By Ali Alskaykha PARALLEL VIRTUAL FILE SYSTEM P V F S P V F S Distributed File System:

By Ali Alskaykha PARALLEL VIRTUAL FILE SYSTEM PVFS PVFS Distributed File System:
Dec 16, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

By Ali Alskaykha
PARALLEL VIRTUAL FILE SYSTEM
PV FS PV FS
D i s t r i b u t e d Fi l e S y s t e m :

Outline
Before PVFS
PVFS Definition
Develop PVFS
Objectives and Goals
Architecture
PVFS
Cooperative Cache for PVFS (Coopc-PVFS)
Performance
PVFS2 and Improvements
Summary
Before PVFSIf my business has exploded, my desktops are out of storage,
and information is scattered everywhere!
Each user keeps his files on his PC; when someone needs a file they grab it with a USB flash drive or via email. When business grew the PCs are running out of storage. That's time to consolidate, centralize, and share file storage across the network.
There are three basic ways:
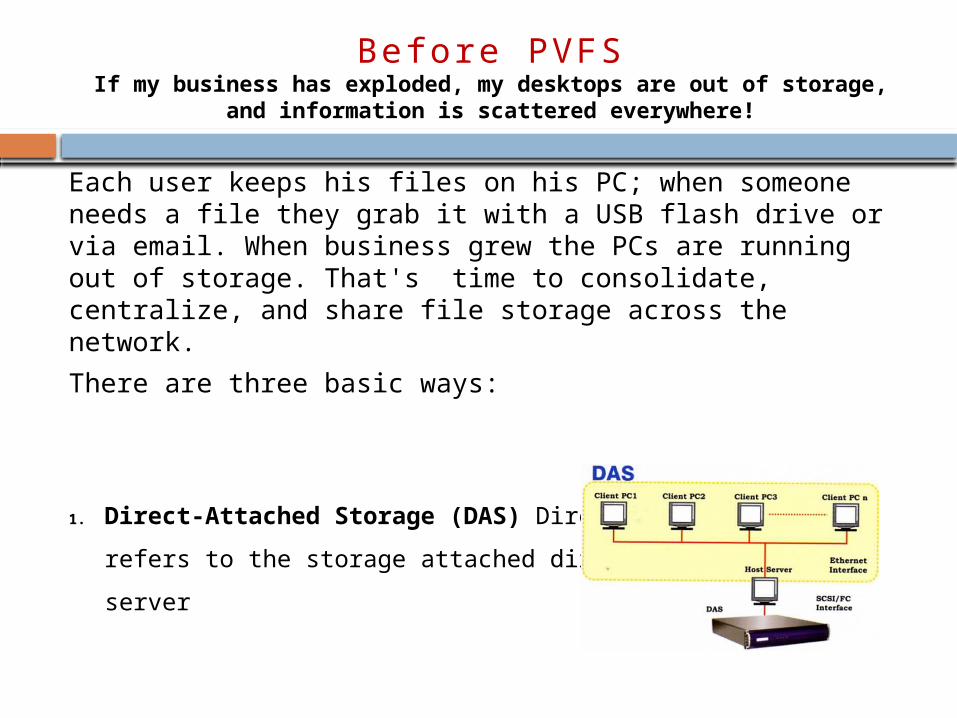
1. Direct-Attached Storage (DAS) Direct attached storage refers
to the storage attached directly to a PC or server
Before PVFSIf my business has exploded, my desktops are out of storage,
and information is scattered everywhere!
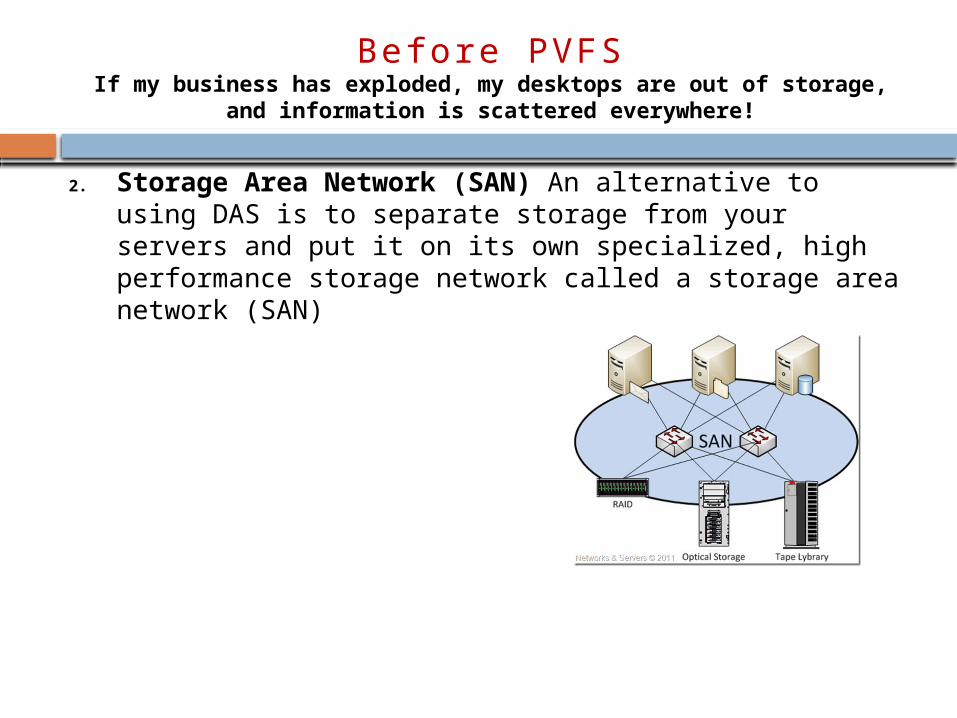
2. Storage Area Network (SAN) An alternative to using DAS is to separate storage from your servers and put it on its own specialized, high performance storage network called a storage area network (SAN)

Before PVFSIf my business has exploded, my desktops are out of storage,
and information is scattered everywhere!
3. Network File System (NFS)
NFS is a client/server application developed by Sun Microsystems It lets a user view, store and update files on a remote computer as though the files were on the user's local machine. The basic function of the NFS server is to allow its file systems to be accessed by any computer on an IP network. NFS clients access the server files by mounting the servers exported file systems.

Before PVFSIf my business has exploded, my desktops are out of storage,
and information is scattered everywhere!
Having all your data stored in a central location presents a number of problems:
Scalability: arises when the number of computing nodes exceeds the performance capacity of the machine exporting the file system; could add more memory, processing power and network interfaces at the NFS server, but you will soon run out of CPU, memory and PCI slots; the higher the node count, the less bandwidth (file I/O) individual node processes end up with
Availability: if NFS server goes down all the processing nodes have to wait until the server comes back into life.
Solution: Parallel Virtual File System (PVFS)

Parallel Virtual File System(PVFS)
Parallel Virtual File System (PVFS) is an open source implementation of a parallel file system developed specifically for Beowulf class parallel computers and Linux operating system
It is joint project between Clemson University and Argonne National Laboratory
PVFS has been released and supported under a GPL license since 1998.
File System – allows users to store and retrieve data using common file access methods (open, close, read, write)
Parallel – stores data on multiple independent machines with separate network connections
Virtual – exists as a set of user-space daemons storing data on local file systems

Develop PVFS
First developed in 1993 as parallel file system
To study I/O patterns of parallel programs
1994, PVFS version 1 for a cluster of DEC Alpha workstations
1994, PVFS version 1 ported to Linux, released 1997
as open source
1999, PVFS version 2 (PVFS2) developed, released
2003
2005, PVFS version 1 retired
PVFS
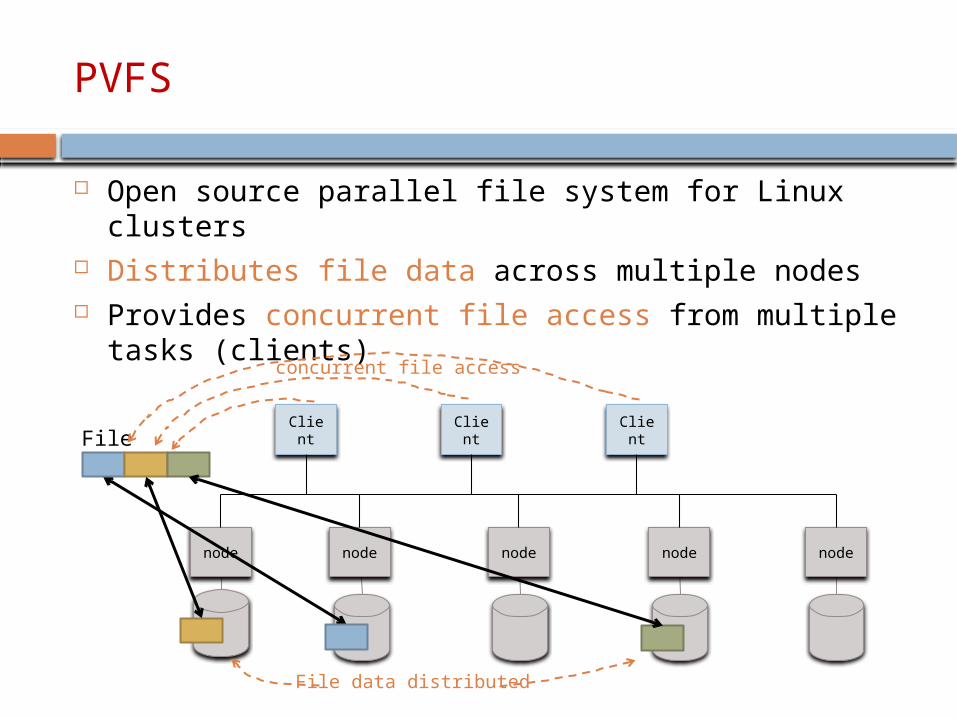
Open source parallel file system for Linux clusters Distributes file data across multiple nodes Provides concurrent file access from multiple tasks
(clients)
node node node node node
Client
Client
ClientFile
concurrent file access
File data distributed

Objectives
Objectives
Needed basic software platform to purpose further
research in parallel I/O and parallel file systems for Linux
clusters
Need of parallel file system for Linux clusters for high-
performance I/O

Goals
Goals
Provide high-bandwidth access to file data for concurrent
read/write operations from multiple tasks
Support multiple I/O APIs:
Native PVFS API
UNIX/POSIX I/O API
MPI-IO
Robust and scalable
Easy for others to install and use

A RC H I T E C T U R E
Design Overview
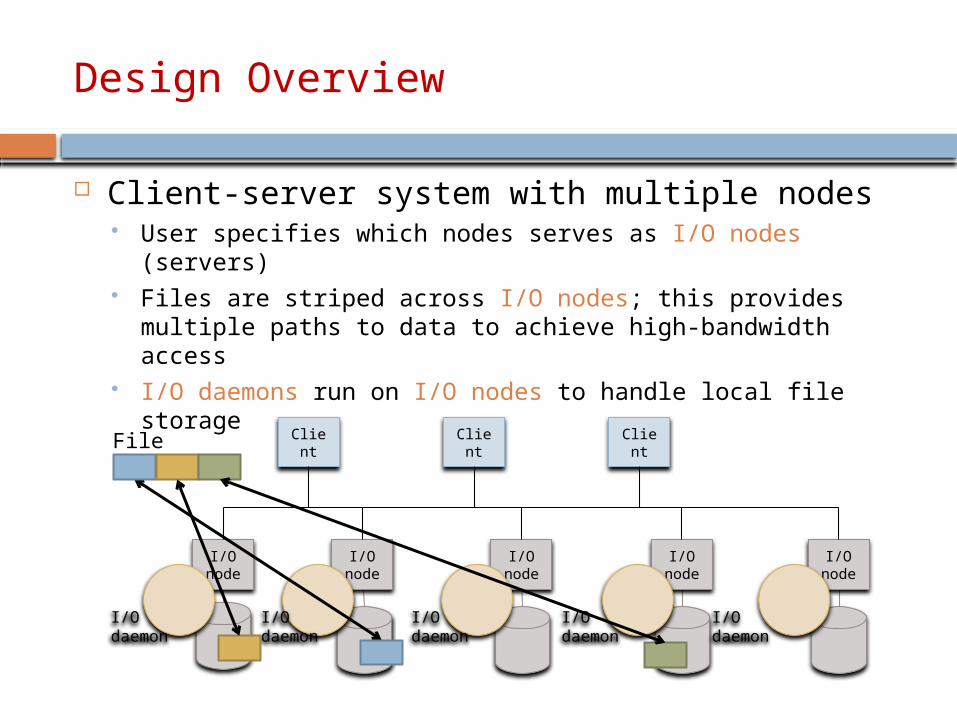
Client-server system with multiple nodes User specifies which nodes serves as I/O nodes (servers) Files are striped across I/O nodes; this provides multiple paths
to data to achieve high-bandwidth access I/O daemons run on I/O nodes to handle local file storage
I/O node
I/O node
I/O node
I/O node
I/O node
I/O daemon I/O daemon I/O daemon I/O daemon I/O daemon
Client
Client
Client
File

Design Overview (cont’d)
Single manger daemon to manage storage and
access to all metadata of PVFS files
Read/write is handled by client library and I/O
daemons
TCP for internal communication
User-level implementation; no kernel modifications
needed
Linux kernel module is available

File Metadata Manager
I/O node 0
I/O node 1
I/O node 2
I/O node 3
I/O node 4
I/O node 5
inode...basepcountssize
12345...2365536
Metadata
Stripe size: 65535 bytes
/local/f12345 /local/f12345 /local/f12345
Manger daemon manages storage of and access to all metadata
Metadata describes characteristics of file: permissions, owner/group, and physical distribution of file data
File: /pvfs/foo
/pvfs/foo
Manger
Daemon

I/O File Access and Data Storage
I/O daemons handles I/O file access and the storage of its file portion on local file system on the I/O node
Clients establish connections with I/O daemons to perform read/write operations
Client library sends descriptor of file region a client wants to access to I/O daemons
I/O node
I/O node
I/O node
I/O node
I/O node
I/O daemon I/O daemon I/O daemon I/O daemon I/O daemon
Client
Client
Client
File
Establish connection
Client Library
Sends descriptor

Cooperative Cache (Coopc-PVFS)
Created for PVFS because PVFS does not support file
system caching facility (client side)
To reduce servers’ load and increase high performance
Client caches file blocks in client’s memory
Cached file blocks shared among clients
File block requests managed by a cache manager
Scalable as number of clients increases
More memory in cooperative cache than in single file system
cache
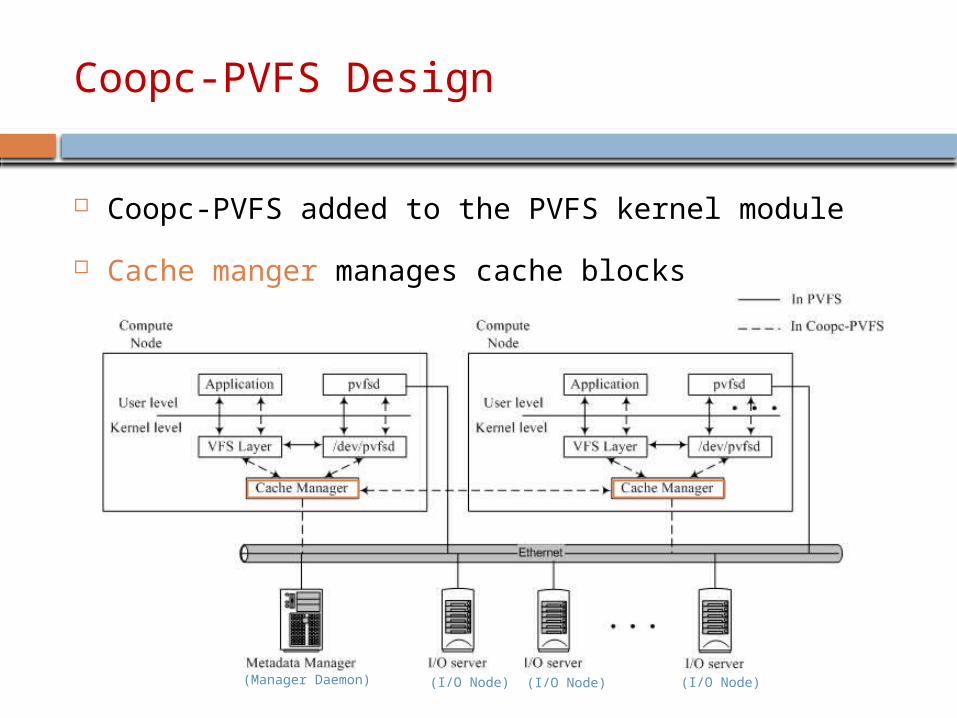
Coopc-PVFS Design
Coopc-PVFS added to the PVFS kernel module
Cache manger manages cache blocks
(I/O Node) (I/O Node) (I/O Node)(Manager Daemon)

Coopc-PVFS Info Management
Hint-based cooperative cache: method to maintain
accurate information about cached blocks in clients
Manager Daemon keeps list of clients that opened file
before
Client that opens file gets metadata of file and opened
clients lists
Cache manager exchanges information about cached blocks
with other clients’ cache manager when client reads a block
that’s not in its cache

Coopc-PVFS Consistency
Cache manger invalidates blocks cached in other
clients before writing block to I/O node (server)
Application
Cache Manager Cache Manager Cache Manager
Manager Daemon I/O node I/O node I/O node
Writes to block
Block invalidation propagation request InvalidateInvalidate
Write block to I/O node

Coopc-PVFS Implementation
Cache manager does the memory management of cache blocks. Allocates cache blocks from kernel memory

P E R F O R M A N C E

Test Types
PVFS tested on two different high-speed networks: Fast Ethernet vs Myrinet
Coopc-PVFS: PVFS vs Coopc-PVFS Cache vs No cache

PVFS Test Config
60 nodes:
some as I/O nodes
some as compute nodes
Disk transfer rate: 13.5 to 21.5 MB/sec
File-stripe size: 16 KB
Variants for testing on Fast Ethernet and Myrinet:
Number of I/O nodes accessed
Compute nodes
I/O file size

Fast Ethernet Results
46 MB/sec
90 MB/sec
177 MB/sec
42 MB/sec
83 MB/sec
166 MB/sec
Reached limit of scalability with 24 compute nodes
222 MB/sec226 MB/sec

Myrinet Results
138 MB/sec
255 MB/sec
450 MB/sec
93 MB/sec
180 MB/sec
325 MB/sec
650 MB/sec
687 MB/sec
460 MB/sec
670 MB/sec
Largest number of compute nodes tested: 45

BTIO Benchmark Results
Matrix computation is done then writes solution data to a file at time intervals
Fix number of 16 I/O nodes was used
MB/sec

Coopc-PVFS Test Config
6 nodes:
Disk transfer rate: 13.5 to 21.5 MB/sec
File-stripe size: 64 KB
Variants for testing:
I/O node (sever) cache and no cache
Coopc-PVFS cache and no cache
Manager Daemon
I/O node client client client client

Coopc-PVFS Matrix Multi Test
Server No
Cache
Server Cache
No one caches
Server cache
Coopc cache data
PVFS Coopc-PVFS
Matrix Multiplication program is read-dominant program
Read time reduced to almost 0 in Coopc-PVFS because file is cached once it is read
When server doesn’t cache in PVFS, Waiting time is larger than other cases because read time is larger than other cases

Coopc-PVFS BTIO Benchmark
BTIO benchmark programs are write-dominant
Used 4 BTIO programs
Read time of Coopc-PVFS shorter than in PVFS because clients cache files
Write time of Coopc-PVFS is longer than in PVFS

PVFS2 and Improvements
Distributed metadata to avoid single point of failure
and performance bottleneck
As systems continue to scale it becomes ever more likely
that any such single point of contact might become a
bottleneck for applications
Stateless servers and clients (no locking
subsystems)
If server crashes another can be restarted
Added redundancy support

Summary
PVFS High performance parallel I/O for Linux clusters Scalable as number of I/O nodes increases Supports multiple I/O APIs Performance benefits from high-speed network
Cooperative Cache for PVFS Allows client to request file to another client instead of server Scalable as number of clients increases Block invalidation for consistency (client-initiated validation) Improves performance for reading, but not for writing

Works Cited
Philip H. Carns, Walter B. Ligon, III, Robert B. Ross and Rajeev Thakur, "PVFS: A Parallel File System for Linux Clusters," In Proc. of the 4th Annual Linux Showcase and Conference, October 2000, pages 317--327
In-Chul Hwang, Hojoong Kim, Hanjo Jung, Dong-Hwan Kim, Hojin Ghim, Seung-Ryoul Maeng, and Jung-Wan Cho, "Design and Implementation of the Cooperative Cache for PVFS", Lecture Notes in Computer Science, Volume 3036/2004, pages 43 – 50
PVFS website http://www.parl.clemson.edu/pvfs/ (old) http://www.pvfs.org/ (current)
Parallel Virtual File System Wiki http://en.wikipedia.org/wiki/Parallel_Virtual_File_System
Related Documents











