z
1-pnorm(4.5,4,sqrt(6))
[1] 0.4191282
b) ¿Cuál es la probabilidad de que el total de los pesos de los artículos sea
inferior o igual a 21 kg?
1 10...Y X X
( ) 2 10 20Y E Y 2 1.5 10 15Y
21 20
0.258 0.601815
Y
Y
YP P Z
pnorm(21,20,sqrt(15))
[1] 0.6018733
2. Estadística o Estadígrafo.
Es cualquier función real o vectorial de los elementos de una m.a. nXXX ...,,, 21
la cual no contiene parámetros desconocidos y se denota por 1, , nT t X X
No se debe confundir este concepto con valor estadístico, el cual es cualquier cantidad cuyo valor se puede calcular a partir de datos muestrales. Antes de obtener la información, hay incertidumbre en cuanto a cuál será el resultado del valor estadístico.Por lo tanto un valor estadístico es una variable aleatoria y estará denotada por una letra mayúscula; una minúscula se emplea para
representar el valor calculado del valor estadístico. Así, la media muestral X es un valor estadístico (variable aleatoria) y x es un valor calculado. También la
varianza muestral 2S es un valor estadístico (variable aleatoria) y 2s es un valor calculado. Ejemplo:
Sea 1, ..., nX X una m.a. extraída de una población cuya función de densidad de
probabilidad es ,f x ( es un parámetro de la población), entonces las
siguientes estadísticas son de gran interés para hacer inferencia con relación a los parámetros de la población.

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
89
11 1 1, ,
n
i
in
X
T t X X Xn
(media muestral)
2
2 12 2 1, ,
1
n
i
in
X X
T t X X Sn
(variancia muestral)
3 3 1 11, , min , ,n nT t X X X X X (mínimo valor de la muestra)
4 4 1 1, , max , ,n nnT t X X X X X (máximo valor de la muestra)
5 5 1 1, , n n
T t X X R X X (amplitud total de la muestra)
6 6 1 75 25, , nT t X X ric P P (rango intercuartil de la muestra)
2
2 1 17 7 1, , , ;
1
n n
i i
i in
X X X
T t X X X Sn n
3. Distribuciones Muestrales Es la distribución de probabilidad de una estadística, la cual se genera a partir de todas las posibles muestras de tamaño fijado, elegidas al azar de una población determinada. En el caso de una población seria todas las muestras de tamaño n , para
generar la distribución de X , 2S , p , etc.
En el caso de dos poblaciones independientes, todas las muestras de tamaño
1n de la primera población con todas las muestras de tamaño 2n de la segunda
población, para generar la distribución de 1 2X X , 1 2p p , 2 2
1 2S S .
En el caso de dos poblaciones dependientes, todas las muestras de tamaño n
de la diferencia i i iD X Y , para generar la distribución de DX .
Esquemáticamente tendríamos el siguiente procedimiento:
Una población P, con cierto parámetro de interés.
P θ
…
T1=t1(x1,x2,…,xn)
T2=t2(x1,x2,…,xn)
Tb=tb(x1,x2,…,xn) θ t
fT(t)

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
90
Todas las b muestras elegidas de la población de acuerdo a cierto procedimiento.
Para cada muestra, se calcula el valor t de la estadística. Los valores de t forman una nueva población, cuya distribución recibe el
nombre de distribución muestral de T.
Cuando la población es infinita, tenemos que concebir la distribución muestral como una distribución muestral teórica, pues es imposible extraer todas las muestras aleatorias posibles. Cuando la población es finita y de tamaño moderado, podemos construir una distribución muestral experimental, seleccionando todas las muestras aleatorias posibles de un tamaño dado, calculando para cada muestra el valor de la estadística junto con su probabilidad de ocurrencia. En general, cuando estudiamos una distribución muestral, estamos interesados en conocer las siguientes características:
Su forma funcional (representación grafica de su función de densidad) Su media Su desviación estándar.
4.1 Distribución muestral de la media
Es la distribución que se forma con los promedios muestrales que se obtienen de cada una de las muestras posibles de tamaño n que se puede extraer de
una población de tamaño N . Teorema
Si de una población P de tamaño N con media X y varianza 2
X , se extraen
todas las m.a.posibles nXXX ...,,, 21 de tamaño n y para cada una de ellas se
calcula el promedio, entonces: Si el muestreo es con reemplazo de una población finita o sin reemplazo de
una población infinita, se cumple que:
XXE X y
22 X
XVar X
n
Si el muestreo es sin reemplazo de una población de tamaño N, se cumple que:
XXE X y
22
1
X
X
N nVar X
n N
1N
nNse conoce como factor de corrección de población finita (fcpf).
En el caso que el muestreo es sin reemplazoy si el tamaño de la población es
grande, entonces el f.c.p.f. puede ser expresado por 1 1N n n
fN N
.
Donde f es conocida como la fracción de muestreo, lo que conlleva a que por

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
91
fines prácticos si 0.05f , elf.c.p.f. puede ser omitido y por lo tanto
2
2 X
XVar X
n
Ejemplo Suponga que los ingresos mensuales (en nuevos soles) en el mes de febrero de todas las empresas agroindustriales existentes en Ica son: 50000, 60000, 70000, 70000 y 80000.
La población 50000, 60000, 70000, 70000, 80000.P tiene los siguientes
parámetros:
1 50000+60000+70000+70000 + 8000066000
5
N
i
i
X
N
2
2 1 104000000
N
i
i
X
N
a) Seleccione sin reemplazo todas las muestras posibles de tamaño 2, determine
la media y variancia de la distribución muestral de X . Si el muestreo se hace sin reemplazo en una población finita de tamaño N y si el orden en que se seleccionan las muestras no tiene importancia, el número
de todas las muestras posibles de tamaño nesta dado por N
n
.
Para nuestro caso tendríamos 5
102
muestras posibles
R ingre=c(50000, 60000, 70000, 70000, 80000)
ingre=as.matrix(ingre)
library(sampling)
msr=writesample(2,5)
promsr=(msr%*%ingre)/2
tablasr=table(promsr)/10
b) Seleccione con reemplazo todas las muestras posibles de tamaño 2, determine
la media y variancia de la distribución muestral de X . Si el muestreo se hace con reemplazo en una población finita de tamaño N, el
número de todas las muestras posibles de tamaño nestá dado por nN .
Para nuestro caso tendríamos 25 25 muestras posibles R # Esta función en R para obtener una distribución de la
media aproximada
srswr(2,5)
mcr=matrix(0,25,5)
for (i in 1:25)

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
92
{
mcr[i,] = srswr(2,5)
}
promcr=(mcr%*%ingre)/2
tablacr=table(promcr)/25
4.2 Distribución de la media o promedio muestral cuando la variable en
análisis tiene una Distribución Normal Teorema
Si nXXX ...,,, 21 es una muestra aleatoria de tamaño n, donde iX es extraída de
una distribución normal con media X y varianza 2
X ; entonces la variable
aleatoria X tiene una distribución normal con media X
y varianza 2
X (donde
la varianza de X depende del tipo de muestreo es decir si es multiplicado o no por el factor de corrección de población finita)
Es decir, si 2,~ XXNX 2,~XX
NX
Entonces X se estandariza de la siguiente forma ~ (0,1)X
X
XZ N
4.3 Distribución de la media o promedio muestral, cuando la variable en
análisis no tiene una distribución normal. Teorema Central del Límite
Si nXXX ...,,, 21 es una muestra aleatoria de una distribución (distinta a la
distribución normal) con media X y varianza 2
X , entonces, para n
suficientemente grande (n≥ 30) X tiene una distribución aproximadamente
normal con media X
y varianza 2
X (donde la varianza de X depende del
tipo de muestreo para que pueda ser multiplicado por el factor de corrección de población finita).
Es decir, si 2~ ? ,X XX y se extrae una muestra n (donde 30n )
2~ ( , )X X
aX N
Por lo tanto la estandarización de X seria ~ (0,1)X
aX
XZ N
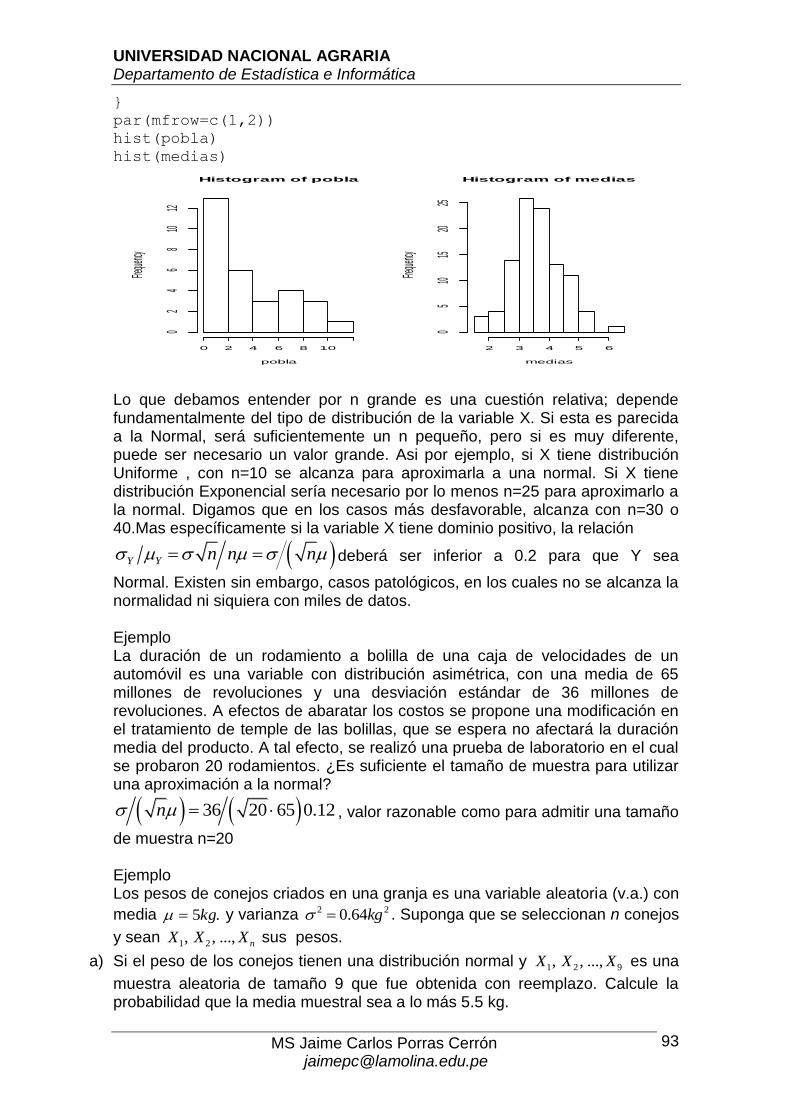
Un programa en R que simula el Teorema Central del Límite N=30
n=10
nm=choose(N,n)
pobla=rexp(N,1/5)
pobla
medias=rep(0,100)
for (i in 1:100)
{
medias[i]=mean(sample(pobla,n,replace=F))
UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
93
}
par(mfrow=c(1,2))
hist(pobla)
hist(medias)
Lo que debamos entender por n grande es una cuestión relativa; depende fundamentalmente del tipo de distribución de la variable X. Si esta es parecida a la Normal, será suficientemente un n pequeño, pero si es muy diferente, puede ser necesario un valor grande. Asi por ejemplo, si X tiene distribución Uniforme , con n=10 se alcanza para aproximarla a una normal. Si X tiene distribución Exponencial sería necesario por lo menos n=25 para aproximarlo a la normal. Digamos que en los casos más desfavorable, alcanza con n=30 o 40.Mas específicamente si la variable X tiene dominio positivo, la relación
Y Y n n n deberá ser inferior a 0.2 para que Y sea
Normal. Existen sin embargo, casos patológicos, en los cuales no se alcanza la normalidad ni siquiera con miles de datos. Ejemplo La duración de un rodamiento a bolilla de una caja de velocidades de un automóvil es una variable con distribución asimétrica, con una media de 65 millones de revoluciones y una desviación estándar de 36 millones de revoluciones. A efectos de abaratar los costos se propone una modificación en el tratamiento de temple de las bolillas, que se espera no afectará la duración media del producto. A tal efecto, se realizó una prueba de laboratorio en el cual se probaron 20 rodamientos. ¿Es suficiente el tamaño de muestra para utilizar una aproximación a la normal?
36 20 65 0.12n , valor razonable como para admitir una tamaño
de muestra n=20 Ejemplo Los pesos de conejos criados en una granja es una variable aleatoria (v.a.) con
media .5kg y varianza 2 20.64kg . Suponga que se seleccionan n conejos
y sean nXXX ...,,, 21 sus pesos.
a) Si el peso de los conejos tienen una distribución normal y 921 ...,,, XXX es una
muestra aleatoria de tamaño 9 que fue obtenida con reemplazo. Calcule la probabilidad que la media muestral sea a lo más 5.5 kg.
Histogram of pobla
pobla
Freque
ncy
0 2 4 6 8 10
02
46
810
12Histogram of medias
medias
Freque
ncy
2 3 4 5 6
05
1015
2025

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
94
5)( X
XE
22 0.64
( )9
X
XVar X
n
2 0.64 0.80.267
9 3
X
Xn
5.5 5( 5.5) ( 1.87) 0.9693
0.267
X
X
XP X P P Z
R pnorm(5.5, mean=5, sd=sqrt((.64/9)))
[1] 0.9696036
b) Si el peso de los conejos tiene una distribución normal y 921 ...,,, XXX es una
muestra aleatoria simple de tamaño 9 que fue obtenida sin reemplazo de una población de 100 conejos. Calcule la probabilidad de que la media muestral sea a lo más 5.5 kg.
( ) 5XXE X
22 0.64 100 9
( )1 9 100 1
X
X
N nVar X
n N
2 0.64 100 90.256
1 9 100 1
X
X
N n
n N
5.5 5( 5.5) ( 1.95) 0.9744
0.256
X
X
XP X P P Z
R pnorm(5.5, mean=5, sd=0.256)
[1] 0.9745976
c) Si 4521 ...,,, XXX es una muestra aleatoria simple del peso de 45 conejos y si el
tamaño de la población de conejos en la granja es de 1000. Calcule la probabilidad de que el peso promedio de los conejos sea menor a 4.7 kg. Por fines prácticos calculamos la fracción de muestreo f para saber si se utiliza el f.c.p.f.
450.05
1000f
5)( X
XE

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
95
22 0.64
( )45
X
XVar X
n
2 0.640.1193
45
X
Xn
4.7 5( 4.7) ( 2.51) 0.006
0.1193
X
X
XP X P P Z
R pnorm(4.7, mean=5, sd=0.1193)
[1] 0.005957211
Ejemplo El tiempo de permanencia (en semanas) de los depósitos de ahorro en el banco Money S.A. tiene una distribución exponencial con media 3 semanas y variancia 7 semanas2 Si se elige al azar y sin reemplazo 35 depósitos de ahorro de un total de 1000 existentes, hallar la probabilidad de que la diferencia del tiempo de permanencia promedio de los depósitos de la muestra con el primer cuartil de su distribución se encuentre entre 1 y 2 semanas. W: Tiempo de permanencia (en semanas) de los depósitos de ahorro.
3W 2 7W , ~ 3,7W Exp . Como 35n y 1000N entonces
3W 2 7
0.235W
, entonces 3,0.2~a
W N
11 2 ?P W Q 1 0.25P W Q
1 30.25
0.2
QP Z
R qnorm(0.25, mean=0, sd=1)
[1] -0.6744898
11
30.6744898 2.69835
0.2
1 2.69835 2 3.69835 4.69835P W P W
R pnorm(4.69835, mean=3, sd=sqrt(0.2))-
[1] 0.999927
pnorm(3.69835, mean=3, sd=sqrt(0.2))
[1] 0.940804
3.69835 4.69835 0.999927 0.940804 0.059123P W
4.4 Distribución de la diferencia de promedios muestrales 1 2X X
Teorema
Si de dos poblaciones independientes distribuidas con medias 1 , 2 y
variancias 2
1 , 2
2 se extraen muestras de tamaños 1 2n y n , respectivamente;
entonces, la variable aleatoria 21 XX (diferencia de promedios muestrales)

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
96
tendrá una distribución con media 1 2X X
y variancia1 2
2
X X
(según el tipo de
muestreo): Si las muestras son aleatorias (con reemplazo) de poblaciones normales o se
cumple con el Teorema Central del Límite 1 230 30n y n con otro tipo de
distribución.
1 2 1 2
2 22 1 2
1 2
1 2
X X X Xy
n n
Si las muestras son aleatorias simples (sin reemplazo) de poblaciones de
tamaños N1 y N2normales o se cumple el Teorema Central del Límite:
1 2 1 2
2 22 1 1 1 2 2 2
1 2
1 1 2 21 1X X X X
N n N ny
n N n N
Por lo tanto si:
1 1
2 211 1 1~ , ~ ,
XXX N X N ó
1 1
2 211 1 1~ ? , ~ ,
XXaX X N
2 2
2 222 2 2~ , ~ ,
XXX N X N ó
2 2
2 222 2 2~ ? , ~ ,
XXaX X N
1 2 1 2
21 2 ~ ,
X XX XX X N
ó 1 2 1 2
21 2 ~ ,
X XX XaX X N
entonces
1 2
1 2
1 2
X X
X XX X
Z
Ejemplo El tiempo que lleva efectuar un procedimiento de montaje para el método 1 tiene distribución normal con media 35 segundos y variancia 20 segundos2 mientras que con un método 2 tiene distribución normal con media 31 segundos y variancia 17 segundos2. Si se selecciona una muestra de 40 empleados entrenados con el método 1 y 50 entrenados con el método 2.
a) Halle la probabilidad de que el promedio muestral con el método 1 sea superior al promedio muestral con el método 2 en por lo menos 5 seg. Solución
X1: Tiempo para efectuar un procedimiento de montaje con el método 1. X2: Tiempo para efectuar un procedimiento de montaje con el método 2.
1
20~ 35,
40X N
y 2
17~ 31,
50X N
2
2
2
1
2
12121 ,~
nnNXX
por lo tanto
50
17
40
20,3135~21 NXX
1 2 ~ 4.0;0.84X X N
1 2
1 2
1 2
1 2
5 45 1.09 0.1379
0.84
X X
X X
X XP X X P P Z
R

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
97
1- pnorm(5, mean=4, sd=sqrt(0.84))
b) Determine la probabilidad de que el promedio muestral con el método 2 menos
el promedio muestral con el método 1 sea a lo más -3, si las muestras se eligen sin reemplazo de una población de 400 empleados entrenados con el método 1 y 500 empleados entrenados con el método 2.
11,~
2
22
2
2
2
1
11
1
2
11212
N
nN
nN
nN
nNXX
2 1
17 500 50 20 400 40~ 31 35,
50 500 1 40 400 1X X N
)7577.0,4(~12 NXX
2 1
2 1
2 1
2 1
3 43 1.15 0.8749
0.7577
X X
X X
X XP X X P P Z
R pnorm(-3, mean=-4, sd=sqrt(0.7577))
c) Calcule c1 y c2 tal que:
2 1 2 11 2 10.7817 0.2033P c X X c y P X X c
Considere los parámetros de la pregunta b)
4.5 Distribución de la proporción muestral p
Dependiendo del tipo de muestreo asociado a un experimento aleatorio, se tiene:
A. Cuando el muestreo es con reemplazo Si de una población en la cual la probabilidad de éxito es , se extraen
muestras aleatorias con reemplazo de tamaño n ; entonces, la variable
aleatoria p (que expresa la proporción de éxitos en la muestra) tiene como
función de probabilidad:
1 21 0, , , ,1
0
n npnp
p
np
f p np n n
de otra forma
Donde p E p y 21
pV p
n
B. Cuando el muestreo es sin reemplazo
Sea una población de tamaño N en la cual existen A elementos que poseen
una característica de interés y B N A elementos no poseen esta
característica y además A N (la probabilidad de obtener un éxito). Si de esta
población se extrae al azar muestras aleatorias sin reemplazo de tamaño n ,
entonces la variable aleatoria p que expresa la proporción de éxitos en la

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
98
muestra (proporción de elementos que poseen la característica de interés) tiene como función de probabilidad:
1 2
0, , , ,1
0
p
A B
np n npp
Nf p n n
n
de otra forma
Donde p
AE p
N y
21
1p
N nV p
n N
Ejemplo Una empresa dedicada a la comercialización de harina de trigo y soya tiene 8 distribuidores de los cuales 5 de ellos solo distribuyen harina de trigo. Si se eligen al azar 4 distribuidores y se define p como la proporción de
distribuidores que solo distribuyen harina de trigo, halle la probabilidad de que la proporción de distribuidores de harina de trigo en la muestra este entre 0.4 y 0.8 inclusive.
a) Si el muestreo es con reemplazo
50.625
8
A
N
4 44 1 2 30.625 1 0.625 0, , , ,1
4 4 4 4
0
p n p
p
pf p p
de otra forma
1.6 3.2 2 3 2 3
0.4 0.84 4 4 4 4 4
P p P p P p P p P p
2 2 3 14 4
0.4 0.8 0.625 0.375 0.625 0.3752 3
P p
0.4 0.8 0.3295898 0.3662109 0.6958008P p
R dbinom(2,4,0.625)+ dbinom(3,4,0.625)
b) Si el muestreo es sin reemplazo
5 3
4 4 4 1 2 3 0, , , ,1
8 4 4 4
4
0
p
p pp
f p
de otra forma

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
99
1.6 3.2 2 3 2 3
0.4 0.84 4 4 4 4 4
P p P p P p P p P p
5 3 5 3
2 2 3 10.4 0.8 0.4285714 0.4285714 0.8571429
8 8
4 4
P p
R dhyper(2,5,3,4)+dhyper(3,5,3,4)
4.6 Aproximación Normal a la distribución de proporción muestral.
Cuando n es grande (por lo general, n 30), la variable aleatoria p se aproxima a una distribución normal. Esto resulta de aplicar el Teorema Central delLímite
Por lo tanto si 2~ ( ) 30 ~ ,p pa
p f p y n p N
Donde:
p y 2
p depende del tipo de muestreo o forma de extracción de la muestra.
Cuando el muestreo es con reemplazo o el tamaño de la población N es grande se define como:
np
)1(2
Cuando el muestreo es sin reemplazo o el tamaño de la muestra es finita se define como:
2 (1 )
1p
N n
n N
Luego para una muestra suficientemente grande puede aplicarse la distribución normal para aproximar las probabilidades de ocurrencia en una distribución de una proporción muestral de la siguiente manera:
1 2
1 2
1 1
2 2
p p
p pn n
P p p p P Z
1 2
1 2
1 1
2 2
p p
p pn n
P p p p P Z

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
100
1 2
1 2
1 1
2 2
p p
p pn n
P p p p P Z
1 2
1 2
1 1
2 2
p p
p pn n
P p p p P Z
Donde el término 1 2n se le llama factor de corrección por continuidad, el cual
se aplica para lograr una mayor aproximación de la probabilidad deseada. Una regla práctica que se sigue con frecuencia establece que la distribución
muestral de p es aproximadamente normal si tanto n y n(1-) son mayores a 5.
Ejemplo
En cierto distrito de una ciudad el 20% usualmente compran la revista Magali Tvi. Si se elige una muestra aleatoria de 100 personas sin reem .9 .plazo, hallar la probabilidad de que la proporción muestral de personas que compran la revista Magali Tvi, sea mayor o igual del 10% peromenor del 17%:
p=0.2
0.20(1 0.20)0.04
100p
1 1
0.10 0.20 0.17 0.202 100 2 100
(0.10 0.17)0.04 0.04
P p P Z
10 1 17 10.20 0.20
100 200 100 200(0.10 0.17)
0.04 0.04P p P Z
(0.10 0.17) 0.875 2.625 0.1864P p P Z P Z
R Sin el factor de continuidad
pnorm(0.17,0.2,0.04) – pnorm(0.1,0.2,0.04)
[1] 0.2204177
Con el factor de continuidad variable ya estadanrizada
pnorm(-0.875)-pnorm(-2.625)
[1] 0.1864545
4.7 Distribución de la diferencias de Proporciones Muestrales 1 2p p

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
101
Sean 1 y 2 las proporciones de éxitos (que poseen la característica de
interés) de dos poblaciones independientes 1N y 2N . De la primera población
se extraen muestras aleatorias de tamaño 1n y de la segunda población
muestras aleatorias de tamaño 2n . Sean 1p y 2p las proporciones de las
muestras extraídas de la primera y segunda población respectivamente. Luego,
la diferencia de proporciones muestrales 1 2p p p tendrá una distribución
con media 1 2p y variancia 2
p (la cual depende del tipo de muestreo y
del tamaño de las poblaciones)
Cuando el muestreo es con reemplazo o los tamaños de las poblaciones N1 y N2 son grandes entonces:
2 1 1 2 2
1 2
(1 ) (1 )p
n n
Cuando el muestreo es sin reemplazo o los tamaños de las poblaciones N1 y N2son finitosentonces:
2 1 1 1 1 2 2 2 2
1 1 2 2
(1 ) (1 )
1 1p
N n N n
n N n N
Ejemplo Suponga que se ha adquirido el lote I (con 5 chips de computadora) y el lote II (con 4 chips de computadora). Cada lote contiene dos artículos defectuosos. Si en un proceso de control de calidad se elige al azar sin reemplazo e independientemente 3 artículos del lote I y 2 del lote II, hallar la distribución de
la diferencia de proporciones muestrales 1 2p p p de artículos defectuosos
Como el muestreo es sin reemplazo se tiene
Lote I: 1 1 1 15, 2, 2 /5 0.4, 3N A n
Lote II: 2 2 1 24, 2, 2 / 4 0.5, 2N A n
1
1 1
1
1
2 3
3 3 3 1 2 0, , ,1
5 3 3
3
0
p
p pp
f p
de otra forma
2
2 2
2
2
2 2
2 2 2 1 0, ,1
4 2
2
0
p
p pp
f p
de otra forma
Las funciones de probabilidad 1p y 2p también puede ser expresada como:
1
1
1
1
1
1/10 0
6 /10 1/ 3
3/10 2 / 3
0
p
p
pf p
p
de otra forma
2
2
2
2
2
1/ 6 0
4 / 6 1/ 2
1/ 6 1
0
p
p
pf p
p
de otra forma
A partir de estas funciones de probabilidad se obtienen los posibles valores de
la diferencia de proporciones 1 2p p p y sus probabilidades de ocurrencia
de la siguiente manera:
1p 2p 1 2p p p
1 21 2p pf p f p f p

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
102
0 0 0 1 10 1 6 1 60
0 1/2 -3/6 1 10 4 6 4 60
0 1 -1 1 10 1 6 1 60
1/3 0 2/6 6 10 1 6 6 60
1/3 1/2 -1/6 6 10 4 6 24 60
1/3 1 -4/6 6 10 1 6 6 60
2/3 0 4/6 3 10 1 6 3 60
2/3 1/2 1/6 3 10 4 6 12 60
2/3 1 -2/6 3 10 1 6 3 60
Por lo tanto, la distribución exacta de la diferencia de proporciones
1 60 1,0
6 60 4 6,2 6
4 60 3 6
3 60 2 6,4 6
24 60 1 6
12 60 1 6
0
p
p
p
p
f p p
p
p
de otra forma
4.8 Aproximación Normal a la distribución de la diferencia de proporciones muestrales
Cuando los tamaños de las muestras 1n y 2n son grandes 1 230 30n y n ,
la variable aleatoria 1 2p p p (definida como la diferencia de proporciones
muestrales) tiene una distribución aproximadamente normal con media
1 2p y varianza 2
p . La distribución normal puede ser utilizada en
estos casos para estimar o aproximar las probabilidades de ocurrencia en una distribución de una diferencia de proporciones muestrales de la siguiente manera:
Si 1 230 30n y n entonces 2~ ,a
p pp N , luego ~ (0,1)a
p
p
pZ N
La varianza 2
p depende del tipo de muestreo (con reemplazo y sin reemplazo)
y si los tamaños de las poblaciones son grandes Para esta aproximación también se requiere de un factor de corrección por
continuidad, el cual es numéricamente igual a 1 2
1
2n n. Pero para una
aproximación a la normal se requiere que 1 230 30n y n , luego 1 2 900n n y

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
103
1 2
1 10.0005555
2 1800n n . En este caso se puede observar que el factor por
continuidad no tiene mucho efecto sobre las probabilidades estimadas. Por esta razón, en la aproximación normal de la distribución de diferencia de proporciones muestrales no se usa en la práctica el factor de corrección por continuidad. Ejemplo: Dos fábricas A y B producen artículos similares. La fábrica A tiene el 7 % de defectuosos, y la fábrica B tiene un 5% de defectuosos. Si se extrae una muestra aleatoria de 2000 unidades de la fábrica A y una muestra de 2500 unidades de la fábrica B sin reemplazo, ¿cuál es la probabilidad de que la muestra de la fábrica A tenga una proporción mayor de artículos defectuosos que la muestra de la fábrica B en por lo menos 1%? Solución:
0.07A , 0.05B , 2000An , 2500Bn
0.01 ?A BP p p
0.01 (0.07 0.05)
0.010.07(1 0.07) 0.05(1 0.05)
2000 2500
( ) 0.01 (0.07 0.05)
(1 ) (1 ) 0.07(1 0.07) 0.05(1 0.05)
2000 2500
( 1.39) 1
p
A B
p
A B A B
A A B B
A B
pP p p P
p pP
n n
P Z
( 1.39) 1 0.0823 0.9177P Z

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
104
Ejercicios Propuestos
1. El tiempo que sobrevive un pez en aguas contaminadas tiene distribución normal con media 92 días y variancia de 9 dias2. Si un pez sobrevivió más de 89 días, ¿cuál es la probabilidad que sobreviva como máximo 93.5 días?.
2. La empresa de petróleos Fuel Company S.A. realizó un estudio, donde determinó que las ventas diarias (en cientos de galones) de gasolina de 84 octanos en dos de sus estaciones en los distritos de San Miguel (X1) y Surco
(X2) tienen distribución normal. 1 ~ 40,24X N y 2 ~ 42,20X N .
a) Si se extrae una muestra aleatoria sin reemplazo de 15 registros de un total de 1000 del distrito de San Miguel. ¿cuál es la probabilidad de que la venta promedio muestral en este distrito difiera de su venta promedio poblacional en menos de 200 galones?
b) Si se eligen al azar y con reemplazo 10 registros de venta del distrito de Surco ¿cuál es la probabilidad de que exactamente dos registros superen en venta la cantidad de 42 cientos de galones.
3. El diámetro (en cm.) de un cable eléctrico, es una variable aleatoria con la siguiente función de densidad:
6 1 0 1f x x x x
Si se selecciona una muestra aleatoria sin reemplazo de 100 cables de un lote de 5000 cables, ¿cuál es la probabilidad de que el diámetro promedio de los 100 cables sea mayor a 0.52 cm.
4. Al salir de la línea de ensamblaje, 100 de un total de 400 automóviles, necesitan ajuste de algún tipo.
a) Si se seleccionan al azar 20 de ellos, ¿Cuál es la probabilidad de que la proporción muestral de vehículos que necesitan ajuste sea mayor o igual a 0.2 y menor o igual a 0.3?. Considere los casos en que el muestreo es con y sin reemplazo.
b) Calcule las probabilidades pedidas en a) considerando una muestra de 50 vehículos y utilizando aproximación normal.
5. Si 2
25~ 0,25 , ~ 20,25 , ~X N Y N W y son variables mutuamente
independientes.
a) Determine el valor de 1k tal que 13 0.95P X k W
b) Determine el valor de 2k tal que 13
2
2
1
20 0.9j
j
P Y k
6. Si 1 2~ 40,25 , ~ 50,25X N X N y son variables aleatorias mutuamente
independientes. Si 1 10n y 2 24n , determine el valor de k tal que:

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
105
10
22
2 1,
1
40 0.95j
j
P S k X
7. Después de una serie de experimentos se estima que el número medio de días
que sobrevive una especie de reptil es 167 días, con una desviación estándar de 3 días. Si la distribución de los días sobrevividos es normal.
a) ¿Cuál es el porcentaje de reptiles que sobreviven menos de 170 días, pero más de 160 días?
b) Si se seleccionan al azar 49 reptiles, ¿cuál es la probabilidad que el tiempo medio de supervivencia sea superior a los 167.5 días?
8. La cantidad neta de arroz, en kg, que envasa la máquina marca Alfa es una variable aleatoria distribuida normalmente con una media de 50 kg y una desviación estándar de 0.5 kg.
a) Si se seleccionan al azar 36 bolsas, ¿cuál es la probabilidad que la cantidad media de arroz envasada se encuentre entre 49.92 y 50.08 kg?
b) Si se seleccionan al azar 36 bolsas de un lote de 200 bolsas, ¿cuál es la probabilidad que la cantidad media de arroz envasada sea inferior a los 49.95 kg.?
c) Se sabe que la cantidad neta de arroz, en kg., que envasa la máquina marca Beta, también es una variable aleatoria distribuida normalmente con una media de 49.95 kg. y una desviación estándar de 0.2 kg. Si se eligen al azar 36 bolsas envasadas por la máquina Alfa y 49 bolsas envasadas por la máquina Beta, ¿cuál es la probabilidad que la cantidad media de arroz envasado por la máquina marca Alfa sea superior a la cantidad media de arroz envasada por la máquina marca Beta?
9. Para cierta región se conoce que el 15% de los créditos otorgados por la financiera A tienen al menos una cuota de pago vencida y que los montos (en decenas de miles de dólares) de los créditos otorgados por dicha financiera tienen una distribución normal con una media de 5.56 y una variancia de 9. Del mismo modo, para otra región se conoce que el 24% de los créditos aprobados por la financiera B tienen al menos una cuota de pago vencida y que los montos (en decenas de miles de dólares) de los créditos otorgados por dicha financiera también tienen una distribución normal con una media de 6 y una variancia de 4. Los directivos de ambas financieras sostienen que los créditos por montos menores a 50000 dólares tienen una menor probabilidad de atrasos en los compromisos de pago. Por otro lado, también se conoce que la financiera A ha otorgado un total de 800 créditos, mientras que la financiera B ha otorgado un total de 1200 créditos.
a) Si se eligen al azar y sin reemplazo 10 créditos otorgados por la financiera A, halle la probabilidad que el monto promedio de la muestra supere a la media de su distribución en no más de 1500 dólares.
b) Si se eligen al azar y sin reemplazo 32 créditos otorgados por la financiera A, halle la probabilidad que el porcentaje de créditos con cuotas de pago vencidas supere a su media poblacional en al menos 0.04.

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
106
c) Si se eligen al azar y sin reemplazo 36 créditos otorgados por la financiera B, halle la probabilidad que el porcentaje de créditos con cuotas de pago vencidas sea inferior a 0.21.
d) Si para cada financiera se seleccionan al azar y sin reemplazo 40 créditos, halle la probabilidad que la proporción de créditos por montos superiores 60000 dólares de la muestra de la financiera A supere a la correspondiente proporción de la muestra de la financiera B en no más de 0.05.
e) Si se eligen al azar y con reemplazo 40 créditos otorgados por la financiera B, halle la probabilidad que la proporción de créditos con cuotas de pago vencidas difiera de la media de su distribución en al menos 0.03.
10. Suponga que X, la resistencia a la ruptura de una cuerda (en libras), tiene una distribución N(100, 16).Si se extrae una muestra de 6 cuerdas, calcule:
4.19
1
)( 2
n
xxP
i
11. Sean las variables aleatorias z y w con las siguientes distribuciones de
probabilidad: z 2
2 , w 2
12 . Hallar a y b si: 04.011
bw
z
aP y
99.01
bw
zP
12. Dos compañías A y B fabrican cierto componente. La duración para los
fabricados por A tiene una desviación típica de 40 horas en tanto que la duración de los fabricados por B tienen una desviación típica de 50 horas. Se toma una muestra de 8 componentes de A y 16 de B. Hallar la probabilidad que la varianza de la primera muestra sea a lo más el doble de la segunda.
13. Se tienen dos tipos de procesos (A y B) para producir un artículo. Los tiempos
de producción para el proceso A muestran un comportamiento promedio de 3 horas y una variancia de 2.56 horas2; mientras que el proceso B muestra un comportamiento promedio de 3.06 horas y una variancia de 1.44 horas2. Si se eligen al azar y sin reemplazo 64 artículos producidos con el proceso A (de un total de 300 artículos producidos) y 49 producidos con el proceso B (de un total de 450 artículos producidos). Halle la probabilidad de que el tiempo promedio de producción de la muestra del proceso A difiera del correspondiente tiempo promedio de producción de la muestra de B en no menos de 30 minutos.
14. El 49% de los adultos jóvenes (personas de 21 a 25 años) de clase A y el 65% de los de la clase B contribuyen económicamente con los gastos del hogar.
a) Si se toma una muestra con reemplazo de 25 adultos jóvenes de la clase A ¿Cuál es la probabilidad que la proporción muestral de adultos jóvenes que contribuyen económicamente con los gastos del hogar sea mayor o igual del 15% pero menor que el 25%.
b) Si se toma una muestra sin reemplazo de 50 adultos jóvenes de la clase B ¿Cuál es la probabilidad que la proporción muestral de adultos jóvenes que contribuyen económicamente con los gastos del hogar sea mayor del 55% pero menor o igual que el 70%.

UNIVERSIDAD NACIONAL AGRARIA Departamento de Estadística e Informática
MS Jaime Carlos Porras Cerrón [email protected]
107
c) Si se toma una muestra aleatoria sin reemplazo de 100 adultos jóvenes de cada nivel socioeconómico ¿cuál es la probabilidad de que la proporción muestral de adultos jóvenes de clase B que contribuyen económicamente con los gastos del hogarsea superior en más del 10% a la de los adultos jóvenes de la clase A?.
15. Suponga que la distribución de los pesos de las bolsas de café molido de la marca A es normal con media 228 gr. y desviación estándar 10 gr. Para las bolsas de café de la marca B, la distribución de pesos es también normal con media 232 gr. y desviación estándar 12 gr. Las dos marcas se venden a los establecimientos en cajas de 60 bolsas. Si se seleccionan al azar una caja de la marca A y 80 cajas de la marca B, y se establece:
80 2
2,
1
60 232228 60
100 144
B jA
j
XX
R
Determine la distribución de R. (Presente todo su procedimiento)
16. Sean ,Y W variables independientes tal que ~ 30,60Y N , ~ 35,60W N . Si
16Yn y 22Wn , halle el valor de k tal que 0.95P J k y
2 2
5
15 21Y W
Y WJ
S S
.
17. Sean X e Y dos variables aleatorias independientes tales que: X ~ T con una
variancia de 1.25, Y ~ 2 con una media de 6.Halle: P[ | X | > 1.372 Y< 11.152 ].
Related Documents











